La ricerca di similarità in banche dati
|
|
|
- Raffaele Belloni
- 6 anni fa
- Visualizzazioni
Transcript
1 La ricerca di similarità in banche dati Uno dei problemi più comunemente affrontati con metodi bioinformatici è quello di trovare omologie di sequenza interrogando una banca dati. L idea di base è che proteine omologhe derivano da un progenitore comune e, quindi, condividono ampie regioni simili. Comparando la similarità tra la nostra sequenza (query) e tutte quelle contenute in una banca dati possiamo stimare la percentuale di similarità e da questa inferire una eventuale omologia (attenzione ai termini!!).
2 La ricerca di similarità in banche dati Quando le sequenze sono molto simili è ovvio assumere che sono anche omologhe, ma, nella maggior parte dei casi questo non si verifica quando bisogna confrontarsi con bassi livelli di similarità. In molti casi, tuttavia veri omologhi funzionali hanno bassi livelli di similarità e non è affatto facile discriminare falsi omologhi da veri omologhi. In mancanza di elementi funzionali la discriminazione tra veri e falsi omologhi si fonda su considerazioni statistiche. In sintesi sulla base della percentuale di similarità si assegna un punteggio ad ogni singolo appaiamento di sequenze e si valuta la probabilità di avere lo stesso punteggio per caso. Tanto più bassi sono i valori di probabilità tanto più significativo risulta l allineamento. Ci sono due grossi problemi da risolvere: Lo sviluppo di algoritmi capaci di identificare sequenze simili alla sequenza query tra milioni di sequenze target e la scelta di metodi statistisci a cui affidare la decisione di quali siano le sequenze significative. I principali programmi di interrogazione di banche dati, come FASTA, BLAST e SSEARCH si caratterizzano essenzialmente per l approccio a questi problemi.
3 La ricerca di similarità: accuratezza TP = positivi veri (il metodo dice che è omologa e in effetti corrisponde al vero) FP = falsi positivi (il metodo dice che è omologa quando invece non lo è) TN = negativi veri (il metodo dice che non è omologa e in effetti corrisponde al vero) FN = falsi negativi (il metodo dice che non è omologa quando invece lo è) (TP+FN) = effettivi positivi nella banca dati (TP+FP) = positivi predetti dal metodo falsi e veri È omologa? Sì No Predetta come omologa? Sì No TP FN FP TN
4 La ricerca di similarità: accuratezza Sensibilità = TP / (TP + FN) è la percentuale di esempi predetti correttamente dal metodo sulla totalità di quelli che sono realmente presenti in banca dati. Selettività = TP / (TP + FP) (detta anche PPV Positive Predictive Value) è la percentuale di volte in cui la predizione positiva si rivela corretta. Specificità = TN / (TN + FP) è la percentuale di esempi predetti come negativi sul totale di quelli effettivamente negativi Esempio: Omologia reale tra proteine: (A, B, C), (D, E), (F, G, H) Predizione: A B, C B C C A, E D B E B F A, H G F H F, G Risultati: TP = 8 FP = 4 FN = 6 TN = > 38 Sens = 8 / (8+6) = 0.57 Sel = 8 / (8+4) = 0.66 Spec = 38 / (38+4) = 0.90
5 La ricerca di similarità: accuratezza In genere ad ogni predizione è affiancata una stima di affidabilità. I valori di sensibilità e selettività si calcolano soltanto per quelle predizioni che superano un valore minimo di affidabilità (threshold, soglia). La scelta della soglia e fatta su basi statistiche ed e determinante. In generale i metodi cercano un compromesso per cui: Alta sensibilità bassa selettività e specificità e viceversa In base alla soglia scelta si possono ottenere valori di sensibilità e selettività molto diversi tra di loro. Per questo entrambi i valori vanno riferiti allo stesso valore di soglia per poter essere paragonati. Esempio: Omologia reale tra proteine: (A, B, C), (D, E), (F, G, H) A B, C 10 B C 5 C A, E 10 D B 5 E B 5 F A, H 15 G F 5 H F, G 15 Soglia >= 5: TP = 8 FP = 4 FN = 6 TN = 38 Sens = 0.57 Sel = 0.66 Spec = 0.90 Soglia >= 10: TP = 6 FP = 2 FN = 8 TN = 40 Sens = 0.42 Sel = 0.75 Spec = 0.95 Sel. = TP / (TP + FP) Sens.= TP / (TP + FN) Spec = TN / (TN + FP) Soglia >= 15: TP = 3 FP = 1 FN = 11 TN = 41 Sens = 0.21 Sel = 0.75 Spec = 0.97
6
7
8 La ricerca di similarità: accuratezza Alternativa: ROC (receiver operator characteristic) Grafico che rappresenta l andamento della sensibilità in base alla selettività, basato su soglia mobile. Permette di visualizzare tutte le combinazioni contemporaneamente. Intuitivamente, il metodo A funziona meglio di quello B se ha una curva con valori sempre maggiori dell altro. In termini matematici si può calcolare l area sotto la curva (valore AUC = area under curve) per quantificare la performance dei metodi.
9 1 0,9 0,7; 0,9 1; 1 0,8 0,3; 0,8 0,6; 0,8 0,7; 0,8 0,7 0,2; 0,7 0,25; 0,6 sensitivity 0,6 0,5 0,4 0,1; 0,57 0,2; 0,55 0,15; 0,5 0,05; 0,42 0,15; 0,4 0,25; 0,5 0,35; 0,6 metodo 1 metodo 2 metodo 3 default 0,3 0,2 0,05; 0,2 0,03; 0,15 0, ,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 1 specificity
10 La ricerca di similarità: i metodi Pairwise alignment allineamenti a coppie 1. Analisi della matrice a punti (dot matrix) 2. Programmazione dinamica (dynamic programming) allineamenti locale e globale. algoritmi che trovano la soluzione ottima. 3. Metodo delle n-tuple (Fasta, Blast) le banche dati crescono a dismisura e gli algoritmi ottimi sono computazionalmente molto lunghi. Compromesso tra velocità e precisione per avvicinarsi alla soluzione ottima ideale. In questo caso si parla di euristica. I metodi delle n-ple sono difficili da quantificare in complessità di calcolo ma in generale l ordine passa da O(n 2 ) a O(n).
11 FASTA FASTA è un programma che cerca similarità locali utilizzando l algoritmo di Pearson e Lipman La sua strategia è quella di suddividere la sequenza query in tante sottosequenze lunghe 1 o 2 amminoacidi (parole). Il passo seguente è quello di suddivere tutte le sequenze della banca dati in sequenze di stessa lunghezza e di calcolare la posizione delle varie parole in tutte le sequenze. Per velocizzare i calcoli il programma ha già preparato una tabella con tutte le possibili combinazioni di due o tre amminoacidi ( 20 x 20 = 400 combinazioni) e calcola il numero e la posizione delle varie parole che compongono ogni singola sequenza. parola 1 2 n Per esempio data una query di sequenza: MAPESRTGSAATATSTD MA AP PE ES.. e una libreria di n sequenze avremo: 1) LCSPAPATREYFELFARIGIDKK 2) ETAHGSAATATWKLINCV n) MA - - AP 5 - PE - - ES - - SR - - RT - - TG - GS - 5 SA - 6 AA - 7 AT 7 8,10 TA - 2,9 AT - 10 TS - - ST - - ecc.
12 FASTA Subito dopo FASTA si preoccupa di calcolare il cosiddetto offset. Dopo aver determinato tutte le parole in comune tra la sequenza query e tutte le altre sequenze della banca dati, si preoccupa di determinarne le posizioni relative, per identificare quelle con amminoacidi comuni in un allineamento senza interruzioni. In pratica calcola la differenza tra le posizioni parole nella query e quelle corrispondenti in ciascuna delle sequenze della banca dati. parola query 1 2 n offset 1 offset 2 offset n (1-query) (2-query) (n-query) MA AP PE ES SR 5 RT TG 7 GS SA AA AT , , -1 TA 12-2, , -3 AT TS ST
13 FASTA Siccome nella tabella di offset, a valori uguali corrispondono amminoacidi allineati, si possono costruire allineamenti di proteine Query MAPESRTGSAATATSTD Sequenza 2 ETAHGSAATATWKLINCV Utilizzando opportune matrici di sostituzione, come BLOSUM 62 o PAM 240, si possono assegnare valori numerici ai vari allineamenti, scegliere le 10 regioni con i valori più alti e sommarle insieme ottenendo il valore chiamato init1. Tutti i valori di init1 vengono ordinati per valori decrescenti e i migliori vengono utilizzati per l analisi successiva E possibile introdurre gap o inserzioni per allungare l estensione dell allineamento pagando delle penalizzazioni ( il punteggio init1 si abbassa ) Query PK---MAPESRTGSAATATSTD-N-V Sequenza 2 PKACVVMETAHGSAATATWKLINCV I nuovi valori vengono ricalcolati con le stesse procedure e la somma dei nuovi dieci valori è chiamata initn. Ancora una volta i valori di initn vengono ordinati per valori decrescenti dal migliore al peggiore. I migliori valori, infine, vengono allineati alla sequenza query con un algoritmo di allineamento globale e i punteggi finali sono indicati opt.
14 FASTA a) Ricerca parole identiche tra le due seq. b) Ricerca diagonali (k-ple sulla stessa diagonale sono considerate parte dell allineamento senza gap se non distano troppo per un parametro fissato). Calcolo di init1 con le matrici solo i 10 più alti sono classificati ed il più alto utilizzato c) Allungamento con gap e calcolo di initn. Questa ricongiunzione viene effettuata se la penalità di ricongiungimento, proporzionale alla distanza tra le regioni di similarità, é inferiore al contributo dato al punteggio di similarità dalla regione di similarità che viene ricongiunta nell'allineamento. d) Nella quarta ed ultima fase, l'allineamento precedentemente ottenuto viene ulteriormente ottimizzato utilizzando la procedura di allineamento descritta da Chao et al. (1992) che utilizza un algoritmo per l'allineamento di due sequenze all'interno di una banda diagonale di dimensioni predeterminate. Il punteggio di similarità calcolato in questa ultima fase viene denominato punteggio opt.
15 Dopo aver calcolato i punteggi finali (opt) FASTA elabora i risultati per stimare la significatività statistica dei risultati operando come segue: Genera un numero statisticamente significativo di combinazioni di sequenze con la stessa lunghezza e la stessa composizione amminoacidica della sequenza query Per ciascuna di esse lancia un FASTA contro un subset della banca dati Calcola la media (mu μ), la deviazione standard (rho σ), assumendo che i valori si distribuiscano in modo normale (cioè con una distribuzione casuale di Poisson) Confronta i valori opt ottenuti con il valore medio della distribuzione ricavandone la probabilità di avere quel particolare valore di opt per caso

16 Z score lo Z score è definito come: Z score = (opt query M random)/ deviazione standard random è una misura di quanto il valore di opt si discosta dalla deviazione standard media. indica di quante dev. Standard si discosta (4 indica già che siamo fuori della distribuzione) Deviazione standard è l indice di dispersione della distribuzione σ = ( x μ) N 2
17 Calcoli statistici Statistica dei confronti locali tra due sequenze Per stimare se il punteggio di allineamento tra due sequenze è dovuto al caso oppure è significativo si fanno un certo numero di confronti (sequence space) di una delle due sequenze (la Query) di stessa composizione AA ma con ordine casuale contro la seconda sequenza (il Subject). L equazione che mette in relazione il punteggio grezzo per capire se è significativo o no è l E value: E( x S è il punteggio grezzo S) E( S) = kmne λs K dipende dal numero di allineamenti prova effettuati (sequence space) λ dipende dalla matrice di sostituzione m ed n sono le lunghezze delle due sequenze

18 Punteggio grezzo S
19 E value E(S) Le prove di raccolta dei punteggi avranno una distribuzione simile a quella normale ma che in realtà si chiama distribuzione dei valori estremi (Gumbel distribution o EVD) A Yev X Se si vuole sapere quanto significativo è il punteggio ottenuto dal mio allineamento reale in confronto alla distribuzione ottenuta secondo quanto detto prima, allora si ricorre all Evalue che indica: Il numero di differenti allineamenti con uno score (x) equivalente o migliore di quello ottenuto dal mio allineamento (chiamato S) che possono capitare per caso in una ricerca in database. Più basso è tale valore e più significativo è il mio allineamento E( x S) E( S) = kmne λs
20 Bit-score Il punteggio grezzo S ha in sé scarso significato perché è come un valore numerico che indica la similarità tra le due sequenze ma senza una unità di misura che possa essere utilizzata per il confronto con altre ricerche. 1. In pratica non riassume l essenza statistica del sistema di punteggio utilizzato per calcolare se quello che si osserva è veramente significativo o no. 2. Infatti uno stesso allineamento può avere punteggi S diversi se si utilizzano matrici di sostituzione diverse che attribuiscono a match, mismatch e gap valori diversi 3. A tale scopo è stato introdotto il bit score che consente di ottenere una normalizzazione dei punteggi. S si normalizza come segue: Da cui deriva che l E value è: S ln S' = λ ln 2 K E = mn2 S ' E, di conseguenza, dipende solo dai parametri di lunghezza delle sequenze. Esiste infine un altra misura che è il P value molto simile all E value
21 Calcolo E value nel caso di ricerca in banca dati Nel caso di ricerca in banca dati le equazioni precedenti sono: E( x E = S) mn2 S ' E( S) = kmne λs L unica differenza è nel significato. Nel caso di FASTA se m è la lunghezza della sequenza query n è è il numero delle sequenze della banca dati S ln S' = λ ln 2 K K e λ sono calcolati dinamicamente per ogni singola ricerca
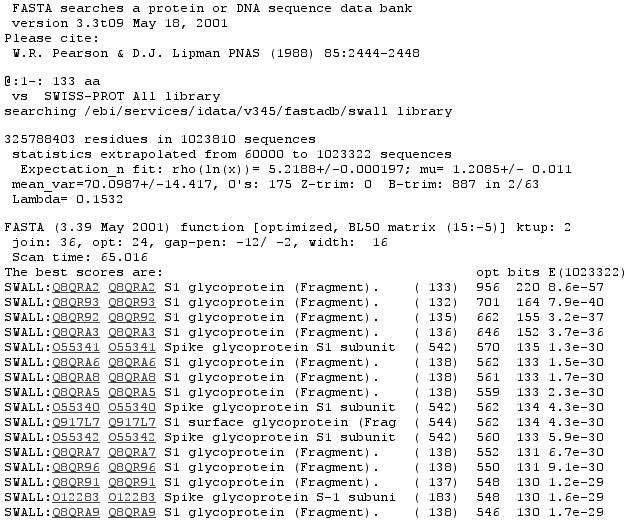
22
23
24 La distribuzione dei veri e falsi positivi la ricerca della giusta soglia
Programmazione dinamica
 Programmazione dinamica Fornisce l allineamento ottimale tra due sequenze semplici variazioni dell algoritmo producono allineamenti globali o locali l allineamento calcolato dipende dalla scelta di alcuni
Programmazione dinamica Fornisce l allineamento ottimale tra due sequenze semplici variazioni dell algoritmo producono allineamenti globali o locali l allineamento calcolato dipende dalla scelta di alcuni
La ricerca di similarità: i metodi
 La ricerca di similarità: i metodi Pairwise alignment allineamenti a coppie 1. Analisi della matrice a punti (dot matrix) 2. Programmazione dinamica (dynamic programming) allineamenti locale e globale.
La ricerca di similarità: i metodi Pairwise alignment allineamenti a coppie 1. Analisi della matrice a punti (dot matrix) 2. Programmazione dinamica (dynamic programming) allineamenti locale e globale.
Z-score. lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random
/ deviazione standard random") Z-score lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random è una misura di quanto il valore di opt si discosta dalla deviazione standard media. indica di quante dev.
Z-score lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random è una misura di quanto il valore di opt si discosta dalla deviazione standard media. indica di quante dev.
BLAST. W = word size T = threshold X = elongation S = HSP threshold
 BLAST Blast (Basic Local Aligment Search Tool) è un programma che cerca similarità locali utilizzando l algoritmo di Altschul et al. Anche Blast, come FASTA, funziona: 1. scomponendo la sequenza query
BLAST Blast (Basic Local Aligment Search Tool) è un programma che cerca similarità locali utilizzando l algoritmo di Altschul et al. Anche Blast, come FASTA, funziona: 1. scomponendo la sequenza query
Quarta lezione. 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST
 Quarta lezione 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST Ricerca di omologhe in banche dati Proteina vs. proteine Gene (traduzione in aa) vs. proteine Gene vs. geni
Quarta lezione 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST Ricerca di omologhe in banche dati Proteina vs. proteine Gene (traduzione in aa) vs. proteine Gene vs. geni
FASTA. Lezione del
 FASTA Lezione del 10.03.2016 Omologia vs Similarità Quando si confrontano due sequenze o strutture si usano spesso indifferentemente i termini somiglianza o omologia per indicare che esiste un rapporto
FASTA Lezione del 10.03.2016 Omologia vs Similarità Quando si confrontano due sequenze o strutture si usano spesso indifferentemente i termini somiglianza o omologia per indicare che esiste un rapporto
Ricerca di omologia di sequenza
 Ricerca di omologia di sequenza RICERCA DI OMOLOGIA DI SEQUENZA := Data una sequenza (query), una banca dati, un sistema per il confronto e una soglia statistica trovare le sequenze della banca più somiglianti
Ricerca di omologia di sequenza RICERCA DI OMOLOGIA DI SEQUENZA := Data una sequenza (query), una banca dati, un sistema per il confronto e una soglia statistica trovare le sequenze della banca più somiglianti
Le sequenze consenso
 Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Algoritmi di Allineamento
 Algoritmi di Allineamento CORSO DI BIOINFORMATICA Corso di Laurea in Biotecnologie Università Magna Graecia Catanzaro Outline Similarità Allineamento Omologia Allineamento di Coppie di Sequenze Allineamento
Algoritmi di Allineamento CORSO DI BIOINFORMATICA Corso di Laurea in Biotecnologie Università Magna Graecia Catanzaro Outline Similarità Allineamento Omologia Allineamento di Coppie di Sequenze Allineamento
FASTA: Lipman & Pearson (1985) BLAST: Altshul (1990) Algoritmi EURISTICI di allineamento
 BLAST: Altshul (1990) Algoritmi EURISTICI di allineamento") Algoritmi EURISTICI di allineamento Sono nati insieme alle banche dati, con lo scopo di permettere una ricerca per similarità rapida anche se meno accurata contro le migliaia di sequenze depositate. Attualmente
Algoritmi EURISTICI di allineamento Sono nati insieme alle banche dati, con lo scopo di permettere una ricerca per similarità rapida anche se meno accurata contro le migliaia di sequenze depositate. Attualmente
UNIVERSITÀ DEGLI STUDI DI MILANO. Bioinformatica. A.A semestre I. Allineamento veloce (euristiche)
") Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I 3 Allineamento veloce (euristiche) Banche dati primarie e secondarie Esistono due categorie
Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I 3 Allineamento veloce (euristiche) Banche dati primarie e secondarie Esistono due categorie
Luigi Santoro. Hyperphar Group S.p.A., MIlano
 Come modellare il rischio Luigi Santoro Hyperphar Group S.p.A., MIlano Gli argomenti discussi Le definizioni del termine rischio L utilità di un modello predittivo di rischio Come costruire modelli predittivi
Come modellare il rischio Luigi Santoro Hyperphar Group S.p.A., MIlano Gli argomenti discussi Le definizioni del termine rischio L utilità di un modello predittivo di rischio Come costruire modelli predittivi
Quanti soggetti devono essere selezionati?
 Quanti soggetti devono essere selezionati? Determinare una appropriata numerosità campionaria già in fase di disegno dello studio molto importante è molto Studi basati su campioni troppo piccoli non hanno
Quanti soggetti devono essere selezionati? Determinare una appropriata numerosità campionaria già in fase di disegno dello studio molto importante è molto Studi basati su campioni troppo piccoli non hanno
ALLINEAMENTO DI SEQUENZE
 ALLINEAMENTO DI SEQUENZE Procedura per comparare due o piu sequenze, volta a stabilire un insieme di relazioni biunivoche tra coppie di residui delle sequenze considerate che massimizzino la similarita
ALLINEAMENTO DI SEQUENZE Procedura per comparare due o piu sequenze, volta a stabilire un insieme di relazioni biunivoche tra coppie di residui delle sequenze considerate che massimizzino la similarita
Stima della qualità dei classificatori per l analisi dei dati biomolecolari
 Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni
 La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
L'implementazione delle ROC Curve nei modelli GAMLSS come strumento di previsione per i Big Data
 L'implementazione delle ROC Curve nei modelli GAMLSS come strumento di previsione per i Big Data Paolo Mariani, Andrea Marletta Dipartimento di Economia, Metodi Quantitativi e Strategie di Impresa, Università
L'implementazione delle ROC Curve nei modelli GAMLSS come strumento di previsione per i Big Data Paolo Mariani, Andrea Marletta Dipartimento di Economia, Metodi Quantitativi e Strategie di Impresa, Università
1 4 Esempio 2. Si determini la distribuzione di probabilità della variabile casuale X = punteggio ottenuto lanciando un dado. Si ha immediatamente:
 CAPITOLO TERZO VARIABILI CASUALI. Le variabili casuali e la loro distribuzione di probabilità In molte situazioni, dato uno spazio di probabilità S, si è interessati non tanto agli eventi elementari (o
CAPITOLO TERZO VARIABILI CASUALI. Le variabili casuali e la loro distribuzione di probabilità In molte situazioni, dato uno spazio di probabilità S, si è interessati non tanto agli eventi elementari (o
PROBABILITA. Distribuzione di probabilità
 DISTRIBUZIONI di PROBABILITA Distribuzione di probabilità Si definisce distribuzione di probabilità il valore delle probabilità associate a tutti gli eventi possibili connessi ad un certo numero di prove
DISTRIBUZIONI di PROBABILITA Distribuzione di probabilità Si definisce distribuzione di probabilità il valore delle probabilità associate a tutti gli eventi possibili connessi ad un certo numero di prove
Valutazione dei test diagnostici
 Valutazione dei test diagnostici Maria Miceli M. Miceli 2011 1 Diagnosi individuale (test di laboratorio) Esame collaterale nell ambito dell iter diagnostico condotto generalmente su animali sintomatici
Valutazione dei test diagnostici Maria Miceli M. Miceli 2011 1 Diagnosi individuale (test di laboratorio) Esame collaterale nell ambito dell iter diagnostico condotto generalmente su animali sintomatici
Laboratorio di Didattica di elaborazione dati 5 STIMA PUNTUALE DEI PARAMETRI. x i. SE = n.
 5 STIMA PUNTUALE DEI PARAMETRI [Adattato dal libro Excel per la statistica di Enzo Belluco] Sia θ un parametro incognito della distribuzione di un carattere in una determinata popolazione. Il problema
5 STIMA PUNTUALE DEI PARAMETRI [Adattato dal libro Excel per la statistica di Enzo Belluco] Sia θ un parametro incognito della distribuzione di un carattere in una determinata popolazione. Il problema
Corso di Visione Artificiale. Texture. Samuel Rota Bulò
 Corso di Visione Artificiale Texture Samuel Rota Bulò Texture Le texture sono facili da riconoscere ma difficili da definire. Texture Il fatto di essere una texture dipende dal livello di scala a cui si
Corso di Visione Artificiale Texture Samuel Rota Bulò Texture Le texture sono facili da riconoscere ma difficili da definire. Texture Il fatto di essere una texture dipende dal livello di scala a cui si
Proprietà della varianza
 Proprietà della varianza Proprietà della varianza Proprietà della varianza Proprietà della varianza Intermezzo: ma perché dovremmo darci la pena di studiare come calcolare la varianza nel caso di somme,
Proprietà della varianza Proprietà della varianza Proprietà della varianza Proprietà della varianza Intermezzo: ma perché dovremmo darci la pena di studiare come calcolare la varianza nel caso di somme,
SCHEDA DIDATTICA N 7
 FACOLTA DI INGEGNERIA CORSO DI LAUREA IN INGEGNERIA CIVILE CORSO DI IDROLOGIA PROF. PASQUALE VERSACE SCHEDA DIDATTICA N 7 LA DISTRIBUZIONE NORMALE A.A. 01-13 La distribuzione NORMALE Uno dei più importanti
FACOLTA DI INGEGNERIA CORSO DI LAUREA IN INGEGNERIA CIVILE CORSO DI IDROLOGIA PROF. PASQUALE VERSACE SCHEDA DIDATTICA N 7 LA DISTRIBUZIONE NORMALE A.A. 01-13 La distribuzione NORMALE Uno dei più importanti
Universita degli Studi di Siena
 Universita degli Studi di Siena Facolta di Ingegneria Dispense del corso di Sistemi di Supporto alle Decisioni I La Programmazione Dinamica Chiara Mocenni Corso di Laurea triennale in Ingegneria Gestionale
Universita degli Studi di Siena Facolta di Ingegneria Dispense del corso di Sistemi di Supporto alle Decisioni I La Programmazione Dinamica Chiara Mocenni Corso di Laurea triennale in Ingegneria Gestionale
Introduzione alla statistica 2/ed. Marilyn K. Pelosi, Theresa M. Sandifer, Paola Cerchiello, Paolo Giudici
 CAPITOLO 6 LE VARIABILITA CASUALI E LE DISTRIBUZIONI DI PROBABILITA VERO FALSO 1. V F La probabilità che X assuma un valore compreso tra 3 e 4 incluso può essere scritto come P(3
CAPITOLO 6 LE VARIABILITA CASUALI E LE DISTRIBUZIONI DI PROBABILITA VERO FALSO 1. V F La probabilità che X assuma un valore compreso tra 3 e 4 incluso può essere scritto come P(3
Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni:
: Allineamento di sequenze (parte 1) Antonella Meloni:") Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni: antonella.meloni@ifc.cnr.it Sequenza A= stringa formata da N simboli, dove i simboli apparterranno ad un certo alfabeto. A
Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni: antonella.meloni@ifc.cnr.it Sequenza A= stringa formata da N simboli, dove i simboli apparterranno ad un certo alfabeto. A
Valutazione delle Prestazioni di un Classificatore. Performance Evaluation
 Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Le variabili casuali o aleatorie
 Le variabili casuali o aleatorie Intuitivamente un numero casuale o aleatorio è un numero sul cui valore non siamo certi per carenza di informazioni - ad esempio la durata di un macchinario, il valore
Le variabili casuali o aleatorie Intuitivamente un numero casuale o aleatorio è un numero sul cui valore non siamo certi per carenza di informazioni - ad esempio la durata di un macchinario, il valore
La statistica e i test diagnostici
 La statistica e i test diagnostici Laura Ventura Dipartimento di Scienze Statistiche Università degli Studi di Padova ventura@stat.unipd.it XXIII Settimana della Cultura Scientifica e Tecnologica Liceo
La statistica e i test diagnostici Laura Ventura Dipartimento di Scienze Statistiche Università degli Studi di Padova ventura@stat.unipd.it XXIII Settimana della Cultura Scientifica e Tecnologica Liceo
Allineamento e similarità di sequenze
 Allineamento e similarità di sequenze Allineamento di Sequenze L allineamento tra due o più sequenza può aiutare a trovare regioni simili per le quali si può supporre svolgano la stessa funzione; La similarità
Allineamento e similarità di sequenze Allineamento di Sequenze L allineamento tra due o più sequenza può aiutare a trovare regioni simili per le quali si può supporre svolgano la stessa funzione; La similarità
Matematica per Analisi dei Dati,
 Matematica per Analisi dei Dati, 230209 1 Spazio vettoriale R n Sia n un intero positivo fissato Lo spazio vettoriale R n e l insieme delle n ple ordinate di numeri reali, che rappresenteremo sempre come
Matematica per Analisi dei Dati, 230209 1 Spazio vettoriale R n Sia n un intero positivo fissato Lo spazio vettoriale R n e l insieme delle n ple ordinate di numeri reali, che rappresenteremo sempre come
Corso di Bioinformatica
 Corso di Bioinformatica Cortona - Novembre 2002 Metodi Computazionali per l'analisi delle sequenze Dr. Sabino Liuni Istituto di Tecnologie Biomediche- CNR Sezione di Bioinformatica e Genomica - Bari Sabino@area.ba
Corso di Bioinformatica Cortona - Novembre 2002 Metodi Computazionali per l'analisi delle sequenze Dr. Sabino Liuni Istituto di Tecnologie Biomediche- CNR Sezione di Bioinformatica e Genomica - Bari Sabino@area.ba
Probabilità classica. Distribuzioni e leggi di probabilità. Probabilità frequentista. Probabilità soggettiva
 Probabilità classica Distribuzioni e leggi di probabilità La probabilità di un evento casuale è il rapporto tra il numero dei casi favorevoli ed il numero dei casi possibili, purchè siano tutti equiprobabili.
Probabilità classica Distribuzioni e leggi di probabilità La probabilità di un evento casuale è il rapporto tra il numero dei casi favorevoli ed il numero dei casi possibili, purchè siano tutti equiprobabili.
Lezione 6. Analisi di sequenze biologiche e ricerche in database
 Lezione 6 Analisi di sequenze biologiche e ricerche in database Schema della lezione Allinemento: definizioni Allineamento di due sequenze Ricerca di singola sequenza in banche dati (Alignment-based database
Lezione 6 Analisi di sequenze biologiche e ricerche in database Schema della lezione Allinemento: definizioni Allineamento di due sequenze Ricerca di singola sequenza in banche dati (Alignment-based database
Strumenti di indagine per la valutazione psicologica
 Strumenti di indagine per la valutazione psicologica 2.3 Validazione di un test clinico Davide Massidda davide.massidda@gmail.com Definire un cut-off Per ogni scala del questionario, sommando o mediando
Strumenti di indagine per la valutazione psicologica 2.3 Validazione di un test clinico Davide Massidda davide.massidda@gmail.com Definire un cut-off Per ogni scala del questionario, sommando o mediando
Il ragionamento diagnostico
 Il ragionamento diagnostico 1 l accertamento della condizione patologica viene eseguito All'inizio del decorso clinico, per una prima diagnosi In qualsiasi punto del decorso clinico, per conoscere lo stato
Il ragionamento diagnostico 1 l accertamento della condizione patologica viene eseguito All'inizio del decorso clinico, per una prima diagnosi In qualsiasi punto del decorso clinico, per conoscere lo stato
Capitolo 8. Intervalli di confidenza. Statistica. Levine, Krehbiel, Berenson. Casa editrice: Pearson. Insegnamento: Statistica
 Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
Distribuzione Gaussiana - Facciamo un riassunto -
 Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Bioinformatica. Analisi del genoma
 Bioinformatica Analisi del genoma GABRIELLA TRUCCO CREMA, 5 APRILE 2017 Cosa è il genoma? Insieme delle informazioni biologiche, depositate nella sequenza di DNA, necessarie alla costruzione e mantenimento
Bioinformatica Analisi del genoma GABRIELLA TRUCCO CREMA, 5 APRILE 2017 Cosa è il genoma? Insieme delle informazioni biologiche, depositate nella sequenza di DNA, necessarie alla costruzione e mantenimento
Corso di Statistica Esercitazione 1.8
 Corso di Statistica Esercitazione.8 Test su medie e proporzioni Prof.ssa T. Laureti a.a. 202-203 Esercizio Un produttore vuole monitorare i valori dei livelli di impurità contenute nella merce che gli
Corso di Statistica Esercitazione.8 Test su medie e proporzioni Prof.ssa T. Laureti a.a. 202-203 Esercizio Un produttore vuole monitorare i valori dei livelli di impurità contenute nella merce che gli
Operazioni tra matrici e n-uple
 CAPITOLO Operazioni tra matrici e n-uple Esercizio.. Date le matrici 0 4 e dati λ = 5, µ =, si calcoli AB, BA, A+B, B A, λa+µb. Esercizio.. Per ognuna delle seguenti coppie di matrici A, B e scalari λ,
CAPITOLO Operazioni tra matrici e n-uple Esercizio.. Date le matrici 0 4 e dati λ = 5, µ =, si calcoli AB, BA, A+B, B A, λa+µb. Esercizio.. Per ognuna delle seguenti coppie di matrici A, B e scalari λ,
Bioinformatica ed applicazioni di bioinformatica strutturale!
 Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
DISTRIBUZIONE NORMALE (1)
") DISTRIBUZIONE NORMALE (1) Nella popolazione generale molte variabili presentano una distribuzione a forma di campana, bene caratterizzata da un punto di vista matematico, chiamata distribuzione normale
DISTRIBUZIONE NORMALE (1) Nella popolazione generale molte variabili presentano una distribuzione a forma di campana, bene caratterizzata da un punto di vista matematico, chiamata distribuzione normale
L A B C di R. Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010
 L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
Modello computazionale per la predizione di siti di legame per fattori di trascrizione
 Modello computazionale per la predizione di siti di legame per fattori di trascrizione Attività di tirocinio svolto presso il Telethon Institute of Genetics and Medicine Relatori Prof. Giuseppe Trautteur
Modello computazionale per la predizione di siti di legame per fattori di trascrizione Attività di tirocinio svolto presso il Telethon Institute of Genetics and Medicine Relatori Prof. Giuseppe Trautteur
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3
 Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Indicatori compositi. Dott. Cazzaniga Paolo. Dip. di Scienze Umane e Sociali
 Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Indicatori [1/4] Gli indicatori: sintetizzano le caratteristiche di un fenomeno colgono aspetti e problemi del fenomeno che non hanno una immediata
Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Indicatori [1/4] Gli indicatori: sintetizzano le caratteristiche di un fenomeno colgono aspetti e problemi del fenomeno che non hanno una immediata
PROCEDURE DI CALCOLO DELLA COMBINAZIONE DEGLI INERTI REALI
 PROCEDURE DI CALCOLO DELLA COMBINAZIONE DEGLI INERTI REALI Non esistono già disponibili in natura materiali lapidei con distribuzione granulometrica eguale a quella ideale richiesta per un inerte da destinare
PROCEDURE DI CALCOLO DELLA COMBINAZIONE DEGLI INERTI REALI Non esistono già disponibili in natura materiali lapidei con distribuzione granulometrica eguale a quella ideale richiesta per un inerte da destinare
ISTOGRAMMI E DISTRIBUZIONI:
 ISTOGRAMMI E DISTRIBUZIONI: i 3 4 5 6 7 8 9 0 i 0. 8.5 3 0 9.5 7 9.8 8.6 8. bin (=.) 5-7. 7.-9.4 n k 3 n k 6 5 n=0 =. 9.4-.6 5 4.6-3.8 3 Numero di misure nell intervallo 0 0 4 6 8 0 4 6 8 30 ISTOGRAMMI
ISTOGRAMMI E DISTRIBUZIONI: i 3 4 5 6 7 8 9 0 i 0. 8.5 3 0 9.5 7 9.8 8.6 8. bin (=.) 5-7. 7.-9.4 n k 3 n k 6 5 n=0 =. 9.4-.6 5 4.6-3.8 3 Numero di misure nell intervallo 0 0 4 6 8 0 4 6 8 30 ISTOGRAMMI
STATISTICA 1 ESERCITAZIONE 6
 STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
Distribuzione normale
 Distribuzione normale istogramma delle frequenze di un insieme di misure relative a una grandezza che varia con continuità popolazione molto numerosa, costituita da una quantità praticamente illimitata
Distribuzione normale istogramma delle frequenze di un insieme di misure relative a una grandezza che varia con continuità popolazione molto numerosa, costituita da una quantità praticamente illimitata
C.I. di Metodologia clinica
 C.I. di Metodologia clinica Modulo 5. I metodi per la sintesi e la comunicazione delle informazioni sulla salute Quali errori influenzano le stime? L errore casuale I metodi per la produzione delle informazioni
C.I. di Metodologia clinica Modulo 5. I metodi per la sintesi e la comunicazione delle informazioni sulla salute Quali errori influenzano le stime? L errore casuale I metodi per la produzione delle informazioni
λ è detto intensità e rappresenta il numero di eventi che si
 ESERCITAZIONE N 1 STUDIO DI UN SISTEMA DI CODA M/M/1 1. Introduzione Per poter studiare un sistema di coda occorre necessariamente simulare gli arrivi, le partenze e i tempi di ingresso nel sistema e di
ESERCITAZIONE N 1 STUDIO DI UN SISTEMA DI CODA M/M/1 1. Introduzione Per poter studiare un sistema di coda occorre necessariamente simulare gli arrivi, le partenze e i tempi di ingresso nel sistema e di
Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari"
 Levine, Krehbiel, Berenson Statistica Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari" Unità Integrata Organizzativa
Levine, Krehbiel, Berenson Statistica Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari" Unità Integrata Organizzativa
standardizzazione dei punteggi di un test
 DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
8 Metodi iterativi per la risoluzione di sistemi lineari
 8 Metodi iterativi per la risoluzione di sistemi lineari È dato il sistema lineare Ax = b con A R n n e x, b R n, con deta 0 Si vogliono individuare dei metodi per determinarne su calcolatore la soluzione,
8 Metodi iterativi per la risoluzione di sistemi lineari È dato il sistema lineare Ax = b con A R n n e x, b R n, con deta 0 Si vogliono individuare dei metodi per determinarne su calcolatore la soluzione,
Gli errori nella verifica delle ipotesi
 Gli errori nella verifica delle ipotesi Nella statistica inferenziale si cerca di dire qualcosa di valido in generale, per la popolazione o le popolazioni, attraverso l analisi di uno o più campioni E
Gli errori nella verifica delle ipotesi Nella statistica inferenziale si cerca di dire qualcosa di valido in generale, per la popolazione o le popolazioni, attraverso l analisi di uno o più campioni E
LE MISURE. attendibilità = x i - X
 LE MISURE COCETTI PRELIMIARI: MISURA, ATTEDIBILITÀ, PRECISIOE, ACCURATEZZA Il modo corretto di fornire il risultato di una qualunque misura è quello di dare la migliore stima della quantità in questione
LE MISURE COCETTI PRELIMIARI: MISURA, ATTEDIBILITÀ, PRECISIOE, ACCURATEZZA Il modo corretto di fornire il risultato di una qualunque misura è quello di dare la migliore stima della quantità in questione
Analisi della regressione multipla
 Analisi della regressione multipla y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inferenza Assunzione del Modello Classico di Regressione Lineare (CLM) Sappiamo che, date le assunzioni Gauss- Markov,
Analisi della regressione multipla y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inferenza Assunzione del Modello Classico di Regressione Lineare (CLM) Sappiamo che, date le assunzioni Gauss- Markov,
Argomenti Capitolo 1 Richiami
 Argomenti Capitolo 1 Richiami L insieme dei numeri reali R si rappresenta geometricamente con l insieme dei punti di una retta orientata su cui sia stato fissato un punto 0 e un segmento unitario. L insieme
Argomenti Capitolo 1 Richiami L insieme dei numeri reali R si rappresenta geometricamente con l insieme dei punti di una retta orientata su cui sia stato fissato un punto 0 e un segmento unitario. L insieme
Sismica a Rifrazione: fondamenti. Sismica rifrazione - Michele Pipan
 Sismica a Rifrazione: fondamenti 1 Sismica a Rifrazione: fondamenti Onde P ed S (2) Velocita delle Onde P: Velocita delle Onde S : Definiamo poi il rapporto di Poisson σ come 2 λ Sismica a Rifrazione:
Sismica a Rifrazione: fondamenti 1 Sismica a Rifrazione: fondamenti Onde P ed S (2) Velocita delle Onde P: Velocita delle Onde S : Definiamo poi il rapporto di Poisson σ come 2 λ Sismica a Rifrazione:
Elementi di Psicometria
 Elementi di Psicometria 7-Punti z e punti T vers. 1.0a (21 marzo 2011) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca 2010-2011 G. Rossi (Dip. Psicologia)
Elementi di Psicometria 7-Punti z e punti T vers. 1.0a (21 marzo 2011) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca 2010-2011 G. Rossi (Dip. Psicologia)
Teoria e tecniche dei test. Concetti di base
 Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
STATISTICA AZIENDALE Modulo Controllo di Qualità
 STATISTICA AZIENDALE Modulo Controllo di Qualità A.A. 009/10 - Sottoperiodo PROA DEL 14 MAGGIO 010 Cognome:.. Nome: Matricola:.. AERTENZE: Negli esercizi in cui sono richiesti calcoli riportare tutte la
STATISTICA AZIENDALE Modulo Controllo di Qualità A.A. 009/10 - Sottoperiodo PROA DEL 14 MAGGIO 010 Cognome:.. Nome: Matricola:.. AERTENZE: Negli esercizi in cui sono richiesti calcoli riportare tutte la
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati.
 La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
percorso 4 Estensione on line lezione 2 I fattori della produzione e le forme di mercato La produttività La produzione
 Estensione on line percorso 4 I fattori della produzione e le forme di mercato lezione 2 a produzione a produttività Una volta reperiti i fattori produttivi necessari l imprenditore dovrà decidere come
Estensione on line percorso 4 I fattori della produzione e le forme di mercato lezione 2 a produzione a produttività Una volta reperiti i fattori produttivi necessari l imprenditore dovrà decidere come
L errore percentuale di una misura è l errore relativo moltiplicato per 100 ed espresso in percentuale. Si indica con e p e risulta: e ( e 100)%
%") UNITÀ L ELBORZIONE DEI DTI IN FISIC 1. Gli errori di misura.. Errori di sensibilità, errori casuali, errori sistematici. 3. La stima dell errore. 4. La media, la semidispersione e lo scarto quadratico
UNITÀ L ELBORZIONE DEI DTI IN FISIC 1. Gli errori di misura.. Errori di sensibilità, errori casuali, errori sistematici. 3. La stima dell errore. 4. La media, la semidispersione e lo scarto quadratico
CAPITOLO V. DATABASE: Il modello relazionale
 CAPITOLO V DATABASE: Il modello relazionale Il modello relazionale offre una rappresentazione matematica dei dati basata sul concetto di relazione normalizzata. I principi del modello relazionale furono
CAPITOLO V DATABASE: Il modello relazionale Il modello relazionale offre una rappresentazione matematica dei dati basata sul concetto di relazione normalizzata. I principi del modello relazionale furono
Tutorato di Chimica Analitica 2016/2017
 Tutorato di Chimica Analitica 2016/2017 Friendly reminder La notazione scientifica Modo per indicare un risultato con numerose cifre decimali come prodotto di una potenza di 10 esempio Cifre significative
Tutorato di Chimica Analitica 2016/2017 Friendly reminder La notazione scientifica Modo per indicare un risultato con numerose cifre decimali come prodotto di una potenza di 10 esempio Cifre significative
Lezione 7. Allineamento di sequenze biologiche
 Lezione 7 Allineamento di sequenze biologiche Allineamento di sequenze Determinare la similarità e dedurre l omologia Allineare Definire il numero di passi necessari per trasformare una sequenza nell altra
Lezione 7 Allineamento di sequenze biologiche Allineamento di sequenze Determinare la similarità e dedurre l omologia Allineare Definire il numero di passi necessari per trasformare una sequenza nell altra
DATI INVALSI SUGLI APPRENDIMENTI Italiano-Matematica. Anno scolastico 2011/2012
 DATI INVALSI SUGLI APPRENDIMENTI Italiano-Matematica Anno scolastico 2011/2012 In questo documento verranno riportate le informazioni che riguardano i dati relativi all Istituto Tecnico Industriale A.
DATI INVALSI SUGLI APPRENDIMENTI Italiano-Matematica Anno scolastico 2011/2012 In questo documento verranno riportate le informazioni che riguardano i dati relativi all Istituto Tecnico Industriale A.
L analisi dei dati. Primi elementi. EEE- Cosmic Box proff.: M.Cottino, P.Porta
 L analisi dei dati Primi elementi Metodo dei minimi quadrati Negli esperimenti spesso si misurano parecchie volte due diverse variabili fisiche per investigare la relazione matematica tra le due variabili.
L analisi dei dati Primi elementi Metodo dei minimi quadrati Negli esperimenti spesso si misurano parecchie volte due diverse variabili fisiche per investigare la relazione matematica tra le due variabili.
Una Libreria di Algebra Lineare per il Calcolo Scientifico
 Una Libreria di Algebra Lineare per il Calcolo Scientifico Introduzione Il Lavoro di Tesi Introduzione al Metodo Ridurre l Occupazione di Memoria Metodo di Memorizzazione degli Elementi Risultati Attesi
Una Libreria di Algebra Lineare per il Calcolo Scientifico Introduzione Il Lavoro di Tesi Introduzione al Metodo Ridurre l Occupazione di Memoria Metodo di Memorizzazione degli Elementi Risultati Attesi
LA DISTRIBUZIONE NORMALE
 LA DISTRIBUZIONE NORMALE Italo Nofroni Statistica medica - Facoltà di Medicina Sapienza - Roma La più nota ed importante distribuzione di probabilità è, senza alcun dubbio, la Distribuzione normale, anche
LA DISTRIBUZIONE NORMALE Italo Nofroni Statistica medica - Facoltà di Medicina Sapienza - Roma La più nota ed importante distribuzione di probabilità è, senza alcun dubbio, la Distribuzione normale, anche
Variabili aleatorie discrete. Giovanni M. Marchetti Statistica Capitolo 5 Corso di Laurea in Economia
 Variabili aleatorie discrete Giovanni M. Marchetti Statistica Capitolo 5 Corso di Laurea in Economia 2015-16 1 / 45 Variabili aleatorie Una variabile aleatoria è simile a una variabile statistica Una variabile
Variabili aleatorie discrete Giovanni M. Marchetti Statistica Capitolo 5 Corso di Laurea in Economia 2015-16 1 / 45 Variabili aleatorie Una variabile aleatoria è simile a una variabile statistica Una variabile
Allineamenti di sequenze: concetti e algoritmi
 Allineamenti di sequenze: concetti e algoritmi 1 globine: a- b- mioglobina Precoce esempio di allineamento di sequenza: globine (1961) H.C. Watson and J.C. Kendrew, Comparison Between the Amino-Acid Sequences
Allineamenti di sequenze: concetti e algoritmi 1 globine: a- b- mioglobina Precoce esempio di allineamento di sequenza: globine (1961) H.C. Watson and J.C. Kendrew, Comparison Between the Amino-Acid Sequences
Attività Precedenze Tempo (gg) A - 5 B - 10 C A 3 D B 2 E B 4 F C, D 6 G F, E 3
 A - 5 B - 10 C A 3 D B 2 E B 4 F C, D 6 G F, E 3") Partiamo da un Esempio per il calcolo CPM Si parte da una tabella dove si riporta l elenco di tutte le attività da svolgere e vi si esplicitano le relazioni di precedenza tra di esse e i tempi per il loro
Partiamo da un Esempio per il calcolo CPM Si parte da una tabella dove si riporta l elenco di tutte le attività da svolgere e vi si esplicitano le relazioni di precedenza tra di esse e i tempi per il loro
Versione di Controllo
 Università degli Studi di Trento test di ammissione ai corsi di laurea in Fisica - Matematica - Informatica Ingegneria dell Informazione e Organizzazione d Impresa Ingegneria dell Informazione e delle
Università degli Studi di Trento test di ammissione ai corsi di laurea in Fisica - Matematica - Informatica Ingegneria dell Informazione e Organizzazione d Impresa Ingegneria dell Informazione e delle
A W T V A S A V R T S I A Y T V A A A V R T S I A Y T V A A A V L T S I
 COME CALCOLARE IL PUNTEIO DI UN ALLINEAMENTO? Il problema del calcolo del punteggio di un allineamento può essere considerato in due modi diversi che, però, sono le due facce di una stessa medaglia al
COME CALCOLARE IL PUNTEIO DI UN ALLINEAMENTO? Il problema del calcolo del punteggio di un allineamento può essere considerato in due modi diversi che, però, sono le due facce di una stessa medaglia al
Teorema del Limite Centrale
 Teorema del Limite Centrale Problema. Determinare come la media campionaria x e la deviazione standard campionaria s misurano la media µ e la deviazione standard σ della popolazione. È data una popolazione
Teorema del Limite Centrale Problema. Determinare come la media campionaria x e la deviazione standard campionaria s misurano la media µ e la deviazione standard σ della popolazione. È data una popolazione
L indagine campionaria Lezione 3
 Anno accademico 2007/08 L indagine campionaria Lezione 3 Docente: prof. Maurizio Pisati Variabile casuale Una variabile casuale è una quantità discreta o continua il cui valore è determinato dal risultato
Anno accademico 2007/08 L indagine campionaria Lezione 3 Docente: prof. Maurizio Pisati Variabile casuale Una variabile casuale è una quantità discreta o continua il cui valore è determinato dal risultato
Indici di posizione e dispersione per distribuzioni di variabili aleatorie
 Indici di posizione e dispersione per distribuzioni di variabili aleatorie 12 maggio 2017 Consideriamo i principali indici statistici che caratterizzano una distribuzione: indici di posizione, che forniscono
Indici di posizione e dispersione per distribuzioni di variabili aleatorie 12 maggio 2017 Consideriamo i principali indici statistici che caratterizzano una distribuzione: indici di posizione, che forniscono
Esercitazione n. 3 - Corso di STATISTICA - Università della Basilicata - a.a. 2011/12 Prof. Roberta Siciliano
 Esercitazione n. 3 - Corso di STATISTICA - Università della Basilicata - a.a. 2011/12 Prof. Roberta Siciliano Esercizio 1 Una moneta viene lanciata 6 volte. Calcolare a) La probabilità che escano esattamente
Esercitazione n. 3 - Corso di STATISTICA - Università della Basilicata - a.a. 2011/12 Prof. Roberta Siciliano Esercizio 1 Una moneta viene lanciata 6 volte. Calcolare a) La probabilità che escano esattamente
DISTRIBUZIONI DI CAMPIONAMENTO
 DISTRIBUZIONI DI CAMPIONAMENTO 12 DISTRIBUZIONE DI CAMPIONAMENTO DELLA MEDIA Situazione reale Della popolazione di tutti i laureati in odontoiatria negli ultimi 10 anni, in tutte le Università d Italia,
DISTRIBUZIONI DI CAMPIONAMENTO 12 DISTRIBUZIONE DI CAMPIONAMENTO DELLA MEDIA Situazione reale Della popolazione di tutti i laureati in odontoiatria negli ultimi 10 anni, in tutte le Università d Italia,
q xi Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p i >0;
 Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p1 p6 p i >0; 6! i=1 p i =1 Sequenza di dna/proteine x con probabilita q x Probabilita dell intera sequenza n " i!1 q xi Massima verosimiglianza
Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p1 p6 p i >0; 6! i=1 p i =1 Sequenza di dna/proteine x con probabilita q x Probabilita dell intera sequenza n " i!1 q xi Massima verosimiglianza
Risoluzione di problemi ingegneristici con Excel
 Risoluzione di problemi ingegneristici con Excel Problemi Ingegneristici Calcolare per via numerica le radici di un equazione Trovare l equazione che lega un set di dati ottenuti empiricamente (fitting
Risoluzione di problemi ingegneristici con Excel Problemi Ingegneristici Calcolare per via numerica le radici di un equazione Trovare l equazione che lega un set di dati ottenuti empiricamente (fitting
Corso di Matematica per la Chimica. Dott.ssa Maria Carmela De Bonis a.a
 Dott.ssa Maria Carmela De Bonis a.a. 2013-14 Risoluzione di Equazioni non lineari Sia F C 0 ([a, b]), cioé F è una funzione continua in un intervallo [a, b] R, tale che F(a)F(b) < 0 1.5 1 F(b) 0.5 0 a
Dott.ssa Maria Carmela De Bonis a.a. 2013-14 Risoluzione di Equazioni non lineari Sia F C 0 ([a, b]), cioé F è una funzione continua in un intervallo [a, b] R, tale che F(a)F(b) < 0 1.5 1 F(b) 0.5 0 a
Ulteriori Conoscenze di Informatica e Statistica
 ndici di forma Ulteriori Conoscenze di nformatica e Statistica Descrivono le asimmetrie della distribuzione Carlo Meneghini Dip. di fisica via della Vasca Navale 84, st. 83 ( piano) tel.: 06 55 17 72 17
ndici di forma Ulteriori Conoscenze di nformatica e Statistica Descrivono le asimmetrie della distribuzione Carlo Meneghini Dip. di fisica via della Vasca Navale 84, st. 83 ( piano) tel.: 06 55 17 72 17
Elementi di Algebra Lineare Matrici e Sistemi di Equazioni Lineari
 Elementi di Algebra Lineare Matrici e Sistemi di Equazioni Lineari Antonio Lanteri e Cristina Turrini UNIMI - 2016/2017 Antonio Lanteri e Cristina Turrini (UNIMI - 2016/2017 Elementi di Algebra Lineare
Elementi di Algebra Lineare Matrici e Sistemi di Equazioni Lineari Antonio Lanteri e Cristina Turrini UNIMI - 2016/2017 Antonio Lanteri e Cristina Turrini (UNIMI - 2016/2017 Elementi di Algebra Lineare
Analogico vs. Digitale. LEZIONE II La codifica binaria. Analogico vs digitale. Analogico. Digitale
 Analogico vs. Digitale LEZIONE II La codifica binaria Analogico Segnale che può assumere infiniti valori con continuità Digitale Segnale che può assumere solo valori discreti Analogico vs digitale Il computer
Analogico vs. Digitale LEZIONE II La codifica binaria Analogico Segnale che può assumere infiniti valori con continuità Digitale Segnale che può assumere solo valori discreti Analogico vs digitale Il computer
Metodi per la risoluzione di sistemi lineari
 Metodi per la risoluzione di sistemi lineari 1 Sistemi di equazioni lineari 1.1 Determinante di matrici quadrate Ad ogni matrice quadrata A è associato un numero reale det(a) detto determinante della matrice
Metodi per la risoluzione di sistemi lineari 1 Sistemi di equazioni lineari 1.1 Determinante di matrici quadrate Ad ogni matrice quadrata A è associato un numero reale det(a) detto determinante della matrice
Lezione n. 1 (a cura di Irene Tibidò)
") Lezione n. 1 (a cura di Irene Tibidò) Richiami di statistica Variabile aleatoria (casuale) Dato uno spazio campionario Ω che contiene tutti i possibili esiti di un esperimento casuale, la variabile aleatoria
Lezione n. 1 (a cura di Irene Tibidò) Richiami di statistica Variabile aleatoria (casuale) Dato uno spazio campionario Ω che contiene tutti i possibili esiti di un esperimento casuale, la variabile aleatoria
Indicatori di Posizione e di Variabilità. Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica
 Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
RETI DI TELECOMUNICAZIONE
 RETI DI TELECOMUNICAZIONE Modelli delle Sorgenti di Traffico Generalità Per la realizzazione di un modello analitico di un sistema di telecomunicazione dobbiamo tenere in considerazione 3 distinte sezioni
RETI DI TELECOMUNICAZIONE Modelli delle Sorgenti di Traffico Generalità Per la realizzazione di un modello analitico di un sistema di telecomunicazione dobbiamo tenere in considerazione 3 distinte sezioni
La distribuzione delle frequenze. T 10 (s)
") 1 La distribuzione delle frequenze Si vuole misurare il periodo di oscillazione di un pendolo costituito da una sferetta metallica agganciata a un filo (fig. 1). A Figura 1 B Ricordiamo che il periodo
1 La distribuzione delle frequenze Si vuole misurare il periodo di oscillazione di un pendolo costituito da una sferetta metallica agganciata a un filo (fig. 1). A Figura 1 B Ricordiamo che il periodo
Vedi: Probabilità e cenni di statistica
 Vedi: http://www.df.unipi.it/~andreozz/labcia.html Probabilità e cenni di statistica Funzione di distribuzione discreta Istogrammi e normalizzazione Distribuzioni continue Nel caso continuo la probabilità
Vedi: http://www.df.unipi.it/~andreozz/labcia.html Probabilità e cenni di statistica Funzione di distribuzione discreta Istogrammi e normalizzazione Distribuzioni continue Nel caso continuo la probabilità
Teoria e tecniche dei test
 Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario