Statistical learning Strumenti quantitativi per la gestione
|
|
|
- Fabio Montanari
- 8 anni fa
- Visualizzazioni
Transcript
1 Statistical learning Strumenti quantitativi per la gestione Emanuele Taufer Vendite Simbologia Reddito Statistical learning A cosa ci serve f? 1 Previsione 2 Inferenza Previsione Errore riducibile e errore irriducibile Inferenza Esempi Come stimare f una panoramica Metodi parametrici Metodi non parametrici Esempio: Income data 2.3 Vera f 2.4 Modello lineare 2.5 Thin plate spline basso adattamento 2.6 Thin plate spline alto adattamento Trade off flessibilità interpretabilità Supervised e unsupervised Statistical Learning Problemi di regressione e di classificazione Valutazione della bontà del modello Test MSE e training MSE Esempio 1: f non lineare Esempio 2: f lineare Esempio 3: f non lineare Bias Variance trade off Scomposizione Bias Var Esempi 1,2,3 Classificazione Tasso di errore training e test Il classificatore di Bayes Classificatore KNN Esempio K=3 Esempio 1 Esempio 1 Error rates Riferimenti bibliografici Vendite file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 1/19

2 Supponiamo di voler capire come migliorare le vendite di un determinato prodotto. Il Set di dati Advertising consiste nelle vendite del prodotto in 200 diversi mercati, insieme ai budget pubblicitari per il prodotto in ciascuno di quei mercati per tre diversi media: TV, radio, e giornali. Non è possibile aumentare direttamente le vendite del prodotto. D altra parte, si può controllare la pubblicità in ciascuno dei tre media. Pertanto, se stabiliamo che vi è un associazione tra pubblicità e vendite, allora possiamo agire sul budget pubblicitario, e quindi, indirettamente sulle vendite. In altre parole, l obiettivo è quello di sviluppare un modello accurato utilizzabile per prevedere le vendite sulla base dei budget per i tre media. Tre regressioni separate (linea blu) Vendite su pubblicità TV, Radio e Giornali Possiamo prevedere le vendite utilizzando questi tre? Forse possiamo fare meglio utilizzando un modello Simbologia Vendite f(tv, Radio, Giornali) Nell esempio, Vendite è la variabile risposta o dipendente o obbiettivo che desideriamo prevedere. Genericamente indicata con Y. TV è una variabile indipendente o input o predittore. Chiamiamola X 1. Analogamente definiamo Radio come X 2 e così via. Possiamo fare riferimento genericamente al vettore input X = ( X 1, X 2, X 3 ) T A questo punto possiamo riscrivere il nostro modello come Y = f(x) + ε file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 2/19

3 dove ε è un termine d errore casuale, che è indipendente da X e ha media zero. In questa formulazione f rappresenta l informazione sistematica che X fornisce su Y. Reddito Y = f(x) + ε Come altro esempio, si consideri la relazione tra reddito e anni di educazione per 30 persone nel set di dati sul reddito (income). Il grafico suggerisce che si potrebbe essere in grado di prevedere il reddito con gli anni di educazione. Tuttavia, la funzione f che collega la variabile input alla variabile output è sconosciuta in generale. In questa situazione si deve stimare f basandosi sui punti osservati. Statistical learning In sostanza, il termine Statistical learning si riferisce ad una serie di approcci per la stima di f. In questa prima lezione si delineano alcuni dei principali concetti teorici che si presentano nella stima di f, nonché gli strumenti per valutare la bontà delle stime ottenute. A cosa ci serve? Due ragioni principali 1 Previsione f file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 3/19

4 Con una buona f possiamo fare previsioni di Y in base a nuovi punti X = x 2 Inferenza Possiamo capire quali componenti di X 1 X 2 X p sono importanti per spiegare Y, e quali sono irrilevanti. Ad esempio Anzianità e Anni di Educazione hanno un grande impatto sul reddito, ma Stato civile di solito no. A seconda della complessità di f, potremmo essere in grado di capire come ogni componente di X agisce su Y. Previsione In molte situazioni, un insieme di input X è prontamente disponibile, ma l output Y non può essere facilmente ottenuto. In questa situazione, siamo in grado di prevedere Y con dove rappresenta la nostra stima per, e rappresenta la previsione risultante per. In questo approccio, è spesso trattato come una scatola nera, nel senso che, tipicamente, non ci interessa la forma esatta di, purché fornisca previsioni accurate per Y. Errore riducibile e errore irriducibile L accuratezza di come previsione per Y dipende da due quantità; l errore riducibile e l errore irriducibile. Errore riducibile generalmente X = (,,, ) Y^ = (X) f Y^ Y Y^ non è una stima perfetta per f, e questo introduce qualche errore. Questo errore è riducibile perché possiamo potenzialmente migliorare l accuratezza di utilizzando tecniche via via migliori di Statistical learning per stimare f. Errore irriducibile Y è anche una funzione di ε che, per definizione, non può essere previsto con X. la variabilità associato a ε influisce sull accuratezza delle nostre previsioni. ε può contenere variabili non misurate che sono utili nel predire Y : ε può contenere variazione intrinseca al fenomeno. X Y^ = (X) Si consideri una data stima e un insieme di predittori, che producono la previsione. Supponiamo per un momento che sia f che X siano fissi. Si ha E(Y Y^) 2 = E[f(X) + ε (X)] 2 = [f(x) (X)] 2 + errore riducibile V ar(ε) errore irriducibile E(Y ^ 2 file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 4/19

5 rappresenta la media, o valore atteso, del quadrato della differenza tra il valore previsto e effettivo di Y, V ar(ε) la varianza associata all errore ε.questo valore è quasi sempre sconosciuto in pratica. Inferenza In questo caso è importante capire la relazione tra X e Y, o più specificamente, comprendere come Y cambia in funzione di X 1,, Xp. Quali fattori predittivi sono associati con la risposta? È spesso il caso che solo una piccola frazione dei predittori disponibili siano sostanzialmente associati a Y. Identificare i pochi predittori importanti può essere estremamente utile. Qual è la relazione tra la risposta e ogni predittore? Alcuni predittori possono avere un rapporto positivo con Y, nel senso che aumentando il predittore aumenta anche Y. Altri predittori possono avere una relazione opposta. Il rapporto tra la risposta e un dato predittore può dipendere anche i valori degli altri predittori. Il rapporto tra Y e X è lineare? O è più complicato? Storicamente, la maggior parte dei metodi per stimare f hanno preso forma lineare. In alcune situazioni, tale ipotesi è ragionevole o auspicabile. Ma spesso il vero rapporto è più complicato. Esempi Si consideri una società che è interessata a condurre una campagna di direct marketing. L obiettivo è quello di identificare le persone che risponderanno positivamente a una mail, sulla base di osservazioni di variabili demografiche misurata su ogni singola unità. Si consideri il problema relativo al set di dati Advertising che consiste nelle vendite del prodotto in 200 diversi mercati, insieme con budget pubblicitari per il prodotto in ciascuno di quei mercati per tre diversi media: TV, radio, e giornali. In un contesto immobiliare, si può cercare di legare il valore delle case per input quali il tasso di criminalità, la zonizzazione, la distanza da un fiume, la qualità dell aria, presenza di scuole, livello di reddito della comunità, le dimensioni delle case, e così via. In alternativa, si può semplicemente essere interessati a predire il valore di una casa date le sue caratteristiche Come stimare Simbologia E(Y Y^) 2 f una panoramica Abbiamo a disposizione una serie di casi, i dati osservati, che useremo per stimare f. Indicheremo sempre con n il numero di unità osservate. I dati usati per stimare f vengono definiti training data. x ij rappresenta il valore del predittore j, o input, per l osservazione i, dove i = 1, 2,, n j = 1, 2,, p. e file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 5/19

6 Corrispondentemente, I cd training data sono dunque rappresenta la variabile di risposta per l osservazione i esima. Vogliamo trovare una funzione tale che per ogni osservazione. In linea di massima, la maggior parte dei metodi di statistical learning possono essere classificati in parametrici nonparametrici Metodi parametrici I metodi parametrici implicano un approccio in due fasi: y i {( x 1, y 1 ), ( x 2, y 2 ),, ( x n, y n )}, dove x i = ( x i1, x i2,, x ip ) T Y (X) (X, Y ) 1. In primo luogo, si fa una supposizione circa la forma funzionale, o la forma di f. 2. Dopo aver selezionato un modello ( f ), abbiamo bisogno di una procedura di stima di f che utilizza i training data. Per esempio, una semplice ipotesi è che f sia lineare in X: f(x) = β 0 β 1 X 1 β 2 X 2 β p X p in questo caso il problema della stima di f è notevolmente semplificato. Uno deve solo stimare p + 1 coefficienti β 0, β 1,, β p. Anche se non è quasi mai corretto, un modello lineare è spesso una buona, ed interpretabile, approssimazione a. f(x) Il potenziale svantaggio di un approccio parametrico è che il modello che scegliamo di solito non corrisponde alla vera f. Se il modello scelto è troppo lontano da f, allora la nostra stima sarà povera (o fuorviante). Possiamo cercare di risolvere questo problema scegliendo modelli flessibili che possono adattarsi a diverse forme funzionali possibili per f. In generale, adattando un modello più flessibile richiede la stima di un maggior numero di parametri. Modelli troppo complessi possono portare ad un fenomeno noto come overfitting dei dati. In sostanza il modello segue gli errori, o rumore, troppo da vicino. Metodi non parametrici I metodi non parametrici non fanno ipotesi esplicite circa la forma funzionale di f. Invece cercano una stima di f che sia il più vicino possibile ai punti dati Tali approcci possono avere un grande vantaggio rispetto agli approcci parametrici: evitando l assunzione di una forma funzionale particolare f, hanno il potenziale per adattarsi con precisione una gamma più ampia di possibili forme per f. file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 6/19
 = + + + +. β 0 β 1 X 1 β 2 X 2 β p X p in questo caso il problema della stima di f è notevolmente semplificato.")
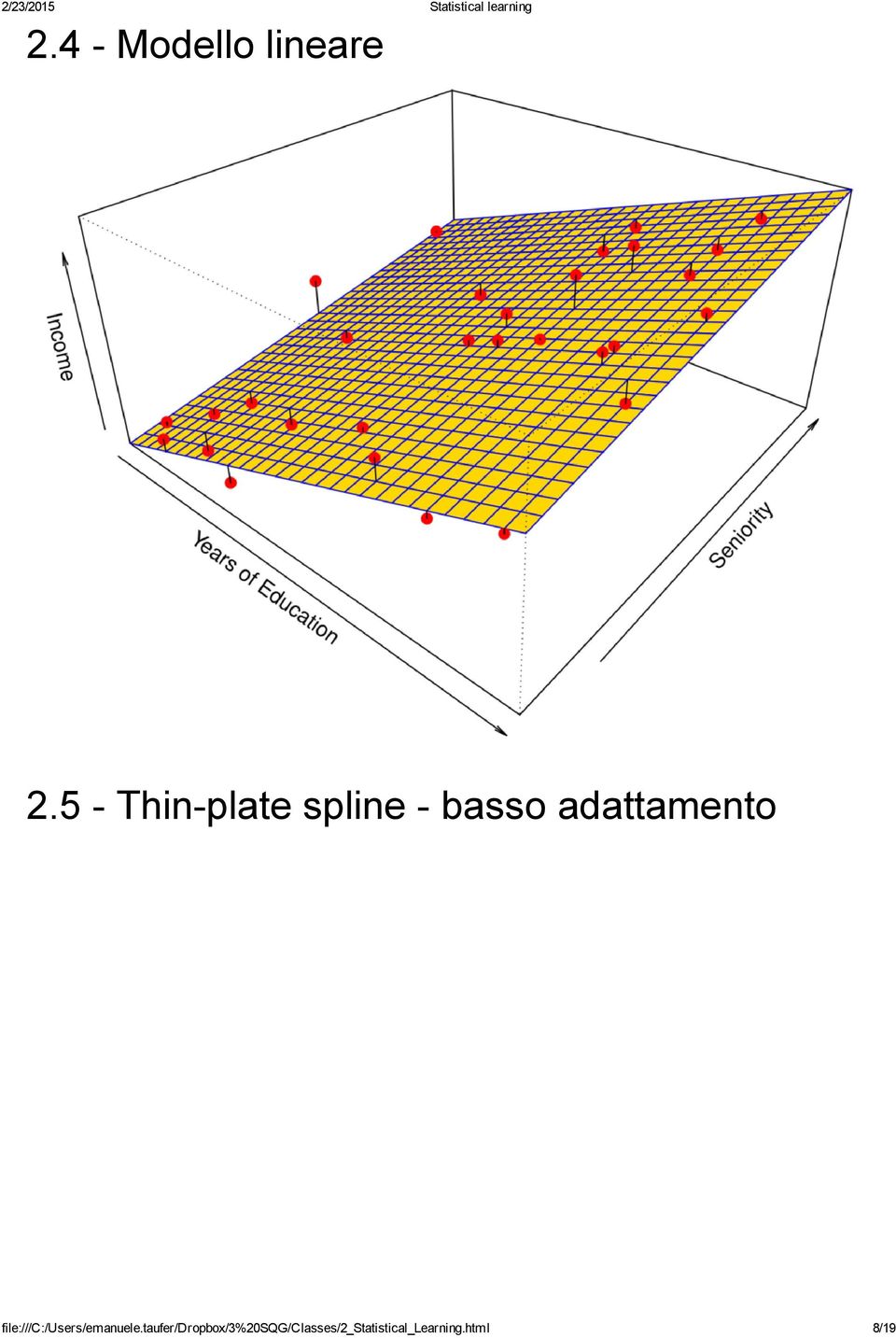
7 Ma gli approcci non parametrici soffrono di un inconveniente: poiché non riducono il problema della stima di f a quello di un piccolo numero di parametri ( p + 1) di solito un numero di osservazioni ( n) elevato è richiesto per ottenere una stima accurata di f. Esempio: Income data Nei grafici seguenti, proviamo a confrontare diverse soluzioni di stima di f per il problema I grafici seguenti mostrano: Income = f(years of education, Seniority) la vera f sottostante ai dati (generati al computer) il modello parametrico un modello thin plate spline (non parametrico) con basso grado di adattamento con elevato grado di adattamento 2.3 Vera f income + education + seniority. β 0 β 1 β 2 file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 7/19
 la vera f sottostante ai dati (generati al computer) il modello parametrico un modello thin plate spline (non parametrico) con basso")

8 2.4 Modello lineare 2.5 Thin plate spline basso adattamento file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 8/19
9 2.6 Thin plate spline alto adattamento file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 9/19

10 Trade off flessibilità interpretabilità Tra i molti metodi disponibili, alcuni sono meno flessibili, o più restrittivi, nel senso che possono produrre solo relativamente piccola gamma di forme per stimare f. Se siamo interessati all inferenza, modelli restrittivi sono più interpretabili Se siamo interessati alla previsione la precisione del modello diventa fondamentale Supervised e unsupervised Statistical Learning Molti problemi di Statistical learning rientrano in una delle due categorie: supervised e unsupervised. Nel Supervised learning abbiamo sia variabili input ( X) che output ( Y ). regressione lineare, regressione logistica, modelli additivi generalizzati, etc. Nell unsupervised learning, tipicamente, non è osservata la variabile risposta Y. cluster analysis: ad esempio raggruppare consumatori in base a caratteristiche demografiche osservate sperando che queste possano essere associate ad abitudini di consumo. Problemi di regressione e di classificazione Le variabili possono essere caratterizzate come file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 10/19
 che output ( Y ).")
11 Quantitative (misurate su scala numerica) Qualitative (Classificano l unità in una di K classi differenti) Tipicamente se la Y è quantitativa si parla di regressione Se la Y è qualitativa si parla di classificazione In entrambi i casi possiamo avere variabili input, X, sia di tipo qualitativo che quantitativo. Valutazione della bontà del modello Una delle misure più usate per la valutazione dei modelli è l errore quadratico medio o MSE (mean squared error) nell acronimo inglese: n 1 MSE = ( y i ( x i )) 2 ( x i ) n i=1 L MSE sarà piccolo se i valori previsti, sono molto vicini ai valori osservati ; viceversa tenderà a crescere tanto più sono le differenze previsti osservati che differiscono sostanzialmente. y i L MSE definito sopra è calcolato utilizzando i training data Tuttavia, si è più interessati alla precisione delle predizioni che otteniamo quando applichiamo dati nuovi, i cd test data. a Test MSE e training MSE {(, ), (, ),, (, )} Dati i training data x 1 y 1 x 2 y 2 x n y n modello con training MSE molto basso. può essere relativamente semplice trovare un ( x 0 ) y 0 (, ) Invece, vogliamo sapere se è approssimativamente uguale a, dove x 0 y 0 è un osservazione nuova, non presente nei training data. Vogliamo scegliere il metodo che dà un test MSE molto basso. Se abbiamo un gran numero di osservazioni test, potremmo calcolare Ave( y 0 ( x 0 )) 2, dove Ave sta per media (average). Ossia l errore quadratico medio di previsione per le osservazioni test ( X 0, Y 0 ). In altre parole, vorremmo selezionare il modello per il quale, il test MSE sia il più piccolo possibile. Tipicamente test MSE e training MSE possono differire sostanzialmente. Se uno ha a disposizione due set di dati, training e test può provare ad adattare diversi modelli ai training data e scegliere quello che presenta test MSE più basso. Se questo non è il caso si può ricorrere ad altre tecniche, ad esempio la cross validazione, che discuteremo nelle prossime lezioni. Esempio 1: f non lineare file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 11/19
 n i=1 L MSE sarà piccolo se i valori previsti, sono molto vicini ai valori osservati ; viceversa tenderà a crescere tanto più sono le differenze previsti osservati che differiscono")
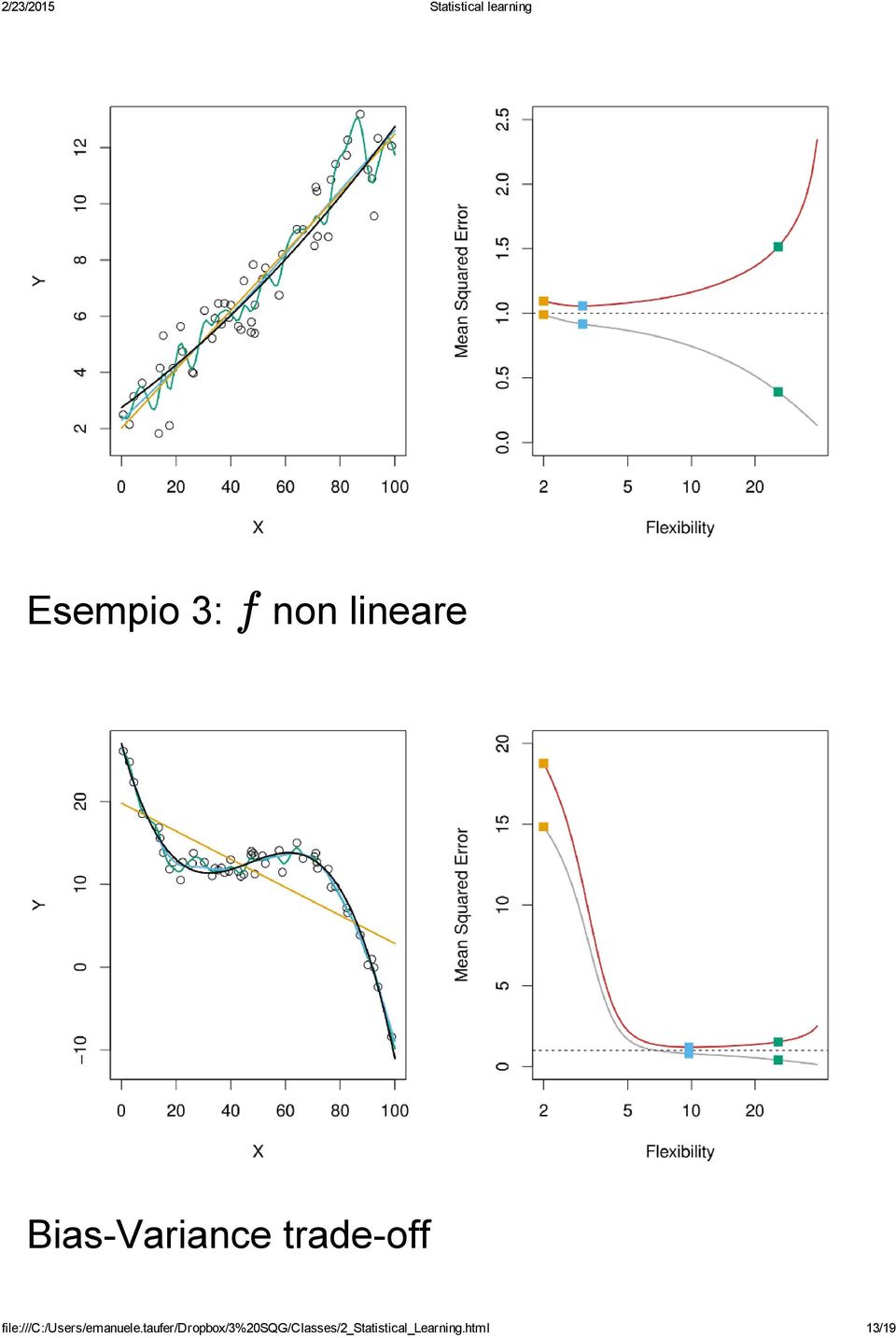
12 La figura sopra mostra: A sinistra: i dati simulati da f (in nero) e tre possibili stime: regressione lineare (arancio); smoothing splines (blu e verde) A destra: test MSE (rosso) e training MSE (grigio) La flessibilità è misurata in termini di parametri (più parametri più flessibilità) la regressione lineare in questo caso ha due parametri (intercetta e pendenza) L andamento a U del test MSE è molto tipico e mostra che un overfitting dei dati è spesso fuorviante Esempio 2: f lineare file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 12/19

13 Esempio 3: f non lineare Bias Variance trade off file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 13/19
14 La forma a U osservata nel Test MSE è il risultato di due caratteristiche, spesso in contrasto tra loro, delle tecniche di statistical learning: la varianza ed il bias ( o distorsione) Il valore atteso del test MSE può essere scritto V ar( )) E( y 0 ( x 0 )) 2 = V ar( ( x 0 )) + [Bias( ( x 0 ))] 2 + V ar(ε) misura il cambiamento atteso di data diverso. Diversi training data infatti ottengono diverse flessibilità del metodo di stima, maggiore è la variabilità di. Bias( ( x 0 )) = E( ( x 0 ) f( x 0 )) se la sua stima avviene attraverso un training. In generale, più elevata la si riferisce all errore introdotto approssimando un problema reale, che può essere estremamente complicato, con un modello semplice. Ad esempio, la regressione lineare presuppone che vi sia un rapporto lineare tra Y e X 1, X2,, X p. E improbabile che sia così in realtà e quindi l uso della regressione lineare indurrà distrosione nella stima di f Scomposizione Bias Var Esempi 1,2,3 Di regola, più è flessibile il metodo che si usa, più la varianza tenderà ad aumentare ed il bias a diminuire. Il tasso relativo di variazione di queste due quantità determina se il test MSE aumenta o diminuisce. Tuttavia, ad un certo punto, l aumento della flessibilità ha poco impatto sul bias, ma inizia ad aumentare significativamente la varianza. Quando questo accade il test MSE aumenta. Classificazione Molti dei concetti discussi finora, quale il bias variance trade off, valgono anche nel caso della classificazione con modifiche minime dovute al fatto che Y non è più numerica. f {( x 1, y 1 ),, ( x n, y n )},, Supponiamo di stimare sulla base dei training data, dove ora sono qualitative file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 14/19 ^ y 1 y n

15 L approccio più comune per quantificare la bontà della stima 1 n n i=1 I( ) y i y^i è il tasso di errore per i training data dove è la classe prevista per la esima unità da. y^i i I( ) y i y^i è un indicatore, ossia è uguale a 0 se y i = y^i, uguale a 1 se y i y^i La formula calcola la frazione di classificazioni scorrette. Tasso di errore training e test Analogamente a quanto discusso per il contesto della regressione, si è di solito più interessati alla performance di nel caso di unità non presenti nei training data Definiamo allora il tasso di errore test (test error rate) associato ad un set di osservazioni test del tipo ( x 0, y 0 ): Una buona è quella per cui il test error rate è il più basso possibile. Il classificatore di Bayes E possibile dimostrare che il test error rate definito sopra è minimo, in media, quando la procedura di classificazione è fatta usando una semplicissima regola che assegna l unità alla classe più probabile data l informazione dei predittori. Il classificatore di Bayes assegna l osservazione test, con predittore x 0, alla classe j, ( ), per la quale è massima. j = 1, 2, K P( = j X = ) Y 0 x 0 è una probabilità condizionata: la probabilità che Y = j data l informazione fornita da x 0. Il classificatore di Bayes produce il minor test error rate possibile, definito Bayes error rate. In pratica non riusciamo mai a calcolare il classificatore di Bayes poichè non c è informazione a sufficienza. Classificatore KNN Ave(I( )) y i y^i P(Y = j X = ) x 0 Dato un intero positivo K e un osservazione test x 0, il classificatore KNN ( K nearest neighbors) identifica i K punti più vicini a x 0, rappresentati da N 0. stima la probabilità condizionale per classe j come frazione di punti in N 0 la cui risposta è uguale a j: 1 P r(y = j X = ) = I( = j) file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 15/19 i 0
 associato ad un set di osservazioni test del tipo ( x 0, y 0 ): Una buona è quella per cui il test error rate è il più basso possibile.")

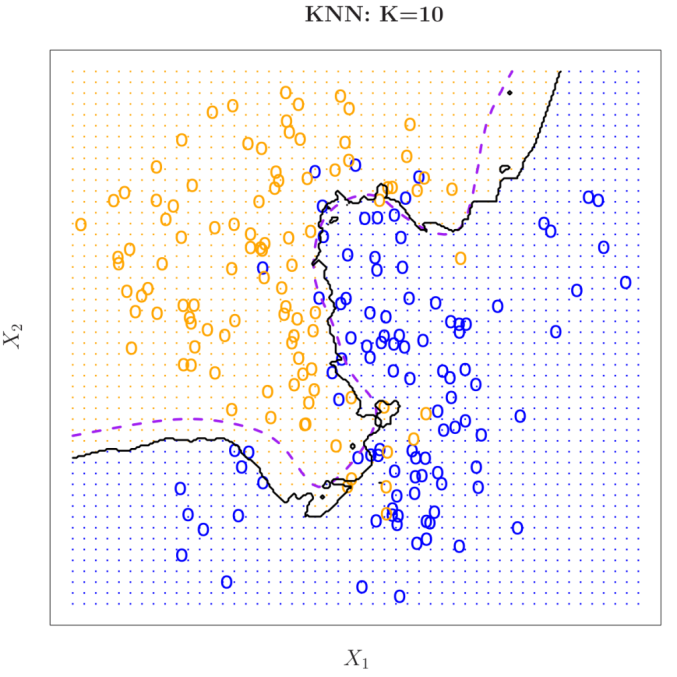
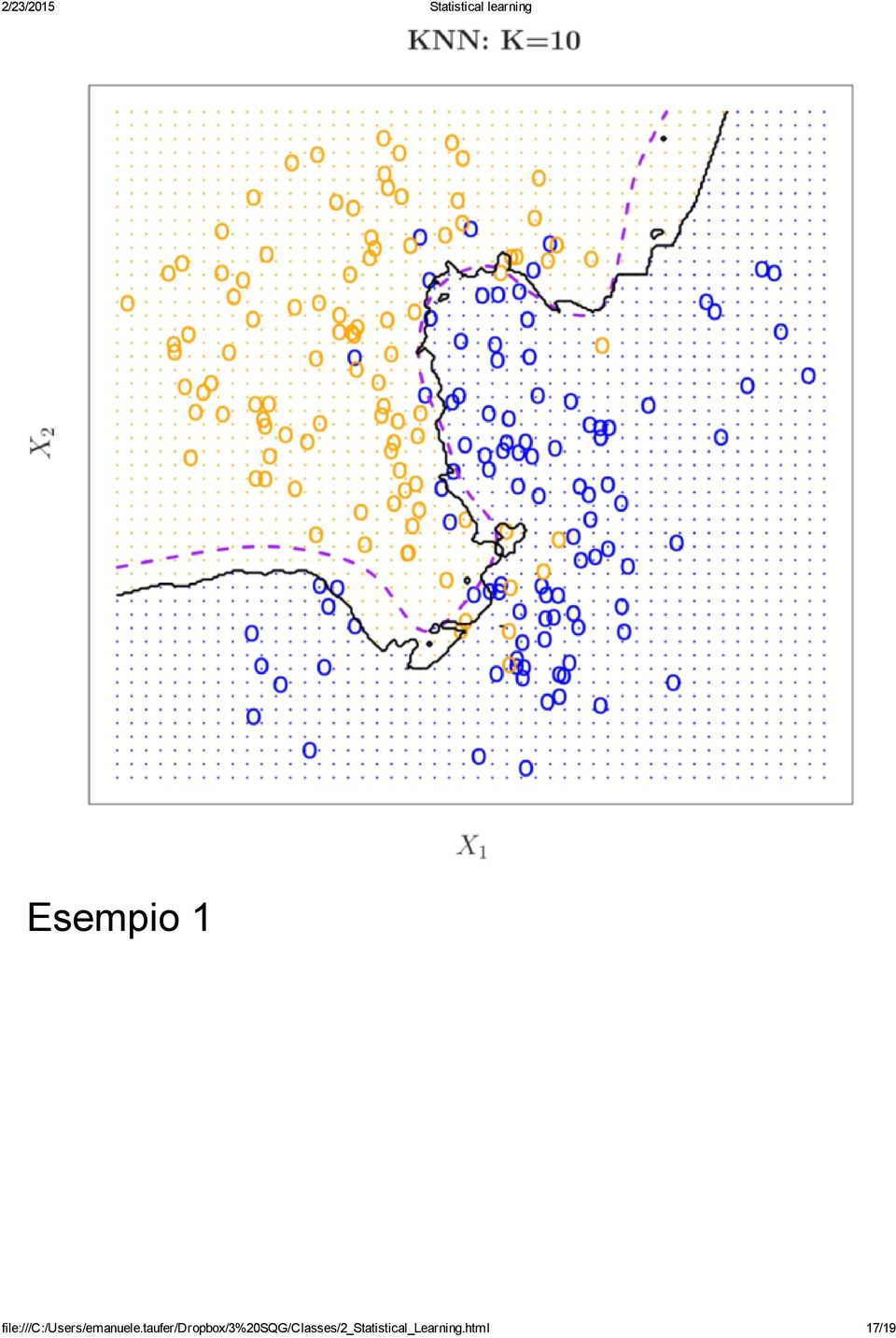
16 P r(y = j X = ) = I( = j) 1 x 0 K i N 0 y i Infine, KNN applica la regola di Bayes e classifica l osservazione test x 0 nella classe con il maggior probabilità. Esempio K=3 Esempio 1 file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 16/19

17 Esempio 1 file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 17/19
18 Error rates file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 18/19
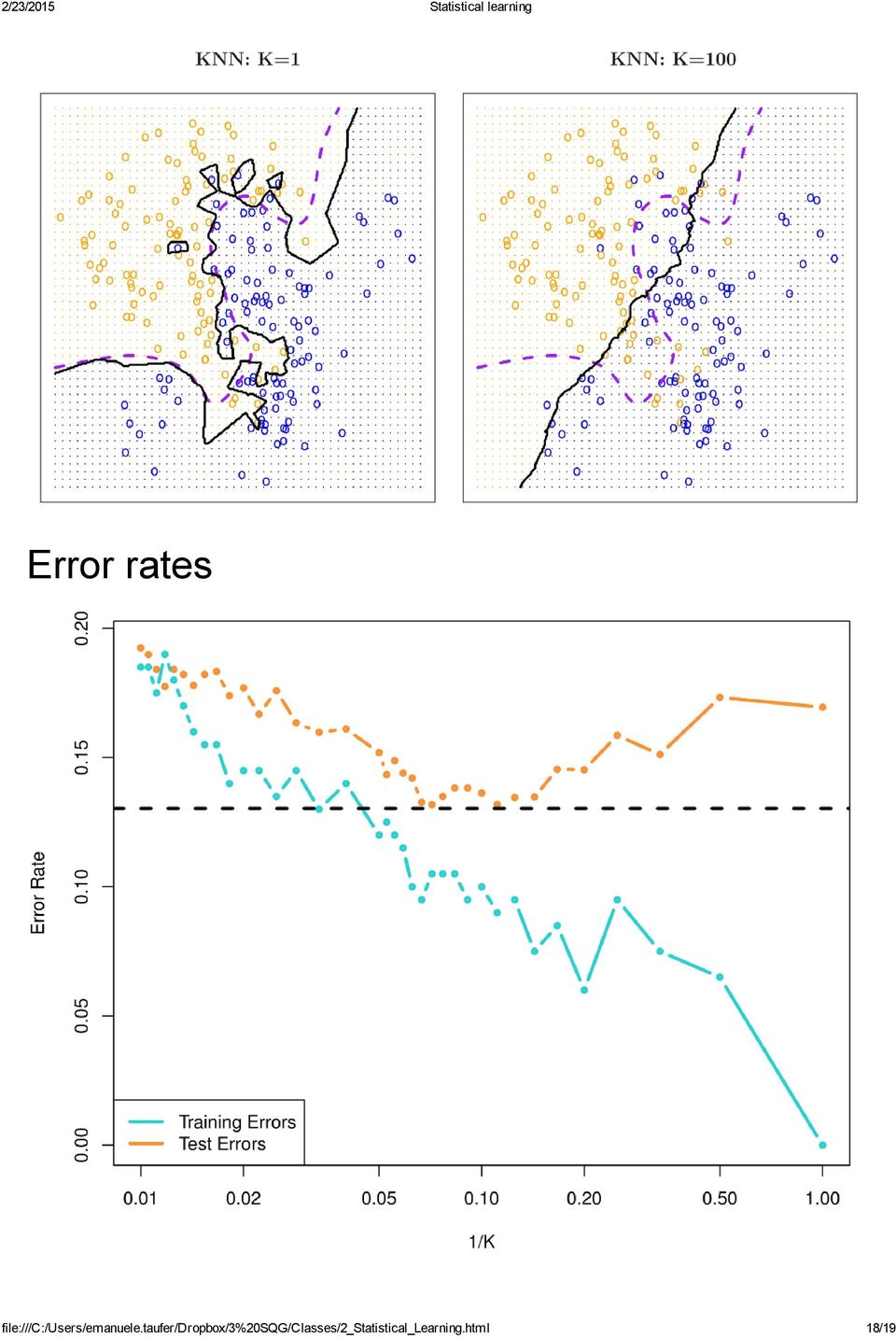
19 Riferimenti bibliografici An Introduction to Statistical Learning, with applications in R" (Springer, 2013) Alcune delle figure in questa presentazione sono tratte dal testo con il permesso degli autori: G. James, D. Witten, T. Hastie e R. Tibshirani " file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html 19/19

Regressione logistica. Strumenti quantitativi per la gestione
 Regressione logistica Strumenti quantitativi per la gestione Emanuele Taufer file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/4a_rlg.html#(1) 1/25 Metodi di classificazione I metodi usati per analizzare
Regressione logistica Strumenti quantitativi per la gestione Emanuele Taufer file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/4a_rlg.html#(1) 1/25 Metodi di classificazione I metodi usati per analizzare
Regressione logistica
 Regressione logistica Strumenti quantitativi per la gestione Emanuele Taufer Metodi di classificazione Tecniche principali Alcuni esempi Data set Default I dati La regressione logistica Esempio Il modello
Regressione logistica Strumenti quantitativi per la gestione Emanuele Taufer Metodi di classificazione Tecniche principali Alcuni esempi Data set Default I dati La regressione logistica Esempio Il modello
Regressione Mario Guarracino Data Mining a.a. 2010/2011
 Regressione Esempio Un azienda manifatturiera vuole analizzare il legame che intercorre tra il volume produttivo X per uno dei propri stabilimenti e il corrispondente costo mensile Y di produzione. Volume
Regressione Esempio Un azienda manifatturiera vuole analizzare il legame che intercorre tra il volume produttivo X per uno dei propri stabilimenti e il corrispondente costo mensile Y di produzione. Volume
Analisi di scenario File Nr. 10
 1 Analisi di scenario File Nr. 10 Giorgio Calcagnini Università di Urbino Dip. Economia, Società, Politica giorgio.calcagnini@uniurb.it http://www.econ.uniurb.it/calcagnini/ http://www.econ.uniurb.it/calcagnini/forecasting.html
1 Analisi di scenario File Nr. 10 Giorgio Calcagnini Università di Urbino Dip. Economia, Società, Politica giorgio.calcagnini@uniurb.it http://www.econ.uniurb.it/calcagnini/ http://www.econ.uniurb.it/calcagnini/forecasting.html
Statistical learning. Strumenti quantitativi per la gestione
 Statistical learning Strumenti quantitativi per la gestione Emanuele Taufer file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html#(1) 1/42 Vendite Supponiamo di voler capire
Statistical learning Strumenti quantitativi per la gestione Emanuele Taufer file:///c:/users/emanuele.taufer/dropbox/3%20sqg/classes/2_statistical_learning.html#(1) 1/42 Vendite Supponiamo di voler capire
Verifica di ipotesi e intervalli di confidenza nella regressione multipla
 Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Capitolo 13: L offerta dell impresa e il surplus del produttore
 Capitolo 13: L offerta dell impresa e il surplus del produttore 13.1: Introduzione L analisi dei due capitoli precedenti ha fornito tutti i concetti necessari per affrontare l argomento di questo capitolo:
Capitolo 13: L offerta dell impresa e il surplus del produttore 13.1: Introduzione L analisi dei due capitoli precedenti ha fornito tutti i concetti necessari per affrontare l argomento di questo capitolo:
LEZIONE n. 5 (a cura di Antonio Di Marco)
") LEZIONE n. 5 (a cura di Antonio Di Marco) IL P-VALUE (α) Data un ipotesi nulla (H 0 ), questa la si può accettare o rifiutare in base al valore del p- value. In genere il suo valore è un numero molto piccolo,
LEZIONE n. 5 (a cura di Antonio Di Marco) IL P-VALUE (α) Data un ipotesi nulla (H 0 ), questa la si può accettare o rifiutare in base al valore del p- value. In genere il suo valore è un numero molto piccolo,
risulta (x) = 1 se x < 0.
 = 1 se x < 0.") Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Pro e contro delle RNA
 Pro e contro delle RNA Pro: - flessibilità: le RNA sono approssimatori universali; - aggiornabilità sequenziale: la stima dei pesi della rete può essere aggiornata man mano che arriva nuova informazione;
Pro e contro delle RNA Pro: - flessibilità: le RNA sono approssimatori universali; - aggiornabilità sequenziale: la stima dei pesi della rete può essere aggiornata man mano che arriva nuova informazione;
VALORE DELLE MERCI SEQUESTRATE
 La contraffazione in cifre: NUOVA METODOLOGIA PER LA STIMA DEL VALORE DELLE MERCI SEQUESTRATE Roma, Giugno 2013 Giugno 2013-1 Il valore economico dei sequestri In questo Focus si approfondiscono alcune
La contraffazione in cifre: NUOVA METODOLOGIA PER LA STIMA DEL VALORE DELLE MERCI SEQUESTRATE Roma, Giugno 2013 Giugno 2013-1 Il valore economico dei sequestri In questo Focus si approfondiscono alcune
Aspettative, Produzione e Politica Economica
 Aspettative, Produzione e Politica Economica In questa lezione: Studiamo gli effetti delle aspettative sui livelli di spesa e produzione. Riformuliamo il modello IS-LM in un contesto con aspettative. Determiniamo
Aspettative, Produzione e Politica Economica In questa lezione: Studiamo gli effetti delle aspettative sui livelli di spesa e produzione. Riformuliamo il modello IS-LM in un contesto con aspettative. Determiniamo
Perché si fanno previsioni?
 Perché si fanno previsioni? Si fanno previsioni per pianificare un azione quando c è un lag fra momento della decisione e momento in cui l evento che ci interessa si verifica. ESEMPI decisioni di investimento
Perché si fanno previsioni? Si fanno previsioni per pianificare un azione quando c è un lag fra momento della decisione e momento in cui l evento che ci interessa si verifica. ESEMPI decisioni di investimento
MICROECONOMIA La teoria del consumo: Alcuni Arricchimenti. Enrico Saltari Università di Roma La Sapienza
 MICROECONOMIA La teoria del consumo: Alcuni Arricchimenti Enrico Saltari Università di Roma La Sapienza 1 Dotazioni iniziali Il consumatore dispone ora non di un dato reddito monetario ma di un ammontare
MICROECONOMIA La teoria del consumo: Alcuni Arricchimenti Enrico Saltari Università di Roma La Sapienza 1 Dotazioni iniziali Il consumatore dispone ora non di un dato reddito monetario ma di un ammontare
Statistica. Lezione 6
 Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
Principi di analisi causale Lezione 2
 Anno accademico 2007/08 Principi di analisi causale Lezione 2 Docente: prof. Maurizio Pisati Logica della regressione Nella sua semplicità, l espressione precedente racchiude interamente la logica della
Anno accademico 2007/08 Principi di analisi causale Lezione 2 Docente: prof. Maurizio Pisati Logica della regressione Nella sua semplicità, l espressione precedente racchiude interamente la logica della
Domande a scelta multipla 1
 Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
GESTIONE DELLE TECNOLOGIE AMBIENTALI PER SCARICHI INDUSTRIALI ED EMISSIONI NOCIVE LEZIONE 10. Angelo Bonomi
 GESTIONE DELLE TECNOLOGIE AMBIENTALI PER SCARICHI INDUSTRIALI ED EMISSIONI NOCIVE LEZIONE 10 Angelo Bonomi CONSIDERAZIONI SUL MONITORAGGIO Un monitoraggio ottimale dipende dalle considerazioni seguenti:
GESTIONE DELLE TECNOLOGIE AMBIENTALI PER SCARICHI INDUSTRIALI ED EMISSIONI NOCIVE LEZIONE 10 Angelo Bonomi CONSIDERAZIONI SUL MONITORAGGIO Un monitoraggio ottimale dipende dalle considerazioni seguenti:
Equivalenza economica
 Equivalenza economica Calcolo dell equivalenza economica [Thuesen, Economia per ingegneri, capitolo 4] Negli studi tecnico-economici molti calcoli richiedono che le entrate e le uscite previste per due
Equivalenza economica Calcolo dell equivalenza economica [Thuesen, Economia per ingegneri, capitolo 4] Negli studi tecnico-economici molti calcoli richiedono che le entrate e le uscite previste per due
VERIFICA DELLE IPOTESI
 VERIFICA DELLE IPOTESI Nella verifica delle ipotesi è necessario fissare alcune fasi prima di iniziare ad analizzare i dati. a) Si deve stabilire quale deve essere l'ipotesi nulla (H0) e quale l'ipotesi
VERIFICA DELLE IPOTESI Nella verifica delle ipotesi è necessario fissare alcune fasi prima di iniziare ad analizzare i dati. a) Si deve stabilire quale deve essere l'ipotesi nulla (H0) e quale l'ipotesi
(a cura di Francesca Godioli)
") lezione n. 12 (a cura di Francesca Godioli) Ad ogni categoria della variabile qualitativa si può assegnare un valore numerico che viene chiamato SCORE. Passare dalla variabile qualitativa X2 a dei valori
lezione n. 12 (a cura di Francesca Godioli) Ad ogni categoria della variabile qualitativa si può assegnare un valore numerico che viene chiamato SCORE. Passare dalla variabile qualitativa X2 a dei valori
Statistical learning. Strumenti quantitativi per la gestione. Emanuele Taufer
 Statistical learning Strumenti quantitativi per la gestione Emanuele Taufer Vendite (Sales) Supponiamo di voler capire come migliorare le vendite di un determinato prodotto. Il Set di dati Advertising
Statistical learning Strumenti quantitativi per la gestione Emanuele Taufer Vendite (Sales) Supponiamo di voler capire come migliorare le vendite di un determinato prodotto. Il Set di dati Advertising
f(x) = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da
 = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da") Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
Librerie digitali. Video. Gestione di video. Caratteristiche dei video. Video. Metadati associati ai video. Metadati associati ai video
 Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Metodi statistici per l economia (Prof. Capitanio) Slide n. 9. Materiale di supporto per le lezioni. Non sostituisce il libro di testo
 Slide n. 9. Materiale di supporto per le lezioni. Non sostituisce il libro di testo") Metodi statistici per l economia (Prof. Capitanio) Slide n. 9 Materiale di supporto per le lezioni. Non sostituisce il libro di testo 1 TEST D IPOTESI Partiamo da un esempio presente sul libro di testo.
Metodi statistici per l economia (Prof. Capitanio) Slide n. 9 Materiale di supporto per le lezioni. Non sostituisce il libro di testo 1 TEST D IPOTESI Partiamo da un esempio presente sul libro di testo.
La dispersione dei prezzi al consumo. I risultati di un indagine empirica sui prodotti alimentari.
 La dispersione dei prezzi al consumo. I risultati di un indagine empirica sui prodotti alimentari. Giovanni Anania e Rosanna Nisticò EMAA 14/15 X / 1 Il problema Un ottimo uso del vostro tempo! questa
La dispersione dei prezzi al consumo. I risultati di un indagine empirica sui prodotti alimentari. Giovanni Anania e Rosanna Nisticò EMAA 14/15 X / 1 Il problema Un ottimo uso del vostro tempo! questa
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 29-Analisi della potenza statistica vers. 1.0 (12 dicembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Elementi di Psicometria con Laboratorio di SPSS 1 29-Analisi della potenza statistica vers. 1.0 (12 dicembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Statistica e biometria. D. Bertacchi. Variabili aleatorie. V.a. discrete e continue. La densità di una v.a. discreta. Esempi.
 Iniziamo con definizione (capiremo fra poco la sua utilità): DEFINIZIONE DI VARIABILE ALEATORIA Una variabile aleatoria (in breve v.a.) X è funzione che ha come dominio Ω e come codominio R. In formule:
Iniziamo con definizione (capiremo fra poco la sua utilità): DEFINIZIONE DI VARIABILE ALEATORIA Una variabile aleatoria (in breve v.a.) X è funzione che ha come dominio Ω e come codominio R. In formule:
1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:
 Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:") Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
Aspettative, consumo e investimento
 Aspettative, consumo e investimento In questa lezione: Studiamo come le aspettative di reddito e ricchezza futuro determinano le decisioni di consumo e investimento degli individui. Studiamo cosa determina
Aspettative, consumo e investimento In questa lezione: Studiamo come le aspettative di reddito e ricchezza futuro determinano le decisioni di consumo e investimento degli individui. Studiamo cosa determina
PROBABILITÀ - SCHEDA N. 2 LE VARIABILI ALEATORIE
 Matematica e statistica: dai dati ai modelli alle scelte www.dima.unige/pls_statistica Responsabili scientifici M.P. Rogantin e E. Sasso (Dipartimento di Matematica Università di Genova) PROBABILITÀ -
Matematica e statistica: dai dati ai modelli alle scelte www.dima.unige/pls_statistica Responsabili scientifici M.P. Rogantin e E. Sasso (Dipartimento di Matematica Università di Genova) PROBABILITÀ -
Economia Internazionale e Politiche Commerciali (a.a. 12/13)
") Economia Internazionale e Politiche Commerciali (a.a. 12/13) Soluzione Esame (11 gennaio 2013) Prima Parte 1. (9 p.) (a) Ipotizzate che in un mondo a due paesi, Brasile e Germania, e due prodotti, farina
Economia Internazionale e Politiche Commerciali (a.a. 12/13) Soluzione Esame (11 gennaio 2013) Prima Parte 1. (9 p.) (a) Ipotizzate che in un mondo a due paesi, Brasile e Germania, e due prodotti, farina
Regressione lineare multipla Strumenti quantitativi per la gestione
 Regressione lineare multipla Strumenti quantitativi per la gestione Emanuele Taufer Regressione lineare multipla (RLM) Esempio: RLM con due predittori Stima dei coefficienti e previsione Advertising data
Regressione lineare multipla Strumenti quantitativi per la gestione Emanuele Taufer Regressione lineare multipla (RLM) Esempio: RLM con due predittori Stima dei coefficienti e previsione Advertising data
Capitolo 10 Z Elasticità della domanda
 Capitolo 10 Z Elasticità della domanda Sommario Z 1. L elasticità della domanda rispetto al prezzo. - 2. La misura dell elasticità. - 3. I fattori determinanti l elasticità. - 4. L elasticità rispetto
Capitolo 10 Z Elasticità della domanda Sommario Z 1. L elasticità della domanda rispetto al prezzo. - 2. La misura dell elasticità. - 3. I fattori determinanti l elasticità. - 4. L elasticità rispetto
La teoria dell offerta
 La teoria dell offerta Tecnologia e costi di produzione In questa lezione approfondiamo l analisi del comportamento delle imprese e quindi delle determinanti dell offerta. In particolare: è possibile individuare
La teoria dell offerta Tecnologia e costi di produzione In questa lezione approfondiamo l analisi del comportamento delle imprese e quindi delle determinanti dell offerta. In particolare: è possibile individuare
Domande a scelta multipla 1
 Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale
 Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale Facoltà di Scienze della Comunicazione Università di Teramo Scelta
Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale Facoltà di Scienze della Comunicazione Università di Teramo Scelta
come nasce una ricerca
 PSICOLOGIA SOCIALE lez. 2 RICERCA SCIENTIFICA O SENSO COMUNE? Paola Magnano paola.magnano@unikore.it ricevimento: martedì ore 10-11 c/o Studio 16, piano -1 PSICOLOGIA SOCIALE COME SCIENZA EMPIRICA le sue
PSICOLOGIA SOCIALE lez. 2 RICERCA SCIENTIFICA O SENSO COMUNE? Paola Magnano paola.magnano@unikore.it ricevimento: martedì ore 10-11 c/o Studio 16, piano -1 PSICOLOGIA SOCIALE COME SCIENZA EMPIRICA le sue
Capitolo 25: Lo scambio nel mercato delle assicurazioni
 Capitolo 25: Lo scambio nel mercato delle assicurazioni 25.1: Introduzione In questo capitolo la teoria economica discussa nei capitoli 23 e 24 viene applicata all analisi dello scambio del rischio nel
Capitolo 25: Lo scambio nel mercato delle assicurazioni 25.1: Introduzione In questo capitolo la teoria economica discussa nei capitoli 23 e 24 viene applicata all analisi dello scambio del rischio nel
RELAZIONE TRA VARIABILI QUANTITATIVE. Lezione 7 a. Accade spesso nella ricerca in campo biomedico, così come in altri campi della
 RELAZIONE TRA VARIABILI QUANTITATIVE Lezione 7 a Accade spesso nella ricerca in campo biomedico, così come in altri campi della scienza, di voler studiare come il variare di una o più variabili (variabili
RELAZIONE TRA VARIABILI QUANTITATIVE Lezione 7 a Accade spesso nella ricerca in campo biomedico, così come in altri campi della scienza, di voler studiare come il variare di una o più variabili (variabili
L Analisi della Varianza ANOVA (ANalysis Of VAriance)
") L Analisi della Varianza ANOVA (ANalysis Of VAriance) 1 CONCETTI GENERALI Finora abbiamo descritto test di ipotesi finalizzati alla verifica di ipotesi sulla differenza tra parametri di due popolazioni
L Analisi della Varianza ANOVA (ANalysis Of VAriance) 1 CONCETTI GENERALI Finora abbiamo descritto test di ipotesi finalizzati alla verifica di ipotesi sulla differenza tra parametri di due popolazioni
Moneta e Tasso di cambio
 Moneta e Tasso di cambio Come si forma il tasso di cambio? Determinanti del tasso di cambio nel breve periodo Determinanti del tasso di cambio nel lungo periodo Che cos è la moneta? Il controllo dell offerta
Moneta e Tasso di cambio Come si forma il tasso di cambio? Determinanti del tasso di cambio nel breve periodo Determinanti del tasso di cambio nel lungo periodo Che cos è la moneta? Il controllo dell offerta
Slide Cerbara parte1 5. Le distribuzioni teoriche
 Slide Cerbara parte1 5 Le distribuzioni teoriche I fenomeni biologici, demografici, sociali ed economici, che sono il principale oggetto della statistica, non sono retti da leggi matematiche. Però dalle
Slide Cerbara parte1 5 Le distribuzioni teoriche I fenomeni biologici, demografici, sociali ed economici, che sono il principale oggetto della statistica, non sono retti da leggi matematiche. Però dalle
Dimensione di uno Spazio vettoriale
 Capitolo 4 Dimensione di uno Spazio vettoriale 4.1 Introduzione Dedichiamo questo capitolo ad un concetto fondamentale in algebra lineare: la dimensione di uno spazio vettoriale. Daremo una definizione
Capitolo 4 Dimensione di uno Spazio vettoriale 4.1 Introduzione Dedichiamo questo capitolo ad un concetto fondamentale in algebra lineare: la dimensione di uno spazio vettoriale. Daremo una definizione
Automazione Industriale (scheduling+mms) scheduling+mms. adacher@dia.uniroma3.it
 scheduling+mms. adacher@dia.uniroma3.it") Automazione Industriale (scheduling+mms) scheduling+mms adacher@dia.uniroma3.it Introduzione Sistemi e Modelli Lo studio e l analisi di sistemi tramite una rappresentazione astratta o una sua formalizzazione
Automazione Industriale (scheduling+mms) scheduling+mms adacher@dia.uniroma3.it Introduzione Sistemi e Modelli Lo studio e l analisi di sistemi tramite una rappresentazione astratta o una sua formalizzazione
Capitolo 26: Il mercato del lavoro
 Capitolo 26: Il mercato del lavoro 26.1: Introduzione In questo capitolo applichiamo l analisi della domanda e dell offerta ad un mercato che riveste particolare importanza: il mercato del lavoro. Utilizziamo
Capitolo 26: Il mercato del lavoro 26.1: Introduzione In questo capitolo applichiamo l analisi della domanda e dell offerta ad un mercato che riveste particolare importanza: il mercato del lavoro. Utilizziamo
Finanza Aziendale. Lezione 13. Introduzione al costo del capitale
 Finanza Aziendale Lezione 13 Introduzione al costo del capitale Scopo della lezione Applicare la teoria del CAPM alle scelte di finanza d azienda 2 Il rischio sistematico E originato dalle variabili macroeconomiche
Finanza Aziendale Lezione 13 Introduzione al costo del capitale Scopo della lezione Applicare la teoria del CAPM alle scelte di finanza d azienda 2 Il rischio sistematico E originato dalle variabili macroeconomiche
Lineamenti di econometria 2
 Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) Aspetti Statistici della Regressione Aspetti Statistici della Regressione
Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) Aspetti Statistici della Regressione Aspetti Statistici della Regressione
Indici di dispersione
 Indici di dispersione 1 Supponiamo di disporre di un insieme di misure e di cercare un solo valore che, meglio di ciascun altro, sia in grado di catturare le caratteristiche della distribuzione nel suo
Indici di dispersione 1 Supponiamo di disporre di un insieme di misure e di cercare un solo valore che, meglio di ciascun altro, sia in grado di catturare le caratteristiche della distribuzione nel suo
Introduzione alle relazioni multivariate. Introduzione alle relazioni multivariate
 Introduzione alle relazioni multivariate Associazione e causalità Associazione e causalità Nell analisi dei dati notevole importanza è rivestita dalle relazioni causali tra variabili Date due variabili
Introduzione alle relazioni multivariate Associazione e causalità Associazione e causalità Nell analisi dei dati notevole importanza è rivestita dalle relazioni causali tra variabili Date due variabili
La Minimizzazione dei costi
 La Minimizzazione dei costi Il nostro obiettivo è lo studio del comportamento di un impresa che massimizza il profitto sia in mercati concorrenziali che non concorrenziali. Ora vedremo la fase della minimizzazione
La Minimizzazione dei costi Il nostro obiettivo è lo studio del comportamento di un impresa che massimizza il profitto sia in mercati concorrenziali che non concorrenziali. Ora vedremo la fase della minimizzazione
Calcolo del Valore Attuale Netto (VAN)
") Calcolo del Valore Attuale Netto (VAN) Il calcolo del valore attuale netto (VAN) serve per determinare la redditività di un investimento. Si tratta di utilizzare un procedimento che può consentirci di
Calcolo del Valore Attuale Netto (VAN) Il calcolo del valore attuale netto (VAN) serve per determinare la redditività di un investimento. Si tratta di utilizzare un procedimento che può consentirci di
La distribuzione Normale. La distribuzione Normale
 La Distribuzione Normale o Gaussiana è la distribuzione più importante ed utilizzata in tutta la statistica La curva delle frequenze della distribuzione Normale ha una forma caratteristica, simile ad una
La Distribuzione Normale o Gaussiana è la distribuzione più importante ed utilizzata in tutta la statistica La curva delle frequenze della distribuzione Normale ha una forma caratteristica, simile ad una
Capitolo 12 La regressione lineare semplice
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara
Nota interpretativa. La definizione delle imprese di dimensione minori ai fini dell applicazione dei principi di revisione internazionali
 Nota interpretativa La definizione delle imprese di dimensione minori ai fini dell applicazione dei principi di revisione internazionali Febbraio 2012 1 Mandato 2008-2012 Area di delega Consigliere Delegato
Nota interpretativa La definizione delle imprese di dimensione minori ai fini dell applicazione dei principi di revisione internazionali Febbraio 2012 1 Mandato 2008-2012 Area di delega Consigliere Delegato
MONOPOLIO, MONOPOLISTA
 Barbara Martini OBIETTIVI IL SIGNIFICATO DI MONOPOLIO, IN CUI UN SINGOLO MONOPOLISTA È L UNICO PRODUTTORE DI UN BENE COME UN MONOPOLISTA DETERMINA L OUTPUT ED IL PREZZO CHE MASSIMIZZANO IL PROFITTO LA
Barbara Martini OBIETTIVI IL SIGNIFICATO DI MONOPOLIO, IN CUI UN SINGOLO MONOPOLISTA È L UNICO PRODUTTORE DI UN BENE COME UN MONOPOLISTA DETERMINA L OUTPUT ED IL PREZZO CHE MASSIMIZZANO IL PROFITTO LA
Il metodo della regressione
 Il metodo della regressione Consideriamo il coefficiente beta di una semplice regressione lineare, cosa significa? È una differenza tra valori attesi Anche nel caso classico di variabile esplicativa continua
Il metodo della regressione Consideriamo il coefficiente beta di una semplice regressione lineare, cosa significa? È una differenza tra valori attesi Anche nel caso classico di variabile esplicativa continua
Corso di. Dott.ssa Donatella Cocca
 Corso di Statistica medica e applicata Dott.ssa Donatella Cocca 1 a Lezione Cos'è la statistica? Come in tutta la ricerca scientifica sperimentale, anche nelle scienze mediche e biologiche è indispensabile
Corso di Statistica medica e applicata Dott.ssa Donatella Cocca 1 a Lezione Cos'è la statistica? Come in tutta la ricerca scientifica sperimentale, anche nelle scienze mediche e biologiche è indispensabile
Indice di rischio globale
 Indice di rischio globale Di Pietro Bottani Dottore Commercialista in Prato Introduzione Con tale studio abbiamo cercato di creare un indice generale capace di valutare il rischio economico-finanziario
Indice di rischio globale Di Pietro Bottani Dottore Commercialista in Prato Introduzione Con tale studio abbiamo cercato di creare un indice generale capace di valutare il rischio economico-finanziario
ECONOMIA DEL LAVORO. Lezioni di maggio (testo: BORJAS) L offerta di lavoro
 L offerta di lavoro") ECONOMIA DEL LAVORO Lezioni di maggio (testo: BORJAS) L offerta di lavoro Offerta di lavoro - Le preferenze del lavoratore Il luogo delle combinazioni di C e L che generano lo stesso livello di U (e.g.
ECONOMIA DEL LAVORO Lezioni di maggio (testo: BORJAS) L offerta di lavoro Offerta di lavoro - Le preferenze del lavoratore Il luogo delle combinazioni di C e L che generano lo stesso livello di U (e.g.
Lineamenti di econometria 2
 Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) La Regressione Multipla La Regressione Multipla La regressione multipla
Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) La Regressione Multipla La Regressione Multipla La regressione multipla
www.andreatorinesi.it
 La lunghezza focale Lunghezza focale Si definisce lunghezza focale la distanza tra il centro ottico dell'obiettivo (a infinito ) e il piano su cui si forma l'immagine (nel caso del digitale, il sensore).
La lunghezza focale Lunghezza focale Si definisce lunghezza focale la distanza tra il centro ottico dell'obiettivo (a infinito ) e il piano su cui si forma l'immagine (nel caso del digitale, il sensore).
L analisi dei rischi: l aspetto statistico Ing. Pier Giorgio DELLA ROLE Six Sigma Master Black Belt
 L analisi dei rischi: l aspetto statistico Ing. Pier Giorgio DELL ROLE Six Sigma Master lack elt Dicembre, 009 Introduzione Nell esecuzione dei progetti Six Sigma è di fondamentale importanza sapere se
L analisi dei rischi: l aspetto statistico Ing. Pier Giorgio DELL ROLE Six Sigma Master lack elt Dicembre, 009 Introduzione Nell esecuzione dei progetti Six Sigma è di fondamentale importanza sapere se
Master della filiera cereagricola. Impresa e mercati. Facoltà di Agraria Università di Teramo. Giovanni Di Bartolomeo Stefano Papa
 Master della filiera cereagricola Giovanni Di Bartolomeo Stefano Papa Facoltà di Agraria Università di Teramo Impresa e mercati Parte prima L impresa L impresa e il suo problema economico L economia studia
Master della filiera cereagricola Giovanni Di Bartolomeo Stefano Papa Facoltà di Agraria Università di Teramo Impresa e mercati Parte prima L impresa L impresa e il suo problema economico L economia studia
OSSERVAZIONI TEORICHE Lezione n. 4
 OSSERVAZIONI TEORICHE Lezione n. 4 Finalità: Sistematizzare concetti e definizioni. Verificare l apprendimento. Metodo: Lettura delle OSSERVAZIONI e risoluzione della scheda di verifica delle conoscenze
OSSERVAZIONI TEORICHE Lezione n. 4 Finalità: Sistematizzare concetti e definizioni. Verificare l apprendimento. Metodo: Lettura delle OSSERVAZIONI e risoluzione della scheda di verifica delle conoscenze
Il concetto di elasticità della domanda rispetto al prezzo è di importanza cruciale per anticipare l esito di variazioni di prezzo (legate ad esempio
 L elasticità Cap.4 L elasticità Fin ora abbiamo visto come domanda e offerta di un bene reagiscano a variazioni del prezzo del bene Sono state tutte considerazioni qualitative (direzione del cambiamento)
L elasticità Cap.4 L elasticità Fin ora abbiamo visto come domanda e offerta di un bene reagiscano a variazioni del prezzo del bene Sono state tutte considerazioni qualitative (direzione del cambiamento)
Regressione non lineare con un modello neurale feedforward
 Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
2. Leggi finanziarie di capitalizzazione
 2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
PIL : produzione e reddito
 PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
GESTIONE INDUSTRIALE DELLA QUALITÀ A
 GESTIONE INDUSTRIALE DELLA QUALITÀ A Lezione 10 CAMPIONAMENTO (pag. 62-64) L indagine campionaria all interno di una popolazione consiste nell estrazione di un numero limitato e definito di elementi che
GESTIONE INDUSTRIALE DELLA QUALITÀ A Lezione 10 CAMPIONAMENTO (pag. 62-64) L indagine campionaria all interno di una popolazione consiste nell estrazione di un numero limitato e definito di elementi che
LA CORRELAZIONE LINEARE
 LA CORRELAZIONE LINEARE La correlazione indica la tendenza che hanno due variabili (X e Y) a variare insieme, ovvero, a covariare. Ad esempio, si può supporre che vi sia una relazione tra l insoddisfazione
LA CORRELAZIONE LINEARE La correlazione indica la tendenza che hanno due variabili (X e Y) a variare insieme, ovvero, a covariare. Ad esempio, si può supporre che vi sia una relazione tra l insoddisfazione
CAPITOLO 10 I SINDACATI
 CAPITOLO 10 I SINDACATI 10-1. Fate l ipotesi che la curva di domanda di lavoro di una impresa sia data da: 20 0,01 E, dove è il salario orario e E il livello di occupazione. Ipotizzate inoltre che la funzione
CAPITOLO 10 I SINDACATI 10-1. Fate l ipotesi che la curva di domanda di lavoro di una impresa sia data da: 20 0,01 E, dove è il salario orario e E il livello di occupazione. Ipotizzate inoltre che la funzione
= variazione diviso valore iniziale, il tutto moltiplicato per 100. \ Esempio: PIL del 2000 = 500; PIL del 2001 = 520:
 Fig. 10.bis.1 Variazioni percentuali Variazione percentuale di x dalla data zero alla data uno: x1 x 0 %x = 100% x 0 = variazione diviso valore iniziale, il tutto moltiplicato per 100. \ Esempio: PIL del
Fig. 10.bis.1 Variazioni percentuali Variazione percentuale di x dalla data zero alla data uno: x1 x 0 %x = 100% x 0 = variazione diviso valore iniziale, il tutto moltiplicato per 100. \ Esempio: PIL del
Metodi statistici per le ricerche di mercato
 Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2014-2015 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2014-2015 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
4 3 4 = 4 x 10 2 + 3 x 10 1 + 4 x 10 0 aaa 10 2 10 1 10 0
 Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Capitolo 26. Stabilizzare l economia: il ruolo della banca centrale. Principi di economia (seconda edizione) Robert H. Frank, Ben S.
 Robert H. Frank, Ben S.") Capitolo 26 Stabilizzare l economia: il ruolo della banca centrale In questa lezione Banca centrale Europea (BCE) e tassi di interesse: M D e sue determinanti; M S ed equilibrio del mercato monetario;
Capitolo 26 Stabilizzare l economia: il ruolo della banca centrale In questa lezione Banca centrale Europea (BCE) e tassi di interesse: M D e sue determinanti; M S ed equilibrio del mercato monetario;
Indice. 1 Il settore reale --------------------------------------------------------------------------------------------- 3
 INSEGNAMENTO DI ECONOMIA POLITICA LEZIONE VI IL MERCATO REALE PROF. ALDO VASTOLA Indice 1 Il settore reale ---------------------------------------------------------------------------------------------
INSEGNAMENTO DI ECONOMIA POLITICA LEZIONE VI IL MERCATO REALE PROF. ALDO VASTOLA Indice 1 Il settore reale ---------------------------------------------------------------------------------------------
Osservazioni sulla continuità per le funzioni reali di variabile reale
 Corso di Matematica, I modulo, Università di Udine, Osservazioni sulla continuità Osservazioni sulla continuità per le funzioni reali di variabile reale Come è noto una funzione è continua in un punto
Corso di Matematica, I modulo, Università di Udine, Osservazioni sulla continuità Osservazioni sulla continuità per le funzioni reali di variabile reale Come è noto una funzione è continua in un punto
1 Serie di Taylor di una funzione
 Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
Nella prima parte del corso l attenzione è venuta appuntandosi sui problemi inerenti la valutazione di investimenti aziendali e di strumenti
 Nella prima parte del corso l attenzione è venuta appuntandosi sui problemi inerenti la valutazione di investimenti aziendali e di strumenti finanziari in un contesto di flussi finanziari certi, tuttavia
Nella prima parte del corso l attenzione è venuta appuntandosi sui problemi inerenti la valutazione di investimenti aziendali e di strumenti finanziari in un contesto di flussi finanziari certi, tuttavia
1. Distribuzioni campionarie
 Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
Analisi della performance temporale della rete
 Analisi della performance temporale della rete In questo documento viene analizzato l andamento nel tempo della performance della rete di promotori. Alcune indicazioni per la lettura di questo documento:
Analisi della performance temporale della rete In questo documento viene analizzato l andamento nel tempo della performance della rete di promotori. Alcune indicazioni per la lettura di questo documento:
I mercati dei beni e i mercati finanziari: il modello IS-LM. Assunzione da rimuovere. Investimenti, I
 I mercati dei beni e i mercati finanziari: il modello IS-LM Assunzione da rimuovere Rimuoviamo l ipotesi che gli Investimenti sono una variabile esogena. Investimenti, I Gli investimenti delle imprese
I mercati dei beni e i mercati finanziari: il modello IS-LM Assunzione da rimuovere Rimuoviamo l ipotesi che gli Investimenti sono una variabile esogena. Investimenti, I Gli investimenti delle imprese
Gli input sono detti anche fattori di produzione: terra, capitale, lavoro, materie prime.
 LA TECNOLOGIA Studio del comportamento dell impresa, soggetto a vincoli quando si compiono scelte. La tecnologia rientra tra vincoli naturali e si traduce nel fatto che solo alcuni modi di trasformare
LA TECNOLOGIA Studio del comportamento dell impresa, soggetto a vincoli quando si compiono scelte. La tecnologia rientra tra vincoli naturali e si traduce nel fatto che solo alcuni modi di trasformare
u 1 u k che rappresenta formalmente la somma degli infiniti numeri (14.1), ordinati al crescere del loro indice. I numeri u k
, ordinati al crescere del loro indice. I numeri u k") Capitolo 4 Serie numeriche 4. Serie convergenti, divergenti, indeterminate Data una successione di numeri reali si chiama serie ad essa relativa il simbolo u +... + u +... u, u 2,..., u,..., (4.) oppure
Capitolo 4 Serie numeriche 4. Serie convergenti, divergenti, indeterminate Data una successione di numeri reali si chiama serie ad essa relativa il simbolo u +... + u +... u, u 2,..., u,..., (4.) oppure
 Stima per intervalli Nei metodi di stima puntuale è sempre presente un ^ errore θ θ dovuto al fatto che la stima di θ in genere non coincide con il parametro θ. Sorge quindi l esigenza di determinare una
Stima per intervalli Nei metodi di stima puntuale è sempre presente un ^ errore θ θ dovuto al fatto che la stima di θ in genere non coincide con il parametro θ. Sorge quindi l esigenza di determinare una
La variabile casuale Binomiale
 La variabile casuale Binomiale Si costruisce a partire dalla nozione di esperimento casuale Bernoulliano che consiste in un insieme di prove ripetute con le seguenti caratteristiche: i) ad ogni singola
La variabile casuale Binomiale Si costruisce a partire dalla nozione di esperimento casuale Bernoulliano che consiste in un insieme di prove ripetute con le seguenti caratteristiche: i) ad ogni singola
REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE
 N. 1235/2011 DELLA COMMISSIONE") 30.11.2011 Gazzetta ufficiale dell Unione europea L 317/17 REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE del 29 novembre 2011 recante modifica del regolamento (CE) n. 1222/2009 del Parlamento europeo
30.11.2011 Gazzetta ufficiale dell Unione europea L 317/17 REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE del 29 novembre 2011 recante modifica del regolamento (CE) n. 1222/2009 del Parlamento europeo
Multicollinearità Strumenti quantitativi per la gestione
 Strumenti quantitativi per la gestione Emanuele Taufer Quando non tutto va come dovrebbe I dati Scatter plot Correlazioni RLS e RLM Individuare la MC Variance Inflation Factor Cosa fare in caso di MC Alcune
Strumenti quantitativi per la gestione Emanuele Taufer Quando non tutto va come dovrebbe I dati Scatter plot Correlazioni RLS e RLM Individuare la MC Variance Inflation Factor Cosa fare in caso di MC Alcune
Il concetto di valore medio in generale
 Il concetto di valore medio in generale Nella statistica descrittiva si distinguono solitamente due tipi di medie: - le medie analitiche, che soddisfano ad una condizione di invarianza e si calcolano tenendo
Il concetto di valore medio in generale Nella statistica descrittiva si distinguono solitamente due tipi di medie: - le medie analitiche, che soddisfano ad una condizione di invarianza e si calcolano tenendo
Statistica multivariata. Statistica multivariata. Analisi multivariata. Dati multivariati. x 11 x 21. x 12 x 22. x 1m x 2m. x nm. x n2.
 Analisi multivariata Statistica multivariata Quando il numero delle variabili rilevate sullo stesso soggetto aumentano, il problema diventa gestirle tutte e capirne le relazioni. Cercare di capire le relazioni
Analisi multivariata Statistica multivariata Quando il numero delle variabili rilevate sullo stesso soggetto aumentano, il problema diventa gestirle tutte e capirne le relazioni. Cercare di capire le relazioni
lezione 18 AA 2015-2016 Paolo Brunori
 AA 2015-2016 Paolo Brunori Previsioni - spesso come economisti siamo interessati a prevedere quale sarà il valore di una certa variabile nel futuro - quando osserviamo una variabile nel tempo possiamo
AA 2015-2016 Paolo Brunori Previsioni - spesso come economisti siamo interessati a prevedere quale sarà il valore di una certa variabile nel futuro - quando osserviamo una variabile nel tempo possiamo
Misure di base su una carta. Calcoli di distanze
 Misure di base su una carta Calcoli di distanze Per calcolare la distanza tra due punti su una carta disegnata si opera nel modo seguente: 1. Occorre identificare la scala della carta o ricorrendo alle
Misure di base su una carta Calcoli di distanze Per calcolare la distanza tra due punti su una carta disegnata si opera nel modo seguente: 1. Occorre identificare la scala della carta o ricorrendo alle
Indice generale. OOA Analisi Orientata agli Oggetti. Introduzione. Analisi
 Indice generale OOA Analisi Orientata agli Oggetti Introduzione Analisi Metodi d' analisi Analisi funzionale Analisi del flusso dei dati Analisi delle informazioni Analisi Orientata agli Oggetti (OOA)
Indice generale OOA Analisi Orientata agli Oggetti Introduzione Analisi Metodi d' analisi Analisi funzionale Analisi del flusso dei dati Analisi delle informazioni Analisi Orientata agli Oggetti (OOA)
DIFFERENZIARE LE CAMPAGNE DI MARKETING La scelta del canale adeguato
 Via Durini, 23-20122 Milano (MI) Tel.+39.02.77.88.931 Fax +39.02.76.31.33.84 Piazza Marconi,15-00144 Roma Tel.+39.06.32.80.37.33 Fax +39.06.32.80.36.00 www.valuelab.it valuelab@valuelab.it DIFFERENZIARE
Via Durini, 23-20122 Milano (MI) Tel.+39.02.77.88.931 Fax +39.02.76.31.33.84 Piazza Marconi,15-00144 Roma Tel.+39.06.32.80.37.33 Fax +39.06.32.80.36.00 www.valuelab.it valuelab@valuelab.it DIFFERENZIARE
ESERCITAZIONE 13 : STATISTICA DESCRITTIVA E ANALISI DI REGRESSIONE
 ESERCITAZIONE 13 : STATISTICA DESCRITTIVA E ANALISI DI REGRESSIONE e-mail: tommei@dm.unipi.it web: www.dm.unipi.it/ tommei Ricevimento: su appuntamento Dipartimento di Matematica, piano terra, studio 114
ESERCITAZIONE 13 : STATISTICA DESCRITTIVA E ANALISI DI REGRESSIONE e-mail: tommei@dm.unipi.it web: www.dm.unipi.it/ tommei Ricevimento: su appuntamento Dipartimento di Matematica, piano terra, studio 114
Dipartimento di Economia Aziendale e Studi Giusprivatistici. Università degli Studi di Bari Aldo Moro. Corso di Macroeconomia 2014
 Dipartimento di Economia Aziendale e Studi Giusprivatistici Università degli Studi di Bari Aldo Moro Corso di Macroeconomia 2014 1. Assumete che = 10% e = 1. Usando la definizione di inflazione attesa
Dipartimento di Economia Aziendale e Studi Giusprivatistici Università degli Studi di Bari Aldo Moro Corso di Macroeconomia 2014 1. Assumete che = 10% e = 1. Usando la definizione di inflazione attesa
Relazioni tra variabili
 Università degli Studi di Padova Facoltà di Medicina e Chirurgia Corso di Laurea in Medicina e Chirurgia - A.A. 009-10 Scuole di specializzazione in: Medicina Legale, Medicina del Lavoro, Igiene e Medicina
Università degli Studi di Padova Facoltà di Medicina e Chirurgia Corso di Laurea in Medicina e Chirurgia - A.A. 009-10 Scuole di specializzazione in: Medicina Legale, Medicina del Lavoro, Igiene e Medicina
STATISTICA IX lezione
 Anno Accademico 013-014 STATISTICA IX lezione 1 Il problema della verifica di un ipotesi statistica In termini generali, si studia la distribuzione T(X) di un opportuna grandezza X legata ai parametri
Anno Accademico 013-014 STATISTICA IX lezione 1 Il problema della verifica di un ipotesi statistica In termini generali, si studia la distribuzione T(X) di un opportuna grandezza X legata ai parametri
Esercitazione n.1 (v.c. Binomiale, Poisson, Normale)
") Esercizio 1. Un azienda produce palline da tennis che hanno probabilità 0,02 di essere difettose, indipendentemente l una dall altra. La confezione di vendita contiene 8 palline prese a caso dalla produzione
Esercizio 1. Un azienda produce palline da tennis che hanno probabilità 0,02 di essere difettose, indipendentemente l una dall altra. La confezione di vendita contiene 8 palline prese a caso dalla produzione