Statistica per le ricerche di mercato
|
|
|
- Antonietta Beretta
- 6 anni fa
- Visualizzazioni
Transcript
1 Statistica per le ricerche di mercato A.A. 2012/13 Dr. Luca Secondi 15. Tecniche di analisi statistica multivariata per la segmentazione del mercato Cluster Analysis 1
2 Cluster analysis La cluster analysis è una tecnica che conduce alla classificazione delle unità statistiche in gruppi (cluster) aventi le proprietà di omogeneità interna e disomogeneità esterna (tra i gruppi). Nel marketing viene frequentemente applicata a supporto di decisioni sia strategiche che operative. 1. Analisi di segmentazione e studio del comportamento della clientela. Ogni ricerca di segmentazione si propone di identificare gruppi di entità (persone, mercati, organizzazioni) che condividano determinate caratteristiche (benefici ricercati nel prodotto/servizio, attitudini, propensione all acquisto, preferenze nei confronti dei diversi media). E evidente in tal senso l utilità potenziale di una metodologia di classificazione automatica. 2. Sviluppo e ricerca di opportunità per potenziali nuovi prodotti. Attraverso la classificazione di marchi e prodotti, si possono determinare delle nicchie competitive all interno di una più ampia struttura di mercato. Un azienda può esaminare la gamma corrente delle sue offerte in relazione a quella dei concorrenti, determinando fino a che punto un prodotto corrente o potenziale è posizionato isolatamente o insiste su un area ad alta densità competitiva. In questo tipo di applicazione, la cluster analysis si affianca e integra le tecniche di mapping multidimensionale, come il multidimensional scaling, l analisi discriminante e la factor analysis. 3. Scelta di aree-test di mercato:.tali applicazioni riguardano l identificazione di insiemi relativamente omogenei di aree-test, in modo da consentire una generalizzazione dei risultati ottenuti in un area alle rimanenti che appartengono al medesimo cluster, riducendo in questo modo il numero complessivo di aree-test necessarie. 2
3 Cluster analysis La cluster analysis ha l obiettivo di raggruppare un insieme di unità in un certo numero di gruppi sulla base delle loro similarità in relazione alle p variabili contenute nella matrice dei dati X. I dati di partenza per l implementazione di una analisi cluster possono essere sia la matrice dei dati X (di dimensione nxp) che la matrice delle distanze D (di dimensione nxn) calcolata utilizzando, a seconda della natura delle variabili, un indice appropriato (ad esempio, per caratteri quantitativi, la distanza Euclidea). Nel processo classico di segmentazione per omogeneità la cluster analysis rappresenta il secondo step. Come già accennato, l analisi delle componenti principali (ACP) applicata in via preliminare alle variabili disponibili nella matrice dei dati, ne costituisce invece la prima fase. Se k componenti principali tengono conto di una percentuale elevata della varianza totale, si può effettuare la clusterizzazione direttamente sugli scores di tali componenti principali, che costituiscono il segnale degli aspetti rilevanti. 3
4 Cluster analysis L analisi cluster (o analisi dei gruppi) consente la suddivisione del campione di unità in due o più gruppi con caratteristiche di coesione interna (le unità assegnate ad un medesimo gruppo devono essere tra loro simili) e di separazione esterna (i gruppi devono essere il più possibile distinti). I metodi di formazione dei gruppi vengono distinti in gerarchici e non gerarchici. I metodi gerarchici si distinguono in metodi di tipo agglomerativo e metodi di tipo divisivo. I metodi di tipo agglomerativo (o bottom up) consentono di ottenere una famiglia di partizioni, con un numero di gruppi da n a 1, partendo da quella banale in cui tutte le unità sono distinte per giungere a quella in cui tutti gli elementi sono riuniti in un unico gruppo. I metodi di tipo divisivo (o top-down) che partono dall insieme di tutte le unità statistiche ed effettuano successive separazioni in gruppi di tale insieme. I metodi non gerarchici forniscono un unica partizione delle n unità in g gruppi, con g fissato a priori. 4
5 Cluster analysis Metodi gerarchici agglomerativi [MGA] Il dendrogramma Output principale di una clusterizzazione gerarchica 5
6 Cluster analysis Metodi gerarchici agglomerativi [MGA] I metodi gerarchici agglomerativi procedono per agglomerazioni successive delle unità statistiche. La procedura parte da n gruppi (formati cioè da un solo individuo/una sola unità statistica), per poi passare a n-1 gruppi, dei quali n-2 formati da un solo individuo e 1 formato da due individui; passa poi a n-2 gruppi, n-3, n-4, fino ad arrivare a un unico gruppo costituito da tutte le n unità statistiche del collettivo. L obiettivo ovviamente non è quello di arrivare ad un unico gruppo costituito da tutte le unità, bensì quello di raggruppare le n unità statistiche in un certo numero (limitato) di gruppi. La scelta del numero di gruppi dovrà scaturire da un soddisfacente compromesso tra la necessità di mantenere una sufficiente omogeneità all interno dei gruppi e quella di tenere basso tale numero, in modo da non rendere eccessivamente articolata l interpretazione del raggruppamento (evitare quindi nelle analisi di mercato la proliferazione di differenti strategie di marketing). 6
7 Richiamo della nozione di misura di distanza La partizione dell insieme di unità in vari sottogruppi avviene come si è appena visto per passi, utilizzando una misura di distanza (o di similarità) tra le unità che tenga conto delle informazioni a disposizione contenute nell insieme di p variabili osservate. Tale misura può assumere espressioni diverse a seconda della natura delle variabili prese in considerazione. Quando le variabili sono quantitative si potrà per esempio utilizzare la distanza Euclidea (che costituisce un caso specifico della distanza di Minkowski per λ=2) p d = x x ir ik rk k = 1 λ 1/ λ p d = x x ( ) ir ik rk k = 1 2 1/2 Quando le variabili sono qualitative si potrà per esempio utilizzare il coefficiente di Jaccard (indice di similarità) Quando si presenta la situazione in cui le variabili osservate su un campione di individui sono miste, un indice di similarità utilizzato è l indice di Gower. s(a,b) = s(b, A); s(a, B) > 0; s(a, B) cresce al crescere della similarità fra A e B. Una volta calcolata la distanza (o la similarità) tra tutte le possibili coppie di unità, si ottiene la matrice di distanze (o di similarità). 7
8 Cluster analysis Metodi gerarchici agglomerativi [MGA] 1. Si parte da n gruppi, ognuno dei quali è formato da una unità del collettivo. La distanza tra i gruppi è fornita dalla matrice delle distanze D 0 d12 d13... d1 n 0 d23... d 2n D = dn 1, n 0 2. Si cerca il minimo valore all interno della matrice delle distanze (escluso la diagonale principale che contiene tutti valori pari a zero). Esso identifica le due unità più simili, cioè quelle che presentano profili di riga più omogenei nella matrice dei dati. 3. Si procede alla fusione delle unità corrispondenti a tale valore minimo. Poiché le due unità oggetto di fusione non esistono più come soggetti singoli vengono eliminate dalla matrice delle distanze D le due righe e le due colonne corrispondenti, ottenendo una nuova matrice delle distanze D n-2,n-2 4. Si aggiunge una nuova riga e una nuova colonna che contiene le distanze tra il nuovo gruppo ottenuto dalla fusione dei due precedenti e tutte le altre unità che continuano a esistere singolarmente, in modo da ottenere una nuova matrice D n-1,n-1 5. Si torna a eseguire lo step 2 e seguenti in modo iterativo, riducendo la matrice D di una unità a ogni iterazione, fino a quando si arriva alla configurazione finale costituita da un solo gruppo formato da tutte le n unità del collettivo preso in esame. 8
9 Cluster analysis Metodi gerarchici agglomerativi [MGA] Analisi dei gruppi MGA Come eseguire lo step 4? [Come ricalcolare ad ogni iterazione la riga e la colonna da aggiungere alla matrice che contengono le distanze tra il gruppo appena formato e tutte le altre unità (o gruppi già pre-esistenti)] In generale, occorre definire un criterio per la formazione dei gruppi e quindi introdurre un criterio che permetta di calcolare le distanze tra gruppi o tra un unità e un gruppo Gli algoritmi gerarchici proposti in letteratura sono molteplici e si differenziano unicamente per il criterio che regola la valutazione delle distanze tra i gruppi. Tra i criteri più utilizzati vi sono: Criterio del legame singolo (Single Linkage) Criterio del legame completo (Complete Linkage) Criterio di McQuitty Criterio del legame medio Metodo del centroide Metodo di Ward 9
10 Cluster analysis Metodi gerarchici agglomerativi [MGA] Notazione: C k : K-esimo gruppo (originariamente k-esima unità); N k : numero di unità nel k-esimo gruppo (originariamente N k =1); D KL : misura di distanza tra il gruppo C K e il C L Si ipotizzi che D KL sia il minimo valore nella matrice delle distanze e dunque che i gruppi C K e C L vengano fusi in un unico gruppo chiamato C M 10
![Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del legame singolo (Single linkage o del vicino più prossimo nearest-neighbour) La distanza fra un nuovo cluster e un caso individuale](/docs-images/69/61693985/images/11-0.jpg "(o un altro cluster precedentemente formatosi) è pari alla distanza minima fra il caso individuale stesso e un caso nel cluster.")
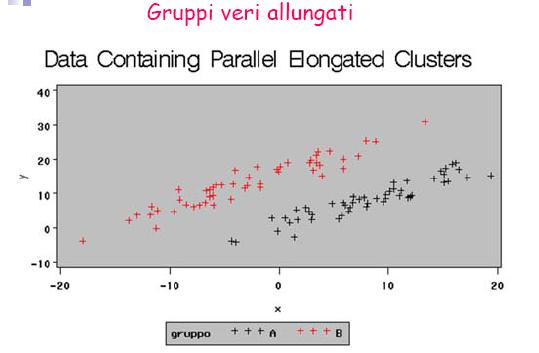
11 Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del legame singolo (Single linkage o del vicino più prossimo nearest-neighbour) La distanza fra un nuovo cluster e un caso individuale (o un altro cluster precedentemente formatosi) è pari alla distanza minima fra il caso individuale stesso e un caso nel cluster. In altre parole in ogni fase dell algoritmo la distanza tra due cluster è data dalla distanza tra i loro punti più vicini. Indicato con J un generico gruppo preesistente si ha: D JM = min(d JK,D JL ) Vantaggi: permette di individuare gruppi di qualsiasi forma, purché ben separati Svantaggi:effetto di concatenamento, cioè ad ogni fusione le unità non ancora classificate tendono ad essere incorporate in gruppi già esistenti piuttosto che formare nuovi gruppi. 11
![Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del legame completo (Complete linkage o del vicino più lontano ) La distanza fra due cluster è data dalla distanza fra i loro punti più](/docs-images/69/61693985/images/12-1.jpg "lontani.")
12 Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del legame completo (Complete linkage o del vicino più lontano ) La distanza fra due cluster è data dalla distanza fra i loro punti più lontani. Per il gruppo enerico preesistente J si ha: D JM = max(d JK,D JL ) A differenza del metodo del legame singolo, il metodo del legame completo è molto influenzato dalla presenza di valori anomali, tanto da suggerire una preventiva analisi ad hoc. Tende inoltre a produrre molti gruppi di dimensioni simili.
![Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio di McQuitty (media aritmetica semplice) Le distanze tra il nuovo gruppo risultante dalla fusione e tutti i preesistenti sono definite](/docs-images/69/61693985/images/13-1.jpg "come la media aritmetica semplice tra le distanze che, prima della fusione, avevano i gruppi oggetto di fusione con tutti gli altri.")
13 Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio di McQuitty (media aritmetica semplice) Le distanze tra il nuovo gruppo risultante dalla fusione e tutti i preesistenti sono definite come la media aritmetica semplice tra le distanze che, prima della fusione, avevano i gruppi oggetto di fusione con tutti gli altri. Per il generico gruppo preesistente j si ha cioè: D JM = (D JK + D JL ) / 2 Criterio del legame medio (media aritmetica ponderata) Le distanze tra il nuovo gruppo risultante dalla fusione e tutti i preesistenti sono definite come media aritmetica tra le distanze che, prima della fusione, avevano i gruppi oggetto di fusione con tutti gli altri, ponderata con le numerosità dei gruppi oggetto di fusione. Per il generico gruppo preesistente J si ha: D JM = (D JK N K + D JL N L ) / N M Si collocano in posizione intermedia, tra quello del legame singolo e quello del legame completo, per quanto attiene a vantaggi e svantaggi. Inoltre tende a unire gruppi con bassa varianza interna e a produrre gruppi con varianze interne simili 13
![Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del centroide (distanza euclidea tra i centroidi) Il criterio del centroide fa parte del gruppo di criteri (insieme anche al criterio](/docs-images/69/61693985/images/14-1.jpg "di Ward che discuteremo a breve), in cui i gruppi vengono definiti a partire, invece che dalla matrice delle distanze, dalla matrice dei dati X contenente i profili delle n unità secondo p variabili")
14 Cluster analysis Metodi gerarchici agglomerativi [MGA] Criterio del centroide (distanza euclidea tra i centroidi) Il criterio del centroide fa parte del gruppo di criteri (insieme anche al criterio di Ward che discuteremo a breve), in cui i gruppi vengono definiti a partire, invece che dalla matrice delle distanze, dalla matrice dei dati X contenente i profili delle n unità secondo p variabili quantitative. Le distanze tra i gruppi è posta pari alla distanza euclidea tra i centroidi o baricentri, costruiti dai valori medi delle p variabili considerate, calcolati sulle unità appartenenti ai gruppi. Anche in questo caso vengono fusi i gruppi che presentano distanza minima. Rispetto alla maggior parte dei metodi gerarchici, il metodo del centroide risulta più robusto riguardo all influenza dei valori anomali. 14
15 Cluster analysis Metodi gerarchici agglomerativi [MGA] Metodo di Ward (scomposizione della devianza) Si basa sulla scomposizione della devianza totale in devianza entro i gruppi e devianza tra i gruppi. A ogni iterazione viene considerata l unione di tutte le possibili coppie di gruppi e viene fusa la coppia che dà luogo alla minore varianza entro i gruppi. Pensato originariamente per applicazione su distanze euclidee, può essere utilizzato con altre misure di distanza. Ha il difetto di produrre gruppi di dimensioni pressoché analoghe e di essere molto sensibile agli outliers. 15
16 Cluster analysis Metodi gerarchici agglomerativi [MGA] Il dendrogramma Il processo di fusione realizzato impiegando uno dei metodi appena descritti può essere rappresentato graficamente attraverso il dendrogramma che riporta su due assi, le unità che partecipano al processo di fusione e il livello di distanza a cui avviene la fusione tra i diversi gruppi che si vengono formando per agglomerazioni successive. Dall esame del dendrogramma è possibile ricavare utili indicazioni riguardo al numero dei gruppi da considerare. Ai livelli in cui l'indice di aggregazione cresce vistosamente e' chiaro che la fusione avviene a un costo elevato e quindi e' conveniente fermare il processo. Non esistono comunque dei criteri oggettivi per determinare il numero dei gruppi. È il principale strumento di interpretazione dell output di cluster analysis gerarchica che costituisce un modo efficace di visualizzare le fasi della procedura. 16
17 Cluster analysis Metodi gerarchici agglomerativi [MGA] Il dendrogramma A B C D E A D E BC A 0 0,26 0,68 0,45 0,44 A 0 0,45 0,44 0,68 B 0 0,11 0,39 0,68 D 0 0,82 0,52 C 0 0,52 0,19 E 0 0,68 D 0 0,82 BC 0 E 0 D BC AE BC AED D 0 0,52 0,45 BC 0 0,68 BC 0 0,68 AED 0 AE 0 Esempio criterio del legame completo (Bracalente et al. Pag.240) d D=0.68 D=0.44 D=0.45 D=0.11 B C E A D unità legame completo
18 Cluster analysis Metodi gerarchici agglomerativi [MGA] Una classificazione gerarchica produce come risultato una successione di partizioni di n classi, n 1 classi, e così via no a una classe sola. Il fatto di non produrre un solo raggruppamento e' un vantaggio dei metodi gerarchici perché permette di studiare diverse strutture possibili per i dati, con un numero diverso di gruppi. Spesso il numero dei gruppi e' incognito e lo studio del dendrogramma e' utile per fare delle congetture. Tuttavia ogni indice di aggregazione produce una gerarchia diversa e ciò talvolta può creare delle difficoltà di interpretazione. Se la diversità dei risultati non e' rilevante, ossia le partizioni indotte sono pressappoco le stesse, si può pensare che esistano dei gruppi naturali. Ma a volte criteri diversi forniscono delle descrizioni abbastanza diverse dei dati e quindi sono difficilmente accordabili. Quindi conviene provare sempre più criteri e misure di distanza
19 Scatter plot Criterio del legame singolo var ind1 ind2 ind4 ind5 ind var2 ind3 L2 dissimilarity measure Dendrogram for _clus_1 cluster analysis L2 dissimilarity measure Criterio del legame completo Dendrogram for _clus_2 cluster analysis L2 dissimilarity measure Criterio del legame medio Dendrogram for _clus_3 cluster analysis
20 Cluster analysis Metodi gerarchici agglomerativi [MGA] Il dendrogramma riportato nella slide seguente fa riferimento alla clusterizzazione di un insieme di clienti di un azienda industriale, raggruppati sulla base di una serie di valutazioni sugli elementi del servizio. Le linee verticali segnalano l unione di due cluster, le posizioni di tali linee nelle scale indicano la distanza alla quale tali cluster vengono aggregati; le distanze sono riscalate per comodità di rappresentazione, assumendo un valore tra 1 (distanza minima) e 25 (distanza massima). Nell esempio: i clienti aggregati nelle prime fasi dalla procedura sono il 4, il 12 e l 1, il 2 e il 27, il 3 e il 5; nell ultima fase il cluster contenente i casi dal 4 al 22 (nella sequenza presentata in verticale) viene aggregato al cluster contenente i rimanenti casi (nel grafico, dal 18 al 38). Le ripartizioni in un dato numero di cluster possono essere ottenute sezionando verticalmente il dendrogramma; i cluster possono essere individuati muovendosi da destra verso sinistra. L output di una procedura gerarchica non contiene alcun indicatore numerico che supporti direttamente la scelta del numero corretto di cluster. Nel dendrogramma si può notare come la terz ultima aggregazione (che riduce i cluster da cinque a quattro) avvenga a livello di distanza tra i cluster relativamente elevata rispetto sia alle precedenti (che riducono il numero dei cluster fino a cinque) sia rispetto alle successive (che portano a soluzioni in due e tre cluster). 20
21 Cluster analysis Metodi gerarchici agglomerativi [MGA] 21
22 Cluster analysis Metodi gerarchici agglomerativi [MGA] Distanza TAGLIO: 2 gruppi Unità 22
23 Cluster analysis Metodi gerarchici agglomerativi [MGA] 0.9 BILANCI.STA Legame Singolo Distanze Euclidee 4.0 BILANCI.STA Legame Completo Distanze Euclidee Distanze Legami O Q L H F I D B P U T S R N V M E G C A Distanze Legami T S O P R N Q U V M H F L I D B G E C A 9 BILANCI.STA Metodo di Ward Distanze Euclidee Distanze Legami U Q V M T S O R N P E H F L I D B G C A 23
24 Cluster analysis Metodi non gerarchici I metodi non gerarchici (MNG) effettuano, attraverso procedure iterative, il raggruppamento direttamente nel numero prefissato di gruppi Il metodo delle k medie (k-means) costituisce l algoritmo di classificazione non gerarchico di uso più comune ed è implementato nei principali packages statistici. Tale algoritmo conduce alla classificazione delle unità statistiche in k gruppi distinti, con k fissato a priori. L algoritmo che conduce alla formazione dei gruppi è caratterizzato da una procedura iterativa, che ammette nelle varie fasi una riallocazione degli elementi già clusterizzati, in modo da consentire un progressivo miglioramento delle partizioni ottenute. Tali metodi assumono che il numero desiderato di gruppi sia fissato a priori. L ipotesi non è in alcun modo limitante, in quanto vi è la possibilità di ripetere rapidamente le analisi più volte cambiando la richiesta del numero di cluster e confrontando le soluzioni attraverso l esame di opportuni indicatori statistici. 24
25 Cluster analysis Metodi non gerarchici Algoritmo K-means 1. Il primo passo di tale metodo consiste nello specificare k punti iniziali (o seeds, detti anche semi o punti origine) ossia k punti nello spazio p-dimensionale: un punto iniziale per ciascun gruppo da costituire. 2. Ciascuna delle n unità viene assegnata provvisoriamente a un cluster il cui seed risulta il più vicino (sulla base della distanza minima). 3. Vengono calcolati i baricentri (o centroidi) dei k gruppi provvisori appena costruiti, cioè i valori medi delle p variabili nei gruppi. 4. Se la distanza minima non è ottenuta in corrispondenza del centroide del gruppo di appartenenza, si procede a riallocare l unità al cluster corrispondente al centroide più vicino. 5. Si procede in modo iterativo (rieseguendo lo step 3) a ricalcolare i centroidi e riallocare le unità fino a che non si raggiunge una configurazione stabile, ossia fino a che tutte le unità vengono riassegnate allo stesso gruppo del passo precedente. 25
26 Cluster analysis Metodi non gerarchici Algoritmo K-means 7 Dati di partenza Algoritmo K-means 7 Si inseriscono i due seed e si assegnano le unità Si calcolano i centroidi dei gruppi provvisori e si riassegnano le unità Si ricalcolano i centroidi e si riassegnano le unità; non essendoci modifiche nel raggruppamento il processo termina
27 Cluster analysis Metodi non gerarchici Il problema principale dell analisi è legato alla determinazione del numero di cluster (segmenti) più opportuno. Gli elementi utili per la scelta e l interpretazione della soluzione di cluster analysis non gerarchica sono: 1. numerosità delle osservazioni (dimensioni) di ciascun cluster; 2. tabella di analisi della varianza (o simili); 3. caratteristiche dei cluster individuati. Nel caso in cui uno o più di questi criteri non forniscano indicazioni soddisfacenti, occorre rilanciare la procedura di cluster analysis non gerarchica, modificando il numero di cluster richiesti. 27
28 Cluster analysis Metodi non gerarchici 1. Numerosità delle osservazioni (dimensioni) di ciascun cluster Le dimensioni di ciascun cluster dovrebbero essere preferibilmente omogenee o almeno non inferiori ad un limite che definisce la significatività operativa del cluster stesso (segmento). La presenza di segmenti formati da un numero ridottissimo di unità potrebbe segnalare la presenza di dati atipici (outlier) che andrebbero eliminati prima di lanciare la procedura o comunque trattati separatamente. Nella tabella è riportata la numerosità dei gruppi nella cluster analysis condotta sui cinque fattori ottenuti nell esempio esempio acquisto abbigliamento formale (ipotizzando di aver richiesto 3 cluster). Il risultato appare accettabile in quanto, tenendo conto del numero di osservazioni del data base di partenza (di cui occorre verificare la significatività statistica), la ripartizione nei cluster appare relativamente omogenea. 28
29 Cluster analysis Metodi non gerarchici 1. Numerosità delle osservazioni (dimensioni) di ciascun cluster Numerosità dei cluster Numero di casi in ogni cluster Cluster 1 28 Cluster 2 35 Cluster 3 37 Validi 100 Mancanti 0 29
30 Cluster analysis Metodi non gerarchici 2. Tabella di analisi della varianza I software applicativi forniscono alcune tabelle utili per valutare la qualità statistica della clusterizzazione. In genere viene proposta la tabella di analisi della varianza, che permette, tramite un test F su ciascuna variabile, di valutare la significatività della clusterizzazione. Le variabili che mostrano un livello di significatività osservato del test F inferiore alla soglia predefinita (tipicamente il 5%) presentano medie statisticamente diverse nei cluster. Nell esempio, il fattore prezzo non ha un importanza differenziata nei vari cluster (p-value superiore al 5%), potrebbe essere opportuno, compatibilmente con la significatività numerica dei cluster, cercare una soluzione con un numero più elevato di segmenti. 30
31 Cluster analysis Metodi non gerarchici 2. Tabella di analisi della varianza ANOVA Cluster Errore Media dei quadrati Gradi libertà Media dei quadrati Gradi libertà F Signif. Significatività esterna Praticità prodotto/ processo d acquisto Qualità prodotto Riconoscibilità interna Prezzo
32 Cluster analysis Metodi non gerarchici 2. Tabella di analisi della varianza Una soluzione di cluster analysis è accettabile quando tutte le variabili mostrano un test F significativo (e possibilmente omogeneo nel valore). Aumentando il numero di cluster, la significatività migliora globalmente. Se, nonostante l aumento del numero di cluster, il livello di significatività di una singola variabile non migliora, è possibile che tale variabile sia in realtà tendenzialmente omogenea nei suoi valori su tutto il campione, pertanto è preferibile eliminarla dalla procedura di clusterizzazione. Particolare attenzione deve essere posta sulla significatività delle variabili più rilevanti per la segmentazione dal punto di vista del marketing. 32
33 Cluster analysis Metodi non gerarchici 3. Caratteristiche dei cluster finali La tabella dei centri finali mostra la media dei cluster per ciascuna variabile utilizzata nella procedura. Grazie a questa tabella è possibile individuare le caratteristiche dei cluster rispetto alle variabili considerate e giudicare la leggibilità in termini di marketing dei cluster stessi. Centri dei cluster finali Cluster Riconoscibilità esterna Praticità prodotto/processo d acquisto Qualità prodotto Riconoscibilità interna Prezzo
34 Cluster analysis Metodi non gerarchici 3. Caratteristiche dei centri finali Considerando che le variabili utilizzate (componenti principali) sono variabili standardizzate (ovvero con media 0 e varianza 1), si può osservare che: il cluster 1 assegna un importanza relativamente elevata al fattore 2 (praticità) e bassa ai fattori 3 (qualità) e 4 (riconoscibilità interna); il cluster 2 risulta attento a quasi tutti gli aspetti del prodotto, in particolare alla qualità; il cluster 3 assegna un importanza relativamente elevata al fattore 4 (riconoscibilità interna) e bassa alla praticità e alla riconoscibilità esterna. 34


35 Quale metodo scegliere? Un esempio tratto dalle dispense del corso di statistica Multivariata della prof.ssa Rampichini



36

37
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che:
 Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Cluster Analysis Obiettivo: assegnazione di osservazioni a gruppi di unità statistiche non definiti a priori e tali che: le unità appartenenti ad uno di essi sono il più possibile omogenee i gruppi sono
Statistica per le ricerche di mercato
 Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2014/15 Prof.ssa Tiziana Laureti 01. Introduzione al corso 1 Statistica per le ricerche
Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2014/15 Prof.ssa Tiziana Laureti 01. Introduzione al corso 1 Statistica per le ricerche
Metodi di classificazione. Loredana Cerbara
 Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Loredana Cerbara I metodi di classificazione, anche detti in inglese cluster analysis, attengono alla categoria dei metodi esplorativi. Esistono centinaia di metodi di classificazione dei dati ed hanno
Statistica per le ricerche di mercato
 Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2012/13 Dr. Luca Secondi 01. Introduzione al corso 1 Statistica per le ricerche di mercato
Università degli studi della Tuscia Dipartimento di Economia e Impresa Statistica per le ricerche di mercato a.a. 2012/13 Dr. Luca Secondi 01. Introduzione al corso 1 Statistica per le ricerche di mercato
La matrice delle correlazioni è la seguente:
 Calcolo delle componenti principali tramite un esempio numerico Questo esempio numerico puó essere utile per chiarire il calcolo delle componenti principali e per introdurre il programma SPAD. IL PROBLEMA
Calcolo delle componenti principali tramite un esempio numerico Questo esempio numerico puó essere utile per chiarire il calcolo delle componenti principali e per introdurre il programma SPAD. IL PROBLEMA
ESERCIZIO 1. Vengono riportati di seguito i risultati di un analisi discriminante.
 ESERCIZIO 1. Vengono riportati di seguito i risultati di un analisi discriminante. Test di uguaglianza delle medie di gruppo SELF_EFF COLL_EFF COIN_LAV IMPEGNO SODDISF CAP_IST COLLEGHI Lambda di Wilks
ESERCIZIO 1. Vengono riportati di seguito i risultati di un analisi discriminante. Test di uguaglianza delle medie di gruppo SELF_EFF COLL_EFF COIN_LAV IMPEGNO SODDISF CAP_IST COLLEGHI Lambda di Wilks
COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING febbraio I
 COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING febbraio 2008 - I 1) Per un insieme di modelli di smartphone si sono costruiti i boxplot degli scostamenti standardizzati del prezzo e del peso ed
COGNOME E NOME MATR. ANALISI DEI DATI PER IL MARKETING febbraio 2008 - I 1) Per un insieme di modelli di smartphone si sono costruiti i boxplot degli scostamenti standardizzati del prezzo e del peso ed
Strategie top-down. Primitive di trasformazione top-down. Primitive di trasformazione top-down
 Strategie top-down A partire da uno schema che descrive le specifiche mediante pochi concetti molto astratti, si produce uno schema concettuale mediante raffinamenti successivi che aggiungono via via più
Strategie top-down A partire da uno schema che descrive le specifiche mediante pochi concetti molto astratti, si produce uno schema concettuale mediante raffinamenti successivi che aggiungono via via più
Analisi delle corrispondenze
 Capitolo 11 Analisi delle corrispondenze L obiettivo dell analisi delle corrispondenze, i cui primi sviluppi risalgono alla metà degli anni 60 in Francia ad opera di JP Benzécri e la sua equipe, è quello
Capitolo 11 Analisi delle corrispondenze L obiettivo dell analisi delle corrispondenze, i cui primi sviluppi risalgono alla metà degli anni 60 in Francia ad opera di JP Benzécri e la sua equipe, è quello
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione
 I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
I modelli lineari generalizzati per la tariffazione nel ramo RCA: applicazione Giuseppina Bozzo Giuseppina Bozzo Considerazioni preliminari La costruzione di un GLM è preceduta da alcune importanti fasi:
L A B C di R. Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010
 L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
5 La valutazione dell attività di ricerca dei dipartimenti
 5 La valutazione dell attività di ricerca dei dipartimenti La VQR aveva, tra i suoi compiti, quello di fornire alle istituzioni una graduatoria dei dipartimenti universitari in riferimento a ciascuna area
5 La valutazione dell attività di ricerca dei dipartimenti La VQR aveva, tra i suoi compiti, quello di fornire alle istituzioni una graduatoria dei dipartimenti universitari in riferimento a ciascuna area
ANALISI DEI DATI PER IL MARKETING 2014
 ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it ANALISI DELLE CORRISPONDENZE (cap. VII) Problema della riduzione delle dimensioni L ANALISI DELLE COMPONENTI PRINCIPALI
ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it ANALISI DELLE CORRISPONDENZE (cap. VII) Problema della riduzione delle dimensioni L ANALISI DELLE COMPONENTI PRINCIPALI
Cluster Analysis Distanze ed estrazioni Marco Perugini Milano-Bicocca
 Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Le Ricerche di Marketing rappresentano il necessario presupposto per la definizione di vincenti strategie di mercato, poiché forniscono il supporto
 Le Ricerche di Marketing rappresentano il necessario presupposto per la definizione di vincenti strategie di mercato, poiché forniscono il supporto di dati affidabili e accurati alle decisioni manageriali
Le Ricerche di Marketing rappresentano il necessario presupposto per la definizione di vincenti strategie di mercato, poiché forniscono il supporto di dati affidabili e accurati alle decisioni manageriali
Indicatori di Posizione e di Variabilità. Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica
 Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
Metodi computazionali per i Minimi Quadrati
 Metodi computazionali per i Minimi Quadrati Come introdotto in precedenza si considera la matrice. A causa di mal condizionamenti ed errori di inversione, si possono avere casi in cui il e quindi S sarebbe
Metodi computazionali per i Minimi Quadrati Come introdotto in precedenza si considera la matrice. A causa di mal condizionamenti ed errori di inversione, si possono avere casi in cui il e quindi S sarebbe
Analisi delle corrispondenze
 Analisi delle corrispondenze Obiettivo: analisi delle relazioni tra le modalità di due (o più) caratteri qualitativi Individuazione della struttura dell associazione interna a una tabella di contingenza
Analisi delle corrispondenze Obiettivo: analisi delle relazioni tra le modalità di due (o più) caratteri qualitativi Individuazione della struttura dell associazione interna a una tabella di contingenza
Capitolo 1. Analisi Discriminante. 1.1 Introduzione. 1.2 Un analisi discriminante Descrizione del dataset
 Capitolo 1 Analisi Discriminante 1.1 Introduzione L analisi discriminante viene condotta per definire una modalità di assegnazione dei casi a differenti gruppi, in funzione di una serie di variabili fra
Capitolo 1 Analisi Discriminante 1.1 Introduzione L analisi discriminante viene condotta per definire una modalità di assegnazione dei casi a differenti gruppi, in funzione di una serie di variabili fra
ESERCIZIO 1. Vengono riportati di seguito i risultati di una cluster analysis gerarchica.
 ESERCIZIO. Vengono riportati di seguito i risultati di una cluster analysis gerarchica. Programma di agglomerazione Stadio 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 Stadio di formazione accorpati del
ESERCIZIO. Vengono riportati di seguito i risultati di una cluster analysis gerarchica. Programma di agglomerazione Stadio 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 0 5 6 7 8 9 Stadio di formazione accorpati del
Corso di Laurea: Diritto per le Imprese e le istituzioni a.a Statistica. Statistica Descrittiva 3. Esercizi: 5, 6. Docente: Alessandra Durio
 Corso di Laurea: Diritto per le Imprese e le istituzioni a.a. 2016-17 Statistica Statistica Descrittiva 3 Esercizi: 5, 6 Docente: Alessandra Durio 1 Contenuti I quantili nel caso dei dati raccolti in classi
Corso di Laurea: Diritto per le Imprese e le istituzioni a.a. 2016-17 Statistica Statistica Descrittiva 3 Esercizi: 5, 6 Docente: Alessandra Durio 1 Contenuti I quantili nel caso dei dati raccolti in classi
Appunti su Indipendenza Lineare di Vettori
 Appunti su Indipendenza Lineare di Vettori Claudia Fassino a.a. Queste dispense, relative a una parte del corso di Matematica Computazionale (Laurea in Informatica), rappresentano solo un aiuto per lo
Appunti su Indipendenza Lineare di Vettori Claudia Fassino a.a. Queste dispense, relative a una parte del corso di Matematica Computazionale (Laurea in Informatica), rappresentano solo un aiuto per lo
Analisi della varianza
 Analisi della varianza Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona ANALISI DELLA VARIANZA - 1 Abbiamo k gruppi, con un numero variabile di unità statistiche.
Analisi della varianza Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona ANALISI DELLA VARIANZA - 1 Abbiamo k gruppi, con un numero variabile di unità statistiche.
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2
 - ESERCITAZIONE 2") CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2 Dott.ssa Antonella Costanzo a.costanzo@unicas.it TIPI DI MEDIA: GEOMETRICA, QUADRATICA, ARMONICA Esercizio 1. Uno scommettitore puntando una somma iniziale
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 2 Dott.ssa Antonella Costanzo a.costanzo@unicas.it TIPI DI MEDIA: GEOMETRICA, QUADRATICA, ARMONICA Esercizio 1. Uno scommettitore puntando una somma iniziale
L ALGORITMO DEL SIMPLESSO REVISIONATO
 L ALGORITMO DEL SIMPLESSO REVISIONATO L'algoritmo del simplesso revisionato costituisce una diversa implementazione dell algoritmo standard tesa a ridurre, sotto certe condizioni, il tempo di calcolo e
L ALGORITMO DEL SIMPLESSO REVISIONATO L'algoritmo del simplesso revisionato costituisce una diversa implementazione dell algoritmo standard tesa a ridurre, sotto certe condizioni, il tempo di calcolo e
Statistica. Campione
 1 STATISTICA DESCRITTIVA Temi considerati 1) 2) Distribuzioni statistiche 3) Rappresentazioni grafiche 4) Misure di tendenza centrale 5) Medie ferme o basali 6) Medie lasche o di posizione 7) Dispersione
1 STATISTICA DESCRITTIVA Temi considerati 1) 2) Distribuzioni statistiche 3) Rappresentazioni grafiche 4) Misure di tendenza centrale 5) Medie ferme o basali 6) Medie lasche o di posizione 7) Dispersione
Valori Medi. Docente Dott.ssa Domenica Matranga
 Valori Medi Docente Dott.ssa Domenica Matranga Valori medi Medie analitiche - Media aritmetica - Media armonica - Media geometrica - Media quadratica Medie di posizione - Moda -Mediana - Quantili La media
Valori Medi Docente Dott.ssa Domenica Matranga Valori medi Medie analitiche - Media aritmetica - Media armonica - Media geometrica - Media quadratica Medie di posizione - Moda -Mediana - Quantili La media
I metodi di Classificazione automatica
 L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
L Analisi Multidimensionale dei Dati Una Statistica da vedere I metodi di Classificazione automatica Matrici e metodi Strategia di AMD Anal Discrimin Segmentazione SI Per riga SI Matrice strutturata NO
Statistica. Alfonso Iodice D Enza
 Statistica Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () Statistica 1 / 33 Outline 1 2 3 4 5 6 () Statistica 2 / 33 Misura del legame Nel caso di variabili quantitative
Statistica Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () Statistica 1 / 33 Outline 1 2 3 4 5 6 () Statistica 2 / 33 Misura del legame Nel caso di variabili quantitative
La segmentazione del mercato. Cap 3
 La segmentazione del mercato Cap 3 Determinare i bisogni e i desideri dei consumatori Segmentazione E l insieme delle attività tese a determinare la suddivisione del mercato in gruppi di consumatori simili
La segmentazione del mercato Cap 3 Determinare i bisogni e i desideri dei consumatori Segmentazione E l insieme delle attività tese a determinare la suddivisione del mercato in gruppi di consumatori simili
RANKER: strumento software per il calcolo e la valutazione comparata di indici sintetici
 La misurazione di fenomeni multidimensionali: indici sintetici ed esperienze a confronto RANKER: strumento software per il calcolo e la valutazione comparata di indici sintetici Giulio Barcaroli, Marco
La misurazione di fenomeni multidimensionali: indici sintetici ed esperienze a confronto RANKER: strumento software per il calcolo e la valutazione comparata di indici sintetici Giulio Barcaroli, Marco
INTERPOLAZIONE. Introduzione
 Introduzione INTERPOLAZIONE Quando ci si propone di indagare sperimentalmente la legge di un fenomeno, nel quale intervengono due grandezze x, y simultaneamente variabili, e una dipendente dall altra,
Introduzione INTERPOLAZIONE Quando ci si propone di indagare sperimentalmente la legge di un fenomeno, nel quale intervengono due grandezze x, y simultaneamente variabili, e una dipendente dall altra,
La statistica. Elaborazione e rappresentazione dei dati Gli indicatori statistici. Prof. Giuseppe Carucci
 La statistica Elaborazione e rappresentazione dei dati Gli indicatori statistici Introduzione La statistica raccoglie ed analizza gruppi di dati (su cose o persone) per trarne conclusioni e fare previsioni
La statistica Elaborazione e rappresentazione dei dati Gli indicatori statistici Introduzione La statistica raccoglie ed analizza gruppi di dati (su cose o persone) per trarne conclusioni e fare previsioni
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva
 Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA
 ANALISI DELLA VARIANZA") PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA PROCEDURA/TECNICA DI ANALISI DEI DATI SPECIFICAMENTE DESTINATA A STUDIARE LA RELAZIONE TRA UNA VARIABILE NOMINALE (ASSUNTA
PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA PROCEDURA/TECNICA DI ANALISI DEI DATI SPECIFICAMENTE DESTINATA A STUDIARE LA RELAZIONE TRA UNA VARIABILE NOMINALE (ASSUNTA
Elementi di Statistica
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Analisi delle componenti principali
 Analisi delle componenti principali Serve a rappresentare un fenomeno k-dimensionale tramite un numero inferiore o uguale a k di variabili incorrelate, ottenute trasformando le variabili osservate Consiste
Analisi delle componenti principali Serve a rappresentare un fenomeno k-dimensionale tramite un numero inferiore o uguale a k di variabili incorrelate, ottenute trasformando le variabili osservate Consiste
Teoria e tecniche dei test
 Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Segmentazione e Marketing 121. Università di Bologna Andrea De Marco
 Segmentazione e Marketing 121 Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo con cui "raggruppiamo" in insiemi omogenei elementi
Segmentazione e Marketing 121 Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo con cui "raggruppiamo" in insiemi omogenei elementi
PROBLEMI ALGORITMI E PROGRAMMAZIONE
 PROBLEMI ALGORITMI E PROGRAMMAZIONE SCIENZE E TECNOLOGIE APPLICATE CLASSE SECONDA D PROGRAMMARE = SPECIFICARE UN PROCEDIMENTO CAPACE DI FAR SVOLGERE AD UNA MACCHINA UNA SERIE ORDINATA DI OPERAZIONI AL
PROBLEMI ALGORITMI E PROGRAMMAZIONE SCIENZE E TECNOLOGIE APPLICATE CLASSE SECONDA D PROGRAMMARE = SPECIFICARE UN PROCEDIMENTO CAPACE DI FAR SVOLGERE AD UNA MACCHINA UNA SERIE ORDINATA DI OPERAZIONI AL
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista
 Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
L ATTUARIO NELLA SPESA SANITARIA. Giovanna Ferrara 26 Ottobre 2015
 L ATTUARIO NELLA SPESA SANITARIA Giovanna Ferrara 26 Ottobre 2015 Settore privato 2 Indicatori di costo Distribuzione per età del costo delle prestazioni sanitarie - Annuari Statistici Costo 600 500 400
L ATTUARIO NELLA SPESA SANITARIA Giovanna Ferrara 26 Ottobre 2015 Settore privato 2 Indicatori di costo Distribuzione per età del costo delle prestazioni sanitarie - Annuari Statistici Costo 600 500 400
TECNICHE DI POSIZIONAMENTO
 TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
TECNICHE DI POSIZIONAMENTO Discriminant analysis: definizione di n (generalmente 2) funzioni lineari discriminanti, basate su valutazioni quantitative di attributi, utilizzate per posizionare oggetti (marche,
standardizzazione dei punteggi di un test
 DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
Segmentazione e Marketing 121
 Segmentazione e Marketing 121 Corso di Laurea in Informatica per il Management Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo
Segmentazione e Marketing 121 Corso di Laurea in Informatica per il Management Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo
STATISTICA AZIENDALE Modulo Controllo di Qualità
 STATISTICA AZIENDALE Modulo Controllo di Qualità A.A. 009/10 - Sottoperiodo PROA DEL 14 MAGGIO 010 Cognome:.. Nome: Matricola:.. AERTENZE: Negli esercizi in cui sono richiesti calcoli riportare tutte la
STATISTICA AZIENDALE Modulo Controllo di Qualità A.A. 009/10 - Sottoperiodo PROA DEL 14 MAGGIO 010 Cognome:.. Nome: Matricola:.. AERTENZE: Negli esercizi in cui sono richiesti calcoli riportare tutte la
Livello di misura Scala Nominale Scala Ordinale Scala di Rapporti. Scala Nominale
 Esercitazione Supponiamo che il collettivo che si vuole studiare sia composto da un gruppo di turisti. La seguente tabella raccoglie l osservazione di alcuni caratteri di interesse. Costo Soggetto Titolo
Esercitazione Supponiamo che il collettivo che si vuole studiare sia composto da un gruppo di turisti. La seguente tabella raccoglie l osservazione di alcuni caratteri di interesse. Costo Soggetto Titolo
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
4 Autovettori e autovalori
 4 Autovettori e autovalori 41 Cambiamenti di base Sia V uno spazio vettoriale tale che dim V n Si è visto in sezione 12 che uno spazio vettoriale ammette basi distinte, ma tutte con la medesima cardinalità
4 Autovettori e autovalori 41 Cambiamenti di base Sia V uno spazio vettoriale tale che dim V n Si è visto in sezione 12 che uno spazio vettoriale ammette basi distinte, ma tutte con la medesima cardinalità
DESCRITTIVE, TEST T PER IL CONFRONTO DELLE MEDIE DI CAMPIONI INDIPENDENTI.
 Corso di Laurea Specialistica in Biologia Sanitaria, Universita' di Padova C.I. di Metodi statistici per la Biologia, Informatica e Laboratorio di Informatica (Mod. B) Docente: Dr. Stefania Bortoluzzi
Corso di Laurea Specialistica in Biologia Sanitaria, Universita' di Padova C.I. di Metodi statistici per la Biologia, Informatica e Laboratorio di Informatica (Mod. B) Docente: Dr. Stefania Bortoluzzi
Statistica Esercitazione. alessandro polli facoltà di scienze politiche, sociologia, comunicazione
 Statistica Esercitazione alessandro polli facoltà di scienze politiche, sociologia, comunicazione Obiettivo Esercizio 1. Questo e alcuni degli esercizi che proporremo nei prossimi giorni si basano sul
Statistica Esercitazione alessandro polli facoltà di scienze politiche, sociologia, comunicazione Obiettivo Esercizio 1. Questo e alcuni degli esercizi che proporremo nei prossimi giorni si basano sul
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 3
 - ESERCITAZIONE 3") CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 3 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Sintesi a cinque e misure di variabilità rispetto ad un centro Una catena di fast-food ha selezionato
CORSO DI STATISTICA (parte 1) - ESERCITAZIONE 3 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Sintesi a cinque e misure di variabilità rispetto ad un centro Una catena di fast-food ha selezionato
Segmentazione di immagini in scala di grigio basata su clustering
 Segmentazione di immagini in scala di grigio basata su clustering Davide Anastasia, Nicola Cogotti 24 gennaio 06 1 Analisi del problema La segmentazione di immagini consiste nella suddivisione in un certo
Segmentazione di immagini in scala di grigio basata su clustering Davide Anastasia, Nicola Cogotti 24 gennaio 06 1 Analisi del problema La segmentazione di immagini consiste nella suddivisione in un certo
Proposta sistema elettorale per elezioni parlamentari
 Circolo PD Parigi Data: 11 Agosto 2013 Edizione: 2.0 Proposta sistema elettorale per elezioni parlamentari Questo documento illustra la proposta di un nuovo sistema elettorale pensato per l elezione legislativa
Circolo PD Parigi Data: 11 Agosto 2013 Edizione: 2.0 Proposta sistema elettorale per elezioni parlamentari Questo documento illustra la proposta di un nuovo sistema elettorale pensato per l elezione legislativa
Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale
 UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
Compiti tematici dai capitoli 2,3,4
 Compiti tematici dai capitoli 2,3,4 a cura di Giovanni M. Marchetti 2016 ver. 0.8 1. In un indagine recente, i rispondenti sono stati classificati rispetto al sesso, lo stato civile e l area geografica
Compiti tematici dai capitoli 2,3,4 a cura di Giovanni M. Marchetti 2016 ver. 0.8 1. In un indagine recente, i rispondenti sono stati classificati rispetto al sesso, lo stato civile e l area geografica
Intervallo di fiducia del coefficiente angolare e dell intercetta L intervallo di fiducia del coefficiente angolare (b 1 ) è dato da:
 è dato da:") Analisi chimica strumentale Intervallo di fiducia del coefficiente angolare e dell intercetta L intervallo di fiducia del coefficiente angolare (b 1 ) è dato da: (31.4) dove s y è la varianza dei valori
Analisi chimica strumentale Intervallo di fiducia del coefficiente angolare e dell intercetta L intervallo di fiducia del coefficiente angolare (b 1 ) è dato da: (31.4) dove s y è la varianza dei valori
Statistica 1 A.A. 2015/2016
 Corso di Laurea in Economia e Finanza Statistica 1 A.A. 2015/2016 (8 CFU, corrispondenti a 48 ore di lezione frontale e 24 ore di esercitazione) Prof. Luigi Augugliaro 1 / 27 Numeri indici e rapporti statistici
Corso di Laurea in Economia e Finanza Statistica 1 A.A. 2015/2016 (8 CFU, corrispondenti a 48 ore di lezione frontale e 24 ore di esercitazione) Prof. Luigi Augugliaro 1 / 27 Numeri indici e rapporti statistici
3.3 FORMULAZIONE DEL MODELLO E CONDIZIONI DI
 3.3 FORMULAZIONE DEL MODELLO E CONDIZIONI DI ESISTENZA DI UN PUNTO DI OTTIMO VINCOLATO Il problema di ottimizzazione vincolata introdotto nel paragrafo precedente può essere formulato nel modo seguente:
3.3 FORMULAZIONE DEL MODELLO E CONDIZIONI DI ESISTENZA DI UN PUNTO DI OTTIMO VINCOLATO Il problema di ottimizzazione vincolata introdotto nel paragrafo precedente può essere formulato nel modo seguente:
La variabilità. Dott. Cazzaniga Paolo. Dip. di Scienze Umane e Sociali
 Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione [1/2] Gli indici di variabilità consentono di riassumere le principali caratteristiche di una distribuzione (assieme alle medie) Le
Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione [1/2] Gli indici di variabilità consentono di riassumere le principali caratteristiche di una distribuzione (assieme alle medie) Le
ANALISI DEI DATI PER IL MARKETING 2014
 ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
ANALISI DEI DATI PER IL MARKETING 2014 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE CAP IX, pp.367-457 Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis
Scale di Misurazione Lezione 2
 Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Strutture dati e loro organizzazione. Gabriella Trucco
 Strutture dati e loro organizzazione Gabriella Trucco Introduzione I linguaggi di programmazione di alto livello consentono di far riferimento a posizioni nella memoria principale tramite nomi descrittivi
Strutture dati e loro organizzazione Gabriella Trucco Introduzione I linguaggi di programmazione di alto livello consentono di far riferimento a posizioni nella memoria principale tramite nomi descrittivi
Elementi di Probabilità e Statistica
 Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
Analisi statistica e matematico-finanziaria II. Alfonso Iodice D Enza Università degli studi di Cassino e del Lazio Meridionale
 delle sui delle Analisi statistica e matematico-finanziaria II Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino e del Lazio Meridionale sulle particolari ali dei dati Outline
delle sui delle Analisi statistica e matematico-finanziaria II Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino e del Lazio Meridionale sulle particolari ali dei dati Outline
STATISTICA 1 ESERCITAZIONE 6
 STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
STATISTICA 1 ESERCITAZIONE 6 Dott. Giuseppe Pandolfo 5 Novembre 013 CONCENTRAZIONE Osservando l ammontare di un carattere quantitativo trasferibile su un collettivo statistico può essere interessante sapere
Capitolo 12. Suggerimenti agli esercizi a cura di Elena Siletti. Esercizio 12.1: Suggerimento
 Capitolo Suggerimenti agli esercizi a cura di Elena Siletti Esercizio.: Suggerimento Per verificare se due fenomeni sono dipendenti in media sarebbe necessario confrontare le medie condizionate, in questo
Capitolo Suggerimenti agli esercizi a cura di Elena Siletti Esercizio.: Suggerimento Per verificare se due fenomeni sono dipendenti in media sarebbe necessario confrontare le medie condizionate, in questo
Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari"
 Levine, Krehbiel, Berenson Statistica Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari" Unità Integrata Organizzativa
Levine, Krehbiel, Berenson Statistica Capitolo 5 Variabili aleatorie discrete notevoli Insegnamento: Statistica Applicata Corso di Laurea in "Scienze e Tecnologie Alimentari" Unità Integrata Organizzativa
MISURE DI SINTESI 54
 MISURE DI SINTESI 54 MISURE DESCRITTIVE DI SINTESI 1. MISURE DI TENDENZA CENTRALE 2. MISURE DI VARIABILITÀ 30 0 µ Le due distribuzioni hanno uguale tendenza centrale, ma diversa variabilità. 30 0 Le due
MISURE DI SINTESI 54 MISURE DESCRITTIVE DI SINTESI 1. MISURE DI TENDENZA CENTRALE 2. MISURE DI VARIABILITÀ 30 0 µ Le due distribuzioni hanno uguale tendenza centrale, ma diversa variabilità. 30 0 Le due
Statistica. Alfonso Iodice D Enza
 Statistica Alfonso Iodice D Enza iodicede@gmail.com Università degli studi di Cassino () Statistica 1 / 24 Outline 1 2 3 4 5 () Statistica 2 / 24 Dipendenza lineare Lo studio della relazione tra caratteri
Statistica Alfonso Iodice D Enza iodicede@gmail.com Università degli studi di Cassino () Statistica 1 / 24 Outline 1 2 3 4 5 () Statistica 2 / 24 Dipendenza lineare Lo studio della relazione tra caratteri
Statistica Descrittiva Soluzioni 3. Medie potenziate
 ISTITUZIONI DI STATISTICA A. A. 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
ISTITUZIONI DI STATISTICA A. A. 2007/2008 Marco Minozzo e Annamaria Guolo Laurea in Economia del Commercio Internazionale Laurea in Economia e Amministrazione delle Imprese Università degli Studi di Verona
Guida al calcolo del maggior ricavo o compenso per i contribuenti non soggetti agli studi di settore o ai parametri. (art. 7, Legge n.
 Guida al calcolo del maggior ricavo o compenso per i contribuenti non soggetti agli studi di settore o ai parametri (art. 7, Legge n. 289 del 2002) Di seguito sono riportate le informazioni utili al contribuente
Guida al calcolo del maggior ricavo o compenso per i contribuenti non soggetti agli studi di settore o ai parametri (art. 7, Legge n. 289 del 2002) Di seguito sono riportate le informazioni utili al contribuente
RISOLUZIONE APPROSSIMATA DI UN EQUAZIONE
 RISOLUZIONE APPROSSIMATA DI UN EQUAZIONE Introduzione Si vogliano individuare, se esistono, le radici o soluzioni dell equazione f(x)=0. Se f(x) è un polinomio di grado superiore al secondo o se è una
RISOLUZIONE APPROSSIMATA DI UN EQUAZIONE Introduzione Si vogliano individuare, se esistono, le radici o soluzioni dell equazione f(x)=0. Se f(x) è un polinomio di grado superiore al secondo o se è una
Indicatori compositi. Dott. Cazzaniga Paolo. Dip. di Scienze Umane e Sociali
 Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Indicatori [1/4] Gli indicatori: sintetizzano le caratteristiche di un fenomeno colgono aspetti e problemi del fenomeno che non hanno una immediata
Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Indicatori [1/4] Gli indicatori: sintetizzano le caratteristiche di un fenomeno colgono aspetti e problemi del fenomeno che non hanno una immediata
Maria Brigida Ferraro + Luca Tardella
 Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
Cluster Maria Brigida Ferraro + Luca Tardella e-mail: mariabrigida.ferraro@uniroma1.it, ferraromb@gmail.com Lezione #3: Cluster Obiettivi del modulo Cluster 1 Introduzione ai problemi di classificazione
Metodologia Sperimentale Agronomica / Metodi Statistici per la Ricerca Ambientale
 DIPARTIMENTO DI SCIENZE AGRARIE E AMBIENTALI PRODUZIONE, TERRITORIO, AGROENERGIA Marco Acutis marco.acutis@unimi.it www.acutis.it CdS Scienze della Produzione e Protezione delle Piante (g59) CdS Biotecnologie
DIPARTIMENTO DI SCIENZE AGRARIE E AMBIENTALI PRODUZIONE, TERRITORIO, AGROENERGIA Marco Acutis marco.acutis@unimi.it www.acutis.it CdS Scienze della Produzione e Protezione delle Piante (g59) CdS Biotecnologie
Corso di Psicometria Progredito
 Corso di Psicometria Progredito 4.1 I principali test statistici per la verifica di ipotesi: Il test t Gianmarco Altoè Dipartimento di Pedagogia, Psicologia e Filosofia Università di Cagliari, Anno Accademico
Corso di Psicometria Progredito 4.1 I principali test statistici per la verifica di ipotesi: Il test t Gianmarco Altoè Dipartimento di Pedagogia, Psicologia e Filosofia Università di Cagliari, Anno Accademico
Excel. È data la distribuzione di 1863 famiglie italiane secondo il numero di componenti:
 Excel È data la distribuzione di 1863 famiglie italiane secondo il numero di componenti: Calcolare per ogni classe della distribuzione: (a) le frequenze relative; Sia data la distribuzione degli studenti
Excel È data la distribuzione di 1863 famiglie italiane secondo il numero di componenti: Calcolare per ogni classe della distribuzione: (a) le frequenze relative; Sia data la distribuzione degli studenti
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati.
 La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Obiettivi Strumenti Cosa ci faremo? Probabilità, distribuzioni campionarie. Stimatori. Indici: media, varianza,
 Obiettivi Strumenti Cosa ci faremo? inferenza Probabilità, distribuzioni campionarie uso stima Stimatori significato teorico descrizione Indici: media, varianza, calcolo Misure di posizione e di tendenza
Obiettivi Strumenti Cosa ci faremo? inferenza Probabilità, distribuzioni campionarie uso stima Stimatori significato teorico descrizione Indici: media, varianza, calcolo Misure di posizione e di tendenza
Il teorema di Rouché-Capelli
 Luciano Battaia Questi appunti (1), ad uso degli studenti del corso di Matematica (A-La) del corso di laurea in Commercio Estero dell Università Ca Foscari di Venezia, campus di Treviso, contengono un
Luciano Battaia Questi appunti (1), ad uso degli studenti del corso di Matematica (A-La) del corso di laurea in Commercio Estero dell Università Ca Foscari di Venezia, campus di Treviso, contengono un
La regressione lineare. Rappresentazione analitica delle distribuzioni
 La regressione lineare Rappresentazione analitica delle distribuzioni Richiamiamo il concetto di dipendenza tra le distribuzioni di due caratteri X e Y. Ricordiamo che abbiamo definito dipendenza perfetta
La regressione lineare Rappresentazione analitica delle distribuzioni Richiamiamo il concetto di dipendenza tra le distribuzioni di due caratteri X e Y. Ricordiamo che abbiamo definito dipendenza perfetta
Regressione Lineare Multipla
 Regressione Lineare Multipla Fabio Ruini Abstract La regressione ha come scopo principale la previsione: si mira, cioè, alla costruzione di un modello attraverso cui prevedere i valori di una variabile
Regressione Lineare Multipla Fabio Ruini Abstract La regressione ha come scopo principale la previsione: si mira, cioè, alla costruzione di un modello attraverso cui prevedere i valori di una variabile
Strumenti informatici Realizzare un test z, un test t e un test F per campioni indipendenti con Excel e SPSS
 Strumenti informatici 5.2 - Realizzare un test z, un test t e un test F per campioni indipendenti con Excel e SPSS Sia Excel che SPSS consentono di realizzare in modo abbastanza rapido il test sulle medie
Strumenti informatici 5.2 - Realizzare un test z, un test t e un test F per campioni indipendenti con Excel e SPSS Sia Excel che SPSS consentono di realizzare in modo abbastanza rapido il test sulle medie
Introduzione alla programmazione Esercizi risolti
 Esercizi risolti 1 Esercizio Si determini se il diagramma di flusso rappresentato in Figura 1 è strutturato. A B C D F E Figura 1: Diagramma di flusso strutturato? Soluzione Per determinare se il diagramma
Esercizi risolti 1 Esercizio Si determini se il diagramma di flusso rappresentato in Figura 1 è strutturato. A B C D F E Figura 1: Diagramma di flusso strutturato? Soluzione Per determinare se il diagramma
Statistica multivariata 27/09/2016. D.Rodi, 2016
 Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Indici di variabilità relativa
 Fonti e strumenti statistici per la comunicazione Prof.ssa Isabella Mingo A.A. 2014-2015 Indici di variabilità relativa Consentono di effettuare confronti sulla variabilità di fenomeni che presentano unità
Fonti e strumenti statistici per la comunicazione Prof.ssa Isabella Mingo A.A. 2014-2015 Indici di variabilità relativa Consentono di effettuare confronti sulla variabilità di fenomeni che presentano unità
Variabilità o Dispersione Definizione Attitudine di un fenomeno ad assumere diverse modalità
 Punti deboli della media aritmetica Robustezza: sensibilità ai valori estremi Non rappresentava nei confronti di distribuzioni asimmetriche. La media aritmetica è un valore rappresentativo nei confronti
Punti deboli della media aritmetica Robustezza: sensibilità ai valori estremi Non rappresentava nei confronti di distribuzioni asimmetriche. La media aritmetica è un valore rappresentativo nei confronti
Fondamenti di Informatica 6. Algoritmi e pseudocodifica
 Vettori e matrici #1 Fondamenti di Informatica 6. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile A.A. 2010-2011 1 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
Vettori e matrici #1 Fondamenti di Informatica 6. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile A.A. 2010-2011 1 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
Clustering Mario Guarracino Data Mining a.a. 2010/2011
 Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Clustering Introduzione Il raggruppamento di popolazioni di oggetti (unità statistiche) in base alle loro caratteristiche (variabili) è da sempre oggetto di studio: classificazione delle specie animali,
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
MODELLI DI SVALUTAZIONE
 Milano, 8 aprile 2014 MODELLI DI SVALUTAZIONE Metodologie e problematiche di applicazione al confidi INDICE Contesto di riferimento ed obiettivo dell intervento Approccio metodologico proposto FASE 1 -
Milano, 8 aprile 2014 MODELLI DI SVALUTAZIONE Metodologie e problematiche di applicazione al confidi INDICE Contesto di riferimento ed obiettivo dell intervento Approccio metodologico proposto FASE 1 -
3.1 Classificazione dei fenomeni statistici Questionari e scale di modalità Classificazione delle scale di modalità 17
 C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
DALL ANALISI DI SETTORE ALL ANALISI DEI CONCORRENTI
 DALL ANALISI DI SETTORE ALL ANALISI DEI CONCORRENTI CAPITOLO QUARTO Grant R. L analisi strategica per le decisioni aziendali, Il Mulino, Bologna, 1999 1 L ANALISI DEI CONCORRENTI Per alcune imprese, la
DALL ANALISI DI SETTORE ALL ANALISI DEI CONCORRENTI CAPITOLO QUARTO Grant R. L analisi strategica per le decisioni aziendali, Il Mulino, Bologna, 1999 1 L ANALISI DEI CONCORRENTI Per alcune imprese, la