Calcolo parallelo con MPI (2ª parte)
|
|
|
- Paolo Palla
- 5 anni fa
- Visualizzazioni
Transcript



1
2 Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2
3 Modalità di comunicazione Una comunicazione tipo point-to-point può essere: Blocking: il controllo è restituito al processo che ha invocato la primitiva di comunicazione solo quando la stessa è stata completata Non blocking: il controllo è restituito al processo che ha invocato la primitiva di comunicazione quando la stessa è stata eseguita il controllo sull effettivo completamento della comunicazione deve essere fatto in seguito nel frattempo il processo può eseguire altre operazioni 3

4 Criteri di completamento della comunicazione Dal punto di vista non locale, ovvero di entrambi i processi coinvolti nella comunicazione, è rilevante il criterio in base al quale si considera completata la comunicazione Funzionalità Syncronous send Buffered send Standard send Receive Criterio di completamento è completa quando è terminata la ricezione del messaggio è completa quando è terminata la scrittura dei dati da comunicare sul buffer predisposto (non dipende dal receiver!) Può essere implementata come una syncronous o una buffered send è completa quando il messaggio è arrivato Nella libreria MPI esistono diverse primitive di comunicazione point-to-point, che combinano le modalità di comunicazione ed i criteri di completamento 4
5 Syncronous SEND blocking: MPI_Ssend Per il completamento dell operazione il sender deve essere informato dal receiver che il messaggio è stato ricevuto Gli argomenti della funzione sono gli stessi della MPI_Send Pro: è la modalità di comunicazione point-to-point più semplice ed affidabile Contro: può comportare rilevanti intervalli di tempo in cui i processi coinvolti non hanno nulla di utile da fare, se non attendere che la comunicazione sia terminata 5
6 Syncronous Send: un esempio 6
7 Buffered SEND blocking: MPI_Bsend Una buffered send è completata immediatamente, non appena il processo ha copiato il messaggio su un opportuno buffer di trasmissione Il programmatore non può assumere la presenza di un buffer di sistema allocato per eseguire l operazione, ma deve effettuare un operazione di BUFFER_ATTACH per definire un area di memoria di dimensioni opportune come buffer per il trasferimento di messaggi BUFFER_DETACH per rilasciare le aree di memoria di buffer utilizzate Pro ritorno immediato dalla primitiva di comunicazione Contro È necessaria la gestione esplicita del buffer Implica un operazione di copia in memoria dei dati da trasmettere 7
8 Gestione dei buffer: MPI_Buffer_attach In C MPI_Buffer_attach(void *buf, int size) In Fortran MPI_BUFFER_ATTACH(BUF, SIZE, ERR) Consente al processo sender di allocare il send buffer per una successiva chiamata di MPI_Bsend Argomenti: buf è l indirizzo iniziale del buffer da allocare size è un int (INTEGER) e contiene la dimensione in byte del buffer da allocare 8
9 Gestione dei buffer: MPI_Buffer_detach In C MPI_Buffer_detach(void *buf, int *size) In Fortran MPI_BUFFER_DETACH(BUF, SIZE, ERR) Consente di rilasciare il buffer creato con MPI_Buffer_attach Argomenti: buf è l indirizzo iniziale del buffer da deallocare size è un int* (INTEGER) e contiene la dimensione in byte del buffer deallocato 9
10 Buffered Send: un esempio 10
11 Buffered Send: un esempio (FORTRAN) 11
12 Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-topoint La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 12
13 Comunicazioni non-blocking Una comunicazione non-blocking è tipicamente costituita da tre fasi successive: 1. L inizio della operazione di send o receive del messaggio 2. Lo svolgimento di un attività che non implichi l accesso ai dati coinvolti nella operazione di comunicazione avviata 3. Controllo/attesa del completamento della comunicazione Pro Performance: una comunicazione non-blocking consente di: sovrapporre fasi di comunicazioni con fasi di calcolo ridurre gli effetti della latenza di comunicazione Le comunicazioni non-blocking evitano situazioni di deadlock Contro La programmazione di uno scambio di messaggi con funzioni di comunicazione non-blocking è (leggermente) più complicata 13

14 SEND non-blocking: MPI_Isend Dopo che la spedizione è stata avviata il controllo torna al processo sender Prima di riutilizzare le aree di memoria coinvolte nella comunicazione, il processo sender deve controllare che l operazione sia stata completata, attraverso opportune funzioni della libreria MPI Anche per la send non-blocking, sono previste le diverse modalità di completamento della comunicazione 14

15 RECEIVE non-blocking : MPI_Irecv Dopo che la fase di ricezione è stata avviata il controllo torna al processo receiver Prima di utilizzare in sicurezza i dati ricevuti, il processo receiver deve verificare che la ricezione sia completata, attraverso opportune funzioni della libreria MPI Una receive non-blocking può essere utilizzata per ricevere messaggi inviati sia in modalità blocking che non blocking 15
16 In C Binding di MPI_Isend e MPI_Irecv int MPI_Isend(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm, MPI_request *req) int MPI_Irecv(void *buf, int count, MPI_Datatype dtype, int src, int tag, MPI_Comm comm, MPI_request *req) In Fortran MPI_ISEND(buf, count, dtype, dest, tag, comm, req, err) MPI_IRECV(buf, count, dtype, src, tag, comm, req, err) Le funzione MPI_Isend e MPI_Irecv prevedono un argomento aggiuntivo rispetto alle MPI_Send e MPI_Recv: un handler di tipo MPI_Request (INTEGER) è necessario per referenziare l operazione di send/receive nella fase di controllo del completamento della stessa 16
17 Comunicazioni non blocking: completamento Quando si usano comunicazioni point-to-point non blocking è essenziale assicurarsi che la fase di comunicazione sia completata per: utilizzare i dati del buffer (dal punto di vista del receiver) riutilizzare l area di memoria coinvolta nella comunicazione (dal punto di vista del sender) La libreria MPI mette a disposizione dell utente due tipi di funzionalità per il test del completamento di una comunicazione: tipo WAIT : consente di fermare l esecuzione del processo fino a quando la comunicazione in argomento non sia completata tipo TEST: ritorna al processo chiamante un valore TRUE se la comunicazione in argomento è stata completata, FALSE altrimenti 17
18 In C Binding di MPI_Wait int MPI_Wait(MPI_Request *request, MPI_Status *status) In Fortran MPI_WAIT (REQUEST, STATUS, ERR) Argomenti: [IN] request è l handler necessario per referenziare la comunicazione di cui attendere il completamento (INTEGER) [OUT] status conterrà lo stato (envelope) del messaggio di cui si attende il completamento (INTEGER) 18
19 In C Binding di MPI_Test int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status) In Fortran MPI_TEST (REQUEST, FLAG, STATUS, ERR) Argomenti [IN] [OUT] [OUT] request è l handler necessario per referenziare la comunicazione di cui controllare il completamento (INTEGER) flag conterrà TRUE se la comunicazione è stata completata, FALSE altrimenti (LOGICAL) status conterrà lo stato (envelope) del messaggio di cui si attende il completamento (INTEGER(*)) 19
20 La struttura di un codice con send non blocking 20
21 Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-topoint La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 21
22 Programma della 3 sessione di laboratorio Modalità di completamento della comunicazione Uso della syncronous send, della buffered send e delle funzioni di gestione dei buffer (Esercizio 12) Uso delle funzioni di comunicazione non-blocking Non blocking circular shift (Esercizio 13) Array Smoothing (Esercizio 14) 22
23 Funzioni per il timing: MPI_Wtime e MPI_Wtick È importante conoscere il tempo impiegato dal codice nelle singole parti per poter analizzare le performance MPI_Wtime: fornisce il numero floating-point di secondi intercorso tra due sue chiamate successive double starttime, endtime; starttime = MPI_Wtime();... stuff to be timed... endtime = MPI_Wtime(); printf("that took %f seconds\n",endtime-starttime); MPI_Wtick: ritorna la precisione di MPI_Wtime, cioè ritorna 10 ³ se il contatore è incrementato ogni millesimo di secondo. NOTA: anche in FORTRAN sono funzioni 23
24 Syncronous Send blocking Esercizio 12 Modificare il codice dell Esercizio 2, utilizzando la funzione MPI_Ssend per la spedizione di un array di float Misurare il tempo impiegato nella MPI_Ssend usando la funzione MPI_Wtime 24
25 Send buffered blocking Esercizio 12 Modificare l Esercizio 2, utilizzando la funzione MPI_Bsend per spedire un array di float N.B.: la MPI_Bsend prevede la gestione diretta del buffer di comunicazione da parte del programmatore Misurare il tempo impiegato nella MPI_Bsend usando la funzione MPI_Wtime 25
 utilizzando le funzioni di comunicazione non-blocking per evitare la condizione deadlock per N=2000")
26 Circular Shift non-blocking Esercizio 13 Modificare il codice dello shift circolare periodico in versione naive (Esercizio 6) utilizzando le funzioni di comunicazione non-blocking per evitare la condizione deadlock per N=
![Array smoothing Esercizio 14 dato un array A[N] stampare il vettore A per ITER volte: calcolare un](/docs-images/97/132198278/images/27-1.jpg "nuovo array B in cui ogni elemento sia uguale alla media aritmetica del suo valore e dei suoi K primi")

27 Array smoothing Esercizio 14 dato un array A[N] stampare il vettore A per ITER volte: calcolare un nuovo array B in cui ogni elemento sia uguale alla media aritmetica del suo valore e dei suoi K primi vicini al passo precedente nota: l array è periodico, quindi il primo e l ultimo elemento di A sono considerati primi vicini Stampare il vettore B Copiare B in A e continuare l iterazione 27 A[N] B i B[N]




28 Array smoothing: algoritmo parallelo Esercizio 14 Array A Array A Work Array Work Array Work Array 28
29 Array smoothing: algoritmo parallelo Esercizio 14 Il processo di rank 0 genera l array globale di dimensione N, divisibile per il numero P di processi inizializza il vettore A con A[i] =i distribuisce il vettore A ai P processi i quali riceveranno N loc elementi nell array locale Ciascun processo ad ogni passo di smoothing: Avvia le opportune send non-blocking verso i propri processi primi vicini per spedire i suoi elementi Avvia le opportune receive non-blocking dai propri processi primi vicini per ricevere gli elementi dei vicini Effettua lo smoothing dei soli elementi del vettore che non implicano la conoscenza di elementi di A in carico ad altri processi Dopo l avvenuta ricezione degli elementi in carico ai processi vicini, effettua lo smoothing dei rimanenti elementi del vettore Il processo di rank 0 ad ogni passo raccoglie i risultati parziali e li stampa 29
30 Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-topoint La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 30



31 Oltre MPI_Comm_World: i comunicatori Un comunicatore definisce l universo di comunicazione di un insieme di processi MPI_Comm_World Oltre ad MPI_Comm_World, in un programma MPI possono essere definiti altri comunicatori per specifiche esigenze, quali: utilizzare funzioni collettive solo all interno di un sotto insieme dei processi del comunicatore di default utilizzare uno schema identificativo dei processi conveniente per un particolare pattern di comunicazione 31
32 Le componenti del comunicatore Gruppo di processi: un set ordinato di processi il gruppo è usato per identificare i processi ad ogni processo all interno di un gruppo è assegnato un indice (rank), utile per identificare il processo stesso Contesto: utilizzato dal comunicatore per gestire l invio/ricezione di messaggi Contiene, ad esempio, l informazione sullo stato di un messaggio da ricevere inviato con una MPI_Isend Attributi: ulteriori informazioni eventualmente associate al comunicatore Il rank del processo in grado di eseguire operazioni di I/O La topologia di comunicazione sottesa 32
33 Topologie virtuali di processi Definizione di un nuovo schema identificativo dei processi conveniente per lavorare con uno specifico pattern di comunicazione: semplifica la scrittura del codice può consentire ad MPI di ottimizzare le comunicazioni Creare una topologia virtuale di processi in MPI significa definire un nuovo comunicatore, con attributi specifici Tipi di topologie: Cartesiane: ogni processo è identificato da un set di coordinate cartesiane ed è connesso ai propri vicini da una griglia virtuale Ai bordi della griglia può essere impostata o meno la periodicità Grafo (al di fuori di questo corso) 33
34 Circular shift: una topologia cartesiana 1D Ogni processo comunica alla sua destra un dato L ultimo processo del gruppo comunica il dato al primo 34

35 Topologia cartesiana 2D Ad ogni processo è associata una coppia di indici che rappresentano le sue coordinate in uno spazio cartesiano 2D Ad esempio, le comunicazioni possono avvenire tra primi vicini con periodicità lungo la direzione X tra primi vicini senza periodicità lungo la direzione Y 35
36 In C Creare un comunicatore con topologia cartesiana int MPI_Cart_create(MPI_Comm comm_old,int ndims,int *dims, int *periods,int reorder,mpi_comm *comm_cart) In Fortran MPI_CART_CREATE(COMM_OLD, NDIMS, DIMS, PERIODS, REORDER, COMM_CART, IERROR) [IN] [IN] [IN] [IN] [IN] [OUT] comm_old: comunicatore dal quale selezionare il gruppo di processi (INTEGER) ndims: numero di dimensioni dello spazio cartesiano (INTEGER) dims: numero di processi lungo ogni direzione dello spazio cartesiano (INTEGER(*)) periods: periodicità lungo le direzioni dello spazio cartesiano (LOGICAL(*)) reorder: il ranking dei processi può essere riordinato per utilizzare al meglio la rete di comunicazione (LOGICAL) comm_cart: nuovo comunicatore con l attributo topologia cartesiana (INTEGER) 36
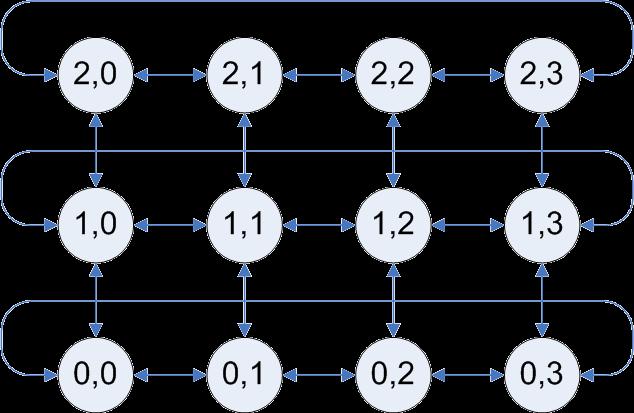
37 Come usare MPI_Cart_create 37
38 Alcune utili funzionalità MPI_Dims_Create: Calcola le dimensioni della griglia bilanciata ottimale rispetto al numero di processi e la dimensionalità della griglia dati in input Utile per calcolare un vettore dims di input per la funzione MPI_Cart_Create Mapping tra coordinate cartesiane e rank MPI_Cart_coords: sulla base della topologia definita all interno del comunicatore, ritorna le coordinate corrispondenti al processo con un fissato rank MPI_Cart_rank: sulla base della topologia definita all interno del comunicatore, ritorna il rank del processo con un fissato set di coordinate cartesiane 38
39 In C [IN] nnodes: numero totale di processi (INTEGER) [IN] ndims: dimesionalità dello spazio cartesiano (INTEGER) [IN]/[OUT] dims: numero di processi lungo le direzioni dello spazio cartesiano (INTEGER(*)) Se una entry = 0 MPI_Dims_create calcola il numero di processi lungo quella direzione Se una entry 0 MPI_Dims_create calcola il numero di processi lungo le direzioni libere compatibilmente col numero totale di processi e i valori definiti dall utente Binding di MPI_Dims_Create int MPI_Dims_create(int nnodes, int ndims, int *dims) In Fortran MPI_DIMS_CREATE(NNODES, NDIMS, DIMS, IERROR) 39
40 In C Rank -> Coordinate: MPI_Cart_coords int MPI_Cart_coords(MPI_Comm comm, int rank, int maxdims, int *coords) In Fortran MPI_CART_COORDS(COMM, RANK, MAXDIMS, COORDS, IERROR) Dato il rank del processo, ritorna le coordinate cartesiane associate Argomenti: [IN] comm: comunicatore con topologia cartesiana (INTEGER) [IN] rank: rank del processo del quale si vogliano conoscere le coordinate (INTEGER) [IN] maxdims: dimensionalità dello spazio cartesiano (INTEGER) [OUT] coords: coordinate del processo rank (INTEGER(*)) 40
41 In C Coordinate -> Rank: MPI_Cart_rank int MPI_Cart_rank(MPI_Comm comm, int *coords, int *rank) In Fortran MPI_CART_RANK(COMM, COORDS, RANK, IERROR) Date le coordinate cartesiane del processo, ritorna il rank associato Argomenti: [IN] comm: comunicatore con topologia cartesiana (INTEGER) [IN] coords: coordinate del processo (INTEGER(*)) [OUT] rank: rank del processo di coordinate coords (INTEGER) 41
42 In C Determina il rank del processo al/dal quale inviare/ricevere dati Argomenti: [IN] comm: comunicatore con topologia cartesiana (INTEGER) [IN] [IN] [OUT] [OUT] Sendrecv in topologia cartesiana int MPI_Cart_shift(MPI_Comm comm, int direction, int disp, int *rank_source, int *rank_dest) In Fortran MPI_CART_SHIFT(COMM, DIRECTION, DISP, SOURCE, DEST, IERROR) direction: indice della coordinata lungo la quale fare lo shift (INTEGER) [la numerazione degli indici parte da 0] disp: entità dello shift (> 0: upward, < 0: downward) (INTEGER) source: rank del processo dal quale ricevere i dati (INTEGER) dest: rank del processo al quale inviare i dati (INTEGER) 42
43 Shift Circolare con topologia cartesiana 1D in C Circular shift senza topologia Circular shift con topologia cartesiana 43
44 Sottocomunicatori MPI_Comm_split: Crea un comunicatore per un sottoinsieme di processi Utile per mettere in comunicazione solo alcuni processi definiti su un comunicatore con topologia 44
45 In C Mpi_Comm_split int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm *newcomm) In Fortran MPI_COMM_SPLIT(COMM, COLOR, KEY, NEWCOMM, IERROR) Crea un sottocomunicatore Argomenti: [IN] comm: comunicatore d origine (INTEGER) [IN] [IN] [OUT] color: valore di controllo per l assegnazione del sottoinsieme (INTEGER) [non può essere negativo] key: valore di controllo per l assegnazione del rank (INTEGER) newcomm: nome del sottocomunicatore (INTEGER) 45
46 Alcuni esempi Sottocomunicatore riga di MPI_COMM_WORLD con topologia cartesiana 2D /* Inizializzazione */ MPI_Comm_rank(MPI_COMM_WORLD, &myrank) dims[0] = 4 /* 4 righe */ dims[1] = 3 /* 3 colonne */ /* definiti period e reorder */ MPI_Cart_create(MPI_COMM_WORLD, 2, dims, period, reorder, &comm_cart) MPI_Cart_coords(comm_cart, myrank, 2, mycoords) color = mycoords[0] /* indice di riga */ key = mycoords[1] /* indice di colonna */ MPI_Comm_split(MPI_COMM_WORLD, color, key, &comm_row) MPI_Comm_rank(comm_row, &myrank_row) Sottocomunicatore pari di MPI_COMM_WORLD /* Inizializzazione */ MPI_Comm_rank(MPI_COMM_WORLD, &myrank) color = myrank%2 /* solo i processi pari */ key = myrank /* il controllo avviene su tutti i processi */ MPI_Comm_split(MPI_COMM_WORLD, color, key, &comm_evennum) MPI_Comm_rank(comm_evennum, &myrank_evennum) 46
47 Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-topoint La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 47
48 Programma della 4 sessione di laboratorio Topologie virtuali Circular shift con topologia cartesiana 1D (Esercizio 15) Media aritmetica sui primi vicini in una topologia cartesiana 2D (Esercizio 16) 48
49 Circular shift con topologia cartesiana 1D Esercizio 15 Modificare il codice Shift Circolare con MPI_Sendrecv (Esercizio 7), in modo che siano utilizzate le funzionalità di MPI per le virtual topologies per determinare gli argomenti della funzione MPI_Sendrecv Nota: usare la funzione MPI_Cart_shift per determinare i processi sender /receiver della MPI_Sendrecv 49

50 Media aritmetica sui primi vicini in topologia 2D Esercizio 16 I processi sono distribuiti secondo una griglia rettangolare Ogni processo: Inizializza una variabile intera A con il valore del proprio rank calcola la media di A sui primi vicini Il processo di rank 0: Raccoglie i risultati dagli altri processi Riporta in output i risultati raccolti utilizzando un formato tabella organizzato secondo le coordinate dei vari processi 50

51 Media aritm. sui primi vicini: flowchart delle comunicazioni Esercizio 16 MPI_Dims_create MPI_Cart_create MPI_Cart_shift MPI_Sendrecv MPI_Cart_shift MPI_Sendrecv MPI_Cart_shift MPI_Sendrecv MPI_Cart_shift MPI_Sendrecv 51
Calcolo parallelo con MPI (2ª parte)
") Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
Calcolo parallelo con MPI (2ª parte) Approfondimento sulle comunicazioni point-to-point La comunicazione non blocking Laboratorio n 3 MPI virtual topologies Laboratorio n 4 2 Modalità di comunicazione
Circular shift: una topologia cartesiana 1D
 Circular shift: una topologia cartesiana 1D Ogni processo comunica alla sua destra un dato L ultimo processo del gruppo comunica il dato al primo 1 Topologia cartesiana 2D Ad ogni processo è associata
Circular shift: una topologia cartesiana 1D Ogni processo comunica alla sua destra un dato L ultimo processo del gruppo comunica il dato al primo 1 Topologia cartesiana 2D Ad ogni processo è associata
Calcolo Parallelo con MPI (2 parte)
") 2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
2 Calcolo Parallelo con MPI (2 parte) Approfondimento sulle comunicazioni point-to-point Pattern di comunicazione point-to-point: sendrecv Synchronous Send Buffered Send La comunicazione non-blocking Laboratorio
Non blocking. Contro. La programmazione di uno scambio messaggi con funzioni di comunicazione non blocking e' (leggermente) piu' complicata
 piu' complicata") Non blocking Una comunicazione non blocking e' tipicamente costituita da tre fasi successive: L inizio della operazione di send/receive del messaggio Lo svolgimento di un attivita' che non implichi l accesso
Non blocking Una comunicazione non blocking e' tipicamente costituita da tre fasi successive: L inizio della operazione di send/receive del messaggio Lo svolgimento di un attivita' che non implichi l accesso
MPI Quick Refresh. Super Computing Applications and Innovation Department. Courses Edition 2017
 MPI Quick Refresh Super Computing Applications and Innovation Department Courses Edition 2017 1 Cos è MPI MPI acronimo di Message Passing Interface http://www.mpi-forum.org MPI è una specifica, non un
MPI Quick Refresh Super Computing Applications and Innovation Department Courses Edition 2017 1 Cos è MPI MPI acronimo di Message Passing Interface http://www.mpi-forum.org MPI è una specifica, non un
Comunicazione. La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI
 Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
Comunicazione La comunicazione point to point e' la funzionalita' di comunicazione fondamentale disponibile in MPI Concettualmente la comunicazione point to point e' molto semplice: Un processo invia un
A.d'Alessio. Calcolo Parallelo. Esempi di topologie
 Message Passing Interface MPI Le topologie 1 Esempi di topologie Anello Griglia Toro L utilizzo di una topologia per la progettazione di un algoritmo in ambiente MIMD è spesso legata alla geometria intrinseca
Message Passing Interface MPI Le topologie 1 Esempi di topologie Anello Griglia Toro L utilizzo di una topologia per la progettazione di un algoritmo in ambiente MIMD è spesso legata alla geometria intrinseca
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 1 Message Passing Interface MPI www.mcs.anl.gov./research/projects/mpi/
Le topologie. Message Passing Interface MPI Parte 2. Topologie MPI. Esempi di topologie. Definizione: topologia. Laura Antonelli
 Topologie MPI Message Passing Interface MPI Parte 2 Le topologie. Laura Antonelli 1 2 Esempi di topologie Definizione: topologia Una topologia è la geometria virtuale in cui si immaginano disposti i processi
Topologie MPI Message Passing Interface MPI Parte 2 Le topologie. Laura Antonelli 1 2 Esempi di topologie Definizione: topologia Una topologia è la geometria virtuale in cui si immaginano disposti i processi
int MPI_Recv (void *buf, int count, MPI_Datatype type, int source, int tag, MPI_Comm comm, MPI_Status *status);
;") Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Send e Receive La forma generale dei parametri di una send/receive bloccante int MPI_Send (void *buf, int count, MPI_Datatype type, int dest, int tag, MPI_Comm comm); int MPI_Recv (void *buf, int count,
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Laboratorio di Calcolo Parallelo
 Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Laboratorio di Calcolo Parallelo Lezione : Aspetti avanzati ed esempi in MPI Francesco Versaci & Alberto Bertoldo Università di Padova 6 maggio 009 Francesco Versaci (Università di Padova) Laboratorio
Alcuni strumenti per lo sviluppo di software su architetture MIMD
 Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Alcuni strumenti per lo sviluppo di software su architetture MIMD Calcolatori MIMD Architetture SM (Shared Memory) OpenMP Architetture DM (Distributed Memory) MPI 2 MPI : Message Passing Interface MPI
Introduzione a MPI Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
Introduzione a MPI Algoritmi e Calcolo Parallelo Riferimenti! Tutorial on MPI Lawrence Livermore National Laboratory https://computing.llnl.gov/tutorials/mpi/ Cos è MPI? q MPI (Message Passing Interface)
MPI avanzato. Introduzione al calcolo parallelo
 MPI avanzato Introduzione al calcolo parallelo Pack Il sistema MPI permette di unire dati diversi in un unico buffer, che può essere usato per le comunicazioni. In questo modo l applicazione può migliorare
MPI avanzato Introduzione al calcolo parallelo Pack Il sistema MPI permette di unire dati diversi in un unico buffer, che può essere usato per le comunicazioni. In questo modo l applicazione può migliorare
Programmazione di base
 1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
1 0.1 INTRODUZIONE Al giorno d oggi il calcolo parallelo consiste nell esecuzione contemporanea del codice su più processori al fine di aumentare le prestazioni del sistema. In questo modo si superano
Programma della 1 sessione di laboratorio
 Programma della 1 sessione di laboratorio Familiarizzare con l ambiente MPI Hello World in MPI (Esercizio 1) Esercizi da svolgere Send/Receive di un intero e di un array di float (Esercizio 2) Calcolo
Programma della 1 sessione di laboratorio Familiarizzare con l ambiente MPI Hello World in MPI (Esercizio 1) Esercizi da svolgere Send/Receive di un intero e di un array di float (Esercizio 2) Calcolo
Presentazione del corso
 Cosa è il calcolo parallelo Serie di Fibonacci Serie geometrica Presentazione del corso Calcolo parallelo: MPI Introduzione alla comunicazione point-to-point Le sei funzioni di base Laboratorio 1 Introduzione
Cosa è il calcolo parallelo Serie di Fibonacci Serie geometrica Presentazione del corso Calcolo parallelo: MPI Introduzione alla comunicazione point-to-point Le sei funzioni di base Laboratorio 1 Introduzione
Introduzione Generalitá sull uso degli array Array allocabili Funzioni intrinseche. Array. Fondamenti di Informatica T (A-K) AA
 AA") allocabili AA 2013-2014 allocabili Introduzione Un array rappresenta un gruppo di variabili (o costanti) dello stesso tipo, a cui si fa riferimento con un singolo nome. Si definisce anche vettore un array
allocabili AA 2013-2014 allocabili Introduzione Un array rappresenta un gruppo di variabili (o costanti) dello stesso tipo, a cui si fa riferimento con un singolo nome. Si definisce anche vettore un array
Calcolo parallelo. Una sola CPU (o un solo core), per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi.
, per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi.") Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo. Una sola CPU (o un solo core), per quanto potenti,
Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo. Una sola CPU (o un solo core), per quanto potenti,
Caratteristiche di un linguaggio ad alto livello
 Caratteristiche di un linguaggio ad alto livello Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono
Caratteristiche di un linguaggio ad alto livello Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono
Cominciamo ad analizzare la rappresentazione delle informazioni... di Cassino. C. De Stefano Corso di Fondamenti di Informatica Università degli Studi
 Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono l algoritmo Cominciamo ad analizzare la
Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono l algoritmo Cominciamo ad analizzare la
Lezione 8 Struct e qsort
 Lezione 8 Struct e qsort Rossano Venturini rossano@di.unipi.it Pagina web del corso http://didawiki.cli.di.unipi.it/doku.php/informatica/all-b/start Esercizio 3 QuickSort strambo Modificare il Quicksort
Lezione 8 Struct e qsort Rossano Venturini rossano@di.unipi.it Pagina web del corso http://didawiki.cli.di.unipi.it/doku.php/informatica/all-b/start Esercizio 3 QuickSort strambo Modificare il Quicksort
Lezione 6 Struct e qsort
 Lezione 6 Struct e qsort Rossano Venturini rossano.venturini@unipi.it Pagina web del corso http://didawiki.cli.di.unipi.it/doku.php/informatica/all-b/start Struct Struct Fino ad ora abbiamo utilizzato
Lezione 6 Struct e qsort Rossano Venturini rossano.venturini@unipi.it Pagina web del corso http://didawiki.cli.di.unipi.it/doku.php/informatica/all-b/start Struct Struct Fino ad ora abbiamo utilizzato
MPI è una libreria che comprende:
 1 Le funzioni di MPI MPI è una libreria che comprende: Funzioni per definire l ambiente Funzioni per comunicazioni uno a uno Funzioni percomunicazioni collettive Funzioni peroperazioni collettive 2 1 3
1 Le funzioni di MPI MPI è una libreria che comprende: Funzioni per definire l ambiente Funzioni per comunicazioni uno a uno Funzioni percomunicazioni collettive Funzioni peroperazioni collettive 2 1 3
Funzioni, Stack e Visibilità delle Variabili in C
 Funzioni, Stack e Visibilità delle Variabili in C Laboratorio di Programmazione I Corso di Laurea in Informatica A.A. 2018/2019 Argomenti del Corso Ogni lezione consta di una spiegazione assistita da slide,
Funzioni, Stack e Visibilità delle Variabili in C Laboratorio di Programmazione I Corso di Laurea in Informatica A.A. 2018/2019 Argomenti del Corso Ogni lezione consta di una spiegazione assistita da slide,
MPI: comunicazioni point-to-point
 - c.calonaci@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Argomenti Programmazione a scambio di messaggi Introduzione a MPI Modi di comunicazione Comunicazione
- c.calonaci@cineca.it Gruppo Supercalcolo - Dipartimento Sistemi e Tecnologie 29 settembre 5 ottobre 2008 Argomenti Programmazione a scambio di messaggi Introduzione a MPI Modi di comunicazione Comunicazione
Le strutture. UNIVERSITÀ DEGLI STUDI DEL SANNIO Benevento DING DIPARTIMENTO DI INGEGNERIA
 UNIVERSITÀ DEGLI STUDI DEL SANNIO Benevento DING DIPARTIMENTO DI INGEGNERIA CORSO DI "PROGRAMMAZIONE I" Prof. Franco FRATTOLILLO Dipartimento di Ingegneria Università degli Studi del Sannio Le strutture
UNIVERSITÀ DEGLI STUDI DEL SANNIO Benevento DING DIPARTIMENTO DI INGEGNERIA CORSO DI "PROGRAMMAZIONE I" Prof. Franco FRATTOLILLO Dipartimento di Ingegneria Università degli Studi del Sannio Le strutture
5. I device driver. Device driver - gestori delle periferiche. Struttura interna del sistema operativo Linux. Tipi di periferiche. Tipi di periferiche
 Device driver - gestori delle periferiche Struttura interna del sistema operativo Linux Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi periferici Interagiscono con
Device driver - gestori delle periferiche Struttura interna del sistema operativo Linux Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi periferici Interagiscono con
Esercizi Programmazione I
 Esercizi Programmazione I 0 Ottobre 016 Esercizio 1 Funzione valore assoluto Il file.c di questo esercizio deve contenere nell ordine, il prototipo (dichiarazione) di una una funzione abs, che prende in
Esercizi Programmazione I 0 Ottobre 016 Esercizio 1 Funzione valore assoluto Il file.c di questo esercizio deve contenere nell ordine, il prototipo (dichiarazione) di una una funzione abs, che prende in
Il linguaggio C. Puntatori e dintorni
 Il linguaggio C Puntatori e dintorni 1 Puntatori : idea di base In C è possibile conoscere e denotare l indirizzo della cella di memoria in cui è memorizzata una variabile (il puntatore) es : int a = 50;
Il linguaggio C Puntatori e dintorni 1 Puntatori : idea di base In C è possibile conoscere e denotare l indirizzo della cella di memoria in cui è memorizzata una variabile (il puntatore) es : int a = 50;
Gruppo di collaboratori Calcolo Parallelo
 Gruppo di collaboratori Calcolo Parallelo Il calcolo parallelo, in generale, è l uso simultaneo di più processi per risolvere un unico problema computazionale Per girare con più processi, un problema è
Gruppo di collaboratori Calcolo Parallelo Il calcolo parallelo, in generale, è l uso simultaneo di più processi per risolvere un unico problema computazionale Per girare con più processi, un problema è
I.I.S. G.B. PENTASUGLIA MATERA ISTITUTO TECNICO SETTORE TECNOLOGICO LICEO SCIENTIFICO SCIENZE APPLICATE. Classe: 5Ci
 I.I.S. G.B. PENTASUGLIA MATERA ISTITUTO TECNICO SETTORE TECNOLOGICO LICEO SCIENTIFICO SCIENZE APPLICATE Disciplina: Tecnologie e Progettazione di Sistemi Informatici e di Telecomunicazione Cognome e Nome:
I.I.S. G.B. PENTASUGLIA MATERA ISTITUTO TECNICO SETTORE TECNOLOGICO LICEO SCIENTIFICO SCIENZE APPLICATE Disciplina: Tecnologie e Progettazione di Sistemi Informatici e di Telecomunicazione Cognome e Nome:
Corso di Fondamenti di Informatica Università degli Studi di Cassino
 Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono l algoritmo Cominciamo ad analizzare la
Un linguaggio ad alto livello deve offrire degli strumenti per: rappresentare le informazioni di interesse dell algoritmo definire le istruzioni che costituiscono l algoritmo Cominciamo ad analizzare la
Modello a scambio di messaggi
 Modello a scambio di messaggi Aspetti caratterizzanti il modello Canali di comunicazione Primitive di comunicazione 1 Aspetti caratterizzanti il modello modello architetturale di macchina (virtuale) concorrente
Modello a scambio di messaggi Aspetti caratterizzanti il modello Canali di comunicazione Primitive di comunicazione 1 Aspetti caratterizzanti il modello modello architetturale di macchina (virtuale) concorrente
Equivalenza di espressioni. Equivalenze. Equivalenze. Due espressioni sono equivalenti se: Atomizzazione delle selezioni σ F1 F2 (E) σ F1 (σ F2 (E))
 σ F1 (σ F2 (E))") Equivalenza di espressioni Due espressioni sono equivalenti se: E 1 R E 2 se E 1 (r = E 2 (r per ogni istanza r di R (equivalenza dipendente dallo schema E 1 E 2 se E 1 R E 2 per ogni schema R (equivalenza
Equivalenza di espressioni Due espressioni sono equivalenti se: E 1 R E 2 se E 1 (r = E 2 (r per ogni istanza r di R (equivalenza dipendente dallo schema E 1 E 2 se E 1 R E 2 per ogni schema R (equivalenza
Presentazione del corso
 Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Presentazione del corso Cosa è il calcolo parallelo Calcolo parallelo: MPI (base e avanzato) Calcolo parallelo: OpenMP 2 Claudia Truini - Luca Ferraro - Vittorio Ruggiero 1 Problema 1: Serie di Fibonacci
Laboratorio di Informatica I
 Struttura della lezione Lezione 6: Array e puntatori Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Università degli Studi di Salerno Una funzione per i numeri di Fibonacci
Struttura della lezione Lezione 6: Array e puntatori Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Università degli Studi di Salerno Una funzione per i numeri di Fibonacci
Funzioni, Stack e Visibilità delle Variabili in C
 Funzioni, Stack e Visibilità delle Variabili in C Programmazione I e Laboratorio Corso di Laurea in Informatica A.A. 2016/2017 Calendario delle lezioni Lez. 1 Lez. 2 Lez. 3 Lez. 4 Lez. 5 Lez. 6 Lez. 7
Funzioni, Stack e Visibilità delle Variabili in C Programmazione I e Laboratorio Corso di Laurea in Informatica A.A. 2016/2017 Calendario delle lezioni Lez. 1 Lez. 2 Lez. 3 Lez. 4 Lez. 5 Lez. 6 Lez. 7
MPI: MESSAGE PASSING INTERFACE
 MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
MPI: MESSAGE PASSING INTERFACE Lorenzo Simionato lorenzo@simionato.org Dicembre 2008 Questo documento vuol essere una brevissima introduzione ad MPI. Per un approfondimento dettagliato, si rimanda invece
Lezione 6: Array e puntatori
 Lezione 6: Array e puntatori Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Università degli Studi di Salerno Struttura della lezione Una funzione per i numeri di Fibonacci
Lezione 6: Array e puntatori Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Università degli Studi di Salerno Struttura della lezione Una funzione per i numeri di Fibonacci
Laboratorio di Programmazione 1. Docente: dr. Damiano Macedonio Lezione 5 31/10/2013
 Laboratorio di Programmazione 1 1 Docente: dr. Damiano Macedonio Lezione 5 31/10/2013 Original work Copyright Sara Migliorini, University of Verona Modifications Copyright Damiano Macedonio, University
Laboratorio di Programmazione 1 1 Docente: dr. Damiano Macedonio Lezione 5 31/10/2013 Original work Copyright Sara Migliorini, University of Verona Modifications Copyright Damiano Macedonio, University
Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE. Francesco Tura. F. Tura
 Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE Francesco Tura francesco.tura@unibo.it 1 Lo strumento dell informatico: ELABORATORE ELETTRONICO [= calcolatore = computer] Macchina multifunzionale Macchina
Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE Francesco Tura francesco.tura@unibo.it 1 Lo strumento dell informatico: ELABORATORE ELETTRONICO [= calcolatore = computer] Macchina multifunzionale Macchina
Informatica (A-K) 5. Algoritmi e pseudocodifica
 5. Algoritmi e pseudocodifica") Vettori e matrici #1 Informatica (A-K) 5. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile & Ambientale A.A. 2011-2012 2 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
Vettori e matrici #1 Informatica (A-K) 5. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile & Ambientale A.A. 2011-2012 2 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
Nella propria home directory creare una sottodirectory chiamata es08, in cui metteremo tutti i file C di oggi.
 Laboratorio 8 Nella propria home directory creare una sottodirectory chiamata es08, in cui metteremo tutti i file C di oggi. Note Quando dovete usare o ritornare dei valori booleani, usate la seguente
Laboratorio 8 Nella propria home directory creare una sottodirectory chiamata es08, in cui metteremo tutti i file C di oggi. Note Quando dovete usare o ritornare dei valori booleani, usate la seguente
Strutture dati e loro organizzazione. Gabriella Trucco
 Strutture dati e loro organizzazione Gabriella Trucco Introduzione I linguaggi di programmazione di alto livello consentono di far riferimento a posizioni nella memoria principale tramite nomi descrittivi
Strutture dati e loro organizzazione Gabriella Trucco Introduzione I linguaggi di programmazione di alto livello consentono di far riferimento a posizioni nella memoria principale tramite nomi descrittivi
Fortran per Ingegneri
 Fortran per Ingegneri Lezione 4 A.A. 2014/2015 Marco Redolfi marco.redolfi@unitn.it Simone Zen simone.zen@unitn.it Formati e Formattazione Finora abbiamo letto valori da tastiera e scritto sullo schermo
Fortran per Ingegneri Lezione 4 A.A. 2014/2015 Marco Redolfi marco.redolfi@unitn.it Simone Zen simone.zen@unitn.it Formati e Formattazione Finora abbiamo letto valori da tastiera e scritto sullo schermo
Fondamenti di Informatica 6. Algoritmi e pseudocodifica
 Vettori e matrici #1 Fondamenti di Informatica 6. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile A.A. 2010-2011 1 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
Vettori e matrici #1 Fondamenti di Informatica 6. Algoritmi e pseudocodifica Corso di Laurea in Ingegneria Civile A.A. 2010-2011 1 Semestre Prof. Giovanni Pascoschi Le variabili definite come coppie
I tipi strutturati e i record in C++
 I tipi strutturati e i record in C++ Docente: Ing. Edoardo Fusella Dipartimento di Ingegneria Elettrica e Tecnologie dell Informazione Via Claudio 21, 4 piano laboratorio SECLAB Università degli Studi
I tipi strutturati e i record in C++ Docente: Ing. Edoardo Fusella Dipartimento di Ingegneria Elettrica e Tecnologie dell Informazione Via Claudio 21, 4 piano laboratorio SECLAB Università degli Studi
Unità Didattica 4 Linguaggio C. Vettori. Puntatori. Funzioni: passaggio di parametri per indirizzo.
 Unità Didattica 4 Linguaggio C Vettori. Puntatori. Funzioni: passaggio di parametri per indirizzo. 1 Vettori Struttura astratta: Insieme di elementi dello stesso tipo, ciascuno individuato da un indice;
Unità Didattica 4 Linguaggio C Vettori. Puntatori. Funzioni: passaggio di parametri per indirizzo. 1 Vettori Struttura astratta: Insieme di elementi dello stesso tipo, ciascuno individuato da un indice;
Introduzione al C++ (continua)
") Introduzione al C++ (continua) I puntatori Un puntatore è una variabile che contiene un indirizzo di memoria pi_greco 3.141592 pi_greco_ptr indirizzo di 3.141592 & DEREFERENZIAZIONE RIFERIMENTO * se x
Introduzione al C++ (continua) I puntatori Un puntatore è una variabile che contiene un indirizzo di memoria pi_greco 3.141592 pi_greco_ptr indirizzo di 3.141592 & DEREFERENZIAZIONE RIFERIMENTO * se x
Modelli di programmazione parallela
 Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
Struttura interna del sistema operativo Linux
 Struttura interna del sistema operativo Linux 5. I device driver A cura di: Anna Antola Giuseppe Pozzi DEI, Politecnico di Milano anna.antola/giuseppe.pozzi@polimi.it -versione del 30 marzo 2004-1-04.-04
Struttura interna del sistema operativo Linux 5. I device driver A cura di: Anna Antola Giuseppe Pozzi DEI, Politecnico di Milano anna.antola/giuseppe.pozzi@polimi.it -versione del 30 marzo 2004-1-04.-04
Fondamenti di Informatica
 Vettori e matrici #1 Le variabili definite come coppie sono dette variabili scalari Fondamenti di Informatica 5. Algoritmi e pseudocodifica Una coppia è una variabile
Vettori e matrici #1 Le variabili definite come coppie sono dette variabili scalari Fondamenti di Informatica 5. Algoritmi e pseudocodifica Una coppia è una variabile
CAP9. Device drivers
 Struttura interna del sistema operativo Linux CAP9. Device drivers Device drivers Gestori di periferiche Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi periferici
Struttura interna del sistema operativo Linux CAP9. Device drivers Device drivers Gestori di periferiche Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi periferici
A. Ferrari. informatica. Java basi del linguaggio. Alberto Ferrari Informatica
 informatica Java basi del linguaggio Alberto Ferrari Informatica struttura di un programma Java /** * Classe EsempioProgramma * Un esempio di programmazione in Java * @author 4A Informatica */ public class
informatica Java basi del linguaggio Alberto Ferrari Informatica struttura di un programma Java /** * Classe EsempioProgramma * Un esempio di programmazione in Java * @author 4A Informatica */ public class
2. Teoria. [7 punti] La comunicazione tra processi nel sistema UNIX.
![2. Teoria. [7 punti] La comunicazione tra processi nel sistema UNIX.](/thumbs/99/141079558.jpg "2. Teoria. [7 punti] La comunicazione tra processi nel sistema UNIX.") 1. Unix [12 punti] Prova Scritta di Recupero del 5 Aprile 2004 Si scriva un programma C che utilizzi le system call di UNIX e che realizzi un comando UNIX avente la seguente sintassi: esame fsize fin fout
1. Unix [12 punti] Prova Scritta di Recupero del 5 Aprile 2004 Si scriva un programma C che utilizzi le system call di UNIX e che realizzi un comando UNIX avente la seguente sintassi: esame fsize fin fout
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A Pietro Frasca.
 Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2016-17 Pietro Frasca Lezione 5 Martedì 25-10-2016 Definizione di processo Esiste una distinzione concettuale
Università di Roma Tor Vergata Corso di Laurea triennale in Informatica Sistemi operativi e reti A.A. 2016-17 Pietro Frasca Lezione 5 Martedì 25-10-2016 Definizione di processo Esiste una distinzione concettuale
Capitolo 2 GOCCE DI JAVA. Domande a risposte multiple
 GOCCE D AVA Capitolo 2 Domande a risposte multiple Selezionando una risposta, il bottone corrispondente diventa verde se la risposta è giusta, altrimenti diventa rosso. 2 1. Quale dei seguenti non è un
GOCCE D AVA Capitolo 2 Domande a risposte multiple Selezionando una risposta, il bottone corrispondente diventa verde se la risposta è giusta, altrimenti diventa rosso. 2 1. Quale dei seguenti non è un
Corso di Programmazione I
 Corso di Programmazione I I puntatori in C e C++ I puntatori in C Il C prevede puntatori a funzione e puntatori a dati di qualsiasi natura, semplici o strutturati. In particolare il puntatore viene utilizzato
Corso di Programmazione I I puntatori in C e C++ I puntatori in C Il C prevede puntatori a funzione e puntatori a dati di qualsiasi natura, semplici o strutturati. In particolare il puntatore viene utilizzato
Le basi del linguaggio Java
 Le basi del linguaggio Java Compilazione e interpretazione Quando si compila il codice sorgente scritto in Java, il compilatore genera il codice compilato, chiamato bytecode. È un codice generato per una
Le basi del linguaggio Java Compilazione e interpretazione Quando si compila il codice sorgente scritto in Java, il compilatore genera il codice compilato, chiamato bytecode. È un codice generato per una
Fondamenti di Informatica T-1
 Fondamenti di Informatica T-1 Array Tutor: Allegra De Filippo allegra.defilippo@unibo.it a.a. 2016/2017 Fondamenti di Informatica T-1 Allegra De Filippo 1 / 14 ARRAY (1) Un vettore (array) è un insieme
Fondamenti di Informatica T-1 Array Tutor: Allegra De Filippo allegra.defilippo@unibo.it a.a. 2016/2017 Fondamenti di Informatica T-1 Allegra De Filippo 1 / 14 ARRAY (1) Un vettore (array) è un insieme
Esercitazioni 13 e 14
 Università degli Studi della Calabria Corso di Laurea in Ingegneria Informatica A.A. 2001/2002 Sistemi Operativi Corsi A e B Esercitazioni 13 e 14 Comunicazione tra processi (IPC) Meccanismo per la comunicazione
Università degli Studi della Calabria Corso di Laurea in Ingegneria Informatica A.A. 2001/2002 Sistemi Operativi Corsi A e B Esercitazioni 13 e 14 Comunicazione tra processi (IPC) Meccanismo per la comunicazione
Cicli annidati ed Array multidimensionali
 Linguaggio C Cicli annidati ed Array multidimensionali Cicli Annidati In C abbiamo 3 tipi di cicli: while(exp) { do { while(exp); for(exp;exp;exp3) { Cicli annidati: un ciclo all interno del corpo di un
Linguaggio C Cicli annidati ed Array multidimensionali Cicli Annidati In C abbiamo 3 tipi di cicli: while(exp) { do { while(exp); for(exp;exp;exp3) { Cicli annidati: un ciclo all interno del corpo di un
Il linguaggio C funzioni e puntatori
 Salvatore Cuomo Il linguaggio C funzioni e puntatori Lezione n. 8 Parole chiave: Linguaggio C, procedure, funzioni. Corso di Laurea: Informatica Insegnamento: Programmazione II, modulo di Laboratorio Email
Salvatore Cuomo Il linguaggio C funzioni e puntatori Lezione n. 8 Parole chiave: Linguaggio C, procedure, funzioni. Corso di Laurea: Informatica Insegnamento: Programmazione II, modulo di Laboratorio Email
Le classi in java. Un semplice programma java, formato da una sola classe, assume la seguente struttura:
 Le classi in java Un semplice programma java, formato da una sola classe, assume la seguente struttura: class Domanda static void main(string args[]) System.out.println( Quanti anni hai? ); La classe dichiarata
Le classi in java Un semplice programma java, formato da una sola classe, assume la seguente struttura: class Domanda static void main(string args[]) System.out.println( Quanti anni hai? ); La classe dichiarata
Calcolo parallelo. Una sola CPU (o un solo core), per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi
, per quanto potenti, non sono sufficienti o richiederebbero tempi lunghissimi") Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo Una sola CPU (o un solo core), per quanto potenti,
Calcolo parallelo Ci sono problemi di fisica, come le previsioni meteorologiche o alcune applicazioni grafiche, che richiedono un enorme potenza di calcolo Una sola CPU (o un solo core), per quanto potenti,
Le strutture. Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune.
 Le strutture Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune. Dichiarazione di una struttura: struct point { int x; int y; }; La dichiarazione di una struttura
Le strutture Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune. Dichiarazione di una struttura: struct point { int x; int y; }; La dichiarazione di una struttura
Il Modello a scambio di messaggi
 Il Modello a scambio di messaggi 1 Interazione nel modello a scambio di messaggi Se la macchina concorrente e` organizzata secondo il modello a scambio di messaggi: PROCESSO=PROCESSO PESANTE non vi è memoria
Il Modello a scambio di messaggi 1 Interazione nel modello a scambio di messaggi Se la macchina concorrente e` organizzata secondo il modello a scambio di messaggi: PROCESSO=PROCESSO PESANTE non vi è memoria
SQL SQL. Definizione dei dati. Domini. Esistono 6 domini elementari:
 SQL SQL (pronunciato anche come l inglese sequel): acronimo di Structured Query Language (linguaggio di interrogazione strutturato) Linguaggio completo che presenta anche proprietà di: DDL (Data Definition
SQL SQL (pronunciato anche come l inglese sequel): acronimo di Structured Query Language (linguaggio di interrogazione strutturato) Linguaggio completo che presenta anche proprietà di: DDL (Data Definition
Il problema dello I/O e gli Interrupt. Appunti di Sistemi per la cl. 4 sez. D A cura del prof. Ing. Mario Catalano
 Il problema dello I/O e gli Interrupt Appunti di Sistemi per la cl. 4 sez. D A cura del prof. Ing. Mario Catalano Il Calcolatore e le periferiche Periferica Decodifica Indirizzi Circuiti di Controllo Registri
Il problema dello I/O e gli Interrupt Appunti di Sistemi per la cl. 4 sez. D A cura del prof. Ing. Mario Catalano Il Calcolatore e le periferiche Periferica Decodifica Indirizzi Circuiti di Controllo Registri
Prova di Laboratorio del [ Corso A-B di Programmazione (A.A. 2004/05) Esempio: Media Modalità di consegna:
 Esempio: Media Modalità di consegna:") Prova di Laboratorio del 12.1.2005 [durata 90 min.] Corso A-B di Programmazione (A.A. 2004/05) 1. Leggere da tastiera un insieme di numeri interi ed inserirli in un vettore A 2. Calcolare tramite una funzione
Prova di Laboratorio del 12.1.2005 [durata 90 min.] Corso A-B di Programmazione (A.A. 2004/05) 1. Leggere da tastiera un insieme di numeri interi ed inserirli in un vettore A 2. Calcolare tramite una funzione
Programmazione Java Struttura di una classe, Costruttore, Riferimento this
 Programmazione Java Struttura di una classe, Costruttore, Riferimento this romina.eramo@univaq.it http://www.di.univaq.it/romina.eramo/tlp Roadmap > Struttura di una classe > Costruttore > Riferimento
Programmazione Java Struttura di una classe, Costruttore, Riferimento this romina.eramo@univaq.it http://www.di.univaq.it/romina.eramo/tlp Roadmap > Struttura di una classe > Costruttore > Riferimento
Programmazione Orientata agli Oggetti. Emilio Di Giacomo e Walter Didimo
 Programmazione Orientata agli Oggetti Emilio Di Giacomo e Walter Didimo Una metafora dal mondo reale la fabbrica di giocattoli progettisti Un semplice giocattolo Impara i suoni Dall idea al progetto Toy
Programmazione Orientata agli Oggetti Emilio Di Giacomo e Walter Didimo Una metafora dal mondo reale la fabbrica di giocattoli progettisti Un semplice giocattolo Impara i suoni Dall idea al progetto Toy
Oggetti. Definizioni di Classi II
 Programmazione a Oggetti Definizioni di Classi II Sommario Costruzioni di oggetti Campi e metodi di classe Overloading Istanziazione di oggetti Costruzione di un oggetto Processo complesso che comprende
Programmazione a Oggetti Definizioni di Classi II Sommario Costruzioni di oggetti Campi e metodi di classe Overloading Istanziazione di oggetti Costruzione di un oggetto Processo complesso che comprende
Le strutture. Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune.
 Le strutture Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune. Dichiarazione di una struttura: struct point { int x; int y; }; La dichiarazione di una struttura
Le strutture Una struttura C è una collezione di variabili di uno o più tipi, raggruppate sotto un nome comune. Dichiarazione di una struttura: struct point { int x; int y; }; La dichiarazione di una struttura
Architettura dei calcolatori e sistemi operativi. Input Output. IO 3 Device driver
 Architettura dei calcolatori e sistemi operativi Input Output IO 3 Device driver Device driver - gestori delle periferiche Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi
Architettura dei calcolatori e sistemi operativi Input Output IO 3 Device driver Device driver - gestori delle periferiche Sono moduli software che realizzano l interfacciamento e la gestione dei dispositivi
Strutture. Array dei nomi degli esami (MAX ESAMI è il massimo numero degli esami). Array con i crediti degli esami.
. Array con i crediti degli esami.") Consideriamo l esercizio assegnato la scorsa lezione per rappresentare il libretto di uno studente. Per memorizzare i dati si sono utilizzati tre array: char* nomiesami[max ESAMI] Array dei nomi degli
Consideriamo l esercizio assegnato la scorsa lezione per rappresentare il libretto di uno studente. Per memorizzare i dati si sono utilizzati tre array: char* nomiesami[max ESAMI] Array dei nomi degli
Ingresso ed Uscita in C. Informatica 1 / 15
 Ingresso ed Uscita in C Informatica 1 / 15 Input e Output in C Linguaggio C: progettato per essere semplice e con poche istruzioni Non esistono istruzioni di ingresso / uscita (I/O)!!! Ingresso ed uscita
Ingresso ed Uscita in C Informatica 1 / 15 Input e Output in C Linguaggio C: progettato per essere semplice e con poche istruzioni Non esistono istruzioni di ingresso / uscita (I/O)!!! Ingresso ed uscita
Programmazione lato client. JavaScript. Applicazioni di Rete M. Ribaudo - DISI. JavaScript
 Programmazione lato client Netscape: Microsoft: JScript ECMAScript (ECMA-262) (European Computer Manufactures Association) 1 Linguaggio di script interpretato con alcune caratteristiche Object Oriented
Programmazione lato client Netscape: Microsoft: JScript ECMAScript (ECMA-262) (European Computer Manufactures Association) 1 Linguaggio di script interpretato con alcune caratteristiche Object Oriented
Concetti base di MPI. Introduzione alle tecniche di calcolo parallelo
 Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Concetti base di MPI Introduzione alle tecniche di calcolo parallelo MPI (Message Passing Interface) Origini MPI: 1992, "Workshop on Standards for Message Passing in a Distributed Memory Environment MPI-1.0:
Programmazione a Oggetti Lezione 8. Definizioni di Classi II
 Programmazione a Oggetti Lezione 8 Definizioni di Classi II Sommario Costruzione di un oggetto Processo complesso che comprende varie fasi: 1. Allocare spazio per ogni campo - in ordine testuale - inizializza
Programmazione a Oggetti Lezione 8 Definizioni di Classi II Sommario Costruzione di un oggetto Processo complesso che comprende varie fasi: 1. Allocare spazio per ogni campo - in ordine testuale - inizializza
Array. Aggragati di variabili omogenee...
 Array Aggragati di variabili omogenee... Cosa è un array È un insieme di variabili omogenee identificato da un indice, ad esempio Se devo leggere 1 numeri dallo standard input e memorizzarli all'interno
Array Aggragati di variabili omogenee... Cosa è un array È un insieme di variabili omogenee identificato da un indice, ad esempio Se devo leggere 1 numeri dallo standard input e memorizzarli all'interno
Puntatori e array. Violetta Lonati
 Puntatori e array Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Violetta Lonati Puntatori e array
Puntatori e array Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Violetta Lonati Puntatori e array
18 - Vettori. Programmazione e analisi di dati Modulo A: Programmazione in Java. Paolo Milazzo
 18 - Vettori Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://pages.di.unipi.it/milazzo milazzo di.unipi.it Corso di
18 - Vettori Programmazione e analisi di dati Modulo A: Programmazione in Java Paolo Milazzo Dipartimento di Informatica, Università di Pisa http://pages.di.unipi.it/milazzo milazzo di.unipi.it Corso di
Introduzione al calcolo parallelo per il metodo degli elementi finiti
 Introduzione al calcolo parallelo per il metodo degli elementi finiti Simone Parisotto Università di Verona Dipartimento di Informatica 24 Aprile 2013 Simone Parisotto 24 Aprile 2013 1 / 28 Introduzione
Introduzione al calcolo parallelo per il metodo degli elementi finiti Simone Parisotto Università di Verona Dipartimento di Informatica 24 Aprile 2013 Simone Parisotto 24 Aprile 2013 1 / 28 Introduzione
Introduzione al linguaggio C Dati aggregati
 Introduzione al linguaggio C Dati aggregati Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica 5 ottobre
Introduzione al linguaggio C Dati aggregati Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica 5 ottobre
Introduzione al linguaggio C Puntatori
 Introduzione al linguaggio C Puntatori Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica 19 ottobre 2017
Introduzione al linguaggio C Puntatori Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica 19 ottobre 2017
Introduzione alla programmazione in linguaggio C
 Introduzione alla programmazione in linguaggio C Il primo programma in C commento Header della libreria Funzione principale Ogni istruzione in C va terminata con un ; Corso di Informatica AA. 2007-2008
Introduzione alla programmazione in linguaggio C Il primo programma in C commento Header della libreria Funzione principale Ogni istruzione in C va terminata con un ; Corso di Informatica AA. 2007-2008
Tipi di dati scalari (casting e puntatori) Alessandra Giordani Lunedì 10 maggio 2010
 Alessandra Giordani Lunedì 10 maggio 2010") Tipi di dati scalari (casting e puntatori) Alessandra Giordani agiordani@disi.unitn.it Lunedì 10 maggio 2010 http://disi.unitn.it/~agiordani/ I tipi di dati scalari I tipi aritmetici, i tipi enumerativi
Tipi di dati scalari (casting e puntatori) Alessandra Giordani agiordani@disi.unitn.it Lunedì 10 maggio 2010 http://disi.unitn.it/~agiordani/ I tipi di dati scalari I tipi aritmetici, i tipi enumerativi
Esercitazione 00 Introduzione a Matlab
 1 Esercitazione 00 Introduzione a Matlab Corso di Strumentazione e Controllo di Impianti Chimici Prof. Davide Manca Tutor: Giuseppe Pesenti PSE-Lab 2 Tutor: Giuseppe Pesenti giuseppe.pesenti@polimi.it
1 Esercitazione 00 Introduzione a Matlab Corso di Strumentazione e Controllo di Impianti Chimici Prof. Davide Manca Tutor: Giuseppe Pesenti PSE-Lab 2 Tutor: Giuseppe Pesenti giuseppe.pesenti@polimi.it
C. De Stefano Corso di Fondamenti di Informatica Università degli Studi di Cassino
 Array In alcuni casi, l informazione che bisogna elaborare consiste di un aggregazione di valori, piuttosto che di un valore solo. Questo significa che sarebbe conveniente indicare l insieme di valori
Array In alcuni casi, l informazione che bisogna elaborare consiste di un aggregazione di valori, piuttosto che di un valore solo. Questo significa che sarebbe conveniente indicare l insieme di valori