WEKA Data Mining System
|
|
|
- Camillo Pinna
- 4 anni fa
- Visualizzazioni
Transcript
1 Alma Mater Studiorum Università di Bologna WEKA Data Mining System Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella Presentazione di: Fabio Bertozzi, Giacomo Carli 1
2 WEKA: the bird Gallirallus australis (Sparrman, 1786) Uccello nativo della Nuova Zelanda Altezza: 50 cm Peso: 1 Kg Onnivoro In via di estinzione Maschio e femmina si occupano della prole Secondo una leggenda neozelandase rubano oggetti luccicanti e sacchi di zucchero 2
3 WEKA: Introduzione Software di machine learning e data mining Università di Waikato (Nuova Zelanda) Scritto in Java Licenza GNU Main features: Interfaccia grafica Set di tool per data pre-processing, Possibilità di utilizzare numerosi algoritmi di clustering, per alberi decisionali DT, di ricerca di regole associative AR Indici di valutazione sulla bontà dell algoritmo 3



4 WEKA: apertura del software
5 Database in bank Nome della relazione Lista degli attributi e loro age sex region income married {NO,YES} Attributo children car {NO,YES} Attributo save_act current_act mortgage pep {YES,NO} Area dati con enumerazione delle 40,MALE,TOWN, ,YES,3,YES,NO,YES,YES,NO 51,FEMALE,INNER_CITY, ,YES,0,YES,YES,YES,NO,NO 23,FEMALE,TOWN, ,YES,3,NO,NO,YES,NO,NO 57,FEMALE,RURAL, ,YES,0,NO,YES,NO,NO,NO 57,FEMALE,TOWN, ,YES,2,NO,YES,YES,NO,YES 22,MALE,RURAL, ,NO,0,NO,NO,YES,NO,YES 58,MALE,TOWN, ,YES,0,YES,YES,YES,NO,NO 37,FEMALE,SUBURBAN, ,YES,2,YES,NO,NO,NO,NO Ricerca di una soluzione che permetta di utilizzare fonti differenti Scelte: Formato file semplice e intelleggibile Struttura piatta del database Necessità di preprocessing dei dati 5
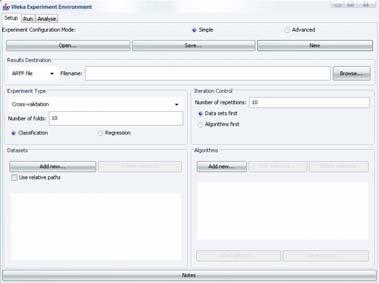
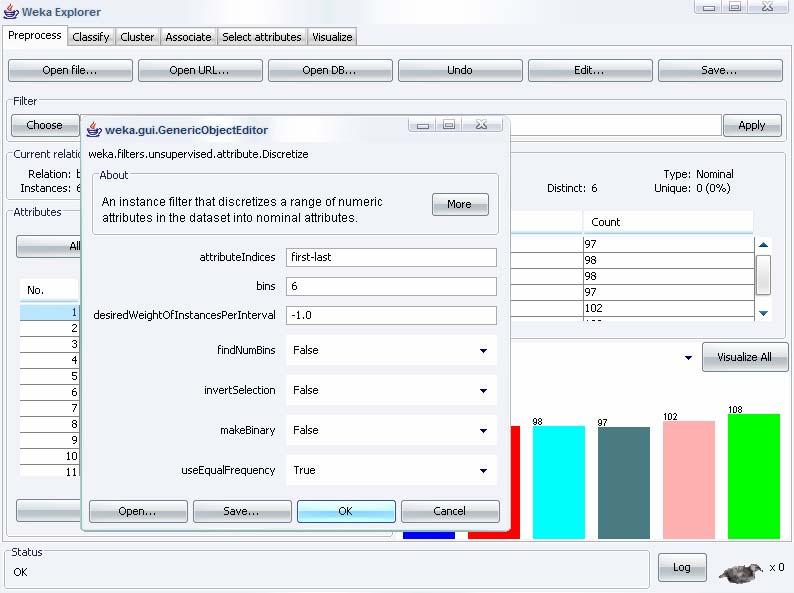
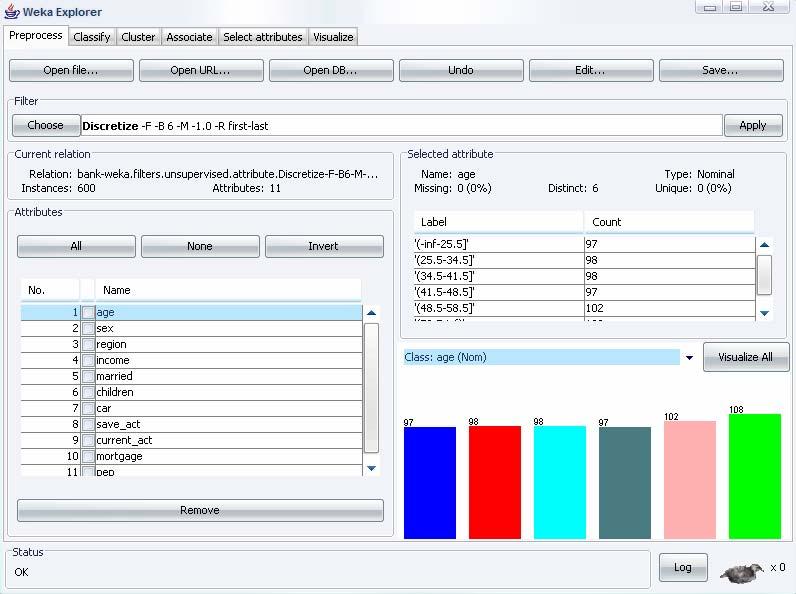
6 Explorer: pre-processing dei dati ARFF CSV Formati aperti C4.5 binary letti da un URL database SQL usando JDBC Conteggio tuple Presentazione dei dati all utente Distribuzione dei valori degli attributi Analisi cross-attributo Funzioni Pre-Processing: i tool di preprocessing di Weka sono chiamati Filters discretizzazione normalizzazione Selezione, trasformazione e combinazione degli attributi Rappresentazioni grafiche 6

7 7

8 8
9 9
10 10
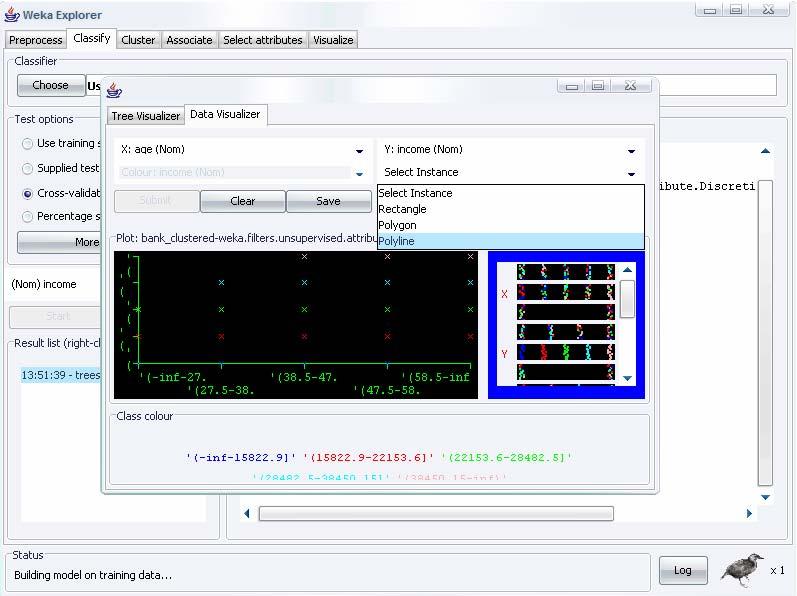
11 Explorer: i classifiers Classifiers modelli per predire attributi numerici e nominali Esempio: Decision Trees Algoritmi tradizionali Metodo: User Classifier J48 è l implementazione di Weka dell algoritmo C4.5, creato da Ross Quinlan dell Università di Sydney. L algoritmo genera un decision tree. Metodo di selezione degli attributi in base all IG Possibilità di utilizzare un Training Set con dati mancanti Possibilità di utilizzare attributi con valori numerici continui Non c è necessità di discretizzare Ogni passo di split dell albero è svolto dall utente che seleziona un cluster tramite una rappresentazione bidimensionale dei dati Limiti: Buona conoscenza del dominio Struttura semplice dei dati, Cluster facilimente riconoscibili 11
12 12
13 13
14 14
15 15

16 16

17 17
18 18
19 19
20 20
21 21

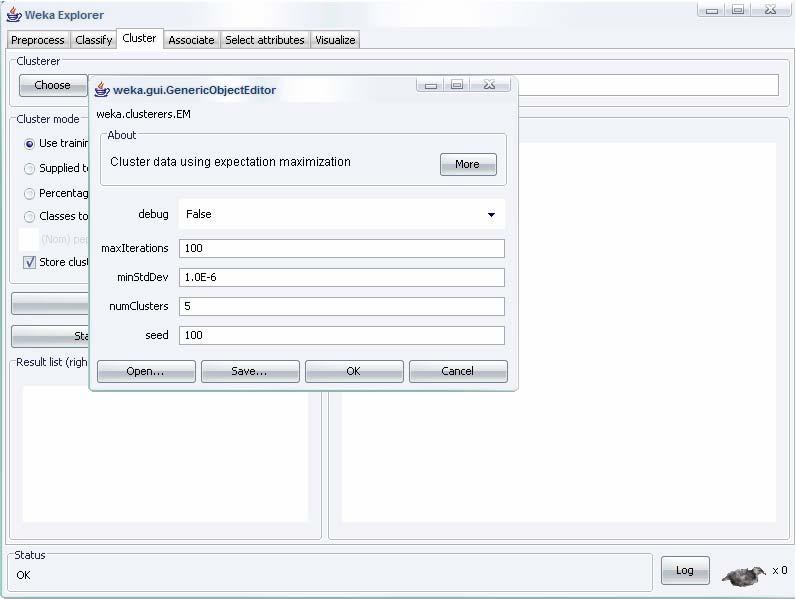
22 22
23 23
24 24
25 25

26 26

27 27
28 28
29 Explorer: clustering data WEKA può eseguire numerosi algoritmi di clustering: k-means, Clustering basato sulla densità Visualizzazione dei cluster ottenuti con comparazione su vari attributi Possibilità di eseguire misure di bontà sui risultati degli algoritmi 29
30 Algoritmo Expectation Maximization Variante raffinata di K-means 30
31 31
32 32
33 Attributi selezionati 33
34 34

35 35
36 Età 36 Reddito
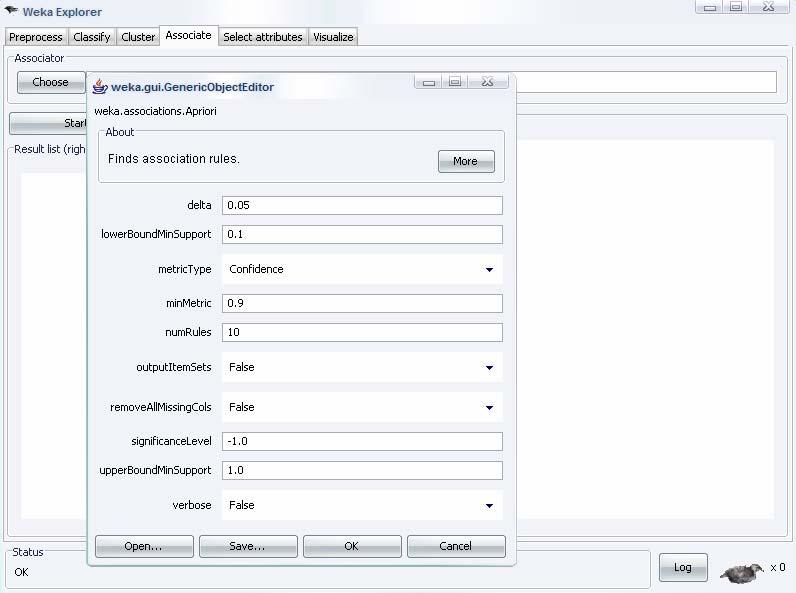
37 Explorer: ricerca di regole associative WEKA contiene un implementazione dell algoritmo Apriori nella scheda Associate : Lavora su dati discreti Identifica le relazioni tra attributi e gruppi di attributi Ricerca le regole che eccedono il supporto minimo e hanno confidenza superiore al valore prestabilito 37
38 38
39 39
40 40
41 41
42 42
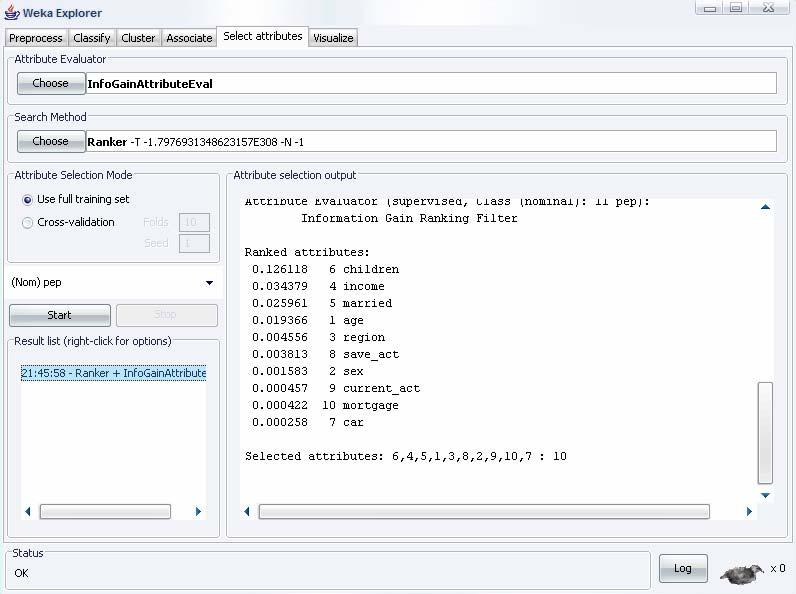
43 Explorer: attribute selection Strumento utile per ricercare quali sono gli attributi (o subset di attributi) maggiormente predittivi Il metodo di selezione è articolato in due parti: Search method: best-first, forward selection, random, exhaustive, genetic algorithm, ranking Evaluation method: Correlazione Information gain Test chi-quadro Esempio semplice: Ordina gli attributi in base all IG Search method: ranking Evaluation Method: Information Gain WEKA consente combinazioni (abbastanza) libere dei metodi 43
44 44
45 45
46 46
47 47
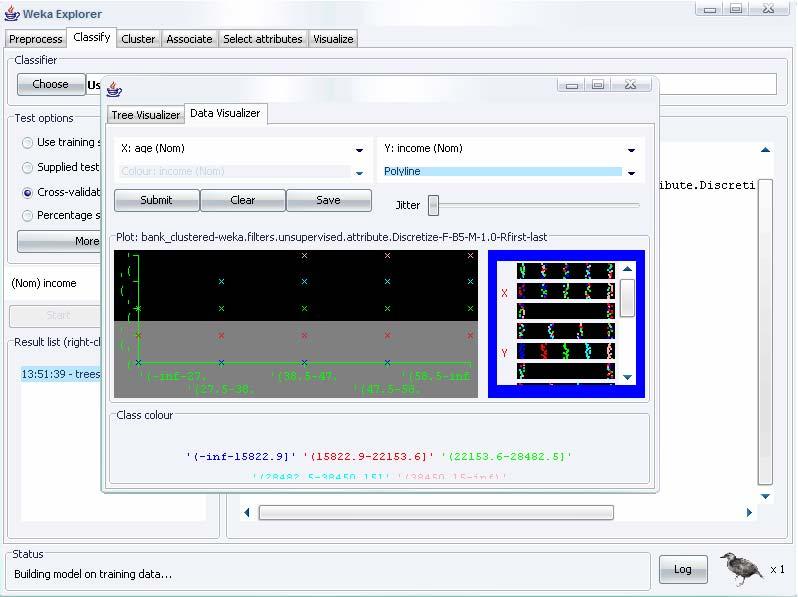
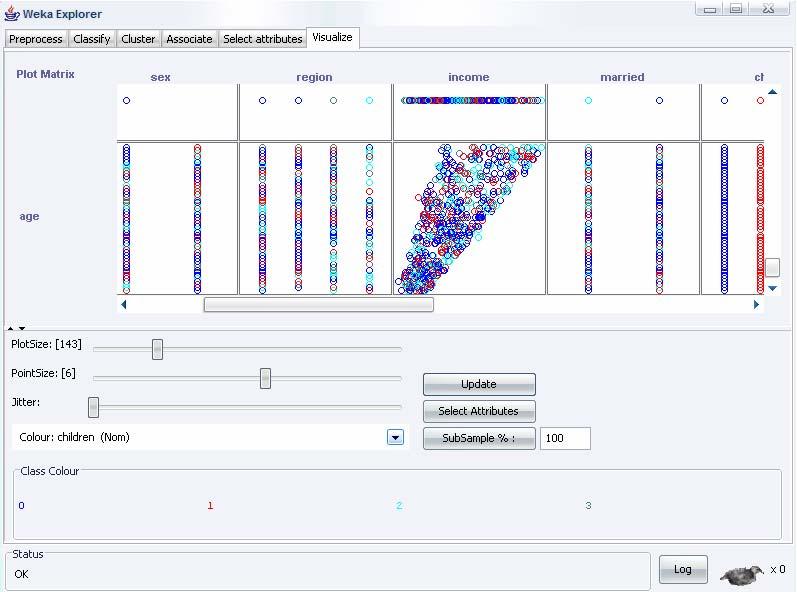
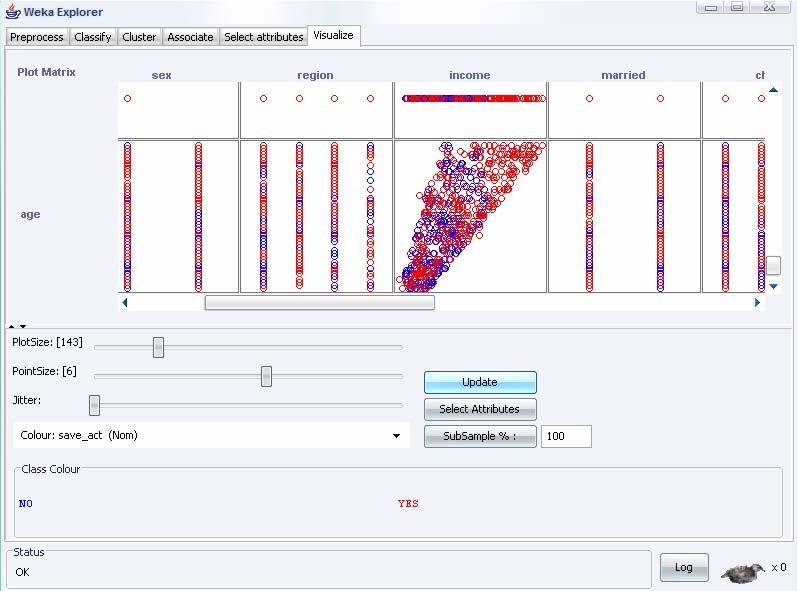
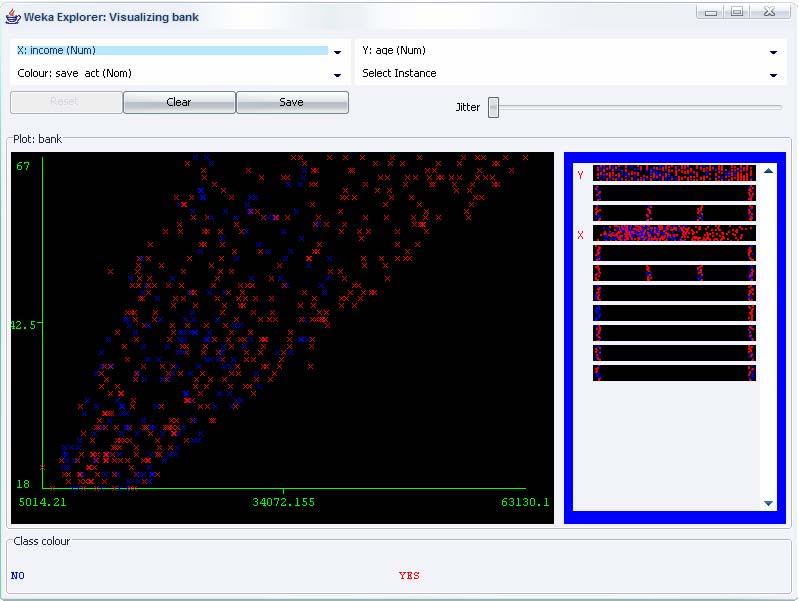
48 Explorer: data visualization Semplice funzione che permette di analizzare in maniera visiva i dati WEKA visualizza singoli attributi in un grafico 1-D e coppie di attributi 2-D Limite: mancanza di visualizzazione 3-D che viene risolta introducendo in un grafico 2-D diversi colori Parametri di visualizzazione: I valori delle classi sono rappresentati con diversi colori L opzione Jitter permettere di visualizzare i punti nascosti per gli attributi nominali Funzioni di zoom, dimensionamento dei grafici e dei punti rappresentati 48

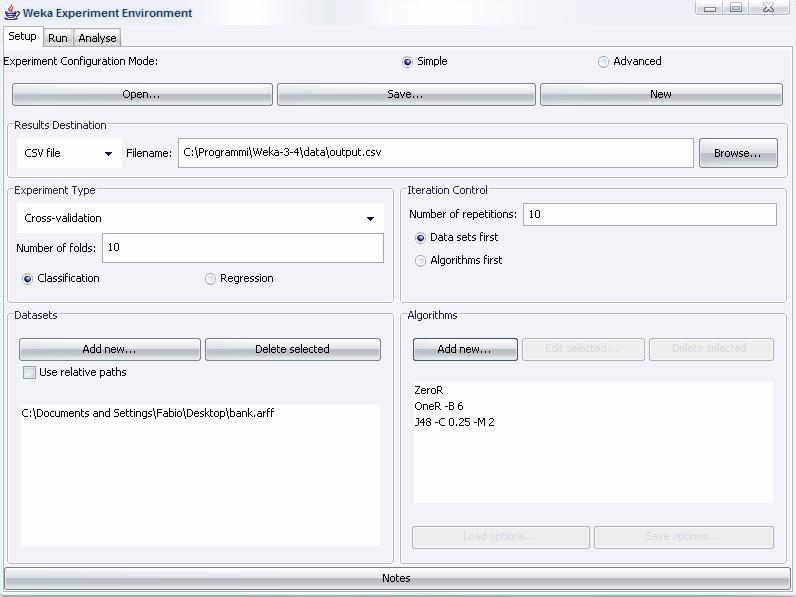
49 49

50 50
51 51

52 52
53 53
54 54
55 55
56 WEKA: Experimenter L Experimenter permette di comparare diversi modelli di apprendimento Adatto per problemi di regressione e classificazione I risultati possono essere trasveriti in un database Metodi di valutazione: Cross-validazione Curva di apprendimento I metodi di valutazione possono essere reiterati per diverse configurazioni dei parametri dei modelli di apprendimento 56
57 57
58 58

59 59
60 60
61 61
62 62
63 63
64 64
65 65
66 Analisi dei risultati Export dei risultati in: ARFF file CSV file (Comma Separated Values) JDBC database Importato in Excel Analisi statistica dei dati Scheda Analyse di WEKA : Matrice di analisi sui diversi run dataset analizzati modelli di apprendimento % di istanze classificate correttamente Notazioni: v: risultato statisticamente migliore rispetto allo schema base *: risultato statisticamente peggiore rispetto allo schema base Vettore (xx/yy/zz): indica su quanti dataset lo schema è stato migliore/equivalente/peggiore rispetto allo schema base 66
67 Analisi dei risultati: Cross Validazione Algoritmo 1. Il dataset è diviso in k subset. 2. Ogni subset è diviso in training set e test set 3. For i:=1 to k 1. Definisci una funzione che predice i dati 2. testa la funzione sui K-1 dataset precedenti come test set 3. Calcolo del Mean Absolute Error 4. Computa l errore medio su tutti i k subset Funzione con rumore Funzione senza rumore Vantaggio: utilizzando tanti subset, il metodo è poco influenzato da come sono suddivisi i dati. All aumentare di K si ottiene una maggiore precisione della previsione Svantaggio: l algoritmo deve iterare k volte per svolgere una valutazione 67
68 68
69 69
70 70
71 WEKA: Knowledge Flow Interfaccia grafica innovativa che rappresenta un flusso informativo Basato sulla piattaforma Java Beans DB sorgenti, classifiers, etc. sono beans e possono essere connessi graficamente I Layout ottenuti possono essere salvati Cambiando le impostazioni del datasource, si può eseguire lo stesso flusso su diversi dataset Esempio di un tipico flusso di dati: data source filter classifier evaluator 71
72 72
73 73
74 74
75 75
76 76

77 77
78 dopo alcuni passaggi 78

79 79

80 80

81 Classe di appartenenza Classe prevista 81

82 WEKA: the bird Grazie per l attenzione! 82
WEKA. Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua
 WEKA BIOINFORMATICS AND BIG DATA ANALYTICS Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua Indice Cosa è weka Tecnologie Hands On Weka Weka Explorer KnowledgeFlow /Simple CLI Caricare il dataset Il
WEKA BIOINFORMATICS AND BIG DATA ANALYTICS Ing. Antonio Brunetti Prof. Vitoantonio Bevilacqua Indice Cosa è weka Tecnologie Hands On Weka Weka Explorer KnowledgeFlow /Simple CLI Caricare il dataset Il
Classificazione con Weka Testi degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Classificazione con Weka Testi degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Pre processing bank data Il date set bank-data.csv 600 istanze Nessun dato missing Attributo
Classificazione con Weka Testi degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Pre processing bank data Il date set bank-data.csv 600 istanze Nessun dato missing Attributo
Reti neurali con weka Testi degli esercizi
 Reti neurali con weka Testi degli esercizi Dott.ssa Elisa Turricchia Alma Mater Studiorum - Università di Bologna ANN in weka Linee guida Scelta dell algoritmo di classificazione Classifiers/Functions/MultilyerPerceptron
Reti neurali con weka Testi degli esercizi Dott.ssa Elisa Turricchia Alma Mater Studiorum - Università di Bologna ANN in weka Linee guida Scelta dell algoritmo di classificazione Classifiers/Functions/MultilyerPerceptron
Il software Weka. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learning scritto in Java e distribuito sotto la GNU Public License) Waikato
Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learning scritto in Java e distribuito sotto la GNU Public License) Waikato
Weka Project. Weka. Weka Project. Formato.arff. Modalità di utilizzo di Weka. Formato.arff
 Weka Project Weka Machine Learning Algorithms in Java Waikato Environment for Knowledge Analysis Algoritmi di Data Mining e Machine Learning realizzati in Java Preprocessing Classificazione Clustering
Weka Project Weka Machine Learning Algorithms in Java Waikato Environment for Knowledge Analysis Algoritmi di Data Mining e Machine Learning realizzati in Java Preprocessing Classificazione Clustering
Il software Weka. Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License)
") Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License) Waikato
Il software Weka Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Weka Un software per il Data Mining/Machine learningscritto in Java e distribuito sotto la GNU Public License) Waikato
Reti neurali con weka Soluzioni degli esercizi
 Reti neurali con weka Soluzioni degli esercizi Dott.ssa Elisa Turricchia Alma Mater Studiorum - Università di Bologna ANN in weka Linee guida Scelta dell algoritmo di classificazione Classifiers/Functions/MultilyerPerceptron
Reti neurali con weka Soluzioni degli esercizi Dott.ssa Elisa Turricchia Alma Mater Studiorum - Università di Bologna ANN in weka Linee guida Scelta dell algoritmo di classificazione Classifiers/Functions/MultilyerPerceptron
Sistemi per la gestione delle basi di dati
 Sistemi per la gestione delle basi di dati Esercitazione #5 Data mining Obiettivo Applicare algoritmi di data mining per la classificazione al fine di analizzare dati reali mediante l utilizzo dell applicazione
Sistemi per la gestione delle basi di dati Esercitazione #5 Data mining Obiettivo Applicare algoritmi di data mining per la classificazione al fine di analizzare dati reali mediante l utilizzo dell applicazione
Strumenti per l Analisi l. ed il Preprocessing dei dati. Francesco Folino. Introduzione
 Strumenti per l Analisi l ed il Preprocessing dei dati Francesco Folino Obiettivo Introdurre gli aspetti essenziali della fase di preparazione dei dati Acquisire padronanza di un processo tipicamente artigianale
Strumenti per l Analisi l ed il Preprocessing dei dati Francesco Folino Obiettivo Introdurre gli aspetti essenziali della fase di preparazione dei dati Acquisire padronanza di un processo tipicamente artigianale
Il software Weka Soluzioni degli esercizi
 Il software Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Pre processing bank data Il date set bank-data.csv 600 istanze Nessun dato missing Attributo
Il software Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Pre processing bank data Il date set bank-data.csv 600 istanze Nessun dato missing Attributo
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Sistemi Informativi per le decisioni
 Sistemi Informativi per le decisioni Professore Ing. Marco Patella Anno accademico 2006-2007 Presentazione a cura di Di Leo Valentina - Palmieri Francesco Knowledge Discovery La maggior parte delle aziende
Sistemi Informativi per le decisioni Professore Ing. Marco Patella Anno accademico 2006-2007 Presentazione a cura di Di Leo Valentina - Palmieri Francesco Knowledge Discovery La maggior parte delle aziende
Pre-elaborazione dei dati (Data pre-processing)
") Pre-elaborazione dei dati (Data pre-processing) I dati nel mondo reale sono sporchi incompleti: mancano valori per gli attributi, mancano attributi importanti, solo valori aggregati rumorosi: contengono
Pre-elaborazione dei dati (Data pre-processing) I dati nel mondo reale sono sporchi incompleti: mancano valori per gli attributi, mancano attributi importanti, solo valori aggregati rumorosi: contengono
Multi classificatori. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Tesina Intelligenza Artificiale Maria Serena Ciaburri s A.A
 Tesina Intelligenza Artificiale Maria Serena Ciaburri s231745 A.A. 2016-2017 Lo scopo di questa tesina è quello di clusterizzare con l algoritmo K-Means i dati presenti nel dataset MNIST e di calcolare
Tesina Intelligenza Artificiale Maria Serena Ciaburri s231745 A.A. 2016-2017 Lo scopo di questa tesina è quello di clusterizzare con l algoritmo K-Means i dati presenti nel dataset MNIST e di calcolare
Data Journalism. Analisi dei dati. Angelica Lo Duca
 Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
I Componenti del processo decisionale 7
 Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Business Intelligence per i Big Data
 Business Intelligence per i Big Data Esercitazione di laboratorio n. 6 L obiettivo dell esercitazione è il seguente: - Applicare algoritmi di data mining per la classificazione al fine di analizzare dati
Business Intelligence per i Big Data Esercitazione di laboratorio n. 6 L obiettivo dell esercitazione è il seguente: - Applicare algoritmi di data mining per la classificazione al fine di analizzare dati
Regole associative con Weka
 Regole associative con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Apriori parametri e output In questa fase utilizzeremo il data set CensusTrainining.arff
Regole associative con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Apriori parametri e output In questa fase utilizzeremo il data set CensusTrainining.arff
Regole associative con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Regole associative con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Apriori parametri e output In questa fase utilizzeremo il data set CensusTrainining.arff
Regole associative con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Apriori parametri e output In questa fase utilizzeremo il data set CensusTrainining.arff
Data mining: classificazione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
Business Intelligence per i Big Data
 Business Intelligence per i Big Data Esercitazione di laboratorio N. 6 (Prima parte) Dati strutturati Il dataset denominato UsersSmall (UsersSmall.xls) è disponibile sul sito del corso (http://dbdmg.polito.it/wordpress/teaching/business-intelligence/).
Business Intelligence per i Big Data Esercitazione di laboratorio N. 6 (Prima parte) Dati strutturati Il dataset denominato UsersSmall (UsersSmall.xls) è disponibile sul sito del corso (http://dbdmg.polito.it/wordpress/teaching/business-intelligence/).
Analisi di un dataset di perizie assicurative. Esercitazione Data Mining
 Analisi di un dataset di perizie assicurative Esercitazione Data Mining Ricapitoliamo L obiettivo dell analisi che si intende condurre è l estrapolazione di un modello per il riconoscimento automatico
Analisi di un dataset di perizie assicurative Esercitazione Data Mining Ricapitoliamo L obiettivo dell analisi che si intende condurre è l estrapolazione di un modello per il riconoscimento automatico
1 PROCESSI STOCASTICI... 11
 1 PROCESSI STOCASTICI... 11 Introduzione... 11 Rappresentazione dei dati biomedici... 11 Aleatorietà delle misure temporali... 14 Medie definite sul processo aleatorio... 16 Valore atteso... 16 Esercitazione
1 PROCESSI STOCASTICI... 11 Introduzione... 11 Rappresentazione dei dati biomedici... 11 Aleatorietà delle misure temporali... 14 Medie definite sul processo aleatorio... 16 Valore atteso... 16 Esercitazione
Selezione del modello Strumenti quantitativi per la gestione
 Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Ricerca di outlier. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Data Science e Tecnologie per le Basi di Dati
 Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
SQL Server Integration Services. SQL Server 2005: ETL - 1. Integration Services Project
 Database and data mining group, SQL Server 2005 Integration Services SQL Server 2005: ETL - 1 Database and data mining group, Integration Services Project Permette di gestire tutti i processi di ETL Basato
Database and data mining group, SQL Server 2005 Integration Services SQL Server 2005: ETL - 1 Database and data mining group, Integration Services Project Permette di gestire tutti i processi di ETL Basato
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
Analisi dei Dati. Lezione 9 - Preprocessing dei dati
 Analisi dei Dati Lezione 9 - Preprocessing dei dati Motivazioni I dati nel mondo reale sono sporchi incompleti: mancano valori per gli attributi, mancano attributi importanti, solo valori aggregati rumorosi:
Analisi dei Dati Lezione 9 - Preprocessing dei dati Motivazioni I dati nel mondo reale sono sporchi incompleti: mancano valori per gli attributi, mancano attributi importanti, solo valori aggregati rumorosi:
MATRICE TUNING competenze versus unità didattiche, Corso di Laurea in Informatica (classe L-31), Università degli Studi di Cagliari
, Università degli Studi di Cagliari") A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
Classificazione Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 2006/2007
 Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Naïve Bayesian Classification
 Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Classificazione DATA MINING: CLASSIFICAZIONE - 1. Classificazione
 M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
EcoManager Web. EcoManager SERVER
 Sistema centrale per la raccolta e l elaborazione dei dati provenienti da una rete di monitoraggio della qualità dell aria sviluppato da Project Automation S.p.A. Il sistema svolge le funzionalità tipiche
Sistema centrale per la raccolta e l elaborazione dei dati provenienti da una rete di monitoraggio della qualità dell aria sviluppato da Project Automation S.p.A. Il sistema svolge le funzionalità tipiche
DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager
 DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager Smart Vision - Le tecnologie per l industria del futuro Machine Learning Famiglie di machine learning
DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager Smart Vision - Le tecnologie per l industria del futuro Machine Learning Famiglie di machine learning
Weka: Weikato university Environment for Knowledge Analysis
 : Weikato university Environment for Knowledge Analysis Corso di Data e Text Mining Ing. Andrea Tagarelli Università della Calabria Acknowledgements: Salvatore Ruggieri, Dip. di Informatica, Univ. di Pisa
: Weikato university Environment for Knowledge Analysis Corso di Data e Text Mining Ing. Andrea Tagarelli Università della Calabria Acknowledgements: Salvatore Ruggieri, Dip. di Informatica, Univ. di Pisa
Classificazione Mario Guarracino Data Mining a.a. 2010/2011
 Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Indicizzazione di feature locali. Annalisa Franco
 1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Indice generale. Ringraziamenti...xiii. Introduzione. Capitolo 1 Che cosa si intende per scienza dei dati?... 1
 Ringraziamenti...xiii Introduzione...xv Informazioni su questo libro...xv A chi si rivolge questo libro...xvi Questioni di software...xvi Note sugli apici...xvii Il forum del libro...xvii Esercitazioni...xviii
Ringraziamenti...xiii Introduzione...xv Informazioni su questo libro...xv A chi si rivolge questo libro...xvi Questioni di software...xvi Note sugli apici...xvii Il forum del libro...xvii Esercitazioni...xviii
Modelli matematici e Data Mining
 Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
L analisi dei dati. L analisi dei dati. Le basi di dati. Le basi dati 10/04/2010. Claudio Locci - Vincenzo Rundeddu Le basi dati.
 L analisi dei dati L analisi dei dati Claudio Locci - Vincenzo Rundeddu Le basi dati Le variabili uno strumento open source per l analisi dei dati 1 2 Le basi dati Le basi di dati Base dati/database Dataframe
L analisi dei dati L analisi dei dati Claudio Locci - Vincenzo Rundeddu Le basi dati Le variabili uno strumento open source per l analisi dei dati 1 2 Le basi dati Le basi di dati Base dati/database Dataframe
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Alberi di Regressione
 lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Classificazione k-nn con R. Strumenti quantitativi per la gestione
 Classificazione k-nn con R Strumenti quantitativi per la gestione Emanuele Taufer file:///g:/il%20mio%20drive/2%20corsi/3%20sqg/labs/l1-knn.html#(1) 1/16 Altezza e peso degli adulti Le statistiche sull
Classificazione k-nn con R Strumenti quantitativi per la gestione Emanuele Taufer file:///g:/il%20mio%20drive/2%20corsi/3%20sqg/labs/l1-knn.html#(1) 1/16 Altezza e peso degli adulti Le statistiche sull
Preprocessing. Corso di AA, anno 2017/18, Padova. Fabio Aiolli. 27 Novembre Fabio Aiolli Preprocessing 27 Novembre / 14
 Preprocessing Corso di AA, anno 2017/18, Padova Fabio Aiolli 27 Novembre 2017 Fabio Aiolli Preprocessing 27 Novembre 2017 1 / 14 Pipeline di Apprendimento Supervisionato Analisi del problema Raccolta,
Preprocessing Corso di AA, anno 2017/18, Padova Fabio Aiolli 27 Novembre 2017 Fabio Aiolli Preprocessing 27 Novembre 2017 1 / 14 Pipeline di Apprendimento Supervisionato Analisi del problema Raccolta,
Statistica computazionale
 Creazione SAS data set da dati esterni Statistica computazionale a.a. 2008/09 Appunti lezione del 2/3/09 Istruzioni SAS nel passo di DATA; External File Interface (EFI); Import Wizard Carla Rampichini
Creazione SAS data set da dati esterni Statistica computazionale a.a. 2008/09 Appunti lezione del 2/3/09 Istruzioni SAS nel passo di DATA; External File Interface (EFI); Import Wizard Carla Rampichini
C.da Di Dio - Villaggio S. Agata Messina Italy P.I c.f AMBIENTE STATISTICO. Release /03/2018.
 AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
SITO WEB (sistema dolly accessibile agli iscritti)
") Academy Big Data Corso di Alta Formazione METODOLOGIE, TECNICHE E TOOL PER L ANALISI DI BIG DATA SITO WEB (sistema dolly accessibile agli iscritti) https://dolly.ingmo.unimore.it/2018/course/view.php?id=650
Academy Big Data Corso di Alta Formazione METODOLOGIE, TECNICHE E TOOL PER L ANALISI DI BIG DATA SITO WEB (sistema dolly accessibile agli iscritti) https://dolly.ingmo.unimore.it/2018/course/view.php?id=650
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Computazione per l interazione naturale: macchine che apprendono
 Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
MASTER UNIVERSITARIO
 MASTER UNIVERSITARIO I Analisi Dati per la Business Intelligence e Data Science in collaborazione con Gestito da: V edizione 2016/2017 Dipartimento di Culture, Politica e Società Dipartimento di Informatica
MASTER UNIVERSITARIO I Analisi Dati per la Business Intelligence e Data Science in collaborazione con Gestito da: V edizione 2016/2017 Dipartimento di Culture, Politica e Società Dipartimento di Informatica
Sviluppo Applicativi Personalizzati per l Automazione delle Analisi SPC
 Sviluppo Applicativi Personalizzati per l Automazione delle Analisi SPC Report Automatici Interfacce Operatore Analisi Automatiche Operazioni Pianificate Risposte alle Esigenze del Cliente Negli anni abbiamo
Sviluppo Applicativi Personalizzati per l Automazione delle Analisi SPC Report Automatici Interfacce Operatore Analisi Automatiche Operazioni Pianificate Risposte alle Esigenze del Cliente Negli anni abbiamo
Interfaccia grafica SPTool di Matlab per
 Interfaccia grafica SPTool di Matlab per l analisi dei segnali nel dominio del discreto e della frequenza, e l elaborazione dei segnali con il dimensionamento di filtri Appunti a cura dell Ing. Marco Deidda
Interfaccia grafica SPTool di Matlab per l analisi dei segnali nel dominio del discreto e della frequenza, e l elaborazione dei segnali con il dimensionamento di filtri Appunti a cura dell Ing. Marco Deidda
Training Set Test Set Find-S Dati Training Set Def: Errore Ideale Training Set Validation Set Test Set Dati
 " #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
" #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
Segmentazione automatica della carotide basata sulla classificazione dei pixel
 Segmentazione automatica della carotide basata sulla classificazione dei pixel Samanta Rosati, Filippo Molinari, Gabriella Balestra Biolab, Dipartimento di Elettronica e Telecomunicazioni, Politecnico
Segmentazione automatica della carotide basata sulla classificazione dei pixel Samanta Rosati, Filippo Molinari, Gabriella Balestra Biolab, Dipartimento di Elettronica e Telecomunicazioni, Politecnico
WEKA only deals with flat files
 WEKA: versions!!there are several versions of WEKA:!!WEKA 3.0: book version compatible with description in data mining book!!weka 3.2: GUI version adds graphical user interfaces (book version is command-line
WEKA: versions!!there are several versions of WEKA:!!WEKA 3.0: book version compatible with description in data mining book!!weka 3.2: GUI version adds graphical user interfaces (book version is command-line
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Intelligenza Artificiale Complementi ed Esercizi
 Intelligenza Artificiale Complementi ed Esercizi Reti Neurali AA 2013-2014 Il riconoscimento dei caratteri scritti a mano Handwritten Recognition Il problema Data una cifra scritta a mano, riconoscere
Intelligenza Artificiale Complementi ed Esercizi Reti Neurali AA 2013-2014 Il riconoscimento dei caratteri scritti a mano Handwritten Recognition Il problema Data una cifra scritta a mano, riconoscere
Data Science. Docente. ore per lezioni frontali. Qualifica, sede di afferenza e SSD. Assegnista di ricerca, Università di Bari
 MODULO FORMATIVO numero 0 Giovanni SEMERARO A0 - Allineamento. lezioni Allineamento competenze Concetti di base dei database relazionali e modello entità relazioni Concetti di base di programmazione Java
MODULO FORMATIVO numero 0 Giovanni SEMERARO A0 - Allineamento. lezioni Allineamento competenze Concetti di base dei database relazionali e modello entità relazioni Concetti di base di programmazione Java
QUANTIZZATORE VETTORIALE
 QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
Data Science A.A. 2018/2019
 Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
Esercizio: apprendimento di congiunzioni di letterali
 input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
OntoMaker. Creazione dell ontologia
 OntoMaker OntoMaker è stato progettato per fornire uno strumento di facile utilizzo anche da parte di utenti non esperti nel campo informatico. Per la realizzazione e la manutenzione costante delle ontologie
OntoMaker OntoMaker è stato progettato per fornire uno strumento di facile utilizzo anche da parte di utenti non esperti nel campo informatico. Per la realizzazione e la manutenzione costante delle ontologie
Elementi di Apprendimento Automatico
 Elementi di Apprendimento Automatico Riferimenti Bibliografici: Tom Mitchell, Machine Learning, McGraw Hill, 1998 1 Quando è Necessario l Apprendimento (Automatico)? Quando il sistema deve... adattarsi
Elementi di Apprendimento Automatico Riferimenti Bibliografici: Tom Mitchell, Machine Learning, McGraw Hill, 1998 1 Quando è Necessario l Apprendimento (Automatico)? Quando il sistema deve... adattarsi
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Standard per Data Mining
 Standard per Data Mining Sistemi informativi per le Decisioni Slide a cura di prof. Claudio Sartori Iniziative di Standard per Data Mining I modelli di Data Mining e statistici generati dagli strumenti
Standard per Data Mining Sistemi informativi per le Decisioni Slide a cura di prof. Claudio Sartori Iniziative di Standard per Data Mining I modelli di Data Mining e statistici generati dagli strumenti
Gestione Fatture Elettroniche P.A.
 00 Assistenza tecnica 0371 / 594.3550 sosinfinity. assistenza@ zucchetti.it 0371 / 594.3928 Sommario Introduzione - 3 - Importazione singola fattura (e relative ricevute/notifiche) - 3 - Importazione Notifiche
00 Assistenza tecnica 0371 / 594.3550 sosinfinity. assistenza@ zucchetti.it 0371 / 594.3928 Sommario Introduzione - 3 - Importazione singola fattura (e relative ricevute/notifiche) - 3 - Importazione Notifiche
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Microsoft Access. Nozioni di base. Contatti: Dott.ssa Silvia Bonfanti
 Microsoft Access Nozioni di base Contatti: Dott.ssa Silvia Bonfanti silvia.bonfanti@unibg.it Introduzione In questa lezione vedremo lo strumento Microsoft Access ed impareremo come realizzare con esso
Microsoft Access Nozioni di base Contatti: Dott.ssa Silvia Bonfanti silvia.bonfanti@unibg.it Introduzione In questa lezione vedremo lo strumento Microsoft Access ed impareremo come realizzare con esso
Computazione per l interazione naturale: Modelli dinamici
 Computazione per l interazione naturale: Modelli dinamici Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: Modelli dinamici Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Classificazione Validazione Decision Tree & kmeans. Renato Mainetti
 Classificazione Validazione Decision Tree & kmeans Renato Mainetti Apprendimento Supervisionato e Non Supervisionato: forniamo input e output Non supervisionato: forniamo solo input 2 Apprendimento Supervisionato
Classificazione Validazione Decision Tree & kmeans Renato Mainetti Apprendimento Supervisionato e Non Supervisionato: forniamo input e output Non supervisionato: forniamo solo input 2 Apprendimento Supervisionato
Araniti E., Gatto F., Marrara D., Rodà D., Romano R.
 Araniti E., Gatto F., Marrara D., Rodà D., Romano R. Sommario Introduzione...1 QlikView...4 Dissesto statico ed idrogeologico...5 Incendi normali...6 Incendi di natura dolosa...8 Interventi per incidenti
Araniti E., Gatto F., Marrara D., Rodà D., Romano R. Sommario Introduzione...1 QlikView...4 Dissesto statico ed idrogeologico...5 Incendi normali...6 Incendi di natura dolosa...8 Interventi per incidenti
Alberi di decisione: c4.5
 Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Data Import pulizia dati e Probabilità. Renato Mainetti
 Data Import pulizia dati e Probabilità Renato Mainetti Importare dati in Matlab: Abbiamo visto come sia possibile generare array e matrici di dati. Per ora abbiamo sempre inserito i dati manualmente o
Data Import pulizia dati e Probabilità Renato Mainetti Importare dati in Matlab: Abbiamo visto come sia possibile generare array e matrici di dati. Per ora abbiamo sempre inserito i dati manualmente o
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Paolo Mogorovich
 Sistemi Informativi Territoriali Paolo Mogorovich www.di.unipi.it/~mogorov .4 Dati vettoriali - Tecniche di rappresentazione Un layer areale può essere rappresentato utilizzando diverse tecniche. Per esempio:
Sistemi Informativi Territoriali Paolo Mogorovich www.di.unipi.it/~mogorov .4 Dati vettoriali - Tecniche di rappresentazione Un layer areale può essere rappresentato utilizzando diverse tecniche. Per esempio:
Clustering. Clustering
 1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
POLITECNICO DI TORINO. Tesi di Laurea. Tecnica di compressione finalizzata alla classificazione di dati
 POLITECNICO DI TORINO Facoltà di Ingegneria Corso di Laurea in Ingegneria Informatica Tesi di Laurea Tecnica di compressione finalizzata alla classificazione di dati Relatore prof. Paolo Garza Candidato
POLITECNICO DI TORINO Facoltà di Ingegneria Corso di Laurea in Ingegneria Informatica Tesi di Laurea Tecnica di compressione finalizzata alla classificazione di dati Relatore prof. Paolo Garza Candidato
Data Science. ore per lezioni frontali. Qualifica, sede di afferenza e SSD. Assegnista di ricerca, Università di Bari
 MODULO FORMATIVO numero 0 responsabile del modulo Giovanni SEMERARO A0 - Allineamento. lezioni Allineamento competenze Fedelucio Narducci Assegnista di ricerca, Università di Bari 25 25 1,0 Totali 25 0
MODULO FORMATIVO numero 0 responsabile del modulo Giovanni SEMERARO A0 - Allineamento. lezioni Allineamento competenze Fedelucio Narducci Assegnista di ricerca, Università di Bari 25 25 1,0 Totali 25 0
Un layer areale può essere rappresentato utilizzando diverse tecniche.
 Dati vettoriali - Tecniche di rappresentazione Dati vettoriali - Tecniche di rappresentazione Sistemi Informativi Territoriali Paolo Mogorovich www.di.unipi.it/~mogorov Un layer areale può essere rappresentato
Dati vettoriali - Tecniche di rappresentazione Dati vettoriali - Tecniche di rappresentazione Sistemi Informativi Territoriali Paolo Mogorovich www.di.unipi.it/~mogorov Un layer areale può essere rappresentato
COMPARAZIONE DI SISTEMI DI APPRENDIMENTO AUTOMATICO
 UNIVERSITÀ DEGLI STUDI DI BARI ALDO MORO FACOLTÀ DI SCIENZE MATEMATICHE, FISICHE E NATURALI DIPARTIMENTO DI INFORMATICA CORSO DI LAUREA MAGISTRALE IN INFORMATICA ESAME DI INTELLIGENZA ARTIFICIALE COMPARAZIONE
UNIVERSITÀ DEGLI STUDI DI BARI ALDO MORO FACOLTÀ DI SCIENZE MATEMATICHE, FISICHE E NATURALI DIPARTIMENTO DI INFORMATICA CORSO DI LAUREA MAGISTRALE IN INFORMATICA ESAME DI INTELLIGENZA ARTIFICIALE COMPARAZIONE
Esperienze di Advanced Analytics nella statistica ufficiale: strumenti e progetti
 Esperienze di Advanced Analytics nella statistica ufficiale: strumenti e progetti Direzione Centrale per le tecnologie informatiche e della comunicazione Introduzione I Big Data nella statistica ufficiale
Esperienze di Advanced Analytics nella statistica ufficiale: strumenti e progetti Direzione Centrale per le tecnologie informatiche e della comunicazione Introduzione I Big Data nella statistica ufficiale
il software per l marketing ideato da Fotonica
 il software per l e-mail marketing ideato da Fotonica La soluzione per gestire autonomamente il marketing e la comunicazione on line, permette la creazione di campagne di comunicazione rapide, personali
il software per l e-mail marketing ideato da Fotonica La soluzione per gestire autonomamente il marketing e la comunicazione on line, permette la creazione di campagne di comunicazione rapide, personali
exoml xml Fattura Elettronica ver
 exoml xml Fattura Elettronica ver. 1.2.1 1 LICENZA TUTTO INCLUSO SUBITO OPERATIVI Introduzione 2 Il prodotto exoml nasce dalla necessità dei nostri clienti di rispondere alla normativa sulla Fatturazione
exoml xml Fattura Elettronica ver. 1.2.1 1 LICENZA TUTTO INCLUSO SUBITO OPERATIVI Introduzione 2 Il prodotto exoml nasce dalla necessità dei nostri clienti di rispondere alla normativa sulla Fatturazione
Informatica per le discipline umanistiche 2 lezione 11
 Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
SUPPORT VECTOR MACHINES. a practical guide
 SUPPORT VECTOR MACHINES a practical guide 1 SUPPORT VECTOR MACHINES Consideriamo un problema di classificazione binaria, a partire da uno spazio di input X R n e uno spazio di output Y = { 1, 1} Training
SUPPORT VECTOR MACHINES a practical guide 1 SUPPORT VECTOR MACHINES Consideriamo un problema di classificazione binaria, a partire da uno spazio di input X R n e uno spazio di output Y = { 1, 1} Training
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
Flickr image classification
 Flickr image classification Relazione progetto Social Media Management Università degli studi di Catania Dipartimento di Matematica e Informatica CANCEMI DAMIANO - W82000075 1 Introduzione Questo progetto
Flickr image classification Relazione progetto Social Media Management Università degli studi di Catania Dipartimento di Matematica e Informatica CANCEMI DAMIANO - W82000075 1 Introduzione Questo progetto
Analysis Service. Dutto Riccardo IPSI - tel Dutto Riccardo - SQL Server 2008.
 SQL Server Business Intelligence Development Studio Analysis Service Dutto Riccardo riccardo.dutto@polito.it IPSI - tel.7991 http://dbdmg.polito.it/ Il Data warehouse Sorgenti dati operazionali DB relazionali
SQL Server Business Intelligence Development Studio Analysis Service Dutto Riccardo riccardo.dutto@polito.it IPSI - tel.7991 http://dbdmg.polito.it/ Il Data warehouse Sorgenti dati operazionali DB relazionali
Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello
 Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682