Lezione 4. Alberi di decisione: Estensioni, valutazione
|
|
|
- Eleonora Spada
- 5 anni fa
- Visualizzazioni
Transcript
1 Lezione 4 Alberi di decisione: Estensioni, valutazione venerdì, 05 Novembre 2004 Giuseppe Manco References: Chapter 3, Mitchell Chapter 7 Han, Kamber Chapter 5 Eibe, Frank Model evaluation
2 Algorithm Build-DT (D, Attributi) IF tutti gli esempi hanno la stessa etichetta THEN RETURN (nodo foglia con etichetta) ELSE IF Attributi =Ø THEN RETURN (foglia con etichetta di maggioranza) ELSE scegli il migliore attributo A come radice FOR EACH valore v di A Crea una diramazione dalla radice con la condizione A = v IF {x D: x.a = v} = Ø THEN RETURN (foglia con etichetta di maggioranza) ELSE Build-DT ({x D: x.a = v}, Attributi ~ {A}) Model evaluation
3 Criteri per trovare il migliore split Information gain (ID3 C4.5) Entropia, un concetto basato sulla teoria dell informazione Misura l impurità di uno split Seleziona l attributo che massimizza la riduzione di entropia Gini index (CART) Seleziona l attributo che minimizza l impurità Statistica del χ2 su tabelle di contingenza (CHAID) Misura la correlazione tra un attributo e l etichetta di classe Seleziona l attributo con la massima correlazione
4 Altri criteri per la costruzione di alberi di decisione Schemi di branching: Binari o a k vie Attributi categorici/continui Stop rule: come decidere se un nodo è una foglia: Tutti gli esempi appartengono alla stessa classe La misura di qualità al di sopra di una certa soglia Non ci sono più attributi da splittare Non ci sono più istanza nella partizione Labeling rule: un nodo foglia è etichettato con la classe a cui la maggior parte degli esempi nel nodo appartengono
5 Attributi con valori continui Due metodi principali Discretization Non supervisionata Supervisionata (e.g., ChiMerge) Esercizio: valutare come cambia l accuratezza se si utilizza il ChiMerge Utilizzo di soglie per creare split binari Esempio: A a produce I sottoinsiemi A a and A > a Information gain/gini/chi-quadro può essere calcolata su tali soglie Come si ottengono le soglie? FOR EACH attributo continuo A Si suddividano gli esempi {x D} in base ai valori di x.a FOR EACH coppia ordinata (l, u) di valori di A con etichette differenti Si valuti il guadagno del treshold risultante D A (l+u)/2, D A > (l+u)/2 Computazionalmente molto dispendioso Model evaluation
6 Weather data valori nominali Outlook Temperature Humidity Windy Play Sunny Hot High False No Sunny Hot High True No Overcast Hot High False Yes Rainy Mild Normal False Yes If outlook = sunny and humidity = high then play = no If outlook = rainy and windy = true then play = no If outlook = overcast then play = yes If humidity = normal then play = yes If none of the above then play = yes Model witten evaluation & eibe
7 Weather data valori numerici Outlook Temperature Humidity Windy Play Sunny False No Sunny True No Overcast False Yes Rainy False Yes If outlook = sunny and humidity > 83 then play = no If outlook = rainy and windy = true then play = no If outlook = overcast then play = yes If humidity < 85 then play = yes If none of the above then play = yes
8 esempio Split sull attributo temperature: Yes No Yes Yes Yes No No Yes Yes Yes No Yes Yes No Esempio: temperature < 71.5: yes/4, no/2 temperature 71.5: yes/5, no/3 Info([4,2],[5,3]) = 6/14 info([4,2]) + 8/14 info([5,3]) = bits Model witten evaluation & eibe
9 Complessità computazionale Si ordinano le istanze in base ai valori dell attributo numerico O (n log n) D. Abbiamo bisogno di ripeterlo per ogni nodo dell albero? A: No! Basta derivare l ordinamento da un ordinamento predefinito O (n) Svantaggio: bisogna creare un array per ogni attributo Model witten evaluation & eibe
10 Aumentare le prestazioni Possiamo valutare l entropia nei vari punti differenti (Fayyad & Irani, 1992) classe Yes No Yes Yes Yes No No Yes Yes Yes No Yes Yes No X Tagli potenziali I tagli tra i valori della stessa classe non sono ottimali
11 Split binari e multipli Lo split su un attributo nominale consuma l attributo L attributo nominale è testato al più una volta in ogni cammino La cosa non vale per gli attributi numerici! Possono essere testati più di una volta Conseguenza: albero complicato da leggere pre-discretizzazione Split multipli Model witten evaluation & eibe
12 Attributi nominali Problema: Attributi con un ampio numero di valori (casi estremi: i codici ID) I sottoinsiemi è probabile che siano meno impuri se c è un grande numero di valori Information gain è portata a scegliere attributi con un grande numero di valori La conseguenza è l overfitting (selezione di un attributo non ottimale per la predizione) Model evaluation
13 PlayTennis con ID code ID Outlook Temperature Humidity Windy Play? A sunny hot high false No B sunny hot high true No C overcast hot high false Yes D rain mild high false Yes E rain cool normal false Yes F rain cool normal true No G overcast cool normal true Yes H sunny mild high false No I sunny cool normal false Yes J rain mild normal false Yes K sunny mild normal true Yes L overcast mild high true Yes M overcast hot normal false Yes N rain mild high true No

14 Split per l attributo ID Code L entropia è 0 (poiché ogni nodo radice è puro, avendo un solo caso. Information gain è massimale per ID code Model witten&eibe evaluation
15 Gain ratio [1] Una modifica dell information Gain che riduce l influenza degli attributi nominali desiderata Grande quando i dati sono uniformemente distribuiti Piccolo quando tutti i dati appartengono ad un solo ramo Il Gain ratio considera sia il numero che la dimensione delle partizioni quando valuta un attributo Corregge l information gain con l informazione intrinseca di uno split Model witten&eibe evaluation
16 Gain Ratio [2] Gain ratio (Quinlan 86) Normalizza l information Gain: Gain GainRatio v ( D,A) - H( D) H( D ) ( D,A) v values(a) D D ( D,A) ( ) Gain SplitInformation D, A v SplitInformation D, A ( ) v values(a) D v D Dv lg D SpliInfo: entropia della distribuzione delle istanze nella partizione
17 Gain Ratio [3] Esempio: SplitInfo per ID code info ([1,1, K,1]) = 14 ( 1/14 log1/14) = L importanza dell attributo diminiuisce quando SplitInfo aumenta Gain ratio: bits 0.940bits gain_ratio ("ID_code") = = 3.807bits 0.246
18 Gain ratio per weather data Outlook Temperature Info: Info: Gain: Gain: Split info: info([5,4,5]) Split info: info([4,6,4]) Gain ratio: 0.247/ Gain ratio: 0.029/ Humidity Windy Info: Info: Gain: Gain: Split info: info([7,7]) Split info: info([8,6]) Gain ratio: 0.152/ Gain ratio: 0.048/ Model witten&eibe evaluation
19 Ancora gain ratio ID code ha ancora un Gain Ratio maggiore Soluzione: test ad hoc Problemi ipercompensazione Un attributo può essere scelto esclusivamente in base allo SplitInfo Soluzione: Consideriamo solo gli attributi con un Information Gain più grande della media Li confrontiamo sul gain ratio Model witten&eibe evaluation
20 Valori mancanti Che succede se alcune istanze non hanno tutti i valori? Due situazioni differenti Apprendimento: si valuta Gain (D, A), ma per qualche x D, un valore di A non è dato Classificazione: si classifica x senza conoscere il valore di A Soluzioni: effettuiamo una scelta nel calcolare Gain(D, A) Day Outlook Temperature Humidity Wind PlayTennis? 1 Sunny Hot High Light No 2 Sunny Hot High Strong No 3 Overcast Hot High Light Yes 4 Rain Mild High Light Yes 5 Rain Cool Normal Light Yes 6 Rain Cool Normal Strong No 7 Overcast Cool Normal Strong Yes 8 Sunny Mild??? Light No 9 Sunny Cool Normal Light Yes 10 Rain Mild Normal Light Yes 11 Sunny Mild Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Light Yes 14 Rain Mild High Strong No [9+, 5-] Outlook Sunny Overcast [2+, 3-] [4+, 0-] Rain [3+, 2-]
21 Approcci ai valori mancanti Il valore mancante è un valore a sé CHAID, C4.5 Imputazione: scegliamo il valore più probabile Sostiuiamo il valore con la media/mediana/moda La sostituzione può essere globale al dataset o locale al nodo Proporzioniamo la scelta Si assegna una probabilità p i ad ogni valore v i di x.a [Quinlan, 1993] Assegniamo una frazione p i di x ad ogni discendente nell albero Utilizziamo i pesi per calcolare Gain (D, A) In entrambi gli approcci, classifichiamo i nuovi esempi allo stesso modo
22 Esempio imputiamo x.a 1 variante: Humidity = Normal 2 variante: Humidity = High (tutti I casi No sono High) Day Outlook Temperature Humidity Wind PlayTennis? 1 Sunny Hot High Light No 2 Sunny Hot High Strong No 3 Overcast Hot High Light Yes 4 Rain Mild High Light Yes 5 Rain Cool Normal Light Yes 6 Rain Cool Normal Strong No 7 Overcast Cool Normal Strong Yes 8 Sunny Mild??? Light No 9 Sunny Cool Normal Light Yes 10 Rain Mild Normal Light Yes 11 Sunny Mild Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Light Yes 14 Rain Mild High Strong No Scelta pesata 0.5 High, 0.5 Normal Gain < 0.97 Test: <?, Hot, Normal, Strong> 1/3 Yes + 1/3 Yes + 1/3 No = Yes 1,2,8,9,11 [2+,3-] No Humidity? High 1,2,8 [0+,3-] Yes Outlook? Sunny Overcast Rain Normal 9,11 [2+,0-] Yes 3,7,12,13 [4+,0-] 1,2,3,4,5,6,7,8,9,10,11,12,13,14 [9+,5-] No Strong 6,14 [0+,2-] Wind? Light 4,5,6,10,14 [3+,2-] Yes 4,5,10 [3+,0-] Model evaluation
23 Valori mancanti in CART: Surrogati CART si basa sui valori di altri attributi Esempio: l attributo INCOME Gli attributi Education o Occupation possono essere surrogati education alta = income alto Conseguenza: Inferiamo i valori dai surrogati Model evaluation
24 Scalabilità Che succede se il dataset è troppo grande per la memoria centrale? Approcci iniziali: Costruzione incrementale dell albero (Quinlan 86) Combinazione degli alberi costruiti su partizioni separate (Chan & Stolfo 93) Riduzione del dataset tramite campionamento (Cattlet 91) Obiettovo: gestire dati dell ordine di 1G con 1K attributi Vari approcci rivelatisi di successo SLIQ (Mehta et al. 96) SPRINT (Shafer et al. 96) PUBLIC (Rastogi & Shim 98) RainForest (Gehrke et al. 98) Model evaluation
25 Il rasoio di Occam e gli alberi di decisione Preference Biases / Language Biases Preference bias Espresso ( codificato ) nell algoritmo di learning Euristica di ricerca Language bias Espresso nel linguaggio di rappresentazione Restrizione dello spazio di ricerca Rasoio di Occam: motivazioni Le ipotesi compatte sono meno frequenti delle ipotesi complesse Conseguenza: meno probabile che siano coincidenze
26 Rasoio di Occam: argomenti contro Che vuol dire ipotesi compatte? Esistono varie definizioni di compattezza Alberi con un numero primo di nodi che usano Z come primo attributo Perché non preferire alberi che assegnano priorità agli attributi? Model evaluation
27 Errore Si possono ottenere ipotesi consistenti? È auspicabile? error D (h)= {x h(x) c(x), <x,c(x)> D} È sempre possibile ottenere un albero con l errore minimale Perché? È auspicabile? Model evaluation
28 Valutazione dell errore errore Matrice di confusione Classe attuale A B Classe predetta A TP FP B FN TN Accuratezza = (TP+TN)/(TP+TN+FP+FN) Errore = 1-accuratezza Model evaluation
29 Weather Day Outlook Temperature Humidity Wind PlayTennis? 1 Sunny Hot High Light No 2 Sunny Hot High Strong No 3 Overcast Hot High Light Yes 4 Rain Mild High Light Yes 5 Rain Cool Normal Light Yes 6 Rain Cool Normal Strong No 7 Overcast Cool Normal Strong Yes 8 Sunny Mild High Light No 9 Sunny Cool Normal Light Yes 10 Rain Mild Normal Light Yes 11 Sunny Mild Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Light Yes 14 Rain Mild High Strong No
30 Albero di decisione C4.5 Day Outlook Temperature Humidity Wind PlayTennis? 1 Sunny Hot High Light No 2 Sunny Hot High Strong No 3 Overcast Hot High Light Yes 4 Rain Mild High Light Yes 5 Rain Cool Normal Light Yes 6 Rain Cool Normal Strong No 7 Overcast Cool Normal Strong Yes 8 Sunny Mild High Light No 9 Sunny Cool Normal Light Yes 10 Rain Mild Normal Light Yes 11 Sunny Mild Normal Strong Yes 12 Overcast Mild High Strong Yes 13 Overcast Hot Normal Light Yes 14 Rain Mild High Strong No 1,2,3,4,5,6,7,8,9,10,11,12,13,14 [9+,5-] Outlook? 1,2,8,9,11 [2+,3-] High Humidity? Sunny Overcast Rain Normal Yes 3,7,12,13 [4+,0-] Strong Wind? Light 4,5,6,10,14 [3+,2-] No Yes No Yes 1,2,8 [0+,3-] 9,11 [2+,0-] 6,14 [0+,2-] 4,5,10 [3+,0-]
31 Overfitting L albero indotto 1,2,3,4,5,6,7,8,9,10,11,12,13,14 [9+,5-] Outlook? 1,2,8,9,11 Sunny Overcast Rain [2+,3-] Humidity? Yes Wind? High Normal 3,7,12,13 [4+,0-] Strong 4,5,6,10,14 [3+,2-] Light 1,2,8 [0+,3-] 15 [0+,1-] No 9,11,15 [2+,1-] Hot No Rumore nel training set Istanza 15: <Sunny, Hot, Normal, Strong, -> L etichetta correttà è + Temp? Mild Yes 11 [1+,0-] Cool L albero misclassifica l istanza No 6,14 [0+,2-] Yes Se aggiustiamo l albero con questa istanza 9 [1+,0-] Yes 4,5,10 [3+,0-] Il nuovo albero si comporterà peggio del precedente Si adatta al rumore!
32 Overfitting Definizione h presenta overfitting su D se un ipotesi alternativa h per la quale Model evaluation error D (h) < error D (h ) but error test (h) > error test (h ) Cause tipiche: traiing set troppo piccolo (le decisioni sono basate su pochi dati); rumore Come si allevia l overfitting? Prevenzione Selezionare solo gli attributi rilevanti (utili nel modello) Richiede una misura della rilevanza aggiramento Schivare il problema quando c è sentore che sta per avvenire Valutare h su un insieme di test e fermare la costruzione del modello quando le performances scadono Riabilitazione terapia di recupero Costruzione del modello, eliminazione degli elementi che contribuiscono all overfitting
33 Combattere l overfitting Prevenzione aggiramento accuratezza Numero di nodi Training set test set Come selezionare il modello migliore Si misurano le performances su training set e su un validation set separato Minimum Description Length (MDL): si minimizza size(h T) + size (misclassificazioni (h T))
34 Rimuovere l overfitting Due approcci Pre-pruning (aggiramento): si ferma lo sviluppo dell albero se durante la costruzione si determina che le scelte non sono più affidabili Post-pruning (rimozione): si sviluppa l intero albero e si rimuovono I nodi che non hanno una ragione sufficiente d essere Post-pruning preferibile nella pratica: il pre-pruning si potrebbe fermare troppo presto
35 Basato su test statistici Prepruning Quando non c è dipendenza statisticamente rilevante tra gli attributi e la classe, il nodo non viene sviluppato CHAID: test del chi-quadro Utilizzato anche in ID3, insieme all information gain Solo gli attributi statisticamente significativi possono essere selezionati per information gain Model evaluation
36 Pruning per la riduzione dell errore errore Approccio Post-Pruning Dividiamo i dati intraining e Validation Set Function Prune(T, n:node) Rimuovi il sottoalbero che ha la radice in n Trasforma n in una foglia (con l etichetta di maggioranza associata) Algorithm Reduced-Error-Pruning (D) Partiziona D in D train, D validation Costruisci l albero T on D train WHILE l accuratezza su D validation diminuisce DO FOR EACH nodo non-foglia T Temp[candidate] Prune (T, candidate) Accuracy[candidate] Test (Temp[candidate], D validation ) T T Temp con il miglior valore di accuratezza RETURN T

37 Rimpiazzamento del sottoalbero

38 Rimpiazzamento del sottoalbero
39 Risultati Accuratezza Numero di nodi training set test set albero Post-pruned sul test set Eliminando nodi, l errore diminuisce NB:D validation è differente sia da D train che da D test Model evaluation
40 Se il dataset è abbastanza grande Dati 70% Casualmente 30% Training Set Si sviluppa l albero Test Set Si valuta l accuratezza
41 Se il dataset non è così grande K-fold Cross-validation 90% dati 10% Ripeti K volte Training Set Val. Set accuratezza = media e varianza Delle accuratezza Usato per sviluppare 10 alberi differenti Colleziona Le accuratezze

42 Riorganizzazione del sottoalbero Eliminazione di un nodo Ridistribuzione delle istanze Più lento del rimpiazzamento del sottoalbero X Model witten evaluation & eibe
43 Post-Pruning Pruning di regole Utilizzato ffrequentement Variante utilizzata in C4.5 Algorithm Rule-Post-Pruning (D) ottieni T from D sviluppa l albero su D finché non c è fitting totale Converti T in un insieme di regole equivalenti generalizza ogni regola indipendentemente cancellando tutte le precondizioni la cui cancellazione causa un aumento dell accuratezza stimata Ordina le regole ottenute per ordine di accuratezza
44 Conversione di un albero Outlook? Sunny Overcast Rain Humidity? Yes Wind? High Normal Strong Light No Yes No Yes Esempio IF (Outlook = Sunny) (Humidity = High) THEN PlayTennis = No IF (Outlook = Sunny) (Humidity = Normal) THEN PlayTennis = Yes
45 Di più sull errore Il pruning va applicato solo se riduce l errore stimato C4.5 Otteniamo gli intervalli di confidenza sul training set Utilizziamo una stima derivata da tale insieme per il pruning Model witten evaluation & eibe
46 Due definizioni di errore Errore vero Visione probabilistica error Errore sul campione Visione frequentistica Quanto error S (h) approssima error D (h)? D ( h) = P ( c( x) h( x)) x D 1 error = s ( h) δ ( c( x) h( x)) n x S
47 Esempio h misclassifica 12 esempi su 40 S 12 error S ( h) = = Qual è error D (h)?
48 Dato S di dimensione n Si valuti error S (h) Stime,Previsioni error S (h) è una variabile casuale Cosa possiamo concludere? Model evaluation
49 Se Intervalli di confidenza [1] S contiene n istanza n>30 allora Con probabilità 95%, error D (h) si trova nell intervallo error S ( h) ± 1.96 error S ( h)(1 error n S ( h)) Model evaluation
50 Intervalli di confidenza [2] Se S contiene n istanza n>30 allora Con probabilità N%, error D (h) si trova nell intervallo error S ( h) ± z N error S ( h)(1 error n S ( h)) N% 50% 68% 80% 90% 95% 98% 99% z N
51 error S (h) è una variabile casuale La probabilità di osservare r misclassificazioni: P( r) n! r!( n r)! r n r = errord ( h) (1 errord ( h))
52 Probabilità Binomiale P(r) = probabilità di avere r teste nel lancio della monetina P(head) = p Media Varianza E [ X ] = P( i) = Var[ X ] = i E np [( ) ] 2 X E[ X ] = np(1 p) Devianza σ X = Var[ X ] = np(1 p)
53 error S (h) error S (h) segue una distribuzione binomiale Per definizione, Assumendo E[ X i error X Var[ X i ] = µ i S n 1 ( h) = X = X n i= 1 0 se c( xi ) = h( xi ) = 1 altrimenti 2 ] = σ i Otteniamo E[ X ] = µ 2 σ Var[ X ] = n
54 Media Approssimiamo error S (h) µ errors ( h ) = error D ( h) devianza Utilizzando la distribuzione normale media σ error ( h)(1 error n ( h D D )) error S ( h) = µ errors ( h ) = error D ( h) varianza σ error ( h)(1 error n ( h S S )) error S ( h)
55 Distribuzione Normale densità distribuzione media varianza p ( x µ ) 1 2 2σ ( x) = e 2 Var[ X ] = σ 2πσ P( a X < b) E[X ] = µ 2 b = a 2 p( x) dx
56 Distribuzione Normale 80% dell area (probabilità) si trova in µ+1.28σ N% dell area (probabilità) si trova in µ+z N σ N% 50% 68% 80% 90% 95% 98% 99% z N
57 Intervalli di confidenza Se S contiene n istanze, n>30 allora Con probabilità N%, error S (h) si trova nell intervallo error D ( h) ± error ( h)(1 error n equivalentemente, error D (h) si trova nell intervallo error S ( h) ± In base al teorema del Limite Centrale, z z N N error D D ( h)(1 error n D D ( h)) ( h)) error S ( h) ± z N error S ( h)(1 n error S ( h))
58 Calcolo degli intervalli di confidenza Si sceglie il parametro da stimare error D (h) Si sceglie un approssimazione error S (h) Si determina la probabilità che governa l approssimazione error S (h) è binomiale, approssimata dalla distribuzione normale per n>30 Si trovano gli intervalli (L,U) per cui N% della probabilità ricade in [L,U] Si usa la tabella dei valori z N Model evaluation
59 L approccio C4.5 Valore trasformato dell errore (e): e p p( 1 p) / N (ovvero, sottraiamo la media e dividiamo per la devianza) La distribuzione ottenuta è normale Equazione risultante: Pr e p z z = p(1 p) / N c Risolvendo per p (assumendo il limite maggiore): p = e + 2 z 2N ± z e N 2 e N + 2 z 4N z N Model witten evaluation & eibe
60 Il C4.5 La stima dell errore del sottoalbero è la somma pesata della stima degli errori delle sue foglie Stima dell errore ad un nodo (upper bound): e = f 2 z + 2N + z f N 2 f N + 2 z 4N z N se c = 25% allora z = 0.69 (dalla distribuzione normale) f è l errore del training set N è il numero di istanze nella foglia

61 Example f = 5/14 e = 0.46 e < 0.51 pruning! f=0.33 e=0.47 f=0.5 e=0.72 f=0.33 e=0.47 Model witten evaluation & eibe Combinato con i pesi 6:2:6 dà 0.51
62 Pruning in CART Costruzione di un albero massimale CART determina una sequenza di pruning L ordine in cui i nodi dovrebbero essere rimossi Model evaluation
63 L ordine di pruning Elimina il nodo più debole Il nodo che aggiunge la minima accuratezza I nodi più piccoli tendono ad essere rimossi prima Se più nodi hanno lo stesso contributo, vengono rimossi tutti Model evaluation



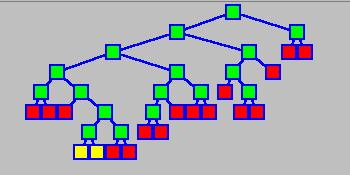
64 Esempio 24 Terminal Nodes 21 Terminal Nodes 20 Terminal Nodes 18 Terminal Nodes
65 Test della sequenza Con il test set, scegliamo l albero ottimale tra quelli ottenuti dalla sequenza di pruning Le performance di tutti gli alberi sono misurate L ottimale non è necessariamente quello con l errore minimo Il più piccolo più vicino a quello d errore minimo Cross-validation Model evaluation
66 Sommario tool C4.5 CART CHAID Arietà dello split Criterio di split stop vs. pruning Tipo di attributi Binario/multiplo Binario Multiplo information gain gini index χ 2 prune prune Stop Categorico/continuo Categorico/continuo categorico
67 Sommario Attributi continui Valori mancanti Rasoio di Occam Preference biases, language biases Overfitting Prevenzione, aggiramento, aggiustamento
Alberi di decisione: Estensioni, valutazione
 Alberi di decisione: Estensioni, valutazione Giuseppe Manco References: Chapter 3, Mitchell Chapter 7 Han, Kamber Chapter 5 Eibe, Frank IF tutti gli esempi hanno la stessa etichetta THEN RETURN (nodo foglia
Alberi di decisione: Estensioni, valutazione Giuseppe Manco References: Chapter 3, Mitchell Chapter 7 Han, Kamber Chapter 5 Eibe, Frank IF tutti gli esempi hanno la stessa etichetta THEN RETURN (nodo foglia
Alberi di decisione: Estensioni, valutazione
 Lezione 5 Alberi di decisione: Estensioni, valutazione Mercoledì, 31 Gennaio 2007 Giuseppe Manco References: Chapter 3, Mitchell Chapter 7 Han, Kamber Chapter 5 Eibe, Frank Algorithm Build-DT (D, Attributi)
Lezione 5 Alberi di decisione: Estensioni, valutazione Mercoledì, 31 Gennaio 2007 Giuseppe Manco References: Chapter 3, Mitchell Chapter 7 Han, Kamber Chapter 5 Eibe, Frank Algorithm Build-DT (D, Attributi)
Valutazione di modelli
 Valutazione di modelli venerdì, 03 Novembre 2006 Giuseppe Manco References: Chapter 3, Mitchell Chapters 4.5, 5.7, Tan, Steinbach, Kumar Underfitting, Overfitting 500 cerchi, 500 triangoli. Cerchi: 0.5
Valutazione di modelli venerdì, 03 Novembre 2006 Giuseppe Manco References: Chapter 3, Mitchell Chapters 4.5, 5.7, Tan, Steinbach, Kumar Underfitting, Overfitting 500 cerchi, 500 triangoli. Cerchi: 0.5
ID3: Selezione Attributo Ottimo
 Sistemi di Elaborazione dell Informazione 49 ID3: Selezione Attributo Ottimo Vari algoritmi di apprendimento si differenziano soprattutto (ma non solo) dal modo in cui si seleziona l attributo ottimo:
Sistemi di Elaborazione dell Informazione 49 ID3: Selezione Attributo Ottimo Vari algoritmi di apprendimento si differenziano soprattutto (ma non solo) dal modo in cui si seleziona l attributo ottimo:
Apprendimento di Alberi di Decisione: Bias Induttivo
 istemi di Elaborazione dell Informazione 54 Apprendimento di Alberi di Decisione: Bias Induttivo Il Bias Induttivo è sulla ricerca! + + A1 + + + A2 + +...... + + A2 A3 + + + A2 A4...... istemi di Elaborazione
istemi di Elaborazione dell Informazione 54 Apprendimento di Alberi di Decisione: Bias Induttivo Il Bias Induttivo è sulla ricerca! + + A1 + + + A2 + +...... + + A2 A3 + + + A2 A4...... istemi di Elaborazione
Alberi di Decisione (2)
") Alberi di Decisione (2) Corso di AA, anno 2018/19, Padova Fabio Aiolli 05 Novembre 2018 Fabio Aiolli Alberi di Decisione (2) 05 Novembre 2018 1 / 19 Apprendimento di alberi di decisione: Bias induttivo
Alberi di Decisione (2) Corso di AA, anno 2018/19, Padova Fabio Aiolli 05 Novembre 2018 Fabio Aiolli Alberi di Decisione (2) 05 Novembre 2018 1 / 19 Apprendimento di alberi di decisione: Bias induttivo
Alberi di Decisione (2)
") Alberi di Decisione (2) Corso di AA, anno 2017/18, Padova Fabio Aiolli 25 Ottobre 2017 Fabio Aiolli Alberi di Decisione (2) 25 Ottobre 2017 1 / 18 Apprendimento di alberi di decisione: Bias induttivo Come
Alberi di Decisione (2) Corso di AA, anno 2017/18, Padova Fabio Aiolli 25 Ottobre 2017 Fabio Aiolli Alberi di Decisione (2) 25 Ottobre 2017 1 / 18 Apprendimento di alberi di decisione: Bias induttivo Come
Data mining: classificazione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione Dipartimento di Elettronica e Informazione Apprendimento Supervisionato I dati considerati considerati degli esempi di un fenomeno
Ingegneria della Conoscenza e Sistemi Esperti Lezione 4: Alberi di Decisione Dipartimento di Elettronica e Informazione Apprendimento Supervisionato I dati considerati considerati degli esempi di un fenomeno
Classificazione DATA MINING: CLASSIFICAZIONE - 1. Classificazione
 M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
Sistemi Intelligenti 42. Apprendimento PAC
 Sistemi Intelligenti 42 Apprendimento PAC Usando la disuguaglianza precedente ed altre considerazioni è possibile mostrare che alcune classi di concetti non sono PAC-apprendibili dato uno specifico algoritmo
Sistemi Intelligenti 42 Apprendimento PAC Usando la disuguaglianza precedente ed altre considerazioni è possibile mostrare che alcune classi di concetti non sono PAC-apprendibili dato uno specifico algoritmo
Training Set Test Set Find-S Dati Training Set Def: Errore Ideale Training Set Validation Set Test Set Dati
 " #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
" #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
3.2 Decision-Tree Learning
 18 CAPITOLO 3. MODELLAZIONE PREDITTIVA dello spazio delle ipotesi per il nuovo linguaggio e lo si confronti con lo spazio originario e con uno spazio senza bias, assumendo di avere F features discrete
18 CAPITOLO 3. MODELLAZIONE PREDITTIVA dello spazio delle ipotesi per il nuovo linguaggio e lo si confronti con lo spazio originario e con uno spazio senza bias, assumendo di avere F features discrete
Apprendimento basato sulle istanze
 Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Alberi di Decisione. Corso di AA, anno 2017/18, Padova. Fabio Aiolli. 23 Ottobre Fabio Aiolli Alberi di Decisione 23 Ottobre / 16
 Alberi di Decisione Corso di AA, anno 2017/18, Padova Fabio Aiolli 23 Ottobre 2017 Fabio Aiolli Alberi di Decisione 23 Ottobre 2017 1 / 16 Alberi di decisione (Decision Trees) In molte applicazioni del
Alberi di Decisione Corso di AA, anno 2017/18, Padova Fabio Aiolli 23 Ottobre 2017 Fabio Aiolli Alberi di Decisione 23 Ottobre 2017 1 / 16 Alberi di decisione (Decision Trees) In molte applicazioni del
Alberi di Decisione. Fabio Aiolli Sito web del corso
 Alberi di Decisione Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Alberi di Decisione In molte applicazioni del mondo reale non è sufficiente
Alberi di Decisione Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Alberi di Decisione In molte applicazioni del mondo reale non è sufficiente
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Decision Trees. Giovedì, 25 gennaio Giuseppe Manco
 Lezione 4 Decision Trees Giovedì, 25 gennaio 2007 Giuseppe Manco Riferimenti: Chapter 3, Mitchell Section 5.2 Hand, Mannila, Smith Section 7.3 Han, Kamber Chapter 6 Witten, Frank Outline Alberi di decisione
Lezione 4 Decision Trees Giovedì, 25 gennaio 2007 Giuseppe Manco Riferimenti: Chapter 3, Mitchell Section 5.2 Hand, Mannila, Smith Section 7.3 Han, Kamber Chapter 6 Witten, Frank Outline Alberi di decisione
Alberi di decisione: c4.5
 Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Valutazione delle Prestazioni di un Classificatore. Performance Evaluation
 Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Valutazione delle Prestazioni di un Classificatore Performance Evaluation Valutazione delle Prestazioni Una volta appreso un classificatore è di fondamentale importanza valutarne le prestazioni La valutazione
Sistemi Intelligenti 57. Alberi di Decisione. funzioni target con valori di output discreti (in generale più di 2 valori);
;") Sistemi Intelligenti 57 Alberi di Decisione In molte applicazioni del mondo reale non è sufficiente apprendere funzioni booleane con ingressi binari. Gli Alberi di Decisione sono particolarmente adatti
Sistemi Intelligenti 57 Alberi di Decisione In molte applicazioni del mondo reale non è sufficiente apprendere funzioni booleane con ingressi binari. Gli Alberi di Decisione sono particolarmente adatti
Alberi di decisione: c4.5
 Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Alberi di decisione: c4.5 c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato ad uno dei primi sistemi di questo genere, CLS (Concept Learning Systems) di E.B.
Apprendimento Automatico
 Apprendimento Automatico Metodi Bayesiani Fabio Aiolli 11 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 11 Dicembre 2017 1 / 19 Metodi Bayesiani I metodi Bayesiani forniscono tecniche computazionali
Apprendimento Automatico Metodi Bayesiani Fabio Aiolli 11 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 11 Dicembre 2017 1 / 19 Metodi Bayesiani I metodi Bayesiani forniscono tecniche computazionali
Data mining: classificazione DataBase and Data Mining Group of Politecnico di Torino
 DataBase and Data Mining Group of Database and data mining group, Database and data mining group, DataBase and Data Mining Group of DataBase and Data Mining Group of So dati insieme di classi oggetti etichettati
DataBase and Data Mining Group of Database and data mining group, Database and data mining group, DataBase and Data Mining Group of DataBase and Data Mining Group of So dati insieme di classi oggetti etichettati
Introduzione alla Modellazione Predittiva Dal ML al DM: Concept Learning
 Introduzione alla Modellazione Predittiva Dal ML al DM: Giuseppe Manco Riferimenti: Chapter 2, Mitchell Chapter 10 Hand, Mannila, Smith Chapter 7 Han, Kamber Apprendimento dagli esempi Nozioni (teoriche)
Introduzione alla Modellazione Predittiva Dal ML al DM: Giuseppe Manco Riferimenti: Chapter 2, Mitchell Chapter 10 Hand, Mannila, Smith Chapter 7 Han, Kamber Apprendimento dagli esempi Nozioni (teoriche)
Lecture 10. Combinare Classificatori. Metaclassificazione
 Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione Dipartimento di Elettronica e Informazione Politecnico di Milano Perchè le Regole? Le regole (if-then) sono espressive e leggibili
Ingegneria della Conoscenza e Sistemi Esperti Lezione 5: Regole di Decisione Dipartimento di Elettronica e Informazione Politecnico di Milano Perchè le Regole? Le regole (if-then) sono espressive e leggibili
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Decision Trees. venerdì, 7 ottobre Giuseppe Manco
 Decision Trees venerdì, 7 ottobre 2009 Giuseppe Manco Riferimenti: Chapter 3, Mitchell Section 5.2 Hand, Mannila, Smith Section 7.3 Han, Kamber Chapter 6 Witten, Frank Alberi di decisione Esempi Modelli:
Decision Trees venerdì, 7 ottobre 2009 Giuseppe Manco Riferimenti: Chapter 3, Mitchell Section 5.2 Hand, Mannila, Smith Section 7.3 Han, Kamber Chapter 6 Witten, Frank Alberi di decisione Esempi Modelli:
Lecture 8. Combinare Classificatori
 Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Reti Neurali. Giuseppe Manco. References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop. Reti Neurali
 Giuseppe Manco References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop Perceptron Learning Unità neurale Gradiente Discendente Reti Multi-Layer Funzioni nonlineari Reti di funzioni nonlineari
Giuseppe Manco References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop Perceptron Learning Unità neurale Gradiente Discendente Reti Multi-Layer Funzioni nonlineari Reti di funzioni nonlineari
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Multi classificatori. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Multi classificatori Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Combinazione di classificatori Idea: costruire più classificatori di base e predire la classe di appartenza di
Classificazione Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 2006/2007
 Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Rischio statistico e sua analisi
 F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
Dr. A. Appice. Alberi di Decisione. Caso di studio di Metodi Avanzati di Programmazione AA 2012-2013
 Alberi di Decisione Caso di studio di Metodi Avanzati di Programmazione AA 2012-2013 Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di dati
Alberi di Decisione Caso di studio di Metodi Avanzati di Programmazione AA 2012-2013 Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di dati
Alberi di Regressione
 lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
Apprendimento Bayesiano
 Apprendimento Automatico 232 Apprendimento Bayesiano [Capitolo 6, Mitchell] Teorema di Bayes Ipotesi MAP e ML algoritmi di apprendimento MAP Principio MDL (Minimum description length) Classificatore Ottimo
Apprendimento Automatico 232 Apprendimento Bayesiano [Capitolo 6, Mitchell] Teorema di Bayes Ipotesi MAP e ML algoritmi di apprendimento MAP Principio MDL (Minimum description length) Classificatore Ottimo
Data Science e Tecnologie per le Basi di Dati
 Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Problemi di ordinamento
 Problemi di ordinamento Input: una sequenza di n numeri a 1, a 2,..., a n ; Output: una permutazione a 1, a 2,..., a n di a 1, a 2,..., a n tale che a 1 a 2... a n. Generalmente, la sequenza è rappresentata
Problemi di ordinamento Input: una sequenza di n numeri a 1, a 2,..., a n ; Output: una permutazione a 1, a 2,..., a n di a 1, a 2,..., a n tale che a 1 a 2... a n. Generalmente, la sequenza è rappresentata
Stima della qualità dei classificatori per l analisi dei dati biomolecolari
 Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Stima della qualità dei classificatori per l analisi dei dati biomolecolari Giorgio Valentini e-mail: valentini@dsi.unimi.it Rischio atteso e rischio empirico L` apprendimento di una funzione non nota
Esercizio: apprendimento di congiunzioni di letterali
 input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
Introduzione al Machine Learning
 InfoLife Introduzione al Machine Learning Laboratorio di Bioinformatica InfoLife Università di Foggia - Consorzio C.IN.I. Dott. Crescenzio Gallo crescenzio.gallo@unifg.it 1 Cos è il Machine Learning? Fa
InfoLife Introduzione al Machine Learning Laboratorio di Bioinformatica InfoLife Università di Foggia - Consorzio C.IN.I. Dott. Crescenzio Gallo crescenzio.gallo@unifg.it 1 Cos è il Machine Learning? Fa
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Informatica 3. LEZIONE 16: Heap - Codifica di Huffmann. Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann
 Informatica 3 LEZIONE 16: Heap - Codifica di Huffmann Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann Informatica 3 Lezione 16 - Modulo 1 Heap e code di priorità Introduzione
Informatica 3 LEZIONE 16: Heap - Codifica di Huffmann Modulo 1: Heap e code di priorità Modulo 2: Esempio applicativo: codifica di Huffmann Informatica 3 Lezione 16 - Modulo 1 Heap e code di priorità Introduzione
Classificazione Bayesiana
 Classificazione Bayesiana Selezionare, dato un certo pattern x, la classe ci che ha, a posteriori, la massima probabilità rispetto al pattern: P(C=c i x)>p(c=c j x) j i Teorema di Bayes (TDB): P(A B) =
Classificazione Bayesiana Selezionare, dato un certo pattern x, la classe ci che ha, a posteriori, la massima probabilità rispetto al pattern: P(C=c i x)>p(c=c j x) j i Teorema di Bayes (TDB): P(A B) =
C4.5 Algorithms for Machine Learning
 C4.5 Algorithms for Machine Learning C4.5 Algorithms for Machine Learning Apprendimento di alberi decisionali c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato
C4.5 Algorithms for Machine Learning C4.5 Algorithms for Machine Learning Apprendimento di alberi decisionali c4.5 [Qui93b,Qui96] Evoluzione di ID3, altro sistema del medesimo autore, J.R. Quinlan Ispirato
Lezione 6. Altri metodi di classificazione. Bayesian Learning
 Lezione 6 Altri metodi di classificazione. Giuseppe Manco Readings: Sections 6.1-6.5, Mitchell Chapter 2, Bishop Chapter 4, Hand-Mannila-Smith Artificial Neural Networks (ANN) L output Y è 1 se almeno
Lezione 6 Altri metodi di classificazione. Giuseppe Manco Readings: Sections 6.1-6.5, Mitchell Chapter 2, Bishop Chapter 4, Hand-Mannila-Smith Artificial Neural Networks (ANN) L output Y è 1 se almeno
Esercizi d esamed. Spazio delle versioni
 Esercizi d esamed Spazio delle versioni Si consideri il problema EnjoySport visto a lezione descritto dagli attributi Sky Air Temp Humid Wind Water Forecast Si definisca uno spazio delle ipotesi costituito
Esercizi d esamed Spazio delle versioni Si consideri il problema EnjoySport visto a lezione descritto dagli attributi Sky Air Temp Humid Wind Water Forecast Si definisca uno spazio delle ipotesi costituito
Selezione del modello Strumenti quantitativi per la gestione
 Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Contenuto del capitolo
 Capitolo 8 Stima 1 Contenuto del capitolo Proprietà degli stimatori Correttezza: E(Stimatore) = parametro da stimare Efficienza Consistenza Intervalli di confidenza Per la media - per una proporzione Come
Capitolo 8 Stima 1 Contenuto del capitolo Proprietà degli stimatori Correttezza: E(Stimatore) = parametro da stimare Efficienza Consistenza Intervalli di confidenza Per la media - per una proporzione Come
Data Science A.A. 2018/2019
 Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 6 Modelli di Classificazione Data Science 2018/2019 1 Definizione Si collocano tra i metodi di apprendimento supervisionato e mirano
Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 6 Modelli di Classificazione Data Science 2018/2019 1 Definizione Si collocano tra i metodi di apprendimento supervisionato e mirano
Lecture 10. Clustering
 Lecture 10 Giuseppe Manco Readings: Chapter 8, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Outline Introduction K-means clustering Hierarchical clustering: COBWEB Apprendimento supervisionato
Lecture 10 Giuseppe Manco Readings: Chapter 8, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Outline Introduction K-means clustering Hierarchical clustering: COBWEB Apprendimento supervisionato
Minimi quadrati e massima verosimiglianza
 Minimi quadrati e massima verosimiglianza 1 Introduzione Nella scorsa lezione abbiamo assunto che la forma delle probilità sottostanti al problema fosse nota e abbiamo usato gli esempi per stimare i parametri
Minimi quadrati e massima verosimiglianza 1 Introduzione Nella scorsa lezione abbiamo assunto che la forma delle probilità sottostanti al problema fosse nota e abbiamo usato gli esempi per stimare i parametri
Classificazione I. Classificazione: Definizione
 Classificazione I Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Classificazione: Definizione Data una collezione di record (training set ) Ogni record è composto da un insieme di
Classificazione I Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Classificazione: Definizione Data una collezione di record (training set ) Ogni record è composto da un insieme di
Statistica Inferenziale
 Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Costruzione di macchine. Modulo di: Progettazione probabilistica e affidabilità. Marco Beghini. Lezione 7: Basi di statistica
 Costruzione di macchine Modulo di: Progettazione probabilistica e affidabilità Marco Beghini Lezione 7: Basi di statistica Campione e Popolazione Estrazione da una popolazione (virtualmente infinita) di
Costruzione di macchine Modulo di: Progettazione probabilistica e affidabilità Marco Beghini Lezione 7: Basi di statistica Campione e Popolazione Estrazione da una popolazione (virtualmente infinita) di
Università di Pavia Econometria. Richiami di Statistica. Eduardo Rossi
 Università di Pavia Econometria Richiami di Statistica Eduardo Rossi Università di Pavia Campione casuale Siano (Y 1, Y 2,..., Y N ) variabili casuali tali che le y i siano realizzazioni mutuamente indipendenti
Università di Pavia Econometria Richiami di Statistica Eduardo Rossi Università di Pavia Campione casuale Siano (Y 1, Y 2,..., Y N ) variabili casuali tali che le y i siano realizzazioni mutuamente indipendenti
Parallel Frequent Set Counting
 Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Divide et impera (Divide and Conquer) Dividi il problema in sottoproblemi piu` semplici e risolvili ricorsivamente
 Dividi il problema in sottoproblemi piu` semplici e risolvili ricorsivamente") Divide et impera (Divide and Conquer) Dividi il problema in sottoproblemi piu` semplici e risolvili ricorsivamente Divide et impera - Schema generale Divide-et-impera (P, n) if n k then risolvi direttamente
Divide et impera (Divide and Conquer) Dividi il problema in sottoproblemi piu` semplici e risolvili ricorsivamente Divide et impera - Schema generale Divide-et-impera (P, n) if n k then risolvi direttamente
Teoria e tecniche dei test
 Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Spesso sono definite anche le seguenti operazioni:
 Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una
 Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Code a priorità Una coda a priorità è una struttura dati astratta che permette di rappresentare un insieme di elementi su cui è definita una relazione d ordine. Sono definite almeno le seguenti operazioni:
Apprendimento Automatico: Apprendimento di Concetti da Esempi
 Apprendimento Automatico: Apprendimento di Concetti da Esempi Che cos è l apprendimento di concetti Inferire una funzione booleana (funzione obiettivo o concetto) a partire da esempi di addestramento dati
Apprendimento Automatico: Apprendimento di Concetti da Esempi Che cos è l apprendimento di concetti Inferire una funzione booleana (funzione obiettivo o concetto) a partire da esempi di addestramento dati
Metodi supervisionati di classificazione
 Metodi supervisionati di classificazione Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI - Dipartimento di Scienze dell'informazione Classificazione bio-molecolare di tessuti e geni Diagnosi a livello
Metodi supervisionati di classificazione Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI - Dipartimento di Scienze dell'informazione Classificazione bio-molecolare di tessuti e geni Diagnosi a livello
Verifica delle ipotesi
 Statistica inferenziale Stima dei parametri Verifica delle ipotesi Concetti fondamentali POPOLAZIONE o UNIVERSO Insieme degli elementi cui si rivolge il ricercatore per la sua indagine CAMPIONE Un sottoinsieme
Statistica inferenziale Stima dei parametri Verifica delle ipotesi Concetti fondamentali POPOLAZIONE o UNIVERSO Insieme degli elementi cui si rivolge il ricercatore per la sua indagine CAMPIONE Un sottoinsieme
Per regnare occorre tenere divisi i nemici e trarne vantaggio. fai ad ogni passo la scelta più conveniente
 Progetto di algoritmi sequenziali (un solo esecutore ) Divide et Impera Per regnare occorre tenere divisi i nemici e trarne vantaggio Greedy fai ad ogni passo la scelta più conveniente Buoni risultati
Progetto di algoritmi sequenziali (un solo esecutore ) Divide et Impera Per regnare occorre tenere divisi i nemici e trarne vantaggio Greedy fai ad ogni passo la scelta più conveniente Buoni risultati
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
Riconoscimento e recupero dell informazione per bioinformatica Classificazione: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Introduzione
ESERCITAZIONE N. 5 corso di statistica
 ESERCITAZIONE N. 5corso di statistica p. 1/27 ESERCITAZIONE N. 5 corso di statistica Marco Picone Università Roma Tre ESERCITAZIONE N. 5corso di statistica p. 2/27 Introduzione Variabili aleatorie discrete
ESERCITAZIONE N. 5corso di statistica p. 1/27 ESERCITAZIONE N. 5 corso di statistica Marco Picone Università Roma Tre ESERCITAZIONE N. 5corso di statistica p. 2/27 Introduzione Variabili aleatorie discrete
Richiami di inferenza statistica Strumenti quantitativi per la gestione
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Lecture 14. Association Rules
 Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
Richiami di inferenza statistica. Strumenti quantitativi per la gestione. Emanuele Taufer
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Parte III: Algoritmo di Branch-and-Bound
 Parte III: Algoritmo di Branch-and-Bound Sia Divide et Impera z* = max {c T x : x S} (1) un problema di ottimizzazione combinatoria difficile da risolvere. Domanda: E possibile decomporre il problema (1)
Parte III: Algoritmo di Branch-and-Bound Sia Divide et Impera z* = max {c T x : x S} (1) un problema di ottimizzazione combinatoria difficile da risolvere. Domanda: E possibile decomporre il problema (1)
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale a.a. 2013-14 Vito Claudio Ostuni Data analysis and pre-processing Dataset iniziale Feature
Problema del cammino minimo
 Algoritmi e Strutture di Dati II Problema del cammino minimo Un viaggiatore vuole trovare la via più corta per andare da una città ad un altra. Possiamo rappresentare ogni città con un nodo e ogni collegamento
Algoritmi e Strutture di Dati II Problema del cammino minimo Un viaggiatore vuole trovare la via più corta per andare da una città ad un altra. Possiamo rappresentare ogni città con un nodo e ogni collegamento
Statistica. Capitolo 10. Verifica di Ipotesi su una Singola Popolazione. Cap. 10-1
 Statistica Capitolo 1 Verifica di Ipotesi su una Singola Popolazione Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Formulare ipotesi nulla ed ipotesi alternativa
Statistica Capitolo 1 Verifica di Ipotesi su una Singola Popolazione Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Formulare ipotesi nulla ed ipotesi alternativa
Concetti di teoria dei campioni ad uso degli studenti di Statistica Economica e Finanziaria, A.A. 2017/2018. Giovanni Lafratta
 Concetti di teoria dei campioni ad uso degli studenti di Statistica Economica e Finanziaria, A.A. 2017/2018 Giovanni Lafratta ii Indice 1 Spazi, Disegni e Strategie Campionarie 1 2 Campionamento casuale
Concetti di teoria dei campioni ad uso degli studenti di Statistica Economica e Finanziaria, A.A. 2017/2018 Giovanni Lafratta ii Indice 1 Spazi, Disegni e Strategie Campionarie 1 2 Campionamento casuale
Algoritmi Greedy. Tecniche Algoritmiche: tecnica greedy (o golosa) Un esempio
 Un esempio") Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
In questa lezione. Heap binario heapsort. [CLRS10] cap. 6, par Prof. E. Fachini - Intr. Alg.
![In questa lezione. Heap binario heapsort. [CLRS10] cap. 6, par Prof. E. Fachini - Intr. Alg.](/thumbs/92/108221303.jpg "In questa lezione. Heap binario heapsort. [CLRS10] cap. 6, par Prof. E. Fachini - Intr. Alg.") In questa lezione Heap binario heapsort [CLRS10] cap. 6, par. 6.1-6.4!1 Heap binari Un heap binario è una struttura dati consistente di un array visto come un albero binario. A= 5 60 65 30 50 18 40 25
In questa lezione Heap binario heapsort [CLRS10] cap. 6, par. 6.1-6.4!1 Heap binari Un heap binario è una struttura dati consistente di un array visto come un albero binario. A= 5 60 65 30 50 18 40 25
La classificazione. Sommario. Intuizioni sul concetto di classificazione. Descrivete la propensione all acquisto acquisto dei clienti
 Sommario La classificazione Intuizioni sul task di classificazione Classificazione e apprendimento induttivo valutazione di un modello di classificazione Tipi di modelli di classificazione alberi di decisione
Sommario La classificazione Intuizioni sul task di classificazione Classificazione e apprendimento induttivo valutazione di un modello di classificazione Tipi di modelli di classificazione alberi di decisione
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 e applicazioni al dominio del Contact Management Parte IV: valutazione dei Università degli Studi di Udine Cross- In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System
e applicazioni al dominio del Contact Management Parte IV: valutazione dei Università degli Studi di Udine Cross- In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati
 Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
Classificazione bio-molecolare di tessuti e geni come problema di apprendimento automatico e validazione dei risultati Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI Dip. Scienze dell'informazione
La codifica di sorgente
 Tecn_prog_sist_inform Gerboni Roberta è la rappresentazione efficiente dei dati generati da una sorgente discreta al fine poi di trasmetterli su di un opportuno canale privo di rumore. La codifica di canale
Tecn_prog_sist_inform Gerboni Roberta è la rappresentazione efficiente dei dati generati da una sorgente discreta al fine poi di trasmetterli su di un opportuno canale privo di rumore. La codifica di canale
Machine Learning:Version Space. Sommario
 Machine Learning:Version Space Sommario Ripasso di alcune definizioni sul ML Lo spazio delle ipotesi H Apprendimento di una funzione booleana: il concept learning Version Space Spazio delle Ipotesi H
Machine Learning:Version Space Sommario Ripasso di alcune definizioni sul ML Lo spazio delle ipotesi H Apprendimento di una funzione booleana: il concept learning Version Space Spazio delle Ipotesi H
Statistica Applicata all edilizia: Stime e stimatori
 Statistica Applicata all edilizia E-mail: orietta.nicolis@unibg.it 15 marzo 2011 Statistica Applicata all edilizia: Indice 1 2 Statistica Applicata all edilizia: Uno dei problemi principali della statistica
Statistica Applicata all edilizia E-mail: orietta.nicolis@unibg.it 15 marzo 2011 Statistica Applicata all edilizia: Indice 1 2 Statistica Applicata all edilizia: Uno dei problemi principali della statistica
Campionamento. Una grandezza fisica e' distribuita secondo una certa PDF
 Campionamento Una grandezza fisica e' distribuita secondo una certa PDF La pdf e' caratterizzata da determinati parametri Non abbiamo una conoscenza diretta della pdf Possiamo determinare una distribuzione
Campionamento Una grandezza fisica e' distribuita secondo una certa PDF La pdf e' caratterizzata da determinati parametri Non abbiamo una conoscenza diretta della pdf Possiamo determinare una distribuzione
Elaborazione statistica di dati
 Elaborazione statistica di dati 1 CONCETTI DI BASE DI STATISTICA ELEMENTARE 2 Taratura strumenti di misura IPOTESI: grandezza da misurare identica da misura a misura Per la presenza di errori casuali,
Elaborazione statistica di dati 1 CONCETTI DI BASE DI STATISTICA ELEMENTARE 2 Taratura strumenti di misura IPOTESI: grandezza da misurare identica da misura a misura Per la presenza di errori casuali,
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3
 Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
5.1 Metodo Branch and Bound
 5. Metodo Branch and Bound Consideriamo un generico problema di ottimizzazione min{ c(x) : x X } Idea: Ricondurre la risoluzione di un problema difficile a quella di sottoproblemi più semplici effettuando
5. Metodo Branch and Bound Consideriamo un generico problema di ottimizzazione min{ c(x) : x X } Idea: Ricondurre la risoluzione di un problema difficile a quella di sottoproblemi più semplici effettuando
Problemi, istanze, soluzioni
 lgoritmi e Strutture di Dati II 2 Problemi, istanze, soluzioni Un problema specifica una relazione matematica tra dati di ingresso e dati di uscita. Una istanza di un problema è formata dai dati di un
lgoritmi e Strutture di Dati II 2 Problemi, istanze, soluzioni Un problema specifica una relazione matematica tra dati di ingresso e dati di uscita. Una istanza di un problema è formata dai dati di un
La codifica di sorgente
 Tecn_prog_sist_inform Gerboni Roberta è la rappresentazione efficiente dei dati generati da una sorgente discreta al fine poi di trasmetterli su di un opportuno canale privo di rumore. La codifica di canale
Tecn_prog_sist_inform Gerboni Roberta è la rappresentazione efficiente dei dati generati da una sorgente discreta al fine poi di trasmetterli su di un opportuno canale privo di rumore. La codifica di canale
Capitolo 8. Intervalli di confidenza. Statistica. Levine, Krehbiel, Berenson. Casa editrice: Pearson. Insegnamento: Statistica
 Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Progettazione di un Sistema di Machine Learning
 Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Progettazione di un Sistema di Machine Learning Esercitazioni per il corso di Logica ed Intelligenza Artificiale Rosati Jessica Machine Learning System Un sistema di Machine learning apprende automaticamente
Espressioni aritmetiche
 Espressioni aritmetiche Consideriamo espressioni costruite a partire da variabili e costanti intere mediante applicazione delle operazioni di somma, sottrazione, prodotto e divisione (intera). Ad esempio:
Espressioni aritmetiche Consideriamo espressioni costruite a partire da variabili e costanti intere mediante applicazione delle operazioni di somma, sottrazione, prodotto e divisione (intera). Ad esempio:
Teoria dei Fenomeni Aleatori AA 2012/13
 Introduzione alla Statistica Nella statistica, anziché predire la probabilità che si verifichino gli eventi di interesse (cioè passare dal modello alla realtà), si osserva un fenomeno se ne estraggono
Introduzione alla Statistica Nella statistica, anziché predire la probabilità che si verifichino gli eventi di interesse (cioè passare dal modello alla realtà), si osserva un fenomeno se ne estraggono
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione