Lecture 10. Clustering
|
|
|
- Romina Quarta
- 4 anni fa
- Visualizzazioni
Transcript
1 Lecture 10 Giuseppe Manco Readings: Chapter 8, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman
2 Outline Introduction K-means clustering Hierarchical clustering: COBWEB
3 Apprendimento supervisionato Dati Un insieme X di istanze su dominio multidimensionale Un funzione target c Il linguaggio delle ipotesi H Un insieme di allenamento D = {<x,c(x)>} Determinare L ipotesi h H tale che h(x) = c(x) per ogni x D Che sia consistente con il training set
4 Supervised vs. Unsupervised Learning Supervised learning (classificazione) Supervisione: il training set contiene l etichetta che indica la classe da apprendere I nuovi dati sono classificati sulla base di quello che si apprende dal training set Unsupervised learning (clustering) L etichetta di classe è sconosciuta Le istanze sono fornite con l obiettivo di stabilire se vi sono raggruppamenti (classi) tra i dati
5 Classificazione, Classificazione: Apprende un metodo per predire la classe dell istanza da altre istanze pre-classificate
6 Trova raggruppamenti naturali nei dati non etichettati Applicazioni tipiche Tool stand-alone to get insight into data distribution Passo di preprocessing per altri algoritmi
7 Trova raggruppamenti naturali nei dati non etichettati Applicazioni tipiche Tool stand-alone to get insight into data distribution Passo di preprocessing per altri algoritmi
8 Trova raggruppamenti naturali nei dati non etichettati Applicazioni tipiche Tool stand-alone to get insight into data distribution Passo di preprocessing per altri algoritmi
9 Trova raggruppamenti naturali nei dati non etichettati Applicazioni tipiche Tool stand-alone to get insight into data distribution Passo di preprocessing per altri algoritmi
10 , clusters Raggruppamento di dati in classi (clusters) che abbiano una significatività alta similarità intra-classe Bassa similarità inter-classe Qualità di uno schema di clustering La capacità di ricostruire la struttura nascosta similarità
11 Similarità, distanza Distanza d(x,y) Misura la dissimilarità tra gli oggetti Similarità s(x,y) S(x,y) 1/d(x,y) Esempio Proprietà desiderabili Definizione application-dependent Può richiedere normalizzazione Diverse definizioni per differenti tipi di attributi
12 Esempio Istanz X 1 X 2 X 3 I I I I I I I I I I
13 Similarità e dissimilarità tra oggetti La distanza è utilizzata per misurare la similarità (o dissimilarità) tra due istanze Distanza di Minkowski (Norma L p ): Dove x = (x 1, x 2,, x d ) e y = (y 1, y 2,, y d ) sono due oggetti d-dimensionali, e p è un numero primo se p = 1, d è la distanza Manhattan Se p=
14 Similarità e dissimilarità tra oggetti [2] se p = 2, d è la distanza euclidea: Proprietà Translation-invariant Scale variant Varianti Distanza pesata Distanza Mahalanobis
15 Esempio Euclidea mahalanobis manhattan
16 Similarità e dissimilarità tra oggetti [3] Similarità del coseno Proprietà Translation variant Scale invariant Similarità di Jaccard (Tanimoto)
17 Rappresentazione grafica x = 2A 1 + 3A 2 + 5A 3 A y = 3A 1 + 7A 2 + A 3 3 Q = 0A 1 + 0A 2 + 2A 3 5 x = 2A 1 + 3A 2 + 5A 3 Q = 0A 1 + 0A 2 + 2A A 1 y = 3A 1 + 7A 2 + A 3 A 2 7
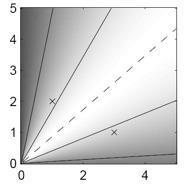
18 Rappresentazione grafica euclidea Coseno Jaccard
19 Esempio Euclidea Coseno Jaccard
20 Attributi binari Distanza di Hamming Distanza Manhattan quando i valori possibili sono 0 o 1 In pratica, conta il numero di mismatches
21 Attributi binari Utilizzando la tabella di contingenza Oggetto y Oggetto x
22 Dissimilarità tra attributi binari Esempio gender è simmetrico Tutti gli altri sono asimmetrici Poniamo Y e P uguale a 1, e N a 0
23 Variabili Nominali Generalizzazione del meccanismo di variabili binarie Metodo 1: Matching semplice m: # di matches, p: # di attributi nominali metodo 2: binarizzazione Metodo 3: Jaccard su insiemi
24 Combinare dissimilarità x,y x R, y R : attributi numerici x n, y n : attributi nominali Va garantita la stessa scala
25 Metodi di clustering Una miriade di metodologie differenti: Dati numerici/simbolici Deterministici/probabilistici Partizionali/con overlap Gerarchici/piatti Top-down/bottom-up
26 per enumerazione Utilizzando come criterio Il numero di possibili clusterings sarebbe S(10,4)=34.105
27 L algoritmo più semplice: K-means Algorithm K-Means(D, k) m D.size // numero di istanze FOR i 1 TO k DO µ i random // scegli un punto medio a caso WHILE (condizione di terminazione) FOR j 1 TO m DO // calcolo del cluster membership h argmin 1 i k dist(x j, µ i ) C[h] x j FOR i 1 TO k DO µ i RETURN Make-Predictor (w, P)
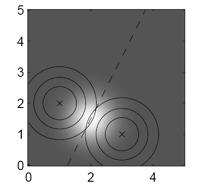
28 Esempio [1] Y Scegliamo 3 centri iniziali X
29 Esempio [1] Y k 1 Scegliamo 3 centri iniziali k 2 k 3 X
30 Esempio [2] Y k 1 Assegniamo ogni punto al cluster più vicino k 2 k 3 X
31 Esempio [3] Y Ricalcoliamo il centroide k 2 k 2 k 1 k 1 k 3 k 3 X
32 Esempio [3] Y Ricalcoliamo il centroide k 2 k 2 k 1 k 1 k 3 k 3 X
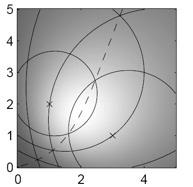
33 Esempio [4] Riassegniamo i punti ai Y clusters k 1 k 2 k 3 X
34 Esempio [5] Punti riassegnati Y k 1 k 2 k 3 X
35 Esempio [5] Punti riassegnati Y k 1 k 2 k 3 X
36 Esempio [5] Punti riassegnati Y k 1 k 2 k 3 X
37 Esempio [5] Punti riassegnati Y k 1 k 2 k 3 X
38 Esempio [5] Y Ricalcoliamo i centroidi k 1 k 2 k 3 X
39 Esempio [7] k 1 Y k 2 k 3 X
40 Quale criterio di stop? Cos è il centroide? Misura della compattezza di un cluster Misura della compattezza del clustering Teorema Ad una generica iterazione t,
41 Il metodo K-Means Vantaggi: Relativamente efficiente: O(tkn), dove n è il numero di oggetti, k il numero di clusters e t il numero di iterazioni. Di solito, k, t << n. Al confronto: PAM: O(k(n-k) 2 ), CLARA: O(ks 2 + k(n-k)) Converge ad un ottimo locale. L ottimo globale può essere trovato ricorrendo a varianti (ad esempio, basati su algoritmi genetici) Punti critici Applicabile solo quando il punto medio ha senso Attributi nominali? K va dato in input Qual è il numero ottimale? Incapace di gestire outliers e rumore Non adatto a scoprire forme non convesse
42 Varianti Selezione dei centri iniziali Strategie per calcolare i centroidi L algoritmo k-modes (Huang 98) Dati categorici Usiamo le mode invece dei centroidi Usiamo Hamming L update si basa sul cambiamento di frequenze Modelli misti: k-prototype
43 Varianti K-medoids invece del centroide, usa il punto mediano La media di 1, 3, 5, 7, 9 è La media di 1, 3, 5, 7, 1009 è La mediana di 1, 3, 5, 7, 1009 è Problema: come calcolare il medoide?
44 Varianti K-medoids invece del centroide, usa il punto mediano La media di 1, 3, 5, 7, 9 è La media di 1, 3, 5, 7, 1009 è La mediana di 1, 3, 5, 7, 1009 è Problema: come calcolare il medoide? 5
45 Varianti K-medoids invece del centroide, usa il punto mediano La media di 1, 3, 5, 7, 9 è La media di 1, 3, 5, 7, 1009 è La mediana di 1, 3, 5, 7, 1009 è Problema: come calcolare il medoide? 5 205
46 Varianti K-medoids invece del centroide, usa il punto mediano La media di 1, 3, 5, 7, 9 è La media di 1, 3, 5, 7, 1009 è La mediana di 1, 3, 5, 7, 1009 è Problema: come calcolare il medoide?
47 Algoritmo PAM 1. Seleziona k oggetti m 1,, m k arbitrariamente da D m 1,, m k rappresentano i medoidi 2. Assegna ogni oggetto x D al cluster j (1 j k) che ne minimizza la distanza dal medoide Calcola cost(s) current 3. Per ogni coppia (m,x) 1. Calcola cost(s) x m 4. Seleziona la coppia (m,x) per cui cost(s) x m è minimale 5. Se cost(s) x m < cost(s) current Scambia m con x 6. Ritorna al passo 3 (2)
48 Problemi con PAM Più robusto del k-means in presenza di rumore e outliers Un medoide è meno influenzato del centroide dalla presenza di outliers Efficiente su pochi dati, non scala su dati di grandi dimensioni. O(k(n-k) 2 ) per ogni iterazione Alternative basate sul campionamento CLARA( LARge Applications) CLARANS
49 Varianti al K-Medoid CLARA [Kaufmann and Rousseeuw,1990] Parametro addizionale: numlocal Estrae numlocal campioni dal dataset Applica PAM su ogni campione Restituisce il migliore insieme di medoidi come output Svantaggi: L efficienza dipende dalla dimensione del campione Non necessariamente un clustering buono sul campione rappresenta un clustering buono sull intero dataset Sample bias CLARANS [Ng and Han, 1994) Due ulteriori parametri: maxneighbor e numlocal Vengono valutate al più maxneighbor coppie (m,x) La prima coppia (m,x) per cui cost(s) x m < cost(s) current è scambiata Evita il confronto con la coppia minimale Si ripete la progedura numlocal volte per evitare il minimo locale. runtime(clarans) < runtime(clara) < runtime(pam)
50 Scelta dei punti iniziali [Fayyad, Reina and Bradley 1998] costruisci m campioni differenti da D Clusterizza ogni campione, fino ad ottenere m stime per i k rappresentanti A = (A 1, A 2,, A k ), B = (B 1, B 2,, B k ),..., M = (M 1, M 2,, M k ) Clusterizza DS= A B M m volte utilizzando gli insiemi A, B,..., M come centri iniziali Utilizza il risultato migliore come inizializzazione sull intero dataset

51 Inizializzazione D Centri su 4 campioni Centri effettivi
52 Scelta del parametro k Iterazione Applica l algoritmo per valori variabili di k K=1, 2, Scegli il clustering migliore Come scegliere il clustering migliore? La funzione cost(s) è strettamente decrescente K 1 > k 2 cost(s 1 ) < cost(s 2 ) Indici di bontà di un cluster
53 Indici di bontà In generale, si valuta intra-similarità e intersimilarità a(x): distanza media di x dagli oggetti del cluster A cui x appartiene b(x): distanza media di x dagli oggetti del secondo cluster B più prossimo a x Coefficiente su x s x =-1: x è più prossimo agli elementi di B s x = 0: non c è differenza tra A e B s x = 1: x è stato clusterizzato bene Generalizzazione s c Media dell indice su tutti gli oggetti Valori bassi: clustering debole Valori alti: clustering robusto
54 Minimum description Length Il principio del Minimum Description Length Rasoio di Occam: le ipotesi più semplici sono più probabili (Il termine Pr(D) non dipende da M e può essere ignorato) Più alto è Pr(M D), migliore è il modello
55 Minimum Description Length, Numero ottimale di clusters Fissiamo un range possibile di valori per k k = 1...K (con K abbastanza alto) Calcoliamo Pr(M k D) per ogni k Il valore k che esibisce il valore più alto è il migliore Problema: Come calcoliamo Pr(M k D)?
56 Bayesian Information Criterion e Minimum Description Length Problema: calcolare Idea: adottiamo il trick del logaritmo Cosa rappresentano i due termini? = accuratezza del modello = complessità del modello
57 Bayesian Information Criterion = accuratezza del modello Assunzione: algoritmo K-Means, distanza euclidea La giustificazione è data dall interpretazione gaussiana del clustering K-Means
58 Bayesian Information Criterion = complessità del modello Intuitivamente, quanti più cluster ci sono, più il clustering è complesso E quindi, meno è probabile Adottando un criterio basato sull encoding (in bit) dell informazione relativa i clusters, otteniamo Per ogni tuple nel dataset, codifichiamo a quale cluster appartiene
59 Bayesian Information Criterion Codifica il costo di un clustering M fatto di k clusters Direttamente proporzionale al costo del clustering dei dati Più i cluster sono omogenei, meno costoso è il clustering Inversamente proporzionale al costo del modello Quanti meno clusters ci sono, meno costoso è il clustering α è una costante di normalizzazione (serve a confrontare valori che potrebbero avere scale diverse)
Clustering. Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi
 Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Apprendimento basato sulle istanze
 Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Clustering. Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi
 Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
Clustering. Clustering
 1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Campionamento. Una grandezza fisica e' distribuita secondo una certa PDF
 Campionamento Una grandezza fisica e' distribuita secondo una certa PDF La pdf e' caratterizzata da determinati parametri Non abbiamo una conoscenza diretta della pdf Possiamo determinare una distribuzione
Campionamento Una grandezza fisica e' distribuita secondo una certa PDF La pdf e' caratterizzata da determinati parametri Non abbiamo una conoscenza diretta della pdf Possiamo determinare una distribuzione
Introduzione alla Modellazione Predittiva Dal ML al DM: Concept Learning
 Introduzione alla Modellazione Predittiva Dal ML al DM: Giuseppe Manco Riferimenti: Chapter 2, Mitchell Chapter 10 Hand, Mannila, Smith Chapter 7 Han, Kamber Apprendimento dagli esempi Nozioni (teoriche)
Introduzione alla Modellazione Predittiva Dal ML al DM: Giuseppe Manco Riferimenti: Chapter 2, Mitchell Chapter 10 Hand, Mannila, Smith Chapter 7 Han, Kamber Apprendimento dagli esempi Nozioni (teoriche)
Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
Sistemi di Elaborazione dell Informazione 170. Caso Non Separabile
 Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Clustering Mario Guarracino Data Mining a.a. 2010/2011
 Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Esercizio: apprendimento di congiunzioni di letterali
 input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
input: insieme di apprendimento istemi di Elaborazione dell Informazione 18 Esercizio: apprendimento di congiunzioni di letterali Algoritmo Find-S /* trova l ipotesi più specifica consistente con l insieme
Lecture 12. Clustering
 Lecture Marteì 0 novembre 00 Giuseppe Manco Reaings: Chapter 8 Han an Kamber Chapter Hastie Tibshirani an Frieman gerarchico Il settaggio i parametri in alcune situazioni è complicato Cluster gerarchici
Lecture Marteì 0 novembre 00 Giuseppe Manco Reaings: Chapter 8 Han an Kamber Chapter Hastie Tibshirani an Frieman gerarchico Il settaggio i parametri in alcune situazioni è complicato Cluster gerarchici
Ricerca di outlier. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Apprendimento Automatico
 Apprendimento Automatico Metodi Bayesiani - Naive Bayes Fabio Aiolli 13 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 13 Dicembre 2017 1 / 18 Classificatore Naive Bayes Una delle tecniche più semplici
Apprendimento Automatico Metodi Bayesiani - Naive Bayes Fabio Aiolli 13 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 13 Dicembre 2017 1 / 18 Classificatore Naive Bayes Una delle tecniche più semplici
Statistica per l Impresa
 Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Alcuni concetti geometrici
 Alcuni concetti geometrici spazio Euclideo bidimensionale X P x 1 x 1 x x 11 x 1 x 1 x x 1 P 1 P 1 (x 11, x 1 ) P (x 1, x ) O x 11 x 1 X 1 O (0, 0) In generale,, in uno spazio Euclideo p-dimensionale il
Alcuni concetti geometrici spazio Euclideo bidimensionale X P x 1 x 1 x x 11 x 1 x 1 x x 1 P 1 P 1 (x 11, x 1 ) P (x 1, x ) O x 11 x 1 X 1 O (0, 0) In generale,, in uno spazio Euclideo p-dimensionale il
Cluster Analysis Distanze ed estrazioni Marco Perugini Milano-Bicocca
 Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Apprendimento Automatico
 Apprendimento Automatico Metodi Bayesiani Fabio Aiolli 11 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 11 Dicembre 2017 1 / 19 Metodi Bayesiani I metodi Bayesiani forniscono tecniche computazionali
Apprendimento Automatico Metodi Bayesiani Fabio Aiolli 11 Dicembre 2017 Fabio Aiolli Apprendimento Automatico 11 Dicembre 2017 1 / 19 Metodi Bayesiani I metodi Bayesiani forniscono tecniche computazionali
Data Journalism. Analisi dei dati. Angelica Lo Duca
 Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Cenni di apprendimento in Reti Bayesiane
 Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Lecture 10. Combinare Classificatori. Metaclassificazione
 Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Lecture 10 Combinare Classificatori Combinare classificatori (metodi ensemble) Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s: X X (sampling, transformazione,
Lecture 8. Combinare Classificatori
 Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Lecture 8 Combinare Classificatori Giovedì, 18 novembre 2004 Francesco Folino Combinare classificatori Problema Dato Training set D di dati in X Un insieme di algoritmi di learning Una trasformazione s:
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Video Analysis (cenni) Annalisa Franco
 Annalisa Franco") 1 Video Analysis (cenni) Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Visual motion Un video è una sequenza di frame catturati nel corso del tempo Il valori dell immagine sono
1 Video Analysis (cenni) Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Visual motion Un video è una sequenza di frame catturati nel corso del tempo Il valori dell immagine sono
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Apprendimento Bayesiano
 Apprendimento Automatico 232 Apprendimento Bayesiano [Capitolo 6, Mitchell] Teorema di Bayes Ipotesi MAP e ML algoritmi di apprendimento MAP Principio MDL (Minimum description length) Classificatore Ottimo
Apprendimento Automatico 232 Apprendimento Bayesiano [Capitolo 6, Mitchell] Teorema di Bayes Ipotesi MAP e ML algoritmi di apprendimento MAP Principio MDL (Minimum description length) Classificatore Ottimo
Kernel Methods. Corso di Intelligenza Artificiale, a.a Prof. Francesco Trovò
 Kernel Methods Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 14/05/2018 Kernel Methods Definizione di Kernel Costruzione di Kernel Support Vector Machines Problema primale e duale
Kernel Methods Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 14/05/2018 Kernel Methods Definizione di Kernel Costruzione di Kernel Support Vector Machines Problema primale e duale
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
e applicazioni al dominio del Contact Management Parte V: combinazione di Università degli Studi di Udine In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System 1/10 Contenuti
Metodi supervisionati di classificazione
 Metodi supervisionati di classificazione Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI - Dipartimento di Scienze dell'informazione Classificazione bio-molecolare di tessuti e geni Diagnosi a livello
Metodi supervisionati di classificazione Giorgio Valentini e-mail: valentini@dsi.unimi.it DSI - Dipartimento di Scienze dell'informazione Classificazione bio-molecolare di tessuti e geni Diagnosi a livello
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Stima dei Redshift Fotometrici tramite il network SOM + K-NN
 Stima dei Redshift Fotometrici tramite il network + K-NN Università di Napoli Federico II December 21, 2016 Corso Astroinformatica Federico II Napoli Overview 1 Introduzione Obiettivo Scientifico PhotoZ
Stima dei Redshift Fotometrici tramite il network + K-NN Università di Napoli Federico II December 21, 2016 Corso Astroinformatica Federico II Napoli Overview 1 Introduzione Obiettivo Scientifico PhotoZ
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
Algoritmi Greedy. Tecniche Algoritmiche: tecnica greedy (o golosa) Un esempio
 Un esempio") Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
Learning finite Mixture- Models. Giuseppe Manco
 Learning finite Mixture- Models Giuseppe Manco Clustering La problematica del clustering è relativa al learning non supervisionato Abbiamo un dataset con istanze la cui etichetta è sconosciuta Obiettivo
Learning finite Mixture- Models Giuseppe Manco Clustering La problematica del clustering è relativa al learning non supervisionato Abbiamo un dataset con istanze la cui etichetta è sconosciuta Obiettivo
Silvia Rossi. Cenni sulla complessità. Informatica. Lezione n. Parole chiave: Corso di Laurea: Insegnamento: Programmazione I
 Silvia Rossi Cenni sulla complessità 23 Lezione n. Parole chiave: Corso di Laurea: Informatica Insegnamento: Programmazione I Email Docente: srossi@na.infn.it A.A. 2009-2010 Abbiamo visto che dato un problema
Silvia Rossi Cenni sulla complessità 23 Lezione n. Parole chiave: Corso di Laurea: Informatica Insegnamento: Programmazione I Email Docente: srossi@na.infn.it A.A. 2009-2010 Abbiamo visto che dato un problema
Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello
 Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 e applicazioni al dominio del Contact Management Parte IV: valutazione dei Università degli Studi di Udine Cross- In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System
e applicazioni al dominio del Contact Management Parte IV: valutazione dei Università degli Studi di Udine Cross- In collaborazione con dott. Enrico Marzano, CIO Gap srl progetto Active Contact System
Statistica di base per l analisi socio-economica
 Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Minimi quadrati e massima verosimiglianza
 Minimi quadrati e massima verosimiglianza 1 Introduzione Nella scorsa lezione abbiamo assunto che la forma delle probilità sottostanti al problema fosse nota e abbiamo usato gli esempi per stimare i parametri
Minimi quadrati e massima verosimiglianza 1 Introduzione Nella scorsa lezione abbiamo assunto che la forma delle probilità sottostanti al problema fosse nota e abbiamo usato gli esempi per stimare i parametri
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
QUANTIZZATORE VETTORIALE
 QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
TEORIA DELL INFORMAZIONE ED ENTROPIA FEDERICO MARINI
 TEORIA DELL INFORMAZIONE ED ENTROPIA DI FEDERICO MARINI 1 OBIETTIVO DELLA TEORIA DELL INFORMAZIONE Dato un messaggio prodotto da una sorgente, l OBIETTIVO è capire come si deve rappresentare tale messaggio
TEORIA DELL INFORMAZIONE ED ENTROPIA DI FEDERICO MARINI 1 OBIETTIVO DELLA TEORIA DELL INFORMAZIONE Dato un messaggio prodotto da una sorgente, l OBIETTIVO è capire come si deve rappresentare tale messaggio
Computazione per l interazione naturale: macchine che apprendono
 Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
Reti Neurali. Giuseppe Manco. References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop. Reti Neurali
 Giuseppe Manco References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop Perceptron Learning Unità neurale Gradiente Discendente Reti Multi-Layer Funzioni nonlineari Reti di funzioni nonlineari
Giuseppe Manco References: Chapter 4, Mitchell Chapter 1-2,4, Haykin Chapter 1-4, Bishop Perceptron Learning Unità neurale Gradiente Discendente Reti Multi-Layer Funzioni nonlineari Reti di funzioni nonlineari
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Algoritmi di classificazione supervisionati
 Corso di Bioinformatica Algoritmi di classificazione supervisionati Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di apprendimento supervisionato per problemi di biologia computazionale
Corso di Bioinformatica Algoritmi di classificazione supervisionati Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di apprendimento supervisionato per problemi di biologia computazionale
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Università degli Studi di Roma Tor Vergata
 Funzioni kernel Note dal corso di Machine Learning Corso di Laurea Specialistica in Informatica a.a. 2010-2011 Prof. Giorgio Gambosi Università degli Studi di Roma Tor Vergata 2 Queste note derivano da
Funzioni kernel Note dal corso di Machine Learning Corso di Laurea Specialistica in Informatica a.a. 2010-2011 Prof. Giorgio Gambosi Università degli Studi di Roma Tor Vergata 2 Queste note derivano da
Capitolo 3: Ottimizzazione non vincolata parte III. E. Amaldi DEI, Politecnico di Milano
 Capitolo 3: Ottimizzazione non vincolata parte III E. Amaldi DEI, Politecnico di Milano 3.4 Metodi di ricerca unidimensionale In genere si cerca una soluzione approssimata α k di min g(α) = f(x k +αd k
Capitolo 3: Ottimizzazione non vincolata parte III E. Amaldi DEI, Politecnico di Milano 3.4 Metodi di ricerca unidimensionale In genere si cerca una soluzione approssimata α k di min g(α) = f(x k +αd k
Selezione del modello Strumenti quantitativi per la gestione
 Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Selezione del modello Strumenti quantitativi per la gestione Emanuele Taufer Migliorare il modello di regressione lineare (RL) Metodi Selezione Best subset Selezione stepwise Stepwise forward Stepwise
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering Salvatore Orlando
 Clustering Salvatore Orlando Data e Web Mining. - S. Orlando 1 Cos è un analisi di clustering Obiettivo dell analisi di clustering Raggruppare oggetti in gruppi con un certo grado di omogeneità Cluster:
Clustering Salvatore Orlando Data e Web Mining. - S. Orlando 1 Cos è un analisi di clustering Obiettivo dell analisi di clustering Raggruppare oggetti in gruppi con un certo grado di omogeneità Cluster:
Clustering. Cos è un analisi di clustering
 Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità)
") Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità) Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università
Computazione per l interazione naturale: modelli a variabili latenti (clustering e riduzione di dimensionalità) Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione Naturale! Prof. Giuseppe Boccignone! Dipartimento di Informatica Università di Milano! boccignone@di.unimi.it boccignone.di.unimi.it/in_2015.html
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione Naturale! Prof. Giuseppe Boccignone! Dipartimento di Informatica Università di Milano! boccignone@di.unimi.it boccignone.di.unimi.it/in_2015.html
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione possibile [Jain
Riconoscimento e recupero dell informazione per bioinformatica Clustering Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione possibile [Jain
Metodologie di Clustering
 Metodologie di Clustering Nota preliminare Esistono moltissimi algoritmi di clustering Questi algoritmi possono essere analizzati da svariati punti di vista La suddivisione principale tuttavia è quella
Metodologie di Clustering Nota preliminare Esistono moltissimi algoritmi di clustering Questi algoritmi possono essere analizzati da svariati punti di vista La suddivisione principale tuttavia è quella
Apprendimento Automatico
 Apprendimento Automatico Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Rappresentazione dei dati con i kernel Abbiamo una serie di oggetti S
Apprendimento Automatico Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Rappresentazione dei dati con i kernel Abbiamo una serie di oggetti S
Template matching Il problema del riconoscimento
 emplate matching Il problema del riconoscimento Nel contesto dell interpretazione delle immagini, l obiettivo centrale è quello di riconoscere gli oggetti presenti all interno di un immagine. Riconoscere
emplate matching Il problema del riconoscimento Nel contesto dell interpretazione delle immagini, l obiettivo centrale è quello di riconoscere gli oggetti presenti all interno di un immagine. Riconoscere
Analisi di Raggruppamento
 Analisi di Raggruppamento Gianluca Amato Corso di Laurea Specialistica in Economia Informatica Università G. D'Annunzio di Chieti-Pescara ultimo aggiornamento: 25/05/09 1 Cosa è l'analisi di raggruppamento?
Analisi di Raggruppamento Gianluca Amato Corso di Laurea Specialistica in Economia Informatica Università G. D'Annunzio di Chieti-Pescara ultimo aggiornamento: 25/05/09 1 Cosa è l'analisi di raggruppamento?
METODI DI STIMA DELL ORDINE p
 METODI DI STIMA DELL ORDINE p Per la scelta dell ordine ottimo p per un modello AR, si definisce un criterio di errore che indichi qual è l ordine ottimo per quel modello. L approccio più semplice è quello
METODI DI STIMA DELL ORDINE p Per la scelta dell ordine ottimo p per un modello AR, si definisce un criterio di errore che indichi qual è l ordine ottimo per quel modello. L approccio più semplice è quello
Rischio statistico e sua analisi
 F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
Preprocessing. Corso di AA, anno 2017/18, Padova. Fabio Aiolli. 27 Novembre Fabio Aiolli Preprocessing 27 Novembre / 14
 Preprocessing Corso di AA, anno 2017/18, Padova Fabio Aiolli 27 Novembre 2017 Fabio Aiolli Preprocessing 27 Novembre 2017 1 / 14 Pipeline di Apprendimento Supervisionato Analisi del problema Raccolta,
Preprocessing Corso di AA, anno 2017/18, Padova Fabio Aiolli 27 Novembre 2017 Fabio Aiolli Preprocessing 27 Novembre 2017 1 / 14 Pipeline di Apprendimento Supervisionato Analisi del problema Raccolta,
LA TEORIA DELLA COMPLESSITÀ COMPUTAZIONALE
 LA TEORIA DELLA COMPLESSITÀ COMPUTAZIONALE INTRODUZIONE OBIETTIVO: classificare gli algoritmi a seconda delle risorse utilizzate - risorse necessarie (lower bound) - risorse sufficienti (upper bound) Aspetti
LA TEORIA DELLA COMPLESSITÀ COMPUTAZIONALE INTRODUZIONE OBIETTIVO: classificare gli algoritmi a seconda delle risorse utilizzate - risorse necessarie (lower bound) - risorse sufficienti (upper bound) Aspetti
Codifica di canale. (dalle dispense e dalle fotocopie) Trasmissione dell Informazione
 Trasmissione dell Informazione") Codifica di canale (dalle dispense e dalle fotocopie) Codici lineari a blocchi Un codice lineare (n,k) è un codice che assegna una parola lunga n ad ogni blocco lungo k. Si dice che il codice abbia un
Codifica di canale (dalle dispense e dalle fotocopie) Codici lineari a blocchi Un codice lineare (n,k) è un codice che assegna una parola lunga n ad ogni blocco lungo k. Si dice che il codice abbia un
Funzioni kernel. Docente: Nicolò Cesa-Bianchi versione 18 maggio 2018
 F94) Metodi statistici per l apprendimento Funzioni kernel Docente: Nicolò Cesa-Bianchi versione 18 maggio 2018 I predittori lineari possono soffrire di un errore di bias molto elevato in quanto predittore
F94) Metodi statistici per l apprendimento Funzioni kernel Docente: Nicolò Cesa-Bianchi versione 18 maggio 2018 I predittori lineari possono soffrire di un errore di bias molto elevato in quanto predittore
Reti Neurali (Parte I)
") Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
Reti Neurali in Generale
 istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
Data mining: classificazione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
Algoritmi e Strutture Dati
 Algoritmi e Strutture Dati Capitolo 4 Ordinamento Ordinamento Dato un insieme S di n oggetti presi da un dominio totalmente ordinato, ordinare S Esempi: ordinare una lista di nomi alfabeticamente, o un
Algoritmi e Strutture Dati Capitolo 4 Ordinamento Ordinamento Dato un insieme S di n oggetti presi da un dominio totalmente ordinato, ordinare S Esempi: ordinare una lista di nomi alfabeticamente, o un
ANALISI DEI CLUSTER. In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di
 ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Classificazione DATA MINING: CLASSIFICAZIONE - 1. Classificazione
 M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
M B G Classificazione ATA MINING: CLASSIFICAZIONE - 1 Classificazione Sono dati insieme di classi oggetti etichettati con il nome della classe di appartenenza (training set) L obiettivo della classificazione
SDE Marco Riani
 SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
Training Set Test Set Find-S Dati Training Set Def: Errore Ideale Training Set Validation Set Test Set Dati
 " #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
" #!! Suddivisione tipica ( 3 5 6 & ' ( ) * 3 5 6 = > ; < @ D Sistemi di Elaborazione dell Informazione Sistemi di Elaborazione dell Informazione Principali Paradigmi di Apprendimento Richiamo Consideriamo
Unsupervised Learning
 Unsupervised Learning Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 21/05/2018 Unsupervised Learning Unsupervised learning Clustering Dimensionality reduction Data visualization
Unsupervised Learning Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 21/05/2018 Unsupervised Learning Unsupervised learning Clustering Dimensionality reduction Data visualization
Learning and Clustering
 Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Reti Neurali. Corso di AA, anno 2016/17, Padova. Fabio Aiolli. 2 Novembre Fabio Aiolli Reti Neurali 2 Novembre / 14. unipd_logo.
 Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Clustering. Corso di Apprendimento Automatico Laurea Magistrale in Informatica Nicola Fanizzi
 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari 3 febbraio 2009 Sommario Introduzione iterativo basato su distanza k-means e sue generalizzazioni:
Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari 3 febbraio 2009 Sommario Introduzione iterativo basato su distanza k-means e sue generalizzazioni:
Regressione Lineare. Corso di Intelligenza Artificiale, a.a Prof. Francesco Trovò
 Regressione Lineare Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 23/04/2018 Regressione Lineare Supervised Learning Supervised Learning: recap È il sottocampo del ML più vasto
Regressione Lineare Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 23/04/2018 Regressione Lineare Supervised Learning Supervised Learning: recap È il sottocampo del ML più vasto
Indici di. tendenza centrale: posizione: variabilità e dispersione: -quantili -decili -percentili. -Media -Moda -Mediana
 Indici di posizione: -quantili -decili -percentili tendenza centrale: -Media -Moda -Mediana variabilità e dispersione: -Devianza - Varianza -Deviazione standard Indici di tendenza centrale Indici di tendenza
Indici di posizione: -quantili -decili -percentili tendenza centrale: -Media -Moda -Mediana variabilità e dispersione: -Devianza - Varianza -Deviazione standard Indici di tendenza centrale Indici di tendenza
Esplorazione grafica di dati multivariati. N. Del Buono
 Esplorazione grafica di dati multivariati N. Del Buono Scatterplot Scatterplot permette di individuare graficamente le possibili associazioni tra due variabili Variabile descrittiva (explanatory variable)
Esplorazione grafica di dati multivariati N. Del Buono Scatterplot Scatterplot permette di individuare graficamente le possibili associazioni tra due variabili Variabile descrittiva (explanatory variable)
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: similarità Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizioni
Riconoscimento e recupero dell informazione per bioinformatica Clustering: similarità Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizioni
Indicizzazione di feature locali. Annalisa Franco
 1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
Statistica per l Impresa
 Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 9 maggio 2018 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità Metodi gerarchici
Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 9 maggio 2018 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità Metodi gerarchici
Prova scritta di ASM - Modulo Analisi Esplorativa del
 Cognome:... Nome:... Matricola:......... Prova scritta di ASM - Modulo Analisi Esplorativa del 14.02.2017 La durata della prova è di 90 minuti. Si svolgano gli esercizi A e B riportando il risultato dove
Cognome:... Nome:... Matricola:......... Prova scritta di ASM - Modulo Analisi Esplorativa del 14.02.2017 La durata della prova è di 90 minuti. Si svolgano gli esercizi A e B riportando il risultato dove
WEKA Data Mining System
 Alma Mater Studiorum Università di Bologna WEKA Data Mining System Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella Presentazione di: Fabio Bertozzi, Giacomo Carli 1 WEKA: the bird
Alma Mater Studiorum Università di Bologna WEKA Data Mining System Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella Presentazione di: Fabio Bertozzi, Giacomo Carli 1 WEKA: the bird
Camil Demetrescu, Irene Finocchi, Giuseppe F. Italiano. Usa la tecnica del divide et impera:
 MergeSort Usa la tecnica del divide et impera: 1 Divide: dividi l array a metà 2 Risolvi i due sottoproblemi ricorsivamente 3 Impera: fondi le due sottosequenze ordinate 1 Esempio di esecuzione 7 2 4 5
MergeSort Usa la tecnica del divide et impera: 1 Divide: dividi l array a metà 2 Risolvi i due sottoproblemi ricorsivamente 3 Impera: fondi le due sottosequenze ordinate 1 Esempio di esecuzione 7 2 4 5
1 Esercizio - caso particolare di ottimalità
 Corso: Gestione ed elaborazione grandi moli di dati Lezione del: 5 giugno 2006 Argomento: Compressione aritmetica e Tecniche di compressione basate su dizionario Scribes: Andrea Baldan, Michele Ruvoletto
Corso: Gestione ed elaborazione grandi moli di dati Lezione del: 5 giugno 2006 Argomento: Compressione aritmetica e Tecniche di compressione basate su dizionario Scribes: Andrea Baldan, Michele Ruvoletto
Clustering. Introduzione Definizioni Criteri Algoritmi. Clustering Gerarchico
 Introduzione Definizioni Criteri Algoritmi Gerarchico Centroid-based K-means Fuzzy K-means Expectation Maximization (Gaussian Mixture) 1 Definizioni Con il termine (in italiano «raggruppamento») si denota
Introduzione Definizioni Criteri Algoritmi Gerarchico Centroid-based K-means Fuzzy K-means Expectation Maximization (Gaussian Mixture) 1 Definizioni Con il termine (in italiano «raggruppamento») si denota