Sistemi superscalari. Contenuto della lezione. Unità multifunzionali parallele Architetture superscalari Esecuzione fuori ordine
|
|
|
- Aurelia Paoletti
- 8 anni fa
- Visualizzazioni
Transcript
1 Sistemi superscalari Contenuto della lezione Unità multifunzionali parallele Architetture superscalari Esecuzione fuori ordine Calcolatori (G.B.) Superscalari 1

2 Architettura superscalare Lo stadio viene anche detto Instruction Issue Calcolatori (G.B.) Superscalari 3

3 Ipotesi sui CPI delle unità Classe UF C PI add/sub UI1 1 mul UI2 2 addf/mulf FPU 4 Ipotizzeremo che venga emessa verso lo stadio EX una istruzione alla volta potrà al massimo essere ritirata una istruzione alla volta per ora di superscalare c è solo il parallelismo tra le UF; non c è l esecuzione di più di un istruzione alla volta!! Calcolatori (G.B.) Superscalari 4

4 Emissione in ordine Determina il completamento fuori ordine. Esempio: 1 (100) mulf f1,f7,f8 4 cicli in FPU 2 (104) add r2,r4,r5 1 ciclo in IU1 3 (108) mul r3,r10,r11 2 cicli in IU2 4 (112) addf f4, f6,f6 4 cicli in FPU Profilo di esecuzione Calcolatori (G.B.) Superscalari 5

5 Tre metodi Lo stato di macchina deve corrispondere all ordine del programma Completamento in ordine: si forzano le istruzioni ad essere completate seguendo l'ordine architetturale Buffer di Riordinamento: le istruzioni sono completate fuori ordine ma sono forzate a modificare lo stato della macchina seguendo l'ordine architetturale History Buffer: le istruzioni possono aggiornare lo stato in qualsiasi ordine, conservando però la possibilità di ripristinare uno stato coerente in presenza di conflitti. Calcolatori (G.B.) Superscalari 6

6 Modello RSR: Reservation Shift Register Formato mul entra qui Calcolatori (G.B.) Superscalari 7

7 Uso campi RSR V: Bit di validità; dice se la posizione contiene informazioni o se è da ritenersi vuota. PC: PC dell istruzione; necessario per ripristinare uno stato coerente in caso di predizione di salto errata. UF: al completamento di una istruzione (uscita da RSR) serve a individuare da quale UF deve essere preso il risultato da trasmettere a Rd. Rd: individua il registro di destinazione del risultato Non c è bisogno di tenere traccia di Rd nelle (pipeline delle) UF. Calcolatori (G.B.) Superscalari 8

8 Completamento in ordine Si ottiene attraverso la prenotazione di RSR in modo forzare la conclusione secondo l'ordine del programma. Due aspetti: Completamento in ordine rispetto ai registri Completamento in ordine rispetto alla memoria Nel completamento in ordine rispetto ai registri si tratta di prenotare il bus dei risultati in modo che le istruzioni non passino avanti Calcolatori (G.B.) Superscalari 9

9 Rispetto ai registri L istruzione che occupa la posizione j in RSR occupa anche tutte le precedenti Per occupare le posizioni si usa V Nelle posizioni occupate che non contengono una effettiva istruzione si usa dummy per in campo UF. L istruzione che trova la posizione occupata attende che si liberi (ovvero che le istruzioni che la precedevano abbiano superato la posizione) Calcolatori (G.B.) Superscalari 10

10 Sequenza e profilo di esecuzione 4 clock 1clock 1 clock Calcolatori (G.B.) Superscalari 11

11 Rispetto alla memoria (Store) Due metodi (equivalenti): non viene emesso alcun comando di memorizzazione (store) prima che le istruzioni precedentemente emesse (tra cui eventuali istruzioni di diramazione) siano state completate in modo corretto: l istruzione ST resta nel registro di emissione fino a quando RSR non è vuoto. La memoria è considerata come un unità funzionale. Analogamente a ogni altra istruzione, store occupa una posizione in RSR in modo che questa raggiunga la cima quando tutte le istruzioni emesse in precedenza sono state completate. Al raggiungimento della cima di RSR, l'unità load/store viene comandata all'esecuzione della memorizzazione richiesta. Calcolatori (G.B.) Superscalari 12

12 Buffer di riordinamento (ROB) Se non ci fosse il problema dell accesso al bus basterebbe solo il ROB a tenere l ordine Calcolatori (G.B.) Superscalari 13

13 Sequenza Calcolatori (G.B.) Superscalari 14

14 Sequenza Calcolatori (G.B.) Superscalari 15

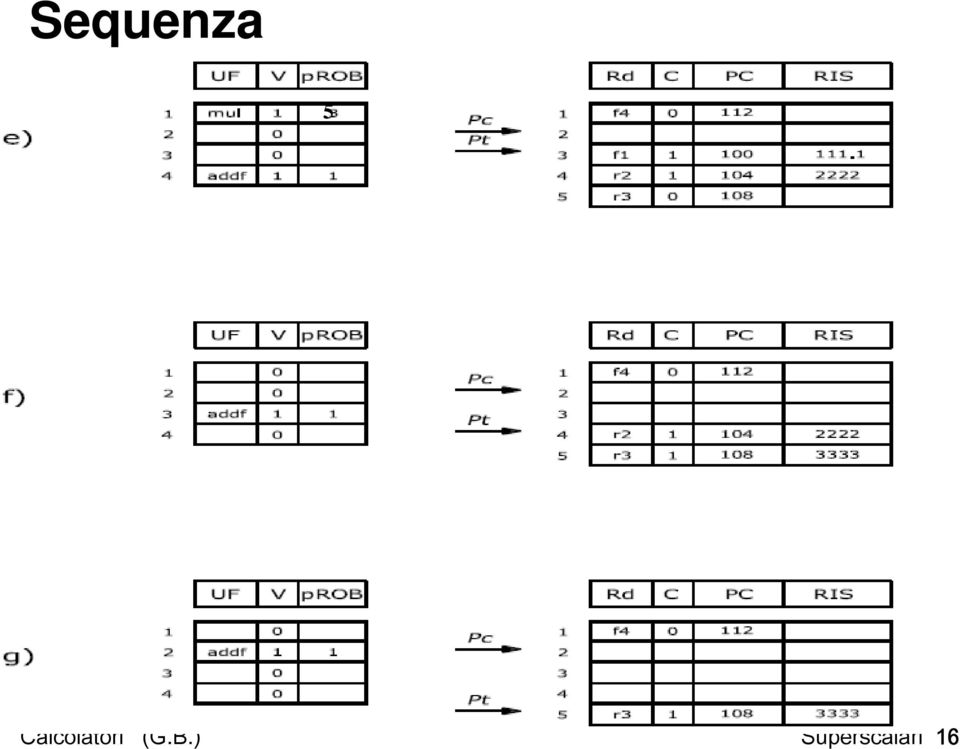
15 Sequenza 5 Calcolatori (G.B.) Superscalari 16
16 Profili di esecuzione con il ROB Nel libro c è un errore nella caption Calcolatori (G.B.) Superscalari 17

17 Bypass Per anticipare i risultati ancora non consegnati Ovviamente qui ci va un MUX Calcolatori (G.B.) Superscalari 18

18 History buffer (HB) L istruzione completata dalla sua UF scrive immediatamente i risultati in RF, ma il vecchio valore contenuto in RF resta in HB fino a che l istruzione non emerge L ordine di emissione deve garantire coerenza rispetto alle dipendenze dati I motivi per ripristinare lo stato corrente sono legati alle interruzioni e alle previsioni di salto errate Calcolatori (G.B.) Superscalari 19

19 History Buffer (HB) Ci vuole un percorso RF HB Calcolatori (G.B.) Superscalari 20
 Superscalari 20")
20 Gestione conflitti di controllo Predizione errata con esecuzione fuori ordine: istruzioni provenienti dal percorso errato possono essere state completate prima della soluzione della diramazione. In tal caso, lo stato della macchina è modificato ed occorre ripristinare lo stato che si aveva prima dell istruzione di diramazione Nota: Nel caso della pipeline lineare bastava svuotarla delle istruzioni prese dal percorso errato. Calcolatori (G.B.) Superscalari 21

21 Ripristino stato coerente (con ROB) Si associa alle istruzioni il bit EPR (errata predizione, che ha significato per le sole diramazioni) Quando l istruzione emerge dalla testa del ROB se EPR è asserito si svuota la pipeline (il ROB) di tutte le istruzioni sul percorso errato (che vengono dietro nel ROB) e si inizia a ricaricare dalla effettiva destinazione. Equivale a non far scrivere nei registri e in memoria alle istruzioni che risultano sul cammino mal predetto Calcolatori (G.B.) Superscalari 22
22 Ripristino stato coerente (con HB) Si aggiunge EPR. Quando un istruzione di diramazione arriva in testa ad HB, se EPR è asserito: Viene bloccato HB e viene bloccata l'emissione di nuove istruzioni da parte dell'issue Register Si attende che le operazioni ancora attive vengano completate (cioè che si svuoti la pipeline) Partendo dalla coda verso la testa, vengono cancellati gli elementi in HB e, contemporaneamente, vengono riscritti nei registri di destinazione i vecchi valori, contenuti nel buffer, fino ad arrivare alla prima istruzione sul percorso sbagliato L'esecuzione del programma riprende prelevando l'istruzione proveniente dal percorso corretto. Calcolatori (G.B.) Superscalari 23
23 Superscalari? Abbiamo assunto l emissione e il ritiro di una istruzione alla volta Se viene emessa una sola istruzione alla volta non accadrà mai che vengano eseguite più di una istruzione per clock Decodificare ed emettere più istruzioni in parallelo Ritirare più istruzioni in parallelo Calcolatori (G.B.) Superscalari 24
24 Come fare con il ROB Le macchine correnti leggono dalla cache linee che possono contenere più parole Per esempio linee di 4 parole (128 bit) Qui c è il ROB Calcolatori (G.B.) Superscalari 25
25 Esempio: il Pentium NB: Non c è il ROB Due pipe in parallelo 8 K byte 8 K byte Calcolatori (G.B.) Superscalari 26
26 La pipeline del Pentium Calcolatori (G.B.) Superscalari 27
27 Pipeline Pentium Calcolatori (G.B.) Superscalari 28
28 Pentium Le due pipe non erano perfettamente uguali; la pipe U aveva una sorta di predominanza Normalmente venivano emesse due istruzioni in parallelo, ma questo (a seconda delle istruzioni) non sempre era possibile Al termine venivano consegnate due istruzioni in parallelo (se era possibile) sempre conservando l ordine del programma Calcolatori (G.B.) Superscalari 29
29 In generale Se si emettono e si ritirano più istruzioni in parallelo vuol dire che ci sono più percorsi verso le unità di esecuzione e più percorsi (bus) verso il ROB utilizzabili in parallelo Si complica la gestione dei bus dei risultati: occorre garantire che se un istruzione viene emessa essa, al completamento, troverà un percorso verso il ROB Calcolatori (G.B.) Superscalari 30
30 Emissione e ritiro Il ROB fa da buffer e deve essere riempito secondo l ordine del programma. Resta quindi il problema della prenotazione delle posizioni nel ROB L emissione deve avvenire in modo che ad un generico clock completi un numero di istruzioni non superiore al numero di percorsi verso il ROB (altrimenti occorre stallare alcune FU, con ripercussione sull emissione) Non è detto che si possano sempre emettere tante istruzioni quanti sono i percorsi alle FU Calcolatori (G.B.) Superscalari 31
31 Esempio Supponiamo che ci sia la possibilità di emettere e di ritirare fino a 3 istruzioni in parallelo (la pipeline è quella del trasp. n. 3) 1. mul r2,r6,r1 ; 2 cicli 2. mulf f12,f8,f10 ; 4 cicli 3. add r4,r5,r6 ; 1 ciclo 4. mul r3,r7,r7 ; 2 cicli 5. sub r8,r9,r8 ; 1 ciclo 6. add r20,r21,r22 ; 1 ciclo 7. mul r3,r4,45 ; 2 ciclo 8. mul r2,r2,r2 ; 2 cicli 9. mulf f2,f3,f4 ; 4 cicli 10.add r5,r6,r7 ; 1 ciclo Possono essere emesse in parallelo Emesse queste 2 Emesse queste 2 Calcolatori (G.B.) Superscalari 32
32 Primi due clock 3 1 ROB ROB Calcolatori (G.B.) Superscalari 33
33 3 e 4 clock 6 ROB ROB Calcolatori (G.B.) Superscalari 34
34 Al clock successivo (ipotesi: il ROB è lungo quanto serve) (3 emesse) Successivamente possono essere prelevate 2, 3 e 4 Al clock di poi verrebbero prelevate 5, 6 e 7 Calcolatori (G.B.) Superscalari 35
35 Emissione/Ritiro Nell ipotesi di 3 percorsi verso il ROB e 3 FU non ci possono essere conflitti in uscita alle FU: l emissione può avvenire appena possibile Se ci sono meno percorsi che FU c è conflitto tutte le volte che sullo stesso clock completa un numero di istruzioni superiore al numero dei percorsi. Richiede RSR (più complesso) Il ROB è limitato: è possibile che si debba sospendere l emissione per evitare il trabocco Calcolatori (G.B.) Superscalari 36
36 Dipendenze Nell esempio precedente non c erano dipendenze tra le istruzioni (solo vincoli legati al numero di FU e al numero di percorsi) 1. ld r1,v1(r0) ; 3 cicli 2. mul r1,r1,r1 ; 2 cicli 3. mulf f2,f3,f4 ; 4 cicli 4. add r4,r5,r6 ; 1 ciclo 5. st x(r8),r7 ; 2 cicli 2 non può essere emessa deve aspettare che 1 abbia scritto il registro r1: si blocca l emissione Calcolatori (G.B.) Superscalari 37
37 Dipendenze ld r1,v1(r0) ;3 c mul r1,r1,r1 ;2 c Quanto aspetta mul prima di essere emessa? 4 clock se il risultato viene comunque parcheggiato in ROB 3 clock se non c è il passaggio da ROB per le istruzioni che completano e non hanno da aspettare il completamento delle precedenti Bisogna migliorare lo schema precedente in modo da poter emettere le istruzioni seguenti che non hanno dipendenze (esecuzione fuori ordine) Calcolatori (G.B.) Superscalari 38
38 Soluzione 1 Prevedere uno (o più) slot di attesa per ogni FU, in modo che un istruzione come la mul possa essere comunque emessa consentendo di avanzare con l emissione delle istruzioni che seguono ld r1,v1(r0) mul r1,r1,r1 mulf f2,f3,f4 add r4,r5,r6 st x(r8),r7 mulf f1,f2,f5 Emesse assieme: mul va ad attendere nello slot di IU2 Emesse assieme: mulf va ad attendere nello slot di FPU Tecnica usata dal PowerPC Calcolatori (G.B.) Superscalari 39
39 PowerPC Emissione Decode Queue Dispatch Queue Calcolatori (G.B.) Superscalari 40
40 PowerPC pipeline Calcolatori (G.B.) Superscalari 41
41 PowerPC pipeline Queste hanno 2 slot di attesa Calcolatori (G.B.) Superscalari 42
42 Soluzione Posizionare diversamente il ROB Lo stadio di emissione emette direttamente in ROB Emette quando nel ROB c è posto (non serve RSR) 2. Le unità di esecuzione prelevano dal ROB e riscrivono i risultati nel ROB 3. Lo stadio di WB preleva dal ROB Calcolatori (G.B.) Superscalari 43
43 Soluzione 2 Calcolatori (G.B.) Superscalari 44
44 Soluzione 2 E lo schema del Pentium Pro (e seguenti) Calcolatori (G.B.) Superscalari 45
45 Il Pentium Pro (Novembre 1995) Calcolatori (G.B.) Superscalari 46
46 Pipeline Pentium Pro 12 stadi Fetch/Decode primi 8 stadi Dispatch/Execute 3 (di più, di più!) stadi intermedi Retirement stadio finale Calcolatori (G.B.) Superscalari 47
47 Schema Intel (oggi introvabile) Fetch/Decode Unit: Front-End di emissione in ordine Dispatch/Execute Unit: Esecuzione fuori ordine Retirement Unit: prelievo da ROB e scrittura nei registri Calcolatori (G.B.) Superscalari 48
48 Dispatch/execution unit Calcolatori (G.B.) Superscalari 49
49 Un piccolo dettaglio L architettura Intel ha un repertorio CISC Istruzioni di diverso formato (da 1 a 8 e più byte) Repertorio esteso Pochi registri di uso generale Per rendere efficiente la pipeline: Istruzioni architetturali trasformate in microoperazioni (uop) dallo stadio di decodifica Ridenominazione dei registri Una uop è una tripla (due sorgenti e una destinazione) Calcolatori (G.B.) Superscalari 50
50 Trattamento microop Calcolatori (G.B.) Superscalari 51
51 Dettagli La stazione di decodifica contiene 3 decodificatori (stadio ID0) Ad ogni clock possono essere decodificate fino a 3 istruzioni IA e possono uscire dal decodificatore fino a 6 uop [a valle del decodificatore c è un buffer (stadio ID1) di 6 posizioni] Le istruzioni IA che generano più di una uop devono essere necessariamente decodificate dal decodificatore D2 (microcode). Calcolatori (G.B.) Superscalari 52
52 ... Dettagli Lo stadio RAT/allocator ha capienza per 3 uop (ne può incamerare/rilasciare 3 a ciclo di clock). Il ROB può contenere fino a 40 uop. I registri fisici sono nel ROB e sono 40 Funzione dello stadio RAT/allocator: Assegnare un numero d ordine progressivo alle uop all atto dell immissione (in sequenza) nel ROB Mappare gli otto registri dell architettura nei 40 registri fisici RAT/allocator è l ultimo stadio in ordine Calcolatori (G.B.) Superscalari 53
53 Esecuzione fuori Ordine Nel ROB le uop vengono eseguite in base al loro stato (dipendenza dati e disponibilità operandi) e disponibilità delle risorse necessarie alla loro esecuzione. La ricerca può far avanzare anche di 20 o 30 istruzioni all'interno del ROB Le micro-op che soddisfano ai requisiti vengono prelevate dal ROB e passate alle effettive unità di esecuzione. Il processo di selezione si svolge nello stadio DS (RS) che dispone di 5 porte di comunicazione con le unità deputate all'esecuzione delle uop. Calcolatori (G.B.) Superscalari 54
54 Esecuzione fuori ordine Se viene predetta una diramazione: si possono emettere le istruzioni dalla nuova posizione, ma se la predizione è errata le istruzioni sulla via mal predetta non devono avere alcun effetto. Si parla di esecuzione Speculativa. Le interruzioni costituiscono una complicazione orrenda: l interruzione può arrivare in qualunque istante. Occorre salvare uno stato congruente (alcune istruzioni potrebbero essere già completate, ma vanno annullate e rifatte quando tornerà il controllo) Calcolatori (G.B.) Superscalari 55
55 ... nel ROB Per ogni ciclo di clock possono essere avviate fino 3 uop (non 5). I risultati (incerti) dell'esecuzione speculativa non possono essere passati come risultati effettivi: vengono immagazzinati nuovamente nel ROB. Se una predizione di salto condizionato (da parte del BTB) si rivela errata, lo stato di tutte le micro-op eseguite in maniera speculativa in seguito al salto vengono rimosse dal ROB; la vera destinazione del salto condizionato viene passata al BTB, che provvede ad aggiornare i bit di predizione. Calcolatori (G.B.) Superscalari 56
56 ..Prestazioni Cicli di clock richiesti per l esecuzione: Addizioni intere: 1 Addizioni floating: 3 con tasso (massimo) di uscita di una per ciclo di clock Moltiplicazioni floating: 5 con tasso di uscita di una ogni 2 cicli di clock Moltiplicazioni intere: 4 con tasso di uscita di una per ciclo di clock. La divisione floating non è in pipeline e richiede17 cicli in singola precisione, 32 in doppia precisione, 37 in precisione estesa. Calcolatori (G.B.) Superscalari 57
57 Register Renaming IA prevede solo 8 registri di uso generale MOV EAX,50 ADD MEM1,EAX MOV EAX,77 ADD MEM2,EAX Due tratti di codice indipendenti se non usassero lo stesso registro EAX viene mappato su due registri fisici differenti le istruzioni possono essere avviate in parallelo comporta l analisi del flusso dati e delle interdipendenze. Al sito Intel si trovano tutorial sull architettura PentiumPro e sull esecuzione fuori ordine Calcolatori (G.B.) Superscalari 58
58 Un occhiata agli sviluppi successivi Calcolatori (G.B.) Superscalari 59
59 Pentium Pro (meglio questa della successiva) Calcolatori (G.B.) Superscalari 60
60 P6 (Pentium 6)? In realtà Fetch/decode si fa da L1 cache Calcolatori (G.B.) Superscalari 61
61 Pentium 4 Calcolatori (G.B.) Superscalari 62 Questo schema è corretto (Trace Cache)
62 Il Pentium 4 (2002) Calcolatori (G.B.) Superscalari 63
63 Trace Cache Calcolatori (G.B.) Superscalari 64
64 Pentium 4 Trace cache Tiene le microop, in modo da evitare la decodifica tutte le volte La trace cache non è presente in tutti i modelli successivi Pipeline a 20 stadi Bus Quad pumped (???!!!!!!) Multithreading (Hyper-Threading) Dicevano di portarlo a 10 GHz si sono fermati in zona 4 GHz. Calcolatori (G.B.) Superscalari 65
65 Quad pumped Viene usato il fronte di salita e quello di discesa Dal clock si derivano 2 due segnali sfasati di 90 in modo da avere 4 fronti Ne consegue che la frequenza del trasferimento sul bus risulta 4 volte quella del clock. In pratica un bus dichiarato a 800 MHz si basa su un clock a 200 MHz Calcolatori (G.B.) Superscalari 66
66 Hyper-Threading Calcolatori (G.B.) Superscalari 67
67 Multi Processor System tradizionale Calcolatori (G.B.) Superscalari 68
68 Multi Core Racchiudere nello stesso chip più processori Si contendono il bus esterno Per il resto sono indipendenti Calcolatori (G.B.) Superscalari 69
69 Perché multi core Minori consumi di due distinti processori Minor occupazione sulla scheda E un modo per accrescere le prestazioni attraverso il parallelismo Come se fossero due processori distinti, con l arbitraggio del bus all interno del chip Parallelismo effettivo Se non ci fosse il problema del bus: potenziale raddoppio delle prestazioni (se si riuscisse a farli lavorare al 100% in parallelo) Nella pratica se si ottiene un miglioramento dell 80% è grassa Sistemi operativi e applicazioni conformi Calcolatori (G.B.) Superscalari 70
70 Threading Multithread : Threads ottenuti attraverso l allocazione del processore (time-slice) SMT (Simultaneous multithreading) : Threads eseguiti simultameamente sullo stesso processore, ovvero senza time-slicing E la logica del core che permette l esecuzione parallela ottimizzando l uso delle risorse Esempio: Se un thread è in attesa che la FPU completi, un altro può usare la IU Hyper-Threading è il nome di Intel per SMT (Intel la chiama HTT, HyperThreading Technology) Calcolatori (G.B.) Superscalari 71
71 Senza SMT : L2 Cache and Control Integer L unità per interi resta bloccata se FPU ci mette troppo, oppure se l accesso alla cache da parte del BTBthread corrente provoca miss ecc. L1 D-Cache D-TLB Schedulers Uop queues Rename/Alloc Trace Cache Decoder Questa è la pipeline del Pentium 4 semplificata Floating Point ucode ROM Bus BTB and I-TLB Thread 1: floating point Calcolatori (G.B.) Superscalari 72
72 Senza SMT : un solo thread (che usa FPU) L1 D-Cache D-TLB L2 Cache and Control Integer Floating Point Schedulers Uop queues Rename/Alloc BTB Trace Cache ucode ROM Decoder Bus BTB and I-TLB Thread 1: floating point Calcolatori (G.B.) Superscalari 73
73 Senza SMT : un solo thread (che usa IU) L1 D-Cache D-TLB L2 Cache and Control Integer Floating Point Schedulers Uop queues Rename/Alloc BTB Trace Cache ucode ROM Decoder Bus BTB and I-TLB Thread 2: integer operation Calcolatori (G.B.) Superscalari 74
74 Con SMT : I due corrono in parallelo L1 D-Cache D-TLB L2 Cache and Control Integer Floating Point Schedulers Uop queues Rename/Alloc BTB Trace Cache ucode ROM Decoder Bus BTB and I-TLB Thread 2: Thread 1: floating point integer operation Calcolatori (G.B.) Superscalari 75
75 Impossibile L1 D-Cache D-TLB L2 Cache and Control Integer Floating Point Schedulers Uop queues Rename/Alloc BTB Trace Cache ucode ROM Bus Decoder BTB and I-TLB Thread 1 Thread 2 IMPOSSIBLE Impossible se c è una sola unità IU Calcolatori (G.B.) Superscalari 76
76 SMT non è parallelismo vero! OS e applicazioni vedono il singolo thread come se fosse un processore virtuale Le risorse (cache, decoder, ) sono a comune Il chip ha una sola copia di ogni risorsa eccetto quelle che danno lo stato del processore virtuale Migliora il threading (del 30% se va bene) Il passo successivo è: multicore/multithread Calcolatori (G.B.) Superscalari 77
77 SMT Dual-core : 4 thr (parallelismo effettivo) L1 D-Cache D-TLB L1 D-Cache D-TLB L2 Cache and Control Integer BTB Schedulers Uop queues Rename/Alloc Trace Cache Decoder Floating Point ucode ROM L2 Cache and Control Integer BTB Schedulers Uop queues Rename/Alloc Trace Cache Decoder Floating Point ucode ROM Bus BTB and I-TLB Bus BTB and I-TLB Calcolatori (G.B.) Superscalari 78 Thread 1 Thread 3 Thread 2 Thread 4
78 Lo stato delle cose (multicore-hyperthread) Calcolatori (G.B.) Superscalari 79
79 Questo computer portatile Intel Core i7-2620m Processor 2 core 4 thread (2 per core) Come se ci fossero 4 processori logici 2,7 GHz 4 MB cache (il modello i ha 4 core e 8 thread) Calcolatori (G.B.) Superscalari 80
80 Gestione attività Windows Calcolatori (G.B.) Superscalari 81
81 La legge di Moore Calcolatori (G.B.) Superscalari 83
Sistemi superscalari. Contenuto della lezione. Unità multifunzionali parallele Architetture superscalari Esecuzione fuori ordine
 Sistemi superscalari Contenuto della lezione Unità multifunzionali parallele Architetture superscalari Esecuzione fuori ordine Calcolatori (G.B.) Superscalari 1 Estensioni al modello di pipe lineare Un
Sistemi superscalari Contenuto della lezione Unità multifunzionali parallele Architetture superscalari Esecuzione fuori ordine Calcolatori (G.B.) Superscalari 1 Estensioni al modello di pipe lineare Un
Architettura hardware
 Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
CPU pipeline 4: le CPU moderne
 Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/17
Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/17
Lezione n.19 Processori RISC e CISC
 Lezione n.19 Processori RISC e CISC 1 Processori RISC e Superscalari Motivazioni che hanno portato alla realizzazione di queste architetture Sommario: Confronto tra le architetture CISC e RISC Prestazioni
Lezione n.19 Processori RISC e CISC 1 Processori RISC e Superscalari Motivazioni che hanno portato alla realizzazione di queste architetture Sommario: Confronto tra le architetture CISC e RISC Prestazioni
CPU pipeline 4: le CPU moderne
 Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
CPU. Maurizio Palesi
 CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
Laboratorio di Informatica
 per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
Calcolatori Elettronici
 Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
L unità di elaborazione pipeline L unità Pipelining
 Struttura del processore L unità di elaborazione pipeline Corso ACSO prof. Cristina SILVANO Politecnico di Milano Incremento delle Per migliorare ulteriormente le si può: ridurre il periodo di clock aumentare
Struttura del processore L unità di elaborazione pipeline Corso ACSO prof. Cristina SILVANO Politecnico di Milano Incremento delle Per migliorare ulteriormente le si può: ridurre il periodo di clock aumentare
Aggiornato il 18 giugno 2015. 1 Questa affermazione richiede una precisazione. A parità di altre condizioni, l eliminazione dello stadio ME allunga la
 8 Questo documento contiene le soluzioni ad un numero selezionato di esercizi del Capitolo 8 del libro Calcolatori Elettronici - Architettura e organizzazione, Mc-Graw Hill 2009. Sarò grato a coloro che
8 Questo documento contiene le soluzioni ad un numero selezionato di esercizi del Capitolo 8 del libro Calcolatori Elettronici - Architettura e organizzazione, Mc-Graw Hill 2009. Sarò grato a coloro che
Struttura del calcolatore
 Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Calcolatori Elettronici. La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo
 Calcolatori Elettronici La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo La pipeline CRITICITÀ SUI DATI Calcolatori Elettronici - Pipeline (2) - Slide 2 L. Tarantino
Calcolatori Elettronici La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo La pipeline CRITICITÀ SUI DATI Calcolatori Elettronici - Pipeline (2) - Slide 2 L. Tarantino
C. P. U. MEMORIA CENTRALE
 C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
La macchina di Von Neumann. Archite(ura di un calcolatore. L unità di elaborazione (CPU) Sequenza di le(ura. Il bus di sistema
 Sequenza di le(ura. Il bus di sistema") La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
Il Processore: i registri
 Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Quinto Homework. Indicare il tempo necessario all'esecuzione del programma in caso di avvio e ritiro fuori ordine.
 Quinto Homework 1) Si vuole progettare una cache a mappatura diretta per un sistema a 32 bit per una memoria da 2 GB (quindi sono solo 31 i bit utili per gli indirizzi) e blocchi di 64 byte. Rispondere
Quinto Homework 1) Si vuole progettare una cache a mappatura diretta per un sistema a 32 bit per una memoria da 2 GB (quindi sono solo 31 i bit utili per gli indirizzi) e blocchi di 64 byte. Rispondere
I componenti di un Sistema di elaborazione. CPU (central process unit)
") I componenti di un Sistema di elaborazione. CPU (central process unit) I componenti di un Sistema di elaborazione. CPU (central process unit) La C.P.U. è il dispositivo che esegue materialmente gli ALGORITMI.
I componenti di un Sistema di elaborazione. CPU (central process unit) I componenti di un Sistema di elaborazione. CPU (central process unit) La C.P.U. è il dispositivo che esegue materialmente gli ALGORITMI.
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.7. Il moltiplicatore binario e il ciclo di base di una CPU
 Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
La memoria centrale (RAM)
") La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
Esercitazione sulle CPU pipeline
 Esercitazione sulle CPU pipeline Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato perché
Esercitazione sulle CPU pipeline Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato perché
Il processore. Il processore. Il processore. Il processore. Architettura dell elaboratore
 Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
4 3 4 = 4 x 10 2 + 3 x 10 1 + 4 x 10 0 aaa 10 2 10 1 10 0
 Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
DIMENSIONI E PRESTAZIONI
 DIMENSIONI E PRESTAZIONI Prof. Enrico Terrone A. S: 2008/09 Le unità di misura Le due unità di misura fondamentali dell hardware sono: i Byte per le dimensioni della memoria gli Hertz (Hz) per le prestazioni
DIMENSIONI E PRESTAZIONI Prof. Enrico Terrone A. S: 2008/09 Le unità di misura Le due unità di misura fondamentali dell hardware sono: i Byte per le dimensioni della memoria gli Hertz (Hz) per le prestazioni
I sistemi di numerazione
 I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
SISTEMI OPERATIVI. Prof. Enrico Terrone A. S: 2008/09
 SISTEMI OPERATIVI Prof. Enrico Terrone A. S: 2008/09 Che cos è il sistema operativo Il sistema operativo (SO) è il software che gestisce e rende accessibili (sia ai programmatori e ai programmi, sia agli
SISTEMI OPERATIVI Prof. Enrico Terrone A. S: 2008/09 Che cos è il sistema operativo Il sistema operativo (SO) è il software che gestisce e rende accessibili (sia ai programmatori e ai programmi, sia agli
Schedulazione dinamica. Elettronica dei Calcolatori 1
 Schedulazione dinamica Elettronica dei Calcolatori 1 Schedulazione dinamica delle operazioni Impossibile risolvere tutti i conflitti staticamente I possibile predire tutti i salti condizionati HW fa durante
Schedulazione dinamica Elettronica dei Calcolatori 1 Schedulazione dinamica delle operazioni Impossibile risolvere tutti i conflitti staticamente I possibile predire tutti i salti condizionati HW fa durante
Più processori uguale più velocità?
 Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
CALCOLATORI ELETTRONICI 29 giugno 2011
 CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
Siamo così arrivati all aritmetica modulare, ma anche a individuare alcuni aspetti di come funziona l aritmetica del calcolatore come vedremo.
 DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
COME È FATTO IL COMPUTER
 1 di 8 15/07/2013 17:07 COME È FATTO IL COMPUTER Le componenti fondamentali Un computer, o elaboratore di dati, è composto da una scheda madre alla quale sono collegate periferiche di input e output, RAM
1 di 8 15/07/2013 17:07 COME È FATTO IL COMPUTER Le componenti fondamentali Un computer, o elaboratore di dati, è composto da una scheda madre alla quale sono collegate periferiche di input e output, RAM
PROVA INTRACORSO TRACCIA A Pagina 1 di 6
 PROVA INTRACORSO DI ELEMENTI DI INFORMATICA MATRICOLA COGNOME E NOME TRACCIA A DOMANDA 1 Calcolare il risultato delle seguenti operazioni binarie tra numeri interi con segno rappresentati in complemento
PROVA INTRACORSO DI ELEMENTI DI INFORMATICA MATRICOLA COGNOME E NOME TRACCIA A DOMANDA 1 Calcolare il risultato delle seguenti operazioni binarie tra numeri interi con segno rappresentati in complemento
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14. Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 11 Martedì 12-11-2013 1 Tecniche di allocazione mediante free list Generalmente,
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 11 Martedì 12-11-2013 1 Tecniche di allocazione mediante free list Generalmente,
Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa. Raccolta prove scritte. Prova scritta
 Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa Raccolta prove scritte Realizzare una classe thread Processo che deve effettuare un numero fissato di letture da una memoria
Corso di Sistemi Operativi Ingegneria Elettronica e Informatica prof. Rocco Aversa Raccolta prove scritte Realizzare una classe thread Processo che deve effettuare un numero fissato di letture da una memoria
Memoria Virtuale. Anche la memoria principale ha una dimensione limitata. memoria principale (memoria fisica) memoria secondaria (memoria virtuale)
 memoria secondaria (memoria virtuale)") Memoria Virtuale Anche la memoria principale ha una dimensione limitata. Possiamo pensare di superare questo limite utilizzando memorie secondarie (essenzialmente dischi) e vedendo la memoria principale
Memoria Virtuale Anche la memoria principale ha una dimensione limitata. Possiamo pensare di superare questo limite utilizzando memorie secondarie (essenzialmente dischi) e vedendo la memoria principale
ARCHITETTURE MICROPROGRAMMATE. 1. Necessità di un architettura microprogrammata 1. Cos è un architettura microprogrammata? 4
 ARCHITETTURE MICROPROGRAMMATE. 1 Necessità di un architettura microprogrammata 1 Cos è un architettura microprogrammata? 4 Struttura di una microistruzione. 5 Esempi di microprogrammi 9 Esempio 1 9 Esempio
ARCHITETTURE MICROPROGRAMMATE. 1 Necessità di un architettura microprogrammata 1 Cos è un architettura microprogrammata? 4 Struttura di una microistruzione. 5 Esempi di microprogrammi 9 Esempio 1 9 Esempio
Esame di INFORMATICA
 Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Calcolatori Elettronici. La memoria gerarchica La memoria virtuale
 Calcolatori Elettronici La memoria gerarchica La memoria virtuale Come usare la memoria secondaria oltre che per conservare permanentemente dati e programmi Idea Tenere parte del codice in mem princ e
Calcolatori Elettronici La memoria gerarchica La memoria virtuale Come usare la memoria secondaria oltre che per conservare permanentemente dati e programmi Idea Tenere parte del codice in mem princ e
Architettura hw. La memoria e la cpu
 Architettura hw La memoria e la cpu La memoria centrale e la CPU Bus controllo Bus indirizzi Bus dati Bus di collegamento con la cpu indirizzi controllo dati Bus Indirizzi 11 Bus controllo Leggi/scrivi
Architettura hw La memoria e la cpu La memoria centrale e la CPU Bus controllo Bus indirizzi Bus dati Bus di collegamento con la cpu indirizzi controllo dati Bus Indirizzi 11 Bus controllo Leggi/scrivi
I componenti di un Sistema di elaborazione. Memoria centrale. È costituita da una serie di CHIP disposti su una scheda elettronica
 I componenti di un Sistema di elaborazione. Memoria centrale Memorizza : istruzioni dati In forma BINARIA : 10001010101000110101... È costituita da una serie di CHIP disposti su una scheda elettronica
I componenti di un Sistema di elaborazione. Memoria centrale Memorizza : istruzioni dati In forma BINARIA : 10001010101000110101... È costituita da una serie di CHIP disposti su una scheda elettronica
Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica. prof. ing. Corrado Santoro
 Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica prof. ing. Corrado Santoro Schema a blocchi di una CPU Arithmetic Logic Unit Control Unit Register File BUS Control
Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica prof. ing. Corrado Santoro Schema a blocchi di una CPU Arithmetic Logic Unit Control Unit Register File BUS Control
Pronto Esecuzione Attesa Terminazione
 Definizione Con il termine processo si indica una sequenza di azioni che il processore esegue Il programma invece, è una sequenza di azioni che il processore dovrà eseguire Il processo è quindi un programma
Definizione Con il termine processo si indica una sequenza di azioni che il processore esegue Il programma invece, è una sequenza di azioni che il processore dovrà eseguire Il processo è quindi un programma
Appunti di informatica. Lezione 2 anno accademico 2015-2016 Mario Verdicchio
 Appunti di informatica Lezione 2 anno accademico 2015-2016 Mario Verdicchio Sistema binario e logica C è un legame tra i numeri binari (0,1) e la logica, ossia la disciplina che si occupa del ragionamento
Appunti di informatica Lezione 2 anno accademico 2015-2016 Mario Verdicchio Sistema binario e logica C è un legame tra i numeri binari (0,1) e la logica, ossia la disciplina che si occupa del ragionamento
Introduzione. Coordinazione Distribuita. Ordinamento degli eventi. Realizzazione di. Mutua Esclusione Distribuita (DME)
") Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Gestione della memoria centrale
 Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Calcolatori Elettronici B a.a. 2008/2009
 Calcolatori Elettronici B aa 28/29 MEMORIA VIRTUALE: ESERCIZI Massimiliano Giacomin 1 Dal Tema d esame 2 set 26 [ES 7] (omissis) Supponendo che gli indirizzi virtuali siano a 32 bit e che la dimensione
Calcolatori Elettronici B aa 28/29 MEMORIA VIRTUALE: ESERCIZI Massimiliano Giacomin 1 Dal Tema d esame 2 set 26 [ES 7] (omissis) Supponendo che gli indirizzi virtuali siano a 32 bit e che la dimensione
Appunti sulla Macchina di Turing. Macchina di Turing
 Macchina di Turing Una macchina di Turing è costituita dai seguenti elementi (vedi fig. 1): a) una unità di memoria, detta memoria esterna, consistente in un nastro illimitato in entrambi i sensi e suddiviso
Macchina di Turing Una macchina di Turing è costituita dai seguenti elementi (vedi fig. 1): a) una unità di memoria, detta memoria esterna, consistente in un nastro illimitato in entrambi i sensi e suddiviso
Introduzione. Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD... 6
 Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
La macchina programmata Instruction Set Architecture (1)
") Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
Architettura del calcolatore
 Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
Parte II.2 Elaboratore
 Parte II.2 Elaboratore Elisabetta Ronchieri Università di Ferrara Dipartimento di Economia e Management Insegnamento di Informatica Dicembre 1, 2015 Elisabetta Elisabetta Ronchieri II Software Argomenti
Parte II.2 Elaboratore Elisabetta Ronchieri Università di Ferrara Dipartimento di Economia e Management Insegnamento di Informatica Dicembre 1, 2015 Elisabetta Elisabetta Ronchieri II Software Argomenti
= 0, 098 ms. Da cui si ricava t 2 medio
 1. Una macchina ha uno spazio degli indirizzi a 32 bit e una pagina di 8 KB. La tabella delle pagine è completamente nell hardware, con una parola a 32 bit per voce. Quando parte un processo, la tabella
1. Una macchina ha uno spazio degli indirizzi a 32 bit e una pagina di 8 KB. La tabella delle pagine è completamente nell hardware, con una parola a 32 bit per voce. Quando parte un processo, la tabella
LABORATORIO DI SISTEMI
 ALUNNO: Fratto Claudio CLASSE: IV B Informatico ESERCITAZIONE N : 1 LABORATORIO DI SISTEMI OGGETTO: Progettare e collaudare un circuito digitale capace di copiare le informazioni di una memoria PROM in
ALUNNO: Fratto Claudio CLASSE: IV B Informatico ESERCITAZIONE N : 1 LABORATORIO DI SISTEMI OGGETTO: Progettare e collaudare un circuito digitale capace di copiare le informazioni di una memoria PROM in
1.4b: Hardware. (Memoria Centrale)
") 1.4b: Hardware (Memoria Centrale) Bibliografia Curtin, Foley, Sen, Morin Informatica di base, Mc Graw Hill Ediz. Fino alla III : cap. 3.11, 3.13 IV ediz.: cap. 2.8, 2.9 Questi lucidi Memoria Centrale Un
1.4b: Hardware (Memoria Centrale) Bibliografia Curtin, Foley, Sen, Morin Informatica di base, Mc Graw Hill Ediz. Fino alla III : cap. 3.11, 3.13 IV ediz.: cap. 2.8, 2.9 Questi lucidi Memoria Centrale Un
Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18
 Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Calcolatore: sottosistemi Processore o CPU (Central Processing
Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Calcolatore: sottosistemi Processore o CPU (Central Processing
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione.
 Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Aumentare il parallelismo a livello di istruzione (1)
") Aumentare il parallelismo a livello di istruzione (1) Architetture Avanzate dei Calcolatori Valeria Cardellini Parallelismo Il parallelismo consente di migliorare le prestazioni grazie all esecuzione simultanea
Aumentare il parallelismo a livello di istruzione (1) Architetture Avanzate dei Calcolatori Valeria Cardellini Parallelismo Il parallelismo consente di migliorare le prestazioni grazie all esecuzione simultanea
Valutazione delle Prestazioni
 Valutazione delle Prestazioni Sia data una macchina X, definiamo: 1 PrestazioneX = --------------------------- Tempo di esecuzione X La prestazione aumenta con il diminuire del tempo di esecuzione (e diminuisce
Valutazione delle Prestazioni Sia data una macchina X, definiamo: 1 PrestazioneX = --------------------------- Tempo di esecuzione X La prestazione aumenta con il diminuire del tempo di esecuzione (e diminuisce
Varie tipologie di memoria
 Varie tipologie di memoria velocita` capacita` registri CPU memoria cache memoria secondaria (Hard Disk) Gestione della memoria Una parte della viene riservata per il SO I programmi per poter essere eseguiti
Varie tipologie di memoria velocita` capacita` registri CPU memoria cache memoria secondaria (Hard Disk) Gestione della memoria Una parte della viene riservata per il SO I programmi per poter essere eseguiti
Migliorare le prestazioni di processori e memorie
 Migliorare le prestazioni di processori e memorie Corso: Architetture degli Elaboratori Docenti: F. Barbanera, G. Bella UNIVERSITA DI CATANIA Dip. di Matematica e Informatica Tipologie dei Miglioramenti
Migliorare le prestazioni di processori e memorie Corso: Architetture degli Elaboratori Docenti: F. Barbanera, G. Bella UNIVERSITA DI CATANIA Dip. di Matematica e Informatica Tipologie dei Miglioramenti
MODELLO CLIENT/SERVER. Gianluca Daino Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena daino@unisi.it
 MODELLO CLIENT/SERVER Gianluca Daino Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena daino@unisi.it POSSIBILI STRUTTURE DEL SISTEMA INFORMATIVO La struttura di un sistema informativo
MODELLO CLIENT/SERVER Gianluca Daino Dipartimento di Ingegneria dell Informazione Università degli Studi di Siena daino@unisi.it POSSIBILI STRUTTURE DEL SISTEMA INFORMATIVO La struttura di un sistema informativo
Algoritmo. I dati su cui opera un'istruzione sono forniti all'algoritmo dall'esterno oppure sono il risultato di istruzioni eseguite precedentemente.
 Algoritmo Formalmente, per algoritmo si intende una successione finita di passi o istruzioni che definiscono le operazioni da eseguire su dei dati (=istanza del problema): in generale un algoritmo è definito
Algoritmo Formalmente, per algoritmo si intende una successione finita di passi o istruzioni che definiscono le operazioni da eseguire su dei dati (=istanza del problema): in generale un algoritmo è definito
APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI
 APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI Indice 1 Le frazioni algebriche 1.1 Il minimo comune multiplo e il Massimo Comun Divisore fra polinomi........ 1. Le frazioni algebriche....................................
APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI Indice 1 Le frazioni algebriche 1.1 Il minimo comune multiplo e il Massimo Comun Divisore fra polinomi........ 1. Le frazioni algebriche....................................
Coordinazione Distribuita
 Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Architettura hardware
 Ricapitolando Architettura hardware la parte che si può prendere a calci Il funzionamento di un elaboratore dipende da due fattori principali 1) dalla capacità di memorizzare i programmi e i dati 2) dalla
Ricapitolando Architettura hardware la parte che si può prendere a calci Il funzionamento di un elaboratore dipende da due fattori principali 1) dalla capacità di memorizzare i programmi e i dati 2) dalla
4. Operazioni aritmetiche con i numeri binari
 I Numeri Binari 4. Operazioni aritmetiche con i numeri binari Contare con i numeri binari Prima di vedere quali operazioni possiamo effettuare con i numeri binari, iniziamo ad imparare a contare in binario:
I Numeri Binari 4. Operazioni aritmetiche con i numeri binari Contare con i numeri binari Prima di vedere quali operazioni possiamo effettuare con i numeri binari, iniziamo ad imparare a contare in binario:
CALCOLATORI ELETTRONICI 29 giugno 2010
 CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
Introduzione. Il principio di localizzazione... 2 Organizzazioni delle memorie cache... 4 Gestione delle scritture in una cache...
 Appunti di Calcolatori Elettronici Concetti generali sulla memoria cache Introduzione... 1 Il principio di localizzazione... 2 Organizzazioni delle memorie cache... 4 Gestione delle scritture in una cache...
Appunti di Calcolatori Elettronici Concetti generali sulla memoria cache Introduzione... 1 Il principio di localizzazione... 2 Organizzazioni delle memorie cache... 4 Gestione delle scritture in una cache...
. A primi passi con microsoft a.ccepss SommarIo: i S 1. aprire e chiudere microsoft access Start (o avvio) l i b tutti i pro- grammi
 l i b tutti i pro- grammi") Capitolo Terzo Primi passi con Microsoft Access Sommario: 1. Aprire e chiudere Microsoft Access. - 2. Aprire un database esistente. - 3. La barra multifunzione di Microsoft Access 2007. - 4. Creare e salvare
Capitolo Terzo Primi passi con Microsoft Access Sommario: 1. Aprire e chiudere Microsoft Access. - 2. Aprire un database esistente. - 3. La barra multifunzione di Microsoft Access 2007. - 4. Creare e salvare
Esercizi su. Funzioni
 Esercizi su Funzioni ๒ Varie Tracce extra Sul sito del corso ๓ Esercizi funz_max.cc funz_fattoriale.cc ๔ Documentazione Il codice va documentato (commentato) Leggibilità Riduzione degli errori Manutenibilità
Esercizi su Funzioni ๒ Varie Tracce extra Sul sito del corso ๓ Esercizi funz_max.cc funz_fattoriale.cc ๔ Documentazione Il codice va documentato (commentato) Leggibilità Riduzione degli errori Manutenibilità
Sommario. Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi.
 Algoritmi 1 Sommario Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi. 2 Informatica Nome Informatica=informazione+automatica. Definizione Scienza che si occupa dell
Algoritmi 1 Sommario Definizione di informatica. Definizione di un calcolatore come esecutore. Gli algoritmi. 2 Informatica Nome Informatica=informazione+automatica. Definizione Scienza che si occupa dell
Sistemi Operativi. 5 Gestione della memoria
 Gestione della memoria Compiti del gestore della memoria: Tenere traccia di quali parti della memoria sono libere e quali occupate. Allocare memoria ai processi che ne hanno bisogno. Deallocare la memoria
Gestione della memoria Compiti del gestore della memoria: Tenere traccia di quali parti della memoria sono libere e quali occupate. Allocare memoria ai processi che ne hanno bisogno. Deallocare la memoria
Algoritmi e strutture dati. Codici di Huffman
 Algoritmi e strutture dati Codici di Huffman Memorizzazione dei dati Quando un file viene memorizzato, esso va memorizzato in qualche formato binario Modo più semplice: memorizzare il codice ASCII per
Algoritmi e strutture dati Codici di Huffman Memorizzazione dei dati Quando un file viene memorizzato, esso va memorizzato in qualche formato binario Modo più semplice: memorizzare il codice ASCII per
DMA Accesso Diretto alla Memoria
 Testo di rif.to: [Congiu] - 8.1-8.3 (pg. 241 250) 08.a DMA Accesso Diretto alla Memoria Motivazioni Organizzazione dei trasferimenti DMA Arbitraggio del bus di memoria Trasferimento di un blocco di dati
Testo di rif.to: [Congiu] - 8.1-8.3 (pg. 241 250) 08.a DMA Accesso Diretto alla Memoria Motivazioni Organizzazione dei trasferimenti DMA Arbitraggio del bus di memoria Trasferimento di un blocco di dati
La Gestione delle risorse Renato Agati
 Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Aumentare il parallelismo a livello di istruzione (2)
") Processori multiple-issue issue Aumentare il parallelismo a livello di istruzione (2) Architetture Avanzate dei Calcolatori Valeria Cardellini Nei processori multiple-issue vengono lanciate più istruzioni
Processori multiple-issue issue Aumentare il parallelismo a livello di istruzione (2) Architetture Avanzate dei Calcolatori Valeria Cardellini Nei processori multiple-issue vengono lanciate più istruzioni
CALCOLATORI ELETTRONICI 31 marzo 2015
 CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.6. Unità di controllo microprogrammata
 Lezione n.6 Unità di controllo microprogrammata 1 Sommario Unità di controllo microprogrammata Ottimizzazione, per ottimizzare lo spazio di memoria occupato Il moltiplicatore binario Esempio di architettura
Lezione n.6 Unità di controllo microprogrammata 1 Sommario Unità di controllo microprogrammata Ottimizzazione, per ottimizzare lo spazio di memoria occupato Il moltiplicatore binario Esempio di architettura
La memoria - generalità
 Calcolatori Elettronici La memoria gerarchica Introduzione La memoria - generalità n Funzioni: Supporto alla CPU: deve fornire dati ed istruzioni il più rapidamente possibile Archiviazione: deve consentire
Calcolatori Elettronici La memoria gerarchica Introduzione La memoria - generalità n Funzioni: Supporto alla CPU: deve fornire dati ed istruzioni il più rapidamente possibile Archiviazione: deve consentire
Calcolo numerico e programmazione Architettura dei calcolatori
 Calcolo numerico e programmazione Architettura dei calcolatori Tullio Facchinetti 30 marzo 2012 08:57 http://robot.unipv.it/toolleeo Il calcolatore tre funzionalità essenziali:
Calcolo numerico e programmazione Architettura dei calcolatori Tullio Facchinetti 30 marzo 2012 08:57 http://robot.unipv.it/toolleeo Il calcolatore tre funzionalità essenziali:
Esempio: aggiungere j
 Esempio: aggiungere j Eccezioni e interruzioni Il progetto del controllo del processore si complica a causa della necessità di considerare, durante l esecuzione delle istruzioni, il verificarsi di eventi
Esempio: aggiungere j Eccezioni e interruzioni Il progetto del controllo del processore si complica a causa della necessità di considerare, durante l esecuzione delle istruzioni, il verificarsi di eventi
Il microprocessore 8086
 1 Il microprocessore 8086 LA CPU 8086 Il microprocessore 8086 fa parte della famiglia 80xxx della INTEL. Il capostipite di questa famiglia è stato l 8080, un microprocessore ad 8 bit che ha riscosso un
1 Il microprocessore 8086 LA CPU 8086 Il microprocessore 8086 fa parte della famiglia 80xxx della INTEL. Il capostipite di questa famiglia è stato l 8080, un microprocessore ad 8 bit che ha riscosso un
PRODUZIONE PAGELLE IN FORMATO PDF
 Requisiti minimi: PRODUZIONE, FIRMA E PUBBLICAZIONE DELLA PAGELLA ELETTRONICA CON ALUNNI WINDOWS PRODUZIONE PAGELLE IN FORMATO PDF Argo Alunni Windows aggiornato alla versione più recente. Adobe PDF CREATOR,
Requisiti minimi: PRODUZIONE, FIRMA E PUBBLICAZIONE DELLA PAGELLA ELETTRONICA CON ALUNNI WINDOWS PRODUZIONE PAGELLE IN FORMATO PDF Argo Alunni Windows aggiornato alla versione più recente. Adobe PDF CREATOR,
Funzioni in C. Violetta Lonati
 Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
Ciclo di Istruzione. Ciclo di Istruzione. Controllo. Ciclo di Istruzione (diagramma di flusso) Lezione 5 e 6
 Lezione 5 e 6") Ciclo di Istruzione Può essere suddiviso in 4 tipi di sequenze di microoperazioni (cioè attività di calcolo aritmetico/logico, trasferimento e memorizzazione dei dati), non tutte necessariamente da realizzare
Ciclo di Istruzione Può essere suddiviso in 4 tipi di sequenze di microoperazioni (cioè attività di calcolo aritmetico/logico, trasferimento e memorizzazione dei dati), non tutte necessariamente da realizzare
Scheduling della CPU. Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux
 Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Sistemi Operativi IMPLEMENTAZIONE DEL FILE SYSTEM. Implementazione del File System. Struttura del File System. Implementazione
 IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
Capitolo Quarto...2 Le direttive di assemblaggio di ASM 68000...2 Premessa...2 1. Program Location Counter e direttiva ORG...2 2.
 Capitolo Quarto...2 Le direttive di assemblaggio di ASM 68000...2 Premessa...2 1. Program Location Counter e direttiva ORG...2 2. Dichiarazione di dati: le direttive DS e DC...3 2.1 Direttiva DS...3 2.2
Capitolo Quarto...2 Le direttive di assemblaggio di ASM 68000...2 Premessa...2 1. Program Location Counter e direttiva ORG...2 2. Dichiarazione di dati: le direttive DS e DC...3 2.1 Direttiva DS...3 2.2
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Architettura dei computer
 Architettura dei computer In un computer possiamo distinguere quattro unità funzionali: il processore (CPU) la memoria principale (RAM) la memoria secondaria i dispositivi di input/output Il processore
Architettura dei computer In un computer possiamo distinguere quattro unità funzionali: il processore (CPU) la memoria principale (RAM) la memoria secondaria i dispositivi di input/output Il processore
Tutorato 11 dicembre 2015
 Tutorato 11 dicembre 2015 Calcolo delle prestazioni Nomenclatura T: periodo del ciclo di clock. Equivale al tempo di durata di un ciclo del clock, ovvero al reciproco della frequenza di clock: T = 1 F
Tutorato 11 dicembre 2015 Calcolo delle prestazioni Nomenclatura T: periodo del ciclo di clock. Equivale al tempo di durata di un ciclo del clock, ovvero al reciproco della frequenza di clock: T = 1 F
Esercizi Multiplazione TDM Accesso Multiplo TDMA
 Esercizi Multiplazione TDM Accesso Multiplo TDMA Esercizio 1 Un sistema di multiplazione TDM presenta una trama di 10 slot e in ciascuno slot vengono trasmessi 128 bit. Se il sistema è usato per multiplare
Esercizi Multiplazione TDM Accesso Multiplo TDMA Esercizio 1 Un sistema di multiplazione TDM presenta una trama di 10 slot e in ciascuno slot vengono trasmessi 128 bit. Se il sistema è usato per multiplare
Dispense di Informatica per l ITG Valadier
 La notazione binaria Dispense di Informatica per l ITG Valadier Le informazioni dentro il computer All interno di un calcolatore tutte le informazioni sono memorizzate sottoforma di lunghe sequenze di
La notazione binaria Dispense di Informatica per l ITG Valadier Le informazioni dentro il computer All interno di un calcolatore tutte le informazioni sono memorizzate sottoforma di lunghe sequenze di
Gestione della memoria. Paginazione Segmentazione Segmentazione con paginazione
 Gestione della memoria Paginazione Segmentazione Segmentazione con paginazione Modello di paginazione Il numero di pagina serve come indice per la tabella delle pagine. Questa contiene l indirizzo di base
Gestione della memoria Paginazione Segmentazione Segmentazione con paginazione Modello di paginazione Il numero di pagina serve come indice per la tabella delle pagine. Questa contiene l indirizzo di base
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Corso di Informatica
 CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it La memoria principale 2 izzazione della memoria principale ria principale è organizzata come
CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it La memoria principale 2 izzazione della memoria principale ria principale è organizzata come
Informatica. Rappresentazione dei numeri Numerazione binaria
 Informatica Rappresentazione dei numeri Numerazione binaria Sistemi di numerazione Non posizionali: numerazione romana Posizionali: viene associato un peso a ciascuna posizione all interno della rappresentazione
Informatica Rappresentazione dei numeri Numerazione binaria Sistemi di numerazione Non posizionali: numerazione romana Posizionali: viene associato un peso a ciascuna posizione all interno della rappresentazione
Ingegneria del Software T
 Home Finance 1 Requisiti del cliente 1 Si richiede di realizzare un sistema per la gestione della contabilità familiare. Il sistema consente la classificazione dei movimenti di denaro e la loro memorizzazione.
Home Finance 1 Requisiti del cliente 1 Si richiede di realizzare un sistema per la gestione della contabilità familiare. Il sistema consente la classificazione dei movimenti di denaro e la loro memorizzazione.
L unità di controllo. Il processore: unità di controllo. Le macchine a stati finiti. Struttura della macchina a stati finiti
 Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune
Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune