Tecnologie bioinformatiche
|
|
|
- Alessandro Bianco
- 8 anni fa
- Visualizzazioni
Transcript
1 Tecnologie bioinformatiche Paolo Romano Istituto Nazionale per la Ricerca sul Cancro skype: p.romano)

2 Sommario Ontologie dei dati Integrazione dati in biologia Automazione delle procedure in rete Workflow management systems Per approfondimenti, contattatemi 2

3 Ontologie Un ontologia è la specificazione formale della conoscenza di un determinato ambito, usalmente ristretto. Un ontologia consiste di: una serie di concetti, un vocabolario controllato per esprimerli, le relazioni tra di essi. Un ontologia può essere utilizzata per: aggiungere contenuto semantico a un database, migliorare l accesso ai dati, facilitare l integrazione dei dati. Consente al ricercatore di comprendere il significato assegnato ai dati anche senza competenze informatiche. 3

4 Open Biomedical Ontologies Open Biomedical Ontologies (OBO) Foundry Un incubatore per lo sviluppo coordinato di ontologie biomediche L obiettivo è la definizione di un insieme omogeneo di ontologie (di alta qualità) interoperanti, cioé in grado di consentire un efficace interoperabilità dei sistemi informativi che le utilizzano Sono definite utilizzando l OBO language 4

5 Alcune delle ontologie Ontologie base Gene Ontology (GO), MGED Ontology (MO) Ontologie nate come sviluppo di quelle base Cell Ontology (CO), Ontology for Biomedical Investigations (OBI) Ontologie upper-level (concetti chiave, riusabili) Foundational Model of Anatomy (FMA) Galen Bio Upper Ontology Ontologie pensate per sviluppi futuri Phenotype, Attribute and Trait Ontology (PATO) Clinical Bioinformatics Ontology (CBO) 5
 Clinical Bioinformatics")
6 Un esperimento Predizione della struttura di una proteina per omologia 6

7 Requisiti In un analisi svolta dai ricercatori, è necessario che sappiano: Quali servizi usare e come usarli In quale ordine usarli Come trasferire dati tra servizi Come conciliare la semantica dei servizi In un analisi automatizzata, è richiesta una conoscenza simile: trovare il tipo di servizio necessario per uno specifico task (e.g. allineamento sequenze, recupero di struttura di proteina) trovare le implementazioni reali (istanze) di quel servizio (e.g. BLAST, fornito da NCBI) comporre questi servizi per ottenere un insieme dinamico di servizi che svolga il task (workflows). Una ontologia può consentire di descrivere, ricercare e comporre i servizi fornendo concetti relativi a tipo di elaborazione e tipo di dati 7
 comporre questi servizi per ottenere un insieme dinamico di servizi che svolga il task (workflows).")
8 BioMoby BioMoby fornisce un framework per l interoperabilità che definisce: Un ontologia di domini (Namespace Ontology) Un ontologia dei tipi di dati (Data Type Ontology) Un ontologia per i servizi (Service Ontology) Le ontologie sono aggiornabili dall utente (end-userextensible), pubbliche e in continua evoluzione. Il framework include anche: Un Web Service registry (MOBY Central), nel quale i servizi sono descritti e possono essere scoperti tramite le ontologie Una Web Service message structure, che specifica il linguaggio che consente la comunicazione tra servizi, client e registri 8
, nel quale i servizi sono descritti e possono essere scoperti tramite le")
9 MOBY protocol Gordon P, Sensen C, Seahawk: moving beyond HTML in Web-based bioinformatics analysis 9

10 Namespace Ontology Q: Di quali dati parliamo? La Namespace Ontology consente la contestualizzazione degli identificatori dei database biomedici definendo namespaces validi. Consiste in un vocabolario controllato con ca. 300 termini, quali: KEGG_ID (KEGG record), NCBI_gi (GenBank records), GO (Gene Ontology records) La combinazione di un namespace e di un ID per un BioMoby Object ne rappresenta uno unique identifier 10
, NCBI_gi (GenBank records), GO (Gene Ontology records) La")
11 Data Type Ontology Q: Come è rappresentato il dato? La Data Type Ontology consente di rappresentare tipi di dati in maniera ben definita (well-defined). Consente anche la trasformazione automatica dei dati in formati diversi e il parsing necessario per estrarre le informazioni da tipi di dati complessi Consiste in una gerarchia is-a, con due relazioni: has-a (cardinalità uno) e has (cardinalità zero o più ). Gli elementi dell ontologia hanno tre proprietà: namespace (un termine della relativa ontology), id (identificativo di record), articlename (semantica della relazione verso l oggetto). Questa ontologia consiste di più di 300 diverse definizioni, compresi molti formati di uso comune 11
, id (identificativo di record), articlename (semantica della relazione verso l")
12 Creazione di nuovi oggetti 12

13 Service Ontology La Service Ontology consente di raggruppare in categorie i tool bioinformatici La Service Ontology è una gerarchia is-a che definisce i tipi di analisi dei dati; ad esempio, comprende: Retrieval (recupero di record da un db), Parsing (estrazione di informazioni da formati noti), Conversion (conversioni di formatoper tipi di dati noti). L utilizzo di sotto-classi consente di definire i tipi di analisi a diversi livelli di precisione. E.g., Analysis ha una sotto-classe Pairwise Sequence Comparison. 13 Q: Cosa posso fare con questi dati?

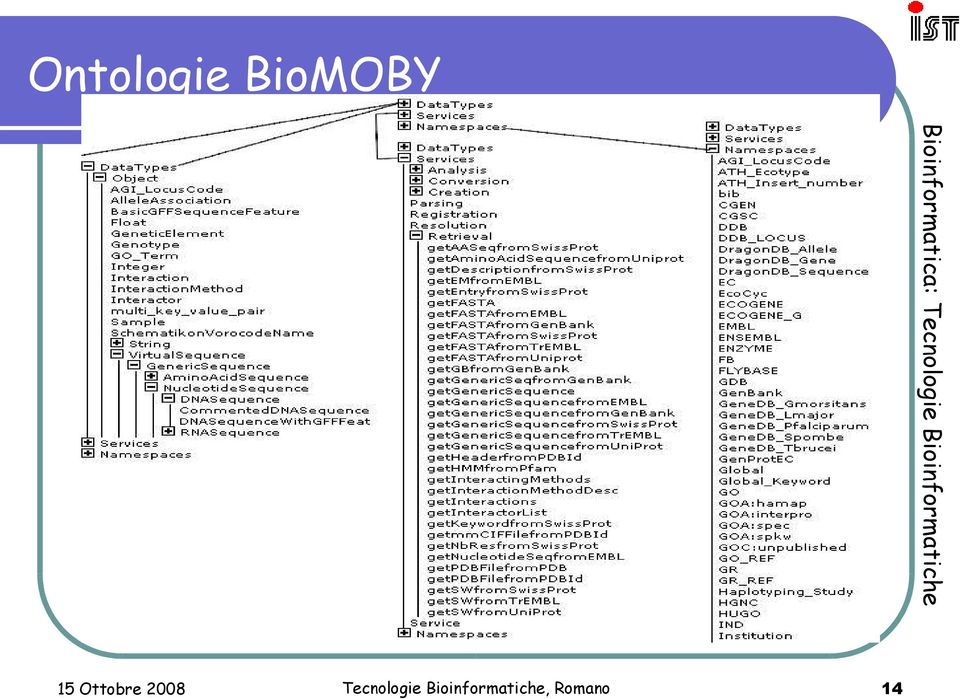
14 Ontologie BioMOBY 14
15 BioMOBY Reference Wilkinson MD, Links M, BioMOBY: An open source biological web services proposal, Briefings in Bioinformatics, 2002, 3(4): Kawas E, Senger M, Wilkinson MD, BioMoby extensions to the Taverna workflow management and enactment software, BMC Bioinformatics 2006, 7:523 BioMOBY web site: MOBY Dashboard: 15

16 Obiettivi dell integrazione L integrazione dei dati e l automazione dei processi sono necessari per: o Ottenere una visione complessiva e più precisa di tutte le informazioni disponibili o Eseguire automaticamente interrogazioni e/o analisi che coinvolgono più database e software Eseguire con efficienza analisi che coinvolgono grosse quantità di dati o o Realizzare un effettivo data mining 16

17 Integrazione: longevità L integrazione necessita di stabilità: o o o o Buona conoscenza e comprensione del dominio Buona definizione dei dati Standardizzazione Obiettivi ben definiti L integrazione teme: o o o o o o Incertezza nella comprensione del dominio Eterogeneità dei dati e dei sistemi Specializzazione dei dati Rapida evoluzione dei dati Spontaneità, sperimentalismo Mancanza di obiettivi predefiniti 17

18 Specificità dell integrazione o o o o Una pre-analisi delle informazioni è impossibile: dati e conoscenze cambiano frequentemente e rapidamente La complessità delle informazioni non permette di creare modelli validi in diversi ambiti e nel tempo La disponibilità di strumenti assestati riduce le possibilità di implementare standard comuni Le esigenze e gli obiettivi di ricerca evolvono rapidamente, seguendo le nuove acquisizioni e teorie Strumenti tradizionali (data warehouse, software di integrazione SRS) pongono problemi: dimensione, aggiornamento, struttura variabile L integrazione deve essere sviluppata con sistemi flessibili, adattabili ed espandibili 18 In ambito biologico:
 pongono problemi: dimensione, aggiornamento, struttura variabile L integrazione deve essere sviluppata con sistemi flessibili, adattabili ed espandibili")
19 Integrazione dati L automazione dei processi di integrazione e d analisi dati si ottiene o o o o o o o Creando modelli dati condivisi degli oggetti biologici Definendo linguaggi XML con vocabolari controllati (schema definito) Memorizzando i dati nei formati XML Utilizzando Web Services per lo scambio dei dati tra software Caratterizzando i dati e le analisi tramite un ontologia dei dati e dei task bioinformatici Codificando i processi d analisi sotto forma di workflow Creando portali user-friendly per l utilizzo più ampio possibile dei workflow 19

20 XML (extensible Markup Language) Linguaggio Markup estensibile: o o o Supera limiti HTML (orientato all impaginazione) Semplice definizione e implementazione nuovi documenti tramite Document Type Definitions (DTDs) Modulare, nuovi DTD possono utilizzare i precedenti Utilizzabile da applicazioni software: o o o o Corretto (Well formed, conforme allo standard XML) Valido (conforme al DTD) Definizioni standardizzate (namespaces) Analisi sintattica ed estrazione dati automatiche 20
 Valido (conforme al DTD) Definizioni standardizzate (namespaces) Analisi sintattica ed estrazione dati")
21 AA standard; RNA; EST; 337 BP. AA415057; AA OCT-1997 (Rel. 53, Created) 14-DEC-1999 (Rel. 62, Last updated, Version 2) Mg0001 RCW Lambda Zap Express Library Pyricularia grisea cdna clone RCW1 5', mrna sequence. EST. Magnaporthe grisea Eukaryota; Fungi; Ascomycota; Pezizomycotina; Sordariomycetes; Sordariomycetes incertae sedis; Magnaporthaceae; Magnaporthe. [1] Wu S.-C., Bernstein B.D., Darvill A.G., Albersheim P.; "Expressed sequence tags of the rice blast fungus grown on rice cell walls"; Unpublished. UNILIB; 863; 863. Contact: Sheng-Cheng Wu CCRC University of Georgia 220 Riverbend Road, Athens, GA , USA Tel: Fax: Seq primer: T3. ID AC SV DT DT DE DE KW OS OC OC RN RP RA RT RT RL DR CC CC CC CC CC CC CC CC 21
22 Key Location/Qualifiers source /db_xref="taxon:148305" /db_xref="unilib:863" /note="vector: Lambda Zap; Messenger RNAs prepared from Magnaporthe grisea grown at 23C in the dark with constant gyratory shaking (100 rpm) in Vogel's medium containing 0.5% isolated rice cell walls as the sole carbon source" /organism="magnaporthe grisea" /strain="cp987" /clone="rcw1" /clone_lib="rcw Lambda Zap Express Library" /tissue_type="mycelium" /dev_stage="day 5 post-inoculation" Sequence 337 BP; 56 A; 111 C; 74 ctttttcaat cagcccgaga actcctggtt tcatcgcata gcccgttctt tggttccaga caactctttc aaaatggtat tattagcctc ccttgcttca cgctctcgag cttttcagag caccgctcgc ggccagggca aatccacaac aagcaggttg ttgtcgactg gttcgccctt G; 96 T; 0 gggttttctg taccacaagc ctcacgatcc cagtgctgct tctcctgagg tcgtatt other; cctgttctga ctgggacatt ctcgcgcgtt tcccgttccc cccgcggccg cagctacttg gatttcccag cgcttggtcc tctcgactgc ccacgaggac // 22 FH FH FT FT FT FT FT FT FT FT FT FT FT FT FT XX SQ
23 <!ELEMENT interpro (name, type, examplelist, memberlist, publist, parlist*, chlist*, seclist*, abstract)> name (#PCDATA)> type (#PCDATA)> abstract (#PCDATA cite dbxref sub sup p li i ol reaction pre)*> examplelist (example*)> example (#PCDATA protein dbxref cite)*> publist (publication*)> memberlist (dbxref*)> protein (#PCDATA protein)*> <!ATTLIST interpro id <!ATTLIST dbxref db dbkey name <!ATTLIST protein sptr_ac status start end ID #REQUIRED> CDATA #IMPLIED CDATA #IMPLIED CDATA #IMPLIED> DTD per Interpro CDATA #REQUIRED (? T P F N) #IMPLIED CDATA #IMPLIED CDATA #IMPLIED> 23 <!ELEMENT <!ELEMENT <!ELEMENT <!ELEMENT <!ELEMENT <!ELEMENT <!ELEMENT <!ELEMENT
24 <interpro id="ipr000002"> Record Interpro XML <name>fizzy/cdc20 domain</name> <type>domain</type> <abstract> This domain is found in proteins </abstract> <examplelist> <example> <protein sptr_ac="q12834" />Mammalian protein, p55cdc </example> <example> <protein sptr_ac="q09649" /> </example> </examplelist> <publist> <publication pub_id="pub "> <authorlist>shirayama M., Toth A., Galova M., Nasmyth K.</authorlist> <title>apc(cdc20) promotes exit from mitosis by </title> <dbxref db="medline" dbkey=" " /> <journal>nature</journal> <location firstpage="203" lastpage="207" volume="402" /> <year>1999</year> </publication> </publist> <memberlist> <dbxref db="prefile" dbkey="ps50218" name="fizzy_domain" /> <dbxref db="prodom" dbkey="pd004563" name="pd004563" /> </memberlist> </interpro> 24
25 Linguaggi XML in biologia Sequenze Bioinformatic Sequence Markup Language (BSML) Agave Proteine (SPML) NCBI outputs (BlastXML) Microarray (MAGE-ML) Systems Biology Markup Language (SBML) Variabilità individuale Biological Variation Markup Language (BVML) 25
26 Web Services Interfacce programmatiche (API) per l accesso a servizi di rete basate su XML e protocolli standard di trasporto (HTTP, SOAP) Consentono alle applicazioni di accedere ai dati in maniera intelligente: individuazione dei contenuti e comprensione semantica Sono disponibili standard per la loro descrizione (WSDL), identificazione (UDDI) e composizione (WSFL) Utilizzano dati identificativi e descrittivi delle informazioni e dei servizi offerti (metadata) 26
27 WSDL: descrivere il WS Web Services Description Language (WSDL) Standard per la descrizione dei Web Services Comprende dettagli per l accesso concreti: localizzazione e modalità di accesso Comprende funzionalità astratte Implementazioni di WSDL per: SOAP, HTTP, MIME 27
28 UDDI: Registrare i servizi Universal Description, Discovery and Integration (UDDI) Realizzazione di un framework per la descrizione dei Web Services, indipendente da HW e SW Consente la creazione di registri di Web Services Basato su standard World Wide Web Consortium (W3C) and Internet Engineering Task Force (IETF) Esistono alternative: biomoby 28
29 WSFL: Comporre servizi complessi Web Services Flow Language (WSFL) Consente di descrivere insiemi di web services Flow models: specifica come utilizzare un insieme di web services per raggiungere un certo obiettivo Global models: descrive le interazioni tra più web services e il comportamento globale di un insieme Recursive composition: ogni model (flow o global) è un nuovo Web Service e può rientrare in altri modelli Esistono alternative: WSCDL (Web Services Choreography Description Language) Scufl (Simple Conceptual Unified Flow Language) XPDL (XML Processes Description Language) 29
30 Web Services in bioinformatica EMBOSS, XEMBL, Interpro (EBI) eutils (NCBI) cabio (NCICB) KEGG API GeneCruiser, Biosphere (microarray) SIMAP (proteine) Cataloghi CABRI (risorse biologiche) Mutazioni TP53 SoapLab (tool per sviluppare WS) BioMOBY (WS registry) 30
31 CABRI Common Access to Biological Resources and Information Obiettivi Distribuzione di materiali biologici di qualità Linee Guida per la conservazione del materiale Cataloghi integrati tramite SRS Shopping cart Partners 12 CRB europei, 28 collezioni + IST Materiali Microrganismi (Batteri, lieviti, funghi filiformi) Linee cellulari animali e umane, ibridomi, linee B tip. HLA Plasmidi, fagi, virus, sonde DNA Complessivamente più di risorse 31
32 IARC TP53 database IARC TP53 Mutation Database Release 9: 19,809 mutazioni somatiche, 1,769 articoli Informazioni: mutazione, materiale, stile di vita Vocabolari e annotazioni standard Ricerche on-line richiedono interazione Implementazione SRS del database IARC TP53 Basato su SRS Definizione di un DTD ad-hoc Trasferimento dati basato su XML Accesso programmatico semplificato 32
33 Web Services per CABRI e TP53 Riproducendo il comportamento attuale: Ricerca per nome, identificatore e a testo libero (CABRI) Ricerca per funzioni e proprietà (TP53) Combinare risultati Integrare I dati con altri sorgenti tramite ID o termini comuni Due tipologie di Service: Ricerca per una specifica proprietà e restituzione degli ID Ricerca per ID e restituzione del record completo 33 Implementare Web Services che consentano: L accesso ai database CABRI e TP53 tramite i siti SRS La possibilità di includere questi task in workflow complessi
34 Soaplab: SOAP-based Analysis Web Service Soaplab is a set of Web Services providing a programatic access to some applications on remote computers. It is often referred to as an Analysis (Web) Service (Martin Senger, EBI). Consente di implementare Web Services in grado di accedere a: Applicazioni locali eseguibili con command-line Applicazioni presenti in EMBOSS Contenuto di qualunque pagina Web (GowLab) Requisiti Apache Tomcat servlet engine, Axis SOAP toolkit, Java perl, mysql 34
35 Soaplab 35
36 Soaplab: getcelllineidsbyname appl: getcelllineidsbyname [ documentation: "Get cell lines by name from CABRI human and animal cell lines catalogues (see groups: "CABRI" nonemboss: "Y" comment: "launcher get" supplier: " comment: "method [{$libs}-nam:'$name'] -ascii ] string: libs [ parameter: "Y ] string: name [ parameter: "Y ] outfile: result [ ] 36
37 Soaplab: getcelllinesbyid appl: getcelllinesbyid [ documentation: "Get cell lines by Id from CABRI human and animal cell lines catalogues (see groups: "CABRI" nonemboss: "Y" comment: "launcher get" supplier: " comment: "method -e [{$libs}:'$id'] -ascii" ] string: libs [ parameter: "Y ] string: id [ parameter: "Y ] outfile: result [ ] 37
38 Web Services CABRI Involved catalogues Input Output getbacteriaidsbyname Bacteria strains lib(s), name id(s) getbacteriaidsbyproperty Bacteria strains lib(s), text id(s) getbacteriabyid Bacteria strains id full record getfungiidsbyname Filamentous fungi strains lib(s), name id(s) getfungiidsbyproperty Filamentous fungi strains lib(s), text id(s) getfungibyid Filamentous fungi strains id full record getyeastidsbyname Yeasts strains lib(s), name id(s) getyeastidsbyproperty Yeasts strains lib(s), text id(s) getyeastsbyid Yeasts strains id full record getplasmididsbyname Plasmids lib(s), name id(s) getplasmididsbyproperty Plasmids lib(s), text id(s) getplasmidsbyid Plasmids id full record getphageidsbyname Phages lib(s), name id(s) getphageidsbyproperty Phages lib(s), text id(s) getphagesbyid Phages id full record getcelllinesidsbyname Human and animal cell lines lib(s), name id(s) getcelllinesidsbyproperty Human and animal cell lines lib(s), text id(s) getcelllinesbyid Human and animal cell lines id full record getresourceidsbyname All lib(s), name id(s) getresourcesbyid All id full record Web Service Name 38
39 Web Services TP53 Input Output getp53mutationsbyproperty lib, text Full record getp53mutationsbyids Id Full record getp53mutationidsbytype lib, mutation type id(s) getp53mutationidsbyeffect lib, effect id(s) getp53mutationidsbyexon lib, exon number id(s) getp53mutationidsbyintron lib, intron number id(s) getp53mutationidsbycodonnumber lib, codon number id(s) getp53mutationidsbycpgsite lib, cpg site (true/false) id(s) getp53mutationidsbysplicesite lib splice site (true/false) id(s) getp53mutationidsbymetastasislocalization lib, metastasis localization (organ) id(s) getp53mutationidsbytumororigin id(s) lib, origin (primary, secondary, ) Web Service Name 39
40 Workflow Obiettivo: implementazione di processi di analisi dei dati in ambienti standardizzati Vantaggi principali: efficienza: in quanto procedura automatica, libera il ricercatore dai compiti ripetitivi sul web e contribuisce a una good practice, reproducibilità: le analisi possono essere ripetute nel tempo, riuso: I risultati intermedi possono essere riutilizzati, tracciabilità: il workflow è eseguito in un ambiente trasparente nel quale la provenienza dei dati può essere verificata a posteriori. 40 A computerized facilitation or automation of a business process, in whole or part". (Workflow Management Coalition)
41 Workflow per database CABRI 41
42 Workflow per database TP53 42
43 Workflow management systems Gestione di workflow per applicazioni bioinformatiche: Biopipe, un add-on per bioperl GPipe, una estensione dell interfaccia Pise Taverna (EBI), una componente della piattaforma mygrid Pegasys (University of British Columbia) EGene (Universidade de São Paulo) Wildfire (Bioinformatics Institute, Singapore) Pipeline Pilot (SciTegic) BioWBI, Bioinformatic Workflow Builder Interface, di IBM Richiedono una notevole conoscenza dei sistemi coinvolti e competenze e tempo per lo sviluppo dei workflow. 43
44 Workflow management systems Tipologia Stand-alone Libreria software Linguaggio XML XScufl Pipeline XML Disponibilità Open source Open source URL ProGenGrid Stand-alone NA NA DiscoveryNet Kepler GPipe Stand-alone Stand-alone Interfaccia Web, servizi locali Stand-alone Interfaccia Web, servizi remoti Portale DPML MoML GPipe XML Commercial Open source Open source NA XPDL Open source Public use XScufl XPDL Proprietary Open source Commerciale Pegasys DAG GEL Triana Workflow Language Proprietary WSFL e XScufl NA Open source Open source Open source -star.edu.sg/wildfire/ Commercial Open source Open source EGene BioWMS BioWEP BioWBI Pegasys Wildfire Triana Interfaccia Web, servizi locali Stand-alone Stand-alone Stand-alone Pipeline Pilot FreeFluo Biomake Stand-alone Libreria software Libreria software Software Taverna Workbench Biopipe Presentano diverse tipologie e utilizzano diversi standard 44
45 Workflow management: Taverna Taverna Workbench consente di costruire workflow per analisi complesse accedere a processori sia remoti che locali definire processori alternativi eseguire i workflow visualizzare i risultati in diversi formati descrivere i dati bioinformatici tramite un ontologia Requirements: java, Windows or Linux Open source: Current version: (Taverna 2.0 in beta) 45
46 Taverna: processori disponibili Web Services descritti tramite WSDL Mette a disposizione i servizi descritti Web Services accessibili tramite server Soaplab Mette a disposizione i servizi forniti da server Soaplab Registri BioMOBY Interagisce con un MOBY Central repository per accedere ai servizi registrati Workflow Incorpora interi workflow definiti con Scufl o aggiunge singoli processori Biomart Interagisce con database Biomart per comporre query ed estrarre dati SeqHound Interroga SeqHound (Sequence and Structure Database Management System), un insieme di Web Services basati sul modello dati NCBI, e accede a informazioni di sequenza e struttura Processori locali Funzioni Java in grado di elaborare liste e stringhe, definire valori costanti, eseguire semplici elaborazioni, leggere e scrivere file. È anche possibile scrivere propri script con beanshell 46
47 Taverna: GUI La Graphical User Interface (GUI) comprende: Advanced Model Explorer (AME) Workflow diagram Available services Run workflow Enactor invocation Opzioni: default services, workflow editor, debug Feature extra: FETA search engine 47
48 48
49 49
50 50
51 51
52 52
53 53
54 54
55 55
56 56
57 57
58 58
59 59
60 60
61 61
62 62
63 63
64 64
65 65
66 66
67 67
68 68
69 69
70 70
71 71
72 72
73 73
74 74
75 75
76 76
77 Taverna references Oinn T, Addis M, Ferris J, Marvin D, Senger M, Greenwood M, Carver T, Glover K, Pocock MR, Wipat A, Li P, Taverna: a tool for the composition and enactment of bioinformatics workflows, Bioinformatics 2004, 20(17): Radetzki U, Leser U, Schulze-Rauschenbach SC, Zimmermann J, Lüssem J, Bode T, Cremers AB, Adapters, shims, and glue service interoperability for in silico experiments, Bioinformatics 2006, 22(9): Taverna web site: 77
78 WfMS: problemi Network issues Quality of Service Availability / Access restrictions Speed / Timeouts Practical issues Long running jobs -> timeouts / time limits Huge data I/O -> timeouts / time limits Access to Grid networks & services Human interactions Data reuse / data caching Heterogeneity of WS, complexity of WS I/O Heterogeneity of data -> shims, adapters (format conversions), data manipulation Some solutions? Scheduling: job IDs, monitoring execution Reference data models Semantic Web Services 78
79 Portals: list of requirements Workflow repository Workflow run time environment Workflow edit, upload & download Semi-automatic workflow editing Reference repository Workflow search By type By authors By linked publications By services (ontology) Workflow description Annotation Tagging Peer reviewing, ratings Workflow execution Pre-run workflow diagnosis Automated process logging Data management Interactive workflows Taverna Portal Party, Manchester, September 28-29, 2006 (partial list) 79
80 biowep: obiettivi Workflow Enacment Portal for Bioinformatics Obiettivi del sistema: Mettere a disposizione di ricercatori non esperti un insieme predefinito di workflow (testati, validati, annotati, mantenuti) Consentire la ricerca e la selezione dei workflow sulla base di una loro annotazione basata su una semplice ontologia dei processori bioinformatici (dominio, task, i/o) e della tipologia dell utente (interessi e ruolo) Consentire l esecuzione interattiva dei workflow selezionati Consentire la memorizzazione e il recupero dei risultati dei workflow eseguiti 80
81 biowep: caratteristiche Il sistema: è scritto in java + javascript è parzialmente basato su software open source (Taverna WB, FreeFluo, Tomcat e mysql) accede a dati e analisi disponibili tramite Web Services può svolgere anche elaborazione locali archivia i workflow in formato Scufl o XPDL è distribuito free (licenza LGPL) Prototipo disponibile on-line: (sito supporto) (portale) 81
82 biowep: architettura 82
83 biowep: workflow e utenza I workflow sono: creati dall amministratore o inviati da utenti con Taverna o BioWMS archiviati in formato Scufl o XPDL aggiornati (workflow vs versione) annotati sulla base di un ontologia dei task in bioinformatica (dominio, task, dati I/O) Gli utenti: accedono in remoto al sistema sono registrati (accesso controllato) lavorano in un proprio ambiente (sessioni, risultati, wf) 83
84 Annotazione dei workflow I workflow sono annotati sulla base di: una semplice ontologia per processori bioinformatici: dominio applicativo task input e output l ontologia deriva da quella di Taverna: nuova struttura alcune aggiunte (biological resources, images, ) in via di ulteriore sviluppo e adattamento 84
85 Annotazione dei workflow Tipo di elaborazione Dato in input Dominio applicativo Dato in output 85
86 Registrazione e profilo utenti Gli utenti sono classificati in base a: ruolo ricoperto informatico / medico / ricercatore / paziente / giornalista / ambito di ricerca di interesse I workflow sono proposti sulla base di: ruolo / ambito di interesse precedenti esecuzioni 86
87 biowep 87
88 biowep 88
89 biowep 89
90 biowep 90
91 biowep 91
92 biowep 92
93 biowep 93
94 biowep 94
95 biowep 95
96 biowep 96
97 WfMS: Limiti e prospettive I WfMS sono una metodologia in grado di affrontare la data integration in biologia Come visto, hanno limitazioni: Astrazione nella definizione dei task Prestazioni dei processi automatizzati Riproducibilità delle analisi 97
98 WfMS: astrazione Ai ricercatori interessano i risultati scientifici. Progettare e implementare workflow, affrontare i problemi di accesso e compatibilità dei WS è per loro un peso La conoscenza dei WS, dei formati dei dati, e un minimo di competenza di programmazione restano necessari: le GUI non aiutano Un interfaccia semantica può invece aiutare se comprende: gestione dei metadati, annotazione dei WS e dei database, conversione automatica dei formati, ricerca e identificazione dei WS più appropriati per le necessità degli utenti, composizione automatica dei workflow. La miglior interfaccia dovrebbe consentire ai ricercatori di costruire i workflow decrivendo i processi d analisi in linguaggio (quasi) naturale. 98
99 WfMS: prestazioni I ricercatori vogliono i migliori risultati nel minor tempo possibile, a prescindere dal database, sito o supercomputer utilizzato (transparenza completa); per questo, sono utili: riuso dei risultati intermedi, policy per distribuzione dei task (limitare data transfer) metadati per descrivere i servizi selezione automatica dei migliori WS (più veloce, affidabile) I ricercatori non devono preoccuparsi dei problemi tecnici: elevato traffico di rete, crash di reti e siti; per questo, sono utili: trasparenza delle sorgenti informative, uso di servizi alternativi per le analisi critiche, capacità di identificare errori, ripetere analisi interrotte, sospendere l esecuzione e far ripartire i workflow interrotti 99
100 WfMS: riproducibilità delle analisi La ripetibilità degli esperimenti è un requisito fondamentale in biologia. Tracce delle esecuzioni devono essere conservate per consentirla. NB! Le analisi in-silico sono soggetete ai frequneti aggiornamenti e all evoluzione dei database. Una perfetta riproducibilità è molto difficile! La traccia deve includere i metadati relativi all esecuzione: informazioni ovvie (descrizione del workflow, input usati, software e siti utilizzati), dati non ovvi (versioni dei software e dei database, sistemi operativi dei computer dove è eseguito il software), quest infomazione deve essere fornita dai WS I WfMS forniscono sempre più feature di data provenance. 100
101 Semantic Web: capacità l integrazione di sistemi informativi eterogenei, in quanto opera come un meta-database su sistemi informativi eterogenei un ambiente distribuito, nel quale si possono ridure i problemi legati alla necessità di mantenere copie locali dei database, affromntando nello stesso tempo il problema dell evoluzione dei dati una conoscenza in evoluzione, perché si basa su ontologie per la definizione della semantica dei dati (evitando quindi una semnatica condivisa implicita o rigidamente codifica nelle strutture dati e nei software d analisi) 101 Il Semantic Web può aiutare ad affrontare queste limitazioni perché consente:
102 Tecnologie semantiche: ontologie Molti sforzi in questa direzione sono attualmente in corso. L associazione di termini e concetti ontologici ai dati esistenti è ancora allo stato iniziale e si riferisce a poche, riconosciute e ben note ontologies, e.g. Gene Ontology. L annotazione di tutte le informazioni disponibili con concetti ontologici è un task enorme. La definizione di nuove ontologie collegate a quelle esistenti è necessaria per gestire il gran numero di sistemi informativi esistenti e consentirne il collegamento L aggiunta di contenuti semantici ai database attuali darà un contributo essenziale all integrazione dei dati biologici. 102 Definitioni condivise della conoscenza (ontologie)
103 Tecnologie semantiche: RDF stores Database biologici in formato RDF o OWL stanno apparendo come dimostrazione o prototipi Molta informazione è ancora disponibile solo in formati non strutturati o parzialmente strutturati, accessibile solo tramite interfaccia web Questo è dovuto alla necessità di mantenere i sistemi di produzione in funzione e accessibili tramite gli strumenti d analisi attuali Le più recenti implementazioni includono versioni XML La conversione automatica dei dati da XML a RDF può costituire un passaggio fondamentale per l effettivo utilizzo di tool semantici 103
Workflow management systems in supporto alla biologia: verso l automazione dell accesso ai dati e alla loro analisi in rete
 Workflow management systems in supporto alla biologia: verso l automazione dell accesso ai dati e alla loro analisi in rete Paolo Romano Istituto Nazionale per la Ricerca sul Cancro (paolo.romano@istge.it)
Workflow management systems in supporto alla biologia: verso l automazione dell accesso ai dati e alla loro analisi in rete Paolo Romano Istituto Nazionale per la Ricerca sul Cancro (paolo.romano@istge.it)
Introduzione al Semantic Web
 Corso di Laurea Specialistica in Ingegneria Gestionale Corso di Sistemi Informativi Modulo II A. A. 2013-2014 Giuseppe Loseto Dal Web al Semantic Web 2 Dal Web al Semantic Web: Motivazioni Il Web dovrebbe
Corso di Laurea Specialistica in Ingegneria Gestionale Corso di Sistemi Informativi Modulo II A. A. 2013-2014 Giuseppe Loseto Dal Web al Semantic Web 2 Dal Web al Semantic Web: Motivazioni Il Web dovrebbe
Presentazione di Cedac Software
 Agenda Presentazione di Cedac Software SOA ed ESB Analisi di un caso studio Esempi Q&A Presentazione di Cedac Software 1 2 Presentazione di Cedac Software S.r.l. Divisione Software Azienda nata nel 1994
Agenda Presentazione di Cedac Software SOA ed ESB Analisi di un caso studio Esempi Q&A Presentazione di Cedac Software 1 2 Presentazione di Cedac Software S.r.l. Divisione Software Azienda nata nel 1994
Enrico Fagnoni <e.fagnoni@e-artspace.com> BOTK IN A NUTSHELL
 Enrico Fagnoni BOTK IN A NUTSHELL 20/01/2011 1 Business Ontology ToolKit Business Ontology Toolkit (BOTK) è un insieme estensibile di strumenti per realizzare applicazioni basate
Enrico Fagnoni BOTK IN A NUTSHELL 20/01/2011 1 Business Ontology ToolKit Business Ontology Toolkit (BOTK) è un insieme estensibile di strumenti per realizzare applicazioni basate
WorkFlow Management Systems
 WorkFlow Management Systems Cosa è un? Automazione di un processo aziendale (business process) con: documenti, informazioni e compiti partecipanti insieme predefinito di regole obiettivo comune 2 Esempi
WorkFlow Management Systems Cosa è un? Automazione di un processo aziendale (business process) con: documenti, informazioni e compiti partecipanti insieme predefinito di regole obiettivo comune 2 Esempi
Simple & Efficient. www.quick-software-line.com
 Cosa è XML? extensible Markup Language Linguaggio è una definizione limitativa XML serve a descrivere con precisione qualsiasi informazione XML è estensibile. Ovvero non ha tag predefiniti come HTML XML
Cosa è XML? extensible Markup Language Linguaggio è una definizione limitativa XML serve a descrivere con precisione qualsiasi informazione XML è estensibile. Ovvero non ha tag predefiniti come HTML XML
Capitolo 4 Pianificazione e Sviluppo di Web Part
 Capitolo 4 Pianificazione e Sviluppo di Web Part Questo capitolo mostra come usare Microsoft Office XP Developer per personalizzare Microsoft SharePoint Portal Server 2001. Spiega come creare, aggiungere,
Capitolo 4 Pianificazione e Sviluppo di Web Part Questo capitolo mostra come usare Microsoft Office XP Developer per personalizzare Microsoft SharePoint Portal Server 2001. Spiega come creare, aggiungere,
Ontologie e World Wide Web: la diffusione della conoscenza.
 Università degli Studi dell Insubria Facoltà di Scienze Matematiche, Fisiche, Naturali Sede di Como Corso di Laurea in Scienze e Tecnologie dell Informazione Ontologie e World Wide Web: la diffusione della
Università degli Studi dell Insubria Facoltà di Scienze Matematiche, Fisiche, Naturali Sede di Como Corso di Laurea in Scienze e Tecnologie dell Informazione Ontologie e World Wide Web: la diffusione della
Università degli studi di Ferrara. Sviluppo di un Web Service per la classificazione del suolo e sua integrazione sul Portale SSE
 Università degli studi di Ferrara Facoltà di scienze MM.FF.NN. Corso di Laurea Specialistica in Informatica Sviluppo di un Web Service per la classificazione del suolo e sua integrazione sul Portale SSE
Università degli studi di Ferrara Facoltà di scienze MM.FF.NN. Corso di Laurea Specialistica in Informatica Sviluppo di un Web Service per la classificazione del suolo e sua integrazione sul Portale SSE
Un portale semantico per i Beni Culturali
 Un portale semantico per i Beni Culturali A. Ciapetti, D. Berardi, A. Donnini, M. Lorenzini, M.E. Masci, D. Merlitti, S. Norcia, F. Piro (Etcware) M. De Vizia Guerriero, O. Signore (CNR W3C Italia) EVA
Un portale semantico per i Beni Culturali A. Ciapetti, D. Berardi, A. Donnini, M. Lorenzini, M.E. Masci, D. Merlitti, S. Norcia, F. Piro (Etcware) M. De Vizia Guerriero, O. Signore (CNR W3C Italia) EVA
Introduzione ai Web Services Alberto Polzonetti
 PROGRAMMAZIONE di RETE A.A. 2003-2004 Corso di laurea in INFORMATICA Introduzione ai Web Services alberto.polzonetti@unicam.it Introduzione al problema della comunicazione fra applicazioni 2 1 Il Problema
PROGRAMMAZIONE di RETE A.A. 2003-2004 Corso di laurea in INFORMATICA Introduzione ai Web Services alberto.polzonetti@unicam.it Introduzione al problema della comunicazione fra applicazioni 2 1 Il Problema
1. BASI DI DATI: GENERALITÀ
 1. BASI DI DATI: GENERALITÀ BASE DI DATI (DATABASE, DB) Raccolta di informazioni o dati strutturati, correlati tra loro in modo da risultare fruibili in maniera ottimale. Una base di dati è usualmente
1. BASI DI DATI: GENERALITÀ BASE DI DATI (DATABASE, DB) Raccolta di informazioni o dati strutturati, correlati tra loro in modo da risultare fruibili in maniera ottimale. Una base di dati è usualmente
xmlegeseditor un editore open-source per la redazione di testi normativi
 xmlegeseditor un editore open-source per la redazione di testi normativi Tommaso Agnoloni, Pierluigi Spinosa http://www.ittig.cnr.it/xmleges agnoloni@ittig.cnr.it ITTIG-CNR Istituto di Teorie e Tecniche
xmlegeseditor un editore open-source per la redazione di testi normativi Tommaso Agnoloni, Pierluigi Spinosa http://www.ittig.cnr.it/xmleges agnoloni@ittig.cnr.it ITTIG-CNR Istituto di Teorie e Tecniche
MetaMAG METAMAG 1 IL PRODOTTO
 METAMAG 1 IL PRODOTTO Metamag è un prodotto che permette l acquisizione, l importazione, l analisi e la catalogazione di oggetti digitali per materiale documentale (quali immagini oppure file di testo
METAMAG 1 IL PRODOTTO Metamag è un prodotto che permette l acquisizione, l importazione, l analisi e la catalogazione di oggetti digitali per materiale documentale (quali immagini oppure file di testo
RICERCA DELL INFORMAZIONE
 RICERCA DELL INFORMAZIONE DOCUMENTO documento (risorsa informativa) = supporto + contenuto analogico o digitale locale o remoto (accessibile in rete) testuale, grafico, multimediale DOCUMENTO risorsa continuativa
RICERCA DELL INFORMAZIONE DOCUMENTO documento (risorsa informativa) = supporto + contenuto analogico o digitale locale o remoto (accessibile in rete) testuale, grafico, multimediale DOCUMENTO risorsa continuativa
BASE DI DATI: introduzione. Informatica 5BSA Febbraio 2015
 BASE DI DATI: introduzione Informatica 5BSA Febbraio 2015 Di cosa parleremo? Base di dati relazionali, modelli e linguaggi: verranno presentate le caratteristiche fondamentali della basi di dati. In particolare
BASE DI DATI: introduzione Informatica 5BSA Febbraio 2015 Di cosa parleremo? Base di dati relazionali, modelli e linguaggi: verranno presentate le caratteristiche fondamentali della basi di dati. In particolare
Il CMS Moka. Giovanni Ciardi Regione Emilia Romagna
 Il CMS Moka Giovanni Ciardi Regione Emilia Romagna Moka è uno strumento per creare applicazioni GIS utilizzando oggetti (cartografie, temi, legende, database, funzioni) organizzati in un catalogo condiviso.
Il CMS Moka Giovanni Ciardi Regione Emilia Romagna Moka è uno strumento per creare applicazioni GIS utilizzando oggetti (cartografie, temi, legende, database, funzioni) organizzati in un catalogo condiviso.
Lezione 1. Introduzione e Modellazione Concettuale
 Lezione 1 Introduzione e Modellazione Concettuale 1 Tipi di Database ed Applicazioni Database Numerici e Testuali Database Multimediali Geographic Information Systems (GIS) Data Warehouses Real-time and
Lezione 1 Introduzione e Modellazione Concettuale 1 Tipi di Database ed Applicazioni Database Numerici e Testuali Database Multimediali Geographic Information Systems (GIS) Data Warehouses Real-time and
L o. Walter Ambu http://www.japsportal.org. japs: una soluzione agile (www.japsportal.org)
") L o JAPS: una soluzione Agile Walter Ambu http://www.japsportal.org 1 Lo sviluppo del software Mercato fortemente competitivo ed in continua evoluzione (velocità di Internet) Clienti sempre più esigenti
L o JAPS: una soluzione Agile Walter Ambu http://www.japsportal.org 1 Lo sviluppo del software Mercato fortemente competitivo ed in continua evoluzione (velocità di Internet) Clienti sempre più esigenti
Addition X DataNet S.r.l. www.xdatanet.com www.xdatanet.com
 Addition è un applicativo Web che sfrutta le potenzialità offerte da IBM Lotus Domino per gestire documenti e processi aziendali in modo collaborativo, integrato e sicuro. www.xdatanet.com Personalizzazione,
Addition è un applicativo Web che sfrutta le potenzialità offerte da IBM Lotus Domino per gestire documenti e processi aziendali in modo collaborativo, integrato e sicuro. www.xdatanet.com Personalizzazione,
Dai sistemi documentari al knowledge management: un'opportunità per la pubblica amministrazione
 Dai sistemi documentari al knowledge management: un'opportunità per la pubblica amministrazione Reingegnerizzazione dei sistemi documentari e knowledge management Paola Montironi Quadro di riferimento
Dai sistemi documentari al knowledge management: un'opportunità per la pubblica amministrazione Reingegnerizzazione dei sistemi documentari e knowledge management Paola Montironi Quadro di riferimento
KON 3. Knowledge ON ONcology through ONtology
 KON 3 Knowledge ON ONcology through ONtology Obiettivi di KON 3 Scopo di questo progetto èquello di realizzare un sistema di supporto alle decisioni, basato su linee guida e rappresentazione semantica
KON 3 Knowledge ON ONcology through ONtology Obiettivi di KON 3 Scopo di questo progetto èquello di realizzare un sistema di supporto alle decisioni, basato su linee guida e rappresentazione semantica
automation using workflow technology and web services Vassilacopoulos Med. Inform. (September 2003) vol. 28, no. 3,
 vol. 28, no. 3,") Emergency healthcare process automation using workflow technology and web services M. Poulymenopoulou, F. Malamateniou, G. Vassilacopoulos Med. Inform. (September 2003) vol. 28, no. 3, 195 207 Processo
Emergency healthcare process automation using workflow technology and web services M. Poulymenopoulou, F. Malamateniou, G. Vassilacopoulos Med. Inform. (September 2003) vol. 28, no. 3, 195 207 Processo
Training sulle soluzioni SAP BusinessObjects BI4
 Training sulle soluzioni SAP BusinessObjects BI4 dai valore alla formazione nella Business Intelligence: iscriviti ai training proposti da Méthode, scopri i vantaggi che la BI può dare al tuo business!
Training sulle soluzioni SAP BusinessObjects BI4 dai valore alla formazione nella Business Intelligence: iscriviti ai training proposti da Méthode, scopri i vantaggi che la BI può dare al tuo business!
Portale Multicanale delle PA del territorio della Regione Emilia-Romagna: un inizio di rete semantica di informazioni
 Portale Multicanale delle PA del territorio della Regione Emilia-Romagna: un inizio di rete semantica di informazioni Grazia Cesari Regione Emilia-Romagna ForumPA Roma 10 Maggio 2006 Con il supporto di
Portale Multicanale delle PA del territorio della Regione Emilia-Romagna: un inizio di rete semantica di informazioni Grazia Cesari Regione Emilia-Romagna ForumPA Roma 10 Maggio 2006 Con il supporto di
SRS (Sequence Retrieval System) della EBI che mette a disposizione anche dello spazio sul server per memorizzare le richerche.
 della EBI che mette a disposizione anche dello spazio sul server per memorizzare le richerche.") I due centri maggiori, EBI e NCBI hanno sviluppato sistemi dedicati di RETRIEVAL allo scopo di ottenere il massimo delle informazioni con il minimo sforzo da parte dell utente SRS (Sequence Retrieval System)
I due centri maggiori, EBI e NCBI hanno sviluppato sistemi dedicati di RETRIEVAL allo scopo di ottenere il massimo delle informazioni con il minimo sforzo da parte dell utente SRS (Sequence Retrieval System)
DOCFINDERWEB SERVICE E CLIENT
 DOCFINDERWEB SERVICE E CLIENT Specifiche tecniche di interfacciamento al Web Service esposto da DocPortal Versione : 1 Data : 10/03/2014 Redatto da: Approvato da: RICCARDO ROMAGNOLI CLAUDIO CAPRARA Categoria:
DOCFINDERWEB SERVICE E CLIENT Specifiche tecniche di interfacciamento al Web Service esposto da DocPortal Versione : 1 Data : 10/03/2014 Redatto da: Approvato da: RICCARDO ROMAGNOLI CLAUDIO CAPRARA Categoria:
Telerilevamento e GIS Prof. Ing. Giuseppe Mussumeci
 Corso di Laurea Magistrale in Ingegneria per l Ambiente e il Territorio A.A. 2014-2015 Telerilevamento e GIS Prof. Ing. Giuseppe Mussumeci Strutture di dati: DB e DBMS DATO E INFORMAZIONE Dato: insieme
Corso di Laurea Magistrale in Ingegneria per l Ambiente e il Territorio A.A. 2014-2015 Telerilevamento e GIS Prof. Ing. Giuseppe Mussumeci Strutture di dati: DB e DBMS DATO E INFORMAZIONE Dato: insieme
Approccio stratificato
 Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Infrastruttura di produzione INFN-GRID
 Infrastruttura di produzione INFN-GRID Introduzione Infrastruttura condivisa Multi-VO Modello Organizzativo Conclusioni 1 Introduzione Dopo circa tre anni dall inizio dei progetti GRID, lo stato del middleware
Infrastruttura di produzione INFN-GRID Introduzione Infrastruttura condivisa Multi-VO Modello Organizzativo Conclusioni 1 Introduzione Dopo circa tre anni dall inizio dei progetti GRID, lo stato del middleware
extensible Markup Language
 XML a.s. 2010-2011 extensible Markup Language XML è un meta-linguaggio per definire la struttura di documenti e dati non è un linguaggio di programmazione un documento XML è un file di testo che contiene
XML a.s. 2010-2011 extensible Markup Language XML è un meta-linguaggio per definire la struttura di documenti e dati non è un linguaggio di programmazione un documento XML è un file di testo che contiene
I MODULI Q.A.T. PANORAMICA. La soluzione modulare di gestione del Sistema Qualità Aziendale
 La soluzione modulare di gestione del Sistema Qualità Aziendale I MODULI Q.A.T. - Gestione clienti / fornitori - Gestione strumenti di misura - Gestione verifiche ispettive - Gestione documentazione del
La soluzione modulare di gestione del Sistema Qualità Aziendale I MODULI Q.A.T. - Gestione clienti / fornitori - Gestione strumenti di misura - Gestione verifiche ispettive - Gestione documentazione del
Reti di Telecomunicazione Lezione 6
 Reti di Telecomunicazione Lezione 6 Marco Benini Corso di Laurea in Informatica marco.benini@uninsubria.it Lo strato di applicazione protocolli Programma della lezione Applicazioni di rete client - server
Reti di Telecomunicazione Lezione 6 Marco Benini Corso di Laurea in Informatica marco.benini@uninsubria.it Lo strato di applicazione protocolli Programma della lezione Applicazioni di rete client - server
CMDBuild: un progetto open source di supporto alla gestione ICT (e non solo) Approfondimenti Tecnici. Francesco Zanitti Tecnoteca S.r.
 Approfondimenti Tecnici. Francesco Zanitti Tecnoteca S.r.") 1 1 CMDBuild: un progetto open source di supporto alla gestione ICT (e non solo) Approfondimenti Tecnici Francesco Zanitti Tecnoteca S.r.l 2 Modello di persistenza - 1 Com'è stato implementato CMDBuild
1 1 CMDBuild: un progetto open source di supporto alla gestione ICT (e non solo) Approfondimenti Tecnici Francesco Zanitti Tecnoteca S.r.l 2 Modello di persistenza - 1 Com'è stato implementato CMDBuild
MagiCum S.r.l. Progetto Inno-School
 MagiCum S.r.l. Progetto Inno-School Area Web Autore: Davide Revisione: 1.2 Data: 23/5/2013 Titolo: Innopedia File: Documentazione_tecnica Sito: http://inno-school.netsons.org/ Indice: 1. Presentazione
MagiCum S.r.l. Progetto Inno-School Area Web Autore: Davide Revisione: 1.2 Data: 23/5/2013 Titolo: Innopedia File: Documentazione_tecnica Sito: http://inno-school.netsons.org/ Indice: 1. Presentazione
Rappresentazione della Conoscenza. Lezione 10. Rappresentazione della conoscenza, D. Nardi, 2004, Lezione 10 0
 Rappresentazione della Conoscenza Lezione 10 Rappresentazione della conoscenza, D. Nardi, 2004, Lezione 10 0 Sistemi ed applicazioni Sistemi di rappresentazione della conoscenza basati su logiche descrittive.
Rappresentazione della Conoscenza Lezione 10 Rappresentazione della conoscenza, D. Nardi, 2004, Lezione 10 0 Sistemi ed applicazioni Sistemi di rappresentazione della conoscenza basati su logiche descrittive.
Software di gestione della stampante
 Questo argomento include le seguenti sezioni: "Uso del software CentreWare" a pagina 3-11 "Uso delle funzioni di gestione della stampante" a pagina 3-13 Uso del software CentreWare CentreWare Internet
Questo argomento include le seguenti sezioni: "Uso del software CentreWare" a pagina 3-11 "Uso delle funzioni di gestione della stampante" a pagina 3-13 Uso del software CentreWare CentreWare Internet
Per capire meglio l ambito di applicazione di un DWhouse consideriamo la piramide di Anthony, L. Direzionale. L. Manageriale. L.
 DATA WAREHOUSE Un Dataware House può essere definito come una base di dati di database. In molte aziende ad esempio ci potrebbero essere molti DB, per effettuare ricerche di diverso tipo, in funzione del
DATA WAREHOUSE Un Dataware House può essere definito come una base di dati di database. In molte aziende ad esempio ci potrebbero essere molti DB, per effettuare ricerche di diverso tipo, in funzione del
Archiviazione digitale per SAP con DocuWare
 Connect to SAP bis 6.1 Product Info Archiviazione digitale per SAP con DocuWare Connect to SAP collega DocuWare attraverso un interfaccia certificata con il modulo SAP ArchiveLink incorporato in SAP NetWeaver.
Connect to SAP bis 6.1 Product Info Archiviazione digitale per SAP con DocuWare Connect to SAP collega DocuWare attraverso un interfaccia certificata con il modulo SAP ArchiveLink incorporato in SAP NetWeaver.
OpenSPCoop Un Implementazione Open Source della specifica SPCoop di Cooperazione Applicativa
 OpenSPCoop Un Implementazione Open Source della specifica SPCoop di Cooperazione Applicativa Tito Flagella tito@link.it http://openspcoop.org La Cooperazione Applicativa Regolamentazione delle modalità
OpenSPCoop Un Implementazione Open Source della specifica SPCoop di Cooperazione Applicativa Tito Flagella tito@link.it http://openspcoop.org La Cooperazione Applicativa Regolamentazione delle modalità
Legge e apprende nozioni in qualsiasi lingua, le contestualizza ed è in grado di elaborarle e riutilizzarle quando serve
 More than human, XSENSE è la prima Intelligenza Artificiale in grado di simulare il processo cognitivo di un essere umano nell imparare il linguaggio umano, in completa autonomia e senza configurazioni
More than human, XSENSE è la prima Intelligenza Artificiale in grado di simulare il processo cognitivo di un essere umano nell imparare il linguaggio umano, in completa autonomia e senza configurazioni
Introduzione alle basi di dati. Gestione delle informazioni. Gestione delle informazioni. Sistema informatico
 Introduzione alle basi di dati Introduzione alle basi di dati Gestione delle informazioni Base di dati Modello dei dati Indipendenza dei dati Accesso ai dati Vantaggi e svantaggi dei DBMS Gestione delle
Introduzione alle basi di dati Introduzione alle basi di dati Gestione delle informazioni Base di dati Modello dei dati Indipendenza dei dati Accesso ai dati Vantaggi e svantaggi dei DBMS Gestione delle
I Sistemi Informativi Geografici. Laboratorio GIS 1
 I Sistemi Informativi Geografici Laboratorio GIS 1 Sistema Informativo Geografico Strumento computerizzato che permette di posizionare ed analizzare oggetti ed eventi che esistono e si verificano sulla
I Sistemi Informativi Geografici Laboratorio GIS 1 Sistema Informativo Geografico Strumento computerizzato che permette di posizionare ed analizzare oggetti ed eventi che esistono e si verificano sulla
Software di sistema e software applicativo. I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche
 Software di sistema e software applicativo I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche Software soft ware soffice componente è la parte logica
Software di sistema e software applicativo I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche Software soft ware soffice componente è la parte logica
Caratteristiche principali. Contesti di utilizzo
 Dalle basi di dati distribuite alle BASI DI DATI FEDERATE Antonella Poggi Dipartimento di Informatica e Sistemistica Antonio Ruberti Università di Roma La Sapienza Anno Accademico 2006/2007 http://www.dis.uniroma1.it/
Dalle basi di dati distribuite alle BASI DI DATI FEDERATE Antonella Poggi Dipartimento di Informatica e Sistemistica Antonio Ruberti Università di Roma La Sapienza Anno Accademico 2006/2007 http://www.dis.uniroma1.it/
Protocolli applicativi: FTP
 Protocolli applicativi: FTP FTP: File Transfer Protocol. Implementa un meccanismo per il trasferimento di file tra due host. Prevede l accesso interattivo al file system remoto; Prevede un autenticazione
Protocolli applicativi: FTP FTP: File Transfer Protocol. Implementa un meccanismo per il trasferimento di file tra due host. Prevede l accesso interattivo al file system remoto; Prevede un autenticazione
ISTITUTO TECNICO ECONOMICO MOSSOTTI
 CLASSE III INDIRIZZO S.I.A. UdA n. 1 Titolo: conoscenze di base Conoscenza delle caratteristiche dell informatica e degli strumenti utilizzati Informatica e sistemi di elaborazione Conoscenza delle caratteristiche
CLASSE III INDIRIZZO S.I.A. UdA n. 1 Titolo: conoscenze di base Conoscenza delle caratteristiche dell informatica e degli strumenti utilizzati Informatica e sistemi di elaborazione Conoscenza delle caratteristiche
Il software impiegato su un computer si distingue in: Sistema Operativo Compilatori per produrre programmi
 Il Software Il software impiegato su un computer si distingue in: Software di sistema Sistema Operativo Compilatori per produrre programmi Software applicativo Elaborazione testi Fogli elettronici Basi
Il Software Il software impiegato su un computer si distingue in: Software di sistema Sistema Operativo Compilatori per produrre programmi Software applicativo Elaborazione testi Fogli elettronici Basi
Istruzioni di installazione di IBM SPSS Modeler Text Analytics (licenza per sito)
") Istruzioni di installazione di IBM SPSS Modeler Text Analytics (licenza per sito) Le seguenti istruzioni sono relative all installazione di IBM SPSS Modeler Text Analytics versione 15 mediante un licenza
Istruzioni di installazione di IBM SPSS Modeler Text Analytics (licenza per sito) Le seguenti istruzioni sono relative all installazione di IBM SPSS Modeler Text Analytics versione 15 mediante un licenza
Realizzazione di un Tool per l iniezione automatica di difetti all interno di codice Javascript
 tesi di laurea di difetti all interno di codice Javascript Anno Accademico 2009/2010 relatore Ch.mo prof. Porfirio Tramontana correlatore Ch.mo ing. Domenico Amalfitano candidato Vincenzo Riccio Matr.
tesi di laurea di difetti all interno di codice Javascript Anno Accademico 2009/2010 relatore Ch.mo prof. Porfirio Tramontana correlatore Ch.mo ing. Domenico Amalfitano candidato Vincenzo Riccio Matr.
Corso: Sistemi di elaborazione delle informazioni 2. Anno Accademico: 2007/2008. Docente: Mauro Giacomini
 Corso: Sistemi di elaborazione delle informazioni 2. Anno Accademico: 2007/2008. Docente: Mauro Giacomini Organizzazione no-profit per lo sviluppo di standard che fornisce linee guida per: lo scambio la
Corso: Sistemi di elaborazione delle informazioni 2. Anno Accademico: 2007/2008. Docente: Mauro Giacomini Organizzazione no-profit per lo sviluppo di standard che fornisce linee guida per: lo scambio la
Progettaz. e sviluppo Data Base
 Progettaz. e sviluppo Data Base! Introduzione ai Database! Tipologie di DB (gerarchici, reticolari, relazionali, oodb) Introduzione ai database Cos è un Database Cos e un Data Base Management System (DBMS)
Progettaz. e sviluppo Data Base! Introduzione ai Database! Tipologie di DB (gerarchici, reticolari, relazionali, oodb) Introduzione ai database Cos è un Database Cos e un Data Base Management System (DBMS)
Semantic Web e gestione collaborativa della conoscenza di dominio: prospettive, vantaggi e casi d'uso. Ing. Christian Morbidoni, Ph.
 Semantic Web e gestione collaborativa della conoscenza di dominio: prospettive, vantaggi e casi d'uso Ing. Christian Morbidoni, Ph.D Semantic Web su Desktop e Intranet RDF(S)/OWL: strumenti di rappresentazione
Semantic Web e gestione collaborativa della conoscenza di dominio: prospettive, vantaggi e casi d'uso Ing. Christian Morbidoni, Ph.D Semantic Web su Desktop e Intranet RDF(S)/OWL: strumenti di rappresentazione
Riccardo Dutto, Paolo Garza Politecnico di Torino. Riccardo Dutto, Paolo Garza Politecnico di Torino
 Integration Services Project SQL Server 2005 Integration Services Permette di gestire tutti i processi di ETL Basato sui progetti di Business Intelligence di tipo Integration services Project SQL Server
Integration Services Project SQL Server 2005 Integration Services Permette di gestire tutti i processi di ETL Basato sui progetti di Business Intelligence di tipo Integration services Project SQL Server
Sommario. Introduzione Architettura Client-Server. Server Web Browser Web. Architettura a Due Livelli Architettura a Tre Livelli
 Sommario Introduzione Architettura Client-Server Architettura a Due Livelli Architettura a Tre Livelli Server Web Browser Web Introduzione La storia inizia nel 1989 Tim Berners-Lee al CERN, progetto WWW
Sommario Introduzione Architettura Client-Server Architettura a Due Livelli Architettura a Tre Livelli Server Web Browser Web Introduzione La storia inizia nel 1989 Tim Berners-Lee al CERN, progetto WWW
Architettura client-server
 Architettura client-server In un architettura client-server ci sono due calcolatori connessi alla rete: un client che sottopone richieste al server un server in grado di rispondere alle richieste formulate
Architettura client-server In un architettura client-server ci sono due calcolatori connessi alla rete: un client che sottopone richieste al server un server in grado di rispondere alle richieste formulate
BPEL: Business Process Execution Language
 Ingegneria dei processi aziendali BPEL: Business Process Execution Language Ghilardi Dario 753708 Manenti Andrea 755454 Docente: Prof. Ernesto Damiani BPEL - definizione Business Process Execution Language
Ingegneria dei processi aziendali BPEL: Business Process Execution Language Ghilardi Dario 753708 Manenti Andrea 755454 Docente: Prof. Ernesto Damiani BPEL - definizione Business Process Execution Language
Al giorno d oggi, i sistemi per la gestione di database
 Introduzione Al giorno d oggi, i sistemi per la gestione di database implementano un linguaggio standard chiamato SQL (Structured Query Language). Fra le altre cose, il linguaggio SQL consente di prelevare,
Introduzione Al giorno d oggi, i sistemi per la gestione di database implementano un linguaggio standard chiamato SQL (Structured Query Language). Fra le altre cose, il linguaggio SQL consente di prelevare,
b) Dinamicità delle pagine e interattività d) Separazione del contenuto dalla forma di visualizzazione
 Dinamicità delle pagine e interattività d) Separazione del contenuto dalla forma di visualizzazione") Evoluzione del Web Direzioni di sviluppo del web a) Multimedialità b) Dinamicità delle pagine e interattività c) Accessibilità d) Separazione del contenuto dalla forma di visualizzazione e) Web semantico
Evoluzione del Web Direzioni di sviluppo del web a) Multimedialità b) Dinamicità delle pagine e interattività c) Accessibilità d) Separazione del contenuto dalla forma di visualizzazione e) Web semantico
Architettura del. Sintesi dei livelli di rete. Livelli di trasporto e inferiori (Livelli 1-4)
") Architettura del WWW World Wide Web Sintesi dei livelli di rete Livelli di trasporto e inferiori (Livelli 1-4) - Connessione fisica - Trasmissione dei pacchetti ( IP ) - Affidabilità della comunicazione
Architettura del WWW World Wide Web Sintesi dei livelli di rete Livelli di trasporto e inferiori (Livelli 1-4) - Connessione fisica - Trasmissione dei pacchetti ( IP ) - Affidabilità della comunicazione
9. Architetture di Dominio
 9. Architetture di Dominio imparare dall esperienza comune Andrea Polini Ingegneria del Software Corso di Laurea in Informatica (Ingegneria del Software) 9. Architetture di Dominio 1 / 20 Sommario 1 Architetture
9. Architetture di Dominio imparare dall esperienza comune Andrea Polini Ingegneria del Software Corso di Laurea in Informatica (Ingegneria del Software) 9. Architetture di Dominio 1 / 20 Sommario 1 Architetture
Corso di Basi di Dati e Conoscenza
 Corso di Basi di Dati e Conoscenza Gestione dei Dati e della Conoscenza Primo Emicorso - Basi di Dati Roberto Basili a.a. 2012/13 1 Obbiettivi Formativi Scenario Le grandi quantità di dati accumulate nelle
Corso di Basi di Dati e Conoscenza Gestione dei Dati e della Conoscenza Primo Emicorso - Basi di Dati Roberto Basili a.a. 2012/13 1 Obbiettivi Formativi Scenario Le grandi quantità di dati accumulate nelle
Librerie digitali. Introduzione. Cos è una libreria digitale?
 Librerie digitali Introduzione Cos è una libreria digitale? William Arms "An informal definition of a digital library is a managed collection of information, with associated services, where the information
Librerie digitali Introduzione Cos è una libreria digitale? William Arms "An informal definition of a digital library is a managed collection of information, with associated services, where the information
PROGRAMMAZIONE MODULARE DI INFORMATICA CLASSE QUINTA - INDIRIZZO MERCURIO SEZIONE TECNICO
 PROGRAMMAZIONE MODULARE DI INFORMATICA CLASSE QUINTA - INDIRIZZO MERCURIO SEZIONE TECNICO Modulo 1: IL LINGUAGGIO HTML Formato degli oggetti utilizzati nel Web Elementi del linguaggio HTML: tag, e attributi
PROGRAMMAZIONE MODULARE DI INFORMATICA CLASSE QUINTA - INDIRIZZO MERCURIO SEZIONE TECNICO Modulo 1: IL LINGUAGGIO HTML Formato degli oggetti utilizzati nel Web Elementi del linguaggio HTML: tag, e attributi
Knowledge Management
 [ ] IL K-BLOG Cosa è il KM Il Knowledge Management (Gestione della Conoscenza) indica la creazione, la raccolta e la classificazione delle informazioni, provenienti da varie fonti, che vengono distribuite
[ ] IL K-BLOG Cosa è il KM Il Knowledge Management (Gestione della Conoscenza) indica la creazione, la raccolta e la classificazione delle informazioni, provenienti da varie fonti, che vengono distribuite
lem logic enterprise manager
 logic enterprise manager lem lem Logic Enterprise Manager Grazie all esperienza decennale in sistemi gestionali, Logic offre una soluzione modulare altamente configurabile pensata per la gestione delle
logic enterprise manager lem lem Logic Enterprise Manager Grazie all esperienza decennale in sistemi gestionali, Logic offre una soluzione modulare altamente configurabile pensata per la gestione delle
Siti web centrati sui dati (Data-centric web applications)
") Siti web centrati sui dati (Data-centric web applications) 1 A L B E R T O B E L U S S I A N N O A C C A D E M I C O 2 0 1 2 / 2 0 1 3 WEB La tecnologia del World Wide Web (WWW) costituisce attualmente
Siti web centrati sui dati (Data-centric web applications) 1 A L B E R T O B E L U S S I A N N O A C C A D E M I C O 2 0 1 2 / 2 0 1 3 WEB La tecnologia del World Wide Web (WWW) costituisce attualmente
UNIVERSITA DEGLI STUDI DI NAPOLI FEDERICO II
 UNIVERSITA DEGLI STUDI DI NAPOLI FEDERICO II CORSO DI LAUREA IN INFORMATICA Anno Accademico 2010-2011 Tutor Accademico Prof. Guido Russo Tutor Aziendale Dott. Massimo Brescia Candidato Ettore Mancini VOGCLUSTERS
UNIVERSITA DEGLI STUDI DI NAPOLI FEDERICO II CORSO DI LAUREA IN INFORMATICA Anno Accademico 2010-2011 Tutor Accademico Prof. Guido Russo Tutor Aziendale Dott. Massimo Brescia Candidato Ettore Mancini VOGCLUSTERS
Protocollo di metadata harvesting OAI-PMH Lavoro pratico 2
 Docente: prof.silvio Salza Candidato: Protocollo di metadata harvesting OAI-PMH Open Archive Initiative OAI (Open Archive Initiative) rendere facilmente fruibili gli archivi che contengono documenti prodotti
Docente: prof.silvio Salza Candidato: Protocollo di metadata harvesting OAI-PMH Open Archive Initiative OAI (Open Archive Initiative) rendere facilmente fruibili gli archivi che contengono documenti prodotti
Basi di dati. Corso di Laurea in Ingegneria Informatica Canale di Ingegneria delle Reti e dei Sistemi Informatici - Polo di Rieti
 Basi di dati Corso di Laurea in Ingegneria Informatica Canale di Ingegneria delle Reti e dei Sistemi Informatici - Polo di Rieti Anno Accademico 2008/2009 Introduzione alle basi di dati Docente Pierangelo
Basi di dati Corso di Laurea in Ingegneria Informatica Canale di Ingegneria delle Reti e dei Sistemi Informatici - Polo di Rieti Anno Accademico 2008/2009 Introduzione alle basi di dati Docente Pierangelo
Ministerial NEtwoRk for Valorising Activities in digitisation. Museo & Web CMS Una piattaforma open source per la gestione di siti web accessibili
 Ministerial NEtwoRk for Valorising Activities in digitisation Museo & Web CMS Una piattaforma open source per la gestione di siti web accessibili Il passo successivo: Museo & Web CMS Piattaforma opensource
Ministerial NEtwoRk for Valorising Activities in digitisation Museo & Web CMS Una piattaforma open source per la gestione di siti web accessibili Il passo successivo: Museo & Web CMS Piattaforma opensource
Database. Si ringrazia Marco Bertini per le slides
 Database Si ringrazia Marco Bertini per le slides Obiettivo Concetti base dati e informazioni cos è un database terminologia Modelli organizzativi flat file database relazionali Principi e linee guida
Database Si ringrazia Marco Bertini per le slides Obiettivo Concetti base dati e informazioni cos è un database terminologia Modelli organizzativi flat file database relazionali Principi e linee guida
BANCHE DATI. Informatica e tutela giuridica
 BANCHE DATI Informatica e tutela giuridica Definizione La banca dati può essere definita come un archivio di informazioni omogenee e relative ad un campo concettuale ben identificato, le quali sono organizzate,
BANCHE DATI Informatica e tutela giuridica Definizione La banca dati può essere definita come un archivio di informazioni omogenee e relative ad un campo concettuale ben identificato, le quali sono organizzate,
SQL Server 2005. Introduzione all uso di SQL Server e utilizzo delle opzioni Olap. Dutto Riccardo - SQL Server 2005.
 SQL Server 2005 Introduzione all uso di SQL Server e utilizzo delle opzioni Olap SQL Server 2005 SQL Server Management Studio Gestione dei server OLAP e OLTP Gestione Utenti Creazione e gestione DB SQL
SQL Server 2005 Introduzione all uso di SQL Server e utilizzo delle opzioni Olap SQL Server 2005 SQL Server Management Studio Gestione dei server OLAP e OLTP Gestione Utenti Creazione e gestione DB SQL
Progetto Turismo Pisa
 2012 Progetto Turismo Pisa Deliverable D2.2 Realizzazione del prototipo per la navigazione dell infrastruttura di conoscenza Coordinamento: Fosca Fosca Giannotti Salvatore Rinzivillo KDD KDD Lab, Lab,
2012 Progetto Turismo Pisa Deliverable D2.2 Realizzazione del prototipo per la navigazione dell infrastruttura di conoscenza Coordinamento: Fosca Fosca Giannotti Salvatore Rinzivillo KDD KDD Lab, Lab,
Oreste Signore, <oreste@w3.org> Responsabile Ufficio Italiano W3C Area della Ricerca CNR - via Moruzzi, 1-56124 Pisa
 http://www.w3c.it/education/2012/upra/basicinternet/#(1) 1 of 16 Oreste Signore, Responsabile Ufficio Italiano W3C Area della Ricerca CNR - via Moruzzi, 1-56124 Pisa Master in Comunicazione
http://www.w3c.it/education/2012/upra/basicinternet/#(1) 1 of 16 Oreste Signore, Responsabile Ufficio Italiano W3C Area della Ricerca CNR - via Moruzzi, 1-56124 Pisa Master in Comunicazione
Il World Wide Web. Il Servizio World Wide Web (WWW) WWW WWW WWW WWW. Storia WWW: obbiettivi WWW: tecnologie Le Applicazioni Scenari Futuri.
 WWW WWW WWW WWW. Storia WWW: obbiettivi WWW: tecnologie Le Applicazioni Scenari Futuri.") Il Servizio World Wide Web () Corso di Informatica Generale (Roberto BASILI) Teramo, 20 Gennaio, 2000 Il World Wide Web Storia : obbiettivi : tecnologie Le Applicazioni Scenari Futuri La Storia (1990)
Il Servizio World Wide Web () Corso di Informatica Generale (Roberto BASILI) Teramo, 20 Gennaio, 2000 Il World Wide Web Storia : obbiettivi : tecnologie Le Applicazioni Scenari Futuri La Storia (1990)
Università degli studi Roma Tre Dipartimento di informatica ed automazione. Tesi di laurea
 Università degli studi Roma Tre Dipartimento di informatica ed automazione Tesi di laurea Reingegnerizzazione ed estensione di uno strumento per la generazione di siti Web Relatore Prof. P.Atzeni Università
Università degli studi Roma Tre Dipartimento di informatica ed automazione Tesi di laurea Reingegnerizzazione ed estensione di uno strumento per la generazione di siti Web Relatore Prof. P.Atzeni Università
Content Management Systems
 Content Management Systems Gabriele D Angelo http://www.cs.unibo.it/~gdangelo Università degli Studi di Bologna Dipartimento di Scienze dell Informazione Aprile, 2005 Scaletta della lezione
Content Management Systems Gabriele D Angelo http://www.cs.unibo.it/~gdangelo Università degli Studi di Bologna Dipartimento di Scienze dell Informazione Aprile, 2005 Scaletta della lezione
Ontologie per le neuroscienze: Human Brain Project
 Ontologie per le neuroscienze: Human Brain Project Università degli Studi di Firenze 15 Ottobre 2012 Panoramica Human Brain Project 1 Human Brain Project 2 3 4 5 Human Brain Project Obiettivi del progetto
Ontologie per le neuroscienze: Human Brain Project Università degli Studi di Firenze 15 Ottobre 2012 Panoramica Human Brain Project 1 Human Brain Project 2 3 4 5 Human Brain Project Obiettivi del progetto
WBT Authoring. Web Based Training STUDIO
 Web Based Training STUDIO AU-1.0-IT http://www.must.it Introduzione è un applicazione on-line in grado di soddisfare un gran numero di esigenze nel campo della formazione a distanza e della comunicazione.
Web Based Training STUDIO AU-1.0-IT http://www.must.it Introduzione è un applicazione on-line in grado di soddisfare un gran numero di esigenze nel campo della formazione a distanza e della comunicazione.
Componenti Web: client-side e server-side
 Componenti Web: client-side e server-side side Attività di applicazioni web Applicazioni web: un insieme di componenti che interagiscono attraverso una rete (geografica) Sono applicazioni distribuite logicamente
Componenti Web: client-side e server-side side Attività di applicazioni web Applicazioni web: un insieme di componenti che interagiscono attraverso una rete (geografica) Sono applicazioni distribuite logicamente
CONTENT MANAGEMENT SYSTEM
 CONTENT MANAGEMENT SYSTEM P-2 PARLARE IN MULTICANALE Creare un portale complesso e ricco di informazioni continuamente aggiornate, disponibile su più canali (web, mobile, iphone, ipad) richiede competenze
CONTENT MANAGEMENT SYSTEM P-2 PARLARE IN MULTICANALE Creare un portale complesso e ricco di informazioni continuamente aggiornate, disponibile su più canali (web, mobile, iphone, ipad) richiede competenze
Liceo Tecnologico. Indirizzo Informatico e Comunicazione. Indicazioni nazionali per Piani di Studi Personalizzati
 Indirizzo Informatico e Comunicazione Indicazioni nazionali per Piani di Studi Personalizzati Indirizzo Informatico e Comunicazione Discipline con attività di laboratorio 3 4 5 Fisica 132 Gestione di progetto
Indirizzo Informatico e Comunicazione Indicazioni nazionali per Piani di Studi Personalizzati Indirizzo Informatico e Comunicazione Discipline con attività di laboratorio 3 4 5 Fisica 132 Gestione di progetto
Informatica per la comunicazione" - lezione 10 -
 Informatica per la comunicazione" - lezione 10 - Evoluzione del Web" Nell evoluzione del Web si distinguono oggi diverse fasi:" Web 1.0: la fase iniziale, dal 1991 ai primi anni del 2000" Web 2.0: dai
Informatica per la comunicazione" - lezione 10 - Evoluzione del Web" Nell evoluzione del Web si distinguono oggi diverse fasi:" Web 1.0: la fase iniziale, dal 1991 ai primi anni del 2000" Web 2.0: dai
Prodotto <ADAM DASHBOARD> Release <1.0> Gennaio 2015
 Prodotto Release Gennaio 2015 Il presente documento e' stato redatto in coerenza con il Codice Etico e i Principi Generali del Controllo Interno Sommario Sommario... 2 Introduzione...
Prodotto Release Gennaio 2015 Il presente documento e' stato redatto in coerenza con il Codice Etico e i Principi Generali del Controllo Interno Sommario Sommario... 2 Introduzione...
Una piattaforma per la negoziazione di servizi business to business attraverso la rete Internet
 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Corso di Laurea in Ingegneria Gestionale della Logistica e della Produzione Una piattaforma per la negoziazione di servizi business to
Università degli Studi di Napoli Federico II Facoltà di Ingegneria Corso di Laurea in Ingegneria Gestionale della Logistica e della Produzione Una piattaforma per la negoziazione di servizi business to
Creare ontologie ONTOLOGIE, DESCRIPTION LOGIC, PROTÉGÉ STEFANO DE LUCA
 Creare ontologie ONTOLOGIE, DESCRIPTION LOGIC, PROTÉGÉ STEFANO DE LUCA Punto di partenza: materia per ragionare Gli agenti intelligenti possono usare tecniche deduttive per raggiungere il goal Per fare
Creare ontologie ONTOLOGIE, DESCRIPTION LOGIC, PROTÉGÉ STEFANO DE LUCA Punto di partenza: materia per ragionare Gli agenti intelligenti possono usare tecniche deduttive per raggiungere il goal Per fare
Il modello di ottimizzazione SAM
 Il modello di ottimizzazione control, optimize, grow Il modello di ottimizzazione Il modello di ottimizzazione è allineato con il modello di ottimizzazione dell infrastruttura e fornisce un framework per
Il modello di ottimizzazione control, optimize, grow Il modello di ottimizzazione Il modello di ottimizzazione è allineato con il modello di ottimizzazione dell infrastruttura e fornisce un framework per
Gestione del workflow
 Gestione del workflow Stefania Marrara Corso di Tecnologie dei Sistemi Informativi 2004/2005 Progettazione di un Sistema Informativo Analisi dei processi Per progettare un sistema informativo è necessario
Gestione del workflow Stefania Marrara Corso di Tecnologie dei Sistemi Informativi 2004/2005 Progettazione di un Sistema Informativo Analisi dei processi Per progettare un sistema informativo è necessario
Generazione Automatica di Asserzioni da Modelli di Specifica
 UNIVERSITÀ DEGLI STUDI DI MILANO BICOCCA FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI Corso di Laurea Magistrale in Informatica Generazione Automatica di Asserzioni da Modelli di Specifica Relatore:
UNIVERSITÀ DEGLI STUDI DI MILANO BICOCCA FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI Corso di Laurea Magistrale in Informatica Generazione Automatica di Asserzioni da Modelli di Specifica Relatore:
Processo parte VII. Strumenti. Maggiore integrazione. Sviluppo tecnologico
 Strumenti Processo parte VII Leggere Cap. 9 Ghezzi et al. Strumenti software che assistono gli ingegneri del software in tutte le fasi del progetto; in particolare progettazione codifica test Evoluzione
Strumenti Processo parte VII Leggere Cap. 9 Ghezzi et al. Strumenti software che assistono gli ingegneri del software in tutte le fasi del progetto; in particolare progettazione codifica test Evoluzione
Corso di Informatica
 Corso di Informatica Modulo T2 1 Sistema software 1 Prerequisiti Utilizzo elementare di un computer Significato elementare di programma e dati Sistema operativo 2 1 Introduzione In questa Unità studiamo
Corso di Informatica Modulo T2 1 Sistema software 1 Prerequisiti Utilizzo elementare di un computer Significato elementare di programma e dati Sistema operativo 2 1 Introduzione In questa Unità studiamo
Titolo Perché scegliere Alfresco. Titolo1 ECM Alfresco
 Titolo Perché scegliere Alfresco Titolo1 ECM Alfresco 1 «1» Agenda Presentazione ECM Alfresco; Gli Strumenti di Alfresco; Le funzionalità messe a disposizione; Le caratteristiche Tecniche. 2 «2» ECM Alfresco
Titolo Perché scegliere Alfresco Titolo1 ECM Alfresco 1 «1» Agenda Presentazione ECM Alfresco; Gli Strumenti di Alfresco; Le funzionalità messe a disposizione; Le caratteristiche Tecniche. 2 «2» ECM Alfresco
19. LA PROGRAMMAZIONE LATO SERVER
 19. LA PROGRAMMAZIONE LATO SERVER Introduciamo uno pseudocodice lato server che chiameremo Pserv che utilizzeremo come al solito per introdurre le problematiche da affrontare, indipendentemente dagli specifici
19. LA PROGRAMMAZIONE LATO SERVER Introduciamo uno pseudocodice lato server che chiameremo Pserv che utilizzeremo come al solito per introdurre le problematiche da affrontare, indipendentemente dagli specifici
Applicazioni web centrati sui dati (Data-centric web applications)
") Applicazioni web centrati sui dati (Data-centric web applications) 1 ALBERTO BELUSSI ANNO ACCADEMICO 2009/2010 WEB La tecnologia del World Wide Web (WWW) costituisce attualmente lo strumento di riferimento
Applicazioni web centrati sui dati (Data-centric web applications) 1 ALBERTO BELUSSI ANNO ACCADEMICO 2009/2010 WEB La tecnologia del World Wide Web (WWW) costituisce attualmente lo strumento di riferimento
IL SISTEMA INFORMATIVO
 IL SISTEMA INFORMATIVO In un organizzazione l informazione è una risorsa importante al pari di altri tipi di risorse: umane, materiali, finanziarie, (con il termine organizzazione intendiamo un insieme
IL SISTEMA INFORMATIVO In un organizzazione l informazione è una risorsa importante al pari di altri tipi di risorse: umane, materiali, finanziarie, (con il termine organizzazione intendiamo un insieme
Rete Regionale Integrata clinico-biologica per la Medicina Rigenerativa IDENTIFICATIVO PROGETTO: CUP G73F12000150004
 Rete Regionale Integrata clinico-biologica per la Medicina Rigenerativa IDENTIFICATIVO PROGETTO: CUP G73F12000150004 Rilascio Piattaforma Informatica Ing. Virna Lomonaco Regione siciliana Assessorato alle
Rete Regionale Integrata clinico-biologica per la Medicina Rigenerativa IDENTIFICATIVO PROGETTO: CUP G73F12000150004 Rilascio Piattaforma Informatica Ing. Virna Lomonaco Regione siciliana Assessorato alle
WorkFLow (Gestione del flusso pratiche)
") WorkFLow (Gestione del flusso pratiche) Il workflow è l'automazione di una parte o dell'intero processo aziendale dove documenti, informazioni e compiti vengono passati da un partecipante ad un altro al
WorkFLow (Gestione del flusso pratiche) Il workflow è l'automazione di una parte o dell'intero processo aziendale dove documenti, informazioni e compiti vengono passati da un partecipante ad un altro al
Archivi e database. Prof. Michele Batocchi A.S. 2013/2014
 Archivi e database Prof. Michele Batocchi A.S. 2013/2014 Introduzione L esigenza di archiviare (conservare documenti, immagini, ricordi, ecc.) è un attività senza tempo che è insita nell animo umano Primi
Archivi e database Prof. Michele Batocchi A.S. 2013/2014 Introduzione L esigenza di archiviare (conservare documenti, immagini, ricordi, ecc.) è un attività senza tempo che è insita nell animo umano Primi