Semantica: un sistema per l indicizzazione, il retrieval semantico di learning objects e la generazione automatica di corsi didattici
|
|
|
- Lucrezia Pappalardo
- 8 anni fa
- Visualizzazioni
Transcript
1 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Specialistica Semantica: un sistema per l indicizzazione, il retrieval semantico di learning objects e la generazione automatica di corsi didattici Relatori: Candidato: Ch.mo prof. Angelo Chianese Ch.mo Ing. Vincenzo Moscato matr. 885/184 Anno Accademico
2 A nonno Gerardo e nonno Olindo A mamma, papà e Dina A Federica Lentamente muore chi non capovolge il tavolo, chi è infelice sul lavoro, chi non rischia la certezza per l'incertezza, per inseguire un sogno... Lentamente muore chi abbandona un progetto prima di iniziarlo, chi non fa domande sugli argomenti che non conosce, chi non risponde quando gli chiedono qualcosa che conosce... Soltanto l'ardente pazienza porterà al raggiungimento di una splendida felicità. (P. Neruda)
3
4 Indice Analitico Indice delle figure...iv Ringraziamenti...viii Introduzione. L information retrieval e la semantica...1 L analisi e il retrieval semantico...3 L information retrieval e i motori di ricerca semantici...5 Verso la comprensione del significato...7 Il retrieval semantico dei learning objects...9 Sommario dei capitoli della Tesi...11 Capitolo 1. Il Semantic Web, i sistemi e i modelli di retrieval Il Web Semantico: un illusione realizzabile L architettura del Web Semantico L informazione e la sua rappresentazione I sistemi attuali di Information Retrieval L estrazione delle informazioni dai contenuti e la relevant information Gli ostacoli del linguaggio naturale Architettura di alto livello di un sistema di information retrieval I modelli di information retrieval I modelli booleano e vettoriale...34 Capitolo 2. Le tecnologie del Semantic Web Il Semantic Web Stack Resource Description Framework Una rete semantica di concetti di un dominio: l ontologia Applicazioni e problemi legati all approccio ontologico Ontologie vs Database: schema concettuale vs dati Ontology Web Language (OWL) Le ontologie CUONTO e DOMONTO Le ontologie persistenti e JENA...70 i
5 Capitolo 3. - una soluzione ontologica I Learning Objects: atomi di conoscenza Ontologie nell e-learning Annotare i learning objects: XML o RDF? Un retrieval efficace dei learning objects Stato dell'arte dei sistemi per l'annotazione e il retrieval di risorse didattiche : un modello di macchina semantica La struttura di alto livello della macchina semantica Il centro dei significati: WordNet Le ontologie della macchina semantica La Knowledge Base Modello di comunicazione della macchina semantica Verso il prototipo di macchina semantica Capitolo 4. - progettazione ed implementazione Architettura logica di Semantica Learning Object Repository Il modulo Discovery Semantic Knowledge Base (SKB) Knowledge Management System Ontology Management System Le ontologie del sistema Preprocessing del testo Indexing dei Learning Objects Vettore dei significati Vettore delle content units Vettore delle binding annotations Memorizzazione nella knowledge base I modelli di retrieval di learning object e approcci per la generazione automatica di corsi Progettazione ed implementazione Il modello dei sottosistemi Diagrammi del Knowledge Management System Diagrammi dell Ontology Management System Diagrammi del Discovery Diagrammi del Learning Object Repository I diagrammi delle classi e delle tabelle principali di Semantica ii
6 Capitolo 5. I moduli della Web Application Semantica I moduli di retrieval della web application Modulo di ricerca basato sul Sense Boolean Retrieval Model (SBRM) Modulo di ricerca basato sul Content Unit Retrieval Model (CURM) Modulo di ricerca basato sull Ontology Driven Retrieval Model (ODRM) Approcci e moduli per la generazione dei corsi didattici Il modello Content Unit Adaptive Courseware Generation (CUACG) Il modello Ontology Driver Adaptive Courseware Generation (ODACG) Il modulo di generazione semiautomatica dei corsi Il modulo di generazione automatica dei corsi Editing dei contenuti didattici Sperimentazione Conclusioni e sviluppi futuri Appendice A. La mappa della web application Semantica Appendice B. I patterns e le tecnologie utilizzati in Semantica B.1 Pattern Domain Model B.2 Pattern Data Transfer Object B.3 Pattern Strategy B.4 Pattern Singleton B.5 IBATIS B.6 JENA B.7 JWordNet B.8 Middleware RMI Bibliografia e Sitografia iii
7 Indice delle Figure Capitolo 1. Il Semantic Web, i sistemi e i modelli di retrieval...14 Figura 1.1: Semantic Web Stack...17 Figura 1.2: Sistema di Information Retrieval...22 Figura 1.3: Indexing di documenti...24 Figura 1.4: Text processing...27 Figura 1.5: Struttura di alto livello di un sistema di IR...29 Figura 1.6: Architettura di un sistema di IR...30 Figura 1.7: I modelli di Information Retrieval...32 Figura 1.8: Estensioni dei modelli di Information Retrieval...33 Figura 1.9: Modello Booleano...35 Figura 1.10: Modello Vettoriale...39 Capitolo 2. Le tecnologie del Semantic Web...42 Figura 2.1: Proposta del Web di Tim Berners-Lee (1989)...44 Figura 2.2: L'evoluzione del Web...45 Figura 2.3: Struttura a gradini degli standard del Semantic Web...46 Figura 2.4: Struttura ad albero di un documento XML...47 Figura 2.5: Le relazioni semantiche in un documento XML...48 Figura 2.6: Statement RDF (tripla soggetto-predicato-oggetto)...49 Figura 2.7: Serializzazioni di un documento RDF...50 Figura 2.8: Costrutti del linguaggio RDF...51 Figura 2.9: La castagna ontologica...54 Figura 2.10: Le ontologie media-specific e content-specific...56 Figura 2.11: Ontologie vs. Database...58 Figura 2.12: L'approccio ontologico: una rete di concetti...61 Figura 2.13: I livelli semantici del Semantic Web Stack...63 Figura 2.14: OWL-Lite, OWL-DL e OWL-Full...64 Figura 2.15: L'ontologia didattica CUONTO (classi e proprietà)...66 Figura 2.16: L'ontologia di dominio DOMONTO (classi e proprietà)...67 Figura 2.17: Ontologia CUONTO: proprietà delle content units...68 Figura 2.18: Ontologia DOMONTO: le classi Concept e Learning Object...69 Figura 2.19: Ontologia DOMONTO: Classe ConceptScheme...70 iv
8 Capitolo 3. - una soluzione ontologica...73 Figura 3.1: Componenti fondamentali dell'e-learning...75 Figura 3.2: I tre livelli del Modello della Conoscenza...79 Figura 3.3: La risorsa informativa e le sue componenti...89 Figura 3.4: Struttura di alto livello della macchina semantica...90 Figura 3.5: Il Meta-Modello SKOS...96 Figura 3.6: Modello di comunicazione della macchina semantica...99 Capitolo 4. - progettazione ed implementazione Figura 4.1: Architettura logica della macchina semantica Figura 4.2: Struttura di un learning object in Semantica Figura 4.3: Il modulo Discovery Figura 4.4: Il modulo Semantic Knowledge Base Figura 4.5: Il modulo Knowledge Management System Figura 4.6: Il modulo Ontology Management System Figura 4.7: Le ontologie del sistema Semantica Figura 4.8: Una ontologia del sistema Semantica: CuONTO Figura 4.9: Architettura di un sistema di Informational Retrieval Figura 4.10: Esempio di inverted index Figura 4.11: Il vettore dei significati Figura 4.12: TextProcessing Operations Figura 4.13: Vettore risultante del TextProcessing Figura 4.14: Vettore delle content units Figura 4.15: Vettore delle binding annotations Figura 4.16: Diagramma delle componenti del sistema Semantica Figura 4.17: Diagrammi del Knowledge Management System Figura 4.18: Diagrammi del Discovery Figura 4.19: Diagrammi del Learning Object Repository Capitolo 5. I moduli della Web Application Semantica Figura 5.1: Home Page della web application Semantica Figura 5.2: Pannello principale della web application Semantica Figura 5.3: Il modulo del Sense Boolean Retrieval Model Figura 5.4: Risultati del Sense Boolean Retrieval Model Figura 5.5: Content Unit Retrieval Model (CURM) v
9 Figura 5.6: Il modulo del Content Unit Retrieval Model Figura 5.7: Risultati del Content Unit Retrieval Model Figura 5.8: ODRM: costruzione del Conceptual Information Need Vector Figura 5.9: Il modulo dell'ontology Driven Retrieval Model Figura 5.10: Il risultato dell'ontology Driven Retrieval Model (modalità esplicita) Figura 5.11: Il risultato dell'ontology Driven Retrieval Model (modalità non esplicita) Figura 5.12: Courseware Generation (pannello di gestione dei corsi) Figura 5.13: I modelli di Courseware Generation Figura 5.14: Modalità semiautomatica di Courseware Generation Figura 5.15: Modalità semiautomatica di Course Generation: i vincoli del CUACG Figura 5.16: Risultati del CUACG secondo l'approccio semiautomatico Figura 5.17: Modalità semiautomatica di Courseware Generation: il modulo ODACG Figura 5.18: Risultati del modulo ODACG di Courseware Generation Figura 5.19: Modalità automatica di Courseware Generation: il modulo CUACG Figura 5.20: Modalità automatica di Courseware Generation: strategia pedagogica Figura 5.21: Risultati del modulo CUACG per la generazione automatica di corsi Figura 5.22: Pannello di amministrazione per l'editing dei contenuti didattici Figura 5.23: Editing dei contenuti didattici (inserimento informazioni del LO) Figura 5.24: Editing dei contenuti didattici (inserimento dei documenti del LO) Figura 5.25: Editing dei contenuti didattici (creazione delle CU annotations) Figura 5.26: Editing dei contenuti didattici (creazione delle Binding Annotations) Figura 5.27: Precision e Recall per una data richiesta di informazione Figura 5.28: Grafico Precision-Recall Figura 5.29: Risultati sperimentali del courseware generation Figura 5.30: IdeaWeb vi
10 vii
11 Ringraziamenti Ed eccomi qui, dopo non pochi sacrifici, alla materializzazione di un sogno che è iniziato 6 anni fa. È proprio vero: se nella vita hai un obiettivo, credendoci e non tirandosi mai indietro, lo si raggiunge. Ma l'arrivo alla meta ambita non arriva solo perchè lo si desidera, secondo me. È un cocktail di tanti elementi, dove le capacità personali e la voglia di fare sono sì al primo posto, ma dipende anche dalle persone che si incontrano lungo quel percorso che si chiama Vita. Ed io di persone giuste, nel momento giusto del mio cammino, ne ho incontrate davvero tante, ed ho paura di dimenticarne qualcuna. Questo lavoro e il risultato della mia carriera universitaria lo dedico a tutti quelli che mi hanno aiutato, stimato e voluto bene. Da dove iniziamo con i ringraziamenti? Ovviamente da mamma e papà, perchè tutto questo è dovuto a loro. Ai loro sacrifici, ai loro insegnamenti...al loro amore, che hanno trasmesso a me e a mia sorella. I momenti belli e brutti li ho condivisi con loro... le difficoltà le ho superate insieme a loro. Modelli di vita ed esempi da seguire, insegnamenti che porterò nel cuore per tutta la vita. Punti di riferimento nel mio percorso sono stati anche e soprattutto i miei nonni. Ricordo con affetto e commozione nonno Olindo e nonno Gerardo, che nonostante non ci siano più, rimane ancora viva in me la loro presenza. Ringrazio Dio per avermi dato una sorella che meglio di Dina non poteva capirmi. Ma il fratello maggiore non sono io? Eppure sono io ad aver imparato da lei. Forse lei è anche più diligente, vogliosa e pazientosa di me. Specie quando ci si ritrova con una persona testarda e capricciosa come il sottoscritto. Ah, e grazie per avermi stampato la tesi. Che faticaccia, vero? Oltre a dirti grazie, Dina, ti chiedo anche scusa per tutte le volte in cui ho voluto far valere la mia autorità di fratello maggiore. viii
12 Ho voluto dedicare questa tesi ad un'altra persona importante e fondamentale nella mia vita. La ragazza con cui ho vissuto i momenti più belli in questi ultimi due anni, Federica. Volevo dirti che ti adoro e che mi spiace per le volte in cui, nei momenti di maggiore impegno, mi hai trovato eccessivamente distante e nervoso. Questo risultato è anche merito tuo, che mi hai dato la tranquillità e la forza, sapendo di essere fiera di me, in ogni mia scelta o progetto. Ti amo. La mia grande fortuna è stata quella di aver trovato una famiglia completa, disponibile, che mi ha aiutato nei momenti in cui ne ho avuto bisogno. In particolare, ringrazio di cuore zio Gerardo, zio Peppino, zia Carmela e zio Pietro, per esserci stati sempre. Grazie davvero. Ringrazio tutti i miei parenti, che anche se non ho citato tutti esplicitamente non vuol dire che siano stati meno presenti degli altri. Ma è doveroso ringraziare i miei tanti cugini, che riempiono e movimentano le mie giornate, tra cui Carmine, con cui sono cresciuto e mi sono confrontato negli anni. Quindi, un grande abbraccio a Giuseppina, Serena, Laura, Federica, Fabiola, Alessia, Antonietta e Martina. Io e Carmine, beati tra le donne! Passiamo adesso agli amici. Beh, qui l'elenco è davvero lungo. È proprio vero che chi trova un amico trova un tesoro. I miei Amici (con la A maiuscola) sono stati sempre con me, mi hanno accompagnato fino a questo grande obiettivo e sono sicuro che ci saranno anche per quelli a venire. Mi permetto di esprimere per ognuno di loro quello che penso e sento. Donato, amico da una vita: persona buonissima (anche troppo), che dà anche senza ricevere. Sempre disponibile e contento per i risultati di un suo amico. Fratello che ti rispetta e che è leale. Ti voglio bene. Nicola, un altro fratello maggiore. Siamo cresciuti sulle sue disgrazie ( ). Un'altra persona che c'è sempre stata e sempre ci sarà. Grande Nick! Mimmo, il fenomenale El Director. Divertente e serio nello stesso tempo. Amico da cui farsi consigliare, specie nelle grandi decisioni. Ti stimo molto. Gerardo, e che ne parliamo a fare? Ricordo solo che mi è capitato per caso come vicino di banco al liceo e da allora non sono più riuscito a spiccicarmelo di dosso. Tra gli amici che contano, ma che non fanno solo numero. È stato difficile vivere con te, ma sono sopravvissuto. Adesso potrei adattarmi a tutto. Paolo, che dire di te? Innanzitutto grazie, perchè ogni volta che mi sono rivolto a te sei stato sempre disponibile. Persona davvero gentile, che trova la soluzione a qualunque problema. Stima reciproca già dalla prima volta che ci siamo conosciuti. Punto di riferimento. ix
13 E' arrivato il momento di ringraziare anche Giannuzza? Penso proprio di si. E quanti grazie ti dovrei dire? Penso proprio parecchi. Grazie perchè prima di tutto sei stato il mio oracolo virtuale. Mi è sembrato già dall'inizio di conoscerti da sempre e mi sono sentito a mio agio nel parlare con te del più e del meno. A volte le parole non sempre riescono a dire quello che veramente uno prova. In questo caso ti dico solo che vorrei che tu ci fossi sempre, come ora. Adesso è il turno di mio cugino Ilvo ed Italo. L'avervi avuto come amici negli anni più belli della mia vita, in cui tutti eravamo spensierati, è stato per me una grande ricchezza. Ne faremo ancora tante insieme, sicuramente! Grazie a Gerarda per il grande aiuto che mi ha dato nella stesura della tesi. Dai consigli alle correzioni. Ragazza speciale, come poche ne esistono. Che mi vuole bene, forse senza davvero meritarlo. Ti ammiro e ti sarò sempre riconoscente per come mi hai fatto sentire e per la stima che nutri nei miei confronti. Un grande saluto alla nostra amica Teresa e la sorella Anna. Grazie Terè, per avermi confortato (anche se virtualmente) in questo periodo impegnativo. Nel ricordare gli anni del Liceo, mi vengono in mente i bei momenti vissuti con i miei compagni di classe. A questo punto ringrazio Maria Concetta, che non si è mai dimenticata di me dopo le superiori e che sento sempre con piacere. Sei adorabile, Mara! Grazie anche ad Alessandro, che mi fa sempre piacere rivedere in quel di Senerchia. E c'è da ringraziare anche Rocco Iannone, che sono davvero felice di avere in famiglia ( ), perchè sei una persona umile, semplice e rispettosa, forse la persona giusta per mia sorella (si, ma non la fare incazzare!). Ma indimenticabili sono anche le ore dopo la scuola. Quei pomeriggi passati a giocare a pallone e a suonare. Grazie a Nicola, Donato, Angelo e Peppuccio per aver fatto nascere in me l'amore per la musica e per lo stare in gruppo. Gli anni in cui si suonava rimarranno impressi nel mio cuore e nella mente! Un grazie e un saluto di grande affetto e stima ai miei amici Gabriella, Angelo il mio pseudobassista ( ), Mariano e Antonio. Da loro ho imparato davvero tanto e mi sono divertito durante i primi anni qui a Napoli. Ho ancora molto da imparare da voi e ci divertiremo ancora parecchio, contateci! Un grande abbraccio a Daniela Ferrai, nonostante mi abbia abbandonato alla triennale per andare all'estero. Potevi rimanere un altro po' con me. Mi stavo ad annoià dopo che te ne sei andata! E vorrei rimproverare Katia. Mi potevi invitare alla tua laurea (prr). Comunque grazie anche a te per esserci stata! Tra gli amici di Napoli saluto e ricordo Generoso, Sabrina, x
14 Fabiana e Luisa. Belle le serate e le feste con voi! Stare lontano da casa è stato duro. Ma ho avuto la fortuna di avere in casa dei coinquilini stupendi, che sono diventati in primis anche i miei amici fidati. Grazie Andrea per essere così come sei, di persone come te ne esistono davvero poche. Mi è dispiaciuto davvero quando hai lasciato Napoli. Idem per Antonio Roberto. Un anno con te mi è sembrato un'eternità. Scusa per aver fatto valere la mia anzianità. Ma le matricole devono essere guidate ( ). Infine, voglio ringraziare Gerardo e Marco, con cui ho vissuto quest'ultimo anno in tranquillità. E' merito di questa serenità che mi ha aiutato in questo sprint finale. Scusatemi per la freddezza con cui mi sono ritrovato a volte. I momenti di tensione e di difficoltà capitano a tutti. Vi voglio bene. Voglio bene anche a Raffaele, Alfonso, Vittorio e Viscardi. A quest'ultimo dico che sono davvero felice della tua guarigione e del fatto che hai ripreso a studiare. Meriti davvero tanto dalla vita. Adesso è il momento degli amici di Università. Che dire? Sono commosso e onorato di aver condiviso con voi questa fatica. Come diceva Gramsci, lo studio è un mestiere faticoso. Ma mi avete aiutato a non sentire questo sforzo, facendomelo piacere con la vostra presenza. Quindi, ringrazio i sempre presenti Enzo ed Enzino e, chi è stato con noi i primi anni di università, Danilo, Francesco, Tommaso, Sabatino e Paolo. Senza di voi non sarei arrivato a questo traguardo. Colleghi ma soprattutto amici anche fuori l'università. Sono orgoglioso di avervi conosciuto. Basta poco per capire quanto una persona sia speciale e se ci si può fidare di lei. Infatti, il tempo per conoscere Biagio, Roberto e Clemente è stato poco, ma ho subito capito l' animo nobile di questi ragazzi. I mesi della tesi sono stati con voi davvero divertenti. Persone con cui si può fare gruppo, si lavora bene, ci si può confrontare e che sanno consigliare. Sempre disponibili. Un grazie di cuore. E Loredana e Laura? Belli i pomeriggi passati con voi a studiare. Non per lo studio sicuro, ma per la gioia che trasmettevate anche in quei momenti di fatica. Fondamentali nei momenti finali della mia carriera universitaria. Spero vivamente anche per quelli a venire! Grazie anche a Massimo (di Loredana) per la continua disponibilità, Pex (grande personalità), Francesco Cesareo (persona rispettosissima). Saluto con affetto anche gli amici del CSIF (dott. Delosa, Alfredo e Giuseppe), il prof. Pescapè e Carmen Baruffini, con cui ho lavorato serenamente e con motivazione durante i mesi del partime. Esperienza che mi ha formato e di cui farò tesoro. xi
15 Ringrazio i ragazzi del laboratorio LABADAM: Ernesto, Vincenzo, Battista, Giorgia, Marina, Paolo, Roberto, Francesco, Michele, Pasquale e il grande Antonio Penta (a quest'ultimo auguro un futuro di successi). Grazie per questi ultimi mesi. Davvero un bel gruppo! La mia riconoscenza per la fantastica compagnia va a Raffaele, Francesco, Nello, che insieme a Paolo hanno riempito le mie lunghe giornate universitarie durante il periodo della tesi. Grazie dei consigli e della compagnia. Non lo dimenticherò! Vorrei chiudere questa lunga lista di ringraziamenti, esprimendo la mia piena riconoscenza all' Ing. Moscato, che oltre ad avermi aiutato nella trattazione di questo argomento di tesi, è stato soprattutto un amico. L'aver creduto nelle mie capacità, ha tirato fuori il meglio che avevo per affrontare questo lavoro. Stesso discorso vale per il prof. Chianese, che ammiro per la capacità di far piacere e appassionare noi studenti alle cose che facciamo. Grazie per la fiducia e per la proposta di rimanere in un gruppo affiatato e familiare come il vostro! Grazie al genio di Mario Caropreso, senza il quale questo tentativo non sarebbe mai nato. Sono rimasto affascinato dalla cura, dalla perfezione e dalla passione con la quale ha iniziato questo progetto. Ho cercato di fare del mio meglio per non schernire il grande lavoro da te avviato! Spero di non aver dimenticato nessuno. In tal caso mi scuso e magari provvederò a ringraziarvi di persona. Dopo 6 anni di ingegneria la memoria inizia a vacillare. Comunque farò tesoro di tutto quello che mi avete dato e trasmesso, per non deludervi e per realizzare tutti i miei progetti, con il vostro aiuto ancora una volta. GRAZIE A TUTTI! Francesco xii
16 xiii
17 Introduzione L'information Retrieval e la semantica In questo lavoro di tesi si affronta il problema articolato del retrieval semantico, su cui esiste vastissima letteratura a riguardo. Il nostro approccio fa un uso massiccio di ontologie, intese come tentativi di formulare uno schema concettuale esaustivo e rigoroso nell ambito di un dato dominio. Il termine più giusto è proprio tentativo, visto che risulta impossibile uniformare il modo di pensare degli individui. In effetti, non sempre due persone hanno il medesimo punto di vista riguardo un determinato concetto. Lo stesso linguaggio è affetto da ambiguità e un concetto può essere definito, ovvero può acquistare un senso, solo se inserito in un dato contesto, un dato dominio. Sono questi i problemi che verranno via via sollevati e affrontati mediante tentativi in questo lavoro di tesi. Come primo assaggio introduciamo un po di nomenclatura: il Natural Language Processing (NLP) è inteso come quella branca dell intelligenza artificiale e della linguistica computazionale che studia i problemi della generazione e della comprensione automatica del linguaggio naturale umano. Poiché ci troviamo in un corso di laurea di Ingegneria Informatica, possiamo subito comprendere che il termine automatico è inteso come l utilizzo di un mezzo capace di effettuare elaborazioni, quindi un calcolatore. I sistemi che effettuano una conversione dei campioni di informazione del linguaggio umano in altre forme di rappresentazione, in modo da essere facilmente manipolabili computazionalmente, sono degli esempi di tentativo. 1
18 Malgrado una cerca enfasi giornalistica, siamo tuttavia ancora lontani non soltanto dall avere a disposizione applicazioni di ricerca di nuovo tipo, ovvero che non siano basate sul semplice matching sintattico, ma anche dall avere capito chiaramente come queste applicazioni potranno migliorare la user experience. Emblematica è la rinuncia da parte degli esperti del settore, tra cui Yahoo che, allo stato attuale, piuttosto che porsi l obiettivo (ambizioso ma di difficile definizione) di sostituire la tradizionale ricerca full text con una ricerca diversa ( concettuale o semantica ), ha capito che i risultati ottenuti dall utilizzo dei metadati strutturati (RDF come vedremo) possono servire, ove possibile a migliorare la già esistente ricerca full text. [1] Per introdurre il mio lavoro di tesi, ho il piacere di citare una risposta eloquente ad una domanda diretta, capace di far intuire cosa è stato qui realizzato. Domanda. Che cos è un motore di ricerca semantico? Risposta. Oggi non è pensabile un motore di ricerca semantica per tutto il web, come Google, ma per alcuni settori, quando il problema non è troppo complesso e ci si limita ad un contesto specifico, è possibile implementare soluzioni che consentono di guadagnare tempo e ottenere risultati migliori [2] Le parole-chiave che possiamo estrapolare dalla precedente risposta sono: settore, sinonimo di dominio applicativo, e contesto, sinonimo di luogo in cui si acquista un significato. La situazione ideale sarebbe quella di trovare una soluzione universale che vada bene per tutte le istanze del problema, ma risulta lontana anni luce. Non sarà mai possibile, ed è auspicabile che non lo sia mai, che tutti gli individui la pensino in modo uguale. Ognuno di noi matura una propria coscienza, una propria esperienza e un modo diverso di vedere le cose. Volendo continuare, di fronte a questi problemi che resistono alla soluzione, le reazioni sono due: 2
19 1. sfidare virilmente la difficoltà, affermando che il problema è risolvibile e basta risolverlo, anche impiegandoci tempo e denaro (o addirittura alcuni dicono che è già stato risolto); 2. indebolire gli obiettivi e accontentarsi di risolvere il problema, non nel caso generale, ma in alcuni (possibilmente tanti) casi particolari ( divide et impera ). L analisi e il retrieval semantico Per chi non lo avesse capito, il mio intento è quello di creare un approccio al retrieval semantico. Anche se inserito in un contesto particolare (il campo dell elearning), il retrieval può essere esteso al caso generale di ricerca di qualsiasi contenuto, che possa essere opportunamente annotato ( ove possibile ). È difficile definire che cosa sia il significato e già a cominciare dai più celebri filosofi Aristotele e Platone, non si è riusciti a trovare una definizione universale. Ancora più difficile è definire e valutare un sistema che afferma di utilizzare una analisi semantica. Per muoverci all interno del nostro scenario, ci serviamo di una strumento potentissimo: l ontologia, che definiremo meglio in seguito. Per ora accontentiamoci di definirla come un modo per estrarre fatti, intesi come descrizioni di eventi e situazioni accaduti e descritti linguisticamente. Insomma una sorta di descrizione formale di ciò che esiste in un dominio a partire dalla quale si possono effettuare inferenze. L'inferenza è il processo con il quale da una proposizione accolta come vera, si passa a una proposizione la cui verità è considerata contenuta nella prima. Avendo a disposizione le opportune risorse, nel nostro caso una rete semantica, il nostro approccio manifesta una certa capacità di effettuare inferenze basate sul significato delle parole. Ma per poter far ciò, dobbiamo prevedere un buon sistema di analisi del testo che sia composto di almeno tre elementi principali: - un lessico che fornisce significati e relazioni tra significati; - un parser che fornisce analisi sintattiche ricostruendo la struttura della frase; - uno o più moduli di interpretazione che trattano fenomeni semantici, 3
20 dall identificazione delle relazioni soggetto/oggetto/complementi alla capacità (di solito dipendente da dominio) di identificare fatti, eventi e relazioni tra di essi. Citazione. a quanto pare c è semantica e semantica e non tutte le semantiche sono uguali. [3] Il significato della precedente frase è che il termine semantica viene usato per indicare diverse situazioni: - semantica nel senso di Semantic Web : la rete diventa una gigantesca macchina inferenziale fondata su più o meno arcani sistemi di metadati; - semantica nel senso di approcci probabilistici (approcci bayesiani, latent semantic search analisys e simili). Fino a poco tempo fa questi erano gli unici a parlare di semantic search; per costoro il significato emerge, in qualche modo, da complicati ragionamenti sulle occorrenze e co-occorenze di elementi linguistici (o anche non linguistici); - semantica come sinonimo di qualunque cosa che faccia un analisi del testo che vada oltre i caratteri di cui è composto. Per costoro anche una semplice normalizzazione morfologica (che consente di trattare cane e cani come la stessa forma) è semantica; - semantica come sinonimo di semantica lessicale. Per costoro vale il seguente ragionamento: i significati e le relazioni tra significati, da che mondo e mondo, si trovano nei dizionari; io ho un grosso dizionario, quindi faccio analisi semantica. Talvolta questi grossi dizionari, magari specifici di dominio, sono chiamati appunto ontologie. Sembrerà assurdo, ma in questo lavoro si è cercato di fondere tutti i precedenti punti: un approccio al problema della ricerca semantica di contenuti condivisi e distribuiti, mediante implementazione di retrieval models, tecniche di analisi testuale ed utilizzo di ontologie. Citazione. Ogni buona rete semantica può generalizzare le relazioni di sinonimia (o quasi-sinonimia) [4] 4
21 Cosa vuol dire la precedente frase? Volendo dare una interpretazione personale, un sistema di analisi e retrieval semantico effettua delle inferenze, passando da un concetto ad un altro e saltando tra relazioni semantiche (non solo di sinonimia). È in questo modo che si può costruire una knowledge base, che si arricchisce con l esperienza, scoprendo i concetti e le relazioni semantiche tra di essi. L unico modo per risolvere il problema dell ambiguità dei significati è quello di capire il contesto in cui ci si trova. In letteratura esistono tantissimi approcci per risolvere questo problema, tra cui, come vedremo, il word sense disambiguation. L information retrieval e i motori di ricerca semantici Quello che ci possiamo chiedere a questo punto è a cosa serva l information retrieval (IR). Possiamo avanzare un esempio emblematico, tratto una ricerca svolta su una sindrome che ancora oggi affligge gli internauti: la search engine fatigue. Su SearchEngineLand [5] si legge che circa il 72% degli Americani soffrono della sindrome da ricerca, fatica che si concretizza in frustrazione così forte da spingere coloro che hanno speso fino a 2 ore per fare ricerche su di un argomento - apparentemente senza trovare soddisfazione - a lasciare fisicamente il computer. Ecco perché l interesse dei più grandi motori di ricerca attuali è stato rivolto allo studio di nuove tecniche di indexing e retrieval dei dati. Magari perché non provare proprio ad occuparsi di ricerca semantica? Information retrieval è, tuttavia, un concetto più generico, che abbraccia un po tutto il problema, dal matching sintattico a quello semantico. Eppure l interesse per il Natural Language Processing sembra essersi affievolito: non interessa più effettuare un analisi automatica del linguaggio e, dunque, un approccio che vada ad analizzare le query dell utente, ma l approccio è rivolto più che altro sulle tecniche di annotazione e indexing che possono dare un significato alle informazioni distribuite in rete [10]. Eppure in questo lavoro di tesi, si analizzano entrambi gli approcci, fornendo un confronto per entrambi i punti di vista. Non si ha la pretesa di indicare quale dei due approcci sia il migliore, ma si cerca di capire se effettivamente quel processo sia utile. 5
22 Un esempio concreto di applicativi frutto degli studi di IR, con il quale ci cimentiamo quotidianamente, sono i motori di ricerca. Oggi una delle principali sfide che questi sistemi artificiali si trovano ad affrontare è data dalla necessità di recuperare, da una enorme massa di dati e documenti web, quella che viene comunemente definita "the relevant information". Per evitare, cioè, delle situazioni di information overload - o come direbbe il grande filosofo Jean Baudrillard, per evitare che " l inflazione delle informazioni produca deflazione di senso " - diventa sempre più importante, per gli attuali motori, riuscire a soddisfare con facilità e, soprattutto senza perdite di tempo, le queries di coloro che cercano informazioni attraverso il web. La realizzazione concreta di un web effettivamente "intelligente" - in cui gli agenti informatici, cioè i motori di ricerca, siano in grado di riconoscere semanticamente il contenuto del testo e di dare in risposta solo quei documenti che, sulla base delle richieste effettuate, risultino essere effettivamente rilevanti per colui che ha effettuato la ricerca - rimane, però, ad oggi, un obiettivo ancora lontano da venire. Una buona definizione di motore di ricerca semantico potrebbe essere questa [6]: Definizione I.1. Un motore di ricerca semantico è un motore di ricerca che si pone l obiettivo ambizioso di comprendere così bene la vostra domanda, da essere in grado di fornirvi LA risposta corretta La lettera maiuscola non è stata lasciata a caso, perché vuole far notare che un attuale motore di ricerca riceve una query e ci fornisce un elenco di risultati che non sono LA risposta alla nostra domanda, ma che possono contenere la risposta al nostro bisogno informativo. Secondo la definizione data, un motore di ricerca semantico fa qualcosa (o meglio dovrebbe fare qualcosa) di più ambizioso, risparmiando un bel po di fatica: gli strumenti di analisi e comprensione in suo possesso sono tali da saltare il passo dell elenco di tutti i contenuti, per passare direttamente al soddisfacimento del bisogno informativo. In poche parole, si riduce il numero dei passi necessari a soddisfare la ricerca. 6
23 Finora il trovare la risposta giusta è sempre stato interpretato come un processo interattivo, in cui l utente fa una ricerca, riceve dei risultati, ne dà una giusta valutazione, infine pone una nuova ricerca che restringe o allarga o modifica la prima. L idea è sempre stata che la natura della domanda avesse come conseguenza l impossibilità di tentare di dare una risposta esatta: l unica strada percorribile è fornire l insieme delle migliori risposte lasciando all utente il compito di navigarle (Information Retrieval). I propugnatori della ricerca semantica così definita avvicinano il caso della ricerca più al question answering che all information retrieval. In ambiti ristretti il question answering è sicuramente possibile ed efficace, ma la sostituzione di un Google con un gigantesco oracolo che risponde correttamente a qualunque domanda, sembra ancora un po lontana. Un esempio di applicazione che ha fornito un possibile approccio alla question answering è dato da AskWiki [7], in cui la precisione nel retrieval dei risultati viene affrontata con una profonda comprensione della domanda dell utente. Ecco un primo esempio di sistema che cerca di trovare il significato delle parole e di elaborarle computazionalmente. Un motore di ricerca che utilizza l approccio semantico al linguaggio naturale ( semantico qui è da contrapporre a basato su keywords ) dovrebbe offrire i seguenti vantaggi: comprensione dell intento che guida le query; maggiore e proficua comprensione dei documenti disponibili sul web; migliore matching tra intento della query e significato dei documenti; valorizzazione delle risposte e non delle semplici keywords. Verso la comprensione del significato Il funzionamento molto spesso poco soddisfacente dei più comuni motori di ricerca per Internet (Google, Yahoo, Live ed altri), quando si cercano informazioni specifiche e non di massa, ha portato ad un rinnovato interesse per approcci alternativi che superino le tecnologie attuali. Per molte tipologie di ricerche (anche se non per tutte), un motore basato sull interpretazione del linguaggio consentirebbe innanzi tutto di porre le proprie domande nello stesso modo con cui si chiedono informazioni alle persone [..]. 7
24 Il concetto base della tecnologia semantica è di avere una comprensione del significato dei contenuti per riuscire a gestire la conoscenza a livello concettuale (e non più solo attraverso parole-chiave), in modo molto più simile a quanto fanno le persone. Queste parole di Marco Varone [2] ci danno un idea del cambiamento che è in atto nel mondo dei motori di ricerca, un cambiamento che muove dal riconoscere i limiti delle tecnologie di ricerca attualmente diffuse (ovvero basate su keywords e variazioni sul tema del PageRank). Il cambiamento consiste nella migrazione, al momento lenta e faticosa, verso tecnologie di ricerca che ammettono la centralità del linguaggio naturale, visto non solo come un insieme di parole chiave o tags, ma più realisticamente come struttura complessa in cui sintassi e semantica concorrono a costruire il significato. I problemi che affliggono le teorie semantiche dell interpretazione del linguaggio naturale non sono pochi: il principale, è certamente, il problema posto dall interpretazione del significato singolo di ogni termine o parola in una determinata lingua. Gli strumenti di ricerca basati sul NLP trovano nella classificazione generalista tramite ontologie di concetti la loro ragion d essere. La strada alternativa, e ad oggi in completo fermento, consiste nell aggiungere alla classificazione generalista per tag, un motore linguistico in grado di analizzare e riconoscere in modo automatico le classi dei concetti, i concetti stessi, le persone, e così via, sino a livelli particolareggiati di affinamento della ricerca. Grazie all individuazione del giusto significato di un termine fra i tanti possibili e alle relazioni semantiche tra i diversi concetti, il risultato (auspicato) è quello di afferrare il vero contenuto di un testo. L unica tecnologia che consente di arrivare davvero a una forma di comprensione della lingua è la semantica: è una strada decisamente in salita, ma è inutile continuare a prendere delle scorciatoie, perché i fatti dimostrano che non si arriva a destinazione. Parole che fanno sperare nel cambiamento (in un futuro prossimo), anche se è bene restare con i piedi per terra, non promettere troppo e troppo presto e cercare di arrivare per gradi al premio più ambito: la soddisfazione degli utenti. 8
25 Il retrieval semantico dei learning objects Come riusciamo ad estrarre, dalla nostra mente, le informazioni che ci servono per risolvere un determinato problema? Quali sono i meccanismi che regolano il recupero delle informazioni immagazzinate nella nostra memoria? Come fanno gli esseri umani ad estrarre, con tale straordinaria abilità, una certa informazione solo nel momento in cui essa diviene rilevante per la risoluzione di un determinato compito cognitivo? Il tentativo di rispondere a quesiti di questo tipo segnò, verso la fine degli anni '40, la nascita, in campo psicologico, di una nuova area di ricerca che prese il nome di Information Retrieval (il termine fu coniato da Calvin Mooers). In anni più recenti, con l avvento della rivoluzione tecnologica determinata dalla diffusione dell informatica e di internet - e soprattutto con l aumento esponenziale della mole di informazioni immagazzinate su documenti in formato digitale - i temi di ricerca dell Information Retrieval hanno trovato nuova linfa e nuova dimensione applicativa nel campo dell informatica. Mentre prima, infatti, (agli albori della disciplina) gli studi del settore si concentravano soprattutto sul come, nella mente umana, avvenisse la fase di "retrieval" (recupero) informativo, oggi quando si parla di Information Retrieval ci si riferisce inequivocabilmente a quell ambito di ricerca che si occupa di studiare l insieme delle tecniche utilizzate per il recupero dell informazione in formato elettronico (Wikipedia). È bene sapere che un sistema di retrieval, per poter recuperare l informazione, usa i linguaggi di interrogazione basati su comandi testuali. Vedremo poi in seguito di cosa si sta parlando. Ora qui vogliamo capire per quale motivo si vuole perfezionare la ricerca dei contenuti didattici o learning objects, così denominati nel campo dell e-learning. Definizione I.2. «Un learning object è ogni risorsa digitale che può essere riutilizzata per supportare l apprendimento.» (D. A. Wiley) Il motivo sostanzialmente è dovuto al fatto che per i contenuti didattici si ha la medesima necessità di recuperare informazioni, specie nel caso in cui gli stessi risultino in quantità elevate e si vogliano facilmente riutilizzare per nuovi usi o per 9
26 assemblare dei veri e propri corsi didattici. Infatti, i learning objects costituiscono particolari tipi di risorse di apprendimento auto consistenti, dotate di modularità, reperibilità, riutilizzo e interoperabilità, che ne consentono la possibilità di impiego in contesti diversi. La parola chiave è riutilizzabilità, che, come sanno gli esperti del settore dell e- learning, è una proprietà essenziale che viene assicurata per fare in modo che i learning objects possano essere utilizzati ovunque e comunque. Ma la riutilizzabilità non è l unica prerogativa. Esistono, infatti, molte altre proprietà che un oggetto didattico deve possedere: innanzitutto, queste proprietà vengono garantite mediante l adozione di standard, che migliorano la stessa portabilità e la fruibilità dei materiali. Per maggiori informazioni su questi standard è possibile far riferimento al mio precedente lavoro di tesi [8]. Lo slogan adottato in ambito e-learning per garantire le proprietà precedenti è sempre lo stesso: everywhere, every time, everyone : everywhere : con ogni sistema operativo e ogni browser; every time : usabile, cioè comprensibile (testi, icone, navigazione) per l utente di riferimento; everyone : accessibile, in modo da non creare forme di esclusione basate sulla tecnologia. Ma se oltre a queste prerogative introduciamo un metodo per il recupero delle unità di apprendimento efficace e immediato, allora riusciamo meglio a garantire la riusabilità delle stesse risorse. L osservatorio ANEE ha definito l e-learning come una metodologia di insegnamento e apprendimento che coinvolge sia il prodotto sia il processo formativo. Per prodotto formativo si intende ogni tipologia di materiale messo a disposizione in rete. Per processo formativo si intende, invece, la gestione dell intero iter didattico che coinvolge gli aspetti di erogazione, fruizione, interazione, valutazione. Peculiarità dell e-learning è l alta flessibilità garantita al discente dalla reperibilità sempre e ovunque dei contenuti formativi, che gli permettono l autogestione e l autodeterminazione del proprio apprendimento. 10
27 La formazione a distanza attraverso le nuove tecnologie assicura vantaggi notevoli, primo tra tutti un estrema flessibilità di tempo e di spazio: il discente non è più costretto ad essere presente nel medesimo luogo dell insegnante e può studiare anche da casa quando e quanto vuole. Se a questo aggiungiamo il miglioramento dell accesso all istruzione, l aumento della qualità del contenuto formativo, una sua gestione più flessibile, la possibilità di misurare facilmente i risultati e la diminuzione dei costi, capiamo perché la formazione a distanza è al giorno d oggi molto appetita in tutti gli ambienti didattico/formativi [58]. Purtroppo gli attuali sistemi di didattica non sono privi di difetti. La principale pecca dei sistemi attualmente in commercio è che essi non sfruttano le potenzialità del mezzo che hanno a disposizione, utilizzandolo come mero veicolo di informazione e non come strumento capace di elaborare tale informazione in maniera intelligente e personalizzata [53]. Sommario dei capitoli della Tesi In questa Introduzione abbiamo introdotto i concetti che verranno via via affrontati nei dettagli nei prossimi capitoli. Abbiamo focalizzato le problematiche dovute all'ambiguità del linguaggio e gli obiettivi che ci siamo preposti, attraverso un tentativo che faccia un uso massiccio di ontologie. Nel Capitolo 1 si parla del Semantic Web e di tutte quelle tecnologie che vengono utilizzate, o almeno cercano di essere impiegate, per la sua realizzazione. Si introduce il problema della irrealizzabilità di un Web Semantico nel breve periodo, ma si tenta di impiegare gli standard e le tecnologie che costituiscono il Semantic Web Stack in domini più ristretti, dove le problematiche sono meno stringenti e superabili. Vengono, inoltre, introdotti dei modelli di retrieval. Nel Capitolo 2 vengono approfondite le tecnologie del Semantic Web, impiegate nel nostro caso nel dominio dell'e-learning. Per cui si approfondisce l'uso del linguaggio RDF e OWL, e dunque, delle ontologie, per poi introdurre quelle utilizzate dal nostro sistema: l'ontologia didattica CuOnto e quella di dominio, DOMONTO. Ci si sofferma brevemente sulle ontologie persistenti. Nel Capitolo 3 si entra nel vivo del nostro approccio:, una soluzione ontologica. Si introduce il campo applicativo del nostro lavoro, ovvero quello dell'indexing e del retrieval semantico di contenuti didattici (learning 11
28 objects). Si cerca di capire come mai l'utilizzo delle ontologie risulti vantaggioso in domini ristretti e come mai si debbano annotare i learning objects per introdurre semantica nei contenuti didattici. Sempre in questo capitolo viene descritta la struttura di alto livello e il modello della macchina semantica, parlando delle sue ontologie, della base di conoscenza (knowledge base) da essa posseduta e del suo modello di comunicazione. Nel Capitolo 4 si arriva alla vera e propria fase di progettazione e di implementazione della macchina semantica, con un primo tentativo di utilizzo della stessa. Si spiega il funzionamento di ogni singolo componente dell'architettura logica della macchina, capendo quali sono le informazioni che vengono da essa trattate ed elaborate. Si evidenzia la fase di indexing della macchina semantica con le singole operazioni che vengono effettuate sui contenuti testuali e sulla struttura dei learning objects. Infine, si parla dei modelli di retrieval di learning objects e degli approcci alla generazione automatica dei corsi. Nel Capitolo 5 viene presentata la web application Semantica, primo tentativo di utilizzo della macchina semantica. Si analizza il funzionamento dei singoli moduli della web application, spiegando nei dettagli i modelli di retrieval. Dunque, si affronta il processo di retrieval da parte dell'utente finale, con esempi d'uso dei tre modelli implementati. Vengono presentati, infine, gli approcci per la generazione automatica e semiautomatica dei corsi, il processo di editing dei contenuti didattici e la sperimentazione di questi approcci per la creazione di corsi personalizzati. 12
29 13
30 Capitolo 1 Il Semantic Web, i sistemi e i modelli di retrieval Come già anticipato nell introduzione, lo scenario attuale del World Wide Web è quello di un enorme insieme di testi collegati in qualche modo tra di loro. Questi collegamenti tra i contenuti disseminati sulla rete sono classificabili in due categorie: - collegamenti sintattici: sono legati al funzionamento di qualche codice di programmazione, localizzando la risorsa con un URL (Uniform Resourse Locator ) univoco sulla rete; - collegamenti, meglio detti annotazioni, che descrivono il significato di una risorsa, che oltre a portare in un determinato luogo, dovrebbero descrivere il luogo verso cui porta (capacità semantica). Ebbene, queste due dimensioni ci portano alla definizione dell attuale Web e del futuro e auspicabile Web Semantico. Il termine Web Semantico è stato proposto per la prima volta nel 2001 da Tim Berners-Lee. Da allora il termine è stato associato all idea di un Web nel quale agiscano agenti intelligenti (creati senza ricorrere all intelligenza artificiale ad alti livelli), applicazioni in grado di comprendere il significato dei testi presenti sulla rete e perciò in grado di guidare l utente direttamente verso l informazione ricercata, oppure di sostituirsi a lui nello svolgimento di alcune operazioni. In questo lavoro di tesi non ci occupiamo degli agenti intelligenti, per cui si rimanda a [7] e [8] per approfondimenti. 14
31 Secondo la visione di Lee, l attendibilità di una informazione (tramite ricerche incrociate o in dipendenza del contesto) dovrebbe essere verificata utilizzando un meccanismo simile alle famigerate catene di S. Antonio. Utilizzando questa tecnologia si può automatizzare la ricerca delle pagine, poiché all atto della creazione del contenuto delle pagine le informazioni sono definite ed inserite secondo precise regole semantiche (per questo è stato coniato il termine Web Semantico). Il Web Semantico è quindi un nuovo modo di concepire i documenti per il World Wide Web. Secondo la definizione di Tim Berners-Lee [10]: Definizione 1.1. "Il Web Semantico è un'estensione del Web corrente in cui le informazioni hanno un ben preciso significato e in cui computer e utenti lavorano in cooperazione" Le possibilità offerte dal Web Semantico sono tante e tali che non si sono ancora approfondite le sue potenzialità. Per questo, più che di tecnologia, si parla di visione del Web Semantico. 1.1 Il Web Semantico: un illusione realizzabile Voglio riportare una interessante intervista ad uno dei più apprezzati studiosi italiani della rete, Nicola Guarino, direttore a Trento di una sede distaccata (il laboratorio di Ontologia Applicata) dell Istituto di Scienze e Tecnologie della Cognizione del Car, che fa il punto sulle prospettive di sviluppo dei sapere in Internet [11]. Guarino promuove un approccio fortemente interdisciplinare, che combini informatica, ricerca filosofica, linguistica e scienze cognitive nella elaborazione delle cosiddette ontologie informatiche, che stanno alla base di una tecnologia come quella del web semantico. Semplice è anche la sua definizione di Web Semantico: Citazione. Il progetto legato all idea di web semantico è quello di rendere comprensibile ad un computer una pagina web, che solitamente è stata creata per essere compresa da un essere umano [ ] // un calcolatore sa acquisire e collegare le varie informazioni (ndr, in modo semantico) 15
32 La comprensione delle cose di un essere umano è l implicito riferimento ad una ontologia. Ad esempio, la distinzione tra due oggetti differenti che hanno il medesimo segno - l informazione infatti è costituita da un segno, ossia la forma, e il significante, descrizione dell oggetto o semplicemente il suo significato - è prettamente ontologica. L idea allora è stata quella di annotare ai contenuti di una pagina web i rispettivi riferimenti ontologici, definiti secondo una prefissata descrizione di tutti i possibili oggetti e delle loro relazioni, che sarà appunto l ontologia a cui il calcolatore può accedere. In questo modo si tenta di rendere il computer capace di interpretare e collegare informazioni provenienti da contesti differenti nel modo più naturale ed efficiente possibile. Lo stesso Guarino sembra scettico riguardo alla creazione di una ontologia universale ed onnicomprensiva. Nella pratica, infatti, molto dipende dall obiettivo concreto che ci si prefigge. Se ci interessa un contesto limitato risulta efficiente una descrizione solo di quegli oggetti che in quel contesto possono comparire. Ciò che è cruciale, però, è che l ontologia sia ben fondata e per crearla è necessario un ragionevole accordo tra gli esperti dell ambito che consideriamo, ma anche il contributo di un intelligente approccio filosofico, che può giovarsi dei risultati della filosofia analitica, ma anche della stessa ontologia classica. Citazione. Quella del Semantic Web è una strada ardua e tutta in salita e affronta problemi (come quello di far parlare banche dati eterogenee) che da decenni in informatica non si riesce a risolvere in modo soddisfacente. È molto pericoloso creare delle aspettative troppo alte che, una volta disattese, rischiano di minare ogni fiducia nelle ricerche in questo settore 1.2 L architettura del Web Semantico Scrivere del codice in grado di compiere operazioni semantiche dipende dallo schema utilizzato per archiviare le informazioni. Lo schema (ad esempio uno schema XML) è un insieme di regole sull'organizzazione dei dati; può definire relazioni fra i dati e può anche esprimere vincoli tra classi di dati. L'idea del Web Semantico nasce estendendo l'idea di utilizzare schemi per 16
33 descrivere domini di informazione. I metadati devono mappare i dati rispetto a classi, o concetti, di questo schema di dominio. In questo modo si hanno strutture in grado di descrivere e automatizzare i collegamenti esistenti fra i dati. Il Web Semantico è, come l'xml, un ambiente dichiarativo, in cui si specifica il significato dei dati, e non il modo in cui si intende utilizzarli. La semantica dei dati consiste nel dare alla macchina delle informazioni utili in modo che essa possa utilizzare i dati nel modo corretto, convertendoli eventualmente. Riassumendo, il Web Semantico si compone di tre livelli fondamentali: 1. i dati; 2. i metadati, che riportano questi dati ai concetti di uno schema; 3. le classi di dati, ossia le relazioni fra concetti espresse nello schema. Guardiamo ora più in profondità la struttura alla base della visione del Web Semantico. Faremo riferimento a un diagramma piramidale [10]: Figura 1.1: Semantic Web Stack 17
34 Il Web Semantico ha quindi una architettura a livelli, che però non è stata ancora sviluppata completamente. Ciò avverrà nei prossimi anni. Vediamo ora il diagramma più in dettaglio: 1. il Web Semantico si basa sullo standard URI (Uniform Resource Identifiers), per la definizione univoca degli indirizzi Internet; 2. al livello superiore si trova XML (extensible Markup Language), che gioca un ruolo di base con i namespace e gli XML Schema. Con XML è possibile modellare secondo le proprie esigenze, e senza troppi vincoli, la realtà che si considera: per questo è un linguaggio che porta con sé alcune informazioni sulla semantica degli oggetti. Questa libertà lo rende poco adatto, però, a definire completamente la struttura e l interscambio di informazioni tra diverse realtà, quindi è stata favorita la creazione di un nuovo linguaggio; 3. RDF (Resource Description Framework ) e RDF Schema, che costituiscono il linguaggio per descrivere le risorse e i loro tipi. Derivano da XML; 4. più in alto si pone il livello ontologico. Una ontologia che permette di descrivere le relazioni tra i tipo di elementi (per esempio questa è una proprietà transitiva ) senza, però, fornire informazioni su come utilizzare queste relazioni dal punto di vista computazionale; 5. la firma digitale è di significativa importanza in diversi strati nel modello astratto del Web Semantico. La crittografia a chiave pubblica è una tecnica nota da qualche anno, ma non ancora diffusa su larga scala, forse perché impone una scelta binaria tra fiducia o non fiducia, mentre sarebbe necessaria una infrastruttura in cui le parti possano essere riconosciute e accettate in specifici domini. Con questo accorgimento, la firma digitale potrebbe essere utilizzata per stabilire la provenienza delle ontologie e delle deduzioni, oltre che dei dati; 6. il livello logico è il livello immediatamente superiore. A questo livello le asserzioni esistenti sul Web possono essere utilizzate per derivare nuova conoscenza. Tuttavia, i sistemi deduttivi non sono normalmente interoperabili, per cui invece di progettare un unico sistema onnicomprensivo per supportare il ragionamento, si potrebbe pensare di definire un linguaggio universale per rappresentare le dimostrazioni. I 18
35 sistemi potrebbero quindi autenticare con la firma digitale queste dimostrazioni ed esportarle ad altri sistemi che le potrebbero incorporare nel Web Semantico. Approfondiremo i livelli dell URI, dell RDF e delle Ontologie nel prossimo capitolo. In questo, invece, vogliamo esaltare i modelli di retrieval. 1.3 L informazione e la sua rappresentazione Ricordiamo il problema da cui siamo partiti e a cui vogliamo applicare una nostra possibile soluzione: la crescente disponibilità di risorse informative unita alla facilità del loro accesso tramite il World Wide Web ha creato una situazione nota come information overload, situazione in cui il navigatore si trova in un mare di informazioni senza riuscire a localizzare quelle necessarie. I moderni motori di ricerca cercano le informazioni semplicemente tramite una corrispondenza sintattica fra i termini della query scritta dall utente e i termini indice con cui sono memorizzati i documenti. I motori di ricerca possono soltanto fare corrispondenze, non interpretare i contenuti del documento che elaborano. Ovviamente, questa limitazione porta ad un peggioramento del servizio offerto, in quanto la ricerca non è in grado di sfruttare i rapporti semantici esistenti fra le parole del lessico. Ad esempio, una ricerca effettuata per un certo termine può essere non adatta a recuperare documenti che non utilizzano esplicitamente il termine ma un suo sinonimo (ovvero recuperare la dimensione semantica del testo). Tuttavia, vi è un problema di congruenza dell informazione rispetto al bisogno informativo dell utente: la stessa informazione, infatti, può essere utile in un determinato contesto, mentre in un altro può essere totalmente irrilevante. Secondo la teoria classica della comunicazione [12], l informazione è una grandezza misurabile legata alla probabilità dei simboli che compongono un messaggio da trasmettere. Secondo tale teoria, l informazione è quindi strettamente legata al problema di trasmissione di dati lungo un canale di comunicazione e non ha un significato, nel senso che tale significato è irrilevante nei confronti del problema di trasmissione. La dimensione semantica dell informazione viene recuperata da MacKay - affermando che l informazione è 19
36 un aumento o cambiamento della conoscenza -, da Nauta jr. e dalle teorie semiotiche di Pierce e Morris. Sempre MacKay sostiene che si guadagna informazione quando conosciamo qualcosa che prima non conoscevamo, quando ciò che conosciamo è mutato. [14] Secondo Pierce, la semantica è data dalla corrispondenza di un significante con un significato. Tale corrispondenza rappresenta il segno, che è una costruzione mentale. Morris, sulle orme di Pierce, elabora un modello di informazione strutturata a livelli: - livello semantico, ovvero corrispondenza fra significati e significanti; - livello pragmatico, ovvero corrispondenza fra significati e azioni provocate presso il destinatario dell informazione; - livello sintattico, ovvero mera trasmissione di simboli. Per ulteriori approfondimenti sulla semiotica e sulla teoria dell informazione si faccia riferimento alla teoria matematica della comunicazione di Shannon [12] e al modello semiotico-informazionale di Umberto Eco [13]. L informatica, e in particolare l information retrieval, si sono per lo più basati sulla dimensione sintattica dell informazione. Per garantire migliori prestazioni nella ricerca, siamo costretti ad introdurre anche la semantica delle informazioni nel retrieval dei contenuti sul World Wide Web. La semiotica è lo studio dei segni e dei simboli e del modo in cui il significato viene costruito e capito. I contributi di Pierce e Morris hanno fondato le basi della semiotica moderna, nella quale centrale è il concetto di segno. La funzione principale del segno è quella di rappresentare un oggetto. È il segno che ha un significato, non l oggetto. Il segno non è strettamente legato alla parola: esso può essere un immagine, un suono, un gesto, un comportamento. Il fatto importante è la correlazione (referenza) fra segno e oggetto (referente). Dunque, in semiotica un codice è un insieme strutturato di regole che abbina unità di un sistema sintattico, dette significanti, con unità di un sistema semantico, i significati. Noi cercheremo, appunto, di rifarci a questa struttura, andando al di là della mera rappresentazione dei segni e concentrandoci sul recupero della dimensione semantica dei concetti, che ci servirà per collegarli tra di loro e guidare la ricerca dei contenuti in modo più intelligente. 20
37 1.4 I sistemi attuali di Information Retrieval Riprendendo quanto detto nella parte introduttiva, l information retrieval è l insieme delle tecniche che consentono di individuare facilmente le informazioni rilevanti per uno specifico bisogno formativo. Tuttavia, più che di informazione, nell IR si dovrebbe parlare di document, in quanto non riesce (almeno allo stato attuale) a misurare una informazione. Infatti, i sistemi di IR informano circa l esistenza o meno dei documenti collegati ad una richiesta. Essi lavorano su termini indicizzati per individuare e restituire documenti, dove per termine indicizzato si intende una parola chiave oppure un insieme di termini che sono significativi nel contesto del documento (spesso una parola del documento stesso). L attività fondamentale di un sistema di IR è quella del matching fra i termini indicizzati e la query dell utente. Ci sono diverse modalità di accesso alle informazioni su Web e tali modalità dipendono sia dalla natura dell informazione, sia dalle esigenze dell utente: - l utente può, infatti, navigare per mezzo di attivazione di link (paradigma point and click) - oppure, mediante specificazione esplicita delle sue esigente, formulando una richiesta formale da passare ai sistemi di Informational Retrieval Systems o Search Engine Database Management Systems (sistemi per il reperimento automatico di informazioni). Allo stato attuale già esistono sistemi di retrieval, che apprendono le preferenze degli utenti sulla base dei loro acquisti precedenti, specie nell ambito del commercio elettronico. Essi sono detti Recommender Systems. Altri sistemi IR, mediante dialogo guidato, apprendono ciò che l utente desidera (Sistemi di supporto alle decisioni). Dunque, i cosiddetti sistemi per il reperimento automatico delle informazioni si distinguono in due categorie: - sistemi per la gestione di basi di dati (DBMS), in cui le informazioni sono costituite da dati e l utente li richiede esplicitamente tramite una richiesta formale per mezzo di un linguaggio di interrogazione; 21
38 - sistemi di information retrieval (motori di ricerca), dove le informazioni sono contenute in documenti (generalmente testuali). L utente richiede esplicitamente dei documenti descrivendone il contenuto tramite una richiesta formale per mezzo di un linguaggio di interrogazione. Ovviamente, qui ci si sofferma sulla seconda categoria di sistemi, in cui l informazione può essere di diversi tipi: testuale, visuale o vocale, benché la maggior parte dei sistemi di IR consentono la rappresentazione e il reperimento di soli testi contenuti in documenti. Il problema di identificare l informazione rilevante (relevant information) tra le esigenze di uno specifico utente è di tipo decisionale: la decisione è basata sulla abilità di stabilire la rilevanza di un documento rispetto alle reali e soggettivi esigenze di un utente. Problema molto complesso, caratterizzato da imprecisione e incertezza. Figura 1.2: Sistema di Information Retrieval 22
39 Dunque, lo scopo di un sistema di information retrieval è stimare la rilevanza dei documenti sulla base di un confronto tra la rappresentazione formale dei documenti e le queries. I componenti di base di un sistema IR sono: - archivi di documenti: il documento è l unità di informazione reperibile. Può essere costituito da un testo in forma narrativa (testuale) o essere composto da parti narrative, pittoriali, codificate, ecc. - rappresentazione formale dei documenti: sintetizza il contenuto informativo dei documenti - linguaggio di query: in una query sono espresse le condizioni per la selezione dei documenti di interesse per l utente; - meccanismo di matching : confronta la rappresentazione dei documenti con le condizioni di selezione espresse nella query. Il matching tra termini può essere di diversi tipi [15]: - exact match: la rappresentazione della query corrisponde esattamente alla rappresentazione del documento nel sistema; - partial match: solo una parte dei termini usati nella formulazione della query corrisponde alla rappresentazione del documento nel sistema; - positional match: prende in considerazione la posizione dei termini usati nella query nella rappresentazione del documento; - range match: si può utilizzare in espressioni numeriche. Scopo del meccanismo di indicizzazione dei documenti è fornire al meccanismo di matching una sintesi del contenuto dei documento per un reperimento efficace degli stessi in fase di retrieval. Il problema diventa quello della definizione di una rappresentazione formale del contenuto informativo dei documenti basata sull associazione di indici o descrittori ai documenti. 23
40 Figura 1.3: Indexing di documenti La procedura di indexing è basata sull associazione manuale o sull estrazione automatica da un documento di frasi o termini (indici) che ne rappresentano il contenuto informativo. L indicizzazione detta Full Text consiste nell estrazione automatica da un documento di tutti i termini in esso contenuti a meno di un sottoinsieme non significativo costituito da preposizioni, articoli, ecc., elencati in una lista detta stop-list (i termini troppo frequenti non sono considerati buoni indici). La maggior parte degli approcci seguiti per l indexing sono di tipo statistico e solo quando si considerano domini della conoscenza alquanto specifici è possibile applicare delle buone tecniche di comprensione del linguaggio naturale. Non è nemmeno consigliabile una associazione manuale di indici, perché vale la soggettività dei giudizi umani e costituisce un approccio costoso e impraticabile quando si hanno molti documenti. L idea di base dell indicizzazione dei documenti è quella di ridurre e semplificare il contenuto di un documento, arrivando ad un insieme limitato e significativo di termini che lo rappresentino (parole, frasi, nomi, link, metadati ), creando il cosiddetto inverted file. Ma oltre all operazione precedente, bisogna anche assegnare un peso agli elementi selezionati. La maggior parte dei sistemi di IR combinano: - frequenza di un termine in un documento (Term Frequency, TF); - frequenza di un termine in tutto l archivio (Inverse Document Frequency); - lunghezza dei documenti. 24
41 Evidentemente, se una parola compare più volte in un documento, allora ha una certa importanza, ma se compare poche volte in un documento lungo allora è meno importante. Inoltre, l importanza di quel termine si riduce qualora tutti i documenti in archivio contengono quell occorrenza, essendo in tal modo quel termine stesso non un buon descrittore. Per quanto riguarda la query, l idea per migliorare il meccanismo di retrieval, potrebbe essere quella di espanderla per catturare i sinonimi o concetti legati con qualche relazione semantica. Dunque, le fasi da seguire nel processo di retrieval sono: confronto tra query e documenti; verifica della presenza di indici nel documento; utilizzo dei pesi degli indici come base per la definizione dell ordinamento dei documenti nella lista presentata all utente. Gli indici con peso elevato sono più importanti. In conclusione, un sistema di Information Retrieval ha lo scopo di recuperare documenti da una collezione per rispondere alle queries dell utente, ma si differenzia da un sistema di data retrieval, perché quest ultimo determina quali documenti di una collezione contengono le parole-chiave della query, anche se ciò non è sufficiente a soddisfare il bisogno di informazione dell utente. Infatti, è necessario tener presente che all utente di un sistema di IR interessa non tanto recuperare i dati che soddisfano una particolare query, bensì le informazioni riguardanti un particolare argomento. 1.5 L estrazione delle informazioni dai contenuti e la relevant information L information retrieval deve fare i conti con il testo in linguaggio naturale che non è sempre ben strutturato e può essere semanticamente ambiguo. Dunque, per essere efficace nel suo intento di rispondere al bisogno di informazione dell utente, un sistema di IR deve in qualche modo interpretare il contenuto dei documenti ed ordinarli a seconda del grado di rilevanza rispetto a ciascuna query. Per fare ciò è necessario estrarre l informazione sintattica e 25
42 semantica dal testo. La difficoltà non sta solo nella scelta del modo in cui estrarre tali informazioni, ma anche in come utilizzarle per stabilirne la rilevanza. Pertanto la nozione di rilevanza è fondamentale per l IR [16]. In effetti, lo scopo principale di un sistema di IR è di recuperare tutti i documenti rilevanti per la query dell'utente cercando di recuperare il minor numero possibile di documenti non rilevanti. L efficacia del recupero delle informazioni è influenzata sia dal modo in cui l utente specifica l insieme di parole che esprimono la semantica della propria richiesta di informazione, sia dal modo in cui un sistema di IR rappresenta i documenti in una collezione. Questi ultimi di solito vengono rappresentati, come già anticipato, da un insieme di index terms o keywords, che vengono estratti direttamente dal testo dei documenti in maniera automatica o generate da un esperto. La rappresentazione di un documento con l intero insieme delle parole che lo costituiscono viene detta appunto full text. Si passa da una rappresentazione full text ad una rappresentazione con keywords. Tuttavia, per collezioni voluminose potrebbe essere necessario dover ridurre l insieme di keywords e questo può essere ottenuto, come approfondiremo, attraverso: - l eliminazione di articoli e congiunzioni (stop-words); - l uso di stemming (che riduce parole a una radice grammaticale comune); - l identificazione di gruppi di nomi (che elimina aggettivi, verbi e avverbi). Queste operazioni sul testo vengono dette text operations. La rappresentazione del documento attraverso l insieme delle parole contenute è chiaramente la più precisa, ma anche quella che comporta i costi computazionali più alti. Adotteremo tale approccio in questo lavoro: rappresentare i documenti di un learning object in modo sintetico, estraendo in modo automatico le informazioni e memorizzandole in una knownledge base del sistema. I meccanismi di estrazione, elaborazione e memorizzazione saranno appunto quelle corrispondenti al processo di text processing descritto. Vedremo i dettagli nei prossimi capitoli. 26
43 Figura 1.4: Text processing 1.6 Gli ostacoli del linguaggio naturale Le informazioni all interno dei documenti e le stesse queries vengono rappresentate da espressioni del linguaggio umano, costituendo un ulteriore complicazione del task dell Information Retrieval. Uno dei problemi principali è la polisemia: a differenza dei linguaggi formali, dove ai simboli terminali (le parole del linguaggio) corrisponde un unico significato, nel caso dei linguaggi naturali i simboli terminali possono avere più di un significato (polisemia). La polisemia nel processo di IR si presenta ogni volta che una query contiene parole per l appunto polisemiche, facendo in modo che i documenti ritornati possono non contenere l informazione ricercata. La sinonimia, ovvero l esistenza di parole con significato equivalente o identico, ha per certi versi un effetto contrario: infatti in questo caso, in risposta ad una query che contenga una parola con sinonimi, la probabilità che l insieme dei documenti ritornati sia incompleto rispetto all insieme dei documenti rilevanti per la query è sicuramente superiore al caso in cui la query non contenga parole con sinonimi.il problema della sinonimia può essere risolto facendo ricorso a risorse lessicali come i thesauri, i quali data una certa parola, permettono di trovarne i sinonimi [17]. Invece, la risoluzione della polisemia avviene attraverso il processo di disambiguazione semantica (Word Sense Disambiguation, WSD). 27
44 Ci soffermeremo sull ultimo approccio in questo lavoro e utilizzeremo un dizionario per il recupero dei significati dei concetti della lingua inglese, ovvero WordNet della Princeton University. Purtroppo, la realizzazione di un algoritmo efficiente per la disambiguazione semantica è tuttora un problema aperto nel campo dell elaborazione del linguaggio naturale. È stato dimostrato [18] che l indicizzazione semantica può migliorare l information retrieval, ma solo se la disambiguazione semantica è eseguita a meno del 30% di errore. Purtroppo lo stato dell arte attuale nel campo della WSD non è ancora in grado di fornire disambiguatori con una precisione superiore al 70% per tutte le categorie lessicali. 1.7 Architettura di alto livello di un sistema di information retrieval Un sistema di IR è costituito essenzialmente da tre parti principali: l input, l output e il processore. L input del sistema è caratterizzato dalla richiesta dell utente, espressa in uno specifico linguaggio, e dai documenti su cui fare la ricerca di informazione. I documenti e le queries, come già visto, per poter essere utilizzati dal sistema devono avere una medesima rappresentazione che può essere diretta, cioè coincidente con i documenti stessi, o indiretta, ovvero data da surrogati. Il processore realizza la fase vera e propria di ricerca e di recupero sulle rappresentazioni dei documenti in risposta alle richieste dell utente, quindi è il blocco principale in cui vengono implementate le tecniche e le strategie di recupero delle informazioni, che verranno spiegate più avanti in dettaglio, ovvero quei meccanismi che permettono di confrontare la richiesta con le rappresentazioni di documenti. Infine, l output consiste in una serie di documenti che dovrebbero soddisfare la richiesta dell utente. L utente potrebbe soddisfare il suo bisogno di informazione in diversi steps, traendo spunto dall output per nuove direzioni di ricerca (feedback). 28
45 Figura 1.5: Struttura di alto livello di un sistema di IR Un sistema di retrieval prima di iniziare il recupero dell informazione deve eseguire su una collezione di documenti un pre-processo, in cui vengono applicate al testo le operazioni che trasformano i documenti originali in una rappresentazione degli stessi. In questa fase ogni documento viene descritto tramite i termini indice e ad ognuno di essi viene assegnato un peso che quantifica l importanza di un termine per descrivere il contesto semantico del documento. Una volta definita una vista logica dei documenti si passa alla fase di indicizzazione in cui il sistema di IR costruisce un indice del testo. Definito un indice, questo viene collegato ad uno o più documenti. Un indice è una struttura dati critica poiché permette solo in seguito una ricerca veloce su grandi volumi di dati. Dopo aver indicizzato il database dei documenti, il sistema è pronto per effettuare una ricerca, quindi l utente può specificare la propria richiesta, la quale viene analizzata e trasformata tramite le stesse operazioni applicate al testo. Il sistema, quindi, processa la query e cerca i documenti che corrispondono meglio alla richiesta. L indice scelto, precedentemente costruito, influenza la velocità di processamento delle query. Il sistema prima di fornire all utente i documenti recuperati li riordina in base ad un grado di rilevanza determinato da una misura di similarità. La precedente descrizione costituisce un possibile approccio all architettura di un sistema di IR e, sempre per via illustrativa, si mostra nella figura seguente una sua possibile schematizzazione: 29
46 Figura 1.6: Architettura di un sistema di IR 1.8 I modelli di information retrieval Uno dei principali problemi dei sistemi di IR è quello di predire quali documenti siano rilevanti e quali no; la rilevanza si ottiene a partire da un algoritmo di ranking, il quale tenta di stabilire, sulla base di una misura di similarità, un ordinamento dei documenti recuperati. Un tale algoritmo opera secondo dei criteri di rilevanza dei documenti, ossia insiemi di regole che permettono di stabilire quali documenti siano rilevanti e quali no; criteri diversi producono differenti modelli di IR. Il modello definisce la filosofia di fondo di un information retrieval system, ovvero attorno a quali principi generali si è sviluppato il sistema. L uso di un modello concettuale influenza o determina il linguaggio di interrogazione, la rappresentazione dei documenti, la struttura dei file ed i criteri di recupero dei documenti. I modelli di ricerca per le informazioni sul Web possono essere classificati in base all approccio adottato: 30
47 content-based: questo metodo raccoglie le preferenze esplicite dell utente e valuta l attinenza delle pagine in base alle preferenze dell utente e al contenuto collaborative: questo metodo determina la rilevanza delle informazioni in base alla somiglianza fra gli utenti piuttosto che la somiglianza fra le informazioni in sé; domain-knowledge based: utilizza sia le preferenze dell utente sia una base di conoscenza organizzata in domini per migliorare la rilevanza dei risultati di ricerca; ontology-based: l utente sceglie i concetti dall ontologia e il sistema restituisce le pagine che contengono quel concetto. Le ontologie permettono di stabilire senza incertezza e necessità di interpretazione il significato di un concetto. Ecco una definizione formale di un modello di IR: Definizione 1.2. Un modello di IR è una quadrupla [D, Q, F, R (qi, dj )] dove: o o o o D è un insieme composto dalle rappresentazioni logiche dei documenti nella collezione; Q è un insieme composto dalle rappresentazioni logiche delle necessità informative dell utente. Queste rappresentazioni sono chiamate queries; F è un framework per rappresentare i documenti, le queries e le loro relazioni; R( qi, dj ) è una funzione di ranking che associa un numero reale e una rappresentazione di un documento dj appartenente a D ad una query qi appartenente a Q. Questo ranking definisce un ordinamento tra i documenti in funzione della query qi. In letteratura, vengono proposti tre modelli di IR [20]: - booleano - vettoriale - probabilistico 31
48 In realtà questi sono dei modelli classici che rientrano all interno di una tassonomia più ramificata dei modelli di retrieval, come mostra la seguente figura: Figura 1.7: I modelli di Information Retrieval Le due macrofamiglie sono costituite dai modelli matematici e dai modelli cognitivi. I primi considerano la struttura hardware/software che accetta come input una richiesta da un utente e restituisce un elenco di documenti, ad ognuno dei quali viene assegnato un punteggio. Di solito, tali modelli si concentrano sulle modalità di rappresentazione dei documenti e delle richieste e definiscono una funzione di matching. Essi prelevano strumenti formali e risultati dai più disparati campi, dall algebra lineare al calcolo della probabilità, dalla statistica alla logica. 32

49 I modelli cognitivi, invece, si concentrano sull interazione con l utente e le tipologie dei suoi bisogni e comportamenti. Questi modelli sono specifici, utilizzando strumenti della psicologia. L utente viene visto come un sottosistema e se ne studia l interazione con gli altri sottosistemi del modello. Nella categoria dei modelli matematici ricadono gli exact match models e i partial match models. I primi prevedono che la richiesta venga soddisfatta comparando la rappresentazione della query con quella dei documenti e recuperando soltanto i documenti la cui rappresentazione soddisfi un matching totale con la rappresentazione della query. I secondi prevedono che la richiesta venga soddisfatta sempre eseguendo la comparazione fra le rappresentazioni di queries e documenti, ma assegnando un punteggio, detto rank, ad ogni documento, che tenga conto dell aderenza della rappresentazione del documento alla rappresentazione. Noi utilizzeremo questa seconda categoria di modelli. Infine, i modelli ah hoc e fondati sono rispettivamente modelli che si basano su intuizioni e non supportati da nessuna teoria matematica e modelli che si basano su precise branche della matematica. Approfondiremo nei prossimi paragrafi solo i modelli classici che ci servono per descrivere il nostro lavoro di tesi. Nella figura seguente si mostrano i tre modelli con le rispettive estensioni che si sono avvicendate nel corso della sperimentazione sui sistemi di IR, per chi fosse interessato ad un loro approfondimento. Figura 1.8: Estensioni dei modelli di Information Retrieval 33
50 1.9 I modelli booleano e vettoriale I modelli classici considerano ogni documento come descritto da un insieme di parole-chiave rappresentative dette anche termini indice. Un termine è essenzialmente una parola la cui semantica aiuta a ricordare gli argomenti principali di un documento. Dunque i termini sono utilizzati per indicizzare e riassumere il contenuto di un documento. In generale, i termini sono essenzialmente nomi, poiché in quanto tali hanno un significato preciso ed è quindi più facile capire la loro semantica. Gli aggettivi, i verbi, gli avverbi e le congiunzioni sono meno utili, in quanto hanno una funzione complementare. Dato un documento, non tutti i termini sono ugualmente utili per descrivere il contenuto, infatti, ve ne possono essere alcuni che possono essere più vaghi di altri. Decidere sull importanza di un termine non è un problema banale. Tuttavia, esistono delle misure che è possibile legare ai termini: ad esempio, se in una data collezione di documenti una parola appare in ognuno di essi, allora si deduce che esso è completamente inutile come termine, perché non dice nulla su quale documento l utente può essere interessato. Dunque, termini distinti hanno una varia rilevanza per descrivere la semantica del documento. Questo effetto viene catturato attraverso l assegnazione di pesi numerici ad ogni termine del documento, che quantificano l importanza del termine nel descrivere il contenuto del documento. Definizione 1.3. Sia t il numero dei termini indice in una collezione e k i, un generico termine indice, K =k 1,..., k t è l'insieme di tutti i termini indice. Un peso w i, j 0 è associato ad ogni termine k j di un documento d j. Per ogni termine k i che non compare nel testo del documento d j, w i, j =0. Al documento d j è associato un vettore d j = w 1, j,w 2, j..., w m, j. Inoltre, sia d j la funzione che restituisce il peso associato al termine k i in ogni vettore m-dimensionale allora g i d j =w i, j. In generale, si assume (per semplicità) che i pesi dei termini siano mutuamente indipendenti, ciò significa che il peso w i, j associato alla coppia K i,d j non 34
51 dà alcuna informazione riguardo al peso w i 1, j associato alla coppia K i 1,d j. Il modello booleano è stato il primo modello per l information retrieval utilizzato [21] e si basa sulla teoria degli insiemi e sull algebra booleana. Tale modello definisce insiemi di documenti e operazioni standard su di essi. Per definire il modello bisogna decidere la modalità di rappresentazione dei documenti e delle queries e la funzione di ranking. Figura 1.9: Modello Booleano Le queries e i documenti sono, infatti, intesi come vettori di booleani, ovvero con termini indici la cui presenza è segnalata da un 1 e l assenza da uno 0. Più precisamente, una query q è composta dai termini indice collegati dai tre operatori not, and e or e viene espressa come disgiunzione di vettori congiuntivi (Disjuntive Normal Form DNF): Per esempio, la query q=k a k b k c può essere scritta in DNF come [ q dnf = 1,1,1 1,1,0 1,0,0 ] dove ogni componente è un vettore booleano di pesi binari associato alla tupla k a, k b, k c. 35
52 Definizione 1.4. Per il Modello Booleano, le variabili dei pesi dei termini indice sono tutti binari, cioè espressione booleana. Sia w i, j {0,1}. Una query q è una convenzionale q dnf la DNF di una query q, e q cc ognuna delle sue componenti. La similarità di un documento d j alla query q è definita come: simil d j,q = { 1 se q cc q cc q dnf k i, g i d j =g i q cc 0 altrimenti } Se simil d j,q =1 allora il modello Booleano predice che il documento d j è rilevante per la query q, altrimenti la predizione è che il documento non è rilevante. Dunque, data una query q i, la funzione di matching recupera il documento rappresentato da d j se e solo se q i è conseguenza logica di d j secondo la logica booleana. Tale modello è semplice e chiaro ma ha lo svantaggio di avere un matching esatto in cui un documento è rilevante o non rilevante, senza gradi parziali di rilevanza. Inoltre, non è semplice esprimere le richieste di informazione. Il modello vettoriale, d altro canto, sopperisce alle carenze del modello booleano, fornendo un framework che permette la corrispondenza parziale con la query [22]. Esso appartiene alla categoria dei modelli a punteggio (Ranked Model) e viene classificato tra i modelli di tipo statistico. Questo è reso possibile assegnando ai termini indice dei pesi non binari, nei documenti e nelle queries, per poter esprimere le occorrenze di un dato termine in un documento. Questi pesi vengono poi utilizzati per calcolare il grado di somiglianza tra la query dell utente ed ogni documento memorizzato nel sistema. Definizione 1.5. Nel modello Vettoriale, il peso w i, j associato alla coppia k i,d j è positivo e non binario. Inoltre, anche ai termini indice della query viene assegnato un peso. Sia w i, q il peso associato alla coppia [k i,q], dove w i, q 0. Il vettore della query q è quindi definito come 36
53 q= w 1,q,w 2,q,..., w t, q, dove t è il numero totale dei termini indice nel sistema. Il vettore di un documento d j è rappresentato da q= w 1,q, w 2,q,..., w t, q. Quindi, un documento d j e una query q sono rappresentati come un vettore di dimensioni t. Si parla, dunque, anche di Vector Space Model, visto che ci si pone di valutare il grado di somiglianza tra il documento d j e la query q come correlazione tra i vettori d j e q. Questa correlazione può essere quantificata, ad esempio, come il coseno dell'angolo tra i due vettori: d simil d j, q = j q d j q = t i=1 t w i, j w i,q i =1 2 w i, j t i=1 2 w i, q dove d j e q sono il modulo del vettore del j-esimo documento e del vettore relativo alla query. Poiché w i, j 0 e w i, q 0 il risultato di simil(q, d j ) assume un valore compreso tra 0 e 1. Così, invece di tentare di predire se un documento è rilevante o no, il modello Vettoriale ordina i documenti secondo il loro grado di somiglianza alla query. I pesi dei termini indice possono essere calcolati in molti modi. L'idea alla base delle tecniche più efficienti è legata al concetto di cluster, proposto da Salton. Si pensi ai documenti come ad una collezione C di oggetti e alla query come una vaga specificazione di un insieme A di oggetti. In questo scenario, il problema dell'ir può essere allora ridotto a quello di determinare quali documenti sono nell'insieme A e quali no; in particolare in un problema di clustering occorre risolvere due sottoproblemi. Occorre determinare quali sono le caratteristiche che descrivono al meglio gli oggetti dell'insieme A (si parla quindi di similarità intracluster) e quali sono le caratteristiche che meglio distinguono gli oggetti dell'insieme A dagli oggetti della collezione C (dissimilarità inter-cluster). 37
54 Nel modello Vettoriale, la similarità intra-cluster è quantificata misurando la frequenza di un termine k i in un documento d i ; questa viene detta Fattore TF (Term Frequency) e misura quanto un termine descrive i contenuti del documento. La dissimilarità inter-cluster è invece quantificata misurando l'inverso della frequenza di un termine k i tra i documenti della collezione (Fattore IDF o Inverse Document Frequency). La motivazione dell'uso del Fattore IDF è che i termini che appaiono in molti documenti non sono molto utili a distinguere un documento rilevante da uno che non lo è. Definizione 1.6. Sia N il numero totale di documenti del sistema e n i il numero dei documenti in cui compare il termine indice k i. Sia freq i, j la frequenza del termine k i nel documento d i. Allora la frequenza normalizzata f i, j del termine k i nel documento d j è data da f i, j = freq i, j max i freq i, j dove il massimo è calcolato tra tutti i termini menzionati nel testo del documento d j. Se il termine k i non compare nel documento d j allora f i, j =0. Inoltre, l' Inverse Document Frequency del termine k i è dato da idf i =log N n i Il più noto schema per determinare i pesi dei termini usano i pesi dati da w i, j = f i, j idf i o da una variante di questa formula. Questi sono detti schemi TF-IDF. Sono state proposte alcune varianti alla espressione per i pesi w i, j, tuttavia quella descritta prima rimane un buon schema per la determinazione dei pesi per molte collezioni. Per il peso dei termini della query, Saltono propone la formula w i, q f i,q idf i freq i, q max i freq i,q log N n i dove freq i, q indica la frequenza del termine k i nel testo della richiesta dell'informazione q. 38

55 I vantaggi del modello vettoriale sono diversi, in particolare l'uso dei pesi migliora la performance del recupero dei documenti e consente il recupero dei documenti che approssimano le condizioni della query. Inoltre, la formula di ranking con il coseno ordina i documenti secondo il grado di somiglianza con la query. Uno svantaggio, invece, del modello Vettoriale è dato dal fatto che i termini indice sono sempre assunti mutuamente indipendenti. Figura 1.10: Modello Vettoriale: rappresentazione vettoriale dei documenti rispetto ad una query (x:speech, y:language e z:processing) Dunque, sintetizzando, nel modello vettoriale un documento viene rappresentato come un vettore d i = w i,1, w i,2,..., w i, n, dove w i, j è un valore numerico compreso tra [0,1] che può essere interpretato come la rilevanza di d i nei confronti del termine t j, oppure come una misura di quanto il termine t j contribuisce alla rappresentazione del contenuto di d i. Per quanto riguarda le queries, anche esse vengono rappresentate come vettori. 39
56 Il fatto che i documenti vengano rappresentati come vettori comporta che la similarità fra un documento e una richiesta può essere vista in termini di distanza euclidea fra i vettori che li rappresentano: più vicini sono i vettori, più simili sono il documento e la richiesta (similarità calcolata, ad esempio, come coseno tra i vettori, come già visto nella formula di questo paragrafo). La formula di ranking basata sul coseno ordina i documenti in base al loro grado di similarità con la query. Il fatto che si debba presumere l indipendenza dei termini a due a due, comporta uno svantaggio pratico, in quanto nei documenti reali ciò avviene raramente, in quanto spesso alcuni termini tendono a co-occorrere più frequentemente di altri. In termini geometrici, evitare di basarsi su questa ipotesi necessita di considerare gli assi cartesiani non più ortogonali: più dipendenti fra di loro sono i due termini e più piccolo è l angolo che separa gli assi cartesiani corrispondenti ad essi. Si è provato, tuttavia, che tenere conto di queste dipendenze è computazionalmente difficile e non porta a miglioramenti sostanziali. 40
57 41
58 Capitolo 2 Le tecnologie del Semantic Web Nel capitolo precedente abbiamo introdotto il concetto di ontologia, proponendola come soluzione alla realizzazione del Web Semantico. Partiremo dalla sua definizione e dalle tecniche e tecnologie che sono state proposte per la sua applicazione. Ricordiamo una definizione esemplificativa del Web Semantico, inteso come una estensione dell'attuale Web, in cui le risorse sono corredate da descrizioni semantiche, scritte, cioè, secondo una determinata ontologia che fornisce la semantica dei dati. Da questa definizione possiamo subito capire come l'ontologia sia la chiave di volta del Web Semantico, detto anche Web 3.0, per distinguerlo dal Web attuale che si è "fermato" alla seconda generazione. Volendo utilizzare definizioni formali del concetto di ontologia, possiamo dire che essa è intesa come "concettualizzazione di una specificazione" (Gruber) [23] o come "teoria logico-formale per l'espressione di un vocabolario condiviso" o ancora "concettualizzazione di un dominio condiviso" [24]. Secondo un altro esperto del settore, Neches, l'ontologia "definisce i termini base e le relazioni che includono il vocabolario di un'area e le regole per combinare i termini e le relazioni allo scopo di definire estensioni al vocabolario". Guarino, invece, la definisce come una "teoria logica che dà una giustificazione esplicita e parziale di una concettualizzazione". Si crea così una "nuova visione del Web", in cui l'ontologia rappresenta un accordo consensuale sulla definizione di concetti e relazioni che caratterizzano la conoscenza del dominio stabilito, 42
59 garantendo la possibilità di applicare regole di inferenza (ragionamento) sia per stabilire nuove asserzioni deducibili (nuova conoscenza sulla base di quella a disposizione) sia per organizzare e recuperare in modo intelligente ed efficiente le informazioni presenti sul web. Noi proporremo una giustificazione all approccio delle ontologie di dominio, sviluppando un modello di ontologia che risolva il problema della interoperabilità semantica. Sulla base di tale nuovo concetto, elaboreremo un modello di macchina semantica, ossia un modello di macchina in grado di comunicare semanticamente con altre macchine. Tale approccio verrà poi calato all interno di uno scenario pratico, che è quello del retrieval semantico di learning objects. 2.1 Il Semantic Web Stack Molti credono che le tecnologie semantiche siano il salto epocale tecnologico prossimo venturo. Ormai è storia. Tim Berners-Lee, tra il 1989 e il 1991, lavorando presso il CERN di Ginevra, creò il Web. Il Web, prima del suo lavoro, semplicemente non esisteva. Nei quasi venti anni successivi si è evoluto, arrivando alle nuove frontiere di oggi: Web 2.0, Social Networking, AJAX, mashup di contenuti e browser [25]. La figura seguente riporta la rappresentazione grafica della proposta originale di Berners-Lee al CERN nel 1989 [26]: è possibile notare il diagramma che espone concetti legati da relazioni di tipo describes o includes, o ancora associazioni statiche refers to e metainformazioni semantiche delle relazioni e dei contenuti. Le associazioni statiche, oltre al linguaggio ipertestuale, sono la parte del web utilizzata ad oggi. E la parte semantica? Semplicemente, in questi anni, non è (ancora) stata implementata. Questo non vuol dire però che sia stata abbandonata: il lavoro svolto da Tim Berners-Lee e dal W3C (fondato dallo stesso Berners-Lee nel 1994) è indirizzato, da sempre, verso questo obiettivo: XML, WSDL, XML Schema, XPath, RDF, OWL, SPARQL sono tutte Recommendation (standard) e/o Working Draft del W3C, sulla roadmap del Semantic Web. I motivi alla base dell'avvio rallentato della parte semantica del Web sono più di carattere tecnologico e pratico che di tipo concettuale o di design: la rete, intesa come 43
60 composizione di strutture hardware, di applicazioni software e di standard condivisi, non era (e probabilmente non è ancora) completamente pronta a supportare un'infrastruttura Web Semantica. Figura 2.1: Proposta del Web di Tim Berners-Lee (1989) Le strutture semantiche migliorano la condivisione e il trattamento delle informazioni e grazie alle tecnologie del Web Semantico sarà possibile definire una base cognitiva distribuita che va oltre il singolo dato, aggregando le fonti informative in un unica entità di conoscenza strutturata, interrogabile da agenti di ricerca basati su criteri semantici. 44
61 Figura 2.2: L'evoluzione del Web Obiettivo degli standard alla base del Semantic Web è creare una rete spontaneamente predisposta alle ricerche semantiche. L approccio è completamente innovativo: la parola o anche l immagine o il file multimediale vengono contrassegnati con un tag semantico (definito con XML, OWL o RDF ), definendo la struttura semantica delle informazioni. Il Semantic Web va inteso come una struttura a gradini, in cui ogni livello è la base per gli standard definiti ai livelli superiori. Nel capitolo precedente abbiamo già visto lo stack delle tecnologie base del Web Semantico. Nei prossimi descriviamo per sommi capi i singoli layer, per poi soffermarci nei dettagli sui livelli che interessano il nostro progetto. 45
62 Figura 2.3: Struttura a gradini degli standard del Semantic Web Resource Description Framework: RDF è uno standard XML del W3C per la definizione di un modello di rappresentazione dei metadati, il cui compito è promuovere l interoperabilità tra applicazioni basata sullo scambio sul Web di informazioni comprensibili dalle macchine (machine understandable) [27]. L RDF si basa su XML (XML, XML Schema e namespace), URI e Unicode. Di seguito si riporta una breve descrizione di ciascuno di questi elementi. Uniform Resource Identifier (URI) è una stringa che identifica univocamente una risorsa generica. Tale risorsa può essere un indirizzo web, un documento, un immagine, un file, un servizio, un indirizzo di posta elettronica. Gli URL (Uniform Resource Locator) sono un sottoinsieme degli URI. Mediante URL si identificano risorse specifiche della rete, come ad esempio pagine web, immagini, etc., facendo riferimento alla loro localizzazione e mettendo in evidenza la modalità di accesso (il protocollo) [28]. L Unicode è, invece, un sistema di codifica che assegna un numero (o meglio, una combinazione di bit) a ogni carattere in maniera indipendente dal programma, dalla piattaforma e dalla lingua (e dal suo sistema di scrittura) [29] XML (extensible Markup Language) è un metalinguaggio che permette di definire sintatticamente linguaggi di mark-up. Nato come linguaggio utile allo scambio dei dati, permette di esplicitare la struttura, quindi la sintassi, di un documento in modo formale mediante marcatori (mark-up) che vanno inclusi all interno del testo. Per definire la struttura di un documento XML, o più precisamente la 46
63 grammatica che tale documento deve rispettare, esistono linguaggi quali DTD e XML Schema [30]. Entrambi sono strumenti per eseguire la validazione del documento XML. XML si limita a descrivere dati senza entrare nel merito della semantica contenuta. Un documento XML rispecchia la classica struttura ad albero (gerarchica), all interno del quale le informazioni sono correlate secondo una relazione di subordinazione (classificazione). Nei documenti XML, i dati riportati acquistano un loro significato dettato esclusivamente da un modello gerarchico/classificatorio la cui interpretazione è a discrezione umana e non è comprensibile dalla macchina, non essendo presente un esplicito formalismo di definizione della classificazione. Figura 2.4: Struttura ad albero di un documento XML 2.2 Resource Description Framework Ad oggi, l informazione utile, contenuta all interno di una qualsiasi risorsa, è strutturata in modo tale da essere machine-readable (ovvero leggibile da una macchina), ma non machine-understandable (comprensibile da una macchina). La mancanza di una caratterizzazione semantica, ossia sul significato deducibile, pone infatti un limite nelle operazioni di elaborazione automatica delle informazioni sul web. Per colmare le lacune che impediscono alla macchina di interpretare l informazione possono essere utilizzati metadati, cioè descrizioni aggiuntive ai dati. Questa è appunto la funzione di RDF, il quale introduce un formalismo per la rappresentazione di metadati basato sul concetto di statement (asserzioni) codificati in triple: soggetto-predicato-oggetto. 47
64 Figura 2.5: Le relazioni semantiche in un documento XML In questo modo, RDF (che è una implementazione di XML) introduce maggiore capacità espressiva permettendo di definire diverse tipologie di relazione secondo un modello relazionale/predittivo. L idea è quella di poter utilizzare la struttura dati organizzata secondo un grafo orientato: sui nodi di questo grafo sono poste le risorse (soggetto e oggetto dello statement), mentre gli archi del grafo rappresentano le relazioni (predicato dello statement). È possibile così aggiungere connessioni (relazioni) tra molteplici risorse, permettendone l estensione della conoscenza. Come si può vedere nel grafo precedente, tra i nodi del grafo (orientato) sono definite delle relazioni (unidirezionali). Il grafo è una generalizzazione dell albero. Ogni nodo ha un numero arbitrario di nodi vicini e può contenere cicli. In generale, può essere associata un informazione utile sia ai nodi che ai collegamenti (archi), specifica di RDF, costituita da due componenti: RDF Model and Syntax e RDF Schema. RDF Model and Syntax: definisce il data model RDF (modello dei dati), che descrive le risorse e la sintassi XML utilizzata per specificare tale modello. Non definisce alcun livello di gerarchia o di relazione. Il modello si basa su tre oggetti: - Resource (risorsa): indica ciò che viene descritto mediante RDF e può essere una risorsa Web (ad esempio una pagina HTML, un documento XML o parti di esso) o anche una risorsa esterna al Web (ad esempio un libro, un quadro, ecc.). Una risorsa è qualunque entità associabile ad un URI. - Property (proprietà / predicato): indica una proprietà, un attributo o una relazione utilizzata per descrivere una risorsa. Il significato e le 48
65 caratteristiche di questa componente vengono definite tramite RDF Schema. - Statement (asserzione o espressione): è l elemento che descrive la risorsa ed è costituito da un soggetto (che rappresenta la resource), un predicato (che esprime la property) e da un oggetto (chiamato value) che indica il valore della proprietà. La struttura di uno statement (asserzione) RDF è composta da una tripla, ovvero da soggetto-predicato-oggetto. Figura 2.6: Statement RDF (tripla soggetto-predicato-oggetto) RDF Statement: come già detto in RDF è definita una logica dei predicati, in cui le informazioni sono esprimibili con asserzioni (statement) costituite da triple formate da: - soggetto (ciò di cui si parla) - predicato (la proprietà, l attributo, la caratteristica che si vuole descrivere) - oggetto (il valore della proprietà) Ad ogni tripla è associabile un grafo, dove ogni elemento è identificato da un URI. Lo standard prevede anche una notazione grafica per le asserzioni RDF: graficamente una risorsa viene rappresentata con un ellisse, le proprietà vengono rappresentate come archi etichettati e i valori corrispondenti a sequenze di caratteri vengono rappresentati come rettangoli. Per approfondimenti ed esempi, consultare [31]. Per quanto riguarda la rappresentazione fisica, un grafo RDF può essere serializzato in diversi modi. Le principali serializzazioni adottabili per un grafo RDF sono: 49
66 1. XML: serializzato in un file XML 2. N-TRIPLE: serializzato come insieme di triple soggetto-predicato-oggetto 3. N3 (Notation 3): si serializza il grafo descrivendo, una per volta, una risorsa e tutte le sue proprietà (è la notazione utilizzata nel nostro progetto, in fase di editing dei contenuti) 4. TURTLE: Terse RDF Triple Language, estensione di N-Triple. Figura 2.7: Serializzazioni di un documento RDF RDF Schema: il puro RDF serve unicamente per descrivere modelli di dati e può esprimere semplici affermazioni con un soggetto, un predicato e un oggetto. Tuttavia, quando si usa RDF per descrivere gli oggetti di un particolare dominio è indispensabile tenere conto della natura del dominio. In pratica l ambito interessato va considerato in termini reali : le categorie (classi di oggetti appartenenti al 50
67 dominio), le relazioni possibili tra gli oggetti, le regole che governano queste relazioni devono possedere certe caratteristiche per risultare valide. RDF Schema permette di definire il significato e le caratteristiche delle proprietà e delle relazioni che esistono tra queste e le risorse descritte nel data model RDF. RDF Schema fornisce un insieme di risorse e proprietà predefinite. L insieme delle risorse e delle relative proprietà di base è detto vocabolario dell RDF Schema. Attraverso tale vocabolario base è possibile definire specifici vocabolari per i metadati e creare relazioni tra oggetti. I concetti messi a disposizione da RDF Schema sono quelli di: - Classe e Sottoclasse; - Sottoproprietà; - Dominio e condominio di una proprietà; - Commenti, etichette e informazioni addizionali (SeeAlso). Attraverso uno Schema RDF è possibile assegnare un significato ai vari termini utilizzati nelle asserzioni RDF; una risorsa può, per esempio, essere definita come istanza di una classe (o di più classi) e le classi possono essere organizzate in modo gerarchico, permettendo di derivare, per ereditarietà, nuova conoscenza. Inoltre, fornisce un meccanismo di specializzazione delle proprietà, definendone i vincoli di applicabilità e organizzandole gerarchicamente. In questo modo è possibile aggiungere connessioni (relazioni) tra molteplici risorse permettendone di fatto l estensione del significato (semantica). I principali costrutti sono <rdfs:class>, <rdfs:subclassof>, <rdfs:domain>, <rdfs:range>, <rdfs:subpropertyof> che consentono di organizzare in tassonomie le classi e le relazioni (Properties) del dominio a seconda della loro generalità. Figura 2.8: Costrutti del linguaggio RDF 51
68 RDF Schema arricchisce RDF attraverso un semplice sistema di tipi. Volendo fare "un'analogia didattica" tra RDFS e la programmazione object oriented (OOP), si può dire: nell'oo si definiscono le classi che rappresentano una descrizione di una categoria di oggetti, individuati da comportamenti e caratteristiche simili, i relativi comportamenti vengono definiti "metodi" mentre le caratteristiche sono delle "proprietà". Le classi possono essere estese per ereditarne dati e comportamenti (relazione IS-A) e gli oggetti sono istanze di classi. RDFS prevede anch'esso la creazione di classi e l'ereditarietà, ma non prevede la definizione di metodi, visto che è orientato alla modellazione dei dati e non al comportamento di questi ultimi. Più che contenitori, le classi RDFS sono dei descrittori (concetti o proprietà) in relazione semantica tra di loro. SPARQL: SPARQL è una specifica sviluppata dal W3C RDF Data Access Working Group a supporto dell interrogazione dei documenti RDF. Infatti, per utilizzare le basi di conoscenza formalizzate secondo questi standard RDF è necessario un linguaggio per interrogarle. Esistono diversi linguaggi di interrogazione funzionalmente equivalenti: SPARQL, RDQL, ARQ, ecc. [32] In questo lavoro è stato utilizzato il linguaggio di interrogazione SPARQL, che permette di costruire informazioni su triple e applicarle al modello dei dati. Interrogare un documento RDF significa quindi selezionare una risorsa in funzione del verificarsi di opportune proprietà su essa (viene rimarcata l analogia con il data model relazionale). Le queries SPARQL adottano la sintassi TURTLE e si basano sul meccanismo di pattern matching e in particolare su un costrutto, il triple pattern [35], che ricalca la configurazione a triple delle asserzioni RDF fornendo un modello flessibile per la ricerca di corrispondenze.?soggetto predicato?oggetto Le variabili rappresentano le incognite dell interrogazione, mentre il predicato è una costante. Data una base dati RDF, le triple (statement), che trovano riscontro nel modello definito da triple pattern, assoceranno i propri termini alle variabili corrispondenti. 52
69 Definito il modello su cui le queries SPARQL si basano, diamo un'occhiata veloce alla sintassi delle queries: SELECT <elenco variabili da valorizzare> FROM <risorsa contenente asserzioni> WHERE {<elenco triple pattern>. } Come si nota, vi è un'analogia con SQL: nella clausola SELECT vengono elencate le variabili da valorizzare ai fini del risultato, nella clausola FROM viene definita la base dati, documento RDF, su cui eseguire la query, nella clausola WHERE vengono elencati, tra parentesi graffe, i criteri di selezione, ovvero i triple pattern. Un esempio di query SPARQL sull'asserzione precedente potrebbe essere: SELECT?nome WHERE?nome ha indirizzo ? Da notare che la variabile da valorizzare (?nome nella clausola SELECT) deve comparire anche come incognita di interrogazione (?nome clausola WHERE); in caso contrario SPARQL non sarebbe in grado di valorizzarla. In questo lavoro è stato utilizzato un utilissimo framework che va sotto il nome di JENA. Questo framework open-source, sviluppato dal Semantic Web Research Bristol Lab della HP, fornisce le API per la creazione, interrogazione e gestione in modo programmatico di RDF. Si rimanda al sito ufficiale per approfondimenti [33] e all appendice e al paragrafo di questa tesi per dettagli sulle ontologie persistenti. Per approfondimenti sul linguaggio SPARQL si veda [34]. 2.3 Una rete semantica di concetti di un dominio: l ontologia Abbiamo già introdotto il concetto di ontologia, ma vogliamo presentare una bellissima definizione, che ci fa capire la sua utilità : una ontologia è come una rete semantica di concetti appartenenti ad un dominio legati tra loro da relazioni di vario tipo: tassonomico (IS-A), metonimico (PART-OF), telico (PURPOSE-OF) ecc. [24]. 53
70 Definizione 2.1. Formalmente una ontologia può essere definita come una tripla O = {C, R, A}, dove C = insieme di concetti del dominio di interesse, R = insieme di relazioni tra i concetti appartenenti a C ed A = insieme di assiomi (se A è vuoto, l ontologia è detta non assiomatizzata). Gli insiemi C ed R individuano un grafo G = {(V, E)}, tale che: V C, ed E = {(c1, c2) ε C x C }. Una ontologia può presentare vari livelli di formalizzazione, ma deve necessariamente includere un vocabolario di termini (concept names) con associate definizioni (assiomi) e relazioni tassonomiche. Essa è una sorta di stadio preliminare di una base di conoscenza, il cui obiettivo è la descrizione dei concetti necessari a parlare di un certo dominio. Una base di conoscenza include la conoscenza necessaria a modellare ed elaborare un problema, a derivare nuova conoscenza, a provare teoremi, a rispondere a domande concernenti un certo dominio. La presenza di ontologie e la capacità di ragionare sulla conoscenza che esse ci permettono di rappresentare, consentono di emulare la logica umana basata sulla cognizione di causa in una determinata realtà. Figura 2.9: La castagna ontologica La precedente figura mostra quella che in gergo è detta castagna ontologica. Si vede subito l organizzazione a livelli delle ontologie: - Upper Domain Ontology: qui si collocano i concetti generali comuni a più domini applicativi, concetti dunque astratti, di livello 54
71 filosofico. - Application Ontology: qui si collocano concetti specifici ma non elementari delle singole applicazioni che caratterizzano uno specifico dominio. - Lower Domain Ontology: qui si collocano i concetti elementari che non possono essere ulteriormente rifiniti o decomposti. Secondo tale suddivisione possiamo dire che il livello Upper Domain Ontologies è l anello di congiunzione delle varie ontologie del livello Application Ontologies, essendo queste una specializzazione dell Upper Domain Ontologies. Una ontologia, quindi, si pone l obiettivo di modellare un dominio di interesse, definendone lo schema concettuale. Questa non è però sufficiente a descrivere in modo esaustivo la conoscenza di dominio, ed è dunque necessario aggiungere altri componenti. Per arrivare ad avere una Knowledge Base completa, ovvero la completa base di conoscenza che rappresenta fedelmente ed esaurientemente un determinato dominio di interesse, dobbiamo aggiungere un insieme di dati e un insieme di regole. Definizione 2.2. Possiamo definire una Knowledge Base (KB) l insieme costituito da: - un ontologia: schema concettuale del dominio in questione, in cui si definiscono degli assiomi sui concetti da rappresentare; - un insieme di fatti, ovvero di istanze dei concetti definiti nell ontologia; - regole: insieme di regole sul quale inferire nuova conoscenza, ovvero sul quale ragionare per aggiungere nuovi fatti. Per dettagli relativi agli approcci alla progettazione di una ontologia si veda [37] e [24]. 55
72 2.4 Applicazioni e problemi legati all approccio ontologico Sempre in [24] vengono citati degli esempi di applicazione delle ontologie: qui a noi interessa particolarmente l utilizzo delle ontologie per l annotazione semantica di collezioni multimediali e di oggetti non necessariamente testuali. La semantica di tali oggetti, infatti, è difficilmente estraibile dalle macchine. Le ontologie multimediali possono essere di due tipi: - media-specific: presentano tassonomie per i diversi media type e descrivono le proprietà dei diversi media. Ad esempio, il video può includere proprietà che identifichino la durata del clip e degli intervalli; - content-specific: descrivono il tema della risorsa, ovvero il suo contenuto. Essendo queste ontologie non dipendenti dal formato della risorsa che si intende descrivere, possono essere riutilizzate per la descrizione di qualsiasi oggetto digitale (html, pdf, word, jpg, gif, ecc.), il cui contenuto informativo sia coerente con il dominio in questione. Qualora, invece, sia necessario far riferimento ad uno specifico media-type, è possibile combinare le due ontologie media-specific e content-specific. Figura 2.10: Le ontologie media-specific e content-specific 56
73 Altro esempio di applicazione è quello delle piattaforme e-learning: le ontologie e il Web Semantico sono oggi un mezzo molto importante anche per il supporto a tali piattaforme. Un azienda che voglia realizzare una tale piattaforma non può prescindere da un organizzazione ottimale ed efficiente dei corsi proposti e del materiale didattico ed integrativo proposto ai learner. Una o più ontologie fornirebbero la giusta terminologia per l organizzazione di tutto il materiale e di tutte le attività formative proposte. Inoltre, attraverso le ontologie è oggi possibile creare piattaforme e-learning che mettono a disposizione dei learner percorsi formativi personalizzati, sulla base della conoscenza pregressa dello studente e degli obiettivi che si pone il corso stesso. Ma il Semantic Web (che ora possiamo intendere il Web esteso attraverso l uso di ontologie [41]) è solo una delle possibili applicazioni delle ontologie. Esistono numerosi altri campi di utilizzo tra cui: knowledge management, data integration, content management, e-commerce, information filtering, problem solving, ecc. Ogni volta che occorre condividere informazioni indipendentemente dalle tecnologie utilizzate, dall architettura delle informazioni e dal dominio di applicazione è possibile (e spesso conveniente) ricorrere alle ontologie. Lo hanno già capito alcune aziende (Mondeca, Ontoprise, TopQuadrant, ecc.) che hanno fatto della realizzazione di soluzioni ontology-based il loro core business. Tuttavia, i problemi che le ontologie comportano sono notevoli: infatti, l approccio ontologico sottende la possibilità di rappresentare in maniera oggettiva la conoscenza, considerando la conoscenza stessa un astrazione superindividuale, come sistema di idee intersoggettive che si evolve nella comunità. Inoltre, vi è il problema della costruzione delle ontologie: infatti, due individui diversi verosimilmente produrranno due concettualizzazioni diverse di uno stesso dominio. Questi problemi scoraggiano la creazione di grandi ontologie universali (ontologia di alto livello) e fanno propendere verso la creazione di ontologie di dominio. Anche con l adozione di ontologie di dominio permangono dei problemi: resta, infatti, il problema che due applicazioni per poter comunicare devono utilizzare la stessa ontologia di dominio, oppure devono esistere dei meccanismi di mapping fra ontologie in grado di far corrispondere l ontologia di un applicazione all ontologia di un altra. Questo ramo della ricerca è però ancora lontano da una soluzione utile [36]. 57
74 2.5 Ontologie vs Database: schema concettuale vs dati Seppur molto evidente per gli esperti di rappresentazione della conoscenza, la differenza tra Ontologie e Database, risulta essere non sempre molto chiara. Molti, infatti, potrebbero obiettare che entrambi servano ad immagazzinare dati e che l utilizzo di ontologie nella gestione di grosse quantità di dati non porti nessun valore aggiuntivo rispetto all utilizzo di un comune database. Per comprendere a fondo la differenza tra l utilizzo di un ontologia e di un database, è necessario comprendere che utilizzare un'ontologia significa adottare un approccio orientato allo schema concettuale, che descrive il dominio in cui ci muoviamo, mentre utilizzare un Database Relazionale, significa affrontare il problema con un approccio orientato ai dati. Si potrebbe obiettare che anche un database relazionale ha un proprio schema concettuale per descrivere la realtà in cui ci troviamo, ma il potere espressivo dei linguaggi utilizzati per definire i due schemi concettuali (ontologia e database relazionale) è ben diverso, di conseguenza le informazioni che questi ci offrono sono enormemente differenti. Un ontologia, infatti, è molto più ricca di informazioni rispetto ad un semplice schema concettuale di un database. Inoltre, uno schema concettuale di un database ha lo scopo unico di descrivere le entità (i dati) - che andremo ad immagazzinare -, mentre un ontologia ha lo scopo di descrivere i concetti. Figura 2.11: Ontologie vs. Database 58
75 Dunque, mentre le entità di uno schema concettuale di un DB sono descritte solamente attraverso una lista di attributi e di relazioni, i concetti di un ontologia presentano una descrizione molto più ricca. Infatti, OWL, Ontology Web Language (come vedremo), ci mette a disposizione una serie di costrutti appartenenti alle logiche descrittive e, dunque, ci consente di andare ben oltre il semplice elenco di attributi. La descrizione di un concetto, infatti, avviene mediante la composizione ricorsiva di costrutti logici che ci permettono di definire un concetto come l intersezione, l unione, il complemento, la disgiunzione o l enumerazione di più concetti. Le relazioni tra i concetti, possono essere definite come relazioni funzionali (invertibili e non) e/o come relazioni transitive e/o simmetriche. Infine, possiamo anche definire una serie di restrizioni sui singoli attributi di un concetto. Tutto ciò rende chiaro che il potere espressivo di un linguaggio come OWL sia di gran lunga maggiore di quello di un linguaggio SQL Like e che lo schema concettuale di un DB porti con se un minor numero di informazioni rispetto ad un ontologia. A questo punto ci si potrebbe chiedere a cosa serve avere un potere espressivo così alto se un DB relazionale è in grado farci immagazzinare prima e recuperare dopo le informazioni che vogliamo trattare. Un potere espressivo più alto corrisponde ad una migliore organizzazione dei contenuti e, quindi, ad una migliore fruibilità degli stessi. I contenuti che immagazziniamo sono, infatti, catalogati secondo lo schema concettuale in uso. La fruibilità dei contenuti stessi dipende ovviamente dal tipo di catalogazione. Dunque più lo schema concettuale che utilizziamo per catalogare i nostri contenuti è elevato, più la catalogazione che possiamo fare è efficiente. Una catalogazione fatta attraverso un semplice DB relazionale, pur se ben progettata, rispecchia in termini di efficienza la poca ricchezza di informazioni che porta con se lo schema concettuale del DB. La catalogazione fatta attraverso uno schema concettuale ricco come quello di un ontologia ci consente di sfruttare in fase di recupero delle risorse catalogate la ricchezza delle informazioni che l ontologia stessa ci offre, di conseguenza la fase di recupero delle risorse catalogate risulta essere più efficiente. 59
76 Un database relazionale, infatti, è accessibile attraverso query SQL like, ovvero espressioni logiche piuttosto semplici, in grado di farci recuperare solo ciò che abbiamo realmente e fisicamente immagazzinato. L accesso ad un ontologia, invece, può essere eseguito utilizzando dei reasoner, ossia dei software capaci di ragionare (per una lista dettagliata di tool e software per l utilizzo delle ontologie si veda [38]). Attraverso il ragionamento artificiale di questi reasoner siamo dunque in grado di effettuare ricerche molto più complesse ed efficienti - la complessità delle ricerche dipende, come detto in precedenza, dalla complessità dello schema concettuale in uso e quindi dall ontologia -. Un reasoner, in effetti, è in grado di inferire conoscenza, di apprendere, cioè, nuova conoscenza sfruttando lo schema concettuale in uso (ontologia) e i fatti conosciuti al momento della ricerca. Un reasoner è quindi in grado di emulare il ragionamento umano, andando a recuperare quelle informazioni non esplicitamente espresse, ma comunque presenti in modo implicito. Ad esempio, affermiamo che: 1. Mario è padre di Giuseppe; 2. Giuseppe è fratello di Andrea; 3. Bruno è zio di Andrea. Attraverso l interrogazione di un semplice DB relazionale non potremmo sapere che Bruno è anche lo zio di Giuseppe. Un reasoner invece, attraverso un processo inferenziale, è in grado di darci questa informazione, che pur se non espressa in modo esplicito, è vera e presente nel nostro dominio. Dunque, in un contesto in cui è necessario immagazzinare e catalogare una grande quantità di informazioni, un approccio ai dati (DB relazionale) risulta essere alla lunga meno efficiente di un approccio concettuale (ontologia), con ovvia conseguenza di una peggiore fruibilità dei contenuti, a discapito degli utenti che impegnano il loro tempo e le loro energie per raggiungere risultati non sempre efficienti. 60
77 Figura 2.12: L'approccio ontologico: una rete di concetti 2.6 Ontology Web Language (OWL) Riprendendo la descrizione dei layers dello stack protocollare del Semantic Web, passiamo ora ad esaminare un altra tecnologia fondamentale per l utilizzo delle ontologie, ovvero l' OWL (Ontology Web Language). Riassumendo in poche parole le informazioni di cui si è parlato nei paragrafi precedenti, il web semantico si propone di dare un "senso", aggiungere "significato" alle pagine web e ai collegamenti ipertestuali, dando la possibilità di cercare in modo diverso rispetto alle tradizionali ricerche testuali. Tutto questo non in virtù di sistemi di intelligenza artificiale, reti neurali o ragionamenti sull'etimologia delle parole, ma "semplicemente" grazie all'uso di un sistema di marcatura dei documenti, all'adozione di un linguaggio gestibile da applicazioni e tramite l'introduzione di vocabolari specifici, creando insiemi di frasi 61
78 sulle quali poter definire relazioni fra elementi marcati. Il web semantico per funzionare deve disporre di informazioni strutturate e di regole di deduzione, in modo da risalire alle informazioni richieste da una interrogazione. La base di conoscenza del Semantic Web viene espressa tramite RDF, che consente di esprimere delle triple nella forma di soggetto, predicato e oggetto. Nonostante RDF sia processabile da un programma, esso serve unicamente per descrivere modelli di dati. Tuttavia, quando si usa RDF per descrivere gli oggetti di un particolare dominio è indispensabile tenere conto della natura di tale dominio, in termini di categorie o classi di oggetti, di relazioni possibili tra gli oggetti e di regole cui queste relazioni devono sottostare per essere "valide". A questo "insieme di meta-informazioni valide per un dominio di interesse", ci si riferisce solitamente col nome di "ontologia". Avendo a disposizione un'ontologia è possibile scrivere un ragionatore (un programma in grado di applicare regole) che partendo da una base di conoscenza definita su questa ontologia tragga delle conclusioni, o meglio, sia in grado di inferire [39]. Un reasoner molto utilizzato per la verifica della consistenza di una ontologia - e non solo per fare inferenze - è il software Racer dell Università di Amburgo [42]. Partendo da una ontologia di riferimento e da un modello di dati espresso in OWL, un agente software intelligente può usufruire di queste meta-informazioni per fare semplici ragionamenti sui dati: se Tizio è il miglior amico di Caio allora Tizio conosce Caio. Questo processo chiamato reasoning è uno dei principi cardine del Semantic Web, in quanto consente di inferire nuova conoscenza ricavando affermazioni che non erano specificate esplicitamente nei dati iniziali; tante più sono le caratteristiche o vincoli strutturali del dominio espresse con linguaggio ontologico, tanto più potente potrà essere il ragionamento applicabile ai dati iniziali. 62
79 Figura 2.13: I livelli semantici del Semantic Web Stack RDFS di per sé non è sufficiente a descrivere tali informazioni in modo da permettere ad un agente di effettuare ragionamenti complessi in completa autonomia; si limita a definire le relazioni di ereditarietà, il concetto di risorsa, di proprietà, di tipo, di collezione e poco altro e non riesce a descrivere completamente le relazioni che intercorrono tra le risorse. Una ontologia, come già detto, rappresenta la concettualizzazione di un dominio, ossia una descrizione formale di un insieme di concetti e delle relazioni che intercorrono tra essi. OWL permette proprio questo. Ontologia nell ambito filosofico si riferisce allo studio dell esistenza. La teoria dell esistenza si occupa di dare risposte a domande del tipo: Che cos è l esistenza? Quali proprietà possono spiegarla? Come queste proprietà la spiegano? [41] In Informatica - o meglio nell Intelligenza Artificiale - l ontologia è la descrizione dei concetti e delle relazioni esistenti comprensibili da una macchina, che permette la classificazione e il ragionamento induttivo. OWL permette di rappresentare una ontologia e quindi la descrizione di una specifica concettualizzazione. Il Web Ontology Language è un linguaggio di markup per rappresentare esplicitamente significato e semantica dei termini con vocabolari e relazioni tra i termini. Tale rappresentazione dei termini e delle relative relazioni è chiamata ontologia appunto. L obiettivo è permettere ad applicazioni software di elaborare il contenuto delle informazioni dei documenti scritti in OWL - uno standard W3C che fa parte del W3C Semantic Web Framework [40]. 63
80 Legato alle basi di conoscenza e alle ontologie troviamo il concetto di inferenza, con il quale si vuole indicare il meccanismo di deduzione di nuove informazioni da una base di conoscenza. Inferire X significa concludere che X è vero; un'inferenza è la conclusione tratta da un insieme di fatti o circostanze. Il linguaggio OWL parte dai concetti base di RDFS e li estende introducendo costrutti per la definizione delle relazioni tra le classi e delle relative cardinalità. OWL è rilasciato in tre diverse versioni, con complessità e potere espressivo crescenti secondo un sistema a "scatole cinesi": OWL-Lite, OWL-DL e OWL-Full. Figura 2.14: OWL-Lite, OWL-DL e OWL-Full Le tre versioni di OWL hanno complessità e potere espressivo crescenti. OWL-Lite è la versione sintatticamente più semplice, attraverso cui è possibile definire gerarchie di classi e vincoli poco complessi. OWL-DL è la versione intermedia; offre un potere espressivo più elevato e mantiene la completezza computazionale (tutte le conclusioni sono computabili) e la decidibilità (tutte le computazioni si concludono in un tempo finito). OWL-Full offre la massima espressività, senza offrire alcuna garanzia circa la completezza e decidibilità. Ogni versione del linguaggio include ed estende la precedente. In altre parole, un ontologia OWL-Lite è sempre valida anche in OWL-DL (ma non il contrario); un ontologia OWL-DL è sempre valida anche in OWL-Full (ma non il contrario). 64
81 Per approfondimenti sui concetti fondamentali del linguaggio OWL (classi, proprietà, gerarchie di classi, domini e range, tipologie di proprietà, individui, restrizioni, etc.) fare riferimento al reference W3C [40] o alla dispensa [39], in cui si illustra il funzionamento dell editor open source Protègè per la definizione di ontologie OWL, che è quello utilizzato in questo lavoro di tesi. (Protègè, ). 2.7 Le ontologie CUONTO e DOMONTO I componenti principali di una ontologia OWL sono tre: individui, che rappresentano gli oggetti del dominio di interesse; proprietà, ovvero relazioni binarie (che collegano due oggetti per volta) tra individui; classi, ossia i gruppi di individui. Le classi OWL possono essere organizzate in gerarchie di superclassi e sottoclassi dette tassonomie e sono tutte derivate dalla superclasse owl: Thing. Le proprietà sono, come già detto, relazioni binarie tra individui e OWL ne ammette due tipologie principali: - le proprietà object, che collegano individui ad individui; - le proprietà datatype, che collegano individui a valori di tipi ammissibili per XML e/o RDF. Altro concetto importante è quello di dominio : un dominio di una proprietà è la classe (o l insieme di classi) i cui individui appartenenti possono essere valori della proprietà. In altre parole, una proprietà collega individui appartenenti ad un dominio ad individui appartenenti ad un range. Le prosperità OWL possono avere diverse caratteristiche, tra cui la transitività, la simmetria e la funzionalità. È possibile dichiarare, inoltre, che alcune proprietà sono inverse rispetto ad altre. Per ulteriori dettagli, fare riferimento a [41]. In questo lavoro si prescinde dalla progettazione di una ontologia, ma possiamo citare i passi fondamentali per la sua modellazione [62]: determinazione dell ambito dell ontologia considerazione della possibilità di riuso dell ontologia esistente 65
82 enumerazione dei termini importanti nell ontologia definizione di classi e gerarchie di classi definizione delle proprietà delle classi creazione delle istanze Di seguito mostriamo alcuni screenshot tratte dell ambiente Protègè delle due ontologie utilizzate nel nostro progetto (che descriveremo nel capitolo seguente): CUONTO e DOMONTO (classi e sottoclassi, object property e datatype property). Inoltre, riportiamo i diagrammi delle classi principali delle ontologie citate, esportate grazie ad Altova SemanticWorks [42]. Figura 2.15: L'ontologia didattica CUONTO (classi e proprietà) 66


83 Figura 2.16: L'ontologia di dominio DOMONTO (classi e proprietà) 67
84 Figura 2.17: Ontologia CUONTO: proprietà delle content units 68
85 Figura 2.18: Ontologia DOMONTO: le classi Concept e Learning Object 69
86 Figura 2.19: Ontologia DOMONTO: Classe ConceptScheme 2.8 Le ontologie persistenti e JENA In, abbiamo utilizzato un framework opensource per la realizzazione di una applicazione Java che fosse ontology-based. Tale framework è JENA [44], sviluppato dal Semantic Web Research Group di HP Labs. Inizialmente nacque per realizzare applicazioni che supportassero RDF e RDFS, ma poi venne esteso ai linguaggi per le ontologie tra cui OWL e DAML+OIL. Non volendo entrare nei dettagli, enunciamo qui solo alcune caratteristiche importanti di JENA. Pur supportando diversi linguaggi per l espressione di ontologie, JENA offre un unica API neutrale rispetto al linguaggio. Ciò consente di operare sulle ontologie senza preoccuparsi del linguaggio attraverso il quale l ontologia stessa verrà serializzata. Tutte le ontologie vengono gestite in JENA attraverso l interfaccia OntModel (implementata dalla classe OntModelImpl). Per creare una nuova ontologia è necessario invocare il metodo createontologymodel 70

87 della factory ModelFactory. Il linguaggio ontologico da utilizzare è specificato attraverso l URI o con costanti, come mostra la tabella seguente: Dopo aver creato l ontologia è necessario definire il default namespace: una stringa di caratteri che verrà utilizzata come prefisso standard per tutte le classi, le proprietà e gli individui definiti all interno di un ontologia. Ciò consente di mantenere diverse ontologie grazie a namespace diversi. Per dettagli relativi al popolamento di una ontologia con classi, proprietà ed individui, far riferimento all ottima dispensa di Nicola Capuano, dell Università degli Studi di Salerno [41]. Uno strumento molto potente offerto da JENA e che è stato utilizzato nel nostro progetto è quello delle ontologie persistenti. Tali ontologie, pur mantenendo le stesse funzionalità delle ontologie normali, non hanno bisogno di essere serializzate e deserializzate in file XML, essendo esse legate ad un database esterno che mantiene tutti gli statement RDF di cui l ontologia è composta. Ciò consente di lavorare, mantenendo performances elevate, anche con ontologie di grosse dimensioni. Quando poi si rende necessaria la distribuzione di un ontologia persistente all esterno, è sempre possibile esportarne una copia in formato XML. Maggiori dettagli sulle ontologie persistenti in JENA sono forniti in [45] attraverso un esempio di utilizzo e in [46] attraverso la descrizione di un modello che utilizza ontologie persistenti (model-driven ontology). 71
88 72
89 Capitolo 3 - una soluzione ontologica Tutte le soluzioni e le tecnologie citate nei capitoli precedenti e utili per la realizzazione (si spera) del Semantic Web, possono essere utilizzate in architetture legate a domini ben definiti e sicuramente più ristretti del Web. È possibile, cioè, mettere a servizio di comunità ristrette di utenti, ottenendo scopi ben precisi, gli schemi semantici visti e farli operare in campi e domini ben delimitati, dove i problemi legati alle ontologie potrebbero essere meno accentuati. Si otterrebbe una sorta di universalità in quel dominio applicativo, dove gli utenti potrebbero essere d accordo sui concetti e sulle relazioni che li collegano. Il nostro campo applicativo è costituito dall e-learning. Vorrei citare due grandi applicazioni sviluppate secondo una struttura ontologica: Edutella Project [48] e Merlot [49]. Il progetto Edutella è nato a partire dal 2002 e ha realizzato la prima rete P2P i cui contenuti sono stati catalogati tramite metadati espressi in linguaggio RDF. Questo progetto open-source è nato principalmente per lo scambio di materiale didattico per corsi di e-learning, ma potenzialmente potrebbe diventare la più vasta rete di costruzione collaborativa della conoscenza mai esistita. Il suo nome è sicuramente ispirato a Gnutella, storica rete P2P, ma la grande differenza si fonda sulla tecnologia utilizzata. Tramite l uso dei metadati e di una fitta rete di ontologie, ogni risorsa potrà essere classificata in maniera chiara e strutturale. Edutella permetterà all utente di accedere il modo rapido ed intuitivo al materiale didattico, costruendosi automaticamente un proprio percorso di studio ottimale [50]. 73
90 MERLOT offre un repository su web di learning objects (LOR, Learning Objects Repository. In questo campo organizzare una piattaforma secondo strutture ontologiche diventa estremamente produttivo. Un corso di informatica può contenere, ad esempio, una parte relativa alla programmazione di base che può essere ripresa e poi ampliata in un corso di calcolatori elettronici. Se i vari materiali didattici sono organizzati in unità (learning objects), ogni singola unità può essere collegata alle altre e ricomposta in un nuovo corso. È proprio questo che ci proponiamo: utilizzare i modelli di ricerca semantica (che si poggiano sulle ontologie) per generare automatica dei corsi didattici, oltre che reperire le risorse. A questo punto abbiamo tutti i requisiti e le tecnologie per farlo. 3.1 I Learning Objects: atomi di conoscenza Prima di proseguire ed entrare nel merito del nostro progetto, vogliamo ricordare alcune nozioni fondamentali dell e-learning, ovvero cosa si intende per Learning Objects (LOs) e i metadati ad essi associati. I Learning Objects sono blocchi autonomi tra loro ed indipendenti dal contesto che possono essere assemblati (tra loro) in ogni momento in cui ciò è richiesto ed in base alle esigenze del discente [55]. In giro circolano tante definizioni di Learning Objects, la più accreditata è quella data da David Wiley che definisce i Learning Object come ogni risorsa digitale che può essere riutilizzata per supportare l apprendimento. In questa definizione è inclusa qualsiasi cosa che possa essere resa disponibile online. Quindi, i LOs li possiamo pensare come atomi di conoscenza autoconsistenti. Oggigiorno i soggetti erogatori di formazione stanno passando alla modalità di erogazione del materiale didattico basato sull approccio Learning Object per via del più alto livello qualitativo riconosciuto ad esso rispetto ai metodi precedenti. Inoltre, i Learning Objects possono essere riusati se opportunamente specificati e realizzati. Le principali caratteristiche che debbono avere i LOs sono due: 74
 [56], per formare nuovi moduli")
91 - combinazione, della quale si occupano i computer agent, che possono comporre in modo automatico e dinamico le lezioni, personalizzandole per i singoli utenti. I LOs, grazie al fatto di avere i metadata che li esplicitano, possono essere individuati, aggiornati e ricomposti, dagli LCMS (Learning Content Management System) [56], per formare nuovi moduli didattici rispondenti in modo innovativo agli obiettivi formativi dei learners - percorso di apprendimento personalizzato e riadattabile dinamicamente alle esigenze del learner -, nel rispetto dei vincoli imposti dalla strategia di obiettivo formativo delle aziende, università ed enti cui il learner dipende. - granularità, che è la caratteristica che esprime le dimensioni di un LO. Vi è abbastanza aleatorietà in ciò e possiamo affermare che una risorsa per attribuire una dimensione al LO possa essere sicuramente il buon senso. Maggiore è la combinazione e la granularità dei LOs definiti, migliore sarà la loro riusabilità in diversi contesti didattici, più facile sarà la loro localizzabilità e più agevole sarà il loro uso personalizzato alle caratteristiche dello studente. Figura 3.1: Componenti fondamentali dell'e-learning L approccio basato sui Learning Objects è sempre più diffuso. Standard internazionali come AICC, IMS e SCORM [56] stanno risolvendo il problema della interoperabilità fra le diverse piattaforme di formazione a distanza. Creare LOs 75
92 efficaci e realmente riutilizzabili, però, non è solo un problema tecnologico; richiede una specifica metodologia di progettazione e realizzazione, seguendo la quale, è possibile realizzare in tempi rapidi e a costi contenuti LO di elevata qualità. Per garantire che i Learning Objects siano aggregati, suddivisi e riutilizzati è necessario standardizzare la loro descrizione, ovvero definire quello che in gergo si chiama set di metadati. I metadati (LOM, Learning Objects Metadata) sono definiti come quei dati che non si riferiscono direttamente ai contenuti concreti di un LO, ma li classificano, nel senso che rinviano ai contenuti di apprendimento del LO. Per l elenco del set di metadati di IMS vedere l articolo [57]. 3.2 Ontologie nell e-learning L e-learning consente la personalizzazione del percorso didattico, sulle esigenze/preferenze dei singoli discenti, se si utilizzano strumenti software che consentono di rendere dinamico il corso e, quindi, renderlo modificabile sia dai docenti, sia dai tutors e sia dai discenti in linea con la teoria costruttivista [51]. Vi sono delle problematiche che emergono nel far ciò e per risolverle è necessario l utilizzo di ontologie nella costruzione e fruizione di corsi in modalità e-learning. Nei corsi in modalità e-learning contenenti Reusable Learning Object, si esprime, quindi, il loro contenuto semantico attraverso concetti appartenenti ad una ontologia che descriva il dominio del corso. Costruita l ontologia, su di essa si basa la ricerca semantica dei Learning Objects. Possiamo pensare all ontologia come la mappa dei percorsi che portano da un LO ad un altro o anche che tenga traccia dei percorsi didattici di un utente. Un primo esempio può essere osservato nella piattaforma Intelligent Web Teacher (IWT) [52], la quale utilizza nel modello della conoscenza anch essa ontologie: in IWT, le ontologie sono strutture a grafo che consentono di descrivere formalmente un dominio didattico attraverso la specificazione di un vocabolario di concetti e l identificazione delle relazioni intercorrenti fra essi [53]. In IWT è il docente a creare l ontologia, ossia una mappa concettuale per rappresentare il flusso dei concetti obiettivo di un corso. [54] 76
93 In Italia, purtroppo, gli attuali sistemi di didattica a distanza non sono privi di difetti: problemi come l information retrieval e l integrazione tra sistemi e-learning non sono ancora risolti. L esigenza di rendere riutilizzabile, accessibile ed interoperabile la conoscenza codificata nei diversi sistemi di e-learning, ha portato a riconsiderare le modalità con le quali i contenuti per l apprendimento vengono creati su sistemi software proprietari, inutilizzabili cioè in altri contesti. Le prospettive future prevedono lo scambio, l integrazione e la costruzione collaborativi di conoscenza usufruendo di ampi repository di conoscenze a cui si potrà accedere in modo rapido ed intuitivo attraverso software adeguati (vedi il già citato Edutella). Questo problema del recupero efficiente degli oggetti di apprendimento è molto sentito perché è vicino al problema della ricerca dei documenti attraverso i motori e gli indici di rete. Cercare informazioni in Internet comporta un altissimo tasso di rumore, cioè di documenti non pertinenti. Per questo motivo, fin da subito, si è stabilito che i LOs dovessero essere dotati di un sistema di classificazione il più possibile completo ed efficiente: i metadati (LOM) [59]. 3.3 Annotare i learning objects: XML o RDF? Nasce una problematica che ci induce a giustificare il perché si sia introdotto un nuovo linguaggio nello stack del Semantic Web in luogo dell XML, che oltretutto è il linguaggio ufficiale utilizzato per la scrittura dei LOM. La descrizione a marcatori dell XML non è sufficiente a convogliare una semantica che esprima relazioni tra concetti. Con esso è possibile formalizzare la conoscenza attraverso espressioni del tipo soggetto-predicato-oggetto i cui termini e restrizioni operative sono definite in apposite strutture che abbiamo chiamato RDF-Schema. In sostanza mentre l XML aiuta a dichiarare una struttura di conoscenza, l RDF aggiunge ad essa l aspetto relazionale. Con RDF ogni oggetto descritto è una risorsa identificata in modo univoca sul Web, attraverso la sua URL o URI [58]. Dunque, rispetto a XML, di cui è un figlio, RDF ha alcuni vantaggi, come per esempio la possibilità di definire agevolmente il tipo e le proprietà degli oggetti (si 77
94 tratta sempre di un insieme definito di risorse, proprietà e valori). RDF limita e focalizza alcune caratteristiche di XML per renderlo un linguaggio rivolto alla descrizione di un oggetto, delle sue proprietà, e delle relazioni con gli altri oggetti. Le differenze tra RDF e XML sono fondamentalmente due: RDF è stato pensato espressamente per esprimere metadati. XML fa molte cose, e può anche essere usato per descrivere metadati, ma generalmente ha un rapporto molto più stretto con i dati, contiene già in sé dei dati che possono essere richiamati. RDF esprime metadati, nel senso più proprio: descrive contenuti di un documento che in esso non sono presenti. XML è centrato su una struttura a inclusione, riesce perciò ad esprimere senza difficoltà le relazioni di parentela o di essere parte di, ma per le altre relazioni dimostra dei limiti. Se volessi esprimere una relazione associativa fra due classi, cioè dire che esse hanno una relazione ma non sono incluse una nell'altra, con XML dovrei ricorrere agli ID e agli IDREF. Ma abbiamo anche visto che l RDF, pur essendo un linguaggio potente per sua rappresentazione della conoscenza, non ha di per sé alcun modo di operare inferenze o deduzioni. Bisogna rifarsi ad un ulteriore livello che riesca ad associare i concetti a regole logiche d uso attraverso software specifici: questo livello è proprio quello delle ontologie. Citazione. Le ontologie hanno un ruolo fondamentale nella risoluzione di interoperabilità semantica tra sistemi e-learning [58]. Esiste una interessante proposta costituita dallo standard IEEE Learning Object Metadata RDF binding [60], che fornisce una rappresentazione dello IEEE LOM in RDF. La proposta di questo standard è quello di fornire un legame tra LOM con RDF per concedere lo scambio di istanze di Learning Object Metadata (LOM) tra sistemi che implementano il modello di dati IEEE LOM (P ). Questo legame è definito come un set di costruttori RDF che facilitano l inserimento metadati di contenuto formativo nel Web Semantico. La figura seguente mostra quelli che sarebbero i livelli previsti in questo modello della conoscenza (i tre livelli del Modello della Conoscenza): 78
95 Figura 3.2: i tre livelli del Modello della Conoscenza Come è possibile vedere, il livello 3 di descrizione di dominio, vale a dire il livello ontologico, permette una rappresentazione formale di un concetto oltre alla rappresentazione semantica e sintattica dello stesso. Si considera che la concessione del Web Semantico permetterà un nuovo livello di servizi nei sistemi e- learning. Le ontologie permettono appunto l interoperabilità semantica. L interoperabilità è definita dalla IEEE come l abilità di due o più sistemi o componenti di scambiare l informazione e di utilizzare l informazione che è stata scambiata. Nei sistemi e-learning, l interoperabilità permette lo scambio e la riutilizzazione delle risorse educative (tutorial, documenti, lucidi) che sono stati sviluppati nelle piattaforme educative eterogenee. Esso permette di: - aumentare la qualità e varietà delle risorse educativa nel mercato; - preservare il capitale investito in tecnologia e sviluppo di risorse educative, giacché una risorsa educativa potrà essere scambiata o utilizzata senza la necessità di realizzare modificazioni costose; - garantire che gli utenti con differenti piattaforme hardware e software possano accedere alle risorse educative di diverse fonti con perdite minime di contenuto e funzionalità. Per riuscire ad avere una completa interoperabilità nei sistemi e-learning è necessario: - definire una sintassi e una semantica comune per la descrizione di risorse educative (standard e tecnologie di Web Semantico); - stabilire un sistema di comunicazione, mediazione e scambio delle risorse educative [61]. 79
96 Il tutto dovrebbe essere governato da standard che preservino e garantiscano le proprietà fondamentali per l e-learning: accessibilità, interoperabilità, riusabilità, adattabilità, durabilità, produttività. Le più importanti organizzazioni e gruppi che lavorano nel campo delle specificazioni e degli standard in e-learning sono: Aviation Industry CBT Commitee (AICC), IEEE Learning Tecnologies Standards Comité, IMS Global Consortium, Advanced Distributed Learning (ADL), Alliance of Remote nstructional and Distribution Networks for Europe (ARIADNE). Un esempio di soluzione ontologica al problema dell eterogeneità delle piattaforme e-learning e al problema dell Information Retrieval è stato proposto dall Università di Trento ed è riferito in questo articolo [58]. Inoltre, in [63] viene presentata una soluzione che utilizza le ontologie ALOCoM (Abstract Learning Content Model) e IBM s Darwin Information Type Architecture (DIDA), interfacciandosi con il sistema Edutella per lo scambio dei contenuti didattici. In [64] viene presentato un sistema olistico che permette l annotazione semantica automatica, l indexing e il retrieval di documenti (piattaforma KIM, Knowledge and Information Management), basato sul processo di estrazione (information extraction) non di tutte le parti del discorso (parole, frasi, ecc.) ma solo delle named entities, ossia quei concetti che si riferiscono a nomi propri di persona, cose, luoghi, organizzazioni, ecc. (Named Entity Recognition) [64]. Il nostro approccio sarà più generale, rivolto all estrazione e all indexing di tutti i concetti presenti in un vocabolario condiviso, non solo appartenenti a named entities. Interessante anche il progetto VICE del Centro di Ricerca Informatica Interattiva dell Università degli Studi dell Insubria [65], in cui si propone una piattaforma innovativa per la creazione di un repository di LO e moduli didattici, supportato dall uso di metadati e definendo ontologie disciplinari. 3.4 Un retrieval efficace dei learning objects Introduciamo finalmente la nostra soluzione, focalizzando il problema che intendiamo risolvere. Per rendere i learning objects realmente riutilizzabili bisogna affrontare due macrocategorie di problemi: 80
97 1. interoperabilità tecnologica: si tratta di rendere disponibili per il riuso LOs prodotti su piattaforme differenti e che possono adottare diversi formati; 2. retrieval efficace: il retrieval dei learning objects deve tenere conto anche delle proprietà educative e pedagogiche di ogni risorsa didattica. Queste proprietà devono essere tenute in considerazione quando i learning objects vengono assemblati per generare dei corsi didattici. Noi intendiamo risolvere il secondo problema, visto che il primo prevede la definizione di un processo di standardizzazione, che vede come protagonisti AICC, ADL SCORM, IEEE LTSC, IMS, DUBLIN CORE, ecc., standard che tuttavia non risolvono il secondo problema, visto che non supportano la definizione di una semantica formale. Ecco la frase eloquente che ci introduce la chiave di volta del nostro progetto: Citazione. Annotare semanticamente le risorse didattiche può essere definito come il processo di allegare descrizioni semantiche alle risorse collegando queste ultime ad un certo numero di classi e proprietà definite in ontologie [66]. Per fare ciò ci serviamo dei metadati, classificabili in tre categorie: metadati standard, che permettono di definire una struttura gerarchica che non contempla nessun tipo di relazione semantica fra i metadati (come IEEE LOM); metadati semi-semantici, che utilizzano solitamente uno standard per la descrizione dei learning object, ma collegano i metadati ad una rete semantica che offre diversi tipi di relazioni fra i learning objects; metadati semantici, utilizzati in applicazioni che si basano completamente sulle ontologie di dominio. Esse usano RDF come veicolo per esprimere la semantica di una risorsa didattica. Domanda. Ma perché il Semantic Web e, quindi, tutte le tecnologie che lo realizzano, può essere lo strumento principale per garantire l interoperabilità e l accesso efficace alle risorse formative? 81
98 Risposta. 1. Il Web Semantico permette di legare i learning objects a delle ontologie condivise. Questo permette la costruzione di corsi a misura di utente, interrogando semanticamente le risorse didattiche per le informazioni di interesse. 2. Il Web Semantico offre anche dei meccanismi per la navigazione concettuale all interno dei learning objects. 3. Nel Web Semantico l utente può cercare il materiale desiderato: l ontologia fa da collegamento fra i bisogni dell utente e le caratteristiche del materiale didattico. 4. Il Web Semantico offre un supporto all evoluzione del materiale tramite i meccanismi di annotazione semantica del contenuto. Il suggerimento è quello di migliorare l utilizzo dei metadati, prevedendo metadati basati sulle ontologie. Le ontologie, infatti, hanno il compito di far corrispondere ad ogni metadato un preciso significato, in maniera tale da garantire l interoperabilà. In [36] si considera un learning object come un oggetto tridimensionale, le cui dimensioni sono: - il contenuto, la dimensione di ciò di cui il learning object parla; - il contesto, la dimensione del modo in cui il contenuto viene fornito; - la struttura, la dimensione che appartiene all organizzazione dei learning object in corsi completi, in quanto raramente essi vengono utilizzati isolati. In tale discorso, dunque, le ontologie possono e devono essere applicate a diversi livelli: - ontology content, che descrive i concetti di base del dominio in cui l apprendimento avviene; - pedagogical ontology, che focalizza il contesto del learning object (può classificare un LO come esempio, teorema, lezione, esercizio, ecc.). Una strategia pedagogica definisce, ad esempio, l ordine di successione dei learning objects in base al loro ruolo, asserendo che un esempio deve sempre seguire una definizione; - structural ontology: che descrive la struttura di un corso didattico. 82
99 3.5 Stato dell'arte dei sistemi per l'annotazione e il retrieval di risorse didattiche Molte sono state ad oggi le proposte di sistemi per l annotazione e recupero semantico di risorse didattiche in ambienti di e-learning. Di seguito si riporta un breve stato dell arte descrivente le caratteristiche e pecularieta dei principali approcci. In [109] gli autori presentano quelle che devono essere le caratteristiche principali di un approccio atto all implementazione di uno scenario di e-learning basato sul Web Semantico basato sull utilizzo di ontologie per la descrizione delle risorse didattiche. In particolare, essi suggeriscono di migliorare l utilizzo dei metadati tramite metadati basati sulle ontologie. Le ontologie hanno quindi il compito di far corrispondere ad ogni metadato un preciso significato, in maniera tale da garantire l interoperabilita. Inoltre, il problema di fornire un significato comune si presenta a diversi livelli fra loro ortogonali di un learning object. Infatti, dal punto di vista di uno studente un learning object si puo considerare come un oggetto tridimensionale; queste tre dimensioni sono: il contenuto, la dimensione di cio di cui il learning object parla; il contesto, la dimensione del modo in cui il contenuto viene fornito; la struttura, la dimensione che pertiene all organizzazione dei learning object in corsi completi, in quanto raramente essi vengono utilizzati isolati. Il sistema Courseware Watchdog [110,111] propone un approccio basato su ontologie per il retrieval di learning object in grado di soddisfare i seguenti requisiti: il sistema deve capire l ontologia e navigare all interno del contenuto; il sistema deve essere in grado di recuperare il materiale rilevante; il sistema deve dare la possibilità di interrogare repository di risorse semantiche annotate; il sistema deve effettuare il clustering dei documenti secondo l'ontologia; il sistema deve essere in grado di aggiornare l ontologia e la knowledege base quando giungono nuovi dati. L architettura è centrata intorno ad un sistema di gestione delle ontologie realizzato utilizzando il framework KAON. Le ontologie, definite OIMODELS (Ontology-instance-models) consistono di concetti, relazioni fra concetti, istanze, proprieta delle istanze, tutte riferite come entita. L altro elemento centrale dell architettura e il text corpus, che contiene un insieme di documenti e 83
100 per ogni documento contiene il testo, i metadati e altre informazioni. L astrazione per il text corpus e offerta da Text-to-Onto, un estensione del framework KAON che offre dei meccanismi di text mining per l analisi dei documenti. I due elementi piu interessanti di questo approccio sono il focused crawling utilizzato per recuperare le risorse didattiche rilevanti dal Web e il subjective clustering per il raggruppamento delle risorse didattiche restituite dal crawler. Infine, il sistema si configura come un consumer nei confronti del network Edutella [112], una rete peer-to-peer per lo scambio di risorse didattiche. Il sistema PeOnto [113] propone un insieme di 5 ontologie in grado di supportare i diversi servizi di una piattaforma di e-learning. Esse sono : curriculum ontology che rappresenta l insieme degli obiettivi formativi che un organizzazione vuole che le persone raggiungano; language ontology - che descrive la struttura di un particolare dominio di studio; pedagogy ontology - descrive le procedure di instructional design e le relazioni fra le risorse e le attivita di apprendimento; people ontology - descrive la struttura delle persone coinvolte nel processo educativo e le relazioni fra esse; PEA ontology che descrive le responsabilita degli agenti software intelligenti utilizzati dalla piattaforma di e-learning. Il sistema e-aula [114] ha lo scopo del progetto di generare dinamicamente dei corsi didattici assemblando le risorse didattiche tenendo conto del background dell allievo, dei suoi obiettivi e del suo stile di apprendimento. Per realizzare questo obiettivi, gli autori propongono di annotare i learning object con due tipi di informazioni: informazioni pedagogiche, utili a catturare la funzione educativa svolta da un LO; informazioni sul contesto, metadati circa il contenuto di una risorsa didattica. Un learning object viene quindi annotato in riferimento a due ontologie: l ontologia pedagogica, che si riferisce al ruolo educativo, e l ontologia di dominio, che si riferisce al dominio di appartenenza della risorsa. Il profilo dell allievo viene modellato utilizzando IMS Learning Design specification. In base alle informazioni presenti, il sistema assembla i LO e genera un corso completo applicando una trasformazione XSLT ai LO selezionati. Il sistema ELENA [115] mira a creare un sistema in grado di riempire il gap esistente fra i correnti sistemi di adaptive e-learning e i repository dinamici di learning object. Gli autori propongono un architettura basata sui servizi in grado di offrire funzioni di personalizzazione tramite web-service che sfruttano le 84
101 annotazioni semantiche dei learning object. Il sistema utilizza tre tipi di ontologie: ontologia dei learning ojbect - per la descrizione delle risorse didattiche viene utilizzata un ontologia modellata secondo lo standard Dublin Core; ontologia di dominio - permette di tenere traccia dei concetti che fanno parte di un dominio e delle loro relazioni reciproche; ontologia per gli allievi - permette di descrivere le informazioni relative ai discenti. Il componente centrale dell architettura e il Personal Learning Assistant Service, il cui compito è quello di utilizzare i servizi offerti dal sistema per cercare risorse, corsi e percorsi di apprendimento completi adatti all utente. Il componente fornisce un interfaccia di ricerca che interagisce con un ontologia per costruire le query e che permette di rifinire le query che presentano concetti non presenti nell ontologia. Il Query Rewriting Service estende poi la query dell utente aggiungendo ulteriori vincoli e variabili non presenti nella query originaria. Questa estensione e basata su una serie di euristiche. Ad esempio, il servizio può aggiungere dei vincoli basati sulle preferenze dell utente e le abilita linguistiche. Oppure può estendere la query in base alle esperienze di apprendimento precedenti memorizzate all interno del profilo se lo scopo e quello di migliorare le abilita dell utente. Il Recommendation Service fornisce delle annotazioni delle risorse didattiche basate sulle informazioni del profilo dell utente. Queste annotazioni si riferiscono al ruolo educativo della risorsa, alla sua compatibilita con il profilo dell utente, etc. La derivazione di queste annotazioni viene effettuata tramite l uso di euristiche. Il Link Generation Service utilizza delle euristiche per creare collegamenti semantici fra le risorse didattiche tenendo in conto le informazioni contenute nel profilo dell utente. L Ontology Service mantiene una o piu ontologie e può essere interrogato per restituire l intera ontologia, una parte di essa, o può rispondere a query del tipo trova tutti i sottoconcetti di un concetto C, ma anche query sulle relazioni, del tipo chi è autore del concetto C. Il servizio è in grado di supportare anche l evoluzione delle ontologie nel tempo. Il Mapping Service permette di definire delle corrispondenze fra ontologie in maniera tale che i vari servizi non siano obbligati ad utilizzare le stesse ontologie. Questo servizio può essere utilizzato per esempio per ottenere la corrispondenza di un concetto C da una certa ontologia verso un concetto C' di un'altra ontologia, oppure per far corrispondere un istanza I formulata in termini di un'ontologia ad un'istanza I' formulata in termini di un'altra ontologia. Repository Service fornisce un accesso a qualunque repository di learning object connesso ad una rete. I repository possono essere semplici files, singoli database, federazioni di database o reti P2P. Il 85
102 L approccio proposto in [116] mira a creare un architettura per il riutilizzo dei learning object in maniera flessibile. Gli autori partono dalla constatazione che i correnti modelli di aggregazione per i learning object permettono il riuso di un intero LO, ma non permettono il riutilizzo dei componenti a grana fine. Gli autori suggeriscono un generico content model chiamato ALOCoM che definisce i LO e i loro componenti. Il modello fa una differenza fra Content Fragment (CF), ContentObject (CO), Learning Object (LO). I CF sono unita di contenuto in una forma di base, come ad esempio testo, audio e video. Praticamente, i CF sono le risorse digitali grezze. Essi possono essere specializzati nei due raggruppamenti di risorse discrete (immagini e testo) o continue (audio, video, simulazioni e animazioni). I CO aggregano i CF e aggiungono funzionalita di navigazione. I CO possono aggregare anche altri CO. Il successivo livello di aggregazione prevede che i CO si associno in un LO che aggiunge anche gli obiettivi didattici. Infine, il sistema QBLS [117] è un sistema che utilizza le tecnologie e gli standard del Web Semantico per permettere il riuso delle risorse didattiche. Il sistema si basa sull utilizzo di due ontologie. La prima ontologia e un ontologia di dominio. Anzichè creare ontologie di dominio in OWL o RDF, gli autori suggeriscono di utilizzare lo standard SKOS (Simple Knowledge Organization System) proposto dal W3C, che e facile da utilizzare e offre una discreta potenza espressiva. La seconda ontologia e un ontologia pedagogica. L ontologia pedagogica permette di applicare una strategia pedagogica durante la generazione di un corso. Una strategia pedagogica definisce ad esempio l ordine di successione dei learning object in base al loro ruolo, asserendo che un esempio deve sempre seguire una definizione. Il retrieval dei learning object avviene sulla base dell ontologia di dominio: i learning object vengono annotati rispetto ai concetti contenuti nell ontologia; in fase di retrieval, il sistema recupera tutte le risorse che contengono il concetto scelto dall utente e altri concetti collegati che vengono scoperti tramite il meccanismo di inferenza. Gli approcci proposti delineano quelle che sono le linee guide sia funzionali che architetturali nell implementazione di un sistema di annotazione e retrieval semantico di learning object. La nostra proposta utilizza molte delle idee esposte al fine di giungere ad una soluzione innovativa ed efficace. 86
103 3.6 : un modello di macchina semantica I requisiti da cui partiamo per la progettazione del nostro progetto sono fondamentalmente due: garantire flessibilità; massimizzare l interoperabilità. Il primo requisito si riferisce alla capacità del software di adattarsi ad esigenze diverse. Nel caso specifico, il nostro ambito applicativo è quello del retrieval dei learning objects, ma è possibile utilizzare il progetto anche in domini differenti, in cui si voglia recuperare contenuti degli ambiti più disparati. L interoperabilità è la capacità di diverse soluzioni di collaborare tra loro. Tale requisito è garantito grazie all adozione di standard (come abbiamo già visto). Il problema degli standard è che essi devono essere abbastanza generici da mettere d accordo tutti gli utilizzatori, ma abbastanza specifici da soddisfare le esigenze di tutti. Tuttavia, il nostro approccio mira a dotare il software di un interoperabilità operativa insita nel modello, ovvero che non dipenda da alcuno standard se non dal modello stesso. In questo capitolo, abbiamo introdotto un importante soluzione al problema dell interoperabilità: l'approccio ontologico. Ebbene, vogliamo sottolineare che la nostra soluzione considera la semantica delle informazioni descrivendola tramite delle ontologie. Tuttavia, volendo risolvere un problema molto generale come l'interoperabilità, ne generiamo altri più specifici derivati dall uso delle ontologie: le ontologie sono difficili da condividere ; le ontologie devono essere costruite; le ontologie devono costituire una concettualizzazione condivisa. Il problema principale è che affinché un ontologia possa risolvere i problemi di interoperabilità è necessario che essa sia condivisa, ovvero che un certo numero di sistemi la utilizzi. Sarà il tempo a dire quali ontologie risulteranno vincitrici. 87
104 Inoltre, da un punto di vista squisitamente pratico, è poco probabile che due persone riescano a produrre la stessa concettualizzazione di un dominio. Per macchina semantica intendiamo un sistema software in grado di elaborare e interpretare informazioni presenti sul Web tramite ontologie. I requisiti della macchina da realizzare sono: la macchina deve interpretare la semantica delle informazioni; la macchina deve garantire flessibilità per trattare ogni tipo di informazione; la macchina deve garantire interoperabilità con altre macchine, deve cioè essere in grado di comunicare informazioni ad altre macchine senza perdere la semantica. In tale modello, l'informazione è costituita da segni, in accordo alle teorie semiotiche di Pierce e Morris. Un segno si compone di un significato e di un significante: - significante: aspetto esterno, visibile di un segno (una parola, una porzione di un immagine ); - significato: (di un significante) ha bisogno di un contesto in cui viene utilizzato ed è quel concetto che quel determinato significante veicola. Un problema rilevante è costituito dal fatto che lo stesso significante può avere più significati (polisemia) se usato in discorsi diversi, ma anche da soggetti diversi. Tale informazione grezza (ovvero non strutturata), di cui è visibile solo la composizione in significanti e non in significati, viene racchiusa in una risorsa informativa, la quale aggiunge all informazione stessa: un dominio informativo o descrizione del contenuto; la scomposizione informativa o suddivisione dell'informazione in unità di contenuto; il contesto informativo o descrizione esplicita del contesto; la componente interstrutturale o descrizione della struttura; il contenitore informativo o descrizione della tipologia di informazione. 88
105 La risorsa informativa è un vero e proprio contenitore per informazioni a cui si può associare un URL. Il dominio informativo racchiude l insieme dei concetti che descrivono una risorsa, nonché le relazioni semantiche tra questi concetti. La scomposizione informativa rappresenta l insieme di unità di contenuto di un informazione. Il contesto informativo contiene delle indicazioni esplicite circa la contestualizzazione dell informazione, utili per una sua corretta interpretazione. La componente interstrutturale contiene indicazioni circa altre risorse che sono collegate semanticamente alla risorsa informativa. Il contenitore informativo descrive la tipologia di informazione contenuta (pagina di giornale, rivista, notizia, ) Contesto informativo Componente interstrutturale Dominio informativo Contenitore informativo Scomposizione informativa Figura 3.3: La risorsa informativa e le sue componenti 3.7 La struttura di alto livello della macchina semantica Mostriamo di seguito la struttura di alto livello della nostra macchina semantica. Essa è progettata tenendo conto della struttura dell informazione, così come descritto al paragrafo precedente. Essa, infatti, dovrà essere in grado di trattare i diversi livelli in cui può essere vista una risorsa informativa. 89
106 Figura 3.4: Struttura di alto livello della macchina semantica La struttura può essere suddivisa in due parti costituenti: la parte intenzionale e quella estensionale. La parte intenzionale è formata dalle ontologie che rappresentano forme a priori della conoscenza, cioè indipendenti dalla conoscenza stessa e attraverso le quali si dà conoscenza. La parte estensionale è costituita dalla knowledge base, che immagazzina la conoscenza posseduta dalla macchina e codificata mediante le forme a priori. Il nucleo della macchina è costituito dal centro dei significati, che contiene tutti i significati conosciuti dalla macchina. Inoltre, vi è un modulo di comunicazione che consente l acquisizione di nuove risorse informative e la pubblicazione di quelle possedute dalla macchina. 90
107 Approfondiamo di seguito i diversi componenti di alto livello della macchina semantica, fornendo una sintesi ed una integrazione della tesi di Mario Caropreso, che anticipa teoricamente i modelli adottati per la successiva progettazione ed implementazione del sistema Semantica. Questo mio lavoro di tesi vuole, infatti, fornire ulteriori dettagli al già ricco e stupefacente lavoro di Caropreso, su cui fonda le basi questa sperimentazione. 3.8 Il centro dei significati: WordNet Il centro dei significati contiene tutti i significati conosciuti dalla macchina semantica. Come abbiamo già visto, quando abbiamo parlato dell informazione, il significato esprime un concetto, un idea alla quale rimanda un termine, un significante. Il centro dei significati della nostra macchina semantica è strutturato in modo simile a WordNet, il database lessicale della Princeton University. Per capire dunque come opera il centro dei significati della macchina semantica, introduciamo i concetti fondamenti del database WordNet [67]. Il WordNet è un database lessicale elettronico, la cui struttura è ispirata alle attuali teorie psicolinguistiche legate alla memoria lessicale umana. È sviluppato presso l università di Princeton dal Cognitive Science Laboratory e gratuitamente scaricabile. WordNet organizza nomi, verbi, aggettivi ed avverbi in insiemi di sinonimi (synset), dove ognuno di loro rappresenta un concetto. I synset, inoltre, sono legati tra loro attraverso diverse relazioni, come la sinonimia, antonimia, iponiami, iperonimia, ecc. [68] La differenza dalle classiche procedure per organizzare informazioni lessicali, come ad esempio i dizionari, consiste nel fatto che le parole non sono organizzate in una lunga lista ordinata, ma sono legate in modo gerarchico. WordNet è considerato la più grande risorsa disponibile per i ricercatori nei campi della linguistica computazionale, dell analisi testuale e di altre aree associate. In esso i lemmi sono organizzati in synset divisi in 4 categorie: nomi, verbi, aggettivi e avverbi. 91
108 Questa suddivisione in categorie, pur comportando una ridondanza rispetto ai dizionari classici, ha il vantaggio di visualizzare in modo chiaro le diverse categorie e di sfruttarle al meglio in base alle loro diverse strutture. In WordNet, uno stesso termine può appartenere a synset diversi, a seconda del suo significato. Fra synset si instaurano delle relazioni semantiche secondo una modalità di organizzazione che sembra ricalcare quella della memoria umana. È proprio per questo motivo che abbiamo scelto WordNet per implementare la memoria dei significati della nostra macchina semantica: la struttura organizza i concetti lessicali come si fa nella memoria di un essere umano. A noi interessa operare sui significati e non sui significanti e Wordnet memorizza, infatti, solo i primi, rendendo indipendente il sistema dal formato di rappresentazione dei contenuti. Inizialmente WordNet è stato ideato come un insieme di relazione semantiche tra concetti lessicali, ma con il proseguire del progetto si è osservato che c era un altro tipo di relazione che non poteva essere trascurato: le relazioni lessicali. Infatti, WordNet organizza le relazioni in due principali categorie e sono: relazioni semantiche, le quali esprimono un legame tra i significati come la specializzazione e la generalizzazione (iperonimia e iponimia); relazione lessicali, le quali esprimono un legame tra i lemmi come la sinonimia, la polisemia e l antonimia. La sinonimia è la relazione più importante in WordNet, infatti dalla sola relazione di sinonimia tra i vari lemmi si può facilmente risalire al significato, eliminando o limitando i problemi di ambiguità semantica. La definizione di sinonimia in termini di sostituibilità divide necessariamente il WordNet in nomi, verbi, aggettivi e avverbi; infatti, parole che appartengono a diverse categorie sintattiche non possono essere interscambiate. La antonimia è una relazione tra lemmi, la quale indica che uno è il contrario dell altro. La iponimia è la relazione che lega un concetto verso un concetto più generale di cui ne costituisce la specializzazione. 92
109 L iperonimia è la relazione che lega un concetto verso un concetto più specifico di cui rappresenta la generalizzazione. La meronimia lega un concetto verso un insieme di concetti che lo compongono. L olonimia è la relazione che lega un concetto verso un concetto che lo contiene. La relazione di iperonimia/iponimia è la relazione sulla quale gli studiosi basano la teoria sul sistema di memoria semantica. Esso è di tipo gerarchico e può essere schematizzato come un albero (nel senso grafico del termine). La proprietà fondamentale di un albero è che un cammino dalla radice alle foglie non debba mai essere un loop. L albero viene costruito seguendo la catena di termini in relazione di iponimia. La struttura creata è una sequenza di livelli che va da molti termini specifici al livello più basso a pochi termini generici a livello più alto. Con questo sistema si ovvia al problema della ridondanza, soprattutto per basi di dati che contengono molti termini: il termine al livello n ha tutte le proprietà del termine al livello n-1 ad esso collegato e ne aggiunge delle altre. E così via scendendo o salendo nella scala gerarchica. Basta quindi memorizzare solo le informazioni che caratterizzano l oggetto stesso, mentre si possono tralasciare quelle che già sono memorizzate per l oggetto padre. In letteratura è dimostrato che WordNet viene utilizzato con grande successo negli algoritmi di Word Sense Disambiguation (WSD), in particolare quando si tratta di contenuti testuali. In [69] e [70] vengono riportati i risultati sperimentali dell utilizzo di WordNet nel processo di disambiguazione. La risoluzione di ambiguità semantiche dei termini, come vedremo più dettagliatamente in seguito, consiste nel determinare in maniera automatica il significato più appropriato di una parola in base al contesto nel quale essa si trova. WordNet, in quanto rete semantica, viene utilizzato come strumento per determinare il senso di una parola basandosi sulle relazioni semantiche fra i vicini della parola stessa. Sempre in [70] viene spiegato che la costruzione di una mappa concettuale, ovvero una lista di concetti e delle relazioni che li collegano per la costruzione di frasi di senso compiuto, è fondamentale per la realizzazione di un accurata rappresentazione della conoscenza del dominio in cui opera un utente. Molti 93
110 algoritmi di linguistica computazionale utilizzano WordNet per disambiguare il senso di una parola in una mappa concettuale, usando la mappa stessa per carpire il contesto in cui tale parola opera. L operazione di realizzazione del centro dei significati è detta di concept mapping e l algoritmo che la realizza sfrutta WordNet per determinare il senso dei concetti e ricercare il loro giusto contesto. Inoltre, ancora in [70] viene presentato un algoritmo WSD che costruisce una mappa concettuale usando WordNet per la disambiguazione. Grazie a WordNet viene definito il concetto di distanza semantica, direttamente connesso a quello di similarità semantica, che fornisce una misura della similarità semantica fra due lemmi. Si può affermare che il calcolo della similarità semantica fra due lemmi si basa sulla lunghezza del cammino necessario a percorrere la distanza che li separa dal concetto minimo comune [71]. 3.9 Le ontologie della macchina semantica La nostra macchina semantica è in possesso di forme a priori che si possono raggruppare in: ontologia dell informazione: definisce il concetto di informazione e i concetti che la descrivono, tra cui risorsa informativa, dominio informativo, scomposizione informativa, unità di contenuto, contesto informativo, componente interstrutturale, contenitore informativo; ontologia di linguaggio: definisce un nuovo linguaggio in cui scrivere l RDF per descrizione delle risorse sul Web Semantico. Il nuovo linguaggio si chiama N-RDF ed è una estensione di RDF che non necessita di una ontologia esplicita, ma utilizza implicitamente il centro dei significati come ontologia implicita. N-RDF permette di esprimere statement i cui componenti sono direttamente i significati. In N-RDF, la tripla <soggettopredicato-valore > è descritta in termini di sensi prelevati dal centro dei significati. Le descrizioni N-RDF si prestano anche ad essere facilmente interrogate mediante SPARQL. In realtà, anche N-RDF impone una codifica, ma la codifica è relativa ad un vocabolario universale, su cui è presente un consenso più vasto, non un vocabolario di dominio, su cui è invece necessario un accordo preventivo in caso di mancata soddisfazione 94
111 di tutti gli attori in gioco. Inoltre, N-RDF mette a disposizione un meccanismo di istanziazione tramite il quale è possibile creare istanze di significati e definire proprietà [36]; ontologia per i domini: l ontologia contiene il concetti che permettono di descrivere i domini ed è modellata a parte dall ontologia SKOS (Simple Knowledge Organization System) [72]. SKOS è un area di lavoro che sviluppa specifiche e standard per supportare l uso dei sistemi di organizzazione della conoscenza (KOS) nel quadro del web semantico. Iniziatosi a sviluppare dal luglio del 2003 all interno del progetto SWAD-E (Semantic Web Advanced Development for Europe), esso intendeva definire un modello per thesaurus - un insieme di termini e di relazioni tra essi, che costituiscono il lessico specialistico da usare per descrivere il contenuto dei documenti pubblicati in un certo ambito disciplinare - compatibile con gli standard ISO più importanti. Il Meta-Modello di SKOS permette di definire concetti e conceptschemes. Un concetto è un oggetto atomico, un unità di pensiero che può in qualche modo essere descritto o definito, mentre un concept-schema è una collezione, un insieme di concetti. Come esempio di concetto possiamo prendere qualsiasi parola del vocabolario, mentre un concept-schema è il vocabolario inteso come lista di termini. Ogni concetto è identificato da una label che ci permette di accedere al concetto. Le relazioni tra concetti appartenenti allo stesso concept-schema sono definite come relazioni semantiche, mentre relazioni tra concetti appartenenti a conceptschema diversi sono definite come semantic mapping. 95
112 Figura 3.5: Il Meta-Modello SKOS SKOS è un framework molto utile ed interessante per collegare strumenti di indicizzazione semantica tradizionali, che sono un patrimonio di tecniche molto sofisticato e valido sviluppato nel corso di oltre un secolo di ricerche, con le recenti tecnologie telematiche ed in particolare il Web. Dunque, sul facsimile di SKOS, tratteremo un dominio come un ConceptScheme, ovvero come insieme costituito da concetti. Un Concept sarà un idea astratta o una nozione, un unità di pensiero. I concetti all interno di un dominio saranno collegati fra di loro tramite delle proprietà chiamate SemanticRelation. In realtà SemanticRelation è una superproprietà che ha tre specializzazioni: broader: punta verso un concetto più generico del concetto descritto (il concetto descritto è un child per il concetto); narrower: punta verso un concetto più specifico di quello descritto (il concetto descritto è un parent per il concetto); related: indica una generica relazione semantica a cui viene assegnato un nome. 96
113 Ogni concetto ha una label e un insieme di significati collegati presi dal centro dei significati, ognuno dei quali con un peso w appartenente a [0,1]. ontologia per i contesti: permette la costruzione di descrizioni del contesto di una risorsa informativa. Il linguaggio utilizzato è sempre N-RDF, che viene però strutturato secondo l ontologia. Una descrizione si compone di una parte dichiarativa e una parte descrittiva. La parte dichiarativa permette di definire le entità locali che saranno usate nel contesto e saranno attribuite ad esse delle proprietà. Ad esempio, se nella descrizione vogliamo fare riferimento ad una certa entità chiamata Napoleone, la definiamo tramite N-RDF come istanza del significato persona e ne elenchiamo le proprietà utili. La parte descrittiva permette invece di enunciare dei fatti tramite triple N-RDF. Queste fatti servono per inquadrare l informazione all interno di un contesto. L insieme delle parti dichiarativa e descrittiva costituisce il contesto informativo La Knowledge Base La rappresentazione della conoscenza è un insieme di convenzioni e formalismi per esprimere la conoscenza. Una buona rappresentazione della conoscenza può facilitare la soluzione di un problema riducendone la complessità. Il problema è generale e non nuovo ed è affrontato in vari settori, quali: linguaggi di programmazione, intelligenza artificiale, base di dati, ecc. [73] Tuttavia, non esiste una teoria sulla rappresentazione della conoscenza e un modello uniforme che la rappresenti. Le caratteristiche di un metodo di rappresentazione sono: a) potenza espressiva: capacità di esprimere in modo completo vari domini di conoscenza con differenti caratteristiche; b) facile comprensione della notazione; c) efficienza: capacità di strutturare la conoscenza in modo che ne venga facilitato e velocizzato l utilizzo e l accesso durante la risoluzione del problema evitando ridondanze; d) flessibilità, modificabilità, estensibilità: che costituiscono caratteristiche essenziali per una base di conoscenza. 97
114 I metodi per la rappresentazione della conoscenza sono: logica dei predicati: semanticamente ben definita, altamente dichiarativa, apparato deduttivo assolutamente generale. La base della conoscenza è costituita da una collezione di asserzioni della logica dei predicati del primo ordine; le regole di inferenza permettono di dedurre nuove asserzioni (teoremi) non esplicitamente contenute nella base di conoscenza iniziale. Frames e reti semantiche: metodi di rappresentazione ad oggetti, ampiamente influenzati dalla logica dei predicati. Nell articolo [74], viene mostrato il ruolo dei metadati e le caratteristiche fondamentali di RDF visti come strumenti vitali per la rappresentazione della conoscenza in maniera comprensibile alla macchina e per porre le basi al Semantic Web. Nella nostra macchina semantica, la Knowledge Base contiene la conoscenza codificata rispetto alle ontologie viste in precedenza. Essa è suddivisa in: repository di risorse informative: contiene le risorse informatiche che la macchina può condividere con il mondo esterno; entità riconosciute: istanze dei significati del centro dei significati che vengono utilizzate nella parte descrittiva del contesto informativo. Tale componente mette a disposizione delle primitive in grado di leggere le proprietà di un entità, esaminare le relazioni semantiche, aggiungere o cancellare entità, cercare entità, determinare se esiste una relazione semantica fra due o più entità; contesti: vengono memorizzati all interno della KB. Essi vengono usati come supporto in tutte le operazioni che coinvolgono l interpretazione delle informazioni; domini: rappresentano le concettualizzazioni di specifici settori della conoscenza della macchina. Tale componente mette a disposizione delle primitive per la navigazione concettuale di un dominio e la gestione dell evoluzione delle conoscenze ivi 98
115 contenute; contenitori informativi: rappresentano informazioni che il sistema possiede. Ogni contenitore informativo contiene la descrizione del tipo di informazione e l insieme dei segni che la compongono Modello di comunicazione della macchina semantica In questo paragrafo si intende elaborare un modello di comunicazione che preservi la semantica, partendo dai seguenti presupposti: l informazione deve essere strutturata in segni, segno (come abbiamo visto) inteso come una coppia (s, m), dove s appartiene ad un insieme di significanti S ed m ad un insieme di significati M; il modello di trasmissione adottato è quello di Shannon-Weaver : l insieme dei significanti S viene codificato in un insieme di simboli e i simboli vengono trasmessi lungo il canale. In ricezione, il destinatario riceve i simboli e applica un processo di decodifica per risalire dall insieme dei simboli all insieme dei significati. La sorgente codifica solo il significante (e non i significati). Figura 3.6: Modello di comunicazione della macchina semantica Per recuperare il significato, e quindi ricostruire la corrispondenza (s, m) abbiamo deciso di adottare per la trasmissione semantica il modello 99
116 semiotico-informazionale di Eco, in cui il compito di ricostruire la coppia è affidato al destinatario dotato di capacità ermeneutiche, in grado cioè di interpretare il senso prodotto dal mittente a partire dai significati riconosciuti e dal contesto della comunicazione. Partendo da questi presupposti, il modello di comunicazione adottato, che si può inquadrare all interno dei moduli metasemiotici proposti da Nauta. Qui i soggetti coinvolti sono due: 1. macchina semantica, che funge da destinatario della comunicazione; 2. risorsa informativa, che funge da mittente. In realtà, i ruoli potrebbero interscambiarsi, ma la risorsa è vista come un entità attiva nel processo di comunicazione, che avvia di sua iniziativa la trasmissione. La trasmissione si articola in due fasi: 1. la fase di decisione : consiste nel determinare per ogni significante s il significato m inteso dal mittente (significazione); 2. la fase di interpretazione : consiste nel collegare l informazione appena decodificata alla conoscenza del sistema (vi è informazione quando vi è aumento della conoscenza [MacKay]). Approfondiamo teoricamente le due fasi, partendo da quella di decisione. La fase di decisione si basa sull assunzione che i significanti trasmessi raramente sono tra di loro indipendenti e quindi, studiando tutte le possibili relazioni semantiche fra i significanti, è possibile risalire al significato originario. Mostriamo di seguito un algoritmo proposto come soluzione del problema di Natural Language Processing, noto come Word Sense Disambiguation, che consiste nel determinare per ogni parola di un testo il suo significato più probabile tramite l ontologia [75] (nel nostro caso l ontologia potrebbe essere fornita da Wordnet o altre come vedremo). Tale algoritmo è noto come Maximum Relatedness Disambiguation (MRD): 100
117 foreach meaning mti of target signifier st { set scorei = 0 foreach signifier sj in context_window { skip to next_signifier if j==t foreach meaning mjk of sj { temp_score[j] = relatedness(mti,mjk) } winning_score = maximum (temp_score[]) if (winning_score > threshold) then scorei += winning_score } } select mti that scorei is the maximum of score[] Questo algoritmo lavora su una context-window, ovvero una finestra che contiene n significati e si sposta sull insieme dei significati man mano che l algoritmo procede. La sua dimensione dipende dall informazione che si sta trattando (nel caso di informazioni testuali, la lunghezza media potrebbe essere quella di una frase). La funzione relatedness è una funzione di similarità semantica che dati due sensi restituisce un valore reale che ne indica la similarità. Esistono diverse metriche in letteratura per misurare la similarità semantica e si rimanda alle due pubblicazioni [76] e [77] per approfondimenti sugli algoritmi di WSD, su quello di MRD e sulle misure di relatedness e similarity. Tutte le misure lavorano su ontologie che descrivono il dominio cui appartiene la coppia di sensi e sono indipendenti dal significante. 101
118 La risorsa informativa partecipa attivamente al processo di decisione del mittente, in due modi: 1. tramite l invio del contesto informativo le cui informazioni possono essere utilizzate per guidare il processo di disambiguazione; 2. la risorsa informativa può rispondere a queries nelle quali il destinatario chiede esplicitamente qual è il significato di un certo significante. La fase di interpretazione, che avviene a valle della decisione, consiste a sua volte di due fasi: la prima fase è quella del collegamento dell informazione ad un certo dominio (determinazione dell intorno cognitivo) e consiste nel modificare i domini contenuti nella knowledge base in maniera tale da rappresentare anche il dominio informativo della risorsa appena acquisita. Per intorno cognitivo si intende l insieme dei concetti che riguardano una determinata informazione. Affinché la determinazione sia valida, è necessario che la risorsa informativa e la macchina semantica siano allineate, ovvero abbiano la stessa visione dell intorno cognitivo. Tuttavia, non ci dilunghiamo su tali concetti, ai quali si può far riferimento al lavoro di Caropreso. Ci interessa solo sapere che la fase di determinazione è condotta da un protocollo di negoziazione, rappresentato tramite degli automi a stati finiti ([36], p. 106). Una volta che le macchine sono allineate, è necessario procedere alla determinazione dell intorno materiale, tramite l invio da parte del mittente del contesto informatico della risorsa. Questo invio viene evitato se nella fase di decodifica la macchina ha già inviato il contesto. Il destinatario effettua un processo di riconoscimento delle entità contenute all interno della descrizione del contesto. Se le entità non vengono riconosciute, allora esse vengono aggiunte alla conoscenza del sistema. Nel caso in cui la descrizione del contesto rimandi ad entità non dichiarate nella parte dichiarativa del contesto informativo il destinatario può richiedere al mittente di inviare le informazioni mancanti. Una volta terminate le due determinazioni degli intorni cognitivi e materiali l informazione è stata interpretata. Il mittente invia tutte le componenti dell informazione e il destinatario le aggiunge alla knowledge base. Ogniqualvolta una componente viene aggiunta, essa viene legata alla porzione di dati che secondo l ontologia presenta la massima similarità semantica. 102
119 3.12 Verso il prototipo di macchina semantica In questo capitolo abbiamo introdotto i modelli e le tecnologie utilizzate per la successiva progettazione ed implementazione della nostra macchina semantica. Nel capitolo successivo utilizzeremo questi concetti per realizzare e sperimentare il nostro prototipo di macchina semantica. L applicazione, seppur qui indipendente dal dominio applicativo, verrà calata all interno di un caso pratico: quello del retrieval semantico dei learning objects e della generazione automatica dei corsi, obiettivi di questa tesi. Da notare che i campi applicativi della macchina semantica possono essere i più disparati, essendo le problematiche e le soluzioni provenienti dal Semantic Web, che tuttavia si pone ancora lontano da una possibile implementazione reale. 103
120 104
121 Capitolo 4 - progettazione ed implementazione In questo capitolo si entra nel merito della progettazione del sistema Semantica e della implementazione, sfruttando i requisiti, le tecnologie, i modelli e le basi teoriche introdotte nei capitoli precedenti. Il mio apporto personale al presente lavoro, iniziato splendidamente da Mario Caropreso, è stato quello di aver ultimato l implementazione del sistema e di costruire il web server per la successiva sperimentazione. Dunque, verrà prima introdotto il lavoro di progettazione, entrando nei dettagli delle funzionalità dei moduli del sistema, delle scelte progettuali e dei criteri utilizzati, tutti giustificabili dalle fondamenta teoriche da cui siamo partiti. Come già anticipato, siamo passati dall applicazione dell approccio teorico ad un caso pratico, che è quello dei retrieval semantico di learning object e della generazione automatica di corsi didattici. La descrizione dei moduli verrà correlata da diagrammi e schemi di progettazione, utili per capire l interazione e la struttura dell intero progetto. Il punto di partenza è stato quello di introdurre un modello teorico di macchina semantica, come visto nel capitolo precedente, in grado di risolvere il problema della perdita di significato durante la trasmissione di informazioni senza presentare i problemi di flessibilità e interoperabilità degli approcci classici basati su ontologie. 105
122 L approccio proposto vuole essere una giustificazione della validità epistemologica e metodologica dell approccio che utilizza le ontologie di dominio. Come tale, esso può essere applicato a qualunque dominio in cui sia richiesta una gestione dell informazione e della conoscenza. 4.1 Architettura logica di Semantica Si propone l architettura di alto livello del sistema Semantica per il retrieval semantico di learning objects, basato sul modello di macchina semantica descritto nel capitolo precedente. Descriviamo nei dettagli ogni singolo componente della struttura per capire come funziona e come vengono implementati i modelli finora trattati. Figura 4.1: Architettura logica della macchina semantica 106
123 Il sistema tratta come risorse informative i learning objects (LOs) e li memorizza all interno del componente denominato Learning Object Repository (LOR). Il Discovery si occupa di prelevare i LOs dal repository e di analizzare le risorse, al fine di estrarre da essi un complesso di informazioni che costituiscono la conoscenza racchiusa all interno del learning object. Il sistema divide le istanze (dati) dal modello concettuale, racchiudendo i primi nella Knowledge Base e i secondi nelle ontologie (definendo gli schemi per la base di conoscenza). La conoscenza del sistema è memorizzata, quindi, all interno di una Semantic Knowledge Management System (KMS), grazie al quale il Discovery può memorizzare nella base di conoscenza le informazioni estratte. Il KMS esegue una operazione di indexing sulle informazioni ricevute, in maniera tale da consentire la ricerca alle applicazioni richiedenti. La semantica dei dati contenuti nella knowledge base viene formalizzata dall Ontology Management System (OMS), che contiene i modelli delle ontologie gestite dal sistema. Il Web Server contiene le due applicazioni, ovvero quella di ricerca semantica e quella di generazione automatica dei corsi. Nei paragrafi successivi vengono approfonditi nei dettagli i diversi componenti del sistema Learning Object Repository Il LOR contiene i learning objects di Semantica. Questo componente ignora il formato originario dei LOs e il modo in cui vengono caricati nel repository, per cui è possibile prelevare gli oggetti da qualunque sorgente e poi inserirli nel sistema, riconducendoli al formato previsto da Semantica. Sulle orme del modello SCAM (Simple Content Aggregation Model) [78], il quale fornisce un framework per la semplificazione dello storage e dell accesso ai 107
124 metadati per differenti applicazioni - dividendoli in due insiemi di diversa granularità (SCAM records e SCAM contexts) -, un learning object, in Semantica, deve possedere una certa struttura per poter essere trattato: Figura 4.2: Struttura di un learning object in Semantica I learning objects vengono rappresentati in due modi dal sistema: 1. learning object come insieme di documenti (modalità non strutturata); 2. learning object come insieme di content unit (modalità strutturata). Infatti, l insieme dei documenti che costituiscono un learning object ne definiscono il suo contenuto testuale, sul quale verranno effettuate le elaborazioni che vedremo. Il Document è dunque un unità testuale contenuta all interno di una risorsa didattica, che deve avere qualche attinenza con gli altri documenti dello stesso LO, altrimenti l algoritrmo di retrieval ha pessime prestazioni. La collezione di documenti può essere non ordinata, in quanto ciò è irrilevante per il sistema, che è interessato al contenuto informativo di una risorsa didattica e non all ordine. SemanticTable e ContextKeySense. Il modello SCAM dà anche la possibilità di associare al learning object una Semantic Table (tavola semantica) e una serie di Context KeySense (sensi chiave del contesto). Una tavola semantica è un insieme di coppie (T, S), dove T è un termine 108
125 appartenente al learning object ed S è un senso appartenente al dizionario. Una tavola semantica permette di conoscere preventivamente il significato con cui un determinato termine viene utilizzato all interno del learning object, permettendo di risolvere, senza applicare alcun algoritmo, le situazioni di ambiguità che possono nascere per il fatto che alcuni termini possono avere più di un significato. Nel caso in cui un termine compaia con la stessa forma ma con sensi diversi, la tavola semantica permette di indicare esplicitamente quante volte il termine si presenta con un senso e quante volte con un altro. L utente può associare ad un learning object una serie di sensi chiave, allo stesso modo di come al giorno d oggi si assegnano ad una pagina web delle parolechiave. I sensi-chiave vengono utilizzati nel processo di disambiguazione di un testo. L idea è quella di fare in modo che i sensi-chiave diano un idea del contesto dei termini utilizzati nel learning object, in maniera tale da consentire la giusta interpretazione dei termini del documento. La seconda modalità di rappresentazione di un learning object, lo vede come un insieme di unità di contenuto più piccole, le content units. In questo modo si dà una struttura al learning object, sfruttando la scomposizione informatica di una informazione come previsto dal modello di macchina semantica. Un unità di contenuto è una porzione di testo di un learning object in grado di esprimere un determinato concetto di apprendimento. Da notare che le due modalità non sono esclusive e possono essere utilizzate contemporaneamente. Esse costituiscono due viste di un learning object: una vista strutturata, in quanto rappresenta il learning object come collezione di unità di contenuto; una vista non strutturata, in cui il learning object è una semplice collezione di documenti. Indipendentemente dalla vista usata, ad ogni risorsa è possibile associare delle Binding Annotations, una sorta di metadato semantico (ovvero scritto secondo una ontologia formale). Una binding annotation permette di legare un learning object ad uno o più concetti presenti all interno delle ontologie di dominio che fanno parte del sistema, sfruttando quindi il dominio informativo di una informazione. 109
126 Le applicazioni possono rivolgersi al Learning Object Repository per ottenere i learning objects non ancora analizzati e possono decidere di prelevare tutto il learning object o soltanto una particolare vista Il modulo Discovery Il modulo Discovery ha il compito di analizzare i learning objects ed estrarvi conoscenza da immagazzinare all interno della knowledge base. Discovery si compone di diversi moduli, ognuno atto ad tirar fuori un particolare tipo di informazione. Figura 4.3: Il modulo Discovery Il modulo TextProcessing opera sulla vista non strutturata e ha il compito di analizzare i documenti contenuti all interno di un learning object e sottoporli ad una serie di passi di elaborazione, al fine di ottenere una rappresentazione dell oggetto sotto forma di vettore di significati. Per ogni learning object il modulo fornisce in output un vettore di triple detto vettore dei significati. Ogni tripla contiene un termine del documento, il significato prelevato dal dizionario e la frequenza della coppia termine-significato all interno del documento. Il modulo ContentUnitExtraction opera sulla vista strutturata di un learning object e ha il compito di esaminare le content units che compongono la risorsa didattica. Per ogni content unit trovata, il modulo crea un istanza memorizzabile all interno della knowledge base. Il modulo OntologyBindingResolver analizza le binding associations di un 110
127 learning object per determinare i concetti delle ontologie di dominio a cui esso si riferisce. Per ogni binding association il modulo genera un istruzione di collegamento il cui scopo è quello di permettere alla knowledge base di associare il learning object alla corretta ontologia. Una volta che l output dei tre moduli di Discovery è stato elaborato, il componente accede al Knowledge Management System per memorizzare le informazioni elaborate Semantic Knowledge Base (SKB) Figura 4.4: Il modulo Semantic Knowledge Base Qui vengono memorizzate tutte le informazioni che il sistema utilizza. Anche esso è strutturato in sottomoduli, ognuno dei quali memorizza un tipo di informazione. Il dizionario può essere definito come un ontologia superiore linguistica e contiene tutti i termini di una determinata lingua. Per ogni termine esso fornisce i suoi possibili significati e definisce le relazioni semantiche fra i termini (le più importanti delle quali sono la sinonimia, iperonimia/iponimia, metonimia/omonimia). Nell implementazione attuale del sistema, il dizionario utilizzato è WordNet [67] per la lingua inglese, visto come estensione linguistica del centro dei significati della macchina semantica. 111
128 Il lexicon tiene traccia di tutti i termini conosciuti dal sistema. Ogniqualvolta il sistema incontra un nuovo termine, esso cerca di ricondurlo ad uno memorizzato nel lexicon e gli assegna un identificativo univoco. Il lexicon tiene traccia sia dei termini che sono presenti nel dizionario sia di quelli non presenti (come ad esempio nomi di località, di persone). Il term inverted index è la struttura dati scelta per la memorizzazione dei termini contenuti nei documenti. Tale struttura dati prevede che per ogni termine conosciuto dal sistema (e quindi presente nel lexicon) sia presente una lista, detta posting list, che contiene gli identificativi dei learning objects in cui quel termine viene utilizzato e la relativa frequenza. Il semantic tuple space è il componente che permette la memorizzazione delle unità di contenuto di cui si compone un learning object. Tale componente è realizzato utilizzando il modello dello spazio delle tuple introdotto negli anni 80 dal sistema Linda. L STS rappresenta l astrazione di uno spazio di memoria virtuale condiviso in cui le applicazioni possono scambiarsi dati tramite primitive di scrittura, lettura e rimozione. I dati che vengono scambiati sono detti tuple. Una tupla corrisponde ad un unità di contenuto. Il modello è detto semantico perché le tuple che possono essere scambiate sono descritte da un apposita ontologia del sistema, detta CuOnto. Questo comporta due implicazioni. La prima è che ogni tupla ha un significato, un ruolo, all interno dello spazio; la seconda è che lo spazio di memoria virtualizzato dall STS è uno spazio strutturato, in quanto le tuple sono in relazione fra di loro. Tali relazioni sono sempre descritte dall ontologia. Il domain repository contiene le descrizioni dei domini del sistema. Un dominio rappresenta una conoscenza di un certo ambito, rappresentata sotto forma di insieme di concetti legati fra di loro. Il binding repository è un componente il cui compito è quello di tenere traccia delle associazioni fra i learning objects e i concetti contenuti all interno del domain repository. 112
129 4.1.4 Knowledge Management System Figura 4.5: Il modulo Knowledge Management System Il Knowledge Management System è il componente software che gestisce la knowledge base semantica del sistema. Il compito di questo componente è quello di fornire delle astrazioni dei diversi repository di conoscenza del sistema, offrendo alle applicazioni dei metodi per l aggiunta di nuova conoscenza, la navigazione all interno delle fonti di conoscenza e il recupero di informazioni tramite query. Il knowledge indexer è il componente che ha la responsabilità di ricevere le informazioni dal modulo Discovery e prepararle per la memorizzazione all interno della knowledge base. Il tuple manager mette a disposizione le primitive per scrivere, leggere, rimuovere tuple dallo spazio delle tuple ed eseguire ricerche. Il term search permette di eseguire ricerche sull inverted index che coinvolgono uno o più termini. Il dictionary browser, il lexicon access e il domain explorer sono dei wrapper per il dizionario, il lexicon e il domain repository. 113
130 Il domain evolution permette l aggiornamento dei domini del sistema. Il retrieval model è un componente che permette al sistema di implementare diverse modalità di retrieval dei dati contenuti all interno della knowledge base Ontology Management System Figura 4.6: Il modulo Ontology Management System Il model holder permettere di caricare in memoria un modello di ontologia per eseguire delle operazioni. Il componente utilizza un formato interno per la rappresentazione delle ontologie basato su una struttura a grafo. Ciò permette il caricamento di ontologie scritte in formati differenti - e non necessariamente in OWL - separando l OMS dalle modalità con cui le ontologie sono rappresentate. Il DB Reader permette di leggere un ontologia da un insieme di tabelle in un database relazionale. La memorizzazione di un ontologia all interno di un database comporta notevoli vantaggi. Infatti il sistema non ha la necessità di copiare il contenuto dell ontologia (che può contenere una mole notevole di dati) nella memoria principale, ma può lasciarli nel database relazionale e creare una vista ontologica dei dati, creando una sorta di ontologia virtuale. L ontologia è virtuale nel senso che non è materializzata, ma ogniqualvolta il sistema necessita di un certo concetto accede direttamente al database. Questo modulo è realizzato utilizzando le funzionalità del framework KAON 2 [79]. 114
131 L Ontology Explorer consente la navigazione all interno dei concetti e delle relazioni presenti all interno di un ontologia, permettendone la visualizzazione. L Ontology Query Service è un componente in grado di eseguire delle interrogazioni sull ontologia e fornire al richiedente i concetti che rispondono alla query. Le queries sono formulate in SPARQL [34] Le ontologie del sistema Figura 4.7: Le ontologie del sistema Semantica Nel capitolo 2, abbiamo già introdotto due ontologie utilizzate dalla macchina semantica, ovvero la Cuonto e la Domonto. Queste ontologie forniscono la semantica dei dati contenuti all interno della Knowledge Base. Quindi, le ontologie in possesso del sistema sono: un sottoinsieme dell ontologia dell informazione la cui radice è la definizione di unità di contenuto, denominata Cuonto; l ontologia di dominio Domonto; una serie di ontologie specifiche dell applicazione denominate Pedagogical Strategies. 115
132 Figura 4.8: Una ontologia del sistema Semantica: CuONTO L ontologia Cuonto è una task ontology che descrive la semantica delle content units che compongono un learning object. Come è possibile vedere nel capitolo 2, l ontologia individua diverse classi che hanno una radice in comune denominata ContentUnit, distinguendo poi le unità di contenuto in due macrocategorie: Fundamental e Auxiliary. Essa è modellata a partire dall ontologia pedagogica di Ullrich, a cui si rimanda per ulteriori informazioni sulle classi [80]. L ontologia definisce proprietà in grado di identificare, annotare e collegare tra di loro le content units. In particolare, le proprietà hastext ed hastitle permettono di collegare una content unit ad un testo effettivo e di darle un titolo. Inoltre, hasdocument indica l identificativo del documento a cui la content unit fa riferimento. Altre proprietà indicano il contesto in cui operano le content units (come hasfield, haslearningcontext, ecc.), tenendo traccia del ruolo pedagogico 116
133 svolto dalla content unit. La struttura viene definita dalle proprietà isfor e inversefor (per collegare oggetti di tipo Auxiliary a quelli di tipo Fundamental) e isa e inverseisa (per definire gerarchie IS-A). La propedeuticità tra content units può essere definita grazie alle proprietà isrequiredby / requires. Non approfondiamo ulteriormente l ontologia Domonto poiché già se ne è parlato nel Capitolo 3 a proposito dell ontologia SKOS. Rimandiamo ad un riferimento utile che parla dell'ontologia Alocom, che mira a creare un architettura per il riutilizzo dei learning objects in maniera flessibile, per permettere il riutilizzo degli stessi, anche con un approccio a grana fine [81]. Il sistema può gestire diversi approcci per la generazione dinamica di corsi di apprendimento, utilizzando il materiale presente all interno della Knowledge Base. Per questo scopo si serve di una strategia pedagogica. Una strategia pedagogica è un insieme di regole che stabiliscono come scegliere le content units per comporre un corso. Vedremo meglio in seguito come si applica tale strategia per la generazione automatica dei corsi. 4.2 Preprocessing del testo Prima di descrivere i dettagli sul funzionamento del modulo Discovery, responsabile di prelevare i contenuti dal repository ed estrarre da essi conoscenza (Discovery sta appunto per Scopritore di conoscenza), vogliamo introdurre un argomento su cui esiste molta letteratura: il preprocessing testuale dei contenuti informativi ([16] [82]). Questa fase è fondamentale e presente in tutte le architetture dei moderni sistemi di information retrieval: 117

134 Figura 4.9: Architettura di un sistema di Informational Retrieval Il preprocessing consiste in un processo, che precede la fase di elaborazione delle queries, per ottimizzare la lista dei termini, che identificano una collezione. Questa ottimizzazione può essere ottenuta eliminando quei termini che sono poveri di informazioni. Durante questa fase possono essere eseguite tutte o parte delle seguenti operazioni sul testo: - analisi lessicale del testo: è il processo di convertire la serie di caratteri formanti il testo del documento in una serie di parole candidate per essere termini indice. Così, uno dei maggior obiettivi della fase dell'analisi lessicale e l'identificazione delle parole nel testo. Questo avviene attraverso il trattamento della punteggiatura, delle cifre e delle lettere maiuscole e minuscole; - eliminazione delle stopwords: ha come obiettivo la selezione delle parole, attraverso la rimozione di quelle considerate inutili per il recupero. Di solito le parole candidate ad essere Stopwords sono gli articoli, le preposizioni e le congiunzioni. Un vantaggio dell'eliminazione delle Stopwords è la riduzione della dimensione della struttura di indicizzazione. Stopwords può essere estesa includendo, oltre agli articoli, alle preposizioni e congiunzioni, anche alcuni verbi, avverbi ed aggettivi di uso frequente, anche se questo potrebbe ridurre il Recall. 118
135 Per esempio, pensiamo ad un utente che voglia cercare i documenti contenenti la frase to be or not to be : l'eliminazione delle Stopwords porta a considerare solo il termine be, rendendo quasi impossibile il riconoscimento dei documenti che contengono la frase esatta. Questo è uno dei motivi per cui alcuni motori di ricerca preferiscono inserire tutte le parole del documento come termine indice; - stemming delle parole rimanenti: al fine di considerare parole che hanno varianti morfologiche diverse come una unica parola, ma con simile interpretazione semantica, è utile l'operazione di stemming. Questa sostituisce ad una parola il suo rispettivo stem. Uno stem è la porzione di parola ottenuta rimuovendo prefissi e suffissi. Un esempio tipico è la parola connect che è lo stem per le sue varianti connected, connecting, connection e connections. Lo stemming è utile per migliorare la performance di un sistema di Information Retrieval, in quanto riduce le varianti di una stessa parola-radice ad un concetto comune. Inoltre, questa operazione presenta il vantaggio di ridurre il numero dei termini indici che identificano una collezione, con la conseguente riduzione della dimensione della struttura di indicizzazione. Nonostante questi vantaggi, in Information Retrieval ci sono state delle dispute riguardo ai benefici dello stemming sulle performance del recupero; risultati di diversi studi hanno portato conclusioni contrastanti sull'uso dello stemming [83], anche se attualmente sembra essere quello che dia i risultati migliori; - selezione dei termini indice: dato un insieme di termini per un documento, non tutti i termini sono ugualmente utili per descrivere il contenuto del documento. Infatti, vi sono dei termini che possono meno rappresentativi di altri. Decidere sull'importanza di un termine per riassumere il contenuto di un documento non è un problema banale. Una tecnica molto semplice consiste nel selezionare le parole più frequenti all'interno del documento, anche se il contrario, ovvero che le parole meno frequenti siano meno importanti, non è sempre vero: infatti, una parola fondamentale per il contenuto del documento potrebbe comparire esclusivamente nel titolo e non essere più ripetuta all'interno del documento. 119
136 Lemmatizzazione e lemmatizzazione semantica Il processo di lemmatizzazione consiste nel ricondurre una parola in una forma flessa o coniugata nel lemma corrispondente: il lemma è una forma canonica della parola, che può essere trovata in un dizionario. I lemmi corrispondenti ai nomi hanno la forma singolare (ad esempio, il lemma di sedie è sedia), quelli corrispondenti agli aggettivi hanno la forma singolare maschile (ad esempio, il lemma di belle è bello), e quelli corrispondenti ai verbi hanno la forma dell'infinito del verbo (ad esempio, il lemma di mangio è mangiare). Se il dizionario utilizzato contiene anche informazioni semantiche (come l'ontologia WordNet descritta nel capitolo precedente), è possibile passare dal lemma ad una rappresentazione semantica, che in WordNet viene chiamata Synset. Il passaggio dal lemma alla semantica non è semplice, per via del problema della polisemia. Per esempio la parola calcio può avere più significati: lo sport, l'elemento chimico, la parte di un'arma o un'azione compiuta calciando. L'unico modo per consentire a ciascuna parola un unico significato consiste nell'effettuare la disambiguazione semantica, come abbiamo visto (word sense disambiguation). 4.3 Indexing dei Learning Objects Per indicizzazione (indexing) si intende l attività di individuazione di keywords. Esistono diverse tecniche di indexing, tra cui la inverted file, suffix array e signature files. Nel nostro progetto abbiamo utilizzato soltanto la tecnica inverted file, la più diffusa e utilizzate nell ambito dell IR. Per le altre tecniche si rimanda a [84]. Un inverted file o inverted index è un meccanismo orientato alle parole per indicizzare una collezione di testo con lo scopo di velocizzare l operazione di ricerca. La struttura dell'inverted file è composta da due elementi: il vocabolario e le occorrenze. Il vocabolario è l insieme di tutte le parole nel testo e per ognuna di queste viene conservata una lista di tutte le posizioni nel testo dove essa compare. L insieme di tutte queste liste viene chiamato occorrenze. 120
137 Le posizioni possono far riferimento a caratteri o a parole. Le posizioni relative alle parole semplificano le queries, mentre quelle relative ai caratteri facilitano l accesso diretto alle posizioni corrispondenti nel testo. Figura 4.10: Esempio di inverted index Introdotti i precedenti concetti, elaborazione testuale e inverted file, entriamo ora nei dettagli del funzionamento del modulo Discovery, il quale, come già detto, è responsabile del prelievo dei contenuti dal repository e dell estrazione della conoscenza. Le informazioni raccolte dal modulo sono rappresentate da tre vettori: 1 vettore dei significati; 2 vettore delle content units; 3 vettore delle binding annotations Vettore dei significati Figura 4.11: Il vettore dei significati Questo vettore è costituito da tre elementi: termine del learning object; significato di termine prelevato dal dizionario; frequenza della coppia termine-significato all interno del learning object. 121
138 Ricordando la struttura del Discovery, il componente TextProcessing è il responsabile dell estrazione dei vettori di significati dai learning objects. Il linguistic preprocessing, condotto in questo componente, ha lo scopo di creare classi di equivalenza fra i termini del documento per ricondurli ai termini del dizionario. Nel seguente diagramma viene riportata la sequenza delle attività di tale componente: Figura 4.12: TextProcessing Operations 122
139 (Fase 1) Tokenization: trasforma il documento testuale in una collezione di termini, detti token, individuandoli grazie agli spazi e ai segni di punteggiatura. (Fase 2) Stop Word Removal: dal vettore dei token ottenuto vengono eliminati tutti i token corrispondenti a parole contenute all interno di una lista di parole da rimuovere (stopword list). (Fase 3) Lemmatization: l approccio da noi utilizzato prevede di utilizzare la lemmatization tramite WordNet (in luogo dello stemming) per riportare ciascun termine alla sua forma non flessa. WordNet implementa una strategia mista per la ricerca dei termini, ovvero applica un algoritmo di stemming che va avanti finché non viene trovata una forma presente nel database. Il vettore dei termini viene così ampliato aggiungendo per ogni termine la sua index word, che è una parola che rappresenta una entry all interno del database lessicale WordNet e che rappresenta una forma non flessa presente nel dizionario che può essere associata ad uno o più termini presenti all interno del documento. Nel caso in cui una parola del documento non sia riconducile a nessuna index word presente all interno del dizionario, essa non sarà associata a nessun termine indice. (Fase 4) Lexicon Binding: consiste nel legare le coppie termini-index al lessico contenuto nella Knowledge Base. Se una parola non è contenuta nel lexicon allora essa viene aggiunta e viene creato un nuovo identificativo. (Fase 5) Part-of-Speech Tagging: bisogna effettuare un analisi morfo-sintattica del documento: ogni parola può, infatti, avere un significato diverso a seconda del fatto di essere usata come aggettivo, nome, avverbio o verbo. Il problema di etichettatura delle parti del discorso è visto come un problema di classificazione su cui esiste numerosa letteratura ed è il più studiato nel campo del Natural Language Processing [85]. Per realizzare questa fase, ci siamo serviti di un algoritmo sviluppato dallo Stanford NLP Group denominato Log-linear Part-of-Speech Tagger [86]. Determinata, quindi, l etichetta POS per ogni termine del vettore dei termini, siamo in grado di accedere a WordNet per ottenere, per ciascun termine, i significati che esso ha nel lessico. 123
140 (Fase 6) Semantic Table Association: sorge così il problema che molti termini non hanno un significato univoco, ma presentano una pluralità di sensi. Inoltre, la sostituzione di un termine con il suo significato può comportare una perdita di informazione e un aggiunta di rumore alla rappresentazione, motivo per cui è importante scegliere il senso di un termine. Dunque, l approccio usato è quello di applicare al vettore che si intende costruire la tavola semantica del learning object. I termini che non sono presenti nella tavola semantica saranno quelli che verranno sottoposti al processo di disambiguazione, che costituisce la fase seguente. (Fase 7) Word Sense Disambiguation: come già anticipato, abbiamo adottato un algoritmo di disambiguazione basato sul contesto, ovvero individuare il senso di un termine considerando anche i sensi dei termini vicini che forniscono il contesto in cui un senso viene usato. L algoritmo è quello di cui abbiamo parlato nel capitolo precedente, ovvero il Maximum Relatedness Disambiguation previsto dal modello di macchina semantica [77]. Tale algoritmo considera per ogni termine tutti i suoi possibili sensi e per ciascuno di essi calcola la similarità semantica fra il senso in questione e ognuno dei sensi delle parole vicine alla parola in esame. Le parole i cui sensi vengono considerati sono tutte quelle contenute all interno di una finestra di dimensione n detta context-window. Alla context-windows vengono aggiunti anche i context-keysense del learning object, se presenti. Al termine del processo viene selezionato il senso che riporta la massima similarità semantica con i sensi delle parole vicine. La funzione di similarità semantica adottata è quella di Wu-Palmer [76], la quale individua il least common ancestor dei due concetti (LCA), ovvero il più specifico significato che i due significati condividono come antenato. La lunghezza del percorso dalla radice all LCA viene scalato dalla somma delle profondità dei due concetti, secondo la formula: simil s, t = 2 depth lca depth s depth t Una volta che per ogni termine è stato individuato il senso corrispondente, alle index words presenti nel vettore si sostituiscono i relativi sensi. Il processo di WSD non è completamente automatico, proprio perché l utente può guidare il processo 124
141 di disambiguazione di un learning object utilizzando i due strumenti visti in precedenza: tavola semantica e ContextKeySense. (Fase 8-9) Sense Vector Representation e Scoring: una volta elaborato il vettore dei sensi di un documento si passa ad ottenere un nuovo vettore ottenuto aggregando i significati identici ed assegnando ad ogni significato la sua frequenza all interno del documento a cui appartiene. Tale frequenza viene denominata Sense Document Frequency (SDF). Una volta che il sistema ha elaborato i vettori dei sensi per ogni singolo documento, passa alla fusione di tali vettori secondo un meccanismo di aggregazione dei sensi uguali, ottenendo il vettore dei sensi per il learning object. Tale vettore dei sensi riporta per ogni significato la sua frequenza aggregata, detta sense aggregate document frequency (SADF), che è uguale alla somma delle frequenze con cui il significato compare nei singoli documenti. Inoltre, il sistema associa ad ogni significato la sua densità all interno della risorsa didattica. La densità di un significato (sense density) è uguale alla sua SADF diviso il numero totale di sensi contenuti nel learning object, scalata per l inverso del numero di documenti che compongono il learning object: sensed s = SADF s S D dove S è il numero di sensi contenuti in un learning object e D è il numero di documenti contenuti all interno di un learning object. Il vettore risultante conterrà quindi per ogni entry senso, learning object, documento, sadf, sensed. Figura 4.13: Vettore risultante del TextProcessing 125
142 4.3.2 Vettore delle Content Units Il compito di estrarre da un learning object le sue content units è del componente denominato Content Unit Extraction. Le unità di contenuto permettono di definire la struttura e il significato di un documento, ma la loro definizione richiede un approccio semiautomatico. Figura 4.14: Vettore delle content units L approccio semiautomatico che utilizziamo è quello dell'annotazione semantica, che non è altro che una nota formale aggiunta ad una specifica parte del testo. Annotare semanticamente una risorsa è, come abbiamo visto, il processo di collegamento delle entità presenti nel testo alla loro descrizione semantica. Ogni learning object del nostro sistema viene quindi accompagnato da un insieme di triple RDF che ne costituiscono l annotazione. Il componente preleva il file RDF delle annotazioni e le elabora. Per ogni istanza di un concetto il sistema crea una corrispondente unità di contenuto e la inserisce all interno del vettore delle unità di contenuto. Per quanto riguarda le proprietà delle istanze che contengono testo (come la descrizione o il titolo), l approccio è di trasformare tali campi testuali in vettori dei significati. Questo vettore viene quindi memorizzato in una tabella che riporta l identificativo del termine, l identificativo del significato (se c è) e l identificativo dell unità di contenuto in cui compare Vettore delle binding annotations Un learning object può contenere delle indicazioni che servono a collegarlo ad una o più ontologie di dominio. Come abbiamo visto, queste indicazioni vengono dette Binding Annotations. Ogni binding annotation (BA) contiene il nome dell ontologia di dominio e il nome del concetto contenuto. Quando il sistema trova che per un learning object sono presenti delle Binding Annotation invoca il 126
143 componente Ontology Binding Revolver, il cui compito è di estrarle e creare degli oggetti detti istruzioni di binding che permettono alla knowledge base di memorizzarle. Figura 4.15: Vettore delle binding annotations Memorizzazione nella knowledge base L output del componente Discovery viene inviato successivamente al Knowledge Management System, per la memorizzazione a cura del componente chiamato Knowledge Indexer. Questo componente dirige il processo di memorizzazione in questo modo: 1) i vettori di significati vengono memorizzati all interno del Term Inverted Index; 2) il vettore delle Content Units viene elaborato e ogni content unit viene inserita all interno del Semantic Tuple Space; 3) il vettore delle istruzioni di binding viene eseguito e i legami vengono memorizzati all interno del Binding Manager. 4.4 I modelli di retrieval di learning object e approcci per la generazione automatica di corsi In questo paragrafo vengono introdotti, senza entrare nei dettagli, i modelli di retrieval di learning objects implementati nel sistema Semantica e gli approcci per la generazione automatica di corsi didattici. Tutti i modelli verranno approfonditi nei dettagli in seguito, quando si descriverà l implementazione del sistema nel Web Server. Adesso ci interessa sapere che i modelli di retrieval previsti in Semantica sono 3 e che gli approcci per il courseware generation sono 2 (combinano i modelli di retrieval e ne sfruttano i risultati). Ogni modello sfrutta un tipo di informazione contenuta all interno della knowledge base ed è in grado di soddisfare uno o più requisiti dell utente. 127
144 I modelli di retrieval di learning objects sono: 1. Sense Boolean Retrieval Model (SBRM): simile al meccanismo tradizionale utilizzato dai motori di ricerca, con la differenza che lavora sui sensi e non sulla rappresentazione lessicografica del termine; 2. Content Unit Retrieval Model (CURM): permette di cercare un learning object sulla base delle unità di contenuto che possiede; 3. Ontology Driven Retrieval Model (ODRM): cerca i learning objects sulla base dei concetti di un ontologia di dominio che contiene. Le informazioni contenute all interno della Knowledge Base possono essere utilizzate per assemblare dinamicamente i learning objects e creare dei corsi personalizzati. L utente può utilizzare due meccanismi per la generazione automatica dei corsi. Essi differiscono per la modalità con cui l utente sceglie i learning objects componenti: 1. ContentUnit Adaptative Courseware Generation (CUACG): utilizza il modello CURM per il retrieval dei learning objects e prevede la possibilità di generare automaticamente dei corsi didattici permettendo all utente di definire in maniera precisa gli obiettivi di apprendimento, le conoscenze già acquisite e i vincoli. Infine, viene applicata una strategia pedagogica nella fase finale di generazione. 2. Ontology Driven Adaptive Courseware Generation (ODACG): utilizza il modello ODRM per il retrieval di learning objects da utilizzare per la generazione automatica dei corsi. Permette all utente di navigare nella knowledge base e di selezionare un dominio in cui generare il corso. In tale dominio, sceglierà i concetti che corrisponderanno a determinati learning objects, assemblati nel corso nella fase finale. Per ulteriori approfondimenti, si segnalano qui alcuni articoli che trattano i precedenti modelli e alcuni approcci alla generazione dei corsi: per il Sense Boolean Retrieval Model si segnalano gli articoli [87] e [88]; per il Content Unit Retrieval Model si segnala il capitolo scritto da Rob Koper sulle tecniche di combinazione e il riuso di contenuti didattici [89]; per l Ontology Driven Retrieval Model si segnala l articolo [90] e il libro 128
145 [91]; esempi ed approcci per la generazione automatica di corsi didattici rilevanti sono si trovano in [92], [93 e [94]; 4.5 Progettazione ed implementazione In questo paragrafo viene trattata l implementazione dell architettura logica del sistema Semantica, i cui requisiti fondamentali sono: ricerca di learning objects sia in base al contenuto sia in base al contesto di apprendimento in cui la risorsa si può inserire; assemblaggio dinamico di learning objects per creare corsi completi sulla base di richieste dell utente: conoscenze da acquisire, conoscenze già acquisite, vincoli temporali. Le tecnologie e i patterns utilizzati per l implementazione del progetto sono descritte nell Appendice di questa tesi e qui semplicemente enumerate: l'implementazione dell architettura logica della macchina semantica è stata effettuata secondo i canoni della programmazione ad oggetti e, dunque, si è utilizzato JAVA [95]. Inoltre, Java è stato utilizzato per la programmazione del lato controller della web application in cui è stata calata la macchina semantica (JAVA servlet); il database scelto per la gestione dei dati dell architettura logica e del web server (quest ultimo descritto in seguito) è Oracle 10g [96]; i patterns di progettazione utilizzati sono: Domain Model [97], Data Transfer Object [99], Strategy [98], Singleton [100], e per la progettazione del web server, il pattern Model-View-Controller [101]; il web server utilizzato è Apache Tomcat 5.5 [102], essendo le pagine della web application scritte interamente in codice JSP (JavaServletPages) [103], oltre che chiaramente in HTML; per la persistenza dei dati è stato utilizzato il framework IBATIS [104], che implementa il pattern Domain Model; il sistema è realizzato secondo un architettura distribuita. Dunque, per permettere ai vari oggetti di comunicare è stato utilizzato il middleware RMI (RemoteMethodInvocation) [105]; 129
146 per la connessione al database lessicale WordNet ci siamo serviti della libreria JWordNet [106] e per la gestione della persistenza dei modelli ontologici, nonché per la manipolazione degli stessi e la creazione di documenti RDF e interrogazioni SPARQL ci siamo serviti del framework Java JENA, già discusso nei capitoli precedenti [33]. Per dettagli relativi alla progettazione e all approccio intrapreso (costituito da un high level design e low level design) fare riferimento alla tesi di Mario Caropreso [36]. Il mio personale apporto al lavoro di implementazione è stato quello di ultimare i modelli di retrieval - il CURM e l ODRM, in particolare -, cercando un modo per poterli combinare e fornire così una migliore affidabilità nel retrieval dei learning objects e la successiva implementazione dei due approcci di generazione dei corsi (l ODACG e il CUACG), prevedendo una proposta semiautomatica e completamente automatica. Il tutto è stato poi integrato in un Portale Web, per fornire un primo esempio di utilizzo del sistema Semantica, realizzando quello che abbiamo chiamato, che possiamo dividere in tre parti: realizzazione del modello di macchina semantica; progettazione ed implementazione della macchina reale Semantica; integrazione della macchina in un Portale Web, per sperimentazione e futuro utilizzo per il trattamento dei contenuti didattici di Ateneo Il modello dei sottosistemi Il modello di progettazione adottato è quello del software distribuito, il quale consente di definire una buona modularità ed indipendenza dei componenti, un aumento della coesione degli stessi, una riduzione dell accoppiamento grazie alle interfacce di comunicazione, un aumento dell astrazione ed elevata flessibilità. Il modello dei sottosistemi (ovvero la divisione del sistema in componenti) è descritto dal seguente schema: 130
147 Figura 4.16: Diagramma delle componenti del sistema Semantica Di seguito verranno esplosi i diagrammi dei singoli componenti, organizzati secondo una progettazione modulare. Non tutti i moduli descritti nell architettura logica e del modello di macchina semantica sono stati implementati. Si rimanda al Capitolo 4 della tesi di Mario Caropreso per scoprire i dettagli. Nei paragrafi seguenti, oltre ai diagrammi dei componenti, verranno inseriti anche i diagrammi delle classi, con la corrispondenza tra i moduli implementati e quelli corrispondenti dell architettura logica Diagrammi del Knowledge Management System Modulo implementato Moduli corrispondenti dell architettura Indexer Corrisponde al modulo KnowledgeIndexer BindingManager Corrisponde al modulo BindingManager DomainExplorer Corrisponde al modulo DomainExplorer SemanticTupleSpace Corrisponde al modulo TupleManager RetrievalModel Corrisponde al modulo RetrievalModel Dictionary Corrisponde al modulo DictionaryBrowser OntologyManager Modulo di supporto per la manipolazione di ontologie; non corrisponde a nessun modulo dell architettura; CoursewareGeneration Contiene la business logic per la generazione automatica di corsi didattici; non corrisponde a nessun modulo dell architettura 131
148 Figura 4.17: Diagrammi del Knowledge Management System Diagrammi dell Ontology Management System Modulo implementato Moduli corrispondenti dell architettura ModelHolder Corrisponde al modulo ModelHolder OntologyModelManager Permette la manipolazione di un ontologia; realizza le funzionalità dei moduli OntologyExplorer, Ontology Query Service e DatabaseReader 132
149 4.5.4 Diagrammi del Discovery Figura 4.18: Diagrammi del Discovery Modulo implementato Moduli corrispondenti dell architettura TextProcessing Corrisponde al modulo TextProcessing ContentUnitExtraction Corrisponde al modulo ContentUnitExtraction N-RDF Extraction Corrisponde al modulo N-RDFExtraction OntologyBindingResolver Corrisponde al modulo OntologyBindingResolver Crawler Questo modulo preleva i learning object dai learning object repository TextProcessingChain Questo modulo realizza le funzioni di elaborazione testuale Indexer Questo modulo permette di memorizzare la conoscenza prodotta all interno della Knowledge Base 133
150 4.5.5 Diagrammi del Learning Object Repository Figura 4.19: Diagrammi del Learning Object Repository Il componente Retriever si occupa di prelevare i learning object. Il componente Entity rappresenta il domain model del LOR ed è strutturato secondo il pattern del DomainModel. Esso si occupa di gestire gli aspetti legati alla persistenza degli oggetti didattici. 4.6 I diagrammi delle classi e delle tabelle principali di Semantica Di seguito, riportiamo il diagramma del classi principali del sistema Semantica e delle tabelle del database. Per maggiori dettagli su tutti i package e le classi del sistema vedi [36] e la documentazione allegata al software. Mostriamo soltanto i diagrammi UML dei moduli fondamentali del sistema, quali KMS, Discovery, SLOR, OMS, TextProcessing, Retrieval Model e Courseware Generation Model, e le tabelle principali del sistema Semantica. 134

151 135

152 136

153 137

154 138

155 139
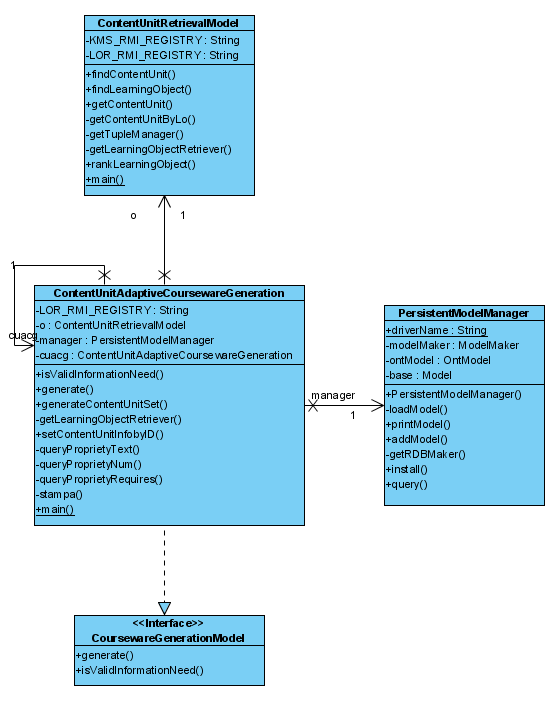
156 140

157 141

158 Tabelle principali del sistema Semantica 142
159 143
160 Capitolo 5 I moduli della Web Application Semantica In questo capitolo si approfondisce la struttura modulare della web application Semantica, la quale integra tutte le caratteristiche e le classi progettate ed implementate nei capitoli precedenti. La web application è stata realizzata in modo tale da permettere una facile integrazione con qualunque piattaforma elearning, prevedendo un modulo di interfaccia che permetta di acquisire e scambiare i dati con quest'ultima. Infatti, ogni componente è inserito in moduli indipendenti ed interoperanti, in modo da rispettare la progettazione e i pattern previsti. Inoltre, il pattern utilizzato per la realizzazione della web application è il Model-View-Controller (MVC) [101], nel quale si mantiene separata la presentazione dei dati all utente finale dalla business logic del sistema e dal modello dei dati. Il web server utilizzato è Apache Tomcat, il quale offre un ambiente di deployment e di esecuzione delle servlet e delle pagine JSP dell applicazione. Il tutto verrà approfondito di seguito, scendendo nei dettagli anche del funzionamento dei modelli di retrieval e di generazione dei corsi e prevedendo esempi d uso dei moduli stessi all interno del web server. L'approfondimento di questi modelli, che costituiscono la business logic dell'applicazione, è stato affrontato di proposito nel capitolo finale di questa tesi per fornire esempi, diagrammi e screenshots dei diversi componenti che costituiscono la web application. 144

161 Si inizia, dunque, dai modelli di retrieval e dalle scelte progettuali e pratiche che sono state adottate per permettere la ricerca dei learning objects e l assemblaggio dei contenuti didattici per la generazione automatica e semiautomatica di corsi. Ecco uno screenshot della pagina di home della web application: Figura 5.1: Home Page della web application Semantica 5.1 I moduli di retrieval della web application La web application rende possibile l utilizzo dei diversi meccanismi di retrieval di learning objects. Le informazioni vengono prelevate dalla knowledge base, fisicamente definita nel database con cui la web application scambia i dati. 145
 3.")
162 Come già detto nel capitolo precedente, i tre modelli di retrieval sono: 1. Sense Boolean Retrieval Model: inserito nell omonimo modulo SBR (SBR module) 2. Content Unit Retrieval Model: anch esso nel modulo omonimo CUR (CUR module) 3. Ontology Driven Retrieval Model: implementato nel modulo ODR (ODR module) Approfondiamo di seguito i modelli e la progettazione dei moduli della web application, rimandando alla documentazione allegata al software per i dettagli relativi al funzionamento di ogni singolo componente del sistema. Figura 5.2: Pannello principale della web application Semantica 146
 più termini che saranno collegati tra di loro tramite operatori booleani.")
163 5.1.1 Modulo di ricerca basato sul Sense Boolean Retrieval Model (SBRM) I modelli di Sense Boolean Retrieval è una estensione del meccanismo tradizionale di ricerca di tipo sintattico. L utente costruisce la SenseQuery, assemblando (attraverso una procedura guidata) più termini che saranno collegati tra di loro tramite operatori booleani. La nostra proposta è una estensione del modello booleano di retrieval con la differenza che non lavora sui termini, bensì sui loro sensi. Ricordando il meccanismo di processing testuale visto per la fase di indexing dei learning objects, la Semantic Knowledge Base memorizzerà in un apposita struttura dati detta Term Inverted Index, il vettore dei significati. Il sistema costruisce cioè in fase di indexing una sorta di spazio in cui ogni learning object viene rappresentato come un vettore (di significati, appunto). In fase di retrieval, l utente costruisce la SenseQuery semplicemente seguendo una procedura guidata che permette di indicare per ogni suo termine il senso (prelevato dal dizionario WordNet). Figura 5.3: Il modulo del Sense Boolean Retrieval Model 147
164 Le singole parole chiave che formano la SenseQuery sono legate da connettivi booleani. In questo modo la query viene trasformata in un vettore dei sensi, che viene inviato al sistema per poter trovare la giusta corrispondenza con un vettore dei significati della KB. I sensi per i quali esiste una corrispondenza nella KB sono definiti sensi vincenti. Dall elenco dei sensi il sistema estrae un elenco dei learning objects che contengono i sensi vincenti. Ad ogni learning object viene attribuito un punteggio p pari alla somma delle densità di significato dei sensi vincenti. A partire dal vettore dei sensi vincenti il sistema individua tutti i sensi presenti all interno di un learning object che sono collegati con i sensi vincenti da un percorso di lunghezza 1 all interno del dizionario. Questi sensi sono detti sensi vincenti secondari. Il sistema aggiunge al punteggio p precedentemente calcolato le sense density dei sensi vincenti secondari. Ogni sense query secondaria viene pesata secondo un valore che tiene conto del tipo di relazione semantica esistente fra il senso vincente e il senso secondario. La formula per il rank di un learning object è la seguente: n m i=0 k=0 p=rank lo = sensd s i sensd s k weight rel si, s k dove si, i = 0... n, è l insieme dei sensi vincenti, s k, k = 0... m, è l insieme dei sensi vincenti secondari (sensi che distano 1 da un qualunque senso vincente, rel s i, s k è una funzione che restituisce il tipo di legame semantico fra il primo termine e il secondo termine e weigth(r) è una funzione che restituisce un numero reale w(0,1) tale che: se il senso vincente è iponimo del senso secondario (relazione di iponimia) allora weigth(r)=0.8 ; se il senso vincente è parte del senso secondario (relazione di meronimia) allora weigth(r)=0.5 ; se il senso vincente comprende il senso secondario (relazione di olonimia) allora weigth(r)=0.5; se il senso vincente è iperonimo (relazione di iperonimia) del termine secondario allora weigth(r)=0.4; 148
165 Si dà, dunque, maggiore peso alla relazione di iponimia, in quanto se il senso vincente è un iponimo del senso secondario allora il senso secondario è più generico del senso vincente, e quindi la densità concettuale del senso secondario è anche la densità concettuale del senso vincente (gerarchia IS-A). La relazione di iperonimia ha peso inferiore per la regola inversa: non si può dire che una istanza del padre sia anche del figlio. Le relazioni di meronimia/omonimia aggiungono informazioni addizionali e quindi hanno un peso intermedio. Figura 5.4: Risultati del Sense Boolean Retrieval Model 149
166 5.1.2 Modulo di ricerca basato sul Content Unit Retrieval Model (CURM) La seconda metodologia di ricerca è basata sulle tecniche del Web Semantico, e in particolare di annotazione semantica tramite RDF ed ontologie OWL. Lo scopo di questa metodologia è consentire una ricerca di learning object sulla base delle unità di contenuto (content unit). Figura 5.5: Content Unit Retrieval Model (CURM) In fase di retrieval, l utente sottopone al sistema una query che viene costruita usando l approccio Query-by-Example (QBE), che è un metodo di creazione della query in cui l utente ricerca contenuti in base ad esempi espliciti (nel nostro caso una select di categorie didattiche), ovvero oggetti di esempio dell ontologia CuONTO. In questo modo si evita di chiedere all utente di digitare delle query esplicite in linguaggio SPARQL per l interrogazione dell ontologia didattica CuONTO; sarà il sistema a formattare nel linguaggio formale la query dell utente e sottoporla al Tuple Manager. 150

167 Figura 5.6: Il modulo del Content Unit Retrieval Model Per ognuno di questi oggetti di esempio l utente specifica delle proprietà che gli oggetti da trovare dovranno rispettare. Il modulo CURM implementato nella web application chiede di specificare due proprietà per la ricerca dei learning objects: 1. la categoria dell unità di contenuto 2. l argomento cui questa unità di contenuto dovrà trattare In realtà, il modello CURM poteva essere dotato di altre modalità, tra cui quella basata sul contesto; ovvero, si poteva permettere la scelta di alcune content unit all interno della knowledge semantica e cercare altre content unit che presentino le content unit selezionate come valori per le proprietà contestuali o strutturali. Ad esempio, l utente può selezionare una content unit specifica e chiedere di ottenere tutte le content unit la cui proprietà requires ha come valore proprio la content unit iniziale (propedeuticità). 151
168 Il modulo CURM è stato, tuttavia, riadattato per la generazione automatica e semiautomatica dei corsi: come vedremo, invece di restituire l elenco dei learning objects, esso permetterà di restituire anche le content unit che soddisfano una serie di vincoli e di strategie pedagogiche, con relative propedeuticità. Per cui verranno utilizzate, per l imposizione dei vincoli, le proprietà degli oggetti dell ontologia CuONTO (in questo primo modello di esempio, sono state utilizzate le sole proprietà hastext e type). L approccio introdotto per migliorare le prestazioni del modello CURM, che altrimenti si ridurrebbe (per le cose dette finora) ad una semplice ricerca dei learning objects sulla base di annotazioni esplicite date in fase di editing (dall autore dei learning objects), è stato quello di collegarlo al modello SBR. Infatti, l argomento che viene specificato dall utente e che costituisce il valore della proprietà hastext (dell ontologia CuONTO) viene sottoposto all SBRM (chiedendo all utente di indicare il senso del termine), il quale restituirà l elenco delle content unit in cui quell argomento viene trattato. Dunque, verranno restituiti due elenchi di content unit: uno dal vero e proprio CURM, in base alle categorie di unità di contenuto cercate, e uno dall SBRM, in base all argomento trattato. L intersezione tra i due elenchi ci darà le unità di contenuto prelevate dal Semantic Tuple Space che soddisfano la query inviata (categoria+argomento). In effetti, collegando il CURM al modello booleano, si compie un ulteriore passo elaborativo: le proprietà testuali (nel nostro caso la sola proprietà hastext) indicano al sistema di accedere alla tabella costruita in fase di indexing per le stesse proprietà (il modulo Discovery effettua un SBRM anche sulla proprietà hastext delle annotazioni delle unità di contenuto). La query viene, dunque, trasformata dal sistema in una query SPARQL e restituirà un unico elenco di unità di contenuto (intersezione) che la soddisfano. A questo punto, il sistema carica i learning object che contengono le unità di contenuto vincenti ed associa ad ogni learning object un punteggio p. Tale punteggio dipende dal numero di unità di contenuto vincenti trovate nell LO moltiplicato per il numero di unità di contenuto proprie di quel LO diviso per il numero di unità di contenuto vincenti totali: p=rank lo = n.cu.vincenti [ lo] n.cu[lo] n.cu.vincenti [totale] I learning object risultanti vengono ordinanti secondo il rank e restituiti all utente secondo tale ordine. 152

169 Figura 5.7: Risultati del Content Unit Retrieval Model Modulo di ricerca basato sull Ontology Driven Retrieval Model (ODRM) Tale modalità fa uso massiccio di ontologie. In particolare, l approccio utilizza le ontologie di dominio per descrivere i diversi domini della didattica. In fase di retrieval, l utente seleziona un'ontologia di dominio e poi uno o più concetti (istanze della classe Concept). Figura 5.8: ODRM: costruzione del Conceptual Information Need Vector 153
 limita la ricerca soltanto a learning object che siano stati esplicitamente collegati ai concetti dell")
170 Si definisce così una query complessa e si sceglie successivamente tra due opzioni di ricerca. Figura 5.9: Il modulo dell'ontology Driven Retrieval Model La prima modalità (modalità esplicita) limita la ricerca soltanto a learning object che siano stati esplicitamente collegati ai concetti dell ontologia di dominio tramite Binding Annotations. L utente costruisce il Conceptual Information Need vector, prelevando i concetti dall ontologia di dominio. In questo caso il sistema accede alla tabella delle Binding Annotations e cerca tutti i learning objects che contengano istanze dei concetti forniti dalla query. 154
171 Figura 5.10: Il risultato dell'ontology Driven Retrieval Model (modalità esplicita) La seconda modalità (modalità non esplicita) abilita la ricerca anche a learning object non esplicitamente annotati. In questo caso il sistema preleva per ogni concetto della query la lista dei sensi collegati ed accede ai vettori dei sensi dei documenti che sono stati creati con l approccio Sense Boolean Retrieval Model. In pratica, questa opzione fa in modo che la query da sottoporre al sistema e valida per l approccio del modello SBR venga generata in maniera del tutto automatica a partire dai concetti definiti all interno dell ontologia di dominio (infatti in fase di editing, l analista di dominio dovrà indicare per ogni concetto il corrispondente senso prelevato dal dizionario). In questo caso, sono i concetti a fornire i sensi, e non l utente. 155
172 Figura 5.11: Il risultato dell'ontology Driven Retrieval Model (modalità non esplicita) In entrambi i casi, il sistema restituisce un elenco dei learning objects che contengono i concetti scelti dall utente nella preparazione della query. In questa versione demo di Semantica, è presente un solo dominio, ovvero quello dell Informatic Archeology, e tutti i concetti ad esso collegati. L elenco dei concetti di tale dominio viene presentato in entrambe le opzioni di ricerca e guida il processo di retrieval. Per rendere più funzionale e completo l ODRM occorrerebbe permettere all utente di navigare, tramite interfaccia grafica, all interno delle ontologie di dominio, e quindi servirebbe un apposito modulo che permetta al sistema di caricare più ontologie di dominio e presentarle all utente finale. 156

173 5.2 Approcci e moduli per la generazione dei corsi didattici Il sistema Semantica, oltre ad offrire una interfaccia per il retrieval dei learning object, è impiegato sperimentalmente per la generazione dei corsi didattici, sfruttando proprio i meccanismi di ricerca visti precedentemente. La web application permette, appunto, la scelta dell approccio di courseware generation, mediante due meccanismi: - meccanismo di generazione semiautomatica dei corsi: l utente viene guidato passo passo nella realizzazione dei corsi, utilizzando in modo combinato tutti i modelli e gli approcci implementati nel sistema. In questo modo può sfruttare i vantaggi di ogni singolo modello di retrieval e reperire il materiale didattica sulla base di una ricerca per argomento, per content unit oppure per concetti di dominio; - meccanismo di generazione automatica di corsi: si sfrutta il modello di ricerca per content unit, definendo una serie di vincoli e di strategie di apprendimento. L utente indicherà tali requisiti in fase di retrieval ed il sistema in modo automatico restituirà un elenco di unità didattiche inserite nel corso creato. Figura 5.12: Courseware Generation (pannello di gestione dei corsi) 157
174 Prima di descrivere i moduli per la generazione dei corsi, introduciamo i due approcci che vengono sfruttati per ottenere questo obiettivo: il ContentUnit Adaptive Courseware Generation (CUACG) e l Ontology Driver Adaptive Courseware Generation (ODACG), così come descritti in [36]. Entrambi sfruttano le informazioni contenute all interno della knowledge base in modo da assemblare dinamicamente i learning object e creare dei corsi personalizzati. I due approcci differiscono per la modalità in cui l utente sceglie i learning object componenti Il modello Content Unit Adaptive Courseware Generation (CUACG) Il modello CUACG utilizza il modello CURM per il retrieval dei learning object. Il modello CUACG prevede la possibilità di generare automaticamente corsi didattici permettendo all utente di definire in maniera precisa gli obiettivi di apprendimento. Infatti, l utente dovrà scegliere gli obiettivi di apprendimento, le conoscenze già acquisite e i vincoli. Un obiettivo di apprendimento è l acquisizione di una determinata content unit. L utente può definire le content unit da acquisire tramite due metodi (come vedremo nei moduli). Il primo prevede una navigazione all interno della Knowledge Base e successiva scelta delle content units; il secondo prevede una ricerca all interno della knowledge base secondo il modello CURM. In entrambi i casi il risultato è un insieme di content unit da acquisire. Con lo stesso tipo di approccio seleziona le conoscenze già acquisite, ovvero quelle content unit da considerare già in possesso dell utente. Infine, l utente può indicare dei vincoli sulle proprietà che le content unit devono possedere. Questi vincoli riguardano le proprietà contestuali, come ad esempio il tempo di apprendimento, difficoltà, la natura dell unità, il grado di istruzione per il quale è stata prevista. Una volta che sono stati scelti i tre fattori di input richiesti dal sistema viene eseguito l algoritmo Reverse Course Generation, il cui pseudocodice è riportato di seguito: 158
175 ReverseCourseGeneration Input: un insieme U di unità di contenuto da acquisire, un insieme P di unità di contenuto di partenza, un insieme V di vincoli, una strategia pedagogica da applicare Output: un insieme di learning object ordinati begin cuset = generatecontentunitset (U, P, V) course = applypedagogicalstrategy(cuset, strategy); return course; end L algoritmo procede in due fasi. Nella prima fase viene generato un insieme di content units che soddisfino i vincoli del problema. In una seconda fase l insieme di content unit viene manipolato per essere trasformato in un insieme di learning object ordinati. Questa operazione è fatta con il supporto di una strategia pedagogica. Una strategia pedagogica è un insieme di regole che stabiliscono come scegliere le content unit. Ad esempio, quante unità didattiche appartenente ad una certa categoria inserire nel corso, oppure si potrebbe volere che ogni oggetto Fundamental sia accompagnato da un certo numero di oggetti Auxiliary, presi con un certo ordine. La prima fase dell algoritmo è gestita dalla procedura GenerateContentUnitSet, la quale riceve come input: 1. un insieme di unità di contenuto da acquisire 2. un insieme di unità di contenuto di partenza 3. un insieme di vincoli L output finale della procedura sarà un insieme di content units che verranno assemblate per formare il corso. Il processo di selezione delle content units tende ad evitare che per ogni corso le content units da acquisire non siano già state inserite nel corso stesso (già acquisite). Inoltre, se una content unit è richiesta (requires) da un'altra, la procedura restituirà anche quella propedeutica (purché non già acquisita). 159
176 Su questo pool di content unit viene fatta una successiva selezione in base ai vincoli imposti dall utente, per restituire soltanto quelle che soddisfino tali vincoli. A questo punto viene eseguita la procedura ApplyPedagogicalStrategy, che ricevute in ingresso l insieme delle content units selezionate e una strategia pedagogica, restituisce un insieme di learning objects ordinati. In realtà, l output finale di questa fase dovrebbe essere costituito dalle unità di contenuto più che dai learning objects in sé. Infatti, essendo un learning object un insieme di documenti e, dunque, di unità di contenuto, l utente potrebbe essere interessato ad una parte di un contenitore più ampio qual è il learning object stesso. Per tale motivo è stato deciso di fare questa modifica concettuale all algoritmo di ReverseGeneration, che rimane tuttavia il principio ispiratore utilizzato per l implementazione del modulo di courseware generation di Semantica. Non riportiamo qui gli pseudocodici delle procedure ([36] pgg ), avendo utilizzato soltanto il principio di funzionamento dell algoritmo e adattandolo al caso pratico della web application. Infatti, la definizione della strategia pedagogica non è implicita nel modello, ma è prevista nel modulo di generazione dei corsi, come vedremo. 160
177 5.2.2 Il modello Ontology Driven Adaptive Courseware Generation (ODACG) Il modello ODACG utilizza il modello ODRM per il retrieval di learning objects. L utente naviga attraverso la knownledge base e seleziona un dominio (ConceptScheme) in cui generare il corso. Il sistema mostra all utente la lista dei concetti presenti in quel determinato dominio e l utente seleziona se desidera generare un corso che copra un certo insieme di concetti. Sulla base dei concetti il sistema usa il modello ODRM e preleva i learning objects appartenenti al dominio e li ordina secondo la successione definita nella gerarchia di dominio. Il corso così assemblato viene fornito all utente. Poiché basato sul modello ODRM, il modello ODACG è stato collegato alla sua prima modalità, ovvero quella che si basa sulle binding annotations esplicite dei learning object. Tuttavia, per una futura ottimizzazione si potrà prevedere l utilizzo della seconda modalità, permettendo l applicazione dell SBRM ai concetti dell ontologia di dominio preventivamente scelta dall utente in fase di retrieval. Volendo esaminare i dettagli, l'utente costruisce il Conceptual Information Need vector con tutti i concetti che desidera dall'ontologia di dominio. A questo punto il sistema interroga, mediante il modello ODRM in modalità esplicita (prima modalità) la knowledge base per il retrieval dei learning objects collegati a tali concetti. A questo punto viene innescato l'algoritmo dell'odacg che itera sui concetti costruendo una query concettuale per ogni concetto. Tale query viene sottoposta all'odrm il quale restituirà tutti i LOs collegati ad essa. L'algoritmo effettua una nuova iterazione sui concetti per verificare se ognuno di essi sia già stato soddisfatto (in tal caso passa ad esaminare altri concetti). Dunque, vengono restituiti soltanto quei learning objects i cui concetti non siano già stati soddisfatti, selezionando fra tutti i LOs quello con il punteggio massimo. Tutti i concetti che vengono coperti da tale LO vengono considerati soddisfatti. Dunque, il risultato dell'algoritmo ODACG sarà il solo LO con il punteggio massimo (tra quelli restituiti dallo stesso modello ODRM in modalità esplicita). Vedremo il funzionamento del modulo ODACG in seguito. 161

178 Figura 5.13: I modelli di Courseware Generation Il modulo di generazione semiautomatica dei corsi Passiamo adesso alla descrizione dei moduli della web application che implementano i due modelli visti in precedenza per la generazione dei corsi. Come anticipato, la generazione può essere guidata dall utente, che seleziona il modello di retrieval o l approccio di courseware generation, per singole o multiple content units. In questo modo l utente può sfruttare i vantaggi di ogni singolo modello ed effettuare delle ricerche per argomento, concetto o tipologia di content unit. Figura 5.14: Modalità semiautomatica di Courseware Generation 162

179 Come è possibile vedere in figura, il modulo chiede all utente la modalità di retrieval per la selezione delle unità di contenuto. Dunque, verrà collegato ad uno dei modelli trattati e selezionerà una per una le content units da acquisire, secondo un approccio che prende spunto dal CUACG, in cui se l utente ha già acquisito in un corso una determinata content unit, non potrà riacquisirla di nuovo. Avendo già spiegato il funzionamento di tutti e tre i moduli di retrieval (SBRM, CURM, ODRM) passiamo a puntualizzare le caratteristiche salienti e le scelte progettuali dei moduli di CUACG e ODACG. Per quanto riguarda il modulo CUACG, come già detto nel modello, l utente dovrà impostare dei vincoli (constraints) sulle unità di contenuto. Tali vincoli saranno i valori delle proprietà definite nell ontologia CuONTO che viene appunto utilizzata dal CUACG. Figura 5.15: Modalità semiautomatica di Course Generation: i vincoli del CUACG 163
180 In questo modo l utente definisce un obiettivo di apprendimento, in cui prepara il sistema a delle query guidate (approccio simile alle Query-by-Example), definendo il valore di alcune, tutte o nessuna proprietà dell ontologia didattica. La business logic che implementa il modello CUACG riceverà, dunque, un set di vincoli, cercherà le content units che soddisferanno quei vincoli e scarterà da tale set le content units precedentemente acquisite nel corso dell utente (algoritmo ReverseCourseGeneration). Non è prevista qui la definizione della strategia pedagogica, inserita invece nel modulo di generazione automatica dei corsi: infatti, sarà l utente a selezionare le unità di contenuto, una per una, da inserire nel corso da generare. Ovviamente, è prevista anche la modifica del singolo corso didattico, sfruttando sempre il courseware generator in modalità semiautomatica (anche dopo aver creato in modo automatico il corso), selezionandolo da un apposita lista dei corsi dell utente (edit course). Figura 5.16: Risultati del CUACG secondo l'approccio semiautomatico (esempio: vincoli delle content unit: Category Definition; Difficult - Medium) 164
181 Il modulo ODACG, che sfrutta il modello omonimo basato sull ODRM, permette all utente di navigare tra i concetti dell ontologia di dominio preventivamente caricata nel sistema. L utente costruisce il Conceptual Information Need vector, prelevando i concetti dall ontologia di dominio. A questo punto il modulo si collega alla prima modalità dell ODRM, che effettua il retrieval di tutti quei learning objects che sono stati annotati con delle binding annotations esplicitamente in fase di editing dei contenuti (vedi in seguito, Editing dei contenuti didattici). Per una futura ottimizzazione sarebbe funzionale l introduzione di un modulo di caricamento di più ontologie di dominio sia per l ODRM che per l ODACG. In questo modo l utente potrà navigare tra i concetti di domini diversi e interrogare il sistema solo per quegli ambiti applicativi. Inoltre, si potrebbe collegare il modello ODACG alla seconda modalità dell ODRM, in cui si ricercano i contenuti didattici sulla base dei significati dei concetti dell ontologia di dominio (anche se i learning object non siano stati esplicitamente annotati con binding annotations). Figura 5.17: Modalità semiautomatica di Courseware Generation: il modulo ODACG 165
182 Figura 5.18: Risultati del modulo ODACG di Courseware Generation Il modulo di generazione automatica dei corsi Il secondo approccio previsto per la generazione dei corsi è automatico. In questa procedura l utente dovrà specificare soltanto gli obiettivi di apprendimento, i vincoli e la strategia pedagogica. Per questo motivo ci siamo basati esclusivamente sul modello CUACG per l implementazione del modulo AUTOGEN. Non è stato utilizzato in tale ambito il modello ODACG perché poco funzionale e meno performante del CUACG. Inoltre, quest ultimo permette di ricercare in maniera più accurata una serie di contenuti sulla base dei valori delle proprietà contestuali delle content units, annotate preventivamente dall autore dei contenuti (CU annotation). In fase di retrieval, l utente ricercherà le content units indicando preventivamente l argomento che dovranno contenere. In questa prima fase, si sfrutta il modello 166

183 SBRM il quale restituirà tutti i learning objects e, dunque, le loro unità didattiche che parlano di quell argomento (corrispondenza semantica e non sintattica, ovviamente). L utente indicherà il termine e il significato selezionato dal dizionario. Figura 5.19: Modalità automatica di Courseware Generation: il modulo CUACG Nel secondo step, il sistema restituirà i learning objects che trattano quell argomento e su di essi verranno definiti i vincoli (constraints). L utente può specificare le categorie di unità didattiche, il livello di apprendimento, il dominio applicativo, la difficoltà, il contesto, ed altro. In questo modo verranno definiti i valori delle proprietà, che il sistema utilizzerà per impostare le query SPARQL per l interrogazione della Knowledge Base. Definiti i vincoli, si passa alla definizione della strategia pedagogica: la scelta progettuale è stata quella di non inserire la definizione della strategia pedagogica nella business logic e, dunque, nel modello CUACG, ma di gestirne la definizione tramite il livello di presentazione, ovvero chiedendo esplicitamente all utente di 167

184 indicare il numero delle unità didattiche suddivise in categorie (quelle definite nei vincoli). In realtà si potrebbero implementare diverse strategie di apprendimento, magari inserendole direttamente nel modello CUACG: ad esempio, nella tesi del Caropreso [36, pg. 136] viene definito l algoritmo che lavora sulle proprietà strutturali delle content units e che applica la strategia pedagogica, ad esempio ottenendo per ogni unità didattica di tipo Fundamental, un certo numero di unità didattiche Auxiliary ordinate in un certo modo. Figura 5.20: Modalità automatica di Courseware Generation: definizione della strategia pedagogica nel modulo CUACG Selezionati i numeri di unità didattiche divise per categorie, il sistema provvede a restituire le content units corrispondenti ai learning objects ritrovati dopo il primo step, partendo dal LO con il punteggio più alto e poi via via considerando i meno significativi. Ad esempio, supponiamo che dopo la prima fase di retrieval (ricerca per argomento), vengano restituiti 3 learning objects ordinati in base al rank e 168

185 composti come segue: - LO n.1 con rank più alto costituito da 1 definizione, 2 introduzioni e 1 conclusione; - LO n.2 costituito da 2 definizioni e 1 conclusione; - LO n. 3 con rank più basso costituito da 1 introduzione, 1 definizione e 1 conclusione; Se l utente è interessato ad assemblare un corso che contenga quell argomento, definendo una strategia pedagogica con 2 definizioni, 3 introduzioni e 4 conclusioni, allora il sistema restituirà: 1. le 2 definizioni prelevate dal LO n.1 e dal LO n.2, scartando la seconda definizione del LO n.2 e quella del LO n.3, non richieste dall utente 2. le 3 introduzioni prelevandone due dal LO n.1 ed una dal LO n.3, visto che il LO n.2 non contiene introduzioni; 3. le 3 conclusioni, non essendone disponibili 4, prelevate da tutti e tre i LOs. Figura 5.21: Risultati del modulo CUACG per la generazione automatica di corsi 169
186 In questo modo il sistema assemblerà il corso, permettendo all utente di salvarlo nella repository dei corsi personalizzati, e avendo la possibilità di modificarlo in qualunque momento con l approccio semiautomatico. 5.3 Editing dei contenuti didattici Nell articolo [107] intitolato Generazione automatica di learning object accessibili a partire da documenti: il sistema di post-produzione di A3 viene proposto un approccio semiautomatico che inizia con la stesura, da parte degli autori, di materiale creato con un editor di testi e che si completa nella realizzazione di LO accessibili e universali. Sulle orme del proposito di tale articolo, abbiamo inserito nel nostro sistema Semantica un modulo per l'editing guidato dei learning objects, in cui il docente può compilare le informazioni relative al contenuto didattico, compresi i documenti che esso possiede e i file delle annotazioni (in formato N3), utilizzando la veste grafica offerta dal pannello di amministrazione (admin's panel). Figura 5.22: Pannello di amministrazione per l'editing dei contenuti didattici 170

187 In questo pannello l'amministratore può inserire un nuovo learning object, può visionare i Los già inseriti nel sistema e collegarsi ai pannelli principali e dei corsi generati. Di seguito mostriamo il processo di editing di un nuovo learning object, mostrando in particolare la procedura di automatizzazione per la creazione delle annotazioni delle content units (CU annotation) e le binding annotations (BA annotation). Fase 1 (inserimento delle informazioni del LO): Figura 5.23: Editing dei contenuti didattici (inserimento informazioni del LO) In questo pannello si inseriscono le informazioni del LO quali il nome, una descrizione del suo contenuto, l'autore, l'url e il numero delle unità di contenuto che esso deve contenere. 171

188 Fase 2 (inserimento dei documenti del LO): Nella seconda fase, l'utente dovrà inserire il nome delle unità didattiche che il LO dovrà prevedere e il path assoluto dei documenti testuali che lo compongono. Il sistema agirà su tali file di testo, memorizzandoli nel database ed eseguendo su di essi le operazioni previste dal modulo Discovery, all'atto dell'indexing. In particolare, i documenti testuali vengono utilizzati dal modello SBRM, il quale esegue in fase di indexing il text processing, così come descritto nel capitolo 4. Figura 5.24: Editing dei contenuti didattici (inserimento dei documenti del LO) Fase 3 (creazione delle CU annotations): Nel terzo step, l'utente compila la form per la creazione automatica delle CU annotations per ogni singola unità didattica. Dovrà specificare i valori delle proprietà 172
189 dell'ontologia CuOnto, che andranno a popolare la Semantic Tuple Space nella quale sono memorizzate tutte le informazioni a cui accede il modulo CURM. Nell'interfaccia grafica, l'utente digiterà anche il valore della proprietà testuale hastext, che verrà elaborata con il TextProcessing del modulo SBRM nella fase di indexing. Questa funzionalità permette dunque di implementare una strategia mista in cui CURM e SBRM "collaborano". Una estensione futura potrebbe essere quella che prevede di utilizzare la strategia mista anche per altre proprietà testuali, oltre quella hastext (nella quale l'utente inseriesce una descrizione dell'argomento trattato in quella unità di contenuto). Figura 5.25: Editing dei contenuti didattici (creazione delle CU annotations) Di seguito si riporta un esempio di file con le annotazioni delle content units in formato N3, in cui vengono annotate due content units con i valori delle proprietà dell'ontologia CuOnto. Il sistema compila in automatico il file di annotazione (CU Annotation) e lo salva nel LOR, in attesa che il Discovery effettui l'aggiornamento della Knowledge Base. 173
190 @prefix p1: < dcterms: < xsd: < dc: < protege: < cuonto: < rdfs: < daml: < rdf: < : < owl: < :Introduction1 a cuonto :Introduction ; cuonto:hasabstractness "neutral" ; cuonto:hasauthor "ficetola" ; cuonto:hascompetency "model" ; cuonto:hasdifficulty "easy" ; cuonto:hasdocument "1" ; cuonto:hasfield "engineering" ; cuonto:haslearningcontext "universitysecondcycle" ; cuonto:hastext "Data management systems have been intensely studied and greatly developed in Computer Applications to Archaeology, since they encouraged the diffused ambition to manage huge and heterogeneous archaeological data sets." ; cuonto:hastitle "Introduction1". :Definition1 a cuonto:definition ; cuonto:hasauthor "ficetola" ; cuonto:hasdocument "2" ; cuonto:hastitle "Definition1". Fase 4 (creazione delle BA annotations): Nel quarto step, l'utente utilizza l'interfaccia guidata per la creazione delle Binding Annotations. Quindi, seleziona i concetti dell'ontologia del dominio del sistema da collegare al learning object che vuole creare. Il sistema creerà in automatico il file in formato N3 delle annotazioni, prelevando gli ID identificativi dei concetti dell'ontologia grazie al Binding Manager. 174
 Di seguito si riporta un esempio di file con le binding annotation del LO in formato N3, in cui vengono collegati due")
191 Figura 5.26: Editing dei contenuti didattici (creazione delle Binding Annotations) Di seguito si riporta un esempio di file con le binding annotation del LO in formato N3, in cui vengono collegati due concepts ("DBMS" e "Technologies") appartenenti all'ontologia di dominio. Il sistema compila in automatico il file di annotazione (BAAnnotation) e lo salva nel LOR, in attesa che il Discovery effettui l'aggiornamento della @prefix :ba1 a p1: < domonto: < dcterms: < xsd: < dc: < protege: < rdfs: < daml: < rdf: < : < owl: < domonto:learningobject ; domonto:instantiate :co4 ; domonto:instantiate :co2. 175
192 Fase 5 (aggiornamento della knowledge base): L'ultimo step, dopo la creazione e il riepilogo delle binding annotations create, consiste nell'aggiornamento della knowledge base del sistema. Basta attivare il modulo Discovery, grazie alla servlet startdiscovery, alla fine della creazione del learning object. L'utente può anche posticipare l'attivazione del Discovery, prevedendo un aggiornamento della KB in un secondo momento (infatti, il sistema tiene memoria dei LOs già acquisiti e di quelli ancora da acquisire). Dopo l'attivazione del Discovery, i vettori dei significati, delle content units e dei concetti vengono inseriti nella KB e utilizzati dai modelli di retrieval e dagli approcci per la generazione dei corsi. 176
193 5.4 Sperimentazione Un sistema di Information Retrieval viene solitamente valutato in funzione della compatibilità dell'insieme delle risposte con le richieste dell'utente (efficacia). Questo è sostanzialmente diverso da quello che accade nel caso della valutazione dei sistemi di Data Retrieval, dove l'enfasi è posta sull'efficienza, ovvero la velocità nel restituire le risposte e la quantità di spazio occupato [16]. Valutare l'efficacia non è un problema semplice, in quanto include diversi aspetti soggettivi, per esempio due utenti con diversi livelli di conoscenza, formulando la stessa richiesta, potrebbero ottenere due diverse valutazioni sull'insieme di documenti reperiti dal sistema. Una valutazione solitamente è basata su una collezione di test, che consiste in una collezione di documenti, un insieme di esempi di richieste di informazione e per ciascuna di esse una lista di documenti rilevanti, fornita da appositi specialisti. La misura dell'efficacia quantifica, per ogni esempio di richiesta di informazione, la somiglianza tra l'insieme di documenti recuperati dal sistema e la lista di documenti rilevanti. Questo permette di dare una stima della bontà di un sistema e quindi della sua strategia utilizzata per il recupero di informazioni. Poiché Semantica è un sistema di IR, calato poi nell'ambito dell'e-learning per la generazione automatica dei corsi didattici, citiamo per completezza le misure di efficacia che su di esso possono essere verificate, richiamando i risultati sperimentali provati dal Caropreso [36]. Definizione 5.1. Si consideri una richiesta di informazione I e il suo insieme R di documenti. Sia R il numero di documenti in questo insieme. Si assuma che una data strategia di recupero (che si sta valutando) elabori la richiesta di informazioni I e generi un insieme di documenti di risposta A. Sia A il numero di documenti di A. Inoltre, sia Ra il numero dei documenti nella intersezione degli insiemi R ed A. 177
194 Precision e Recall sono definite nel modo seguente: Precision: è la frazione di documenti recuperati (insieme A) che è rilevante, cioè Precision= R a A Recall: è la frazione di documenti rilevanti che è stata recuperata, cioè Recall= R a R Figura 5.27: Precision e Recall per una data richiesta di informazione Ha senso tenere in considerazione il Recall solo quando la collezione di documenti è finita; infatti, nel caso di IR su web è impossibile sapere il numero totale di documenti rilevanti, pertanto la valutazione dei web search engines si basa più sulla Precisione (in particolare per via del ranking, data l'importanza di presentare i risultati rilevanti in cima alla lista). Abbiamo valutato le prestazioni del modello di retrieval di Semantica basato sui sensi (SBRM) attraverso le due metriche di precision e recall. Il test set su cui è stata condotta la sperimentazione è costituito da un insieme di learning objects relativi all'archeologia Informatica. Dato un insieme di 20 keywords altamente polisemiche, abbiamo costruito un ground truth consultando degli esperti del dominio della facoltà di Lettere 178
195 dell Università degli Studi di Napoli Federico II. La costruzione di tale ground truth si è resa necessaria per determinare i learning object rilevanti per ogni query. Successivamente, abbiamo effettuato le interrogazioni previste misurando i due parametri di precision e recall e calcolandone la media. Le interrogazioni sono state sottoposte sia al modello SBRM che al modello classico dell information retrieval Vector Space Model (VSM). I risultati della sperimentazione sono descritti nel seguente grafico: Figura 5.28: Grafico Precision-Recall Dall osservazione del grafico possiamo notare come SBRM ci consenta di ottenere un miglioramento del 30% sulla precision e del 20% sul recall rispetto al VSM. Notiamo inoltre come SBRM riesca ad approssimare algoritmicamente la nozione umana di similarità semantica fino all'83%. Valutiamo ora le prestazioni del modulo di courseware generator di Semantica in modalità automatica (modello CUACG), visto che la modalità semiautomatica si basa sull'utilizzo combinato dei modelli di retrieval. I parametri di valutazione della generazione automatica di un corso didattico per un dato argomento richiesto dall'utente in fase di retrieval sono: priorità: quanti contenuti sono attinenti alla query dell'utente, e dunque quanti contenuti trattano quell'argomento, corrispondono agli obiettivi di apprendimento, ai vincoli e alle strategie pedagogiche dell'utente; 179

196 non ripetitività: in relazione agli obiettivi di ricerca, quanti contenuti non ripetono i concetti ricercati, in modo da evitare ridondanze nel corso assemblato; continuità: il corso assemblato non deve avere concetti frammentati nei contenuti didattici, ovvero il corso dovrebbe avere una certa linearità nell'esposizione degli argomenti al discente. Per valutare i precedenti parametri abbiamo sperimentato il sistema Semantica su circa 150 learning objects, appartenenti al dominio dell' Archeologia Informatica e delle tecnologie informatiche di base. Inoltre, nel nostro dataset sperimentale sono stati introdotti dei learning objects (il 10% del totale), non attinenti al dominio informatico, per constatare l'efficienza del nostro sistema di retrieval. Ci aspetteremo, infatti, che tali LOs non vengano inseriti nei corsi didattici, o che magari il processo di retrieval associ loro un rank relativamente basso. Le parole polisemiche utilizzate per il retrieval dei contenuti sono le stesse citate precedentemente e forniteci da esperti del settore. Inoltre, la valutazione delle prestazioni della generazione automatica dei corsi è stata condotta da circa 10 esperti del settore didattico informatico, i quali hanno assegnato dei punteggi da 0 a 10 ai tre parametri su menzionati. Abbiamo messo a confronto i risultati ottenuti assemblando corsi didattici con il modulo di Semantica e corsi generati manualmente dai docenti, per valutare qualitativamente le prestazioni del sistema. Di seguito si riportano i risultati sperimentali: Figura 5.29: Risultati sperimentali del courseware generation (NP = Non priorità; C = Continuità; P = Priorità) 180
197 Dalla tabella si evince che la fase di retrieval dei contenuti didattici in relazione alla keyword inserita ritorna i documenti più vicini semanticamente ai bisogni dell'utente. Il corso assemblato è costituito essenzialmente da contenuti non ridondanti (ovviamente ciò dipende dalla non ridondanza dei learning objects inseriti nel sistema), ma, nei casi in cui il retrieval restituisce risultati con una priorità più bassa, la continuità dei concetti esposti si riduce. 5.5 Conclusioni e sviluppi futuri L'obiettivo che ci eravamo preposti in partenza, ovvero quello della realizzazione di un sistema per il recupero della dimensione semantica delle informazioni, possiamo dire di averlo raggiunto. Dalle prime sperimentazioni, l approccio risulta essere anche promettente. Ovviamente è un primo tentativo di implementazione e sperimentazione della nostra macchina semantica, che lascia aperte molte possibilità di sviluppo futuro. Infatti, per come è stata progettata la macchina semantica, il suo impiego può essere adattato a qualunque ambito ed esigenza. L'approccio è rivolto al recupero di qualunque fonte testuale di informazione, purché annotata semanticamente. Inoltre, i meccanismi di generazione automatica e semiautomatica dei corsi, nel quale è stata calata la nostra macchina semantica, possono essere impiegati per l'indicizzazione, il retrieval e l'assemblaggio dei contenuti didattici di Ateneo. A tal proposito, il motore di ricerca semantica deve essere integrato all interno del software IdeaWeb della piattaforma didattica DOL dell Università degli Studi di Napoli Federico II. IdeaWeb è un authoring tool, un applicativo che permette la creazione di scheletri di corsi didattici ottenuti assemblando contenuti digitali di diverso tipo. Mediante tale integrazione, i docenti che utilizzano IdeaWeb per la creazione di corsi didattici potranno effettuare ricerche semantiche e costruire i corsi in maniera semiautomatica partendo dai contenuti didattici già indicizzati all interno dei repository del sistema. Ovviamente, essendo un primo esempio di utilizzo e di applicazione della macchina semantica, la web application Semantica ed i suoi singoli moduli dovranno essere ottimizzati e prevedere una maggiore flessibilità nell'inserimento dei concetti di ontologie di dominio personalizzate. 181

198 Figura 5.30: IDEAWeb 182
199 183
200 Appendice A Mappa della Web Application Semantica In questa appendice vengono mostrati i diagrammi di interazione delle singole pagine della web application Semantica. Ricordiamo che la web application è scritta interamente in JSP e JAVA e il web server utilizzato è Tomcat. I packages della web application sono mostrati di seguito: SITE: contiene le pagine di gestione dei pannelli di autenticazione, di registrazione e le utilities del sito web; ADMIN: contiene le pagine per l'editing e la gestione dei learning objects; WORDNET: package con le pagine per l'accesso a WORDNET; SBRM: package con il modulo di retrieval SBRM; CURM: package con il modulo di retrieval CURM; ODRM: package con il modulo di retrieval ODRM; COURSEGEN: contiene tutte le pagine per la gestione e la generazione dei corsi didattici, sia in modalità semiautomatica (usando tutti i modelli del sistema SBRM, CURM, ODRM, CUACG, ODACG) sia in modalità automatica (AUTOGEN). 184

201 Alleghiamo di seguito i singoli diagrammi di interazione per ogni package dell'applicazione, compresa la root. ROOT della web application: 185
La felicità per me è un sinonimo del divertimento quindi io non ho un obiettivo vero e proprio. Spero in futuro di averlo.
 Riflessioni sulla felicità.. Non so se sto raggiungendo la felicità, di certo stanno accadendo cose che mi rendono molto più felice degli anni passati. Per me la felicità consiste nel stare bene con se
Riflessioni sulla felicità.. Non so se sto raggiungendo la felicità, di certo stanno accadendo cose che mi rendono molto più felice degli anni passati. Per me la felicità consiste nel stare bene con se
Semantica: un sistema per l indicizzazione, il retrieval semantico di learning objects e la generazione automatica di corsi didattici
 Tesi di laurea Semantica: un sistema per l indicizzazione, il retrieval semantico di learning objects e la generazione automatica di corsi didattici Anno Accademico 2007/2008 Relatori Ch.mo prof. Angelo
Tesi di laurea Semantica: un sistema per l indicizzazione, il retrieval semantico di learning objects e la generazione automatica di corsi didattici Anno Accademico 2007/2008 Relatori Ch.mo prof. Angelo
Mentore. Presentazione
 Mentore Presentazione Chi è Mentore? Il Mio nome è Pasquale, ho 41 anni dai primi mesi del 2014 ho scoperto, che ESISTE UN MONDO DIVERSO da quello che oltre il 95% delle persone conosce. Mi sono messo
Mentore Presentazione Chi è Mentore? Il Mio nome è Pasquale, ho 41 anni dai primi mesi del 2014 ho scoperto, che ESISTE UN MONDO DIVERSO da quello che oltre il 95% delle persone conosce. Mi sono messo
Un pensiero per la nostra Maestra Grazie Maestra Carla!
 Un pensiero per la nostra Maestra Grazie Maestra Carla! Quarta Primaria - Istituto Santa Teresa di Gesù - Roma a.s. 2010/2011 Con tanto affetto... un grande grazie anche da me! :-) Serena Grazie Maestra
Un pensiero per la nostra Maestra Grazie Maestra Carla! Quarta Primaria - Istituto Santa Teresa di Gesù - Roma a.s. 2010/2011 Con tanto affetto... un grande grazie anche da me! :-) Serena Grazie Maestra
COME AVERE SUCCESSO SUL WEB?
 Registro 3 COME AVERE SUCCESSO SUL WEB? Guida pratica per muovere con successo i primi passi nel web MISURAZIONE ED OBIETTIVI INDEX 3 7 13 Strumenti di controllo e analisi Perché faccio un sito web? Definisci
Registro 3 COME AVERE SUCCESSO SUL WEB? Guida pratica per muovere con successo i primi passi nel web MISURAZIONE ED OBIETTIVI INDEX 3 7 13 Strumenti di controllo e analisi Perché faccio un sito web? Definisci
Da dove nasce l idea dei video
 Da dove nasce l idea dei video Per anni abbiamo incontrato i potenziali clienti presso le loro sedi, come la tradizione commerciale vuole. L incontro nasce con una telefonata che il consulente fa a chi
Da dove nasce l idea dei video Per anni abbiamo incontrato i potenziali clienti presso le loro sedi, come la tradizione commerciale vuole. L incontro nasce con una telefonata che il consulente fa a chi
Una risposta ad una domanda difficile
 An Answer to a Tough Question Una risposta ad una domanda difficile By Serge Kahili King Traduzione a cura di Josaya http://www.josaya.com/ Un certo numero di persone nel corso degli anni mi hanno chiesto
An Answer to a Tough Question Una risposta ad una domanda difficile By Serge Kahili King Traduzione a cura di Josaya http://www.josaya.com/ Un certo numero di persone nel corso degli anni mi hanno chiesto
In questa lezione abbiamo ricevuto in studio il Dott. Augusto Bellon, Dirigente Scolastico presso il Consolato Generale d Italia a São Paulo.
 In questa lezione abbiamo ricevuto in studio il Dott. Augusto Bellon, Dirigente Scolastico presso il Consolato Generale d Italia a São Paulo. Vi consiglio di seguire l intervista senza le didascalie 1
In questa lezione abbiamo ricevuto in studio il Dott. Augusto Bellon, Dirigente Scolastico presso il Consolato Generale d Italia a São Paulo. Vi consiglio di seguire l intervista senza le didascalie 1
Tesina per il corso di Psicotecnologie dell apprendimento per l integrazione delle disabilità
 Tesina per il corso di Psicotecnologie dell apprendimento per l integrazione delle disabilità ANALISI DEL TITOLO Per prima cosa cercheremo di analizzare e capire insieme il senso del titolo di questo lavoro:
Tesina per il corso di Psicotecnologie dell apprendimento per l integrazione delle disabilità ANALISI DEL TITOLO Per prima cosa cercheremo di analizzare e capire insieme il senso del titolo di questo lavoro:
GIANLUIGI BALLARANI. I 10 Errori di Chi Non Riesce a Rendere Negli Esami Come Vorrebbe
 GIANLUIGI BALLARANI I 10 Errori di Chi Non Riesce a Rendere Negli Esami Come Vorrebbe Individuarli e correggerli 1 di 6 Autore di Esami No Problem 1 Titolo I 10 Errori di Chi Non Riesce a Rendere Negli
GIANLUIGI BALLARANI I 10 Errori di Chi Non Riesce a Rendere Negli Esami Come Vorrebbe Individuarli e correggerli 1 di 6 Autore di Esami No Problem 1 Titolo I 10 Errori di Chi Non Riesce a Rendere Negli
Indice. 1 Il monitoraggio del progetto formativo --------------------------------------------------------------- 3. 2 di 6
 LEZIONE MONITORARE UN PROGETTO FORMATIVO. UNA TABELLA PROF. NICOLA PAPARELLA Indice 1 Il monitoraggio del progetto formativo --------------------------------------------------------------- 3 2 di 6 1 Il
LEZIONE MONITORARE UN PROGETTO FORMATIVO. UNA TABELLA PROF. NICOLA PAPARELLA Indice 1 Il monitoraggio del progetto formativo --------------------------------------------------------------- 3 2 di 6 1 Il
domenica 24 febbraio 13 Farra, 24 febbraio 2013
 Farra, 24 febbraio 2013 informare su quelle che sono le reazioni più tipiche dei bambini alla morte di una persona cara dare alcune indicazioni pratiche suggerire alcuni percorsi Quali sono le reazioni
Farra, 24 febbraio 2013 informare su quelle che sono le reazioni più tipiche dei bambini alla morte di una persona cara dare alcune indicazioni pratiche suggerire alcuni percorsi Quali sono le reazioni
Il corso di italiano on-line: presentazione
 Il corso di italiano on-line: presentazione Indice Perché un corso di lingua on-line 1. I corsi di lingua italiana ICoNLingua 2. Come è organizzato il corso 2.1. Struttura generale del corso 2.2. Tempistica
Il corso di italiano on-line: presentazione Indice Perché un corso di lingua on-line 1. I corsi di lingua italiana ICoNLingua 2. Come è organizzato il corso 2.1. Struttura generale del corso 2.2. Tempistica
Università per Stranieri di Siena Livello A1
 Unità 20 Come scegliere il gestore telefonico CHIAVI In questa unità imparerai: a capire testi che danno informazioni sulla scelta del gestore telefonico parole relative alla scelta del gestore telefonico
Unità 20 Come scegliere il gestore telefonico CHIAVI In questa unità imparerai: a capire testi che danno informazioni sulla scelta del gestore telefonico parole relative alla scelta del gestore telefonico
Brand Il primo corso per gli imprenditori che vogliono imparare l arma segreta del Brand Positioning Introduzione
 Il primo corso per gli imprenditori che vogliono imparare l arma segreta del Brand Positioning Un corso di Marco De Veglia Brand Positioning: la chiave segreta del marketing Mi occupo di Brand Positioning
Il primo corso per gli imprenditori che vogliono imparare l arma segreta del Brand Positioning Un corso di Marco De Veglia Brand Positioning: la chiave segreta del marketing Mi occupo di Brand Positioning
CORSO VENDITE LIVELLO BASE ESERCIZIO PER L ACQUISIZIONE DEI DATI
 CORSO VENDITE LIVELLO BASE ESERCIZIO PER L ACQUISIZIONE DEI DATI 1. Vai a visitare un cliente ma non lo chiudi nonostante tu gli abbia fatto una buona offerta. Che cosa fai? Ti consideri causa e guardi
CORSO VENDITE LIVELLO BASE ESERCIZIO PER L ACQUISIZIONE DEI DATI 1. Vai a visitare un cliente ma non lo chiudi nonostante tu gli abbia fatto una buona offerta. Che cosa fai? Ti consideri causa e guardi
L intelligenza numerica
 L intelligenza numerica Consiste nel pensare il mondo in termini di quantità. Ha una forte base biologica, sia gli animali che i bambini molto piccoli sanno distinguere poco e molto. È potentissima e può
L intelligenza numerica Consiste nel pensare il mondo in termini di quantità. Ha una forte base biologica, sia gli animali che i bambini molto piccoli sanno distinguere poco e molto. È potentissima e può
Generazione Automatica di Asserzioni da Modelli di Specifica
 UNIVERSITÀ DEGLI STUDI DI MILANO BICOCCA FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI Corso di Laurea Magistrale in Informatica Generazione Automatica di Asserzioni da Modelli di Specifica Relatore:
UNIVERSITÀ DEGLI STUDI DI MILANO BICOCCA FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E NATURALI Corso di Laurea Magistrale in Informatica Generazione Automatica di Asserzioni da Modelli di Specifica Relatore:
LEZIONE 4 DIRE, FARE, PARTIRE! ESERCIZI DI ITALIANO PER BRASILIANI
 In questa lezione ci siamo collegati via Skype con la Professoressa Paola Begotti, docente di lingua italiana per stranieri dell Università Ca Foscari di Venezia che ci ha parlato delle motivazioni che
In questa lezione ci siamo collegati via Skype con la Professoressa Paola Begotti, docente di lingua italiana per stranieri dell Università Ca Foscari di Venezia che ci ha parlato delle motivazioni che
Alunni:Mennella Angelica e Yan Xiujing classe 3 sez. A. A. Metodo per l intervista: video intervista con telecamera. video intervista con cellulare
 Alunni:Mennella Angelica e Yan Xiujing classe 3 sez. A A. Metodo per l intervista: video intervista con telecamera intervista con solo voce registrata video intervista con cellulare intervista con appunti
Alunni:Mennella Angelica e Yan Xiujing classe 3 sez. A A. Metodo per l intervista: video intervista con telecamera intervista con solo voce registrata video intervista con cellulare intervista con appunti
Le basi della Partita Doppia in 1.000 parole Facile e comprensibile. Ovviamente gratis.
 Le basi della Partita Doppia in 1.000 parole Facile e comprensibile. Ovviamente gratis. Qual è la differenza tra Dare e Avere? E tra Stato Patrimoniale e Conto Economico? In 1.000 parole riuscirete a comprendere
Le basi della Partita Doppia in 1.000 parole Facile e comprensibile. Ovviamente gratis. Qual è la differenza tra Dare e Avere? E tra Stato Patrimoniale e Conto Economico? In 1.000 parole riuscirete a comprendere
Cosa ci può stimolare nel lavoro?
 a Cosa ci può stimolare nel lavoro? Quello dell insegnante è un ruolo complesso, in cui entrano in gioco diverse caratteristiche della persona che lo esercita e della posizione che l insegnante occupa
a Cosa ci può stimolare nel lavoro? Quello dell insegnante è un ruolo complesso, in cui entrano in gioco diverse caratteristiche della persona che lo esercita e della posizione che l insegnante occupa
I colloqui scuola-famiglia: le basi per una comunicazione efficace Dott.ssa Claudia Trombetta Psicologa e psicoterapeuta claudia.trombetta@email.
 I colloqui scuola-famiglia: le basi per una comunicazione efficace Dott.ssa Claudia Trombetta Psicologa e psicoterapeuta claudia.trombetta@email.it CTI Monza, 20 Novembre 2015 Prima parte: comprendere
I colloqui scuola-famiglia: le basi per una comunicazione efficace Dott.ssa Claudia Trombetta Psicologa e psicoterapeuta claudia.trombetta@email.it CTI Monza, 20 Novembre 2015 Prima parte: comprendere
Memory Fitness TECNICHE DI MEMORIA
 Memory Fitness TECNICHE DI MEMORIA IL CERVELLO E LE SUE RAPPRESENTAZIONI Il cervello e le sue rappresentazioni (1/6) Il cervello e le sue rappresentazioni (2/6) Approfondiamo ora come possiamo ulteriormente
Memory Fitness TECNICHE DI MEMORIA IL CERVELLO E LE SUE RAPPRESENTAZIONI Il cervello e le sue rappresentazioni (1/6) Il cervello e le sue rappresentazioni (2/6) Approfondiamo ora come possiamo ulteriormente
Come fare una scelta?
 Come fare una scelta? Don Alberto Abreu www.pietrscartata.com COME FARE UNA SCELTA? Osare scegliere Dio ha creato l uomo libero capace di decidere. In molti occasioni, senza renderci conto, effettuiamo
Come fare una scelta? Don Alberto Abreu www.pietrscartata.com COME FARE UNA SCELTA? Osare scegliere Dio ha creato l uomo libero capace di decidere. In molti occasioni, senza renderci conto, effettuiamo
Ipertesti e Internet. Ipertesto. Ipertesto. Prof.ssa E. Gentile. a.a. 2011-2012
 Corso di Laurea Magistrale in Scienze dell Informazione Editoriale, Pubblica e Sociale Ipertesti e Internet Prof.ssa E. Gentile a.a. 2011-2012 Ipertesto Qualsiasi forma di testualità parole, immagini,
Corso di Laurea Magistrale in Scienze dell Informazione Editoriale, Pubblica e Sociale Ipertesti e Internet Prof.ssa E. Gentile a.a. 2011-2012 Ipertesto Qualsiasi forma di testualità parole, immagini,
Introduzione all Information Retrieval
 Introduzione all Information Retrieval Argomenti della lezione Definizione di Information Retrieval. Information Retrieval vs Data Retrieval. Indicizzazione di collezioni e ricerca. Modelli per Information
Introduzione all Information Retrieval Argomenti della lezione Definizione di Information Retrieval. Information Retrieval vs Data Retrieval. Indicizzazione di collezioni e ricerca. Modelli per Information
5. Fondamenti di navigazione e ricerca di informazioni sul Web
 5. Fondamenti di navigazione e ricerca di informazioni sul Web EIPASS Junior SCUOLA PRIMARIA Pagina 43 di 47 In questo modulo sono trattati gli argomenti principali dell universo di Internet, con particolare
5. Fondamenti di navigazione e ricerca di informazioni sul Web EIPASS Junior SCUOLA PRIMARIA Pagina 43 di 47 In questo modulo sono trattati gli argomenti principali dell universo di Internet, con particolare
Mentore. Rende ordinario quello che per gli altri è straordinario
 Mentore Rende ordinario quello che per gli altri è straordinario Vision Creare un futuro migliore per le Nuove Generazioni Come? Mission Rendere quante più persone possibili Libere Finanziariamente Con
Mentore Rende ordinario quello che per gli altri è straordinario Vision Creare un futuro migliore per le Nuove Generazioni Come? Mission Rendere quante più persone possibili Libere Finanziariamente Con
CIRCOLO DIDATTICO DI SAN MARINO Anno Scolastico 2013/2014
 CIRCOLO DIDATTICO DI SAN MARINO Anno Scolastico 2013/2014 RICERCA-AZIONE Insegnare per competenze: Lo sviluppo dei processi cognitivi Scuola Elementare Fiorentino DESCRIZIONE DELL ESPERIENZA Docente: Rosa
CIRCOLO DIDATTICO DI SAN MARINO Anno Scolastico 2013/2014 RICERCA-AZIONE Insegnare per competenze: Lo sviluppo dei processi cognitivi Scuola Elementare Fiorentino DESCRIZIONE DELL ESPERIENZA Docente: Rosa
Siamo così arrivati all aritmetica modulare, ma anche a individuare alcuni aspetti di come funziona l aritmetica del calcolatore come vedremo.
 DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
Scopri il piano di Dio: Pace e vita
 Scopri il piano di : Pace e vita E intenzione di avere per noi una vita felice qui e adesso. Perché la maggior parte delle persone non conosce questa vita vera? ama la gente e ama te! Vuole che tu sperimenti
Scopri il piano di : Pace e vita E intenzione di avere per noi una vita felice qui e adesso. Perché la maggior parte delle persone non conosce questa vita vera? ama la gente e ama te! Vuole che tu sperimenti
I libri di testo. Carlo Tarsitani
 I libri di testo Carlo Tarsitani Premessa Per accedere ai contenuti del sapere scientifico, ai vari livelli di istruzione, si usa comunemente anche un libro di testo. A partire dalla scuola primaria, tutti
I libri di testo Carlo Tarsitani Premessa Per accedere ai contenuti del sapere scientifico, ai vari livelli di istruzione, si usa comunemente anche un libro di testo. A partire dalla scuola primaria, tutti
Proposta di intervento rieducativo con donne operate al seno attraverso il sistema BIODANZA
 Proposta di intervento rieducativo con donne operate al seno attraverso il sistema BIODANZA Tornare a «danzare la vita» dopo un intervento al seno Micaela Bianco I passaggi Coinvolgimento medici e fisioterapiste
Proposta di intervento rieducativo con donne operate al seno attraverso il sistema BIODANZA Tornare a «danzare la vita» dopo un intervento al seno Micaela Bianco I passaggi Coinvolgimento medici e fisioterapiste
Accogliere e trattenere i volontari in associazione. Daniela Caretto Lecce, 27-28 aprile
 Accogliere e trattenere i volontari in associazione Daniela Caretto Lecce, 27-28 aprile Accoglienza Ogni volontario dovrebbe fin dal primo incontro con l associazione, potersi sentire accolto e a proprio
Accogliere e trattenere i volontari in associazione Daniela Caretto Lecce, 27-28 aprile Accoglienza Ogni volontario dovrebbe fin dal primo incontro con l associazione, potersi sentire accolto e a proprio
Sommario. Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi.
 Algoritmi 1 Sommario Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi. 2 Informatica Nome Informatica=informazione+automatica. Definizione Scienza che si occupa dell
Algoritmi 1 Sommario Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi. 2 Informatica Nome Informatica=informazione+automatica. Definizione Scienza che si occupa dell
ADOZIONE E ADOLESCENZA: LA COSTRUZIONE DELL IDENTITÀ E RICERCA DELLE ORIGINI
 ADOZIONE E ADOLESCENZA: LA COSTRUZIONE DELL IDENTITÀ E RICERCA DELLE ORIGINI DOTT. CARLOS A. PEREYRA CARDINI - PROF.SSA ALESSANDRA FERMANI PROF.SSA MORENA MUZI PROF. ELIO RODOLFO PARISI UNIVERSITÀ DEGLI
ADOZIONE E ADOLESCENZA: LA COSTRUZIONE DELL IDENTITÀ E RICERCA DELLE ORIGINI DOTT. CARLOS A. PEREYRA CARDINI - PROF.SSA ALESSANDRA FERMANI PROF.SSA MORENA MUZI PROF. ELIO RODOLFO PARISI UNIVERSITÀ DEGLI
GRUPPO DIAMANTE NETWORK MARKETING MLM
 GRUPPO DIAMANTE NETWORK MARKETING MLM 12 SUGGERIMENTI PER AVERE SUCCESSO COL MARKETING MULTI LIVELLO 1 PARTE I IL NETWORK MARKETING MLM Una domanda che ci viene rivolta spesso è: Come si possono creare
GRUPPO DIAMANTE NETWORK MARKETING MLM 12 SUGGERIMENTI PER AVERE SUCCESSO COL MARKETING MULTI LIVELLO 1 PARTE I IL NETWORK MARKETING MLM Una domanda che ci viene rivolta spesso è: Come si possono creare
Gestione del conflitto o della negoziazione
 1. Gestione del conflitto o della negoziazione Per ognuna delle 30 coppie di alternative scegli quella che è più vera per te. A volte lascio che siano gli altri a prendersi la responsabilità di risolvere
1. Gestione del conflitto o della negoziazione Per ognuna delle 30 coppie di alternative scegli quella che è più vera per te. A volte lascio che siano gli altri a prendersi la responsabilità di risolvere
INTRODUZIONE PRATICA AL LEAN MANAGEMENT
 INTRODUZIONE PRATICA AL LEAN MANAGEMENT Come ottenere più risultati con meno sforzo Immagina di conoscere quella metodologia aziendale che ti permette di: 1. 2. 3. 4. 5. 6. 7. 8. riconoscere e ridurre
INTRODUZIONE PRATICA AL LEAN MANAGEMENT Come ottenere più risultati con meno sforzo Immagina di conoscere quella metodologia aziendale che ti permette di: 1. 2. 3. 4. 5. 6. 7. 8. riconoscere e ridurre
liste di liste di controllo per il manager liste di controllo per il manager liste di controllo per i
 liste di controllo per il manager r il manager liste di controllo per il manager di contr liste di liste di controllo per il manager i controllo trollo per il man liste di il man liste di controllo per
liste di controllo per il manager r il manager liste di controllo per il manager di contr liste di liste di controllo per il manager i controllo trollo per il man liste di il man liste di controllo per
Mario Basile. I Veri valori della vita
 I Veri valori della vita Caro lettore, l intento di questo breve articolo non è quello di portare un insegnamento, ma semplicemente di far riflettere su qualcosa che noi tutti ben sappiamo ma che spesso
I Veri valori della vita Caro lettore, l intento di questo breve articolo non è quello di portare un insegnamento, ma semplicemente di far riflettere su qualcosa che noi tutti ben sappiamo ma che spesso
RICERCA DELL INFORMAZIONE
 RICERCA DELL INFORMAZIONE DOCUMENTO documento (risorsa informativa) = supporto + contenuto analogico o digitale locale o remoto (accessibile in rete) testuale, grafico, multimediale DOCUMENTO risorsa continuativa
RICERCA DELL INFORMAZIONE DOCUMENTO documento (risorsa informativa) = supporto + contenuto analogico o digitale locale o remoto (accessibile in rete) testuale, grafico, multimediale DOCUMENTO risorsa continuativa
La gestione delle emozioni: interventi educativi e didattici. Dott.ssa Monica Dacomo
 La gestione delle emozioni: interventi educativi e didattici Dott.ssa Monica Dacomo Attività per la scuola secondaria di I grado Chi o cosa provoca le nostre emozioni? Molti pensano che siano le altre
La gestione delle emozioni: interventi educativi e didattici Dott.ssa Monica Dacomo Attività per la scuola secondaria di I grado Chi o cosa provoca le nostre emozioni? Molti pensano che siano le altre
PLIDA Progetto Lingua Italiana Dante Alighieri Certificazione di competenza in lingua italiana
 PLIDA Progetto Lingua Italiana Dante Alighieri Certificazione di competenza in lingua italiana giugno 2011 PARLARE Livello MATERIALE PER L INTERVISTATORE 2 PLIDA Progetto Lingua Italiana Dante Alighieri
PLIDA Progetto Lingua Italiana Dante Alighieri Certificazione di competenza in lingua italiana giugno 2011 PARLARE Livello MATERIALE PER L INTERVISTATORE 2 PLIDA Progetto Lingua Italiana Dante Alighieri
Database 1 biblioteca universitaria. Testo del quesito
 Database 1 biblioteca universitaria Testo del quesito Una biblioteca universitaria acquista testi didattici su indicazione dei professori e cura il prestito dei testi agli studenti. La biblioteca vuole
Database 1 biblioteca universitaria Testo del quesito Una biblioteca universitaria acquista testi didattici su indicazione dei professori e cura il prestito dei testi agli studenti. La biblioteca vuole
I WEBQUEST SCIENZE DELLA FORMAZIONE PRIMARIA UNIVERSITÀ DEGLI STUDI DI PALERMO. Palermo 9 novembre 2011
 I WEBQUEST SCIENZE DELLA FORMAZIONE PRIMARIA Palermo 9 novembre 2011 UNIVERSITÀ DEGLI STUDI DI PALERMO Webquest Attività di indagine guidata sul Web, che richiede la partecipazione attiva degli studenti,
I WEBQUEST SCIENZE DELLA FORMAZIONE PRIMARIA Palermo 9 novembre 2011 UNIVERSITÀ DEGLI STUDI DI PALERMO Webquest Attività di indagine guidata sul Web, che richiede la partecipazione attiva degli studenti,
Intervista a Gabriela Stellutti, studentessa di italiano presso la Facoltà di Lettere dell Università di São Paulo (FFLCH USP).
.") In questa lezione abbiamo ricevuto Gabriella Stellutti che ci ha parlato delle difficoltà di uno studente brasiliano che studia l italiano in Brasile. Vi consiglio di seguire l intervista senza le didascalie
In questa lezione abbiamo ricevuto Gabriella Stellutti che ci ha parlato delle difficoltà di uno studente brasiliano che studia l italiano in Brasile. Vi consiglio di seguire l intervista senza le didascalie
Alla ricerca dell algoritmo. Scoprire e formalizzare algoritmi.
 PROGETTO SeT Il ciclo dell informazione Alla ricerca dell algoritmo. Scoprire e formalizzare algoritmi. Scuola media Istituto comprensivo di Fagagna (Udine) Insegnanti referenti: Guerra Annalja, Gianquinto
PROGETTO SeT Il ciclo dell informazione Alla ricerca dell algoritmo. Scoprire e formalizzare algoritmi. Scuola media Istituto comprensivo di Fagagna (Udine) Insegnanti referenti: Guerra Annalja, Gianquinto
COME MOTIVARE IL PROPRIO FIGLIO NELLO STUDIO
 COME MOTIVARE IL PROPRIO FIGLIO NELLO STUDIO Studiare non è tra le attività preferite dai figli; per questo i genitori devono saper ricorrere a strategie di motivazione allo studio, senza arrivare all
COME MOTIVARE IL PROPRIO FIGLIO NELLO STUDIO Studiare non è tra le attività preferite dai figli; per questo i genitori devono saper ricorrere a strategie di motivazione allo studio, senza arrivare all
Che volontari cerchiamo? Daniela Caretto Lecce, 27-28 aprile
 Che volontari cerchiamo? Daniela Caretto Lecce, 27-28 aprile Premessa All arrivo di un nuovo volontario l intero sistema dell associazione viene in qualche modo toccato. Le relazioni si strutturano diversamente
Che volontari cerchiamo? Daniela Caretto Lecce, 27-28 aprile Premessa All arrivo di un nuovo volontario l intero sistema dell associazione viene in qualche modo toccato. Le relazioni si strutturano diversamente
FINESTRE INTERCULTURALI
 Scuola Classe 1C FINESTRE INTERCULTURALI DIARIO DI BORDO 2013 / 2014 IC Gandhi - Secondaria di primo grado Paolo Uccello Insegnante / materia lettere Data Febbraio Durata 4h TITOLO DELLA FINESTRA INTERCULTURALE
Scuola Classe 1C FINESTRE INTERCULTURALI DIARIO DI BORDO 2013 / 2014 IC Gandhi - Secondaria di primo grado Paolo Uccello Insegnante / materia lettere Data Febbraio Durata 4h TITOLO DELLA FINESTRA INTERCULTURALE
La carriera universitaria e l inserimento nel mondo del lavoro dei laureati in Ingegneria dei Materiali
 La carriera universitaria e l inserimento nel mondo del lavoro dei laureati in Ingegneria dei Materiali Studenti che hanno conseguito la laurea specialistica nell anno solare 2009 Questa indagine statistica
La carriera universitaria e l inserimento nel mondo del lavoro dei laureati in Ingegneria dei Materiali Studenti che hanno conseguito la laurea specialistica nell anno solare 2009 Questa indagine statistica
YouLove Educazione sessuale 2.0
 YouLove Educazione sessuale 2.0 IL NOSTRO TEAM Siamo quattro ragazze giovani e motivate con diverse tipologie di specializzazione, due psicologhe, una dottoressa in Servizi Sociali e una dottoressa in
YouLove Educazione sessuale 2.0 IL NOSTRO TEAM Siamo quattro ragazze giovani e motivate con diverse tipologie di specializzazione, due psicologhe, una dottoressa in Servizi Sociali e una dottoressa in
PROCESSO DI INDICIZZAZIONE SEMANTICA
 PROCESSO DI INDICIZZAZIONE SEMANTICA INDIVIDUAZIONE DEI TEMI/CONCETTI SELEZIONE DEI TEMI/CONCETTI ESPRESSIONE DEI CONCETTI NEL LINGUAGGIO DI INDICIZZAZIONE TIPI DI INDICIZZAZIONE SOMMARIZZAZIONE INDICIZZAZIONE
PROCESSO DI INDICIZZAZIONE SEMANTICA INDIVIDUAZIONE DEI TEMI/CONCETTI SELEZIONE DEI TEMI/CONCETTI ESPRESSIONE DEI CONCETTI NEL LINGUAGGIO DI INDICIZZAZIONE TIPI DI INDICIZZAZIONE SOMMARIZZAZIONE INDICIZZAZIONE
Il concetto di Dare/Avere
 NISABA SOLUTION Il concetto di Dare/Avere Comprendere i fondamenti delle registrazioni in Partita Doppia Sara Mazza Edizione 2012 Sommario Introduzione... 3 Il Bilancio d Esercizio... 4 Stato Patrimoniale...
NISABA SOLUTION Il concetto di Dare/Avere Comprendere i fondamenti delle registrazioni in Partita Doppia Sara Mazza Edizione 2012 Sommario Introduzione... 3 Il Bilancio d Esercizio... 4 Stato Patrimoniale...
La Posta svizzera SecurePost SA, Oensingen
 La Posta svizzera SecurePost SA, Oensingen Il datore di lavoro Richard Mann Circa un anno e mezzo fa, nell ambito del progetto Integrazione di persone disabili presso la Posta, abbiamo assunto una nuova
La Posta svizzera SecurePost SA, Oensingen Il datore di lavoro Richard Mann Circa un anno e mezzo fa, nell ambito del progetto Integrazione di persone disabili presso la Posta, abbiamo assunto una nuova
Nina Cinque. Guida pratica per organizzarla perfettamente in una sola settimana! Edizioni Lefestevere
 Nina Cinque Guida pratica per organizzarla perfettamente in una sola settimana! Edizioni Lefestevere TITOLO: FESTA DI COMPLEANNO PER BAMBINI: Guida pratica per organizzarla perfettamente in una sola settimana!
Nina Cinque Guida pratica per organizzarla perfettamente in una sola settimana! Edizioni Lefestevere TITOLO: FESTA DI COMPLEANNO PER BAMBINI: Guida pratica per organizzarla perfettamente in una sola settimana!
GRUPPI DI INCONTRO per GENITORI
 Nell ambito delle attività previste dal servizio di Counseling Filosofico e di sostegno alla genitorialità organizzate dal nostro Istituto, si propone l avvio di un nuovo progetto per l organizzazione
Nell ambito delle attività previste dal servizio di Counseling Filosofico e di sostegno alla genitorialità organizzate dal nostro Istituto, si propone l avvio di un nuovo progetto per l organizzazione
IDEE PER LO STUDIO DELLA MATEMATICA
 IDEE PER LO STUDIO DELLA MATEMATICA A cura del 1 LA MATEMATICA: perché studiarla??? La matematica non è una disciplina fine a se stessa poichè fornisce strumenti importanti e utili in molti settori della
IDEE PER LO STUDIO DELLA MATEMATICA A cura del 1 LA MATEMATICA: perché studiarla??? La matematica non è una disciplina fine a se stessa poichè fornisce strumenti importanti e utili in molti settori della
FINESTRE INTERCULTURALI
 Scuola Classe 1C FINESTRE INTERCULTURALI DIARIO DI BORDO 2013 / 2014 IC Gandhi - Secondaria di primo grado Paolo Uccello Insegnante / materia Anelia Cassai/lettere Data Febbraio Durata 4h TITOLO DELLA
Scuola Classe 1C FINESTRE INTERCULTURALI DIARIO DI BORDO 2013 / 2014 IC Gandhi - Secondaria di primo grado Paolo Uccello Insegnante / materia Anelia Cassai/lettere Data Febbraio Durata 4h TITOLO DELLA
Maschere a Venezia VERO O FALSO
 45 VERO O FALSO CAP I 1) Altiero Ranelli è il direttore de Il Gazzettino di Venezia 2) Altiero Ranelli ha trovato delle lettere su MONDO-NET 3) Colombina è la sorella di Pantalone 4) La sera di carnevale,
45 VERO O FALSO CAP I 1) Altiero Ranelli è il direttore de Il Gazzettino di Venezia 2) Altiero Ranelli ha trovato delle lettere su MONDO-NET 3) Colombina è la sorella di Pantalone 4) La sera di carnevale,
Modulo: Scarsità e scelta
 In queste pagine è presentato un primo modello di conversione di concetti, schemi e argomentazioni di natura teorica relativi all argomento le scelte di consumo (presentato preliminarmente in aula e inserito
In queste pagine è presentato un primo modello di conversione di concetti, schemi e argomentazioni di natura teorica relativi all argomento le scelte di consumo (presentato preliminarmente in aula e inserito
UN REGALO INASPETTATO
 PIANO DI LETTURA dai 5 anni UN REGALO INASPETTATO FERDINANDO ALBERTAZZI Illustrazioni di Barbara Bongini Serie Bianca n 64 Pagine: 48 Codice: 566-0469-6 Anno di pubblicazione: 2012 L AUTORE Scrittore e
PIANO DI LETTURA dai 5 anni UN REGALO INASPETTATO FERDINANDO ALBERTAZZI Illustrazioni di Barbara Bongini Serie Bianca n 64 Pagine: 48 Codice: 566-0469-6 Anno di pubblicazione: 2012 L AUTORE Scrittore e
CORSO DI INFORMATICA PER ADULTI
 ISTITUTO COMPRENSIVO DI ROVELLASCA CORSO DI INFORMATICA PER ADULTI Docente: Ing. ALDO RUSSO 18 novembre 2015 LA PAROLA ALL ESPERTO Il posto dello strumento informatico nella cultura è tale che l educazione
ISTITUTO COMPRENSIVO DI ROVELLASCA CORSO DI INFORMATICA PER ADULTI Docente: Ing. ALDO RUSSO 18 novembre 2015 LA PAROLA ALL ESPERTO Il posto dello strumento informatico nella cultura è tale che l educazione
Il Problem-Based Learning dalla pratica alla teoria
 Il Problem-Based Learning dalla pratica alla teoria Il Problem-based learning (apprendimento basato su un problema) è un metodo di insegnamento in cui un problema costituisce il punto di inizio del processo
Il Problem-Based Learning dalla pratica alla teoria Il Problem-based learning (apprendimento basato su un problema) è un metodo di insegnamento in cui un problema costituisce il punto di inizio del processo
Donacibo 2015 Liceo classico statale Nicola Spedalieri di Catania
 Donacibo 2015 Liceo classico statale Nicola Spedalieri di Catania Sono Graziella, insegno al liceo classico e anche quest anno non ho voluto far cadere l occasione del Donacibo come momento educativo per
Donacibo 2015 Liceo classico statale Nicola Spedalieri di Catania Sono Graziella, insegno al liceo classico e anche quest anno non ho voluto far cadere l occasione del Donacibo come momento educativo per
www.domuslandia.it Il portale dell edilizia di qualità domuslandia.it è prodotto edysma sas
 domuslandia.it è prodotto edysma sas L evoluzione che ha subito in questi ultimi anni la rete internet e le sue applicazioni finalizzate alla pubblicità, visibilità delle attività che si svolgono e di
domuslandia.it è prodotto edysma sas L evoluzione che ha subito in questi ultimi anni la rete internet e le sue applicazioni finalizzate alla pubblicità, visibilità delle attività che si svolgono e di
Il database management system Access
 Il database management system Access Corso di autoistruzione http://www.manualipc.it/manuali/ corso/manuali.php? idcap=00&idman=17&size=12&sid= INTRODUZIONE Il concetto di base di dati, database o archivio
Il database management system Access Corso di autoistruzione http://www.manualipc.it/manuali/ corso/manuali.php? idcap=00&idman=17&size=12&sid= INTRODUZIONE Il concetto di base di dati, database o archivio
risulta (x) = 1 se x < 0.
 = 1 se x < 0.") Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
COME PARLARE DI DISLESSIA IN CLASSE.
 COME PARLARE DI DISLESSIA IN CLASSE. UNA METAFORA PER SPIEGARE I DSA La psicologa americana ANIA SIWEK ha sviluppato in anni di pratica professionale un modo semplice ed efficace di spiegare i DSA ai bambini,
COME PARLARE DI DISLESSIA IN CLASSE. UNA METAFORA PER SPIEGARE I DSA La psicologa americana ANIA SIWEK ha sviluppato in anni di pratica professionale un modo semplice ed efficace di spiegare i DSA ai bambini,
Il funzionamento di prezzipazzi, registrazione e meccanismi
 Prima di spiegare prezzipazzi come funziona, facciamo il punto per chi non lo conoscesse. Nell ultimo periodo si fa un gran parlare di prezzipazzi ( questo il sito ), sito che offre a prezzi veramente
Prima di spiegare prezzipazzi come funziona, facciamo il punto per chi non lo conoscesse. Nell ultimo periodo si fa un gran parlare di prezzipazzi ( questo il sito ), sito che offre a prezzi veramente
Introduzione L insegnante: Oggi impareremo a conoscere le nostre capacità e quelle degli altri. Impareremo anche come complementarsi a vicenda.
 www.gentletude.com Impara la Gentilezza 5 FARE COMPLIMENTI AGLI ALTRI Guida Rapida Obiettivi: i bambini saranno in grado di: di identificare i talenti e i punti di forza propri e degli altri, e scoprire
www.gentletude.com Impara la Gentilezza 5 FARE COMPLIMENTI AGLI ALTRI Guida Rapida Obiettivi: i bambini saranno in grado di: di identificare i talenti e i punti di forza propri e degli altri, e scoprire
LA DISTRIBUZIONE DI PROBABILITÀ DEI RITORNI AZIONARI FUTURI SARÀ LA MEDESIMA DEL PASSATO?
 LA DISTRIBUZIONE DI PROBABILITÀ DEI RITORNI AZIONARI FUTURI SARÀ LA MEDESIMA DEL PASSATO? Versione preliminare: 25 Settembre 2008 Nicola Zanella E-Mail: n.zanella@yahoo.it ABSTRACT In questa ricerca ho
LA DISTRIBUZIONE DI PROBABILITÀ DEI RITORNI AZIONARI FUTURI SARÀ LA MEDESIMA DEL PASSATO? Versione preliminare: 25 Settembre 2008 Nicola Zanella E-Mail: n.zanella@yahoo.it ABSTRACT In questa ricerca ho
Manifesto TIDE per un Educazione allo Sviluppo accessibile
 Manifesto TIDE per un Educazione allo Sviluppo accessibile Pagina 2 Contenuto Il progetto TIDE...4 Il manifesto TIDE...6 La nostra Dichiarazione...8 Conclusioni...12 Pagina 3 Il progetto TIDE Verso un
Manifesto TIDE per un Educazione allo Sviluppo accessibile Pagina 2 Contenuto Il progetto TIDE...4 Il manifesto TIDE...6 La nostra Dichiarazione...8 Conclusioni...12 Pagina 3 Il progetto TIDE Verso un
GIORNATA DEL VOLONTARIATO. Torino 7 aprile 2013. regionale a tutti i volontari piemontesi che hanno accolto l invito a
 GIORNATA DEL VOLONTARIATO Torino 7 aprile 2013 Desidero porgere un caloroso saluto a nome dell intera Assemblea regionale a tutti i volontari piemontesi che hanno accolto l invito a partecipare a questa
GIORNATA DEL VOLONTARIATO Torino 7 aprile 2013 Desidero porgere un caloroso saluto a nome dell intera Assemblea regionale a tutti i volontari piemontesi che hanno accolto l invito a partecipare a questa
Casa di cura e di riposo per anziani di Gundeldingen, Basilea (BS)
") Casa di cura e di riposo per anziani di Gundeldingen, Basilea (BS) Werner Wassermann, datore di lavoro La signora L. lavora da noi da tanto tempo. È stata capo reparto e noi, ma anche gli altri collaboratori
Casa di cura e di riposo per anziani di Gundeldingen, Basilea (BS) Werner Wassermann, datore di lavoro La signora L. lavora da noi da tanto tempo. È stata capo reparto e noi, ma anche gli altri collaboratori
Dizionario Italiano/Lingua dei segni italiana
 DIZLIS 2.0 CTS IPSSS E. De Amicis Dizionario Italiano/Lingua dei segni italiana Un dizionario è un'opera che raccoglie, in modo ordinato secondo criteri anche variabili da un'opera all'altra, le parole
DIZLIS 2.0 CTS IPSSS E. De Amicis Dizionario Italiano/Lingua dei segni italiana Un dizionario è un'opera che raccoglie, in modo ordinato secondo criteri anche variabili da un'opera all'altra, le parole
COME AFFRONTARE UN COLLOQUIO DI SELEZIONE
 Emanuele Lajolo di Cossano COME AFFRONTARE UN COLLOQUIO DI SELEZIONE Università degli Studi - Torino, 19 aprile 2010 La prima cosa da fare PERCHE SONO QUI? QUAL E IL MIO OBIETTIVO? CHE COSA VOGLIO ASSOLUTAMENTE
Emanuele Lajolo di Cossano COME AFFRONTARE UN COLLOQUIO DI SELEZIONE Università degli Studi - Torino, 19 aprile 2010 La prima cosa da fare PERCHE SONO QUI? QUAL E IL MIO OBIETTIVO? CHE COSA VOGLIO ASSOLUTAMENTE
Lezione n 2 L educazione come atto ermeneutico (2)
") Lezione n 2 L educazione come atto ermeneutico (2) Riprendiamo l analisi interrotta nel corso della precedente lezione b) struttura dialogica del fatto educativo Per rispondere a criteri ermenutici, l
Lezione n 2 L educazione come atto ermeneutico (2) Riprendiamo l analisi interrotta nel corso della precedente lezione b) struttura dialogica del fatto educativo Per rispondere a criteri ermenutici, l
Memory Fitness TECNICHE DI MEMORIA
 Memory Fitness TECNICHE DI MEMORIA IMPARIAMO DAGLI ERRORI Impariamo dagli errori (1/5) Impariamo dagli errori (2/5) Il più delle volte siamo portati a pensare o ci hanno fatto credere di avere poca memoria,
Memory Fitness TECNICHE DI MEMORIA IMPARIAMO DAGLI ERRORI Impariamo dagli errori (1/5) Impariamo dagli errori (2/5) Il più delle volte siamo portati a pensare o ci hanno fatto credere di avere poca memoria,
relazionarvi su cosa sta capitando e sui progetti che stanno bambine avrebbero bisogno di essere appadrinate come dicono
 Carissimi amici, Sono appena tornato dal Paraguay, e vorrei un po relazionarvi su cosa sta capitando e sui progetti che stanno evolvendo. All hogar le cose si stanno normalizzando. Direi che le bambine
Carissimi amici, Sono appena tornato dal Paraguay, e vorrei un po relazionarvi su cosa sta capitando e sui progetti che stanno evolvendo. All hogar le cose si stanno normalizzando. Direi che le bambine
Una semplice visita in officina con intervista
 Una semplice visita in officina con intervista Ricevo i prezzi più velocemente. Questo mi aiuta molto. Il carpentiere metallico specializzato Martin Elsässer ci parla del tempo. Una semplice visita in
Una semplice visita in officina con intervista Ricevo i prezzi più velocemente. Questo mi aiuta molto. Il carpentiere metallico specializzato Martin Elsässer ci parla del tempo. Una semplice visita in
CONSIGLI PER POTENZIARE L APPRENDIMENTO DELLA LINGUA
 CONSIGLI PER POTENZIARE L APPRENDIMENTO DELLA LINGUA Possiamo descrivere le strategie di apprendimento di una lingua straniera come traguardi che uno studente si pone per misurare i progressi nell apprendimento
CONSIGLI PER POTENZIARE L APPRENDIMENTO DELLA LINGUA Possiamo descrivere le strategie di apprendimento di una lingua straniera come traguardi che uno studente si pone per misurare i progressi nell apprendimento
LE STRATEGIE DI COPING
 Il concetto di coping, che può essere tradotto con fronteggiamento, gestione attiva, risposta efficace, capacità di risolvere i problemi, indica l insieme di strategie mentali e comportamentali che sono
Il concetto di coping, che può essere tradotto con fronteggiamento, gestione attiva, risposta efficace, capacità di risolvere i problemi, indica l insieme di strategie mentali e comportamentali che sono
U.V.P. la base del Marketing U. V. P. Non cercare di essere un uomo di successo. Piuttosto diventa un uomo di valore Albert Einstein
 U.V.P. la base del Marketing U. V. P. Non cercare di essere un uomo di successo. Piuttosto diventa un uomo di valore Albert Einstein U.V.P. la base del Marketing U. V. P. Unique Value Propositon U.V.P.
U.V.P. la base del Marketing U. V. P. Non cercare di essere un uomo di successo. Piuttosto diventa un uomo di valore Albert Einstein U.V.P. la base del Marketing U. V. P. Unique Value Propositon U.V.P.
COME NON PERDERE TEMPO NEL NETWORK MARKETING!
 COME NON PERDERE TEMPO NEL NETWORK MARKETING Grazie per aver scaricato questo EBOOK Mi chiamo Fabio Marchione e faccio network marketing dal 2012, sono innamorato e affascinato da questo sistema di business
COME NON PERDERE TEMPO NEL NETWORK MARKETING Grazie per aver scaricato questo EBOOK Mi chiamo Fabio Marchione e faccio network marketing dal 2012, sono innamorato e affascinato da questo sistema di business
Scuola dell Infanzia Parrocchiale San Domenico Via C.P. Taverna n.6 20050 Canonica di Triuggio Tel.0362.997127 P.I. 00985860964
 Pagina 1 di 7 PREMESSA E FINALITA La sezione primavera nasce, all interno della scuola dell Infanzia nel settembre 2007 come sperimentazione messa in atto dal Ministro Fioroni e continua fino ad oggi.
Pagina 1 di 7 PREMESSA E FINALITA La sezione primavera nasce, all interno della scuola dell Infanzia nel settembre 2007 come sperimentazione messa in atto dal Ministro Fioroni e continua fino ad oggi.
Introduzione al Semantic Web
 Corso di Laurea Specialistica in Ingegneria Gestionale Corso di Sistemi Informativi Modulo II A. A. 2013-2014 Giuseppe Loseto Dal Web al Semantic Web 2 Dal Web al Semantic Web: Motivazioni Il Web dovrebbe
Corso di Laurea Specialistica in Ingegneria Gestionale Corso di Sistemi Informativi Modulo II A. A. 2013-2014 Giuseppe Loseto Dal Web al Semantic Web 2 Dal Web al Semantic Web: Motivazioni Il Web dovrebbe
Il Sito web professionale dedicato al settore Trasportatori e spedizionieri. Provalo subito all indirizzo web: www.soluzionicreative.
 Il Sito web professionale dedicato al settore Trasportatori e spedizionieri GlobeAround è il sito web studiato e sviluppato per soddisfare le esigenze di visibilità e comunicazione delle aziende che operano
Il Sito web professionale dedicato al settore Trasportatori e spedizionieri GlobeAround è il sito web studiato e sviluppato per soddisfare le esigenze di visibilità e comunicazione delle aziende che operano
BASI DI DATI per la gestione dell informazione. Angelo Chianese Vincenzo Moscato Antonio Picariello Lucio Sansone
 BASI DI DATI per la gestione dell informazione Angelo Chianese Vincenzo Moscato Antonio Picariello Lucio Sansone Libro di Testo 22 Chianese, Moscato, Picariello e Sansone BASI DI DATI per la Gestione dell
BASI DI DATI per la gestione dell informazione Angelo Chianese Vincenzo Moscato Antonio Picariello Lucio Sansone Libro di Testo 22 Chianese, Moscato, Picariello e Sansone BASI DI DATI per la Gestione dell
Internet i vostri figli vi spiano! La PAROLA-CHIAVE: cacao Stralci di laboratorio multimediale
 Internet i vostri figli vi spiano! La PAROLA-CHIAVE: cacao Stralci di laboratorio multimediale Ins: nel laboratorio del Libro avevamo detto che qui, nel laboratorio multimediale, avremmo cercato qualcosa
Internet i vostri figli vi spiano! La PAROLA-CHIAVE: cacao Stralci di laboratorio multimediale Ins: nel laboratorio del Libro avevamo detto che qui, nel laboratorio multimediale, avremmo cercato qualcosa
LOCUZIONI AL MONDO. Il mistero di ogni persona (22/4/2013 24/4/2013) Testi tradotti dai messaggi originali pubblicati sul sito Locutions to the World
 Testi tradotti dai messaggi originali pubblicati sul sito Locutions to the World") LOCUZIONI AL MONDO Il mistero di ogni persona (22/4/2013 24/4/2013) Testi tradotti dai messaggi originali pubblicati sul sito Locutions to the World 2 Sommario 1. La decisione della SS. Trinità al tuo
LOCUZIONI AL MONDO Il mistero di ogni persona (22/4/2013 24/4/2013) Testi tradotti dai messaggi originali pubblicati sul sito Locutions to the World 2 Sommario 1. La decisione della SS. Trinità al tuo
Amore in Paradiso. Capitolo I
 4 Amore in Paradiso Capitolo I Paradiso. Ufficio dei desideri. Tanti angeli vanno e vengono nella stanza. Arriva un fax. Lo ha mandato qualcuno dalla Terra, un uomo. Quando gli uomini vogliono qualcosa,
4 Amore in Paradiso Capitolo I Paradiso. Ufficio dei desideri. Tanti angeli vanno e vengono nella stanza. Arriva un fax. Lo ha mandato qualcuno dalla Terra, un uomo. Quando gli uomini vogliono qualcosa,
L UOMO L ORGANIZZAZIONE
 UNITÀ DIDATTICA 1 L UOMO E L ORGANIZZAZIONE A.A 2007 / 2008 1 PREMESSA Per poter applicare con profitto le norme ISO 9000 è necessario disporre di un bagaglio di conoscenze legate all organizzazione aziendale
UNITÀ DIDATTICA 1 L UOMO E L ORGANIZZAZIONE A.A 2007 / 2008 1 PREMESSA Per poter applicare con profitto le norme ISO 9000 è necessario disporre di un bagaglio di conoscenze legate all organizzazione aziendale
Alessandro Ricci Psicologo Psicoterapeuta Università Salesiana di Roma
 Alessandro Ricci Psicologo Psicoterapeuta Università Salesiana di Roma LA COPPIA NON PUO FARE A MENO DI RICONOSCERE E ACCETTARE CHE L ALTRO E UN TU E COME TALE RAPPRESENTA NON UN OGGETTO DA MANIPOLARE
Alessandro Ricci Psicologo Psicoterapeuta Università Salesiana di Roma LA COPPIA NON PUO FARE A MENO DI RICONOSCERE E ACCETTARE CHE L ALTRO E UN TU E COME TALE RAPPRESENTA NON UN OGGETTO DA MANIPOLARE
MOCA. Modulo Candidatura. http://www.federscacchi.it/moca. moca@federscacchi.it. [Manuale versione 1.0 marzo 2013]
![MOCA. Modulo Candidatura. http://www.federscacchi.it/moca. moca@federscacchi.it. [Manuale versione 1.0 marzo 2013]](/thumbs/25/5308947.jpg "MOCA. Modulo Candidatura. http://www.federscacchi.it/moca. moca@federscacchi.it. [Manuale versione 1.0 marzo 2013]") MOCA Modulo Candidatura http://www.federscacchi.it/moca moca@federscacchi.it [Manuale versione 1.0 marzo 2013] 1/12 MOCA in breve MOCA è una funzionalità del sito web della FSI che permette di inserire
MOCA Modulo Candidatura http://www.federscacchi.it/moca moca@federscacchi.it [Manuale versione 1.0 marzo 2013] 1/12 MOCA in breve MOCA è una funzionalità del sito web della FSI che permette di inserire
Il motore semantico della PA piemontese. Marta Garabuggio - Regione Piemonte Carlo Fortunato CSI - Piemonte
 Marta Garabuggio - Regione Piemonte Carlo Fortunato CSI - Piemonte Sommario Lo scenario Il web della PA piemontese Gli obiettivi La soluzione individuata La tassonomia a faccette Il vocabolario controllato
Marta Garabuggio - Regione Piemonte Carlo Fortunato CSI - Piemonte Sommario Lo scenario Il web della PA piemontese Gli obiettivi La soluzione individuata La tassonomia a faccette Il vocabolario controllato
I sistemi di accumulo di energia elettrica nel residenziale. Roma, 17 settembre 2013
 I sistemi di accumulo di energia elettrica nel residenziale Roma, 17 settembre 2013 Intervento di Claudio Andrea Gemme, Presidente ANIE Confindustria Signore e Signori, buongiorno. Grazie a tutti voi per
I sistemi di accumulo di energia elettrica nel residenziale Roma, 17 settembre 2013 Intervento di Claudio Andrea Gemme, Presidente ANIE Confindustria Signore e Signori, buongiorno. Grazie a tutti voi per