Università degli Studi di Cassino e del Lazio Meridionale
|
|
|
- Sabrina Costa
- 8 anni fa
- Visualizzazioni
Transcript
1 di Cassino e del Lazio Meridionale Corso di Pipeline Anno Accademico Francesco Tortorella

2 Progettazione del datapath Prima soluzione: d.p. a ciclo singolo Semplice da realizzare Condizionato dal worst case (istruzione più lenta) Ogni unità funzionale è usata una volta sola per ciclo Si può dare di più? Pipeline Da dove partiamo?
 Ogni unità funzionale è")
3 Il datapath a ciclo singolo PCSrc Add M ux 1 4 RegWrite Shift left 2 Add result 0 PC Read address Instruction [31 0] Instruction memory Instruction [25 21] Instruction [20 16] 1 M ux Instruction [15 11] 0 RegDst Instruction [15 0] Read register 1 Read register 2 Write register Write data Read data 1 Read data 2 Registers 16 Sign 32 extend Src M ux 1 0 control Zero result MemWrite Address Write data Data memory MemRead Read data MemtoReg M ux 1 0 Instruction [5 0] Op

4 5 fasi per l esecuzione di un istruzione IFetch: Instruction Fetch e aggiornamento PC Dec: Registers Fetch e decodifica istruzione Exec: Esecuzione (R-type) Calcolo dell indirizzo di memoria (I-type) Mem: Lettura dato dalla memoria (lw) Scrittura dato in memoria (sw) WB: Scrittura del risultato nel register file Eseguite da tutte le istruzioni?
 WB: Scrittura del risultato nel register file Eseguite da tutte le")
5 Dove si realizzano le varie fasi? Flusso di esecuzione Eccezioni al flusso di esecuzione

6 Dal ciclo singolo al pipeline Come permettere l utilizzo dell hardware da più istruzioni in contemporanea? Si inseriscono registri tra i vari stadi Mantengono le informazioni prodotte nel ciclo precedente Si ottiene una pipeline a 5 stadi Frequenza di clock potenzialmente 5 volte più alta

7 Datapath basato su pipeline System clock

8 Prime considerazioni I registri sono presenti tra le varie parti del datapath, ognuna delle quali realizza una particolare fase. I registri separano una sezione dall altra, evitando così che le diverse istruzioni in esecuzione interferiscano tra loro. Il flusso dei dati è da sinistra verso destra con due eccezioni significative: WB scrive il risultato nel file register, nel mezzo del data path Uno dei possibili valori per l aggiornamento del PC proviene dalla sezione MEM Solo le istruzioni successive possono essere influenzate da questi movimenti dati in direzione opposta al flusso consueto: WB -> ID provoca data hazards (alea sui dati) MEM -> IF provoca control hazards (alea sul controllo)

9 Esecuzione di lw

10 Esecuzione di lw

11 Esecuzione di lw

12 Esecuzione di lw
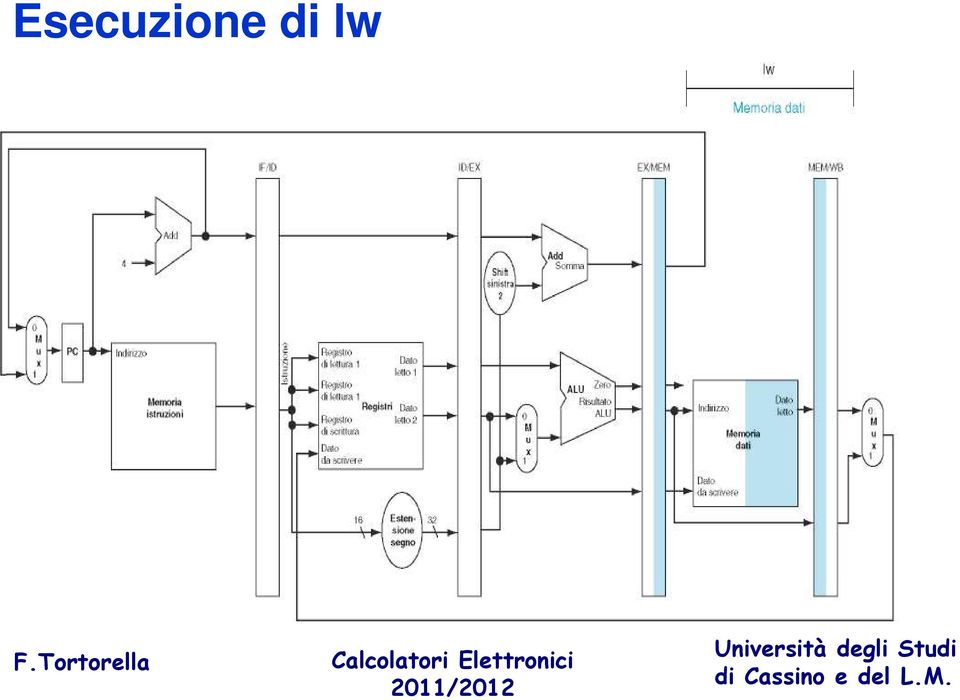
13 Esecuzione di lw

14 Esecuzione di sw Che cosa cambia? IF, ID uguali In EX viene inoltrato il contenuto di Rt In MEM viene scritto il valore in memoria Che cosa succede in WB?

15 Esecuzione di sw (EX)
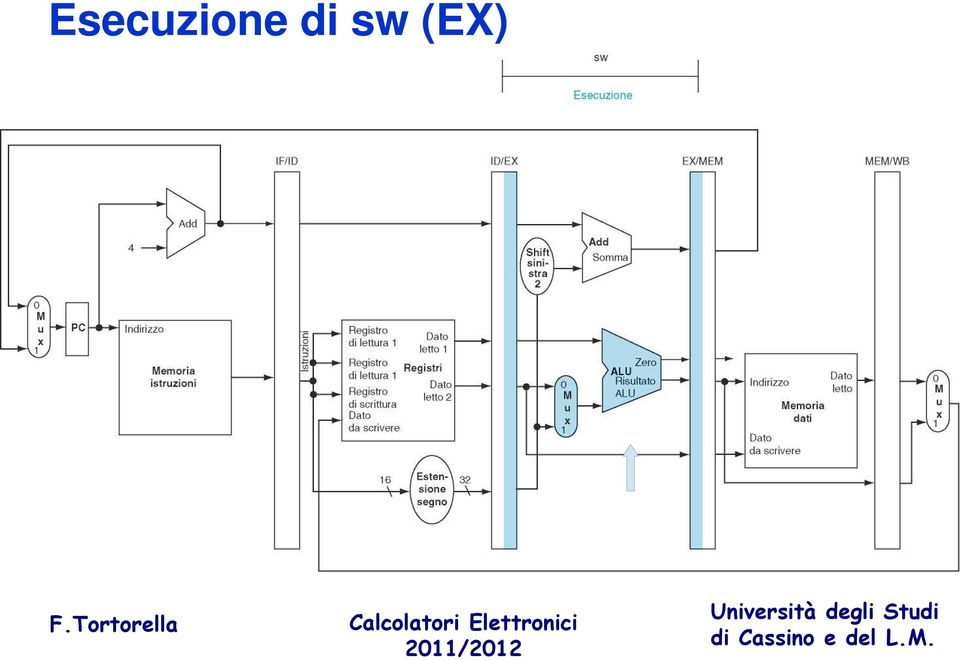
16 Esecuzione di sw (MEM)
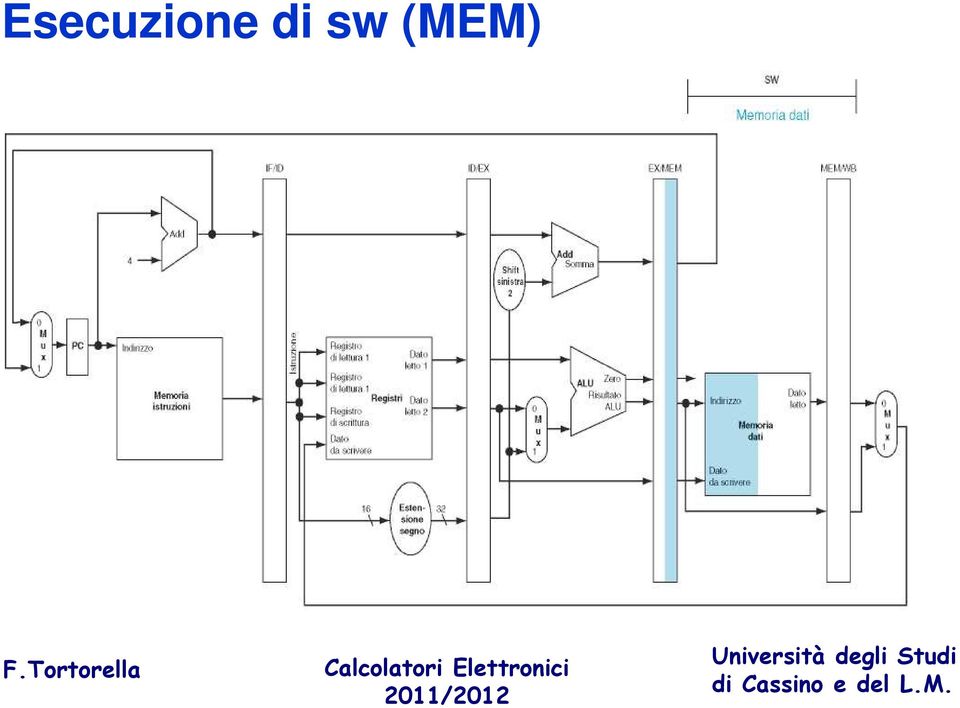
17 Esecuzione di sw (WB)

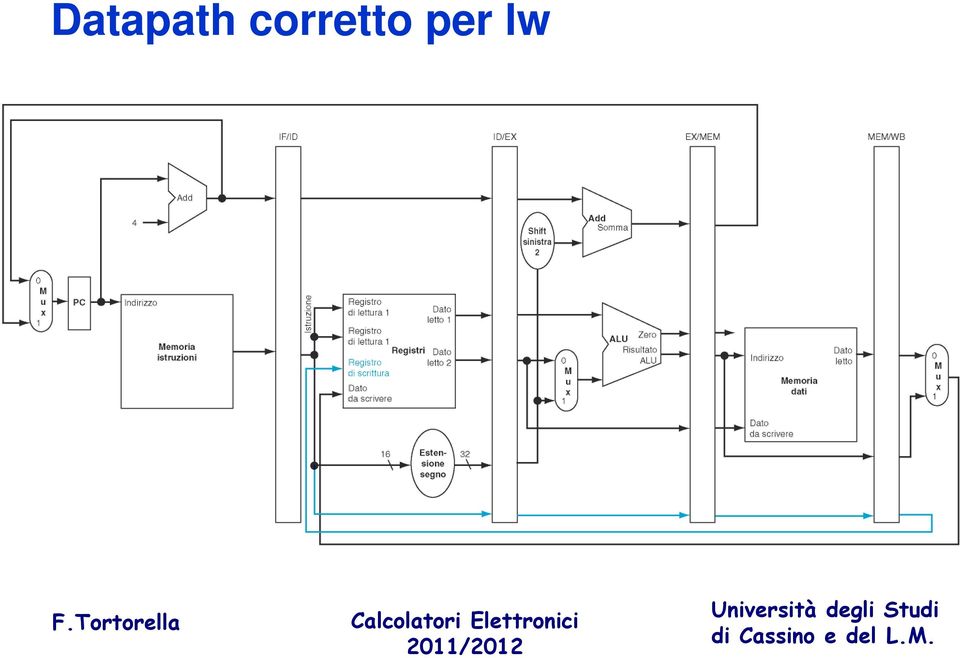
18 Problemi nell esecuzione di lw?

19 Datapath corretto per lw
20 Unità di controllo della pipeline

21 Segnali di controllo

22 Istruzioni / Segnali di controllo Branch Write Mem Sono raggruppati secondo lo stadio in cui sono attivi I primi due stadi non contengono segnali di controllo Perchè?
23 Distribuzione dei segnali di controllo I segnali vengono determinati durante la fase ID Vengono usati nelle tre fasi successive: vanno quindi inoltrati fra gli stadi.
24 Datapath pipelined completo (quasi...)
 Sono necessari diagrammi che si riferiscano a più cicli di clock (diagrammi a più cicli) A")
25 Rappresentazione grafica della pipeline Necessario rappresentare la situazione della pipeline in un certo istante Quali istruzioni si stanno eseguendo? In quale stadio? I diagrammi visti finora rappresentano la situazione in un solo ciclo di clock (diagrammi a singolo ciclo) Sono necessari diagrammi che si riferiscano a più cicli di clock (diagrammi a più cicli) A questo scopo si adopra una rappresentazione sintetica del datapath
26 Rappresentazione grafica della pipeline Consideriamo la sequenza di cinque istruzioni: lw $10, 20($1) sub $11, $2, $3 add $12, $3, $4 lw $13, 24($1) add $14, $5, $6 E supponiamo di voler considerare la loro esecuzione sul datapath pipelined al progredire del clock
27 Avanzamento delle istruzioni
28 Diagramma a più cicli
29 Situazione al ciclo 5 (CC5)
30 Confronto tra le implementazioni Ciclo singolo: Clk Cycle 1 Cycle 2 Load Store Waste Pipeline: lw IFetch Dec Exec Mem WB sw IFetch Dec Exec Mem WB wasted cycles R-type IFetch Dec Exec Mem WB Stessa latenza Throughput diverso
31 Ritardo del Write Si ritarda di un ciclo il write delle istruzioni R-type Tutte le istruzioni accedono al Write Port del R.F. nel 5 passo nessun conflitto Il 4 passo (Mem) per le istr. R-type è in effetti un passo NOP R-type Ifetch Reg/Dec Exec Mem Wr Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7 Cycle 8 Cycle 9 Clock R-type Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec Mem Wr Load Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec Mem Wr R-type Ifetch Reg/Dec Exec Mem Wr
32 Il pipeline ottimizza il throughput Tempo (cicli di clock) I n s t r. Inst 0 Inst 1 Una volta che il pipeline è pieno, si completa un istruzione ad ogni ciclo O r d e r Inst 2 Inst 3 Inst 4 Tempo di riempimento del pipeline
33 Come l ISA MIPS favorisce il pipelining Tutte le istruzioni hanno la stessa lunghezza Più semplice il fetch nel 1 passo e il decode nel 2 passo Pochi formati di istruzione (3) con simmetria tra i formati Possibile cominciare la lettura del register file nel 2 passo Le operazioni in memoria limitate alle istruzioni di load/store Possibile usare il passo di execute per calcolare gli indirizzi Ogni istruzione MIPS scrive al più un risultato e lo fa verso la fine del pipeline
34 Problemi dal pipelining? Alee Alee strutturali: tentativo di usare contemporaneamente la stessa risorsa da parte di due istruzioni differenti Alee sui dati : tentativo di usare i dati prima che siano disponibili Gli operandi sorgente di un istruzione sono prodotti da un istruzione precedente che è ancora nel pipeline Istruzione di Load seguita immediatamente da un istruzione che richiede l operando del load come sorgente per un operazione sull Alee sul controllo: tentativo di prendere una decisione prima che la condizione sia stata valutata Istruzioni di salto È sempre possibile eliminare le alee inserendo dei tempi morti ( bolle ), ma si abbassa l efficienza
35 Alea strutturale 1: memoria unica Tempo (cicli di clock) I n s t r. lw Inst 1 Mem Reg Mem Reg Mem Reg Mem Reg Lettura dati dalla memoria O r d e r Inst 2 Inst 3 Mem Reg Mem Reg Mem Reg Mem Reg Inst 4 Lettura istruzione dalla memoria Mem Reg Mem Reg
36 Alea strutturale 1: memoria unica Soluzione: Creazione di una seconda memoria irrealizzabile e inefficiente Ne simuliamo la presenza tramite una memoria cache separata in cache istruzioni e cache dati.
37 Alea strutturale 2: accesso ai registri Tempo (cicli di clock) I n s t r. add r1, Inst 1 O r d e r Inst 2 add r2,r1, Inst 4 Possibile alea Read Before Write
38 Alea strutturale 2: accesso ai registri L accesso ai registri è molto veloce: richiede meno di metà del tempo necessario ad un operazione Soluzione: si introduce la convenzione Scrittura sui registri durante la prima metà del ciclo di clock Lettura dai registri durante la seconda metà del ciclo di clock Risultato : possibile realizzare senza problemi un Read ed un Write durante lo stesso ciclo di clock
39 Alea strutturale 2: accesso ai registri Tempo (cicli di clock) I n s t r. add r1, Inst 1 O r d e r Inst 2 add r2,r1, Inst 4 Possibile alea Read Before Write
40 Alea sui dati Consideriamo la sequenza di istruzioni add $t0, $t1, $t2 sub $t4, $t0,$t3 and $t5, $t0,$t6 or $t7, $t0,$t8 xor $t9, $t0,$t10
41 Alea sui dati L influenza su fasi precedenti produce alee I n s t r. O r d e r add $t0, $t1, $t2 sub $t4, $t0,$t3 and $t5, $t0,$t6 or $t7, $t0,$t8 xor $t9, $t0,$t10
42 Alea sui dati L influenza su fasi precedenti produce alee I n s t r. O r d e r add $t0, $t1, $t2 sub $t4, $t0,$t3 and $t5, $t0,$t6 or $t7, $t0,$t8 xor $t9, $t0,$t10 alea Read Before Write
43 Alea sui dati: soluzione 1 add $t0, $t1, $t2 stall stall Possibile risolvere inserendo dei tempi morti (stall) ma peggiora il throughput sub $t4, $t0,$t3 and $t5, $t0,$t6
44 Alea sui dati: soluzione 2 I n s t r. O r d e r add $t0, $t1, $t2 sub $t4, $t0,$t3 and $t5, $t0,$t6 or $t7, $t0,$t8 Si propagano i dati in avanti appena sono disponibili verso le unità che li richiedono (forwarding) xor $t9, $t0,$t10
45 Forwarding
46 Forwarding Il risultato dell istruzione sub è già disponibile al termine dello stadio EX (CC3). Le altre istruzioni hanno bisogno di quel dato negli stadi CC4 (and) e CC5 (or) Dove si trova il dato in quegli istanti? CC4: nel registro EX/MEM CC5: nel registro MEM/WB Come è quindi possibile capire che è necessario il forwarding? 1a: EX/MEM.RegistroRd == ID/EX.Registro.Rs 1b: EX/MEM.RegistroRd == ID/EX.Registro.Rt 2a: MEM/WB.RegistroRd == ID/EX.Registro.Rs 2b: MEM/WB.RegistroRd == ID/EX.Registro.Rt
47 Forwarding Condizione 1a Condizione 2b
48 Forwarding: come si modifica il Datapath?
49 Forwarding: come si modifica il Datapath?
50 Alea sui dati da Load Simile al precedente, ma con una difficoltà in più I n s t r. O r d e r lw r1,100(r2) sub r4,r1,r5 and r6,r1,r7 or r8, r1, r9 xor r4,r1,r5 Load-use data hazard
51 Alea sui dati da Load: forwarding I n s t r. O r d e r lw r1,100(r2) sub r4,r1,r5 and r6,r1,r7 or r8, r1, r9 xor r4,r1,r5 Forwarding insufficiente. Necessario uno stall?
52 Alea sui dati da Load Il controllo deve bloccare il pipeline interlock lw $t0, 0($t1) IF ID/RF EX MEM WB I$ Reg D$ Reg sub $t3,$t0,$t2 and $t5,$t0,$t4 bub I$ Reg D$ Reg ble I$ bub Reg D$ Reg ble bub ble or $t7,$t0,$t6 I$ Reg D$
53 Alea sui dati da Load Lo spazio per l istruzione dopo un load è chiamato load delay slot Se l istruzione usa il risultato del load, allora il controllo dovrà forzare uno stall per un ciclo. Non necessario se il traduttore inserisce nello slot un istruzione non dipendente dal load (reordering) traduttore cosciente del pipelining Anche se questo non fosse possibile, si può risolvere ugualmente il problema inserendo un NOP nello slot Chi inserisce il NOP?
54 Alea sui dati da Load Lo stall è equivalente ad un NOP lw $t0, 0($t1) I$ Reg D$ Reg nop bub ble bub ble bub ble bub ble bub ble sub $t3,$t0,$t2 and $t5,$t0,$t4 I$ Reg D$ Reg I$ Reg D$ Reg or $t7,$t0,$t6 I$ Reg D$
55 Nota storica Il MIPS è stato il primo progetto di processore a non risolvere il load-use data hazard con interlock e stall Acronimo reale per il MIPS: Microprocessor without Interlocked Pipeline Stages
56 I n s t r. O r d e r Alea di controllo: salto beq Instr 1 Instr 2 Instr 3 Instr 4 Time (clock cycles) I$ Reg D$ Reg I$ Reg D$ Reg I$ Reg D$ Reg I$ Reg D$ Reg I$ Reg D$ Reg Dove si realizza il confronto per il salto?
57 Alea di controllo: salto L unità per il confronto e la decisione è nel terzo stage ( stage) Quindi altre due istruzioni dopo il beq entreranno nel pipeline, quale che sia il risultato del confronto Comportamento (desiderato) del salto Se il confronto fallisce continua la normale esecuzione Se il confronto è verificato, non eseguire altre istruzioni successive al salto e vai all indirizzo specificato
58 Alea di controllo: salto. Soluzione 1 Blocco del pipeline finchè il confronto non sia stato realizzato Inserimento di NOP Conseguenza: i salti richiedono 3 cicli di clock (assumendo che il confronto si faccia nel 3 stage)
59 Alea di controllo: salto. Soluzione 2.1 Soluzione 2.1: Anticipazione del confronto al passo 2 Appena l istruzione è decodificata, si può decidere immediatamente e modificare il PC (se necessario) In questo modo entra solo un istruzione nel pipeline necessario solo un NOP
60 Alea di controllo: salto. Soluzione 2.1 I n s t r. O r d e r Inserimento di una bolla add beq lw Time (clock cycles) I$ Reg D$ Reg I$ Reg D$ Reg bub ble 2 cicli per branch ancora lento I$ Reg D$ Reg
61 Alea di controllo: salto. Soluzione 2.2 Soluzione 2.2 (ridefinizione del salto) Vecchia definizione: in caso di salto, nessuna istruzione successiva al branch deve essere eseguita Nuova definizione: in ogni caso, viene eseguita l istruzione che segue immediatamente il branch (definita branch-delay slot) Questo approccio viene definito Delayed Branch
62 Note sul Branch-Delay Slot Caso peggiore Inserimento di un NOP nello slot Caso migliore È possibile trovare un istruzione precedente al branch che possa essere posticipata al branch senza alterare il flusso di controllo (e dei dati) Dipende dalle capacità del traduttore Anche i jump hanno un delay slot
63 Esempio: Nondelayed vs. Delayed Branch Nondelayed Branch Delayed Branch or $8, $9,$10 add $1,$2,$3 add $1,$2,$3 sub $4, $5,$6 beq $1, $4, Exit xor $10, $1,$11 sub $4, $5,$6 beq $1, $4, Exit or $8, $9,$10 xor $10, $1,$11 Exit: Exit:
64 Riassumendo... Il pipelining migliora le prestazioni incrementando il throughput delle istruzioni: sfrutta l Instruction Level Parallelism Esegue più istruzioni in parallelo Ogni istruzione ha la stessa latenza E soggetto ad alee Strutturali, di dati, di controllo Gli stalli riducono le prestazioni Ma sono necessari per ottenere risultati corretti Il compilatore può riorganizzare il codice per evitare alee e stalli Richiede conoscenza dell architettura pipelined
65 Come aumentare l ILP? Esecuzione parallela (Multiple Issue) superscalare Replica degli stadi di pipeline (pipeline multiple) Si avviano più istruzioni nel ciclo di clock Parallelizzazione statica dell esecuzione (Static MI) Il compilatore raggruppa le istruzioni da eseguire insieme Le impacchetta in insiemi di esecuzione (issue slots) Individua ed evita le alee Parallelizzazione dinamica dell esecuzione (Dynam. MI) La CPU esamina il flusso di istruzioni e sceglie quali eseguire in ogni ciclo Il compilatore può aiutare nel riordinare le istruzioni La CPU risolve le alee utilizzando opportune tecniche a runtime.
66 Parallelizzazione statica Il compilatore raggruppa le istruzioni in pacchetti di esecuzione Gruppi di istruzioni che possono partire nello stesso ciclo Determinati dalle risorse richieste Ogni pacchetto può essere visto come un istruzione molto lunga che specifica molte operazioni contemporanee VLIW: Very Long Instruction Word
67 Parallelizzazione statica Il compilatore deve impedire alee (se possibile) Riordina le istruzioni nei pacchetti Nessuna dipendenza all interno del pacchetto Possibili dipendenze tra pacchetti Quando inevitabile, inserimento di NOP
68 Parallelizzazione dinamica Processori superscalari La CPU decide quante e quali istruzioni avviare in un ciclo (0, 1, 2, ) Da evitare alee strutturali e di dati Non necessario lo scheduling da parte del compilatore Anche se può aiutare La CPU deve garantire che l esecuzione sia fedele a quanto definito nel programma Possibile l esecuzione fuori ordine (out of order) delle istruzioni per evitare stalli (es. dovuti a lw)
69 Speculazione (non economica ) Permette di indovinare le caratteristiche di un istruzione Inizia l operazione appena possibile Verifica se la previsione è stata corretta Se OK, completa l operazione; altrimenti trona indietro Esempi: branch prediction E comune alla parallelizzazione statica e dinamica.
70 Organizzazione di una CPU superscalare La pipeline è divisa in tre unità principali Una unità per l instruction fetch e avvio dell esecuzione Istruzioni avviate in ordine Un gruppo di più unità funzionali in parallelo Ogni unità ha una Reservation Station che mantiene gli operandi e memorizza l operazione Può eseguire istruzioni fuori ordine Una unità di consegna Preleva i risultati dalle unità funzionali e li salva nei Reorder Buffers Salva i risultati garantendo una consegna in ordine

71 Organizzazione di una CPU superscalare Preserves dependencies Hold pending operands Results also sent to any waiting reservation stations
72 Esempi Microprocessor Year Clock Rate Pipeline Stages Issue width Out-of-order/ Speculation Cores i MHz 5 1 No 1 5W Power Pentium MHz 5 2 No 1 10W Pentium Pro MHz 10 3 Yes 1 29W P4 Willamette MHz 22 3 Yes 1 75W P4 Prescott MHz 31 3 Yes 1 103W Core MHz 14 4 Yes 2 75W Core 2 Yorkfield MHz 16 4 Yes 4 95W Core i7 Gulftown MHz 16 4 Yes 6 130W
Università degli Studi di Cassino e del Lazio Meridionale
 Università degli Studi di Cassino e del Lazio Meridionale di Pipeline Anno Accademico Alessandra Scotto di Freca Si ringrazia il prof.francesco Tortorella per il materiale didattico Progettazione del datapath
Università degli Studi di Cassino e del Lazio Meridionale di Pipeline Anno Accademico Alessandra Scotto di Freca Si ringrazia il prof.francesco Tortorella per il materiale didattico Progettazione del datapath
CALCOLATORI ELETTRONICI 29 giugno 2011
 CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
CALCOLATORI ELETTRONICI 31 marzo 2015
 CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
CPU. Maurizio Palesi
 CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
CPU Central Processing Unit 1 Organizzazione Tipica CPU Dispositivi di I/O Unità di controllo Unità aritmetico logica (ALU) Terminale Stampante Registri CPU Memoria centrale Unità disco Bus 2 L'Esecutore
CALCOLATORI ELETTRONICI 29 giugno 2010
 CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
CALCOLATORI ELETTRONICI 15 aprile 2014
 CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
L unità di elaborazione pipeline L unità Pipelining
 Struttura del processore L unità di elaborazione pipeline Corso ACSO prof. Cristina SILVANO Politecnico di Milano Incremento delle Per migliorare ulteriormente le si può: ridurre il periodo di clock aumentare
Struttura del processore L unità di elaborazione pipeline Corso ACSO prof. Cristina SILVANO Politecnico di Milano Incremento delle Per migliorare ulteriormente le si può: ridurre il periodo di clock aumentare
Architettura di tipo registro-registro (load/store)
") Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
Schedulazione dinamica. Elettronica dei Calcolatori 1
 Schedulazione dinamica Elettronica dei Calcolatori 1 Schedulazione dinamica delle operazioni Impossibile risolvere tutti i conflitti staticamente I possibile predire tutti i salti condizionati HW fa durante
Schedulazione dinamica Elettronica dei Calcolatori 1 Schedulazione dinamica delle operazioni Impossibile risolvere tutti i conflitti staticamente I possibile predire tutti i salti condizionati HW fa durante
Esercitazione sulle CPU pipeline
 Esercitazione sulle CPU pipeline Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato perché
Esercitazione sulle CPU pipeline Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato perché
Calcolatori Elettronici. La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo
 Calcolatori Elettronici La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo La pipeline CRITICITÀ SUI DATI Calcolatori Elettronici - Pipeline (2) - Slide 2 L. Tarantino
Calcolatori Elettronici La Pipeline Criticità sui dati Criticità sul controllo Cenni sull unità di controllo La pipeline CRITICITÀ SUI DATI Calcolatori Elettronici - Pipeline (2) - Slide 2 L. Tarantino
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Calcolatori Elettronici
 Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
Calcolatori Elettronici La Pipeline Superpipeline Pipeline superscalare Schedulazione dinamica della pipeline Processori reali: l architettura Intel e la pipeline dell AMD Opteron X4 Ricapitolando Con
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO
 ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
CPU pipeline 4: le CPU moderne
 Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
Lezione n.19 Processori RISC e CISC
 Lezione n.19 Processori RISC e CISC 1 Processori RISC e Superscalari Motivazioni che hanno portato alla realizzazione di queste architetture Sommario: Confronto tra le architetture CISC e RISC Prestazioni
Lezione n.19 Processori RISC e CISC 1 Processori RISC e Superscalari Motivazioni che hanno portato alla realizzazione di queste architetture Sommario: Confronto tra le architetture CISC e RISC Prestazioni
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO
 ESERCIZIO Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
ESERCIZIO Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
MODELLO DLX IN UNISIM
 Architettura e descrizione del modello MODELLO DLX IN UNISIM RINGRAZIAMENTI : I materiali per questa presentazione sono tratti dal tutorial ufficiale di UNISIM - https://unisim.org/site/tutorials/start
Architettura e descrizione del modello MODELLO DLX IN UNISIM RINGRAZIAMENTI : I materiali per questa presentazione sono tratti dal tutorial ufficiale di UNISIM - https://unisim.org/site/tutorials/start
La macchina di Von Neumann. Archite(ura di un calcolatore. L unità di elaborazione (CPU) Sequenza di le(ura. Il bus di sistema
 Sequenza di le(ura. Il bus di sistema") La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
Esempio: aggiungere j
 Esempio: aggiungere j Eccezioni e interruzioni Il progetto del controllo del processore si complica a causa della necessità di considerare, durante l esecuzione delle istruzioni, il verificarsi di eventi
Esempio: aggiungere j Eccezioni e interruzioni Il progetto del controllo del processore si complica a causa della necessità di considerare, durante l esecuzione delle istruzioni, il verificarsi di eventi
CPU pipeline 4: le CPU moderne
 Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/17
Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/17
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
Aumentare il parallelismo a livello di istruzione (2)
") Processori multiple-issue issue Aumentare il parallelismo a livello di istruzione (2) Architetture Avanzate dei Calcolatori Valeria Cardellini Nei processori multiple-issue vengono lanciate più istruzioni
Processori multiple-issue issue Aumentare il parallelismo a livello di istruzione (2) Architetture Avanzate dei Calcolatori Valeria Cardellini Nei processori multiple-issue vengono lanciate più istruzioni
Calcolatori Elettronici B a.a. 2008/2009
 Calcolatori Elettronici B a.a. 2008/2009 Tecniche Pipeline: Gestione delle criticità Massimiliano Giacomin 1 Pipeline: i problemi Idealmente, il throughput è di una istruzione per ciclo di clock! Purtroppo,
Calcolatori Elettronici B a.a. 2008/2009 Tecniche Pipeline: Gestione delle criticità Massimiliano Giacomin 1 Pipeline: i problemi Idealmente, il throughput è di una istruzione per ciclo di clock! Purtroppo,
L unità di controllo. Il processore: unità di controllo. Le macchine a stati finiti. Struttura della macchina a stati finiti
 Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune
Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune
L unità di controllo di CPU multi-ciclo
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano A.A. 23-24 /2 Sommario I segnali di controllo
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano A.A. 23-24 /2 Sommario I segnali di controllo
Valutazione delle Prestazioni
 Valutazione delle Prestazioni Sia data una macchina X, definiamo: 1 PrestazioneX = --------------------------- Tempo di esecuzione X La prestazione aumenta con il diminuire del tempo di esecuzione (e diminuisce
Valutazione delle Prestazioni Sia data una macchina X, definiamo: 1 PrestazioneX = --------------------------- Tempo di esecuzione X La prestazione aumenta con il diminuire del tempo di esecuzione (e diminuisce
Architettura del calcolatore
 Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
Architettura del calcolatore La prima decomposizione di un calcolatore è relativa a due macro-componenti: Hardware Software Architettura del calcolatore L architettura dell hardware di un calcolatore reale
Tecniche di parallelismo, processori RISC
 Testo di riferimento: [Congiu] 9.1-9.3 (pg. 253 264) Tecniche di parallelismo, processori RISC 09.a Pipelining Altre tecniche di parallelismo Processori superscalari Caratteristiche dei processori RISC
Testo di riferimento: [Congiu] 9.1-9.3 (pg. 253 264) Tecniche di parallelismo, processori RISC 09.a Pipelining Altre tecniche di parallelismo Processori superscalari Caratteristiche dei processori RISC
Calcolatori Elettronici
 Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo Condizioni SEGNALI DI CONTROLLO PC emoria indirizzo IR dato letto UNITA DI ELABORAZIONE
Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo Condizioni SEGNALI DI CONTROLLO PC emoria indirizzo IR dato letto UNITA DI ELABORAZIONE
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.7. Il moltiplicatore binario e il ciclo di base di una CPU
 Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Struttura del calcolatore
 Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Struttura del calcolatore Proprietà: Flessibilità: la stessa macchina può essere utilizzata per compiti differenti, nessuno dei quali è predefinito al momento della costruzione Velocità di elaborazione
Quinto Homework. Indicare il tempo necessario all'esecuzione del programma in caso di avvio e ritiro fuori ordine.
 Quinto Homework 1) Si vuole progettare una cache a mappatura diretta per un sistema a 32 bit per una memoria da 2 GB (quindi sono solo 31 i bit utili per gli indirizzi) e blocchi di 64 byte. Rispondere
Quinto Homework 1) Si vuole progettare una cache a mappatura diretta per un sistema a 32 bit per una memoria da 2 GB (quindi sono solo 31 i bit utili per gli indirizzi) e blocchi di 64 byte. Rispondere
Metodi Software per ottenere ILP
 Metodi Software per ottenere ILP Calcolatori Elettronici 2 http://www.dii.unisi.it/~giorgi/didattica/calel2 Scaletta Tecnologie nel compilatore BRANCH PREDICTION A SOFTWARE (nel compilatore) - Gia vista
Metodi Software per ottenere ILP Calcolatori Elettronici 2 http://www.dii.unisi.it/~giorgi/didattica/calel2 Scaletta Tecnologie nel compilatore BRANCH PREDICTION A SOFTWARE (nel compilatore) - Gia vista
Architettura (10/9/2003) Pag. 1/6. Cognome e Nome (in stampatello):
 Pag. 1/6. Cognome e Nome (in stampatello):") Architettura (10/9003) Pag. 1/6 Esame di Architettura (matr.0-1) del 10/9003 Per Fondamenti di Architettura NON rispondere Per le domande a risposta multipla cerchiare la risposta scelta. Non alle domande
Architettura (10/9003) Pag. 1/6 Esame di Architettura (matr.0-1) del 10/9003 Per Fondamenti di Architettura NON rispondere Per le domande a risposta multipla cerchiare la risposta scelta. Non alle domande
Aggiornato il 18 giugno 2015. 1 Questa affermazione richiede una precisazione. A parità di altre condizioni, l eliminazione dello stadio ME allunga la
 8 Questo documento contiene le soluzioni ad un numero selezionato di esercizi del Capitolo 8 del libro Calcolatori Elettronici - Architettura e organizzazione, Mc-Graw Hill 2009. Sarò grato a coloro che
8 Questo documento contiene le soluzioni ad un numero selezionato di esercizi del Capitolo 8 del libro Calcolatori Elettronici - Architettura e organizzazione, Mc-Graw Hill 2009. Sarò grato a coloro che
C. P. U. MEMORIA CENTRALE
 C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
C. P. U. INGRESSO MEMORIA CENTRALE USCITA UNITA DI MEMORIA DI MASSA La macchina di Von Neumann Negli anni 40 lo scienziato ungherese Von Neumann realizzò il primo calcolatore digitale con programma memorizzato
ARCHITETTURE MICROPROGRAMMATE. 1. Necessità di un architettura microprogrammata 1. Cos è un architettura microprogrammata? 4
 ARCHITETTURE MICROPROGRAMMATE. 1 Necessità di un architettura microprogrammata 1 Cos è un architettura microprogrammata? 4 Struttura di una microistruzione. 5 Esempi di microprogrammi 9 Esempio 1 9 Esempio
ARCHITETTURE MICROPROGRAMMATE. 1 Necessità di un architettura microprogrammata 1 Cos è un architettura microprogrammata? 4 Struttura di una microistruzione. 5 Esempi di microprogrammi 9 Esempio 1 9 Esempio
La memoria centrale (RAM)
") La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
Sistemi Operativi. Scheduling della CPU SCHEDULING DELLA CPU. Concetti di Base Criteri di Scheduling Algoritmi di Scheduling
 SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
Sistemi Operativi SCHEDULING DELLA CPU. Sistemi Operativi. D. Talia - UNICAL 5.1
 SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
SCHEDULING DELLA CPU 5.1 Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling Real-Time
DMA Accesso Diretto alla Memoria
 Testo di rif.to: [Congiu] - 8.1-8.3 (pg. 241 250) 08.a DMA Accesso Diretto alla Memoria Motivazioni Organizzazione dei trasferimenti DMA Arbitraggio del bus di memoria Trasferimento di un blocco di dati
Testo di rif.to: [Congiu] - 8.1-8.3 (pg. 241 250) 08.a DMA Accesso Diretto alla Memoria Motivazioni Organizzazione dei trasferimenti DMA Arbitraggio del bus di memoria Trasferimento di un blocco di dati
Architettura hardware
 Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
In realtà, non un solo microprocessore, ma un intera famiglia, dalle CPU più semplici con una sola pipeline a CPU molto complesse per applicazioni ad
 Principi di architetture dei calcolatori: l architettura ARM. Mariagiovanna Sami Che cosa è ARM In realtà, non un solo microprocessore, ma un intera famiglia, dalle CPU più semplici con una sola pipeline
Principi di architetture dei calcolatori: l architettura ARM. Mariagiovanna Sami Che cosa è ARM In realtà, non un solo microprocessore, ma un intera famiglia, dalle CPU più semplici con una sola pipeline
Aumentare il parallelismo a livello di istruzione (1)
") Aumentare il parallelismo a livello di istruzione (1) Architetture Avanzate dei Calcolatori Valeria Cardellini Parallelismo Il parallelismo consente di migliorare le prestazioni grazie all esecuzione simultanea
Aumentare il parallelismo a livello di istruzione (1) Architetture Avanzate dei Calcolatori Valeria Cardellini Parallelismo Il parallelismo consente di migliorare le prestazioni grazie all esecuzione simultanea
Calcolatori Elettronici B a.a. 2006/2007
 Calcolatori Elettronici B a.a. 2006/2007 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Due tipi di unità funzionali Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in ingresso
Calcolatori Elettronici B a.a. 2006/2007 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Due tipi di unità funzionali Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in ingresso
Instruction Level Parallelism Andrea Gasparetto
 Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Come si definisce il concetto di performance? Tempo di esecuzione di un programma. numero di task/transazioni eseguiti per unità di tempo
 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Sistemi Operativi. Interfaccia del File System FILE SYSTEM : INTERFACCIA. Concetto di File. Metodi di Accesso. Struttura delle Directory
 FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
L architettura di riferimento
 Architetture degli elaboratori e delle reti Lezione 10 L architettura di riferimento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 10 1/27
Architetture degli elaboratori e delle reti Lezione 10 L architettura di riferimento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 10 1/27
Architetture moderne
 Architetture moderne Esecuzione delle istruzioni in pipeline Predizione dei branch Multiple issue Register renaming Esecuzione fuori ordine Cache non bloccanti Architetture avanzate - 1 Pipelining PIPELINING
Architetture moderne Esecuzione delle istruzioni in pipeline Predizione dei branch Multiple issue Register renaming Esecuzione fuori ordine Cache non bloccanti Architetture avanzate - 1 Pipelining PIPELINING
Unità di controllo della pipeline
 Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica. prof. ing. Corrado Santoro
 Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica prof. ing. Corrado Santoro Schema a blocchi di una CPU Arithmetic Logic Unit Control Unit Register File BUS Control
Architettura della CPU e linguaggio assembly Corso di Abilità Informatiche Laurea in Fisica prof. ing. Corrado Santoro Schema a blocchi di una CPU Arithmetic Logic Unit Control Unit Register File BUS Control
La macchina programmata Instruction Set Architecture (1)
") Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
INCREMENTO DELLE PRESTAZIONI DI UN PROCESSORE
 1 INCREMENTO DELLE PRESTAZIONI DI UN PROCESSORE TIPI DI PARALLELISMO E CLASSIFICAZIONE DI FLYNN PIPELINING DELLE ISTRUZIONI I PROCESSORI SUPERSCALARI I PROCESSORI VLIW MULTITHREADING, CHIP MULTI PROCESSOR
1 INCREMENTO DELLE PRESTAZIONI DI UN PROCESSORE TIPI DI PARALLELISMO E CLASSIFICAZIONE DI FLYNN PIPELINING DELLE ISTRUZIONI I PROCESSORI SUPERSCALARI I PROCESSORI VLIW MULTITHREADING, CHIP MULTI PROCESSOR
Il processore. Il processore. Il processore. Il processore. Architettura dell elaboratore
 Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Il processore Architettura dell elaboratore Il processore La esegue istruzioni in linguaggio macchina In modo sequenziale e ciclico (ciclo macchina o ciclo ) Effettuando operazioni di lettura delle istruzioni
Lezione 3: Architettura del calcolatore
 Lezione 3: Architettura del calcolatore Architettura di Von Neumann BUS, CPU e Memoria centrale Ciclo di esecuzione delle istruzioni Architettura del calcolatore Il calcolatore è: uno strumento programmabile
Lezione 3: Architettura del calcolatore Architettura di Von Neumann BUS, CPU e Memoria centrale Ciclo di esecuzione delle istruzioni Architettura del calcolatore Il calcolatore è: uno strumento programmabile
Tutorato Architettura degli elaboratori
 Tutorato Architettura degli elaboratori Dott. Damiano Braga Before we start.. Orario 12 Aprile h. 14.00-16.00 aula F6 20 Aprile h. 11.30-13.30 aula F6 10 Maggio h. 14.00-16.00 aula F4 18 Maggio h. 11.30-13.30
Tutorato Architettura degli elaboratori Dott. Damiano Braga Before we start.. Orario 12 Aprile h. 14.00-16.00 aula F6 20 Aprile h. 11.30-13.30 aula F6 10 Maggio h. 14.00-16.00 aula F4 18 Maggio h. 11.30-13.30
Architettura hw. La memoria e la cpu
 Architettura hw La memoria e la cpu La memoria centrale e la CPU Bus controllo Bus indirizzi Bus dati Bus di collegamento con la cpu indirizzi controllo dati Bus Indirizzi 11 Bus controllo Leggi/scrivi
Architettura hw La memoria e la cpu La memoria centrale e la CPU Bus controllo Bus indirizzi Bus dati Bus di collegamento con la cpu indirizzi controllo dati Bus Indirizzi 11 Bus controllo Leggi/scrivi
Coordinazione Distribuita
 Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Valutazione delle Prestazioni. Valutazione delle Prestazioni. Architetture dei Calcolatori (Lettere. Tempo di risposta e throughput
 Valutazione delle Prestazioni Architetture dei Calcolatori (Lettere A-I) Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Valutazione delle Prestazioni Architetture dei Calcolatori (Lettere A-I) Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Von Neumann. John Von Neumann (1903-1957)
") Linguaggio macchina Von Neumann John Von Neumann (1903-1957) Inventore dell EDVAC (Electronic Discrete Variables AutomaFc Computer), la prima macchina digitale programmabile tramite un soiware basata su
Linguaggio macchina Von Neumann John Von Neumann (1903-1957) Inventore dell EDVAC (Electronic Discrete Variables AutomaFc Computer), la prima macchina digitale programmabile tramite un soiware basata su
Scheduling. Sistemi Operativi e Distribuiti A.A. 2004-2005 Bellettini - Maggiorini. Concetti di base
 Scheduling Sistemi Operativi e Distribuiti A.A. 2-25 Bellettini - Maggiorini Concetti di base Il massimo utilizzo della CPU si ottiene mediante la multiprogrammazione Ogni processo si alterna su due fasi
Scheduling Sistemi Operativi e Distribuiti A.A. 2-25 Bellettini - Maggiorini Concetti di base Il massimo utilizzo della CPU si ottiene mediante la multiprogrammazione Ogni processo si alterna su due fasi
Organizzazione della memoria principale Il bus
 Corso di Alfabetizzazione Informatica 2001/2002 Organizzazione della memoria principale Il bus Organizzazione della memoria principale La memoria principale è organizzata come un insieme di registri di
Corso di Alfabetizzazione Informatica 2001/2002 Organizzazione della memoria principale Il bus Organizzazione della memoria principale La memoria principale è organizzata come un insieme di registri di
Testi di Esercizi e Quesiti 1
 Architettura degli Elaboratori, 2009-2010 Testi di Esercizi e Quesiti 1 1. Una rete logica ha quattro variabili booleane di ingresso a 0, a 1, b 0, b 1 e due variabili booleane di uscita z 0, z 1. La specifica
Architettura degli Elaboratori, 2009-2010 Testi di Esercizi e Quesiti 1 1. Una rete logica ha quattro variabili booleane di ingresso a 0, a 1, b 0, b 1 e due variabili booleane di uscita z 0, z 1. La specifica
COS È UN LINGUAGGIO? LINGUAGGI DI ALTO LIVELLO LA NOZIONE DI LINGUAGGIO LINGUAGGIO & PROGRAMMA
 LINGUAGGI DI ALTO LIVELLO Si basano su una macchina virtuale le cui mosse non sono quelle della macchina hardware COS È UN LINGUAGGIO? Un linguaggio è un insieme di parole e di metodi di combinazione delle
LINGUAGGI DI ALTO LIVELLO Si basano su una macchina virtuale le cui mosse non sono quelle della macchina hardware COS È UN LINGUAGGIO? Un linguaggio è un insieme di parole e di metodi di combinazione delle
Università degli Studi di Cassino
 Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella prof@quarella.
 Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella prof@quarella.net Prestazioni Si valutano in maniera diversa a seconda dell
Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella prof@quarella.net Prestazioni Si valutano in maniera diversa a seconda dell
Architettura di un calcolatore: introduzione
 Corso di Calcolatori Elettronici I Architettura di un calcolatore: introduzione Prof. Roberto Canonico Università degli Studi di Napoli Federico II Dipartimento di Ingegneria Elettrica e delle Tecnologie
Corso di Calcolatori Elettronici I Architettura di un calcolatore: introduzione Prof. Roberto Canonico Università degli Studi di Napoli Federico II Dipartimento di Ingegneria Elettrica e delle Tecnologie
Lezione 1: L architettura LC-3 Laboratorio di Elementi di Architettura e Sistemi Operativi 10 Marzo 2014
 Lezione 1: L architettura LC-3 Laboratorio di Elementi di Architettura e Sistemi Operativi 10 Marzo 2014 Ricorda... Il ciclo di esecuzione di un istruzione è composto da sei fasi: FETCH DECODE ADDRESS
Lezione 1: L architettura LC-3 Laboratorio di Elementi di Architettura e Sistemi Operativi 10 Marzo 2014 Ricorda... Il ciclo di esecuzione di un istruzione è composto da sei fasi: FETCH DECODE ADDRESS
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Sistemi Operativi SCHEDULING DELLA CPU
 Sistemi Operativi SCHEDULING DELLA CPU Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling
Sistemi Operativi SCHEDULING DELLA CPU Scheduling della CPU Concetti di Base Criteri di Scheduling Algoritmi di Scheduling FCFS, SJF, Round-Robin, A code multiple Scheduling in Multi-Processori Scheduling
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.6. Unità di controllo microprogrammata
 Lezione n.6 Unità di controllo microprogrammata 1 Sommario Unità di controllo microprogrammata Ottimizzazione, per ottimizzare lo spazio di memoria occupato Il moltiplicatore binario Esempio di architettura
Lezione n.6 Unità di controllo microprogrammata 1 Sommario Unità di controllo microprogrammata Ottimizzazione, per ottimizzare lo spazio di memoria occupato Il moltiplicatore binario Esempio di architettura
Calcolatori Elettronici
 Calcolatori Elettronici Classificazione dei calcolatori elettronici Sistemi basati sull architettura di Von Neumann Sistemi basati sull architettura Harward Architettura dei calcolatori: definizioni Evoluzione
Calcolatori Elettronici Classificazione dei calcolatori elettronici Sistemi basati sull architettura di Von Neumann Sistemi basati sull architettura Harward Architettura dei calcolatori: definizioni Evoluzione
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
Tecniche per il progetto di sistemi elettronici tolleranti ai guasti
 Tecniche per il progetto di sistemi elettronici tolleranti ai guasti Fulvio Corno, Maurizio Rebaudengo, Matteo Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica Le tecniche di
Tecniche per il progetto di sistemi elettronici tolleranti ai guasti Fulvio Corno, Maurizio Rebaudengo, Matteo Sonza Reorda Politecnico di Torino Dipartimento di Automatica e Informatica Le tecniche di
Sistema operativo: Gestione della memoria
 Dipartimento di Elettronica ed Informazione Politecnico di Milano Informatica e CAD (c.i.) - ICA Prof. Pierluigi Plebani A.A. 2008/2009 Sistema operativo: Gestione della memoria La presente dispensa e
Dipartimento di Elettronica ed Informazione Politecnico di Milano Informatica e CAD (c.i.) - ICA Prof. Pierluigi Plebani A.A. 2008/2009 Sistema operativo: Gestione della memoria La presente dispensa e
Siamo così arrivati all aritmetica modulare, ma anche a individuare alcuni aspetti di come funziona l aritmetica del calcolatore come vedremo.
 DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18
 Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Calcolatore: sottosistemi Processore o CPU (Central Processing
Corso di Calcolatori Elettronici I A.A. 2010-2011 Il processore Lezione 18 Università degli Studi di Napoli Federico II Facoltà di Ingegneria Calcolatore: sottosistemi Processore o CPU (Central Processing
Approccio stratificato
 Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Progettaz. e sviluppo Data Base
 Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
Il pipelining: tecniche di base
 Definizione di pipelining Il pipelining: tecniche di base Architetture Avanzate dei Calcolatori E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di
Definizione di pipelining Il pipelining: tecniche di base Architetture Avanzate dei Calcolatori E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
Calcolatori Elettronici
 Calcolatori Elettronici Classificazione dei calcolatori elettronici Sistemi basati sull architettura di von Neumann rchitettura dei calcolatori: definizioni Evoluzione dell architettura rchitettura della
Calcolatori Elettronici Classificazione dei calcolatori elettronici Sistemi basati sull architettura di von Neumann rchitettura dei calcolatori: definizioni Evoluzione dell architettura rchitettura della
Scheduling della CPU. Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux
 Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Università degli Studi di Cassino
 Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
File system II. Sistemi Operativi Lez. 20
 File system II Sistemi Operativi Lez. 20 Gestione spazi su disco Esiste un trade-off,tra spreco dello spazio e velocità di trasferimento in base alla dimensione del blocco fisico Gestione spazio su disco
File system II Sistemi Operativi Lez. 20 Gestione spazi su disco Esiste un trade-off,tra spreco dello spazio e velocità di trasferimento in base alla dimensione del blocco fisico Gestione spazio su disco
Linguaggi di programmazione
 Linguaggi di programmazione Un calcolatore basato sul modello di von Neumann permette l esecuzione di un programma, cioè di una sequenza di istruzioni descritte nel linguaggio interpretabile dal calcolatore
Linguaggi di programmazione Un calcolatore basato sul modello di von Neumann permette l esecuzione di un programma, cioè di una sequenza di istruzioni descritte nel linguaggio interpretabile dal calcolatore
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Corso di Sistemi di Elaborazione delle informazioni
 Corso di Sistemi di Elaborazione delle informazioni LEZIONE 2 (HARDWARE) a.a. 2011/2012 Francesco Fontanella Tre concetti Fondamentali Algoritmo; Automa (o anche macchina); Calcolo; 2 Calcolatore MACCHINA
Corso di Sistemi di Elaborazione delle informazioni LEZIONE 2 (HARDWARE) a.a. 2011/2012 Francesco Fontanella Tre concetti Fondamentali Algoritmo; Automa (o anche macchina); Calcolo; 2 Calcolatore MACCHINA
Alberto Ferrante. Security Association caching of a dedicated IPSec crypto processor: dimensioning the cache and software interface
 Alberto Ferrante Security Association caching of a dedicated IPSec crypto processor: dimensioning the cache and software interface Relatore: Prof. Roberto Negrini Correlatore: Dott. Jefferson Owen (STM)
Alberto Ferrante Security Association caching of a dedicated IPSec crypto processor: dimensioning the cache and software interface Relatore: Prof. Roberto Negrini Correlatore: Dott. Jefferson Owen (STM)
Un sistema operativo è un insieme di programmi che consentono ad un utente di
 INTRODUZIONE AI SISTEMI OPERATIVI 1 Alcune definizioni 1 Sistema dedicato: 1 Sistema batch o a lotti: 2 Sistemi time sharing: 2 Sistema multiprogrammato: 3 Processo e programma 3 Risorse: 3 Spazio degli
INTRODUZIONE AI SISTEMI OPERATIVI 1 Alcune definizioni 1 Sistema dedicato: 1 Sistema batch o a lotti: 2 Sistemi time sharing: 2 Sistema multiprogrammato: 3 Processo e programma 3 Risorse: 3 Spazio degli
Il Processore: i registri
 Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Il Processore: i registri Il processore contiene al suo interno un certo numero di registri (unità di memoria estremamente veloci) Le dimensioni di un registro sono di pochi byte (4, 8) I registri contengono
Sistemi Operativi MECCANISMI E POLITICHE DI PROTEZIONE. D. Talia - UNICAL. Sistemi Operativi 13.1
 MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1
 MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
MECCANISMI E POLITICHE DI PROTEZIONE 13.1 Protezione Obiettivi della Protezione Dominio di Protezione Matrice di Accesso Implementazione della Matrice di Accesso Revoca dei Diritti di Accesso Sistemi basati
Dispensa di Informatica I.1
 IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
Archivi e database. Prof. Michele Batocchi A.S. 2013/2014
 Archivi e database Prof. Michele Batocchi A.S. 2013/2014 Introduzione L esigenza di archiviare (conservare documenti, immagini, ricordi, ecc.) è un attività senza tempo che è insita nell animo umano Primi
Archivi e database Prof. Michele Batocchi A.S. 2013/2014 Introduzione L esigenza di archiviare (conservare documenti, immagini, ricordi, ecc.) è un attività senza tempo che è insita nell animo umano Primi
L architettura del calcolatore (Prima parte)
") L architettura del calcolatore (Prima parte) Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin Calcolatore astratto e reale Concetto astratto
L architettura del calcolatore (Prima parte) Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin Calcolatore astratto e reale Concetto astratto
Introduzione. Coordinazione Distribuita. Ordinamento degli eventi. Realizzazione di. Mutua Esclusione Distribuita (DME)
") Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,