Architetture. Paride Dagna. SuperComputing Applications and Innovation Department 18/02/2013
|
|
|
- Agnese Speranza
- 8 anni fa
- Visualizzazioni
Transcript


1 Architetture Paride Dagna SuperComputing Applications and Innovation Department 18/02/2013

2 Introduzione Grazie alle moderne tecniche di programmazione e agli strumenti di sviluppo attualmente disponibili, risulta piuttosto semplice scrivere applicazioni seriali o parallele, anche per il programmatore meno esperto. Il processo di ottimizzazione del codice è invece un percorso molto più complesso che richiede esperienza e una buona conoscenza dell architettura dei sistemi disponibili. In fase di progettazione del modello, conoscere le caratteristiche e le risorse hardware dei sistemi (cpu, memorie, rete di interconnessione) è fondamentale per riuscire a sfruttare in modo ottimale tutte le potenzialità delle moderne architetture.

, a parità di cores, un incremento medio delle performance di 5-6 volte 500000 450000 400000 350000 300000 469800")
3 Elapsed time (sec) Introduzione Codice agli elementi spettrali per la simulazione tridimensionale di eventi sismici su larga scala Un attenta revisione del software nella parte di calcolo, comunicazione fra i processi e I/O ha permesso di ottenere su Fermi (Blue Gene/Q), a parità di cores, un incremento medio delle performance di 5-6 volte Elapsed time n Cores Pure MPI Hybrid MPI + 2 OpenMP Hybrid MPI + 4 OpenMP Hybrid MPI + 8 OpenMP

4 Architettura di von Neumann Costituita da: Ogni locazione di memoria consiste di un indirizzo utilizzato per accedere alla locazione ed il suo contenuto. Central processing unit (CPU) Random Access Memory (RAM) Interconnessione CPU RAM (Bus) Unità logico aritmetica per l esecuzione delle istruzioni BUS per la comunicazione dati - istruzioni CPU RAM Unità di controllo program counter Registri memoria veloce Contenuto della locazione. Dati o istruzioni

5 Architettura di von Neumann I dati sono trasferiti dalla memoria alla CPU (fetch o read) I dati sono trasferiti dalla CPU alla memoria (written to memory o stored) La separazione di CPU e memoria è conosciuta come la «von Neumann bottleneck» perché è il bus di interconnessione che determina a che velocità si può accedere ai dati e alle istruzioni. Le moderne CPU sono in grado di eseguire istruzioni almeno cento volte più velocemente rispetto al tempo richiesto per recuperare (fetch) i dati in RAM

6 Caching - Virtual Memory - Instruction Level Parallelism L evoluzione dei sistemi e dei microprocessori e l ingegnerizzazione dei calcolatori ha affrontato il «von Neumann bottleneck» seguendo tre percorsi paralleli: Caching Memorie molto veloci presenti sul chip del processore. Esistono cache di primo, secondo e terzo livello. Virtual memory Sistema sviluppato per fare in modo che la RAM funzioni come una cache per lo storage di grosse moli di dati. Instruction level parallelism Tecnica utilizzata per avere più unità funzionali nella CPU che eseguono istruzioni in parallelo (pipelining multiple issue)

7 Caching La cache è una collezione di locazioni di memoria che possono essere accedute dalla CPU in pochissimi cicli di clock. Nelle moderne soluzioni hardware le cache risiedono nello stesso chip della CPU. Cache 1 livello Cache 2 livello Cache 3 livello La memorizzazione di dati e istruzioni in cache segue i due principi universalmente accettati di località spaziale e temporale, basati sull idea che i programmi tendano ad utilizzare dati ed istruzioni che sono fisicamente vicini ai dati e alle istruzioni appena eseguite.

 :: A REAL :: sum=0.")
8 Caching Dati e istruzioni sono memorizzati in blocchi (cache block o cache lines) e non singolarmente. Tipicamente dati e istruzioni vengono letti e memorizzati sulle linee di cache a gruppi di 8 o 16. REAL,DIMENSION(1000) :: A REAL :: sum=0.0 DO I = 1, 1000 sum = sum + A(I) END DO fortran float a[1000]; int sum =0.0; for(i=0; i<1000; i++){ sum+=a[i]; } c/c++ Questa tecnica incrementa notevolmente le prestazioni del calcolo dal momento che la CPU trova subito in cache dati e istruzioni senza la necessità di doverli reperire in RAM e quindi dover passare per il collo di bottiglia del BUS. Nei moderni processori a 2 o 3 livelli di cache le informazioni vengono cercate in modo gerarchico dal primo livello fino al terzo (L1 L2 L3)
![0 DO I = 1, 1000 sum = sum + A(I) END DO fortran float a[1000]; int sum =0.](/docs-images/45/2544778/images/page_8.jpg "0; for(i=0; i<1000; i++){ sum+=a[i]; } c/c++ Questa tecnica incrementa notevolmente le prestazioni del calcolo dal momento che la CPU trova subito in cache dati e istruzioni senza la")
9 Caching Cache fully associative ogni linea di dati o istruzioni presa dalla RAM può essere memorizzata in una qualsiasi linea della cache Cache n-way set associative ogni linea di dati o istruzioni presa dalla RAM può essere memorizzata in una qualsiasi delle n differenti locazioni Cache direct mapped ogni linea di dati o istruzioni presa dalla RAM può essere memorizzata in un unica linea di cache

10 Caching Cache fully associative Cache n-way set associative Cache direct mapped Cache RAM Cache RAM Cache RAM Line 0 Line 0 Line 0 Line 0 Line 0 Line 0 Line 1 Line 1 Line 1 Line 1 Line 1 Line 1 Line 2 Line 2 Line 2 Line 2 Line 2 Line 2 Line 3 Line 3 Line 3 Line 3 Line 3 Line 3 Line 4 Line 4 Line 4 Line 4 Line 4 Line 4 Line 5 Line 5 Line 5 Line 5 Line 5 Line 5 Line 6 Line 6 Line 6 Line 6 Line 6 Line 6 Cache fully associative: ogni blocco di RAM può essere mappato su una linea qualsiasi di cache Cache n-way associative: ogni blocco di RAM può essere mappato su n linee di cache Cache direct mapped: ogni blocco di RAM può essere mappato su una sola linea di cache

11 Virtual memory Le caches permettono di accedere velocemente a dati e istruzioni che risiedono sulla RAM. Quando si utilizzano grandi data sets o programmi molto complessi può accadere che non tutti i dati e le istruzioni possano essere contenute in RAM. Questo è un evento abbastanza frequente negli attuali sistemi operativi che supportano l esecuzione di molti processi contemporanei (multitasking). Le risorse di memoria sono condivise fra i vari processi che hanno la necessità di trovare disponibili dati e istruzioni. La virtual memory è stata sviluppata così che la RAM possa comportarsi come una cache per lo storage secondario (hard disk). Vengono possibilmente mantenute in RAM solo le risorse attive dei processi. Le parti inattive vengono invece mantenute nello spazio di swap.

12 Virtual memory Anche la memoria virtuale opera in blocchi chiamati pages. Dal momento che l accesso allo storage secondario è centinaia di volte più lento rispetto alla RAM, la dimensione delle pages è relativamente elevata (4-16 kb). La virtualizzazione delle pages è necessaria per la gestione dinamica della memoria virtuale da assegnare ai processi nei sistemi multitasking. Quando un programma viene compilato, alle sue pages sono assegnati dei numeri di pagina virtuali. Quando viene lanciato, viene creata una page table che mappa i numeri di pagina virtuali a indirizzi fisici. L effetto secondario è il raddoppio del tempo necessario per l accesso ad una locazione di memoria reale in RAM ma in questo modo si è certi che processi diversi non cerchino di accedere agli stessi indirizzi fisici. L indirizzo virtuale deve essere trasformato in un indirizzo di memoria fisico reale.

13 Instruction level parallelism Instruction-level parallelism (ILP), migliora le prestazioni del processore permettendo l utilizzo contemporaneo delle diverse unità funzionali disponibili. Due possibili approcci per avere ILP sono: Pipelining, dove le unità funzionali sono organizzate in stadi; multiple issue, dove diverse istruzioni indipendenti possono essere inizializzate. La pipeline funziona come una catena di montaggio dove le varie unità funzionali possono lavorare in modo indipendente su dati diversi.


14 Instruction level parallelism La pipeline migliora le performance connettendo in sequenza diverse unità funzionali. Nei processori multiple issue le unità funzionali e anche le pipeline sono replicate per eseguire in parallelo istruzioni differenti all interno di un programma o la stessa istruzione su dati diversi. Se le unità funzionali sono schedulate a compile-time il sistema di multiple issue è detto statico, se sono schedulate a run-time il sistema è detto dinamico. Un processore che supporta il multiple issue dinamico è detto superscalare.

15 Classificazione architetture - Flynn La classificazione di Flynn categorizza un'architettura in base alla molteplicità dell'hardware usato per manipolare lo stream di istruzioni e dati. La tassonomia di Flynn racchiude le architetture dei computer in quattro categorie: SISD : single instruction, single data. Corrisponde alla classica achitettura di von Neumann, sistema scalare monoprocessore. SIMD : single instruction, multiple data. Architetture vettoriali, processori vettoriali, GPU. MISD : multiple instruction, single data. Non esistono soluzioni hardware che sfruttino questa architettura. MIMD : multiple instruction, multiple data. Più processori/cores interpretano istruzioni diverse e operano su dati diversi. Le moderne soluzioni di calcolo sono in realtà date da una combinazione delle categorie previste da Flynn.



16 Classificazione architetture - SISD E il classico sistema di von Neumann a cui appartengono i calcolatori con una sola unità esecutiva ed una sola memoria. Il singolo processore obbedisce ad un singolo flusso di istruzioni (programma sequenziale) ed esegue queste istruzioni ogni volta su un singolo flusso di dati. I limiti di prestazione di questa architettura vengono ovviati aumentando il bus dati ed i livelli di memoria ed introducendo un parallelismo attraverso le tecniche di pipelining e multiple issue.

17 Classificazione architetture - SIMD La stessa istruzione viene eseguita in parallelo su dati differenti. modello computazionale generalmente sincrono Processori vettoriali molte ALU registri vettoriali Unità Load/Store vettoriali Istruzioni vettoriali Memoria interleaved OpenMP, MPI Graphical Processing Unit GPU completamente programmabili molte ALU molte unità Load/Store molte SFU migliaia di threads lavorano in parallelo CUDA

18 Classificazione architetture - MIMD Molteplici streams di istruzioni eseguiti simultaneamente su molteplici streams di dati modello computazionale asincrono Cluster molti nodi di calcolo (centinaia/migliaia) più processori multicore per nodo RAM condivisa sul nodo RAM distribuita fra i nodi livelli di memoria gerarchici OpenMP, MPI, MPI+OpenMP

19 Soluzioni MIMD - IBM - Blue Gene/Q Fermi : 9 posto nella TOP 500 Model: IBM-BlueGene /Q Architecture: 10 BGQ Frame with 2 MidPlanes each Front-end Nodes OS: Red-Hat EL 6.2 Compute Node Kernel: lightweight Linux-like kernel Processor Type: IBM PowerA2, 16 cores, 1.6 GHz Computing Nodes: Computing Cores: RAM: 16GB / node Internal Network: Network interface with 11 links ->5D Torus Disk Space: more than 2PB of scratch space Peak Performance: 2.1 PFlop/s

20 Soluzioni Ibride - Cluster CPU-GPU Soluzioni ibride CPU multi-core + GPU many-core: ogni nodo di calcolo è dotato di processori multicore e schede grafiche con processori dedicati per il GPU computing notevole potenza di calcolo teorica sul singolo nodo ulteriore strato di memoria dato dalla memoria delle GPU OpenMP, MPI, CUDA e soluzioni ibride MPI+OpenMP, MPI+CUDA, OpenMP+CUDA, OpenMP+MPI+CUDA CINECA - PLX

 molti threads")
21 CPU vs GPU Le CPU sono processori general purpose in grado di risolvere qualsiasi algoritmo threads in grado di gestire qualsiasi operazione ma pesanti, al massimo 1 thread per core computazionale. Le GPU sono processori specializzati per problemi che possono essere classificati come «intense data-parallel computations» controllo di flusso molto semplice (control unit ridotta) molti threads leggeri che lavorano in parallelo
22 Multicore vs Manicore Una nuova direzione di sviluppo per l architettura dei microprocessori: incrementare la potenza di calcolo complessiva tramite l aumento del numero di unità di elaborazione piuttosto che della loro potenza la potenza di calcolo e la larghezza di banda delle GPU ha sorpassato quella delle CPU di un fattore 10.
23 Coprocessore Intel Xeon Phy Specifiche principali: Basato su architettura Intel Many Integrated Core (MIC) 60 core/1,053 GHz/240 thread 8 GB di memoria e larghezza di banda di 320 GB/s 1 TFLOPS di prestazioni di picco a doppia precisione Fattore di forma PCIe x16 standard, raffreddamento passivo Sistema operativo Linux*, IP indirizzabile Istruzioni SIMD a 512 bit Approcci tradizionali come MPI, OpenMP
24 Memoria Condivisa - Memoria Distribuita Le architetture MIMD classiche e quelle miste CPU GPU sono suddivise in due categorie Sistemi a memoria condivisa dove ogni singolo core ha accesso a tutta la memoria Sistemi a memoria distribuita dove ogni processore ha la sua memoria privata e comunica con gli altri tramite scambio di messaggi. I moderni sistemi multicore hanno memoria condivisa sul nodo e distribuita fra i nodi. Memoria condivisa Memoria distribuita
25 Memoria Condivisa Nelle architetture a memoria condivisa con processori multicore vi sono generalmente due tipologie di accesso alla memoria principale Uniform Memory Access dove tutti i cores sono direttamente collegati con la stessa priorità alla memoria principale tramite il sistema di interconnessione Non Uniform Memory Access dove ogni processore multicore può avere accesso privilegiato ad un blocco di memoria e accesso secondario agli altri blocchi. Uniform Memory Access Non Uniform Memory Access
26 Reti di interconnessione Sistemi memoria condivisa Nei sistemi a memoria condivisa le due soluzioni maggiormente utilizzate sono buses e crossbars. Il bus è costituito da una serie di canali di comunicazione paralleli corredati da un sistema di controllo di accesso. I canali sono condivisi da tutti i device che sono collegati al bus basso costo ridotto numero di device collegabili possibli conflitti di accesso direttamente proporzionali al numero di processori collegati usati usualmente per la comunicazione cores - memoria locale ai cores P1 P2 M1 M2 P3 P4
27 Reti di interconnessione Sistemi memoria condivisa Il sistema crossbar switch è la metodologia più frequente che si usa per collegare diversi device in shared memory le linee di comunicazione sono link bidirezionali gli switches possono assumere due configurazioni se il rapporto banchi memoria/processori è 1/1 allora ci sarà conflitto solo se 2 cores cercano di accedere allo stesso modulo di memoria contemporaneamente
28 Reti di interconnessione Sistemi memoria distribuita Tutti i sistemi caratterizzati da elevate potenze di calcolo sono composti da diversi nodi, a memoria condivisa sul singolo nodo e distribuita fra i nodi i nodi sono collegati fra di loro da topologie di interconnessione più o meno complesse e costose Le reti di interconnessione commerciali maggiormente utilizzate sono Gigabit Ethernet : la più diffusa, basso costo, basse prestazioni Infiniband : molto diffusa, elevate prestazioni, costo elevato (50% del costo di un cluster) Myrinet : sempre meno diffusa dopo l avvento di infiniband, vi sono comunque ancora sistemi HPC molto importanti che la utilizzano Reti di interconnessione di nicchia Quadrics Cray
29 Reti di interconnessione Sistemi memoria distribuita La topologia ideale è l interconnessione completa dove ogni switch è direttamente collegato a tutti gli altri, ovvero ogni nodo ha una connessione diretta con tutti gli altri. topologia troppo costosa e impossibile da progettare per sistemi costituiti da molti nodi, viene usata come termine di paragone per verificare l efficienza delle topologie reali soluzioni reali sono: anello, toroide, ipercubo, omega, fat tree. la soluzione meno costosa e meno efficiente è la LAN. Interconnessione completa
30 Anello - Toroide L interconnessione ad anello è superiore alla semplice LAN perché permette più connessioni simultanee dati p processori si hanno 2p links. L interconnessione toroidale può essere bidimensionale, tridimensionale o pentadimemsionale (Fermi) più performante della connessione ad anello perché aumenta il numero di connessioni. Anello Toroide bidimensionale
31 Ipercubo L interconnessione ad ipercubo è una topologia molto efficiente che prevede una buona connettività ed è molto utilizzata nei più importanti sistemi HPC l ipercubo monodimensionale è un sistema completamente connesso costituito da due processori l ipercubo bidimensionale è costruito partendo da due ipercubi monodimensionali collegando gli switch corrispondenti l ipercubo tridimensionale è costituito da bue ipercubi bidimensionali un ipercubo di dimensione d ha p=2^d nodi Ipercubo monodimensionale Ipercubo bidimensionale Ipercubo tridimensionale
32 Omega - Crossbar E una topologia che deriva dalla topologia crossbar switch 2 x 2 ma ha una connettività minore costo inferiore rispetto alla crossbar la comunicazione fra alcune coppie di nodi disabilita la possibiltà ad altre coppie di comunicare contemporaneamente. dati p nodi il numero di switch utilizzato è nella rete crossbar il numero di switch è pari a p² 2p log 2 p Crossbar 2 x 2 Omega
33 Fat tree Un' interconnessione fat tree è una rete in cui il numero di livelli è dato dalla formula: log p 4 dove p indica il numero di nodi. Ogni nodo possiede 4 connessioni con il livello inferiore e 2 con quello superiore.
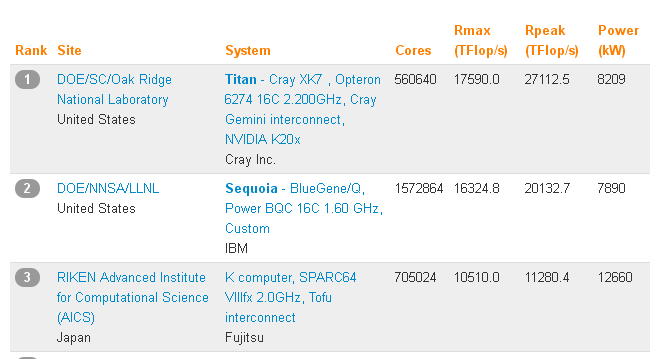
34 Top 500
Architetture. Paride Dagna SuperComputing Applications and Innovation Department 18/02/2013
 Architetture Paride Dagna SuperComputing Applications and Innovation Department 18/02/2013 Introduzione Grazie alle moderne tecniche di programmazione e agli strumenti di sviluppo attualmente disponibili,
Architetture Paride Dagna SuperComputing Applications and Innovation Department 18/02/2013 Introduzione Grazie alle moderne tecniche di programmazione e agli strumenti di sviluppo attualmente disponibili,
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO. A cura di Tania Caprini
 CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
La macchina di Von Neumann. Archite(ura di un calcolatore. L unità di elaborazione (CPU) Sequenza di le(ura. Il bus di sistema
 Sequenza di le(ura. Il bus di sistema") La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
Introduzione. Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD... 6
 Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
Architettura hardware
 Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
Architettura del calcolatore
 Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
Architettura dei computer
 Architettura dei computer In un computer possiamo distinguere quattro unità funzionali: il processore (CPU) la memoria principale (RAM) la memoria secondaria i dispositivi di input/output Il processore
Architettura dei computer In un computer possiamo distinguere quattro unità funzionali: il processore (CPU) la memoria principale (RAM) la memoria secondaria i dispositivi di input/output Il processore
C. P. U. MEMORIA CENTRALE
 C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
CPU. Maurizio Palesi
 CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
Il processore. Il processore. Il processore. Il processore. Architettura dell elaboratore
 Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Parte VIII. Architetture Parallele
 Parte VIII Architetture Parallele VIII.1 Motivazioni Limite di prestazioni delle architetture sequenziali: velocità di propagazione dei segnali, la luce percorre 30 cm in un nsec! Migliore rapporto costo/prestazioni
Parte VIII Architetture Parallele VIII.1 Motivazioni Limite di prestazioni delle architetture sequenziali: velocità di propagazione dei segnali, la luce percorre 30 cm in un nsec! Migliore rapporto costo/prestazioni
Architettura di un calcolatore
 2009-2010 Ingegneria Aerospaziale Prof. A. Palomba - Elementi di Informatica (E-Z) 7 Architettura di un calcolatore Lez. 7 1 Modello di Von Neumann Il termine modello di Von Neumann (o macchina di Von
2009-2010 Ingegneria Aerospaziale Prof. A. Palomba - Elementi di Informatica (E-Z) 7 Architettura di un calcolatore Lez. 7 1 Modello di Von Neumann Il termine modello di Von Neumann (o macchina di Von
Struttura del calcolatore
 Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Laboratorio di Informatica
 per chimica industriale e chimica applicata e ambientale LEZIONE 4 - parte II La memoria 1 La memoriaparametri di caratterizzazione Un dato dispositivo di memoria è caratterizzato da : velocità di accesso,
per chimica industriale e chimica applicata e ambientale LEZIONE 4 - parte II La memoria 1 La memoriaparametri di caratterizzazione Un dato dispositivo di memoria è caratterizzato da : velocità di accesso,
La memoria centrale (RAM)
") La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
Architettura dei calcolatori II parte Memorie
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Architettura dei calcolatori
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Architettura dei calcolatori
Calcolo numerico e programmazione Architettura dei calcolatori
 Calcolo numerico e programmazione Architettura dei calcolatori Tullio Facchinetti 30 marzo 2012 08:57 http://robot.unipv.it/toolleeo Il calcolatore tre funzionalità essenziali:
Calcolo numerico e programmazione Architettura dei calcolatori Tullio Facchinetti 30 marzo 2012 08:57 http://robot.unipv.it/toolleeo Il calcolatore tre funzionalità essenziali:
Organizzazione della memoria
 Memorizzazione dati La fase di codifica permette di esprimere qualsiasi informazione (numeri, testo, immagini, ecc) come stringhe di bit: Es: di immagine 00001001100110010010001100110010011001010010100010
Memorizzazione dati La fase di codifica permette di esprimere qualsiasi informazione (numeri, testo, immagini, ecc) come stringhe di bit: Es: di immagine 00001001100110010010001100110010011001010010100010
La memoria - generalità
 Calcolatori Elettronici La memoria gerarchica Introduzione La memoria - generalità n Funzioni: Supporto alla CPU: deve fornire dati ed istruzioni il più rapidamente possibile Archiviazione: deve consentire
Calcolatori Elettronici La memoria gerarchica Introduzione La memoria - generalità n Funzioni: Supporto alla CPU: deve fornire dati ed istruzioni il più rapidamente possibile Archiviazione: deve consentire
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione.
 Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
STRUTTURE DEI SISTEMI DI CALCOLO
 STRUTTURE DEI SISTEMI DI CALCOLO 2.1 Strutture dei sistemi di calcolo Funzionamento Struttura dell I/O Struttura della memoria Gerarchia delle memorie Protezione Hardware Architettura di un generico sistema
STRUTTURE DEI SISTEMI DI CALCOLO 2.1 Strutture dei sistemi di calcolo Funzionamento Struttura dell I/O Struttura della memoria Gerarchia delle memorie Protezione Hardware Architettura di un generico sistema
SISTEMI DI ELABORAZIONE DELLE INFORMAZIONI
 SISTEMI DI ELABORAZIONE DELLE INFORMAZIONI Prof. Andrea Borghesan venus.unive.it/borg borg@unive.it Ricevimento: martedì, 12.00-13.00. Dip. Di Matematica Modalità esame: scritto + tesina facoltativa 1
SISTEMI DI ELABORAZIONE DELLE INFORMAZIONI Prof. Andrea Borghesan venus.unive.it/borg borg@unive.it Ricevimento: martedì, 12.00-13.00. Dip. Di Matematica Modalità esame: scritto + tesina facoltativa 1
Calcolatori Elettronici
 Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
Esame di INFORMATICA
 Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Corso di Sistemi di Elaborazione delle informazioni
 Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Approccio stratificato
 Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
In un modello a strati il SO si pone come un guscio (shell) tra la macchina reale (HW) e le applicazioni 1 :
 tra la macchina reale (HW) e le applicazioni 1 :") Un Sistema Operativo è un insieme complesso di programmi che, interagendo tra loro, devono svolgere una serie di funzioni per gestire il comportamento del computer e per agire come intermediario consentendo
Un Sistema Operativo è un insieme complesso di programmi che, interagendo tra loro, devono svolgere una serie di funzioni per gestire il comportamento del computer e per agire come intermediario consentendo
Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base
 Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Dispensa di Informatica I.1
 IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
L informatica INTRODUZIONE. L informatica. Tassonomia: criteri. È la disciplina scientifica che studia
 L informatica È la disciplina scientifica che studia INTRODUZIONE I calcolatori, nati in risposta all esigenza di eseguire meccanicamente operazioni ripetitive Gli algoritmi, nati in risposta all esigenza
L informatica È la disciplina scientifica che studia INTRODUZIONE I calcolatori, nati in risposta all esigenza di eseguire meccanicamente operazioni ripetitive Gli algoritmi, nati in risposta all esigenza
Fondamenti di informatica: un po di storia
 Fondamenti di informatica: un po di storia L idea di utilizzare dispositivi meccanici per effettuare in modo automatico calcoli risale al 600 (Pascal, Leibniz) Nell ottocento vengono realizzati i primi
Fondamenti di informatica: un po di storia L idea di utilizzare dispositivi meccanici per effettuare in modo automatico calcoli risale al 600 (Pascal, Leibniz) Nell ottocento vengono realizzati i primi
SISTEMI OPERATIVI. Prof. Enrico Terrone A. S: 2008/09
 SISTEMI OPERATIVI Prof. Enrico Terrone A. S: 2008/09 Che cos è il sistema operativo Il sistema operativo (SO) è il software che gestisce e rende accessibili (sia ai programmatori e ai programmi, sia agli
SISTEMI OPERATIVI Prof. Enrico Terrone A. S: 2008/09 Che cos è il sistema operativo Il sistema operativo (SO) è il software che gestisce e rende accessibili (sia ai programmatori e ai programmi, sia agli
Architettura di un computer
 Architettura di un computer Modulo di Informatica Dott.sa Sara Zuppiroli A.A. 2012-2013 Modulo di Informatica () Architettura A.A. 2012-2013 1 / 36 La tecnologia Cerchiamo di capire alcuni concetti su
Architettura di un computer Modulo di Informatica Dott.sa Sara Zuppiroli A.A. 2012-2013 Modulo di Informatica () Architettura A.A. 2012-2013 1 / 36 La tecnologia Cerchiamo di capire alcuni concetti su
Strutture di Memoria 1
 Architettura degli Elaboratori e Laboratorio 17 Maggio 2013 Classificazione delle memorie Funzionalitá: Sola lettura ROM, Read Only Memory, generalmente usata per contenere le routine di configurazione
Architettura degli Elaboratori e Laboratorio 17 Maggio 2013 Classificazione delle memorie Funzionalitá: Sola lettura ROM, Read Only Memory, generalmente usata per contenere le routine di configurazione
Informatica - A.A. 2010/11
 Ripasso lezione precedente Facoltà di Medicina Veterinaria Corso di laurea in Tutela e benessere animale Corso Integrato: Matematica, Statistica e Informatica Modulo: Informatica Esercizio: Convertire
Ripasso lezione precedente Facoltà di Medicina Veterinaria Corso di laurea in Tutela e benessere animale Corso Integrato: Matematica, Statistica e Informatica Modulo: Informatica Esercizio: Convertire
Laboratorio di Informatica
 per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
Il Sistema Operativo (1)
") E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
La Gestione delle risorse Renato Agati
 Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Architettura dei calcolatori I parte Introduzione, CPU
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica C.I. 1 Informatica ed Elementi di Statistica 2 c.f.u. Anno Accademico 2009/2010 Docente: ing. Salvatore Sorce Architettura dei calcolatori
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica C.I. 1 Informatica ed Elementi di Statistica 2 c.f.u. Anno Accademico 2009/2010 Docente: ing. Salvatore Sorce Architettura dei calcolatori
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Scheduling della CPU. Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux
 Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
La gestione di un calcolatore. Sistemi Operativi primo modulo Introduzione. Sistema operativo (2) Sistema operativo (1)
 Sistema operativo (1)") La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
Il calcolatore elettronico. Parte dei lucidi sono stati gentilmente forniti dal Prof. Beraldi
 Il calcolatore elettronico Parte dei lucidi sono stati gentilmente forniti dal Prof. Beraldi Introduzione Un calcolatore elettronico è un sistema elettronico digitale programmabile Sistema: composto da
Il calcolatore elettronico Parte dei lucidi sono stati gentilmente forniti dal Prof. Beraldi Introduzione Un calcolatore elettronico è un sistema elettronico digitale programmabile Sistema: composto da
Programmazione Avanzata
 Programmazione Avanzata Vittorio Ruggiero (v.ruggiero@cineca.it) Roma, 10 Marzo 2014 AGENDA La mia parte di corso Architetture La cache ed il sistema di memoria Pipeline Profiling seriale Profiling parallelo
Programmazione Avanzata Vittorio Ruggiero (v.ruggiero@cineca.it) Roma, 10 Marzo 2014 AGENDA La mia parte di corso Architetture La cache ed il sistema di memoria Pipeline Profiling seriale Profiling parallelo
Introduzione alle tecnologie informatiche. Strumenti mentali per il futuro
 Introduzione alle tecnologie informatiche Strumenti mentali per il futuro Panoramica Affronteremo i seguenti argomenti. I vari tipi di computer e il loro uso Il funzionamento dei computer Il futuro delle
Introduzione alle tecnologie informatiche Strumenti mentali per il futuro Panoramica Affronteremo i seguenti argomenti. I vari tipi di computer e il loro uso Il funzionamento dei computer Il futuro delle
GPGPU GPGPU. anni piu' recenti e' naturamente aumentata la versatilita' ed usabilita' delle GPU
 GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
Sistemi Operativi GESTIONE DELLA MEMORIA SECONDARIA. D. Talia - UNICAL. Sistemi Operativi 11.1
 GESTIONE DELLA MEMORIA SECONDARIA 11.1 Memoria Secondaria Struttura del disco Scheduling del disco Gestione del disco Gestione dello spazio di swap Struttura RAID Affidabilità Implementazione della memoria
GESTIONE DELLA MEMORIA SECONDARIA 11.1 Memoria Secondaria Struttura del disco Scheduling del disco Gestione del disco Gestione dello spazio di swap Struttura RAID Affidabilità Implementazione della memoria
Sistemi Operativi. Memoria Secondaria GESTIONE DELLA MEMORIA SECONDARIA. Struttura del disco. Scheduling del disco. Gestione del disco
 GESTIONE DELLA MEMORIA SECONDARIA 11.1 Memoria Secondaria Struttura del disco Scheduling del disco Gestione del disco Gestione dello spazio di swap Struttura RAID Affidabilità Implementazione della memoria
GESTIONE DELLA MEMORIA SECONDARIA 11.1 Memoria Secondaria Struttura del disco Scheduling del disco Gestione del disco Gestione dello spazio di swap Struttura RAID Affidabilità Implementazione della memoria
Contenuti. Visione macroscopica Hardware Software. 1 Introduzione. 2 Rappresentazione dell informazione. 3 Architettura del calcolatore
 Contenuti Introduzione 1 Introduzione 2 3 4 5 71/104 Il Calcolatore Introduzione Un computer...... è una macchina in grado di 1 acquisire informazioni (input) dall esterno 2 manipolare tali informazioni
Contenuti Introduzione 1 Introduzione 2 3 4 5 71/104 Il Calcolatore Introduzione Un computer...... è una macchina in grado di 1 acquisire informazioni (input) dall esterno 2 manipolare tali informazioni
Informatica di base. Hardware: CPU SCHEDA MADRE. Informatica Hardware di un PC Prof. Corrado Lai
 Informatica di base Hardware: CPU SCHEDA MADRE HARDWARE DI UN PC 2 Hardware (parti fisiche) Sono le parti fisiche di un Personal Computer (processore, scheda madre, tastiera, mouse, monitor, memorie,..).
Informatica di base Hardware: CPU SCHEDA MADRE HARDWARE DI UN PC 2 Hardware (parti fisiche) Sono le parti fisiche di un Personal Computer (processore, scheda madre, tastiera, mouse, monitor, memorie,..).
RETI E SISTEMI INFORMATIVI
 RETI E SISTEMI INFORMATIVI Prof. Andrea Borghesan venus.unive.it/borg borg@unive.it Ricevimento: mercoledì, 10.00-11.00. Studio 34, primo piano. Dip. Statistica 1 Modalità esame: scritto + tesina facoltativa
RETI E SISTEMI INFORMATIVI Prof. Andrea Borghesan venus.unive.it/borg borg@unive.it Ricevimento: mercoledì, 10.00-11.00. Studio 34, primo piano. Dip. Statistica 1 Modalità esame: scritto + tesina facoltativa
CALCOLATORI ELETTRONICI A cura di Luca Orrù
 Lezione 1 Obiettivi del corso Il corso si propone di descrivere i principi generali delle architetture di calcolo (collegamento tra l hardware e il software). Sommario 1. Tecniche di descrizione (necessarie
Lezione 1 Obiettivi del corso Il corso si propone di descrivere i principi generali delle architetture di calcolo (collegamento tra l hardware e il software). Sommario 1. Tecniche di descrizione (necessarie
ARCHITETTURA DELL ELABORATORE
 1 ISTITUTO DI ISTRUZIONE SUPERIORE ANGIOY ARCHITETTURA DELL ELABORATORE Prof. G. Ciaschetti 1. Tipi di computer Nella vita di tutti giorni, abbiamo a che fare con tanti tipi di computer, da piccoli o piccolissimi
1 ISTITUTO DI ISTRUZIONE SUPERIORE ANGIOY ARCHITETTURA DELL ELABORATORE Prof. G. Ciaschetti 1. Tipi di computer Nella vita di tutti giorni, abbiamo a che fare con tanti tipi di computer, da piccoli o piccolissimi
Reti LAN. IZ3MEZ Francesco Canova www.iz3mez.it francesco@iz3mez.it
 Reti LAN IZ3MEZ Francesco Canova www.iz3mez.it francesco@iz3mez.it Le LAN Una LAN è un sistema di comunicazione che permette ad apparecchiature indipendenti di comunicare fra loro entro un area limitata
Reti LAN IZ3MEZ Francesco Canova www.iz3mez.it francesco@iz3mez.it Le LAN Una LAN è un sistema di comunicazione che permette ad apparecchiature indipendenti di comunicare fra loro entro un area limitata
Un sistema operativo è un insieme di programmi che consentono ad un utente di
 INTRODUZIONE AI SISTEMI OPERATIVI 1 Alcune definizioni 1 Sistema dedicato: 1 Sistema batch o a lotti: 2 Sistemi time sharing: 2 Sistema multiprogrammato: 3 Processo e programma 3 Risorse: 3 Spazio degli
INTRODUZIONE AI SISTEMI OPERATIVI 1 Alcune definizioni 1 Sistema dedicato: 1 Sistema batch o a lotti: 2 Sistemi time sharing: 2 Sistema multiprogrammato: 3 Processo e programma 3 Risorse: 3 Spazio degli
Speedup. Si definisce anche lo Speedup relativo in cui, invece di usare T 1 si usa T p (1).
.") Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Materiali per il modulo 1 ECDL. Autore: M. Lanino
 Materiali per il modulo 1 ECDL Autore: M. Lanino RAM, l'acronimo per "random access memory", ovvero "memoria ad acceso casuale", è la memoria in cui vengono caricati i dati che devono essere utilizzati
Materiali per il modulo 1 ECDL Autore: M. Lanino RAM, l'acronimo per "random access memory", ovvero "memoria ad acceso casuale", è la memoria in cui vengono caricati i dati che devono essere utilizzati
Linux nel calcolo distribuito
 openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero dino@delfavero.it, micky@delfavero.it BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero dino@delfavero.it, micky@delfavero.it BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.7. Il moltiplicatore binario e il ciclo di base di una CPU
 Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
CONCETTI BASE dell'informatica Cose che non si possono non sapere!
 CONCETTI BASE dell'informatica Cose che non si possono non sapere! Pablo Genova I. I. S. Angelo Omodeo Mortara A. S. 2015 2016 COS'E' UN COMPUTER? È una macchina elettronica programmabile costituita da
CONCETTI BASE dell'informatica Cose che non si possono non sapere! Pablo Genova I. I. S. Angelo Omodeo Mortara A. S. 2015 2016 COS'E' UN COMPUTER? È una macchina elettronica programmabile costituita da
All interno del computer si possono individuare 5 componenti principali: SCHEDA MADRE. MICROPROCESSORE che contiene la CPU MEMORIA RAM MEMORIA ROM
 Il computer è un apparecchio elettronico che riceve dati di ingresso (input), li memorizza e gli elabora e fornisce in uscita i risultati (output). Il computer è quindi un sistema per elaborare informazioni
Il computer è un apparecchio elettronico che riceve dati di ingresso (input), li memorizza e gli elabora e fornisce in uscita i risultati (output). Il computer è quindi un sistema per elaborare informazioni
Introduzione all'architettura dei Calcolatori
 Introduzione all'architettura dei Calcolatori Introduzione Che cos è un calcolatore? Come funziona un calcolatore? è possibile rispondere a queste domande in molti modi, ciascuno relativo a un diverso
Introduzione all'architettura dei Calcolatori Introduzione Che cos è un calcolatore? Come funziona un calcolatore? è possibile rispondere a queste domande in molti modi, ciascuno relativo a un diverso
Sommario. Analysis & design delle applicazioni parallele. Misura delle prestazioni parallele. Tecniche di partizionamento.
 Sommario Analysis & design delle applicazioni parallele Misura delle prestazioni parallele Tecniche di partizionamento Comunicazioni Load balancing 2 Primi passi: analizzare il problema Prima di iniziare
Sommario Analysis & design delle applicazioni parallele Misura delle prestazioni parallele Tecniche di partizionamento Comunicazioni Load balancing 2 Primi passi: analizzare il problema Prima di iniziare
Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer.
 I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
Il sistema di I/O. Hardware di I/O Interfacce di I/O Software di I/O. Introduzione
 Il sistema di I/O Hardware di I/O Interfacce di I/O Software di I/O Introduzione 1 Sotto-sistema di I/O Insieme di metodi per controllare i dispositivi di I/O Obiettivo: Fornire ai processi utente un interfaccia
Il sistema di I/O Hardware di I/O Interfacce di I/O Software di I/O Introduzione 1 Sotto-sistema di I/O Insieme di metodi per controllare i dispositivi di I/O Obiettivo: Fornire ai processi utente un interfaccia
Sistemi Operativi IMPLEMENTAZIONE DEL FILE SYSTEM. D. Talia - UNICAL. Sistemi Operativi 9.1
 IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM. Davide Barbieri
 Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Principali versioni dell'hardware CUDA Tesla Fermi Accesso veloce alla memoria globale Accesso veloce alla memoria condivisa
Ottimizzazioni 1 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Principali versioni dell'hardware CUDA Tesla Fermi Accesso veloce alla memoria globale Accesso veloce alla memoria condivisa
Gestione della memoria centrale
 Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Parte IV Architettura della CPU Central Processing Unit
 Parte IV Architettura della CPU Central Processing Unit IV.1 Struttura della CPU All interno di un processore si identificano in genere due parti principali: l unità di controllo e il data path (percorso
Parte IV Architettura della CPU Central Processing Unit IV.1 Struttura della CPU All interno di un processore si identificano in genere due parti principali: l unità di controllo e il data path (percorso
LABORATORIO DI SISTEMI
 ALUNNO: Fratto Claudio CLASSE: IV B Informatico ESERCITAZIONE N : 1 LABORATORIO DI SISTEMI OGGETTO: Progettare e collaudare un circuito digitale capace di copiare le informazioni di una memoria PROM in
ALUNNO: Fratto Claudio CLASSE: IV B Informatico ESERCITAZIONE N : 1 LABORATORIO DI SISTEMI OGGETTO: Progettare e collaudare un circuito digitale capace di copiare le informazioni di una memoria PROM in
1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi
 1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi Il processo E' un programma in esecuzione Tipi di processo Stati di un processo 1 indipendenti
1 Processo, risorsa, richiesta, assegnazione 2 Concorrenza 3 Grafo di Holt 4 Thread 5 Sincronizzazione tra processi Il processo E' un programma in esecuzione Tipi di processo Stati di un processo 1 indipendenti
Sistemi Operativi GESTIONE DELLA MEMORIA CENTRALE. D. Talia - UNICAL. Sistemi Operativi 6.1
 GESTIONE DELLA MEMORIA CENTRALE 6.1 Gestione della Memoria Background Spazio di indirizzi Swapping Allocazione Contigua Paginazione 6.2 Background Per essere eseguito un programma deve trovarsi (almeno
GESTIONE DELLA MEMORIA CENTRALE 6.1 Gestione della Memoria Background Spazio di indirizzi Swapping Allocazione Contigua Paginazione 6.2 Background Per essere eseguito un programma deve trovarsi (almeno
Tipi classici di memoria. Obiettivo. Principi di localita. Gerarchia di memoria. Fornire illimitata memoria veloce. Static RAM. Problemi: Dynamic RAM
 Obiettivo Tipi classici di memoria Fornire illimitata memoria veloce Problemi: costo tecnologia Soluzioni: utilizzare diversi tipi di memoria... Static RAM access times are 2-25ns at cost of $100 to $250
Obiettivo Tipi classici di memoria Fornire illimitata memoria veloce Problemi: costo tecnologia Soluzioni: utilizzare diversi tipi di memoria... Static RAM access times are 2-25ns at cost of $100 to $250
Il calcolatore oggi : UN SISTEMA DI ELABORAZIONE
 Il calcolatore oggi : UN SISTEMA DI ELABORAZIONE hardware Firmware, software memorizzato su chip di silicio Sistema Operativo venduto con l, comprende vari programmi di gestione del sistema Applicativo,
Il calcolatore oggi : UN SISTEMA DI ELABORAZIONE hardware Firmware, software memorizzato su chip di silicio Sistema Operativo venduto con l, comprende vari programmi di gestione del sistema Applicativo,
Organizzazione della memoria principale Il bus
 Corso di Alfabetizzazione Informatica 2001/2002 Organizzazione della memoria principale Il bus Organizzazione della memoria principale La memoria principale è organizzata come un insieme di registri di
Corso di Alfabetizzazione Informatica 2001/2002 Organizzazione della memoria principale Il bus Organizzazione della memoria principale La memoria principale è organizzata come un insieme di registri di
Software relazione. Software di base Software applicativo. Hardware. Bios. Sistema operativo. Programmi applicativi
 Software relazione Hardware Software di base Software applicativo Bios Sistema operativo Programmi applicativi Software di base Sistema operativo Bios Utility di sistema software Software applicativo Programmi
Software relazione Hardware Software di base Software applicativo Bios Sistema operativo Programmi applicativi Software di base Sistema operativo Bios Utility di sistema software Software applicativo Programmi
Università degli Studi di Salerno
 Università degli Studi di Salerno Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Informatica Tesi di Laurea Algoritmi basati su formule di quadratura interpolatorie per GPU ABSTRACT
Università degli Studi di Salerno Facoltà di Scienze Matematiche Fisiche e Naturali Corso di Laurea in Informatica Tesi di Laurea Algoritmi basati su formule di quadratura interpolatorie per GPU ABSTRACT
Architettura del Personal Computer AUGUSTO GROSSI
 Il CASE o CABINET è il contenitore in cui vengono montati la scheda scheda madre, uno o più dischi rigidi, la scheda video, la scheda audio e tutti gli altri dispositivi hardware necessari per il funzionamento.
Il CASE o CABINET è il contenitore in cui vengono montati la scheda scheda madre, uno o più dischi rigidi, la scheda video, la scheda audio e tutti gli altri dispositivi hardware necessari per il funzionamento.
Il Processore: i registri
 Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Più processori uguale più velocità?
 Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Il Sistema Operativo. Di cosa parleremo? Come si esegue un programma. La nozione di processo. Il sistema operativo
 Il Sistema Operativo Di cosa parleremo? Come si esegue un programma. La nozione di processo. Il sistema operativo ... ma Cos'è un S.O.? un PROGRAMMA!... ma Cos'è un programma? PROGRAMMA: 1. algoritmo sequenza
Il Sistema Operativo Di cosa parleremo? Come si esegue un programma. La nozione di processo. Il sistema operativo ... ma Cos'è un S.O.? un PROGRAMMA!... ma Cos'è un programma? PROGRAMMA: 1. algoritmo sequenza
Trasmissione di dati al di fuori di un area locale avviene tramite la commutazione
 Commutazione 05.2 Trasmissione di dati al di fuori di un area locale avviene tramite la Autunno 2002 Prof. Roberto De Prisco -05: Reti a di circuito Università degli studi di Salerno Laurea e Diploma in
Commutazione 05.2 Trasmissione di dati al di fuori di un area locale avviene tramite la Autunno 2002 Prof. Roberto De Prisco -05: Reti a di circuito Università degli studi di Salerno Laurea e Diploma in
Sistema operativo: Gestione della memoria
 Dipartimento di Elettronica ed Informazione Politecnico di Milano Informatica e CAD (c.i.) - ICA Prof. Pierluigi Plebani A.A. 2008/2009 Sistema operativo: Gestione della memoria La presente dispensa e
Dipartimento di Elettronica ed Informazione Politecnico di Milano Informatica e CAD (c.i.) - ICA Prof. Pierluigi Plebani A.A. 2008/2009 Sistema operativo: Gestione della memoria La presente dispensa e
Il memory manager. Gestione della memoria centrale
 Il memory manager Gestione della memoria centrale La memoria La memoria RAM è un vettore molto grande di WORD cioè celle elementari a 16bit, 32bit, 64bit (2Byte, 4Byte, 8Byte) o altre misure a seconda
Il memory manager Gestione della memoria centrale La memoria La memoria RAM è un vettore molto grande di WORD cioè celle elementari a 16bit, 32bit, 64bit (2Byte, 4Byte, 8Byte) o altre misure a seconda
Sistemi Operativi IMPLEMENTAZIONE DEL FILE SYSTEM. Implementazione del File System. Struttura del File System. Implementazione
 IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
IMPLEMENTAZIONE DEL FILE SYSTEM 9.1 Implementazione del File System Struttura del File System Implementazione Implementazione delle Directory Metodi di Allocazione Gestione dello spazio libero Efficienza
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14. Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 11 Martedì 12-11-2013 1 Tecniche di allocazione mediante free list Generalmente,
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 11 Martedì 12-11-2013 1 Tecniche di allocazione mediante free list Generalmente,
Operazioni di Comunicazione di base. Cap.4
 Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
INFORMATICA. Il Sistema Operativo. di Roberta Molinari
 INFORMATICA Il Sistema Operativo di Roberta Molinari Il Sistema Operativo un po di definizioni Elaborazione: trattamento di di informazioni acquisite dall esterno per per restituire un un risultato Processore:
INFORMATICA Il Sistema Operativo di Roberta Molinari Il Sistema Operativo un po di definizioni Elaborazione: trattamento di di informazioni acquisite dall esterno per per restituire un un risultato Processore:
Livello logico digitale. bus e memorie
 Livello logico digitale bus e memorie Principali tipi di memoria Memoria RAM Memorie ROM RAM (Random Access Memory) SRAM (Static RAM) Basata su FF (4 o 6 transistor MOS) Veloce, costosa, bassa densità
Livello logico digitale bus e memorie Principali tipi di memoria Memoria RAM Memorie ROM RAM (Random Access Memory) SRAM (Static RAM) Basata su FF (4 o 6 transistor MOS) Veloce, costosa, bassa densità
Prestazioni computazionali di OpenFOAM sul. sistema HPC CRESCO di ENEA GRID
 Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
ARCHITETTURA DEL CALCOLATORE
 Orologio di sistema (Clock) UNITÀ UNITÀ DI DI INGRESSO Schema a blocchi di un calcolatore REGISTRI CONTROLLO BUS DEL SISTEMA MEMORIA DI DI MASSA Hard Hard Disk Disk MEMORIA CENTRALE Ram Ram ALU CPU UNITÀ
Orologio di sistema (Clock) UNITÀ UNITÀ DI DI INGRESSO Schema a blocchi di un calcolatore REGISTRI CONTROLLO BUS DEL SISTEMA MEMORIA DI DI MASSA Hard Hard Disk Disk MEMORIA CENTRALE Ram Ram ALU CPU UNITÀ
Sistemi Operativi MECCANISMI E POLITICHE DI PROTEZIONE. D. Talia - UNICAL. Sistemi Operativi 13.1
 MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1
 MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
Corso di Informatica
 CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it La memoria principale 2 izzazione della memoria principale ria principale è organizzata come
CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it La memoria principale 2 izzazione della memoria principale ria principale è organizzata come
Il sistema operativo. Sistema operativo. Multiprogrammazione. Il sistema operativo. Gestione della CPU
 Il sistema operativo Sistema operativo Gestione della CPU Primi elaboratori: Monoprogrammati: un solo programma in memoria centrale Privi di sistema operativo Gestione dell hardware da parte degli utenti
Il sistema operativo Sistema operativo Gestione della CPU Primi elaboratori: Monoprogrammati: un solo programma in memoria centrale Privi di sistema operativo Gestione dell hardware da parte degli utenti
L HARDWARE parte 1 ICTECFOP@GMAIL.COM
 L HARDWARE parte 1 COMPUTER E CORPO UMANO INPUT E OUTPUT, PERIFERICHE UNITA DI SISTEMA: ELENCO COMPONENTI COMPONENTI NEL DETTAGLIO: SCHEDA MADRE (SOCKET, SLOT) CPU MEMORIA RAM MEMORIE DI MASSA USB E FIREWIRE
L HARDWARE parte 1 COMPUTER E CORPO UMANO INPUT E OUTPUT, PERIFERICHE UNITA DI SISTEMA: ELENCO COMPONENTI COMPONENTI NEL DETTAGLIO: SCHEDA MADRE (SOCKET, SLOT) CPU MEMORIA RAM MEMORIE DI MASSA USB E FIREWIRE
I componenti di un Sistema di elaborazione. CPU (central process unit)
") I componenti di un Sistema di elaborazione. CPU (central process unit) I componenti di un Sistema di elaborazione. CPU (central process unit) La C.P.U. è il dispositivo che esegue materialmente gli ALGORITMI.
I componenti di un Sistema di elaborazione. CPU (central process unit) I componenti di un Sistema di elaborazione. CPU (central process unit) La C.P.U. è il dispositivo che esegue materialmente gli ALGORITMI.
Dispensa di Fondamenti di Informatica. Architettura di un calcolatore
 Dispensa di Fondamenti di Informatica Architettura di un calcolatore Hardware e software La prima decomposizione di un calcolatore è relativa ai seguenti macro-componenti hardware la struttura fisica del
Dispensa di Fondamenti di Informatica Architettura di un calcolatore Hardware e software La prima decomposizione di un calcolatore è relativa ai seguenti macro-componenti hardware la struttura fisica del