Calcolatori Elettronici B a.a. 2006/2007
|
|
|
- Ruggero Marino Cirillo
- 5 anni fa
- Visualizzazioni
Transcript
1 Calcolatori Elettronici B a.a. 26/27 Tecniche di Controllo Massimiliano Giacomin
2 Schema del processore (e memoria) Durante l esecuzione di un programma applicativo Pa, i circuiti interpretano le istruzioni del programma in linguaggio macchina costituito dal < Pa (tradotto) i servizi OS> Unità di controllo Comandi P C Memoria Registro Istruzioni Segnali da Unità di Elab. a Controllo indirizzo Programma Pa Istruzione [3-26] UNITA DI ELABORAZIONE (DATAPATH) Os Servizi 2
3 Faremo riferimento ad un sottoinsieme delle istruzioni MIPS: Istruzioni aritmetiche: add, sub, and, or, slt add rd, rs, rt // rd rs + rt slt rd, rs, rt // rd = se rs < rt, altrimenti Istruzioni di accesso a memoria: lw rt, offset(rs) // rt M[rs+offset] sw rt, offset(rs) // M[rs+offset] rt Istruzioni di salto condizionato: beq rs, rt, offset // se rs=rt salta a offset istruzioni rispetto a PC (aggiornato a istruzione corrente + 4 bytes!) in bytes: PC + (offset ) Salto incondizionato: j offset // salta all indirizzo in istruzioni ottenuto da: 4 bit di PC offset [3 bit] indirizzo in byte è la concatenazione di 4 bit di PC offset [32 bit] 3
4 Codifica delle istruzioni viste: Op rs rt rd Shift_amount funct Aritmetiche: Tipo-R ADD: op 6 5 SUB: AND: OR: SLT: Op rs rt offset x x = : lw x = : sw beq = + PC + (offset ) lw, sw, beq: Tipo-I Op offset J: Tipo-J PC offset 4
5 Glossario Visuale: indica le risorse individuate in base ad una prima analisi Segnali di controllo dati P C MemRead indirizzo MemWrite MemData IRWrite Registro Istruzioni Istruzione [3-26] Istruzione [25-2] RegWrite Registro letto Registro letto 2 Registri Dato letto A L U zero ris Memoria Istruzione [2-6] Registro scritto Dato letto 2 AluCom Dato scritto Istruzione [5-] Dato scritto [Se è necessario memorizzare istruzione corrente] funct UC ALU AluOp 5
6 Un esempio di controllo combinatorio: Il controllo della ALU Supponiamo che la ALU possa svolgere le 6 operazioni seguenti: AND OR NOR Somma Sottrazione Comparazione di minoranza (set on less than) e sia dotata di 4 ingressi di controllo (della ALU) per codificare le operazioni possibili Il blocco logico che implementa l unità di controllo della ALU avrà 4 uscite, corrispondenti ai 4 bit di controllo che codificano una delle 6 operazioni possibili 6
7 Chiamiamo Op3, Op2, Op, Op le 4 uscite del blocco di controllo della ALU (ovvero l ingresso di controllo della ALU) Unità di controllo della ALU Op3 Op Ingressi di dato ALU Assumiamo la seguente codifica Op3 Op2 Op Op AND OR Somma Sottrazione Set on less than NOR 7
8 Gli ingressi dell unità di controllo della ALU derivano da: Un campo di controllo di 2 bit (ALUOp) che identifica la classe dell istruzione da eseguire come segue: Classe dell istruzione Load word, store word Branch on equal Tipo-R ALUOp Operazione somma sottraz. funct Il campo funzione (funct) dell istruzione (se Tipo-R) I bit ALUOp (ingressi dell unità di controllo ALU) vengono generati dall unità di controllo principale in base al codice operativo (op) dell istruzione 8

9 Relazione fra ingressi di controllo della ALU e istruzioni NB: l appendice C dimentica NOR. In effetti, la NOR non è usata nelle istruzioni prese ad esempio. NB: sono considerati solo Op2 Op (Op3 sempre nel nostro caso) INGRESSI USCITE 9
10 Una volta specificata la relazione (combinatoria!) tra ingressi e uscite mediante una tabella di verità, si possono usare le tecniche viste a Calcolatori A per realizzare la rete combinatoria: ALUOp Funct F3 F2 F F ALUOp ALUOp Op2 Op Op Operazione
11 NB: nella pratica, per passare da specifica a implementazione si usano strumenti CAD: - semplificano il processo di realizzazione (riducendo errori) - applicano algoritmi di ottimizzazione - utilizzano insiemi strutturati di porte logiche e tengono conto del layout e della tecnologia elettronica utilizzata ORA CONSIDERIAMO IL CONTROLLO DEL PROCESSORE. VEDREMO: - SINGOLO CICLO - MULTICICLO - FSM - MICROPROGRAMMATO - CON PIPELINE
12 Controllo di un processore a singolo ciclo NB: schema stilizzato (in particolare, non corrisponde al MIPS) Unità di controllo combinatoria controlli comandi ck write read write MEMORIA DATI REGISTRI P C Memoria indirizzo Programma Pa Os Servizi Unità di elaborazione 2
13 Idea di base Ad ogni ciclo di clock, il registro istruzioni contiene l istruzione corrente L unità di controllo è una rete combinatoria che: - riceve in input l istruzione corrente - produce in output segnali di controllo all unità di elaborazione: controllo multiplexer, read e write ad elementi di memoria, controllo ALU I segnali di controllo determinano, a seconda del tipo di istruzione: - il percorso sorgente-destinazione dei dati mediante: indirizzi e numeri registri + segnali di controllo ai multiplexer - le operazioni aritmetiche e logiche effettivamente svolte mediante: segnali di controllo alle ALU - se un elemento di memoria deve scrivere e/o leggere un dato mediante: segnali di tipo read/write Avremo quindi la determinazione di un percorso del tipo: CK Sorgente F Dest. CK dove: - sorgente e destinazione possono coincidere - valore sorgente disponibile nel corso del ciclo, destinazione scritta alla fine 3
14 ES: operazione di tipo add r, r2, r3 write 2 3 Memoria Istruzioni ck MEMORIA DATI REGISTRI Unità di controllo combinatoria controlli comandi Unità S D di elaborazione - valori dei registri disponibili (poco dopo T prop l inizio del periodo) + si crea percorso sorgente-destinazione (con i comandi relativi) - valori all ingresso della destinazione (registri) stabili entro la fine del ciclo - questi valori sono scritti nel fronte successivo disponibili prossimo ciclo 4
15 Conseguenze: E possibile condividere elementi tra istruzioni diverse (eseguite in cicli diversi del clock!), però Ogni elemento che venga usato più di una volta nell esecuzione di una istruzione deve essere duplicato: - Memoria dati (lw, sw) Memoria programmi (fase di fetch di tutte le istruzioni) - ALU (lw, sw, beq, aritmetiche) Sommatore PC + 4 (tutte le istruzioni) Sommatore PC+offset (beq) 5
16 Consideriamo il caso del MIPS, di cui si vogliono implementare le istruzioni: - Aritmetiche e logiche - lw, sw - beq - j Tipo-R Tipo-I Tipo-J Op rs rt rd Shift_amount funct Op rs rt offset 6 5 Tipo-R Tipo-I Op offset Tipo-J La progettazione è facilitata dal fatto che: - Campo Op sempre in [3-26] - i registri da leggere sono sempre in rs e rt - il registro base [da sommare] per lw e sw è rs [primo ingresso della ALU] - l offset a 6 bit da sommare per beq, lw, sw è in [5-] Il registro su cui scrivere può essere rd (per operaz. di TIPO-R) o rt (per lw) 6
17 Instruction [25 ] Shift Jump address [3 ] left Add PC+4 [3 28] Instruction [3 26] Control RegDst Jump Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite Shift left 2 Add ALU result M u x M u x PC Read address Instruction memory Instruction [3 ] Instruction [25 2] Instruction [2 6] Instruction [5 ] M u x Read register Read data Read register 2 Registers Read Write data 2 register Write data M u x Zero ALU ALU result Address Write data Data memory Read data M u x Instruction [5 ] 6 Sign 32 extend ALU control Instruction [5 ] 7
18 Si vede che: - i segnali di controllo sono determinati in modo combinatorio soltanto sulla base del campo Opcode - non è in generale possibile prevedere l ordine di arrivo dei segnali di controllo: le operazioni non sono eseguite in sequenza, controllo combinatorio (è necessario che T clock sia sufficientemente lungo) Vediamo allora alcuni esempi di esecuzione delle istruzioni 8
19 Esempio: istruzione di tipo-r Instruction [25 ] Shift Jump address [3 ] left Add PC+4 [3 28] Instruction [3 26] Control RegDst Jump Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite Shift left 2 Add ALU result M u x M u x PC Read address Instruction memory Instruction [3 ] Instruction [25 2] Instruction [2 6] Instruction [5 ] M u x Read register Read data Read register 2 Registers Read Write data 2 register Write data M u x Zero ALU ALU result Address Write data Data memory Read data M u x Instruction [5 ] 6 Sign 32 extend ALU control Instruction [5 ] 9
20 Esempio: istruzione di load Instruction [25 ] Shift Jump address [3 ] left Add PC+4 [3 28] Instruction [3 26] Control RegDst Jump Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite Shift left 2 Add ALU result M u x M u x PC Read address Instruction memory Instruction [3 ] Instruction [25 2] Instruction [2 6] Instruction [5 ] Instruction [5 ] M u x Read register Read data Read register 2 Registers Read Write data 2 register Write data 6 Sign 32 extend M u x ALU control Zero ALU ALU result Address Write data Data memory read Read data M u x Instruction [5 ] 2
21 Esempio: istruzione beq Instruction [25 ] Shift Jump address [3 ] left Add PC+4 [3 28] Instruction [3 26] Control RegDst Jump Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite Shift left 2 Add ALU result M u x M u x PC Read address Instruction memory Instruction [3 ] Instruction [25 2] Instruction [2 6] Instruction [5 ] M u x Read register Read data Read register 2 Registers Read Write data 2 register Write data M u x Zero ALU ALU result Address Write data Data memory Read data M u x Instruction [5 ] 6 Sign 32 extend ALU control Instruction [5 ] 2
22 Progetto e realizzazione dell unità di controllo principale RegDst Istruzione[3-26]: campo opcode Jump Branch Memread MemtoReg ALUOp MemWrite ALUSrc RegWrite Progetto e realizzazione corrispondono a quelli di una rete combinatoria: ISTRUZ RegDst Jump Branch Mem Read Memto Reg ALUOp Mem Write ALUSrc Reg Write Tipo-R lw sw X X beq X X j X X X XX X Opcode [6 bit] 22
23 Richiamo su prestazioni Si ricorda che le prestazioni sono valutate sul tempo di esecuzione di un programma! Per valutare soluzioni progettuali diverse, bisogna far riferimento allo stesso programma (o classe di programmi!) T esecuzione = numero_istruzioni * CPI * T clock Fisse a parità di Instruction Set Architecture Tempo medio di esecuzione per istruzione T clock non varia al variare delle istruzioni [progettazione di sistemi a clock variabile non adottata in pratica] E necessario conoscere la distribuzione delle singole istruzioni per valutare CPI [il numero di cicli di clock impiegati varia da istruzione a istruzione] 23
24 Esempi di processori che usano controllo a singolo ciclo: NESSUNO! Perché? Periodo di clock: abbastanza lungo per garantire la stabilità dei segnali attraverso il percorso più lungo tempo di esecuz. costante per diverse istruz. Istruzioni più lente limitano le istruzioni più veloci! Es. lw Memoria Istruz. Reg. File A L U Memoria Dati Reg. File Es. Tipo-R Memoria Istruz. Reg. File A L U Reg. File 24
25 Limitazione aggravata da - istruzioni che utilizzano decine di unità funzionali in serie, ad esempio comprendenti calcoli in virgola mobile! CPI =, ma T clock alto, ovvero frequenza di clock molto bassa! Nel complesso, il tempo di esecuzione di una istruzione è sempre pari al caso peggiore, ovvero a quello dell istruzione più complessa e lunga Altro svantaggio: duplicazione dell HW costi elevati! Nell esempio del MIPS, come visto: - occorrono due memorie diverse [dati e istruzioni] [NB: questo va comunque bene perché negli attuali calcolatori si usa memoria cache + pipeline] - occorrono tre ALU, una per istruzioni aritmetiche confronto operandi in beq calcolo indirizzo lw e sw, una per calcolare PC+4 ed una per calcolare indirizzo di salto beq [la cosa si complica considerando modalità di indirizzamento complesse, ad esempio quelle con autoincremento] 25
26 Una strategia alternativa T istruzione costante e pari a T medio di esecuzione per istruzione Istruzione lunga Istruzione potenzialmente breve Suddividere le istruzioni in fasi : un ciclo di clock per una fase! T esecuzione T 2 esecuzione NB: T 2 esecuzione (il caso peggiore) può in generale essere maggiore del precedente! Tuttavia, le istruzioni più lunghe sono anche meno frequenti: Principio rendere più veloce l evento più frequente comporta un guadagno! 26
27 Controllo di un processore-multiciclo Ogni istruzione divisa in fasi Ad ogni ciclo di clock una fase: controllo sequenziale E possibile utilizzare una stessa unità funzionale più volte nel corso di una istruzione: - unica memoria per istruzioni e dati - una sola ALU, che svolge le funzioni logico aritmetiche delle istruzioni di Tipo-R e beq (per confrontare rs e rt), somma PC+4 (per fetch), somma per calcolare indirizzi nei salti condizionati (beq) e nelle istruzioni lw e sw Necessità di memorizzare risultati intermedi in registri temporanei (non visibili al programmatore): - registri temporanei: salvano dati prodotti in un ciclo di clock e utilizzati dalla stessa istruzione in un ciclo di clock successivo - registri visibili al prog: dati utilizzati da istruzioni successive 27
28 Come visto, ciascuna fase deve essere sufficientemente breve (T clock breve) Bilanciare la suddivisione in fasi, evitare di mettere in serie più unità funzionali lente. Faremo in modo di non mettere in serie più di una delle operazioni: - accesso in memoria (istruzioni o dati) - accesso al register file (due letture e una scrittura) - operazioni della ALU (NB: accesso/scrittura in un registro singolo considerato non oneroso) Ciascuna di queste unità [memoria, register file, ALU] necessita di registri temporanei per memorizzarne il risultato. Sono inoltre necessari multiplexer aggiuntivi per instradare i dati verso le unità funzionali riutilizzate nella stessa istruzione [p.es. MUX per selezionare indirizzo memoria tra PC (per fetch) o uscita ALU (per lw o sw) ] Esistono diverse modalità di specifica e realizzazione del controllo 28
29 Specifica progressiva del sistema di calcolo di un sistema multiciclo Di seguito sono schematizzate le attività che una macchina multiciclo svolge per eseguire le istruzioni del set del MIPS ridotto: le fasi rispettano i vincoli posti in precedenza sulle operazioni che si possono eseguire in serie. Nello specificare le diverse attività di calcolo si sono seguite le convenzioni adottate nel testo. In particolare, sono rese visibili le risorse impegnate nel ciclo in esame. La combinazione delle immagini risulta nello schema 5-28 del testo. 29
30 I ciclo:prelievo dell istruzione I ciclo: IR memoria [PC] ottimistiche: PC PC + 4 PCWrite IorD = MemRead IRWrite AluSrcA = P C indirizzo Memoria Dato scritto MemData Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] RegWrite scritto Dato scritto Registri Registro letto Regist ro letto Registr o Dato letto Dato letto 2 4 A L U AluCom zero ris [indicati i valori affermati e controlli MUX rilevanti] AluSrcB = UC ALU AluOp= [addizione] 3
31 NB: Durante il primo ciclo di clock vengono creati i due percorsi paralleli: PC_out Memoria IR PC_out ALU PC_in + vengono attivati i segnali di scrittura in IR e PC Alla fine del periodo di clock (fronte del clock): PC e IR vengono scritti; i valori sono disponibili nel ciclo di clock successivo Durante il secondo ciclo di clock IR contiene l istruzione da eseguire, PC è già stato incrementato NB: si noti che ciascun percorso contiene soltanto un elemento critico (memoria e ALU); sorgente e destinazione infatti sono registri singoli (PC e IR) 3
32 II ciclo:decodifica e caricamento registri ottimistiche: alimentazione registri: A registro[ir[25-2]]; B registro[ir[2-6]] calcolo indirizzo branch: AluOut PC + (sign_ext(ir[5-]) << 2) Al controllo per decodifica AluSrcA = P C Memoria Registro Istruzioni Istruzione [25-2] Istruzione [2-6] Istruzione [5-] Nota: non si conosce l istruzione in questo passo: tutte le operazioni ottimistiche! Nota: A,B Aluout non sono controllati (memorizzano il valore ad ogni fronte del CK) Istruzione Registro [3-26] letto A Dato A letto Registro letto Registro scritto Dato scritto Est. segno Registri Dato letto 2 B Shift << AluSrcB=3 L U UC ALU AluCom zero ris Alu Out AluOp= [addizione] 32
33 NB: si è detto che nel secondo ciclo è già disponibile l istruzione in IR. D altra parte si dice anche che non si conosce quale sia l istruzione e quindi si effettua la decodifica + le uniche operazioni svolte sono ottimistiche Ciò perché si usa il modello di Moore: uscite del sistema di controllo dipendono solo dallo stato corrente, non dagli ingressi [IR]. FETCH Uscita: - carica IR - PC + 4 Unica transizione possibile! Questa è la decodifica DECODE Uscita: - ottimistiche Transizione dipende da IR! III ciclo caso III ciclo caso 2 Uscita: 33
34 III ciclo:se è branch (beq) IF ([A]= = [B]): PC [AluOut] Attenzione: si ritocca il data path e si introduce PCsource PCWrite = AluSrcA = PCsource= PCWriteCond P C Memoria Registro Istruzioni Registri A questo punto istruzione terminata! (si ricomincia dal primo ciclo prox istruzione) Registro letto Registro letto Registro scritto Dato scritto Dato letto Dato letto 2 A B Shift << AluSrtcB= A L U UC ALU AluCom ris zero Alu Out AluOp= [sottrazione] 34
35 PCWrite III ciclo: se è salto incondizionato (jump) PC PC[3-28] (IR[25-]<<) PCsource = 2 PC[3-28] 44 2 P C indirizzo Memoria Dato scritto MemData Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] IR[25-] 26 Shift << 2 28 Registri 4 32 A L U ris AluCom Alu Out A questo punto l istruzione è terminata! (si ricomincia dal primo ciclo prossima istruzione) UC ALU 35
36 III ciclo:per tipo R AluOut A op B AluSrcA= P C Memoria Registro Istruzioni Istruzione [3-26] Istruzione [2-6] Istruzione [5-] Registri A B 4 A L U AluCom ris zero Alu Out IR[5-] Shift << 2 AluSrcB= UC ALU AluOp= [op in base a funct] 36
37 III ciclo:per tipo accesso a memoria AluOut [A]+ (signext([ir[5-]]) AluSrcA= P C Memoria Registro Istruzioni Istruzione [3-26] Istruzione [2-6] Istruzione [5-] Registri A B A L U AluCom ris zero Alu Out SignExt Shift << 2 UC ALU AluOp= [addizione] AluSrcB= 37
38 IV ciclo: carica parola (lw) MDR memoria [AluOut] IorD= MemRead P C indirizzo Memoria Dato scritto MemData 32 Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] Registro letto Registro letto Registro scritto Dato scritto Registri Dato letto Dato letto 2 A B 4 A L U zero ris Alu Out MDR UC ALU 38
39 IV ciclo: memorizza parola (sw) memoria [AluOut] B (NB: B è stato letto due volte ) IorD= MemWrite P C indirizzo Memoria Dato scritto MemData 32 Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] Registro letto Registro letto Registro scritto Dato scritto Registri Dato letto Dato letto 2 A B 4 A L U zero ris Alu Out MDR UC ALU A questo punto l istruzione è terminata! 39
40 IV ciclo: completamento istruzioni R Reg [IR[5-]] Aluout RegDst= RegWrite P C Memoria o MemData Dato scritto MDR Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] IR[5-] Registro letto Registro letto Registro scritto Dato scritto Registri Dato letto Dato letto 2 A B 4 A L U UC ALU zero ris Alu Out MemToReg = A questo punto l istruzione è terminata! 4
41 V ciclo: completamento lettura da memoria (lw) Reg [IR[2-6]] MDR RegDst= RegWrite P C Memoria o MemData Dato scritto MDR Registro Istruzioni Istruzione [3-26] Istruzione [25-2] Istruzione [2-6] Istruzione [5-] Registro letto Registro letto Registro scritto Dato scritto Registri Dato letto Dato letto 2 A B 4 A L U UC ALU zero ris Alu Out A questo punto istruzione terminata! MemToReg= 4
42 Da queste considerazioni risultano immediatamente: unità di elaborazione (datapath) specifica dell unità di controllo PC M u x Address Write data Memory MemData Instruction [3-26] Instruction [25 2] Instruction [2 6] Instruction [5 ] Instruction register Instruction [5 ] Memory data register PCWriteCond PCWrite IorD MemRead MemWrite MemtoReg IRWrite Instruction [25 ] Outputs Control Op [5 ] M Instruction u [5 ] x M u x PCSource ALUOp ALUSrcB 6 ALUSrcA RegWrite RegDst Read register Read register 2 Registers Write register Write data Sign extend Read data Read data 2 32 Shift left 2 A B 4 M u x M u 2 x Shift left 2 ALU control PC [3-28] Zero ALU ALU result Jump address [3-] ALUOut 2 M u x Instruction [5 ] 42
43 Soluzione alternativa (permette di risparmiare connessioni): bus condiviso interno alla CPU read write read write read write Permette di risparmiare delle linee di dato, ma comporta una riduzione delle prestazioni, perché un bus è meno veloce di una connessione punto-punto Nel seguito, non considereremo questa soluzione (si parla di bus interno alla CPU!) 43
44 Specifica dell unità di controllo: ) Come macchina a stati finiti (Modello di Moore) 2) Come microprogramma Partiamo dalla prima modalità, ottenendo direttamente il diagramma a stati Ad ogni stato sono associate le uscite corrispondenti (cfr. lucidi precedenti): segnali di scrittura/lettura: non indicati segnali di controllo MUX: non indicati valore indifferente 44
45 2 Memory address computation ALUSrcA = ALUSrcB = ALUOp = Start Instruction fetch MemRead ALUSrcA = IorD = IRWrite ALUSrcB = ALUOp = PCWrite PCSource = 6 (Op = 'LW') or (Op = 'SW') Execution ALUSrcA = ALUSrcB = ALUOp= 8 (Op = R-type) Branch completion ALUSrcA = ALUSrcB = ALUOp = PCWriteCond PCSource = Instruction decode/ register fetch (Op = 'BEQ') 9 ALUSrcA = ALUSrcB = ALUOp = (Op = 'J') Jump completion PCWrite PCSource = 3 (Op = 'LW') Memory access (Op = 'SW') 5 Memory access 7 R-type completion MemRead IorD = MemWrite IorD = RegDst = RegWrite MemtoReg = 4 Write-back step RegDst = RegWrite MemtoReg = 45
46 Come può essere realizzata la macchina corrispondente a questa specifica? ) Con una macchina a stati finiti 2) Con tecnica di controllo microprogrammato Vediamo la prima modalità di realizzazione 46
47 Controllo con macchina a stati finiti Durante l esecuzione di un programma applicativo i circuiti interpretano le istruzioni: del programma costituito dal< programma applicativo i servizi OS> Logica di controllo Realizza f, η Unità di controllo Registro di stato P C Memoria Registro Istruzioni indirizzo Programma Os Servizi Istruzione [3-26] Unità di elaborazione 47
48 Automa con stati 4 bit per codificarli (S3-S) memorizzati con 4 flip-flop di tipo D Codifica: assegnamento di un valore a ciascuno stato (useremo numero progressivo) PCWrite Control logic Inputs Outputs PCWriteCond IorD MemRead MemWrite IRWrite MemtoReg PCSource ALUOp ALUSrcB ALUSrcA RegWrite RegDst NS3 NS2 NS NS Dobbiamo realizzare due funzioni logiche combinatorie: - funzione di uscita η(s) restituisce 6 segnali di uscita - funzione di stato futuro f(s, I) restituisce NS3 NS dove s = (S3, S2, S, S) I = (OP5,, OP) Op5 Op4 Op3 Op2 Op Op S3 S2 S S Instruction register opcode field State register 48
49 Tabelle di verità per le uscite di controllo (dipendono solo dallo stato): per semplificarle vengono indicati solo gli stati in cui singole uscite =. PCSource (PCSource PCSource) Dal diagramma di stato, si vede che: - PCSource vale nello stato 9 - PCSource vale nello stato 8 S3 S3 S2 S2 S S S S PCSource PCSource IorD Equazioni logiche: PCSource= S3 S2 S S PCSource= S3 S2 S S Dal diagramma di stato, si vede che vale negli stati 3 e 5 IorD= S3 S2 S S + S3 S2 S S Altre uscite ricavate con considerazioni analoghe S3 S2 S S IorD NB: campi Op don t care ( riga sta per 2 6 = 64 righe!) 49
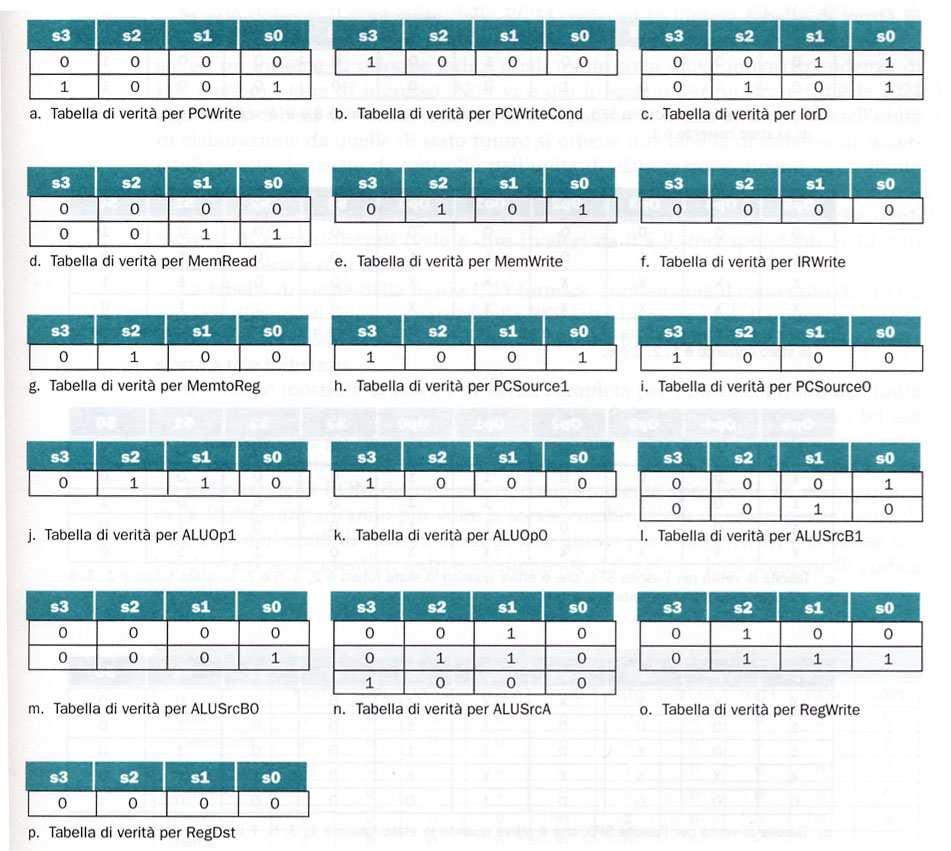
50 5
51 Tabelle di verità per le uscite di stato futuro (dipendono da stato e campi Op) NS: pari a quando stato futuro =, 3, 5, 7, 9 Dall analisi del diagramma di stato, si vede che ad essi si può arrivare: stato : da stato a prescindere da Op stato 3 : da stato 2 con Op = lw [] stato 5: da stato 2 con Op = sw [] stato 7: da stato 6 a prescindere da Op stato 9: da stato con Op = j [] Ciò corrisponde alla tabella di verità: OP5 OP4 OP3 OP2 OP OP S3 S2 S S NS X X X X X X X X X X X X NS = S3 S2 S S + OP5 OP4 OP2 OP OP S3 S2 S S + S3 S2 S S + OP5 OP4 OP3 OP2 OP OP S3 S2 S S 5
52 Con considerazioni analoghe si ricavano le altre uscite di stato futuro Abbiamo la specifica di entrambe le funzioni combinatorie Realizzazione in 2 (*2) modi alternativi: ) Tramite ROM - unica ROM per entrambe le funzioni - due ROM separate 2) Tramite PLA - unica PLA - due PLA separate Confrontiamo le varie soluzioni 52
53 Unica ROM opcode S3--S 4 6 ROM 4 6 Segnali di uscita NS3--NS Dimensione: 2 * 2 = 2 Kbit Parola di uscita Combinazioni possibili dei valori di ingresso 53
54 Definendo un ordine dei bit di ingresso e di uscita, è possibile specificare il contenuto della ROM. Risulta che: - bit di ingresso (stato + opcode) 4 bit di stato futuro - 4 bit ingresso (stato) 6 bit di controllo... 6 bit 2 4 parole (di 6 bit) ciascuna ripetuta 2 6 volte (6 opcode don t care) ovvero: 2 4 *2 6 *6 al posto di 2 4 *6 Possiamo evitare lo spreco dovuto alle ripetizioni per 2 6 usando due ROM separate (stato futuro e uscite controllo): la ROM per le uscite di controllo ha solo 4 ingressi (bit di stato) e quindi evita di ripetere la stessa parola di memoria per tutte le 2 6 combinazioni degli ingressi! 54
55 Due ROM separate S ROM Segnali di uscita opcode S ROM 2 4 NS3-- Dimensione: 2 4 * * 4 = 4,3 Kbit Nelle ROM ci sono comunque molti elementi duplicati: - molte combinazioni dell ingresso non si verificano (ROM le codifica tutte) p.es. ho 4 bit per stati: 6-=6 combinazioni non si verificano - a volte le uscite non dipendono da [tutti] i valori dell ingresso. p.es. da stato si passa sempre a stato per qualunque valore di opcode, mentre ROM 2 duplica la parola NS () per 2 6 volte - inoltre, ROM è completamente codificata 55
56 Unico PLA Ciascuna uscita è OR di termini prodotto (mintermini) Op5 Op4 Op3 Op2 Op Op - Rappresentate solo le righe della tabella di verità con uscita - Ciascun mintermine può rappresentare più righe (input don t care) In questo caso: 7 mintermini ( dipendono solo da stato corrente) Dimensione: proporzionale a *7 + 7*2 = 5 S3 S2 S S PCWrite PCWriteCond IorD MemRead MemWrite IRWrite MemtoReg PCSource PCSource ALUOp ALUOp ALUSrcB ALUSrcB ALUSrcA RegWrite RegDst NS3 NS2 NS NS 56
57 Due PLA ) PLA a 4 ingressi (stato corrente) e 6 uscite di controllo mintermini (quelli che dipendevano solo da stato corrente, usati dalle uscite di controllo) Dimensione: 4* + *6 = 2 2) PLA a ingressi (stato e opcode) e 4 uscite di stato futuro mintermini (cfr. figura del PLA: sono quelli usati da uscite di stato futuro, dei quali 7 dipendono da stato e opcode) Dimensione: * + *4 = 4 Dimensione totale: proporzionale a = 34 57
58 Riepilogo 2 Riduzione a ROM 2 Kbit 4.3 Kbit /5 PLA /5 Riduzione a /4 /3 58
59 FINORA ABBIAMO VISTO: Processore a singolo ciclo [Unità di controllo combinatoria] - specifica e implementazione: cfr. reti combinatorie Processore multi-ciclo [Unità di controllo sequenziale] - specifica come FSM e implementazione come FSM Parti combinatorie: - specifica con tab. di verità equazioni logiche - realizzazione con ROM PLA (singole o doppie) - ORA VEDIAMO LA SPECIFICA COME microprogramma 59
60 Il controllo specificato come microprogramma Nella pratica, set istruzioni più numeroso o istruzioni più complesse (cfr. Intel) drastico aumento del numero degli stati impraticabile rappresentare gli stati esplicitamente! Molti di questi stati raggiungibili in modo sequenziale (es. precedente: da stato_ si passa sempre a stato_ a prescindere da ingressi) idea: utilizzare i concetti della programmazione - Microistruzioni rappresentano segnali al datapath in un ciclo di clock - Controllo del processore rappresentato da un microprogramma (microistruzioni eseguite in sequenza + salti) VANTAGGI Nel caso di molti stati, porta ad una significativa semplificazione nella specifica del controllo! Inoltre, come vedremo questa specifica ha una naturale realizzazione che può essere più economica di una FSM in diversi casi 6
61 Nota bene: Abbiamo: un particolare datapath ISA (che include il formato delle istruzioni macchina) Dobbiamo specificare l unità di controllo! Solo dopo verrà illustrata la realizzazione. 6
62 Passi necessari: ) Definire Formato (rappresentazione simbolica) delle microistruzioni: - Sequenza di campi distinti - Valori (simbolici) che ogni campo può assumere - Segnali di controllo associati a ciascun campo Obiettivi: - leggibilità del microprogramma ciascun campo associato ad una funzione specifica [es. campo per operaz. ALU, 3 per scelta sorgenti e destinazione] - impedire scrittura microistruzioni incoerenti / istruzioni non supportate campi diversi per insiemi disgiunti di segnali di controllo; 62
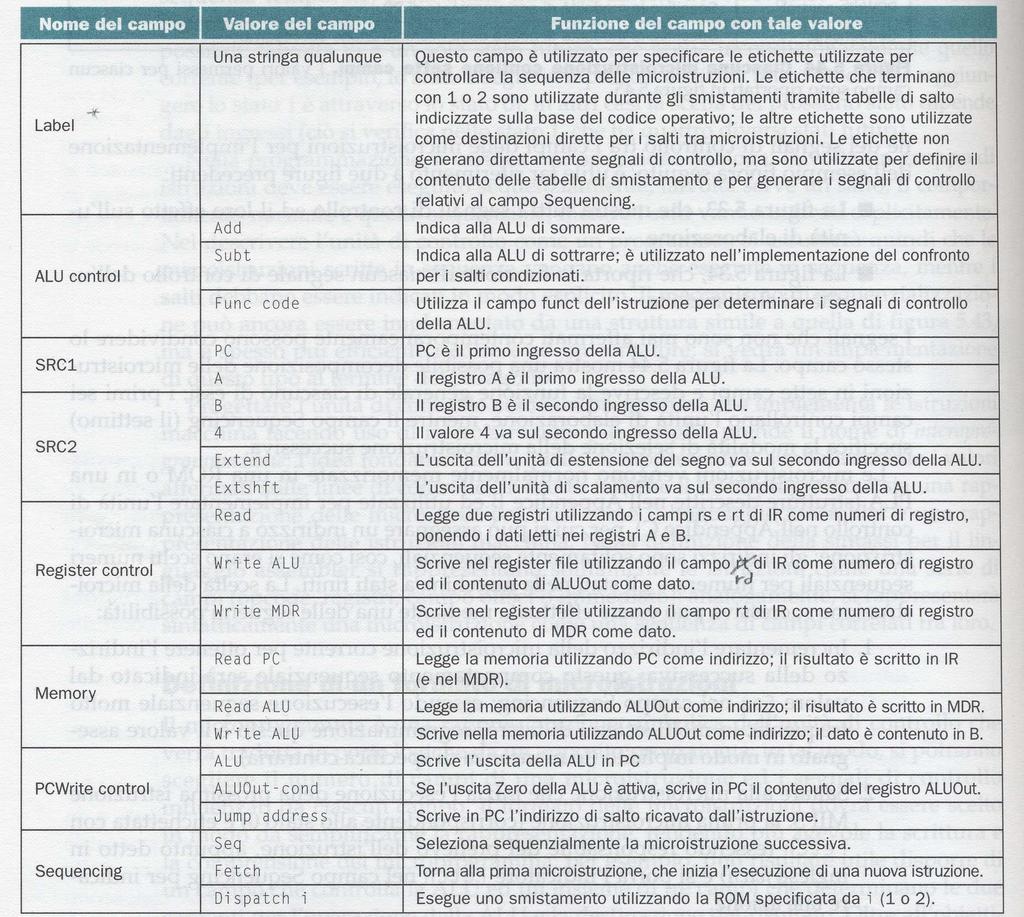
63 63
64 Notare che: In Register control sono previsti due possibili valori per la scrittura dei registri: - Write ALU: scrive nel registro rd il contenuto di ALUout [usato nelle istruzioni di Tipo-R] - Write MDR: scrive nel registro rt il contenuto di MDR [usato nell istruzione lw] Sono quindi escluse le combinazioni: - scrittura in rt del contenuto di ALUout - scrittura in rd del contenuto di MDR possibili con il datapath progettato ma non usate in istruzioni MIPS considerate. In Memory i valori previsti non permettono ad esempio di: - leggere la memoria indirizzata da ALUout e scrivere il valore letto in IR - scrivere in memoria (il dato contenuto in B) nella locazione indirizzata da PC 64
 Comandi non specificati: - a elementi di memoria (lettura e scrittura): = - a MUX e controllo elementi combinatori (ALU): = don t care IRWrite 65")
65 A ciascun campo (a parte Sequencing) possiamo già associare segnali di controllo, il cui valore è determinato dal valore simbolico del campo stesso (cfr. Assembler vs. Linguaggio Macchina) Comandi non specificati: - a elementi di memoria (lettura e scrittura): = - a MUX e controllo elementi combinatori (ALU): = don t care IRWrite 65

66 2) Creare Microprogramma: rappresentazione simbolica del controllo traducibile automaticamente in circuiti logici di controllo. Write MDR Read ALU Write ALU Write ALU Fetch NB: Si vede che il microprogramma corrisponde esattamente al diagramma degli stati individuato nella specifica del processore come FSM. Ciò fa già capire come la realizzazione possa essere effettuata mediante: - sequenzializzatore - macchina a stati finiti! 66
67 Note: Nel microprogramma, le microistruzioni sono disposte in sequenza. Ciascuna istruzione può essere etichettata da una label (campo Label) che serve ad identificarla nei salti. Scelta della microistruzione successiva dipende da campo Sequencing: - Seq: eseguita l istruzione successiva nel microprogramma - Fetch: eseguita la microistruzione di fetch, etichettata con label Fetch, che di fatto corrisponde all esecuzione di una nuova istruzione MIPS - Dispatch i: l istruzione successiva viene scelta, sulla base degli ingressi (campo opcode di IR), entro la tabella di smistamento i. Ciascuna tabella contiene la corrispondenza ingresso (campo opcode) label della istruzione cui saltare Le label nel campo Label terminano con un numero i indicante la tabella di smistamento in cui sono contenute (vedi microprogramma). 67

68 Oltre al microprogramma, dobbiamo definire le tabelle di smistamento (forma simbolica) - sulla base di ciascun possibile valore di opcode, a quale istruzione si salta Con ciò la specifica è completa: - formato microistruzioni - associazione valori campi di controllo - segnali controllo a datapath - microprogramma - tabelle di smistamento Cfr. Ling. Macchina vs. Ling. Assembler 68
69 REALIZZAZIONE DELLA SPECIFICA CON MICROPROGRAMMA Dobbiamo decidere come realizzare: - funzione di sequenzializzazione (determina la sequenza di computazione) - funzione di controllo (determina le uscite di controllo Data Path) Esistono due modalità di realizzazione: - come macchina a stati finiti: Funzione di controllo = funzione di uscita [con PLA o ROM] Funzione di sequenzializzazione = funzione di stato futuro [con PLA o ROM] funzione stato futuro codifica esplicitamente lo stato NB: vedremo brevemente questa tecnica alla fine - Usando una ROM per memorizzare le microistruzioni (funzione di controllo) ed un contatore che fornisce in maniera sequenziale l indirizzo microistruzione (stato futuro): si elimina la codifica esplicita dello stato futuro all interno dell unità di controllo Controllo microprogrammato 69
70 Controllo Microprogrammato Durante l esecuzione di un programma applicativo i circuiti interpretano iterativamente il microprogramma sulle istruzioni del < programma applicativo i servizi OS>. clock Unità di Controllo Microprogramma (ROM o PLA) Contatore di microprogramma Logica selezione dell indirizzo P C Memoria indirizzo Programma applicativo Registro Istruzioni Istruzione [3-26] Unità di Os Servizi elaborazione 7
71 Logica di selezione dell indirizzo, sulla base del segnale di controllo proveniente da microistruzione corrente, sceglie l indirizzo successivo tra: - stato (indirizzo) incrementato - stato (di fetch) - stato determinato da tabelle di dispatch funzione di opcode Segnale di controllo AddrCtl a due bit (proveniente da microistruzione). PLA or ROM Adder State Mux 3 2 AddrCtl Dispatch ROM 2 Dispatch ROM Address select logic Op Instruction register opcode field 7
72 A questo punto possiamo associare i valori simbolici del campo Sequencing al segnale di controllo AddCtl: - Seq AddCtl = - Fetch AddCtl = - Dispatch AddCtl = - Dispatch 2 AddCtl = Abbiamo quindi la corrispondenza completa valori campi-segnali Fase successiva: corrisponde alla compilazione del Linguaggio Assembler in LM Microprogramma in forma simbolica Tabelle di smistamento (simboliche) Formato microistruzioni Associazione campi - segnali ASSEMBLATORE DI MICROCODICE Specifica - ROM di controllo - ROM di smistamento 72
73 ) Traduzione dei campi di ogni microistruzione nei segnali corrisponenti: da microprogramma + tabella di associazione campi-segnali 2) Assegnare indirizzi alle microistruzioni [mantenendo sequenzialità] Specifica ROM di controllo: ogni parola corrisponde a una microistruzione Mantenendo l ordine nel microprogramma (coincidente con codifica stati FSM): Bit 7-2: bit di controllo (NB: corrispondenti a ciascuno stato del diagramma) Bit -: bit di controllo indirizzo: associati a campo Sequencing della microistruzione 73
 NB: gli altri elementi delle ROM [ciascuna con 2 6 * 4 bit] sono vuote in questo caso [perché si sono considerate solo poche")
74 3) Specifica delle ROM di Smistamento da tabelle di smistamento simboliche + indirizzi assegnati alle istruzioni (Tabella label - indirizzo) NB: gli altri elementi delle ROM [ciascuna con 2 6 * 4 bit] sono vuote in questo caso [perché si sono considerate solo poche istruzioni] 74
75 Controllo microprogrammato (realizzato con sequenzializzatore): valutazione Specifica come macchina a stati finiti: abbiamo visto che, nel caso delle 2 ROM: 2 4 * * 4 = uscita stato futuro 6% 94% Istruzioni complesse (p.es. virgola mobile) sono caratterizzate da sequenze di stati indipendenti da ingressi (opcode); all aumentare del set di istruzioni disponibili, queste sequenze diventano via via più frequenti Inoltre, complessità e numerosità delle istruzioni porta ad aumento numero stati totali In una macchina a stati, la funzione di stato futuro deve comunque codificare tutte le transizioni stato-stato: anche per quelle indipendenti da ingressi lo stato destinazione deve essere esplicitamente codificato; in una tabella di verità, vi sarà una riga per ogni transizione [opcode don t care]. Nel controllo microprogrammato, la funzione di controllo ha solo due bit in più per decidere la modalità di selezione: transizioni sequenziali non codificano esplicitamente lo stato destinazione, ma solo che bisogna scegliere il seguente. Le ROM di smistamento memorizzano solo stati cui si arriva in dipendenza dall ingresso! Stati in sequenza non codificati, semplificando unità di controllo wrt. FSM VEDIAMO IN DETTAGLIO 75
76 Implementazione di controllo e smistamento tramite ROM: dimensioni ROM di controllo: microistruzioni 4 bit di indirizzo ciascuna parola (microistruzione) 6+2 = 8 bit Dimensione: 2 4 * 8 = 288 bit ROM di smistamento: indirizzate da Opcode 6 bit di indirizzo ciascuna parola ha 4 bit Dimensione: 2 6 * 4 = 256 bit Dimensione totale = *256 = 8 bit 76
77 Implementazione di controllo e smistamento tramite PLA: dimensioni PLA di controllo: funzione stato (4 bit) bit di controllo di indirizzo Avevamo visto che per 6 uscite si usano mintermini (tutti i stati); quindi i 2 bit di controllo di indirizzo useranno parte di questi mintermini Dimensione: = 4* + *8 = 22 PLA di smistamento : funzione bit di opcode (6 bit) 4 bit di indirizzo [stato] dalla specifica ROM di smistamento si vede che ci sono 5 combinazioni di opcode che interessano: 5 mintermini Dimensione: = 6*5 + 5*4 = 5 PLA di smistamento 2: funzione bit di opcode (6 bit) 4 bit di indirizzo [stato] da specifica ROM di smistamento 2 si vede che ci sono 2 combinazioni di opcode che interessano: 2 mintermini Dimensione: = 6*2 + 2*4 = 2 Dimensione totale = = 29 77
78 Confronto con implementazione a stato esplicito Tramite ROM: Controllo Stato futuro/ smistamento Totale Stato esplicito K Microprog Tramite PLA: Controllo Stato futuro/ smistamento Totale Stato esplicito Microprog Lieve aumento della dimensione per il controllo (dovuta all introduzione dei segnali AddrCt per la scelta della microistruzione successiva) compensato dalla diminuzione della dimensione per stato futuro 78
79 Ottimizzazioni della logica di controllo Favorite dall uso di strumenti CAD ma anche da opportune scelte di progettazione: Minimizzazione logica delle funzioni di controllo e smistamento: - sfruttamento dei termini don t care - individuazione di segnali di ingresso che identificano istruzioni [nell esempio lw e sw sono gli unici ad avere Op5=] semplificando ROM/PLA di smistamento: favorita da scelta progettuale che assegna codici operativi correlati ad istruzioni che condividono stessi stati (stesse microistruzioni) Assegnazione degli stati: stati (indirizzi delle microistruzioni) scelti in modo da semplificare equazioni che legano gli stati alle uscite di controllo [l assemblatore di microcodice può assegnare indirizzi in modo opportuno nel rispetto dei vincoli di sequenzialità delle microistruzioni] 79
80 Riduzione della memoria di controllo mediante tecniche di codifica: riduzione ampiezza delle microistruzioni: - Gruppi di linee nelle microistruzioni possono essere codificate in un minor numero di bit. Es. solo uno tra i 6 bit 3-8 della parola di controllo è attivo: codifica in 3 bit NB: tempo di decodifica di solito trascurabile, costo HW decoder compensato da riduzione costo memoria di controllo - uso di un campo formato delle microistruzioni (formati diversi per microistruzioni!) [fornisce valori di default per segnali di controllo non specificati] p. es. formato per microistruzioni di accesso in memoria e formato per operaz. ALU (specifica implicitamente no read/write memoria) 8
81 In generale: Microcodice orizzontale (minimamente codificato) VS. - più flessibile (può specificare qualunque combinazione di segnali) - aumenta costo dell HW (memoria di controllo più ampia) - favorisce buoni T clock e CPI [ma attenzione a memoria di controllo!] Microcodice verticale (massimamente codificato) - minor costo HW (costo decodificatori < riduzione costo memoria) - peggiori prestazioni (tempo di decodifica che può far aumentare T clock + riduzione combinazioni possibili di segnali nella stessa microistruzione che può richiedere un maggior CPI) 8
82 NB: ABBIAMO VISTO Processore multi-ciclo [Unità di controllo sequenziale] - specifica come FSM e implementazione come FSM - specifica come microprogramma e implementazione con sequenzializzatore Sono possibili anche gli altri due passaggi! specifica come microprogramma e implementazione come FSM Ogni microistruzione corrisponde ad uno stato: codifica (numerica) dello stato dai valori dei campi di controllo delle microistruzioni deriva la funzione: stato uscita [funzione di uscita] dal campo Sequencing di una microistruzione (stato) + tabelle smistamento simboliche [che codificano istruzione futura sulla base di ingressi opcode] deriva la funzione: stato*ingressi stato futuro [funzione di stato futuro] 82
83 specifica come FSM e implementazione con sequenzializzatore Ogni stato corrisponde ad una microistruzione: assegnazione di un ordine agli stati (conviene: transizioni tra stati indipendenti dall ingresso stati posti in sequenza!) dalla funzione di uscita derivano per ogni microistruzione i segnali di controllo da attivare dalla funzione di stato futuro si può stabilire se vi sia un unica transizione verso la microistruzione seguente, verso la microistruzione di fetch o se la transizione dipenda dall ingresso [tabella di smistamento], ovvero: campo Sequencing tabelle di smistamento NB: l uso di strumenti automatici per la realizzazione (in grado di applicare tecniche di ottimizzazione) rende le fasi di specifica e realizzazione relativamente indipendenti! Si può scegliere la specifica che risulta più semplice e gestibile 83
84 Controllo di un processore-multiciclo: Riepilogo specifica e realizzazione Initial representation Finite state diagram Microprogram Sequencing control Explicit next state function Microprogram counter + dispatch ROMS Logic representation Logic equations Truth tables Implementation technique Programmable logic array Read only memory 84
85 In un certo senso, si possono distinguere due tipologie di circuiti di controllo: Combinatori (reti combinatorie): per parte del processo di decodifica e di controllo (es. controllo della ALU), ma vedi anche controllo PIPELINE! - Specifica: Funzioni logiche Tabelle di verità - Realizzazione: PLA ROM Sequenziali: controllo ad alto livello, p.es. sequenzializzazione operazioni nel controllo multiciclo. - Specifica: diagramma a stati finiti (FSM) microprogramma - Realizzazione: Macchina a stati finiti (stato esplicito) Sequenzializzatore (controllo microprogrammato) (si può passare da una delle due tecniche di specifica ad una delle due tecniche di realizzazione) 85
86 Modalità di rappresentazione: scelte per ragioni di semplicità progettuale Realizzazione di stato futuro: sequenzializzatore più efficiente all aumentare del numero di stati e delle sequenze composte da stati consecutivi senza salti Implementazione della logica di controllo [parti combinatorie]: PLA sono più efficienti (vantaggio non sussiste se ROM è densa) ROM è soluzione più adeguata se funzione di controllo è in un chip diverso rispetto a unità di elaborazione (possibilità di cambiare microcodice indipendentemente dal resto del processore) NB: di fatto per ragioni di efficienza l unità di controllo è oggi sempre implementata nello stesso chip. Inoltre, con CAD difficoltà di progettazione PLA non sussiste più. NB2: CACHE ROM di microcodice non molto più veloce di RAM con LM: se microprogramma non è efficiente, sequenze di istruzioni macchina possono essere più efficienti di una corrispondente istruzione complessa! 86
87 Nota sulla realizzazione della logica di controllo: All aumentare della complessità e del costo, si usano nell ordine: - PLA e ROM - Field programmable Devices (PLD e FPGA) - Progettazione custom 87
88 Importanza della specifica Data una specifica, esistono strumenti di progettazione assistita che ne permettono la traduzione in circuiti. P.es. per il controllo multiciclo Descrizione tabellare dell automa o Testo del microprogramma CAD/ CAM Specifica (implementazione) circuitale dell unità di controllo (o circuito realizzato) 88
89 NB: le prestazioni sono influenzate da scelte progettuali a livelli diversi: - A livello di calcolatori : organizzazione delle componenti, parallelismo, ecc. [cfr. CPU singolo ciclo vs. multiciclo vs. pipeline] - A livello di reti logiche : ridurre il numero di livelli di porte logiche - A livello di elettronica digitale: attenzione al carico: evitare di pilotare grandi carichi con piccoli carichi famiglie logiche con prestazioni diverse - A livello di tecnologie microelettroniche: riduzione tempi di setup, hold, propagazione, ecc. e i livelli non sono completamente indipendenti 89
Il controllo specificato come microprogramma
 Il controllo specificato come microprogramma Nella pratica, set istruzioni più numeroso o istruzioni più complesse (cfr. Intel) drastico aumento del numero degli stati Impraticabile rappresentare gli stati
Il controllo specificato come microprogramma Nella pratica, set istruzioni più numeroso o istruzioni più complesse (cfr. Intel) drastico aumento del numero degli stati Impraticabile rappresentare gli stati
Calcolatori Elettronici
 Calcolatori Elettronici CPU multiciclo Massimiliano Giacomin SVANTAGGI DEL PROCESSORE A SINGOLO CICLO Tutte le istruzioni lunghe un ciclo di clock T clock determinato dall istruzione più lenta Istruzioni
Calcolatori Elettronici CPU multiciclo Massimiliano Giacomin SVANTAGGI DEL PROCESSORE A SINGOLO CICLO Tutte le istruzioni lunghe un ciclo di clock T clock determinato dall istruzione più lenta Istruzioni
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 28/29 CPU multiciclo Massimiliano Giacomin Esempi di processori che usano controllo a singolo ciclo: NESSUNO! Perché? Periodo di clock: abbastanza lungo per garantire la
Calcolatori Elettronici A a.a. 28/29 CPU multiciclo Massimiliano Giacomin Esempi di processori che usano controllo a singolo ciclo: NESSUNO! Perché? Periodo di clock: abbastanza lungo per garantire la
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche di Controllo Massimiliano Giacomin Schema del processore (e memoria) Durante l esecuzione di un programma applicativo Pa, i circuiti interpretano le istruzioni
Calcolatori Elettronici B a.a. 27/28 Tecniche di Controllo Massimiliano Giacomin Schema del processore (e memoria) Durante l esecuzione di un programma applicativo Pa, i circuiti interpretano le istruzioni
Lezione 29 Il processore: unità di controllo (2)
") Lezione 29 Il processore: unità di lo (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione 2 Un riepilogo: ruolo della unità di
Lezione 29 Il processore: unità di lo (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione 2 Un riepilogo: ruolo della unità di
Calcolatori Elettronici B a.a. 2004/2005
 Calcolatori Elettronici B a.a. 2004/2005 Tecniche di Controllo: Esercizi Massimiliano Giacomin Calcolo CPI e Prestazioni nei sistemi a singolo ciclo e multiciclo ) Calcolo prestazioni nei sistemi a singolo
Calcolatori Elettronici B a.a. 2004/2005 Tecniche di Controllo: Esercizi Massimiliano Giacomin Calcolo CPI e Prestazioni nei sistemi a singolo ciclo e multiciclo ) Calcolo prestazioni nei sistemi a singolo
CALCOLATORI ELETTRONICI 30 agosto 2010
 CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
L'architettura del processore MIPS
 L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
CALCOLATORI ELETTRONICI 27 giugno 2017
 CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 9 settembre 2011
 CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
Richiami sull architettura del processore MIPS a 32 bit
 Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
CALCOLATORI ELETTRONICI 29 giugno 2015
 CALCOLATORI ELETTRONICI 29 giugno 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Relativamente al confronto tra le implementazioni del processore
CALCOLATORI ELETTRONICI 29 giugno 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Relativamente al confronto tra le implementazioni del processore
Calcolatori Elettronici B a.a. 2006/2007
 Calcolatori Elettronici B a.a. 26/27 Tecniche di Controllo: Esercizi Massimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Calcolatori Elettronici B a.a. 26/27 Tecniche di Controllo: Esercizi Massimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Un quadro della situazione. Lezione 28 Il Processore: unità di controllo (2) Dove siamo nel corso. Organizzazione della lezione. Cosa abbiamo fatto
 Dove siamo nel corso. Organizzazione della lezione. Cosa abbiamo fatto") Un quadro della situazione Lezione 28 Il Processore: unità di lo (2) Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
Un quadro della situazione Lezione 28 Il Processore: unità di lo (2) Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Richiami sull architettura del processore MIPS a 32 bit
 Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
CALCOLATORI ELETTRONICI 27 marzo 2018
 CALCOLATORI ELETTRONICI 27 marzo 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 27 marzo 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 20 gennaio 2012
 CALCOLATORI ELETTRONICI 20 gennaio 2012 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita
CALCOLATORI ELETTRONICI 20 gennaio 2012 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita
L unità di controllo di CPU multi-ciclo. Sommario
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
Il processore: unità di elaborazione
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Calcolatori Elettronici
 Calcolatori Elettronici CPU multiciclo: esercizi Massimiliano Giacomin 1 Prima tipologia di esercizi: valutazione delle prestazioni 2 Specchio riassuntivo su prestazioni e CPI 0) In generale: T esecuzione
Calcolatori Elettronici CPU multiciclo: esercizi Massimiliano Giacomin 1 Prima tipologia di esercizi: valutazione delle prestazioni 2 Specchio riassuntivo su prestazioni e CPI 0) In generale: T esecuzione
Calcolatori Elettronici B a.a. 2004/2005
 Calcolatori Elettronici B a.a. 2004/2005 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Unità funzionali Unità funzionali: Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in
Calcolatori Elettronici B a.a. 2004/2005 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Unità funzionali Unità funzionali: Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in
L unità di controllo di CPU multi-ciclo
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione D3
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione D3
Controllo con macchina a stati finiti
 Controllo con macchina a stati finiti Durante l esecuzione di un programma applicativo i circuiti interpretano le istruzioni: del programma costituito dal< programma applicativo i servizi OS> Logica di
Controllo con macchina a stati finiti Durante l esecuzione di un programma applicativo i circuiti interpretano le istruzioni: del programma costituito dal< programma applicativo i servizi OS> Logica di
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
Progettazione dell unità di elaborazioni dati e prestazioni. Il processore: unità di elaborazione. I passi per progettare un processore
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
CPU a ciclo multiplo: l unità di controllo
 Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Università degli Studi di Cassino
 Corso di Data path multiciclo Anno Accademico 2007/2008 Francesco Tortorella Problemi dell implementazione singolo ciclo Arithmetic & Logical PC Inst Memory Reg File mux ALU mux setup Load PC Inst Memory
Corso di Data path multiciclo Anno Accademico 2007/2008 Francesco Tortorella Problemi dell implementazione singolo ciclo Arithmetic & Logical PC Inst Memory Reg File mux ALU mux setup Load PC Inst Memory
Una CPU multi-ciclo. Sommario
 Una CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/3 http:\\homes.dsi.unimi.it\ borghese Sommario I problemi della
Una CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano 1/3 http:\\homes.dsi.unimi.it\ borghese Sommario I problemi della
Il processore: unità di controllo
 Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune
Il processore: unità di lo Architetture dei Calcolatori (lettere A-I) L unità di lo L unità di lo è responsabile della generazione dei segnali di lo che vengono inviati all unità di elaborazione Alcune
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Architettura degli elaboratori - II Le architetture multi-ciclo
 Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori
Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti
 Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Calcolatori Elettronici B a.a. 2005/2006
 Calcolatori Elettronici B a.a. 25/26 Tecniche di Controllo: Esercizi assimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Calcolatori Elettronici B a.a. 25/26 Tecniche di Controllo: Esercizi assimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Le etichette nei programmi. Istruzioni di branch: beq. Istruzioni di branch: bne. Istruzioni di jump: j
 L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
Esercitazione del 05/05/ Soluzioni
 Esercitazione del 05/05/2005 - Soluzioni Una CPU a ciclo singolo richiede un ciclo di clock di durata sufficiente a permettere la stabilizzazione del circuito nel caso dell istruzione più complicata (con
Esercitazione del 05/05/2005 - Soluzioni Una CPU a ciclo singolo richiede un ciclo di clock di durata sufficiente a permettere la stabilizzazione del circuito nel caso dell istruzione più complicata (con
Architettura degli Elaboratori
 Progetto CPU (multiciclo) slide a cura di Salvatore Orlando e Marta Simeoni Problemi con progetto a singolo ciclo Problemi del singolo ciclo! Ciclo di clock lungo! Istruzioni potenzialmente più veloci
Progetto CPU (multiciclo) slide a cura di Salvatore Orlando e Marta Simeoni Problemi con progetto a singolo ciclo Problemi del singolo ciclo! Ciclo di clock lungo! Istruzioni potenzialmente più veloci
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 2008/2009 LIVELLO ORGANIZZAZIONE: SCHEMI DI BASE Massimiliano Giacomin 1 DUE ASPETTI Progettare circuiti per permettano di: 1. Trasferire l informazione da un punto a un
Calcolatori Elettronici A a.a. 2008/2009 LIVELLO ORGANIZZAZIONE: SCHEMI DI BASE Massimiliano Giacomin 1 DUE ASPETTI Progettare circuiti per permettano di: 1. Trasferire l informazione da un punto a un
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Il Processore: l Unità di Controllo Principale Barbara Masucci
 Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
Esercitazione del 04/05/2006 Soluzioni
 Esercitazione del 04/05/2006 Soluzioni 1. CPU singolo ciclo vs CPU multi ciclo. Una CPU a ciclo singolo richiede un ciclo di clock di durata sufficiente a permettere la stabilizzazione del circuito nel
Esercitazione del 04/05/2006 Soluzioni 1. CPU singolo ciclo vs CPU multi ciclo. Una CPU a ciclo singolo richiede un ciclo di clock di durata sufficiente a permettere la stabilizzazione del circuito nel
Architettura degli elaboratori CPU a ciclo singolo
 Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
CPU pipeline hazards
 Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Implementazione semplificata
 Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Realizzazione a cicli di clock multipli
 Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
CALCOLATORI ELETTRONICI 15 aprile 2014
 CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 15 aprile 2014 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
Sia per la II prova intercorso che per le prove di esame è necessaria la PRENOTAZIONE
 Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
Calcolatori Elettronici
 Calcolatori Elettronici LIVELLO ORGANIZZAZIONE: SCHEMI DI BASE ALU e REGISTER FILE Massimiliano Giacomin 1 DOVE CI TROVIAMO LIVELLO SIST. OP. Application Binary Interface (ABI) ISA Instruction Set Architecture
Calcolatori Elettronici LIVELLO ORGANIZZAZIONE: SCHEMI DI BASE ALU e REGISTER FILE Massimiliano Giacomin 1 DOVE CI TROVIAMO LIVELLO SIST. OP. Application Binary Interface (ABI) ISA Instruction Set Architecture
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura dei calcolatori e sistemi operativi. Il processore Capitolo 4 P&H
 Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
Architettura del calcolatore (Seconda parte)
") Architettura del calcolatore (Seconda parte) Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin LINGUAGGIO E ORGANIZZAZIONE DEL CALCOLATORE Linguaggio assembly
Architettura del calcolatore (Seconda parte) Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin LINGUAGGIO E ORGANIZZAZIONE DEL CALCOLATORE Linguaggio assembly
Università degli Studi di Cassino
 Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Progetto CPU (ciclo singolo) Salvatore Orlando
 Salvatore Orlando") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
Università degli Studi di Cassino e del Lazio Meridionale
 Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
Un altro tipo di indirizzamento. L insieme delle istruzioni (3) Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando
 Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando") Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Lezione 20. della CPU MIPS. Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano
 Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Lezione 20. della CPU MIPS. Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano
 Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Un quadro della situazione. Cosa abbiamo fatto. Lezione 30 Valutazione delle Prestazioni. Dove stiamo andando.. Perché:
 Un quadro della situazione Lezione 3 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
Un quadro della situazione Lezione 3 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
Architettura degli Elaboratori B Introduzione al corso
 Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
Arch. Elab. - S. Orlando 2. unità funzionali possono essere usate più volte per eseguire la stessa
 Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Esempio di riduzione del ciclo di clock Effettua un taglio su grafo delle dipendenze corrispondente al circuito combinatorio, e inserisci
Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Esempio di riduzione del ciclo di clock Effettua un taglio su grafo delle dipendenze corrispondente al circuito combinatorio, e inserisci
Architettura degli elaboratori Tema d esame del 8/2/2016
 Architettura degli elaboratori - Esame del 8 febbraio 6 A.A. -6 Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori Tema d esame del 8//6 Luigi
Architettura degli elaboratori - Esame del 8 febbraio 6 A.A. -6 Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori Tema d esame del 8//6 Luigi
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS)
") Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Processore: Datapath & Control. Progetto CPU (ciclo singolo) Rivediamo i formati delle istruzioni. ISA di un MIPS-lite
 Rivediamo i formati delle istruzioni. ISA di un MIPS-lite") Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Architettura degli elaboratori - CPU multiciclo A.A. 2016/17. Architettura degli elaboratori
 Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori Marco Tarini Dipartimento di Scienze Teoriche e Applicate marco.tarini@uninsubria.it Progetto
Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori Marco Tarini Dipartimento di Scienze Teoriche e Applicate marco.tarini@uninsubria.it Progetto
L architettura del calcolatore (Seconda parte)
") L architettura del calcolatore (Seconda parte) Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin ORGANIZZAZIONE DEL CALCOLATORE: RICHIAMI
L architettura del calcolatore (Seconda parte) Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin ORGANIZZAZIONE DEL CALCOLATORE: RICHIAMI
Istruzioni e linguaggio macchina
 Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
Problemi con progetto a singolo ciclo. Progetto CPU (multiciclo) Esempio di riduzione del ciclo di clock. Datapath multiciclo
 Esempio di riduzione del ciclo di clock. Datapath multiciclo") Problemi con progetto a singolo ciclo Progetto CPU (multiciclo) Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate impiegano lo stesso tempo dell istruzione
Problemi con progetto a singolo ciclo Progetto CPU (multiciclo) Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate impiegano lo stesso tempo dell istruzione
Progetto CPU (multiciclo) Salvatore Orlando
 Salvatore Orlando") Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Problemi con progetto a singolo ciclo Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate
Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Problemi con progetto a singolo ciclo Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate
Università degli Studi di Cassino
 Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
slt $t1,$t2,$t3 if ($t2<$t3) $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante
 $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante") Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Progetto CPU (multiciclo)
") Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Problemi con progetto a singolo ciclo Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate
Progetto CPU (multiciclo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Problemi con progetto a singolo ciclo Problemi del singolo ciclo Ciclo di clock lungo Istruzioni potenzialmente più veloci sono rallentate
CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Argomenti della lezione - Esercizi sulla CPU MIPS a 1 colpo di clock
Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Argomenti della lezione - Esercizi sulla CPU MIPS a 1 colpo di clock
Elementi base per la realizzazione dell unità di calcolo
 Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Architettura degli elaboratori MZ Compito A
 Architettura degli elaboratori MZ 16-4-18 Compito A Cognome e Nome: Matricola: Esercizio 1A. Considerate l architettura MIPS a ciclo singolo in Figura (sul retro). Qual è il valore dei segnali che partono
Architettura degli elaboratori MZ 16-4-18 Compito A Cognome e Nome: Matricola: Esercizio 1A. Considerate l architettura MIPS a ciclo singolo in Figura (sul retro). Qual è il valore dei segnali che partono
Corso di Calcolatori Elettronici MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M.
 di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
Architettura degli Elaboratori e Laboratorio. Matteo Manzali Università degli Studi di Ferrara Anno Accademico
 Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Componenti visti Nelle scorse lezioni abbiamo visto come sono realizzati i seguenti
Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Componenti visti Nelle scorse lezioni abbiamo visto come sono realizzati i seguenti
CALCOLATORI ELETTRONICI 29 giugno 2010
 CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
CALCOLATORI ELETTRONICI 29 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita e
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
Circuiti Sequenziali
 Circuiti Sequenziali I circuiti combinatori sono in grado di calcolare funzioni che dipendono solo dai dati in input I circuiti sequenziali sono invece in grado di calcolare funzioni che dipendono anche
Circuiti Sequenziali I circuiti combinatori sono in grado di calcolare funzioni che dipendono solo dai dati in input I circuiti sequenziali sono invece in grado di calcolare funzioni che dipendono anche
Il linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
CALCOLATORI ELETTRONICI 25 giugno 2018
 CALCOLATORI ELETTRONICI 25 giugno 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche OR, AND, NOT la funzione combinatoria (a 3 ingressi
CALCOLATORI ELETTRONICI 25 giugno 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche OR, AND, NOT la funzione combinatoria (a 3 ingressi
CALCOLATORI ELETTRONICI 29 giugno 2011
 CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
CALCOLATORI ELETTRONICI 29 giugno 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di una PLA la funzione combinatoria (a 3 ingressi e due uscite)
Architettura degli Elaboratori B. Introduzione al corso. Componenti di un calcolatore convenzionale. (ciclo singolo) Progetto CPU. Contenuti del corso
 Progetto CPU. Contenuti del corso") Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Linguaggio Assembly e linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 11 Linguaggio Assembly e linguaggio macchina Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Esercitazione 11. Control-Unit. Data-Path
 Esercitazione 11 Sommario Unità di controllo cablate 1. Unità di controllo L architettura interna di una CPU può essere modellata attraverso una struttura costituita da 2 unità interagenti: percorso dati
Esercitazione 11 Sommario Unità di controllo cablate 1. Unità di controllo L architettura interna di una CPU può essere modellata attraverso una struttura costituita da 2 unità interagenti: percorso dati