RETI NEURALI (II PARTE)
|
|
|
- Virginia Leoni
- 8 anni fa
- Visualizzazioni
Transcript
1 RETI NEURALI (II PARTE)
")
2 HOPFIELD Neural Net
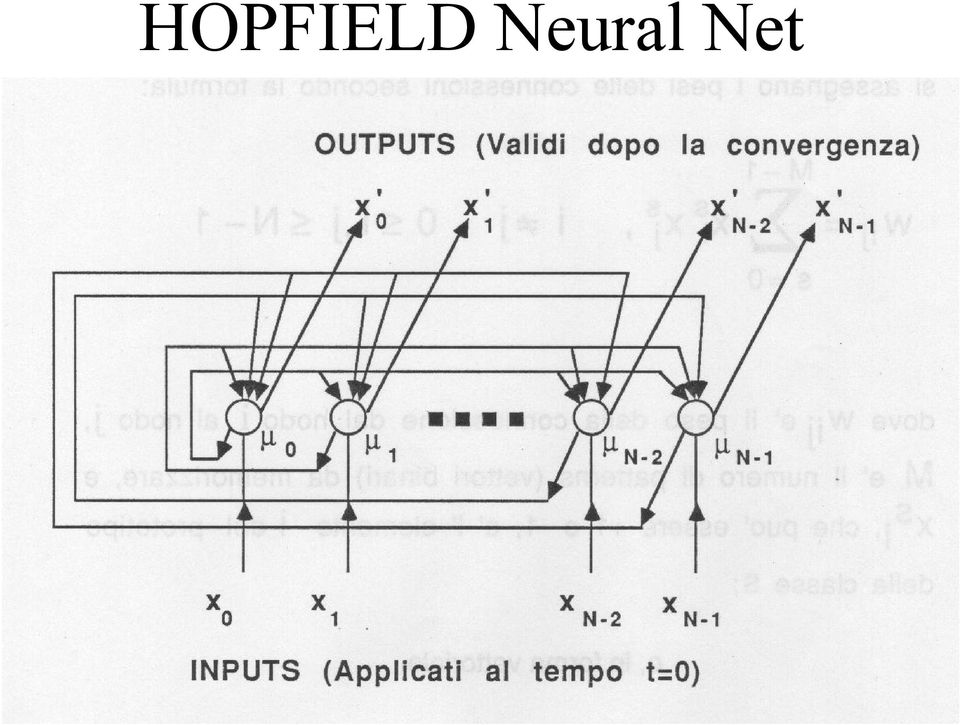
3 è utilizzata come MEMORIA ASSOCIATIVA e come CLASSIFICATORE input e output sono BINARI {+, -} i pesi sono fissati con un apprendimento non iterativo (fixed point learning) al tempo t=0 si dà in input un pattern binario sconosciuto; la rete itera fino a convergere su dei valori di output che rappresentano il pattern più simile all'input presente nella memoria della rete.

4 Algoritmo per le Reti di Hopfield. Apprendimento (fixed point) si assegnano i pesi delle connessioni secondo la formula: w ij M = s= 0 x s i x s j, i j,0 i, j N dove w ij è il peso della connessione dal nodo i al nodo j, M è il numero di patterns (vettori binari) da s memorizzare, e x i, che può essere + o -, è l'elemento i dei prototipo della classe S.
 da s memorizzare, e x i, che può")
5 In forma vettoriale: w = M s= 0 T x s x s esempio: per memorizzare il vettore [ ] accorrerà una rete con 4 unità, la cui matrice dei pesi è calcolata nel modo seguente:
![+] accorrerà una rete con 4 unità, la cui](/docs-images/43/6373763/images/page_5.jpg "matrice dei pesi è calcolata nel modo")
6 [ ] = =

7 2. Elaborazione di un pattern Lo scopo è di riottenere dalla rete il pattern più simile a quello in input, fra quelli memorizzati. 2. si inizializzano le unità con il pattern di input μ i (0) = x i, 0 i N- o, in forma vettoriale μ(0) = x dove μ i (t) è lo stato di attivazione (= output in questo modello) dei nodo i al tempo t e x i {-, +} è l'elemento i-esimo dei vettore di input.
 = x dove μ i (t) è lo stato di attivazione (= output in questo modello) dei nodo i al")
8 2.2 si itera fino alla convergenza μ j (t + ) = f h [ ] N w μ (t),0 j N i= 0 ij i la funzione f h è una funzione non lineare a soglia. Il processo viene iterato finché l'output dei nodi rimane immutato con ulteriori iterazioni. I nodi di output rappresentano il pattern memorizzato nella rete che meglio si accorda con l'input dato.

9 Quando la rete è usata come Memoria Associativa, l'output (dopo la convergenza) costituisce l'intero pattern cercato. Quando è usata come classificatore, bisogna confrontarlo con i prototipi delle M classi per decidere la classificazione.

10 Reti di Hopfield - osservazioni la rete di Hopfield: apprende col prodotto esterno (azzerando la diagonale) accede alla memoria iterando il prodotto interno sogliato con Thr(x) è più potente di un associatore lineare in quanto è in grado di memorizzare vettori non ortogonali (devono però essere linearmente indipendenti).

11 tuttavia il numero di vettori che può essere memorizzato e riottenuto è limitato dal vincolo dell'indipendenza lineare: in media si può memorizzare un numero di patterns pari a 0.5 N (N = numero di nodi della rete) se si memorizzano vettori troppo simili (linearmente dipendenti) il pattern corrispondente diventa instabile, e non è più possibile riottenerlo.
 il pattern corrispondente diventa instabile, e non è più")
12 ESEMPIO DI MEMORIA ASSOCIATIVA CON LA RETE DI HOPFIELD

13 PERCEPTRON

14 è una semplice rete usata per CLASSIFICAZIONE; proposto da Rosenblatt (959) come modello che apprende a classificare semplici patterns; input binario o continuo; output binario; ha un singolo nodo che calcola una somma pesata degli input, gli sottrae una soglia e passa il risultato a una funzione scalino che restituisce + o -, decidendo la classe dei pattern (A o B); fu criticato da Minsky (969) e abbandonato.
; fu criticato da Minsky (969) e")
15 Algoritmo di Apprendimento del PERCEPTRON. Inizializzazione di pesi e soglie Si assegnano a w i (0) (0 i N-l) e θ piccoli valori casuali. w i (t) è il peso sulla connessione dall'input i al tempo t e θ è la soglia dei nodo di output. 2. Presentazione di un nuovo input e dell'output desiderato: Si presenta un vettore in input (valori reali) x = x 0, x l,... x N- insieme con l'output desiderato d(t) (corretta classificazione)
 x")
16 3. Calcolo dell'output corrente: y(t) = f ( ) N w (t) x (t θ ) h i i i= 0
 N w (t) x (t θ")
17 4. Modifica dei pesi (delta rule): w i (t+l) = w i (t) + η [d(t) - y(t)] x i (t), 0 i N- - se l'esempio è di classe B d(t) ={ + se l'esempio è di classe A in queste equazioni η è un coefficiente positivo < e d(t) è l'output corretto (desiderato) per l'input corrente. Si noti che i pesi rimangono immutati se la rete prende una decisione corretta.

18 5. Iterazione ripartendo dal passo 2

19 PERCEPTRON - osservazioni Rosenblatt ha dimostrato che, se l'input proviene da due classi separabili, l'algoritmo di apprendimento del Perceptron converge e posiziona l'iperpiano discriminante fra le due classi. spesso, però, due classi non sono separabili da un iperpiano, come il classico caso dell OR Esclusivo proposto da Minsky come esempio di limite dei Perceptron.

20 in tal caso la procedura di apprendimento oscilla, o, se modificata, trova una soluzione che minimizza l'errore quadratico medio fra gli output voluti e quelli ottenuti. Il problema dei perceptron è l'eccessiva semplicità del modello. Si capì presto, infatti, che un perceptron a più livelli avrebbe avuto una maggior potenza discriminante. Non vi era però alcun algoritmo di apprendimento per il perceptron a più livelli. ulteriori studi hanno portato alla dimostrazione della convergenza di un algoritmo di apprendimento per il perceptron a più livelli (Rumelhart et alii, 986)

21 Il problema dell'or Esclusivo (XOR) Apprendere a discriminare le due classi: classe 0 = {(0, 0), (, l)} classe = {(, 0), (0, )}
22 non è possibile separare le due classi con una retta. quindi il PERCEPTRON non è in grado di apprendere a discriminare le due classi dello XOR.
23 MULTI-LAYER PERCEPTRON
24 Il Multi-Layer Perceptron (MLP) è una rete feed-forward con uno o più livelli di unità interne (hidden units) fra le unità di input e quelle di output; le unità di ogni livello sono connesse con tutte quelle dei livello successivo, senza retroazioni; input continuo, output continuo (0, ), funzione di attivazione Sigmoide; recentemente (986) è stato proposto un algoritmo di apprendimento (Back Propagation); il MLP supera le limitazioni del Perceptron, ed è promettente per varie applicazioni (classificazione, riconoscimento, controllo, sistemi esperti non rule-based);
25 MLP: BACKWARD ERROR PROPAGATION
26 Back Error Propagation Con la BP si modificano i pesi del MLP in modo da minimizzare la funzione di errore: E = dove: E = (d p E p o ) 2 p pj pj j Un metodo classico per minimizzare una funzione èla discesa del gradiente: partendo da un punto casuale ci si muove con passi infinitesimi in direzione opposta al gradiente calcolato nel punto. 2
27 Per far ciò nel caso del MLP bisogna essere in grado di calcolare la derivata parziale della funzione di errore E rispetto ad ogni peso w ji della rete, e poi cambiare il peso secondo la regola: E Δw ji = k w ji
28 calcolando la derivata si ottiene: Δ p w ji = ηδ pi o pj il peso di una connessione deve quindi essere cambiato in modo proporzionale al prodotto di δ (errore sull'unità di arrivo) per a i = o i (valore di attivazione dell'unità di partenza).
29 Si dimostra che δ differisce nel caso di unità di output e di unità interne, e che può essere calcolato con le seguenti formule: δ pi = ( d o )f '(net pi pi pi ) δ pi = k δ pk w ik f '(net pi ) dove δ pi rappresenta la componente dell'errore sull'output imputabile all'unità i-esima (per il pattern p).
30 VETTORI OPPOSTI AI GRADIENTI DI UNA SUPERFICIE DI ERRORE BIDIMENSIONALE IN UN MLP CON DUE PESI.
31 Algoritmo di apprendimento del MLP (Back-Propagation) È un algoritmo che minimizza l'errore quadratico medio fra l'output corrente e quello desiderato di un MLP. Procede modificando i pesi in modo da muoversi in direzione opposta al gradiente della funzione di errore (calcolato rispetto ai pesi).. Inizializzazione di pesi e soglie i pesi e le soglie sono inizializzati a piccoli valori casuali.
32 2. Presentazione di un esempio (vettore di input e corrispondente vettore di output): l'input è un vettore di numeri reali x 0, x,... x N- a cui corrisponde un vettore di output desiderati d 0, d,..., d M-l. Se la rete è usata come classificatore, la classificazione è codificata usando tante unità di output quante sono le classi e ponendo l'output corrispondente alla classe corretta a e tutti gli altri a 0.
33 3. Calcolo degli output correnti: dato un pattern p, procedendo a livelli si calcola l'input di ogni nodo con la formula: net = poi si calcola l'output o pi : o pi = a pi = f(net pi ) con f (z) = + e pi j w ji o j z + θ
34 4. Modifica dei pesi: Si procede a livelli, calcolando l'errore sul livello di output e propagandolo all'indietro fino al primo livello interno; quindi si aggiornano i pesi con la delta rule generalizzata: Δ p w ji = ηδ pi o pj
35 che modifica il peso di una connessione in modo proporzionale all'errore compiuto dall'unità di arrivo (δ pi ) e alla grandezza dell'output dell'unità di partenza (o pj ). L'errore sulle unità viene calcolato con le formule: δ pi = ( d o )f '(net pi pi pi ) δ pi = k δ pk w ik f '(net pi ) con f'(x) = f (x) ( - f (x))
36 la prima calcola l'errore per il livello di output (in base alla differenza fra l'output corrente e quello desiderato), e la seconda lo propaga alle unità interne (in base all'errore delle unità del livello superiore e all'intensità delle connessioni).
37 5. Iterazione a partire dal passo 2. Nel seguito verranno approfonditi i calcoli per la BP.
38 MLP - osservazioni una interessante osservazione (Lippmann, 987) sul MLP è la seguente: Considerando un MLP con f(x) = HLN(X) (=- se x<0, = se x>0) si possono ottenere, in base al numero di livelli, le seguenti superfici di discriminazione nello spazio degli input: livello: iperpiano 2 livelli: regione convessa 3 livelli: regioni comunque complesse, anche concave e disgiunte un comportamento analogo, ma più complesso, si ha usando la sigmoide.
39
40 quindi, il numero di livelli necessari per formare superfici arbitrariamente complesse è tre. il MLP sta ottenendo crescente successo in varie applicazioni (es. pronunzia dell'inglese) problemi dei MLP sono: la convergenza è garantita solo a minimi locali; può essere molto lenta, particolarmente con tre livelli.
41 Come scegliere l architettura ottima Le reti feed-forward sono approssimatori universali, ma una data architettura di rete ha potenzialità limitate. La scelta della corretta architettura di rete adatta a risolvere un dato compito è un problema di ricerca nello spazio delle possibili architetture (il problema dell apprendimento è invece una ricerca nello spazio dei pesi): una rete troppo piccola può essere incapace di risolvere un dato problema; una rete con troppi parametri può creare fenomeni di over-fitting, con iper-apprendimento del training set ed incapacità di generalizzazione.
42 Possibili soluzioni: calcolo della VC-dim dell architettura per stabilire quanti esempi di un dato dominio sono necessari (in rapporto al numero dei pesi) per ottenere buone capacità di apprendimento e generalizzazione; utilizzo della cross-validation e di tecniche trial-enderror; utilizzo di algoritmi genetici di selezione nello spazio delle architetture; algoritmi di accrescimento o growing es. algoritmi Tiling, Tower, Pyramid e Cascade Cor-relation; algoritmi di potatura o pruning es. algoritmi Optimal Brain Damage e Optimal Brain Surgeon
43 RETI NEURALI FEED-FORWARD: la Back-Propagation (approfondimento) O i output layer (m nodi) W Oj i H j hidden layer (l nodi) W Hi j I i input layer (k nodi)
44 Per i nodi hidden vale: H i ( t + ) = squash( bias H i j k + = j= W H i j I j ( t))() dove: squash( x) = f ( x)(2) + e x =
45 Per i nodi di output, vale: O i ( t + ) = squash( bias O i j l + = j= W O i j H j ( t))(3) Dato un set fissato e finito di casi input-output, l errore totale nella performance della rete con un particolare set di pesi può essere calcolato confrontando i vettori di output ottenuti con quelli desiderati per ciascun caso.
46 L errore E è definito come: E = ( O ) 2 i, c Di, c 2 c i (4) dove c è l indice sui casi (coppie input-output), i è l indice sulle unità di output, D e O rispettivamente l output desiderato e quello ottenuto. La procedura di addestramento minimizza E mediante la discesa del gradiente nello spazio dei pesi.
47 In pratica, si variano i pesi in base alla relazione: ΔW Oi j = k E W O i j (5) Questa derivata è semplicemente la somma delle derivate parziali per ciascuno dei casi input-output. Per ciascun caso, le derivate parziali dell errore rispetto a ciascun peso sono calcolate durante un passo backward che segue un passo forward descritto sopra.
48 Il passo backward parte dalle unità di output e propaga all indietro la derivata dell errore per ciascun peso, strato per strato. Per lo strato di output, tenendo conto della (2), si può scrivere che (6) j O i i i i j O i i W x x O O E W E =
49 Si calcola dapprima la variazione dell errore rispetto all output O i per ciascuna unità di output i. Differenziando l equazione (4) per un particolare caso, c, e sopprimendo l indice c si ottiene: E = ( Oi Di )(7) O i
50 Per il secondo contributo, occorre tener presente che: f x e x ( )= + e ) ( ) ( ) ( ) ( f f e e e e e e e e dx df x x 2 x x 2 x x 2 x x = = + + = + + = = + + = + =
51 Quindi: O x i i = O i ( Oi )(8) Infine, poiché è semplicemente una funzione lineare degli stati delle unità hidden e dei pesi delle connessioni a queste unità, è facile calcolare il terzo contributo: x W i O i j = H j (9)
52 In conclusione, i pesi delle connessioni tra i nodi di output e quelli hidden vengono variati secondo l espressione: E ΔWO j = k = k ( Oi Di ) Oi ( Oi ) H j (0) i W O i j Per si utilizza la stessa formula, ponendo H=. bias Oi Nella letteratura, al posto del fattore k, si trova solitamente η, velocità di addestramento (learning rate).
53 Solitamente si pone: δ Oi = ( D O ) O ( O i i i i )() e le formule precedenti diventano: e ΔW O i j Δbias = η δ O i H =η δ O i O i j (2) (3)
54 In modo del tutto analogo si calcola la variazione dei pesi per le connessioni tra i nodi hidden e i nodi di input (e, in generale, per eventuali strati intermedi): poiché la topologia è la stessa, la formula sarà del tutto analoga alla (0), sostituendo all errore in uscita l errore che si ha nel nodo hidden e tenendo conto che si differenzia rispetto ad W H invece che rispetto a W O.
55 Concretamente, l errore nel nodo hidden è la somma di tutti gli errori provenienti dalle connessioni che escono dal nodo hidden verso i nodi di output. Quindi per un nodo hidden si può porre: E = e 2 k (4) 2 k C dove il neurone k è un nodo di output.
56 La (6) qui diventa: (5) j H i i i i j H i i W x x H H E W E = Per la prima componente della derivata parziale vale: (6) i k k k i H e e H E =
57 dove: e k = O k D k (7 ) e, in analogia ai calcoli fatti in precedenza, e H k i = O k ( Ok ) O i (8) W k Per le altre due componenti della derivata parziale il calcolo è simile a quello visto in precedenza (cambiano solo i nomi delle variabili).
58 Quindi complessivamente si ha: (9) ) ( = = = Δ m k k i O O j i i j H k k i W I H H W δ η avendo posto )(20) ( ) ( k k k k O O O O D k = δ
59 Nella pratica, per evitare perturbazioni locali, si filtra la variazione dei pesi, così: E Δw( t) = η + α Δw( t )(2) w( t) dove η è il learning rate, α è detto momento (anche se è più propriamente una viscosità). Valori tipici: η= 0.2 (o 0.5), α=0.9.
60 Considerazioni. Rete EX-OR dopo l addestramento I H O I H
61 H = squash( I I ) H 2 = squash( I I ) O = squash( H H ) I I2 H H2 O
62 I I I = I I I = 0
63 H H H = H
64 0 O H 2 0 I 2 H 0 I
65 KOHONEN's SELF ORGANIZING FEATURE MAPS
66 Ogni nodo è connesso a tutti gli input. I pesi w i di fatto rappresentano un vettore. È questo vettore che viene confrontato con il vettore di input. NODO J w j w j2 w jn x x 2 x n
67 è una rete neurale che si auto organizza per creare dei raggruppamenti in classi (clusters) di esempi non classificati; è utilizzata per costruire dei Quantizzatori Vettoriali e, in genere, per la compressione di dati; la rete (Map) è una griglia bidimensionale di nodi che rappresentano i centri delle classi (campo recettivo);
68 i nodi di input sono connessi completamente al campo recettivo; l'input è un vettore di reali (features); l'apprendimento è non-supervisionato, cioè gli esempi non sono classificati; il numero di classi è prefissato.
69 Algoritmo di Apprendimento per le Reti Auto-Organizzanti Partendo da pesi casuali, si modificano iterativamente i pesi in modo che nodi topologicamente vicini siano sensibili (output elevato) a input fisicamente simili. Dato un input, si prende il nodo che meglio risponde, e si modificano i pesi per rafforzare la sua risposta e, in minor misura, quella dei suoi vicini.
70 . Inizializzazione dei pesi e del raggio di "vicinato" I pesi dagli N input agli M nodi di output sono inizializzati con piccoli valori casuali. Si inizializza il raggio di "vicinato", cioè la distanza entro cui la modifica dei pesi di un nodo si ripercuote sui suoi vicini nella rete.
71 2. Presentazione di un input Si dà in input alla rete un nuovo vettore di reali x 0,... X N-. 3. Calcolo della distanza da tutti i nodi Si calcola la distanza di fra il vettore in input e ogni nodo di output j con la formula = N i= 0 d j (xi(t) wij(t)) dove xi(t) è l'input al nodo i al tempo t e wij(t) è il peso dall'input i al nodo di output j al tempo t. 2
72 4. Selezione del nodo di output con la minima distanza si seleziona il nodo j* con la minima distanza dj. 5. Aggiornamento dei pesi verso il nodo e i suoi vicini Si modificano i pesi verso j* e tutti i nodi dei vicinato definito da NEj*(t) con la formula: w ij (t+) = w ij (t) + η(t) a(j, j*) (x i (t) - w ij (t)) per j NEj*(t) 0 i N- dove il termine η (t) è un coefficiente di incremento che diminuisce col tempo e a(j, j*) è un coefficiente che varia in funzione della distanza del nodo j da j*. Anche la dimensione del vicinato NEj*(t) diminuisce col tempo.
73 6. Iterazione dal passo 2.
74 Self-Organization Da Kohonen,984 The IWs leading from a vector input channel to a receptive field become ordered in relation to their immediate topological neighbors, as a result of an interative process that systematically alters IWs in local, selected PE neighborhoods. An input vector is incident on a receptive field. The PE whose IW vector most closely matches the input vector is selected for modification.
75 The IW vector is adjusted to more closely match the input vector. The IWs of the neighbors of the selected PE are also adiusted, but to a smaller extent. It is this neighborhood reorientation that makes self-organization work.
76
77
78 KOHONEN MAPS - osservazioni Kohonen (984) ha dimostrato la convergenza dell'algoritmo di apprendimento e proposto molti esempi di utilizzo. Ha inoltre proposto l'utilizzo di questa RN come quantizzatore vettoriale per sistemi di riconoscimento dei parlato e, in genere, per la compressione di dati grezzi in classi significative. Questo tipo di RN opera bene con input rumorosi, poiché il numero di classi è prefissato, e i pesi si modificano lentamente.
79 Dopo l'addestramento la rete è in grado di classificare nuovi input sconosciuti in una (o più) delle classi che si è autodefinite. I valori dei nodi di output danno una distribuzione di verosimiglianza dell'appartenenza dell'istanza in input alle M classi. tale modello può anche servire, usato in modo opportuno, per problemi di controllo (es. movimento di robot) e di classificazione.
VC-dimension: Esempio
 VC-dimension: Esempio Quale è la VC-dimension di. y b = 0 f() = 1 f() = 1 iperpiano 20? VC-dimension: Esempio Quale è la VC-dimension di? banale. Vediamo cosa succede con 2 punti: 21 VC-dimension: Esempio
VC-dimension: Esempio Quale è la VC-dimension di. y b = 0 f() = 1 f() = 1 iperpiano 20? VC-dimension: Esempio Quale è la VC-dimension di? banale. Vediamo cosa succede con 2 punti: 21 VC-dimension: Esempio
Pro e contro delle RNA
 Pro e contro delle RNA Pro: - flessibilità: le RNA sono approssimatori universali; - aggiornabilità sequenziale: la stima dei pesi della rete può essere aggiornata man mano che arriva nuova informazione;
Pro e contro delle RNA Pro: - flessibilità: le RNA sono approssimatori universali; - aggiornabilità sequenziale: la stima dei pesi della rete può essere aggiornata man mano che arriva nuova informazione;
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 4 Reti neurali per la classificazione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 4 Reti neurali per la classificazione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com
Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete Neuronale
 Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete euronale Descrizione Il presente lavoro, facente segiuto a quanto descritto precedentemente, ha il fine di: 1) introdurre
Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete euronale Descrizione Il presente lavoro, facente segiuto a quanto descritto precedentemente, ha il fine di: 1) introdurre
SVM. Veronica Piccialli. Roma 11 gennaio 2010. Università degli Studi di Roma Tor Vergata 1 / 14
 SVM Veronica Piccialli Roma 11 gennaio 2010 Università degli Studi di Roma Tor Vergata 1 / 14 SVM Le Support Vector Machines (SVM) sono una classe di macchine di che derivano da concetti riguardanti la
SVM Veronica Piccialli Roma 11 gennaio 2010 Università degli Studi di Roma Tor Vergata 1 / 14 SVM Le Support Vector Machines (SVM) sono una classe di macchine di che derivano da concetti riguardanti la
Dimensione di uno Spazio vettoriale
 Capitolo 4 Dimensione di uno Spazio vettoriale 4.1 Introduzione Dedichiamo questo capitolo ad un concetto fondamentale in algebra lineare: la dimensione di uno spazio vettoriale. Daremo una definizione
Capitolo 4 Dimensione di uno Spazio vettoriale 4.1 Introduzione Dedichiamo questo capitolo ad un concetto fondamentale in algebra lineare: la dimensione di uno spazio vettoriale. Daremo una definizione
Regressione non lineare con un modello neurale feedforward
 Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
Algoritmi di clustering
 Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
Introduzione agli Algoritmi Genetici Prof. Beatrice Lazzerini
 Introduzione agli Algoritmi Genetici Prof. Beatrice Lazzerini Dipartimento di Ingegneria della Informazione Via Diotisalvi, 2 56122 PISA ALGORITMI GENETICI (GA) Sono usati per risolvere problemi di ricerca
Introduzione agli Algoritmi Genetici Prof. Beatrice Lazzerini Dipartimento di Ingegneria della Informazione Via Diotisalvi, 2 56122 PISA ALGORITMI GENETICI (GA) Sono usati per risolvere problemi di ricerca
Documentazione esterna al software matematico sviluppato con MatLab
 Documentazione esterna al software matematico sviluppato con MatLab Algoritmi Metodo di Gauss-Seidel con sovrarilassamento Metodo delle Secanti Metodo di Newton Studente Amelio Francesco 556/00699 Anno
Documentazione esterna al software matematico sviluppato con MatLab Algoritmi Metodo di Gauss-Seidel con sovrarilassamento Metodo delle Secanti Metodo di Newton Studente Amelio Francesco 556/00699 Anno
1 Serie di Taylor di una funzione
 Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
A intervalli regolari ogni router manda la sua tabella a tutti i vicini, e riceve quelle dei vicini.
 Algoritmi di routing dinamici (pag.89) UdA2_L5 Nelle moderne reti si usano algoritmi dinamici, che si adattano automaticamente ai cambiamenti della rete. Questi algoritmi non sono eseguiti solo all'avvio
Algoritmi di routing dinamici (pag.89) UdA2_L5 Nelle moderne reti si usano algoritmi dinamici, che si adattano automaticamente ai cambiamenti della rete. Questi algoritmi non sono eseguiti solo all'avvio
Basi di matematica per il corso di micro
 Basi di matematica per il corso di micro Microeconomia (anno accademico 2006-2007) Lezione del 21 Marzo 2007 Marianna Belloc 1 Le funzioni 1.1 Definizione Una funzione è una regola che descrive una relazione
Basi di matematica per il corso di micro Microeconomia (anno accademico 2006-2007) Lezione del 21 Marzo 2007 Marianna Belloc 1 Le funzioni 1.1 Definizione Una funzione è una regola che descrive una relazione
LEZIONE 23. Esempio 23.1.3. Si consideri la matrice (si veda l Esempio 22.2.5) A = 1 2 2 3 3 0
 A = 1 2 2 3 3 0") LEZIONE 23 231 Diagonalizzazione di matrici Abbiamo visto nella precedente lezione che, in generale, non è immediato che, data una matrice A k n,n con k = R, C, esista sempre una base costituita da suoi
LEZIONE 23 231 Diagonalizzazione di matrici Abbiamo visto nella precedente lezione che, in generale, non è immediato che, data una matrice A k n,n con k = R, C, esista sempre una base costituita da suoi
LE FUNZIONI A DUE VARIABILI
 Capitolo I LE FUNZIONI A DUE VARIABILI In questo primo capitolo introduciamo alcune definizioni di base delle funzioni reali a due variabili reali. Nel seguito R denoterà l insieme dei numeri reali mentre
Capitolo I LE FUNZIONI A DUE VARIABILI In questo primo capitolo introduciamo alcune definizioni di base delle funzioni reali a due variabili reali. Nel seguito R denoterà l insieme dei numeri reali mentre
ESAME DI STATO DI LICEO SCIENTIFICO CORSO SPERIMENTALE P.N.I. 2004
 ESAME DI STAT DI LICE SCIENTIFIC CRS SPERIMENTALE P.N.I. 004 Il candidato risolva uno dei due problemi e 5 dei 0 quesiti in cui si articola il questionario. PRBLEMA Sia la curva d equazione: ke ove k e
ESAME DI STAT DI LICE SCIENTIFIC CRS SPERIMENTALE P.N.I. 004 Il candidato risolva uno dei due problemi e 5 dei 0 quesiti in cui si articola il questionario. PRBLEMA Sia la curva d equazione: ke ove k e
Capitolo 4: Ottimizzazione non lineare non vincolata parte II. E. Amaldi DEIB, Politecnico di Milano
 Capitolo 4: Ottimizzazione non lineare non vincolata parte II E. Amaldi DEIB, Politecnico di Milano 4.3 Algoritmi iterativi e convergenza Programma non lineare (PNL): min f(x) s.v. g i (x) 0 1 i m x S
Capitolo 4: Ottimizzazione non lineare non vincolata parte II E. Amaldi DEIB, Politecnico di Milano 4.3 Algoritmi iterativi e convergenza Programma non lineare (PNL): min f(x) s.v. g i (x) 0 1 i m x S
Ottimizazione vincolata
 Ottimizazione vincolata Ricordiamo alcuni risultati provati nella scheda sulla Teoria di Dini per una funzione F : R N+M R M di classe C 1 con (x 0, y 0 ) F 1 (a), a = (a 1,, a M ), punto in cui vale l
Ottimizazione vincolata Ricordiamo alcuni risultati provati nella scheda sulla Teoria di Dini per una funzione F : R N+M R M di classe C 1 con (x 0, y 0 ) F 1 (a), a = (a 1,, a M ), punto in cui vale l
( x) ( x) 0. Equazioni irrazionali
 ( x) 0. Equazioni irrazionali") Equazioni irrazionali Definizione: si definisce equazione irrazionale un equazione in cui compaiono uno o più radicali contenenti l incognita. Esempio 7 Ricordiamo quanto visto sulle condizioni di esistenza
Equazioni irrazionali Definizione: si definisce equazione irrazionale un equazione in cui compaiono uno o più radicali contenenti l incognita. Esempio 7 Ricordiamo quanto visto sulle condizioni di esistenza
Il concetto di valore medio in generale
 Il concetto di valore medio in generale Nella statistica descrittiva si distinguono solitamente due tipi di medie: - le medie analitiche, che soddisfano ad una condizione di invarianza e si calcolano tenendo
Il concetto di valore medio in generale Nella statistica descrittiva si distinguono solitamente due tipi di medie: - le medie analitiche, che soddisfano ad una condizione di invarianza e si calcolano tenendo
Esperienze di Apprendimento Automatico per il corso di Intelligenza Artificiale
 Esperienze di Apprendimento Automatico per il corso di lippi@dsi.unifi.it Dipartimento Sistemi e Informatica Università di Firenze Dipartimento Ingegneria dell Informazione Università di Siena Introduzione
Esperienze di Apprendimento Automatico per il corso di lippi@dsi.unifi.it Dipartimento Sistemi e Informatica Università di Firenze Dipartimento Ingegneria dell Informazione Università di Siena Introduzione
Esponenziali elogaritmi
 Esponenziali elogaritmi Potenze ad esponente reale Ricordiamo che per un qualsiasi numero razionale m n prendere n>0) si pone a m n = n a m (in cui si può sempre a patto che a sia un numero reale positivo.
Esponenziali elogaritmi Potenze ad esponente reale Ricordiamo che per un qualsiasi numero razionale m n prendere n>0) si pone a m n = n a m (in cui si può sempre a patto che a sia un numero reale positivo.
Codifiche a lunghezza variabile
 Sistemi Multimediali Codifiche a lunghezza variabile Marco Gribaudo marcog@di.unito.it, gribaudo@elet.polimi.it Assegnazione del codice Come visto in precedenza, per poter memorizzare o trasmettere un
Sistemi Multimediali Codifiche a lunghezza variabile Marco Gribaudo marcog@di.unito.it, gribaudo@elet.polimi.it Assegnazione del codice Come visto in precedenza, per poter memorizzare o trasmettere un
Fasi di creazione di un programma
 Fasi di creazione di un programma 1. Studio Preliminare 2. Analisi del Sistema 6. Manutenzione e Test 3. Progettazione 5. Implementazione 4. Sviluppo 41 Sviluppo di programmi Per la costruzione di un programma
Fasi di creazione di un programma 1. Studio Preliminare 2. Analisi del Sistema 6. Manutenzione e Test 3. Progettazione 5. Implementazione 4. Sviluppo 41 Sviluppo di programmi Per la costruzione di un programma
Introduzione al MATLAB c Parte 2
 Introduzione al MATLAB c Parte 2 Lucia Gastaldi Dipartimento di Matematica, http://dm.ing.unibs.it/gastaldi/ 18 gennaio 2008 Outline 1 M-file di tipo Script e Function Script Function 2 Costrutti di programmazione
Introduzione al MATLAB c Parte 2 Lucia Gastaldi Dipartimento di Matematica, http://dm.ing.unibs.it/gastaldi/ 18 gennaio 2008 Outline 1 M-file di tipo Script e Function Script Function 2 Costrutti di programmazione
Algoritmi e strutture dati. Codici di Huffman
 Algoritmi e strutture dati Codici di Huffman Memorizzazione dei dati Quando un file viene memorizzato, esso va memorizzato in qualche formato binario Modo più semplice: memorizzare il codice ASCII per
Algoritmi e strutture dati Codici di Huffman Memorizzazione dei dati Quando un file viene memorizzato, esso va memorizzato in qualche formato binario Modo più semplice: memorizzare il codice ASCII per
Page 1. Evoluzione. Intelligenza Artificiale. Algoritmi Genetici. Evoluzione. Evoluzione: nomenclatura. Corrispondenze natura-calcolo
 Evoluzione In ogni popolazione si verificano delle mutazioni. Intelligenza Artificiale In un ambiente che varia, le mutazioni possono generare individui che meglio si adattano alle nuove condizioni. Questi
Evoluzione In ogni popolazione si verificano delle mutazioni. Intelligenza Artificiale In un ambiente che varia, le mutazioni possono generare individui che meglio si adattano alle nuove condizioni. Questi
Capitolo 1 ANALISI COMPLESSA
 Capitolo 1 ANALISI COMPLESSA 1 1.4 Serie in campo complesso 1.4.1 Serie di potenze Una serie di potenze è una serie del tipo a k (z z 0 ) k. Per le serie di potenze in campo complesso valgono teoremi analoghi
Capitolo 1 ANALISI COMPLESSA 1 1.4 Serie in campo complesso 1.4.1 Serie di potenze Una serie di potenze è una serie del tipo a k (z z 0 ) k. Per le serie di potenze in campo complesso valgono teoremi analoghi
Matematica generale CTF
 Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Domande a scelta multipla 1
 Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
I PROBLEMI ALGEBRICI
 I PROBLEMI ALGEBRICI La risoluzione di problemi è una delle attività fondamentali della matematica. Una grande quantità di problemi è risolubile mediante un modello algebrico costituito da equazioni e
I PROBLEMI ALGEBRICI La risoluzione di problemi è una delle attività fondamentali della matematica. Una grande quantità di problemi è risolubile mediante un modello algebrico costituito da equazioni e
Computational Game Theory
 Computational Game Theory Vincenzo Bonifaci 24 maggio 2012 5 Regret Minimization Consideriamo uno scenario in cui un agente deve selezionare, più volte nel tempo, una decisione tra un insieme di N disponibili:
Computational Game Theory Vincenzo Bonifaci 24 maggio 2012 5 Regret Minimization Consideriamo uno scenario in cui un agente deve selezionare, più volte nel tempo, una decisione tra un insieme di N disponibili:
Corrispondenze e funzioni
 Corrispondenze e funzioni L attività fondamentale della mente umana consiste nello stabilire corrispondenze e relazioni tra oggetti; è anche per questo motivo che il concetto di corrispondenza è uno dei
Corrispondenze e funzioni L attività fondamentale della mente umana consiste nello stabilire corrispondenze e relazioni tra oggetti; è anche per questo motivo che il concetto di corrispondenza è uno dei
Definire all'interno del codice un vettore di interi di dimensione DIM, es. int array[] = {1, 5, 2, 4, 8, 1, 1, 9, 11, 4, 12};
![Definire all'interno del codice un vettore di interi di dimensione DIM, es. int array[] = {1, 5, 2, 4, 8, 1, 1, 9, 11, 4, 12};](/thumbs/24/3689577.jpg "Definire all'interno del codice un vettore di interi di dimensione DIM, es. int array[] = {1, 5, 2, 4, 8, 1, 1, 9, 11, 4, 12};") ESERCIZI 2 LABORATORIO Problema 1 Definire all'interno del codice un vettore di interi di dimensione DIM, es. int array[] = {1, 5, 2, 4, 8, 1, 1, 9, 11, 4, 12}; Chiede all'utente un numero e, tramite ricerca
ESERCIZI 2 LABORATORIO Problema 1 Definire all'interno del codice un vettore di interi di dimensione DIM, es. int array[] = {1, 5, 2, 4, 8, 1, 1, 9, 11, 4, 12}; Chiede all'utente un numero e, tramite ricerca
Esempio. Approssimazione con il criterio dei minimi quadrati. Esempio. Esempio. Risultati sperimentali. Interpolazione con spline cubica.
 Esempio Risultati sperimentali Approssimazione con il criterio dei minimi quadrati Esempio Interpolazione con spline cubica. Esempio 1 Come procedere? La natura del fenomeno suggerisce che una buona approssimazione
Esempio Risultati sperimentali Approssimazione con il criterio dei minimi quadrati Esempio Interpolazione con spline cubica. Esempio 1 Come procedere? La natura del fenomeno suggerisce che una buona approssimazione
2 Argomenti introduttivi e generali
 1 Note Oltre agli esercizi di questa lista si consiglia di svolgere quelli segnalati o assegnati sul registro e genericamente quelli presentati dal libro come esercizio o come esempio sugli argomenti svolti
1 Note Oltre agli esercizi di questa lista si consiglia di svolgere quelli segnalati o assegnati sul registro e genericamente quelli presentati dal libro come esercizio o come esempio sugli argomenti svolti
RICERCA OPERATIVA GRUPPO B prova scritta del 22 marzo 2007
 RICERCA OPERATIVA GRUPPO B prova scritta del 22 marzo 2007 Rispondere alle seguenti domande marcando a penna la lettera corrispondente alla risposta ritenuta corretta (una sola tra quelle riportate). Se
RICERCA OPERATIVA GRUPPO B prova scritta del 22 marzo 2007 Rispondere alle seguenti domande marcando a penna la lettera corrispondente alla risposta ritenuta corretta (una sola tra quelle riportate). Se
INTEGRALI DEFINITI. Tale superficie viene detta trapezoide e la misura della sua area si ottiene utilizzando il calcolo di un integrale definito.
 INTEGRALI DEFINITI Sia nel campo scientifico che in quello tecnico si presentano spesso situazioni per affrontare le quali è necessario ricorrere al calcolo dell integrale definito. Vi sono infatti svariati
INTEGRALI DEFINITI Sia nel campo scientifico che in quello tecnico si presentano spesso situazioni per affrontare le quali è necessario ricorrere al calcolo dell integrale definito. Vi sono infatti svariati
2.1 Definizione di applicazione lineare. Siano V e W due spazi vettoriali su R. Un applicazione
 Capitolo 2 MATRICI Fra tutte le applicazioni su uno spazio vettoriale interessa esaminare quelle che mantengono la struttura di spazio vettoriale e che, per questo, vengono dette lineari La loro importanza
Capitolo 2 MATRICI Fra tutte le applicazioni su uno spazio vettoriale interessa esaminare quelle che mantengono la struttura di spazio vettoriale e che, per questo, vengono dette lineari La loro importanza
Backpropagation in MATLAB
 Modello di neurone BACKPROPAGATION Backpropagation in MATLAB Prof. Beatrice Lazzerini Dipartimento di Ingegneria dell Informazione Via Diotisalvi 2, 56122 Pisa La funzione di trasferimento, che deve essere
Modello di neurone BACKPROPAGATION Backpropagation in MATLAB Prof. Beatrice Lazzerini Dipartimento di Ingegneria dell Informazione Via Diotisalvi 2, 56122 Pisa La funzione di trasferimento, che deve essere
Siamo così arrivati all aritmetica modulare, ma anche a individuare alcuni aspetti di come funziona l aritmetica del calcolatore come vedremo.
 DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
Consideriamo due polinomi
 Capitolo 3 Il luogo delle radici Consideriamo due polinomi N(z) = (z z 1 )(z z 2 )... (z z m ) D(z) = (z p 1 )(z p 2 )... (z p n ) della variabile complessa z con m < n. Nelle problematiche connesse al
Capitolo 3 Il luogo delle radici Consideriamo due polinomi N(z) = (z z 1 )(z z 2 )... (z z m ) D(z) = (z p 1 )(z p 2 )... (z p n ) della variabile complessa z con m < n. Nelle problematiche connesse al
Reti sequenziali sincrone
 Reti sequenziali sincrone Un approccio strutturato (7.1-7.3, 7.5-7.6) Modelli di reti sincrone Analisi di reti sincrone Descrizioni e sintesi di reti sequenziali sincrone Sintesi con flip-flop D, DE, T
Reti sequenziali sincrone Un approccio strutturato (7.1-7.3, 7.5-7.6) Modelli di reti sincrone Analisi di reti sincrone Descrizioni e sintesi di reti sequenziali sincrone Sintesi con flip-flop D, DE, T
Teoria delle code. Sistemi stazionari: M/M/1 M/M/1/K M/M/S
 Teoria delle code Sistemi stazionari: M/M/1 M/M/1/K M/M/S Fabio Giammarinaro 04/03/2008 Sommario INTRODUZIONE... 3 Formule generali di e... 3 Leggi di Little... 3 Cosa cerchiamo... 3 Legame tra N e le
Teoria delle code Sistemi stazionari: M/M/1 M/M/1/K M/M/S Fabio Giammarinaro 04/03/2008 Sommario INTRODUZIONE... 3 Formule generali di e... 3 Leggi di Little... 3 Cosa cerchiamo... 3 Legame tra N e le
Esercizi svolti. 1. Si consideri la funzione f(x) = 4 x 2. a) Verificare che la funzione F(x) = x 2 4 x2 + 2 arcsin x è una primitiva di
 = 4 x 2. a) Verificare che la funzione F(x) = x 2 4 x2 + 2 arcsin x è una primitiva di") Esercizi svolti. Si consideri la funzione f() 4. a) Verificare che la funzione F() 4 + arcsin è una primitiva di f() sull intervallo (, ). b) Verificare che la funzione G() 4 + arcsin π è la primitiva
Esercizi svolti. Si consideri la funzione f() 4. a) Verificare che la funzione F() 4 + arcsin è una primitiva di f() sull intervallo (, ). b) Verificare che la funzione G() 4 + arcsin π è la primitiva
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione Naturale! Prof. Giuseppe Boccignone! Dipartimento di Informatica Università di Milano! boccignone@di.unimi.it boccignone.di.unimi.it/in_2015.html
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione Naturale! Prof. Giuseppe Boccignone! Dipartimento di Informatica Università di Milano! boccignone@di.unimi.it boccignone.di.unimi.it/in_2015.html
2. Leggi finanziarie di capitalizzazione
 2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
Tecniche di riconoscimento statistico
 Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 8 Support Vector Machines Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 8 Support Vector Machines Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Appunti sul corso di Complementi di Matematica - prof. B.Bacchelli. 03 - Equazioni differenziali lineari omogenee a coefficienti costanti.
 Appunti sul corso di Complementi di Matematica - prof. B.Bacchelli 03 - Equazioni differenziali lineari omogenee a coefficienti costanti. Def. Si dice equazione differenziale lineare del secondo ordine
Appunti sul corso di Complementi di Matematica - prof. B.Bacchelli 03 - Equazioni differenziali lineari omogenee a coefficienti costanti. Def. Si dice equazione differenziale lineare del secondo ordine
Reti Neurali Artificiali
 Reti Neurali Artificiali Master in Gestione dei Dati e Bioimmagini a.a. 2012/2013 Prof. Crescenzio Gallo Dipartimento di Medicina Clinica e Sperimentale c.gallo@unifg.it Concetti base [ 2 ] Le Reti Neurali
Reti Neurali Artificiali Master in Gestione dei Dati e Bioimmagini a.a. 2012/2013 Prof. Crescenzio Gallo Dipartimento di Medicina Clinica e Sperimentale c.gallo@unifg.it Concetti base [ 2 ] Le Reti Neurali
1. Distribuzioni campionarie
 Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
EQUAZIONI DIFFERENZIALI. 1. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x 2 log t (d) x = e t x log x (e) y = y2 5y+6
 x = x 2 log t (d) x = e t x log x (e) y = y2 5y+6") EQUAZIONI DIFFERENZIALI.. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x log t (d) x = e t x log x (e) y = y 5y+6 (f) y = ty +t t +y (g) y = y (h) xy = y (i) y y y = 0 (j) x = x (k)
EQUAZIONI DIFFERENZIALI.. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x log t (d) x = e t x log x (e) y = y 5y+6 (f) y = ty +t t +y (g) y = y (h) xy = y (i) y y y = 0 (j) x = x (k)
4 3 4 = 4 x 10 2 + 3 x 10 1 + 4 x 10 0 aaa 10 2 10 1 10 0
 Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Corso di Matematica per la Chimica
 Dott.ssa Maria Carmela De Bonis a.a. 203-4 I sistemi lineari Generalità sui sistemi lineari Molti problemi dell ingegneria, della fisica, della chimica, dell informatica e dell economia, si modellizzano
Dott.ssa Maria Carmela De Bonis a.a. 203-4 I sistemi lineari Generalità sui sistemi lineari Molti problemi dell ingegneria, della fisica, della chimica, dell informatica e dell economia, si modellizzano
u 1 u k che rappresenta formalmente la somma degli infiniti numeri (14.1), ordinati al crescere del loro indice. I numeri u k
, ordinati al crescere del loro indice. I numeri u k") Capitolo 4 Serie numeriche 4. Serie convergenti, divergenti, indeterminate Data una successione di numeri reali si chiama serie ad essa relativa il simbolo u +... + u +... u, u 2,..., u,..., (4.) oppure
Capitolo 4 Serie numeriche 4. Serie convergenti, divergenti, indeterminate Data una successione di numeri reali si chiama serie ad essa relativa il simbolo u +... + u +... u, u 2,..., u,..., (4.) oppure
Matematica e Statistica
 Matematica e Statistica Prova d esame (0/07/03) Università di Verona - Laurea in Biotecnologie - A.A. 0/3 Matematica e Statistica Prova di MATEMATICA (0/07/03) Università di Verona - Laurea in Biotecnologie
Matematica e Statistica Prova d esame (0/07/03) Università di Verona - Laurea in Biotecnologie - A.A. 0/3 Matematica e Statistica Prova di MATEMATICA (0/07/03) Università di Verona - Laurea in Biotecnologie
la scienza della rappresentazione e della elaborazione dell informazione
 Sistema binario Sommario informatica rappresentare informazioni la differenza Analogico/Digitale i sistemi di numerazione posizionali il sistema binario Informatica Definizione la scienza della rappresentazione
Sistema binario Sommario informatica rappresentare informazioni la differenza Analogico/Digitale i sistemi di numerazione posizionali il sistema binario Informatica Definizione la scienza della rappresentazione
SOLUZIONE DEL PROBLEMA 1 TEMA DI MATEMATICA ESAME DI STATO 2015
 SOLUZIONE DEL PROBLEMA 1 TEMA DI MATEMATICA ESAME DI STATO 015 1. Indicando con i minuti di conversazione effettuati nel mese considerato, la spesa totale mensile in euro è espressa dalla funzione f()
SOLUZIONE DEL PROBLEMA 1 TEMA DI MATEMATICA ESAME DI STATO 015 1. Indicando con i minuti di conversazione effettuati nel mese considerato, la spesa totale mensile in euro è espressa dalla funzione f()
x 2 + y2 4 = 1 x = cos(t), y = 2 sin(t), t [0, 2π] Al crescere di t l ellisse viene percorsa in senso antiorario.
![x 2 + y2 4 = 1 x = cos(t), y = 2 sin(t), t [0, 2π] Al crescere di t l ellisse viene percorsa in senso antiorario.](/thumbs/39/18585741.jpg "x 2 + y2 4 = 1 x = cos(t), y = 2 sin(t), t [0, 2π] Al crescere di t l ellisse viene percorsa in senso antiorario.") Le soluzioni del foglio 2. Esercizio Calcolare il lavoro compiuto dal campo vettoriale F = (y + 3x, 2y x) per far compiere ad una particella un giro dell ellisse 4x 2 + y 2 = 4 in senso orario... Soluzione.
Le soluzioni del foglio 2. Esercizio Calcolare il lavoro compiuto dal campo vettoriale F = (y + 3x, 2y x) per far compiere ad una particella un giro dell ellisse 4x 2 + y 2 = 4 in senso orario... Soluzione.
Relazioni statistiche: regressione e correlazione
 Relazioni statistiche: regressione e correlazione È detto studio della connessione lo studio si occupa della ricerca di relazioni fra due variabili statistiche o fra una mutabile e una variabile statistica
Relazioni statistiche: regressione e correlazione È detto studio della connessione lo studio si occupa della ricerca di relazioni fra due variabili statistiche o fra una mutabile e una variabile statistica
LEZIONE 31. B i : R n R. R m,n, x = (x 1,..., x n ). Allora sappiamo che è definita. j=1. a i,j x j.
. Allora sappiamo che è definita. j=1. a i,j x j.") LEZIONE 31 31.1. Domini di funzioni di più variabili. Sia ora U R n e consideriamo una funzione f: U R m. Una tale funzione associa a x = (x 1,..., x n ) U un elemento f(x 1,..., x n ) R m : tale elemento
LEZIONE 31 31.1. Domini di funzioni di più variabili. Sia ora U R n e consideriamo una funzione f: U R m. Una tale funzione associa a x = (x 1,..., x n ) U un elemento f(x 1,..., x n ) R m : tale elemento
Funzioni in C. Violetta Lonati
 Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
13. Campi vettoriali
 13. Campi vettoriali 1 Il campo di velocità di un fluido Il concetto di campo in fisica non è limitato ai fenomeni elettrici. In generale il valore di una grandezza fisica assegnato per ogni punto dello
13. Campi vettoriali 1 Il campo di velocità di un fluido Il concetto di campo in fisica non è limitato ai fenomeni elettrici. In generale il valore di una grandezza fisica assegnato per ogni punto dello
Esempi di funzione. Scheda Tre
 Scheda Tre Funzioni Consideriamo una legge f che associa ad un elemento di un insieme X al più un elemento di un insieme Y; diciamo che f è una funzione, X è l insieme di partenza e X l insieme di arrivo.
Scheda Tre Funzioni Consideriamo una legge f che associa ad un elemento di un insieme X al più un elemento di un insieme Y; diciamo che f è una funzione, X è l insieme di partenza e X l insieme di arrivo.
Comparatori. Comparatori di uguaglianza
 Comparatori Scopo di un circuito comparatore é il confronto tra due codifiche binarie. Il confronto può essere effettuato per verificare l'uguaglianza oppure una relazione d'ordine del tipo "maggiore",
Comparatori Scopo di un circuito comparatore é il confronto tra due codifiche binarie. Il confronto può essere effettuato per verificare l'uguaglianza oppure una relazione d'ordine del tipo "maggiore",
CAPITOLO 16 SUCCESSIONI E SERIE DI FUNZIONI
 CAPITOLO 16 SUCCESSIONI E SERIE DI FUNZIONI Abbiamo studiato successioni e serie numeriche, ora vogliamo studiare successioni e serie di funzioni. Dato un insieme A R, chiamiamo successione di funzioni
CAPITOLO 16 SUCCESSIONI E SERIE DI FUNZIONI Abbiamo studiato successioni e serie numeriche, ora vogliamo studiare successioni e serie di funzioni. Dato un insieme A R, chiamiamo successione di funzioni
CONTINUITÀ E DERIVABILITÀ Esercizi proposti. 1. Determinare lim M(sinx) (M(t) denota la mantissa di t)
 (M(t) denota la mantissa di t)") CONTINUITÀ E DERIVABILITÀ Esercizi proposti 1. Determinare lim M(sin) (M(t) denota la mantissa di t) kπ/ al variare di k in Z. Ove tale limite non esista, discutere l esistenza dei limiti laterali. Identificare
CONTINUITÀ E DERIVABILITÀ Esercizi proposti 1. Determinare lim M(sin) (M(t) denota la mantissa di t) kπ/ al variare di k in Z. Ove tale limite non esista, discutere l esistenza dei limiti laterali. Identificare
MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c
![MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c](/thumbs/25/4541811.jpg "MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c") Caratteristiche MATLAB Linguaggio di programmazione orientato all elaborazione di matrici (MATLAB=MATrix LABoratory) Le variabili sono matrici (una variabile scalare equivale ad una matrice di dimensione
Caratteristiche MATLAB Linguaggio di programmazione orientato all elaborazione di matrici (MATLAB=MATrix LABoratory) Le variabili sono matrici (una variabile scalare equivale ad una matrice di dimensione
RAPPRESENTAZIONE GRAFICA E ANALISI DEI DATI SPERIMENTALI CON EXCEL
 RAPPRESENTAZIONE GRAFICA E ANALISI DEI DATI SPERIMENTALI CON EXCEL 1 RAPPRESENTAZIONE GRAFICA Per l analisi dati con Excel si fa riferimento alla versione 2007 di Office, le versioni successive non differiscono
RAPPRESENTAZIONE GRAFICA E ANALISI DEI DATI SPERIMENTALI CON EXCEL 1 RAPPRESENTAZIONE GRAFICA Per l analisi dati con Excel si fa riferimento alla versione 2007 di Office, le versioni successive non differiscono
GIROSCOPIO. Scopo dell esperienza: Teoria fisica. Verificare la relazione: ω p = bmg/iω
 GIROSCOPIO Scopo dell esperienza: Verificare la relazione: ω p = bmg/iω dove ω p è la velocità angolare di precessione, ω è la velocità angolare di rotazione, I il momento principale d inerzia assiale,
GIROSCOPIO Scopo dell esperienza: Verificare la relazione: ω p = bmg/iω dove ω p è la velocità angolare di precessione, ω è la velocità angolare di rotazione, I il momento principale d inerzia assiale,
Ottimizzazione Multi Obiettivo
 Ottimizzazione Multi Obiettivo 1 Ottimizzazione Multi Obiettivo I problemi affrontati fino ad ora erano caratterizzati da una unica (e ben definita) funzione obiettivo. I problemi di ottimizzazione reali
Ottimizzazione Multi Obiettivo 1 Ottimizzazione Multi Obiettivo I problemi affrontati fino ad ora erano caratterizzati da una unica (e ben definita) funzione obiettivo. I problemi di ottimizzazione reali
Lezione 8. La macchina universale
 Lezione 8 Algoritmi La macchina universale Un elaboratore o computer è una macchina digitale, elettronica, automatica capace di effettuare trasformazioni o elaborazioni su i dati digitale= l informazione
Lezione 8 Algoritmi La macchina universale Un elaboratore o computer è una macchina digitale, elettronica, automatica capace di effettuare trasformazioni o elaborazioni su i dati digitale= l informazione
FUNZIONE. Si scrive: A B f: A B x y=f(x) (si legge: f funzione da A in B) x f y= f(x)
 (si legge: f funzione da A in B) x f y= f(x)") 1 FUNZIONE Dati gli insiemi A e B, si definisce funzione da A in B una relazione o legge o corrispondenza che ad ogni elemento di A associa uno ed un solo elemento di B. Si scrive: A B f: A B f() (si legge:
1 FUNZIONE Dati gli insiemi A e B, si definisce funzione da A in B una relazione o legge o corrispondenza che ad ogni elemento di A associa uno ed un solo elemento di B. Si scrive: A B f: A B f() (si legge:
CURVE DI LIVELLO. Per avere informazioni sull andamento di una funzione f : D IR n IR può essere utile considerare i suoi insiemi di livello.
 CURVE DI LIVELLO Per avere informazioni sull andamento di una funzione f : D IR n IR può essere utile considerare i suoi insiemi di livello. Definizione. Si chiama insieme di livello k della funzione f
CURVE DI LIVELLO Per avere informazioni sull andamento di una funzione f : D IR n IR può essere utile considerare i suoi insiemi di livello. Definizione. Si chiama insieme di livello k della funzione f
RETI DI TELECOMUNICAZIONE
 RETI DI TELECOMUNICAZIONE SISTEMI M/G/1 e M/D/1 Sistemi M/G/1 Nei sistemi M/G/1: i clienti arrivano secondo un processo di Poisson con parametro λ i tempi di servizio hanno una distribuzione generale della
RETI DI TELECOMUNICAZIONE SISTEMI M/G/1 e M/D/1 Sistemi M/G/1 Nei sistemi M/G/1: i clienti arrivano secondo un processo di Poisson con parametro λ i tempi di servizio hanno una distribuzione generale della
Ottimizzazione nella gestione dei progetti Capitolo 4: la gestione dei costi (Programmazione multimodale): formulazioni
: formulazioni") Ottimizzazione nella gestione dei progetti Capitolo 4: la gestione dei costi (Programmazione multimodale): formulazioni CARLO MANNINO Università di Roma La Sapienza Dipartimento di Informatica e Sistemistica
Ottimizzazione nella gestione dei progetti Capitolo 4: la gestione dei costi (Programmazione multimodale): formulazioni CARLO MANNINO Università di Roma La Sapienza Dipartimento di Informatica e Sistemistica
L idea alla base del PID èdi avere un architettura standard per il controllo di processo
 CONTROLLORI PID PID L idea alla base del PID èdi avere un architettura standard per il controllo di processo Può essere applicato ai più svariati ambiti, dal controllo di una portata di fluido alla regolazione
CONTROLLORI PID PID L idea alla base del PID èdi avere un architettura standard per il controllo di processo Può essere applicato ai più svariati ambiti, dal controllo di una portata di fluido alla regolazione
Alcuni consigli per un uso di base delle serie di dati automatiche in Microsoft Excel
 Alcuni consigli per un uso di base delle serie di dati automatiche in Microsoft Excel Le serie Una serie di dati automatica è una sequenza di informazioni legate tra loro da una relazione e contenute in
Alcuni consigli per un uso di base delle serie di dati automatiche in Microsoft Excel Le serie Una serie di dati automatica è una sequenza di informazioni legate tra loro da una relazione e contenute in
Sintesi Combinatoria Uso di componenti diversi dagli operatori elementari. Mariagiovanna Sami Corso di reti Logiche 8 Anno 2007-08
 Sintesi Combinatoria Uso di componenti diversi dagli operatori elementari Mariagiovanna Sami Corso di reti Logiche 8 Anno 27-8 8 Quali componenti, se non AND e OR (e NOT )? Si è detto inizialmente che
Sintesi Combinatoria Uso di componenti diversi dagli operatori elementari Mariagiovanna Sami Corso di reti Logiche 8 Anno 27-8 8 Quali componenti, se non AND e OR (e NOT )? Si è detto inizialmente che
1 Applicazioni Lineari tra Spazi Vettoriali
 1 Applicazioni Lineari tra Spazi Vettoriali Definizione 1 (Applicazioni lineari) Si chiama applicazione lineare una applicazione tra uno spazio vettoriale ed uno spazio vettoriale sul campo tale che "!$%!
1 Applicazioni Lineari tra Spazi Vettoriali Definizione 1 (Applicazioni lineari) Si chiama applicazione lineare una applicazione tra uno spazio vettoriale ed uno spazio vettoriale sul campo tale che "!$%!
Soluzione del tema d esame di matematica, A.S. 2005/2006
 Soluzione del tema d esame di matematica, A.S. 2005/2006 Niccolò Desenzani Sun-ra J.N. Mosconi 22 giugno 2006 Problema. Indicando con A e B i lati del rettangolo, il perimetro è 2A + 2B = λ mentre l area
Soluzione del tema d esame di matematica, A.S. 2005/2006 Niccolò Desenzani Sun-ra J.N. Mosconi 22 giugno 2006 Problema. Indicando con A e B i lati del rettangolo, il perimetro è 2A + 2B = λ mentre l area
Capitolo 2 - Teoria della manutenzione: classificazione ABC e analisi di Pareto
 Capitolo 2 - Teoria della manutenzione: classificazione ABC e analisi di Pareto Il presente capitolo continua nell esposizione di alcune basi teoriche della manutenzione. In particolare si tratteranno
Capitolo 2 - Teoria della manutenzione: classificazione ABC e analisi di Pareto Il presente capitolo continua nell esposizione di alcune basi teoriche della manutenzione. In particolare si tratteranno
Librerie digitali. Video. Gestione di video. Caratteristiche dei video. Video. Metadati associati ai video. Metadati associati ai video
 Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Feature Selection per la Classificazione
 1 1 Dipartimento di Informatica e Sistemistica Sapienza Università di Roma Corso di Algoritmi di Classificazione e Reti Neurali 20/11/2009, Roma Outline Feature Selection per problemi di Classificazione
1 1 Dipartimento di Informatica e Sistemistica Sapienza Università di Roma Corso di Algoritmi di Classificazione e Reti Neurali 20/11/2009, Roma Outline Feature Selection per problemi di Classificazione
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
Calcolatori Elettronici A a.a. 2008/2009 PRESTAZIONI DEL CALCOLATORE Massimiliano Giacomin Due dimensioni Tempo di risposta (o tempo di esecuzione): il tempo totale impiegato per eseguire un task (include
risulta (x) = 1 se x < 0.
 = 1 se x < 0.") Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Sistemi Informativi Territoriali. Map Algebra
 Paolo Mogorovich Sistemi Informativi Territoriali Appunti dalle lezioni Map Algebra Cod.735 - Vers.E57 1 Definizione di Map Algebra 2 Operatori locali 3 Operatori zonali 4 Operatori focali 5 Operatori
Paolo Mogorovich Sistemi Informativi Territoriali Appunti dalle lezioni Map Algebra Cod.735 - Vers.E57 1 Definizione di Map Algebra 2 Operatori locali 3 Operatori zonali 4 Operatori focali 5 Operatori
I sistemi di numerazione
 I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
Corso di Calcolo Numerico
 Corso di Calcolo Numerico Dottssa MC De Bonis Università degli Studi della Basilicata, Potenza Facoltà di Ingegneria Corso di Laurea in Ingegneria Meccanica Corso di Calcolo Numerico - Dottssa MC De Bonis
Corso di Calcolo Numerico Dottssa MC De Bonis Università degli Studi della Basilicata, Potenza Facoltà di Ingegneria Corso di Laurea in Ingegneria Meccanica Corso di Calcolo Numerico - Dottssa MC De Bonis
La propagazione delle onde luminose può essere studiata per mezzo delle equazioni di Maxwell. Tuttavia, nella maggior parte dei casi è possibile
 Elementi di ottica L ottica si occupa dello studio dei percorsi dei raggi luminosi e dei fenomeni legati alla propagazione della luce in generale. Lo studio dell ottica nella fisica moderna si basa sul
Elementi di ottica L ottica si occupa dello studio dei percorsi dei raggi luminosi e dei fenomeni legati alla propagazione della luce in generale. Lo studio dell ottica nella fisica moderna si basa sul
Esempi di algoritmi. Lezione III
 Esempi di algoritmi Lezione III Scopo della lezione Implementare da zero algoritmi di media complessità. Verificare la correttezza di un algoritmo eseguendolo a mano. Imparare a valutare le prestazioni
Esempi di algoritmi Lezione III Scopo della lezione Implementare da zero algoritmi di media complessità. Verificare la correttezza di un algoritmo eseguendolo a mano. Imparare a valutare le prestazioni
LEZIONE 7. Esercizio 7.1. Quale delle seguenti funzioni è decrescente in ( 3, 0) e ha derivata prima in 3 che vale 0? x 3 3 + x2. 2, x3 +2x +3.
 e ha derivata prima in 3 che vale 0? x 3 3 + x2. 2, x3 +2x +3.") 7 LEZIONE 7 Esercizio 7.1. Quale delle seguenti funzioni è decrescente in ( 3, 0) e ha derivata prima in 3 che vale 0? x 3 3 + x2 2 6x, x3 +2x 2 6x, 3x + x2 2, x3 +2x +3. Le derivate sono rispettivamente,
7 LEZIONE 7 Esercizio 7.1. Quale delle seguenti funzioni è decrescente in ( 3, 0) e ha derivata prima in 3 che vale 0? x 3 3 + x2 2 6x, x3 +2x 2 6x, 3x + x2 2, x3 +2x +3. Le derivate sono rispettivamente,
Corso di Informatica Generale (C. L. Economia e Commercio) Ing. Valerio Lacagnina Rappresentazione in virgola mobile
 Ing. Valerio Lacagnina Rappresentazione in virgola mobile") Problemi connessi all utilizzo di un numero di bit limitato Abbiamo visto quali sono i vantaggi dell utilizzo della rappresentazione in complemento alla base: corrispondenza biunivoca fra rappresentazione
Problemi connessi all utilizzo di un numero di bit limitato Abbiamo visto quali sono i vantaggi dell utilizzo della rappresentazione in complemento alla base: corrispondenza biunivoca fra rappresentazione
LA TRASMISSIONE DELLE INFORMAZIONI QUARTA PARTE 1
 LA TRASMISSIONE DELLE INFORMAZIONI QUARTA PARTE 1 I CODICI 1 IL CODICE BCD 1 Somma in BCD 2 Sottrazione BCD 5 IL CODICE ECCESSO 3 20 La trasmissione delle informazioni Quarta Parte I codici Il codice BCD
LA TRASMISSIONE DELLE INFORMAZIONI QUARTA PARTE 1 I CODICI 1 IL CODICE BCD 1 Somma in BCD 2 Sottrazione BCD 5 IL CODICE ECCESSO 3 20 La trasmissione delle informazioni Quarta Parte I codici Il codice BCD
Transitori del primo ordine
 Università di Ferrara Corso di Elettrotecnica Transitori del primo ordine Si consideri il circuito in figura, composto da un generatore ideale di tensione, una resistenza ed una capacità. I tre bipoli
Università di Ferrara Corso di Elettrotecnica Transitori del primo ordine Si consideri il circuito in figura, composto da un generatore ideale di tensione, una resistenza ed una capacità. I tre bipoli
Esempio: dest = parolagigante, lettere = PROVA dest (dopo l'invocazione di tipo pari ) = pprrlogvgante
 = pprrlogvgante") Esercizio 0 Scambio lettere Scrivere la funzione void scambiolettere(char *dest, char *lettere, int p_o_d) che modifichi la stringa destinazione (dest), sostituendone i caratteri pari o dispari (a seconda
Esercizio 0 Scambio lettere Scrivere la funzione void scambiolettere(char *dest, char *lettere, int p_o_d) che modifichi la stringa destinazione (dest), sostituendone i caratteri pari o dispari (a seconda
4. Operazioni elementari per righe e colonne
 4. Operazioni elementari per righe e colonne Sia K un campo, e sia A una matrice m n a elementi in K. Una operazione elementare per righe sulla matrice A è una operazione di uno dei seguenti tre tipi:
4. Operazioni elementari per righe e colonne Sia K un campo, e sia A una matrice m n a elementi in K. Una operazione elementare per righe sulla matrice A è una operazione di uno dei seguenti tre tipi:
MATEMATICA DEL DISCRETO elementi di teoria dei grafi. anno acc. 2009/2010
 elementi di teoria dei grafi anno acc. 2009/2010 Grafi semplici Un grafo semplice G è una coppia ordinata (V(G), L(G)), ove V(G) è un insieme finito e non vuoto di elementi detti vertici o nodi di G, mentre
elementi di teoria dei grafi anno acc. 2009/2010 Grafi semplici Un grafo semplice G è una coppia ordinata (V(G), L(G)), ove V(G) è un insieme finito e non vuoto di elementi detti vertici o nodi di G, mentre
Gli array. Gli array. Gli array. Classi di memorizzazione per array. Inizializzazione esplicita degli array. Array e puntatori
 Gli array Array e puntatori Laboratorio di Informatica I un array è un insieme di elementi (valori) avente le seguenti caratteristiche: - un array è ordinato: agli elementi dell array è assegnato un ordine
Gli array Array e puntatori Laboratorio di Informatica I un array è un insieme di elementi (valori) avente le seguenti caratteristiche: - un array è ordinato: agli elementi dell array è assegnato un ordine