WEKA: Machine Learning Algorithms in java. Ilaria Bordino Ida Mele
|
|
|
- Rebecca Morelli
- 5 anni fa
- Visualizzazioni
Transcript

1 WEKA: Machine Learning Algorithms in java Ilaria Bordino Ida Mele


2 Introduzione a Collezione di algoritmi di Machine Learning Package Java Open Source. Acronimo di Waikato Environment for Knowledge Analysis. Scritto in java, utilizzabile su qualunque sistema operativo dotato di piattaforma java. Home page di : dove si può scaricare il software e dataset di esempio. Manuale: Pagina 2
3 Introduzione a (2) Collezione estensiva di tool per Machine Learning e Data Mining. Classificazione: implementazione java di tutte le tecniche di Machine Learning correntemente utilizzate. Regressione. Regole di associazione. Algoritmi di clustering. Pagina 3
4 : schemi per la classificazione Decision trees Rule learners Naïve Bayes Decision Tables Locally weighted regression SVM Instance-based learners Logistic regression Pagina 4
5 : Predizione Numerica Linear regression Model tree generators Locally weighted regressione Instance-based learners Decision Tables Multi-layer perceptron Pagina 5
6 : Meta Schemi Bagging Boosting Stacking Regression via classification Classification via regression Cost sensitive classification : Schemi per clustering EM Cobweb Pagina 6
7 Installazione Assicurarsi che sulla propria macchina sia presente una installazione del JRE. Scaricare l archivio di e decomprimerlo. Aprire un terminale ed entrare nella directory di. Digitare il comando: java -Xmx512M -jar weka.jar Pagina 7
8 Ambienti operativi SimpleCLI: Ambiente a linea di comando da usare per invocare direttamente le varie classi da cui è composto. Explorer: ambiente da utilizzare per caricare degli insiemi di dati, visualizzare la disposizione degli attributi, preprocessare i dati ed eseguire algoritmi di classificazione, clustering, selezione di attributi e determinazione di regole associative. Pagina 8
9 Ambienti operativi (2) Experimenter: è una versione batch dell'explorer. Consente di impostare una serie di analisi, su vari insiemi di dati e con vari algoritmi, ed eseguirle alla fine tutte insieme. È possibile in questo modo confrontare vari tipi di algoritmi, e determinare quale è il più adatto a uno specifico insieme di dati. Knowledge Flow: una variante dell'explorer, in cui le operazioni da eseguire si esprimono in un ambiente grafico, disegnando un diagramma che esprime il flusso della conoscenza. È possibile selezionare varie componenti (sorgenti di dati, filtri, algoritmi di classificazione) e collegarli in un diagramma tipicamente detto data-flow. Pagina 9

10 Ambienti operativi: Explorer Pagina 10
11 Dati può prelevare i propri dati usando 3 funzioni: Open File: preleva i dati da un file di testo sul computer locale, in formato ARFF, CSV, C45 o Binary serialized istances. Il formato standard di è ARFF. Open URL: preleva i dati da un file su web, in uno dei formati di cui sopra. Open DB: preleva i dati da un server database supportato dai driver JDBC. C'è anche la possibilità di generare dati artificiali: Generate: utilizza dei DataGenerators per creare dati artificiali. Pagina 11
12 Preprocessamento dei dati Una volta aperto l'insieme di dati di interesse, in basso a sinistra compare l'elenco degli attributi che compongono i dati in questione. Cliccando su un attributo, sul lato destro appaiono delle informazioni statistiche. Per attributi nominali abbiamo l'elenco dei possibili valori e, per ognuno di essi, il numero di istanze con quel valore. Per attributi numerici, abbiamo invece informazioni sul valore massimo, minimo, media e deviazione standard, oltre a numero di valori diversi, numero di valori unici e numero di istanze col valore mancante. Pagina 12
13 Preprocessamento dei dati Sotto le informazioni statistiche abbiamo un istogramma. Con gli attributi nominali viene visualizzato, per ogni valore, una barra di altezza proporzionale al numero di istanze con quel valore. Per gli attributi numerici le informazioni sono simili, ma il sistema decide automaticamente in quanti intervalli divedere il range dell'attributo e quindi quante barre visualizzare. Una volta caricati i dati, è possibile modificarli applicando un filtro o una procedura di modifica interattiva. Esempi: modificare tutte le istanze con un valore fisso per un attributo, cancellare o rinominare attributi Pagina 13
14 Formato ARFF ARFF è il formato dati standard di WEKA. Un file ARFF è composto da una intestazione e dal corpo dati vero e proprio. L intestazione contiene il nome del set dei dati e una intestazione degli attributi. Per ogni attributo è possibile specificare il tipo: numerico, categoriale, stringa o data. I dati veri e propri sono forniti creando una riga per ogni istanza, e separando i campi con delle virgole. Ovunque è possibile inserire dei commenti, facendoli precedere dal simbolo %. Pagina 14
15 Formato ARFF: weather % Relazione outlook {sunny, overcast, temperature humidity windy {TRUE, play {yes, sunny,85,85,false,no sunny,80,90,true,no overcast,83,86,false,yes Pagina 15
16 Formato ARFF: esempio (2) Nell esempio fornito osserviamo che: la weather specifica un nome per la relazione. la outlook {sunny, overcast, rainy} specifica che l attributo di nome outlook è di tipo categoriale e può assumere i valori sunny, rainy e overcast. la temperature real specifica che l attributo di nome temperature è di tipo numerico. la indica l inizio dei dati veri e propri. Pagina 16
17 Formato ARFF Si può utilizzare il valore? come dato per indicare un valore mancante. In generale, ogni volta che serve individuare un attributo particolare come la classe dell istanza, ad esempio nei problemi di classificazione o selezione degli attributi, l ultimo attributo gioca questo ruolo. Si può comunque sempre specificare un diverso attributo, caso per caso. Pagina 17
18 Architettura Elenco dei package principali: weka.associations weka.attributeselection weka.classifiers weka.clusterers weka.core weka.estimators weka.experiment weka.filters weka.gui.package weka.gui.experiment weka.gui.explorer Pagina 18
19 Il package weka.core Il package core è il package centrale del sistema. Contiene classi a cui quasi tutte le altre classi fanno accesso. Classi principali: Attribute: un oggetto di questa classe rappresenta un attributo. Contiene il nome dell attributo, il suo tipo e, in caso di attributo nominale, i possibili valori. Instance: un oggetto di questa classe contiene i valori degli attributi di una particolare istanza. Instances: un oggetto di questa classe mantiene un insieme ordinato di istanze, ovvero un dataset. Pagina 19
20 Il package weka.classifiers Contiene implementazioni degli algoritmi più comunemente utilizzati per classificazione e predizione numerica. La classe più importante è Classifier, che definisce la struttura generale di un qualsiasi schema di classificazione o predizione. Contiene due metodi: buildclassifier() e classifyinstance(), che debbono essere implementati da tutti gli algoritmi di apprendimento. Ogni algoritmo di apprendimento è una sottoclasse di Classifier e ridefinisce questi metodi. Pagina 20
21 Il package.clusterers Contiene un implementazione di due importanti metodi di apprendimento non supervisionato: COBWEB ed EM. Il package.estimators Contiene sottoclassi di una generica classe Estimator, che calcola vari tipi di distribuzioni di probabilità. Pagina 21
22 Il package weka.filters Tool per il preprocessamento dei dati: discretizzazione, normalizzazione, resampling, selezione, trasformazione o combinazione di attributi. La classe Filter definisce la struttura generale di tutte le classi che contengono algoritmi di filtering. Tali classi sono tutte implementate come sottoclassi di Filter. Il package weka.attributeselection Mette a disposizione classi per effettuare riduzioni dimensionali su una collezione di dati. Queste classi vengono utilizzate da weka.filters.attributeselectionfilter, ma possono anche essere usate separatemente. Pagina 22
23 Classificatori: J48 Alberi di decisione: metodo di classificazione supervisionato. Un albero di decisione è una semplice struttura in cui i nodi non terminali rappresentano test su uno o più attributi mentre i nodi terminali riflettono i risultati della decisione. Approccio reso popolare da J.R.Quinlan. C4.5 è l ultima implementazione di pubblico dominio del modello di Quinlan. L algoritmo J48 è l implementazione dell albero di decisione C4.5. Pagina 23
24 Alberi di decisione: approccio generale Scegliere un attributo che meglio differenzia i valori dell attributo di output. Creare nell albero un ramo separato per ogni possibile valore dell attributo scelto. Dividere le istanze in sottogruppi che riflettano i valori dell attributo scelto. Pagina 24
25 Alberi di decisione: approccio generale (2) Per ogni sottogruppo, terminare il processo di selezione degli attributi se: (a) tutti i membri di un sottogruppo hanno lo stesso valore per l attributo di output (in questo caso il ramo considerato va etichettato con il valore specificato); (b) il sottogruppo contiene un singolo nodo oppure non è più possibile individuare un attributo in base al quale fare differenziazioni. In questo caso, il ramo considerato viene etichettato con il valore dell attributo di output che caratterizza la maggior parte delle istanze rimanenti. Pagina 25
26 Alberi di decisione: approccio generale (3) Il processo viene ripetuto per ogni sottogruppo che non è stato etichettato come terminale. L algoritmo viene applicato ai dati di training. L albero di decisione creato viene quindi testato su un dataset di test. Se non sono disponibili dati di test J48 esegue cross validation sui dati di training. Pagina 26
27 J48: Opzioni Attributo di output: può essere scelto soltanto tra gli attributi di categoria. Fattore di confidenza: determina il valore da utilizzare per fare pruning (rimozione dei rami che non portano guadagno in termini di accuratezza statistica del modello); default: 25%. Numero minimo di istanze per foglia: un valore alto creerà un modello più generale, un valore basso un albero più specializzato. Pagina 27
28 J48: Opzioni (2) Numero di cartelle per cross validation: determina come costruire e testare il modello in assenza di dati di test. Se questo valore è x, 1 1/x dei dati di training viene usato per costruire il modello e 1/x viene usato per il test. Il processo viene ripetuto x volte, in modo che tutti I dati di training siano usati esattamente una volta nei dati di test. La stima complessiva si ottiene facendo la media delle x stime d errore. Valore tipico: 10. Test data set: permette di specificare un insieme di dati di test. Pagina 28
29 Alberi di decisione: Vantaggi e Svantaggi Vantaggi: semplici da comprendere e da convertire in un insieme di regole di produzione; possono classificare sia dati numerici che di categoria, ma l attributo di output deve essere di categoria; non ci sono assunzioni a priori sulla natura dei dati. Svantaggi: molteplici attributi di output non sono consentiti; gli alberi di decisione sono instabili. Leggere variazioni nei dati di training possono produrre differenti selezioni di attributi ad ogni punto di scelta all interno dell albero. Pagina 29
30 Classificatori: parametri generali Se si utilizza SimpleCLI si possono invocare le classi di. Esempio per utilizzare J48: java weka.classifiers.trees.j48 -t data/weather.arff I parametri generali sono: -t: file di training (formato ARFF) -T: file di test (formato ARFF). Se questo parametro manca, di default si esegue 10-fold cross validation -k: specifica numero di cartelle per cross validation -c: selezionare la variable classe -d: salvare il modello generato dopo il training -l: caricare un modello salvato in precedenza -i: descrizione dettagliata delle prestazioni -o: disabilita output human- readable Pagina 30
31 Altri classificatori bayes.naivebayes meta.classificationviaregression functions.logistic functions.smo lazy.kstar lazy.ibk rules.jrip Pagina 31
32 Explorer: Classificatore Pagina 32
")
33 Explorer: Classificatore (2) Pagina 33
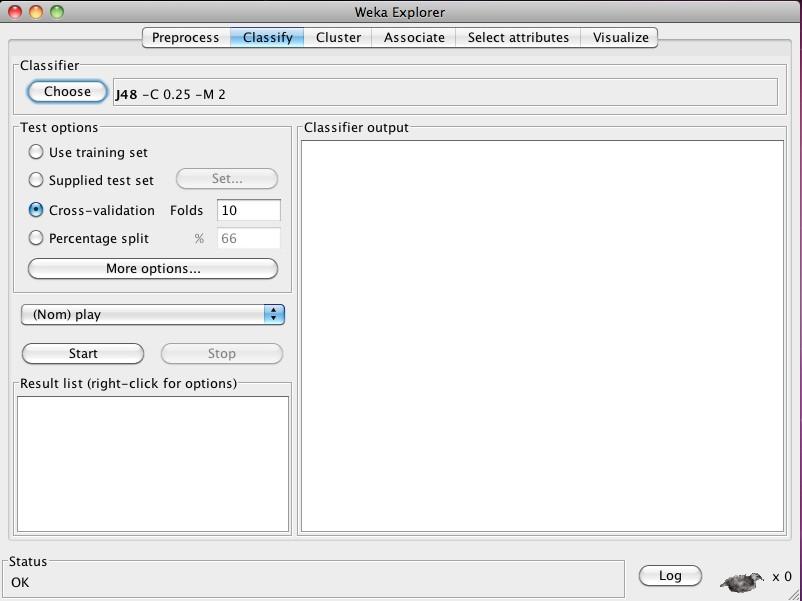

34 Explorer: Classificatore (3) Pagina 34
 1 2 Risultati Pagina")
35 Explorer: Classificatore (4) 1 2 Risultati Pagina 35
36 Output di un classificatore La prima parte è una descrizione leggibile del modello generato. Il nodo alla radice dell albero determina la prima decisione. I numero in parentesi alla fine di ogni foglia indicano il numero di esempi contenuti nella foglia stessa. Se una o più foglie non sono pure (tutti esempi della stessa classe), viene indicato anche il numero di esempi che non sono stati classificati correttamente. Pagina 36
37 Output del classificatore: esempio J48 pruned tree outlook = sunny humidity <= 75: yes (2.0) humidity > 75: no (3.0) outlook = overcast: yes (4.0) outlook = rainy windy = TRUE: no (2.0) windy = FALSE: yes (3.0) Number of Leaves : 5 Size of the tree : 8 Pagina 37
38 Tempo impiegato per l apprendimento Time taken to build model: 0.05 seconds Time taken to test model on training data: 0 seconds Per un albero di decisione l apprendimento è piuttosto veloce e la valutazione ancora di più. Nel caso di schema di apprendimento lazy, la fase di test sarebbe sicuramente molto più lunga di quella di training. Pagina 38
39 Classificatore: valutazione prestazioni = Error on training data == Correctly Classified Instance Incorrectly Classified Instances Kappa statistic Mean absolute error Root mean squared error Relative absolute error Root relative squared error Total Number of Instances % 0% % 0% Pagina 39
40 Classificatore: valutazione prestazioni (2) == Detailed Accuracy By Class == TP Rate FP Rate Precision Recall F-Measure == Confusion Matrix == a b <-- classified as 9 0 a = yes 0 5 b = no Class yes no Classificatore perfetto? Il modello costruto con il training set è troppo ottimistico. Pagina 40

41 Explorer: Classificatore e cross validation 1 2 Risultati Pagina 41
42 Classificatore: cross validation == Stratified cross-validation == Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error 60% Root relative squared error % Total Number of Instances 14 Pagina 42
43 Classificatore: cross validation (2) Risultati più realistici: accuratezza intorno al 64%. Kappa statistic: misura il grado di accordo della predizione con la vera classe 1.0 significa accordo perfetto. Le altre metriche d errore non sono molto significative ai fini della classificazione, ma possono essere usate ad esempio per regressione. Matrice di confusione: istanze classificate correttamente su una diagonale. Pagina 43
44 Classificatore: cross validation (3) == Detailed Accuracy By Class == TP Rate FP Rate Precision Recall F-Measure Class yes no == Confusion Matrix == a b <-- classified as 7 2 a = yes 3 2 b = no Pagina 44
45 Classificatore: valutazione (1) Osserviamo la matrice di confusione: == Confusion Matrix == a b <-- classified as 7 2 a 3 2 b Il numero di istanze classificate correttamente è dato dalla somma della diagonale, mentre le altre istanze sono classificate in modo errato. Ad esempio abbiamo 2 istanze della classe a erroneamente classificate come appartenenti alla classe b e 3 istanze di b sono erroneamente classificate come appartenenti alla classe a. Pagina 45
46 Classificatore: valutazione (2) True Positive rate (TP rate) o Recall è la frazione di esempi classificati come appartenenti alla classe x, fra tutti quelli che sono realmente della classe x. Nella confusion matrix è l'elemento diagonale diviso per la somma degli elementi della riga. Esempio: 7/(7+2)= per la classe a e 2/(3+2)=0.4 per la classe b. False Positive rate (FP rate) è frazione di esempi classificati come appartenenti alla classe x, ma che in realità appartengono a un altra classe, fra tutti quelli che non appartengono alla classe x. Nella matrice è la somma della colonna meno l'elemento diagonale diviso per la somma delle righe nelle altre classi. Esempio: (7+3-7)/(3+2)=3/5=0.6 per la classe a e (2+2-2)/(7+2)= 2/9=0.222 per la classe a. Pagina 46
47 Classificatore: valutazione (3) Precision è la frazione di esempi realmente di classe x fra tutti quelli classificati come x. Nella confusion matrix è l'elemento diagonale diviso per la somma delle colonne rilevanti. Esempio: 7/(7+3)=0.7 per la classe a e 2/ (2+2)=0.5 per la classe b. F-Measure è una misura standard che riassume precision e recall: 2*Precision*Recall/(Precision+Recall). Esempio: 2*0.7*0.778/( )=0.737 per la classe a e 2*0.5*0.4/( )=0.444 per la classe b. Pagina 47
48 Clustering Le tecniche di clustering si applicano per suddividere un insieme di istanze in gruppi che riflettano qualche meccanismo o caratteristica naturale del dominio di appartenenza delle istanze stesse. Queste proprietà fanno sì che delle istanze siano accomunate da una somiglianza più forte rispetto agli altri dati nella collezione. Il clustering richiede approcci differenti da quelli usati per classificazione e regole di associazione. Pagina 48
49 Clustering (2) Lo scopo di un algoritmo di clustering è quello di suddividere un insieme di documenti in gruppi che siano quanto più possibile coerenti internamente, e allo stesso tempo diversi l uno dall altro. I documenti all interno di un cluster dovrebbero essere quanto più possibile diversi da quelli inseriti all interno di un altro cluster. Il clustering è la forma più comune di apprendimento non supervisionato: nessun uso di esperti umani per assegnare le istanze alle classi. Pagina 49
50 Clustering (3) Il clustering è un problema fondamentalmente diverso dalla classificazione: la classificazione è una forma di apprendimento supervisionato. Lo scopo della classificazione è quello di replicare una distinzione in categorie che un assessor umano ha imposto sui dati. L input chiave di un algoritmo di clustering è la misura di distanza che viene usata per suddividere le istanze in gruppi. Pagina 50
51 Tipi di clustering Flat clustering: crea un insieme di cluster piatto, senza una struttura gerarchica che metta in relazione i cluster l uno con l altro. Hierarchical clustering: crea una gerarchia di cluster. Hard clustering: assegna ogni istanza ad esattamente un cluster. Soft clustering: l assegnazione di un documento è una distribuzione su tutti i cluster (es. LSI). Terminologia alternativa: cluster partizionale o esaustivo. Pagina 51
52 Clustering in Information Retrieval Cluster hypothesis: documenti in uno stesso cluster hanno un comportamento simile rispetto a ciò che è rilevante per soddisfare le esigenze informative degli utenti. Se un documento è rilevante per una richiesta di ricerca, assumiamo che anche gli altri documenti all interno dello stesso cluster siano rilevanti. Il clustering ha molte applicazioni in information retrieval. Viene usato per migliorare usabilità, efficienza ed efficacia del sistema di ricerca. Pagina 52
53 Cardinalità Critical issue: determinare K, cardinalità di un clustering. Brute force approach: enumera tutti i possibili clustering e scegli il migliore (non utilizzabile in pratica per via dell esplosione esponenziale del numero di possibili partizioni). La maggior parte degli algoritmi procede per raffinamento iterativo di un partizionamento iniziale: trovare un buon punto di partenza è dunque importante per la qualità della soluzione finale. Pagina 53
54 Valutazione di un clustering Obiettivo generale: alta similarità intra-cluster e bassa similarità inter-cluster (criterio interno di qualità). Il soddisfacimento di questo criterio non garantisce la realizzazione di un applicazione efficace. Approccio alternativo: valutazione diretta nell applicazione di interesse. User study: approccio immediato ma costoso. Altra possibilità: confronta i risultati del clustering con un golden standard. Pagina 54
55 Clustering: Criteri esterni di qualità Purity: assegna ogni cluster alla classe che occorre più frequentemente nel cluster; accuratezza: frazione di documenti assegnati correttamente. Un clustering perfetto ha purity 1, mentre un clustering di cattiva qualità ha purity prossima a 0. Un valore elevato è facile da ottenere quando il numero di cluster è elevato: purity 1 se ogni documento è assegnato a un suo proprio cluster. Purity non dà info utili se cerchiamo un trade off tra la qualità del clustering e il numero di cluster. Pagina 55
56 Clustering: Criteri esterni di qualità (2) Approccio alternativo: vedere il clustering come una serie di decisioni, una per ogni coppia di documenti nella collezione. Vogliamo assegnare due documenti ad uno stesso cluster se sono simili. TP: assegna due documenti simili allo stesso cluster TN: assegna due documenti non simili a cluster differenti FP: assegna due documenti non simili allo stesso cluster FN: assegna due documenti simili a cluster diversi. Pagina 56
57 Criteri esterni di qualità Rand Index calcola la percentuale di decisioni corrette: RI = (TP + TN) / (TP + TN + FP + FN) RI assegna uguale peso a FP e FN; a volte separare documenti simili è considerato più grave che mettere due documenti diversi in uno stesso cluster; F-measure assegna una maggiore penalizzazione a FN: F-measure = 2PR / (P+R), con P=TP/(TP+FP) e R=TP/(TP+FN) Pagina 57
58 K-Means Flat Clustering Algorithm più importante. Obiettivo: minimizzare il valor medio del quadrato della distanza euclidea dei documenti dal centro del cluster a cui sono stati assegnati. Il centro di un cluster è definito come la media di tutti i documenti presenti nel cluster (centroide). Clustering ideale: una sfera che ha il centroide come suo centro di gravità. Pagina 58
59 K-Means (2) Passo 1: scelta di K seed casuali (centri iniziali dei cluster). Passo 2: assegna ogni punto al cluster più vicino. Passo 3: ricalcola i nuovi centroidi. Ripeti i passi 2 e 3 fino al raggiungimento di un qualche criterio di convergenza: esecuzione di un numero di iterazioni prefissato (limita runtime, ma rischio scarsa qualità); assegnazione delle istanze ai cluster non cambia tra due iterazioni successive (no garanzie su runtime). Nella pratica, combina una soglia sullo scarto quadratico medio con un bound sul numero di iterazioni. Pagina 59
60 K-Means (3) La convergenza si prova mostrando che RSS decresce monotonicamente ad ogni iterazione. Non è garantito il raggiungimento di un minimo globale: questo è un problema se l insieme di input contiene molti outlier. La scelta di un outlier come seed iniziale porta spesso alla creazione di cluster singleton. Occorre utilizzare metodi di inizializzazione che forniscano dei buoni seed. Pagina 60
61 K-Means (4) Varie soluzioni per una scelta efficace del seed set: esclusione degli outlier dal seed set; provare molteplici seed e scegliere la soluzione con minor costo; ottenere i centroidi iniziali applicando altri metodi come clustering gerarchico; selezionare un certo numero di punti random per ogni cluster e scegliere il loro centroide come centro iniziale del cluster. Pagina 61
62 K-Means: scelta cardinalità Come scegliere il numero di cluster da creare? Approccio naïve: scegli k che minimizza RSS -> creazione di un set di singleton. Euristiche per stimare minima somma dei quadrati dei residui in funzione di k. Introdurre una penalità per ogni nuovo cluster. Nella pratica la funzione obiettivo deve combinare distorsione e complessità del modello. Pagina 62

63 Explorer: Clusterer SimpleKMeans Pagina 63
")
64 Explorer: Clusterer SimpleKMeans (2) Pagina 64
")
65 Explorer: Clusterer SimpleKMeans (3) Pagina 65
 1 Risultati")
66 Explorer: Clusterer SimpleKMeans (4) 1 Risultati 2 Pagina 66
67 EM Clustering Generalizzazione di K-Means. Model based clustering: assume che i dati siano stati generati seguendo un modello e tenta di ricostruire il modello originale a partire dai dati. Questo modello definisce quindi i cluster e il modo in cui le istanze vengono assegnate ai cluster. Criterio std per la stima dei parametri del modello: Maximum likelihood. Modelli di clustering più flessibili e adattabili a quello che sappiamo sulla distribuzione dei dati. Pagina 67
68 EM Clustering (2) Algoritmo iterativo adattabile a vari tipi di modellazione probabilistica. Goal: determinare una stima a massima verosimiglianza dei parametri del modello, che dipende da alcune variabili nascoste. Itera un alternanza di due passi: Expectation: calcola il valore atteso della likelihood in base alle stima corrente per la distribuzione dei parametri Maximization: calcola I parametri che massimizzano la verosimiglianza attesa determinata al passo precedente. Il passo di expectation determina un assegnazione soft delle istanze ai cluster. Pagina 68
69 EM Clustering (3) Anche se una iterazione non diminuisce la likelihood dei dati osservati, non c è garanzia che l algoritmo converga ad una stima di massima verosimiglianza. Se I valori iniziali dei parametri non sono scelti bene, l algoritmo potrebbe convergere a un ottimo locale. Per evitare questo si possono applicare varie euristiche: Random restart Simulated annealing Pagina 69
70 EM in Alcune opzioni disponibili: numclusters: setta il numero di cluster (default: -1) maxiterations: numero massimo di Iterazioni seed: numero casuale usato come seed minstddev: minima deviazione std consentita Pagina 70


71 Explorer: Clusterer EM Pagina 71
 1 Risultati 2 Pagina")
72 Explorer: Clusterer EM (2) 1 Risultati 2 Pagina 72
73 Feature Selection Obiettivo: selezionare un sottoinsieme di feature rilevanti per costruire modelli di learning robusti. Elimina le feature non rilevanti o rilevanti. Migliora le prestazioni dei modelli di learning: Allevia problemi dovuti a esplosione dimensionale Rafforza la capacità di generalizzazione del modello Velocizza il processo di learning Migliora la leggibilità del modello Permette di acquisire una migliore conoscenza dei dati evidenziandone le proprietà più importante. Pagina 73
74 Feature Selection (2) Teoricamente, una selezione ottimale richiede l esplorazione esaustiva dello spazio di tutti i possibili sottoinsiemi di feature. Nella pratica si seguono due diversi approcci: Feature Ranking: usa una metrica per ordinare le feature ed elimina tutte le feature che non ottengono uno score adeguato. Subset Selection: cerca l insieme di possibili feature per il sottoinsieme ottimale. Pagina 74
75 Feature Selection: Subset selection Valuta la bontà di un insieme di features. Molte euristiche per la ricerca delle feature si basano su greedy hill climbing: valuta iterativamente un sottoinsieme candidato di feature, quindi modifica tale insieme e valuta se l insieme ottenuto è migliore del precedente. La valutazione degli insiemi di feature richiede l uso di opportune metriche. La ricerca esaustiva non è in genere praticabile; al raggiungimento di un criterio di arresto si restituisce l insieme di feature che ha ottenuto il punteggio più alto. Pagina 75
76 Feature Selection: Subset Selection (2) Possibili euristiche per la ricerca: Esaustiva Best first Simulated annealing Algoritmi genetici Greedy forward selection Greedy backward elimination Pagina 76
77 Feature Selection: criteri di arresto Possibili criteri di arresto: lo score assegnato ad un certo insieme supera una certa soglia; il tempo di computazione supera un massimo prestabilito. Pagina 77
78 Explorer: Select Attributes Pagina 78
79 Explorer: Select Attributes (2) Pagina 79
80 Explorer: Select Attributes (3) Pagina 80
81 Explorer: Select Attributes (4) Pagina 81
82 Explorer: Select Attributes (5) Pagina 82
")
83 Explorer: Select Attributes (6) Pagina 83
Weka Project. Weka. Weka Project. Formato.arff. Modalità di utilizzo di Weka. Formato.arff
 Weka Project Weka Machine Learning Algorithms in Java Waikato Environment for Knowledge Analysis Algoritmi di Data Mining e Machine Learning realizzati in Java Preprocessing Classificazione Clustering
Weka Project Weka Machine Learning Algorithms in Java Waikato Environment for Knowledge Analysis Algoritmi di Data Mining e Machine Learning realizzati in Java Preprocessing Classificazione Clustering
WEKA. Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua
 WEKA BIOINFORMATICS AND BIG DATA ANALYTICS Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua Indice Cosa è weka Tecnologie Hands On Weka Weka Explorer KnowledgeFlow /Simple CLI Caricare il dataset Il
WEKA BIOINFORMATICS AND BIG DATA ANALYTICS Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua Indice Cosa è weka Tecnologie Hands On Weka Weka Explorer KnowledgeFlow /Simple CLI Caricare il dataset Il
WEKA Data Mining System
 Alma Mater Studiorum Università di Bologna WEKA Data Mining System Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella Presentazione di: Fabio Bertozzi, Giacomo Carli 1 WEKA: the bird
Alma Mater Studiorum Università di Bologna WEKA Data Mining System Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella Presentazione di: Fabio Bertozzi, Giacomo Carli 1 WEKA: the bird
Alberi di Decisione (2)
") Alberi di Decisione (2) Corso di AA, anno 2018/19, Padova Fabio Aiolli 05 Novembre 2018 Fabio Aiolli Alberi di Decisione (2) 05 Novembre 2018 1 / 19 Apprendimento di alberi di decisione: Bias induttivo
Alberi di Decisione (2) Corso di AA, anno 2018/19, Padova Fabio Aiolli 05 Novembre 2018 Fabio Aiolli Alberi di Decisione (2) 05 Novembre 2018 1 / 19 Apprendimento di alberi di decisione: Bias induttivo
Alberi di Decisione (2)
") Alberi di Decisione (2) Corso di AA, anno 2017/18, Padova Fabio Aiolli 25 Ottobre 2017 Fabio Aiolli Alberi di Decisione (2) 25 Ottobre 2017 1 / 18 Apprendimento di alberi di decisione: Bias induttivo Come
Alberi di Decisione (2) Corso di AA, anno 2017/18, Padova Fabio Aiolli 25 Ottobre 2017 Fabio Aiolli Alberi di Decisione (2) 25 Ottobre 2017 1 / 18 Apprendimento di alberi di decisione: Bias induttivo Come
Data mining: classificazione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
Stima della qualità dei classificatori per l analisi dei dati biomolecolari
 Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Classificazione DATA MINING: CLASSIFICAZIONE - 1. Classificazione
 M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Alberi di decisione: c4.5
 Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
C4.5 Algorithms for Machine Learning
 C4.5 Algorithms for Machine Learning C4.5 Algorithms for Machine Learning Apprendimento di alberi decisionali c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato
C4.5 Algorithms for Machine Learning C4.5 Algorithms for Machine Learning Apprendimento di alberi decisionali c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Classificazione Mario Guarracino Data Mining a.a. 2010/2011
 Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
QUANTIZZATORE VETTORIALE
 QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
Valutazione delle Prestazioni di un Classificatore. Performance Evaluation
 Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Business Intelligence per i Big Data
 Business Intelligence per i Big Data Esercitazione di laboratorio n. 6 L obiettivo dell esercitazione è il seguente: - Applicare algoritmi di data mining per la classificazione al fine di analizzare dati
Business Intelligence per i Big Data Esercitazione di laboratorio n. 6 L obiettivo dell esercitazione è il seguente: - Applicare algoritmi di data mining per la classificazione al fine di analizzare dati
Classificazione Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 2006/2007
 Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Training Set Test Set Find-S Dati Training Set Def: Errore Ideale Training Set Validation Set Test Set Dati
 " #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
" #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
Apprendimento basato sulle istanze
 Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Computazione per l interazione naturale: Modelli dinamici
 Computazione per l interazione naturale: Modelli dinamici Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: Modelli dinamici Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0
 Pagina I EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0 Modulo 4 Foglio elettronico Il seguente Syllabus è relativo al Modulo 4, Foglio elettronico, e fornisce i fondamenti per il test di tipo
Pagina I EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0 Modulo 4 Foglio elettronico Il seguente Syllabus è relativo al Modulo 4, Foglio elettronico, e fornisce i fondamenti per il test di tipo
SQL Server Integration Services. SQL Server 2005: ETL - 1. Integration Services Project
 Database and data mining group, SQL Server 2005 Integration Services SQL Server 2005: ETL - 1 Database and data mining group, Integration Services Project Permette di gestire tutti i processi di ETL Basato
Database and data mining group, SQL Server 2005 Integration Services SQL Server 2005: ETL - 1 Database and data mining group, Integration Services Project Permette di gestire tutti i processi di ETL Basato
Cenni di apprendimento in Reti Bayesiane
 Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità)
") Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità) Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università
Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità) Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università
Selezione del modello Strumenti quantitativi per la gestione
 Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
I Componenti del processo decisionale 7
 Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Sistemi di Elaborazione dell Informazione 170. Caso Non Separabile
 Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Alberi di Regressione
 lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
Multi classificatori. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Alberi di decisione: c4.5
 Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello
 Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Naïve Bayesian Classification
 Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
ID3: Selezione Attributo Ottimo
 Sistemi di Elaborazione dell Informazione 49 ID3: Selezione Attributo Ottimo Vari algoritmi di apprendimento si differenziano soprattutto (ma non solo) dal modo in cui si seleziona l attributo ottimo:
Sistemi di Elaborazione dell Informazione 49 ID3: Selezione Attributo Ottimo Vari algoritmi di apprendimento si differenziano soprattutto (ma non solo) dal modo in cui si seleziona l attributo ottimo:
Apprendimento di Alberi di Decisione: Bias Induttivo
 istemi di Elaborazione dell Informazione 54 Apprendimento di Alberi di Decisione: Bias Induttivo Il Bias Induttivo è sulla ricerca! + + A1 + + + A2 + +...... + + A2 A3 + + + A2 A4...... istemi di Elaborazione
istemi di Elaborazione dell Informazione 54 Apprendimento di Alberi di Decisione: Bias Induttivo Il Bias Induttivo è sulla ricerca! + + A1 + + + A2 + +...... + + A2 A3 + + + A2 A4...... istemi di Elaborazione
Esercizio: apprendimento di congiunzioni di letterali
 input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
Sistemi per la gestione delle basi di dati
 Sistemi per la gestione delle basi di dati Esercitazione #5 Data mining Obiettivo Applicare algoritmi di data mining per la classificazione al fine di analizzare dati reali mediante l utilizzo dell applicazione
Sistemi per la gestione delle basi di dati Esercitazione #5 Data mining Obiettivo Applicare algoritmi di data mining per la classificazione al fine di analizzare dati reali mediante l utilizzo dell applicazione
4. I moduli in Access 2000/2003
 LIBRERIA WEB 4. I moduli in Access 2000/2003 Il modulo è uno degli oggetti del database di Access e rappresenta un insieme di dichiarazioni e routine scritte con il linguaggio Visual Basic, memorizzate
LIBRERIA WEB 4. I moduli in Access 2000/2003 Il modulo è uno degli oggetti del database di Access e rappresenta un insieme di dichiarazioni e routine scritte con il linguaggio Visual Basic, memorizzate
C.da Di Dio - Villaggio S. Agata Messina Italy P.I c.f AMBIENTE STATISTICO. Release /03/2018.
 AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
3.5.1 PREPARAZ1ONE I documenti che si possono creare con la stampa unione sono: lettere, messaggi di posta elettronica, o etichette.
 3.5 STAMPA UNIONE Le funzioni della stampa unione (o stampa in serie) permettono di collegare un documento principale con un elenco di nominativi e indirizzi, creando così tanti esemplari uguali nel contenuto,
3.5 STAMPA UNIONE Le funzioni della stampa unione (o stampa in serie) permettono di collegare un documento principale con un elenco di nominativi e indirizzi, creando così tanti esemplari uguali nel contenuto,
Richiami di inferenza statistica Strumenti quantitativi per la gestione
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Richiami di inferenza statistica. Strumenti quantitativi per la gestione. Emanuele Taufer
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
SUPPORT VECTOR MACHINES. a practical guide
 SUPPORT VECTOR MACHINES a practical guide 1 SUPPORT VECTOR MACHINES Consideriamo un problema di classificazione binaria, a partire da uno spazio di input X R n e uno spazio di output Y = { 1, 1} Training
SUPPORT VECTOR MACHINES a practical guide 1 SUPPORT VECTOR MACHINES Consideriamo un problema di classificazione binaria, a partire da uno spazio di input X R n e uno spazio di output Y = { 1, 1} Training
FILE E INDICI Architettura DBMS
 FILE E INDICI Architettura DBMS Giorgio Giacinto 2010 Database 2 Dati su dispositivi di memorizzazione esterni! Dischi! si può leggere qualunque pagina a costo medio fisso! Nastri! si possono leggere le
FILE E INDICI Architettura DBMS Giorgio Giacinto 2010 Database 2 Dati su dispositivi di memorizzazione esterni! Dischi! si può leggere qualunque pagina a costo medio fisso! Nastri! si possono leggere le
Intelligenza Artificiale
 Intelligenza Artificiale 17 Marzo 2005 Nome e Cognome: Matricola: ESERCIZIO N 1 Ricerca Cieca 5 punti 1.A) Elencare in modo ordinato i nodi (dell'albero sotto) che vengono scelti per l'espansione dalle
Intelligenza Artificiale 17 Marzo 2005 Nome e Cognome: Matricola: ESERCIZIO N 1 Ricerca Cieca 5 punti 1.A) Elencare in modo ordinato i nodi (dell'albero sotto) che vengono scelti per l'espansione dalle
ANALISI DEI CLUSTER. In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di
 ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
Telerilevamento. Esercitazione 5. Classificazione non supervisionata. Apriamo l immagine multi spettrale relativa alla zona di Feltre che si trova in:
 Telerilevamento Esercitazione 5 Classificazione non supervisionata Lo scopo di questa esercitazione è quella di effettuare una classificazione non supervisionata di un immagine SPOT5 acquisita sull area
Telerilevamento Esercitazione 5 Classificazione non supervisionata Lo scopo di questa esercitazione è quella di effettuare una classificazione non supervisionata di un immagine SPOT5 acquisita sull area
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Clustering. Clustering
 1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
MODULO 5 - USO DELLE BASI DI DATI 2 FINALITÁ
 PATENTE EUROPEA DEL COMPUTER 5.0 MODULO 5 Database (Microsoft Access 2007) Parte 3 A cura di Mimmo Corrado Gennaio 2012 MODULO 5 - USO DELLE BASI DI DATI 2 FINALITÁ Il Modulo 5, richiede che il candidato
PATENTE EUROPEA DEL COMPUTER 5.0 MODULO 5 Database (Microsoft Access 2007) Parte 3 A cura di Mimmo Corrado Gennaio 2012 MODULO 5 - USO DELLE BASI DI DATI 2 FINALITÁ Il Modulo 5, richiede che il candidato
Corso di Access. Prerequisiti. Modulo L2A (Access) Struttura delle tabelle
 Struttura delle tabelle") Corso di Access Modulo L2A (Access) 1.3.1 Struttura delle tabelle 1 Prerequisiti Utilizzo elementare del computer Concetti fondamentali di basi di dati Gli oggetti di Access 2 1 Introduzione Il concetto
Corso di Access Modulo L2A (Access) 1.3.1 Struttura delle tabelle 1 Prerequisiti Utilizzo elementare del computer Concetti fondamentali di basi di dati Gli oggetti di Access 2 1 Introduzione Il concetto
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: classificazione probabilistica
 Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione Dipartimento di Elettronica e Informazione Apprendimento Supervisionato I dati considerati considerati degli esempi di un fenomeno
Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione Dipartimento di Elettronica e Informazione Apprendimento Supervisionato I dati considerati considerati degli esempi di un fenomeno
Il programma è distribuito tramite il file compresso TRASFO.zip contenente i file di programma strutturati in 4 cartelle:
 TRASFO V 1.0 Stefano Caldera stefano@geomatica.como.polimi.it M. Grazia Visconti grazia@geomatica.como.polimi.it Il programma è distribuito tramite il file compresso TRASFO.zip contenente i file di programma
TRASFO V 1.0 Stefano Caldera stefano@geomatica.como.polimi.it M. Grazia Visconti grazia@geomatica.como.polimi.it Il programma è distribuito tramite il file compresso TRASFO.zip contenente i file di programma
Analisi di un dataset di perizie assicurative. Esercitazione Data Mining
 Analisi di un dataset di perizie assicurative Esercitazione Data Mining Ricapitoliamo L obiettivo dell analisi che si intende condurre è l estrapolazione di un modello per il riconoscimento automatico
Analisi di un dataset di perizie assicurative Esercitazione Data Mining Ricapitoliamo L obiettivo dell analisi che si intende condurre è l estrapolazione di un modello per il riconoscimento automatico
Laboratorio di Apprendimento Automatico. Fabio Aiolli Università di Padova
 Laboratorio di Apprendimento Automatico Fabio Aiolli Università di Padova Underfitting e Overfitting Complessità spazio ipotesi SVM: aumenta con kernel non lineari, RBF con maggiore pendenza, aumenta con
Laboratorio di Apprendimento Automatico Fabio Aiolli Università di Padova Underfitting e Overfitting Complessità spazio ipotesi SVM: aumenta con kernel non lineari, RBF con maggiore pendenza, aumenta con
Il software Weka. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learning scritto in Java e distribuito sotto la GNU Public License) Waikato
Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learning scritto in Java e distribuito sotto la GNU Public License) Waikato
Apprendimento Automatico
 Apprendimento Automatico Metodi Bayesiani - Naive Bayes Fabio Aiolli 13 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 13 Dicembre 2017 1 / 18 Classificatore Naive Bayes Una delle tecniche più semplici
Apprendimento Automatico Metodi Bayesiani - Naive Bayes Fabio Aiolli 13 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 13 Dicembre 2017 1 / 18 Classificatore Naive Bayes Una delle tecniche più semplici
Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione Dipartimento di Elettronica e Informazione Politecnico di Milano Perchè le Regole? Le regole (if-then) sono espressive e leggibili
Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione Dipartimento di Elettronica e Informazione Politecnico di Milano Perchè le Regole? Le regole (if-then) sono espressive e leggibili
Clustering. Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi
 Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Guida a WordPress. 1. Iscrizione a Wordpress
 Guida a WordPress 1. Iscrizione a Wordpress Digitare il seguente indirizzo: https://it.wordpress.com/ Cliccare su Crea sito web Scegliere un tema, ovvero la struttura principale che assumeranno le pagine
Guida a WordPress 1. Iscrizione a Wordpress Digitare il seguente indirizzo: https://it.wordpress.com/ Cliccare su Crea sito web Scegliere un tema, ovvero la struttura principale che assumeranno le pagine
Introduzione al software R
 Introduzione al software R 1 1 Università di Napoli Federico II cristina.tortora@unina.it il software R Si tratta di un software molto flessibile che permette di compiere praticamente qualsiasi tipo di
Introduzione al software R 1 1 Università di Napoli Federico II cristina.tortora@unina.it il software R Si tratta di un software molto flessibile che permette di compiere praticamente qualsiasi tipo di
Ricerca di outlier. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Computazione per l interazione naturale: classificazione probabilistica
 Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it boccignone.di.unimi.it/in_2016.html
Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it boccignone.di.unimi.it/in_2016.html
Statistica per l Impresa
 Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Computazione per l interazione naturale: clustering e riduzione di dimensionalità
 Computazione per l interazione naturale: clustering e riduzione di dimensionalità Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Computazione per l interazione naturale: clustering e riduzione di dimensionalità Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Rilevazione di messaggi spam con algoritmo Naive-Bayes
 Rilevazione di messaggi spam con algoritmo Naive-Bayes Luca Zanetti matricola nr. 808229 luca.zanetti2@studenti.unimi.it Sommario L individuazione di messaggi spam costituisce uno dei più noti esempi di
Rilevazione di messaggi spam con algoritmo Naive-Bayes Luca Zanetti matricola nr. 808229 luca.zanetti2@studenti.unimi.it Sommario L individuazione di messaggi spam costituisce uno dei più noti esempi di
Classificazione introduzione
 - Classificazione introduzione Vittorio Maniezzo Università di Bologna 1 Ringraziamenti Questi lucidi derivano anche da adattamenti personali di materiale prodotto (fornitomi o reso scaricabile) da: A.
- Classificazione introduzione Vittorio Maniezzo Università di Bologna 1 Ringraziamenti Questi lucidi derivano anche da adattamenti personali di materiale prodotto (fornitomi o reso scaricabile) da: A.
Parallel Frequent Set Counting
 Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
DIFFUSIONE SU GRAFO (rete) E RIPOSIZIONAMENTO DI FARMACI SULLA BASE DELLA SIMILARITA DI STRUTTURA MOLECOLARE
 E RIPOSIZIONAMENTO DI FARMACI SULLA BASE DELLA SIMILARITA DI STRUTTURA MOLECOLARE") 0 DIFFUSIONE SU GRAFO (rete) E RIPOSIZIONAMENTO DI FARMACI SULLA BASE DELLA SIMILARITA DI STRUTTURA MOLECOLARE Cammini aleatori su grafo (Random walk) 0 «processo di esplorazione casuale di un grafo mediante
0 DIFFUSIONE SU GRAFO (rete) E RIPOSIZIONAMENTO DI FARMACI SULLA BASE DELLA SIMILARITA DI STRUTTURA MOLECOLARE Cammini aleatori su grafo (Random walk) 0 «processo di esplorazione casuale di un grafo mediante
Il software Weka. Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License)
") Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License) Waikato
Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License) Waikato
Apprendimento Automatico
 Apprendimento Automatico 1 Apprendimento Automatico Libro di riferimento: Apprendimento Automatico, Tom Mitchell, McGraw Hill, 1998 Tutorial su SVM e Boosting Lucidi http://www.math.unipd.it/ sperduti/ml.html
Apprendimento Automatico 1 Apprendimento Automatico Libro di riferimento: Apprendimento Automatico, Tom Mitchell, McGraw Hill, 1998 Tutorial su SVM e Boosting Lucidi http://www.math.unipd.it/ sperduti/ml.html
Data Journalism. Analisi dei dati. Angelica Lo Duca
 Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati
 Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
Introduzione al Machine Learning
 InfoLife Introduzione al Machine Learning Laboratorio di Bioinformatica InfoLife Università di Foggia - Consorzio C.IN.I. Dott. Crescenzio Gallo crescenzio.gallo@unifg.it 1 Cos è il Machine Learning? Fa
InfoLife Introduzione al Machine Learning Laboratorio di Bioinformatica InfoLife Università di Foggia - Consorzio C.IN.I. Dott. Crescenzio Gallo crescenzio.gallo@unifg.it 1 Cos è il Machine Learning? Fa
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
UML Introduzione a UML Linguaggio di Modellazione Unificato. Corso di Ingegneria del Software Anno Accademico 2012/13
 UML Introduzione a UML Linguaggio di Modellazione Unificato Corso di Ingegneria del Software Anno Accademico 2012/13 1 Che cosa è UML? UML (Unified Modeling Language) è un linguaggio grafico per: specificare
UML Introduzione a UML Linguaggio di Modellazione Unificato Corso di Ingegneria del Software Anno Accademico 2012/13 1 Che cosa è UML? UML (Unified Modeling Language) è un linguaggio grafico per: specificare
Data Science e Tecnologie per le Basi di Dati
 Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Un processo a supporto della classificazione di pagine client Anno Accademico 2006/2007
 tesi di laurea Un processo a supporto della classificazione di pagine client Anno Accademico 2006/2007 relatore Ch.mo prof. Porfirio Tramontana candidato Marco Calandro Matr. 885/73 Introduzione Il passaggio
tesi di laurea Un processo a supporto della classificazione di pagine client Anno Accademico 2006/2007 relatore Ch.mo prof. Porfirio Tramontana candidato Marco Calandro Matr. 885/73 Introduzione Il passaggio
Il software consente di costruire tabelle e grafici e di esportare il proprio lavoro in formato pdf o excel.
 Guida all uso Premessa... 1 1. Home page... 1 2. Accesso al software e alla base dati da consultare... 2 3. Costruzione di una tabella personalizzata... 3 4. Impostazione dei filtri... 5 5. Impostazione
Guida all uso Premessa... 1 1. Home page... 1 2. Accesso al software e alla base dati da consultare... 2 3. Costruzione di una tabella personalizzata... 3 4. Impostazione dei filtri... 5 5. Impostazione
Reti Neurali (Parte I)
") Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
testo Saveris Web Access Software Istruzioni per l'uso
 testo Saveris Web Access Software Istruzioni per l'uso 2 1 Indice 1 Indice 1 Indice... 3 2 Descrizione delle prestazioni... 4 2.1. Utilizzo... 4 2.2. Requisiti di sistema... 4 3 Installazione... 5 3.1.
testo Saveris Web Access Software Istruzioni per l'uso 2 1 Indice 1 Indice 1 Indice... 3 2 Descrizione delle prestazioni... 4 2.1. Utilizzo... 4 2.2. Requisiti di sistema... 4 3 Installazione... 5 3.1.
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Lecture 10. Combinare Classificatori. Metaclassificazione
 Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval
 Information retrieval") Filippo Geraci Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate
Filippo Geraci Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate
Lecture 8. Combinare Classificatori
 Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Data Mining and Machine Learning Lab. Lezione 8 Master in Data Science for Economics, Business and Finance 2018
 Data Mining and Machine Learning Lab. Lezione 8 Master in Data Science for Economics, Business and Finance 2018 18.05.18 Marco Frasca Università degli Studi di Milano SVM - Richiami La Support Vector Machine
Data Mining and Machine Learning Lab. Lezione 8 Master in Data Science for Economics, Business and Finance 2018 18.05.18 Marco Frasca Università degli Studi di Milano SVM - Richiami La Support Vector Machine
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana