MPI è una libreria che comprende:
|
|
|
- Giovanni Poli
- 8 anni fa
- Visualizzazioni
Transcript
1 1 Le funzioni di MPI MPI è una libreria che comprende: Funzioni per definire l ambiente Funzioni per comunicazioni uno a uno Funzioni percomunicazioni collettive Funzioni peroperazioni collettive 2 1

2 3 operazione fondamentale 4 2
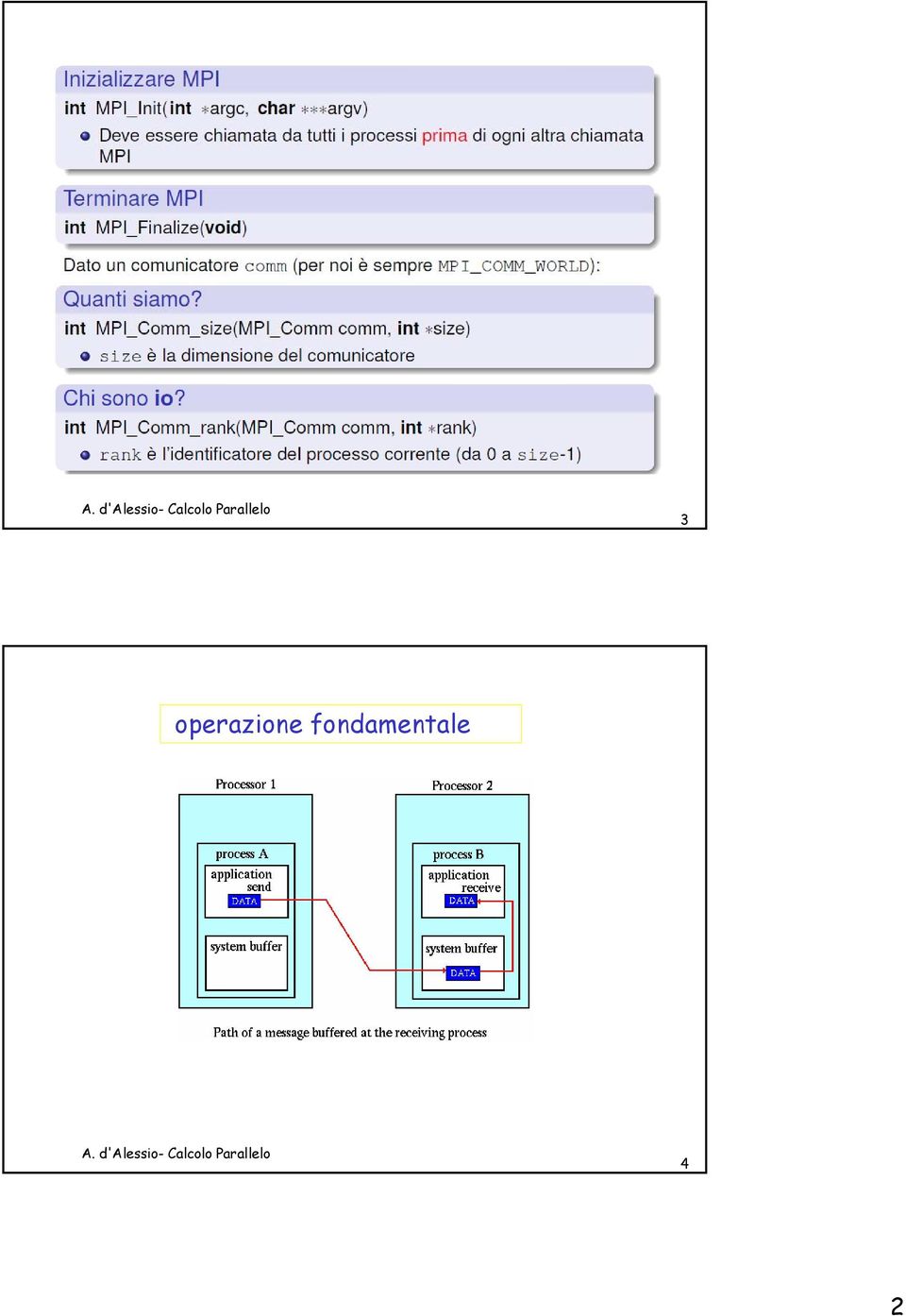
3 La comunicazione di un messaggio La comunicazione di un messaggio può coinvolgere due o più processori. Per comunicazioni che coinvolgono solo due processori Per comunicazioni che coinvolgono più processori Si considerano funzioni MPI per comunicazioni uno a uno Si considerano funzioni MPI per comunicazioni collettive 5 6 3

4 Deadlock Due o più processi si bloccano a vicenda aspettando che uno esegua una azione che serve all altro per terminare la comunicazione e procedere nell esecuzione del programma Problema non facilmente rilevabile Utilizzare comunicazioni bloccanti può causare un deadlock se la modalità è sincrona o il messaggio è di dimensioni maggiori del buffer di sistema 7 Rank=0 send(a,1) recv(b,1) Rank=1 send(a,0) recv(b,0) Unsafe program 0 manda ad 1 il suo vettore a e riceve in b il vettore a di 1 1 manda a 0 il suo vettore a e riceve in b il vettore a di 0 se la modalità è sincrona ci sono due send in attesa di due receive, che possono essere eseguite solo se le send sono completate! 8 4

5 Rank=0 send(a,1) Rank=1 recv(b,0) recv(b,1) send(a,1) In questo caso semplice si evita facendo attenzione all ordine 9 Necessità di una funzione che gestisca internamente l ordine delle operazioni di send e receive MPI_Sendrecv è utile quando un processo deve contemporaneamente inviare e ricevere dati 10 5

6 0 1 0 manda ad 1 il suo vettore a e riceve in b il vettore a di 1 1 manda a 0 il suo vettore a e riceve in b il vettore a di

7 MPI_Sendrecv(voidvoid *sbuf, int scount, MPI_Datatype sdatatype, int dest, int stag,void *rbuf,int rcount, MPI_Datatype rdatatype,int recv, int rtag,mpi_comm comm,mpi_status*status); La prima metà di argomenti è relativa alla send la seconda alla receive 13 Comunicazione tipo shift tutti i processi, tranne l ultimo, inviano un messaggio al processo di rank successivo tutti i processi, tranne il primo,ricevono i messaggio inviato dal processo di rank seguente shift di un dato all interno di una catena di processi sendrecv 14 7

8 shift circolare periodico tutti i processi, tranne l ultimo, inviano un messaggio al processo di rank successivo l ultimo invia un messaggio al primo processo 15 esercizio Shift circolare periodico su tre processori di un array A di interi 16 8

9 Comunicazione collettive di un messaggio 17 Comunicazioni collettive : Nel connumicator com1 P 0 comunica con tutti gli altri processori Communicator com1 3 0 D ABCD 2 A C Communicator com2 1 B P 0 distribuisce a tutti i processori di com2 un elemento del proprio vettore 18 9

10 Spedizione collettiva, uno a molti: Broadcast 19 Spedizione collettiva, uno a molti: #include <stdio.h> #include mpi.h int main(int argc, char *argv[]) { int menum, nproc; int n, tag, num; MPI_Status info; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&menum); if(menum==0) { scanf( %d,&n); } MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Finalize(); return 0; } 20 10
![h int main(int argc, char *argv[]) { int menum, nproc; int n, tag, num; MPI_Status info;](/docs-images/56/9169952/images/page_10.jpg "MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&menum); if(menum==0) { scanf( %d,&n); }")
11 MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD); Il processore P 0 spedisce n, di tipo MPI_INT e di dimensione 1, a tutti i processori dell ambiente ente MPI_COMM_WORLD. one to all 21 In generale : MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm); Il processore con identificativo root spedisce a tutti i processori del comunicator comm lo stesso dato memorizzato in *buffer. Count, datatype, comm devono essere uguali per ogni processore di comm

12 In dettaglio : MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm); *buffer count indirizzo del dato da spedire numero dei dati da spedire datatype tipo dei dati da spedire root comm identificativo del processore che spedisce a tutti identificativo del communicator 23 MPI_Bcast invia a tutti gli stessi dati Se si vogliono inviare dati diversi ad ogni processore Spedizione collettiva di tipo: data scatter Se tutti i processori vogliono inviare dati al root Spedizione collettiva di tipo: data gather 24 12

13 Spedizione collettiva di tipo: data scatter Un processore distribuisce i propri dati agli altri se stesso compreso 25 Spedizione collettiva di tipo: data gather Tutti i processori spediscono i propri dati ad un processore assegnato (es al processore P 0 ) 26 13

14 il processo root (P 0 ) divide in N parti uguali un insieme di dati contigui in memoria invia una parte ad ogni processo in ordine di rank one to all 27 ogni processo,incluso il root (P 0 ) invia il contenuto del proprio send buffer al processo root il processo root riceve i dati e li ordina in funzione del rank del processo sender all to one 28 14

15 Lo scatter in MPI MPI_Scatter(void *send_buff, int send_count, MPI_Datatype send_type, void *recv_buff,int recv_count, MPI _ Datatype recv _ type, int root, MPI_Comm comm); Il processore con identificativo root distribuisce i dati contenuti in send_buff. Il contenuto disend_buff_ viene suddiviso in nproc segmenti ciascuno di lunghezza send_count Il primo segmento viene affidato al processore con identificativo 0, il secondo al processore con identificativo 1, il terzo al processore con identificativo 2, etc. 29 Lo scatter in MPI: in dettaglio MPI_Scatter(void *send_buff, int send_count, MPI_Datatype send_type, void *recv_buff,int recv_count, MPI_Datatype recv_type, int root, MPI_Comm comm); *send_buff indirizzo del dato da spedire send_count numero dei dati da spedire send_type tipo dei dati da spedire *recv_buff indirizzo del dato in cui ricevere recv_count numero dei dati da ricevere recv_type tipo dei dati da ricevere root identificativo del processore che spedisce a tutti comm identificativo del communicator 30 15

16 Spedizione collettiva di tipo scatter: #include <stdio.h> #include mpi.h int main(int argc, char *argv[]) { int menum, nproc; int a[100]; int a2[10]; int root=0; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&nproc); MPI_Comm_rank(MPI_COMM_WORLD,&menum); if (menum==0).inizializza a. MPI_Scatter(a,10,MPI_INT,a2,10,MPI_Int,root,MPI_COMM_WORLD); MPI_Finalize(); return 0; } 31 Il gather in MPI MPI_Gather(void *send_buff, int send_count, MPI_Datatype datatype, void *recv_buff,int recv_count, MPI_Datatype recv_type, int root, MPI_Comm comm); Gli argomentirecv_ sono significativi solo per il processore root L argomento Largomentorecv_countrecv count è il numero di dati da ricevere da ogni processore, non è il numero totale dei dati da ricevere
; MPI_Finalize(); return 0; } 31 Il gather in MPI MPI_Gather(void *send_buff, int send_count, MPI_Datatype datatype, void")
17 raccolta collettiva di tipo gather: #include <stdio.h> #include mpi.h int main(int argc, char *argv[]) { int menum, nproc; int a[nproc]; int a2; int root=0; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&nproc); MPI_Comm_rank(MPI_COMM_WORLD,&menum); a2=menum; if (menum==0) MPI_Gather(a2,1,MPI_INT,a,1,MPI_Int,root,MPI_COMM_WORLD); MPI_Finalize(); return 0; } 33 Il gather in MPI MPI_Gather(void *send_buff, int send_count, MPI_Datatype datatype, void *recv_buff,int recv_count, MPI_Datatype recv_type, int root, MPI_Comm comm); Ogni processore di comm spedisce il contenuto di *send_buff al processore con identificativo root Il processore con identificativo root concatena i dati ricevuti in recv_buff, memorizzando prima i dati ricevuti dal processore 0, poi i dati ricevuti dal processore 1, poi quelli ricevuti dal processore 2, etc 34 17
; Ogni processore di comm spedisce il contenuto di *send_buff al processore con identificativo root Il processore con")
18 Se i dati sono di dimensione diversa MPI_SCATTERV MPI_GATHERV 35 Spedizione collettiva di tipo: all gather è equivalente ad un operazione di gather in cui successivamente il processo root (P 0 )esegue un broadcast è più conveniente ed efficiente che eseguire le due operazioni in sequenza all to all 36 18

19 Allgather in MPI: in dettaglio MPI_Allgather(void *send_buff, int send_count, MPI_Datatype sendtype, void *recv_buff,int recv_count, MPI_Datatype recv_type,mpi_comm comm); *send_buff indirizzo del dato da spedire send_count numero dei dati da spedire sendtype tipo dei dati da spedire *recv_buff indirizzo del riceive buffer recv_count numero di dati da ricevere da ogni processore recv_type comm tipo dei dati da ricevere identificativo del communicator 37 Le operazioni collettive

20 Caratteristiche delle operazioni collettive Inoltre Le operazioni collettive sono eseguite da tutti i processori appartenenti ad un communicator. Tutti i processori che eseguono l operazione collettiva eseguono almeno una comunicazione. L operazione collettiva può richiedere una sincronizzazione. Tutte le operazioni collettive sono bloccanti. 39 Scopo delle operazioni collettive Le operazioni collettive permettono: La Sincronizzazione dei processori. L esecuzione dioperazioni globali (es. ricerca del massimo in un vettore distribuito fra i processori). Gestione ottimizzata i t degli input/output t t seguendo uno schema ad albero
.")
21 MPI_Barrier(MPI_COMM_WORLD); Ogni processore dell ambiente MPI_COMM_WORLD può procedere solo quando tutti gli altri avranno richiamato questa routine. P 0 Attende Esegue P P 2 1 Attende Esegue Attende Esegue Stop 41 Sincronizzazione dei processori : #include <stdio.h> #include mpi.h int main(int argc, char *argv[]) { MPI_Init(&argc,&argv); MPI_Barrier(MPI_COMM_WORLD); MPI_Barrier(MPI_COMMON_WORLD); MPI_Finalize(); } 42 21
22 In generale : MPI_Barrier(MPI_CommMPI_Comm comm); Questa routine fornisce un meccanismo sincronizzante per tutti i processori del communicator comm. Ogni processore si ferma fin quando tutti i processori di comm non n eseguono MPI_Barrier. 43 Operazioni di riduzione MPI possiede una classe di operazioni collettive chiamate operazioni di riduzione. In ciascuna operazione di riduzione tuttitti i processori di un communicator contribuiscono al risultato di un operazione
23 Operazione collettiva : reduce 45 Un semplice programma : #include <stdio.h> #include mpi.h int main(int argc, char *argv[]) { int menum, nproc; int sum, sumtot; MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&menum); MPI_Comm_size(MPI_COMM_WORLD,&nproc); sum=nproc; sumtot=0; sum+=menum; MPI_Reduce(&sum,&sumtot,1,MPI_INT,MPI_SUM,0, MPI_COMM_WORLD); printf( Sono %d sum=%d sumtot=%d\n,menum,sum,sumtot); } MPI_Finalize(); return 0; 46 23
24 Nel programma : MPI_Reduce(&sum,&sumtot,1,MPI_INT,MPI_SUM, 0, MPI_COMM_WORLD); Il processore P 0 otterrà la somma dei elementi sum, di tipo MPI_INT e di dimensione 1, distribuiti tra tutti i processori del communicator MPI_COMM_WORLD. Il risultato lo pone nella propria variabile sumtot. 47 Operazioni di Reduce : Le operazioni globali di Reduce sono implementate in maniera efficiente in quanto: 1) Ottimizzano le comunicazioni tra i processori del communicator coinvolto. Le comunicazioni vengono eseguite seguendo uno schema ad albero. 2) Sfruttano la proprietà associativa e/o la proprietà commutativa
25 In Generale : MPI_Reduce(void *operand, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm); Tutti i processori di comm combinano i propri dati memorizzati in *operand utilizzando l operazione op. Il risultato viene memorizzato in *result di proprietà del processore con identificativo root Count, datatype, comm devono essere uguali per ogni processore di comm. 49 In dettaglio : MPI_Reduce(void *operand, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm); *operand indirizzo dei dati su cui effettuare l operazione. *result indirizzo del dato contenente il risultato. count numero dei dati su cui effettuare l operazione. datatype t tipo degli elementi da spedire. op operazione effettuata. root identificativo del processore che conterrà il risultato comm identificativo del communicator 50 25
26 Operazione collettiva: Reduce L argomento op, che descrive l operazione da eseguire sugli operandi operand, distribuiti fra i processori può essere scelto fra i seguenti valori predefiniti: MPI_MAX MPI_MIN Massimo di un vettore distribuito Minimo di un vettore distribuito MPI_SUM MPI_PROD Somma componente per componente fra vettori distribuiti Prodotto componente per componente fra vettori distribuiti 51 Operazione collettiva: Reduce MPI_MAXLOC MPI_MINLOCMINLOC Massimo e indice di un vettore Minimo e indice di un vettore combina coppie di valori (x i,ind i ) e restituisce (x,ind) x=max(min) x i, ind= corrispondente indice 52 26
27 Operazione collettiva : all reduce 53 Riduzione +replicazione : MPI_Allreduce(void *operand, void *result, int count, MPI_Datatype datatype, MPI_Op op, MPI_Comm comm); *operand indirizzo dei dati su cui effettuare l operazione. *result indirizzo del dato contenente il risultato. count numero dei dati su cui effettuare l operazione. datatype t tipo degli elementi da spedire. op operazione effettuata. comm identificativo del communicator 54 27
28 Si possono definire operatori ad-hoc MPI_Op_create 55 Misurare il tempo double MPI_Wtime(void void) 56 28
29 57 29
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Mai fidarsi. int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1
 { int a,i=2; a = 1*abs(i 1); printf ( %d\n, a); } $ gcc W Wall o first main.c $./first 1") Mai fidarsi int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1 $ gcc fno builtin o second main.c $./second 1 compilatore dipendente Bcast Vediamo la soluzione
Mai fidarsi int main() { int a,i=2; a = 1*abs(i 1); printf ( "%d\n", a); } $ gcc W Wall o first main.c $./first 1 $ gcc fno builtin o second main.c $./second 1 compilatore dipendente Bcast Vediamo la soluzione
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Comunicazione. La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI
 Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
Introduzione a MPI Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
MPI: comunicazioni collettive
 - g.marras@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Collective Communications -Communications involving a group of process -Called by all processes
- g.marras@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Collective Communications -Communications involving a group of process -Called by all processes
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Laboratorio di Calcolo Parallelo
 Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Operazioni di Comunicazione di base. Cap.4
 Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
Operazioni di Comunicazione di base Cap.4 1 Introduzione: operazioni di comunicazioni collettive Gli scambi collettivi coinvolgono diversi processori Sono usati massicciamente negli algoritmi paralleli
MPI Quick Refresh. Super Computing Applications and Innovation Department. Courses Edition 2017
 MPI Quick Refresh Super Computing Applications and Innovation Department Courses Edition 2017 1 Cos è MPI MPI acronimo di Message Passing Interface http://www.mpi-forum.org MPI è una specifica, non un
MPI Quick Refresh Super Computing Applications and Innovation Department Courses Edition 2017 1 Cos è MPI MPI acronimo di Message Passing Interface http://www.mpi-forum.org MPI è una specifica, non un
Programmazione di base
 1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
Non blocking. Contro. La programmazione di uno scambio messaggi con funzioni di comunicazione non blocking e' (leggermente) piu' complicata
 piu' complicata") Non blocking Una comunicazione non blocking e' tipicamente costituita da tre fasi successive: L inizio della operazione di send/receive del messaggio Lo svolgimento di un attivita' che non implichi l accesso
Non blocking Una comunicazione non blocking e' tipicamente costituita da tre fasi successive: L inizio della operazione di send/receive del messaggio Lo svolgimento di un attivita' che non implichi l accesso
A.d'Alessio. Calcolo Parallelo. Esempi di topologie
 Message Passing Interface MPI Le topologie 1 Esempi di topologie Anello Griglia Toro L utilizzo di una topologia per la progettazione di un algoritmo in ambiente MIMD è spesso legata alla geometria intrinseca
Message Passing Interface MPI Le topologie 1 Esempi di topologie Anello Griglia Toro L utilizzo di una topologia per la progettazione di un algoritmo in ambiente MIMD è spesso legata alla geometria intrinseca
Gruppo di collaboratori Calcolo Parallelo
 Gruppo di collaboratori Calcolo Parallelo Il calcolo parallelo, in generale, è l uso simultaneo di più processi per risolvere un unico problema computazionale Per girare con più processi, un problema è
Gruppo di collaboratori Calcolo Parallelo Il calcolo parallelo, in generale, è l uso simultaneo di più processi per risolvere un unico problema computazionale Per girare con più processi, un problema è
Coordinazione Distribuita
 Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza 21.1 Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Message Passing Interface MPI
 Paradigma del message passig Processore Processore Processore N memory memory memory Message Passig Iterface MPI CPU CPU Network CPU Sistema a memoria distribuita Ogi processore ha ua propria memoria locale
Paradigma del message passig Processore Processore Processore N memory memory memory Message Passig Iterface MPI CPU CPU Network CPU Sistema a memoria distribuita Ogi processore ha ua propria memoria locale
Calcolo Parallelo con MPI (2 parte)
") 2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
Presentazione del corso
 Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Introduzione. Coordinazione Distribuita. Ordinamento degli eventi. Realizzazione di. Mutua Esclusione Distribuita (DME)
") Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Coordinazione Distribuita Ordinamento degli eventi Mutua esclusione Atomicità Controllo della Concorrenza Introduzione Tutte le questioni relative alla concorrenza che si incontrano in sistemi centralizzati,
Le topologie. Message Passing Interface MPI Parte 2. Topologie MPI. Esempi di topologie. Definizione: topologia. Laura Antonelli
 Topologie MPI Message Passing Interface MPI Parte 2 Le topologie. Laura Antonelli 1 2 Esempi di topologie Definizione: topologia Una topologia è la geometria virtuale in cui si immaginano disposti i processi
Topologie MPI Message Passing Interface MPI Parte 2 Le topologie. Laura Antonelli 1 2 Esempi di topologie Definizione: topologia Una topologia è la geometria virtuale in cui si immaginano disposti i processi
Gli array. Gli array. Gli array. Classi di memorizzazione per array. Inizializzazione esplicita degli array. Array e puntatori
 Gli array Array e puntatori Laboratorio di Informatica I un array è un insieme di elementi (valori) avente le seguenti caratteristiche: - un array è ordinato: agli elementi dell array è assegnato un ordine
Gli array Array e puntatori Laboratorio di Informatica I un array è un insieme di elementi (valori) avente le seguenti caratteristiche: - un array è ordinato: agli elementi dell array è assegnato un ordine
Sistemi Operativi. Lez. 13: primitive per la concorrenza monitor e messaggi
 Sistemi Operativi Lez. 13: primitive per la concorrenza monitor e messaggi Osservazioni I semafori sono strumenti particolarmente potenti poiché consentono di risolvere ogni problema di sincronizzazione
Sistemi Operativi Lez. 13: primitive per la concorrenza monitor e messaggi Osservazioni I semafori sono strumenti particolarmente potenti poiché consentono di risolvere ogni problema di sincronizzazione
Primi Programmi con MPI 1
 Il cluster che usiamo: spaci Esercitazione: Primi Programmi con MPI http://www.na.icar.cnr.it/grid/#spacina Spacina è un cluster HP XC 6000 / Linux a 64 nodi biprocessore. La configurazione hardware dei
Il cluster che usiamo: spaci Esercitazione: Primi Programmi con MPI http://www.na.icar.cnr.it/grid/#spacina Spacina è un cluster HP XC 6000 / Linux a 64 nodi biprocessore. La configurazione hardware dei
Realizzazione di Politiche di Gestione delle Risorse: i Semafori Privati
 Realizzazione di Politiche di Gestione delle Risorse: i Semafori Privati Condizione di sincronizzazione Qualora si voglia realizzare una determinata politica di gestione delle risorse,la decisione se ad
Realizzazione di Politiche di Gestione delle Risorse: i Semafori Privati Condizione di sincronizzazione Qualora si voglia realizzare una determinata politica di gestione delle risorse,la decisione se ad
Fondamenti di Informatica e Laboratorio T-AB T-16 Progetti su più file. Funzioni come parametro. Parametri del main
 Fondamenti di Informatica e Laboratorio T-AB T-16 Progetti su più file. Funzioni come parametro. Parametri del main Paolo Torroni Dipartimento di Elettronica, Informatica e Sistemistica Università degli
Fondamenti di Informatica e Laboratorio T-AB T-16 Progetti su più file. Funzioni come parametro. Parametri del main Paolo Torroni Dipartimento di Elettronica, Informatica e Sistemistica Università degli
Funzioni in C. Violetta Lonati
 Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
Università degli studi di Milano Dipartimento di Scienze dell Informazione Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Funzioni - in breve: Funzioni Definizione di funzioni
Funzioni. Il modello console. Interfaccia in modalità console
 Funzioni Interfaccia con il sistema operativo Argomenti sulla linea di comando Parametri argc e argv Valore di ritorno del programma La funzione exit Esercizio Calcolatrice 2, presente in tutti i programmi
Funzioni Interfaccia con il sistema operativo Argomenti sulla linea di comando Parametri argc e argv Valore di ritorno del programma La funzione exit Esercizio Calcolatrice 2, presente in tutti i programmi
Testi di Esercizi e Quesiti 1
 Architettura degli Elaboratori, 2009-2010 Testi di Esercizi e Quesiti 1 1. Una rete logica ha quattro variabili booleane di ingresso a 0, a 1, b 0, b 1 e due variabili booleane di uscita z 0, z 1. La specifica
Architettura degli Elaboratori, 2009-2010 Testi di Esercizi e Quesiti 1 1. Una rete logica ha quattro variabili booleane di ingresso a 0, a 1, b 0, b 1 e due variabili booleane di uscita z 0, z 1. La specifica
Concetti base di MPI. Introduzione alle tecniche di calcolo parallelo
 Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Comunicazione tra Processi
 Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Comunicazione tra Processi
 Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Strutture. Strutture e Unioni. Definizione di strutture (2) Definizione di strutture (1)
 Definizione di strutture (1)") Strutture Strutture e Unioni DD cap.10 pp.379-391, 405-406 KP cap. 9 pp.361-379 Strutture Collezioni di variabili correlate (aggregati) sotto un unico nome Possono contenere variabili con diversi nomi
Strutture Strutture e Unioni DD cap.10 pp.379-391, 405-406 KP cap. 9 pp.361-379 Strutture Collezioni di variabili correlate (aggregati) sotto un unico nome Possono contenere variabili con diversi nomi
Il Sistema Operativo
 Il Sistema Operativo Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al meglio le risorse del Sistema
Il Sistema Operativo Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al meglio le risorse del Sistema
Message Passing Interface MPI
 Calcolatori MIMD Architetture SM (Shared Memory) Alcui strumeti per lo sviluppo di software su architetture MIMD OpeMP Architetture DM (Distributed Memory) MPI MPI : Paradigma del message passig Processore
Calcolatori MIMD Architetture SM (Shared Memory) Alcui strumeti per lo sviluppo di software su architetture MIMD OpeMP Architetture DM (Distributed Memory) MPI MPI : Paradigma del message passig Processore
Dall Algoritmo al Programma. Prof. Francesco Accarino IIS Altiero Spinelli Sesto San Giovanni
 Dall Algoritmo al Programma Prof. Francesco Accarino IIS Altiero Spinelli Sesto San Giovanni IL PROGRAMMA Gli algoritmi sono modelli di descrizione astratti e per controllarne il funzionamento devono essere
Dall Algoritmo al Programma Prof. Francesco Accarino IIS Altiero Spinelli Sesto San Giovanni IL PROGRAMMA Gli algoritmi sono modelli di descrizione astratti e per controllarne il funzionamento devono essere
Introduzione al Linguaggio C
 Introduzione al Linguaggio C File I/O Daniele Pighin April 2009 Daniele Pighin Introduzione al Linguaggio C 1/15 Outline File e dati Accesso ai file File I/O Daniele Pighin Introduzione al Linguaggio C
Introduzione al Linguaggio C File I/O Daniele Pighin April 2009 Daniele Pighin Introduzione al Linguaggio C 1/15 Outline File e dati Accesso ai file File I/O Daniele Pighin Introduzione al Linguaggio C
int MPI_Recv (void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status);
;") Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Sistema Operativo. Fondamenti di Informatica 1. Il Sistema Operativo
 Sistema Operativo Fondamenti di Informatica 1 Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al
Sistema Operativo Fondamenti di Informatica 1 Il Sistema Operativo Il Sistema Operativo (S.O.) è un insieme di programmi interagenti che consente agli utenti e ai programmi applicativi di utilizzare al
Boost.MPI Library Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Boost.MPI Library Algoritmi e Calcolo Parallelo Riferimenti! Boost homepage http://www.boost.org/! Tutorial on Boost.MPI http://www.boost.org/doc/libs/1_52_0/doc/html/mpi/ tutorial.html! Tutorial on Boost.Serialization
Boost.MPI Library Algoritmi e Calcolo Parallelo Riferimenti! Boost homepage http://www.boost.org/! Tutorial on Boost.MPI http://www.boost.org/doc/libs/1_52_0/doc/html/mpi/ tutorial.html! Tutorial on Boost.Serialization
3 - Variabili. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 3 - Variabili Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
3 - Variabili Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://www.di.unipi.it/ milazzo milazzo di.unipi.it Corso di
Esempio produttori consumatori. Primitive asincrone
 Primitive asincrone Send non bloccante: il processo mittente, non appena inviato il messaggio, prosegue la sua esecuzione. Il supporto a tempo di esecuzione deve fornire un meccanismo di accodamento dei
Primitive asincrone Send non bloccante: il processo mittente, non appena inviato il messaggio, prosegue la sua esecuzione. Il supporto a tempo di esecuzione deve fornire un meccanismo di accodamento dei
I puntatori e l allocazione dinamica di memoria
 I puntatori e l allocazione dinamica di memoria L allocazione delle variabili Allocazione e rilascio espliciti di memoria Le funzioni malloc e free 2 2006 Politecnico di Torino 1 Allocare = collocare in
I puntatori e l allocazione dinamica di memoria L allocazione delle variabili Allocazione e rilascio espliciti di memoria Le funzioni malloc e free 2 2006 Politecnico di Torino 1 Allocare = collocare in
Il Sistema Operativo (1)
") E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
E il software fondamentale del computer, gestisce tutto il suo funzionamento e crea un interfaccia con l utente. Le sue funzioni principali sono: Il Sistema Operativo (1) La gestione dell unità centrale
Appello di Informatica B
 Politecnico di Milano Facoltà di Ingegneria Industriale 19 febbraio 2004 Appello di Informatica B Prof. Angelo Morzenti - Prof. Vincenzo Martena Cognome e nome: Matricola: Tipo di prova: recupero I prova
Politecnico di Milano Facoltà di Ingegneria Industriale 19 febbraio 2004 Appello di Informatica B Prof. Angelo Morzenti - Prof. Vincenzo Martena Cognome e nome: Matricola: Tipo di prova: recupero I prova
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
ESERCIZIO 1 (Definizione funzioni passaggio parametri per copia)
") ESERCIZIO 1 (Definizione funzioni passaggio parametri per copia) Scrivere una funzione per definire se un numero è primo e un programma principale minimale che ne testa la funzionalità. #include
ESERCIZIO 1 (Definizione funzioni passaggio parametri per copia) Scrivere una funzione per definire se un numero è primo e un programma principale minimale che ne testa la funzionalità. #include
La gestione di un calcolatore. Sistemi Operativi primo modulo Introduzione. Sistema operativo (2) Sistema operativo (1)
 Sistema operativo (1)") La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15. Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15 Pietro Frasca Lezione 5 Martedì 21-10-2014 Thread Come abbiamo detto, un processo è composto
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2014-15 Pietro Frasca Lezione 5 Martedì 21-10-2014 Thread Come abbiamo detto, un processo è composto
Fondamenti di Informatica 2
 Fondamenti di Informatica 2 della prova scritta del 28 Febbraio 2006 Esercizio 1 (4 punti) Date le seguenti variabili int A[] = 2,3,7,-2,5,8,-4; int N = 7; int min = 3; int i; Scrivere la porzione di codice
Fondamenti di Informatica 2 della prova scritta del 28 Febbraio 2006 Esercizio 1 (4 punti) Date le seguenti variabili int A[] = 2,3,7,-2,5,8,-4; int N = 7; int min = 3; int i; Scrivere la porzione di codice
Inizializzazione, Assegnamento e Distruzione di Classi
 Inizializzazione, Assegnamento e Distruzione di Classi Lezione 9 Operazioni Automatiche In ogni programma C++ oggetti classe vengono gestiti automaticamente dal compilatore Inizializzati al momento della
Inizializzazione, Assegnamento e Distruzione di Classi Lezione 9 Operazioni Automatiche In ogni programma C++ oggetti classe vengono gestiti automaticamente dal compilatore Inizializzati al momento della
Gian Luca Marcialis studio degli algoritmi programma linguaggi LINGUAGGIO C
 Università degli Studi di Cagliari Corso di Laurea in Ingegneria Biomedica (Industriale), Chimica, Elettrica, e Meccanica FONDAMENTI DI INFORMATICA 1 http://www.diee.unica.it/~marcialis/fi1 A.A. 2010/2011
Università degli Studi di Cagliari Corso di Laurea in Ingegneria Biomedica (Industriale), Chimica, Elettrica, e Meccanica FONDAMENTI DI INFORMATICA 1 http://www.diee.unica.it/~marcialis/fi1 A.A. 2010/2011
Università degli Studi di Napoli Parthenope. Corso di Calcolo Parallelo e Distribuito. Virginia Bellino Matr. 108/1570
 Università degli Studi di Napoli Parthenope Corso di Calcolo Parallelo e Distribuito Virginia Bellino Matr. 108/1570 Virginia Bellino Progetto 1 Corso di Calcolo Parallelo e Distribuito 2 Indice Individuazione
Università degli Studi di Napoli Parthenope Corso di Calcolo Parallelo e Distribuito Virginia Bellino Matr. 108/1570 Virginia Bellino Progetto 1 Corso di Calcolo Parallelo e Distribuito 2 Indice Individuazione
Comunicazione tra Computer. Protocolli. Astrazione di Sottosistema di Comunicazione. Modello di un Sottosistema di Comunicazione
 I semestre 04/05 Comunicazione tra Computer Protocolli Prof. Vincenzo Auletta auletta@dia.unisa.it http://www.dia.unisa.it/professori/auletta/ Università degli studi di Salerno Laurea in Informatica 1
I semestre 04/05 Comunicazione tra Computer Protocolli Prof. Vincenzo Auletta auletta@dia.unisa.it http://www.dia.unisa.it/professori/auletta/ Università degli studi di Salerno Laurea in Informatica 1
AXO. Operativo. Architetture dei Calcolatori e Sistema. programmazione di sistema
 AXO Architetture dei Calcolatori e Sistema Operativo programmazione di sistema Il sistema operativo Il Sistema Operativo è un insieme di programmi (moduli software) che svolgono funzioni di servizio nel
AXO Architetture dei Calcolatori e Sistema Operativo programmazione di sistema Il sistema operativo Il Sistema Operativo è un insieme di programmi (moduli software) che svolgono funzioni di servizio nel
CAPITOLO 27 SCAMBIO DI MESSAGGI
 CAPITOLO 27 SCAMBIO DI MESSAGGI SCAMBIO DI MESSAGGI Sia che si guardi al microkernel, sia a SMP, sia ai sistemi distribuiti, Quando i processi interagiscono fra loro, devono soddisfare due requisiti fondamentali:
CAPITOLO 27 SCAMBIO DI MESSAGGI SCAMBIO DI MESSAGGI Sia che si guardi al microkernel, sia a SMP, sia ai sistemi distribuiti, Quando i processi interagiscono fra loro, devono soddisfare due requisiti fondamentali:
Le stringhe. Le stringhe
 Informatica: C++ Gerboni Roberta Stringhe di caratteri (esempi di utilizzo dei vettori) Nel linguaggio C++ una stringa è semplicemente un vettore di caratteri Vettori di caratteri La stringa "hello" è
Informatica: C++ Gerboni Roberta Stringhe di caratteri (esempi di utilizzo dei vettori) Nel linguaggio C++ una stringa è semplicemente un vettore di caratteri Vettori di caratteri La stringa "hello" è
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
LINGUAGGI DI PROGRAMMAZIONE
 LINGUAGGI DI PROGRAMMAZIONE Il potere espressivo di un linguaggio è caratterizzato da: quali tipi di dati consente di rappresentare (direttamente o tramite definizione dell utente) quali istruzioni di
LINGUAGGI DI PROGRAMMAZIONE Il potere espressivo di un linguaggio è caratterizzato da: quali tipi di dati consente di rappresentare (direttamente o tramite definizione dell utente) quali istruzioni di
Algebra di Boole: Concetti di base. Fondamenti di Informatica - D. Talia - UNICAL 1. Fondamenti di Informatica
 Fondamenti di Informatica Algebra di Boole: Concetti di base Fondamenti di Informatica - D. Talia - UNICAL 1 Algebra di Boole E un algebra basata su tre operazioni logiche OR AND NOT Ed operandi che possono
Fondamenti di Informatica Algebra di Boole: Concetti di base Fondamenti di Informatica - D. Talia - UNICAL 1 Algebra di Boole E un algebra basata su tre operazioni logiche OR AND NOT Ed operandi che possono
Sistemi Operativi mod. B. Sistemi Operativi mod. B A B C A B C P 1 2 0 0 P 1 1 2 2 3 3 2 P 2 3 0 2 P 2 6 0 0 P 3 2 1 1 P 3 0 1 1 < P 1, >
 Algoritmo del banchiere Permette di gestire istanze multiple di una risorsa (a differenza dell algoritmo con grafo di allocazione risorse). Ciascun processo deve dichiarare a priori il massimo impiego
Algoritmo del banchiere Permette di gestire istanze multiple di una risorsa (a differenza dell algoritmo con grafo di allocazione risorse). Ciascun processo deve dichiarare a priori il massimo impiego
Sincronizzazione e comunicazione tra processi in Unix. usati per trasferire ad un processo l indicazione che un determinato evento si è verificato.
 Processi parte III Sincronizzazione e comunicazione tra processi in Unix Segnali: usati per trasferire ad un processo l indicazione che un determinato evento si è verificato. Pipe: struttura dinamica,
Processi parte III Sincronizzazione e comunicazione tra processi in Unix Segnali: usati per trasferire ad un processo l indicazione che un determinato evento si è verificato. Pipe: struttura dinamica,
Per scrivere una procedura che non deve restituire nessun valore e deve solo contenere le informazioni per le modalità delle porte e controlli
 CODICE Le fonti in cui si possono trovare tutorial o esempi di progetti utilizzati con Arduino si trovano nel sito ufficiale di Arduino, oppure nei forum di domotica e robotica. Il codice utilizzato per
CODICE Le fonti in cui si possono trovare tutorial o esempi di progetti utilizzati con Arduino si trovano nel sito ufficiale di Arduino, oppure nei forum di domotica e robotica. Il codice utilizzato per
I/O su Socket TCP: read()
") I/O su Socket TCP: read() I socket TCP, una volta che la connessione TCP sia stata instaurata, sono accedibili come se fossero dei file, mediante un descrittore di file (un intero) ottenuto tramite una
I/O su Socket TCP: read() I socket TCP, una volta che la connessione TCP sia stata instaurata, sono accedibili come se fossero dei file, mediante un descrittore di file (un intero) ottenuto tramite una
Esempio: dest = parolagigante, lettere = PROVA dest (dopo l'invocazione di tipo pari ) = pprrlogvgante
 = pprrlogvgante") Esercizio 0 Scambio lettere Scrivere la funzione void scambiolettere(char *dest, char *lettere, int p_o_d) che modifichi la stringa destinazione (dest), sostituendone i caratteri pari o dispari (a seconda
Esercizio 0 Scambio lettere Scrivere la funzione void scambiolettere(char *dest, char *lettere, int p_o_d) che modifichi la stringa destinazione (dest), sostituendone i caratteri pari o dispari (a seconda
Introduzione al linguaggio C Gli array
 Introduzione al linguaggio C Gli array Vettori nome del vettore (tutti gli elementi hanno lo stesso nome, c) Vettore (Array) Gruppo di posizioni (o locazioni di memoria) consecutive Hanno lo stesso nome
Introduzione al linguaggio C Gli array Vettori nome del vettore (tutti gli elementi hanno lo stesso nome, c) Vettore (Array) Gruppo di posizioni (o locazioni di memoria) consecutive Hanno lo stesso nome
FONDAMENTI di INFORMATICA L. Mezzalira
 FONDAMENTI di INFORMATICA L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software
FONDAMENTI di INFORMATICA L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software
Header. Unità 9. Corso di Laboratorio di Informatica Ingegneria Clinica BCLR. Domenico Daniele Bloisi
 Corso di Laboratorio di Informatica Ingegneria Clinica BCLR Domenico Daniele Bloisi Docente Ing. Domenico Daniele Bloisi, PhD Ricercatore Dipartimento di Ingegneria Informatica, Automatica e Gestionale
Corso di Laboratorio di Informatica Ingegneria Clinica BCLR Domenico Daniele Bloisi Docente Ing. Domenico Daniele Bloisi, PhD Ricercatore Dipartimento di Ingegneria Informatica, Automatica e Gestionale
Sistemi Operativi Esercizi Sincronizzazione
 Sistemi Operativi Esercizi Sincronizzazione Docente: Claudio E. Palazzi cpalazzi@math.unipd.it Esercizi Sincronizzazione Sistemi Operativi - Claudio Palazzi 14 Semafori (1) Semafori: variabili intere contano
Sistemi Operativi Esercizi Sincronizzazione Docente: Claudio E. Palazzi cpalazzi@math.unipd.it Esercizi Sincronizzazione Sistemi Operativi - Claudio Palazzi 14 Semafori (1) Semafori: variabili intere contano
10.1. Un indirizzo IP viene rappresentato in Java come un'istanza della classe InetAddress.
 ESERCIZIARIO Risposte ai quesiti: 10.1. Un indirizzo IP viene rappresentato in Java come un'istanza della classe InetAddress. 10.2. Un numero intero in Java è compreso nell'intervallo ( 2 31 ) e (2 31
ESERCIZIARIO Risposte ai quesiti: 10.1. Un indirizzo IP viene rappresentato in Java come un'istanza della classe InetAddress. 10.2. Un numero intero in Java è compreso nell'intervallo ( 2 31 ) e (2 31
Esercitazione 7. Procedure e Funzioni
 Esercitazione 7 Procedure e Funzioni Esercizio Scrivere un programma che memorizza in un array di elementi di tipo double le temperature relative al mese corrente e ne determina la temperatura massima,
Esercitazione 7 Procedure e Funzioni Esercizio Scrivere un programma che memorizza in un array di elementi di tipo double le temperature relative al mese corrente e ne determina la temperatura massima,
Sistemi Operativi. Interfaccia del File System FILE SYSTEM : INTERFACCIA. Concetto di File. Metodi di Accesso. Struttura delle Directory
 FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
FILE SYSTEM : INTERFACCIA 8.1 Interfaccia del File System Concetto di File Metodi di Accesso Struttura delle Directory Montaggio del File System Condivisione di File Protezione 8.2 Concetto di File File
La gestione dell input/output da tastiera La gestione dell input/output da file La gestione delle eccezioni
 La gestione dell input/output da tastiera La gestione dell input/output da file La gestione delle eccezioni Autore: Prof. Agostino Sorbara ITIS "M. M. Milano" Autore: Prof. Agostino Sorbara ITIS "M. M.
La gestione dell input/output da tastiera La gestione dell input/output da file La gestione delle eccezioni Autore: Prof. Agostino Sorbara ITIS "M. M. Milano" Autore: Prof. Agostino Sorbara ITIS "M. M.
http://www.programmiamo.altervista.org/c/oop/o...
 PROGRAMMIAMO Programma per la gestione di un conto corrente C++ - Costruttore e distruttore C++ Home Contatti Supponiamo ora di voler scrivere un programma a menu per la gestione di un conto corrente bancario.
PROGRAMMIAMO Programma per la gestione di un conto corrente C++ - Costruttore e distruttore C++ Home Contatti Supponiamo ora di voler scrivere un programma a menu per la gestione di un conto corrente bancario.
La gestione della memoria
 La gestione della memoria DOTT. ING. LEONARDO RIGUTINI DIPARTIMENTO INGEGNERIA DELL INFORMAZIONE UNIVERSITÀ DI SIENA VIA ROMA 56 53100 SIENA UFF. 0577234850-7102 RIGUTINI@DII.UNISI.IT HTTP://WWW.DII.UNISI.IT/~RIGUTINI/
La gestione della memoria DOTT. ING. LEONARDO RIGUTINI DIPARTIMENTO INGEGNERIA DELL INFORMAZIONE UNIVERSITÀ DI SIENA VIA ROMA 56 53100 SIENA UFF. 0577234850-7102 RIGUTINI@DII.UNISI.IT HTTP://WWW.DII.UNISI.IT/~RIGUTINI/
Gestione dei File in C
 Gestione dei File in C Maurizio Palesi DIIT Università di Catania Viale Andrea Doria 6, 95125 Catania mpalesi@diit.unict.it http://www.diit.unict.it/users/mpalesi Sommario In questo documento saranno introdotte
Gestione dei File in C Maurizio Palesi DIIT Università di Catania Viale Andrea Doria 6, 95125 Catania mpalesi@diit.unict.it http://www.diit.unict.it/users/mpalesi Sommario In questo documento saranno introdotte
MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c
![MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c](/thumbs/25/4541811.jpg "MATLAB. Caratteristiche. Dati. Esempio di programma MATLAB. a = [1 2 3; 4 5 6; 7 8 9]; b = [1 2 3] ; c = a*b; c") Caratteristiche MATLAB Linguaggio di programmazione orientato all elaborazione di matrici (MATLAB=MATrix LABoratory) Le variabili sono matrici (una variabile scalare equivale ad una matrice di dimensione
Caratteristiche MATLAB Linguaggio di programmazione orientato all elaborazione di matrici (MATLAB=MATrix LABoratory) Le variabili sono matrici (una variabile scalare equivale ad una matrice di dimensione
Concetto di Funzione e Procedura METODI in Java
 Fondamenti di Informatica Concetto di Funzione e Procedura METODI in Java Fondamenti di Informatica - D. Talia - UNICAL 1 Metodi e Sottoprogrammi Mentre in Java tramite le classi e gli oggetti è possibile
Fondamenti di Informatica Concetto di Funzione e Procedura METODI in Java Fondamenti di Informatica - D. Talia - UNICAL 1 Metodi e Sottoprogrammi Mentre in Java tramite le classi e gli oggetti è possibile
Università degli Studi di Cassino Corso di Fondamenti di Informatica Puntatori. Anno Accademico 2010/2011 Francesco Tortorella
 Corso di Informatica Puntatori Anno Accademico 2010/2011 Francesco Tortorella Variabili, registri ed indirizzi Abbiamo visto che la definizione di una variabile implica l allocazione (da parte del compilatore)
Corso di Informatica Puntatori Anno Accademico 2010/2011 Francesco Tortorella Variabili, registri ed indirizzi Abbiamo visto che la definizione di una variabile implica l allocazione (da parte del compilatore)
ELETTRONICA Tema di Sistemi elettronici automatici Soluzione
 ELETTRONICA Tema di Sistemi elettronici automatici Soluzione La traccia presenta lo sviluppo di un progetto relativo al monitoraggio della temperatura durante un processo di produzione tipico nelle applicazione
ELETTRONICA Tema di Sistemi elettronici automatici Soluzione La traccia presenta lo sviluppo di un progetto relativo al monitoraggio della temperatura durante un processo di produzione tipico nelle applicazione
Architettura MVC-2: i JavaBeans
 Siti web centrati sui dati Architettura MVC-2: i JavaBeans Alberto Belussi anno accademico 2008/2009 Limiti dell approccio SEVLET UNICA La servlet svolge tre tipi di funzioni distinte: Interazione con
Siti web centrati sui dati Architettura MVC-2: i JavaBeans Alberto Belussi anno accademico 2008/2009 Limiti dell approccio SEVLET UNICA La servlet svolge tre tipi di funzioni distinte: Interazione con
Somma di un array di N numeri in MPI
 Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Elaborato di Calcolo Parallelo Somma di un array di N numeri in MPI Anno Accademico 2011/2012 Professoressa Alessandra D Alessio Studenti
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Elaborato di Calcolo Parallelo Somma di un array di N numeri in MPI Anno Accademico 2011/2012 Professoressa Alessandra D Alessio Studenti
CALCOLATORI ELETTRONICI A cura di Luca Orrù. Lezione n.7. Il moltiplicatore binario e il ciclo di base di una CPU
 Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Lezione n.7 Il moltiplicatore binario e il ciclo di base di una CPU 1 SOMMARIO Architettura del moltiplicatore Architettura di base di una CPU Ciclo principale di base di una CPU Riprendiamo l analisi
Cos è una stringa (1) Stringhe. Leggere e scrivere stringhe (1) Cos è una stringa (2) DD Cap. 8 pp. 305-341 KP Cap. 6 pp. 241-247
 Stringhe. Leggere e scrivere stringhe (1) Cos è una stringa (2) DD Cap. 8 pp. 305-341 KP Cap. 6 pp. 241-247") Cos è una stringa (1) Stringhe DD Cap. 8 pp. 305-341 KP Cap. 6 pp. 241-247 Una stringa è una serie di caratteri trattati come una singola unità. Essa potrà includere lettere, cifre, simboli e caratteri
Cos è una stringa (1) Stringhe DD Cap. 8 pp. 305-341 KP Cap. 6 pp. 241-247 Una stringa è una serie di caratteri trattati come una singola unità. Essa potrà includere lettere, cifre, simboli e caratteri
costruttori e distruttori
 costruttori e distruttori Costruttore E un metodo che ha lo stesso nome della classe a cui appartiene: serve per inizializzare un oggetto all atto della sua creazione Ce ne possono essere uno, più di uno,
costruttori e distruttori Costruttore E un metodo che ha lo stesso nome della classe a cui appartiene: serve per inizializzare un oggetto all atto della sua creazione Ce ne possono essere uno, più di uno,
Esercitazione n 4. Obiettivi
 Esercitazione n 4 Obiettivi Progettare e implementare per intero un componente software in Java Linguaggio Java: Classi astratte Utilizzo di costruttori e metodi di superclasse Polimorfismo Esempio guida:
Esercitazione n 4 Obiettivi Progettare e implementare per intero un componente software in Java Linguaggio Java: Classi astratte Utilizzo di costruttori e metodi di superclasse Polimorfismo Esempio guida:
http://esamix.labx Quotazione compareto( ) Quotazione piurecente( ) Quotazione Quotazione Quotazione non trovato count( )
 Quotazione piurecente( ) Quotazione Quotazione Quotazione non trovato count( )") Materiale di ausilio utilizzabile durante l appello: tutto il materiale è a disposizione, inclusi libri, lucidi, appunti, esercizi svolti e siti Web ad accesso consentito in Lab06. L utilizzo di meorie
Materiale di ausilio utilizzabile durante l appello: tutto il materiale è a disposizione, inclusi libri, lucidi, appunti, esercizi svolti e siti Web ad accesso consentito in Lab06. L utilizzo di meorie
Informatica 3. LEZIONE 21: Ricerca su liste e tecniche di hashing. Modulo 1: Algoritmi sequenziali e basati su liste Modulo 2: Hashing
 Informatica 3 LEZIONE 21: Ricerca su liste e tecniche di hashing Modulo 1: Algoritmi sequenziali e basati su liste Modulo 2: Hashing Informatica 3 Lezione 21 - Modulo 1 Algoritmi sequenziali e basati su
Informatica 3 LEZIONE 21: Ricerca su liste e tecniche di hashing Modulo 1: Algoritmi sequenziali e basati su liste Modulo 2: Hashing Informatica 3 Lezione 21 - Modulo 1 Algoritmi sequenziali e basati su
12 - Introduzione alla Programmazione Orientata agli Oggetti (Object Oriented Programming OOP)
") 12 - Introduzione alla Programmazione Orientata agli Oggetti (Object Oriented Programming OOP) Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica,
12 - Introduzione alla Programmazione Orientata agli Oggetti (Object Oriented Programming OOP) Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica,
Siti web centrati sui dati Architettura MVC-2: i JavaBeans
 Siti web centrati sui dati Architettura MVC-2: i JavaBeans 1 ALBERTO BELUSSI ANNO ACCADEMICO 2009/2010 Limiti dell approccio SEVLET UNICA La servlet svolge tre tipi di funzioni distinte: Interazione con
Siti web centrati sui dati Architettura MVC-2: i JavaBeans 1 ALBERTO BELUSSI ANNO ACCADEMICO 2009/2010 Limiti dell approccio SEVLET UNICA La servlet svolge tre tipi di funzioni distinte: Interazione con
GESTIONE DEI PROCESSI
 Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
INFORMATICA 1 L. Mezzalira
 INFORMATICA 1 L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software del modello
INFORMATICA 1 L. Mezzalira Possibili domande 1 --- Caratteristiche delle macchine tipiche dell informatica Componenti hardware del modello funzionale di sistema informatico Componenti software del modello
Ottimizzazione delle interrogazioni (parte I)
") Ottimizzazione delle interrogazioni I Basi di Dati / Complementi di Basi di Dati 1 Ottimizzazione delle interrogazioni (parte I) Angelo Montanari Dipartimento di Matematica e Informatica Università di
Ottimizzazione delle interrogazioni I Basi di Dati / Complementi di Basi di Dati 1 Ottimizzazione delle interrogazioni (parte I) Angelo Montanari Dipartimento di Matematica e Informatica Università di
VERIFICHE E APPROVAZIONI CONTROLLO APPROVAZIONE
 VERIFICHE E APPROVAZIONI VERSIONE REDAZIONE CONTROLLO APPROVAZIONE AUTORIZZAZIONE EMISSIONE NOME DATA NOME DATA NOME DATA V01 L. Neri 25/02/2010 C. Audisio 08/03/10 M.Rosati 09/03/10 STATO DELLE VARIAZIONI
VERIFICHE E APPROVAZIONI VERSIONE REDAZIONE CONTROLLO APPROVAZIONE AUTORIZZAZIONE EMISSIONE NOME DATA NOME DATA NOME DATA V01 L. Neri 25/02/2010 C. Audisio 08/03/10 M.Rosati 09/03/10 STATO DELLE VARIAZIONI
Progettaz. e sviluppo Data Base
 Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
Modello di sviluppo della popolazione: Matrice di Leslie
 Modello di sviluppo della popolazione: Matrice di Leslie April 24, 2007 1 Scopo del progetto Lo scopo è quello di creare un programma parallelo in grado di fare una stima di quale sarà la popolazione in
Modello di sviluppo della popolazione: Matrice di Leslie April 24, 2007 1 Scopo del progetto Lo scopo è quello di creare un programma parallelo in grado di fare una stima di quale sarà la popolazione in
MPI: MESSAGE PASSING INTERFACE
 MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
Il software. la parte contro cui si può solo imprecare. Funzioni principali del sistema operativo. (continua) Gestione della memoria principale
 Gestione della memoria principale") Funzioni principali del sistema operativo Il software la parte contro cui si può solo imprecare Avvio dell elaboratore Gestione del processore e dei processi in Gestione della memoria principale Gestione
Funzioni principali del sistema operativo Il software la parte contro cui si può solo imprecare Avvio dell elaboratore Gestione del processore e dei processi in Gestione della memoria principale Gestione