Modelli Probabilistici per la Computazione Affettiva: Learning/Inferenza parametri
|
|
|
- Guido Spinelli
- 7 anni fa
- Просмотров:
Транскрипт

1 Modelli Probabilistici per la Computazione Affettiva: Learning/Inferenza parametri Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano Dove siamo arrivati // Modelli Teorie: Basi psicologiche e neurobiologiche delle emozioni Modelli: Modelli probabilistici per la computazione affettiva: Apprendimento Inferenza Applicazioni: Esempi di sistemi di computazione affettiva
2 Dove siamo arrivati // Modelli Modello: variabili aleatorie stato mentale (nascosto) generazione inferenza comportamento non verbale (visibile) Dove siamo arrivati // Modelli: approccio frequentistico Modello: variabili aleatorie + parametri stato mentale (nascosto) comportamento non verbale (visibile)
3 Dove siamo arrivati // Modelli: approccio Bayesiano Modello: variabili aleatorie + v. a. latenti (parametri) +iperparametri stato mentale (nascosto) Sono un Bayesiano! comportamento non verbale (visibile) Per un Bayesiano non c è apprendimento, ma sempre e solo inferenza... Il problema dell apprendimento per PGM Il problema, concretamente: struttura conosciuta, dati completi Modello Dati input Learning
4 Il problema dell apprendimento per PGM Il problema, concretamente: struttura incompleta, dati completi Modello Dati input Learning Il problema dell apprendimento per PGM Il problema, concretamente: struttura conosciuta, dati incompleti Modello Dati input Learning
5 Il problema dell apprendimento per PGM Il problema, concretamente: struttura incompleta, dati incompleti Modello Dati input Learning Il problema dell apprendimento per PGM Il problema, concretamente: struttura incompleta con variabili latenti, dati incompleti Modello Dati input Learning
6 Introduzione alla Statistica Bayesiana //metodologia generale Obiettivo: predire un dato x sulla base di n osservazioni S = {x1,..., xn} Tre step: Modello o ipotesi h Specifica del modello h con parametri di tuning generazione dei dati in S per la Inferenza (learning dei parametri) Predizione Statistica Bayesiana //stime puntuali Rinunciando ad un approccio completamente Bayesiano, si possono ottenere stime puntuali dei parametri (ovvero i parametri diventano numeri e non VA) Stima Maximum A Posteriori (MAP) Stima di massima verosimiglianza (Maximum Likelihood, ML)
 Campioni estratti indipendentemente: L ipotesi i.i.d allora oppure usando la log-verosimiglianza Esempio: stima di massima verosimiglianza //caso Gaussiano Un vettore aleatorio forma quadratica di x per il singolo campione")
7 Esempio: stima di massima verosimiglianza //caso Gaussiano Insieme di campioni x1,..., xn da distribuzione Gaussiana di parametri ignoti (identicamente distribuiti) Campioni estratti indipendentemente: L ipotesi i.i.d allora oppure usando la log-verosimiglianza Esempio: stima di massima verosimiglianza //caso Gaussiano Un vettore aleatorio forma quadratica di x per il singolo campione

8 Esempio: stima di massima verosimiglianza // Parametri della Gaussiana Se con covarianza e media da stimare per il singolo campione derivando il secondo termine rispetto a e ripetendo il procedimento di prima media empirica covarianza empirica Esempio: stima di massima verosimiglianza // lancio di moneta Lancio di moneta come Naive Bayes: 100 lanci di moneta... θ x1 x2 x3 x4 x5 x6 x7 x8 x8 x9 x10
9 Esempio: stima di massima verosimiglianza // lancio di moneta Lancio di moneta come Naive Bayes: 100 lanci di moneta... θ xn n = 1,...,100 θ se θ è dato (0.5): Esempio: stima di massima verosimiglianza // lancio di moneta Likelihood per N lanci indipendenti Stima ML = 0 Quindi se dopo N=3 lanci osservo S = {C, C, C} allora = 0 :-(
 in realtà con N piccolo ottengo conclusioni fuorvianti (la moneta è sicuramente truccata: darà sempre CCCCCCC.")
10 Esempio: stima di massima verosimiglianza // lancio di dadi Distribuzione multinoulli o categorica Likelihood per N lanci indipendenti Stima ML Esempio: stima Bayesiana // lancio di moneta Nel setting ML (frequentistico) in realtà con N piccolo ottengo conclusioni fuorvianti (la moneta è sicuramente truccata: darà sempre CCCCCCC...) Approccio Bayesiano: funzione di likelihood: distribuzione di Bernoulli
11 Esempio: stima Bayesiana // lancio di moneta Approccio Bayesiano: a posteriori: distribuzione Beta funzione di likelihood: distribuzione di Bernoulli a priori coniugata di Bernoulli: distribuzione Beta θ xn n = 1,...,100 Esempio: stima Bayesiana // lancio di moneta Approccio Bayesiano: a posteriori: distribuzione Beta funzione di likelihood: distribuzione di Bernoulli a priori coniugata di Bernoulli: distribuzione Beta a priori coniugata di Bernoulli: distribuzione Beta funzione di likelihood: distribuzione di Bernoulli a posteriori: distribuzione Beta
12 Il problema dell apprendimento per PGM Il problema, concretamente: struttura conosciuta, dati completi Modello Dati input Learning Il problema dell apprendimento per PGM //ML per BN: decomponibilità della likelihood Decomposizione della likelihood globale in generale Dati disponibili: m=1 M Nodi / clique del PGM: i =1 likelihood locale sul singolo nodo / clique Abbiamo una Likelihood locale per ogni CPD
13 BN tabellari Caso piu semplice: CPD tabellare E una likelihood multinomiale che conteggia le occorrenze di x Il problema dell apprendimento per PGM //ML per BN: decomponibilità della likelihood Training set likelihood locale likelihood locale
 Learning con parametri condivisi //DBN/HMM Training: coppie di (sequenze di stati, sequenze di osservazioni) Test: predizione di sequenze di stati da sequenze di osservazioni Prima bisogna")
14 Il problema dell apprendimento per PGM //ML per BN: decomponibilità della likelihood distribuzione multinomiale stima di ML della multinomiale (semplicemente: si contano le occorrenze di x e y nei dati) Learning con parametri condivisi //DBN/HMM Training: coppie di (sequenze di stati, sequenze di osservazioni) Test: predizione di sequenze di stati da sequenze di osservazioni Prima bisogna effettuare il learning dei parametri che sono condivisi sia a livello di transizione di stato, sia a livello di emissione/osservazione Mettiamoci nel caso: fully observed (totalmente osservato: stati & emissioni)
15 Learning con parametri condivisi //DBN/HMM: stati osservati stati osservati decomponiamo su tutte le coppie di stati tutti gli istanti t in cui accade la transizione s_i -> s_j # transizioni # volte in cui occorre lo stato s_i Learning con parametri condivisi //DBN/HMM: stati & emissioni osservati Caso di HMM completamente osservato decomponiamo su tutte le coppie di stato / osservazione
16 Il problema dell apprendimento per PGM //Reti Bayesiane: sintesi BN con insiemi disgiunti di parametri: la verosimiglianza è il prodotto di likelihood locali alla CPD (una per variabile) CPD tabellari (CPT): la likelihood locale si decompone ulteriormente in un prodotto di likelihood multinomiali, una per ogni combinazione di genitori BN con CPD condivise (shared): le statistiche sufficienti (conteggi) si accumulano ogni volta che vengono utilizzate le CPD Il problema dell apprendimento per PGM //Reti Bayesiane: inferenza Bayesiana Le a posteriori sui parametri sono indipendenti se i dati X,Y sono completi (d-separazione) Come per MLE possiamo risolvere il problema della stima in modo indipendente

17 Il problema dell apprendimento per PGM //Reti Bayesiane: inferenza Bayesiana Le a posteriori sui parametri sono indipendenti se i dati X,Y sono completi (d-separazione) Come per MLE possiamo risolvere il problema della stima in modo indipendente vale anche fra parametri della stessa famiglia! Il problema dell apprendimento per PGM //Reti Bayesiane: inferenza Bayesiana Le a posteriori sui parametri sono indipendenti se i dati X,Y sono completi (d-separazione) Come per MLE possiamo risolvere il problema della stima in modo indipendente Se la famiglia è multinomiale a priori conteggio evento a posteriori
18 Il problema dell apprendimento per PGM //Reti Bayesiane: inferenza Bayesiana In BN se i parametri sono indipendenti a priori lo sono a posteriori Per BN con parametri multinomiali Stima di Maxlikelihood Stima Bayesiana Apprendimento in MN Nei Markov Network, a differenza delle BN non possiamo più effettuare l apprendimento in forma chiusa. la f di partizione è funzione dei parametri, non è costante! # dati # volte che l entry (a,b) è usata nel fattore qui siamo riusciti a separare i parametri x # occorrenze la Z accoppia i parametri: - la likelihood non si decompone - non c è soluzione in forma chiusa
19 Apprendimento in MN //Modelli log-lineari Per rendere più esplicite le tipologie delle strutture utilizzate è possibile riparametrizzare i fattori in termini di funzioni di energia La distribuzione di Gibbs (Boltzmann) diventa La probabilità di uno stato fisico del sistema è inversamente proporzionale all energia del sistema Apprendimento in MN //Modelli log-lineari Consideriamo in generale il set di features La congiunta è La log-likelihood La funzione di partizione è convessa forma log-sum-exp # esponenziale di valutazioni
20 Funzione di log-partizione Teorema: vettore matrice (Hessiana) Apprendimento in MN //Modelli log-lineari Che cosa ottengo dalla funzione di partizione è convessa è concava concava lineare concava unimodale

 Apprendimento in MN //Modelli log-lineari Come calcolo il gradiente La funzione di log-likelihood è concava: ascesa del gradiente La funzione di log-likelihood negativa è convessa (ha un minimo):")
21 Apprendimento in MN //Modelli log-lineari: Metodo dei momenti Funzione di verosimiglianza Stima di massima verosimiglianza, con media empirica sui dati CALCOLO SULLA SINGOLA CLIQUE I parametri che massimizzano si ottengono per media empirica sui dati aspettazione teorica sul modello aspettazione teorica sul modello Tuttavia non c è soluzione in forma chiusa e devo usare tecniche di ottimizzazione (ascesa del gradiente, massima entropia ecc.) Apprendimento in MN //Modelli log-lineari Come calcolo il gradiente La funzione di log-likelihood è concava: ascesa del gradiente La funzione di log-likelihood negativa è convessa (ha un minimo): discesa del gradiente aspettazione teorica sul modello Oppure uso tecniche più sofisticate: richiede una inferenza ad ogni step n! L-BFGS (quasi-newton)

22 Apprendimento in MN //Modelli log-lineari Come calcolo il gradiente Uso tecniche più sofisticate: Il problema dell apprendimento per PGM //Markov Networks: sintesi A differenza delle BN la likelihood non si disaccoppia, perchè la funzione di partizione accoppia le variabili Non c è soluzione in forma chiusa: problema di ottimizzazione convessa Gradient ascent L-BFGS Altre tecniche Ad ogni step di ottimizzazione devo effettuare un inferenza per calcolare la P Siccome le features sono racchiuse solitamente in una clique, mi basta un passo di calibrazione se uso message passing



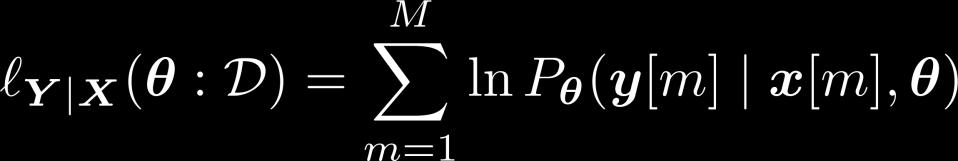
23 Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF Introduciamo i parametri Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF Supponiamo di usare features molto semplici definite sul superpixel s colore medio del super pixel Dati di input etichettati log - conditional likelihood
24 Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF Supponiamo di usare features molto semplici definite sul superpixel s colore medio del super pixel Dati di input etichettati log - conditional likelihood Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF misura feature expectation della feature presa su Y con x[m] fissato
25 Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF misura feature expectation della feature presa su Y con x[m] fissato probabilità a posteriori Il problema dell apprendimento per PGM //Markov Networks: il caso specifico CRF MRF: 1 Inferenza ad ogni passo dell ottimizzazione (gradient ascent) CRF: 1 inferenza per ciascun x[m], m = 1,...,M ad ogni passo dell ottimizzazione (gradient ascent) Però qui faccio inferenza su P(Y x) (tabella più piccola) mentre su MRF faccio inferenza su P(Y, X)
26 Stima MAP per MRF e CRF Mettere un prior sui parametri per avere smoothing sulla soluzione Nei BN era abbastanza semplice (prior coniugate: Multi /Dirichlet) Qui facciamo delle stime MAP dei parametri Stima MAP per MRF e CRF Mettere un prior sui parametri per avere smoothing sulla soluzione Per esempio una Gaussiana a media zero su ogni parametro sigma è iperparametro Gaussiana su parametro i-esimo
27 Stima MAP per MRF e CRF Mettere un prior sui parametri per avere smoothing sulla soluzione Per esempio una Laplace su ogni parametro beta è iperparametro Laplace su parametro i- esimo Stima MAP per MRF e CRF parametri densi L1 parametri sparsi


28 Il problema dell apprendimento per PGM //Dati incompleti, variabili latenti Il problema, concretamente: struttura incompleta con variabili latenti, dati incompleti Modello Dati input Learning Variabili latenti / Dati incompleti Perchè usarle? otteniamo modelli sparsi 17 parametri 59 parametri

29 Variabili latenti / Dati incompleti Perchè usarle? trovare dei cluster nei dati Variabili latenti / Dati incompleti La likelihood è tipicamente multimodale
30 Correlazione dei parametri Se mi mancano dei dati, è come se osservassi meno, non blocco i cammini e quindi ho correlazione fra i parametri 0 dati mancanti su 8 2 dati mancanti su 8 3 dati mancanti su 8 Variabili latenti / Dati incompleti Caso incompleto (multimodale) Caso completo (unimodale)
31 Variabili latenti / Dati incompleti Per massimizzare posso ricorrere all ascesa del gradiente rispetto ai parametri Variabili latenti / Dati incompleti Per BN vale il seguente: Teorema: CPD evidenza del dato m dipendente dai genitori parametri correnti Dobbiamo calcolare per tutti gli i (variabili) e tutti gli m (esempi di input) Possiamo farlo con il clique tree. Però il metodo è generale e si applica anche a CPD non tabellari Alternativa: Expectation-Maximization
![Variabili latenti / Dati incompleti Expectation: Per ciascun dato d[m] e ogni famiglia X,U calcola assegnazione soft Maximization statistiche sufficienti attese ESS Considera le ESS come conteggi](/docs-images/91/105565239/images/32-0.jpg "reali e usa MLE pesato dall ESS Learning con parametri condivisi //DBN/HMM: stati nascosti & emissioni osservati Stati nascosti s_t = x_t: come se fosse una mistura sequenziale Si usa una variante di")
32 Variabili latenti / Dati incompleti Expectation: Per ciascun dato d[m] e ogni famiglia X,U calcola assegnazione soft Maximization statistiche sufficienti attese ESS Considera le ESS come conteggi reali e usa MLE pesato dall ESS Learning con parametri condivisi //DBN/HMM: stati nascosti & emissioni osservati Stati nascosti s_t = x_t: come se fosse una mistura sequenziale Si usa una variante di Expectation-Maximization Passo E: Fissati i parametri inferisco gli stati nascosti Passo M: Fissati gli stati, aggiorno i parametri di transizione e di osservazione Algoritmo di Baum-Welch (EM per HMM)
33 Apprendimento dei parametri //Algoritmo di Baum-Welch (EM per HMM) Date le sequenze di training Passo E: Fissati i parametri inferisco gli stati nascosti Passo M: Fissati gli stati, aggiorno i parametri di transizione e di osservazione
Cenni di apprendimento in Reti Bayesiane
 Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Computazione per l interazione naturale: Modelli dinamici
 Computazione per l interazione naturale: Modelli dinamici Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] boccignone.di.unimi.it/in_2015.html
Computazione per l interazione naturale: Modelli dinamici Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] boccignone.di.unimi.it/in_2015.html
Università di Siena. Teoria della Stima. Lucidi del corso di. Identificazione e Analisi dei Dati A.A
 Università di Siena Teoria della Stima Lucidi del corso di A.A. 2002-2003 Università di Siena 1 Indice Approcci al problema della stima Stima parametrica Stima bayesiana Proprietà degli stimatori Stime
Università di Siena Teoria della Stima Lucidi del corso di A.A. 2002-2003 Università di Siena 1 Indice Approcci al problema della stima Stima parametrica Stima bayesiana Proprietà degli stimatori Stime
Approccio statistico alla classificazione
 Approccio statistico alla classificazione Approccio parametrico e non parametrico Finestra di Parzen Classificatori K-NN 1-NN Limitazioni dell approccio bayesiano Con l approccio bayesiano, sarebbe possibile
Approccio statistico alla classificazione Approccio parametrico e non parametrico Finestra di Parzen Classificatori K-NN 1-NN Limitazioni dell approccio bayesiano Con l approccio bayesiano, sarebbe possibile
Gaussian processes (GP)
") Gaussian processes (GP) Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] [email protected] http://boccignone.di.unimi.it/compaff017.html
Gaussian processes (GP) Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] [email protected] http://boccignone.di.unimi.it/compaff017.html
Statistica Metodologica Avanzato Test 1: Concetti base di inferenza
 Test 1: Concetti base di inferenza 1. Se uno stimatore T n è non distorto per il parametro θ, allora A T n è anche consistente B lim Var[T n] = 0 n C E[T n ] = θ, per ogni θ 2. Se T n è uno stimatore con
Test 1: Concetti base di inferenza 1. Se uno stimatore T n è non distorto per il parametro θ, allora A T n è anche consistente B lim Var[T n] = 0 n C E[T n ] = θ, per ogni θ 2. Se T n è uno stimatore con
Statistica ARGOMENTI. Calcolo combinatorio
 Statistica ARGOMENTI Calcolo combinatorio Probabilità Disposizioni semplici Disposizioni con ripetizione Permutazioni semplici Permutazioni con ripetizioni Combinazioni semplici Assiomi di probabilità
Statistica ARGOMENTI Calcolo combinatorio Probabilità Disposizioni semplici Disposizioni con ripetizione Permutazioni semplici Permutazioni con ripetizioni Combinazioni semplici Assiomi di probabilità
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA
 Metodi per l Analisi dei Dati Sperimentali AA009/010 IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA Sommario Massima Verosimiglianza Introduzione La Massima Verosimiglianza Esempio 1: una sola misura sperimentale
Metodi per l Analisi dei Dati Sperimentali AA009/010 IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA Sommario Massima Verosimiglianza Introduzione La Massima Verosimiglianza Esempio 1: una sola misura sperimentale
1 PROCESSI STOCASTICI... 11
 1 PROCESSI STOCASTICI... 11 Introduzione... 11 Rappresentazione dei dati biomedici... 11 Aleatorietà delle misure temporali... 14 Medie definite sul processo aleatorio... 16 Valore atteso... 16 Esercitazione
1 PROCESSI STOCASTICI... 11 Introduzione... 11 Rappresentazione dei dati biomedici... 11 Aleatorietà delle misure temporali... 14 Medie definite sul processo aleatorio... 16 Valore atteso... 16 Esercitazione
Kernel Methods. Corso di Intelligenza Artificiale, a.a Prof. Francesco Trovò
 Kernel Methods Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 14/05/2018 Kernel Methods Definizione di Kernel Costruzione di Kernel Support Vector Machines Problema primale e duale
Kernel Methods Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 14/05/2018 Kernel Methods Definizione di Kernel Costruzione di Kernel Support Vector Machines Problema primale e duale
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 2 Teoria della decisione Ennio Ottaviani On AIR srl [email protected] http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 2 Teoria della decisione Ennio Ottaviani On AIR srl [email protected] http://www.onairweb.com/corsopr
Indice. centrale, dispersione e forma Introduzione alla Statistica Statistica descrittiva per variabili quantitative: tendenza
 XIII Presentazione del volume XV L Editore ringrazia 3 1. Introduzione alla Statistica 5 1.1 Definizione di Statistica 6 1.2 I Rami della Statistica Statistica Descrittiva, 6 Statistica Inferenziale, 6
XIII Presentazione del volume XV L Editore ringrazia 3 1. Introduzione alla Statistica 5 1.1 Definizione di Statistica 6 1.2 I Rami della Statistica Statistica Descrittiva, 6 Statistica Inferenziale, 6
Università degli Studi Roma Tre Anno Accademico 2016/2017 ST410 Statistica 1
 Università degli Studi Roma Tre Anno Accademico 2016/2017 ST410 Statistica 1 Lezione 1 - Mercoledì 28 Settembre 2016 Introduzione al corso. Richiami di probabilità: spazi di probabilità, variabili aleatorie,
Università degli Studi Roma Tre Anno Accademico 2016/2017 ST410 Statistica 1 Lezione 1 - Mercoledì 28 Settembre 2016 Introduzione al corso. Richiami di probabilità: spazi di probabilità, variabili aleatorie,
Regressione Lineare e Regressione Logistica
 Regressione Lineare e Regressione Logistica Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: [email protected] @famo2spaghi http://stegua.github.com 1 Introduzione
Regressione Lineare e Regressione Logistica Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: [email protected] @famo2spaghi http://stegua.github.com 1 Introduzione
Note introduttive alla probabilitá e alla statistica
 Note introduttive alla probabilitá e alla statistica 1 marzo 2017 Presentiamo sinteticamente alcuni concetti introduttivi alla probabilitá e statistica 1 Probabilità e statistica Probabilità: Un modello
Note introduttive alla probabilitá e alla statistica 1 marzo 2017 Presentiamo sinteticamente alcuni concetti introduttivi alla probabilitá e statistica 1 Probabilità e statistica Probabilità: Un modello
Modelli Grafici Probabilistici (2): concetti generali
: concetti generali") Modelli Grafici Probabilistici (2): concetti generali Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] [email protected]
Modelli Grafici Probabilistici (2): concetti generali Corso di Modelli di Computazione Affettiva Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano [email protected] [email protected]
Esercizi di riepilogo Lezioni
 Esercizi di riepilogo Lezioni 16-17-18 1 Es1: Statistiche del secondo ordine [Pap, 9-2] Si ha un processo X con Determinare media, varianza, e covarianza delle v.a. Z=X(5) e W=X(8) Il processo X è stazionario?
Esercizi di riepilogo Lezioni 16-17-18 1 Es1: Statistiche del secondo ordine [Pap, 9-2] Si ha un processo X con Determinare media, varianza, e covarianza delle v.a. Z=X(5) e W=X(8) Il processo X è stazionario?
Dispensa di Statistica
 Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
PROBABILITÀ ELEMENTARE
 Prefazione alla seconda edizione XI Capitolo 1 PROBABILITÀ ELEMENTARE 1 Esperimenti casuali 1 Spazi dei campioni 1 Eventi 2 Il concetto di probabilità 3 Gli assiomi della probabilità 3 Alcuni importanti
Prefazione alla seconda edizione XI Capitolo 1 PROBABILITÀ ELEMENTARE 1 Esperimenti casuali 1 Spazi dei campioni 1 Eventi 2 Il concetto di probabilità 3 Gli assiomi della probabilità 3 Alcuni importanti