Esame di Architetture Canale MZ Prof. Sterbini 8/6/15
|
|
|
- Prospero Turco
- 6 anni fa
- Visualizzazioni
Transcript
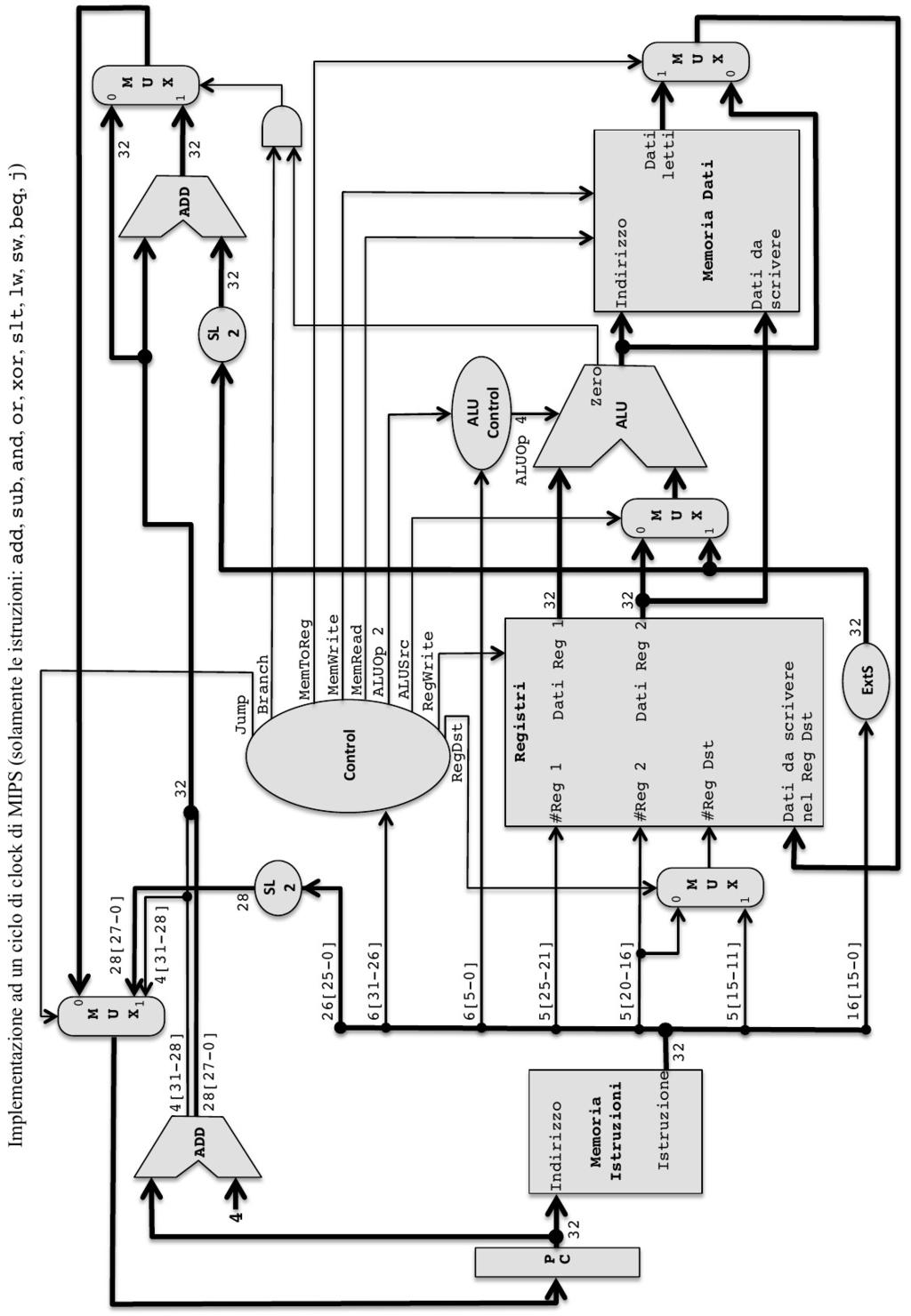
1 Esame di Architetture Canale MZ Prof. Sterbini 8/6/15 Cognome e Nome: Matricola: Parte 1 (per chi non ha superato l'esonero 1 ora) Esercizio 1 (14 punti). In una partita di CPU a ciclo di clock singolo (vedi sul retro) la Control Unit potrebbe essere rotta, producendo il segnale di controllo ALUSrc attivo se e solo se NON è attivo MemRead. Si assume che RegDst sia asserito solo per le istruzioni di tipo R e che MemRead e MemToReg siano asseriti solo per l istruzione lw. a) Si indichino qui sotto quali delle istruzioni base (lw, sw, add, sub, and, or, xor, slt, beq, j, li, addi) funzioneranno male, perché, e quali sono i comportamenti diversi. Soluzione La CPU rotta produrrà solo le due combinazioni di segnali MemRead=0 e ALUSrc=1 oppure MemRead=1 e ALUSrc=0 e quindi le istruzioni che funzioneranno male sono quelle che devono avere la coppia di segnali ALUSrc e MemRead uguali: beq di tipo R lw confronterà $rs con il valore della parte immediata invece che $rt diventeranno istruzioni immediate leggerà il dato dall'indirizzo $rs+$rt invece che da $rs + parte immediata b) si scriva qui sotto un breve programma assembly MIPS (senza pseudoistruzioni) che termina valorizzando il registro $s0 con il valore 1 se il processore è guasto, altrimenti con 0. Soluzione Possiamo sfruttare la lw che legge dal posto sbagliato ad esempio con il frammento di programma li $s0, 1 sw $zero, 12($zero) # un qualsiasi offset diverso da 1 e dalle due word vicine sw $s0, 1($zero) # la costante deve essere uguale al valore di $s0 lw $s0, 12($zero) # se rotta legge da 1 altrimenti da 12 Esercizio 2 (16 punti). Considerate l architettura MIPS a ciclo singolo in figura (diagramma sul retro). Vogliamo aggiungere l'istruzione di tipo I b_odd_sum rs, rt, label (branch if sum is odd) che esegue un salto condizionato all'indirizzo (relativo) corrispondente a label se la somma $rs+$rt è un valore dispari. 1) modificate il diagramma mostrando gli eventuali altri componenti necessari a realizzare l'istruzione 2) indicate sul diagramma i segnali di controllo necessari a realizzare l'istruzione 3) supponendo che l'accesso alle memorie impieghi 75ns, l'accesso ai registri 25ns, le operazioni dell'alu e dei sommatori 150ns, e ignorando gli altri ritardi di propagazione dei segnali, indicate sul diagramma la durata totale del ciclo di clock per permettere l'esecuzione della nuova istruzione e se la durata totale del ciclo di clock necessario è aumentata rispetto alla CPU senza la nuova istruzione Soluzione Per determinare se la somma è dispari basta prendere il bit meno significativo (LSB) del risultato dell'alu. La logica del salto relativo è già presente, per attivarla basta mettere in AND il segnale LSB col (nuovo) segnale b_add_odd da far generare alla CU e quindi metterlo in OR all'ingresso del MUX che abilita il salto relativo. Segnali della CU: b_add_odd=1, branch=0, jump=0, MemToReg=X, MemWrite=0, MemRead=X, AluOp=ADD, ALUSrc=0, RegWrite=0, RegDst=X Tempi: (qua sotto due dataflow della istruzione e dell'aggiornamento del PC che avvengono in parallelo) Fetch = 75ns, ID=25ns, EX=150ns => 250ns Tempo della istruzione = 300ns < 350 della LW PC+4 = 150ns, Salto relativo= 150ns => 300ns Quindi NON va aumentato il periodo del clock
2
3 Esame di Architetture Canale MZ Prof. Sterbini 8/6/15 Cognome e Nome: Matricola: Parte 2 (per tutti 2 ore) Esercizio 3 (16 punti). Considerate l'architettura MIPS con pipeline mostrata in figura (sul retro) ed il frammento di programma qui sotto che calcola l'istogramma della frequenza dei caratteri di un testo. NOTA: sono presenti solo le unità di forwarding presenti nella figura (sul retro). NOTA: assumete che tutte le istruzioni usate nel programma siano di base (nessuna pseudoistruzione). Indicate: 1) tra quali istruzioni sono presenti data hazard, 2) tra quali istruzioni sono presenti control hazard, 3) tra quali istruzioni sono necessari stalli (data e control) (con forwarding) 4) indicate il contenuto della pipeline (quali istruzioni si trovano in quali fasi) alla fine dello 8 colpo di clock (con forwarding) stallo in WB beqz in MEM add in EXE lw in ID stallo in IF 5) quanti cicli di clock sono necessari a eseguire tutto il programma (con forwarding) x(8+3)+3+2+1=13+286=299 Le istruzioni eseguite in totale sono 3+26x(8)+3=6+208=214 quindi in media abbiamo 299/214=1.39 CPI.data TESTO:.asciiz vediamo se oggi me la cavo HISTO:.word 0:256 # istogramma.text main: la $a1, HISTO(0) # indir. dell'istogr. la $a0, TESTO(0) # indir. del testo 0 stalli> next: lb $t1, ($a0) # c = TESTO[i] 2 stalli(la beqz è anticipata alla fase ID)> beqz $t1, fine # se testo finito 1 stallo solo sul salto> add $t2, $a1, $t1 # addr. HISTO[c] 0 stalli> lw $t3, ($t2) # X = HISTO[c] 1 stalli> addi $t3, $t3, 1 # X += 1 0 stalli> sw $t3, ($t2) # HISTO[c] = X addi $a0, $a0, 1 # addr. prox carattere 0 stalli sul lb seguente > j next fine: li $v0, 10 6) quanti ne sarebbero necessari se il forwarding non esistesse Se il FW non esiste allora ogni data-hazard inserisce sempre 2 stalli tranne quello tra addi $a0, $a0, 1 e la lb che contiene la j e quindi inserisce un solo stallo x(8+9)+3+2+1= =457 (in media 457/214=2.13 CPI) 7) riordinate le istruzioni per ridurre al massimo gli stalli (mantenendo invariata la sua semantica) E' possibile spostare l'istruzione addi $a0, $a0, 1 indietro ed eliminare 1 stallo tra lw e addi $t3, $t3, 1 (non conviene spostare add $t2, $a1, $t1 prima del beqz perché la semantica cambia (poco ma cambia)) 8) calcolate quanti cicli di clock sono necessari a eseguire il programma così ottimizzato (con forwarding) x(8+2)+3+2+1=13+260=273 (in media 273/214=1.27 CPI)

4
5 Esame di Architetture Canale MZ Prof. Sterbini 8/6/15 Esercizio 4 (14 punti). cache a due livelli Sia data una gerarchia di memoria con due livelli di cachecome in figura, - La cache L1 è set-associativa a 2 vie con blocchi da 2 word 4 set per ogni via politica di sostituzione LRU - La cache L2 è set-associativa a 4 vie con blocchi da 16 word 2 set per ogni via politica di sostituzione LRU 1) Per la seguente sequenza di accessi si determinino quali sono gli HIT/MISS sui due livelli di cache 2) per ciascuna MISS indicate se è di tipo Caricamento (L), Capacità (Cap) o Conflitto (Conf) 3) calcolate le dimensioni in bit delle due cache compresi i bit di controllo 4) calcolate il tempo medio di accesso (su questa sequenza) se: - tempo di HIT su L1 = 1.5 ns MEM - tempo di HIT su L2 = 15 ns - tempo di accesso a RAM = 75 ns 5) calcolate il numero di istruzioni corrispondente al tempo medio di accesso, se il processore ha una frequenza di clock di 2 GHz e completa una istruzione ogni 3 colpi di clock.. Indirizzo #blocco L Tag Index HIT/MISS M M M H M M M M M M H M M Tipo MISS L L L L L Conf L L Conf L L #blocco L Tag Index HIT/MISS M M M M H H H H H M H Tipo MISS L L L L L CPU L1 L2 Tempo: 2 x Hit1 + 6 x Hit2 + 5 x RAM = 2 x x x 75 = 468 ns Tempo medio di accesso: 468/13 = 36 ns Periodo di clock: 1/2*10^9 s = 0.5 ns Tempo di una istruzione: 3*0.5 = 1.5 ns Tempo di accesso medio misurato in numero di istruzioni: 36 / 1.5 = 24 istruzioni
6 Esame di Architetture Canale MZ Prof. Sterbini 8/6/15 Parte 3 (assembler) Esercizio 5 (30 punti se corretto e ricorsivo, 18 se corretto e iterativo, 0 se non funziona). Vanno svolti sia la funzione 1) che il main 2) 1) Si realizzi la funzione RICORSIVA ricercabinaria che riceve come argomenti: - dati: indirizzo di un vettore contenente elementi interi ORDINATO - inizio: indice del primo elemento del vettore a partire dal quale bisogna cercare - N: il numero di elementi tra cui cercare - X: un numero intero da cercare e cerca con la ricerca dicotomica la posizione del valore X nel vettore dati nel segmento [inizio.. inizio+n-1] e torna - l'indice della posizione di X in V se X è presente in V - il valore -1 se X NON è presente INOLTRE DURANTE LA RICERCA STAMPA LE POSIZIONI DEGLI ELEMNTI ESAMINATI Esempio Input: N: 9 inizio: 0 dati: 1, 45, 97, 97, 100, 122, 300, 900, 2000 X: 97 risultato: 2 (E STAMPA LE POSIZIONI 4 1 2) Esempio di algoritmo ricorsivo da realizzare: - se N=0 non si è trovato il numero, tornare -1 - se N>0 si esamina l'elemento in posizione Y=inizio+N/2 (divisione intera) E SI STAMPA Y SEGUITO DA SPAZIO: se è uguale a X si torna la sua posizione Y se è minore di X si esegue la ricerca sulla metà del vettore che segue la posizione Y (inizia dalla posizione Y+1 e contiene N-Z-1 elementi, con Z=N/2) se è maggiore di X si esegue la ricerca sulla metà del vettore che precede la posizione Y (inizia dalla posizione inizio e contiene Z=N/2 elementi) 2) Si realizzi un programma main che usa la funzione ricercabinaria e che: - legge da stdin: - il valore 0<M<=100 di elementi da inserire in un vettore - la successione di M valori interi ORDINATI e la memorizza nel vettore dati - il valore X da cercare - chiama la funzione ricercabinaria passando gli argomenti M, indirizzo di dati, X e inizio=0 - stampa il risultato
7 Soluzione.globl main.data DATI:.word 0:100.text # $a0: indirizzo del vettore # $a1: indice dell'inizio della parte da cercare # $a2: lunghezza L della parte da cercare # $a3: elemento da cercare X ricercabinaria: bgtz $a2, casoricorsivo # altrimenti la lunghezza è 0 e non lo si è trovato li $v0, -1 # torno -1 jr $ra # torno dalla funzione a chi l'ha chiamata casoricorsivo: subi $sp, $sp, 8 # alloco due word su stack ($a0 mi serve per le stampe) sw $ra, 0($sp) # preservo $ra sw $a0, 4($sp) # preservo $a0 srl $t0, $a2, 1 # Z=L/2 add $t1, $t0, $a1 # indice dell'elemento da esaminare Y=inizio+Z move $a0, $t1 # stampo Y li $v0, 1 # print integer li $a0, ' ' # stampo uno spazio li $v0, 11 # print char lw $a0, 4($sp) # ripristino $a0 dopo le stampe sll $t2, $t1, 2 # calcolo l'offset corrispondente nel vettore add $t2, $t2, $a0 # indirizzo in memoria dell'elemento lw $t2, ($t2) # leggo l'elemento beq $t2, $a3, trovato # se l'ho trovato ne torno la posizione $t1 bgt $t2, $a3, sinistra # se è maggiore di X cerco a sinistra blt $t2, $a3, destra # se è minore di X cerco a destra trovato: move $v0, $t1 # posizione Y dell'elemento trovato nel vettore ritorno: # tutti i casi ricorsivi tornano da qui lw $ra, 0($sp) # ripristino $ra lw $a0, 4($sp) # ripristino $a0 addi $sp, $sp, 8 # disalloco le 2 word da stack jr $ra # torno al chiamante
8 sinistra: move $a2, $t0 # se cerco a sinistra l'inizio resta uguale, la lunghezza è Z=N/2 jal ricercabinaria j ritorno # vado a disallocare stack e ritorno dalla funzione destra: addi $a1, $t1, 1 # se cerco a destra l'inizio è Y+1 sub $a2, $a2, $t0 # e il numero di elementi è L-Z-1 subi $a2, $a2, 1 jal ricercabinaria j ritorno # vado a disallocare stack e ritorno dalla funzione main: li $v0, 5 # read integer move $t0, $v0 # numero di elementi da leggere li $t1, 0 # indice ciclo: li $v0, 5 # read integer sll $t2, $t1, 2 # offset nel vettore sw $v0, DATI($t2) # memorizzo addi $t1, $t1, 1 # prossimo blt $t1, $t0, ciclo # se ancora non si è finito il ciclo la $a0, DATI # indirizzo del vettore DATI li $a1, 0 # si inizia dall'elemento 0 move $a2, $t0 # L li $v0, 5 # read integer move $a3, $v0 # X jal ricercabinaria move $t0, $v0 # mi salvo un attimo il risultato li $a0, '\n' # stampo accapo li $v0, 11 # print char move $a0, $t0 # recupero il risultato li $v0, 1 # print integer li $v0, 10 # end program
Esame di Architetture Canale AL Prof. Sterbini 8/7/13 Compito A
 Esame di Architetture Canale AL Prof. Sterbini 8/7/13 Compito A Esercizio 1A. Si ha il dubbio che in una partita di CPU a ciclo di clock singolo (vedi sul retro) la Control Unit sia rotta, producendo il
Esame di Architetture Canale AL Prof. Sterbini 8/7/13 Compito A Esercizio 1A. Si ha il dubbio che in una partita di CPU a ciclo di clock singolo (vedi sul retro) la Control Unit sia rotta, producendo il
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
ESERCIZIO 1 Si consideri la seguente funzione f (A, B, C, D) non completamente specificata definita attraverso il suo ON-SET e DC-SET:
 non completamente specificata definita attraverso il suo ON-SET e DC-SET:") Università degli Studi di Milano Corso Architettura degli elaboratori e delle reti Prof. Cristina Silvano A.A. 2004/2005 Esame scritto del 15 luglio 2005 Cognome: Matricola: Nome: Istruzioni Scrivere solo
Università degli Studi di Milano Corso Architettura degli elaboratori e delle reti Prof. Cristina Silvano A.A. 2004/2005 Esame scritto del 15 luglio 2005 Cognome: Matricola: Nome: Istruzioni Scrivere solo
Il Processore: l Unità di Controllo Principale Barbara Masucci
 Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
L'architettura del processore MIPS
 L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
Esercitazione su Instruction Level Parallelism
 Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Architettura degli Elaboratori. Classe 3 Prof.ssa Anselmo. Appello del 18 Febbraio Attenzione:
 Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 18 Febbraio 2015 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 18 Febbraio 2015 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Instruction Level Parallelism Andrea Gasparetto
 Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Implementazione semplificata
 Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Le etichette nei programmi. Istruzioni di branch: beq. Istruzioni di branch: bne. Istruzioni di jump: j
 L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
Istruzioni di trasferimento dati
 Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
Esercitazione su Instruction Level Parallelism Salvatore Orlando
 Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Richiami sull architettura del processore MIPS a 32 bit
 Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Riassunto. Riassunto. Ciclo fetch&execute. Concetto di programma memorizzato. Istruzioni aritmetiche add, sub, mult, div
 MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
Richiami sull architettura del processore MIPS a 32 bit
 Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Progettazione dell unità di elaborazioni dati e prestazioni. Il processore: unità di elaborazione. I passi per progettare un processore
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Architettura degli Elaboratori. Classe 3 Prof.ssa Anselmo. Appello del 19 Febbraio Attenzione:
 Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 19 Febbraio 2016 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 19 Febbraio 2016 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
1. Si effettui la divisione di 7/5 utilizzando un efficiente algoritmo e illustrando la corrispondente architettura hardware.
 1. Si effettui la divisione di 7/5 utilizzando un efficiente algoritmo e illustrando la corrispondente architettura hardware. 2. Spiegare i diversi tipi di indirizzamento usati dalle istruzioni del set
1. Si effettui la divisione di 7/5 utilizzando un efficiente algoritmo e illustrando la corrispondente architettura hardware. 2. Spiegare i diversi tipi di indirizzamento usati dalle istruzioni del set
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Istruzioni assembler Istruzione N Registri
 Istruzioni assembler Istruzione N Registri Aritmetica add a, b, c a = b+c addi a, b, num a = b + sub a, b, c a = b - c mul a, b, c a = b*c div a, b, c a = b/c utilizzati Descrizione 3 Somma. Somma b e
Istruzioni assembler Istruzione N Registri Aritmetica add a, b, c a = b+c addi a, b, num a = b + sub a, b, c a = b - c mul a, b, c a = b*c div a, b, c a = b/c utilizzati Descrizione 3 Somma. Somma b e
Programmi in Assembly
 Programmi in Assembly Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/23 Esempio Numeri positivi # Programma che copia tramite
Programmi in Assembly Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/23 Esempio Numeri positivi # Programma che copia tramite
Linguaggio macchina. Architettura degli Elaboratori e delle Reti. Il linguaggio macchina. Lezione 16. Proff. A. Borghese, F.
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Il linguaggio assembly
 Il linguaggio assembly Strutture di controllo P.H. cap. 2.6 1 Argomenti Organizzazione della memoria Istruzioni di trasferimento dei dati Array Le strutture di controllo Istruzioni di salto if then do...
Il linguaggio assembly Strutture di controllo P.H. cap. 2.6 1 Argomenti Organizzazione della memoria Istruzioni di trasferimento dei dati Array Le strutture di controllo Istruzioni di salto if then do...
Il linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Un altro tipo di indirizzamento. L insieme delle istruzioni (3) Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando
 Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando") Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Università degli Studi di Cassino
 Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Architettura di tipo registro-registro (load/store)
") Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
Lezione 20. Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly
 Architettura degli Elaboratori Lezione 20 Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly Prof. F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori Lezione 20 Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly Prof. F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Problemi del ciclo singolo
 Problemi del ciclo singolo Ciclo di clock lungo Istruzioni potenzialmente veloci sono rallentate Impiegano sempre lo stesso tempo dell istruzione più lenta Unità funzionale e collegamenti della parte operativa
Problemi del ciclo singolo Ciclo di clock lungo Istruzioni potenzialmente veloci sono rallentate Impiegano sempre lo stesso tempo dell istruzione più lenta Unità funzionale e collegamenti della parte operativa
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 Memoria cache: Esercizi Massimiliano Giacomin 1 Esercizio: miss della cache e collocazione dei blocchi nella cache Sia data la seguente sequenza di indirizzi a
Calcolatori Elettronici A a.a. 2008/2009 Memoria cache: Esercizi Massimiliano Giacomin 1 Esercizio: miss della cache e collocazione dei blocchi nella cache Sia data la seguente sequenza di indirizzi a
SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI. NUOVO E VECCHIO ORDINAMENTO DIDATTICO 13 Luglio 2004
 SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI NUOVO E VECCHIO ORDINAMENTO DIDATTICO 13 Luglio 2004 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI ESERCIZIO 1 (9 punti) Si
SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI NUOVO E VECCHIO ORDINAMENTO DIDATTICO 13 Luglio 2004 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI ESERCIZIO 1 (9 punti) Si
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Corso di Calcolatori Elettronici MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M.
 di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
ESERCIZIO 1. Sia dato il seguente ciclo di un programma in linguaggio ad alto livello:
 ESERIZIO 1 Sia dato il seguente ciclo di un programma in linguaggio ad alto livello: do { BASE[i] = BASEA[i] + BASEB[i] + IN1 + IN2; i++; } while (i!= N) Il programma sia stato compilato nel seguente codice
ESERIZIO 1 Sia dato il seguente ciclo di un programma in linguaggio ad alto livello: do { BASE[i] = BASEA[i] + BASEB[i] + IN1 + IN2; i++; } while (i!= N) Il programma sia stato compilato nel seguente codice
Lezione 20. Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly
 Architettura degli Elaboratori Lezione 20 Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly Prof. F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori Lezione 20 Assembly MIPS: Il set istruzioni, strutture di controllo in Assembly Prof. F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
CPU pipeline hazards
 Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Realizzazione a cicli di clock multipli
 Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
Caching Andrea Gasparetto
 Tutorato di architettura degli elaboratori Caching Andrea Gasparetto andrea.gasparetto@unive.it Esercizio 1 Dati una cache con 4096 blocchi, e con dimensione dell INDEX di 10 b, determinare il grado di
Tutorato di architettura degli elaboratori Caching Andrea Gasparetto andrea.gasparetto@unive.it Esercizio 1 Dati una cache con 4096 blocchi, e con dimensione dell INDEX di 10 b, determinare il grado di
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Come si definisce il concetto di performance? Tempo di esecuzione di un programma. numero di task/transazioni eseguiti per unità di tempo
 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
CALCOLATORI ELETTRONICI 29 giugno 2010
 CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
Esercitazione su Gerarchie di Memoria
 Esercitazione su Gerarchie di Memoria Introduzione Memoria o gerarchie di memoria: cache, memoria principale, memoria di massa etc. (con possibilità di fallimenti nell accesso) o organizzazione, dimensionamento,
Esercitazione su Gerarchie di Memoria Introduzione Memoria o gerarchie di memoria: cache, memoria principale, memoria di massa etc. (con possibilità di fallimenti nell accesso) o organizzazione, dimensionamento,
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Convenzioni di chiamata a procedure
 Università degli Studi di Milano Laboratorio di Architettura degli Elaboratori II Corso di Laurea in Informatica, A.A. 2016-2017 Convenzioni di chiamata a procedure Nicola Basilico Dipartimento di Informatica
Università degli Studi di Milano Laboratorio di Architettura degli Elaboratori II Corso di Laurea in Informatica, A.A. 2016-2017 Convenzioni di chiamata a procedure Nicola Basilico Dipartimento di Informatica
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS)
") Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
MIPS! !
 MIPS! Sono descritte solamente le istruzioni di MIPS32, le pseudo-istruzioni, System Calls e direttive del linguaggio assembly che sono maggiormente usate.! MIPS è big-endian, cioè, lʼindirizzo di una
MIPS! Sono descritte solamente le istruzioni di MIPS32, le pseudo-istruzioni, System Calls e direttive del linguaggio assembly che sono maggiormente usate.! MIPS è big-endian, cioè, lʼindirizzo di una
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO
 ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
Cicli di clock e istruzioni
 Cicli di clock e istruzioni Numero di cicli di clock differenti per istruzioni differenti Le moltiplicazioni impiegano più tempo delle addizioni Operazioni in virgola mobile impiegano più tempo delle operazioni
Cicli di clock e istruzioni Numero di cicli di clock differenti per istruzioni differenti Le moltiplicazioni impiegano più tempo delle addizioni Operazioni in virgola mobile impiegano più tempo delle operazioni
Miglioramento delle prestazioni
 Miglioramento delle prestazioni Migliorare sia larghezza di banda sia latenza: uso di cache multiple Introdurre una cache separata per istruzioni e dati (split cache) Beneficio: Le operazioni di lettura/scrittura
Miglioramento delle prestazioni Migliorare sia larghezza di banda sia latenza: uso di cache multiple Introdurre una cache separata per istruzioni e dati (split cache) Beneficio: Le operazioni di lettura/scrittura
PRESTAZIONI. senza e con memoria cache
 PRESTAZIONI del processore MIPS pipeline senza e con memoria cache Prestazioni del processore GENERICO (P&H pp 29 31) Definizioni dei parametri di prestazione fondamentali del processore: sia P una prova,
PRESTAZIONI del processore MIPS pipeline senza e con memoria cache Prestazioni del processore GENERICO (P&H pp 29 31) Definizioni dei parametri di prestazione fondamentali del processore: sia P una prova,
CALCOLATORI ELETTRONICI 31 marzo 2015
 CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
CALCOLATORI ELETTRONICI 31 marzo 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Tradurre in linguaggio assembly MIPS il seguente frammento di
Architettura dei calcolatori e sistemi operativi. Il processore Capitolo 4 P&H
 Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
ISA (Instruction Set Architecture) della CPU MIPS
 della CPU MIPS") Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Calcolatori Elettronici
 Calcolatori Elettronici CPU multiciclo: esercizi Massimiliano Giacomin 1 Prima tipologia di esercizi: valutazione delle prestazioni 2 Specchio riassuntivo su prestazioni e CPI 0) In generale: T esecuzione
Calcolatori Elettronici CPU multiciclo: esercizi Massimiliano Giacomin 1 Prima tipologia di esercizi: valutazione delle prestazioni 2 Specchio riassuntivo su prestazioni e CPI 0) In generale: T esecuzione
Linguaggio Assembly e linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
ARCHITETTURE AVANZATE DEI CALCOLATORI, A.A. 2007/08 Soluzione esercizi sul pipelining
 ARCHITETTURE AVANZATE DEI CALCOLATORI, A.A. 2007/08 Soluzione esercizi sul pipelining Esercizio 1) N.B. Nei diagrammi a cicli multipli non sono indicati i registri di pipeline (per semplicità) a) Si tratta
ARCHITETTURE AVANZATE DEI CALCOLATORI, A.A. 2007/08 Soluzione esercizi sul pipelining Esercizio 1) N.B. Nei diagrammi a cicli multipli non sono indicati i registri di pipeline (per semplicità) a) Si tratta
Assembly (3): le procedure
: le procedure") Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 13 1/23 Chiamata
Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 13 1/23 Chiamata
CALCOLATORI ELETTRONICI 15 luglio 2014
 CALCOLATORI ELETTRONICI 15 luglio 2014 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave sensibile ai fronti di salita e se
CALCOLATORI ELETTRONICI 15 luglio 2014 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave sensibile ai fronti di salita e se
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Linguaggio Assembly e linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
La memoria cache. Lab di Calcolatori
 La memoria cache 1 Gap delle prestazioni DRAM - CPU 1000 CPU- DRAM Gap CPU Proc 60%/yr. (2X/1.5yr) 100 10 ProcessorMemory Performance Gap: (grows 50% / year) D R A M DRAM9%/yr.(2X/10 yrs) 1 1980 1981 1982
La memoria cache 1 Gap delle prestazioni DRAM - CPU 1000 CPU- DRAM Gap CPU Proc 60%/yr. (2X/1.5yr) 100 10 ProcessorMemory Performance Gap: (grows 50% / year) D R A M DRAM9%/yr.(2X/10 yrs) 1 1980 1981 1982
Architettura degli elaboratori Tema d esame del 20/01/2016
 Architettura degli elaboratori - Luigi Lavazza A.A. 5/6 Università degli Studi dell Insubria Dipartimento di Informatica e Comunicazione Architettura degli elaboratori Tema d esame del //6 Luigi Lavazza
Architettura degli elaboratori - Luigi Lavazza A.A. 5/6 Università degli Studi dell Insubria Dipartimento di Informatica e Comunicazione Architettura degli elaboratori Tema d esame del //6 Luigi Lavazza
CALCOLATORI ELETTRONICI 15 aprile 2014
 CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
Elementi base per la realizzazione dell unità di calcolo
 Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Il linguaggio macchina
 Il linguaggio macchina Istruzioni macchina (PH 2.4) Indirizzamento (PH 2.9) Costanti a 32-bit (PH 2.9) 1 Linguaggio macchina Le istruzioni in linguaggio assembly devono essere tradotte in linguaggio macchina
Il linguaggio macchina Istruzioni macchina (PH 2.4) Indirizzamento (PH 2.9) Costanti a 32-bit (PH 2.9) 1 Linguaggio macchina Le istruzioni in linguaggio assembly devono essere tradotte in linguaggio macchina
ESERCIZIO 1 Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO
 ESERCIZIO Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
ESERCIZIO Riferimento: PROCESSORE PIPELINE e CAMPI REGISTRI INTER-STADIO Sono dati il seguente frammento di codice assemblatore che comincia all indirizzo indicato, e i valori iniziali specificati per
Calcolatori Elettronici
 Calcolatori Elettronici ISA di riferimento: MIPS Massimiliano Giacomin 1 DOVE CI TROVIAMO Livello funzionale Livello logico Livello circuitale Livello del layout istruzioni macchina, ISA Reti logiche:
Calcolatori Elettronici ISA di riferimento: MIPS Massimiliano Giacomin 1 DOVE CI TROVIAMO Livello funzionale Livello logico Livello circuitale Livello del layout istruzioni macchina, ISA Reti logiche:
PROVA SCRITTA DEL MODULO/CORSO DI. 24 novembre 2016
 PROVA SCRITTA DEL MODULO/CORSO DI 24 novembre 206 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI NOME: COGNOME: MATRICOLA: ESERCIZIO (6 punti) Progettare un riconoscitore
PROVA SCRITTA DEL MODULO/CORSO DI 24 novembre 206 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI NOME: COGNOME: MATRICOLA: ESERCIZIO (6 punti) Progettare un riconoscitore
Linguaggio Assembly e linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI. NUOVO E VECCHIO ORDINAMENTO DIDATTICO 28 Settembre 2006
 SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI NUOVO E VECCHIO ORDINAMENTO DIDATTICO 28 Settembre 26 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI ESERCIZIO 1 (8 punti)
SOLUZIONI DELLA PROVA SCRITTA DEL CORSO DI NUOVO E VECCHIO ORDINAMENTO DIDATTICO 28 Settembre 26 MOTIVARE IN MANIERA CHIARA LE SOLUZIONI PROPOSTE A CIASCUNO DEGLI ESERCIZI SVOLTI ESERCIZIO 1 (8 punti)
Le memorie Cache n-associative
 Le memorie Cache n-associative Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento Patterson: 5.2, 5.3 1/30 Sommario
Le memorie Cache n-associative Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento Patterson: 5.2, 5.3 1/30 Sommario
Architettura degli Elaboratori (modulo II e B) (Compito 24 Giugno 2009)
 (Compito 24 Giugno 2009)") Architettura degli Elaboratori (modulo II e B) (Compito 24 Giugno 2009) Usare un foglio separato per rispondere a due delle domande seguenti, specificando nell intestazione: Titolo del corso (Architettura
Architettura degli Elaboratori (modulo II e B) (Compito 24 Giugno 2009) Usare un foglio separato per rispondere a due delle domande seguenti, specificando nell intestazione: Titolo del corso (Architettura
Progetto CPU (ciclo singolo) Salvatore Orlando
 Salvatore Orlando") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
System Calls, Register Spilling
 System Calls, Register Spilling Ultimo aggiornamento: 8/4/2016 UNIVERSITÀ DEGLI STUDI DI MILANO nicola.basilico@unimi.it http://basilico.di.unimi.it/ Esercizio 3.1 Eseguire il seguente codice assembly
System Calls, Register Spilling Ultimo aggiornamento: 8/4/2016 UNIVERSITÀ DEGLI STUDI DI MILANO nicola.basilico@unimi.it http://basilico.di.unimi.it/ Esercizio 3.1 Eseguire il seguente codice assembly
Elementi di informatica
 Elementi di informatica Architetture degli elaboratori Il calcolatore Un calcolatore è sistema composto da un elevato numero di componenti Il suo funzionamento può essere descritto se lo si considera come
Elementi di informatica Architetture degli elaboratori Il calcolatore Un calcolatore è sistema composto da un elevato numero di componenti Il suo funzionamento può essere descritto se lo si considera come
CALCOLATORI ELETTRONICI 29 giugno 2011
 CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Instruction Level Parallelism Salvatore Orlando
 Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Organizzazione parallela del processore I processori moderni hanno un organizzazione interna che permette di eseguire più istruzioni
Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Organizzazione parallela del processore I processori moderni hanno un organizzazione interna che permette di eseguire più istruzioni
Instruction Level Parallelism
 Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Organizzazione parallela del processore I processori moderni hanno un organizzazione interna che permette di eseguire più istruzioni
Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Organizzazione parallela del processore I processori moderni hanno un organizzazione interna che permette di eseguire più istruzioni
Architettura degli Elaboratori
 circuiti combinatori: ALU slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello 1 ALU ALU (Arithmetic Logic Unit) circuito combinatorio all interno del processore per l esecuzione di istruzioni
circuiti combinatori: ALU slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello 1 ALU ALU (Arithmetic Logic Unit) circuito combinatorio all interno del processore per l esecuzione di istruzioni
Lecture 2: Prime Istruzioni
 [http://www.di.univaq.it/muccini/labarch] Modulo di Laboratorio di Architettura degli Elaboratori Corso di Architettura degli Elaboratori con Laboratorio Docente: H. Muccini Lecture 2: Prime Istruzioni
[http://www.di.univaq.it/muccini/labarch] Modulo di Laboratorio di Architettura degli Elaboratori Corso di Architettura degli Elaboratori con Laboratorio Docente: H. Muccini Lecture 2: Prime Istruzioni
Processore: Datapath & Control. Progetto CPU (ciclo singolo) Rivediamo i formati delle istruzioni. ISA di un MIPS-lite
 Rivediamo i formati delle istruzioni. ISA di un MIPS-lite") Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
MIPS Instruction Set 2
 Laboratorio di Architettura 15 aprile 2011 1 Architettura Mips 2 Chiamata a Funzione 3 Esercitazione Registri MIPS reference card: http://refcards.com/docs/waetzigj/mips/mipsref.pdf 32 registri general
Laboratorio di Architettura 15 aprile 2011 1 Architettura Mips 2 Chiamata a Funzione 3 Esercitazione Registri MIPS reference card: http://refcards.com/docs/waetzigj/mips/mipsref.pdf 32 registri general
21 March : ESERCITAZIONE 01 GESTIONE DELLA MEMORIA VETTORI CONTROLLOO O DI FLUSSO DI UN PROGRAMMA. I. Frosio
 02: ESERCITAZIONE 01 21 March 2011 GESTIONE DELLA MEMORIA VETTORI CONTROLLOO O DI FLUSSO DI UN PROGRAMMA I. Frosio 1 SOMMARIO Organizzazione della memoria Istruzioni di accesso alla memoria Vettori Istruzioni
02: ESERCITAZIONE 01 21 March 2011 GESTIONE DELLA MEMORIA VETTORI CONTROLLOO O DI FLUSSO DI UN PROGRAMMA I. Frosio 1 SOMMARIO Organizzazione della memoria Istruzioni di accesso alla memoria Vettori Istruzioni
Architetture dei Calcolatori
 Architetture dei Calcolatori Lezione 11 -- 10/12/2011 Procedure Emiliano Casalicchio emiliano.casalicchio@uniroma2.it Fattoriale: risparmiamo sull uso dei registri q Rispetto alla soluzione precedente
Architetture dei Calcolatori Lezione 11 -- 10/12/2011 Procedure Emiliano Casalicchio emiliano.casalicchio@uniroma2.it Fattoriale: risparmiamo sull uso dei registri q Rispetto alla soluzione precedente
CPU a singolo ciclo: l unità di controllo, istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
Il pipelining: tecniche di base
 Definizione di pipelining Il pipelining: tecniche di base Architetture Avanzate dei Calcolatori E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di
Definizione di pipelining Il pipelining: tecniche di base Architetture Avanzate dei Calcolatori E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
Le procedure. L insieme delle istruzioni (4) Prima della chiamata di una procedura. Le procedure (2) Architetture dei Calcolatori (lettere A-I)
 Prima della chiamata di una procedura. Le procedure (2) Architetture dei Calcolatori (lettere A-I)") Le procedure L insieme delle istruzioni (4) Architetture dei Calcolatori (lettere A-I) In ogni linguaggio di programmazione si struttura il proprio codice usando procedure (funzioni, metodi, ) L utilizzo
Le procedure L insieme delle istruzioni (4) Architetture dei Calcolatori (lettere A-I) In ogni linguaggio di programmazione si struttura il proprio codice usando procedure (funzioni, metodi, ) L utilizzo
Il pipelining: tecniche di base
 Il pipelining: tecniche di base Il pipelining E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di più istruzioni appartenenti ad un flusso di esecuzione
Il pipelining: tecniche di base Il pipelining E una tecnica per migliorare le prestazioni del processore basata sulla sovrapposizione dell esecuzione di più istruzioni appartenenti ad un flusso di esecuzione
Corso di Informatica
 CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it Il Processore (CPU) 2 rchitettura del processore CPU Unità di Controllo Unità ritmetica Logica
CdLS in Odontoiatria e Protesi Dentarie Corso di Informatica Prof. Crescenzio Gallo crescenzio.gallo@unifg.it Il Processore (CPU) 2 rchitettura del processore CPU Unità di Controllo Unità ritmetica Logica
Architettura degli Elaboratori
 Architettura degli Elaboratori a.a. 2013/14 appello straordinario, 13 aprile 2015 Riportare nome, cognome, numero di matricola e corso A/B Domanda 1 Si consideri la seguente gerarchia di memoria memoria
Architettura degli Elaboratori a.a. 2013/14 appello straordinario, 13 aprile 2015 Riportare nome, cognome, numero di matricola e corso A/B Domanda 1 Si consideri la seguente gerarchia di memoria memoria
Calcolatori Elettronici II parte (CdL Ingegneria Informatica) Esame del 22 settembre 2011 tempo a disposizione: 1 ora e 30 minuti
 Esame del 22 settembre 2011 tempo a disposizione: 1 ora e 30 minuti") Calcolatori Elettronici II parte (CdL Ingegneria Informatica) Esame del 22 settembre 2011 tempo a disposizione: 1 ora e 30 minuti Compito Num. 1 COGNOME:...NOME:... 1) (20%) Si vuole realizzare una CPU
Calcolatori Elettronici II parte (CdL Ingegneria Informatica) Esame del 22 settembre 2011 tempo a disposizione: 1 ora e 30 minuti Compito Num. 1 COGNOME:...NOME:... 1) (20%) Si vuole realizzare una CPU
Classificazione dipendenze
 Classificazione dipendenze 1a. EX/MEM.RegisterRd = ID/EX.registerRs 1b. EX/MEM.RegisterRd = ID/EX.registerRt Il registro (campo Rs oppure Rt di una istruzione) che è stato letto nella fase ID ed il cui
Classificazione dipendenze 1a. EX/MEM.RegisterRd = ID/EX.registerRs 1b. EX/MEM.RegisterRd = ID/EX.registerRt Il registro (campo Rs oppure Rt di una istruzione) che è stato letto nella fase ID ed il cui
Uniamo VM e CACHE. Physically addressed. Physically Addressed. Prestazioni. Ci sono varie alternative architetturali. Sono quelle piu semplici
 Uniamo VM e CACHE Physically addressed Ci sono varie alternative architetturali physically addressed virtually addressed virtually indexed Sono quelle piu semplici un dato puo essere in cache solo se e
Uniamo VM e CACHE Physically addressed Ci sono varie alternative architetturali physically addressed virtually addressed virtually indexed Sono quelle piu semplici un dato puo essere in cache solo se e
Il linguaggio assembly
 Il linguaggio assembly PH 2.3 (continua) 1 Argomenti Organizzazione della memoria Istruzioni di trasferimento dei dati Array Istruzioni logiche 2 1 La memoria del MIPS I contenuti delle locazioni di memoria
Il linguaggio assembly PH 2.3 (continua) 1 Argomenti Organizzazione della memoria Istruzioni di trasferimento dei dati Array Istruzioni logiche 2 1 La memoria del MIPS I contenuti delle locazioni di memoria