Nota: Eventi meno probabili danno maggiore informazione
|
|
|
- Corinna Bernasconi
- 9 anni fa
- Visualizzazioni
Transcript
1 Entropia Informazione associata a valore x avente probabilitá p(x é i(x = log 2 p(x Nota: Eventi meno probabili danno maggiore informazione Entropia di v.c. X P : informazione media elementi di X H(X = x X p(xi(x = x X p(x log 2 p(x Rappresenta l incertezza su esito X p. /49

2 Proprietà dell entropia L unitá di misura dell entropia sono i bits (Usiamo log in base 2 Se si cambia la base del logaritmo, il valore dell entropia cambia solo di un fattore costante Lemma H b (X = H(X lg b Dim. H b (X = x X = lg b p(x lg b p(x = x X x X p(x lg p(x = H (X lg b p(x lg p(x lg b p. 2/49

3 Entropia Binaria (v.c. di Bernulli X = ( a b p p H(X = p lg p +( p lg ( p def = h(p.0 h (p = lg p p h (p = log e p( p h(p 2 min{p, p} h(p p p. 3/49

4 H (X,Y = x X Entropia congiunta Def. Date due v.c. X e Y con d.d.p. congiunta p(x,y, definiamo entropia congiunta la quantità : [ p (x,y lg lg y Y p (x,y = E ] p (X,Y p(x, y y = 0 y = x = 0 /4 /4 x = /2 0 H(X, Y = H(/4, /4, /2 = 2 4 log log 2 = 3 2 bits p. 4/49

5 Entropia condizionata Entropia condizionata H(Y/X: H (Y/X = x X p (xh (Y/X = x H (Y/X = x: entropia di Y sapendo che X = x p(x, y y = 0 y = p(x H(Y/X = x x = 0 /2 /4 3/4 H(2/3, /3 = h(/3 x = /4 0 /4 H(,0 = h( = 0 H(Y/X = 3 4 h ( h ( = 3 4 h ( 3 p(y/x = p(x,y p(x bits p. 5/49

6 Entropia condizionata H (Y/X = x X = x X = x X y Y = x X y Y p (x H (Y/X = x p (x y Y p (y/x lg p (x p (y/x lg p (x,y lg p (y/x p (y/x p (y/x = E [ lg ] p(y/x p. 6/49

7 H (Y/X = x X y Y Entropia condizionata p (x,y lg p (y/x = E [ lg ] p(y/x rappresenta l informazione addizionale media di Y nota X. H(X, Y H(Y/X H(X H(Y p. 7/49

8 Regola della catena H(X,Y = H(X + H(Y/X H (X,Y = x,y = x,y = x,y = x = x p (x,y lg p (x,y = p (x,y lg x,y [ ] p (x,y lg p (x + lg p (y/x p (x,y lg p (x + x,y ( p (x,y lg y p (x lg p (x p (x,y lg p (y/xp(x p (y/x p (x + H (Y/X + H (Y/X = H (X + H (Y/X p. 8/49

9 Regola della catena: dimostrazione alternativa Consideriamo la sequente dimostrazione alternativa: [ ] [ ] H (X,Y = E lg = E lg p (X,Y p(y/xp(x [ ] = E lg p (X + lg p (Y/X [ ] [ ] = E lg + E lg p (X p (Y/X = H (X + H (Y/X Il log trasforma prodotti di probabilitá in somme di entropie p. 9/49
![[ ] = E lg p (X + lg p (Y/X [ ] [ ] = E lg + E lg p (X p (Y/X = H (X + H](/docs-images/44/62049/images/page_9.jpg "(Y/X Il log trasforma prodotti di probabilitá in somme di entropie p.")
10 Mutua Informazione Date due v.c. X e Y con d.p. congiunta p(x,y, la mutua informazione è definita come I(X;Y. = H(X H(X Y = H(Y H(Y X La mutua informazione rappresenta i bit di informazione che una delle variabili fornisce circa l altra. H(X, Y H(X/Y I(X;Y H(Y/X H(X H(Y Nota: uso ; (es I(X,Z;Y I(X;Z,Y p. 0/49

11 Mutua Informazione Es. Lanciamo 0 monete: X rappresenta i valori delle prime 7 monete, Y quelli delle ultime 5. H(X = 7 H(Y = 5, H(X/Y = 5 H(Y/X = 3 I(X;Y = I(Y ;X = 2 p. /49

12 Mutua Informazione I(X;Y = H(X H(X/Y = H(Y H(Y/X = I(Y ;X I(X;Y I(Y ;X = H(X H(X/Y H(Y + H(Y/X = H(X + H(Y/X (H(Y + H(X/Y = H(X,Y H(X,Y = 0 I(X;Y = H(X + H(Y H(X,Y I(X;X = H(X p. 2/49

13 Mutua Informazione Condizionata I(X;Y/Z = H(X/Z H(X/Y Z = H(Y/Z H(Y/XZ Nota: Il condizionamento di Z si applica SIA ad X che ad Y I(X;Y/Z = H(X/Z H(X/Y Z = H(X/Z (H(X, Y/Z H(Y/Z = H(X/Z + H(Y/Z H(X, Y/Z Regola della catena per la mutua informazione I(X,..., X n ;Y = n I(X i ;Y/X,..., X i i= Nota: I(X,..., X n ;Y = H(X,..., X n + H(Y H(X,..., X n, Y p. 3/49

14 Riepilogo/Anteprima N.B.: Le disugualianze saranno provate in seguito Entropia H(X = x X p(x log p(x H(X 0, uguaglianza sse x t.c. p(x = H(X log X, uguaglianza sse p(x = / X x X Il condizionamento non aumenta l entropia H(X/Y H(X uguaglianza sse X,Y indipendenti Regola della catena: H(X,Y = H(X + H(Y/X H(X + H(Y, uguaglianza sse X, Y indipendenti H(X,...,X n = n i= H(X i/x i...x n i= H(X i, uguaglianza sse X,...,X n indipendenti p. 4/49

15 Riepilogo/Anteprima Mutua Informazione: I(X;Y = H(X H(X/Y = H(X + H(Y H(X,Y Simmetrica e positiva: I(X;Y = I(Y ;X 0, uguaglianza sse X, Y indipendenti Infatti I(X;Y = H(X H(X/Y H(X H(X = 0 con H(X/Y = H(X sse X,Y indipendenti p. 5/49

16 Funzioni concave/convesse Def. Una funzione f(x si dice concava su un intervallo (a,b se x,x 2 (a,b e 0 λ f (λ x + ( λ x 2 λ f (x + ( λ f (x 2 f è strettamente concava se la disuguaglianza é stretta per 0 < λ <. Esempio lg x è una funzione strettamente concava di x. Def. Una funzione f(x si dice convessa su un intervallo (a,b se f(x è concava sull intervallo (a,b. Esempio x 2,xlg x sono funzioni strett. convesse di x. p. 6/49

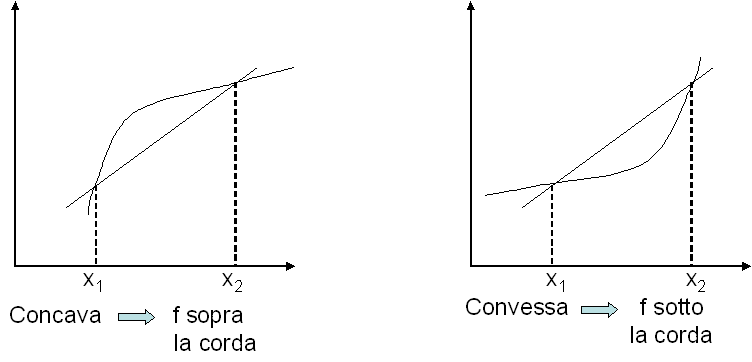
17 p. 7/49
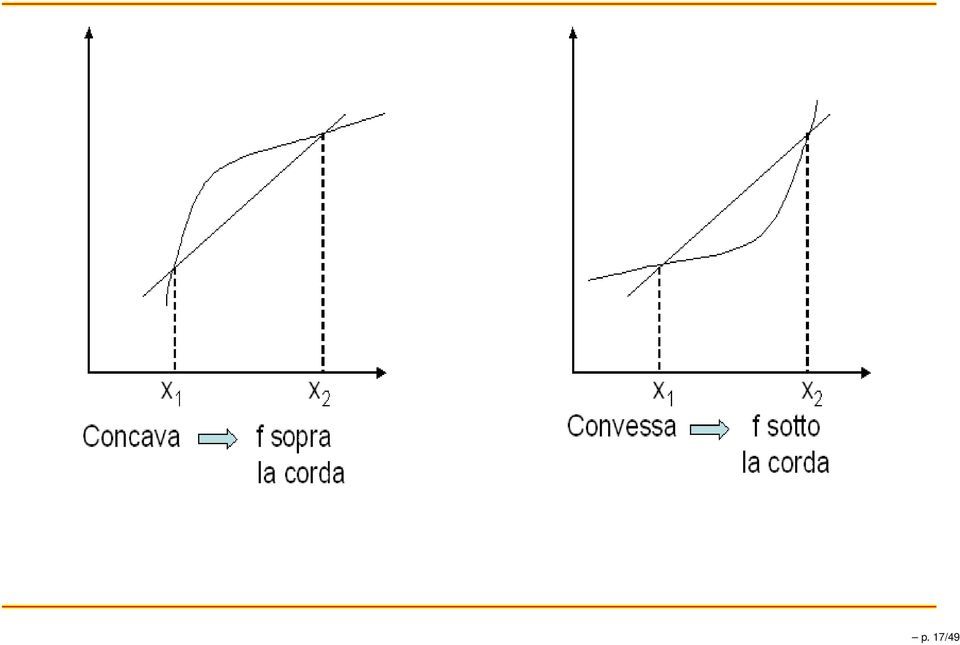
18 Diseguaglianza di Jensen ( x x 2... x n X = f: funzione p p 2... p n ( f(x f(x 2... f(x n f (X =. p p 2... p n Risulta E[f(X] f(e[x], Se f strettamente concava: E[f(X] = f(e[x], sse X è concentrata in un unico punto (cioé é costante p. 8/49
![.. p n Risulta E[f(X] f(e[x], Se f strettamente concava:](/docs-images/44/62049/images/page_18.jpg "E[f(X] = f(e[x], sse X è concentrata in un unico punto")
19 La dimostrazione procede per induzione su X. Base induzione: X = 2. Si consideri la v.c. X = ( x x 2 p p 2 Per la definizione di funzione concava, si ha che E [f (X] = p f(x + p 2 f(x 2 f(p x + p 2 x 2 = f (E [X]. Se f strett. concava l uguaglianza vale sse p = oppure p 2 =. p. 9/49
![concava, si ha che E [f (X] = p f(x + p 2 f(x 2 f(p x + p 2 x 2 = f (E](/docs-images/44/62049/images/page_19.jpg "[X]. Se f strett. concava l uguaglianza vale sse p = oppure p 2 =. p. 9/49")
20 Passo induttivo: Supponiamo che la disuguaglianza di Jensen sia verificata per X = k. Dimostriamo che la disuguaglianza è verificata per X = k. E [f (X] = k p i f (x i = p k f (x k + i= = p k f(x k + ( p k ( k i= k i= p i f(x i p i ( p k f(x i p. 20/49

21 Osserviamo che k i= X = p i ( p k f(x i = E[f(X ] dove X è la v.c. ( x... x k p p k... p k p k L ipotesi induttiva implica E[f(X ] f(e[x ] per cui risulta: E[f(X] p k f(x k + ( p k f ( k i= p i p k x i Applichiamo la definizione di funzione concava al termine destro. p. 2/49
22 Otteniamo E[f(X] f = f ( p k x k + ( p k k i= ( k p i x i = f (E [X]. i= p i p k x i Se f strettamente concava: uguaglianza sse tutti sono = (= in def. f concava: p k = o p k = 0 (cioé k i= p i = se p k = X concentrata in un unico punto (cioé x k (= in i.i.: p k = 0 e, per i.i., X concentrata in un unico punto X concentrata in un unico punto (tra x...x k. p. 22/49
23 Proprietà dell entropia Lemma. Sia X P v.c. con alfabeto X.. H(X 0; uguaglianza sse x X t.c. p(x =. 2. H(X lg X ; l uguaglianza vale sse X è uniformemente distribuita. Dim. Punto. 0 p(x log p(x 0 x Esiste x X con 0 < p(x < sse H(x > 0 p(x log p(x 0 p. 23/49
24 Dim. punto 2. H(X = E lg E ( lg = lg x X P(X ( P(X p(x p(x = lg x X disug. Jensen su lg e = lg X.... p(x p(x... La disuguglianza di Jensen vale con il segno di = sse = c costante, x X. p(x p(x = c p(x = c = x X p(x = x X c = X c. Quindi c = X e p(x = c = X. p. 24/49
25 Condizionamento non aumenta entropia H(Y/X H(Y, uguaglianza sse X e Y indipendenti H(Y/X H(Y = x X y Y = x X y Y = x,y p(x,y lg p(x,y lg p(y/x y Y p(y/x x X y Y p(x,y lg p(y p(y/x lg x,y p(y lg p(y p(x,y lg p(y p(x,y p(y p(y/x = lg x,y p(y/xp(xp(y p(y/x = lg x,y p(xp(y = lg x p(x y p(y = lg x p(x = lg = 0 p. 25/49
26 La disuguglianza di Jensen applicata a vale con il segno di = sse p(y p(y/x (... p(y p(y/x p(x,y... = c costante, x,y. p(y p(y/x = c p(y = c p(y/x Sommando su y = y Y p(y = y Y c p(y/x = c y Y p(y/x = c Quindi p(y = p(y/x, x,y, cioé X,Y sono indipendenti. p. 26/49
27 Corollario H(X,Y H(X + H(Y Corollario H(X,Y/Z = x,y,z p(xyz log p(xy/z = H(X/Z + H(Y/X,Z Dim. (lasciata come esercizio Nota: In generale non è vero che H(X/Y = H(Y/X. p. 27/49
28 Estensione Regola della catena Teorema Siano X,...,X n n v.c. con d.d.p. p(x,...,x n H (X,...,X n = n H (X i /X i...x i= Dim. Procediamo per induzione su n. Per n = 2, applicando la regola della catena abbiamo H (X,X 2 = H (X + H (X 2 /X p. 28/49
29 Iterando (assumiamo l asserto vero per n H (X,...,X n = H (X n /X,...,X n + H (X,...,X n = H(X n /X n...x + H(X n /X n 2...X H(X 2 /X + H(X = n i= H (X i /X i,...,x p. 29/49
30 Teorema H(X,...,X n n H (X i, i= l uguaglianza vale sse X,...,X n sono indipendenti. Dim. H (X,...,X n = n H (X i /X,...,X i n H (X i i= i= L ultima disuguaglianza vale con il segno di = sse X,...,X n sono indipendenti. p. 30/49
31 Divergenza informazionale Def. Date due d.d.p. p(x e q(x, la divergenza informazionale (o entropia relativa, o distanza Kullback Leibler D (p q di p(x e q(x è definita come D (p q = x X p(x lg p(x q(x Divergenza D (p q misura la distanza tra le due d.p. p e q. Non é simmetrica, infatti in generale D (p q D (q p p. 3/49
32 D(p q 0 con l uguaglianza sse p = q Proviamo D(p q 0 usando la disuguaglianza di Jensen: D(p q = x X p(x lg q(x p(x lg x X p(x q(x p(x = lg x X q(x = 0 dove dis. Jensen applicata a v.c. (... q(x p(x p(x... : Uguaglianza sse q(x p(x = c =costante x, da cui = x q(x = c x p(x = c. Quindi c = e q(x = p(x, x. p. 32/49
33 Date due v.c. X e Y con probabilità congiunta p(x,y, la mutua informazione corrisponde all entropia relativa tra p(x, y e p(xp(y: I (X;Y = H(X + H(Y H(X,Y = x X y Y p (x,y lg p (x,y p (x p (y = D (p(x, y p(xp(y p. 33/49
34 Esempio Esempio Y \ X p. 34/49
35 Determiniamo le d.d.p. marginali. Sommando le probabilità in ciascuna colonna: ( X = Sommando le probabilità in ciascuna riga: ( Y = p. 35/49
36 H (X/Y = 4 i= p (y = ih (X/Y = i = 4 H ( 2, 4, 8, H ( 2, 4, 8, H ( 4, 4, 4, 4 + H (, 0, 0, 0 4 = 4 = 4 [ ] 8 3 [ ] = lg [ ] = 8 p. 36/49
37 H (Y/X = 3 8 H(X,Y = H(Y + H(X/Y = = 27 8 I(X;Y = H(X H(X/Y = = 3 8 = H(Y H(Y/X = = 3 8 p. 37/49
38 Esercizio Esercizio Dimostrare che, data la funzione f, risulta H (X H (f (X Suggerimento: considerare H (X, f (X p. 38/49
39 Esempio Condizioni meteo modellate da v.c. X = Yari esce con ombrello in accordo alla v.c. Y = ( y o y n p(y o p(y n con [p(y/x] = ( x p 2 x n 2 X\Y y o y n x p x n 0 Abbiamo P(y o = p(x p p(y o /x p + p(x n p(y o /x n = 2/3, ( quindi Y = y o 2 3 y n 3 p. 39/49
40 X = ( x p 2 x n 2, Y = ( Risulta H(X =, H(Y = h ( 3 y o y n 2 3 3, X\Y y o y n x p x n 0 H(Y/X = x p(xh(y/x = x = 2 h( h( = 2 h( 3 I(X;Y = H(Y H(Y/X = h ( 3 2 h( 3 = 2 h( 3 p. 40/49
41 Zelda per indovinare che tempo fa osserva Yari: Se Yari ha ombrello dice x p Se Yari non ha ombrello, lancia una moneta: se testa dice x n, altr. dice x p Previsione Zelda dipende solo dal comportamento di Yari! Sia Z la v.c. che rappresenta la previsione di Zelda. Per ogni x,y,z p(z/xy = p(z/y Previsione Z(elda fornisce meno informazione su X che l osservazione diretta comportamento di Y (ari!, Formalmente I(X;Z I(X;Y p. 4/49
42 Catene di Markov X,Y,Z formano una catena di Markov (X Y Z sse Z é condizionalmente indipendente da X noto Y, formalmente p(z/xy = p(z/y, x, y, z p. 42/49
43 Teorema del Data Processing Esercizio: X Y Z sse Z Y X Teorema(Data Processing Se X Y Z allora ai(x;z I(X;Y bi(x;z I(Z;Y Dim. Proviamo a. Disuguaglianza b segue applicando a a Z Y X. p. 43/49
44 Se X Y Z allora I(X;Z I(X;Y Poiché X Y Z H(X/Y Z = E[ lg p(x/yz] = E[ lg p(x/y] = H(X/Y Da cui I(X;Y Z = H(X H(X/Y Z = H(X H(X/Y = I(X;Y Inoltre I(X;Y Z = H(X H(X/Y Z H(X H(X/Z = I(X;Z p. 44/49
45 X = ( x p x n 2 2, Stima di v.c. Y/X y o y n x p 3 2 3, Y = x n 0 Zelda per indovinare che tempo fa osserva Yari: Se Yari ha ombrello dice x p Se Yari non ha ombrello dice x n v.c. Z =stima Zelda fa di X conoscendo Y. Z = g(y = { x p x n se Y = y o se Y = y n ( y o 2 3 y n 3 Quale é la probabilità che Zelda fa una stima esatta di X? p. 45/49
46 Disuguaglianza di Fano Siano X,Y v.c.. Vogliamo stimare X dall osservazione di Y. Osserviamo Y, calcoliamo g(y = ˆX (stima di X. Probabilitá X ˆX? Sia P e = Pr{ ˆX X} Teorema (Disuguaglianza di Fano h(p e + P e lg( X H(X Y Nota: Teorema implica P e H(X Y h(p e Nota: P e = 0 H(X Y = 0 Nota: X Y ˆX. lg( X H(X Y lg( X p. 46/49
47 Dim.. Definiamo la v.c. errore E t.c. E = { se X ˆX, cioé E = 0 se X = ˆX ( 0 P e P e H(X Y = H(X Y + H(E X,Y = H(E,X Y = H(E Y + H(X E,Y h(p e + H(X E,Y con H(X E, Y = Pr{E = 0}H(X E = 0, Y + Pr{E = }H(X E =, Y ( P e 0 + P e lg( X = P e lg( X p. 47/49
48 Riepilogo Misure di Informazione Entropia: H(X = x X Limiti: 0 H(X log X, p(x log p(x Il condizionamento non aumenta l entropia: H(X/Y H(X Regola della catena: H(X,...,X n = n i= H(X i/x i...x n i= H(X i, H(X,...,X n /Y,...,Y n n i= H(X i/y i Divergenza informazionale: D (p q = x X p(x lg p(x q(x 0 p. 48/49
49 Riepilogo Misure di Informazione Mutua Informazione: I(X;Y = H(X H(X/Y = H(X + H(Y H(X,Y = D(p(x, y p(xp(y Simmetrica e positiva: I(X;Y = I(Y ;X 0, X,Y indipendenti I(X;Y = H(X H(X/Y = 0 X Y Z I(X;Z I(X;Y Fano: X Y ˆX, P e = Pr{ ˆX X} h(p e + P e lg( X H(X Y p. 49/49
3. TEORIA DELL INFORMAZIONE
 3. TEORIA DELL INFORMAZIONE INTRODUZIONE MISURA DI INFORMAZIONE SORGENTE DISCRETA SENZA MEMORIA ENTROPIA DI UNA SORGENTE NUMERICA CODIFICA DI SORGENTE 1 TEOREMA DI SHANNON CODICI UNIVOCAMENTE DECIFRABILI
3. TEORIA DELL INFORMAZIONE INTRODUZIONE MISURA DI INFORMAZIONE SORGENTE DISCRETA SENZA MEMORIA ENTROPIA DI UNA SORGENTE NUMERICA CODIFICA DI SORGENTE 1 TEOREMA DI SHANNON CODICI UNIVOCAMENTE DECIFRABILI
TEORIA DELL INFORMAZIONE E CODICI. Sandro Bellini. Politecnico di Milano
 TEORIA DELL INFORMAZIONE E CODICI Sandro Bellini Politecnico di Milano Prefazione Queste brevi note sono state scritte per gli studenti del corso di Teoria dell informazione e codici da me tenuto presso
TEORIA DELL INFORMAZIONE E CODICI Sandro Bellini Politecnico di Milano Prefazione Queste brevi note sono state scritte per gli studenti del corso di Teoria dell informazione e codici da me tenuto presso
EQUAZIONI non LINEARI
 EQUAZIONI non LINEARI Francesca Pelosi Dipartimento di Matematica, Università di Roma Tor Vergata CALCOLO NUMERICO e PROGRAMMAZIONE http://www.mat.uniroma2.it/ pelosi/ EQUAZIONI non LINEARI p.1/44 EQUAZIONI
EQUAZIONI non LINEARI Francesca Pelosi Dipartimento di Matematica, Università di Roma Tor Vergata CALCOLO NUMERICO e PROGRAMMAZIONE http://www.mat.uniroma2.it/ pelosi/ EQUAZIONI non LINEARI p.1/44 EQUAZIONI
Introduzione alla Teoria degli Errori
 Introduzione alla Teoria degli Errori 1 Gli errori di misura sono inevitabili Una misura non ha significato se non viene accompagnata da una ragionevole stima dell errore ( Una scienza si dice esatta non
Introduzione alla Teoria degli Errori 1 Gli errori di misura sono inevitabili Una misura non ha significato se non viene accompagnata da una ragionevole stima dell errore ( Una scienza si dice esatta non
Funzioni in più variabili
 Funzioni in più variabili Corso di Analisi 1 di Andrea Centomo 27 gennaio 2011 Indichiamo con R n, n 1, l insieme delle n-uple ordinate di numeri reali R n4{(x 1, x 2,,x n ), x i R, i =1,,n}. Dato X R
Funzioni in più variabili Corso di Analisi 1 di Andrea Centomo 27 gennaio 2011 Indichiamo con R n, n 1, l insieme delle n-uple ordinate di numeri reali R n4{(x 1, x 2,,x n ), x i R, i =1,,n}. Dato X R
La variabile casuale Binomiale
 La variabile casuale Binomiale Si costruisce a partire dalla nozione di esperimento casuale Bernoulliano che consiste in un insieme di prove ripetute con le seguenti caratteristiche: i) ad ogni singola
La variabile casuale Binomiale Si costruisce a partire dalla nozione di esperimento casuale Bernoulliano che consiste in un insieme di prove ripetute con le seguenti caratteristiche: i) ad ogni singola
Note integrative ed Esercizi consigliati
 - a.a. 2006-07 Corso di Laurea Specialistica in Ingegneria Civile (CIS) Note integrative ed consigliati Laura Poggiolini e Gianna Stefani Indice 0 1 Convergenza uniforme 1 2 Convergenza totale 5 1 Numeri
- a.a. 2006-07 Corso di Laurea Specialistica in Ingegneria Civile (CIS) Note integrative ed consigliati Laura Poggiolini e Gianna Stefani Indice 0 1 Convergenza uniforme 1 2 Convergenza totale 5 1 Numeri
Proof. Dimostrazione per assurdo. Consideriamo l insieme complementare di P nell insieme
 G Pareschi Principio di induzione Il Principio di Induzione (che dovreste anche avere incontrato nel Corso di Analisi I) consente di dimostrare Proposizioni il cui enunciato è in funzione di un numero
G Pareschi Principio di induzione Il Principio di Induzione (che dovreste anche avere incontrato nel Corso di Analisi I) consente di dimostrare Proposizioni il cui enunciato è in funzione di un numero
Capitolo Dodicesimo CALCOLO DIFFERENZIALE PER FUNZIONI DI PIÙ VARIABILI
 Capitolo Dodicesimo CALCOLO DIFFERENZIALE PER FUNZIONI DI PIÙ VARIABILI CAMPI SCALARI Sono dati: un insieme aperto A Â n, un punto x = (x, x 2,, x n )T A e una funzione f : A Â Si pone allora il PROBLEMA
Capitolo Dodicesimo CALCOLO DIFFERENZIALE PER FUNZIONI DI PIÙ VARIABILI CAMPI SCALARI Sono dati: un insieme aperto A Â n, un punto x = (x, x 2,, x n )T A e una funzione f : A Â Si pone allora il PROBLEMA
10. Insiemi non misurabili secondo Lebesgue.
 10. Insiemi non misurabili secondo Lebesgue. Lo scopo principale di questo capitolo è quello di far vedere che esistono sottoinsiemi di R h che non sono misurabili secondo Lebesgue. La costruzione di insiemi
10. Insiemi non misurabili secondo Lebesgue. Lo scopo principale di questo capitolo è quello di far vedere che esistono sottoinsiemi di R h che non sono misurabili secondo Lebesgue. La costruzione di insiemi
1. Intorni di un punto. Punti di accumulazione.
 1. Intorni di un punto. Punti di accumulazione. 1.1. Intorni circolari. Assumiamo come distanza di due numeri reali x e y il numero non negativo x y (che, come sappiamo, esprime la distanza tra i punti
1. Intorni di un punto. Punti di accumulazione. 1.1. Intorni circolari. Assumiamo come distanza di due numeri reali x e y il numero non negativo x y (che, come sappiamo, esprime la distanza tra i punti
Calcolo delle Probabilità
 Calcolo delle Probabilità Il calcolo delle probabilità studia i modelli matematici delle cosidette situazioni di incertezza. Molte situazioni concrete sono caratterizzate a priori da incertezza su quello
Calcolo delle Probabilità Il calcolo delle probabilità studia i modelli matematici delle cosidette situazioni di incertezza. Molte situazioni concrete sono caratterizzate a priori da incertezza su quello
ALGEBRA I: NUMERI INTERI, DIVISIBILITÀ E IL TEOREMA FONDAMENTALE DELL ARITMETICA
 ALGEBRA I: NUMERI INTERI, DIVISIBILITÀ E IL TEOREMA FONDAMENTALE DELL ARITMETICA 1. RICHIAMI SULLE PROPRIETÀ DEI NUMERI NATURALI Ho mostrato in un altra dispensa come ricavare a partire dagli assiomi di
ALGEBRA I: NUMERI INTERI, DIVISIBILITÀ E IL TEOREMA FONDAMENTALE DELL ARITMETICA 1. RICHIAMI SULLE PROPRIETÀ DEI NUMERI NATURALI Ho mostrato in un altra dispensa come ricavare a partire dagli assiomi di
Sulla monotonia delle funzioni reali di una variabile reale
 Liceo G. B. Vico - Napoli Sulla monotonia delle funzioni reali di una variabile reale Prof. Giuseppe Caputo Premetto due teoremi come prerequisiti necessari per la comprensione di quanto verrà esposto
Liceo G. B. Vico - Napoli Sulla monotonia delle funzioni reali di una variabile reale Prof. Giuseppe Caputo Premetto due teoremi come prerequisiti necessari per la comprensione di quanto verrà esposto
19. Inclusioni tra spazi L p.
 19. Inclusioni tra spazi L p. Nel n. 15.1 abbiamo provato (Teorema 15.1.1) che, se la misura µ è finita, allora tra i corispondenti spazi L p (µ) si hanno le seguenti inclusioni: ( ) p, r ]0, + [ : p
19. Inclusioni tra spazi L p. Nel n. 15.1 abbiamo provato (Teorema 15.1.1) che, se la misura µ è finita, allora tra i corispondenti spazi L p (µ) si hanno le seguenti inclusioni: ( ) p, r ]0, + [ : p
A i è un aperto in E. i=1
 Proposizione 1. A è aperto se e solo se A c è chiuso. Dimostrazione. = : se x o A c, allora x o A = A o e quindi esiste r > 0 tale che B(x o, r) A; allora x o non può essere di accumulazione per A c. Dunque
Proposizione 1. A è aperto se e solo se A c è chiuso. Dimostrazione. = : se x o A c, allora x o A = A o e quindi esiste r > 0 tale che B(x o, r) A; allora x o non può essere di accumulazione per A c. Dunque
Funzioni di più variabili. Ottimizzazione libera e vincolata
 libera e vincolata Generalità. Limiti e continuità per funzioni di 2 o Piano tangente. Derivate successive Formula di Taylor libera vincolata Lo ordinario è in corrispondenza biunivoca con i vettori di
libera e vincolata Generalità. Limiti e continuità per funzioni di 2 o Piano tangente. Derivate successive Formula di Taylor libera vincolata Lo ordinario è in corrispondenza biunivoca con i vettori di
Equazioni non lineari
 Dipartimento di Matematica tel. 011 0907503 stefano.berrone@polito.it http://calvino.polito.it/~sberrone Laboratorio di modellazione e progettazione materiali Trovare il valore x R tale che f (x) = 0,
Dipartimento di Matematica tel. 011 0907503 stefano.berrone@polito.it http://calvino.polito.it/~sberrone Laboratorio di modellazione e progettazione materiali Trovare il valore x R tale che f (x) = 0,
Corso di teoria dei modelli
 Corso di teoria dei modelli Alessandro Berarducci 22 Aprile 2010. Revised 5 Oct. 2010 Indice 1 Introduzione 2 2 Linguaggi del primo ordine 3 2.1 Linguaggi e strutture......................... 3 2.2 Morfismi................................
Corso di teoria dei modelli Alessandro Berarducci 22 Aprile 2010. Revised 5 Oct. 2010 Indice 1 Introduzione 2 2 Linguaggi del primo ordine 3 2.1 Linguaggi e strutture......................... 3 2.2 Morfismi................................
Ricerca Operativa Esercizi sul metodo del simplesso. Luigi De Giovanni, Laura Brentegani
 Ricerca Operativa Esercizi sul metodo del simplesso Luigi De Giovanni, Laura Brentegani 1 1) Risolvere il seguente problema di programmazione lineare. ma + + 3 s.t. 2 + + 2 + 2 + 3 5 2 + 2 + 6,, 0 Soluzione.
Ricerca Operativa Esercizi sul metodo del simplesso Luigi De Giovanni, Laura Brentegani 1 1) Risolvere il seguente problema di programmazione lineare. ma + + 3 s.t. 2 + + 2 + 2 + 3 5 2 + 2 + 6,, 0 Soluzione.
Appunti di Logica Matematica
 Appunti di Logica Matematica Francesco Bottacin 1 Logica Proposizionale Una proposizione è un affermazione che esprime un valore di verità, cioè una affermazione che è VERA oppure FALSA. Ad esempio: 5
Appunti di Logica Matematica Francesco Bottacin 1 Logica Proposizionale Una proposizione è un affermazione che esprime un valore di verità, cioè una affermazione che è VERA oppure FALSA. Ad esempio: 5
Capitolo 8 - Introduzione alla probabilità
 Appunti di Teoria dei Segnali Capitolo 8 - Introduzione alla probabilità Concetti preliminari di probabilità... Introduzione alla probabilità... Deinizione di spazio degli eventi... Deinizione di evento...
Appunti di Teoria dei Segnali Capitolo 8 - Introduzione alla probabilità Concetti preliminari di probabilità... Introduzione alla probabilità... Deinizione di spazio degli eventi... Deinizione di evento...
3. SPAZI VETTORIALI CON PRODOTTO SCALARE
 3 SPAZI VETTORIALI CON PRODOTTO SCALARE 31 Prodotti scalari Definizione 311 Sia V SV(R) Un prodotto scalare su V è un applicazione, : V V R (v 1,v 2 ) v 1,v 2 tale che: i) v,v = v,v per ogni v,v V ; ii)
3 SPAZI VETTORIALI CON PRODOTTO SCALARE 31 Prodotti scalari Definizione 311 Sia V SV(R) Un prodotto scalare su V è un applicazione, : V V R (v 1,v 2 ) v 1,v 2 tale che: i) v,v = v,v per ogni v,v V ; ii)
1 Alcuni criteri di convergenza per serie a termini non negativi
 Alcuni criteri di convergenza per serie a termini non negativi (Criterio del rapporto.) Consideriamo la serie a (.) a termini positivi (ossia a > 0, =, 2,...). Supponiamo che esista il seguente ite a +
Alcuni criteri di convergenza per serie a termini non negativi (Criterio del rapporto.) Consideriamo la serie a (.) a termini positivi (ossia a > 0, =, 2,...). Supponiamo che esista il seguente ite a +
ANALISI DELLE FREQUENZE: IL TEST CHI 2
 ANALISI DELLE FREQUENZE: IL TEST CHI 2 Quando si hanno scale nominali o ordinali, non è possibile calcolare il t, poiché non abbiamo medie, ma solo frequenze. In questi casi, per verificare se un evento
ANALISI DELLE FREQUENZE: IL TEST CHI 2 Quando si hanno scale nominali o ordinali, non è possibile calcolare il t, poiché non abbiamo medie, ma solo frequenze. In questi casi, per verificare se un evento
1 Definizione: lunghezza di una curva.
 Abstract Qui viene affrontato lo studio delle curve nel piano e nello spazio, con particolare interesse verso due invarianti: la curvatura e la torsione Il primo ci dice quanto la curva si allontana dall
Abstract Qui viene affrontato lo studio delle curve nel piano e nello spazio, con particolare interesse verso due invarianti: la curvatura e la torsione Il primo ci dice quanto la curva si allontana dall
Matematica B - a.a 2006/07 p. 1
 Matematica B - a.a 2006/07 p. 1 Definizione 1. Un sistema lineare di m equazioni in n incognite, in forma normale, è del tipo a 11 x 1 + + a 1n x n = b 1 a 21 x 1 + + a 2n x n = b 2 (1) = a m1 x 1 + +
Matematica B - a.a 2006/07 p. 1 Definizione 1. Un sistema lineare di m equazioni in n incognite, in forma normale, è del tipo a 11 x 1 + + a 1n x n = b 1 a 21 x 1 + + a 2n x n = b 2 (1) = a m1 x 1 + +
Esercizi su lineare indipendenza e generatori
 Esercizi su lineare indipendenza e generatori Per tutto il seguito, se non specificato esplicitamente K indicherà un campo e V uno spazio vettoriale su K Cose da ricordare Definizione Dei vettori v,,v
Esercizi su lineare indipendenza e generatori Per tutto il seguito, se non specificato esplicitamente K indicherà un campo e V uno spazio vettoriale su K Cose da ricordare Definizione Dei vettori v,,v
Teoria degli insiemi
 Teoria degli insiemi pag 1 Easy Matematica di dolfo Scimone Teoria degli insiemi Il concetto di insieme si assume come primitivo, cioè non riconducibile a concetti precedentemente definiti. Sinonimi di
Teoria degli insiemi pag 1 Easy Matematica di dolfo Scimone Teoria degli insiemi Il concetto di insieme si assume come primitivo, cioè non riconducibile a concetti precedentemente definiti. Sinonimi di
Lezioni di Teoria dei Gruppi. Andrea Mori Dipartimento di Matematica Università di Torino
 Lezioni di Teoria dei Gruppi Andrea Mori Dipartimento di Matematica Università di Torino Maggio 2005 Questo lavoro è dedicato alla memoria di Lia Venanzangeli (1959 2004) amica e compagna. Gigni de nihilo
Lezioni di Teoria dei Gruppi Andrea Mori Dipartimento di Matematica Università di Torino Maggio 2005 Questo lavoro è dedicato alla memoria di Lia Venanzangeli (1959 2004) amica e compagna. Gigni de nihilo