Calcolo parallelo, Grid e sistemi ad alta affidabilita'
|
|
|
- Norberto Fede
- 10 anni fa
- Просмотров:
Транскрипт
1 Calcolo parallelo, Grid e sistemi ad alta affidabilita'

2 Finalità del corso Gli obiettivi del corso sono quelli di eseguire una panoramica sugli strumenti che l'open source mette a disposizione nell'ambito del parallel computing e dell'hpc in genere. L'intento principale è mostrare come e perchè i sistemi informatici ad alte prestazioni, o HPC (High Performance Computing), stanno rapidamente diventando un vantaggio competitivo in tutti gli ambienti di ricerca, produzione e business dei nostri giorni. Oggi, non sono più solo scienziati e aziende di grandi dimensioni a utilizzare le soluzioni HPC per migliorare l'efficienza delle proprie soluzioni, ma anche i laboratori di ricerca, gli studi professionali, gli agenti di borsa e in alcuni casi le pubbliche amministrazioni. Descrivere le varie macchine parallele: come funzionano, pregi e difetti Descrivere (qualitativamente) alcuni linguaggi paralleli: OpenMP, MPI Fornire informazioni base per parallelizzare un codice

3 Parte I Ere e modelli di calcolo Evoluzione delle strutture di calcolo e delle reti Introduzione al calcolo parallelo Classificazione delle architetture Applicazioni del calcolo parallelo

4 Ere e modelli di calcolo 1984 Computer Food Chain Mainframe Mini Computer Workstation PC Vector Supercomputer

5 How to Build a Supercomputer: 1980 s A supercomputer was a vector SMP (symmetric multi-processor) Custom CPUs Custom memory Custom packaging Custom interconnects Custom operating system Cray* 2 Costs were Extreme: Around ~$5 million/gigaflop Technology Evolution Tracking: ~1/3 Moore s Law Predictions

6 Ere e modelli di calcolo 1994 Computer Food Chain (hitting wall soon) Mini Computer Workstation (future is bleak) Mainframe Vector Supercomputer PC MPP
 Mainframe Vector")
7 How to Build a Supercomputer: 1990 s A supercomputer was an MPP (massively parallel processor) COTS1 CPUs COTS memory Custom packaging Custom interconnects Custom operating system 1 COTS = Commercial Off The Shelf Intel processor based ASCI - Red Costs were High: Around $200K/gigaFLOP Technology Evolution Tracking: ~1/2 Moore s Law Predictions

8 NCSA 1990 s Former Cluster ~1,500 processor SGI de-commissioned Too costly to maintain Software too expensive Takes up large amounts of floor space (Great for tours, looks impressive, nice displays) Gradually being taken out when floor space required Now being used as network file servers

9 Ere e modelli di calcolo Computer Food Chain (Now and Future)

10 How to Build a Supercomputer: 2000 s A Supercomputer is a Cluster COTS1 CPUs COTS Memory COTS Packaging COTS Interconnects COTS Operating System COTS = Commercial Off The Shelf 1 Loki: an Intel processor based cluster at Los Alamos National Laborry (LANL Costs are Modest: Around $4K/gigaFLOP Technology Evolution Tracks Moore s Law

11 Clustering Today Clustering gained momentum when 3 technologies converged: 1. Very HP Microprocessors workstation performance = yesterday supercomputers 2. High speed communication Comm. between cluster nodes >= between processors in an SMP. 3. Standard tools for parallel/ distributed computing & their growing popularity.

12 Introduzione al calcolo parallelo Cos'è il calcolo parallelo? Perchè ne abbiamo bisogno? Tipi di computer Breve storia dell'hpc Linguaggi di Programmazione Parallela OpenMP e Message Passing Terminologia

13 Cos'è il calcolo parallelo? (parallel computing) Utilizzo simultaneo di più di un processore o computer per risolvere un problema È una evoluzione del calcolo seriale Per girare su piu CPU, un problema è diviso in parti discrete che possono essere risolte concorrentemente Ogni parte è a sua volta divisa in una serie di istruzioni Le istruzioni di ogni parte sono eseguite contemporaneamente su CPU diverse

14 Perchè abbiamo bisogno del calcolo parallelo? Il calcolo seriale per molti problemi è troppo lento. Spesso c'è bisogno di grandi quantità di memoria non accessibili da un singolo pro cessore.

15 Perchè usare il calcolo parallelo? Risolvere problemi più grandi. Risparmiare tempo. Ma anche: Utilizzare un insieme di risorse locali Superare i vincoli di memoria Contenere i costi N processori economici invece che 1 più costoso

16 Perchè usare il calcolo parallelo? Esempio: Previsioni del tempo su scala globale L atmosfera è modellata mediante una suddivisione in celle tridimensionali. Il calcolo di ogni cella è ripetuto molte volte per simularne l andamento temporale. Se supponiamo che: l intera atmosfera sia suddivisa in celle di taglia 1 miglio x 1miglio x 1miglio fino ad un altezza dal suolo di 10 miglia (10 celle in altezza), avremo in totale ~ 5 x 10^8 celle. ogni calcolo richieda 2000 operazioni floating point, allora in un singolo time-step dovremo effettuare 10^12 operazioni floating point.

17 Perchè usare il calcolo parallelo? Esempio (2): Previsioni del tempo su scala globale Se vogliamo simulare una previsione fino a 10 giorni usando un passo temporale di 10 minuti Un computer che lavora ad una potenza di 1 Gflops (10^9 operazioni floating point/sec) impiegherà~ 20 giorni. Per terminare il calcolo in 20 minuti occorrerà un computer operante a 1.2 Tflops (1.2 x 10^12 operazioni floating point/sec). Il più potente calcolatore esistente è capace di oltre 1026 Tflops di picco (IBM Roadrunner) costato 133 milioni di dollari.
.")
18 Perchè usare il calcolo parallelo? (2): Superare i limiti strutturali del calcolo seriale: limiti fisici: Velocità di propagazione di un segnale limiti tecnici: clock estremamente alti causano alta dissipazione > 100 Watt limiti economici notare che: già adesso i processori seriali presentano un parallelismo interno (funzionale): più pipeline indipendenti già adesso un singolo chip può presentare più processori
: più")
19 Calcolo parallelo È l emulazione di ciò che avviene quotidianamente intorno a noi: molti eventi complessi e correlati che avvengono in contemporanea È motivato dalla simulazione numerica di sistemi molto complessi, cioè Grand Challenge Problems : Modellazione del clima globale Simulazioni di reazioni chimiche e nucleari Studio del genoma umano Studio delle proprietà di materiali complessi Simulazione di attività geologica e sismica Progettazione di veicoli più efficienti e sicuri

20 Applicazioni commerciali Attualmente diverse applicazioni commerciali sono un elemento trainante nello sviluppo di computer sempre più veloci Applicazioni che richiedo il processing di grandi moli di dati con algoritmi spesso molto sofisticati esempi: Database paralleli e data mining Esplorazione petrolifera Motori di ricerca per il web Diagnostica medica Grafica avanzata e realtà virtuale Broadcasting su network ed altre tecnologie multimediali Ambienti di lavoro collaborativi virtuali

21 Terminologia Mega -> 10^6 Giga -> 10^9 Tera -> 10^12 Peta -> 10^15 singolo PC -> 1 Gflops macchine parallele entry level -> 10 Gflops macchine parallele livello medio -> 100 Gflops macchine parallele livello alto -> 1000 Gflops = 1 Tflops nota: 1 Mega secondi = s -> 11 giorni 1 Giga secondi = s -> 31 anni
22 Chi utilizza il calcolo parallelo
23 HPC (High Performance Computing) Definizione di HPC: Non ne esiste una precisa ma in genere ogni sistema di calcolo che necessita di più di un 1 Gigaflop/s*; in alternativa e più precisamente ogni computer che ha prestazioni di almeno un ordine di grandezza su periori a quelle di una corrente workstation di fascia alta. Applicazioni dell'hpc large scientific, engineering, and medical applications. business and commerce are applying financial modelling techniques. database applications for fast retrieval of large quantities of data. Virtual Reality. *A Flop is a floating point operation per second. SI prefixes M(ega)Flop is a million Flops, G(iga)Flops 1000 million flops and T(era)Flops billion flops
24 HPC Platforms Supercomputer: Un sistema HPC in grado di processare efficientemente problemi tecnici di larga scala. Cluster: Un sistema HPC che integra i più comuni ed economici componenti reperibili in commercio (commodity compo nents) per processare problemi generali di larga scala (technical computing, business applications, networking services).
25
26 Architecture of high-performance computers The main architectural classes (taxonomy of Flynn) SISD (Single Instruction Single Data) SIMD (Single Instruction Multiple Data) MISD (Multiple Instruction Single Data) MIMD (Multiple Instruction Multiple Data)

27 Classificazione delle architetture parallele Si può classificare in base a due aspetti: Secondo la disposizione fisica della memoria che può essere centralizzata o distribuita. Secondo la condivisione o meno dello spazio di indirizzamento che può essere appunto individuale o condiviso.
28 Architetture a memoria condivisa Si possono dividere in due classi: Uniform Memory Access (UMA) Chiamati anche Symmetric MultiProcessor (SMP) Elaboratori costituiti da più processori identici I tempi d accesso a tutta la memoria sono uguali per ogni processore Non-Uniform Memory Access (NUMA) Sono realizzate attraverso il collegamento di due o più SMP. Ogni SMP può accedere alla memoria degli altri SMP I processori non hanno lo stesso tempo d accesso a tutta la memoria. Se è mantenuta la cache coherency si parla di architetture CCNUMA (Cache Coherent NUMA)
29 Parallel computer architectures: memory centralized shared address space SMP (Symmetric Multiprocessor) architecture uses shared system resources such as memory and I/O subsystem that can be accessed equally from all the processors. As shown in Figure 1, each processor has its own cache which may have several levels. SMP machines have a mechanism to maintain cohe rency of data held in local caches. The connection between the processors (caches) and the memory is built as either a bus or a crossbar switch. A single operating system controls the SMP machine and it schedules processes and threads on processors so that the load is balanced.
30 Architetture a memoria distribuita Ogni processore dispone di un area di memoria locale I processori possono scambiare dati solo attraverso il network di comunicazione Non è previsto un concetto di spazio di indirizzi globale tra i processori: il programmatore deve definire in modo esplicito come e quando comunicare i dati e deve sincronizzare i task residenti su nodi diversi È importante l infrastruttura di comunicazione utilizzata
31 Parallel computer architectures: memory distributed individual address space MPP (Massively Parallel Processors) architecture consists of nodes connec ted by a network that is usually high speed. Each node has its own processor, memory, and I/O subsystem. The operating system is running on each node, so each node can be considered a workstation. Despite the term massively, the number of nodes is not necessarily large. In fact, there is no criteria. What makes the situation more complex is that each node can be an SMP node.
32 Parallel computer architectures memory distributed shared address space NUMA (Non Uniform Memory Access) architecture machines are built on a similar hardware model as MPP, but it typically provides a shared address space to applications using a hardware/software directory ba sed protocol that maintains cache coherency. As in an SMP machine, a single operating system controls the whole system. The memory latency varies according to whether you access local memory directly or remote memory through the interconnect.
33 Cos'è un Cluster? Definizione di Cluster: Collezione di sistemi di calcolo indipendenti (worksta tions or PCs) collegati mediante una rete di interconnes sione a basso costo (commodity interconnection Net work), che viene utilizzata come una singola unificata ri sorsa di calcolo.
34
35 A brief supercomputer history
36 HPC progress in 25 years
37
38 I costi del calcolo parallelo Le macchine parallele sono: in genere di complessa gestione spesso costose in genere voluminose Il calcolo parallelo implica una modifica pesante dei codici codici paralleli non girano su macchine seriali algoritmi intrinsecamente seriali forte legame tra prestazioni ed architettura usata
39 Cluster Vs. Supercomputers Cost: Supercomputers cost 10 to 20 times as much per node (processor) as workstations, PCs, or low end SMPs. Cluster: The sheer volume reduces production costs and amortizes the significant R&D costs over a larger number of units. a low cost solution.
40 The Top 500 Project The Top 500 project started in 1993 Top 500 sites reported Report produced twice a year EUROPE in JUNE USA in NOV Performance based on LINPACK benchmark
41 The Top 500 Project (2) Lista delle più grosse macchine parallele installate (omogenee) Ordinate rispetto un benchmark di risoluzione di un sistema lineare (linpack): sustained performance > 50% ( caso realistico?) È un buon benchmark? È rappresentativo del vostro problema?
42 The top 500 project (3) Le principali installazioni (Novembre 2006)
43 The top 500 project (4) Solo due anni fà: Le principali installazioni (Novembre 2004):
44 Linux Cluster Perchè usare un cluster Linux? poco costoso facile da installare e gestire si possono aggiungere facilmente nodi oppure upgradarli ottimo rapporto prezzo/prestazioni (da 5 a 10 volte migliore rispetto ai tradizionali super computers Per cosa si possono usare? come parallel computer (usando MPI o PVM o OpenMP) come un insieme di CPU as a virtual MP computer (Mosix)
45 Linux Cluster Hardware nodi CPU: PIII, PIV Xeon (fascia bassa) CPU: Itanium (fascia alta) RAM (512 Mb 4 Gb) dischi ATA SerialATA o SCSI Network Fascia bassa: Fast Ethernet (100 Mbps) -Gigabit Ethernet (1Gbps) Fascia alta: Myrinet (1.2Gbps) -QsNet (2.6Gbps)
46 Una rete è definita da: Topologia: struttura della rete di interconnessione Ring Ipercubo tree t Latenza (L): tempo necessario per spedire un messaggio vuoto (tempo di start-up) Bandwidth (B): velocitàdi trasferimento dei dati (Mb/sec.) Tempo di comunicazione (T) di un messaggio di N MB: T = L + N/B
47 Interconnessione di rete Latenza vs. Bandwidth grossa bandwidth e grande latenza: poche comunicazioni ma molto grosse; grossa bandwidth e bassa latenza: il migliore dei mondi possibili; piccola bandwidth e grande latenza: il peggiore dei mondi possibili; piccola bandwidth e bassa latenza: molte comunicazioni molto piccole.
48 Network interconnections costs
49 Tipi di Cluster Beowulf nato come un progetto della NASA, viene utilizzato per ottenere cluster Linux con computer ad elevate prestazioni. OpenMOSIX Soluzione OpenSource che prevede delle modifiche al kernel di Linux. Implementa un meccanismo di adaptive (online) loadbalancing. Utilizza il meccanismo di migrazione dei processi tra nodi per ottenere il massimo vantaggio dalle risorse disponibili. Linux Virtual Server E una soluzione per implementare load-balancing cluster in ambiente Linux applicando opportune modifiche al kernel e strumenti di gestione.
50 Utilizzo dei Cluster High Availability (HA) HA fornisce un ambiente fail-safe attraverso la ridondanza di hardware, software e middleware. High Performance Computing (HPC) HPC tipicamente coinvolge applicazioni parallele su larga scala aggregando la potenza di calcolo di molti computer.
51 Cluster Linux costruito con comuni PC
52 Beowulf Cluster Il cluster può essere assemblato con PC eterogenei Lavora in user space, non necessita di modifiche al Kernel E' ideale per far girare programmi paralleli I nodi del cluster possono anche essere privi di disco di boot. Normalmente il cluster usa una rete privata per connettere i nodi Non è necessaria alcuna configurazione particolare: la sola richiesta è che ogni nodo accetti connessioni tipo rsh dal nodo front-end.
53 Beowulf: vantaggi e svantaggi Vantaggi: Semplice da installare e configurare Svantaggi: non si tiene conto delle caratteristiche dei nodi del cluster (velocità, memoria...) non permette di distribuire dinamicamente il carico di lavoro
54 Mosix E' un insieme di patches per il kernel di Linux. Ne esistono due tipi: Mosix (uso libero) ed OpenMosix (Open Software) permette il bilanciamento dinamico del carico grazie alla migrazione dei processi verso nodi più liberi in termini di memoria e CPU prende in considerazione la velocità dei nodi e la disponibilità di RAM migra i processi sulla base di un algoritmo complesso in modo da assicurare le migliori performance può lavorare su una rete privata, ma anche con una rete pubblica quando un nodo viene spento (shut-down) i suoi job vengono migrati verso gli altri nodi può far girare codici paralleli e multiprocesso
55 Mosix: vantaggi e svantaggi Vantaggi permette di gestire in maniera efficiente i nodi del cluster è trasparente dal lato utente il cluster è facilmente gestibile ed è facile aggiungere o togliere nodi è possibile bloccare i processi in modo da girare sul nodo di start up oppure forzarne la migrazione dispone di un utile interfaccia grafica per l'amministrazione Svantaggi non è detto che possa essere installabile su ogni macchina il suo buon funzionamento dipende dalla velocità della rete di interconnessione le applicazioni che fanno uso di thread non migrano, perciò non esiste ancora supporto per il distributed shared memory
56 Il nuovo cluster del dipartimento di fisica dell'unical Cluster di 16 CPU eterogeneo 8 Nodi 4 Dual Xeon (Kernel Openmosix) 4 Dual Opteron (Kernel 2.6.4) RAM : 2 Gb per nodo (Totale: 16 Gb) Dischi: 480 Gb SerialATA Gb IDE Network Gigabit Ethernet
57 Librerie e software utilizzati Compilers Intel C/C++ Compiler 8.0 Intel Fortran Compiler 8.0 Mpi Libraries Lam/Mpi MPICH2 Math Libraries Atlas Blas Goto Blas Intel Math Kernel Library 7.0 AMD Core Math Library 2.1.0
58 HPL Linpack NxN Cos'è? Risolve sistemi di equazioni lineari misura il tempo di esecuzione per un problema di una data dimensione (size) Cosa misura? Rmax le prestazioni date in Gflop/s ottenute per il problema in esame Rpeak il valore in Gflop/s della prestazione di picco ovverosia la massima ottenibile teoricamente dalla data macchina LINPACK NxN è usato per compilare la lista TOP500 dei 500 più veloci computer al mondo
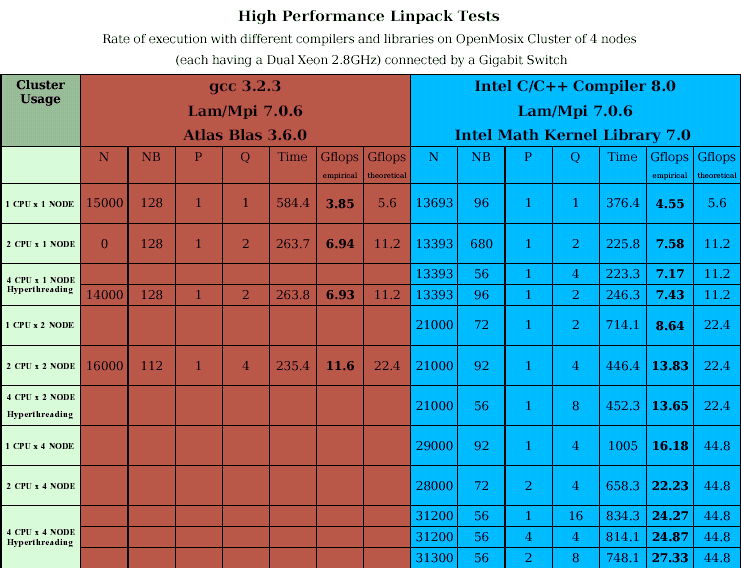
59
60 Analisi dei risultati OpenMosix Cluster 4 dual xeon nodes Poichè gli Xeon possono svolgere 2 operazioni in virgola mobile (doppia precisione) per ciclo. Cioè hanno un massimo teorico utilizzabile di 2 Flops. Allora il massimo teorico per processore è Rpeak = 2 x 2.8 GHz= 5.6 GFlops (circa lo stesso del processore p Ghz che può svolgere 4 Flops per ciclo). Mentre il massimo teorico per l'intero cluster è Rpeak = 8 x 2 x 2.8 GHz= 44.8 Gflops I nostri risultati massimo reale per processore = 4.55 Gflops -> Efficienza=81,25% massimo reale del cluster = Gflops -> Efficienza=61%
61 Analisi dei risultati Beowulf Cluster 4 dual opteron nodes Poichè gli Opteron possono svolgere 2 operazioni in virgola mobile (doppia precisione) per ciclo. Cioè hanno un massimo teorico utilizzabile di 2 Flops. Allora il massimo teorico per processore è Rpeak = 2 x 1.4 GHz= 2.8 GFlops Mentre il massimo teorico per l'intero cluster è Rpeak = 8 x 2 x 1.4 GHz= 22.4 Gflops I nostri risultati massimo reale per processore = Gflops -> Efficienza=84% massimo reale per l'intero cluster = > Efficienza=59%
62 Applicazioni sul Cluster Applicazioni scientifiche Simulazioni di sistemi di particelle Descrizione di plasmi astrofisici Fluidodinamica Automi cellulari Applicazioni Aziendali Database: Mysql Cluster J2EE: Jboss Cluster (sperimentale) Tecniche numeriche: Montecarlo, FFT, differenze finite
63 I calcolatori dell' HPCC Centro di Eccellenza per il calcolo ad alte prestazioni
64 Prestazioni Ulisse Voyager misurato 128,5 GFlops efficienza 80.3% Galileo misurato 54,26 GFlops efficienza 85.3% misurato 119,6 GFlops efficienza 83 % Il nuovo cluster del dipartimento di Fisica misurato 40.5 Gflops efficienza 60 % I costi dei supercomputer dell'hppc: 0,3-1,5 Milioni di Euro Il costo del nuovo cluster del dip. di fisica: Euro
65 Cluster Linux I cluster Linux sono la soluzione HPC col miglior rapporto costo/prestazioni.
66 Parallel Programming Languages? High Performance Fortran (HPF) directive based extension to Fortran works on both shared and distributed memory systems not widely used (more popular in Japan?) not suited to applications using irregular grids OpenMP directive based support for Fortran 90/95 and C/C++ shared memory programming only
67 Most Parallel Programmers use... Fortran 90/95, C/C++ with MPI Fortran 90/95, C/C++ with OpenMP Passaggio esplicito delle variabili da un processo ad un altro perciò ogni processo può gestire un segmento della memoria del pro gramma; può essere usato sia su sistemi a memoria distribuita che a memoria condivisa. Permette la distribuzione di processi e dati su macchine SMP sfrut tando le prestazioni della memoria condivisa di un singolo nodo. Hybrid combination of MPI/OpenMP approccio più recentemente utilizzato.
68 The myth of automatic parallelization (2 common versions) Compilers can do anything (but we may have to wait a while) Automatic parallelization makes it possible (or will soon make it possible) to port any application to a parallel machine and see wonderful speedups without any modifications to the source. Compilers can't do anything (now or never) Automatic parallelization is useless. It ll never work on real code. If you want to port an application to a parallel machine, you have to restructure it extensively. This is a fundamental limitation and will never be overcome.
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO. A cura di Tania Caprini
 CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
CALCOLO PARALLELO SUPERARE I LIMITI DI CALCOLO A cura di Tania Caprini 1 CALCOLO SERIALE: esecuzione di istruzioni in sequenza CALCOLO PARALLELO: EVOLUZIONE DEL CALCOLO SERIALE elaborazione di un istruzione
Linux nel calcolo distribuito
 openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero [email protected], [email protected] BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
openmosix Linux nel calcolo distribuito Dino Del Favero, Micky Del Favero [email protected], [email protected] BLUG - Belluno Linux User Group Linux Day 2004 - Belluno 27 novembre openmosix p. 1 Cos è
Speedup. Si definisce anche lo Speedup relativo in cui, invece di usare T 1 si usa T p (1).
.") Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Speedup Vediamo come e' possibile caratterizzare e studiare le performance di un algoritmo parallelo: S n = T 1 T p n Dove T 1 e' il tempo impegato dal miglior algoritmo seriale conosciuto, mentre T p
Parte VIII. Architetture Parallele
 Parte VIII Architetture Parallele VIII.1 Motivazioni Limite di prestazioni delle architetture sequenziali: velocità di propagazione dei segnali, la luce percorre 30 cm in un nsec! Migliore rapporto costo/prestazioni
Parte VIII Architetture Parallele VIII.1 Motivazioni Limite di prestazioni delle architetture sequenziali: velocità di propagazione dei segnali, la luce percorre 30 cm in un nsec! Migliore rapporto costo/prestazioni
La Gestione delle risorse Renato Agati
 Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Renato Agati delle risorse La Gestione Schedulazione dei processi Gestione delle periferiche File system Schedulazione dei processi Mono programmazione Multi programmazione Gestione delle periferiche File
Informatica. Scopo della lezione
 1 Informatica per laurea diarea non informatica LEZIONE 1 - Cos è l informatica 2 Scopo della lezione Introdurre le nozioni base della materia Definire le differenze tra hardware e software Individuare
1 Informatica per laurea diarea non informatica LEZIONE 1 - Cos è l informatica 2 Scopo della lezione Introdurre le nozioni base della materia Definire le differenze tra hardware e software Individuare
Flops. Differenza tra sustained performance, e di picco (cenni a proposito dei metodi di ottimizzazione, il compilatore ed oltre)
") LaTop500 Flops Differenza tra sustained performance, e di picco (cenni a proposito dei metodi di ottimizzazione, il compilatore ed oltre) La valutazione dell'effettiva potenza di calcolo dev'essere effettuata
LaTop500 Flops Differenza tra sustained performance, e di picco (cenni a proposito dei metodi di ottimizzazione, il compilatore ed oltre) La valutazione dell'effettiva potenza di calcolo dev'essere effettuata
L informatica INTRODUZIONE. L informatica. Tassonomia: criteri. È la disciplina scientifica che studia
 L informatica È la disciplina scientifica che studia INTRODUZIONE I calcolatori, nati in risposta all esigenza di eseguire meccanicamente operazioni ripetitive Gli algoritmi, nati in risposta all esigenza
L informatica È la disciplina scientifica che studia INTRODUZIONE I calcolatori, nati in risposta all esigenza di eseguire meccanicamente operazioni ripetitive Gli algoritmi, nati in risposta all esigenza
Introduzione. Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD... 6
 Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
Appunti di Calcolatori Elettronici Esecuzione di istruzioni in parallelo Introduzione... 1 Classificazione di Flynn... 2 Macchine a pipeline... 3 Macchine vettoriali e Array Processor... 4 Macchine MIMD...
Il clustering HA con Linux: Kimberlite
 Il clustering HA con Linux: Kimberlite Simone Piccardi: [email protected] February 4, 2002 Perché un cluster Un cluster è un insieme di computer in grado di eseguire insieme una certa serie di
Il clustering HA con Linux: Kimberlite Simone Piccardi: [email protected] February 4, 2002 Perché un cluster Un cluster è un insieme di computer in grado di eseguire insieme una certa serie di
VMware. Gestione dello shutdown con UPS MetaSystem
 VMware Gestione dello shutdown con UPS MetaSystem La struttura informatica di una azienda Se ad esempio consideriamo la struttura di una rete aziendale, i servizi offerti agli utenti possono essere numerosi:
VMware Gestione dello shutdown con UPS MetaSystem La struttura informatica di una azienda Se ad esempio consideriamo la struttura di una rete aziendale, i servizi offerti agli utenti possono essere numerosi:
I Thread. I Thread. I due processi dovrebbero lavorare sullo stesso testo
 I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
I Thread 1 Consideriamo due processi che devono lavorare sugli stessi dati. Come possono fare, se ogni processo ha la propria area dati (ossia, gli spazi di indirizzamento dei due processi sono separati)?
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione.
 Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Con il termine Sistema operativo si fa riferimento all insieme dei moduli software di un sistema di elaborazione dati dedicati alla sua gestione. Compito fondamentale di un S.O. è infatti la gestione dell
Architettura di un sistema operativo
 Architettura di un sistema operativo Dipartimento di Informatica Università di Verona, Italy Struttura di un S.O. Sistemi monolitici Sistemi a struttura semplice Sistemi a livelli Virtual Machine Sistemi
Architettura di un sistema operativo Dipartimento di Informatica Università di Verona, Italy Struttura di un S.O. Sistemi monolitici Sistemi a struttura semplice Sistemi a livelli Virtual Machine Sistemi
Architettura hardware
 Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
Architettura dell elaboratore Architettura hardware la parte che si può prendere a calci Sistema composto da un numero elevato di componenti, in cui ogni componente svolge una sua funzione elaborazione
La macchina di Von Neumann. Archite(ura di un calcolatore. L unità di elaborazione (CPU) Sequenza di le(ura. Il bus di sistema
 Sequenza di le(ura. Il bus di sistema") La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
La macchina di Von Neumann rchite(ura di un calcolatore us di sistema Collegamento Unità di Elaborazione (CPU) Memoria Centrale (MM) Esecuzione istruzioni Memoria di lavoro Interfaccia Periferica P 1 Interfaccia
Network Monitoring. Introduzione all attività di Network Monitoring introduzione a Nagios come motore ideale
 Network Monitoring & Introduzione all attività di Network Monitoring introduzione a Nagios come motore ideale Nicholas Pocher Poker SpA - Settimo Torinese, Novembre 2013 1 Indice Il Network Monitoring:
Network Monitoring & Introduzione all attività di Network Monitoring introduzione a Nagios come motore ideale Nicholas Pocher Poker SpA - Settimo Torinese, Novembre 2013 1 Indice Il Network Monitoring:
Architetture Applicative
 Alessandro Martinelli [email protected] 6 Marzo 2012 Architetture Architetture Applicative Introduzione Alcuni esempi di Architetture Applicative Architetture con più Applicazioni Architetture
Alessandro Martinelli [email protected] 6 Marzo 2012 Architetture Architetture Applicative Introduzione Alcuni esempi di Architetture Applicative Architetture con più Applicazioni Architetture
La memoria centrale (RAM)
") La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
La memoria centrale (RAM) Mantiene al proprio interno i dati e le istruzioni dei programmi in esecuzione Memoria ad accesso casuale Tecnologia elettronica: Veloce ma volatile e costosa Due eccezioni R.O.M.
Introduzione al sistema operativo. Laboratorio Software 2008-2009 C. Brandolese
 Introduzione al sistema operativo Laboratorio Software 2008-2009 C. Brandolese Che cos è un sistema operativo Alcuni anni fa un sistema operativo era definito come: Il software necessario a controllare
Introduzione al sistema operativo Laboratorio Software 2008-2009 C. Brandolese Che cos è un sistema operativo Alcuni anni fa un sistema operativo era definito come: Il software necessario a controllare
Scheduling della CPU. Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux
 Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Scheduling della CPU Sistemi multiprocessori e real time Metodi di valutazione Esempi: Solaris 2 Windows 2000 Linux Sistemi multiprocessori Fin qui si sono trattati i problemi di scheduling su singola
Il Sistema Operativo. C. Marrocco. Università degli Studi di Cassino
 Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Il Sistema Operativo Il Sistema Operativo è uno strato software che: opera direttamente sull hardware; isola dai dettagli dell architettura hardware; fornisce un insieme di funzionalità di alto livello.
Introduzione alla Virtualizzazione
 Introduzione alla Virtualizzazione Dott. Luca Tasquier E-mail: [email protected] Virtualizzazione - 1 La virtualizzazione è una tecnologia software che sta cambiando il metodo d utilizzo delle risorse
Introduzione alla Virtualizzazione Dott. Luca Tasquier E-mail: [email protected] Virtualizzazione - 1 La virtualizzazione è una tecnologia software che sta cambiando il metodo d utilizzo delle risorse
Approccio stratificato
 Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Approccio stratificato Il sistema operativo è suddiviso in strati (livelli), ciascuno costruito sopra quelli inferiori. Il livello più basso (strato 0) è l hardware, il più alto (strato N) è l interfaccia
Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella prof@quarella.
 Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella [email protected] Prestazioni Si valutano in maniera diversa a seconda dell
Prestazioni CPU Corso di Calcolatori Elettronici A 2007/2008 Sito Web:http://prometeo.ing.unibs.it/quarella Prof. G. Quarella [email protected] Prestazioni Si valutano in maniera diversa a seconda dell
Lezione 1. Introduzione e Modellazione Concettuale
 Lezione 1 Introduzione e Modellazione Concettuale 1 Tipi di Database ed Applicazioni Database Numerici e Testuali Database Multimediali Geographic Information Systems (GIS) Data Warehouses Real-time and
Lezione 1 Introduzione e Modellazione Concettuale 1 Tipi di Database ed Applicazioni Database Numerici e Testuali Database Multimediali Geographic Information Systems (GIS) Data Warehouses Real-time and
Sistemi operativi e reti A.A. 2013-14. Lezione 2
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 2 Giovedì 10-10-2013 1 Sistemi a partizione di tempo (time-sharing) I
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2013-14 Pietro Frasca Lezione 2 Giovedì 10-10-2013 1 Sistemi a partizione di tempo (time-sharing) I
API e socket per lo sviluppo di applicazioni Web Based
 API e socket per lo sviluppo di applicazioni Web Based Cosa sono le API? Consideriamo il problema di un programmatore che voglia sviluppare un applicativo che faccia uso dei servizi messi a disposizione
API e socket per lo sviluppo di applicazioni Web Based Cosa sono le API? Consideriamo il problema di un programmatore che voglia sviluppare un applicativo che faccia uso dei servizi messi a disposizione
Introduzione alle tecnologie informatiche. Strumenti mentali per il futuro
 Introduzione alle tecnologie informatiche Strumenti mentali per il futuro Panoramica Affronteremo i seguenti argomenti. I vari tipi di computer e il loro uso Il funzionamento dei computer Il futuro delle
Introduzione alle tecnologie informatiche Strumenti mentali per il futuro Panoramica Affronteremo i seguenti argomenti. I vari tipi di computer e il loro uso Il funzionamento dei computer Il futuro delle
Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer.
 I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
I Sistemi Operativi Il Software di Base Il software di base comprende l insieme dei programmi predisposti per un uso efficace ed efficiente del computer. Il sistema operativo è il gestore di tutte le risorse
Progetto Vserver- HighAvailability
 Progetto Vserver- HighAvailability 16.12.2003 Alberto Cammozzo - Dipartimento di Scienze Statistiche - Università di Padova [email protected] Nell'ambito dell'aggiornamento dei servizi in corso si propone
Progetto Vserver- HighAvailability 16.12.2003 Alberto Cammozzo - Dipartimento di Scienze Statistiche - Università di Padova [email protected] Nell'ambito dell'aggiornamento dei servizi in corso si propone
Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base
 Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Sistema operativo Definizione Parte del software che gestisce I programmi applicativi L interfaccia tra il calcolatore e i programmi applicativi Le funzionalità di base Architettura a strati di un calcolatore
Laboratorio di Informatica
 per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
per chimica industriale e chimica applicata e ambientale LEZIONE 4 La CPU e l esecuzione dei programmi 1 Nelle lezioni precedenti abbiamo detto che Un computer è costituito da 3 principali componenti:
GPGPU GPGPU. anni piu' recenti e' naturamente aumentata la versatilita' ed usabilita' delle GPU
 GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
GPGPU GPGPU GPGPU Primi In (General Purpose computation using GPU): uso del processore delle schede grafice (GPU) per scopi differenti da quello tradizionale delle generazione di immagini 3D esperimenti
Informatica di base. Hardware: CPU SCHEDA MADRE. Informatica Hardware di un PC Prof. Corrado Lai
 Informatica di base Hardware: CPU SCHEDA MADRE HARDWARE DI UN PC 2 Hardware (parti fisiche) Sono le parti fisiche di un Personal Computer (processore, scheda madre, tastiera, mouse, monitor, memorie,..).
Informatica di base Hardware: CPU SCHEDA MADRE HARDWARE DI UN PC 2 Hardware (parti fisiche) Sono le parti fisiche di un Personal Computer (processore, scheda madre, tastiera, mouse, monitor, memorie,..).
Architetture Informatiche. Dal Mainframe al Personal Computer
 Architetture Informatiche Dal Mainframe al Personal Computer Architetture Le architetture informatiche definiscono le modalità secondo le quali sono collegati tra di loro i diversi sistemi ( livello fisico
Architetture Informatiche Dal Mainframe al Personal Computer Architetture Le architetture informatiche definiscono le modalità secondo le quali sono collegati tra di loro i diversi sistemi ( livello fisico
Architetture Informatiche. Dal Mainframe al Personal Computer
 Architetture Informatiche Dal Mainframe al Personal Computer Architetture Le architetture informatiche definiscono le modalità secondo le quali sono collegati tra di loro i diversi sistemi ( livello fisico
Architetture Informatiche Dal Mainframe al Personal Computer Architetture Le architetture informatiche definiscono le modalità secondo le quali sono collegati tra di loro i diversi sistemi ( livello fisico
ARCHITETTURE MULTIPROCESSORE E CALCOLO PARALLELO (Motivazioni e Classificazioni)
") ARCHITETTURE MULTIPROCESSORE E CALCOLO PARALLELO (Motivazioni e Classificazioni) Michele Colajanni Università di Modena e Reggio Emilia E-mail: [email protected] Perché le Architetture Multiprocessor?
ARCHITETTURE MULTIPROCESSORE E CALCOLO PARALLELO (Motivazioni e Classificazioni) Michele Colajanni Università di Modena e Reggio Emilia E-mail: [email protected] Perché le Architetture Multiprocessor?
Davide Cesari Massimo Bider Paolo Patruno. Emilia Romagna
 1 IMPLEMENTAZIONE OPERATIVA DI UN MODELLO DI PREVISIONI METEOROLOGICHE SU UN SISTEMA DI CALCOLO PARALLELO LINUX/GNU Davide Cesari Massimo Bider Paolo Patruno Emilia Romagna LM-COSMO-LAMI 2 Il modello LM
1 IMPLEMENTAZIONE OPERATIVA DI UN MODELLO DI PREVISIONI METEOROLOGICHE SU UN SISTEMA DI CALCOLO PARALLELO LINUX/GNU Davide Cesari Massimo Bider Paolo Patruno Emilia Romagna LM-COSMO-LAMI 2 Il modello LM
3. Introduzione all'internetworking
 3. Introduzione all'internetworking Abbiamo visto i dettagli di due reti di comunicazione: ma ce ne sono decine di tipo diverso! Occorre poter far comunicare calcolatori che si trovano su reti di tecnologia
3. Introduzione all'internetworking Abbiamo visto i dettagli di due reti di comunicazione: ma ce ne sono decine di tipo diverso! Occorre poter far comunicare calcolatori che si trovano su reti di tecnologia
Presentazione di virtual desktop client + LTSP server
 + LTSP server + LTSP server Cos'è un virtual desktop? Come si usa? A cosa serve? Perchè non un classico pc? Cos'è un virtual desktop? Di solito è un mini-pc costruito per avere funzionalità di base per
+ LTSP server + LTSP server Cos'è un virtual desktop? Come si usa? A cosa serve? Perchè non un classico pc? Cos'è un virtual desktop? Di solito è un mini-pc costruito per avere funzionalità di base per
Dispensa di Informatica I.1
 IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
IL COMPUTER: CONCETTI GENERALI Il Computer (o elaboratore) è un insieme di dispositivi di diversa natura in grado di acquisire dall'esterno dati e algoritmi e produrre in uscita i risultati dell'elaborazione.
Sistemi Operativi. Conclusioni e nuove frontiere
 Sistemi Operativi (modulo di Informatica II) Conclusioni e nuove frontiere Patrizia Scandurra Università degli Studi di Bergamo a.a. 2008-09 Sommario Definizione di sistema operativo Evoluzione futura
Sistemi Operativi (modulo di Informatica II) Conclusioni e nuove frontiere Patrizia Scandurra Università degli Studi di Bergamo a.a. 2008-09 Sommario Definizione di sistema operativo Evoluzione futura
IL MULTIPROCESSING. Tendenza attuale: distribuire il calcolo tra più processori.
 IL MULTIPROCESSING Il problema: necessità di aumento della potenza di calcolo. La velocità di propagazione del segnale (20 cm/ns) impone limiti strutturali all incremento della velocità dei processori
IL MULTIPROCESSING Il problema: necessità di aumento della potenza di calcolo. La velocità di propagazione del segnale (20 cm/ns) impone limiti strutturali all incremento della velocità dei processori
Comunicazione tra Processi
 Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Comunicazione tra Processi Comunicazioni in un Sistema Distribuito Un sistema software distribuito è realizzato tramite un insieme di processi che comunicano, si sincronizzano, cooperano. Il meccanismo
Sistemi Operativi. Introduzione UNICAL. Facoltà di Ingegneria. Domenico Talia A.A. 2002-2003
 Domenico Talia Facoltà di Ingegneria UNICAL A.A. 2002-2003 1.1 Introduzione Presentazione del corso Cosa è un Sistema Operativo? Sistemi Mainframe Sistemi Desktop Sistemi Multiprocessori Sistemi Distribuiti
Domenico Talia Facoltà di Ingegneria UNICAL A.A. 2002-2003 1.1 Introduzione Presentazione del corso Cosa è un Sistema Operativo? Sistemi Mainframe Sistemi Desktop Sistemi Multiprocessori Sistemi Distribuiti
Prestazioni computazionali di OpenFOAM sul. sistema HPC CRESCO di ENEA GRID
 Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
Prestazioni computazionali di OpenFOAM sul sistema HPC CRESCO di ENEA GRID NOTA TECNICA ENEA GRID/CRESCO: NEPTUNIUS PROJECT 201001 NOME FILE: NEPTUNIUS201001.doc DATA: 03/08/10 STATO: Versione rivista
Software di sistema e software applicativo. I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche
 Software di sistema e software applicativo I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche Software soft ware soffice componente è la parte logica
Software di sistema e software applicativo I programmi che fanno funzionare il computer e quelli che gli permettono di svolgere attività specifiche Software soft ware soffice componente è la parte logica
STRUTTURE DEI SISTEMI DI CALCOLO
 STRUTTURE DEI SISTEMI DI CALCOLO 2.1 Strutture dei sistemi di calcolo Funzionamento Struttura dell I/O Struttura della memoria Gerarchia delle memorie Protezione Hardware Architettura di un generico sistema
STRUTTURE DEI SISTEMI DI CALCOLO 2.1 Strutture dei sistemi di calcolo Funzionamento Struttura dell I/O Struttura della memoria Gerarchia delle memorie Protezione Hardware Architettura di un generico sistema
Classificazione delle Architetture Parallele
 Università degli Studi di Roma Tor Vergata Facoltà di Ingegneria Classificazione delle Architetture Parallele Corso di Sistemi Distribuiti Valeria Cardellini Anno accademico 2009/10 Architetture parallele
Università degli Studi di Roma Tor Vergata Facoltà di Ingegneria Classificazione delle Architetture Parallele Corso di Sistemi Distribuiti Valeria Cardellini Anno accademico 2009/10 Architetture parallele
Sistemi avanzati di gestione dei Sistemi Informativi
 Esperti nella gestione dei sistemi informativi e tecnologie informatiche Sistemi avanzati di gestione dei Sistemi Informativi Docente: Email: Sito: [email protected] http://www.roccatello.it/teaching/gsi/
Esperti nella gestione dei sistemi informativi e tecnologie informatiche Sistemi avanzati di gestione dei Sistemi Informativi Docente: Email: Sito: [email protected] http://www.roccatello.it/teaching/gsi/
Contenuti. Visione macroscopica Hardware Software. 1 Introduzione. 2 Rappresentazione dell informazione. 3 Architettura del calcolatore
 Contenuti Introduzione 1 Introduzione 2 3 4 5 71/104 Il Calcolatore Introduzione Un computer...... è una macchina in grado di 1 acquisire informazioni (input) dall esterno 2 manipolare tali informazioni
Contenuti Introduzione 1 Introduzione 2 3 4 5 71/104 Il Calcolatore Introduzione Un computer...... è una macchina in grado di 1 acquisire informazioni (input) dall esterno 2 manipolare tali informazioni
CALCOLATORI ELETTRONICI A cura di Luca Orrù
 Lezione 1 Obiettivi del corso Il corso si propone di descrivere i principi generali delle architetture di calcolo (collegamento tra l hardware e il software). Sommario 1. Tecniche di descrizione (necessarie
Lezione 1 Obiettivi del corso Il corso si propone di descrivere i principi generali delle architetture di calcolo (collegamento tra l hardware e il software). Sommario 1. Tecniche di descrizione (necessarie
Piano Nazionale di Formazione degli Insegnanti sulle Tecnologie dell'informazione e della Comunicazione. Percorso Formativo C1.
 Piano Nazionale di Formazione degli Insegnanti sulle Tecnologie dell'informazione e della Comunicazione Percorso Formativo C1 Modulo 2 Computer hardware 1 OBIETTIVI Identificare, descrivere, installare
Piano Nazionale di Formazione degli Insegnanti sulle Tecnologie dell'informazione e della Comunicazione Percorso Formativo C1 Modulo 2 Computer hardware 1 OBIETTIVI Identificare, descrivere, installare
Cloud Computing....una scelta migliore. ICT Information & Communication Technology
 Cloud Computing...una scelta migliore Communication Technology Che cos è il cloud computing Tutti parlano del cloud. Ma cosa si intende con questo termine? Le applicazioni aziendali stanno passando al
Cloud Computing...una scelta migliore Communication Technology Che cos è il cloud computing Tutti parlano del cloud. Ma cosa si intende con questo termine? Le applicazioni aziendali stanno passando al
Replica di Active Directory. Orazio Battaglia
 Orazio Battaglia Active Directory è una base di dati distribuita che modella il mondo reale della organizzazione. Definisce gli utenti, i computer le unità organizzative che costituiscono l organizzazione.
Orazio Battaglia Active Directory è una base di dati distribuita che modella il mondo reale della organizzazione. Definisce gli utenti, i computer le unità organizzative che costituiscono l organizzazione.
TYPO3 in azione con l infrastruttura ZEND: affidabilità e sicurezza. Mauro Lorenzutti CTO di Webformat srl mauro.lorenzutti@webformat.
 TYPO3 in azione con l infrastruttura ZEND: affidabilità e sicurezza Mauro Lorenzutti CTO di Webformat srl [email protected] Scaletta Test di performance Monitoring e reportistica errori Integrazione
TYPO3 in azione con l infrastruttura ZEND: affidabilità e sicurezza Mauro Lorenzutti CTO di Webformat srl [email protected] Scaletta Test di performance Monitoring e reportistica errori Integrazione
Gestione della memoria centrale
 Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Gestione della memoria centrale Un programma per essere eseguito deve risiedere in memoria principale e lo stesso vale per i dati su cui esso opera In un sistema multitasking molti processi vengono eseguiti
Turismo Virtual Turismo Virtual Turismo Virtual
 Da una collaborazione nata all inizio del 2011 tra le società Annoluce di Torino e Ideavity di Porto (PT), giovani e dinamiche realtà ICT, grazie al supporto della Camera di Commercio di Torino, nasce
Da una collaborazione nata all inizio del 2011 tra le società Annoluce di Torino e Ideavity di Porto (PT), giovani e dinamiche realtà ICT, grazie al supporto della Camera di Commercio di Torino, nasce
Hardware delle reti LAN
 Hardware delle reti LAN Le reti LAN utilizzano una struttura basata su cavi e concentratori che permette il trasferimento di informazioni. In un ottica di questo tipo, i computer che prendono parte allo
Hardware delle reti LAN Le reti LAN utilizzano una struttura basata su cavi e concentratori che permette il trasferimento di informazioni. In un ottica di questo tipo, i computer che prendono parte allo
Sistemi Operativi UNICAL. Facoltà di Ingegneria. Domenico Talia A.A. 2002-2003 1.1. Sistemi Operativi. D. Talia - UNICAL
 Domenico Talia Facoltà di Ingegneria UNICAL A.A. 2002-2003 1.1 Introduzione Presentazione del corso Cosa è un Sistema Operativo? Sistemi Mainframe Sistemi Desktop Sistemi Multiprocessori Sistemi Distribuiti
Domenico Talia Facoltà di Ingegneria UNICAL A.A. 2002-2003 1.1 Introduzione Presentazione del corso Cosa è un Sistema Operativo? Sistemi Mainframe Sistemi Desktop Sistemi Multiprocessori Sistemi Distribuiti
Sistemi informativi secondo prospettive combinate
 Sistemi informativi secondo prospettive combinate direz acquisti direz produz. direz vendite processo acquisti produzione vendite INTEGRAZIONE TRA PROSPETTIVE Informazioni e attività sono condivise da
Sistemi informativi secondo prospettive combinate direz acquisti direz produz. direz vendite processo acquisti produzione vendite INTEGRAZIONE TRA PROSPETTIVE Informazioni e attività sono condivise da
Sistemi Operativi STRUTTURA DEI SISTEMI OPERATIVI 3.1. Sistemi Operativi. D. Talia - UNICAL
 STRUTTURA DEI SISTEMI OPERATIVI 3.1 Struttura dei Componenti Servizi di un sistema operativo System Call Programmi di sistema Struttura del sistema operativo Macchine virtuali Progettazione e Realizzazione
STRUTTURA DEI SISTEMI OPERATIVI 3.1 Struttura dei Componenti Servizi di un sistema operativo System Call Programmi di sistema Struttura del sistema operativo Macchine virtuali Progettazione e Realizzazione
GESTIONE DEI PROCESSI
 Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
Sistemi Operativi GESTIONE DEI PROCESSI Processi Concetto di Processo Scheduling di Processi Operazioni su Processi Processi Cooperanti Concetto di Thread Modelli Multithread I thread in Java Concetto
La gestione di un calcolatore. Sistemi Operativi primo modulo Introduzione. Sistema operativo (2) Sistema operativo (1)
 Sistema operativo (1)") La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
La gestione di un calcolatore Sistemi Operativi primo modulo Introduzione Augusto Celentano Università Ca Foscari Venezia Corso di Laurea in Informatica Un calcolatore (sistema di elaborazione) è un sistema
Un framework per simulazione massiva distribuita basata su Agenti D-MASON: Architettura. Carmine Spagnuolo
 Un framework per simulazione massiva distribuita basata su Agenti D-MASON: Architettura Carmine Spagnuolo 1 Simulazione Multi-Agente Una simulazione multi-agente è un sistema in cui entità (agenti) intelligenti
Un framework per simulazione massiva distribuita basata su Agenti D-MASON: Architettura Carmine Spagnuolo 1 Simulazione Multi-Agente Una simulazione multi-agente è un sistema in cui entità (agenti) intelligenti
Gerarchia delle memorie
 Memorie Gerarchia delle memorie Cache CPU Centrale Massa Distanza Capacità Tempi di accesso Costo 2 1 Le memorie centrali Nella macchina di Von Neumann, le istruzioni e i dati sono contenute in una memoria
Memorie Gerarchia delle memorie Cache CPU Centrale Massa Distanza Capacità Tempi di accesso Costo 2 1 Le memorie centrali Nella macchina di Von Neumann, le istruzioni e i dati sono contenute in una memoria
Corso di Sistemi di Elaborazione delle informazioni
 Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Corso di Sistemi di Elaborazione delle informazioni Sistemi Operativi Francesco Fontanella Complessità del Software Software applicativo Software di sistema Sistema Operativo Hardware 2 La struttura del
Più processori uguale più velocità?
 Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Applicativo SBNWeb. Configurazione hardware e software di base di un server LINUX per gli applicativi SBNWeb e OPAC di POLO
 Applicativo SBNWeb Configurazione hardware e software di base di un server LINUX per gli applicativi SBNWeb e OPAC di POLO Versione : 1.0 Data : 5 marzo 2010 Distribuito a : ICCU INDICE PREMESSA... 1 1.
Applicativo SBNWeb Configurazione hardware e software di base di un server LINUX per gli applicativi SBNWeb e OPAC di POLO Versione : 1.0 Data : 5 marzo 2010 Distribuito a : ICCU INDICE PREMESSA... 1 1.
Il computer: primi elementi
 Il computer: primi elementi Tommaso Motta T. Motta Il computer: primi elementi 1 Informazioni Computer = mezzo per memorizzare, elaborare, comunicare e trasmettere le informazioni Tutte le informazioni
Il computer: primi elementi Tommaso Motta T. Motta Il computer: primi elementi 1 Informazioni Computer = mezzo per memorizzare, elaborare, comunicare e trasmettere le informazioni Tutte le informazioni
Una delle cose che si apprezza maggiormente del prodotto è proprio la facilità di gestione e la pulizia dell interfaccia.
 Nella breve presentazione che segue vedremo le caratteristiche salienti del prodotto Quick- EDD/Open. Innanzi tutto vediamo di definire ciò che non è: non si tratta di un prodotto per il continuos backup
Nella breve presentazione che segue vedremo le caratteristiche salienti del prodotto Quick- EDD/Open. Innanzi tutto vediamo di definire ciò che non è: non si tratta di un prodotto per il continuos backup
Architetture software
 Sistemi Distribuiti Architetture software 1 Sistemi distribuiti: Architetture software Il software di gestione di un sistema distribuito ha funzionalità analoghe ad un sistema operativo Gestione delle
Sistemi Distribuiti Architetture software 1 Sistemi distribuiti: Architetture software Il software di gestione di un sistema distribuito ha funzionalità analoghe ad un sistema operativo Gestione delle
In un modello a strati il SO si pone come un guscio (shell) tra la macchina reale (HW) e le applicazioni 1 :
 tra la macchina reale (HW) e le applicazioni 1 :") Un Sistema Operativo è un insieme complesso di programmi che, interagendo tra loro, devono svolgere una serie di funzioni per gestire il comportamento del computer e per agire come intermediario consentendo
Un Sistema Operativo è un insieme complesso di programmi che, interagendo tra loro, devono svolgere una serie di funzioni per gestire il comportamento del computer e per agire come intermediario consentendo
La macchina programmata Instruction Set Architecture (1)
") Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
Corso di Laurea in Informatica Architettura degli elaboratori a.a. 2014-15 La macchina programmata Instruction Set Architecture (1) Schema base di esecuzione Istruzioni macchina Outline Componenti di un
Laboratorio di Amministrazione di Sistema (CT0157) parte A : domande a risposta multipla
 parte A : domande a risposta multipla") Laboratorio di Amministrazione di Sistema (CT0157) parte A : domande a risposta multipla 1. Which are three reasons a company may choose Linux over Windows as an operating system? (Choose three.)? a) It
Laboratorio di Amministrazione di Sistema (CT0157) parte A : domande a risposta multipla 1. Which are three reasons a company may choose Linux over Windows as an operating system? (Choose three.)? a) It
Il sistema di I/O. Hardware di I/O Interfacce di I/O Software di I/O. Introduzione
 Il sistema di I/O Hardware di I/O Interfacce di I/O Software di I/O Introduzione 1 Sotto-sistema di I/O Insieme di metodi per controllare i dispositivi di I/O Obiettivo: Fornire ai processi utente un interfaccia
Il sistema di I/O Hardware di I/O Interfacce di I/O Software di I/O Introduzione 1 Sotto-sistema di I/O Insieme di metodi per controllare i dispositivi di I/O Obiettivo: Fornire ai processi utente un interfaccia
TECNICHE DI SIMULAZIONE
 TECNICHE DI SIMULAZIONE INTRODUZIONE Francesca Mazzia Dipartimento di Matematica Università di Bari a.a. 2004/2005 TECNICHE DI SIMULAZIONE p. 1 Introduzione alla simulazione Una simulazione è l imitazione
TECNICHE DI SIMULAZIONE INTRODUZIONE Francesca Mazzia Dipartimento di Matematica Università di Bari a.a. 2004/2005 TECNICHE DI SIMULAZIONE p. 1 Introduzione alla simulazione Una simulazione è l imitazione
Corso di Sistemi Operativi DEE - Politecnico di Bari. Windows vs LINUX. G. Piscitelli - M. Ruta. 1 di 20 Windows vs LINUX
 Windows vs LINUX 1 di 20 Windows vs LINUX In che termini ha senso un confronto? Un O.S. è condizionato dall architettura su cui gira Un O.S. è condizionato dalle applicazioni Difficile effettuare un rapporto
Windows vs LINUX 1 di 20 Windows vs LINUX In che termini ha senso un confronto? Un O.S. è condizionato dall architettura su cui gira Un O.S. è condizionato dalle applicazioni Difficile effettuare un rapporto
Laboratorio di Informatica
 per chimica industriale e chimica applicata e ambientale LEZIONE 4 - parte II La memoria 1 La memoriaparametri di caratterizzazione Un dato dispositivo di memoria è caratterizzato da : velocità di accesso,
per chimica industriale e chimica applicata e ambientale LEZIONE 4 - parte II La memoria 1 La memoriaparametri di caratterizzazione Un dato dispositivo di memoria è caratterizzato da : velocità di accesso,
Sicurezza e Gestione delle Reti (di telecomunicazioni)
") Sicurezza e Gestione delle Reti (di telecomunicazioni) Tommaso Pecorella [email protected] Corso di Studi in Ingegneria Elettronica e delle Telecomunicazioni Corso di Studi in Ingegneria Informatica
Sicurezza e Gestione delle Reti (di telecomunicazioni) Tommaso Pecorella [email protected] Corso di Studi in Ingegneria Elettronica e delle Telecomunicazioni Corso di Studi in Ingegneria Informatica
Lezione 4 La Struttura dei Sistemi Operativi. Introduzione
 Lezione 4 La Struttura dei Sistemi Operativi Introduzione Funzionamento di un SO La Struttura di un SO Sistemi Operativi con Struttura Monolitica Progettazione a Livelli di un SO 4.2 1 Introduzione (cont.)
Lezione 4 La Struttura dei Sistemi Operativi Introduzione Funzionamento di un SO La Struttura di un SO Sistemi Operativi con Struttura Monolitica Progettazione a Livelli di un SO 4.2 1 Introduzione (cont.)
CALCOLATORI ELETTRONICI Lezione n. Arch_Par 3
 CALCOLATORI ELETTRONICI Lezione n. Arch_Par 3 ARRAY PROCESSORS. ARCHITETTURE A PARALLELISMO MASSIVO ESEMPI In questa lezione vengono presentati alcuni esempi di architetture a parallelismo massivo. Si
CALCOLATORI ELETTRONICI Lezione n. Arch_Par 3 ARRAY PROCESSORS. ARCHITETTURE A PARALLELISMO MASSIVO ESEMPI In questa lezione vengono presentati alcuni esempi di architetture a parallelismo massivo. Si
Esame di INFORMATICA
 Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Università di L Aquila Facoltà di Biotecnologie Esame di INFORMATICA Lezione 4 MACCHINA DI VON NEUMANN Anni 40 i dati e i programmi che descrivono come elaborare i dati possono essere codificati nello
Elettronica dei Sistemi Programmabili
 Elettronica dei Sistemi Programmabili Introduzione Stefano Salvatori Università degli Studi Roma Tre ([email protected]) Università degli Studi Roma Tre Elettronica dei Sistemi Programmabili
Elettronica dei Sistemi Programmabili Introduzione Stefano Salvatori Università degli Studi Roma Tre ([email protected]) Università degli Studi Roma Tre Elettronica dei Sistemi Programmabili