Non blocking. Contro. La programmazione di uno scambio messaggi con funzioni di comunicazione non blocking e' (leggermente) piu' complicata
|
|
|
- Enrichetta Moroni
- 7 anni fa
- Visualizzazioni
Transcript
1 Non blocking Una comunicazione non blocking e' tipicamente costituita da tre fasi successive: L inizio della operazione di send/receive del messaggio Lo svolgimento di un attivita' che non implichi l accesso ai dati coinvolti nella operazione di comunicazione avviata L attesa per il completamento della comunicazione Pro Contro Performance: una comunicazione non blocking consente di: sovrapporre fasi di comunicazioni con fasi di calcolo ridurre gli effetti della latenza di comunicazione Le comunicazioni non blocking evitano situazioni di deadlock La programmazione di uno scambio messaggi con funzioni di comunicazione non blocking e' (leggermente) piu' complicata
2 MPI_Isend Dopo che la spedizione e' stata avviata il controllo torna al processo sender Prima di riutilizzare le aree di memoria coinvolte nella comunicazione, il processo sender deve controllare che l operazione sia stata completata, attraverso opportune funzioni della libreria MPI La semantica di MPI definisce anche per la send nonblocking le diverse modalita' di completamento della fase di comunicazione (quindi standard MPI_Isend, synchronous MPI_Issend, ready MPI_Irsend e buffered MPI_Ibsend )
3 MPI_Isend int MPI_Isend(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm, MPI_Request *request) [IN] buf e' l indirizzo iniziale del send buffer [IN] count e' di tipo int e contiene il numero di elementi del send buffer [IN] dtype e' di tipo MPI_Datatype e descrive il tipo di ogni elemento del send buffer [IN] dest e' di tipo int e contiene il rank del receiver all interno del comunicatore comm [IN] tag e' di tipo int e contiene l identificativo del messaggio [IN] comm e' di tipo MPI_Comm ed e' il comunicatore in cui avviene la send [OUT] request e' di tipo MPI_Request e conterra' l handler necessario per referenziare l operazione di send
4 MPI_Irecv Dopo che la fase di ricezione e' stata avviata il controllo torna al processo receiver Prima di utilizzare in sicurezza i dati ricevuti, il processo receiver deve verificare che la ricezione sia completata, attraverso opportune funzioni della libreria MPI Una receive non blocking puo' essere utilizzata per ricevere messaggi inviati sia in modalità blocking che non blocking
5 MPI_Irecv int MPI_Irecv(void *buf, int count, MPI_Datatype dtype, int src, int tag, MPI_Comm comm, MPI_Request *request) [OUT] buf e' l indirizzo iniziale del receive buffer [IN] count e' di tipo int e contiene il numero di elementi del receive buffer [IN] dtype e' di tipo MPI_Datatype e descrive il tipo di ogni elemento del receive buffer [IN] src e' di tipo int e contiene il rank del sender all interno del comunicatore comm [IN] tag e' di tipo int e contiene l identificativo del messaggio [IN] comm e' di tipo MPI_Comm ed è il comunicatore in cui avviene la send [OUT] request e' di tipo MPI_Request e conterrà l handler necessario per referenziare l operazione di receive
6 Test di completamento Quando si usano comunicazioni point to point non blocking e' essenziale assicurarsi che la fase di comunicazione sia completata per utilizzare i dati del buffer (dal punto di vista del receiver) l area di memoria coinvolta nella comunicazione (dal punto di vista del sender) riutilizzare La libreria MPI mette a disposizione dell utente due tipi di funzionalita' per il test del completamento di una comunicazione WAIT : consente di fermare l esecuzione del processo fino a quando la comunicazione in argomento non sia completata tipo tipo TEST: ritorna al processo chiamante un valore TRUE se la comunicazione in argomento e' stata completata, FALSE altrimenti
7 Test di completamento int MPI_Wait(MPI_Request *request, MPI_Status *status) [IN] request e' l handler necessario per referenziare la comunicazione di cui attendere il completamento [OUT] status conterra' lo stato (envelope) del messaggio di cui si attende il completamento int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) [OUT] flag conterra' TRUE se la comunicazione e' stata completata, FALSE altrimenti [OUT] status conterra' lo stato (envelope) del messaggio di cui si attende il completamento
8 non blocking Utilizzando comunicazioni non blocking, puo' accadere che, in un certo istante, ne risultino avviate diverse MPI dispone di primitive che consentono ad un processo di testare/attendere il completamento di una serie di comunicazioni che lo coinvolgono Esistono tre tipologie di primitive di questo tipo, quelle che consentono di verificare il completamento di tutte le comunicazioni in corso (MPI_Testall / MPI_Waitall) una ed una sola delle comunicazioni in corso (MPI_Testany / MPI_Waitany) alcune (alemno una) delle comunicazioni in corso (MPI_Testsome / MPI_Waitsome)
9 int MPI_Waitany (int count, MPI_Request array_of_requests[], int *index, MPI_Status *status) int MPI_Waitsome(int incount, MPI_Request array_of_requests[], int *outcount, int array_of_indices[], MPI_Status array_of_statuses[]) int MPI_Waitall (int count, MPI_Request array_of_requests[], MPI_Status array_of_statuses[])
10 int MPI_Testany(int count, MPI_Request array_of_requests[], int *index, int *flag, MPI_Status *status); int MPI_Testsome(int incount, MPI_Request array_of_requests[], int *outcount, int array_of_indices[], MPI_Status array_of_statuses[]); int MPI_Testall (int count, MPI_Request array_of_requests[], int *flag, MPI_Status array_of_statuses[]);
11 Esempio (19_nonblock): semplice esempio di comunicazione point to point non bloccante Esercizio (20_ring): Consideriamo il solito insieme di processi con topologia ad anello. Ogni processo spedisce il valore del proprio rank a destra. A regime ogni processo spedisce a destra il valore che riceve da sinistra, fino che non avra' ottenuto di nuovo il proprio rank, allora si ferma. Il tutto usando MPI_Isend. (Stampante la somma dei valori ricevuti da ogni processo)
12
13 Collettive Alcune sequenze di comunicazione sono cosi' comuni nella pratica della programmazione parallela che la libreria MPI prevede una serie di routine specifiche per eseguirle: le funzioni di comunicazione collettiva Le comunicazioni collettive sono sempre costruite sulle funzioni di comunicazione point to point, ma utilizzano i piu' efficienti algoritmi noti per l operazione che implementano Nascondono all utente della libreria MPI sequenze di send/receive sovente complicate Una comunicazione collettiva coinvolge tutti i processi di un comunicatore Qualora si voglia effettuare una comunicazione collettiva in cui siano coinvolti solo una frazione dei processi di MPI_COMM_WORLD, e' necessario definire un comunicatore ad hoc
14 MPI_Barrier int MPI_Barrier(MPI_Comm comm) [IN] comm e' di tipo MPI_Comm ed e' il comunicatore a cui appartengono i processi da sincronizzare Nella programmazione parallela ci sono occasioni in cui alcuni processi non posso procedere fino a quando altri processi non hanno completato una operazione. Chiamare una funzione di tipo BARRIER comporta che tutti i processi del comunicatore argomento si fermano in attesa che l ultimo non abbia eseguito la stessa chiamata La BARRIER e' eseguita in software, dunque puo' comportare un certo overhead: inserire chiamate BARRIER solo se strettamente necessario
15 Esempio (20_barrier): cosa succede con o senza barrier? Senza barrier il processo recv attende dati mentre il processo send riempie la matrice. $ mpiexec n 2./alloc 1000 I am proces 0 of 2 my name is cg00 (./alloc) I am proces 1 of 2 my name is cg06 (./alloc) Send time 3: s Recv time 3: s $ mpiexec n 2./alloc 1000 I am proces 1 of 2 my name is cg06 (./alloc) I am proces 0 of 2 my name is cg00 (./alloc) Send time 3: s Recv time 3: s Attenti a dove posizionate le chiamate collettive
 alla")
16 Broadcast E' un operazione One to All. La funzionalita' di BROADCAST consente di copiare dati dalla memoria di un processo root (p0 nella figura) alla stessa locazione degli altri processi appartenenti al comunicatore utilizzato.
17 Esercizio: provate ad implementare una funziona che faccia il broadcast di un vettore di double. $ mpiexec n 9./bcast I am proces 0 of 9 my name is cg00 (./bcast) I am proces 2 of 9 my name is cg03 (./bcast) I am proces 1 of 9 my name is cg02 (./bcast) I am proces 4 of 9 my name is cg04 (./bcast) I am proces 3 of 9 my name is cg01 (./bcast) I am proces 5 of 9 my name is cg06 (./bcast) I am proces 6 of 9 my name is cg08 (./bcast) I am proces 7 of 9 my name is cg07 (./bcast) I am proces 8 of 9 my name is cg05 (./bcast) Bcast time: s
18 MPI_Bcast int MPI_Bcast(void* buf, int count, MPI_Datatype dtype, int root, MPI_Comm comm) [IN/OUT] buf e' l indirizzo del send/receive buffer [IN] count e' di tipo int e contiene il numero di elementi del buffer [IN] dtype e' di tipo MPI_Datatype e descrive il tipo di ogni elemento del buffer [IN] root è di tipo int e contiene il rank del processo root della broadcast [IN] comm e' di tipo MPI_Comm ed e' il comunicatore cui appartengono i processi coinvolti nella broadcast
19 MPI_Bcast Proviamo a fare un confronto di tempi: 21_bcast]$ mpiexec n 9./bcast I am proces 0 of 9 my name is cg00 (./bcast) I am proces 2 of 9 my name is cg03 (./bcast) I am proces 1 of 9 my name is cg02 (./bcast) I am proces 3 of 9 my name is cg01 (./bcast) I am proces 4 of 9 my name is cg04 (./bcast) I am proces 5 of 9 my name is cg06 (./bcast) I am proces 6 of 9 my name is cg08 (./bcast) I am proces 7 of 9 my name is cg07 (./bcast) I am proces 8 of 9 my name is cg05 (./bcast) Bcast mine time: s Bcast time: s
20 Broadcast T1 1 T Tn.. n
21 Broadcast T1 0 T2 1 2 T2 T3 T3 T T3 T4 7 8
22 Broadcast Esercizio (22_bcasttree): provate ad implementare il broadcast secondo l'albero binario riportato in figura $ mpiexec n 9./bcast Bcast mine time: s > 8 comunicazioni Bcast mine tree time: s Bcast time: s
23 Heap Heap operazioni elementari sinistro (i) return 2i desto (i) return 2i + 1 padre (i) return [i/2] dove heapsize[a] n e' la lunghezza dello Heap. ([i/2] = (int) (i/2))
Calcolo Parallelo con MPI (2 parte)
") 2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
Calcolo parallelo con MPI (2ª parte)
") Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
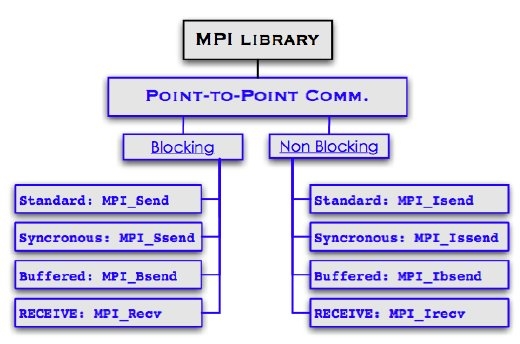
Comunicazione. La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI
 Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
Calcolo parallelo con MPI (2ª parte)
") Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
Laboratorio di Calcolo Parallelo
 Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
MPI è una libreria che comprende:
 1 Le funzioni di MPI MPI è una libreria che comprende: Funzioni per definire l ambiente Funzioni per comunicazioni uno a uno Funzioni percomunicazioni collettive Funzioni peroperazioni collettive 2 1 3
1 Le funzioni di MPI MPI è una libreria che comprende: Funzioni per definire l ambiente Funzioni per comunicazioni uno a uno Funzioni percomunicazioni collettive Funzioni peroperazioni collettive 2 1 3
Introduzione a MPI Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
Mai fidarsi. int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1
 { int a,i=2; a = 1*abs(i 1); printf ( %d\n, a); } $ gcc W Wall o first main.c $./first 1") Mai fidarsi int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1 $ gcc fno builtin o second main.c $./second 1 compilatore dipendente Bcast Vediamo la soluzione
Mai fidarsi int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1 $ gcc fno builtin o second main.c $./second 1 compilatore dipendente Bcast Vediamo la soluzione
Concetti base di MPI. Introduzione alle tecniche di calcolo parallelo
 Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Programmazione di base
 1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
int MPI_Recv (void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status);
;") Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Message Passing Interface (MPI) e Parallel Virtual Machine (PVM)
 e Parallel Virtual Machine (PVM)") Università degli Studi di Bologna Dipartimento di Elettronica Informatica e Sistemistica Message Passing Interface (MPI) e Parallel Virtual Machine (PVM) Introduzione Message passing: esplicita comunicazione
Università degli Studi di Bologna Dipartimento di Elettronica Informatica e Sistemistica Message Passing Interface (MPI) e Parallel Virtual Machine (PVM) Introduzione Message passing: esplicita comunicazione
Presentazione del corso
 Cosa è il calcolo parallelo Serie di Fibonacci Serie geometrica Presentazione del corso Calcolo parallelo: MPI Introduzione alla comunicazione point-to-point Le sei funzioni di base Laboratorio 1 Introduzione
Cosa è il calcolo parallelo Serie di Fibonacci Serie geometrica Presentazione del corso Calcolo parallelo: MPI Introduzione alla comunicazione point-to-point Le sei funzioni di base Laboratorio 1 Introduzione
MPI: comunicazioni collettive
 - g.marras@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Collective Communications -Communications involving a group of process -Called by all processes
- g.marras@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Collective Communications -Communications involving a group of process -Called by all processes
Calcolo parallelo. Una sola CPU (o un solo core), per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi
, per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi") Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo Una sola CPU (o un solo core), per quanto potenti,
Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo Una sola CPU (o un solo core), per quanto potenti,
Modelli di programmazione parallela
 Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
MPI. MPI e' il risultato di un notevole sforzo di numerosi individui e gruppi in un periodo di 2 anni, tra il 1992 ed il 1994
 MPI e' acronimo di Message Passing Interface Rigorosamente MPI non è una libreria ma uno standard per gli sviluppatori e gli utenti, che dovrebbe essere seguito da una libreria per lo scambio di messaggi
MPI e' acronimo di Message Passing Interface Rigorosamente MPI non è una libreria ma uno standard per gli sviluppatori e gli utenti, che dovrebbe essere seguito da una libreria per lo scambio di messaggi
Esercizi su UDP. Esercitazione di Laboratorio di Programmazione di Rete A. Daniele Sgandurra 22/10/2008. Università di Pisa
 Esercizi su UDP Esercitazione di Laboratorio di Programmazione di Rete A Daniele Sgandurra Università di Pisa 22/10/2008 Un Tipico Client UDP Un client UDP invia datagrammi ad un server in attesa di essere
Esercizi su UDP Esercitazione di Laboratorio di Programmazione di Rete A Daniele Sgandurra Università di Pisa 22/10/2008 Un Tipico Client UDP Un client UDP invia datagrammi ad un server in attesa di essere
MPI: comunicazioni point-to-point
 - c.calonaci@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Argomenti Programmazione a scambio di messaggi Introduzione a MPI Modi di comunicazione Comunicazione
- c.calonaci@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Argomenti Programmazione a scambio di messaggi Introduzione a MPI Modi di comunicazione Comunicazione
Presentazione del corso
 Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Programmazione Orientata agli Oggetti. Emilio Di Giacomo e Walter Didimo
 Programmazione Orientata agli Oggetti Emilio Di Giacomo e Walter Didimo Una metafora dal mondo reale la fabbrica di giocattoli progettisti Un semplice giocattolo Impara i suoni Dall idea al progetto Toy
Programmazione Orientata agli Oggetti Emilio Di Giacomo e Walter Didimo Una metafora dal mondo reale la fabbrica di giocattoli progettisti Un semplice giocattolo Impara i suoni Dall idea al progetto Toy
Primi Programmi con MPI 1
 Il cluster che usiamo: spaci Esercitazione: Primi Programmi con MPI http://www.na.icar.cnr.it/grid/#spacina Spacina è un cluster HP XC 6000 / Linux a 64 nodi biprocessore. La configurazione hardware dei
Il cluster che usiamo: spaci Esercitazione: Primi Programmi con MPI http://www.na.icar.cnr.it/grid/#spacina Spacina è un cluster HP XC 6000 / Linux a 64 nodi biprocessore. La configurazione hardware dei
Ambienti di Programmazione per il Software di Base
 Ambienti di Programmazione per il Software di Base Le Funzioni in C Esercizi sulle Funzioni svolti Esercizi sulle Funzioni da svolgere A.A. 2011/2012 Ambienti di Programmazione per il Software di Base
Ambienti di Programmazione per il Software di Base Le Funzioni in C Esercizi sulle Funzioni svolti Esercizi sulle Funzioni da svolgere A.A. 2011/2012 Ambienti di Programmazione per il Software di Base
ALGORITMI E STRUTTURE DATI
 Esercitazioni del corso di: ALGORITMI E STRUTTURE DATI Tutor: Francesca Piersigilli email: francesca.piersigilli@unicam.it Strutture dati elementari Tecniche di organizzazione dei dati: scelta della struttura
Esercitazioni del corso di: ALGORITMI E STRUTTURE DATI Tutor: Francesca Piersigilli email: francesca.piersigilli@unicam.it Strutture dati elementari Tecniche di organizzazione dei dati: scelta della struttura
Operazioni di Comunicazione di base. Cap.4
 Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
Parallelizzazione Laplace 2D: MPI e MPI+OMP. - Cineca - SuperComputing Applications and Innovation Department
 Parallelizzazione Laplace 2D: MPI e MPI+OMP - Cineca - SuperComputing Applications and Innovation Department Outline Parallelizzazione Laplace 2D Parallelizzazione Laplace 2D - MPI bloccante Parallelizzazione
Parallelizzazione Laplace 2D: MPI e MPI+OMP - Cineca - SuperComputing Applications and Innovation Department Outline Parallelizzazione Laplace 2D Parallelizzazione Laplace 2D - MPI bloccante Parallelizzazione
Introduzione al calcolo parallelo per il metodo degli elementi finiti
 Introduzione al calcolo parallelo per il metodo degli elementi finiti Simone Parisotto Università di Verona Dipartimento di Informatica 24 Aprile 2013 Simone Parisotto 24 Aprile 2013 1 / 28 Introduzione
Introduzione al calcolo parallelo per il metodo degli elementi finiti Simone Parisotto Università di Verona Dipartimento di Informatica 24 Aprile 2013 Simone Parisotto 24 Aprile 2013 1 / 28 Introduzione
Boost.MPI Library Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Boost.MPI Library Algoritmi e Calcolo Parallelo Riferimenti! Boost homepage http://www.boost.org/! Tutorial on Boost.MPI http://www.boost.org/doc/libs/1_52_0/doc/html/mpi/ tutorial.html! Tutorial on Boost.Serialization
Boost.MPI Library Algoritmi e Calcolo Parallelo Riferimenti! Boost homepage http://www.boost.org/! Tutorial on Boost.MPI http://www.boost.org/doc/libs/1_52_0/doc/html/mpi/ tutorial.html! Tutorial on Boost.Serialization
14/12/2018 Informatici e di Telecomunicazioni
 Informatici e di Telecomunicazioni 14 dicembre 2018 Parte I Classe V A INF ISIS E.Fermi Prof. Federico Santolini 1 (c) Primitive del servizio di trasporto (1/3) Premessa E utile ribadire che il livello
Informatici e di Telecomunicazioni 14 dicembre 2018 Parte I Classe V A INF ISIS E.Fermi Prof. Federico Santolini 1 (c) Primitive del servizio di trasporto (1/3) Premessa E utile ribadire che il livello
a) Uno stesso problema in minor tempo
 Uno stesso problema in minor tempo") Lezione 4 Dalla prima lezione: Obiettivi del calcolo parallelo: a) Risolvere uno stesso problema in minor tempo b) Risolvere un problema piu grande nello stesso tempo Esempio: previsioni meteorologiche
Lezione 4 Dalla prima lezione: Obiettivi del calcolo parallelo: a) Risolvere uno stesso problema in minor tempo b) Risolvere un problema piu grande nello stesso tempo Esempio: previsioni meteorologiche
Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 2
 Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 2 Dispensa 04 Introduzione ai Tipi astratti di dato A. Miola Febbraio 2007 http://www.dia.uniroma3.it/~java/fondinf2/ Introduzione ADT 1
Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 2 Dispensa 04 Introduzione ai Tipi astratti di dato A. Miola Febbraio 2007 http://www.dia.uniroma3.it/~java/fondinf2/ Introduzione ADT 1
Libreria MPI. (Message Passing Interface)
") Libreria MPI (Message Passing Interface) Standard Message Passing Interface (MPI) Il primo standard de jure per i linguaggi paralleli a scambio di messaggi (definisce le specifiche sintattiche e semantiche,
Libreria MPI (Message Passing Interface) Standard Message Passing Interface (MPI) Il primo standard de jure per i linguaggi paralleli a scambio di messaggi (definisce le specifiche sintattiche e semantiche,
Esercitazione 3 Programmazione Concorrente nel linguaggio go. 13 Novembre 2017
 Esercitazione 3 Programmazione Concorrente nel linguaggio go 13 Novembre 2017 1 Concorrenza in go 2 creazione goroutine Sintassi : Esempio go func IsReady(what string, minutes int64)
Esercitazione 3 Programmazione Concorrente nel linguaggio go 13 Novembre 2017 1 Concorrenza in go 2 creazione goroutine Sintassi : Esempio go func IsReady(what string, minutes int64)
Il modello a scambio di messaggio
 Il modello a scambio di messaggio Ciascun processo evolve in un proprio ambiente che non può essere modificato direttamente da altri processi. Quindi non esiste memoria condivisa e le risorse sono tutte
Il modello a scambio di messaggio Ciascun processo evolve in un proprio ambiente che non può essere modificato direttamente da altri processi. Quindi non esiste memoria condivisa e le risorse sono tutte
Prodotto Matrice - Vettore in MPI - III Strategia
 Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Esercitazione di Calcolo Parallelo Prodotto Matrice - Vettore in MPI - III Strategia Anno Accademico 2010/2011 Prof.ssa Alessandra D'alessio
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Esercitazione di Calcolo Parallelo Prodotto Matrice - Vettore in MPI - III Strategia Anno Accademico 2010/2011 Prof.ssa Alessandra D'alessio
MPI: MESSAGE PASSING INTERFACE
 MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
Sistemi Operativi. Lez. 13: primitive per la concorrenza monitor e messaggi
 Sistemi Operativi Lez. 13: primitive per la concorrenza monitor e messaggi Osservazioni I semafori sono strumenti particolarmente potenti poiché consentono di risolvere ogni problema di sincronizzazione
Sistemi Operativi Lez. 13: primitive per la concorrenza monitor e messaggi Osservazioni I semafori sono strumenti particolarmente potenti poiché consentono di risolvere ogni problema di sincronizzazione
Componenti principali. Programma cablato. Architettura di Von Neumann. Programma cablato. Cos e un programma? Componenti e connessioni
 Componenti principali Componenti e connessioni Capitolo 3 CPU (Unita Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro 1 2 Architettura di Von Neumann Dati e instruzioni in memoria
Componenti principali Componenti e connessioni Capitolo 3 CPU (Unita Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro 1 2 Architettura di Von Neumann Dati e instruzioni in memoria
Spazio di indirizzamento virtuale
 Programmazione M-Z Ingegneria e Scienze Informatiche - Cesena A.A. 016-01 Spazio di indirizzamento virtuale Pietro Di Lena - pietro.dilena@unibo.it // The function name says it all int stack_overflow (){
Programmazione M-Z Ingegneria e Scienze Informatiche - Cesena A.A. 016-01 Spazio di indirizzamento virtuale Pietro Di Lena - pietro.dilena@unibo.it // The function name says it all int stack_overflow (){
Funzioni, Stack e Visibilità delle Variabili in C
 Funzioni, Stack e Visibilità delle Variabili in C Programmazione I e Laboratorio Corso di Laurea in Informatica A.A. 2016/2017 Calendario delle lezioni Lez. 1 Lez. 2 Lez. 3 Lez. 4 Lez. 5 Lez. 6 Lez. 7
Funzioni, Stack e Visibilità delle Variabili in C Programmazione I e Laboratorio Corso di Laurea in Informatica A.A. 2016/2017 Calendario delle lezioni Lez. 1 Lez. 2 Lez. 3 Lez. 4 Lez. 5 Lez. 6 Lez. 7
Laboratorio di Matematica e Informatica 1
 Laboratorio di Matematica e Informatica 1 Matteo Mondini Antonio E. Porreca matteo.mondini@gmail.com porreca@disco.unimib.it Dipartimento di Informatica, Sistemistica e Comunicazione Università degli Studi
Laboratorio di Matematica e Informatica 1 Matteo Mondini Antonio E. Porreca matteo.mondini@gmail.com porreca@disco.unimib.it Dipartimento di Informatica, Sistemistica e Comunicazione Università degli Studi
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2016-17 Pietro Frasca Lezione 8 Martedì 8-11-2016 1 Algoritmi di scheduling basati sulle priorità Assegnano
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2016-17 Pietro Frasca Lezione 8 Martedì 8-11-2016 1 Algoritmi di scheduling basati sulle priorità Assegnano
Espressioni aritmetiche
 Espressioni aritmetiche Consideriamo espressioni costruite a partire da variabili e costanti intere mediante applicazione delle operazioni di somma, sottrazione, prodotto e divisione (intera). Ad esempio:
Espressioni aritmetiche Consideriamo espressioni costruite a partire da variabili e costanti intere mediante applicazione delle operazioni di somma, sottrazione, prodotto e divisione (intera). Ad esempio:
Laboratorio Progettazione Web Le funzioni in PHP. Angelica Lo Duca IIT-CNR 2012/2013
 Laboratorio Progettazione Web Le funzioni in PHP Angelica Lo Duca IIT-CNR angelica.loduca@iit.cnr.it 2012/2013 Funzioni Una funzione è una sequenza di istruzioni che implementano una specifica funzionalità
Laboratorio Progettazione Web Le funzioni in PHP Angelica Lo Duca IIT-CNR angelica.loduca@iit.cnr.it 2012/2013 Funzioni Una funzione è una sequenza di istruzioni che implementano una specifica funzionalità
COMUNICAZIONE SERIALE a cura dell' Ing. Buttolo Marco
 COMUNICAZIONE SERIALE a cura dell' Ing. Buttolo Marco Un PC può comunicare in vari modi con le periferiche. Fondamentalmente esistono due tipi di comunicazione molto comuni: 1. La comunicazione seriale
COMUNICAZIONE SERIALE a cura dell' Ing. Buttolo Marco Un PC può comunicare in vari modi con le periferiche. Fondamentalmente esistono due tipi di comunicazione molto comuni: 1. La comunicazione seriale
Componenti principali
 Componenti e connessioni Capitolo 3 Componenti principali n CPU (Unità Centrale di Elaborazione) n Memoria n Sistemi di I/O n Connessioni tra loro Architettura di Von Neumann n Dati e instruzioni in memoria
Componenti e connessioni Capitolo 3 Componenti principali n CPU (Unità Centrale di Elaborazione) n Memoria n Sistemi di I/O n Connessioni tra loro Architettura di Von Neumann n Dati e instruzioni in memoria
Tipi strutturati - struct
 Fondamenti di Programmazione A Appunti per le lezioni Gianfranco Rossi Tipi strutturati - struct Struttura dati (concreta) struct: sequenza di n elementi (n 0), rispettivamente di tipo t1,,tn (non necessariamente
Fondamenti di Programmazione A Appunti per le lezioni Gianfranco Rossi Tipi strutturati - struct Struttura dati (concreta) struct: sequenza di n elementi (n 0), rispettivamente di tipo t1,,tn (non necessariamente
Programma della 1 sessione di laboratorio
 Programma della 1 sessione di laboratorio Familiarizzare con l ambiente MPI Hello World in MPI (Esercizio 1) Esercizi da svolgere Send/Receive di un intero e di un array di float (Esercizio 2) Calcolo
Programma della 1 sessione di laboratorio Familiarizzare con l ambiente MPI Hello World in MPI (Esercizio 1) Esercizi da svolgere Send/Receive di un intero e di un array di float (Esercizio 2) Calcolo
PROGRAMMAZIONE II canale A-D luglio 2008 TRACCIA DI SOLUZIONE
 PROGRAMMAZIONE II canale A-D 2007-2008 14 luglio 2008 TRACCIA DI SOLUZIONE 1. Si vogliono realizzare mediante puntatori delle liste circolari, cioè delle liste tali che l ultimo elemento della lista punta
PROGRAMMAZIONE II canale A-D 2007-2008 14 luglio 2008 TRACCIA DI SOLUZIONE 1. Si vogliono realizzare mediante puntatori delle liste circolari, cioè delle liste tali che l ultimo elemento della lista punta
Informatica 3. LEZIONE 16: Heap - Codifica di Huffmann. Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann
 Informatica 3 LEZIONE 16: Heap - Codifica di Huffmann Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann Informatica 3 Lezione 16 - Modulo 1 Heap e code di priorità Introduzione
Informatica 3 LEZIONE 16: Heap - Codifica di Huffmann Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann Informatica 3 Lezione 16 - Modulo 1 Heap e code di priorità Introduzione
Algoritmo di Dekker. Algoritmo di Peterson
 shared int turn = P; shared boolean needp = false; shared boolean needq = false; cobegin P // Q coend Riassunto Utile Concorrenza Algoritmo di Dekker process P { needp = true; while (needq) if (turn ==
shared int turn = P; shared boolean needp = false; shared boolean needq = false; cobegin P // Q coend Riassunto Utile Concorrenza Algoritmo di Dekker process P { needp = true; while (needq) if (turn ==
In questa lezione Strutture dati elementari: Pila Coda Loro uso nella costruzione di algoritmi.
 In questa lezione Strutture dati elementari: Pila Coda Loro uso nella costruzione di algoritmi. 1 strutture dati (astratte) Una struttura dati astratti consiste di uno o più insiemi con delle operazioni
In questa lezione Strutture dati elementari: Pila Coda Loro uso nella costruzione di algoritmi. 1 strutture dati (astratte) Una struttura dati astratti consiste di uno o più insiemi con delle operazioni
Componenti e connessioni. Capitolo 3
 Componenti e connessioni Capitolo 3 Componenti principali CPU (Unità Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro Architettura di Von Neumann Dati e instruzioni in memoria (lettura
Componenti e connessioni Capitolo 3 Componenti principali CPU (Unità Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro Architettura di Von Neumann Dati e instruzioni in memoria (lettura
Reti di Calcolatori. Master "Bio Info" Reti e Basi di Dati Lezione 3
 Reti di Calcolatori Sommario Software di rete Livello Trasporto (TCP) Livello Rete (IP, Routing, ICMP) Livello di Collegamento (Data-Link) Livello Trasporto (TCP) I protocolli di trasporto sono eseguiti
Reti di Calcolatori Sommario Software di rete Livello Trasporto (TCP) Livello Rete (IP, Routing, ICMP) Livello di Collegamento (Data-Link) Livello Trasporto (TCP) I protocolli di trasporto sono eseguiti
Università degli Studi di Napoli Parthenope. Corso di Calcolo Parallelo e Distribuito. Virginia Bellino Matr. 108/1570
 Università degli Studi di Napoli Parthenope Corso di Calcolo Parallelo e Distribuito Virginia Bellino Matr. 108/1570 Virginia Bellino Progetto 1 Corso di Calcolo Parallelo e Distribuito 2 Indice Individuazione
Università degli Studi di Napoli Parthenope Corso di Calcolo Parallelo e Distribuito Virginia Bellino Matr. 108/1570 Virginia Bellino Progetto 1 Corso di Calcolo Parallelo e Distribuito 2 Indice Individuazione
Il linguaggio C. Puntatori e dintorni
 Il linguaggio C Puntatori e dintorni 1 Puntatori : idea di base In C è possibile conoscere e denotare l indirizzo della cella di memoria in cui è memorizzata una variabile (il puntatore) es : int a = 50;
Il linguaggio C Puntatori e dintorni 1 Puntatori : idea di base In C è possibile conoscere e denotare l indirizzo della cella di memoria in cui è memorizzata una variabile (il puntatore) es : int a = 50;
Libreria MPI. (Message Passing Interface) Standard Message Passing Interface (MPI)
 Standard Message Passing Interface (MPI)") Libreria MPI (Message Passing Interface) Standard Message Passing Interface (MPI) Il primo standard de jure per i linguaggi paralleli a scambio di messaggi (definisce le specifiche sintattiche e semantiche,
Libreria MPI (Message Passing Interface) Standard Message Passing Interface (MPI) Il primo standard de jure per i linguaggi paralleli a scambio di messaggi (definisce le specifiche sintattiche e semantiche,
Architetture data-flow
 Architetture data-flow Le architetture che abbiamo visto finora sono dette architetture control flow. Ciò sta ad indicare che il flusso dell elaborazione è dettato dall ordine con cui le varie istruzioni
Architetture data-flow Le architetture che abbiamo visto finora sono dette architetture control flow. Ciò sta ad indicare che il flusso dell elaborazione è dettato dall ordine con cui le varie istruzioni
Algoritmi e Programmazione Avanzata. Pile e code. Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino
 Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino Sommario ADT Pile Code. A.A. 2001/2002 APA - 2 1 Sommario ADT Pile Code. A.A. 2001/2002 APA - 3 ADT Le regole che
Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino Sommario ADT Pile Code. A.A. 2001/2002 APA - 2 1 Sommario ADT Pile Code. A.A. 2001/2002 APA - 3 ADT Le regole che
FUNZIONI. Ivan Lanese
 FUNZIONI Ivan Lanese Argomenti Tecniche di debugging Funzioni Di solito i programmi non funzionano int main() { int n, prod = 1; do { cout > n; prod = prod
FUNZIONI Ivan Lanese Argomenti Tecniche di debugging Funzioni Di solito i programmi non funzionano int main() { int n, prod = 1; do { cout > n; prod = prod
19 - Eccezioni. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 19 - Eccezioni Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso
19 - Eccezioni Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso
Dato un insieme S di n elementi totalmente ordinato, l'algoritmo di ordinamento detto HeapSort ha le seguenti caratteristiche:
 Heapsort Dato un insieme S di n elementi totalmente ordinato, l'algoritmo di ordinamento detto HeapSort ha le seguenti caratteristiche: T(n) = O(n log(n)) Alg. Ordinamento ottimale Ordina in loco (niente
Heapsort Dato un insieme S di n elementi totalmente ordinato, l'algoritmo di ordinamento detto HeapSort ha le seguenti caratteristiche: T(n) = O(n log(n)) Alg. Ordinamento ottimale Ordina in loco (niente
Pile e code. Sommario. Algoritmi e Programmazione Avanzata. Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino
 Pile e code Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino Sommario ADT Pile Code. A.A. 2002/2003 APA - Pile e code 2 Politecnico di Torino Pagina 1 di 23 Sommario
Pile e code Fulvio CORNO - Matteo SONZA REORDA Dip. Automatica e Informatica Politecnico di Torino Sommario ADT Pile Code. A.A. 2002/2003 APA - Pile e code 2 Politecnico di Torino Pagina 1 di 23 Sommario
Il Modello a scambio di messaggi
 Il Modello a scambio di messaggi 1 Interazione nel modello a scambio di messaggi Se la macchina concorrente e` organizzata secondo il modello a scambio di messaggi: PROCESSO=PROCESSO PESANTE non vi è memoria
Il Modello a scambio di messaggi 1 Interazione nel modello a scambio di messaggi Se la macchina concorrente e` organizzata secondo il modello a scambio di messaggi: PROCESSO=PROCESSO PESANTE non vi è memoria
Esercizi riassuntivi (Fondamenti di Informatica 2 Walter Didimo) Soluzioni
 Soluzioni") Esercizi riassuntivi (Fondamenti di Informatica 2 Walter Didimo) Soluzioni Esercizio 1 Dire quale è la complessità temporale del seguente metodo, espressa con notazione asintotica O(.) (con la migliore
Esercizi riassuntivi (Fondamenti di Informatica 2 Walter Didimo) Soluzioni Esercizio 1 Dire quale è la complessità temporale del seguente metodo, espressa con notazione asintotica O(.) (con la migliore
Esercitazioni 13 e 14
 Università degli Studi della Calabria Corso di Laurea in Ingegneria Informatica A.A. 2001/2002 Sistemi Operativi Corsi A e B Esercitazioni 13 e 14 Comunicazione tra processi (IPC) Meccanismo per la comunicazione
Università degli Studi della Calabria Corso di Laurea in Ingegneria Informatica A.A. 2001/2002 Sistemi Operativi Corsi A e B Esercitazioni 13 e 14 Comunicazione tra processi (IPC) Meccanismo per la comunicazione
LABORATORIO di Reti di Calcolatori
 LABORATORIO di Reti di Calcolatori Socket in linguaggio C: protocollo connection-oriented 1 of 15 v slide della docente Bibliografia v testo di supporto: D. Maggiorini, Introduzione alla programmazione
LABORATORIO di Reti di Calcolatori Socket in linguaggio C: protocollo connection-oriented 1 of 15 v slide della docente Bibliografia v testo di supporto: D. Maggiorini, Introduzione alla programmazione
Cast implicito. Il cast è fatto automaticamente quando un tipo più basso viene assegnato ad un tipo più alto. byte short int long float double
 Il cast Cast implicito Il cast è fatto automaticamente quando un tipo più basso viene assegnato ad un tipo più alto Per esempio: byte short int long float double int x = 10; float f; f = x; Il valore di
Il cast Cast implicito Il cast è fatto automaticamente quando un tipo più basso viene assegnato ad un tipo più alto Per esempio: byte short int long float double int x = 10; float f; f = x; Il valore di
Cominciamo con un esempio... Utilizzando un sottoprogramma 16/12/2017
 Cominciamo con un esempio... Franco FRATTOLILLO Dipartimento di Ingegneria Università degli Studi del Sannio Corso di "Programmazione I" Corso di Laurea in Ingegneria Informatica / ExAT 1 Franco FRATTOLILLO
Cominciamo con un esempio... Franco FRATTOLILLO Dipartimento di Ingegneria Università degli Studi del Sannio Corso di "Programmazione I" Corso di Laurea in Ingegneria Informatica / ExAT 1 Franco FRATTOLILLO
Esempi di Applicazioni Parallele e di Metodologie di parallelizzazione
 Esempi di Applicazioni Parallele e di Metodologie di parallelizzazione Esempi Applicazioni Parallele Applicazioni embarassing parallel Es.. Calcolo del π Metodo di parallelizzazione Task farm statico Applicazioni
Esempi di Applicazioni Parallele e di Metodologie di parallelizzazione Esempi Applicazioni Parallele Applicazioni embarassing parallel Es.. Calcolo del π Metodo di parallelizzazione Task farm statico Applicazioni
Calcolatori Elettronici Lezione B1 Interfacce
 Calcolatori Elettronici Lezione B1 Interfacce Ing. Gestionale e delle Telecomunicazioni A.A. 2007/08 Gabriele Cecchetti Sommario Moduli di espansione di memoria Organizzazione dello spazio di I/O Interfacce
Calcolatori Elettronici Lezione B1 Interfacce Ing. Gestionale e delle Telecomunicazioni A.A. 2007/08 Gabriele Cecchetti Sommario Moduli di espansione di memoria Organizzazione dello spazio di I/O Interfacce
(Def. funzioni con parametri di tipo matrice)
") ESERCIZIO 1 (Def. funzioni con parametri di tipo matrice) Scrivere un sotto-programma in linguaggio C++ che ricevuta una matrice quadrata come parametro restituisca al chiamante un valore booleano indicante
ESERCIZIO 1 (Def. funzioni con parametri di tipo matrice) Scrivere un sotto-programma in linguaggio C++ che ricevuta una matrice quadrata come parametro restituisca al chiamante un valore booleano indicante
Programmazione multi threaded in Python. Linguaggi dinamici A.A. 2010/2011 1
 Programmazione multi threaded in Python 1 Motivazione all'uso dei thread Pro Scrittura di applicazioni con molteplici eventi asincroni (GUI) Riduzione della latenza di servizio mediante l'uso di un pool
Programmazione multi threaded in Python 1 Motivazione all'uso dei thread Pro Scrittura di applicazioni con molteplici eventi asincroni (GUI) Riduzione della latenza di servizio mediante l'uso di un pool
Corso di Fondamenti di Informatica Linguaggi di Programmazione
 Corso di Informatica Linguaggi di Programmazione Anno Accademico 2011/2012 Francesco Tortorella Linguaggi di programmazione Un calcolatore basato sul modello di von Neumann permette l esecuzione di un
Corso di Informatica Linguaggi di Programmazione Anno Accademico 2011/2012 Francesco Tortorella Linguaggi di programmazione Un calcolatore basato sul modello di von Neumann permette l esecuzione di un
RETI DI CALCOLATORI Home Assignment protocolli a finestra scorrevole. Prima parte
 RETI DI CALCOLATORI Home Assignment protocolli a finestra scorrevole Prima parte Q1. Indicare giustificando la risposta se è possibile o meno che la dimensione della finestra del protocollo Go-Back-N sia
RETI DI CALCOLATORI Home Assignment protocolli a finestra scorrevole Prima parte Q1. Indicare giustificando la risposta se è possibile o meno che la dimensione della finestra del protocollo Go-Back-N sia
Fondamenti di Informatica B
 Fondamenti di Informatica B Lezione n.9 Alberto Broggi Gianni Conte A.A. 2005-2006 Fondamenti di Informatica B DESCRIZIONE E PROGETTO A LIVELLO RTL ESEMPIO DI SISTEMA A LIVELLO RTL: IL MOLTIPLICATORE BINARIO
Fondamenti di Informatica B Lezione n.9 Alberto Broggi Gianni Conte A.A. 2005-2006 Fondamenti di Informatica B DESCRIZIONE E PROGETTO A LIVELLO RTL ESEMPIO DI SISTEMA A LIVELLO RTL: IL MOLTIPLICATORE BINARIO
Spesso sono definite anche le seguenti operazioni:
 Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Sistemi Operativi. Lezione 7-bis Esercizi
 Sistemi Operativi Lezione 7-bis Esercizi Esercizio Problema dei lettori e scrittori Un insieme di processi condivide un file dal quale alcuni possono solo leggere i dati, altri solo scriverli Più lettori
Sistemi Operativi Lezione 7-bis Esercizi Esercizio Problema dei lettori e scrittori Un insieme di processi condivide un file dal quale alcuni possono solo leggere i dati, altri solo scriverli Più lettori
Sommario. Processi e Programmi. Che cosa e un Processo? Lezione 5 Processi e Threads
 Sommario Lezione 5 Processi e Threads Processi e Programmi Implementazione dei Processi Casi di Studio relativi a Processi Thread Casi di Studio relativi a Thread 5.2 Processi e Programmi Che cosa e un
Sommario Lezione 5 Processi e Threads Processi e Programmi Implementazione dei Processi Casi di Studio relativi a Processi Thread Casi di Studio relativi a Thread 5.2 Processi e Programmi Che cosa e un
Chiamata di procedura remota
 Con gli strumenti gia` visti, si puo` realizzare come segue: lato chiamante: send asincrona immediatamente seguita da una receive lato chiamato: una receive seguita, al termine dell azione richiesta, da
Con gli strumenti gia` visti, si puo` realizzare come segue: lato chiamante: send asincrona immediatamente seguita da una receive lato chiamato: una receive seguita, al termine dell azione richiesta, da
Modello a scambio di messaggi
 Modello a scambio di messaggi Aspetti caratterizzanti il modello Canali di comunicazione Primitive di comunicazione 1 Aspetti caratterizzanti il modello modello architetturale di macchina (virtuale) concorrente
Modello a scambio di messaggi Aspetti caratterizzanti il modello Canali di comunicazione Primitive di comunicazione 1 Aspetti caratterizzanti il modello modello architetturale di macchina (virtuale) concorrente
Le Funzioni in C. Fondamenti di Informatica Anno Accademico 2010/2011. Corso di Laurea in Ingegneria Civile Politecnico di Bari Sede di Foggia
 Le Funzioni in C Corso di Laurea in Ingegneria Civile Politecnico di Bari Sede di Foggia Fondamenti di Informatica Anno Accademico 2010/2011 docente: prof. Michele Salvemini 1/24 Sommario Le funzioni Il
Le Funzioni in C Corso di Laurea in Ingegneria Civile Politecnico di Bari Sede di Foggia Fondamenti di Informatica Anno Accademico 2010/2011 docente: prof. Michele Salvemini 1/24 Sommario Le funzioni Il
Programmazione I - corso B a.a prof. Viviana Bono
 Università di Torino Facoltà di Scienze MFN Corso di Studi in Informatica Programmazione I - corso B a.a. 2009-10 prof. Viviana Bono Blocco 12 Riepilogo e complementi sui tipi Ripasso del sistema di tipi
Università di Torino Facoltà di Scienze MFN Corso di Studi in Informatica Programmazione I - corso B a.a. 2009-10 prof. Viviana Bono Blocco 12 Riepilogo e complementi sui tipi Ripasso del sistema di tipi
L assegnamento. Andrea Marin. a.a. 2011/2012. Università Ca Foscari Venezia Laurea in Informatica Corso di Programmazione part-time
 Andrea Marin Università Ca Foscari Venezia Laurea in Informatica Corso di Programmazione part-time a.a. 2011/2012 Abbiamo visto È conveniente definire una macchina astratta C Lo stato della macchina ci
Andrea Marin Università Ca Foscari Venezia Laurea in Informatica Corso di Programmazione part-time a.a. 2011/2012 Abbiamo visto È conveniente definire una macchina astratta C Lo stato della macchina ci
Gestione degli impegni Requisiti generali Si fissi come ipotesi che la sequenza di impegni sia ordinata rispetto al tempo,, e che ogni lavoratore abbi
 Fondamenti di Informatica T-1 modulo 2 Laboratorio 10: preparazione alla prova d esame 1 Esercizio 1 - Gestione degli impegni Gli impegni giornalieri dei dipendenti di un azienda devono essere aggiornati
Fondamenti di Informatica T-1 modulo 2 Laboratorio 10: preparazione alla prova d esame 1 Esercizio 1 - Gestione degli impegni Gli impegni giornalieri dei dipendenti di un azienda devono essere aggiornati
I SISTEMI OPERATIVI. Insieme di programmi che implementano funzioni essenziali per l uso di un sistema elaboratore.
 I SISTEMI OPERATIVI Insieme di programmi che implementano funzioni essenziali per l uso di un sistema elaboratore. Le funzioni di un S.O. non sono definibili in modo esaustivo e puntuale così come non
I SISTEMI OPERATIVI Insieme di programmi che implementano funzioni essenziali per l uso di un sistema elaboratore. Le funzioni di un S.O. non sono definibili in modo esaustivo e puntuale così come non
now is the for men all good come aid
 Alberi binari Supponiamo di volere gestire il problema di contare le occorrenze di tutte le parole presenti in un particolare input. Poichè la lista delle parole non è nota a priori, non siamo in grado
Alberi binari Supponiamo di volere gestire il problema di contare le occorrenze di tutte le parole presenti in un particolare input. Poichè la lista delle parole non è nota a priori, non siamo in grado
Fondamenti di Informatica. Algoritmi di Ricerca e di Ordinamento
 Fondamenti di Informatica Algoritmi di Ricerca e di Ordinamento 1 Ricerca in una sequenza di elementi Data una sequenza di elementi, occorre verificare se un elemento fa parte della sequenza oppure l elemento
Fondamenti di Informatica Algoritmi di Ricerca e di Ordinamento 1 Ricerca in una sequenza di elementi Data una sequenza di elementi, occorre verificare se un elemento fa parte della sequenza oppure l elemento
Prodotto Matrice - Vettore in MPI II Strategia
 Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Esercitazione di Calcolo Parallelo Prodotto Matrice - Vettore in MPI II Strategia Anno Accademico 2010/2011 Prof.ssa Alessandra D'alessio
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Esercitazione di Calcolo Parallelo Prodotto Matrice - Vettore in MPI II Strategia Anno Accademico 2010/2011 Prof.ssa Alessandra D'alessio
Lezione IX Gestione dinamica della memoria
 Programmazione e Laboratorio di Programmazione Lezione IX Gestione dinamica della memoria Programmazione e Laboratorio di Programmazione: Gestione dinamica della memoria 1 Operatore sizeof() Buffer: una
Programmazione e Laboratorio di Programmazione Lezione IX Gestione dinamica della memoria Programmazione e Laboratorio di Programmazione: Gestione dinamica della memoria 1 Operatore sizeof() Buffer: una