Oxygen HPC OpenMP fondamenti. Carmine Spagnuolo
|
|
|
- Pio Genovese
- 8 anni fa
- Visualizzazioni
Transcript
1 Oxygen HPC OpenMP fondamenti Carmine Spagnuolo

2 1 Oxygen HPC Cluster Oxygen Ambiente - Module Environment - Portable Batch System 2 OpenMP 31 fondamend Modello di esecuzione OpenMP core DireGve OpenMP Roadmap 2014 Università degli Studi di Salerno

3 1 Oxygen HPC Cluster Oxygen Ambiente - Module Environment - Portable Batch System 2 OpenMP 31 fondamend Modello di esecuzione OpenMP core DireGve OpenMP Roadmap 2014 Università degli Studi di Salerno

4 Hardware: 9 x DELL PowerEdge PowerEdge C6220: - Processors: 2 x Intel(R) Xeon E5-2680, 8C, 27GHz, 20M Cache, 8GT/s, 130W TDP, Turbo, HT,DDR3-800/1066/1333/1600 MHz; - Memory: 256GB DDR3; - Hard Drive: 6 x 1TB; - Network: 2 x Intel CorporaDon I350 Gigabit, 2 x Intel CorporaDon 82599EB 10- Gigabit SFI/SFP+ Oxygen 2014 Università degli Studi di Salerno

5 Hardware: 12 x GPU NVIDIA Tesla M2090: - CUDA Driver Version / RunDme Version: 55 / 55 - CUDA Capability Major/Minor version number: 20 - Total amount of global memory: 5GB - MulDprocessors, ( 32) CUDA Cores/MP: 512 CUDA Cores - GPU Clock rate: 1301 MHz (130 GHz) - Memory Clock rate: 1848 Mhz - Memory Bus Width: 384- bit - L2 Cache Size: bytes Oxygen 2014 Università degli Studi di Salerno

6 wwwisislabit:8092/phpldapadmin PBS ssh p user@wwwisislabit Oxygen 2014 Università degli Studi di Salerno
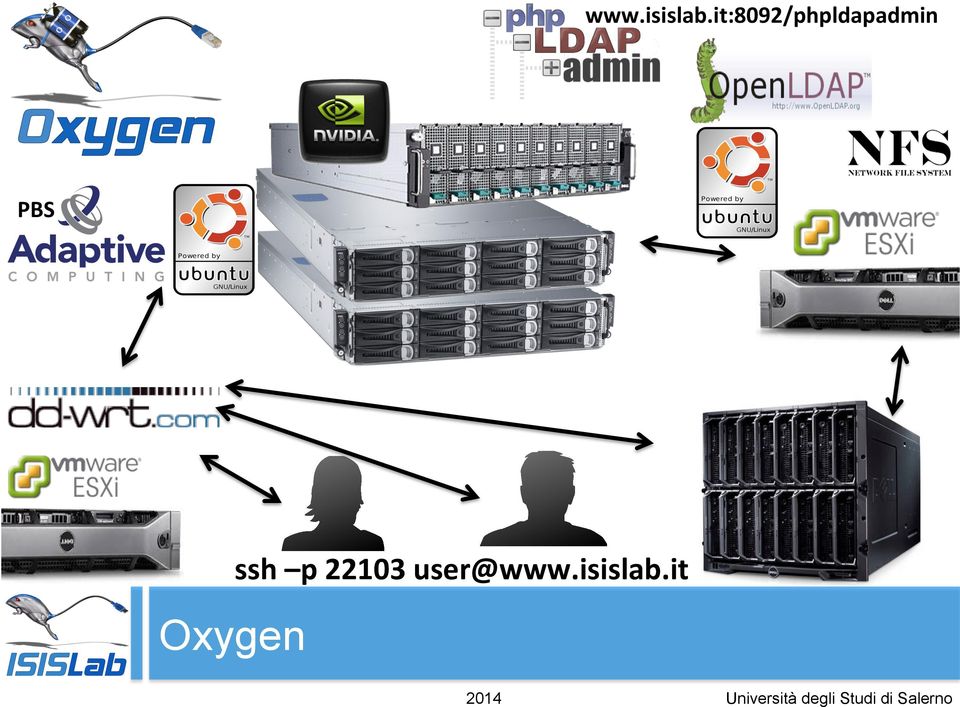
7 Nodi Oxygen: - Oxygen[1-8] - Oxygen1 (2 GPU) - Oxygen5 (8 GPU) SSH - ssh p user@wwwisislabit( ) SSH Key Exchange - ssh- keygen t rsa - cat ssh/id_rsa >> ssh/authorized_keys Oxygen - Ambiente 2014 Università degli Studi di Salerno

8 L ambiente utente è gesdto tramite: Environment Modules - hop://modulessourceforgenet/ Uno strumento per aiutare gli utend a gesdre il loro ambiente di shell Unix o Linux, permeoendo di gesdre le variabili di ambiente in modo dinamico Modules can be loaded and unloaded dynamically and atomically, in a clean fashion Oxygen - Module 2014 Università degli Studi di Salerno

9 Environment Modules: module [ switches ] [ sub- command ] [ sub- command- args ] sub- command 1 available (av) 2 load module- name 3 unload module- name 4 whads module- name 5 list 6 swap module- name1 module- name2 7 purge Oxygen - Module 2014 Università degli Studi di Salerno

10 Oxygen - Module

11 Ambiente di esecuzione: Portable Batch System (PBS) è un sistema di gesdone e controllo del carico su un insieme di nodi: Queuing Scheduling Monitoring PBS 2014 Università degli Studi di Salerno

12 Flow di esecuzione: - Creazione: script Unix per comunicare i vari parametri del job PBS: tempo di esecuzione (walldme), numero e caraoerisdche delle risorse e come eseguire il job - So9omissione: comando qsub [opdons] script_name - Esecuzione: verificato stato comando qstat [opdons] queue- name? - Finalizzazione: quando un job termina lo standard output ed error sono salvad in file e copiad nella cartella dalla quale il job è stato sooomesso PBS 2014 Università degli Studi di Salerno
![Esecuzione: verificato stato comando qstat [opdons] queue- name?](/docs-images/44/1050499/images/page_12.jpg "- Finalizzazione: quando un job termina lo standard output ed error sono salvad in file e copiad nella cartella dalla")
13 Job flow: - Creazione - Sooomissione DireGve: - #PBS - l walldme=hh:mm:ss - #PBS - l pmem=size- GB - #PBS - l nodes=n:ppn=m (N può essere un pardcolare nodo del sistema) - #PBS - q queuename - #PBS j file_name Modalità interagva: - qsub - I - l nodes=1:ppn=1 - l walldme=4:00:00 PBS 2014 Università degli Studi di Salerno

14 Job flow: - Creazione: script Unix per comunicare i vari parametri del job PBS: tempo di esecuzione (walldme), numero e caraoerisdche delle risorse e come eseguire il job PBS 2014 Università degli Studi di Salerno

15 TORQUE PBS, basato sul progeoo PBS originale (OpenPBS, NASA Ames Research Center): - hop://wwwadapdvecompudngcom/products/open- source/torque/ - hop://wwwadapdvecompudngcom/support/download- center/torque- download/ - Feature: 1 Fault Tolerance 2 Scheduling Interface 3 Scalability 4 Usability PBS TORQUE MAUI Scheduler 2014 Università degli Studi di Salerno

16 MAUI scheduler: - hop://wwwadapdvecompudngcom/products/open- source/maui/ (registrazione) - Features: 1 Scalability 2 Rich administrator dashboard tools 3 Simplified HPC job submission and management 4 Grid and muld- cluster workload management capabilides 5 Enforce usage accoundng budgets or provide pay- for use PBS TORQUE MAUI Scheduler 2014 Università degli Studi di Salerno

17 TORQUE PBS installazione: /configure - - with- default- server=one - - with- server- home=/oxygen/var/ spool/pbs - - with- rcp=scp - - with- debug - - enable- nvidia- gpus - - with- nvml*- include=/oxygen/compilers/cuda/55/include - with- nvml- lib=/oxygen/ compilers/cuda/55/lib64 2>&1 tee configure_torquelog make j numero_di_processi make packages torque- package- clients- linux- x86_64sh - - install torque- package- devel- linux- x86_64sh install (solo head node) torque- package- doc- linux- x86_64sh install (solo head node) torque- package- mom- linux- x86_64sh - - install torque- package- server- linux- x86_64sh install (solo head node) trucco echo /opt/torque/lib > /etc/ldsoconfd/torqueconf *NVIDIA Management Library (NVML): A C- based API for monitoring and managing various states of the NVIDIA GPU devices PBS TORQUE MAUI Scheduler 2014 Università degli Studi di Salerno
 trucco echo /opt/torque/lib > /etc/ldsoconfd/torqueconf *NVIDIA Management Library (NVML): A C- based API for monitoring and managing")
18 MAUI scheduler installazione: /configure - - with- pbs=/opt/torque - - with- spooldir=/opt/maui make j numero_di_processi make install Configurazione ambiente PBS e MAUI: oxyegn_set_envsh in /etc/profiled/ #oxygen setup /etc/profiled/modulessh export PATH=$PATH:/opt/torque/bin:/opt/torque/sbin:/opt/maui/sbin:/ opt/maui/bin NOTE OpenMPI /configure - - prefix=/oxygen/compilers/mpi/openmpi/ java- - oracle- 160_ enable- mpi- java - - with- jdk- bindir=/oxygen/compilers/java/oracle/160_25/bin - - with- jdk- headers=/oxygen/compilers/java/oracle/160_25/include - - with- tm=/opt/torque - - enable- mpi- thread- muluple PBS TORQUE MAUI Scheduler 2014 Università degli Studi di Salerno

19 Tempi di esecuzione: UDlizzare le API disponibili nella piaoaforma udlizzata Soluzione Veloce- Veloce Ume ls ac aout myjoberr real 0m0004s wall clock Dme (from start to finish the call) user 0m0003s CPU Dme (user- mode code) sys 0m0000s - CPU Dme (kernel code) user+sys CPU total Ume Oxygen performance 2014 Università degli Studi di Salerno
 user+sys CPU total Ume Oxygen performance 2014 Università degli")
20 PBS Demo

21 1 Oxygen HPC Cluster Oxygen Ambiente 1 Oxygen HPC Cluster Oxygen Module Environment - Portable Batch System 2 OpenMP 31 fondamenu Roadmap 2014 Università degli Studi di Salerno
22 OpenMP (Open MulDprocessing) è un API muldpiaoaforma per la creazione di applicazioni parallele su sistemi a memoria condivisa (Fortran, C e C++) L obiegvo principale di OpenMP è quello di semplificare lo sviluppo di applicazioni muldthread RiferimenD: hop://openmporg/ hop://openmporg/mp- documents/omp- hands- on- SC08pdf Common Mistakes in OpenMP and How To Avoid Them A CollecUon of Best PracUces, Michael Süß and Claudia Leopold OpenMP Università degli Studi di Salerno
23 Compilatori: GNU: gcc 42 in poi [- fopenmp] Oracle [- xopenmp] Intel [- Qopenmp or openmp] PGI (Portland Group Compilers and Tools) [- mp] hop://openmporg/wp/openmp- compilers/ OpenMP Università degli Studi di Salerno
24 OpenMP 31
25 OpenMP 31
26 OpenMP 31
27 OpenMP core syntax I costrug udlizzad in OpenMP sono diregve al compilatore: #pragma omp construct [clause [clause] ] Esempio: #pragma omp parallel num_threads(4) ProtoDpi delle funzioni e i Dpi: #include <omph> Compilazione GCC: gcc - fopenmp hellompc - o helloout HelloWorld Example: #ifdef _OPENMP #include <omph> #endif void main() { #pragma omp parallel { int ID=omp_get_thread_num(); prin ( hello(%d),id); prin ( world(%d)\n,id); hello(3)hello(1)hello(5)world(5) hello(0)world(0) world(3) world(1) hello(2)world(2) hello(4)world(4) OpenMP 31
28 OpenMP Creazione dei Thread Fork- Join Parallelism: il master thread distribuisce un team di thread dinamicamente OpenMP Fork-Join Parallelism 2014 Università degli Studi di Salerno
29 OpenMP Fork-Join model
30 OpenMP creazione dei Thread Il construoo parallel consente di creare i thread Definizione del numero di thread: 1 Clausola alla diregva parallel: #pragma omp parallel num_threads(4); 2 RunDme funcdon: omp_set_thread_num(x); 3 Environment variable: export OMP_NUM_THREADS=x Example: #ifdef _OPENMP #include <omph> #endif void main() { double A[1000]; omp_set_num_threads(4); #pragma omp parallel { int ID=omp_get_thread_num(); func(id,a); BARRIER prin ( all done\n ); OpenMP 31
31 OpenMP sincronizzazione DireGve: cridcal atomic barrier ordered flush lock (simple e nested) In presuto da Golang OpenMP 31
32 OpenMP sincronizzazione DireGve: criucal solo un thread alla volta entra nella regione cridca atomic barrier ordered flush lock (simple e nested) criucal Example: float res; #pragma omp parallel { float B; int i,id,nthrds; id=omp_get_thread_num(); nthrds=omp_get_num_threads(); for(i=id;i<niters;i+nthrds){ B=big_job(); #pragma omp criucal cosume(b,res); I thread aoendono il loro turno e solo un thread alla volta chiama la consume OpenMP 31
33 OpenMP sincronizzazione DireGve: cridcal atomic operazioni in mutua esclusione barrier ordered flush lock (simple e nested) atomic Example: #pragma omp parallel { double tmp, B; B = DOIT(); tmp = big(b); #pragma omp atomic X += tmp; Operazione atomica solo sulla leoura/ aggiornamento di X OpenMP 31
34 OpenMP sincronizzazione DireGve: cridcal atomic barrier ogni thread aoende finché tug non raggiungono la barriera ordered flush lock (simple e nested) barrier Example: #pragma omp parallel { #pragma omp master prin ( I am the MASTER\n ); prin ( ID %d,id); #pragma omp barrier prin ( all done\n ); OpenMP 31
35 OpenMP sincronizzazione DireGve: cridcal atomic Barrier ordered flush lock (simple e nested) OpenMP 31 ordered Example: int i=0; #pragma omp parallel for schedule(stauc)\ ordered for ( i = 0; i <= 10; ++i) { // Do something here #pragma omp ordered prin ("test() iteradon %d\n", i); test() iteradon 0 test() iteradon 1 test() iteradon 2 test() iteradon 3 test() iteradon 4 test() iteradon 5 test() iteradon 6 test() iteradon 7 test() iteradon 8 test() iteradon 9 test() iteradon 10
36 OpenMP sincronizzazione DireGve: cridcal atomic barrier ordered flush lock (simple e nested) flush Example: double A; A = compute(); flush(a); // flush to memory to make sure other // threads can pick up the right value Definisce un sequence point dove ad ogni thread è garandta la consistenza della memoria OpenMP 31
37 OpenMP sincronizzazione DireGve: cridcal atomic barrier ordered flush lock (simple e nested) Modello di memoria: Relaxed Consistency Variante della weak consistency Le operazioni S rispeoano l ordine sequenziale in ogni thread Le operazioni di W e R non possono essere riordinate rispeoo le operazioni S: S W, S R, R S, W S, S S (S=sincronizzazione, W=write e R=read) OpenMP 31
38 OpenMP sincronizzazione DireGve: cridcal atomic barrier ordered flush lock (simple e nested) simple lock Example: Il rilascio del lock implica il flush delle variabili visibili da tug I thread omp_lock_t lck; omp_init_lock(&lck); #pragma omp parallel private (tmp, id) { id = omp_get_thread_num(); tmp = do_lots_of_work(id); omp_set_lock(&lck); prin ( %d %d, id, tmp); omp_unset_lock(&lck); omp_destroy_lock(&lck); OpenMP 31
39 OpenMP Worksharing Consentono la distribuzione dell esecuzione di una regione di codice (in a clever fashion) Worksharing: 1 loop 2 secdons/secdon 3 single 4 task Barriera implicita in uscita ma non in ingresso (clausola nowait può eliminarla) OpenMP 31
40 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 Single 4 task La variabile i diventa automadcamente privata ad ogni thread, ciò può anche essere realizzato tramite la clausola private(i) for Example: #pragma omp parallel { #pragma omp for for (i=0;i<n;i++){ independent_work(i); OpenMP 31
41 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 Single 4 task Clausola schedule: StaDc: esecuzione divisa in chunk, assegnazione round- robin Dynamic: ogni thread richiede un chunk alla volta Guided: esecuzione divisa in chuck di taglia differente, assegnazione dinamica (caso speciale Dynamic) Run- Dme: controllato da variabili di ambiente OpenMP 31 for Example: Codice sequenziale: for (i=0;i<n;i++){ a[i]=a[i]+b[i]; Single Program MulCple Data: #pragma omp parallel { int id, i, Nthrds, istart, iend; id = omp_get_thread_num(); Nthrds = omp_get_num_threads(); istart = id * N / Nthrds; iend = (id+1) * N / Nthrds; if (id == Nthrds- 1) iend = N; for(i=istart;i<iend;i++) {a[i]=a[i]+b[i]; Worksharing: #pragma omp parallel schedule(stauc,1) { #pragma omp for for (i=0;i<n;i++){ work(i);
42 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 Single 4 Task Trucco per testare la dipendenza: Verificare che un loop sequenziale produca lo stesso risultato in reverse order OpenMP 31 for Example: int i, j, A[MAX]; j = 5; for (i=0;i< MAX; i++) { j +=2; A[i] = big(j); int i, A[MAX]; #pragma omp parallel for for (i=0;i< MAX; i++) { int j = 5 + 2*i; A[i] = big(j); Data dependencies: A[0] = 0; A[1] = 1; for(i = 3; i < 99; i++){ A[i] = A[i- 1] + A[i- 2];
43 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 single 4 task Clausola collapse(n) for Example: NO error nested loop #pragma omp parallel { #pragma omp for for (i=0;i<n;i++){ #pragma omp for for (j=0;j<n;j++){ work(i,j); #pragma omp parallel for collapse(2) for (i=0;i<n;i++){ for (j=0;j<n;j++){ work(i,j); OpenMP 31
44 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 single 4 task Clausola reducdon(op,var): op: +, -, *, MIN,MAX var: shared Viene creata una copia locale della variabile (inizializzata in modo appropriato +,0 *,1 +,0) alla terminazione della regione parallela viene aggiornato il valore della variabile condivisa for Example: double ave=00, A[MAX]; int i; for (i=0;i< MAX; i++) { ave + = A[i]; ave = ave/max; double ave=00, A[MAX]; int I; #pragma omp parallel for reducuon (+:ave) for (i=0;i< MAX; i++) { ave + = A[i]; ave = ave/max; OpenMP 31
45 OpenMP Worksharing Worksharing: 1 loop 2 secuons/secuon 3 single 4 task OpenMP 31 for Example: int main() { #pragma omp parallel secuons\ num_threads(4) { prin ("Hello from thread OUT %d\n", omp_get_thread_num()); prin ("Hello from thread OUT %d\n", omp_get_thread_num()); #pragma omp secuon prin ("Hello from thread %d\n", omp_get_thread_num()); #pragma omp secuon prin ("Hello from thread %d\n", omp_get_thread_num()); #pragma omp secuon Hello from thread 0 prin ("Hello from thread %d\n", Hello from thread 0 omp_get_thread_num()); Hello from thread OUT 3 #pragma omp secuon Hello from thread OUT 3 prin ("Hello from thread %d\n", Hello from thread 1 omp_get_thread_num()); Hello from thread 2
46 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 single 4 task Denota un blocco di codice eseguibile da un solo thread single Example: #pragma omp parallel { do_many_things(); #pragma omp single { exchange_boundaries(); do_many_other_things(); Alla terminazione del blocco è presente una barriera implicita OpenMP 31
47 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 single 4 task DireGva introdooa in OpenMp 30 e migliorata in 31 e 40 Task sono unità di lavoro indipendend Ogni task viene assegnato a un thread Il rundme system decide dinamicamente come eseguire i task OpenMP 31
48 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 single 4 task Un thread prepara l esecuzione dei task: packaging (code and data) execudon (un thread del team esegue il task) I task sono gesdd in una coda OpenMP garandsce che alla terminazione della regione parallela ogni task è terminato OpenMP 31
49 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 Single 4 task La diregva task è udle per la parallelizzazione di paoern irregolari e funzioni ricorsive Soluzione 1: Troppa sincronizzazione (nested parallel regions) Poca flessibilità OpenMP 31 task Example: Soluzione 1: void preorder(node *p) { process(p- >data); #pragma omp parallel secuons if (p- >le ) #pragma omp secuon preorder(p- >le ); if (p- >right) #pragma omp secuon preorder(p- >right); Soluzione 2: void preorder (node *p) { process(p- >data); If (p- >le ) #pragma omp task preorder(p- >le ); if (p- >right) #pragma omp task preorder(p- >right);
50 OpenMP Worksharing Worksharing: 1 loop 2 secdons/secdon 3 Single 4 task Sincronizzazione task: taskwait task Example: void traverse(node *p) { If (p- >le ) #pragma omp task traverse(p- >le ); if (p- >right) #pragma omp task traverse(p- >right); if(postorder) #pragma omp taskwait process(p- >data); OpenMP 31
51 OpenMP RunUme Library Modificare/Verificare il numero di thread: - omp_set_num_threads(n) - omp_get_num_threads() - omp_get_thread_num() - omp_get_max_threads() Regione parallela? - omp_in_parallel() GesDone dinamica del numero di thread tra le regioni parallele: - omp_set_dynamic() - omp_get_dynamic() Numero di processori disponibili? - omp_num_procs() OpenMP 31
52 OpenMP Data sharing Nei costrug è possibile definire la visibilità delle variabili: shared private firstprivate, privata ma inizializzata col valore della variabile prima della regione parallela Thread number: 5 x: 5 lastprivate, privata ma alla terminazione della regione Thread number: 9 x: 9 parallela il valore è quello dell uldma Thread number: iterazione 4 x: 4 OpenMP 31 lastprivate Example: x=44; #pragma omp parallel for lastprivate(x) for(i=0;i<=10;i++){ x=i; prin ("Thread number: %d x: %d \n",omp_get_thread_num(),x); prin ("x is %d\n", x); Thread number: 1 Thread number: 2 Thread number: 7 Thread number: 3 Thread number: 8 Thread number: 10 Thread number: 0 Thread number: 6 x is 10 x: 1 x: 2 x: 7 x: 3 x: 8 x: 10 x: 0 x: 6
53 PADABS 2014 Università degli Studi di Salerno
54 wwwdmasonorg wwwisislabit
CLUSTER COKA. Macchine e Risorse
 CLUSTER COKA Macchine e Risorse Il cluster per il progetto COKA si compone complessivamente delle seguenti 5 macchine: rd coka 01 : server con il MIC e le GPU K20; rd gpu 01 : server con GPU C1060; rd
CLUSTER COKA Macchine e Risorse Il cluster per il progetto COKA si compone complessivamente delle seguenti 5 macchine: rd coka 01 : server con il MIC e le GPU K20; rd gpu 01 : server con GPU C1060; rd
Si digita login e password e si clicca su accedi. Si apre la finestra di collegamento:
 Corso di Laurea Specialistica Ingegneria Informatica Laboratorio di Calcolo Parallelo Prof. Alessandra d Alessio GUIDA AL LABORATORIO DI CALCOLO PARALLELO Il progetto SCoPE (www.scope.unina.it) ha messo
Corso di Laurea Specialistica Ingegneria Informatica Laboratorio di Calcolo Parallelo Prof. Alessandra d Alessio GUIDA AL LABORATORIO DI CALCOLO PARALLELO Il progetto SCoPE (www.scope.unina.it) ha messo
Computazione multi-processo. Condivisione, Comunicazione e Sincronizzazione dei Processi. Segnali. Processi e Threads Pt. 2
 Computazione multi-processo Avere più processi allo stesso momento implica/richiede Processi e Threads Pt. 2 Concorrenza ed efficienza Indipendenza e protezione dei dati ma deve prevedere/permettere anche:
Computazione multi-processo Avere più processi allo stesso momento implica/richiede Processi e Threads Pt. 2 Concorrenza ed efficienza Indipendenza e protezione dei dati ma deve prevedere/permettere anche:
Sistemi Operativi. Processi GESTIONE DEI PROCESSI. Concetto di Processo. Scheduling di Processi. Operazioni su Processi. Processi Cooperanti
 GESTIONE DEI PROCESSI 4.1 Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in diversi S.O. 4.2 Concetto di
GESTIONE DEI PROCESSI 4.1 Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in diversi S.O. 4.2 Concetto di
Laboratorio Turing @ Centro Calcolo
 INTRODUZIONE AI CLUSTER DI CALCOLO DEL DIPARTIMENTO DI MATEMATICA Centro di Calcolo Ottobre 2014 A cura di L. Ciambella, A. Gabrielli, A. Seghini {ciambella, gabrielli, seghini}@mat.uniroma1.it Laboratorio
INTRODUZIONE AI CLUSTER DI CALCOLO DEL DIPARTIMENTO DI MATEMATICA Centro di Calcolo Ottobre 2014 A cura di L. Ciambella, A. Gabrielli, A. Seghini {ciambella, gabrielli, seghini}@mat.uniroma1.it Laboratorio
GESTIONE DEI PROCESSI
 Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
Tutorial. Cluster Linux 15-09-2003 Ultimo aggiornamento Ottobre 2004
 Documento tratto dal CD multimediale disponibile presso la biblioteca del Dipartimento di Matematica Tutorial Cluster Linux 15-09-2003 Ultimo aggiornamento Ottobre 2004 Istruzioni base CLUSTER LINUX ULISSE
Documento tratto dal CD multimediale disponibile presso la biblioteca del Dipartimento di Matematica Tutorial Cluster Linux 15-09-2003 Ultimo aggiornamento Ottobre 2004 Istruzioni base CLUSTER LINUX ULISSE
Modello dei processi. Riedizione delle slide della Prof. Di Stefano
 Modello dei processi Riedizione delle slide della Prof. Di Stefano 1 Processi Modello di Processi asincroni comunicanti Process Scheduling Operazioni sui Processi Cooperazione tra Processi Interprocess
Modello dei processi Riedizione delle slide della Prof. Di Stefano 1 Processi Modello di Processi asincroni comunicanti Process Scheduling Operazioni sui Processi Cooperazione tra Processi Interprocess
Sistemi Operativi (modulo di Informatica II) I processi
 I processi") Sistemi Operativi (modulo di Informatica II) I processi Patrizia Scandurra Università degli Studi di Bergamo a.a. 2009-10 Sommario Il concetto di processo Schedulazione dei processi e cambio di contesto
Sistemi Operativi (modulo di Informatica II) I processi Patrizia Scandurra Università degli Studi di Bergamo a.a. 2009-10 Sommario Il concetto di processo Schedulazione dei processi e cambio di contesto
Introduzione ai sistemi operativi
 Introduzione ai sistemi operativi Che cos è un S.O.? Shell Utente Utente 1 2 Utente N Window Compilatori Assembler Editor.. DB SOFTWARE APPLICATIVO System calls SISTEMA OPERATIVO HARDWARE Funzioni di un
Introduzione ai sistemi operativi Che cos è un S.O.? Shell Utente Utente 1 2 Utente N Window Compilatori Assembler Editor.. DB SOFTWARE APPLICATIVO System calls SISTEMA OPERATIVO HARDWARE Funzioni di un
GPGPU GPGPU. anni piu' recenti e' naturamente aumentata la versatilita' ed usabilita' delle GPU
 GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
Prodotto Matrice - Vettore in OpenMP
 Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Elaborato di Calcolo Parallelo Prodotto Matrice - Vettore in OpenMP Anno Accademico 2011/2012 Professoressa Alessandra D Alessio Studenti
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Elaborato di Calcolo Parallelo Prodotto Matrice - Vettore in OpenMP Anno Accademico 2011/2012 Professoressa Alessandra D Alessio Studenti
SISTEMI OPERATIVI THREAD. Giorgio Giacinto 2013. Sistemi Opera=vi
 SISTEMI OPERATIVI THREAD 2 Mo*vazioni» Un programma complesso può eseguire in modo concorrente più funzioni agraverso la creazione e ges=one di processi figli agraverso il meccanismo dei thread» La creazione
SISTEMI OPERATIVI THREAD 2 Mo*vazioni» Un programma complesso può eseguire in modo concorrente più funzioni agraverso la creazione e ges=one di processi figli agraverso il meccanismo dei thread» La creazione
Introduzione ecos. Agenda. Giovanni Perbellini
 Introduzione ecos Giovanni Perbellini Agenda Introduzione ecos Toolchain Download codice sorgente Binutils GCC/G++ Newlib GDB/Insight Compilazione toolchain Selezione Target Compilazione ecos Configtool
Introduzione ecos Giovanni Perbellini Agenda Introduzione ecos Toolchain Download codice sorgente Binutils GCC/G++ Newlib GDB/Insight Compilazione toolchain Selezione Target Compilazione ecos Configtool
Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM. Davide Barbieri
 Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Principali versioni dell'hardware CUDA Tesla Fermi Accesso veloce alla memoria globale Accesso veloce alla memoria condivisa
Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Principali versioni dell'hardware CUDA Tesla Fermi Accesso veloce alla memoria globale Accesso veloce alla memoria condivisa
Posix Threads: l evoluzione dei processi UNIX
 Posix Threads: l evoluzione dei processi UNIX Raffaele Quitadamo, PhD in Computer Science Università di Modena e Reggio Emilia quitadamo.raffaele@unimore.it Sommario Pthreads vs Unix processes L API per
Posix Threads: l evoluzione dei processi UNIX Raffaele Quitadamo, PhD in Computer Science Università di Modena e Reggio Emilia quitadamo.raffaele@unimore.it Sommario Pthreads vs Unix processes L API per
Università di Roma La Sapienza Dipartimento di Matematica gennaio OpenMP. Parte Prima. Fabio Bonaccorso.
 Università di Roma La Sapienza Dipartimento di Matematica 15 31 gennaio 2007 OpenMP Parte Prima Fabio Bonaccorso f.bonaccorso@caspur.it 1 OpenMP OpenMP e' un modello di programmazione parallela a memoria
Università di Roma La Sapienza Dipartimento di Matematica 15 31 gennaio 2007 OpenMP Parte Prima Fabio Bonaccorso f.bonaccorso@caspur.it 1 OpenMP OpenMP e' un modello di programmazione parallela a memoria
Scheduling della CPU Introduzione ai Sistemi Operativi Corso di Abilità Informatiche Laurea in Fisica
 Scheduling della CPU Introduzione ai Sistemi Operativi Corso di Abilità Informatiche Laurea in Fisica prof. Ing. Corrado Santoro A.A. 2010-11 Architettura di un sistema operativo Progr 1 Progr 2 Progr
Scheduling della CPU Introduzione ai Sistemi Operativi Corso di Abilità Informatiche Laurea in Fisica prof. Ing. Corrado Santoro A.A. 2010-11 Architettura di un sistema operativo Progr 1 Progr 2 Progr
Java Virtual Machine
 Java Virtual Machine programmi sorgente: files.java compilatore files.class bytecode linker/loader bytecode bytecode Java API files.class interprete macchina ospite Indipendenza di java dalla macchina
Java Virtual Machine programmi sorgente: files.java compilatore files.class bytecode linker/loader bytecode bytecode Java API files.class interprete macchina ospite Indipendenza di java dalla macchina
Capitolo 3 -- Silberschatz
 Processi Capitolo 3 -- Silberschatz Concetto di processo Un SO esegue una varietà di attività: Sistemi batch job Sistemi time-sharing programmi utenti o task Nel libro i termini job e processo sono usati
Processi Capitolo 3 -- Silberschatz Concetto di processo Un SO esegue una varietà di attività: Sistemi batch job Sistemi time-sharing programmi utenti o task Nel libro i termini job e processo sono usati
Multithreading in Java. Fondamenti di Sistemi Informativi 2014-2015
 Multithreading in Java Fondamenti di Sistemi Informativi 2014-2015 Multithreading La programmazione concorrente consente di eseguire più processi o thread nello stesso momento. Nel secondo caso si parla
Multithreading in Java Fondamenti di Sistemi Informativi 2014-2015 Multithreading La programmazione concorrente consente di eseguire più processi o thread nello stesso momento. Nel secondo caso si parla
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
Schedulazione in RTAI
 Schedulazione in RTAI RTAI: modulo kernel rt_hello_km.c #include #include Thread real-time... Ciclo infinito RT_TASK task; Periodico... void task_routine() { while(1) { /* Codice
Schedulazione in RTAI RTAI: modulo kernel rt_hello_km.c #include #include Thread real-time... Ciclo infinito RT_TASK task; Periodico... void task_routine() { while(1) { /* Codice
Architettura CUDA Corso di sviluppo Nvidia CUDATM. Davide Barbieri
 Architettura CUDA Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Modello Architetturale CUDA Modello di programmazione CUDA Hello World in CUDA Gestione degli errori Terminologia Host
Architettura CUDA Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Modello Architetturale CUDA Modello di programmazione CUDA Hello World in CUDA Gestione degli errori Terminologia Host
ENEA GRID. CRESCO: Corso di introduzione. Autore: Alessandro Secco alessandro.secco@nice-italy.com
 ENEA GRID CRESCO: Corso di introduzione Autore: Alessandro Secco alessandro.secco@nice-italy.com 1 Lezione 1 Introduzione Architettura Connessione Lancio di job Riferimenti 2 Introduzione 3 Introduzione
ENEA GRID CRESCO: Corso di introduzione Autore: Alessandro Secco alessandro.secco@nice-italy.com 1 Lezione 1 Introduzione Architettura Connessione Lancio di job Riferimenti 2 Introduzione 3 Introduzione
Modalità di utilizzo dei server di calcolo del C.E.D. di Frascati
 Modalità di utilizzo dei server di calcolo del C.E.D. di Frascati 1 Macchine per lavori interattivi e batch Nome macch. Arc. Sist. Oper. N cpu RAM Freq. sp3-1 Power III AIX 5.1.3 16 16 GB 375 MHz sp3-2
Modalità di utilizzo dei server di calcolo del C.E.D. di Frascati 1 Macchine per lavori interattivi e batch Nome macch. Arc. Sist. Oper. N cpu RAM Freq. sp3-1 Power III AIX 5.1.3 16 16 GB 375 MHz sp3-2
Gestione dei processi. Marco Cesati. Schema della lezione. Blocco di controllo 2. Sezioni e segmenti. Gestione dei processi. Job.
 Di cosa parliamo in questa lezione? Lezione 4 Cosa è un processo e come viene gestito dal SO 1 e job 2 Il blocco di controllo Sistemi operativi 3 Struttura di un file eseguibile 4 La schedulazione dei
Di cosa parliamo in questa lezione? Lezione 4 Cosa è un processo e come viene gestito dal SO 1 e job 2 Il blocco di controllo Sistemi operativi 3 Struttura di un file eseguibile 4 La schedulazione dei
Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base
 Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15. Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15 Pietro Frasca Lezione 5 Martedì 21-10-2014 Thread Come abbiamo detto, un processo è composto
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15 Pietro Frasca Lezione 5 Martedì 21-10-2014 Thread Come abbiamo detto, un processo è composto
Processi e thread. Dipartimento di Informatica Università di Verona, Italy. Sommario
 Processi e thread Dipartimento di Informatica Università di Verona, Italy Sommario Concetto di processo Stati di un processo Operazioni e relazioni tra processi Concetto di thread Gestione dei processi
Processi e thread Dipartimento di Informatica Università di Verona, Italy Sommario Concetto di processo Stati di un processo Operazioni e relazioni tra processi Concetto di thread Gestione dei processi
Concetto di processo. Processi. Immagine in memoria di un processo. Stati di un processo. Un SO esegue una varietà di attività:
 Impossibile visualizzare l'immagine. Processi Concetto di processo Un SO esegue una varietà di attività: Sistemi batch job Sistemi time-sharing programmi utenti o task Nel libro i termini job e processo
Impossibile visualizzare l'immagine. Processi Concetto di processo Un SO esegue una varietà di attività: Sistemi batch job Sistemi time-sharing programmi utenti o task Nel libro i termini job e processo
Parallelizzazione Laplace 2D: MPI e MPI+OMP. - Cineca - SuperComputing Applications and Innovation Department
 Parallelizzazione Laplace 2D: MPI e MPI+OMP - Cineca - SuperComputing Applications and Innovation Department Outline Parallelizzazione Laplace 2D Parallelizzazione Laplace 2D - MPI bloccante Parallelizzazione
Parallelizzazione Laplace 2D: MPI e MPI+OMP - Cineca - SuperComputing Applications and Innovation Department Outline Parallelizzazione Laplace 2D Parallelizzazione Laplace 2D - MPI bloccante Parallelizzazione
Pronto Esecuzione Attesa Terminazione
 Definizione Con il termine processo si indica una sequenza di azioni che il processore esegue Il programma invece, è una sequenza di azioni che il processore dovrà eseguire Il processo è quindi un programma
Definizione Con il termine processo si indica una sequenza di azioni che il processore esegue Il programma invece, è una sequenza di azioni che il processore dovrà eseguire Il processo è quindi un programma
How build a Fedora HPC cluster running OpenFoam in parallel, using Torque/PBS, OpenMPI, Host-based authentication and NFS
 How build a Fedora HPC cluster running OpenFoam in parallel, using Torque/PBS, OpenMPI, Host-based authentication and NFS Pier Paolo Ciarravano 19/07/2010 Descrizione dell architettura Il cluster si compone
How build a Fedora HPC cluster running OpenFoam in parallel, using Torque/PBS, OpenMPI, Host-based authentication and NFS Pier Paolo Ciarravano 19/07/2010 Descrizione dell architettura Il cluster si compone
Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition
 Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition Enrico Zimuel Senior Consultant & Architect Zend Technologies enrico@zend.com Sommario Zend Server Community Edition (CE) Perchè eseguire
Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition Enrico Zimuel Senior Consultant & Architect Zend Technologies enrico@zend.com Sommario Zend Server Community Edition (CE) Perchè eseguire
Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer.
 I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
Configurazione & Programmazione Profibus DP. in Ambiente Siemens TIA Portal
 Configurazione & Programmazione Profibus DP in Ambiente Siemens TIA Portal Configurazione Optional: Aggiungere File GSD Inserire Masters e Slaves Inserire Sottorete Profibus DP e collegare tutte le interfacce
Configurazione & Programmazione Profibus DP in Ambiente Siemens TIA Portal Configurazione Optional: Aggiungere File GSD Inserire Masters e Slaves Inserire Sottorete Profibus DP e collegare tutte le interfacce
Linux nel calcolo distribuito
 openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero dino@delfavero.it, micky@delfavero.it BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero dino@delfavero.it, micky@delfavero.it BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
PAES. Laurea Specialistica in Informatica. Analisi e sviluppo di un implementazione parallela dell AES per. architetture eterogenee multi/many-core
 PAES Analisi e sviluppo di un implementazione parallela dell AES per architetture eterogenee multi/many-core Candidato Paolo Bernardi Relatore Osvaldo Gervasi Laurea Specialistica in Informatica Contesto
PAES Analisi e sviluppo di un implementazione parallela dell AES per architetture eterogenee multi/many-core Candidato Paolo Bernardi Relatore Osvaldo Gervasi Laurea Specialistica in Informatica Contesto
La Gestione delle risorse Renato Agati
 Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Grid Tutorial Day Palermo, 13 Aprile 2011 Job Description Language Gestione job utente
 Grid Tutorial Day Palermo, 13 Aprile 2011 Marco Cipolla Job Description Language Gestione job utente Jobs e Applicazioni Utente I job permettono l esecuzione di programmi utente sulla GRID Per sottomettere
Grid Tutorial Day Palermo, 13 Aprile 2011 Marco Cipolla Job Description Language Gestione job utente Jobs e Applicazioni Utente I job permettono l esecuzione di programmi utente sulla GRID Per sottomettere
 Unix e GNU/Linux Eugenio Magistretti emagistretti@deis.unibo.it Prima Esercitazione Fork Stefano Monti smonti@deis.unibo.it Unix: sviluppato negli anni '60-'70 presso Bell Labs di AT&T, attualmente sotto
Unix e GNU/Linux Eugenio Magistretti emagistretti@deis.unibo.it Prima Esercitazione Fork Stefano Monti smonti@deis.unibo.it Unix: sviluppato negli anni '60-'70 presso Bell Labs di AT&T, attualmente sotto
Java threads (2) Programmazione Concorrente
 Programmazione Concorrente") Java threads (2) emanuele lattanzi isti information science and technology institute 1/28 Programmazione Concorrente Utilizzo corretto dei thread in Java emanuele lattanzi isti information science and
Java threads (2) emanuele lattanzi isti information science and technology institute 1/28 Programmazione Concorrente Utilizzo corretto dei thread in Java emanuele lattanzi isti information science and
FONDAMENTI di INFORMATICA L. Mezzalira
 FONDAMENTI di INFORMATICA L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software
FONDAMENTI di INFORMATICA L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software
Il kit di installazione delle farm di CMS. Giovanni Organtini CMS/Roma
 Il kit di installazione delle farm di CMS Giovanni CMS/Roma Introduzione CMS in produzione MC dal 1999 Organizzazione della produzione! 2 tornate/anno! O(10 6 eventi)/tornata! Produzione distribuita! Contributo
Il kit di installazione delle farm di CMS Giovanni CMS/Roma Introduzione CMS in produzione MC dal 1999 Organizzazione della produzione! 2 tornate/anno! O(10 6 eventi)/tornata! Produzione distribuita! Contributo
1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi
 1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi Il processo E' un programma in esecuzione Tipi di processo Stati di un processo 1 indipendenti
1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi Il processo E' un programma in esecuzione Tipi di processo Stati di un processo 1 indipendenti
Processi e Thread. Scheduling (Schedulazione)
") Processi e Thread Scheduling (Schedulazione) 1 Scheduling Introduzione al problema dello Scheduling (1) Lo scheduler si occupa di decidere quale fra i processi pronti può essere mandato in esecuzione L
Processi e Thread Scheduling (Schedulazione) 1 Scheduling Introduzione al problema dello Scheduling (1) Lo scheduler si occupa di decidere quale fra i processi pronti può essere mandato in esecuzione L
Il Concetto di Processo
 Processi e Thread Il Concetto di Processo Il processo è un programma in esecuzione. È l unità di esecuzione all interno del S.O. Solitamente, l esecuzione di un processo è sequenziale (le istruzioni vengono
Processi e Thread Il Concetto di Processo Il processo è un programma in esecuzione. È l unità di esecuzione all interno del S.O. Solitamente, l esecuzione di un processo è sequenziale (le istruzioni vengono
Introduzione all ambiente di sviluppo
 Laboratorio II Raffaella Brighi, a.a. 2005/06 Corso di Laboratorio II. A.A. 2006-07 CdL Operatore Informatico Giuridico. Introduzione all ambiente di sviluppo Raffaella Brighi, a.a. 2005/06 Corso di Laboratorio
Laboratorio II Raffaella Brighi, a.a. 2005/06 Corso di Laboratorio II. A.A. 2006-07 CdL Operatore Informatico Giuridico. Introduzione all ambiente di sviluppo Raffaella Brighi, a.a. 2005/06 Corso di Laboratorio
RTAI e scheduling. Andrea Sambi
 RTAI e scheduling Andrea Sambi Scheduling Linux Due politiche di scheduling priority-driven possibili. FIFO priorità uguali Processo 1 iniziato Processo 1: iterazione 1 Processo 1: iterazione 2 Processo
RTAI e scheduling Andrea Sambi Scheduling Linux Due politiche di scheduling priority-driven possibili. FIFO priorità uguali Processo 1 iniziato Processo 1: iterazione 1 Processo 1: iterazione 2 Processo
Add workstations to domain. Adjust memory quotas for a process. Bypass traverse checking. Change the system time. Create a token object
 SeTcb Act as part of the operating system Consente ad un processo di assumere l identità di un qualsiasi utente ottenere così l accesso alle risorse per cui è autorizzato tale utente SeMachineAccount SeIncreaseQuota
SeTcb Act as part of the operating system Consente ad un processo di assumere l identità di un qualsiasi utente ottenere così l accesso alle risorse per cui è autorizzato tale utente SeMachineAccount SeIncreaseQuota
Lezione 2 Principi Fondamentali di SO Interrupt e Caching. Sommario
 Lezione 2 Principi Fondamentali di SO Interrupt e Caching Sommario Operazioni di un SO: principi fondamentali Una visione schematica di un calcolatore Interazione tra SO, Computer e Programmi Utente 1
Lezione 2 Principi Fondamentali di SO Interrupt e Caching Sommario Operazioni di un SO: principi fondamentali Una visione schematica di un calcolatore Interazione tra SO, Computer e Programmi Utente 1
Il descrittore di processo (PCB)
") Il descrittore di processo (PC) Il S.O. gestisce i processi associando a ciascuno di essi un struttura dati di tipo record detta descrittore di processo o Process Control lock (PC) Il PC contiene tutte
Il descrittore di processo (PC) Il S.O. gestisce i processi associando a ciascuno di essi un struttura dati di tipo record detta descrittore di processo o Process Control lock (PC) Il PC contiene tutte
Algoritmi di scheduling
 Capitolo 3 Algoritmi di scheduling Come caso particolare di studio, di seguito è discussa in dettaglio la politica di scheduling del sistema operativo LINUX (kernel precedente alla versione 2.6). Sono
Capitolo 3 Algoritmi di scheduling Come caso particolare di studio, di seguito è discussa in dettaglio la politica di scheduling del sistema operativo LINUX (kernel precedente alla versione 2.6). Sono
Database & FreeBSD. Come configurare il sistema operativo ottimizzando le prestazioni sul DB. GufiCon#3 Milano, 12 Ottobre 2002
 Database & FreeBSD Come configurare il sistema operativo ottimizzando le prestazioni sul DB GufiCon#3 Milano, 12 Ottobre 2002 Gianluca Sordiglioni inzet@gufi.org I database sono applicazioni particolari
Database & FreeBSD Come configurare il sistema operativo ottimizzando le prestazioni sul DB GufiCon#3 Milano, 12 Ottobre 2002 Gianluca Sordiglioni inzet@gufi.org I database sono applicazioni particolari
Il Sistema Operativo (1)
") E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
scheduling Riedizione modifi cata delle slide della Prof. DI Stefano
 scheduling Riedizione modifi cata delle slide della Prof. DI Stefano 1 Scheduling Alternanza di CPU burst e periodi di I/O wait a) processo CPU-bound b) processo I/O bound 2 CPU Scheduler Seleziona uno
scheduling Riedizione modifi cata delle slide della Prof. DI Stefano 1 Scheduling Alternanza di CPU burst e periodi di I/O wait a) processo CPU-bound b) processo I/O bound 2 CPU Scheduler Seleziona uno
Scheduling della CPU. Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux
 Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO. A cura di Tania Caprini
 CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
Terza Esercitazione. Unix - Esercizio 1. Unix System Call Exec Java Introduzione Thread
 Terza Esercitazione Unix System Call Exec Java Introduzione Thread Stefano Monti smonti@deis.unibo.it Unix - Esercizio 1 Scrivere un programma C con la seguente interfaccia:./compilaedesegui
Terza Esercitazione Unix System Call Exec Java Introduzione Thread Stefano Monti smonti@deis.unibo.it Unix - Esercizio 1 Scrivere un programma C con la seguente interfaccia:./compilaedesegui
Prima Esercitazione. Unix e GNU/Linux. GNU/Linux e linguaggio C. Stefano Monti smonti@deis.unibo.it
 Prima Esercitazione GNU/Linux e linguaggio C Stefano Monti smonti@deis.unibo.it Unix e GNU/Linux Unix: sviluppato negli anni '60-'70 presso Bell Labs di AT&T, attualmente sotto il controllo del consorzio
Prima Esercitazione GNU/Linux e linguaggio C Stefano Monti smonti@deis.unibo.it Unix e GNU/Linux Unix: sviluppato negli anni '60-'70 presso Bell Labs di AT&T, attualmente sotto il controllo del consorzio
Mul&programmazione. Ges&one dei processi. Esecuzione parallela. MAC OSX Monitoraggio a9vità. Linux System monitor. Windows Task Manager. A.
 Mul&programmazione Ges&one dei processi A. Ferrari Tu9 i Sistemi Opera&vi moderni sono in grado di eseguire contemporaneamente più di un programma Il numero di programmi in esecuzione è superiore al numero
Mul&programmazione Ges&one dei processi A. Ferrari Tu9 i Sistemi Opera&vi moderni sono in grado di eseguire contemporaneamente più di un programma Il numero di programmi in esecuzione è superiore al numero
VIPA 900-2E641 PSTN VPN
 CONFIGURARE IL DISPOSITIVO DI TELEASSISTENZA VIPA 900-2E641 PSTN VPN Requisiti hardware: Dispositivo VIPA 900-2E641 PSTN VPN con versione di firmware almeno 6_1_s2. Cavo telefonico e linea analogica. Requisiti
CONFIGURARE IL DISPOSITIVO DI TELEASSISTENZA VIPA 900-2E641 PSTN VPN Requisiti hardware: Dispositivo VIPA 900-2E641 PSTN VPN con versione di firmware almeno 6_1_s2. Cavo telefonico e linea analogica. Requisiti
15 - Packages. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 15 - Packages Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
15 - Packages Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
Prestazioni computazionali di OpenFOAM sul. sistema HPC CRESCO di ENEA GRID
 Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
Architettura di un sistema operativo
 Architettura di un sistema operativo Dipartimento di Informatica Università di Verona, Italy Struttura di un S.O. Sistemi monolitici Sistemi a struttura semplice Sistemi a livelli Virtual Machine Sistemi
Architettura di un sistema operativo Dipartimento di Informatica Università di Verona, Italy Struttura di un S.O. Sistemi monolitici Sistemi a struttura semplice Sistemi a livelli Virtual Machine Sistemi
Sistema Operativo. Fondamenti di Informatica 1. Il Sistema Operativo
 Sistema Operativo Fondamenti di Informatica 1 Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al
Sistema Operativo Fondamenti di Informatica 1 Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al
Il computer: primi elementi
 Il computer: primi elementi Tommaso Motta T. Motta Il computer: primi elementi 1 Informazioni Computer = mezzo per memorizzare, elaborare, comunicare e trasmettere le informazioni Tutte le informazioni
Il computer: primi elementi Tommaso Motta T. Motta Il computer: primi elementi 1 Informazioni Computer = mezzo per memorizzare, elaborare, comunicare e trasmettere le informazioni Tutte le informazioni
CVserver. CVserver. Micky Del Favero micky@linux.it. BLUG - Belluno Linux User Group Linux Day 2008 - Feltre 25 ottobre 2008. Un cluster di VServer
 Un cluster di VServer Micky Del Favero micky@linux.it BLUG - Belluno Linux User Group Linux Day 2008 - Feltre 25 ottobre 2008 p. 1 Motivazione Legge di Murphy: Se qualcosa può andare storto allora lo farà.
Un cluster di VServer Micky Del Favero micky@linux.it BLUG - Belluno Linux User Group Linux Day 2008 - Feltre 25 ottobre 2008 p. 1 Motivazione Legge di Murphy: Se qualcosa può andare storto allora lo farà.
Linguaggio C. Fondamenti. Struttura di un programma.
 Linguaggio C Fondamenti. Struttura di un programma. 1 La storia del Linguaggio C La nascita del linguaggio C fu dovuta all esigenza di disporre di un Linguaggio ad alto livello adatto alla realizzazione
Linguaggio C Fondamenti. Struttura di un programma. 1 La storia del Linguaggio C La nascita del linguaggio C fu dovuta all esigenza di disporre di un Linguaggio ad alto livello adatto alla realizzazione
Speedup. Si definisce anche lo Speedup relativo in cui, invece di usare T 1 si usa T p (1).
.") Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Il sistema operativo. Sistema operativo. Multiprogrammazione. Il sistema operativo. Gestione della CPU
 Il sistema operativo Sistema operativo Gestione della CPU Primi elaboratori: Monoprogrammati: un solo programma in memoria centrale Privi di sistema operativo Gestione dell hardware da parte degli utenti
Il sistema operativo Sistema operativo Gestione della CPU Primi elaboratori: Monoprogrammati: un solo programma in memoria centrale Privi di sistema operativo Gestione dell hardware da parte degli utenti
Processi. Laboratorio Software 2008-2009 C. Brandolese
 Processi Laboratorio Software 2008-2009 Introduzione I calcolatori svolgono operazioni simultaneamente Esempio Compilazione di un programma Invio di un file ad una stampante Visualizzazione di una pagina
Processi Laboratorio Software 2008-2009 Introduzione I calcolatori svolgono operazioni simultaneamente Esempio Compilazione di un programma Invio di un file ad una stampante Visualizzazione di una pagina
INFORMATICA. Il Sistema Operativo. di Roberta Molinari
 INFORMATICA Il Sistema Operativo di Roberta Molinari Il Sistema Operativo un po di definizioni Elaborazione: trattamento di di informazioni acquisite dall esterno per per restituire un un risultato Processore:
INFORMATICA Il Sistema Operativo di Roberta Molinari Il Sistema Operativo un po di definizioni Elaborazione: trattamento di di informazioni acquisite dall esterno per per restituire un un risultato Processore:
Sistemi Operativi. Interfaccia del File System FILE SYSTEM : INTERFACCIA. Concetto di File. Metodi di Accesso. Struttura delle Directory
 FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
Lo scheduler di UNIX (1)
") Lo scheduler di UNIX (1) Lo scheduling a basso livello è basato su una coda a più livelli di priorità 1 Lo scheduler di UNIX (2) Si esegue il primo processo della prima coda non vuota per massimo 1 quanto
Lo scheduler di UNIX (1) Lo scheduling a basso livello è basato su una coda a più livelli di priorità 1 Lo scheduler di UNIX (2) Si esegue il primo processo della prima coda non vuota per massimo 1 quanto
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione.
 Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Sistemi Operativi. Scheduling della CPU SCHEDULING DELLA CPU. Concetti di Base Criteri di Scheduling Algoritmi di Scheduling
 SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
Sistemi Operativi SCHEDULING DELLA CPU. Sistemi Operativi. D. Talia - UNICAL 5.1
 SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
File system II. Sistemi Operativi Lez. 20
 File system II Sistemi Operativi Lez. 20 Gestione spazi su disco Esiste un trade-off,tra spreco dello spazio e velocità di trasferimento in base alla dimensione del blocco fisico Gestione spazio su disco
File system II Sistemi Operativi Lez. 20 Gestione spazi su disco Esiste un trade-off,tra spreco dello spazio e velocità di trasferimento in base alla dimensione del blocco fisico Gestione spazio su disco
ASPETTI GENERALI DI LINUX. Parte 2 Struttura interna del sistema LINUX
 Parte 2 Struttura interna del sistema LINUX 76 4. ASPETTI GENERALI DEL SISTEMA OPERATIVO LINUX La funzione generale svolta da un Sistema Operativo può essere definita come la gestione dell Hardware orientata
Parte 2 Struttura interna del sistema LINUX 76 4. ASPETTI GENERALI DEL SISTEMA OPERATIVO LINUX La funzione generale svolta da un Sistema Operativo può essere definita come la gestione dell Hardware orientata
Il Sistema Operativo
 Il Sistema Operativo Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al meglio le risorse del Sistema
Il Sistema Operativo Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al meglio le risorse del Sistema
REQUISITI TECNICI HR INFINITY ZUCCHETTI
 REQUISITI TECNICI HR INFINITY ZUCCHETTI Documento aggiornato al 21 Novembre 2014 (Valido fino al 30/06/2015) Le versioni di sistemi operativi di seguito indicati rappresentano quelle utilizzate nei nostri
REQUISITI TECNICI HR INFINITY ZUCCHETTI Documento aggiornato al 21 Novembre 2014 (Valido fino al 30/06/2015) Le versioni di sistemi operativi di seguito indicati rappresentano quelle utilizzate nei nostri
Simulazione dell esecuzione di processi su architettura multiprocessore
 Simulazione dell esecuzione di processi su architettura multiprocessore Progetto di Sistemi per l Elaborazione delle Informazioni A cura di: Bernardino Frola Sommario Introduzione Struttura Comportamento
Simulazione dell esecuzione di processi su architettura multiprocessore Progetto di Sistemi per l Elaborazione delle Informazioni A cura di: Bernardino Frola Sommario Introduzione Struttura Comportamento
14 - Packages. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 14 - Packages Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
14 - Packages Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
Corso di Laurea in Ingegneria Informatica. Laboratorio di Sistemi Operativi. II anno, III periodo 2 crediti 13 ore di lezione 16 ore di esercitazione
 Corso di Laurea in Ingegneria Informatica Laboratorio di Sistemi Operativi II anno, III periodo 2 crediti 13 ore di lezione 16 ore di esercitazione INFORMAZIONI UTILI Docente: Gianluigi Folino tel. : 0984/831731
Corso di Laurea in Ingegneria Informatica Laboratorio di Sistemi Operativi II anno, III periodo 2 crediti 13 ore di lezione 16 ore di esercitazione INFORMAZIONI UTILI Docente: Gianluigi Folino tel. : 0984/831731
Algebra di Boole: Concetti di base. Fondamenti di Informatica - D. Talia - UNICAL 1. Fondamenti di Informatica
 Fondamenti di Informatica Algebra di Boole: Concetti di base Fondamenti di Informatica - D. Talia - UNICAL 1 Algebra di Boole E un algebra basata su tre operazioni logiche OR AND NOT Ed operandi che possono
Fondamenti di Informatica Algebra di Boole: Concetti di base Fondamenti di Informatica - D. Talia - UNICAL 1 Algebra di Boole E un algebra basata su tre operazioni logiche OR AND NOT Ed operandi che possono
Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa. Raccolta prove scritte. Prova scritta
 Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa Raccolta prove scritte Realizzare una classe thread Processo che deve effettuare un numero fissato di letture da una memoria
Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa Raccolta prove scritte Realizzare una classe thread Processo che deve effettuare un numero fissato di letture da una memoria
Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition
 Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition Enrico Zimuel Senior Consultant & Architect Zend Technologies enrico@zend.com 9 Ottobre 2010 JoomlaDay Verona Sommario Zend Server
Velocizzare l'esecuzione di Joomla! con Zend Server Community Edition Enrico Zimuel Senior Consultant & Architect Zend Technologies enrico@zend.com 9 Ottobre 2010 JoomlaDay Verona Sommario Zend Server
Fondamenti di Informatica 1. Prof. B.Buttarazzi A.A. 2010/2011
 Fondamenti di Informatica 1 Prof. B.Buttarazzi A.A. 2010/2011 Sommario Installazione SOFTWARE JDK ECLIPSE 03/03/2011 2 ALGORITMI E PROGRAMMI PROBLEMA ALGORITMO PROGRAMMA metodo risolutivo linguaggio di
Fondamenti di Informatica 1 Prof. B.Buttarazzi A.A. 2010/2011 Sommario Installazione SOFTWARE JDK ECLIPSE 03/03/2011 2 ALGORITMI E PROGRAMMI PROBLEMA ALGORITMO PROGRAMMA metodo risolutivo linguaggio di
Le command line di Java
 Le command line di Java Esercitazioni di Programmazione 2 Novella Brugnolli brugnoll@science.unitn.it Ambiente di lavoro Per compilare ed eseguire un programma Java abbiamo bisogno di: The JavaTM 2 Platform,
Le command line di Java Esercitazioni di Programmazione 2 Novella Brugnolli brugnoll@science.unitn.it Ambiente di lavoro Per compilare ed eseguire un programma Java abbiamo bisogno di: The JavaTM 2 Platform,
Università degli Studi di Salerno
 Università degli Studi di Salerno Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Informatica Tesi di Laurea Algoritmi basati su formule di quadratura interpolatorie per GPU ABSTRACT
Università degli Studi di Salerno Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Informatica Tesi di Laurea Algoritmi basati su formule di quadratura interpolatorie per GPU ABSTRACT
Introduzione alle applicazioni di rete
 Introduzione alle applicazioni di rete Definizioni base Modelli client-server e peer-to-peer Socket API Scelta del tipo di servizio Indirizzamento dei processi Identificazione di un servizio Concorrenza
Introduzione alle applicazioni di rete Definizioni base Modelli client-server e peer-to-peer Socket API Scelta del tipo di servizio Indirizzamento dei processi Identificazione di un servizio Concorrenza
L HARDWARE parte 1 ICTECFOP@GMAIL.COM
 L HARDWARE parte 1 COMPUTER E CORPO UMANO INPUT E OUTPUT, PERIFERICHE UNITA DI SISTEMA: ELENCO COMPONENTI COMPONENTI NEL DETTAGLIO: SCHEDA MADRE (SOCKET, SLOT) CPU MEMORIA RAM MEMORIE DI MASSA USB E FIREWIRE
L HARDWARE parte 1 COMPUTER E CORPO UMANO INPUT E OUTPUT, PERIFERICHE UNITA DI SISTEMA: ELENCO COMPONENTI COMPONENTI NEL DETTAGLIO: SCHEDA MADRE (SOCKET, SLOT) CPU MEMORIA RAM MEMORIE DI MASSA USB E FIREWIRE
Corso di Sistemi di Elaborazione delle informazioni
 Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Evoluzione dei sistemi operativi (5) Evoluzione dei sistemi operativi (4) Classificazione dei sistemi operativi
 Evoluzione dei sistemi operativi (4) Classificazione dei sistemi operativi") Evoluzione dei sistemi operativi (4) Sistemi multiprogrammati! più programmi sono caricati in contemporaneamente, e l elaborazione passa periodicamente dall uno all altro Evoluzione dei sistemi operativi
Evoluzione dei sistemi operativi (4) Sistemi multiprogrammati! più programmi sono caricati in contemporaneamente, e l elaborazione passa periodicamente dall uno all altro Evoluzione dei sistemi operativi
3 - Variabili. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 3 - Variabili Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
3 - Variabili Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di