Introduzione al Data Mining
|
|
|
- Cesare Volpe
- 5 anni fa
- Visualizzazioni
Transcript
1 Data Mining
2 Introduzione al Data Mining Il Data Mining è la risposta tecnologica all esigenza di saper analizzare e ricavare conoscenze utili, dalle enormi quantità di dati grezzi che si raccolgono ormai in tutti i contesti operativi della nostra società.
3 Introduzione al Data Mining Esempi: p Solo il database del settore consegne della UPS ha una dimensione di 17 Tera-Byte. Questi dati vanno analizzati sia per capire come migliorare il servizio ai clienti, sia per migliorare l efficienza interna dell azienda p p I servizi segreti militari raccolgono una infinità di immagini via satellite, che devono saper classificare per riconoscere se è stato fotografato un semplice trattore o un carro armato! Le aziende farmaceutiche, per progettare un nuovo farmaco, utile e sicuro per l uomo, devono analizzare e selezionare milioni di composti chimici (candidati a divenire farmaco)
4 Introduzione al Data Mining La risposta all esigenza di analisi di queste enormi quantità di dati raccolti è rappresentata dal Data Mining. Il data mining è il processo di analisi, svolto in modo semiautomatico, di una grande quantità di dati grezzi al fine di scoprire il modello ( pattern ) che li governa, o una regola significativa, da cui ricavare conoscenze utili applicabili al nostro contesto operativo (come ad esempio previsioni e classificazioni).
5 Introduzione al Data Mining p Nota: si usa distinguere il concetto di modello (pattern) da quello di regola, perché per modello si intende uno strumento che oltre a fornire l output richiesto descriva anche con quale logica il sistema reale raggiunge quel output. p Mentre per regola si intende un procedimento che ad un dato input permetta di associare il corrispondente output senza necessariamente conoscere il funzionamento intrinseco del sistema reale (questo è il caso delle reti neurali, una tecnica che vedremo di data mining).
6 Data Mining p Estrazione di dati p Processo di esplorazione e analisi di dati (automatico e semiautomatico) di un ampia mole di dati, al fine di scoprire modelli (PATTERN) e regole 6
7 Data Mining: motivazioni p Trovare informazioni nascoste, persone avrebbero bisogno di mesi per scoprirle, p maggior parte dei dati non sono analizzati p Tecniche tradizionali non sono applicabili su dati grezzi (non elaborati) 7
8 Data Mining: definizioni Estrazione di conoscenza non nota (pattern ricorrenti) da grandi basi di dati n Pattern mining n Knowledge discovery in data base (KDD) n Knowledge discovery of hidden pattern n Knowledge extraction n Pattern analysis n Information haversting (raccolta) n Business intelligence 8
9 Data Mining: definizioni The non trivial process of identifying valid, novel, potentially useful and ultimately understandable pattern of data Shapiro,
10 Esempio: prestiti in banca p la banca vuole concedere prestiti solo se si aspetta che il cliente pagherà le rate p Questo problema può essere risolto mediante l estrazione di pattern da dati storici p la banca possiede dati storici sui prestiti che ha già erogato nel passato e sa in quali casi le rate sono state pagate regolarmente o meno p per pattern si intende, ad esempio, una regola che descrive in modo succinto delle informazioni estratte dai dati storici per prevedere se un potenziale cliente pagherà le rate di un prestito regolarmente o meno 10
11 Dati storici 11
12 Creazione del pattern/modello 12
13 Applicazione del pattern/modello 13
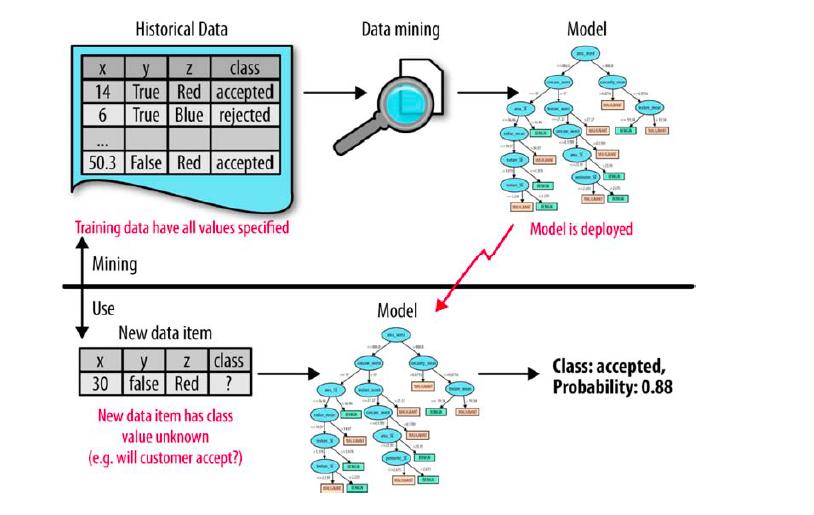
14 14
15 Data Mining p Obiettivi: n Descrittivo: descrivere in modo non evidente (classificare, individuare gruppi in un insieme di dati la cui struttura non è visibile) n Esplicativo: Spiegare (insight), trovare modelli esplicativi (i fattori legati ad un fenomeno, correlazioni) n Predittivo: fare previsioni sul futuro, sul valore di variabili à produzione di nuova conoscenza dai dati 15
16 Data Mining vr Dw vr DB DB/OLTP DW/OLAP DATA MINING Estrazione di dati Riassunti, aggregazioni, trend (descrizione su caratteristiche statiche) Knowledge discovery of hidden pattern (produrre nuova conoscenza) Informazione Analisi Insight & prediction Chi ha comprato i fondi? Quale è la media degli incassi dei fondi venduti per regione in un anno? Chi comprerà un fondo nei prossimi 6 mesi e perche? 16
17 Data Mining vr Dw vr DB DB/OLTP DW/OLAP DATA MINING OLTP, query definite espresse con il linguaggio standard SQL Output è un sottoinsieme dei dati Su dati relazionali (db) Query non definite, no standard Output è un sottoinsieme dei dati Su dati relazionali e multidimensionali (dw) Query non definite, no standard Output non è un sottoinsieme dei dati, ma può essere un modello Su dati relazionali (db) dati multidimensionali (dw) Dati multimediali, spaziali (spatial and temporal db) Grafi (www) Testi 17
18 DATA MINING su TESTI p p Il testo diventa un vettore di termini contenente le occorrenze della parole (numero di volte in cui il termine è presente nel doc) Vettore: insieme di elementi dello stesso tipo, cui si accede per posizione s[0] à accedi al primo elemento del vettore p TEXT MINIG: uso di tecniche di NLP (Natural Language Processing) 18
19 Data Mining vr Statistica Statistica Non automatica, operatore fa i calcoli Verification-driven: guidato dalla verifica di un ipotesi Moli di dati minore Analisi primaria Data minig semi-automatico, macchina fa i calcoli Discovery-driven, non ci sono ipotesi da verificare, scoprire nuove ipotesi Moli di dati molto grandi Analisi secondaria 19

20 Task di data mining 20
21 Task di data mining p Classificare p Stimare p Fare previsioni p Raggruppare p Trovare regole di associazione 21
22 Le Tecniche di Data Mining Le tecniche di data mining servono per trasformare i dati grezzi in informazioni utili. Quindi servono per risolvere p p Problemi di esplorazione dati (Data Mining Non Supervisionato): problemi in cui non sappiamo cosa dover ricercare nei dati e allora lasciamo che siano i dati stessi a indicarci un risultato, a suggerirci la loro struttura (o pattern). Problemi di classificazione e di regressione (Data Mining Supervisionato). In tutti questi problemi sappiamo bene quello che stiamo cercando: in entrambi i casi l obiettivo è prevedere il valore che assumerà una certa variabile detta target (che sarà di tipo categorico nei problemi di classificazione, di tipo numerico nei problemi di regressione).
23 Task di data minig supervisionati Alberi decisionali Reti neurali Non supervisionati Cluster analysis Association rules 23
24 Task supervisionati p Previsione del comportamento di alcune variabili target in funzione delle variabili di input (es previsione di chi sarà insolvente) p Usare i dati disponibili per creare un modello che descriva il comportamento di una variabile target in termini dei dati disponibili 24
25 Task supervisionati p Obiettivi n Classificazione n Stima n Previsione p Tecniche di data mining n Alberi decisionali n Reti neurali 25
26 Classificazione p Assegnazione di un nuovo oggetto ad una classe predefinita dopo averne esaminato le caratteristiche p Valori discreti e booleani (si, no) p Es: assegnazione di un nuovo cliente ad un segmento specifico (gold, silver) p Attribuire una parola chiave ad una notizia (nera, rosa, etc) 26
27 Classificazione Procedimento: p Fase di training su una porzione di dati costituita da esempi già classificati (training set) p Fase di creazione del modello di classificazione applicabile a nuovi dati da classificare p Strumenti: alberi di decisione, reti neurali 27
28 Stima (regressione) p Tratta valori continui p Individuare il valore di una variabile continua (ad esempio, il reddito, il saldo, la quantità venduta di un prodotto) p Si usa la stima per fare classificazioni p Strumenti: alberi di decisione, reti neurali 28
29 Previsione p la classificazione e la stima possono essere usate per fare predizioni sul futuro p Es prevedere le dismissioni dal servizio p Prevedere chi attiverà ADSL tra gli abbonati p Dati storici à modello à applicato a nuovi dati à previsione di un comportamento futuro p Strumenti: alberi di decisione, reti neurali 29
30 Task NON supervisionati p Non c è alcuna variabile target da prevedere (es individuare i gruppi di consumatori con i gusti analoghi) p Obiettivi: n n raggruppare Scoprire associazioni tra variabili p Tecniche di data mining: n Cluster n Regole di associazione 30
31 Clustering p Raggruppamento per affinita, segmentazione di un gruppo eterogeneo in sottogruppi (cluster) più omogenei per certe caratteristiche p Non fa ricorso a classi predefinite, classificazione a posteriori (vr classificazione a priori) p Non usa esempi da cui apprendere p Sta al ricercatore attribuire significato ai gruppi p Prelude altre tecniche di data mining p Strumento: cluster analysis 31
32 32
33 33
34 Regole di associazione p Stabilire quali oggetti possono abbinarsi n Ex quali prodotti si trovano insieme nel carrello della spesa (market basket analysis) n Usato per pianificare la distribuzione dei prodotti sugli scaffali in modo che gli articoli che di solito vengono acquistati insieme si trovino vicino (o lontano.. Cross-selling) p Sequenze di acquisto che occorrono nel tempo p (analisi degli outlier: oggetto non conforme alle caratteristiche degli altri dati: utili per 34 le frodi)
35 Data mining: contesto applicativo p Strumento di ricerca: da usare nella fase di ricerca e sviluppo, ad es. industria farmaceutica, quali molecole sono candidate a diventare farmaci p Miglioramento dei processi: risparmio di risorse, controllo di processi, diagnosi di guasti p Marketing e CRM: parte del CRM analitico, analisi del comportamento d acquisto, per segmentare clienti, focalizzare le offerte su clienti migliori 35
36 Data mining: contesto tecnico p Machine learning (AI): obt far apprendere le macchine da esempi p statistica: uso di tecniche statistiche (come regressione), metodi di campionamento, metodologia sperimentale p DSS: infrastruttura ICT di supporto alle decisioni p HW: elaboratori potenti in grado di elaborare grandi quantità di dati (fino a qualche anno fa non sarebbe stato possibile) 36
37 Data mining: contesto sociale p Raccolta dati su persone p Problematiche n privacy n Diffusione dei dati n Protezione da uso improprio 37
38 Data mining: contesto aziendale p Vale la pena raccogliere un informazione se il ritorno dell investimento è superiore al costo dell investimento fatto per acquisire l informazione p Una conoscenza viene considerata utile se la conoscenza che ne deriva vale più de soldi spesi per scoprirla 38
39 Data mining: applicazioni p marketing p finanza p web p e-commerce p Biotecnologie, farmaceutica, scienze mediche p telecomunicazioni 39
40 40
41 Processo di data minig 1. Data cleaning 2. Data integration 3. Data warehousing 4. Data mining 5. Patter description (modelli esplicativi e predittivi) 6. Pattern evaluation 7. Knowledge 41
42 Processo di data minig p p p p p Fase 1: comprensione del dominio, pulitura dei dati, preprocessing creazione del datawarehouse adatto (60% dello sforzo complessivo) fase 2:individuare tecniche dm utili Fase 3: indivduazione dei pattern, costruzione del modello di realtà: input à modello à output Eta, sesso à modello à il cliente restuirà il prestito Fase 4: Validazione del modello: Fase 5: deployment 42
43 Valutazione del modello p Valutazione dei pattern estratti p Possono essere moltissimi p Necessario un data minig sul data minig p Modello valido se n Comprensibile n Corretto n Affidabile (se testato su nuovi dati, è valido con un certo livello di certezza) 43
44 Casi d uso p Banca deve decidere se autorizza un emissione n Ha tanti dati storici n Ciascuna richiesta è classificata in i) autorizzata, ii) richiedi info, iii)non autorizzata, iv) non autorizzata e informata autorità per truffa p A) si costruisce un modello dei dati storici (training set) ( quali valori degli attributi hanno causato l attribuzione a una classe? ) p B) si usa il modello per classificare e prendere decisioni in relazione a nuove richieste ( dove inserire una nuova richiesta? ) 44
45 Le Tecniche di Data Mining Le principali tecniche di data mining che vedremo sono: Ø Ø Ø Cluster Analysis Alberi Decisionali Reti neurali
46 Cluster Analysis
47 Le Tecniche di Data Mining Le principali tecniche di data mining che vedremo sono: Ø Ø Cluster Analysis Alberi Decisionali
48 Cluster Analysis p p p La Cluster Analysis è una tecnica di data mining non supervisionato (applicato senza ipotesi prima) Per clustering si intende la segmentazione di un gruppo eterogeneo in sottogruppi (cluster) omogenei. Ciò che distingue il clustering dalla classificazione è che qui non si fa ricorso a classi predefinite. Esempi di applicazione: p Rilevare un insieme di sintomi indice di una patologia specifica. p rilevare l appartenenza a sottoculture diverse raggruppando in classi omogenee gli acquisti di materiale video e audio.
49 Clustering analysis p Raggruppamento di dati con caratteristiche simili: i membri sono simili tra loro e diversi dagli altri p Esigenza umana: classificare sulla base di caratteristiche simili 4
50 Clustering analysis Scopo: n Suddivisione di un set di dati complessi in un sottoinsieme di dati più semplice al fine di permettere a tecniche di data mining supervisionato di trovare con più facilità spiegazioni al comportamento p Identificare i gruppi che mi serviranno successivamente per fare gli alberi p Scegliere il numero di cluster (k) che vogliamo K = 1 non ha senso K = num di record non ha senso 5
51 Metodi di rilevazione automatica dei cluster p Metodi agglomerativi: aggregare i record in modo significativo p Metodi divisivi: opposto, tutti i record fanno parte di un unico cluster che viene via via spezzettato finchè ad ogni record corrisponde un cluster 6
52 Cluster Analysis: Algoritmo K-means p L algoritmo suddivide un determinato set di dati in un numero predefinito di cluster: la k di k- means. Il termine means sta per media statistica: la distribuzione media di tutti i componenti di un particolare cluster. p Per formare i cluster, a ogni record vengono assegnate delle coordinate in un determinato spazio dei record. Lo spazio ha tante dimensioni quanti sono i campi nei record. Il valore di ciascun campo rappresenta una coordinata del record. Perché questa interpretazione geometrica sia utile, tutti i campi devono essere trasformati in numeri e i numeri a loro volta normalizzati, in modo che due variazioni in due dimensioni diverse possano essere comparabili.
53 Cluster Analysis: Algoritmo K-means p I record vengono assegnati ai cluster, tramite un processo iterativo che inizia da cluster centrati in posizioni casuali all interno dello spazio dei record e sposta i centroidi (ossia i baricentri dei cluster)
54 Algoritmo k-means 1. Scegliere il num di cluster che si vogliono 2. Prende k record a caso dalla tabella dei fatti e li rende centro di un cluster 3. Per ognuno degli altri punti (record) calcola la distanza* dal centro del cluster e lo posiziona nel cluster del centroide e più vicino 4. Il punto medio del cluster diventa il centroide di un nuovo cluster 5. Si torna al punto 3 (ogni record assegnato al cluster con il centroide più vicino) * (Distanza euclidea) 9
55 Cluster Analysis: Algoritmo K-means
56 Cluster Analysis: Algoritmo K-means Passo 1: scegliamo k=3 e i seguenti semi iniziali:
57 Cluster Analysis: Algoritmo K-means Passo 2: Assegniamo ogni record al cluster con il centroide (o seme) più vicino
58 Cluster Analysis: Algoritmo K-means Passo 3: Il passo due ha individuato nuovi cluster. Ci calcoliamo i centroidi (o semi) di questi
59 Cluster Analysis: Algoritmo K-means Passo 2:Riaggrego ogni record al cluster di centroide più vicino. Notare cosa succede a un dato Un dato inizialmente assegnato al cluster 2, nella seconda iterazione viene assegnato al cluster 3
60 Cluster Analysis: Algoritmo K-means L algoritmo termina perché i centroidi, e quindi i confini dei cluster, non variano piu (i cluster sono definitivi)
61 Cluster Analysis: Algoritmo K-means p Problema: Nel metodo k-means la scelta di k, che determina il numero di cluster che verranno individuati, è predefinita dall utente. Se il numero non corrisponde alla struttura naturale dei dati, la tecnica non darà buoni risultati p Alcuni software forniscono aiuto per la scelta del valore di k ottimale: l utente può fornire un intervallo per il numero di cluster entro cui cercare.
62 Algoritmo k-means p Esempio, raggruppare i clienti in base al momento della giornata in cui comprano maggiormente p Attributi: categoria di clienti (studenti, pensionati, impiegati), periodo (mattino, sera) Cluster Cliente periodo c1 98% pensionati 2% studenti 90% mattino, 10% pomeriggio c2 70% impiegati, 30% pensionati 100% sera c
63 Cluster migliore p quello che ha n Distanza minima tra i suoi membri n Distanza massima con i membri degli altri cluster 18
64 Cluster Analysis Quando usare il rilevamento dei cluster nel data mining Essendo una tecnica non supervisionata, il rilevamento automatico dei cluster può essere applicato quando non conosciamo nulla della struttura da scoprire. D altro canto, però, visto che i cluster individuati automaticamente non hanno alcuna interpretazione naturale, eccetto quella geometrica per cui certi record sono più vicini ad alcuni che non ad altri, potrebbe essere difficile mettere in pratica questi risultati.
65 Applicazioni tipiche p come strumento stand-alone per capire come i dati sono distributi p come passo di pre-processing per altri algoritmi (alberi di decisione) p GIS: creazione di mappe tematiche à osservare aree terrestri simili p Clustering di web log à per scoprire pattern di comportamento sul web 20
66 Esercizio 1 p p p p p Partendo dal dataset di una banca (dataset n 2): creare 3 cluster in modo da capire se ci sono dei raggruppamenti significativi in base a sesso, età e regione creare 5 cluster con le stesse informazioni provare a cambiare i seeds e vedere che cosa cambia nei due casi provare a combinare altre feature 21
67 Esercizio 2 p p Partendo dal dataset di una banca (dataset n 3): creare n cluster in modo da capire se ci sono dei raggruppamenti significativi in base a lunghezza e larghezza del petalo, lunghezza e larghezza del sepalo p 22
Le Tecniche di Data Mining
 Cluster Analysis Le Tecniche di Data Mining Le rinciali tecniche di data mining che vedremo sono: Ø Ø Cluster Analysis Alberi Decisionali Cluster Analysis La Cluster Analysis è una tecnica di data mining
Cluster Analysis Le Tecniche di Data Mining Le rinciali tecniche di data mining che vedremo sono: Ø Ø Cluster Analysis Alberi Decisionali Cluster Analysis La Cluster Analysis è una tecnica di data mining
Business Intelligence
 Business Intelligence Data Mining Introduzione al Data Mining Il Data Mining è la risosta tecnologica all esigenza di saer analizzare e ricavare conoscenze utili, dalle enormi quantità di dati grezzi che
Business Intelligence Data Mining Introduzione al Data Mining Il Data Mining è la risosta tecnologica all esigenza di saer analizzare e ricavare conoscenze utili, dalle enormi quantità di dati grezzi che
Data Mining. Data Mining. Introduzione al Data Mining. Introduzione al Data Mining. Introduzione al Data Mining. Introduzione al Data Mining
 Introduzione al Data Mining Data Mining Il Data Mining è la risosta tecnologica all esigenza di saer analizzare e ricavare conoscenze utili, dalle enormi quantità di dati grezzi che si raccolgono ormai
Introduzione al Data Mining Data Mining Il Data Mining è la risosta tecnologica all esigenza di saer analizzare e ricavare conoscenze utili, dalle enormi quantità di dati grezzi che si raccolgono ormai
Modelli matematici e Data Mining
 Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
Data Science A.A. 2018/2019
 Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
I Componenti del processo decisionale 7
 Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
1. EVOLUZIONE DELLE TECNOLOGIE DI ANALISI DEI DATI
 1. EVOLUZIONE DELLE TECNOLOGIE DI ANALISI DEI DATI 1.1 Evoluzione delle tecnologie informatiche di gestione e analisi dati... 21 1.1.1 Fase 1 Database relazionali e SQL... 21 1.1.2 Fase 2- Data Warehouse
1. EVOLUZIONE DELLE TECNOLOGIE DI ANALISI DEI DATI 1.1 Evoluzione delle tecnologie informatiche di gestione e analisi dati... 21 1.1.1 Fase 1 Database relazionali e SQL... 21 1.1.2 Fase 2- Data Warehouse
MASTER UNIVERSITARIO
 MASTER UNIVERSITARIO I Analisi Dati per la Business Intelligence e Data Science in collaborazione con Gestito da: V edizione 2016/2017 Dipartimento di Culture, Politica e Società Dipartimento di Informatica
MASTER UNIVERSITARIO I Analisi Dati per la Business Intelligence e Data Science in collaborazione con Gestito da: V edizione 2016/2017 Dipartimento di Culture, Politica e Società Dipartimento di Informatica
Classificazione Mario Guarracino Data Mining a.a. 2010/2011
 Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
QUANTIZZATORE VETTORIALE
 QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
Tecnologie, strumenti e processi alle informazioni e l estrazione della conoscenza
 Tecnologie, strumenti e processi per l accesso l alle informazioni e l estrazione della conoscenza Maurizio Lancia Alberto Salvati CNR - Ufficio Sistemi Informativi Sommario Scenario Obiettivi e linee
Tecnologie, strumenti e processi per l accesso l alle informazioni e l estrazione della conoscenza Maurizio Lancia Alberto Salvati CNR - Ufficio Sistemi Informativi Sommario Scenario Obiettivi e linee
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista
 Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Informatica per le discipline umanistiche 2 lezione 11
 Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
MATRICE TUNING competenze versus unità didattiche, Corso di Laurea in Informatica (classe L-31), Università degli Studi di Cagliari
, Università degli Studi di Cagliari") A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
CORSO DI LABORATORIO OTTIMIZZAZIONE COMBINATORIA. Informazioni e programma del corso Introduzione al data mining e machine learning
 CORSO DI LABORATORIO OTTIMIZZAZIONE COMBINATORIA Data Mining Parte I Informazioni e programma del corso Introduzione al data mining e machine learning INFORMAZIONI Il corso di laboratorio Ottimizzazione
CORSO DI LABORATORIO OTTIMIZZAZIONE COMBINATORIA Data Mining Parte I Informazioni e programma del corso Introduzione al data mining e machine learning INFORMAZIONI Il corso di laboratorio Ottimizzazione
Statistica multivariata 27/09/2016. D.Rodi, 2016
 Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Che cosa è la statistica oggi?
 Metodologie Statistiche a supporto delle decisioni aziendali: Revenue/Yield Management Prof. Massimo Aria Ricercatore in Statistica Sociale Una breve premessa: Che cosa è la statistica oggi? 1 Statistica
Metodologie Statistiche a supporto delle decisioni aziendali: Revenue/Yield Management Prof. Massimo Aria Ricercatore in Statistica Sociale Una breve premessa: Che cosa è la statistica oggi? 1 Statistica
e applicazioni al dominio del Contact Management Andrea Brunello Università degli Studi di Udine
 al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
al e applicazioni al dominio del Contact Management Parte I: Il Processo di, Principali tipologie di al Cos è il Il processo di Università degli Studi di Udine Unsupervised In collaborazione con dott.
Knowledge Management E Business Intelligence
 Knowledge Management E Business Intelligence 1 Il valore della Conoscenza DATI: sono nozioni grezze e incomplete. INFORMAZIONI: hanno origine dai dati aggiungendo ad essi valore attraverso processi di
Knowledge Management E Business Intelligence 1 Il valore della Conoscenza DATI: sono nozioni grezze e incomplete. INFORMAZIONI: hanno origine dai dati aggiungendo ad essi valore attraverso processi di
I DATI E LA LORO INTEGRAZIONE 63 4/001.0
 I DATI E LA LORO INTEGRAZIONE 63 4/001.0 L INTEGRAZIONE DEI DATI INTEGRAZIONE DEI DATI SIGNIFICA LA CONDIVISIONE DEGLI ARCHIVI DA PARTE DI PIÙ AREE FUNZIONALI, PROCESSI E PROCEDURE AUTOMATIZZATE NELL AMBITO
I DATI E LA LORO INTEGRAZIONE 63 4/001.0 L INTEGRAZIONE DEI DATI INTEGRAZIONE DEI DATI SIGNIFICA LA CONDIVISIONE DEGLI ARCHIVI DA PARTE DI PIÙ AREE FUNZIONALI, PROCESSI E PROCEDURE AUTOMATIZZATE NELL AMBITO
Data Journalism. Analisi dei dati. Angelica Lo Duca
 Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Introduzione al data mining. Sistemi di elaborazione delle informazioni 2 Anno Accademico Prof. Mauro Giacomini
 Introduzione al data mining Sistemi di elaborazione delle informazioni 2 Anno Accademico 2007-2008 Prof. Mauro Giacomini Definizione Processo che impiega una o più tecniche di apprendimento computerizzate
Introduzione al data mining Sistemi di elaborazione delle informazioni 2 Anno Accademico 2007-2008 Prof. Mauro Giacomini Definizione Processo che impiega una o più tecniche di apprendimento computerizzate
SDE Marco Riani
 SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
BICOOP Churn Analisys
 BICOOP Churn Analisys Definizione del concetto di abbandono e creazione di modelli previsionali Mirco Nanni KDD Lab,ISTI-CNR, Pisa mirco.nanni@isti.cnr.it Master MAINS, 6 luglio 2009 Sommario Introduzione
BICOOP Churn Analisys Definizione del concetto di abbandono e creazione di modelli previsionali Mirco Nanni KDD Lab,ISTI-CNR, Pisa mirco.nanni@isti.cnr.it Master MAINS, 6 luglio 2009 Sommario Introduzione
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello
 Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
NUCLEI FONDANTI COMPETENZE CONTENUTI ABILITA METODOLOGIE E STRUMENTI METODO SCIENTIFICO VEDERE
 NUCLEI FONDANTI COMPETENZE CONTENUTI ABILITA METODOLOGIE E STRUMENTI METODO SCIENTIFICO VEDERE OSSERVARE COMPARARE CLASSIFICARE FORMULARE E VERIFICARE IPOTESI UTILIZZANDO SEMPLICI SCHEMATIZZAZIONI Relazione
NUCLEI FONDANTI COMPETENZE CONTENUTI ABILITA METODOLOGIE E STRUMENTI METODO SCIENTIFICO VEDERE OSSERVARE COMPARARE CLASSIFICARE FORMULARE E VERIFICARE IPOTESI UTILIZZANDO SEMPLICI SCHEMATIZZAZIONI Relazione
Ciascuna Unità di Apprendimento sarà adattata alle peculiarità della classe.
 Lo spazio e le figure Analizzare, confrontare e classificare i poligoni (regolari e non) in base a diversi criteri. Scoprire e descrivere le proprietà del cerchio. Eseguire disegni geometrici utilizzando
Lo spazio e le figure Analizzare, confrontare e classificare i poligoni (regolari e non) in base a diversi criteri. Scoprire e descrivere le proprietà del cerchio. Eseguire disegni geometrici utilizzando
Reti Neurali. Corso di AA, anno 2016/17, Padova. Fabio Aiolli. 2 Novembre Fabio Aiolli Reti Neurali 2 Novembre / 14. unipd_logo.
 Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Computazione per l interazione naturale: macchine che apprendono
 Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
Computazione per l interazione naturale: macchine che apprendono Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Scienze dell Informazione Università di Milano boccignone@dsi.unimi.it
MINISTERO DELL ISTRUZIONE, DELL UNIVERSITÀ E DELLA RICERCA USR-LAZIO ISTITUTO COMPRENSIVO VIA LATINA
 MINISTERO DELL ISTRUZIONE, DELL UNIVERSITÀ E DELLA RICERCA USR-LAZIO ISTITUTO COMPRENSIVO VIA LATINA 303 Via Latina, 303 00179 ROMA 17 Distretto Municipio VII(ex IX) - tel. 06 893 71 483 - fax 06 893 74
MINISTERO DELL ISTRUZIONE, DELL UNIVERSITÀ E DELLA RICERCA USR-LAZIO ISTITUTO COMPRENSIVO VIA LATINA 303 Via Latina, 303 00179 ROMA 17 Distretto Municipio VII(ex IX) - tel. 06 893 71 483 - fax 06 893 74
INFORMATICA TECNOLOGIE DELLA COMUNICAZIONE SAPERI MINIMI DISCIPLINARI
 TECNOLOGIE DELLA COMUNICAZIONE SAPERI MINIMI DISCIPLINARI 1 TECNOLOGIE DELLA COMUNICAZIONE SAPERI MINIMI DISCIPLINARI CLASSE I ITE Sistemi informatici. - Informazioni, dati e loro codifica. - Architettura
TECNOLOGIE DELLA COMUNICAZIONE SAPERI MINIMI DISCIPLINARI 1 TECNOLOGIE DELLA COMUNICAZIONE SAPERI MINIMI DISCIPLINARI CLASSE I ITE Sistemi informatici. - Informazioni, dati e loro codifica. - Architettura
DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager
 DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager Smart Vision - Le tecnologie per l industria del futuro Machine Learning Famiglie di machine learning
DEEP LEARNING PER CONTROLLO QUALITA PRODOTTO E CONTROLLO DI PROCESSO Alessandro Liani, CEO e R&D Manager Smart Vision - Le tecnologie per l industria del futuro Machine Learning Famiglie di machine learning
Sistemi informativi aziendali struttura e processi
 Sistemi informativi aziendali struttura e processi Data mining Copyright 2011 Pearson Italia Uso dei Data Warehouse Esistono tre tipi di applicazioni front-end per data warehouse Analisi statica (reporting)
Sistemi informativi aziendali struttura e processi Data mining Copyright 2011 Pearson Italia Uso dei Data Warehouse Esistono tre tipi di applicazioni front-end per data warehouse Analisi statica (reporting)
CURRICOLO DIPARTIMENTO INFORMATICA PRIMO BIENNIO
 dei limiti nel contesto culturale e sociale in cui vengono applicate CURRICOLO PARTIMENTO INFORMATICA PRIMO BIENNIO MODULO 1 Concetti di base della tecnologia dell informazione Acquisire e interpretare
dei limiti nel contesto culturale e sociale in cui vengono applicate CURRICOLO PARTIMENTO INFORMATICA PRIMO BIENNIO MODULO 1 Concetti di base della tecnologia dell informazione Acquisire e interpretare
Fallimenti delle aziende in Italia
 Fallimenti delle aziende in Italia Dati aggiornati a marzo 2013 Marketing CRIBIS D&B Agenda Analisi dei Fallimenti in Italia Company Profile Gli Strumenti Utilizzati e Metodologia 2 Tipologia di analisi
Fallimenti delle aziende in Italia Dati aggiornati a marzo 2013 Marketing CRIBIS D&B Agenda Analisi dei Fallimenti in Italia Company Profile Gli Strumenti Utilizzati e Metodologia 2 Tipologia di analisi
Ore settimanali di lezione: 3 h di cui 2 in compresenza con l insegnante di Lab. di Informatica prof.ssa E.De Gasperi
 Anno scolastico 2015/2016 Piano di lavoro individuale ISS BRESSANONE-BRIXEN LICEO SCIENTIFICO - LICEO LINGUISTICO - ITE Classe: III ITE Insegnante: Prof.ssa Maria CANNONE Materia: INFORMATICA Ore settimanali
Anno scolastico 2015/2016 Piano di lavoro individuale ISS BRESSANONE-BRIXEN LICEO SCIENTIFICO - LICEO LINGUISTICO - ITE Classe: III ITE Insegnante: Prof.ssa Maria CANNONE Materia: INFORMATICA Ore settimanali
MATRICE TUNING competenze versus unità didattiche, Corso di Laurea Magistrale in Informatica (classe LM-18), Università degli Studi di Cagliari
, Università degli Studi di Cagliari") A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere l elaborazione e l analisi di immagini digitali (acquisizione e rappresentazione, miglioramento, segmentazione ed estrazione di caratteristiche,
A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere l elaborazione e l analisi di immagini digitali (acquisizione e rappresentazione, miglioramento, segmentazione ed estrazione di caratteristiche,
Vivisezione di un algoritmo di machine learning. Francesco ESPOSITO Youbiquitous
 Vivisezione di un algoritmo di machine learning Francesco ESPOSITO Youbiquitous Argomenti Panoramica di algoritmi e problemi Dentro un algoritmo Definire un approssimazione Definire un errore Minimizzare
Vivisezione di un algoritmo di machine learning Francesco ESPOSITO Youbiquitous Argomenti Panoramica di algoritmi e problemi Dentro un algoritmo Definire un approssimazione Definire un errore Minimizzare
ISTITUZIONE SCOLASTICA DI ISTRUZIONE TECNICA LYCÉE TECHNIQUE PROGRAMMAZIONE EDUCATIVA E DIDATTICA ANNUALE PER COMPETENZE A.S.
 ISTITUZIONE SCOLASTICA DI ISTRUZIONE TECNICA LYCÉE TECHNIQUE PROGRAMMAZIONE EDUCATIVA E DIDATTICA ANNUALE PER COMPETENZE A.S. 2018/2019 Materia Classe Informatica 3 IT Competenze (Linee guida+competenze
ISTITUZIONE SCOLASTICA DI ISTRUZIONE TECNICA LYCÉE TECHNIQUE PROGRAMMAZIONE EDUCATIVA E DIDATTICA ANNUALE PER COMPETENZE A.S. 2018/2019 Materia Classe Informatica 3 IT Competenze (Linee guida+competenze
Disciplina: INFORMATICA
 II1 ANNO Indirizzo AFM Articolazione SIA Anno scolastico 2017/2018 Classe 5S Docenti Corongiu, Pazienza Disciplina: INFORMATICA I risultati di apprendimento relativi al profilo educativo, culturale e professionale
II1 ANNO Indirizzo AFM Articolazione SIA Anno scolastico 2017/2018 Classe 5S Docenti Corongiu, Pazienza Disciplina: INFORMATICA I risultati di apprendimento relativi al profilo educativo, culturale e professionale
Alberi di Regressione
 lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
relazioni classe 1 a 2 a 3 a
 MATEMATICA relazioni classe 1 a 2 a 3 a TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE 5. Ricerca dati per ricavare informazioni e costruisce rappresentazioni (tabelle e grafici). Ricava informazioni anche
MATEMATICA relazioni classe 1 a 2 a 3 a TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE 5. Ricerca dati per ricavare informazioni e costruisce rappresentazioni (tabelle e grafici). Ricava informazioni anche
SISTEMI INFORMATIVI DIREZIONALI BUSINESS INTELLIGENCE
 SISTEMI INFORMATIVI DIREZIONALI BUSINESS INTELLIGENCE Punti chiave Cosa sono i sistemi informativi direzionali (SID)? Che differenza con i sistemi di supporto alle attività operative? Qual è il punto di
SISTEMI INFORMATIVI DIREZIONALI BUSINESS INTELLIGENCE Punti chiave Cosa sono i sistemi informativi direzionali (SID)? Che differenza con i sistemi di supporto alle attività operative? Qual è il punto di
INTRODUZIONE AI DBMS. Inoltre i fogli elettronici. Mentre sono poco adatti per operazioni di. Prof. Alberto Postiglione
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
INTRODUZIONE AI DBMS
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Reti Neurali (Parte I)
") Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
Reti Neurali (Parte I) Corso di AA, anno 2017/18, Padova Fabio Aiolli 30 Ottobre 2017 Fabio Aiolli Reti Neurali (Parte I) 30 Ottobre 2017 1 / 15 Reti Neurali Artificiali: Generalità Due motivazioni diverse
Indicizzazione di feature locali. Annalisa Franco
 1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
1 Indicizzazione di feature locali Annalisa Franco annalisa.franco@unibo.it http://bias.csr.unibo.it/vr/ 2 Introduzione I descrittori locali sono vettori di uno spazio N- dimensionale (alta dimensionalità)
DATA MINING. Cos'è il Data Mining: Traduzione letterale: Clustering e Reti di Kohonen
 Cos'è il Data Mining: Traduzione letterale: DATA MINING Data : To mine : informazione scavare,estrarre Clustering e Reti di Kohonen Processo di estrazione di conoscenza (nell'ambito del KDD,knowledge discovery
Cos'è il Data Mining: Traduzione letterale: DATA MINING Data : To mine : informazione scavare,estrarre Clustering e Reti di Kohonen Processo di estrazione di conoscenza (nell'ambito del KDD,knowledge discovery
Standard per Data Mining
 Standard per Data Mining Sistemi informativi per le Decisioni Slide a cura di prof. Claudio Sartori Iniziative di Standard per Data Mining I modelli di Data Mining e statistici generati dagli strumenti
Standard per Data Mining Sistemi informativi per le Decisioni Slide a cura di prof. Claudio Sartori Iniziative di Standard per Data Mining I modelli di Data Mining e statistici generati dagli strumenti
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Competenze chiave europee Competenze di base in tecnologia Senso di iniziativa per imparare ad imparare
 UNITA DI APPRENDIMENTO N. 1 Denominazione: L ENERGIA E LE TECNICHE PER LA PRODUZIONE E L UTILIZZAZIONE DI ENERGIA ELETTRICA Competenze di base in tecnologia Funzioni e trasformazioni nel tempo di alcuni
UNITA DI APPRENDIMENTO N. 1 Denominazione: L ENERGIA E LE TECNICHE PER LA PRODUZIONE E L UTILIZZAZIONE DI ENERGIA ELETTRICA Competenze di base in tecnologia Funzioni e trasformazioni nel tempo di alcuni
I sistemi di reporting e i rapporti direzionali
 I sistemi di reporting e i rapporti direzionali Reporting - Sintesi dei fenomeni aziendali secondo modelli preconfezionati e con frequenza e aggiornamento prestabiliti - contabile (dati economici) - extracontabile
I sistemi di reporting e i rapporti direzionali Reporting - Sintesi dei fenomeni aziendali secondo modelli preconfezionati e con frequenza e aggiornamento prestabiliti - contabile (dati economici) - extracontabile
Programmazione educativo-didattica anno scolastico TECNOLOGIA CLASSE PRIMA PRIMARIA TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE.
 Istituto Maddalena di Canossa Corso Garibaldi 60-27100 Pavia Scuola dell Infanzia Scuola Primaria Scuola Secondaria di 1 grado Programmazione educativo-didattica anno scolastico 2016-2017 TECNOLOGIA CLASSE
Istituto Maddalena di Canossa Corso Garibaldi 60-27100 Pavia Scuola dell Infanzia Scuola Primaria Scuola Secondaria di 1 grado Programmazione educativo-didattica anno scolastico 2016-2017 TECNOLOGIA CLASSE
PROGRAMMAZIONE DIDATTICA A. S. : 2018/2019
 PROGRAMMAZIONE DIDATTICA A. S. : 2018/2019 CLASSE:2A INFO Istituto Tecnico - Settore Tecnologico - Indirizzo Informatica e Telecomunicazioni Articolazione Informatica MATERIA: Scienze e Tecnologie Applicate
PROGRAMMAZIONE DIDATTICA A. S. : 2018/2019 CLASSE:2A INFO Istituto Tecnico - Settore Tecnologico - Indirizzo Informatica e Telecomunicazioni Articolazione Informatica MATERIA: Scienze e Tecnologie Applicate
Computazione per l interazione naturale: macchine che apprendono
 Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
Comput per l inter naturale: macchine che apprendono Corso di Inter uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it http://boccignone.di.unimi.it/ium2_2014.html
UNITA D APPRENDIMENTO. Lo spazio e le figure
 Lo spazio e le figure Utilizzare il piano cartesiano per rappresentare punti mediante le coordinate Effettuare trasformazioni topologiche rilevando le invarianti (guanto di gomma) Individuare e riconoscere
Lo spazio e le figure Utilizzare il piano cartesiano per rappresentare punti mediante le coordinate Effettuare trasformazioni topologiche rilevando le invarianti (guanto di gomma) Individuare e riconoscere
CURRICOLO DI TECNOLOGIA
 ISTITUTO COMPRENSIVO PASSIRANO-PADERNO CURRICOLO DI TECNOLOGIA SCUOLA PRIMARIA Revisione Curricolo di Istituto a.s. 2014-2015T Curricolo suddiviso in obiettivi didattici, nuclei tematici e anni scolastici
ISTITUTO COMPRENSIVO PASSIRANO-PADERNO CURRICOLO DI TECNOLOGIA SCUOLA PRIMARIA Revisione Curricolo di Istituto a.s. 2014-2015T Curricolo suddiviso in obiettivi didattici, nuclei tematici e anni scolastici
SCUOLA PRIMARIA MONOENNIO
 SCUOLA PRIMARIA MONOENNIO Presentazione La definizione delle competenze e degli obiettivi di apprendimento si ritiene valida per tutte le scuole del Circolo. Potrà essere modificata la scelta in riferimento
SCUOLA PRIMARIA MONOENNIO Presentazione La definizione delle competenze e degli obiettivi di apprendimento si ritiene valida per tutte le scuole del Circolo. Potrà essere modificata la scelta in riferimento
Statistica per l Impresa
 Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Elementi di gestione di dati con MS Access 2000
 Elementi di gestione di dati con MS Access 2000 ESERCITAZIONE I Luisa Cutillo - Università Parthenope 1 Concetti introduttivi Un database o base di dati e una collezione di informazioni che esistono per
Elementi di gestione di dati con MS Access 2000 ESERCITAZIONE I Luisa Cutillo - Università Parthenope 1 Concetti introduttivi Un database o base di dati e una collezione di informazioni che esistono per
Le basi di dati. Definizione 1. Lezione 2. Bisogna garantire. Definizione 2 DBMS. Differenza
 Definizione 1 Lezione 2 Le basi di dati Gli archivi di dati Organizzato in modo integrato attraverso tecniche di modellazione di dati Gestiti su memorie di massa Con l obiettivo Efficienza trattamento
Definizione 1 Lezione 2 Le basi di dati Gli archivi di dati Organizzato in modo integrato attraverso tecniche di modellazione di dati Gestiti su memorie di massa Con l obiettivo Efficienza trattamento
Sistemi Informativi Aziendali. Sistemi Informativi Aziendali
 DIPARTIMENTO DI INGEGNERIA INFORMATICA AUTOMATICA E GESTIONALE ANTONIO RUBERTI Cenni al Data Mining 1 Data Mining nasce prima del Data Warehouse collezione di tecniche derivanti da Intelligenza Artificiale,
DIPARTIMENTO DI INGEGNERIA INFORMATICA AUTOMATICA E GESTIONALE ANTONIO RUBERTI Cenni al Data Mining 1 Data Mining nasce prima del Data Warehouse collezione di tecniche derivanti da Intelligenza Artificiale,
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
CURRICOLO DI MATEMATICA
 CURRICOLO DI MATEMATICA AREA LOGICO MATEMATICA CLASSE PRIMA COMPETENZE OBIETTIVI DI APPRENDIMENTO STANDARD DI APPRENDIMENTO ATTESI Riconoscere e risolvere situazioni problematiche utilizzando anche rappresentazioni
CURRICOLO DI MATEMATICA AREA LOGICO MATEMATICA CLASSE PRIMA COMPETENZE OBIETTIVI DI APPRENDIMENTO STANDARD DI APPRENDIMENTO ATTESI Riconoscere e risolvere situazioni problematiche utilizzando anche rappresentazioni
Segmentazione e Marketing 121. Università di Bologna Andrea De Marco
 Segmentazione e Marketing 121 Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo con cui "raggruppiamo" in insiemi omogenei elementi
Segmentazione e Marketing 121 Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo con cui "raggruppiamo" in insiemi omogenei elementi
DISCIPLINA: MATEMATICA
 Opera in modo faticoso e inappropriato nel calcolo e utilizza linguaggi e metodi della disciplina in modo scorretto. Opera in modo faticoso e incerto nel calcolo e utilizza linguaggi e metodi della disciplina
Opera in modo faticoso e inappropriato nel calcolo e utilizza linguaggi e metodi della disciplina in modo scorretto. Opera in modo faticoso e incerto nel calcolo e utilizza linguaggi e metodi della disciplina
Reti Neurali in Generale
 istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
Competenza : 1. Comunicazione efficace Indicatore: 1.1 Comprensione
 SCUOLA SECONDARIA DI PRIMO GRADO TECNOLOGIA Competenza : 1. Comunicazione efficace Indicatore: 1.1 Comprensione Descrittori Descrittori Descrittori 1.1.1 E in grado di comprendere testi e altre fonti di
SCUOLA SECONDARIA DI PRIMO GRADO TECNOLOGIA Competenza : 1. Comunicazione efficace Indicatore: 1.1 Comprensione Descrittori Descrittori Descrittori 1.1.1 E in grado di comprendere testi e altre fonti di
Algoritmi di classificazione supervisionati
 Corso di Bioinformatica Algoritmi di classificazione supervisionati Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di apprendimento supervisionato per problemi di biologia computazionale
Corso di Bioinformatica Algoritmi di classificazione supervisionati Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di apprendimento supervisionato per problemi di biologia computazionale
Il confronto di IRIDE con esperienze simili
 PEOPLE CENTERED APPLICATIONS Il confronto di IRIDE con esperienze simili Le tecnologie Almawave al servizio delle amministrazioni pubbliche, cittadini e imprese Bologna,19 ottobre 2016 Almawave PRINCIPALI
PEOPLE CENTERED APPLICATIONS Il confronto di IRIDE con esperienze simili Le tecnologie Almawave al servizio delle amministrazioni pubbliche, cittadini e imprese Bologna,19 ottobre 2016 Almawave PRINCIPALI
Competenza matematica e competenze di base in scienza e tecnologia COMPETENZE ABILITA CONOSCENZE
 Classe prima COMPETENZE ABILITA CONOSCENZE 1. Vedere e osservare - Saper classificare i materiali in base alle caratteristiche e all utilizzo. - Saper analizzare semplici oggetti, strumenti e macchine
Classe prima COMPETENZE ABILITA CONOSCENZE 1. Vedere e osservare - Saper classificare i materiali in base alle caratteristiche e all utilizzo. - Saper analizzare semplici oggetti, strumenti e macchine
COMPETENZE ABILITA CONOSCENZE
 Classe prima COMPETENZE ABILITA CONOSCENZE 1. Vedere e osservare - Saper classificare i materiali in base alle caratteristiche e all utilizzo. - Saper analizzare semplici oggetti, strumenti e macchine
Classe prima COMPETENZE ABILITA CONOSCENZE 1. Vedere e osservare - Saper classificare i materiali in base alle caratteristiche e all utilizzo. - Saper analizzare semplici oggetti, strumenti e macchine
Data warehouse Introduzione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, D MG B Data warehouse Introduzione INTRODUZIONE - 1 Database and data
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, D MG B Data warehouse Introduzione INTRODUZIONE - 1 Database and data
DESCRITTORI II ANNO SCUOLA PRIMARIA. Numerare in ordine progressivo e regressivo anche rispettando semplici algoritmi di calcolo
 MACRO COMPETENZA OBIETTIVI DI APPRENDIMENTO DISCIPLINARI DESCRITTORI I ANNO SCUOLA PRIMARIA DESCRITTORI II ANNO SCUOLA PRIMARIA DESCRITTORI III ANNO SCUOLA PRIMARIA TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE
MACRO COMPETENZA OBIETTIVI DI APPRENDIMENTO DISCIPLINARI DESCRITTORI I ANNO SCUOLA PRIMARIA DESCRITTORI II ANNO SCUOLA PRIMARIA DESCRITTORI III ANNO SCUOLA PRIMARIA TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE
Segmentazione e Marketing 121
 Segmentazione e Marketing 121 Corso di Laurea in Informatica per il Management Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo
Segmentazione e Marketing 121 Corso di Laurea in Informatica per il Management Università di Bologna Andrea De Marco Segmentazione Cosa Significa? Usiamo la parola "segmentazione" per definire il processo
Indice generale. Ringraziamenti...xiii. Introduzione. Capitolo 1 Che cosa si intende per scienza dei dati?... 1
 Ringraziamenti...xiii Introduzione...xv Informazioni su questo libro...xv A chi si rivolge questo libro...xvi Questioni di software...xvi Note sugli apici...xvii Il forum del libro...xvii Esercitazioni...xviii
Ringraziamenti...xiii Introduzione...xv Informazioni su questo libro...xv A chi si rivolge questo libro...xvi Questioni di software...xvi Note sugli apici...xvii Il forum del libro...xvii Esercitazioni...xviii
Secondo Anno: Informatica Economico-Turistico
 Secondo Anno: Informatica Economico-Turistico Competenze ASSE DEI LINGUAGGI (1) Utilizzare e produrre testi multimediali (1.1) Comprendere i prodotti della comunicazione audiovisiva Elaborare prodotti
Secondo Anno: Informatica Economico-Turistico Competenze ASSE DEI LINGUAGGI (1) Utilizzare e produrre testi multimediali (1.1) Comprendere i prodotti della comunicazione audiovisiva Elaborare prodotti
Informazioni sul corso 1
 Informazioni sul corso 1 Insegnamento: Statistica (gruppo C) Corso di Laurea Triennale in Economia Dipartimento di Economia e Management Università degli Studi di Ferrara Docente: Dott.ssa Angela Grassi
Informazioni sul corso 1 Insegnamento: Statistica (gruppo C) Corso di Laurea Triennale in Economia Dipartimento di Economia e Management Università degli Studi di Ferrara Docente: Dott.ssa Angela Grassi
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
IL CONTESTO LA SCUOLA LA MATEMATICA LA MATEMATICA LA MATEMATICA LA STATISTICA NELLA SCUOLA DI BASE: COSA SI PUO FARE?
 Emilia Salucci Milano, 11 Ottobre 2001 LA STATISTICA NELLA SCUOLA DI BASE: COSA SI PUO FARE? IL CONTESTO Società attuale caratterizzata da Complessità crescente Evoluzione rapida Diffusione strumenti tecnologici
Emilia Salucci Milano, 11 Ottobre 2001 LA STATISTICA NELLA SCUOLA DI BASE: COSA SI PUO FARE? IL CONTESTO Società attuale caratterizzata da Complessità crescente Evoluzione rapida Diffusione strumenti tecnologici
SISTEMI INFORMATIVI E DATABASE
 SISTEMI INFORMATIVI E DATABASE SISTEMA INFORMATIVO AZIENDALE (S.I.) In una realtà aziendale si distingue: DATO elemento di conoscenza privo di qualsiasi elaborazione; insieme di simboli e caratteri. (274,
SISTEMI INFORMATIVI E DATABASE SISTEMA INFORMATIVO AZIENDALE (S.I.) In una realtà aziendale si distingue: DATO elemento di conoscenza privo di qualsiasi elaborazione; insieme di simboli e caratteri. (274,
Pentaho: una soluzione Open per la progettazione e sviluppo di Data Warehouse
 DPTS - DCMT/1 Pentaho: una soluzione Open per la progettazione e sviluppo di Data Warehouse Mariano Crea Istituto Nazionale di Statistica Agenda Data Warehouse Overview La Suite Pentaho Mondrian & JPivot:
DPTS - DCMT/1 Pentaho: una soluzione Open per la progettazione e sviluppo di Data Warehouse Mariano Crea Istituto Nazionale di Statistica Agenda Data Warehouse Overview La Suite Pentaho Mondrian & JPivot:
ISTITUTO D ISTRUZIONE SUPERIORE G.CENA SEZIONE TECNICA ANNO SCOLASTICO 2018/2019 PROGRAMMAZIONE DISCIPLINARE DIPARTIMENTALE DI INFORMATICA DOCENTI
 I.I.S. G. CENA ISTITUTO D ISTRUZIONE SUPERIORE G.CENA SEZIONE TECNICA ANNO SCOLASTICO 2018/2019 PROGRAMMAZIONE DISCIPLINARE DIPARTIMENTALE DI INFORMATICA DOCENTI Nespolo Donatella, Ravasenga Paola CLASSE
I.I.S. G. CENA ISTITUTO D ISTRUZIONE SUPERIORE G.CENA SEZIONE TECNICA ANNO SCOLASTICO 2018/2019 PROGRAMMAZIONE DISCIPLINARE DIPARTIMENTALE DI INFORMATICA DOCENTI Nespolo Donatella, Ravasenga Paola CLASSE
ISTITUTO COMPRENSIVO F. D'ASSISI TEZZE SUL BRENTA (VI)
") ISTITUTO COMPRENSIVO F. D'ASSISI TEZZE SUL BRENTA (VI) PROGRAMMAZIONE DIDATTICA DI MATEMATICA CLASSE 4^ OBIETTIVI FORMATIVI: Leggere, scrivere, confrontare numeri naturali e decimali. CONOSCENZE ABILITA
ISTITUTO COMPRENSIVO F. D'ASSISI TEZZE SUL BRENTA (VI) PROGRAMMAZIONE DIDATTICA DI MATEMATICA CLASSE 4^ OBIETTIVI FORMATIVI: Leggere, scrivere, confrontare numeri naturali e decimali. CONOSCENZE ABILITA
Analisi previsionale per l ottimizzazione della postalizzazione delle promo. KDD Lab. Pisa
 Analisi previsionale per l ottimizzazione della postalizzazione delle promo KDD Lab. Pisa Postalizzazione di promozioni Il processo decisionale: Inventare la promozione Selezionare il target Contattare
Analisi previsionale per l ottimizzazione della postalizzazione delle promo KDD Lab. Pisa Postalizzazione di promozioni Il processo decisionale: Inventare la promozione Selezionare il target Contattare
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Numero OBIETTIVI DI APPRENDIMENTO ABILITÀ CONTENUTI Scoprire e costruire la successione numerica entro la classe delle unità semplici.
 CLASSE SECONDA MATEMATICA COMPETENZE Legge, esplora e descrive la realtà attraverso un appropriata cognizione del linguaggio matematico, che come gli altri linguaggi è costituito da una struttura di forme,
CLASSE SECONDA MATEMATICA COMPETENZE Legge, esplora e descrive la realtà attraverso un appropriata cognizione del linguaggio matematico, che come gli altri linguaggi è costituito da una struttura di forme,
Obiettivi conoscitivi
 Il ruolo chiave dell informazione e delle ricerche di marketing Obiettivi conoscitivi Approfondire il concetto di informazione Evidenziare il ruolo strategico dell informazione all interno dei processi
Il ruolo chiave dell informazione e delle ricerche di marketing Obiettivi conoscitivi Approfondire il concetto di informazione Evidenziare il ruolo strategico dell informazione all interno dei processi