Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
|
|
|
- Patrizia Volpi
- 7 anni fa
- Visualizzazioni
Transcript
1 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis è applicata a matrici di dati non strutturate, cioè le relazioni interne tra gli oggetti non sono note a priori. Se i gruppi di oggetti trovati dalla cluster analysis presentano delle differenze statisticamente significative, allora i gruppi trovati possono essere considerati classi di oggetti.

2 NOTA BENE I metodi di cluster non devono essere confusi con i metodi di classificazione! Metodi di cluster: dati non strutturati Metodi di classificazione: dati strutturati, gli oggetti sono stati campionati da popolazioni diverse e quindi appartengono a classi distinte definite a priori. Metodi di cluster: scopo è trovare raggruppamenti significativi degli oggetti. Metodi di classificazione: scopo è trovare modelli capaci di assegnare correttamente ciascun oggetto alla classe di appartenenza.

3 I metodi di cluster analysis utilizzano le misure di dissimilarità o similarità tra gli oggetti. Punto di partenza : matrice di dissimilarità (similarità) Nota: tutti i metodi che usano le misure di distanza per valutare la dissimilarità non sono invarianti alle trasformazioni delle variabili, quali le scalature.

4 data (n, p) distance distance matrix (n, n) similarity similarity matrix (n, n) clustering algorithm data + class variable interpretation data + clustering variable

5 I clusters vengono definiti in termini di: - separazione - compattezza - forma singleton

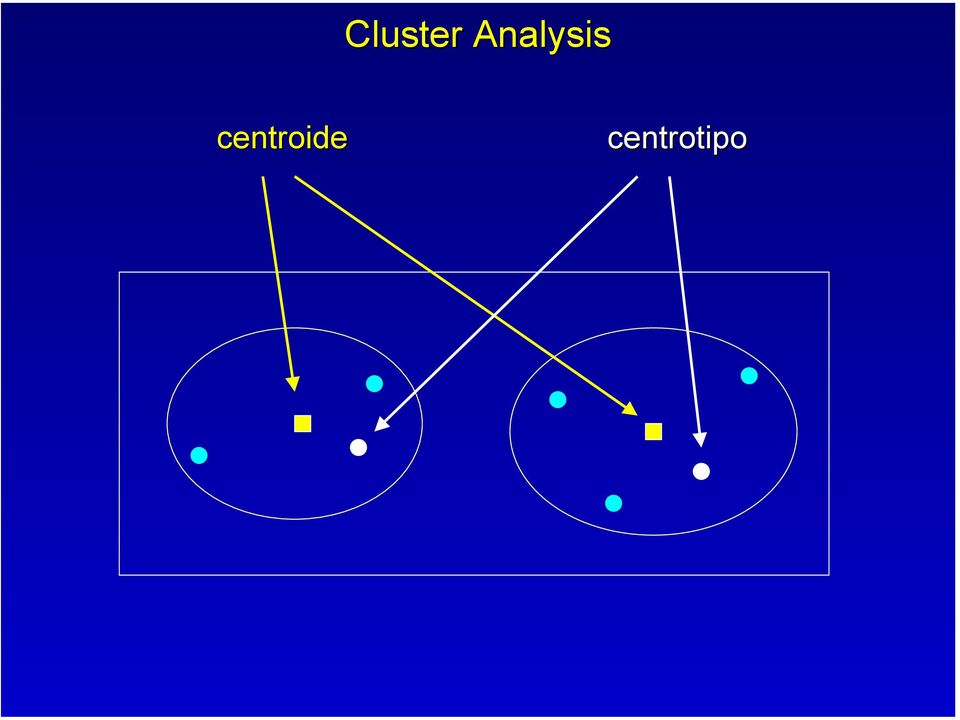
6 centroide centrotipo X2
7 Metodi di clustering - hierarchical methods - agglomerative methods - weighted average linkage - unweighted average linkage - divisive methods - complete linkage... - single linkage - centroid linkage - median linkage - Ward method - McNaughton method - Cavalli-Sforza method - non-hierarchical methods - K-means method - Jarvis-Patrick method - fuzzy methods - graph-theoretical methods...

8 Procedure preliminari 1. selezione del metodo di clustering 2. selezione del tipo di scalatura delle variabili 3. selezione della misura di dissimilarità 4. calcolo della dissimilarità tra tutte le coppie di oggetti 5. calcolo della corrispondente similarità

9 Metodi gerarchici agglomerativi Al passo iniziale, si hanno n clusters ciascuno contenente un singolo oggetto. Algoritmo iterativo: 1. si cercano i due clusters più simili; 2. i due clusters più simili vengono uniti generando un nuovo cluster; 3. si calcola la similarità (o dissimilarità) del nuovo cluster con ciascuno dei clusters esistenti. Questo comporta la cancellazione delle 2 righe e 2 colonne della matrice di similarità (dissimilarità) corrispondenti ai due clusters uniti e l aggiunta di 1 riga e 1 colonna corrispondenti al nuovo cluster.
 corrispondenti ai due clusters")
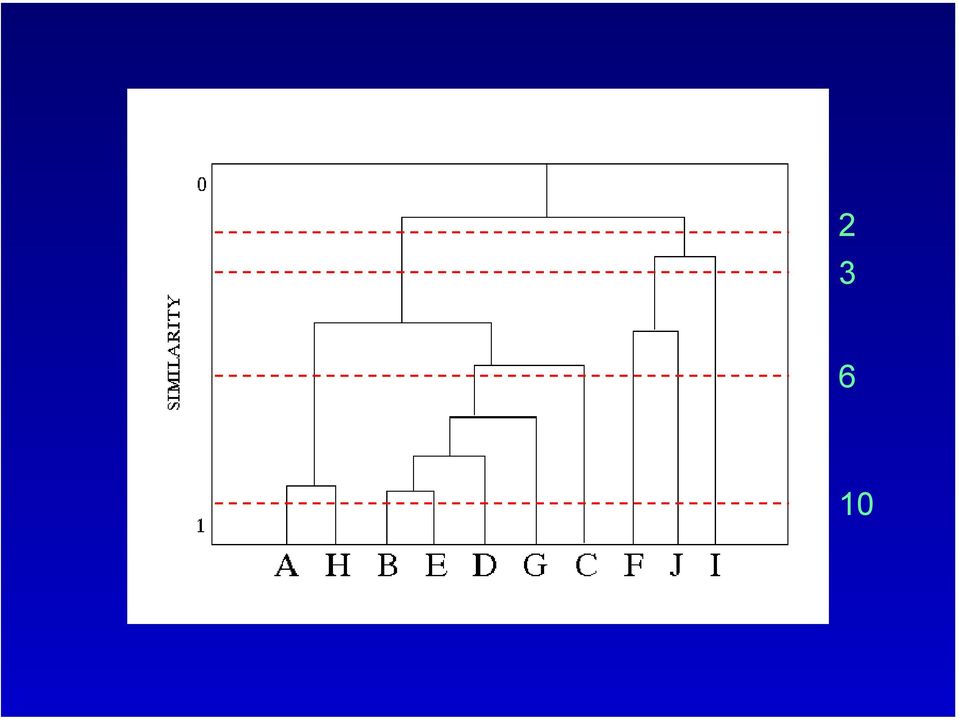
10 L intero processo di clustering può essere riassunto mediante un grafico a forma di albero : DENDROGRAMMA coefficiente di clustering A B C D E

11
12 Regole per calcolare la dissimilarità tra due cluster n k = numero di oggetti del cluster k n f = numero di oggetti del cluster f D kf = dissimilarità tra i clusters k e f Single-linkage linkage : D kf è la più piccola tra le n k n f dissimilarità tra ogni oggetto di k e ogni oggetto di f D kf

13 Regole per calcolare la dissimilarità tra due cluster Complete-linkage linkage : D kf è la più grande tra le n k n f dissimilarità tra ogni oggetto di k e ogni oggetto di f D kf

14 Regole per calcolare la dissimilarità tra due cluster Average-linkage : D kf è la media delle n k n f dissimilarità tra ogni oggetto di k e ogni oggetto di f Centroid-linkage : D kf è la distanza Euclidea al quadrato tra i centroidi dei clusters k e f D kf

15 Regole per calcolare la dissimilarità tra due cluster Nota bene : ogni metodo produce una diversa ripartizione degli oggetti.. E importante scegliere il metodo di clustering prima di effettuare l analisi.

16 Regole per calcolare la dissimilarità tra due cluster Caratteristiche dei metodi agglomerativi : - complete, average e centroid-linkage producono clusters sferici costituiti da oggetti molto simili. - single-linkage linkage produce clusters allungati in cui si possono avere anche coppie di oggetti diversi (concatenamento).

17 Regole per calcolare la dissimilarità tra due cluster Caratteristiche dei metodi agglomerativi : - con il single-linkage linkage un oggetto si unisce ad un gruppo se è simile anche ad un solo oggetto del gruppo. - con il complete-linkage linkage un oggetto si unisce ad un gruppo solo se presenta una certa similarità con tutti gli oggetti del gruppo. Il single-linkage linkage è il metodo più appropriato per individuare outliers

18 Esempio Matrice delle dissimilarità oggetti

19 STEP 1 : Gli oggetti 1 e 3 sono i più simili e quindi vengono uniti formando così il primo cluster al livello di dissimilarità uguale a 1. Utilizzando il single-linkage: linkage: D = min d, d = min 44, = 4 213, D = min d, d = min 44, = 4 413, D = min d, d = min 5, 3 = 3 513, b g b g b g b g b g b g

20 STEP 1 : Matrice delle dissimilarità aggiornata con il single-linkage: linkage: oggetti (1+3) (1+3)
 2 4 5 (1+3) 0 2 4 0 4 5 4")
21 STEP 2 : Gli oggetti 2 e 4 sono i più simili e quindi vengono uniti formando così il secondo cluster al livello di dissimilarità uguale a 2. Utilizzando il single-linkage: linkage: D = min d, d = min 44, = 4 (,), (,) 13 2 (,) 13 4 D = min d, d = min 54, = 4 524, d h b g b g b g
22 STEP 2 : Matrice delle dissimilarità aggiornata con il single-linkage: linkage: oggetti (1+3) (2+4) 5 (1+3) 0 (2+4)
23 STEP 3 : L oggetto 5 e il cluster (1+3) sono i più simili e quindi vengono uniti formando così il terzo cluster al livello di dissimilarità uguale a 3. Utilizzando il single-linkage: linkage: d h b g D = min d 24 13, d 24 5 = min 44, = 4 (, ),(,) (, )(,) (, ) oggetti (1+3+5) (2+4) (1+3+5) 0 (2+4) 4 0
24 STEP 4 : L unica possibilità rimasta è l unione finale dei due clusters (1+3+5) e (2+4) ad un livello di dissimilarità uguale a 4. coefficiente di clustering
25 Esempio: : Wines
26 Esempio: : Wines
27 Esempio: : Wines
28
29
30 Metodi non-gerarchici I metodi di cluster non-gerarchico si differenziano molto tra loro, essendo basati su approcci matematici differenti. Alcuni di loro si chiamano tecniche di ricollocamento, poichè dopo una partizione iniziale degli oggetti, questi vengono spostati da un cluster all altro finchè un criterio di stop è stato soddisfatto. Il metodo K-means è il più noto.
31 Metodo K-means Proposto da MacQueen nel 1967, è un algoritmo di ricollocamento basato sul confronto delle distanze di ogni oggetto dai centroidi dei clusters. Occorre definire a priori il numero G di clusters. centroide del g-esimo cluster : n c x, x, K, x g = g1 g2 gp s
32 Algoritmo del metodo K-means A0. selezione della misura di dissimilarità A1. selezione del numero G di clusters B1. partizione iniziale random degli oggetti in G clusters C1. calcolo dei centroidi dei G clusters C2. calcolo delle distanze tra ciascun oggetto e ciascun centroide C3. collocamento di ogni oggetto nel cluster del centroide più vicino C4. se almeno un oggetto è stato ricollocato, ritorna a C1 D1. stop
33 metodo K-means
34 metodo K-means Normalmente,, i centroidi dei clusters vengono ricalcolati dopo il ricollocamento di tutti gli oggetti. Una variante di questo metodo si basa sul calcolo dei centroidi dei clusters dopo il ricollocamento di ogni singolo oggetto. La partizione finale degli oggetti è influenzata da molti fattori, tra cui il numero scelto di clusters.
35 Metodo di Jarvis-Patrick E un metodo di clustering efficiente basato sulla matrice dei vicini derivata dalla matrice delle dissimilarità. Steps preliminari 1. selezione della misura di dissimilarità 2. definizione della dimensione L della matrice dei vicini 3. definizione del numero k di vicini comuni 4. calcolo della matrice delle dissimilarità 5. calcolo della matrice dei vicini
36 Metodo Jarvis-Patrick Matrice dei vicini (n, L) oggetti 1 v 2 v 3 v L v n
37 Metodo Jarvis-Patrick Algoritmo : Due oggetti s e t vengono collocati nel medesimo cluster se: 1. l oggetto s è nella lista dei vicini dell oggetto t 2. l oggetto t è nella lista dei vicini dell oggetto s 3. i due oggetti hanno k vicini comuni.
38 Metodo Jarvis-Patrick Valori ottimali dei parametri L e k: L = n / 3 k = n / 4 Aumentando i valori di L e k, il numero di clusters ottenuti aumenta, poichè diventa più severa la condizione richiesta per l unione degli oggetti. Nota bene: il numero dei clusters è un risultato del metodo e non deve essere definito a priori dall utente.
39 Esempio : Cheese 134 campioni di formaggio (Parmigiano Reggiano) descritti dalle concentrazioni analitiche dei 21 amminoacidi. Le variabili sono state autoscalate prima dell analisi.
40 Esempio : Cheese Metodo gerarchico complete linkage (distanza( Euclidea) Linkage Distance
41 Esempio : Cheese Metodo gerarchico complete linkage (distanza( Euclidea) PC2 (E.V.% 10.1) PC1 (E.V.% 68.3)
42 Esempio : Cheese Metodo gerarchico single linkage (distanza( Euclidea) 6 5 Linkage Distance
43 Esempio : Cheese Metodo gerarchico single linkage (distanza( Euclidea) PC2 (E.V.% 10.1) PC1 (E.V.% 68.3)
44 Esempio : Cheese Metodo K-means (distanza( Euclidea) 2.5 PC2 (E.V.% 10.1) PC1 (E.V.% 68.3)
45 Esempio : Cheese Metodo di Jarvis-Patrick (distanza( Euclidea,, L=50, k=40) PC2 (E.V.% 10.1) PC1 (E.V.% 68.3)
Statistica per l Impresa
 Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale
 UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
ANALISI DEI CLUSTER. In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di
 ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
ANALISI DEI CLUSTER In questo documento presentiamo alcune opzioni analitiche della procedura di analisi de cluster di SPSS che non sono state incluse nel testo pubblicato. Si tratta di opzioni che, pur
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
SDE Marco Riani
 SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Statistica per l Impresa
 Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008
 Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008 Dott. Chiara Cornalba COMUNICAZIONI La lezione del 30 ottobre è sospesa per missione all estero del Prof. Giudici. Dal 6 Novembre
Analisi Statistica dei Dati Misurazione e gestione dei rischi a.a. 2007-2008 Dott. Chiara Cornalba COMUNICAZIONI La lezione del 30 ottobre è sospesa per missione all estero del Prof. Giudici. Dal 6 Novembre
Cluster Analysis (2 parte)
") Cluster Analysis (2 parte) Esempio 2 Data set: Nel data set Dieta (Dieta.txt, Dieta.sav) sono contenute informazioni sul consumo medio dei principali alimenti in 16 paesi Europei. Paese Cereali (Ce) Riso
Cluster Analysis (2 parte) Esempio 2 Data set: Nel data set Dieta (Dieta.txt, Dieta.sav) sono contenute informazioni sul consumo medio dei principali alimenti in 16 paesi Europei. Paese Cereali (Ce) Riso
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Lecture 12. Clustering
 Lecture Marteì 0 novembre 00 Giuseppe Manco Reaings: Chapter 8 Han an Kamber Chapter Hastie Tibshirani an Frieman gerarchico Il settaggio i parametri in alcune situazioni è complicato Cluster gerarchici
Lecture Marteì 0 novembre 00 Giuseppe Manco Reaings: Chapter 8 Han an Kamber Chapter Hastie Tibshirani an Frieman gerarchico Il settaggio i parametri in alcune situazioni è complicato Cluster gerarchici
APPUNTI DI CLUSTER ANALYSIS (Paola Vicard)
") APPUNTI DI CLUSTER ANALYSIS (Paola Vicard) Obiettivi della cluster analysis La cluster analysis è una delle principali tecniche di analisi statistica multivariata per raggruppare le unità osservate in
APPUNTI DI CLUSTER ANALYSIS (Paola Vicard) Obiettivi della cluster analysis La cluster analysis è una delle principali tecniche di analisi statistica multivariata per raggruppare le unità osservate in
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Clustering. Clustering
 1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
1/40 Clustering Iuri Frosio frosio@dsi.unimi.it Approfondimenti in A.K. Jan, M. N. Murty, P. J. Flynn, Data clustering: a review, ACM Computing Surveys, Vol. 31, No. 3, September 1999, ref. pp. 265-290,
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Filogenesi Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Introduzione alla
Riconoscimento e recupero dell informazione per bioinformatica Filogenesi Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Introduzione alla
Statistica per l Impresa
 Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 9 maggio 2018 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità Metodi gerarchici
Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 9 maggio 2018 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità Metodi gerarchici
Analisi dei Gruppi con R
 Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi dei Gruppi
Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi dei Gruppi
Metodi di classificazione
 I metodi di classificazione sono metodi utilizzati per trovare modelli statistici capaci di assegnare ciascun oggetto di provenienza incognita ad una delle classi esistenti. L applicazione di questi metodi
I metodi di classificazione sono metodi utilizzati per trovare modelli statistici capaci di assegnare ciascun oggetto di provenienza incognita ad una delle classi esistenti. L applicazione di questi metodi
Statistica per le ricerche di mercato
 Statistica per le ricerche di mercato A.A. 2012/13 Dr. Luca Secondi 15. Tecniche di analisi statistica multivariata per la segmentazione del mercato Cluster Analysis 1 Cluster analysis La cluster analysis
Statistica per le ricerche di mercato A.A. 2012/13 Dr. Luca Secondi 15. Tecniche di analisi statistica multivariata per la segmentazione del mercato Cluster Analysis 1 Cluster analysis La cluster analysis
ESERCIZIO 1. Vengono riportati di seguito i risultati di una cluster analysis gerarchica.
 ESERCIZIO. Vengono riportati di seguito i risultati di una cluster analysis gerarchica. Programma di agglomerazione Stadio 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 Stadio di formazione accorpati del
ESERCIZIO. Vengono riportati di seguito i risultati di una cluster analysis gerarchica. Programma di agglomerazione Stadio 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 Stadio di formazione accorpati del
C.da Di Dio - Villaggio S. Agata Messina Italy P.I c.f AMBIENTE STATISTICO. Release /03/2018.
 AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
AMBIENTE STATISTICO SOFTWARE PER L ANALISI STATISTICA DI DATI PROVENIENTI DAL MONITORAGGIO AMBIENTALE Release 4.0 20/03/2018 Manuale d uso Ambiente Statistico è un software sviluppato nell ambito del Progetto
Metodi di classificazione. Loredana Cerbara
 Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Statistica multivariata 27/09/2016. D.Rodi, 2016
 Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Clustering. Alberto Borghese
 Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/39 Riassunto Il clustering K-means
Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/39 Riassunto Il clustering K-means
Cenni sulla cluster analysis
 Cenni sulla cluster analysis Distanze Dato un insieme E, una funzione d: E X E -> R + che ha le seguenti tre proprietà: d(x i, x j ) = 0 x i = x j d(x i, x j ) = d(x j, x i ) d(x i, x j ) d(x j, x h )
Cenni sulla cluster analysis Distanze Dato un insieme E, una funzione d: E X E -> R + che ha le seguenti tre proprietà: d(x i, x j ) = 0 x i = x j d(x i, x j ) = d(x j, x i ) d(x i, x j ) d(x j, x h )
Cluster Analysis Distanze ed estrazioni Marco Perugini Milano-Bicocca
 Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Sistemi Intelligenti Learning and Clustering
 Sistemi Intelligenti Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it
Sistemi Intelligenti Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it
REGISTRO DELLE LEZIONI
 UNIVERSITÀ DEGLI STUDI DI GENOVA Dipartimento di Matematica Corso di laurea in Statistica matematica e trattamento informatico dei dati REGISTRO DELLE LEZIONI dell INSEGNAMENTO o MODULO UFFICIALE Nome:
UNIVERSITÀ DEGLI STUDI DI GENOVA Dipartimento di Matematica Corso di laurea in Statistica matematica e trattamento informatico dei dati REGISTRO DELLE LEZIONI dell INSEGNAMENTO o MODULO UFFICIALE Nome:
Metodi Probabilistici e Statistici per l Analisi dei Dati. Prof. V. Simoncini. Testi di Riferimento
 Metodi Probabilistici e Statistici per l Analisi dei Dati Prof. V. Simoncini e-mail: valeria@dm.unibo.it, valeria@ambra.unibo.it Testi di Riferimento Lucidi di Lezione (http://www.dm.unibo.it/ ~simoncin/datiii.html)
Metodi Probabilistici e Statistici per l Analisi dei Dati Prof. V. Simoncini e-mail: valeria@dm.unibo.it, valeria@ambra.unibo.it Testi di Riferimento Lucidi di Lezione (http://www.dm.unibo.it/ ~simoncin/datiii.html)
Clustering gerarchico con R
 Clustering gerarchico con R Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/3%20sqg/labs/l-10_cluster_h-clust.html#(1) 1/10 Clustering gerarchico in R La funzione di base per
Clustering gerarchico con R Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/3%20sqg/labs/l-10_cluster_h-clust.html#(1) 1/10 Clustering gerarchico in R La funzione di base per
Teoria e Tecniche del Riconoscimento Clustering
 Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Clustering Sommario Tassonomia degli algoritmi di clustering Algoritmi partizionali: clustering sequenziale
Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Clustering Sommario Tassonomia degli algoritmi di clustering Algoritmi partizionali: clustering sequenziale
REGISTRO DELLE LEZIONI
 UNIVERSITÀ DEGLI STUDI DI GENOVA Dipartimento di Matematica Corso di laurea in Statistica matematica e trattamento informatico dei dati REGISTRO DELLE LEZIONI dell INSEGNAMENTO o MODULO UFFICIALE Nome:
UNIVERSITÀ DEGLI STUDI DI GENOVA Dipartimento di Matematica Corso di laurea in Statistica matematica e trattamento informatico dei dati REGISTRO DELLE LEZIONI dell INSEGNAMENTO o MODULO UFFICIALE Nome:
Metodologie di Clustering
 Metodologie di Clustering Nota preliminare Esistono moltissimi algoritmi di clustering Questi algoritmi possono essere analizzati da svariati punti di vista La suddivisione principale tuttavia è quella
Metodologie di Clustering Nota preliminare Esistono moltissimi algoritmi di clustering Questi algoritmi possono essere analizzati da svariati punti di vista La suddivisione principale tuttavia è quella
UNIVERSITÀ DEGLI STUDI DI MILANO. Bioinformatica. A.A semestre I UPGMA
 Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I p4 UPGMA Clustering gerarchico in PERL Implementazione di un algoritmo di clustering Utilizzo
Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I p4 UPGMA Clustering gerarchico in PERL Implementazione di un algoritmo di clustering Utilizzo
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione
 I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
Algoritmi di clustering
 Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
Algoritmi di clustering Dato un insieme di dati sperimentali, vogliamo dividerli in clusters in modo che: I dati all interno di ciascun cluster siano simili tra loro Ciascun dato appartenga a uno e un
Celle di fabbricazione
 Celle di fabbricazione Produzione per parti (Classificazione Impiantistica) Produzione per parti Fabbricazione Montaggio (assemblaggio) Job Shop Celle di fabbricazione Linee transfer A posto fisso Ad Isola
Celle di fabbricazione Produzione per parti (Classificazione Impiantistica) Produzione per parti Fabbricazione Montaggio (assemblaggio) Job Shop Celle di fabbricazione Linee transfer A posto fisso Ad Isola
I metodi di Classificazione automatica
 L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
I modelli di analisi statistica multidimensionale dei dati: La Cluster Analysis Gerarchica
 Titolo della lezione: I modelli di analisi statistica multidimensionale dei dati: La Cluster Analysis Gerarchica Obiettivi dell unità didattica Comprendere l insieme delle procedure che si prefiggono di
Titolo della lezione: I modelli di analisi statistica multidimensionale dei dati: La Cluster Analysis Gerarchica Obiettivi dell unità didattica Comprendere l insieme delle procedure che si prefiggono di
Il problema del clustering
 Il problema del clustering Stefano Rovetta 1 aprile 2003 Sommario Concetto di clustering Definizioni di distanze Modalità di raggruppamento Clustering con la tecnica k-means Clustering gerarchico Cautele
Il problema del clustering Stefano Rovetta 1 aprile 2003 Sommario Concetto di clustering Definizioni di distanze Modalità di raggruppamento Clustering con la tecnica k-means Clustering gerarchico Cautele
Segmentazione di immagini in scala di grigio basata su clustering
 Segmentazione di immagini in scala di grigio basata su clustering Davide Anastasia, Nicola Cogotti 24 gennaio 06 1 Analisi del problema La segmentazione di immagini consiste nella suddivisione in un certo
Segmentazione di immagini in scala di grigio basata su clustering Davide Anastasia, Nicola Cogotti 24 gennaio 06 1 Analisi del problema La segmentazione di immagini consiste nella suddivisione in un certo
Algoritmo del simplesso
 Algoritmo del simplesso Ipotesi : si parte da una S.A.B. e dal tableau A=b in forma canonica. Si aggiunge una riga costituita dagli r j, j =,., n e da -z (valore, cambiato di segno, della f.o. nella s.a.b.)
Algoritmo del simplesso Ipotesi : si parte da una S.A.B. e dal tableau A=b in forma canonica. Si aggiunge una riga costituita dagli r j, j =,., n e da -z (valore, cambiato di segno, della f.o. nella s.a.b.)
TECNICHE DI CLASSIFICAZIONE
 TECNICHE DI CLASSIFICAZIONE La tecnica di classificazione più conosciuta è la cluster analysis, che ha l obiettivo di identificare gruppi di soggetti (o oggetti) omogenei al loro interno ed eterogenei
TECNICHE DI CLASSIFICAZIONE La tecnica di classificazione più conosciuta è la cluster analysis, che ha l obiettivo di identificare gruppi di soggetti (o oggetti) omogenei al loro interno ed eterogenei
Classificazione (aka Cluster Analysis)
") Classificazione (aka Cluster Analysis) Classificazione non gerarchica esk-means Classificazione gerarchica divisiva Classificazione gerarchica agglomerativa Legame: singolo, completo, medio, Coefficiente
Classificazione (aka Cluster Analysis) Classificazione non gerarchica esk-means Classificazione gerarchica divisiva Classificazione gerarchica agglomerativa Legame: singolo, completo, medio, Coefficiente
ANALISI DEI DATI PER IL MARKETING 2014
 ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che:
 Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
LA CLUSTER ANALYSIS IN R
 LA CLUSTER ANALYSIS IN R 1 Cluster gerarchica 1.1 Cluster delle unità sperimentali > sanita= read.table(file.choose(), header =TRUE, row.names=2) > str(sanita) 'data.frame': 20 obs. of 6 variables: $ n
LA CLUSTER ANALYSIS IN R 1 Cluster gerarchica 1.1 Cluster delle unità sperimentali > sanita= read.table(file.choose(), header =TRUE, row.names=2) > str(sanita) 'data.frame': 20 obs. of 6 variables: $ n
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
(a) Si proponga una formulazione di programmazione nonlineare a variabili misto-intere per problema.
 Si proponga una formulazione di programmazione nonlineare a variabili misto-intere per problema.") 6. Clustering In molti campi applicativi si presenta il problema del data mining, che consiste nel suddividere un insieme di dati in gruppi e di assegnare un centro a ciascun gruppo. Ad esempio, in ambito
6. Clustering In molti campi applicativi si presenta il problema del data mining, che consiste nel suddividere un insieme di dati in gruppi e di assegnare un centro a ciascun gruppo. Ad esempio, in ambito
Clustering. Cos è un analisi di clustering
 Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
Clustering Salvatore Orlando Data Mining. - S. Orlando Cos è un analisi di clustering Cluster: collezione di oggetti/dati Simili rispetto a ciascun oggetto nello stesso cluster Dissimili rispetto agli
COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING novembre 2008.
 COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING novembre 2008. ESERCIZIO I Si è applicata l analisi delle componenti principali a 97 modelli di fotocamere digitali, considerando 7 variabili ed ottenendo
COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING novembre 2008. ESERCIZIO I Si è applicata l analisi delle componenti principali a 97 modelli di fotocamere digitali, considerando 7 variabili ed ottenendo
METODI DI CLASSIFICAZIONE. Federico Marini
 METODI DI CLASSIFICAZIONE Federico Marini Introduzione Nella parte introduttiva dell analisi multivariata abbiamo descritto la possibilità di riconoscere l origine di alcuni campioni come uno dei campi
METODI DI CLASSIFICAZIONE Federico Marini Introduzione Nella parte introduttiva dell analisi multivariata abbiamo descritto la possibilità di riconoscere l origine di alcuni campioni come uno dei campi
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
CLUSTERING GERARCHICO
 Clustering Il clustering organizza i geni in gruppi (cluster) con simili pattern di espressione. Spesso i geni apparteni allo stesso cluster sono detti coespressi. Le ragioni per cui si cercano geni coespressi
Clustering Il clustering organizza i geni in gruppi (cluster) con simili pattern di espressione. Spesso i geni apparteni allo stesso cluster sono detti coespressi. Le ragioni per cui si cercano geni coespressi
Tesina Intelligenza Artificiale Maria Serena Ciaburri s A.A
 Tesina Intelligenza Artificiale Maria Serena Ciaburri s231745 A.A. 2016-2017 Lo scopo di questa tesina è quello di clusterizzare con l algoritmo K-Means i dati presenti nel dataset MNIST e di calcolare
Tesina Intelligenza Artificiale Maria Serena Ciaburri s231745 A.A. 2016-2017 Lo scopo di questa tesina è quello di clusterizzare con l algoritmo K-Means i dati presenti nel dataset MNIST e di calcolare
Misure di dispersione (o di variabilità)
") 14/1/01 Misure di dispersione (o di variabilità) Range Distanza interquartile Deviazione standard Coefficiente di variazione Misure di dispersione 7 8 9 30 31 9 18 3 45 50 x = 9 range=31-7=4 x = 9 range=50-9=41
14/1/01 Misure di dispersione (o di variabilità) Range Distanza interquartile Deviazione standard Coefficiente di variazione Misure di dispersione 7 8 9 30 31 9 18 3 45 50 x = 9 range=31-7=4 x = 9 range=50-9=41
Prova scritta di ASM - Modulo Analisi Esplorativa del
 Cognome:... Nome:... Matricola:......... Prova scritta di ASM - Modulo Analisi Esplorativa del 14.02.2017 La durata della prova è di 90 minuti. Si svolgano gli esercizi A e B riportando il risultato dove
Cognome:... Nome:... Matricola:......... Prova scritta di ASM - Modulo Analisi Esplorativa del 14.02.2017 La durata della prova è di 90 minuti. Si svolgano gli esercizi A e B riportando il risultato dove
LA CLASSIFICAZIONE IN SOCIOLOGIA
 ~FICI LABORA1"'0Rl0 SOCIOLOGICO Teoria, Epistemologia, Metodo Cleto Corposanto LA CLASSIFICAZIONE IN SOCIOLOGIA Reti neurali, Discriminant e Cluster Analysis ancoangeli Istituto Universitario Architettura
~FICI LABORA1"'0Rl0 SOCIOLOGICO Teoria, Epistemologia, Metodo Cleto Corposanto LA CLASSIFICAZIONE IN SOCIOLOGIA Reti neurali, Discriminant e Cluster Analysis ancoangeli Istituto Universitario Architettura
2. ALGORITMO DEL SIMPLESSO
 . ALGORITMO DEL SIMPLESSO R. Tadei Una piccola introduzione R. Tadei SIMPLESSO L obiettivo del capitolo è quello di fornire un algoritmo, l algoritmo del simplesso, che risolve qualsiasi problema di programmazione
. ALGORITMO DEL SIMPLESSO R. Tadei Una piccola introduzione R. Tadei SIMPLESSO L obiettivo del capitolo è quello di fornire un algoritmo, l algoritmo del simplesso, che risolve qualsiasi problema di programmazione
1. Sistemi di equazioni lineari. 1.1 Considerazioni preliminari
 1. Sistemi di equazioni lineari 1.1 Considerazioni preliminari I sistemi lineari sono sistemi di equazioni di primo grado in più incognite. Molti problemi di matematica e fisica portano alla soluzione
1. Sistemi di equazioni lineari 1.1 Considerazioni preliminari I sistemi lineari sono sistemi di equazioni di primo grado in più incognite. Molti problemi di matematica e fisica portano alla soluzione
Cluster Analysis 1/40. Cluster Analysis. c 11 giugno 2005 Luca La Rocca
 Cluster Analysis 1/40 Cluster Analysis Cluster Analysis 1/40 Cluster Analysis è un insieme di tecniche esplorative che mirano a raggruppare le unità statistiche di una popolazione sulla base della loro
Cluster Analysis 1/40 Cluster Analysis Cluster Analysis 1/40 Cluster Analysis è un insieme di tecniche esplorative che mirano a raggruppare le unità statistiche di una popolazione sulla base della loro
MODELLI DI ASSEGNAZIONE PER LE RETI STRADALI
 MODELLI DI ASSEGNAZIONE PER LE RETI STRADALI CORSO DI PROGETTAZIONE DEI SISTEMI DI TRASPORTO - I MODELLI DI ASSEGNAZIONE L ASSEGNAZIONE DELLA DOMANDA AD UNA RETE DI TRASPORTO CONSISTE NEL CALCOLARE I FLUSSI
MODELLI DI ASSEGNAZIONE PER LE RETI STRADALI CORSO DI PROGETTAZIONE DEI SISTEMI DI TRASPORTO - I MODELLI DI ASSEGNAZIONE L ASSEGNAZIONE DELLA DOMANDA AD UNA RETE DI TRASPORTO CONSISTE NEL CALCOLARE I FLUSSI
INFORMATICA GENERALE Prof. Alberto Postiglione Dipartimento Scienze della Comunicazione Università degli Studi di Salerno
 INFORMATICA GENERALE Prof. Alberto Postiglione Dipartimento Scienze della Comunicazione Università degli Studi di Salerno : Gli Algoritmi INFORMATICA GENERALE Prof. Alberto Postiglione Dipartimento Scienze
INFORMATICA GENERALE Prof. Alberto Postiglione Dipartimento Scienze della Comunicazione Università degli Studi di Salerno : Gli Algoritmi INFORMATICA GENERALE Prof. Alberto Postiglione Dipartimento Scienze
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Sistemi di Elaborazione dell Informazione 170. Caso Non Separabile
 Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Prova finale del 6 giugno 2011
 Prova finale del 6 giugno 2011 Esercizio A, da svolgere con carta e penna Si consideri la seguente matrice dei dati relativa a 3 unità statistiche e 3 variabili, X 1 e X 2 quantitative, X 3 dicotomica.
Prova finale del 6 giugno 2011 Esercizio A, da svolgere con carta e penna Si consideri la seguente matrice dei dati relativa a 3 unità statistiche e 3 variabili, X 1 e X 2 quantitative, X 3 dicotomica.
Risoluzione di problemi ingegneristici con Excel
 Risoluzione di problemi ingegneristici con Excel Problemi Ingegneristici Calcolare per via numerica le radici di un equazione Trovare l equazione che lega un set di dati ottenuti empiricamente (fitting
Risoluzione di problemi ingegneristici con Excel Problemi Ingegneristici Calcolare per via numerica le radici di un equazione Trovare l equazione che lega un set di dati ottenuti empiricamente (fitting
Risoluzione di sistemi lineari sparsi e di grandi dimensioni
 Risoluzione di sistemi lineari sparsi e di grandi dimensioni Un sistema lineare Ax = b con A R n n, b R n, è sparso quando il numero di elementi della matrice A diversi da zero è αn, con n α. Una caratteristica
Risoluzione di sistemi lineari sparsi e di grandi dimensioni Un sistema lineare Ax = b con A R n n, b R n, è sparso quando il numero di elementi della matrice A diversi da zero è αn, con n α. Una caratteristica
K-means clustering con R
 K-means clustering con R Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/3%20sqg/labs/l-10_cluster_k-means.html#(1) 1/10 Introduzione K-means è un approccio semplice ed elegante
K-means clustering con R Emanuele Taufer file:///c:/users/emanuele.taufer/google%20drive/2%20corsi/3%20sqg/labs/l-10_cluster_k-means.html#(1) 1/10 Introduzione K-means è un approccio semplice ed elegante
1. INTRODUZIONE ALLA CHEMIOMETRIA
 Chemiometria per la Chimica Analitica 1 1. INTRODUZIONE ALLA CHEMIOMETRIA 1.1 Definizione di Chemiometria La Chemiometria è quella disciplina che permette di affrontare problemi sperimentali complessi
Chemiometria per la Chimica Analitica 1 1. INTRODUZIONE ALLA CHEMIOMETRIA 1.1 Definizione di Chemiometria La Chemiometria è quella disciplina che permette di affrontare problemi sperimentali complessi
Capitolo 11 Test chi-quadro
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 11 Test chi-quadro Insegnamento: Statistica Corsi di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara Docenti: Dott.
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 11 Test chi-quadro Insegnamento: Statistica Corsi di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara Docenti: Dott.
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
3. Matrici e algebra lineare in MATLAB
 3. Matrici e algebra lineare in MATLAB Riferimenti bibliografici Getting Started with MATLAB, Version 7, The MathWorks, www.mathworks.com (Capitolo 2) Mathematics, Version 7, The MathWorks, www.mathworks.com
3. Matrici e algebra lineare in MATLAB Riferimenti bibliografici Getting Started with MATLAB, Version 7, The MathWorks, www.mathworks.com (Capitolo 2) Mathematics, Version 7, The MathWorks, www.mathworks.com
L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A.
 L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A. Corso di Economia Industriale Lezione dell 8/01/2010 Valutazione delle peformance Obiettivo: valutare le attività di
L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A. Corso di Economia Industriale Lezione dell 8/01/2010 Valutazione delle peformance Obiettivo: valutare le attività di
ESERCITAZIONE MICROECONOMIA (CORSO B) 21-12-2009 ESEMPI DI ESERCIZI DI TEORIA DEI GIOCHI
 21-12-2009 ESEMPI DI ESERCIZI DI TEORIA DEI GIOCHI") ESERCITZIONE MICROECONOMI (CORSO ) --009 ESEMPI DI ESERCIZI DI TEORI DEI GIOCHI Questo documento contiene alcuni esempi di esercizi di teoria dei giochi. Gli esercizi presentati non corrispondono esattamente
ESERCITZIONE MICROECONOMI (CORSO ) --009 ESEMPI DI ESERCIZI DI TEORI DEI GIOCHI Questo documento contiene alcuni esempi di esercizi di teoria dei giochi. Gli esercizi presentati non corrispondono esattamente
SCHEDA N. 6: CLUSTER ANALYSIS
 La statistica multivariata SCHEDA N. 6: CLUSTER ANALYSIS Nelle schede precedenti abbiamo visto come si rappresentano e si analizzano una o due variabili alla volta: questo tipo di analisi statistiche sono
La statistica multivariata SCHEDA N. 6: CLUSTER ANALYSIS Nelle schede precedenti abbiamo visto come si rappresentano e si analizzano una o due variabili alla volta: questo tipo di analisi statistiche sono
Clustering. Introduzione Definizioni Criteri Algoritmi. Clustering Gerarchico
 Introduzione Definizioni Criteri Algoritmi Gerarchico Centroid-based K-means Fuzzy K-means Expectation Maximization (Gaussian Mixture) 1 Definizioni Con il termine (in italiano «raggruppamento») si denota
Introduzione Definizioni Criteri Algoritmi Gerarchico Centroid-based K-means Fuzzy K-means Expectation Maximization (Gaussian Mixture) 1 Definizioni Con il termine (in italiano «raggruppamento») si denota
PROBABILITÀ SCHEDA N. 5 SOMMA E DIFFERENZA DI DUE VARIABILI ALEATORIE DISCRETE
 PROBABILITÀ SCHEDA N. 5 SOMMA E DIFFERENZA DI DUE VARIABILI ALEATORIE DISCRETE 1. Distribuzione congiunta Ci sono situazioni in cui un esperimento casuale non si può modellare con una sola variabile casuale,
PROBABILITÀ SCHEDA N. 5 SOMMA E DIFFERENZA DI DUE VARIABILI ALEATORIE DISCRETE 1. Distribuzione congiunta Ci sono situazioni in cui un esperimento casuale non si può modellare con una sola variabile casuale,
5. Analisi dei Gruppi (Cluster Analysis)
") 5. Analisi dei Gruppi (Cluster Analysis) Cosa è l analisi dei gruppi? Viene utilizzata per classificare rispondenti in gruppi omogenei detti clusters. Esamina relazioni di interdipendenza: nessuna distinzione
5. Analisi dei Gruppi (Cluster Analysis) Cosa è l analisi dei gruppi? Viene utilizzata per classificare rispondenti in gruppi omogenei detti clusters. Esamina relazioni di interdipendenza: nessuna distinzione
Analisi di dati Microarray: Esercitazione Matlab
 Analisi di dati Microarray: Esercitazione Matlab Laboratorio di Bioinformatica II Pietro Lovato Anno Accademico 2010/2011 Contenuti 1 Introduzione DNA Microarray 2 Lavorare con una singola ibridazione
Analisi di dati Microarray: Esercitazione Matlab Laboratorio di Bioinformatica II Pietro Lovato Anno Accademico 2010/2011 Contenuti 1 Introduzione DNA Microarray 2 Lavorare con una singola ibridazione
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
ICA per analisi di gruppo
 ICA per analisi di gruppo Simone Romano 1 1 Università degli Studi di Salerno Elaborazione di segnali ed immagini biomediche Prof. Fabrizio Esposito. Romano (Università degli Studi di Salerno) ICA per
ICA per analisi di gruppo Simone Romano 1 1 Università degli Studi di Salerno Elaborazione di segnali ed immagini biomediche Prof. Fabrizio Esposito. Romano (Università degli Studi di Salerno) ICA per
Clustering. Utilizziamo per la realizzazione dell'esempio due tipologie di software:
 Esercizio Clustering Utilizziamo per la realizzazione dell'esempio due tipologie di software: - XLSTAT.xls - Cluster.exe XLSTAT.xls XLSTAT.xls è una macro di Excel che offre la possibilità di effettuare
Esercizio Clustering Utilizziamo per la realizzazione dell'esempio due tipologie di software: - XLSTAT.xls - Cluster.exe XLSTAT.xls XLSTAT.xls è una macro di Excel che offre la possibilità di effettuare
FACOLTA DI SCIENZE STATISTICHE Corso di laurea in Statistica, Imprese e Mercati Statistica economica (Prof. Filippucci) Prova del 19/12/07
 Prova del 19/12/07") FACOLTA DI SCIENZE STATISTICHE Corso di laurea in Statistica, Imprese e Mercati Statistica economica (Prof. Filippucci) Prova del 19/12/07 Nome e cognome N. di Matricola 1.) Quale delle seguenti affermazioni
FACOLTA DI SCIENZE STATISTICHE Corso di laurea in Statistica, Imprese e Mercati Statistica economica (Prof. Filippucci) Prova del 19/12/07 Nome e cognome N. di Matricola 1.) Quale delle seguenti affermazioni
PROGETTO IREALP GRUPPO TELECOM ITALIA - FINSIEL SPERIMENTAZIONE DI METODI PER LA MESSA A REGISTRO DELLA BASE CATASTALE SULLA AEROFOTOGRAMMETRIA
 PROGETTO IREALP SPERIMENTAZIONE DI METODI PER LA MESSA A REGISTRO DELLA BASE CATASTALE SULLA AEROFOTOGRAMMETRIA 1 SCOPO: Trasformare la base catastale e metterla a registro con gli elementi portanti del
PROGETTO IREALP SPERIMENTAZIONE DI METODI PER LA MESSA A REGISTRO DELLA BASE CATASTALE SULLA AEROFOTOGRAMMETRIA 1 SCOPO: Trasformare la base catastale e metterla a registro con gli elementi portanti del
LA CASSIFICAZIONE AUTOMATICA PER UNO STUDIO DEL SISTEMA DEI TRASPORTI
 _ LA CLASSIFICAZIONE AUTOMATICA PER UNO STUDIO DEL SISTEMA DEI TRASPORTI Rosaria Lombardo LA CASSIFICAZIONE AUTOMATICA CLASSIFICAZIONE E CLUSTERING 1. Introduzione L analisi dei gruppi, o cluster analysis,
_ LA CLASSIFICAZIONE AUTOMATICA PER UNO STUDIO DEL SISTEMA DEI TRASPORTI Rosaria Lombardo LA CASSIFICAZIONE AUTOMATICA CLASSIFICAZIONE E CLUSTERING 1. Introduzione L analisi dei gruppi, o cluster analysis,
Naïve Bayesian Classification
 Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Università di Pisa A.A. 2004-2005
 Università di Pisa A.A. 2004-2005 Analisi dei dati ed estrazione di conoscenza Corso di Laurea Specialistica in Informatica per l Economia e per l Azienda Tecniche di Data Mining Corsi di Laurea Specialistica
Università di Pisa A.A. 2004-2005 Analisi dei dati ed estrazione di conoscenza Corso di Laurea Specialistica in Informatica per l Economia e per l Azienda Tecniche di Data Mining Corsi di Laurea Specialistica
UNIVERSITÀ DEGLI STUDI DI PAVIA FACOLTÀ DI INGEGNERIA. Matlab: esempi ed esercizi
 UNIVERSITÀ DEGLI STUDI DI PAVIA FACOLTÀ DI INGEGNERIA Matlab: esempi ed esercizi Sommario e obiettivi Sommario Esempi di implementazioni Matlab di semplici algoritmi Analisi di codici Matlab Obiettivi
UNIVERSITÀ DEGLI STUDI DI PAVIA FACOLTÀ DI INGEGNERIA Matlab: esempi ed esercizi Sommario e obiettivi Sommario Esempi di implementazioni Matlab di semplici algoritmi Analisi di codici Matlab Obiettivi
Corso di laurea in Scienze Motorie Corso di Statistica Docente: Dott.ssa Immacolata Scancarello Lezione 15: Metodi non parametrici
 Corso di laurea in Scienze Motorie Corso di Statistica Docente: Dott.ssa Immacolata Scancarello Lezione 15: Metodi non parametrici 1 Metodi non parametrici Statistica classica La misurazione avviene con
Corso di laurea in Scienze Motorie Corso di Statistica Docente: Dott.ssa Immacolata Scancarello Lezione 15: Metodi non parametrici 1 Metodi non parametrici Statistica classica La misurazione avviene con
Vivisezione di un algoritmo di machine learning. Francesco ESPOSITO Youbiquitous
 Vivisezione di un algoritmo di machine learning Francesco ESPOSITO Youbiquitous Argomenti Panoramica di algoritmi e problemi Dentro un algoritmo Definire un approssimazione Definire un errore Minimizzare
Vivisezione di un algoritmo di machine learning Francesco ESPOSITO Youbiquitous Argomenti Panoramica di algoritmi e problemi Dentro un algoritmo Definire un approssimazione Definire un errore Minimizzare
Learning and Clustering
 Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Competitive Intelligence Data Mining - Analisi dei dati
 Competitive Intelligence Data Mining - Analisi dei dati L'applicazione di tecniche di data mining per estrarre conoscenza da banche dati di tipo tecnicoscientifico consente di effettuare studi di "technology
Competitive Intelligence Data Mining - Analisi dei dati L'applicazione di tecniche di data mining per estrarre conoscenza da banche dati di tipo tecnicoscientifico consente di effettuare studi di "technology
Cluster Analysis Analisi completa
 Cluster Analysis Analisi completa Statistica Inferenziale t-test M Q Marco Perugini Milano-Bicocca 1 Logica della Clusters Selezionare le variabili su cui i soggetti possono differire Scalare le variabili
Cluster Analysis Analisi completa Statistica Inferenziale t-test M Q Marco Perugini Milano-Bicocca 1 Logica della Clusters Selezionare le variabili su cui i soggetti possono differire Scalare le variabili
Metodi per la risoluzione di sistemi lineari
 Metodi per la risoluzione di sistemi lineari Sistemi di equazioni lineari. Rango di matrici Come è noto (vedi [] sez.0.8), ad ogni matrice quadrata A è associato un numero reale det(a) detto determinante
Metodi per la risoluzione di sistemi lineari Sistemi di equazioni lineari. Rango di matrici Come è noto (vedi [] sez.0.8), ad ogni matrice quadrata A è associato un numero reale det(a) detto determinante