Sistemi Intelligenti Learning and Clustering
|
|
|
- Paolina Valsecchi
- 6 anni fa
- Visualizzazioni
Transcript
")

1 Sistemi Intelligenti Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica 1/48 Riassunto I tipi di apprendimento Il clustering e le feature Clustering gerarchico Clustering partitivo: K-means 2/48 1
2 I vari tipi di apprendimento x(t+1) = f[x(t), a(t)] a(t) = g[x(t)] Ambiente Agente Supervisionato (learning with a teacher). Viene specificato per ogni pattern di input, il pattern desiderato in output. Semi-Supervisionato. Viene specificato solamente per alcuni pattern di input, il pattern desiderato in output. Non-supervisionato (learning without a teacher). Estrazione di similitudine statistiche tra pattern di input. Clustering. Mappe neurali. Apprendimento con rinforzo (reinforcement learning, learning with a critic). L ambiente fornisce un informazione puntuale, di tipo qualitativo, ad esempio success or fail. 3/48 I gruppi di algoritmi Clustering (data mining) Classification Predictive regression 4/48 2
3 Riassunto I tipi di apprendimento Il clustering e le feature Clustering gerarchico Clustering partitivo: K-means 5/48 Clustering Clustering: raggruppamento degli oggetti in cluster omogenee tra loro. Gli oggetti di un cluster sono più simili tra loro che a quelli degli altri cluster. Raggruppamento per colore Raggruppamento per forme Raggruppamento per tipi.. Clustering Novel name: data mining 6/48 3
4 Clustering L elaborazione verrà poi effettuata sui prototipi che rappresentano ciascun cluster. Piovosità Piccola differenza di piovosità (e temperatura) Grande differenza di piovosità (e temperatura) I pattern appartenenti ad un cluster valido sono più simili l uno con l altro rispetto ai pattern appartenenti ad un cluster differente. Temperatura media 7/48 Il clustering per Confermare ipotesi sui dati (es. E possibile identificare tre diversi tipi di clima in Italia: mediterraneo, continentale, alpino ); Esplorare lo spazio dei dati (es. Quanti tipi diversi di clima sono presenti in Italia? Quante sfere sono presenti in un immagine? ); Semplificare l interpretazione dei dati ( Il clima di ogni città d Italia è approssimativamente mediterraneo, continentale o alpino. ). Ragionare sui dati o elaborare i dati in modo stereotipato. 8/48 4


5 Esempio di clustering Ricerca immagini su WEB. Clustering -> Indicizzazione 9/48 Clustering: definizioni Pattern: un singolo dato X = [x 1, x 2, x D ]. Il dato appartiene quindi ad uno spazio multi-dimensionale (D dimensionale), solitamente eterogeneo. Feature: le caratteristiche dei dati significative per il clustering, possono costituire anch esso un vettore, il vettore delle feature: f 1, f 2, f M. Questo vettore costituisce l input agli algoritmi di clustering. Inclinazione, occhielli, lunghezza, linee orizzontali, archi di cerchio... 10/48 5
6 Clustering: definizioni D: dimensione dello spazio dei pattern; M: dimensione dello spazio delle feature; Cluster: in generale, insieme che raggruppa dati simili tra loro, valutati in base alle feature; Funzione di similarità o distanza: una metrica (o quasi metrica) nello spazio delle feature, usata per quantificare la similarità tra due pattern. Algoritmo: scelta di come effettuare il clustering (motore di clustering). 11/48 Clustering Dati, {X 1... X N } R D Cluster {C 1... C M } {P 1... P M } R D P j is the prototype of cluster j and it represents the set of data inside its cluster. To cluster the data: - The set of data inside each cluster has to be determined (the boundary of a cluster defined) - The cluster boundaries are determined considering features associated to the data. 12/48 6
7 Tassonomia (sintetica) degli algoritmi di clustering Algoritmi gerarchici (agglomerativi, divisivi), e.g. Hirarchical clustering. Algoritmi partizionali, hard: K-means, quad-tree decomposition. Algoritmi partizionali, soft-clustering: fuzzy c-mean, neural-gas, enhanced vector quantization, mappe di Kohonen. Algoritmi statistici: mixture models. 13/48 Analisi mediante clustering Pattern Feature Da Xu and Wunsh, 2005 I cluster ottenuti sono significativi? Il clustering ha operato con successo? NB i cammini all indietro consentono di fare la sintonizzazione dei diversi passi. 14/48 7
8 Il clustering Per una buona review: Xu and Wunsch, IEEE Transactions on Neural Networks, vol. 16, no. 3, Il clustering non è di per sé un problema ben posto. Ci sono diversi gradi di libertà da fissare su come effettuare un clustering. Rappresentazione dei pattern; Calcolo delle feature; Definizione di una misura di prossimità dei pattern attraverso le feature; Tipo di algoritmo di clustering (gerachico o partizionale) Validazione dell output (se necessario) -> Testing. Problema a cui non risponderemo: quanti cluster? Soluzione teorica (criterio di Akaike), soluzione empirica (growing networks di Fritzke). 15/48 Features Globali: livello di luminosità medio, varianza, contenuto in frequenza... Feature locali 16/48 8




9 Features Macchie dense Località. Significatività. Rinoscibilità. Fili 17/48 Rappresentazione dei dati La similarità tra dati viene valutata attraverso le feature. Feature selection: identificazione delle feature più significative per la descrizione dei pattern. Esempio: descrizione del clima e della città di Roma. Roma è caratterizzata da: [17 ; 500mm; ab., 300 chiese] Quali feature scegliere? Come valutare le feature? Analisi statistica del potere discriminante: correlazione tra feature e loro significatività. 18/48 9
10 Similarità tra feature Definizione di una misura di distanza tra due features; Esempio: Distanza euclidea dist (Roma, Milano) = dist ([17 ; 500mm], [13 ; 900mm]) = = Distanza euclidea? = ((17-13) 2 +( ) 2 ) ½ = ~ 400 Ha senso? 19/48 Normalizzazione feature E necessario trovare una metrica corretta per la rappresentazione dei dati. Ad esempio, normalizzare le feature! T Max = 20 T Min = 5 T Norm = (T - T Min )/(T Max - T Min ) P Max = 1000mm P Min = 0mm P Norm = (P - P Min )/(P Max - P Min ) Roma Norm = [ ] Milano Norm = [ ] dist(roma Norm, Milano Norm ) = (( ) 2 +( ) 2 ) ½ = E una buona scelta? 20/48 10
11 Altre funzioni di distanza Mahalanobis: dist(x,y)= (x k -y k )S -1 (x k -y k ), con S matrice di covarianza. (Normalizzazione mediante covarianza) Altre metriche: Distanza euclidea: dist(x,y)=[σ k=1..d (x k -y k ) 2 ] 1/2 Minkowski: dist(x,y)=[σ k=1..d (x k -y k ) p ] 1/p Context dependent: dist(x,y)= f(x, y, context) 21/48 Riassunto I tipi di apprendimento Il clustering e le feature Clustering gerarchico Clustering partitivo: K-means 22/48 11
12 Algoritmi gerarchici divisivi: QTD Quad Tree Decomposition; Suddivisione gerarchica dello spazio delle feature, mediante splitting dei cluster; Criterio di splitting (~distanza tra cluster). 23/48 Algoritmi gerarchici: QTD Clusterizzazione immagini RGB, 512x512; Pattern: pixel (x,y); Feature: canali R, G, B. Distanza tra due pattern (non euclidea): dist (p1, p2) = dist ([R1 G1 B1], [R2 G2 B2]) = max ( R1-R2, G1-G2, B1-B2 ). 24/48 12
13 Algoritmi gerarchici: QTD p1 = [ ] p2 = [ ] p3 = [ ] dist (p1, p2) = dist ([R1 G1 B1], [R2 G2 B2]) = max ( R1-R2, G1-G2, B1-B2 ) = max([ ]) = 50. dist (p2, p3) = 205. dist (p3, p1) = /48 Algoritmi gerarchici: QTD Criterio di splitting: se due pixel all interno dello stesso cluster distano più di una determinata soglia, il cluster viene diviso in 4 cluster. Esempio applicazione: segmentazione immagini, compressione immagini, analisi locale frequenze immagini 26/48 13


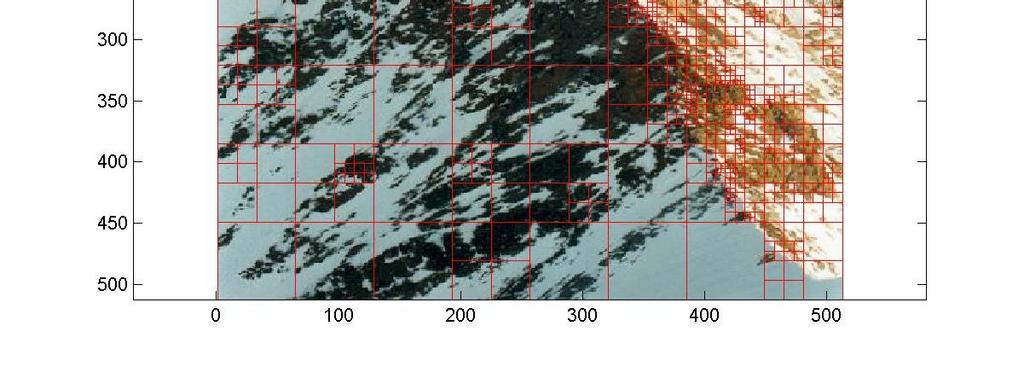
14 QTD: Risultati 27/48 QTD: Risultati 28/48 14

15 QTD: Risultati 29/48 Hierachical Clustering In brief, HC algorithms build a whole hierarchy of clustering solutions Solution at level k is a refinement of solution at level k-1 Two main classes of HC approaches: Agglomerative: solution at level k is obtained from solution at level k-1 by merging two clusters Divisive: solution at level k is obtained from solution at level k-1 by splitting a cluster into two parts Less used because of computational load 30/48 15
16 The 3 steps of agglomerative clustering 1. At start, each input pattern is assigned to a singleton cluster 2. At each step, the two closest clusters are merged into one So the number of clusters is decreased by one at each step 3. At the last step, only one cluster is obtained The clustering process is represented by a dendrogram 31/48 How to obtain the final solution The resulting dendrogram has to be cut at some level to get the final clustering: Cut criterion: number of desired clusters, or threshold on some features of resulting clusters 32/48 16
17 Point-wise dissimilarity Different distances/indices of dissimilarity (point wise) E.g. euclidean, city-block, correlation and agglomeration criteria: Merge clusters C i and C j such that diss(i, j) is minimum (cluster wise) Single linkage: diss(i,j) = min d(x, y), where x is in C i, y in cluster C j Complete linkage: diss(i,j) = max d(x, y), where x is in cluster i, y in cluster j Group Average (GA) and Weighted Average (WA) Linkage: diss(i j) = 33/48 Cluster wise dissimilarity Other agglomeration criteria: Merge clusters C i and C j such that diss(i, j) is minimum Centroid Linkage: diss(i, j) = d( i, j ) Median Linkage: diss(i,j) = d(center i, center j ), where each center i is the average of the centers of the clusters composing C i Ward s: Method: diss(i, j) = increase in the total error sum of squares (ESS) due to the merging of C i and C j Single, complete, and average linkage: graph methods All points in clusters are considered Centroid, median, and Ward s linkage: geometric methods Clusters are summed up by their centers 34/48 17
18 Ward s method It is also known as minimum variance method. Each merging step minimizes the increase in the total ESS: When merging clusters C i and C j, the increase in the total ESS is: Spherical, compact clusters are obtained. The solution at each level k is an approximation to the optimal solution for that level (the one minimizing ESS) 35/48 How HC operates HC algorithms operate on a dissimilarity matrix: For each pair of existant clusters, their dissimilarity value is stored When clusters C i and C j are merged, only dissimilarities for the new resulting cluster have to be computed The rest of the matrix is left untouched 36/48 18
19 The Lance-William recursive formulation Used for iterative implementation. The dissimilarity value between newly formed cluster {C i, C j } and every other cluster C k is computed as: Only values already stored in the dissimilarity matrix are used. Different sets of coefficients correspond to different criteria. Criterion i j Single Link. ½ ½ 0 -½ Complete Link. ½ ½ 0 ½ Group Avg. n i /(n i +n j ) n j /(n i +n j ) 0 0 Weighted Avg. ½ ½ 0 0 Centroid n i /(n i +n j ) n j /(n i +n j ) -n i n j /(n i +n j ) 2 0 Median ½ ½ - ¼ 0 Ward (n i +n k )/(n i +n j +n k ) (n j +n k )/(n i +n j +n k ) -n k /(n i +n j +n k ) 0 37/48 Characteristics of HC Pros: Indipendence from initialization No need to specify a desired number of clusters from the beginning Cons: Computational complexity at least O(N 2 ) Sensitivity to outliers No reconsideration of possibly misclassified points Possibility of inversion phenomena and multiple solutions 38/48 19

 è rappresentativo di")
20 Riassunto I tipi di apprendimento Il clustering e le feature Clustering gerarchico Clustering partitivo: K-means 39/48 I poligoni azzurri rappresentano i diversi cluster ottenuti. Ogni punto marcato all interno del cluster (cluster center) è rappresentativo di tutti i punti del cluster A.A /
21 K-means (partitional): framework Siano X 1,, X D i dati di addestramento, features (per semplicità, definiti in R 2 ); Siano C 1,, C K i prototipi di K cluster, definiti anch essi in R 2 ; ogni prototipo identifica il baricentro del cluster corrispondente; Lo schema di classificazione adottato sia il seguente: X i appartiene a C j se e solo se C j è il prototipo più vicino a X i (distanza euclidea) ; L algoritmo di addestramento permette di determinare le posizioni dei prototipi C j mediante successive approssimazioni. A.A /47 Algoritmo K-means L'obiettivo che l'algoritmo si prepone è di minimizzare la varianza totale intra-cluster. Ogni cluster viene identificato mediante un centroide o punto medio. L'algoritmo segue una procedura iterativa. Inizialmente crea K partizioni e assegna ad ogni partizione i punti d'ingresso o casualmente o usando alcune informazioni euristiche. Quindi calcola il centroide di ogni gruppo. Costruisce quindi una nuova partizione associando ogni punto d'ingresso al cluster il cui centroide è più vicino ad esso. Quindi vengono ricalcolati i centroidi per i nuovi cluster e così via, finché l'algoritmo non converge (Wikipedia). A.A /
22 K-means: addestramento Inizializzazione C j Classificazione X i Aggiornamento C j SI I prototipi C j si sono spostati significativamente? A.A NO Termine addestramento 43/47 Aggiornamento C j : baricentro degli X i classificati da C j. Algoritmo K-means::formalizzazione Dati N pattern in ingresso {x j } e C k prototipi che vogliamo diventino i centri dei cluster, x j e C k R N. Ciascun cluster identifica una regione nello spazio, P k. Valgono le seguenti proprietà: K k 1 x j C k P Q R k K P k k 1 D I cluster coprono lo spazio delle feature I cluster sono disgiunti. Se: x C x C l k j k 2 j l 2 La funzione obbiettivo viene definita come: K N x j ( k ) Ck i 1 j 1 2 A.A /
23 Algoritmo K-means::dettaglio dei passi Inizializzazione. Posiziono in modo arbitrario o guidato i K centri dei cluster. Iterazioni Assegno ciascun pattern al cluster il cui centro è più vicino, formando così un certo numero di cluster ( K). Calcolo la posizione dei cluster, C k, come baricentro dei pattern assegnati ad ogni cluster, sposto quindi la posizione dei centri dei cluster. Condizione di uscita I centri dei cluster non si spostano più. A.A /47 Bad initialization 10 Iter = Final classification A.A /

24 K-Means per immagine RGB Da 255 colori a 33 colori A.A /47 Riassunto I tipi di apprendimento Il clustering e le feature Clustering gerarchico Clustering partitivo: K-means A.A /
Sistemi Intelligenti. Riassunto
 Sistemi Intelligenti Learning and Clustering Alberto Borghese and Iuri Frosio Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento t di Scienze dell Informazione
Sistemi Intelligenti Learning and Clustering Alberto Borghese and Iuri Frosio Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento t di Scienze dell Informazione
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Immagini e clustering
 Immagini e clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it 1/24 http:\\homes.dsi.unimi.it\
Immagini e clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it 1/24 http:\\homes.dsi.unimi.it\
Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale
 UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Stima della qualità dei classificatori per l analisi dei dati biomolecolari
 Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Cluster Analysis. Paese Cereali (Ce) Riso (R) Patate (P) Zucchero (Z) Verdure (Ver) Vino (Vi) Carne (Ca) Latte (L) Burro (B) Uova (U)
 Riso (R) Patate (P) Zucchero (Z) Verdure (Ver) Vino (Vi) Carne (Ca) Latte (L) Burro (B) Uova (U)") Analysis Esempio Stiamo studiando le abitudini alimentari nei Paesi europei. Sulla base dei dati a disposizione, ci chiediamo se si possano individuare sotto-aree con abitudini alimentari simili. Dati:
Analysis Esempio Stiamo studiando le abitudini alimentari nei Paesi europei. Sulla base dei dati a disposizione, ci chiediamo se si possano individuare sotto-aree con abitudini alimentari simili. Dati:
Cluster Analysis (2 parte)
") Cluster Analysis (2 parte) Esempio 2 Data set: Nel data set Dieta (Dieta.txt, Dieta.sav) sono contenute informazioni sul consumo medio dei principali alimenti in 16 paesi Europei. Paese Cereali (Ce) Riso
Cluster Analysis (2 parte) Esempio 2 Data set: Nel data set Dieta (Dieta.txt, Dieta.sav) sono contenute informazioni sul consumo medio dei principali alimenti in 16 paesi Europei. Paese Cereali (Ce) Riso
Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008
 Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008 Dott. Chiara Cornalba COMUNICAZIONI La lezione del 30 ottobre è sospesa per missione all estero del Prof. Giudici. Dal 6 Novembre
Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008 Dott. Chiara Cornalba COMUNICAZIONI La lezione del 30 ottobre è sospesa per missione all estero del Prof. Giudici. Dal 6 Novembre
IL GIOVANE HOLDEN FRANNY E ZOOEY NOVE RACCONTI ALZATE LARCHITRAVE CARPENTIERI E SEYMOUR INTRODUZIONE BY JD SALINGER
 IL GIOVANE HOLDEN FRANNY E ZOOEY NOVE RACCONTI ALZATE LARCHITRAVE CARPENTIERI E SEYMOUR INTRODUZIONE BY JD SALINGER READ ONLINE AND DOWNLOAD EBOOK : IL GIOVANE HOLDEN FRANNY E ZOOEY NOVE RACCONTI ALZATE
IL GIOVANE HOLDEN FRANNY E ZOOEY NOVE RACCONTI ALZATE LARCHITRAVE CARPENTIERI E SEYMOUR INTRODUZIONE BY JD SALINGER READ ONLINE AND DOWNLOAD EBOOK : IL GIOVANE HOLDEN FRANNY E ZOOEY NOVE RACCONTI ALZATE
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Capitolo 6 - Array. Copyright by Deitel & Associates, Inc. and Pearson Education Inc. All Rights Reserved.
 1 Capitolo 6 - Array Array Array Gruppo di locazioni di memoria consecutive Stesso nome e tipo Per riferirsi a un elemento, specificare Nome dell array Posizione Formato: arrayname[ position number ] Primo
1 Capitolo 6 - Array Array Array Gruppo di locazioni di memoria consecutive Stesso nome e tipo Per riferirsi a un elemento, specificare Nome dell array Posizione Formato: arrayname[ position number ] Primo
Apprendimento non supervisionato
 Apprendimento non supervisionato Edmondo Trentin 7 giugno 2010 Autore: Edmondo Trentin Prima trascrizione digitale: Pierluigi Failla (dagli originali di E.T.) Setup: campione di dati non etichettati Figura:
Apprendimento non supervisionato Edmondo Trentin 7 giugno 2010 Autore: Edmondo Trentin Prima trascrizione digitale: Pierluigi Failla (dagli originali di E.T.) Setup: campione di dati non etichettati Figura:
Whole genome SNPs comparison: SNPtree, NDtree, CSI Phylogeny and kmer-based analysis
 Whole genome SNPs comparison: SNPtree, NDtree, CSI Phylogeny and kmer-based analysis Valeria Michelacci NGS course, June 2016 Webserver-based free pipelines available NCBI pipeline FDA GenomeTrakr CGE/DTU
Whole genome SNPs comparison: SNPtree, NDtree, CSI Phylogeny and kmer-based analysis Valeria Michelacci NGS course, June 2016 Webserver-based free pipelines available NCBI pipeline FDA GenomeTrakr CGE/DTU
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Algoritmi di clustering
 Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
A.A. 2006/2007 Laurea di Ingegneria Informatica. Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio
 A.A. 2006/2007 Laurea di Ingegneria Informatica Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio Obbiettivi Acquisire familiarità con la nozione di oggetto Apprendere le proprietà
A.A. 2006/2007 Laurea di Ingegneria Informatica Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio Obbiettivi Acquisire familiarità con la nozione di oggetto Apprendere le proprietà
Di testi ed immagini
 Università Cattolica del Sacro Cuore - Brescia 23/5/2005 Parte I: Richiami di algebra lineare Parte II: Applicazioni Sommario della Parte I 1 Diagonalizzabilità di una matrice Autovalori ed autovettori
Università Cattolica del Sacro Cuore - Brescia 23/5/2005 Parte I: Richiami di algebra lineare Parte II: Applicazioni Sommario della Parte I 1 Diagonalizzabilità di una matrice Autovalori ed autovettori
Teoria e Tecniche del Riconoscimento
 Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Introduzione alla Pattern Recognition Marco Cristani 1 Inquadramento Sistemi di Pattern Recognition
Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Introduzione alla Pattern Recognition Marco Cristani 1 Inquadramento Sistemi di Pattern Recognition
Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2.
 Scuola Sec. SECONDO Grado Gara 2 IND - 15/16 ESERCIZIO 1 Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2. Sono date le seguenti regole: regola(1,[a],b)
Scuola Sec. SECONDO Grado Gara 2 IND - 15/16 ESERCIZIO 1 Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2. Sono date le seguenti regole: regola(1,[a],b)
Corso di laurea magistrale in Informatica Multimedia - Prof. F.Stanco. Segmentazione. A cura di Andrea Tambone
 Corso di laurea magistrale in Informatica Multimedia - Prof. F.Stanco Segmentazione A cura di Andrea Tambone Introduzione Lo scopo della segmentazione è suddividere un immagine in regioni contenenti pixel
Corso di laurea magistrale in Informatica Multimedia - Prof. F.Stanco Segmentazione A cura di Andrea Tambone Introduzione Lo scopo della segmentazione è suddividere un immagine in regioni contenenti pixel
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati
 Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI
 Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Segmentazione automatica della carotide basata sulla classificazione dei pixel
 Segmentazione automatica della carotide basata sulla classificazione dei pixel Samanta Rosati, Filippo Molinari, Gabriella Balestra Biolab, Dipartimento di Elettronica e Telecomunicazioni, Politecnico
Segmentazione automatica della carotide basata sulla classificazione dei pixel Samanta Rosati, Filippo Molinari, Gabriella Balestra Biolab, Dipartimento di Elettronica e Telecomunicazioni, Politecnico
Tipici tempi di esecuzione. Martedì 7 ottobre 2014
 Tipici tempi di esecuzione Martedì 7 ottobre 2014 Punto della situazione Abbiamo definito il tempo di esecuzione di un algoritmo Scelto l analisi asintotica Abbiamo definito le notazioni asintotiche che
Tipici tempi di esecuzione Martedì 7 ottobre 2014 Punto della situazione Abbiamo definito il tempo di esecuzione di un algoritmo Scelto l analisi asintotica Abbiamo definito le notazioni asintotiche che
Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che:
 Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Cluster Analysis Distanze ed estrazioni Marco Perugini Milano-Bicocca
 Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Segmentazione mediante ricerca di forme. Paola Campadelli
 Segmentazione mediante ricerca di forme Paola Campadelli Segmentazione mediante ricerca di forme Template deformabili (Yuille et al. 92) Contorni deformabili (Kaas et al. 87) GVF Snakes (Xu et al. 98)
Segmentazione mediante ricerca di forme Paola Campadelli Segmentazione mediante ricerca di forme Template deformabili (Yuille et al. 92) Contorni deformabili (Kaas et al. 87) GVF Snakes (Xu et al. 98)
Analisi di dati Microarray: Esercitazione Matlab
 Analisi di dati Microarray: Esercitazione Matlab Laboratorio di Bioinformatica II Pietro Lovato Anno Accademico 2010/2011 Contenuti 1 Introduzione DNA Microarray 2 Lavorare con una singola ibridazione
Analisi di dati Microarray: Esercitazione Matlab Laboratorio di Bioinformatica II Pietro Lovato Anno Accademico 2010/2011 Contenuti 1 Introduzione DNA Microarray 2 Lavorare con una singola ibridazione
Fisher Linear discriminant analysis (pag 228)
") Fisher Linear discriminant analysis (pag 228) 1 Nell Analisi delle componenti proncipali PCA si trovano quelle componenti utili per la rappresentazione dei dati Tali componenti non sono utili a discriminare
Fisher Linear discriminant analysis (pag 228) 1 Nell Analisi delle componenti proncipali PCA si trovano quelle componenti utili per la rappresentazione dei dati Tali componenti non sono utili a discriminare
Reti Neurali in Generale
 istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
Statistica per le ricerche di mercato
 Statistica per le ricerche di mercato A.A. 2012/13 Dr. Luca Secondi 15. Tecniche di analisi statistica multivariata per la segmentazione del mercato Cluster Analysis 1 Cluster analysis La cluster analysis
Statistica per le ricerche di mercato A.A. 2012/13 Dr. Luca Secondi 15. Tecniche di analisi statistica multivariata per la segmentazione del mercato Cluster Analysis 1 Cluster analysis La cluster analysis
Data Alignment and (Geo)Referencing (sometimes Registration process)
Referencing (sometimes Registration process)") Data Alignment and (Geo)Referencing (sometimes Registration process) All data aquired from a scan position are refered to an intrinsic reference system (even if more than one scan has been performed) Data
Data Alignment and (Geo)Referencing (sometimes Registration process) All data aquired from a scan position are refered to an intrinsic reference system (even if more than one scan has been performed) Data
Estendere Lean e Operational Excellence a tutta la Supply Chain
 Estendere Lean e Operational Excellence a tutta la Supply Chain Prof. Alberto Portioli Staudacher www.lean-excellence.it Dipartimento Ing. Gestionale Politecnico di Milano alberto.portioli@polimi.it Lean
Estendere Lean e Operational Excellence a tutta la Supply Chain Prof. Alberto Portioli Staudacher www.lean-excellence.it Dipartimento Ing. Gestionale Politecnico di Milano alberto.portioli@polimi.it Lean
Dinamics of Person-to-Person Interactions from Distributed RFID Sensor Networks
 Dinamics of Person-to-Person Interactions from Distributed RFID Sensor Networks Gianluca Crimi gianluca.crimi@studio.unibo.it Università degli Studi di Bologna Corso di Sistemi Complessi Maggio 7, 2014
Dinamics of Person-to-Person Interactions from Distributed RFID Sensor Networks Gianluca Crimi gianluca.crimi@studio.unibo.it Università degli Studi di Bologna Corso di Sistemi Complessi Maggio 7, 2014
6. Partial Least Squares (PLS)
") & C. Di Natale: (PLS) Partial Least Squares PLS toolbox di MATLAB 1 Da PCR a PLS approccio geometrico Nella PCR la soluzione del problema della regressione passa attraverso la decomposizione della matrice
& C. Di Natale: (PLS) Partial Least Squares PLS toolbox di MATLAB 1 Da PCR a PLS approccio geometrico Nella PCR la soluzione del problema della regressione passa attraverso la decomposizione della matrice
Algoritmi e strutture di dati 2
 Algoritmi e strutture di dati 2 Paola Vocca Lezione 2: Tecniche golose (greedy) Lezione1- Divide et impera 1 Progettazione di algoritmi greedy Tecniche di dimostrazione (progettazione) o Greedy algorithms
Algoritmi e strutture di dati 2 Paola Vocca Lezione 2: Tecniche golose (greedy) Lezione1- Divide et impera 1 Progettazione di algoritmi greedy Tecniche di dimostrazione (progettazione) o Greedy algorithms
Appendice A. Conduttori elettrici, sezioni e diametri Appendix A. Wires, Sizes and AWG diameters
 Appendice A. Conduttori elettrici, sezioni e diametri Appendix A. Wires, Sizes and AWG diameters A.1 Misura dei conduttori elettrici, sezioni e diametri AWG and kcmil wires sizes measurement L America
Appendice A. Conduttori elettrici, sezioni e diametri Appendix A. Wires, Sizes and AWG diameters A.1 Misura dei conduttori elettrici, sezioni e diametri AWG and kcmil wires sizes measurement L America
ANALISI DEI DATI PER IL MARKETING 2014
 ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
I metodi di Classificazione automatica
 L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
Linguistica dei Corpora (2) Lezione 8: Principi di Apprendimento Automatico
 Lezione 8: Principi di Apprendimento Automatico") Linguistica dei Corpora (2) Lezione 8: Principi di Apprendimento Automatico Malvina Nissim malvina.nissim@unibo.it 22 Aprile 2009 1 Contesto set Context within ( give []* up within s;) expand
Linguistica dei Corpora (2) Lezione 8: Principi di Apprendimento Automatico Malvina Nissim malvina.nissim@unibo.it 22 Aprile 2009 1 Contesto set Context within ( give []* up within s;) expand
ALLINEAMENTI MULTIPLI
 ALLINEAMENTI MULTIPLI Identificazione di siti funzionalmente importanti Dimostrazione di omologia Filogenesi molecolare Ricerca di somiglianze deboli ma significative in banche dati Predizione di struttura
ALLINEAMENTI MULTIPLI Identificazione di siti funzionalmente importanti Dimostrazione di omologia Filogenesi molecolare Ricerca di somiglianze deboli ma significative in banche dati Predizione di struttura
MACHINE LEARNING e DATA MINING Introduzione. a.a.2015/16 Jessica Rosati jessica.rosati@poliba.it
 MACHINE LEARNING e DATA MINING Introduzione a.a.2015/16 Jessica Rosati jessica.rosati@poliba.it Apprendimento Automatico(i) Branca dell AI che si occupa di realizzare dispositivi artificiali capaci di
MACHINE LEARNING e DATA MINING Introduzione a.a.2015/16 Jessica Rosati jessica.rosati@poliba.it Apprendimento Automatico(i) Branca dell AI che si occupa di realizzare dispositivi artificiali capaci di
I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO
 BY BRUNO OSIMO") I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO READ ONLINE AND DOWNLOAD EBOOK : I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO
I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO READ ONLINE AND DOWNLOAD EBOOK : I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO
Scheda Allarmi Alarm Board MiniHi
 Scheda Allarmi Alarm Board MiniHi Manuale Utente User Manual Italiano English cod. 272680 - rev. 18/04/02 ITALIANO INDIE 1. INTRODUZIONE...2 2. RIONOSIMENTO DEI LIVELLI DI TENSIONE DEL SEGNALE 0-10 VOLT...2
Scheda Allarmi Alarm Board MiniHi Manuale Utente User Manual Italiano English cod. 272680 - rev. 18/04/02 ITALIANO INDIE 1. INTRODUZIONE...2 2. RIONOSIMENTO DEI LIVELLI DI TENSIONE DEL SEGNALE 0-10 VOLT...2
Il problema del clustering
 Il problema del clustering Stefano Rovetta 1 aprile 2003 Sommario Concetto di clustering Definizioni di distanze Modalità di raggruppamento Clustering con la tecnica k-means Clustering gerarchico Cautele
Il problema del clustering Stefano Rovetta 1 aprile 2003 Sommario Concetto di clustering Definizioni di distanze Modalità di raggruppamento Clustering con la tecnica k-means Clustering gerarchico Cautele
Indice della presentazione
 Indice della presentazione Introduzione; Risposta spettrale della vegetazione e riconoscimento incendi; Tecniche di classificazione automatica e mappe del combustibile; Stima di parametri biochimici e
Indice della presentazione Introduzione; Risposta spettrale della vegetazione e riconoscimento incendi; Tecniche di classificazione automatica e mappe del combustibile; Stima di parametri biochimici e
LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI
 Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
GABBIE A RULLINI NEEDLE ROLLER AND CAGE ASSEMBLIES
 GABBIE A RULLINI NEEDLE ROLLER AND CAGE ASSEMBLIES Gabbie a rullini Needle roller and cage assemblies Le gabbie a rullini NBS costituiscono una parte dei cuscinetti volventi. Sono principalmente formate
GABBIE A RULLINI NEEDLE ROLLER AND CAGE ASSEMBLIES Gabbie a rullini Needle roller and cage assemblies Le gabbie a rullini NBS costituiscono una parte dei cuscinetti volventi. Sono principalmente formate
INTECNO TRANSTECNO. MICRO Encoder ME22 ME22 MICRO Encoder. member of. group
 INTECNO MICRO ME22 ME22 MICRO 2 0 1 5 member of TRANSTECNO group Pag. Page Indice Index Descrizione Description I2 Caratteristiche principali Technical features I2 Designazione Classification I2 Specifiche
INTECNO MICRO ME22 ME22 MICRO 2 0 1 5 member of TRANSTECNO group Pag. Page Indice Index Descrizione Description I2 Caratteristiche principali Technical features I2 Designazione Classification I2 Specifiche
A review of some Java basics. Java pass-by-value and List<> references
 A review of some Java basics Java pass-by-value and List references Java is always pass-by-value Java is always pass-by-value. Unfortunately, they decided to call the location of an object a reference.
A review of some Java basics Java pass-by-value and List references Java is always pass-by-value Java is always pass-by-value. Unfortunately, they decided to call the location of an object a reference.
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 1 - Introduzione generale Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 1 - Introduzione generale Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Corso di Bioinformatica. Docente: Dr. Antinisca DI MARCO
 Corso di Bioinformatica Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@univaq.it Analisi Filogenetica Gene Ancestrale duplicazione genica La filogenesi è lo studio delle relazioni evolutive tra
Corso di Bioinformatica Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@univaq.it Analisi Filogenetica Gene Ancestrale duplicazione genica La filogenesi è lo studio delle relazioni evolutive tra
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione
 I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
Analisi dei Gruppi con R
 Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi dei Gruppi
Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi dei Gruppi
Guida all installazione del prodotto 4600 in configurazione plip
 Guida all installazione del prodotto 4600 in configurazione plip Premessa Questo prodotto è stato pensato e progettato, per poter essere installato, sia sulle vetture provviste di piattaforma CAN che su
Guida all installazione del prodotto 4600 in configurazione plip Premessa Questo prodotto è stato pensato e progettato, per poter essere installato, sia sulle vetture provviste di piattaforma CAN che su
07/02/2011. Elementi di Biomeccanica Statica, Cinetica, Esercizi sull analisi delle forze. Mechanics. Statics constant state of motion
 Elementi di Biomeccanica Statica, Cinetica, Esercizi sull analisi delle forze Mechanics Statics constant state of motion Dynamics acceleration present Kinetics of motionless systems Constant velocity systems
Elementi di Biomeccanica Statica, Cinetica, Esercizi sull analisi delle forze Mechanics Statics constant state of motion Dynamics acceleration present Kinetics of motionless systems Constant velocity systems
SLIM LINE ACU Slim solutions
 SLIM LINE ACU Slim solutions I condizionatori della serie KSL Slim line sono studiati per installazione verticale interna o esterna al quadro.questa nuova linea di prodotto è il risultato tecnico più evoluto
SLIM LINE ACU Slim solutions I condizionatori della serie KSL Slim line sono studiati per installazione verticale interna o esterna al quadro.questa nuova linea di prodotto è il risultato tecnico più evoluto
Fiori di campo. Conoscere, riconoscere e osservare tutte le specie di fiori selvatici più note
 Fiori di campo. Conoscere, riconoscere e osservare tutte le specie di fiori selvatici più note M. Teresa Della Beffa Click here if your download doesn"t start automatically Fiori di campo. Conoscere, riconoscere
Fiori di campo. Conoscere, riconoscere e osservare tutte le specie di fiori selvatici più note M. Teresa Della Beffa Click here if your download doesn"t start automatically Fiori di campo. Conoscere, riconoscere
Stringhe. Prof. Lorenzo Porcelli
 Stringhe Prof. Lorenzo Porcelli definizione Una stringa è un vettore di caratteri terminato dal carattere nullo \0. Il carattere nullo finale permette di determinare la lunghezza della stringa. char vet[32];
Stringhe Prof. Lorenzo Porcelli definizione Una stringa è un vettore di caratteri terminato dal carattere nullo \0. Il carattere nullo finale permette di determinare la lunghezza della stringa. char vet[32];
Clustering Salvatore Orlando
 Clustering Salvatore Orlando Data e Web Mining. - S. Orlando 1 Cos è un analisi di clustering Obiettivo dell analisi di clustering Raggruppare oggetti in gruppi con un certo grado di omogeneità Cluster:
Clustering Salvatore Orlando Data e Web Mining. - S. Orlando 1 Cos è un analisi di clustering Obiettivo dell analisi di clustering Raggruppare oggetti in gruppi con un certo grado di omogeneità Cluster:
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
Intelligenza Artificiale. Soft Computing: Reti Neurali Generalità
 Intelligenza Artificiale Soft Computing: Reti Neurali Generalità Neurone Artificiale Costituito da due stadi in cascata: sommatore lineare (produce il cosiddetto net input) net = S j w j i j w j è il peso
Intelligenza Artificiale Soft Computing: Reti Neurali Generalità Neurone Artificiale Costituito da due stadi in cascata: sommatore lineare (produce il cosiddetto net input) net = S j w j i j w j è il peso
Routing. Forwarding e routing
 Routing E necessario stabilire un percorso quando host sorgente e destinazione non appartengono alla stessa rete Router di default si occupa di instradare il traffico all esterno della rete Router sorgente:
Routing E necessario stabilire un percorso quando host sorgente e destinazione non appartengono alla stessa rete Router di default si occupa di instradare il traffico all esterno della rete Router sorgente:
Maria Brigida Ferraro + Luca Tardella
 Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
TECNICHE DI POSIZIONAMENTO
 TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
Fisica Computazionale
 Fisica Computazionale Lavori in Corso a Fisica 2016 Alessandro Gabbana Universitá Degli Studi di Ferrara November 22, 2016 A.Gabbana, R.Tripiccione Fisica Computazionale November 22, 2016 1 / 11 Introduzione
Fisica Computazionale Lavori in Corso a Fisica 2016 Alessandro Gabbana Universitá Degli Studi di Ferrara November 22, 2016 A.Gabbana, R.Tripiccione Fisica Computazionale November 22, 2016 1 / 11 Introduzione
AN INTER-MODELS DISTANCE FOR CLUSTERING UTILITY FUNCTIONS 1
 Statistica Applicata Vol. 18, n. 3, 2006 521 AN INTER-MODELS DISTANCE FOR CLUSTERING UTILITY FUNCTIONS 1 Elvira Romano, Carlo Lauro Dipartimento di Matematica e Statistica, Università di Napoli Federico
Statistica Applicata Vol. 18, n. 3, 2006 521 AN INTER-MODELS DISTANCE FOR CLUSTERING UTILITY FUNCTIONS 1 Elvira Romano, Carlo Lauro Dipartimento di Matematica e Statistica, Università di Napoli Federico
6.5 RNA Secondary Structure. 18 novembre 2014
 6.5 RNA Secondary Structure 18 novembre 2014 Calendario Oggi è la lezione 17/24: ultima lezione su Programmazione dinamica Metodo greedy: 18, 19 Grafi: 20, 21, 22, 23 Reti di flusso: 23, 24 (=mercoledì
6.5 RNA Secondary Structure 18 novembre 2014 Calendario Oggi è la lezione 17/24: ultima lezione su Programmazione dinamica Metodo greedy: 18, 19 Grafi: 20, 21, 22, 23 Reti di flusso: 23, 24 (=mercoledì
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Clustering Mario Guarracino Data Mining a.a. 2010/2011
 Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Apprendimento Automatico
 Apprendimento Automatico Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Pipeline Apprendimento Supervisionato Analisi del problema Raccolta, analisi
Apprendimento Automatico Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Pipeline Apprendimento Supervisionato Analisi del problema Raccolta, analisi
Parole e frequenze. Alessandro Lenci
 Parole e frequenze Alessandro Lenci Università di Pisa, Dipartimento di Linguistica Via Santa Maria, 36, 5600 Pisa, Italy alessandro.lenci@ilc.cnr.it Linguaggio e comunicazione - LO042 Rango di una parola
Parole e frequenze Alessandro Lenci Università di Pisa, Dipartimento di Linguistica Via Santa Maria, 36, 5600 Pisa, Italy alessandro.lenci@ilc.cnr.it Linguaggio e comunicazione - LO042 Rango di una parola
Firmware Division & Floating gpointer adder
 Firmware Division & Floating gpointer adder Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5
Firmware Division & Floating gpointer adder Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5
Clustering. Cos è un analisi di clustering
 Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
Ingegneria del Software 10. Esercizi sulle macchine. Dipartimento di Informatica Università di Pisa A.A. 2014/15
 Ingegneria del Software 10. Esercizi sulle macchine Dipartimento di Informatica Università di Pisa A.A. 2014/15 un passo alla volta Lo studente deve completare il basic level prima di passare a quello
Ingegneria del Software 10. Esercizi sulle macchine Dipartimento di Informatica Università di Pisa A.A. 2014/15 un passo alla volta Lo studente deve completare il basic level prima di passare a quello
Introduzione alle Reti Neurali
 Introduzione alle Reti Neurali Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: stefano.gualandi@unipv.it @famo2spaghi http://stegua.github.com Reti Neurali Terminator
Introduzione alle Reti Neurali Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: stefano.gualandi@unipv.it @famo2spaghi http://stegua.github.com Reti Neurali Terminator
Librerie digitali. Cos è una libreria digitale? Introduzione. Cos è una libreria digitale? Cos è una libreria digitale? Cos è una libreria digitale?
 Librerie digitali Introduzione William Arms "An informal definition of a digital library is a managed collection of information, with associated services, where the information is stored in digital formats
Librerie digitali Introduzione William Arms "An informal definition of a digital library is a managed collection of information, with associated services, where the information is stored in digital formats
Algoritmi di clustering gerarchico. Damiano Carne
 2004 Algoritmi di clustering gerarchico Damiano Carne Genomica funzionale Progetti di sequenziamento quasi terminati (es. Arabidopsis sequenza completata, Progetto Genoma Umano quasi completato.) Quale
2004 Algoritmi di clustering gerarchico Damiano Carne Genomica funzionale Progetti di sequenziamento quasi terminati (es. Arabidopsis sequenza completata, Progetto Genoma Umano quasi completato.) Quale
Organizzazione Fisica dei Dati (Parte II)
") Modello Fisico dei Dati Basi di Dati / Complementi di Basi di Dati 1 Organizzazione Fisica dei Dati (Parte II) Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Modello Fisico
Modello Fisico dei Dati Basi di Dati / Complementi di Basi di Dati 1 Organizzazione Fisica dei Dati (Parte II) Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Modello Fisico
Ottimizzazione dei Sistemi Complessi
 1 Giovedì 4 Maggio 2017 1 Istituto di Analisi dei Sistemi ed Informatica IASI - CNR Ordinamento di Pareto Dati due vettori z 1 e z 2 in R k diciamo che: z 1 domina (secondo Pareto) z 2 (z 1 P z 2 ) se
1 Giovedì 4 Maggio 2017 1 Istituto di Analisi dei Sistemi ed Informatica IASI - CNR Ordinamento di Pareto Dati due vettori z 1 e z 2 in R k diciamo che: z 1 domina (secondo Pareto) z 2 (z 1 P z 2 ) se
Floating pointer adder & Firmware Division. Sommario
 Floating pointer adder & Firmware Division Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5 1/43
Floating pointer adder & Firmware Division Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5 1/43
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Teoria della decisione di Bayes Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario
Riconoscimento e recupero dell informazione per bioinformatica Teoria della decisione di Bayes Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario
LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI
 Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Sistemi Intelligenti Learning: l apprendimento degli agenti
 Sistemi Intelligenti Learning: l apprendimento degli agenti Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Scienze dell Informazione
Sistemi Intelligenti Learning: l apprendimento degli agenti Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Scienze dell Informazione
5.1 Strutture, predittori e identificazione con le rappresentazioni di stato in Matlab
 5.1 Strutture, predittori e identificazione con le rappresentazioni di stato in Matlab 1. Usare una rappresentazione di stato che corrisponda alla struttura definita nella serie 4. Definire poi il modello
5.1 Strutture, predittori e identificazione con le rappresentazioni di stato in Matlab 1. Usare una rappresentazione di stato che corrisponda alla struttura definita nella serie 4. Definire poi il modello
Corso di Ottimizzazione MODELLI MATEMATICI PER IL PROBLEMA DELLO YIELD MANAGEMENT FERROVIARIO. G. Di Pillo, S. Lucidi, L. Palagi
 Corso di Ottimizzazione MODELLI MATEMATICI PER IL PROBLEMA DELLO YIELD MANAGEMENT FERROVIARIO G. Di Pillo, S. Lucidi, L. Palagi in collaborazione con Datamat-Ingegneria dei Sistemi s.p.a. YIELD MANAGEMENT
Corso di Ottimizzazione MODELLI MATEMATICI PER IL PROBLEMA DELLO YIELD MANAGEMENT FERROVIARIO G. Di Pillo, S. Lucidi, L. Palagi in collaborazione con Datamat-Ingegneria dei Sistemi s.p.a. YIELD MANAGEMENT
Statistica per le ricerche di mercato
 Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2012/13 Dr. Luca Secondi 01. Introduzione al corso 1 Statistica per le ricerche di mercato
Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2012/13 Dr. Luca Secondi 01. Introduzione al corso 1 Statistica per le ricerche di mercato
Metodi di classificazione. Loredana Cerbara
 Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Statistica per le ricerche di mercato
 Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2014/15 Prof.ssa Tiziana Laureti 01. Introduzione al corso 1 Statistica per le ricerche
Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2014/15 Prof.ssa Tiziana Laureti 01. Introduzione al corso 1 Statistica per le ricerche
Lecture 14. Association Rules
 Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
Firmware Division & Floating pointer adder
 Firmware Division & Floating pointer adder Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5 1/47
Firmware Division & Floating pointer adder Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimenti sul Patterson: 3.4, 3.5 1/47
Testi del Syllabus. Docente LASAGNI ANDREA Matricola: Insegnamento: ISTITUZIONI DI ECONOMIA POLITICA I. Anno regolamento: 2013
 Testi del Syllabus Docente LASAGNI ANDREA Matricola: 005479 Anno offerta: 2013/2014 Insegnamento: 03934 - ISTITUZIONI DI ECONOMIA POLITICA I Corso di studio: 3004 - ECONOMIA E MANAGEMENT Anno regolamento:
Testi del Syllabus Docente LASAGNI ANDREA Matricola: 005479 Anno offerta: 2013/2014 Insegnamento: 03934 - ISTITUZIONI DI ECONOMIA POLITICA I Corso di studio: 3004 - ECONOMIA E MANAGEMENT Anno regolamento:
3 WORKSHOP DEI LABORATORI DEL CONTROLLO UFFICIALE DI OGM Roma, 23-25 Novembre 2011
 Istituto Zooprofilattico Sperimentale delle Regioni Lazio e Toscana 3 WORKSHOP DEI LABORATORI DEL CONTROLLO UFFICIALE DI OGM Roma, 23-25 Novembre 2011 ILARIA CIABATTI Verification of analytical methods
Istituto Zooprofilattico Sperimentale delle Regioni Lazio e Toscana 3 WORKSHOP DEI LABORATORI DEL CONTROLLO UFFICIALE DI OGM Roma, 23-25 Novembre 2011 ILARIA CIABATTI Verification of analytical methods
Analisi spazio-temporale di social media per l identicazione di eventi
 Analisi spazio-temporale di social media per l identicazione di eventi P. Arcaini 1, G. Bordogna 2,3, E. Mangioni 3, S. Sterlacchini 3 1 Department of Engineering, University of Bergamo 2 National Research
Analisi spazio-temporale di social media per l identicazione di eventi P. Arcaini 1, G. Bordogna 2,3, E. Mangioni 3, S. Sterlacchini 3 1 Department of Engineering, University of Bergamo 2 National Research
Estratto dal Cap. 8 di: Statistics for Marketing and Consumer Research, M. Mazzocchi, ed. SAGE, 2008.
 LEZIONI IN LABORATORIO Corso di MARKETING L. Baldi Università degli Studi di Milano BIVARIATE AND MULTIPLE REGRESSION Estratto dal Cap. 8 di: Statistics for Marketing and Consumer Research, M. Mazzocchi,
LEZIONI IN LABORATORIO Corso di MARKETING L. Baldi Università degli Studi di Milano BIVARIATE AND MULTIPLE REGRESSION Estratto dal Cap. 8 di: Statistics for Marketing and Consumer Research, M. Mazzocchi,