Clustering Mario Guarracino Data Mining a.a. 2010/2011
|
|
|
- Benedetta Cappelli
- 7 anni fa
- Visualizzazioni
Transcript

1 Clustering

2 Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali, catalogazione della flora, patrimonio bibliotecario, gruppi etnici, patrimonio genetico, Gli algoritmi di clustering si propongono di suddividere gli elementi di un insieme in gruppi omogenei di osservazioni, detti cluster. La osservazioni assegnate a ciascun cluster sono tra loro simili e risultano differenti da quelle di altri gruppi.
3 Introduzione Il processo di identificazione di gruppi (cluster) può avvenire con due differenti approcci: Supervisionato: si catalogano gli oggetti in base a dei criteri prestabiliti; Non supervisionato: l aggregazione è meramente esplorativa e si basa sulle caratteristiche rilevate per la singola unità statistica. In questa lezione viene descritto l algoritmo di clustering delle k-medie (non superivisionato) e vengono presentati alcuni indicatori di qualità.
4 Esempio
5 Esempio
6 Esempio
7 Esempio
8 Caratteristiche dei modelli di clustering Flessibilità: capacità grado di analizzare dati contenenti differenti tipi di attributi. Robustezza: stabilità rispetto a piccole perturbazioni nei dati. Efficienza: rapidità nella generazione dei cluster per grandi insiemi di dati e/o numerosi attributi.
9 Tipologie di modelli di clustering Tipologie: Metodi di partizione: ricavano una partizione dei dati in K classi. Adatti a raggruppamenti di forma sferica. Metodi gerarchici: successive suddivisione dei dati. Determinano da soli il numero di cluster Metodi basati sulla densità: sviluppano i cluster in base al numero di elementi in ciascun intorno. Metodi a griglia: il clustering viene effettuato discretizzando prima lo spazio. Si può distinguere tra metodi che assegnano o meno univocamente un elemento ad un cluster, che assegnano o meno tutti gli elementi,
10 Misure Il clustering si basa su misure di similarità tra le osservazioni. Un dataset D si può rappresentare una matrice con le osservazioni sulle righe: La matrice simmetrica di dimensioni m x n delle distanze tra coppie di osservazioni ottenuta ponendo con dist(x i, x k ) distanza tra le osservazioni x i e x k.

11 Misure Osserviamo che risulta possibile trasformare una distanza d ik tra due osservazioni in una misura s ik di similarità, mediante una delle seguenti relazioni dove d max = max i,k d ik denota la massima distanza tra le osservazioni del dataset D. La definizione di un'appropriata nozione di distanza dipende dalla natura degli attributi che costituiscono il dataset D, che possono essere: numerici, binari, categorici nominali, categorici ordinali, a composizione mista.
12 Misure per attributi numerici Se tutti gli attribuiti dal dataset sono numerici si può usare la metrica euclidea tra i vettori dlle osservazioni x i = (x i1, x i2,..., x in ) e x k = ( x k1, x k2,.., x kn ), definita come
13 Misure per attributi numerici In alternativa è possibile considerare la distanza di Manhattan così denominata in quanto per raggiungere un punto da un altro si percorrono i due lati di un rettangolo avente per vertici opposti i punti stessi.
14 Misure per attributi numerici Un altra possibilità, che generalizza sia la distanza euclidea sia la distanza di Manhattan, consiste nella distanza di Minkowski: dove q è un numero intero positivo assegnato. La distanza di Minkowski si riduce alla distanza di Manhattan per q = 1, e alla distanza di Euclide per q = 2.
15 Misure per attributi numerici Un ultima generalizzazione della distanza euclidea si ottiene mediante la distanza di Mahalanobis, difinita come dove rappresenta l'inverso della matrice di covarianza della coppia di osservazioni x i e x k. Se le osservazioni x i e x k sono indipendenti, e la matrice di covarianza si riduce pertanto alla matrice identità, la distanza di Mahalanobis coincide con la distanza euclidea.
16 Misure per attributi numerici Le espressioni descritte per la distanza tra due osservazioni risentono di eventuali attributi che hanno valori assoluti grandi rispetto agli altri. In situazioni estreme, un solo attributo dominante potrebbe condizionare la formazione dei raggruppamenti da parte degli algoritmi di clustering. Esistono alcuno accorgimenti per evitare un simile sbilanciamento nella valutazione delle distanze tra le osservazioni: standardizzazione dei valori degli attributi numerici, in modo da ottenere nuovi valori che si collocano nell'intervallo [-1,1].
17 Misure per attributi binari Se un attributo di x j = (x 1j, x 2j,,x mj ) è binario, allora assume soltanto uno dei due valori 0 o 1. Anche se è possibile calcolare x ij x kj, questa quantità non rappresenta una distanza significativa, come per le metriche che abbiamo definito per gli attributi numerici. i valori 0 e 1 possono essere puramente convenzionali, e potrebbero essere scambiati di significato tra loro.
18 Misure per attributi binari Supponiamo che nel dataset D tutti gli n attributi presenti siano binari. Per procedere nella definizione di una metrica occorre fare riferimento alla tabella Il valore p rappresenta il numero di attributi binari in corrispondenza dei quali entrambe le osservazioni xi e xk assumono valore 0. Analogamente per q, u e v. Vale la relazione n = p + q + u + v.
19 Misure per attributi binari Gli attributi binari possono essere: Simmetrici: la presenza del valore 0 è interessante quanto la presenza del valore 1. Asimmetrici: siamo invece interessati in modo prevalente alla presenza del valore 1, che può manifestarsi in una piccola percentuale delle osservazioni. Se tutti gli n attributi binari sono di natura simmetrica possiamo definire il grado di similarità tra le osservazioni con il coefficiente delle corrispondenze:
20 Misure per attributi binari Supponiamo invece che tutti gli n attributi siano binari e asimmetrici. Per una coppia di attributi asimmetrici risulta molto più interessante l abbinamento dei positivi. Per le variabili binarie asimmetriche si ricorre quindi al coeffciente di Jaccard, definito come:
21 Misure per attributi categorici nominali Un attributo categorico nominale si può interpretare come un attributo binario simmetrico, con un numero di valori assunti maggiore di 2. Quindi, anche per gli attributi nominali si può estendere il coefficiente delle corrispondenze, definito per variabili binarie simmetriche, mediante la nuova espressione dove f indica il numero di attributi per i quali le osservazioni x i e x k assumono lo stesso valore nominale.
22 Metodi per attributi categorici ordinali Gli attributi categorici ordinali possono essere collocati su una scala di ordinamento naturale, con valori numerici arbitrari. Richiedono pertanto una standardizzazione preliminare per poter essere adattati alle metriche definite per gli attributi numerici.
23 Metodi per attributi categorici ordinali Supponiamo di rappresentare i valori di ciascun attributo categorico ordinale mediante la sua posizione nell ordinamento naturale. Se ad es. la variabile corrisponde al grado di istruzione, e può assumere i livelli {elementari, medie, diploma, laurea}, si fa corrispondere il livello {elementari} al valore numerico 1, il livello {medie} al valore 2, e cosi via. Indichiamo con Hj = {1, 2,...Hj} i valori ordinati associati all'attributo ordinale aj.
24 Metodi per attributi categorici ordinali Per standardizzare i valori assunti dall attributo aj nell intervallo [0,1] si ricorre alla trasformazione Dopo avere effettuato la trasformazione indicata per tutte le variabili ordinali, è possibile ricorrere alle misure di distanza per gli attributi numerici.
25 Metodi di partizione I metodi di partizione suddividono un dataset D in K sottogruppi non vuoti C = {C1, C2,..., CK}, dove K m. In genere il numero K di cluster viene assegnato in ingresso agli algoritmi di partizione. I gruppi generati risultano di solito esaustivi ed esclusivi, nel senso che ogni osservazione appartiene a uno e un solo cluster. I metodi di partizione partono con un assegnazione iniziale delle osservazioni ai K cluster. In seguito applicano iterativamente una tecnica di riallocazione delle osservazioni per assegnare alcune osservazioni a un diverso cluster, in modo da accrescere la qualità complessiva della suddivisione.
26 Metodi di partizione Le diverse misure di qualità utilizzate tendono a esprimere il grado di omogeneità delle osservazioni appartenenti a un medesimo cluster e la loro eterogeneità rispetto a osservazioni collocate in altri raggruppamenti. Gli algoritmi si arrestano quando nel corso di un iterazione non si verifica alcuna riallocazione, e pertanto la suddivisione appare stabile rispetto al criterio di valutazione utilizzato. I metodi di partizione hanno quindi natura euristica e operano a ogni passo la scelta che appare localmente più vantaggiosa.
27 Metodi di partizione Procedendo in questo modo non si ha la garanzia di raggiungere una suddivisione che sia globalmente ottimale. Il metodo delle k-medie (k-means) è l algoritmo di partizione più noto. Si tratta di un metodo di clustering abbastanza efficiente per determinare raggruppamenti di forma sferica.

28 Algoritmo delle k-medie Tecnica semplice ma efficace: 1. Scegliere un valore di k, il numero di cluster da generare. 2. Scegliere in modo casuale k osservazioni nel dataset. Questi saranno i centri dei cluster. 3. Collocare ogni altra osservazione nel cluster con il centro più vicino a essa. 4. Utilizzare le osservazioni in ogni cluster per calcolarne il nuovo centro. 5. Se i cluster non si sono modificati allora terminare, altrimenti ripetere il ciclo. Occorre definire un concetto di distanza (vicinanza). La distanza più comune fra osservazioni numeriche è quella euclidea della somma dei quadrati degli scarti.
29 Osservazione X Y f(x) La distanza euclidea fra il punto (x 1, y 1 ) e il punto (x 2, y 2 ) è definita da: ( x y x2) ( y1 2) Sia k = 2 (vogliamo due cluster) e i due centri a caso sono le osservazioni 1 e 3. Quindi i centri sono A = (1.0, 1.5) e B = (2.0, 1.5). L osservazione 5 ha distanza da A uguale a x ( ) 2 ( ) La distanza da B invece è ( ) 2 ( ) Quindi l osservazione 5 va nel secondo cluster, quello che ha centro B. 29
30 L osservazione 4 ha distanza 2.24 da A e 2.00 da B, quindi è nel 2 cluster. L osservazione 6 ha distanza 6.02 da A e 5.41 da B, quindi è nel 2 cluster. L osservazione 2 ha distanza 3.00 da A e 3.16 da B, quindi è nel 1 cluster. I due cluster dopo il primo passo risultano quindi essere {1, 2} e {3, 4, 5, 6}. Il nuovo centro del primo cluster è il nuovo punto A di coordinate (1.0, 3.0), calcolate come medie delle coordinate dei due punti nel primo cluster: nuova x di A = ( ) / 2 = 1.0 e nuova y di A = ( ) / 2 = 3.0 Il nuovo centro B del secondo cluster ha coordinate (3.0, 3.375), calcolate come nuova x di B = ( ) / 4 = 3.0 nuova y di B = ( ) / 4 = I centri sono cambiati. Quindi ripetiamo il ciclo. Nota: i nuovi centri non sono più osservazioni, ma punti inesistenti nel dataset. 30
31 Troviamo che l osservazione 3 è più vicina al nuovo A (distanza 1.80) che al nuovo B (distanza 2.125) quindi si sposta dal secondo al primo cluster. Anche le osservazioni 1 e 2 sono più vicine ad A che a B, quindi restano nel primo cluster. Invece le osservazioni 4, 5 e 6 sono più vicine a B e restano nel secondo cluster. Dopo il secondo ciclo dell algoritmo i due cluster sono {1, 2, 3} e {4, 5, 6} E si continua finché i cluster si stabilizzano. 31
32 Osservazioni Il risultato dipende dalla scelta iniziale dei centri. Per questo motivo si esegue l algoritmo varie volte con diverse scelte iniziali e si cerca un risultato buono, anche se non proprio ottimo (non si possono provare tutte le combinazioni perché numerosissime). Un clustering è buono se si ha una piccola varianza nei cluster e grande varianza fra i cluster. La varianza entro un cluster è la somma dei quadrati delle distanze dei punti dal centro del cluster. La varianza fra cluster è la varianza dei centri dei cluster rispetto al centro dei centri. 32
33 Valutazione dei modelli di clustering i Indichiamo con C = {C 1, C 2,..., C k } l insieme di K cluster generati da un algoritmo di clustering. Un indicatore di omogeneità di ciascun cluster è dato da: detta coesione del cluster. Si può quindi definire la coesione della partizione:

34 Valutazione dei modelli di clustering Un indicatore della disomogeneità tra una coppia di cluster è dato da: Anche in questo caso, la separazione complessiva della partizione è data da:


35 Explorer: clustering data in Weka WEKA contains clusterers for finding groups of similar instances in a dataset Implemented schemes are: k-means, EM, Cobweb, X-means, FarthestFirst Clusters can be visualized and compared to true clusters (if given) Evaluation based on loglikelihood if clustering scheme produces a probability distribution 2/1/2011 University of Waikato 35
36 2/1/2011 University of Waikato 36
37 2/1/2011 University of Waikato 37

38 2/1/2011 University of Waikato 38
39 2/1/2011 University of Waikato 39

40 2/1/2011 University of Waikato 40
41 2/1/2011 University of Waikato 41
42 2/1/2011 University of Waikato 42
43 2/1/2011 University of Waikato 43
44 2/1/2011 University of Waikato 44
45 2/1/2011 University of Waikato 45

46 2/1/2011 University of Waikato 46

47 2/1/2011 University of Waikato 47

48 2/1/2011 University of Waikato 48
49 2/1/2011 University of Waikato 49

50 2/1/2011 University of Waikato 50

51 Esempio Usiamo il file arff Contiene 600 istanze di consumatori, caratterizzati da alcune variabili e la loro preferenza rispetto al prodotto PEP.
52 Esempio Alcune implementazioni di k-means consentono solo valori numerici per gli attributi. Può anche essere necessario normalizzare i valori degli attributi che sono misurati su scale sostanzialmente diverse (ad esempio, "età" e "reddito"). Mentre WEKA fornisce i filtri per realizzare tutte queste attività di pre-elaborazione, non sono necessari per il clustering in WEKA. Questo perché SimpleKMeans gestisce automaticamente una mistura di attributi categorici e numerici.
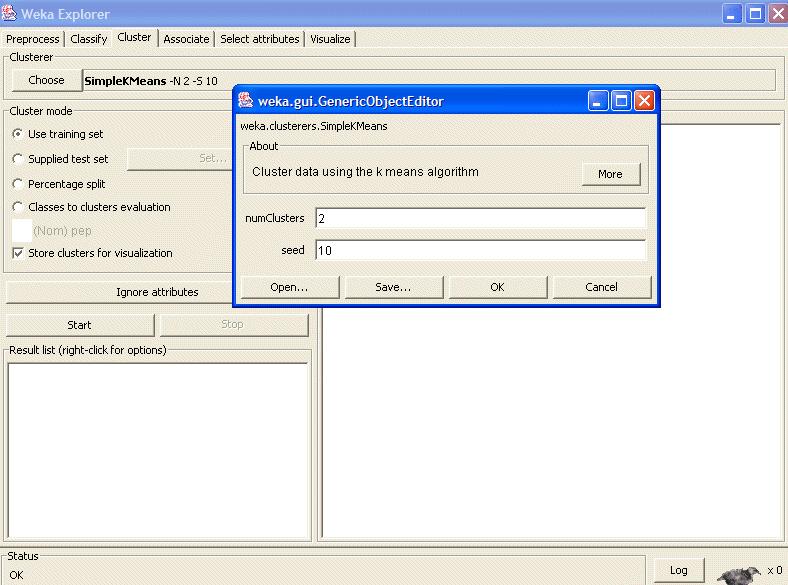
53 Esempio
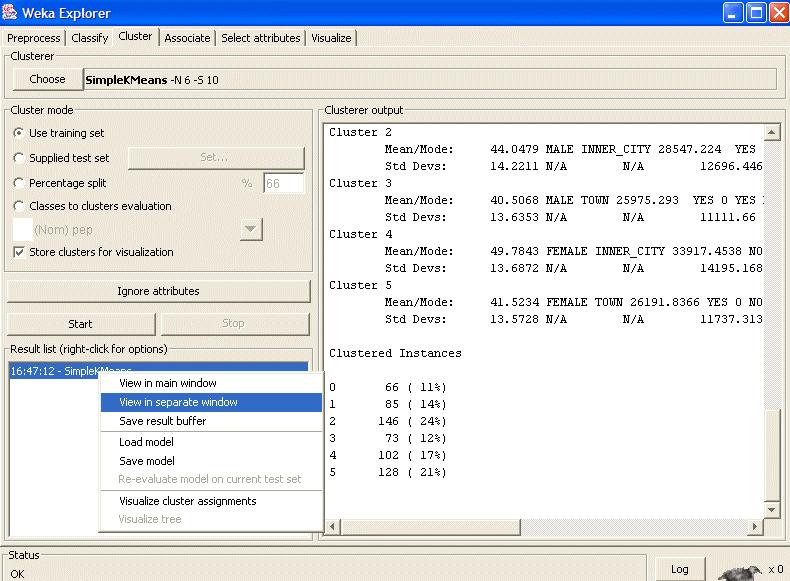
54 Esempio
55 Esempio La finestra dei risultati mostra il centroide di ogni cluster e le statistiche sul numero e percentuale di casi assegnati a gruppi diversi. I centroidi dei cluster sono i vettori media per ogni cluster (così, ogni valore della dimensione del baricentro rappresenta il valore medio per tale dimensione nel cluster). I centroidi possono essere utilizzati per caratterizzare il cluster. Ad esempio, il baricentro per cluster 1 mostra che questo è un segmento di casi che rappresenta per i giovani donne di mezza età (circa 38) che vivono in centro città con un reddito medio di ca. $28,500, che sono sposate con un figlio, ecc Inoltre, questo gruppo hanno, in media, ha detto SI 'al prodotto PEP.
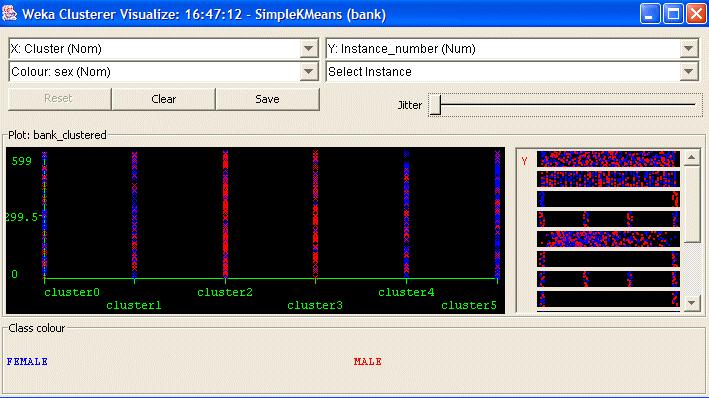
56 Esempio
57 Esempio È possibile scegliere il numero di cluster e uno qualsiasi degli altri attributi per ognuna delle tre diverse dimensioni disponibili (asse x, asse y, e il colore). Diverse combinazioni di scelte si tradurranno in una resa visiva dei rapporti differenti all'interno di ogni cluster. Nell'esempio precedente, abbiamo scelto il numero di cluster come l'asse x, il numero di istanza, come l'asse y, e il sesso "attributo", come la dimensione del colore. Questo si tradurrà in una visualizzazione della distribuzione di maschi e femmine in ogni cluster. Per esempio, si può notare che i cluster 2 e 3 sono dominati dai maschi, mentre i raggruppamenti di 4 e 5 sono dominati dalle femmine.

58 FINE
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Scale di Misurazione Lezione 2
 Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA. Prof.ssa Donatella Siepi tel:
 UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 2 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 2 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
La Statistica: introduzione e approfondimenti
 La Statistica: introduzione e approfondimenti Definizione di statistica Che cosa è la statistica? La statistica è una disciplina scientifica che trae i suoi risultati dalla raccolta, dall elaborazione
La Statistica: introduzione e approfondimenti Definizione di statistica Che cosa è la statistica? La statistica è una disciplina scientifica che trae i suoi risultati dalla raccolta, dall elaborazione
Statistica. POPOLAZIONE: serie di dati, che rappresenta linsieme che si vuole indagare (reali, sperimentali, matematici)
") Statistica La statistica può essere vista come la scienza che organizza ed analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva:
Statistica La statistica può essere vista come la scienza che organizza ed analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva:
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Statistica. Matematica con Elementi di Statistica a.a. 2015/16
 Statistica La statistica è la scienza che organizza e analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva: dalla mole di dati
Statistica La statistica è la scienza che organizza e analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva: dalla mole di dati
Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che:
 Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Misure di diversità tra unità statistiche. Loredana Cerbara
 Misure di diversità tra unità statistiche Loredana Cerbara LA DISTANZA IN STATISTICA In statistica la distanza ha un significato diverso da quello che si può intuire in altre discipline, dove, peraltro,
Misure di diversità tra unità statistiche Loredana Cerbara LA DISTANZA IN STATISTICA In statistica la distanza ha un significato diverso da quello che si può intuire in altre discipline, dove, peraltro,
Rappresentazioni Tabellari e Grafiche. Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica
 Rappresentazioni Tabellari e Grafiche Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Vocabolario Essenziale Unità Statistica Unità elementare
Rappresentazioni Tabellari e Grafiche Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Vocabolario Essenziale Unità Statistica Unità elementare
STATISTICA 1 ESERCITAZIONE 2
 Frequenze STATISTICA 1 ESERCITAZIONE 2 Dott. Giuseppe Pandolfo 7 Ottobre 2013 RAPPRESENTAZIONE GRAFICA DEI DATI Le rappresentazioni grafiche dei dati consentono di cogliere la struttura e gli aspetti caratterizzanti
Frequenze STATISTICA 1 ESERCITAZIONE 2 Dott. Giuseppe Pandolfo 7 Ottobre 2013 RAPPRESENTAZIONE GRAFICA DEI DATI Le rappresentazioni grafiche dei dati consentono di cogliere la struttura e gli aspetti caratterizzanti
INDICATORI DI TENDENZA CENTRALE
 Psicometria (8 CFU) Corso di laurea triennale INDICATORI DI TENDENZA CENTRALE Torna alla pri ma pagina INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore
Psicometria (8 CFU) Corso di laurea triennale INDICATORI DI TENDENZA CENTRALE Torna alla pri ma pagina INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore
Teoria e tecniche dei test. Concetti di base
 Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
Statistica. Campione
 1 STATISTICA DESCRITTIVA Temi considerati 1) 2) Distribuzioni statistiche 3) Rappresentazioni grafiche 4) Misure di tendenza centrale 5) Medie ferme o basali 6) Medie lasche o di posizione 7) Dispersione
1 STATISTICA DESCRITTIVA Temi considerati 1) 2) Distribuzioni statistiche 3) Rappresentazioni grafiche 4) Misure di tendenza centrale 5) Medie ferme o basali 6) Medie lasche o di posizione 7) Dispersione
Analisi delle corrispondenze
 Analisi delle corrispondenze Obiettivo: analisi delle relazioni tra le modalità di due (o più) caratteri qualitativi Individuazione della struttura dell associazione interna a una tabella di contingenza
Analisi delle corrispondenze Obiettivo: analisi delle relazioni tra le modalità di due (o più) caratteri qualitativi Individuazione della struttura dell associazione interna a una tabella di contingenza
INDICATORI DI TENDENZA CENTRALE
 INDICATORI DI TENDENZA CENTRALE INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo indice che riassume o descrive i dati e dipende dalla
INDICATORI DI TENDENZA CENTRALE INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo indice che riassume o descrive i dati e dipende dalla
Prof. Anna Paola Ercolani (Università di Roma) Lez Indicatori di tendenza centrale
 Lez Indicatori di tendenza centrale") INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo indice che riassume o descrive i dati e dipende dalla scala di misura dei dati in
INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo indice che riassume o descrive i dati e dipende dalla scala di misura dei dati in
TRACCIA DI STUDIO. Indici di dispersione assoluta per misure quantitative
 TRACCIA DI STUDIO Un indice di tendenza centrale non è sufficiente a descrivere completamente un fenomeno. Gli indici di dispersione assolvono il compito di rappresentare la capacità di un fenomeno a manifestarsi
TRACCIA DI STUDIO Un indice di tendenza centrale non è sufficiente a descrivere completamente un fenomeno. Gli indici di dispersione assolvono il compito di rappresentare la capacità di un fenomeno a manifestarsi
Classificazione dei caratteri
 Classificazione dei caratteri Carattere Qualitativo (Mutabile Statistica): modalità espresse da attributi Genere, Stato civile, Sett. di attività econ., Titolo di studio, Grado militare Carattere Quantitativo
Classificazione dei caratteri Carattere Qualitativo (Mutabile Statistica): modalità espresse da attributi Genere, Stato civile, Sett. di attività econ., Titolo di studio, Grado militare Carattere Quantitativo
L A B C di R. Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010
 L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
Prof. Giulio Vidotto (Università di Padova) Lez Trasformazione delle misure e significanza delle statistiche
 Lez Trasformazione delle misure e significanza delle statistiche") Trasformazione e Significanza delle Statistiche: Invarianza assoluta Invarianza di riferimento Invarianza di confronto Schemi Riassuntivi Significanza e Trasformazioni delle Statistiche Per cui Data una
Trasformazione e Significanza delle Statistiche: Invarianza assoluta Invarianza di riferimento Invarianza di confronto Schemi Riassuntivi Significanza e Trasformazioni delle Statistiche Per cui Data una
INDICATORI DI TENDENZA CENTRALE
 INDICATORI DI TENDENZA CENTRALE INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo è indice che riassume o descrive i dati e dipende
INDICATORI DI TENDENZA CENTRALE INDICATORI DI TENDENZA CENTRALE Consentono di sintetizzare un insieme di misure tramite un unico valore rappresentativo è indice che riassume o descrive i dati e dipende
Introduzione alla programmazione
 Introduzione alla programmazione Risolvere un problema Per risolvere un problema si procede innanzitutto all individuazione Delle informazioni, dei dati noti Dei risultati desiderati Il secondo passo consiste
Introduzione alla programmazione Risolvere un problema Per risolvere un problema si procede innanzitutto all individuazione Delle informazioni, dei dati noti Dei risultati desiderati Il secondo passo consiste
Statistica Descrittiva Soluzioni 6. Indici di variabilità, asimmetria e curtosi
 ISTITUZIONI DI STATISTICA A A 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
ISTITUZIONI DI STATISTICA A A 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
Variabili aleatorie. Variabili aleatorie e variabili statistiche
 Variabili aleatorie Variabili aleatorie e variabili statistiche Nelle prime lezioni, abbiamo visto il concetto di variabile statistica : Un oggetto o evento del mondo reale veniva associato a una certa
Variabili aleatorie Variabili aleatorie e variabili statistiche Nelle prime lezioni, abbiamo visto il concetto di variabile statistica : Un oggetto o evento del mondo reale veniva associato a una certa
STATISTICA 1 ESERCITAZIONE 6
 STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
Fonte: Esempio a fini didattici
 I principali tipi di grafici Esiste una grande varietà di rappresentazioni grafiche. I grafici più semplici e nello stesso tempo più efficaci e comunemente utilizzati sono: i grafici a barre i grafici
I principali tipi di grafici Esiste una grande varietà di rappresentazioni grafiche. I grafici più semplici e nello stesso tempo più efficaci e comunemente utilizzati sono: i grafici a barre i grafici
UNIVERSITA DEGLI STUDI DI BRESCIA-FACOLTA DI MEDICINA E CHIRURGIA CORSO DI LAUREA IN INFERMIERISTICA SEDE DI DESENZANO dg STATISTICA MEDICA.
 Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Indice della lezione. Incertezza e rischio: sinonimi? Le Ipotesi della Capital Market Theory UNIVERSITA DEGLI STUDI DI PARMA FACOLTA DI ECONOMIA
 UNIVERSIT DEGLI STUDI DI PRM FCOLT DI ECONOMI Indice della lezione Corso di Pianificazione Finanziaria Introduzione al rischio Rischio e rendimento per titoli singoli La Teoria di Portafoglio di Markowitz
UNIVERSIT DEGLI STUDI DI PRM FCOLT DI ECONOMI Indice della lezione Corso di Pianificazione Finanziaria Introduzione al rischio Rischio e rendimento per titoli singoli La Teoria di Portafoglio di Markowitz
Lezione n. 1 _Complementi di matematica
 Lezione n. 1 _Complementi di matematica INTRODUZIONE ALLA STATISTICA La statistica è una disciplina che si occupa di fenomeni collettivi ( cioè fenomeni in cui sono coinvolti più individui o elementi )
Lezione n. 1 _Complementi di matematica INTRODUZIONE ALLA STATISTICA La statistica è una disciplina che si occupa di fenomeni collettivi ( cioè fenomeni in cui sono coinvolti più individui o elementi )
Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
ANALISI DEI DATI PER IL MARKETING 2014
 ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it ANALISI DELLE CORRISPONDENZE (cap. VII) Problema della riduzione delle dimensioni L ANALISI DELLE COMPONENTI PRINCIPALI
ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it ANALISI DELLE CORRISPONDENZE (cap. VII) Problema della riduzione delle dimensioni L ANALISI DELLE COMPONENTI PRINCIPALI
Analisi delle corrispondenze
 Capitolo 11 Analisi delle corrispondenze L obiettivo dell analisi delle corrispondenze, i cui primi sviluppi risalgono alla metà degli anni 60 in Francia ad opera di JP Benzécri e la sua equipe, è quello
Capitolo 11 Analisi delle corrispondenze L obiettivo dell analisi delle corrispondenze, i cui primi sviluppi risalgono alla metà degli anni 60 in Francia ad opera di JP Benzécri e la sua equipe, è quello
Esplorazione dei dati
 Esplorazione dei dati Introduzione L analisi esplorativa dei dati evidenzia, tramite grafici ed indicatori sintetici, le caratteristiche di ciascun attributo presente in un dataset. Il processo di esplorazione
Esplorazione dei dati Introduzione L analisi esplorativa dei dati evidenzia, tramite grafici ed indicatori sintetici, le caratteristiche di ciascun attributo presente in un dataset. Il processo di esplorazione
REGRESSIONE E CORRELAZIONE
 REGRESSIONE E CORRELAZIONE Nella Statistica, per studio della connessione si intende la ricerca di eventuali relazioni, di dipendenza ed interdipendenza, intercorrenti tra due variabili statistiche 1.
REGRESSIONE E CORRELAZIONE Nella Statistica, per studio della connessione si intende la ricerca di eventuali relazioni, di dipendenza ed interdipendenza, intercorrenti tra due variabili statistiche 1.
Definizione 1. Una matrice n m a coefficienti in K é una tabella del tipo. ... K m, detto vettore riga i-esimo, ed a im
 APPUNTI ed ESERCIZI su matrici, rango e metodo di eliminazione di Gauss Corso di Laurea in Chimica, Facoltà di Scienze MM.FF.NN., UNICAL (Dott.ssa Galati C.) Rende, 23 Aprile 2010 Matrici, rango e metodo
APPUNTI ed ESERCIZI su matrici, rango e metodo di eliminazione di Gauss Corso di Laurea in Chimica, Facoltà di Scienze MM.FF.NN., UNICAL (Dott.ssa Galati C.) Rende, 23 Aprile 2010 Matrici, rango e metodo
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
I principali tipi di grafici
 Home / Come utilizzare i dati statistici / Come presentare i dati: le rappresentazioni grafiche / I principali... Capitolo 4 24/24 Capitolo 4 13/24 I dati dell'istat per le vostre ricerche: un accesso
Home / Come utilizzare i dati statistici / Come presentare i dati: le rappresentazioni grafiche / I principali... Capitolo 4 24/24 Capitolo 4 13/24 I dati dell'istat per le vostre ricerche: un accesso
Prova scritta di STATISTICA. CDL Biotecnologie. (Programma di Massimo Cristallo - A)
") Prova scritta di STATISTICA CDL Biotecnologie (Programma di Massimo Cristallo - A) 1. Un associazione di consumatori, allo scopo di esaminare la qualità di tre diverse marche di batterie per automobili,
Prova scritta di STATISTICA CDL Biotecnologie (Programma di Massimo Cristallo - A) 1. Un associazione di consumatori, allo scopo di esaminare la qualità di tre diverse marche di batterie per automobili,
2. Coordinate omogenee e trasformazioni del piano
 . Coordinate omogenee e trasformazioni del piano Nella prima sezione si è visto come la composizione di applicazioni lineari e di traslazioni porta ad una scomoda combinazione di prodotti matriciali e
. Coordinate omogenee e trasformazioni del piano Nella prima sezione si è visto come la composizione di applicazioni lineari e di traslazioni porta ad una scomoda combinazione di prodotti matriciali e
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3
 Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
I principali tipi di grafici
 I principali tipi di grafici Esiste una grande varietà di rappresentazioni grafiche. I grafici più semplici e nello stesso tempo più efficaci e comunemente utilizzati sono: I GRAFICI A BARRE I GRAFICI
I principali tipi di grafici Esiste una grande varietà di rappresentazioni grafiche. I grafici più semplici e nello stesso tempo più efficaci e comunemente utilizzati sono: I GRAFICI A BARRE I GRAFICI
Statistica di base per l analisi socio-economica
 Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva
 Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
Corso di Matematica per la Chimica
 Dott.ssa Maria Carmela De Bonis a.a. 2013-14 Pivoting e stabilità Se la matrice A non appartiene a nessuna delle categorie precedenti può accadere che al k esimo passo risulti a (k) k,k = 0, e quindi il
Dott.ssa Maria Carmela De Bonis a.a. 2013-14 Pivoting e stabilità Se la matrice A non appartiene a nessuna delle categorie precedenti può accadere che al k esimo passo risulti a (k) k,k = 0, e quindi il
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
2. I numeri reali e le funzioni di variabile reale
 . I numeri reali e le funzioni di variabile reale Introduzione Il metodo comunemente usato in Matematica consiste nel precisare senza ambiguità i presupposti, da non cambiare durante l elaborazione dei
. I numeri reali e le funzioni di variabile reale Introduzione Il metodo comunemente usato in Matematica consiste nel precisare senza ambiguità i presupposti, da non cambiare durante l elaborazione dei
Esplorazione grafica di dati multivariati. N. Del Buono
 Esplorazione grafica di dati multivariati N. Del Buono Scatterplot Scatterplot permette di individuare graficamente le possibili associazioni tra due variabili Variabile descrittiva (explanatory variable)
Esplorazione grafica di dati multivariati N. Del Buono Scatterplot Scatterplot permette di individuare graficamente le possibili associazioni tra due variabili Variabile descrittiva (explanatory variable)
Università del Piemonte Orientale. Corsi di Laurea Triennale di Area Tecnica. Corso di Statistica e Biometria
 Università del Piemonte Orientale Corsi di Laurea Triennale di Area Tecnica Corso di Statistica e Biometria Statistica descrittiva: Dati numerici: statistiche di tendenza centrale e di variabilità Corsi
Università del Piemonte Orientale Corsi di Laurea Triennale di Area Tecnica Corso di Statistica e Biometria Statistica descrittiva: Dati numerici: statistiche di tendenza centrale e di variabilità Corsi
Esercizi svolti. delle matrici
 Esercizi svolti. astratti. Si dica se l insieme delle coppie reali (x, y) soddisfacenti alla relazione x + y è un sottospazio vettoriale di R La risposta è sì, perchè l unica coppia reale che soddisfa
Esercizi svolti. astratti. Si dica se l insieme delle coppie reali (x, y) soddisfacenti alla relazione x + y è un sottospazio vettoriale di R La risposta è sì, perchè l unica coppia reale che soddisfa
Probabilita' mediante l'analisi combinatoria D n,k =Disposizioni di n oggetti a k a k (o di classe k)
") Probabilita' mediante l'analisi combinatoria D n,k =Disposizioni di n oggetti a k a k (o di classe k) Nel calcolo del numero di modalita' con cui si presenta un evento e' utile talvolta utilizzare le definizioni
Probabilita' mediante l'analisi combinatoria D n,k =Disposizioni di n oggetti a k a k (o di classe k) Nel calcolo del numero di modalita' con cui si presenta un evento e' utile talvolta utilizzare le definizioni
Metodi e tecniche di analisi dei dati nella ricerca psico-educativa Parte III
 Laboratorio Metodi e tecniche di analisi dei dati nella ricerca psico-educativa Parte III Laura Palmerio Università Tor Vergata A.A. 2005/2006 MISURAZIONE Misurare le variabili Assegnazione di valori numerici
Laboratorio Metodi e tecniche di analisi dei dati nella ricerca psico-educativa Parte III Laura Palmerio Università Tor Vergata A.A. 2005/2006 MISURAZIONE Misurare le variabili Assegnazione di valori numerici
Università di Cassino Corso di Statistica 1 Esercitazione del 15/10/2007 Dott. Alfonso Piscitelli. Esercizio 1
 Università di Cassino Corso di Statistica 1 Esercitazione del 15/10/2007 Dott. Alfonso Piscitelli Esercizio 1 Il seguente data set riporta la rilevazione di alcuni caratteri su un collettivo di 20 soggetti.
Università di Cassino Corso di Statistica 1 Esercitazione del 15/10/2007 Dott. Alfonso Piscitelli Esercizio 1 Il seguente data set riporta la rilevazione di alcuni caratteri su un collettivo di 20 soggetti.
Elementi di Statistica
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Sistemi lineari. Lorenzo Pareschi. Dipartimento di Matematica & Facoltá di Architettura Universitá di Ferrara
 Sistemi lineari Lorenzo Pareschi Dipartimento di Matematica & Facoltá di Architettura Universitá di Ferrara http://utenti.unife.it/lorenzo.pareschi/ lorenzo.pareschi@unife.it Lorenzo Pareschi (Univ. Ferrara)
Sistemi lineari Lorenzo Pareschi Dipartimento di Matematica & Facoltá di Architettura Universitá di Ferrara http://utenti.unife.it/lorenzo.pareschi/ lorenzo.pareschi@unife.it Lorenzo Pareschi (Univ. Ferrara)
a.a Esercitazioni di Statistica Medica e Biometria Corsi di Laurea triennali Ostetricia / Infermieristica Pediatrica I anno
 a.a. 2007-2008 Esercitazioni di Statistica Medica e Biometria Corsi di Laurea triennali Ostetricia / Infermieristica Pediatrica I anno Dott.ssa Daniela Alessi daniela.alessi@med.unipmn.it 1 Argomenti:
a.a. 2007-2008 Esercitazioni di Statistica Medica e Biometria Corsi di Laurea triennali Ostetricia / Infermieristica Pediatrica I anno Dott.ssa Daniela Alessi daniela.alessi@med.unipmn.it 1 Argomenti:
Corso di Laurea: Diritto per le Imprese e le istituzioni a.a Statistica. Statistica Descrittiva 3. Esercizi: 5, 6. Docente: Alessandra Durio
 Corso di Laurea: Diritto per le Imprese e le istituzioni a.a. 2016-17 Statistica Statistica Descrittiva 3 Esercizi: 5, 6 Docente: Alessandra Durio 1 Contenuti I quantili nel caso dei dati raccolti in classi
Corso di Laurea: Diritto per le Imprese e le istituzioni a.a. 2016-17 Statistica Statistica Descrittiva 3 Esercizi: 5, 6 Docente: Alessandra Durio 1 Contenuti I quantili nel caso dei dati raccolti in classi
Esercitazioni di Statistica: ES.1.1
 Esercitazioni di Statistica: ES.1.1 Le componenti fondamentali dell analisi statistica Unità statistica Oggetto dell osservazione di ogni fenomeno individuale che costituisce il fenomeno collettivo Carattere
Esercitazioni di Statistica: ES.1.1 Le componenti fondamentali dell analisi statistica Unità statistica Oggetto dell osservazione di ogni fenomeno individuale che costituisce il fenomeno collettivo Carattere
3) In una distribuzione di frequenza si può ottenere più di una moda Vero Falso
 In una distribuzione di frequenza si può ottenere più di una moda Vero Falso") CLM C Verifica in itinere statistica medica 13-01-2014 1) Indicate a quale categoria (Qualitativa, qualitativa ordinabile, quantitativa discreta, quantitativa continua) appartengono le seguenti variabili:
CLM C Verifica in itinere statistica medica 13-01-2014 1) Indicate a quale categoria (Qualitativa, qualitativa ordinabile, quantitativa discreta, quantitativa continua) appartengono le seguenti variabili:
Altrimenti, il M.C.D. di a e b è anche divisore di r (e.g. a=15,b=6,r=3 che è il M.C.D.)
") Elaboratore Un elaboratore o computer è una macchina digitale, elettronica, automatica capace di effettuare trasformazioni o elaborazioni sui dati digitale l informazione è rappresentata in forma numerica
Elaboratore Un elaboratore o computer è una macchina digitale, elettronica, automatica capace di effettuare trasformazioni o elaborazioni sui dati digitale l informazione è rappresentata in forma numerica
standardizzazione dei punteggi di un test
 DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
Statistica Descrittiva Soluzioni 3. Medie potenziate
 ISTITUZIONI DI STATISTICA A. A. 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
ISTITUZIONI DI STATISTICA A. A. 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
Nozioni di statistica
 Nozioni di statistica Distribuzione di Frequenza Una distribuzione di frequenza è un insieme di dati raccolti in un campione (Es. occorrenze di errori in seconda elementare). Una distribuzione può essere
Nozioni di statistica Distribuzione di Frequenza Una distribuzione di frequenza è un insieme di dati raccolti in un campione (Es. occorrenze di errori in seconda elementare). Una distribuzione può essere
Celle di fabbricazione
 Celle di fabbricazione Produzione per parti (Classificazione Impiantistica) Produzione per parti Fabbricazione Montaggio (assemblaggio) Job Shop Celle di fabbricazione Linee transfer A posto fisso Ad Isola
Celle di fabbricazione Produzione per parti (Classificazione Impiantistica) Produzione per parti Fabbricazione Montaggio (assemblaggio) Job Shop Celle di fabbricazione Linee transfer A posto fisso Ad Isola
I metodi di Classificazione automatica
 L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
Ricerca Operativa. G. Liuzzi. Lunedí 20 Aprile 2015
 1 Lunedí 20 Aprile 2015 1 Istituto di Analisi dei Sistemi ed Informatica IASI - CNR Rilassamento di un problema Rilassare un problema di Programmazione Matematica vuol dire trascurare alcuni (tutti i)
1 Lunedí 20 Aprile 2015 1 Istituto di Analisi dei Sistemi ed Informatica IASI - CNR Rilassamento di un problema Rilassare un problema di Programmazione Matematica vuol dire trascurare alcuni (tutti i)
Analisi della varianza a una via
 Analisi della varianza a una via Statistica descrittiva e Analisi multivariata Prof. Giulio Vidotto PSY-NET: Corso di laurea online in Discipline della ricerca psicologico-sociale SOMMARIO Modelli statistici
Analisi della varianza a una via Statistica descrittiva e Analisi multivariata Prof. Giulio Vidotto PSY-NET: Corso di laurea online in Discipline della ricerca psicologico-sociale SOMMARIO Modelli statistici
Variabili casuali multidimensionali
 Capitolo 1 Variabili casuali multidimensionali Definizione 1.1 Le variabili casuali multidimensionali sono k-ple ordinate di variabili casuali unidimensionali definite sullo stesso spazio di probabilità.
Capitolo 1 Variabili casuali multidimensionali Definizione 1.1 Le variabili casuali multidimensionali sono k-ple ordinate di variabili casuali unidimensionali definite sullo stesso spazio di probabilità.
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA. Prof.ssa Donatella Siepi tel:
 UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 4 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 4 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
1/4 Capitolo 4 Statistica - Metodologie per le scienze economiche e sociali 2/ed Copyright 2008 The McGraw-Hill Companies srl
 1/4 Capitolo 4 La variabilità di una distribuzione Intervalli di variabilità Box-plot Indici basati sullo scostamento dalla media Confronti di variabilità Standardizzazione Statistica - Metodologie per
1/4 Capitolo 4 La variabilità di una distribuzione Intervalli di variabilità Box-plot Indici basati sullo scostamento dalla media Confronti di variabilità Standardizzazione Statistica - Metodologie per
TEORIA DEGLI ERRORI DI MISURA, IL CALCOLO DELLE INCERTEZZE
 TEORIA DEGLI ERRORI DI MISURA, IL CALCOLO DELLE INCERTEZZE Errore di misura è la differenza fra l indicazione fornita dallo strumento e la dimensione vera della grandezza. Supponendo che la grandezza vera
TEORIA DEGLI ERRORI DI MISURA, IL CALCOLO DELLE INCERTEZZE Errore di misura è la differenza fra l indicazione fornita dallo strumento e la dimensione vera della grandezza. Supponendo che la grandezza vera
STATISTICA 1 ESERCITAZIONE 1 CLASSIFICAZIONE DELLE VARIABILI CASUALI
 STATISTICA 1 ESERCITAZIONE 1 Dott. Giuseppe Pandolfo 6 Ottobre 2014 Popolazione statistica: insieme degli elementi oggetto dell indagine statistica. Unità statistica: ogni elemento della popolazione statistica.
STATISTICA 1 ESERCITAZIONE 1 Dott. Giuseppe Pandolfo 6 Ottobre 2014 Popolazione statistica: insieme degli elementi oggetto dell indagine statistica. Unità statistica: ogni elemento della popolazione statistica.
La variabilità. Dott. Cazzaniga Paolo. Dip. di Scienze Umane e Sociali
 Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione [1/2] Gli indici di variabilità consentono di riassumere le principali caratteristiche di una distribuzione (assieme alle medie) Le
Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione [1/2] Gli indici di variabilità consentono di riassumere le principali caratteristiche di una distribuzione (assieme alle medie) Le
Maria Brigida Ferraro + Luca Tardella
 Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
La statistica. Elaborazione e rappresentazione dei dati Gli indicatori statistici. Prof. Giuseppe Carucci
 La statistica Elaborazione e rappresentazione dei dati Gli indicatori statistici Introduzione La statistica raccoglie ed analizza gruppi di dati (su cose o persone) per trarne conclusioni e fare previsioni
La statistica Elaborazione e rappresentazione dei dati Gli indicatori statistici Introduzione La statistica raccoglie ed analizza gruppi di dati (su cose o persone) per trarne conclusioni e fare previsioni
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2
 - ESERCITAZIONE 2") CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Indici di posizione variabilità e forma per caratteri qualitativi Il seguente data set riporta la rilevazione
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Indici di posizione variabilità e forma per caratteri qualitativi Il seguente data set riporta la rilevazione
FUNZIONI. }, oppure la
 FUNZIONI 1. Definizioni e prime proprietà Il concetto di funzione è di uso comune per esprimere la seguente situazione: due grandezze variano l una al variare dell altra secondo una certa legge. Ad esempio,
FUNZIONI 1. Definizioni e prime proprietà Il concetto di funzione è di uso comune per esprimere la seguente situazione: due grandezze variano l una al variare dell altra secondo una certa legge. Ad esempio,
TEST NON PARAMETRICO DI MANN-WHITNEY
 TEST NON PARAMETRICO DI MANN-WHITNEY Questo test viene può essere utilizzato come test di confronto tra due campioni in maniera analoga ai test ipotesi parametrici di confronto medie (test Z se la varianza
TEST NON PARAMETRICO DI MANN-WHITNEY Questo test viene può essere utilizzato come test di confronto tra due campioni in maniera analoga ai test ipotesi parametrici di confronto medie (test Z se la varianza
Statistica. Alfonso Iodice D Enza
 Statistica Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () Statistica 1 / 33 Outline 1 2 3 4 5 6 () Statistica 2 / 33 Misura del legame Nel caso di variabili quantitative
Statistica Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () Statistica 1 / 33 Outline 1 2 3 4 5 6 () Statistica 2 / 33 Misura del legame Nel caso di variabili quantitative
TECNICHE DI POSIZIONAMENTO
 TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
Teoria e tecniche dei test
 Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
NOZIONE DI VARIABILE. Varie accezioni
 NOZIONE DI VARIABILE Varie accezioni - espediente fisico mediante il quale si rileva e si registra lo stato o modalità secondo il/la quale una determinata proprietà (grandezza o attributo) si presenta
NOZIONE DI VARIABILE Varie accezioni - espediente fisico mediante il quale si rileva e si registra lo stato o modalità secondo il/la quale una determinata proprietà (grandezza o attributo) si presenta
Q1 = /4 0 4 = Me = /2 4 = 3
 Soluzioni Esercizi Capitolo - versione on-line Esercizio.: Calcoliamo le densità di frequenza x i x i+1 n i N i a i l i F i 0 1 4 4 1 4/1=4 4/10 = 0.4 1 5 6 4 /4=0.5 6/10 = 0.6 5 10 4 10 5 4/5=0.8 10/10
Soluzioni Esercizi Capitolo - versione on-line Esercizio.: Calcoliamo le densità di frequenza x i x i+1 n i N i a i l i F i 0 1 4 4 1 4/1=4 4/10 = 0.4 1 5 6 4 /4=0.5 6/10 = 0.6 5 10 4 10 5 4/5=0.8 10/10
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Si consideri il sistema a coefficienti reali di m equazioni lineari in n incognite
 3 Sistemi lineari 3 Generalità Si consideri il sistema a coefficienti reali di m equazioni lineari in n incognite ovvero, in forma matriciale, a x + a 2 x 2 + + a n x n = b a 2 x + a 22 x 2 + + a 2n x
3 Sistemi lineari 3 Generalità Si consideri il sistema a coefficienti reali di m equazioni lineari in n incognite ovvero, in forma matriciale, a x + a 2 x 2 + + a n x n = b a 2 x + a 22 x 2 + + a 2n x
Facoltà di Scienze Politiche Corso di laurea in Servizio sociale. Compito di Statistica del 7/1/2003
 Compito di Statistica del 7/1/2003 I giovani addetti all agricoltura in due diverse regioni sono stati classificati per età; la distribuzione di frequenze congiunta è data dalla tabella seguente Età in
Compito di Statistica del 7/1/2003 I giovani addetti all agricoltura in due diverse regioni sono stati classificati per età; la distribuzione di frequenze congiunta è data dalla tabella seguente Età in
3.4 Metodo di Branch and Bound
 3.4 Metodo di Branch and Bound Consideriamo un generico problema di Ottimizzazione Discreta dove X è la regione ammissibile. (P ) z = max{c(x) : x X} Metodologia generale di enumerazione implicita (Land
3.4 Metodo di Branch and Bound Consideriamo un generico problema di Ottimizzazione Discreta dove X è la regione ammissibile. (P ) z = max{c(x) : x X} Metodologia generale di enumerazione implicita (Land
L ALGORITMO DEL SIMPLESSO REVISIONATO
 L ALGORITMO DEL SIMPLESSO REVISIONATO L'algoritmo del simplesso revisionato costituisce una diversa implementazione dell algoritmo standard tesa a ridurre, sotto certe condizioni, il tempo di calcolo e
L ALGORITMO DEL SIMPLESSO REVISIONATO L'algoritmo del simplesso revisionato costituisce una diversa implementazione dell algoritmo standard tesa a ridurre, sotto certe condizioni, il tempo di calcolo e
MATRICI E SISTEMI LINEARI
 1 Rappresentazione di dati strutturati MATRICI E SISTEMI LINEARI Gli elementi di una matrice, detti coefficienti, possono essere qualsiasi e non devono necessariamente essere omogenei tra loro; di solito
1 Rappresentazione di dati strutturati MATRICI E SISTEMI LINEARI Gli elementi di una matrice, detti coefficienti, possono essere qualsiasi e non devono necessariamente essere omogenei tra loro; di solito
Introduzione alla programmazione Algoritmi e diagrammi di flusso. Sviluppo del software
 Introduzione alla programmazione Algoritmi e diagrammi di flusso F. Corno, A. Lioy, M. Rebaudengo Sviluppo del software problema idea (soluzione) algoritmo (soluzione formale) programma (traduzione dell
Introduzione alla programmazione Algoritmi e diagrammi di flusso F. Corno, A. Lioy, M. Rebaudengo Sviluppo del software problema idea (soluzione) algoritmo (soluzione formale) programma (traduzione dell
Programmazione Lineare Intera. Programmazione Lineare Intera p. 1/4
 Programmazione Lineare Intera Programmazione Lineare Intera p. 1/4 Programmazione Lineare Intera Problema di PLI in forma standard: max cx Ax = b x 0, x I n I insieme degli interi. Regione ammissibile:
Programmazione Lineare Intera Programmazione Lineare Intera p. 1/4 Programmazione Lineare Intera Problema di PLI in forma standard: max cx Ax = b x 0, x I n I insieme degli interi. Regione ammissibile:
La codifica digitale
 La codifica digitale Codifica digitale Il computer e il sistema binario Il computer elabora esclusivamente numeri. Ogni immagine, ogni suono, ogni informazione per essere compresa e rielaborata dal calcolatore
La codifica digitale Codifica digitale Il computer e il sistema binario Il computer elabora esclusivamente numeri. Ogni immagine, ogni suono, ogni informazione per essere compresa e rielaborata dal calcolatore
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
DISTRIBUZIONE NORMALE (1)
") DISTRIBUZIONE NORMALE (1) Nella popolazione generale molte variabili presentano una distribuzione a forma di campana, bene caratterizzata da un punto di vista matematico, chiamata distribuzione normale
DISTRIBUZIONE NORMALE (1) Nella popolazione generale molte variabili presentano una distribuzione a forma di campana, bene caratterizzata da un punto di vista matematico, chiamata distribuzione normale
Strategie top-down. Primitive di trasformazione top-down. Primitive di trasformazione top-down
 Strategie top-down A partire da uno schema che descrive le specifiche mediante pochi concetti molto astratti, si produce uno schema concettuale mediante raffinamenti successivi che aggiungono via via più
Strategie top-down A partire da uno schema che descrive le specifiche mediante pochi concetti molto astratti, si produce uno schema concettuale mediante raffinamenti successivi che aggiungono via via più
Metodi di classificazione. Loredana Cerbara
 Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Capitolo 6. La distribuzione normale
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 6 La distribuzione normale Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 6 La distribuzione normale Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
Capitolo 1. Analisi Discriminante. 1.1 Introduzione. 1.2 Un analisi discriminante Descrizione del dataset
 Capitolo 1 Analisi Discriminante 1.1 Introduzione L analisi discriminante viene condotta per definire una modalità di assegnazione dei casi a differenti gruppi, in funzione di una serie di variabili fra
Capitolo 1 Analisi Discriminante 1.1 Introduzione L analisi discriminante viene condotta per definire una modalità di assegnazione dei casi a differenti gruppi, in funzione di una serie di variabili fra
Condizione di allineamento di tre punti
 LA RETTA L equazione lineare in x e y L equazione: 0 con,,, e non contemporaneamente nulli, si dice equazione lineare nelle due variabili e. Ogni coppia ; tale che: 0 si dice soluzione dell equazione.
LA RETTA L equazione lineare in x e y L equazione: 0 con,,, e non contemporaneamente nulli, si dice equazione lineare nelle due variabili e. Ogni coppia ; tale che: 0 si dice soluzione dell equazione.
Il campionamento e l inferenza. Il campionamento e l inferenza
 Il campionamento e l inferenza Popolazione Campione Dai dati osservati mediante scelta campionaria si giunge ad affermazioni che riguardano la popolazione da cui essi sono stati prescelti Il campionamento
Il campionamento e l inferenza Popolazione Campione Dai dati osservati mediante scelta campionaria si giunge ad affermazioni che riguardano la popolazione da cui essi sono stati prescelti Il campionamento