Hazard sul controllo. Sommario
|
|
|
- Fabia Renzi
- 5 anni fa
- Visualizzazioni
Transcript
1 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/30 Sommario Riorganizzazione del codice (delay slot) Esercizi 2/30 1
2 CPU con pipeline 3/30 Esempio di Hazard sul controllo sub $s2, $s1, $s3 IF ID EX $1-$3 MEM beq $t2, $6, 24 IF ID EX Zero if ($s2 == $s5) WB s->$2 MEM or $t7, $s6, $s7 IF ID EX MEM WB add $t4, $s8, $s8 IF ID EX MEM WB and $s5, $s6, $s7 IF ID EX MEM add $t0, $t1, $t2 IF ID EX WB In caso di salto: dovrei avere disponibile all istante in cui inizia l esecuzione dell istruzione or l indirizzo dell istruzione add e non eseguire la or, la add e la and. NB L indirizzo scritto nel PC corretto deve essere disponibile prima dell inizio della fase di fetch. Ho 3 istruzioni sbagliate in pipeline. NB Il PC è master/slave per cui occorre che l indirizzo sia pronto prima dell inizio della fase di fetch. 4/30 2
3 Hazard sul controllo sub $s2, $s1, $s3 beq $t2, $6, 24 or $t7, $s6, $s7 add $t4, $s8, $s8 and $s5, $s6, $s7 add $t0, $t1, $t2 sw $s3, 24($t1) addi $t7, $s6, 10 add $t8, $s2, $s2 and $s5, $s6, $s7 add $t0, $t1, $t2 sub $s2, $s1, $s3 beq $t2, $6, 24 Salto preso Salto non preso add $t8, $s2, $s2 or $t7, $s6, $s7 5/30 Criticità sul controllo and add or beq Il valore del PC può essere aggiornato nella fase di Memoria A.A. Le istruzioni in fase di IF, ID, EX potrebbero non 6/30 dovere essere eseguite. 3
4 Soluzioni alla criticità nel controllo Modifiche strutturali per l anticipazione dei salti. & Riordinamento del codice (delayed branch). 7/31 Modifica della CPU Obbiettivi: - Identificare l hazard durante la fase ID di esecuzione della branch. - Scartare una sola istruzione. 800: sub $s2, $s1, $s3 IF ID EX MEM WB $s1- s->$2 $s3 804: beq $t2, $s6, tag IF ID EX Zero if ($s2 == $s5) MEM 808: or $t7, $s6, $s7 IF ID EX MEM WB.. tag: add $t4, $s8, $s8 IF ID EX MEM WB tag and $s5, $s6, $s7 IF ID EX MEM +4: Tag +8 add $t0, $t1, $t2 IF ID EX WB 8/31 4
5 Come identificare l Hazard nella fase ID If (rs == rt) & (branch = 1) then hazard Hazard: Indirizzo successivo sarà PC Offset * 4, ma ho già caricato (fetch) l istruzione a PC +4.. Traduco in un circuito logico la condizione che produce hazard 9/31 CPU con unità di propagazione 10/31 5

, mentre in caso di salto dovrebbe essere trasferita l istruzione all indirizzo di salto.")
6 Come identificare l Hazard nella fase ID ALU calcolo indirizzo di salto + Comparatore per confrontare Rs e Rt Anticipazione della valutazione della branch: Modifica della CPU nella gestione dei salti: anticipazione del calcolo dell indirizzo di salto. HW addizionale: un comparatore all uscita del Register File. Anticipazione del sommatore. 11/31 Stallo della pipeline. Soluzione dell Hazard sul controllo Dalla fase ID alla WB la beq non fa nulla. Nella fase di IF è l istruzione successiva che viene trasferita nell IR (IF/ID), mentre in caso di salto dovrebbe essere trasferita l istruzione all indirizzo di salto. Quindi: Occorre annullare l istruzione nel registro IF/ID, ed inserire una bubble. Occorre scrivere l indirizzo di salto nel PC. FF DEC EX MEM WB t or beq sub t+1 and nop beq sub La or deve essere scartata. 12/31 6
7 Come scartare un istruzione Si carica nel registro IF/ID un istruzione nulla. Nome campo op rs rt rd shamt funct Dimensione 6-bit 5-bit 5-bit 5-bit 5-bit 6-bit sll $s1, $s2, X (7) $s1 = $s2 = $zero, shmt = 0 Nome campo op rs rt rd shamt funct Dimensione 6-bit 5-bit 5-bit 5-bit 5-bit 6-bit sll $zero, $zero, (0) Il registro $zero non viene utilizzato come registro destinazione 13/31 CPU con pipeline completa della gestione degli hazard sul controllo 14/31 7
8 CPU con pipeline completa della gestione degli hazard sul controllo 15/30 Gestione della criticità Soluzione HW: Decisione ritardata. Ci si affida all hardware della CPU per gestire l eliminazione delle istruzioni (flush). Soluzione SW: Aggiunta di un branch delay slot, un istruzione successiva a quella di salto che viene sempre eseguita indipendentemente dall esito della branch. Contiamo sul compilatore/assemblatore per mettere dopo l istruzione di salto una istruzione che andrebbe comunque eseguita indipendentemente dal salto (ad esempio posticipo un istruzione precedente la branch). 16/30 8
9 Esempio di riorganizzazione del codice per le istruzioni di branch if (a = = b) if (a = = b) { s2 = s0 + s1; { s2 = s0 + s1; } s3 = s4 + s5; } else { s3 = s4 + s5; } s3 = s4 + s5; salta: s6 = 2; s6 = 2; 17/30 Esempio di riorganizzazione del codice - II if (a = = b) if (a = = b) { s2 = s0 + s1; { s2 = s0 + s1; s5 = s4 + s3; } } else else { { t2 = t0 + t1; t2 = t0 + t1; s5 = s4 + s3; } } s5 = s4 + s3; t5 = 2; t5 = 2; 18/30 9
10 Esempio di delayed branch Originale From target From before salto: sub $t5, $t8, $s8 add $s4, $t0, $t1 beq $s5, $s6, salto and $s0, $s0, $s1 add $t5, $t4, $t3 add $t6, $t7, $t7 salto: sub $t5, $t8, $s8 add $s4, $t0, $t1 beq $s5, $s6, salto add $t5, $t4, $t3 and $s0, $s0, $s1 add $t6, $t7, $t7 salto: add $s4, $t0, $t1 beq $s5, $s6, salto sub $t5, $t8, $s8 and $s0, $s0, $s1 add $t5, $t4, $t3 add $t6, $t7, $t7 L istruzione add $t5, $t4, $t3 o sub $t5, $t8, $s8 viene comunque eseguita, il salto (se richiesto) avviene all istante successivo. Riempio quindi con queste istruzioni lo slot dopo la banch, denominato branch delay slot. Controllo di non inserire Hazard sui dati L istruzione target può essere posizionata prima o dopo a seconda che la beq salti prima o dopo. 19/30 CPU con pipeline completa della gestione degli hazard. 20/30 10

11 Branch prediction buffer Branch prediction ad esempio tramite: branch prediction buffer (4 kbyte nel Pentium 4). PC #bit < 32 Bit meno significativi del PC Problema: Previsione relativa ad una beq con gli stessi bit meno significativi del PC. E un problema? Bit che indica se l ultima volta il salto era stato eseguito o meno. beq $t0, $t1, SALTA add $s0, $s1, $s2 sub $s3, $s4, $s5 or $6$7$8 $s6 $s7, $s8 SALTA: and $t2, $t3, $t4 In questo caso suppongo di non dovere saltare. Procedo in sequenza. Se la previsione è sbagliata, devo annullare la add e saltare a SALTA. Algoritmi di ottimizzazione dello scheduling per predizione ottima del salto. 21/30 Branch Prediction buffer a 2 bit PC no error With 1 error no error With 1 error 22/30 11

 Tournament predictors.")
12 Sintesi della FSM della Branch Prediction I=Taken I=NotTaken Y S=Taken 0 errors Taken 0 errors S = Taken 1 error Taken 0 errors S=Not Taken 0 errors Not Taken 1 error S = Not Taken 1 error Taken 1 error Taken 1 error Not Taken 1 error Not Taken 0 errors Not Taken 0 errors Predict taken Predict taken Predict Not taken Predict Not taken no error With 1 error no error With 1 error 23/30 Evoluzioni della branch prediction 1) Correlating predictors. Comportamento locale e globale dei salti. Tipicamente 2 predittori a 2 bit. Viene scelto il predittore che correla meglio con la storia del salto. 2) Tournament predictors. Vengono utilizzati predittori multipli a 1 o 2 bit, e per ogni branch viene selezionato il predittore migliore. Il selettore selezione quale dei due bit di informazione utilizzare, in base alla loro accuratezza di predizione. Solitamente viene utilizzato un predittore che analizza informazioni locali (di contesto), un altro che analizza informazioni globali (di contesto). Informazioni di contesto possono ad esempio essere contenuto di registri. Il codice di selezione per il selettore viene memorizzato del lbranch prediction i buffer. 24/30 12
13 Salto incondizionato Utilizzato all interno dei cicli for / while. Non pone problemi. Si risolve con la riorganizzazione del codice 400: add $s0, $s1, $s2 400: j : j : add $s0, $s1, $s2 Label 408: and $s1, $s2, $s3 408: and $s2, $s2, $s : or $t0, $t1, $t : or $t0, $t1, $t : sub $t3, $t4, $t : sub $t3, $t4, $t5 j lavora nella fase di decodifica. difi Viene eseguita un istruzione i prima del salto: delayed d jump. Riempio tutti gli slot di esecuzione. L esecuzione avviene fuori ordine, ma l utente non vede differenze. Come viene modificata la CPU (parte di datapath e parte di controllo)? 25/30 Salto incondizionato soluzione II Prendo l istruzione dalla destinazione del salto. 400: add $s0, $s1, $s2 400: add $s0, $s1, $s2 404: j : j Label 408: and $s1, $s2, $s3 408: or $t0, $t1, $t2 412: and $s2, $s2, $s : or $t0, $t1, $t : sub $t3, $t4,$t : sub $t3, $t4, $t5 Riempio tutti gli slot di esecuzione. L assemblatere (ri)ordina il codice. 26/30 13
14 Esercizio Data la CPU sopra, specificare il contenuto di TUTTE le linee (dati e controllo) quando è in esecuzione il seguente segmento di codice: 0x400 addi $t3, $t1, 32 0x404 sub $t4, $t1, $t1 0x408 add $t1, $t2, $t3 0x 40C beq $t1, $s0, 40 0x410 sw $s2, 64($s0) quando l istruzione di addi si trova in fase di WB. Specificare sullo schema (con colore o con tratto grosso) quali linee, all interno dei diversi stadi, trasportino dati e segnali di controllo utili all esecuzione dell istruzione, 27/30 riferendosi alla situazione in cui l istruzione addi è in fase WB I registri del Register File 0 zero constant 0 1 at reserved for assembler 2 v0 expression evaluation & 3 v1 function results 4 a0 arguments 5 a1 6 a2 7 a3 8 t0 temporary: caller saves... (callee can clobber) 15 t7 16 s0 callee saves... (caller can clobber) 23 s7 24 t8 temporary (cont d) 25 t9 26 k0 reserved for OS kernel 27 k1 28 gp Pointer to global area 29 sp Stack pointer 30 fp frame pointer (s8) 31 ra Return Address (HW) 28/30 14

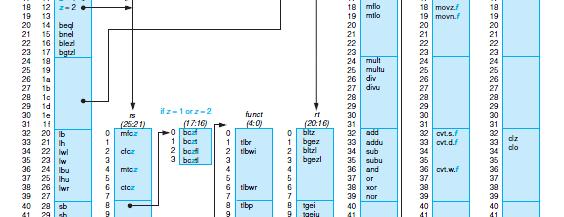

15 I codici operativi 29/30 Sommario Riorganizzazione del codice (delay slot) Esercizi 30/30 15
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/22 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/22 Sommario Riorganizzazione
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/28 Sommario Riorganizzazione
Stall on load e Hazard sul controllo
 Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
Università degli Studi di Milano - Corso Architettura II Prof. Borghese Appello del
 Università degli Studi di Milano - Corso Architettura II Prof. Borghese Appello del 24.02.2016 Cognome e nome: Matricola: 1. [7] Data la CPU N. 1, specificare il contenuto di tutte le linee (dati e controllo).
Università degli Studi di Milano - Corso Architettura II Prof. Borghese Appello del 24.02.2016 Cognome e nome: Matricola: 1. [7] Data la CPU N. 1, specificare il contenuto di tutte le linee (dati e controllo).
La struttura delle istruzioni elementari: il linguaggio Macchina. Sommario
 La struttura delle istruzioni elementari: il linguaggio Macchina Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul
La struttura delle istruzioni elementari: il linguaggio Macchina Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
Architettura degli Elaboratori Gestione dei control-hazard nella pipeline. Prof. Andrea Sterbini
 Architettura degli Elaboratori Gestione dei control-hazard nella pipeline Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti - Spostare Jump nella fase IF - Come gestire i control hazard - Eliminare
Architettura degli Elaboratori Gestione dei control-hazard nella pipeline Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti - Spostare Jump nella fase IF - Come gestire i control hazard - Eliminare
CPU pipeline hazards
 Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Fetch Decode Execute Program Counter controllare esegue prossima
 Stored Program Istruzioni sono stringhe di bit Programmi: sequenze di istruzioni Programmi (come i dati) memorizzati in memoria La CPU legge le istruzioni dalla memoria (come i dati) Ciclo macchina (ciclo
Stored Program Istruzioni sono stringhe di bit Programmi: sequenze di istruzioni Programmi (come i dati) memorizzati in memoria La CPU legge le istruzioni dalla memoria (come i dati) Ciclo macchina (ciclo
Una CPU multi-ciclo. Sommario
 Una CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/3 http:\\homes.dsi.unimi.it\ borghese Sommario I problemi della
Una CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/3 http:\\homes.dsi.unimi.it\ borghese Sommario I problemi della
Istruzioni di trasferimento dati
 Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
ISA e linguaggio macchina
 ISA e linguaggio macchina Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1, D2. 1/55
ISA e linguaggio macchina Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1, D2. 1/55
Dal sorgente all eseguibile I programmi Assembly. Prof. Alberto Borghese Dipartimento di Scienze dell Informazione
 Dal sorgente all eseguibile I programmi Assembly Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Riferimenti sul Patterson: Cap. 2.10 + Appendice B, tranne B.7
Dal sorgente all eseguibile I programmi Assembly Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Riferimenti sul Patterson: Cap. 2.10 + Appendice B, tranne B.7
Sommario. Gestione delle criticità sui dati nella pipeline. CPU con pipeline. Criticità nei dati. Hazard nei dati: soluzione tramite compilatore
 Gestione delle criticità sui dati nella pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Sommario di tipo R. di lw. Università degli Studi di Milano 1/33
Gestione delle criticità sui dati nella pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Sommario di tipo R. di lw. Università degli Studi di Milano 1/33
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Stall on load. Sommario
 Stall on load Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/24 Sommario Identificazione delle criticità
Stall on load Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/24 Sommario Identificazione delle criticità
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti
 Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli elaboratori - II Le architetture multi-ciclo
 Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori
Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori
L'architettura del processore MIPS
 L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
Architettura degli elaboratori - II Introduzione
 Architettura degli elaboratori - II Introduzione Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
Architettura degli elaboratori - II Introduzione Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
Architettura degli elaboratori CPU a ciclo singolo
 Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano iferimento sul Patterson: capitolo 4.2, 4.4,
Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano iferimento sul Patterson: capitolo 4.2, 4.4,
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
L unità di controllo di CPU multi-ciclo
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione D3
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione D3
Le etichette nei programmi. Istruzioni di branch: beq. Istruzioni di branch: bne. Istruzioni di jump: j
 L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
L unità di controllo di CPU a singolo ciclo. Sommario
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2,
Linguaggio macchina e register file
 Linguaggio macchina e register file Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4,
Linguaggio macchina e register file Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4,
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
L unità di controllo di CPU multi-ciclo. Sommario
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Istruzioni di controllo del flusso
 Istruzioni di controllo del flusso Il flusso di esecuzione è normalmente sequenziale Le istruzioni di controllo cambiano la prossima istruzione da eseguire Istruzioni di salto condizionato branch if equal
Istruzioni di controllo del flusso Il flusso di esecuzione è normalmente sequenziale Le istruzioni di controllo cambiano la prossima istruzione da eseguire Istruzioni di salto condizionato branch if equal
Come si definisce il concetto di performance? Tempo di esecuzione di un programma. numero di task/transazioni eseguiti per unità di tempo
 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Trend di sviluppo delle pipeline
 Trend di sviluppo delle pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@.unimi.it Università degli Studi di Milano Patterson 4.10, 4.11 1/36 Sommario Superpipeline
Trend di sviluppo delle pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@.unimi.it Università degli Studi di Milano Patterson 4.10, 4.11 1/36 Sommario Superpipeline
Architettura degli elaboratori CPU a ciclo singolo
 Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
Richiami sull architettura del processore MIPS a 32 bit
 Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Interrupt ed Eccezioni
 Interrupt ed Eccezioni Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento al Patterson, versione 5: 4.9, 5.4 e A.7 1/27 http:\\borghese.di.unimi.it\
Interrupt ed Eccezioni Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento al Patterson, versione 5: 4.9, 5.4 e A.7 1/27 http:\\borghese.di.unimi.it\
slt $t1,$t2,$t3 if ($t2<$t3) $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante
 $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante") Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/60 Sommario v La CPU v Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/60 Sommario v La CPU v Sintesi di
Università degli Studi di Cassino
 Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Richiami sull architettura del processore MIPS a 32 bit
 Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Una CPU multi-ciclo. Sommario
 Una CPU multi-ciclo Prof. lberto orghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano iferimento sul Patterson: Sezioni 5.5 e 5.6 1/30 http:\\homes.dsi.unimi.it\
Una CPU multi-ciclo Prof. lberto orghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano iferimento sul Patterson: Sezioni 5.5 e 5.6 1/30 http:\\homes.dsi.unimi.it\
Architettura dei calcolatori e sistemi operativi. Pipelining e Hazard Capitolo 4 P&H
 Architettura dei calcolatori e sistemi operativi Pipelining e Hazard Capitolo 4 P&H 16. 11. 2015 Problema dei conflitti Conflitti strutturali: tentativo di usare la stessa risorsa da parte di diverse istruzioni
Architettura dei calcolatori e sistemi operativi Pipelining e Hazard Capitolo 4 P&H 16. 11. 2015 Problema dei conflitti Conflitti strutturali: tentativo di usare la stessa risorsa da parte di diverse istruzioni
Linguaggio macchina. Architettura degli Elaboratori e delle Reti. Il linguaggio macchina. Lezione 16. Proff. A. Borghese, F.
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Il linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Una CPU multi-ciclo. Sommario
 Una CPU multi-ciclo Prof. lberto orghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano iferimento sul Patterson: Sezione D3 1/30 http:\\borghese.di.unimi.it\
Una CPU multi-ciclo Prof. lberto orghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano iferimento sul Patterson: Sezione D3 1/30 http:\\borghese.di.unimi.it\
Hazard e forwarding. Sommario
 Hazard e forwarding Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento al Patterson, 5th edition: 4.7 1/34 Sommario Dipendenza
Hazard e forwarding Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento al Patterson, 5th edition: 4.7 1/34 Sommario Dipendenza
Corso di Calcolatori Elettronici MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M.
 di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
Esercitazione del 05/05/ Soluzioni
 Esercitazione del 05/05/2010 - Soluzioni Criticità nella distribuzione dei dati e dei flussi Anche se in media una CPU pipelined richiede un ciclo di clock per istruzione, le singole istruzioni richiedono
Esercitazione del 05/05/2010 - Soluzioni Criticità nella distribuzione dei dati e dei flussi Anche se in media una CPU pipelined richiede un ciclo di clock per istruzione, le singole istruzioni richiedono
Il Linguaggio Assembly: Controllo del flusso: istruzioni e costrutti
 Il Linguaggio Assembly: Controllo del flusso: istruzioni e costrutti Prof. Alberto Borghese Ing. Iuri Frosio Dipartimento di Scienze dell Informazione borghese,frosio@dsi.unimi.it Università degli Studi
Il Linguaggio Assembly: Controllo del flusso: istruzioni e costrutti Prof. Alberto Borghese Ing. Iuri Frosio Dipartimento di Scienze dell Informazione borghese,frosio@dsi.unimi.it Università degli Studi
Un quadro della situazione. Lezione 15 Il Set di Istruzioni (3) Dove siamo nel corso. Organizzazione della lezione. Cosa abbiamo fatto
 Dove siamo nel corso. Organizzazione della lezione. Cosa abbiamo fatto") Un quadro della situazione Lezione 15 Il Set di Istruzioni (3) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
Un quadro della situazione Lezione 15 Il Set di Istruzioni (3) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
Riassunto. Riassunto. Ciclo fetch&execute. Concetto di programma memorizzato. Istruzioni aritmetiche add, sub, mult, div
 MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
La CPU pipeline. Principio intuitivo della pipe-line. Architettura degli Elaboratori e delle Reti. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti La CPU pipeline A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano CPU Pipeline 1 Principio intuitivo della
Architettura degli Elaboratori e delle Reti La CPU pipeline A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano CPU Pipeline 1 Principio intuitivo della
Calcolatori Elettronici T Ingegneria Informatica. ISA DLX: implementazione pipelined
 Calcolatori Elettronici T Ingegneria Informatica ISA DL: implementazione pipelined Principio del Pipelining Il pipelining è oggi la principale tecnica di base impiegata per rendere veloce una CP. L idea
Calcolatori Elettronici T Ingegneria Informatica ISA DL: implementazione pipelined Principio del Pipelining Il pipelining è oggi la principale tecnica di base impiegata per rendere veloce una CP. L idea
Pipeline Problemi 1. Pipeline Problemi 2
 Problemi 1 Vari fenomeni pregiudicano il raggiungimento del massimo di parallelismo teorico (stallo) Sbilanciamento delle fasi Durata diversa per fase e per istruzione Problemi strutturali La sovrapposizione
Problemi 1 Vari fenomeni pregiudicano il raggiungimento del massimo di parallelismo teorico (stallo) Sbilanciamento delle fasi Durata diversa per fase e per istruzione Problemi strutturali La sovrapposizione
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS)
") Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Lezione 17 Il Set di Istruzioni (3)
") Lezione 17 Il Set di Istruzioni (3) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione Un richiamo su: Operazioni aritmetiche (add
Lezione 17 Il Set di Istruzioni (3) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione Un richiamo su: Operazioni aritmetiche (add
Architettura degli elaboratori - II Introduzione
 Architettura degli elaboratori - II Introduzione Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson 5th edition: capitolo
Architettura degli elaboratori - II Introduzione Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson 5th edition: capitolo
ESERCIZIO 1 Si consideri la seguente funzione f (A, B, C, D) non completamente specificata definita attraverso il suo ON-SET e DC-SET:
 non completamente specificata definita attraverso il suo ON-SET e DC-SET:") Università degli Studi di Milano Corso Architettura degli elaboratori e delle reti Prof. Cristina Silvano A.A. 2004/2005 Esame scritto del 15 luglio 2005 Cognome: Matricola: Nome: Istruzioni Scrivere solo
Università degli Studi di Milano Corso Architettura degli elaboratori e delle reti Prof. Cristina Silvano A.A. 2004/2005 Esame scritto del 15 luglio 2005 Cognome: Matricola: Nome: Istruzioni Scrivere solo
Classificazione dipendenze
 Classificazione dipendenze 1a. EX/MEM.RegisterRd = ID/EX.registerRs 1b. EX/MEM.RegisterRd = ID/EX.registerRt Il registro (campo Rs oppure Rt di una istruzione) che è stato letto nella fase ID ed il cui
Classificazione dipendenze 1a. EX/MEM.RegisterRd = ID/EX.registerRs 1b. EX/MEM.RegisterRd = ID/EX.registerRt Il registro (campo Rs oppure Rt di una istruzione) che è stato letto nella fase ID ed il cui
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Gestione delle eccezioni (CPU multiciclo) La CPU pipeline
 La CPU pipeline") Architettura degli Elaboratori e delle Reti Lezione 22 Gestione delle eccezioni (CPU multiciclo) La CPU pipeline A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi
Architettura degli Elaboratori e delle Reti Lezione 22 Gestione delle eccezioni (CPU multiciclo) La CPU pipeline A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi
Instruction Level Parallelism Andrea Gasparetto
 Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Rappresentazione dell informazione
 Rappresentazione dell informazione Codifica dei numeri Rappresentazioni in base 2, 8, 10 e 16 Rappresentazioni M+S, C1 e C2 Algoritmi di conversione di base Algoritmi di somma, moltiplicazione e divisione
Rappresentazione dell informazione Codifica dei numeri Rappresentazioni in base 2, 8, 10 e 16 Rappresentazioni M+S, C1 e C2 Algoritmi di conversione di base Algoritmi di somma, moltiplicazione e divisione
ESERCIZIO 1. Sia dato il seguente ciclo di un programma in linguaggio ad alto livello:
 ESERIZIO 1 Sia dato il seguente ciclo di un programma in linguaggio ad alto livello: do { BASE[i] = BASEA[i] + BASEB[i] + IN1 + IN2; i++; } while (i!= N) Il programma sia stato compilato nel seguente codice
ESERIZIO 1 Sia dato il seguente ciclo di un programma in linguaggio ad alto livello: do { BASE[i] = BASEA[i] + BASEB[i] + IN1 + IN2; i++; } while (i!= N) Il programma sia stato compilato nel seguente codice
Un altro tipo di indirizzamento. L insieme delle istruzioni (3) Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando
 Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando") Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
CPU a ciclo multiplo: l unità di controllo
 Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
CPU pipeline 4: le CPU moderne
 Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
Architettura degli Elaboratori e delle Reti Lezione 25 CPU pipeline 4: le CPU moderne Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 25 1/16
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
CPU multiciclo eccezioni CPU pipeline
 Architettura degli Elaboratori e delle Reti Lezione 22 CPU multiciclo eccezioni CPU pipeline Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 22 CPU multiciclo eccezioni CPU pipeline Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Autilia Vitiello Dip. di Informatica ed Applicazioni Stecca 7, 2 piano, stanza 12
 Autilia Vitiello Dip. di Informatica ed Applicazioni Stecca 7, 2 piano, stanza 12 vitiello@dia.unisa.it http://www.dia.unisa.it/~avitiello Presentazione Corso di Architettura matricole congruo a 0: prof.
Autilia Vitiello Dip. di Informatica ed Applicazioni Stecca 7, 2 piano, stanza 12 vitiello@dia.unisa.it http://www.dia.unisa.it/~avitiello Presentazione Corso di Architettura matricole congruo a 0: prof.
CALCOLATORI ELETTRONICI 30 agosto 2010
 CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CPU a singolo ciclo: l unità di controllo, istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
Architettura degli Elaboratori. Classe 3 Prof.ssa Anselmo. Appello del 18 Febbraio Attenzione:
 Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 18 Febbraio 2015 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 18 Febbraio 2015 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Assembly (3): le procedure
: le procedure") Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano (Patterson-Hennessy:
Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano (Patterson-Hennessy:
Esercitazione del 14/05/ Soluzioni
 Esercitazione del 14/0/2009 - Soluzioni 1) Criticità nella distribuzione dei dati e dei flussi Anche se in media una CPU pipelined richiede un ciclo di clock per istruzione, le singole istruzioni richiedo
Esercitazione del 14/0/2009 - Soluzioni 1) Criticità nella distribuzione dei dati e dei flussi Anche se in media una CPU pipelined richiede un ciclo di clock per istruzione, le singole istruzioni richiedo
Progettazione dell unità di elaborazioni dati e prestazioni. Il processore: unità di elaborazione. I passi per progettare un processore
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Architettura degli Elaboratori. Classe 3 Prof.ssa Anselmo. Pre-appello del 12 Gennaio Attenzione:
 Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Pre-appello del 12 Gennaio 2018 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Pre-appello del 12 Gennaio 2018 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Trend di sviluppo delle pipeline
 Trend di sviluppo delle pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@.unimi.it Università degli Studi di Milano Patterson 4.10, 4.11 1/35 Sommario Superpipeline
Trend di sviluppo delle pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@.unimi.it Università degli Studi di Milano Patterson 4.10, 4.11 1/35 Sommario Superpipeline
Informazioni varie. Lezione 18 Il Set di Istruzioni (5) Dove siamo nel corso. Un quadro della situazione
 Dove siamo nel corso. Un quadro della situazione") Informazioni varie Lezione 18 Il Set di Istruzioni (5) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno La lezione di martedì 20 maggio (9-12) non si tiene
Informazioni varie Lezione 18 Il Set di Istruzioni (5) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno La lezione di martedì 20 maggio (9-12) non si tiene
Il linguaggio macchina
 Il linguaggio macchina Istruzioni macchina (PH 2.4) Indirizzamento (PH 2.9) Costanti a 32-bit (PH 2.9) 1 Linguaggio macchina Le istruzioni in linguaggio assembly devono essere tradotte in linguaggio macchina
Il linguaggio macchina Istruzioni macchina (PH 2.4) Indirizzamento (PH 2.9) Costanti a 32-bit (PH 2.9) 1 Linguaggio macchina Le istruzioni in linguaggio assembly devono essere tradotte in linguaggio macchina
Linguaggio Assembly e linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e Laboratorio. Matteo Manzali Università degli Studi di Ferrara Anno Accademico
 Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Criticità sui dati Questo è l esempio utilizzato per spiegare il funzionamento della
Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Criticità sui dati Questo è l esempio utilizzato per spiegare il funzionamento della
Il processore: unità di elaborazione
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Esercitazione su Instruction Level Parallelism Salvatore Orlando
 Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Esercitazione su Instruction Level Parallelism Salvatore Orlando Arch. Elab. - S. Orlando 1 Pipeline con e senza forwarding Si considerino due processori MIPS (processore A e B) entrambi con pipeline a
Problemi del ciclo singolo
 Problemi del ciclo singolo Ciclo di clock lungo Istruzioni potenzialmente veloci sono rallentate Impiegano sempre lo stesso tempo dell istruzione più lenta Unità funzionale e collegamenti della parte operativa
Problemi del ciclo singolo Ciclo di clock lungo Istruzioni potenzialmente veloci sono rallentate Impiegano sempre lo stesso tempo dell istruzione più lenta Unità funzionale e collegamenti della parte operativa
Assembly (3): le procedure
: le procedure") Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 13 1/23 Chiamata
Architettura degli Elaboratori e delle Reti Lezione 13 Assembly (3): le procedure Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 13 1/23 Chiamata
Istruzioni e linguaggio macchina
 Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
Esercitazione del 30/04/ Soluzioni
 Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
Modifiche di orario. Lezione 19 Il Set di Istruzioni (6) Dove siamo nel corso. Un quadro della situazione
 Dove siamo nel corso. Un quadro della situazione") Modifiche di orario Lezione 19 Il Set di Istruzioni (6) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Al posto della lezione di domani giovedì 22/5 (12-1)
Modifiche di orario Lezione 19 Il Set di Istruzioni (6) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Al posto della lezione di domani giovedì 22/5 (12-1)
Architettura degli Elaboratori. Classe 3 Prof.ssa Anselmo. Appello del 19 Febbraio Attenzione:
 Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 19 Febbraio 2016 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.
Cognome.. Nome.... Architettura degli Elaboratori Classe 3 Prof.ssa Anselmo Appello del 19 Febbraio 2016 Attenzione: Inserire i propri dati nell apposito spazio sottostante e in testa a questa pagina.