INTRODUZIONE AL LIVELLO FISICO: FILE, PAGINE, RECORD E INDICI
|
|
|
- Andrea Mele
- 6 anni fa
- Visualizzazioni
Transcript
1 INTRODUZIONE AL LIVELLO FISICO: FILE, PAGINE, RECORD E INDICI Roberto Basili Corso di Basi di Dati a.a. 2013/14
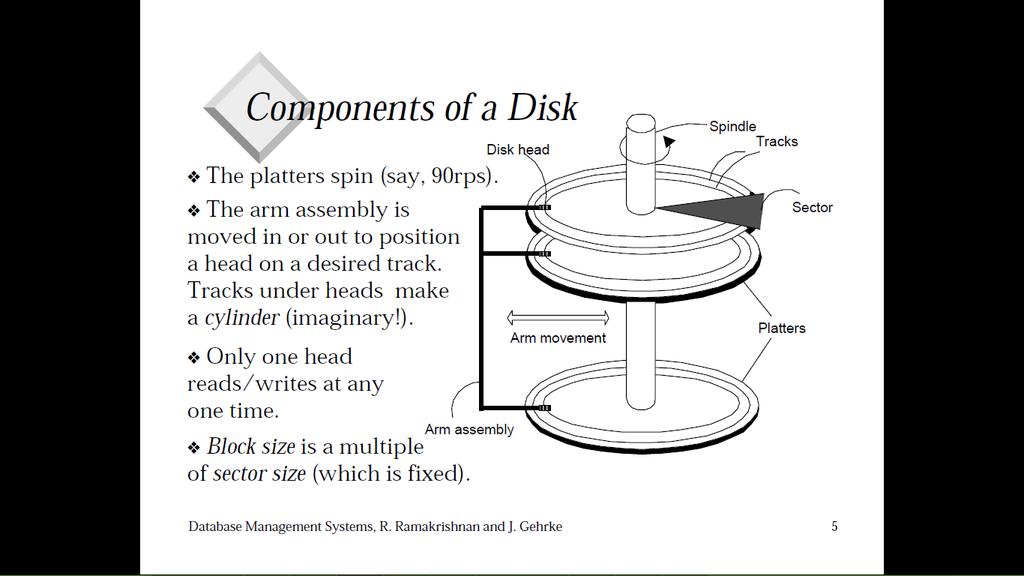
2 Dati su dispositivi di memorizzazione esterni Dischi: si può leggere qualunque pagina a costo fisso Nastri: si possono leggere le pagine solo in sequenza Organizzazione del file: metodo per registrare un file di record su un dispositivo di memorizzazione esterno Architettura: il gestore di buffer carica le pagine dal dispositivo di memorizzazione esterno al buffer nella memoria principale. Lo strato di gestione dei file e quello degli indici eseguono le chiamate al gestore di buffer

3
4

5
6

7

8

9

10

11
12
13

14
15
16
17

18
19

20
21

22

23

24
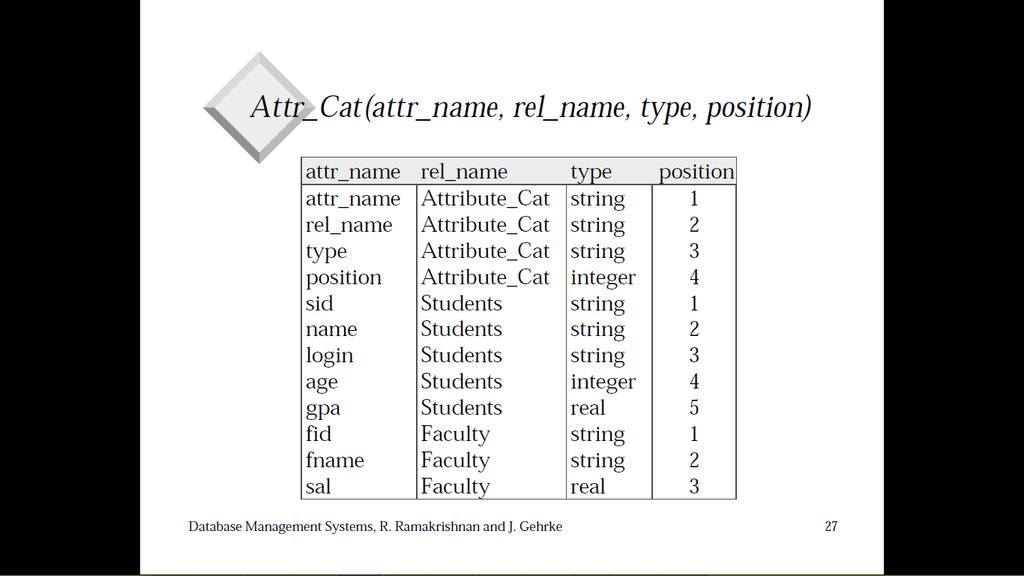
25
26 Organizzazioni alternative dei file Esistono molte alternative, ciascuna ideale per qualche situazione e non molto buona in altre : file heap (ordine casuale): va bene quando l accesso tipico è una scansione di file per leggere tutti i record file ordinato: ottimale quando i record devono essere letti in qualche ordine, o quando si ha bisogno solo di un intervallo di record indici: strutture di dati per organizzare i record in alberi o tramite hashing come i file ordinati, essi velocizzano le ricerche di sottoinsiemi di record, basate su valori in certi campi ( chiavi di ricerca ) gli aggiornamenti sono molto più veloci che nei file ordinati
27 Indici Un indice su un file velocizza le selezioni sui campi che compongono la chiave di ricerca per l indice Qualunque sottoinsieme dei campi di una relazione può essere la chiave di ricerca per un indice sulla relazione La chiave di ricerca non è la chiave (insieme minimo di campi che identificano univocamente un record in una relazione) Un indice contiene una collezione di data entry, e supporta il reperimento efficiente di tutte le data entry k* con un dato valore k della chiave Avendo la data entry k* possiamo trovare i record con chiave k in al più un I/O di disco (fra poco i dettagli...)
28 Indici ad albero B+ Pagine Non-foglia Pagine foglia (ordinate sulla chiave di ricerca) Le pagine foglia contengono data entry, e sono collegate (prec & succ) Le altre pagine contengono index entry, usate solo per guidare le ricerche Entry dell indice P 0 K 1 P 1 K 2 P 2 K m P m
29 Esempio di albero B+ Radice 17 Notate l ordinamento delle data entry nel livello delle foglie Entry <= 17 Entry > * 3* 5* 7* 8* 14* 16* 22* 24* 27* 29* 33* 34* 38* 39* Trovare 28*? 29*? Tutte >15* e <30* Inserimento/cancellazione: trovare la data entry nella foglia, poi cambiarla. A volte bisogna aggiustare i nodi genitori E qualche volta la modifica si propaga a tutto l albero
30 Indici basati su hash Buoni per selezioni basate su uguaglianze L indice è una collezione di bucket Bucket = pagina primaria più zero o più pagine addizionali I bucket contengono le data entry Funzione hash h: h(r) = bucket cui appartiene (la data entry per) il record r. h si applica ai campi della chiave di ricerca di r In questo schema non c è bisogno di index entry
31 Alternative per le data entry k* nell indice In una data entry k* possiamo memorizzare: record di dati con valore di chiave K, oppure <k, rid dei record di dati con valore della chiave di ricerca k>, oppure <k, lista dei rid dei record di dati con chiave di ricerca k> la scelta dell alternativa per le data entry è ortogonale alla tecnica di indicizzazione usata per localizzare le data entry con un dato valore di chiave K esempi di tecnica di indicizzazione: alberi B+, strutture basate su hash tipicamente, l indice contiene informazioni aggiuntive che guidano le ricerche verso le data entry desiderate
32 Alternative per le data entry (segue) Alternativa 1: se si usa questa alternativa, la struttura a indice è una organizzazione di file per i record di dati (piuttosto che un file heap o un file ordinato) al più un indice su una data collezione di record di dati può usare l Alternativa 1 (altrimenti, i record di dati sono duplicati, il che porta a memorizzazione ridondante e potenziale inconsistenza) se i record di dati sono molto grandi, il numero di pagine contenente le data entry è alto. Tipicamente, ciò implica che la dimensione delle informazioni aggiuntive nell indice è anch essa molto grande
33 Alternative per le data entry (segue) Alternative 2 e 3: Le data entry tipicamente sono molto più piccole dei record di dati. Quindi, meglio dell Alternativa 1 con record di dati grandi, specialmente se le chiavi di ricerca sono piccole (la porzione della struttura ad indice usata per dirigere la ricerca, che dipende dalla dimensione delle data entry, è molto più piccola rispetto all Alternativa 1) L alternativa 3 è più compatta dell Alternativa 2, ma porta a data entry di dimensioni variabili; anche se le chiavi di ricerca sono di lunghezza fissa
34 Classificazione degli indici Primario o secondario: se la chiave di ricerca contiene la chiave primaria, allora è chiamato indice primario Indice univoco: la chiave di ricerca contiene una chiave candidata Clustered e non clustered: se l ordine dei record di dati è lo stesso, o quasi, delle data entry, allora è chiamato indice clustered L Alternativa 1 implica un indice clustered; nella pratica, anche gli indici clustered implicano l Alternativa 1 (poiché i file ordinati sono rari) Un file può essere clustered su al più una chiave di ricerca Il costo della lettura dei record di dati usando l indice varia fortemente in base al fatto che l indice sia clustered oppure no!
35 Indici clustered e non clustered Supponiamo che venga usata l Alternativa 2 per le data entry, e che i record di dati siano memorizzati in un file heap Per costruire un indice clustered, prima ordiniamo il file heap (con dello spazio libero su ciascuna pagina per gli inserimenti futuri) Potrebbero essere necessarie delle pagine aggiuntive per gli inserimenti (quindi, l ordine dei record di dati è quasi uguale, ma non identico, a quello delle data entry) A cluster Entry dell indice Ricerca diretta delle data entry Non a cluster Data entry Data entry (File indice) (File dati) Record di dati Record di dati
36 Modello di costo per la nostra analisi Tralasciamo i costi della CPU, per semplicità: B: il numero di pagine di dati R: il numero di record per pagina D: tempo (medio) per leggere o scrivere una pagina su disco La misura del numero di I/O di pagina tralascia il guadagno dovuto al precaricamento di una sequenza di pagine; quindi, anche il costo di I/O è solo approssimato Analisi del caso medio; basata su diverse assunzioni semplificatrici Abbastanza buona per mostrare la tendenza generale!
37 Confronto tra le organizzazioni di file File heap (ordine casuale; inserimento alla fine del file) File ordinati su <età, sal> File clustered ad albero B+, Alternativa (1), chiave di ricerca <età, sal> File heap con indice hash non clustered su chiave di ricerca <età, sal>
38 Operazioni da confrontare Scansione: lettura di tutti i record dal disco Ricerca con selezione di uguaglianza Ricerca con selezione di intervallo Inserimento di un record Cancellazione di un record
39 Ipotesi nella nostra analisi File heap: selezione di uguaglianza sulla chiave; un solo risultato File ordinati: file compattati dopo le cancellazioni Indici: Alternative (2), (3): dimensione delle data entry = 10% della dimensione dei record Hash: niente bucket aggiuntivi 80% di occupazione delle pagine => dimensione del file = 1.25 volte la dimensione dei dati Albero: 67% di occupazione (valore tipico) Implica una dimensione di file = 1.5 volte la dimensione dei dati
40 Ipotesi (segue) Scansioni: i livelli foglia di un indice ad albero sono collegati le data entry dell indice più il file vero e proprio vengono scansionati per indici non clustered Ricerche con selezione di intervallo: usiamo gli indici ad albero per restringere l insieme di record di dati restituito, ma tralasciamo gli indici hash
41 Costo delle operazioni (1) Heap (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inserimento (e) Cancellazio ne (2) Ordinato (3) Clustered (4) Indice ad albero non clustered (5) Indice hash non clustered Diverse ipotesi alla base di queste (grossolane) stime!
42 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D Diverse ipotesi alla base di queste (grossolane) stime!
43 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D (2) Ordinato BD Dlog 2B D(log 2 B + Numero di pagine con record compatibili) Ricerca + BD Ricerca +BD Diverse ipotesi alla base di queste (grossolane) stime!
44 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D (2) Ordinato BD Dlog 2B D(log 2 B + Numero di pagine con record compatibili) Ricerca + BD Ricerca +BD (3) Clustered 1.5BD Dlog F 1.5B D(log F 1.5B + Numero di pagine con record compatibili) Ricerca + D Ricerca +D Diverse ipotesi alla base di queste (grossolane) stime!
45 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D (2) Ordinato BD Dlog 2B D(log 2 B + Numero di pagine con record compatibili) Ricerca + BD Ricerca +BD (3) Clustered 1.5BD Dlog F 1.5B D(log F 1.5B + Numero di pagine con record compatibili) (4) Indice ad albero non clustered BD(R+0.15) D(1 + log F 0.15B) D(log F 0.15B + Numero di pagine con record compatibili) Ricerca + D Ricerca + 2D Ricerca +D Ricerca + 2D Diverse ipotesi alla base di queste (grossolane) stime!
46 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D (2) Ordinato BD Dlog 2B D(log 2 B + Numero di pagine con record compatibili) Ricerca + BD Ricerca +BD (3) Clustered 1.5BD Dlog F 1.5B D(log F 1.5B + Numero di pagine con record compatibili) (4) Indice ad albero non clustered (5) Indice hash non clustered BD(R+0.15) D(1 + log F 0.15B) D(log F 0.15B + Numero di pagine con record compatibili) Ricerca + D Ricerca + 2D BD(R+0.125) 2D BD Ricerca + 2D Ricerca +D Ricerca + 2D Ricerca + 2D Diverse ipotesi alla base di queste (grossolane) stime!
47 Costo delle operazioni (a) Scansione (b) Uguaglianza (c ) Intervallo (d) Inseriment o (e) Cancellazio ne (1) Heap BD 0.5BD BD 2D Ricerca +D (2) Ordinato BD Dlog 2B D(log 2 B + Numero di pagine con record compatibili) Ricerca + BD Ricerca +BD (3) Clustered 1.5BD Dlog F 1.5B D(log F 1.5B + Numero di pagine con record compatibili) (4) Indice ad albero non clustered (5) Indice hash non clustered BD(R+0.15) D(1 + log F 0.15B) D(log F 0.15B + Numero di pagine con record compatibili) Ricerca + D Ricerca + 2D BD(R+0.125) 2D BD Ricerca + 2D Ricerca +D Ricerca + 2D Ricerca + 2D Diverse ipotesi alla base di queste (grossolane) stime!
48 Comprendere il carico di lavoro Per ciascuna interrogazione nel carico di lavoro: A quali relazioni accede? Quali attributi vengono restituiti? Quali attributi sono coinvolti nelle condizioni di selezione/join? Quanto selettive sono, probabilmente, tali condizioni? Per ciascun aggiornamento nel carico di lavoro: Quali attributi sono coinvolti nelle condizioni di selezione/join? Quanto selettive sono, probabilmente, tali condizioni? Il tipo di aggiornamento (INSERT, DELETE, UPDATE) e gli attributi che vengono modificati
49 Scelta degli indici Quali indici dovremmo creare? Quali relazioni dovrebbero avere indici? Quali campi dovrebbero costituire la chiave di ricerca? Dovremmo creare più di un indice? Per ciascun indice, che tipo di indice dovremmo usare? Clustered? Hash/albero?
50 Scelta degli indici (segue) Un approccio: consideriamo a turno le interrogazioni più importanti. Consideriamo il miglior piano usando gli indici correnti, e vediamo se è possibile un piano migliore con un indice aggiuntivo. Se sì, creiamolo. Ovviamente, ciò implica la comprensione di come un DBMS valuta le interrogazioni e crea i piani di valutazione delle interrogazioni! Per ora discutiamo semplici interrogazioni di una tabella
51 Scelta degli indici (segue) Prima di creare un indice, dobbiamo anche considerare l impatto sugli aggiornamenti nel carico di lavoro! Compromesso: gli indici possono velocizzare le interrogazioni, rallentare gli aggiornamenti. Anche richiedere spazio su disco
52 Linee guida per la selezione degli indici Gli attributi nella clausola WHERE sono candidati come chiavi dell indice Chiavi di ricerca multi-attributo dovrebbero essere prese in considerazione quando una clausola WHERE contiene diverse condizioni Provare a scegliere gli indici che supportano quante più interrogazioni possibile. Poiché solo un indice per ogni relazione può essere clustered, sceglierlo in base alle interrogazioni importanti che più traggono beneficio dal clustering
53 Esempi di indici clustered Un indice ad albero B+ su I.età può essere usato per selezionare le tuple Quanto è selettiva la condizione? L indice è clustered? Consideriamo l interrogazione con GROUP BY Se molte tuple hanno I.età > 10, usare l indice su I.età e ordinare le tuple restituite può essere costoso L indice clustered I.rnum può essere migliore! Interrogazioni con selezione di uguaglianza e duplicati Il clustering su I.hobby aiuta! SELECT I.rnum FROM Imp I WHERE I.età > 40 SELECT I.rnum, COUNT(*) FROM Imp I WHERE I.età > 10 GROUP BY I.rnum SELECT I.rnum FROM Imp I WHERE I.hobby= Francobolli
54 Indici con chiavi di ricerca composite Chiavi di ricerca composite: ricerca su una combinazione di campi Interrogazioni con selezione di uguaglianza: il valore di ogni campo è uguale a un valore costante. Ad esempio, con riferimento all indice <sal, età>: età = 20 and sal = 75 Interrogazioni con selezione di intervallo: il valore di alcuni campi non è una costante. Ad esempio: età = 20 and sal > 10 le data entry nell indice sono ordinate per chiave di ricerca per supportare le interrogazioni con selezione di intervallo ordine lessicografico, oppure ordine spaziale Esempi di indice con chiave composita che usa l ordine lessicografico 11,80 12,10 12,20 13,75 <età, sal> 10,12 20,12 75,13 80,11 <sal, età> Data entry nell indice ordinate per <sal, età> nome età sal bob cal joe sue Record di dati ordinati per nome <età> <sal> Data entry ordinate per <sal>
55 Chiavi di ricerca composite Per trovare i record di Imp con età = 30 AND sal = 4000, un indice su <età, sal> sarebbe meglio di un indice su età o di un indice su sal La scelta della chiave dell indice è ortogonale al clustering etc. Se la condizione è 20 < età < 30 AND 3000 < sal < 5000 È meglio un indice clustered ad albero su <età, sal> o su <sal, età> Se la condizione è età = 30 AND 3000 < sal < 5000 Un indice clustered <età, sal> è molto meglio di un indice su <sal, età> Gli indici compositi sono più grandi, e aggiornati più spesso
56 Piani basati solo sull indice Se è disponibile un indice opportuno, a molte interrogazioni si può rispondere senza leggere alcuna tupla da alcuna delle relazioni coinvolte <I.rnum> <I.rnum, I.sal> Indice ad albero! SELECT I.rnum, COUNT(*) FROM Imp I GROUP BY I.rnum SELECT I.rnum, MIN(I.sal) FROM Imp I GROUP BY I.rnum <I.età, I.sal> oppure <I.sal, I.età> Indice ad albero! SELECT AVG(I.sal) FROM Imp I WHERE I.età = 25 AND E.sal BETWEEN 3000 AND 5000
57 Piani basati solo sull indice (segue) Piani basati solo sull indice sono possibili se la chiave è <rnum, età> o se abbiamo un indice ad albero con chiave <età, rnum> SELECT I.rnum, COUNT(*) FROM Imp I WHERE I.età = 30 Quale è migliore? GROUP BY I.rnum Che succede se consideriamo la seconda interrogazione? SELECT I.rnum, COUNT(*) FROM Imp I WHERE I.età > 30 GROUP BY I.rnum
58 Piani basati solo sull indice (segue) Si possono trovare piani basati solo sull indice anche per interrogazione che coinvolgono più di una tabella: ne parleremo più avanti <I.rnum> SELECT R.mgr FROM Rep R, Imp I WHERE R.rnum = I.rnum <I.rnum, I.iid> SELECT R.mgr, I.iid FROM Rep R, Imp I WHERE R.rnum = I.rnum
59 Sommario Esistono molte organizzazioni di file alternative, ciascuna appropriata in certe situazioni Se le interrogazioni con selezione di intervallo sono frequenti, l ordinamento del file o la costruzione di un indice sono importanti Indici basati su hash sono buoni solo per ricerche con selezione di uguaglianza File ordinati e indici basati su alberi sono migliori per ricerche con selezione di intervallo; buoni anche per ricerche con selezione di uguaglianza (nella pratica i file sono raramente mantenuti ordinati: è meglio un indice ad albero B+) Un indice è una collezione di data entry più un modo per trovare rapidamente le data entry quando vengono dati dei valori per la chiave.
60 Sommario (segue) Le data entry possono in realtà essere record di dati, coppie <chiave, rid> oppure coppie <chiave, lista-di-rid> La scelta è ortogonale alla tecnica di indicizzazione usata per localizzare le data entry con un dato valore per la chiave Si possono avere diversi indici su un dato file di record di dati, ciascuno con una diversa chiave di ricerca Gli indici possono essere classificati in clustered e non clustered, primari e secondari, densi o sparsi. Le differenze hanno conseguenze importanti sull utilità e sulle prestazioni
61 Sommario (segue) Capire la natura del carico di lavoro per l applicazione, e gli obiettivi prestazionali, è essenziale per sviluppare un buon progetto Quali sono le interrogazioni e gli aggiornamenti importanti? Quali attributi/relazioni sono coinvolti?
62 Sommario (segue) Gli indici devono essere scelti per velocizzare le interrogazioni importanti (e magari qualche aggiornamento!) Il mantenimento degli indici incide sugli aggiornamenti dei campi chiave Scegliete indici che possono aiutare molte interrogazioni, se possibile Costruite indici per supportare strategie basate solo sull indice L uso del clustering è una decisione importate; soltanto un indice per ogni relazione può essere clustered! L ordine dei campi nella chiave di un indice composito può essere importante
File e Indici. T. Catarci, M. Scannapieco, Corso di Basi di Dati, A.A. 2008/2009, Sapienza Università di Roma
 File e Indici 1 File Dati di un DBMS memorizzati come record Un file è una collezione di record Organizzazione del file: metodo per registrare un file su un dispositivo di memorizzazione esterno Un record
File e Indici 1 File Dati di un DBMS memorizzati come record Un file è una collezione di record Organizzazione del file: metodo per registrare un file su un dispositivo di memorizzazione esterno Un record
FILE E INDICI Architettura DBMS
 FILE E INDICI Architettura DBMS Giorgio Giacinto 2010 Database 2 Dati su dispositivi di memorizzazione esterni! Dischi! si può leggere qualunque pagina a costo medio fisso! Nastri! si possono leggere le
FILE E INDICI Architettura DBMS Giorgio Giacinto 2010 Database 2 Dati su dispositivi di memorizzazione esterni! Dischi! si può leggere qualunque pagina a costo medio fisso! Nastri! si possono leggere le
PROGETTAZIONE FISICA
 PROGETTAZIONE FISICA IL CATALOGO DI SISTEMA Le tabelle di catalogo! Un DBMS memorizza su tabelle di catalogo le informazioni su! ciascuna tabella! nome della tabella e struttura del file! nome e tipo di
PROGETTAZIONE FISICA IL CATALOGO DI SISTEMA Le tabelle di catalogo! Un DBMS memorizza su tabelle di catalogo le informazioni su! ciascuna tabella! nome della tabella e struttura del file! nome e tipo di
Strutture fisiche e strutture di accesso ai dati
 Strutture fisiche e strutture di accesso ai dati 1 A L B E R T O B E L U S S I P R I M A P A R T E A N N O A C C A D E M I C O 2 0 1 2-2 0 1 3 Gestore dei metodi di accesso 2 E il modulo del DBMS che esegue
Strutture fisiche e strutture di accesso ai dati 1 A L B E R T O B E L U S S I P R I M A P A R T E A N N O A C C A D E M I C O 2 0 1 2-2 0 1 3 Gestore dei metodi di accesso 2 E il modulo del DBMS che esegue
Memorizzazione di una relazione
 Heap file File ordinati Indici o Hash o B+-tree Costo delle operazioni algebriche Simboli: NP: numero di pagine NR: numero record LP: lunghezza pagina LR: lunghezza record Memorizzazione di una relazione
Heap file File ordinati Indici o Hash o B+-tree Costo delle operazioni algebriche Simboli: NP: numero di pagine NR: numero record LP: lunghezza pagina LR: lunghezza record Memorizzazione di una relazione
Organizzazione Fisica dei Dati (Parte II)
") Modello Fisico dei Dati Basi di Dati / Complementi di Basi di Dati 1 Organizzazione Fisica dei Dati (Parte II) Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Modello Fisico
Modello Fisico dei Dati Basi di Dati / Complementi di Basi di Dati 1 Organizzazione Fisica dei Dati (Parte II) Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Modello Fisico
INDICI PER FILE. Accesso secondario. Strutture ausiliarie di accesso
 INDICI PER FILE Strutture ausiliarie di accesso 2 Accesso secondario Diamo per scontato che esista già un file con una certa organizzazione primaria con dati non ordinati, ordinati o organizzati secondo
INDICI PER FILE Strutture ausiliarie di accesso 2 Accesso secondario Diamo per scontato che esista già un file con una certa organizzazione primaria con dati non ordinati, ordinati o organizzati secondo
Pag Politecnico di Torino 1
 Introduzione Strutture fisiche di accesso Definizione di indici in SQL Progettazione fisica Linguaggio SQL: costrutti avanzati D B M G D B M G2 Organizzazione fisica dei dati All interno di un DBMS relazionale,
Introduzione Strutture fisiche di accesso Definizione di indici in SQL Progettazione fisica Linguaggio SQL: costrutti avanzati D B M G D B M G2 Organizzazione fisica dei dati All interno di un DBMS relazionale,
Strutture di accesso ai dati: B + -tree
 Strutture di accesso ai dati: B + -tree A L B E R T O B E L U S S I S E C O N D A P A R T E A N N O A C C A D E M I C O 2 0 0 9-2 0 0 Osservazione Quando l indice aumenta di dimensioni, non può risiedere
Strutture di accesso ai dati: B + -tree A L B E R T O B E L U S S I S E C O N D A P A R T E A N N O A C C A D E M I C O 2 0 0 9-2 0 0 Osservazione Quando l indice aumenta di dimensioni, non può risiedere
Basi di Dati e Sistemi Informativi. Organizzazione fisica dei dati. Corso di Laurea in Ing. Informatica Ing. Gestionale Magistrale
 Giuseppe Loseto Corso di Laurea in Ing. Informatica Ing. Gestionale Magistrale Struttura DBMS Gestore delle interrogazioni Decide le strategie di accesso ai dati per rispondere alle interrogazioni Gestore
Giuseppe Loseto Corso di Laurea in Ing. Informatica Ing. Gestionale Magistrale Struttura DBMS Gestore delle interrogazioni Decide le strategie di accesso ai dati per rispondere alle interrogazioni Gestore
Cognome Nome Matricola Ordin.
 Basi di dati II, primo modulo Tecnologia delle basi di dati Prova parziale 27 marzo 2009 Compito A Scrivere il nome su questo foglio e su quello protocollo. Rispondere su questo foglio, eventualmente con
Basi di dati II, primo modulo Tecnologia delle basi di dati Prova parziale 27 marzo 2009 Compito A Scrivere il nome su questo foglio e su quello protocollo. Rispondere su questo foglio, eventualmente con
Parte 6 Esercitazione sull accesso ai file
 Gestione dei dati Parte 6 Esercitazione sull accesso ai file Maurizio Lenzerini, Riccardo Rosati Facoltà di Ingegneria Sapienza Università di Roma Anno Accademico 2012/2013 http://www.dis.uniroma1.it/~rosati/gd/
Gestione dei dati Parte 6 Esercitazione sull accesso ai file Maurizio Lenzerini, Riccardo Rosati Facoltà di Ingegneria Sapienza Università di Roma Anno Accademico 2012/2013 http://www.dis.uniroma1.it/~rosati/gd/
una chiave primaria o secondaria => B+tree primario o secondario (NL,g e h diversi) clustered o unclustered => ho un piano di accesso diverso!!
 clustered o unclustered => ho un piano di accesso diverso!!") RIASSUNTO Devo controllare la clausola WHERE e decidere se sto lavorando su : una chiave primaria o secondaria => B+tree primario o secondario (NL,g e h diversi) clustered o unclustered => ho un piano
RIASSUNTO Devo controllare la clausola WHERE e decidere se sto lavorando su : una chiave primaria o secondaria => B+tree primario o secondario (NL,g e h diversi) clustered o unclustered => ho un piano
Progettazione fisica delle basi di dati. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 Progettazione fisica delle basi di dati Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Introduzione v Dopo il progetto ER, la tarduzione in relazionale, il raffinamento dello schema e
Progettazione fisica delle basi di dati Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Introduzione v Dopo il progetto ER, la tarduzione in relazionale, il raffinamento dello schema e
Casi di studio per il tuning delle strutture fisiche (Shasha)
") Casi di studio per il tuning delle strutture fisiche (Shasha) Employee (SSN, Name, Dept, Manager, Salary) Student(SSN, Name, Course, Grade, Stipend,WrittenEvaluation) dal testo: D. Shasha. Database Tuning:
Casi di studio per il tuning delle strutture fisiche (Shasha) Employee (SSN, Name, Dept, Manager, Salary) Student(SSN, Name, Course, Grade, Stipend,WrittenEvaluation) dal testo: D. Shasha. Database Tuning:
Indici multilivello dinamici (B-alberi e B + -alberi) Alberi di ricerca - 1. Un esempio. Alberi di ricerca - 3. Alberi di ricerca - 2
 Alberi di ricerca - 1. Un esempio. Alberi di ricerca - 3. Alberi di ricerca - 2") INDICI MULTILIVELLO DINAMICI Indici multilivello dinamici (B-alberi e B + -alberi) Gli indici multilivello dinamici (B-alberi e B + -alberi) sono casi speciali di strutture ad albero. Un albero è formato
INDICI MULTILIVELLO DINAMICI Indici multilivello dinamici (B-alberi e B + -alberi) Gli indici multilivello dinamici (B-alberi e B + -alberi) sono casi speciali di strutture ad albero. Un albero è formato
5. Strutture di indici per file
 5. Strutture di indici per file I file hanno un'organizzazione primaria, ossia possono essere organizzati su disco in maniera ordinata, non ordinata, oppure a hash. Per velocizzare le operazioni di reperimento
5. Strutture di indici per file I file hanno un'organizzazione primaria, ossia possono essere organizzati su disco in maniera ordinata, non ordinata, oppure a hash. Per velocizzare le operazioni di reperimento
Introduzione alla valutazione delle interrogazioni. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 Introduzione alla valutazione delle interrogazioni Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Introduzione alla valutazione delle interrogazioni v Piano: albero composto da operatori
Introduzione alla valutazione delle interrogazioni Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Introduzione alla valutazione delle interrogazioni v Piano: albero composto da operatori
Strutture fisiche di accesso
 Strutture fisiche di accesso Esercitazioni - Basi di dati (complementi) Autore: Dr. Simone Grega Esercizio 1 Siano date le seguenti informazioni: B=4096 bytes la dimensione di un blocco H=12 bytes la dimensione
Strutture fisiche di accesso Esercitazioni - Basi di dati (complementi) Autore: Dr. Simone Grega Esercizio 1 Siano date le seguenti informazioni: B=4096 bytes la dimensione di un blocco H=12 bytes la dimensione
Organizzazione fisica dei dati: Gli Indici
 Organizzazione fisica dei dati: Gli Indici Basi di dati: Architetture e linee di evoluzione - Seconda edizione Capitolo 1 Appunti dalle lezioni Indici Struttura ausiliaria per l'accesso ai record di un
Organizzazione fisica dei dati: Gli Indici Basi di dati: Architetture e linee di evoluzione - Seconda edizione Capitolo 1 Appunti dalle lezioni Indici Struttura ausiliaria per l'accesso ai record di un
I file utente sistema operativo nome
 I file I File sono l unità base di informazione nell interazione tra utente e sistema operativo Un file e costituito da un insieme di byte attinenti ad un unica entità logica fino a un po di tempo fa i
I file I File sono l unità base di informazione nell interazione tra utente e sistema operativo Un file e costituito da un insieme di byte attinenti ad un unica entità logica fino a un po di tempo fa i
Ottimizzazione e organizzazione fisica
 Parte VIII Organizzazione fisica Basi di dati - prof. Silvio Salza - a.a. 2014-2015 VIII - 1 Ottimizzazione e organizzazione fisica L Ottimizzatore genera i piani esecutivi delle interrogazioni Un piano
Parte VIII Organizzazione fisica Basi di dati - prof. Silvio Salza - a.a. 2014-2015 VIII - 1 Ottimizzazione e organizzazione fisica L Ottimizzatore genera i piani esecutivi delle interrogazioni Un piano
Algebra Relazionale. T. Catarci, M. Scannapieco, Corso di Basi di Dati, A.A. 2008/2009, Sapienza Università di Roma
 Algebra Relazionale 1 Linguaggi di interrogazione relazionale Linguaggi di interrogazione: permettono la manipolazione e il reperimento di dati da una base di dati Il modello relazionale supporta LI semplici
Algebra Relazionale 1 Linguaggi di interrogazione relazionale Linguaggi di interrogazione: permettono la manipolazione e il reperimento di dati da una base di dati Il modello relazionale supporta LI semplici
I B+ Alberi. Sommario
 I B+ Alberi R. Basili (Basi di Dati, a.a. 2002-3) Sommario Indici organizzati secondo B + -alberi Motivazioni ed Esempio Definizione Ricerca in un B + -albero Esempio Vantaggi Inserimento/Cancellazione
I B+ Alberi R. Basili (Basi di Dati, a.a. 2002-3) Sommario Indici organizzati secondo B + -alberi Motivazioni ed Esempio Definizione Ricerca in un B + -albero Esempio Vantaggi Inserimento/Cancellazione
ORGANIZZAZIONE FISICA DEI DATI
 ORGANIZZAZIONE FISICA DEI DATI Un requisito fondamentale di un sistema di gestione di basi di dati è l efficienza, cioè la capacità di rispondere alle richieste dell utente il più rapidamente possibile
ORGANIZZAZIONE FISICA DEI DATI Un requisito fondamentale di un sistema di gestione di basi di dati è l efficienza, cioè la capacità di rispondere alle richieste dell utente il più rapidamente possibile
Organizzazione fisica dei dati. L. Vigliano
 Organizzazione fisica dei dati 2 punti di vista Come costruire un DB? Flusso di progetto, schemi logici livello logico Come memorizzare i dati? Struttura dei dati livello fisico DBMS : Architettura a livelli
Organizzazione fisica dei dati 2 punti di vista Come costruire un DB? Flusso di progetto, schemi logici livello logico Come memorizzare i dati? Struttura dei dati livello fisico DBMS : Architettura a livelli
Esercizio 10.1 Soluzione
 Esercizio 10.1 Calcolare il fattore di blocco e il numero di blocchi occupati da una relazione con T = 1000000) di tuple di lunghezza fissa pari a L = 200 byte in un sistema con blocchi di dimensione pari
Esercizio 10.1 Calcolare il fattore di blocco e il numero di blocchi occupati da una relazione con T = 1000000) di tuple di lunghezza fissa pari a L = 200 byte in un sistema con blocchi di dimensione pari
I DATI E LA LORO INTEGRAZIONE 63 4/001.0
 I DATI E LA LORO INTEGRAZIONE 63 4/001.0 L INTEGRAZIONE DEI DATI INTEGRAZIONE DEI DATI SIGNIFICA LA CONDIVISIONE DEGLI ARCHIVI DA PARTE DI PIÙ AREE FUNZIONALI, PROCESSI E PROCEDURE AUTOMATIZZATE NELL AMBITO
I DATI E LA LORO INTEGRAZIONE 63 4/001.0 L INTEGRAZIONE DEI DATI INTEGRAZIONE DEI DATI SIGNIFICA LA CONDIVISIONE DEGLI ARCHIVI DA PARTE DI PIÙ AREE FUNZIONALI, PROCESSI E PROCEDURE AUTOMATIZZATE NELL AMBITO
PIL Percorsi di Inserimento Lavorativo
 PIL - 2008 Percorsi di Inserimento Lavorativo Basi di Dati - Lezione 2 Il Modello Relazionale Il modello relazionale rappresenta il database come un insieme di relazioni. Ogni RELAZIONE è una tabella con:
PIL - 2008 Percorsi di Inserimento Lavorativo Basi di Dati - Lezione 2 Il Modello Relazionale Il modello relazionale rappresenta il database come un insieme di relazioni. Ogni RELAZIONE è una tabella con:
La gestione delle interrogazioni
 La gestione delle interrogazioni Basi di dati: Architetture e linee di evoluzione - Seconda edizione Capitolo 1 Appunti dalle lezioni Esecuzione e ottimizzazione delle query Un modulo del DBMS Query processor
La gestione delle interrogazioni Basi di dati: Architetture e linee di evoluzione - Seconda edizione Capitolo 1 Appunti dalle lezioni Esecuzione e ottimizzazione delle query Un modulo del DBMS Query processor
CdL in Medicina Veterinaria - STPA AA
 CdL in Medicina Veterinaria - STPA AA 2007-08 I Files I files I Files sono l unità base di informazione nell interazione tra utente e sistema operativo Costituito da un insieme di byte (di natura omogenea)
CdL in Medicina Veterinaria - STPA AA 2007-08 I Files I files I Files sono l unità base di informazione nell interazione tra utente e sistema operativo Costituito da un insieme di byte (di natura omogenea)
Lezione 22 La Memoria Interna (1)
") Lezione 22 La Memoria Interna (1) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione Dove siamo e dove stiamo andando La gerarchia
Lezione 22 La Memoria Interna (1) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Organizzazione della lezione Dove siamo e dove stiamo andando La gerarchia
SQL: Structured Query Language. T. Catarci, M. Scannapieco, Corso di Basi di Dati, A.A. 2008/2009, Sapienza Università di Roma
 SQL: Structured Query Language 1 SQL:Componenti Principali Data Manipulation Language (DML): interrogazioni, inserimenti, cancellazioni, modifiche Data Definition Language (DDL): creazione, cancellazione
SQL: Structured Query Language 1 SQL:Componenti Principali Data Manipulation Language (DML): interrogazioni, inserimenti, cancellazioni, modifiche Data Definition Language (DDL): creazione, cancellazione
SQL: DDL, VI, Aggiornamenti e Viste
 SQL: DDL, VI, Aggiornamenti e Viste 1 SQL è più di un semplice linguaggio di interrogazione v Linguaggio di definizione dati (Data-definition language, DDL): Crea/distrugge/modifica relazioni e viste Definisce
SQL: DDL, VI, Aggiornamenti e Viste 1 SQL è più di un semplice linguaggio di interrogazione v Linguaggio di definizione dati (Data-definition language, DDL): Crea/distrugge/modifica relazioni e viste Definisce
Strutture dati per insiemi disgiunti
 Strutture dati per insiemi disgiunti Servono a mantenere una collezione S = {S 1, S 2,..., S k } di insiemi disgiunti. Ogni insieme S i è individuato da un rappresentante che è un particolare elemento
Strutture dati per insiemi disgiunti Servono a mantenere una collezione S = {S 1, S 2,..., S k } di insiemi disgiunti. Ogni insieme S i è individuato da un rappresentante che è un particolare elemento
Manuale SQL. Manuale SQL - 1 -
 Manuale SQL - 1 - Istruzioni DDL Creazione di una tabella : CREATE TABLE Il comando CREATE TABLE consente di definire una tabella del database specificandone le colonne, con il tipo di dati ad esse associate,
Manuale SQL - 1 - Istruzioni DDL Creazione di una tabella : CREATE TABLE Il comando CREATE TABLE consente di definire una tabella del database specificandone le colonne, con il tipo di dati ad esse associate,
Il sistema operativo deve fornire una visione astratta dei file su disco e l'utente deve avere la possibilità di:
 Il File System Il sistema operativo deve fornire una visione astratta dei file su disco e l'utente deve avere la possibilità di: identificare ogni file con un nome (filename) astraendo completamente dalla
Il File System Il sistema operativo deve fornire una visione astratta dei file su disco e l'utente deve avere la possibilità di: identificare ogni file con un nome (filename) astraendo completamente dalla
Basi di Dati. Corso di Informatica. Memorizzazione dei Dati. Accesso ai Dati. Corso di Laurea in Conservazione e Restauro dei Beni Culturali
 Corso di Laurea in Conservazione e Restauro dei Beni Culturali Corso di Informatica Gianluca Torta Dipartimento di Informatica Tel: 011 670 6782 Mail: torta@di.unito.it Basi di Dati lo scopo delle Basi
Corso di Laurea in Conservazione e Restauro dei Beni Culturali Corso di Informatica Gianluca Torta Dipartimento di Informatica Tel: 011 670 6782 Mail: torta@di.unito.it Basi di Dati lo scopo delle Basi
Elena Baralis 2007 Politecnico di Torino 1
 Introduzione Istruzione INSERT Istruzione DELETE Istruzione UPDATE Linguaggio SQL: fondamenti 2 (1/3) Inserimento di tuple Cancellazione di tuple Modifica di tuple 4 (2/3) INSERT inserimento di nuove tuple
Introduzione Istruzione INSERT Istruzione DELETE Istruzione UPDATE Linguaggio SQL: fondamenti 2 (1/3) Inserimento di tuple Cancellazione di tuple Modifica di tuple 4 (2/3) INSERT inserimento di nuove tuple
Structured Query Language
 IL LINGUAGGIO SQL Structured Query Language Contiene sia il DDL sia il DML, quindi consente di: Definire e creare il database Effettuare l inserimento, la cancellazione, l aggiornamento dei record di un
IL LINGUAGGIO SQL Structured Query Language Contiene sia il DDL sia il DML, quindi consente di: Definire e creare il database Effettuare l inserimento, la cancellazione, l aggiornamento dei record di un
Librerie digitali. Uso di XML per memorizzare i metadati. Descrizione generale. XML per memorizzare i metadati. Motivi dell uso di XML
 Librerie digitali Uso di XML per memorizzare i metadati Descrizione generale Ad ogni dato associo un file XML che descrive il contenuto del dato stesso Memorizzo su file system sia il dato sia il file
Librerie digitali Uso di XML per memorizzare i metadati Descrizione generale Ad ogni dato associo un file XML che descrive il contenuto del dato stesso Memorizzo su file system sia il dato sia il file
Esercizi Capitolo 7 - Hash
 Esercizi Capitolo 7 - Hash Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore PDF lo consente, è possibile saltare alle rispettive
Esercizi Capitolo 7 - Hash Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore PDF lo consente, è possibile saltare alle rispettive
Tabelle esempio: Impiegato/Dipartimento
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : SQL (4) Query di aggiornamento Prof. Alberto Postiglione
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : SQL (4) Query di aggiornamento Prof. Alberto Postiglione
Indici. Sistemi Informativi L-B. Home Page del corso: Versione elettronica: Indici.pdf
 Indici Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: Indici.pdf Sistemi Informativi L-B Perché gli indici Le organizzazioni dei file viste
Indici Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: Indici.pdf Sistemi Informativi L-B Perché gli indici Le organizzazioni dei file viste
Sistemi Informativi L-B. Home Page del corso: Versione elettronica: Indici.pdf. Sistemi Informativi L-B
 Indici Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: Indici.pdf Sistemi Informativi L-B Perché gli indici Le organizzazioni dei file viste
Indici Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: Indici.pdf Sistemi Informativi L-B Perché gli indici Le organizzazioni dei file viste
<Nome Tabella>.<attributo>
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : SQL (2) Tabelle mult., variabili, aggreg, group Prof. Alberto
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : SQL (2) Tabelle mult., variabili, aggreg, group Prof. Alberto
Ordinamento per inserzione e per fusione
 Ordinamento per inserzione e per fusione Alessio Orlandi 15 marzo 2010 Fusione: problema Problema Siano A e B due array di n A e n B interi rispettivamente. Si supponga che A e B siano ordinati in modo
Ordinamento per inserzione e per fusione Alessio Orlandi 15 marzo 2010 Fusione: problema Problema Siano A e B due array di n A e n B interi rispettivamente. Si supponga che A e B siano ordinati in modo
I formati delle istruzioni
 Appunti di Calcolatori Elettronici Le istruzioni I formati delle istruzioni... 1 Criteri generali di progettazione dei formati delle istruzioni... 2 Cenni all indirizzamento... 4 Indirizzamento immediato...
Appunti di Calcolatori Elettronici Le istruzioni I formati delle istruzioni... 1 Criteri generali di progettazione dei formati delle istruzioni... 2 Cenni all indirizzamento... 4 Indirizzamento immediato...
Introduzione alle memorie cache. Cristina Silvano, 06/01/2013 versione 2 1
 Introduzione alle memorie cache Corso ACSO prof. Cristina SILVANO Politecnico di Milano Cristina Silvano, 06/01/2013 versione 2 1 Obiettivo Sommario Livelli della gerarchia di memoria Memoria cache: concetti
Introduzione alle memorie cache Corso ACSO prof. Cristina SILVANO Politecnico di Milano Cristina Silvano, 06/01/2013 versione 2 1 Obiettivo Sommario Livelli della gerarchia di memoria Memoria cache: concetti
Ottimizzazione delle query. Stima dell IO: Per generare i piani si considera: --> Generare e confrontare i piani Query
 Ottimizzazione delle query Ottimizzazione delle query --> Generare e confrontare i piani Genera Query Piani Leggere il capitolo 15 del Garcia-Molina et al. Lucidi derivati da quelli di Hector Garcia-Molina
Ottimizzazione delle query Ottimizzazione delle query --> Generare e confrontare i piani Genera Query Piani Leggere il capitolo 15 del Garcia-Molina et al. Lucidi derivati da quelli di Hector Garcia-Molina
Algoritmi Greedy. Tecniche Algoritmiche: tecnica greedy (o golosa) Un esempio
 Un esempio") Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
Algoritmi Greedy Tecniche Algoritmiche: tecnica greedy (o golosa) Idea: per trovare una soluzione globalmente ottima, scegli ripetutamente soluzioni ottime localmente Un esempio Input: lista di interi
Interrogazioni nidificate
 Interrogazioni nidificate Nella clausola where si possono utilizzare valori prodotti da altre istruzioni select utilizzando any (qualsiasi) o all (tutti) insieme agli operatori di confronto Trovare nome,
Interrogazioni nidificate Nella clausola where si possono utilizzare valori prodotti da altre istruzioni select utilizzando any (qualsiasi) o all (tutti) insieme agli operatori di confronto Trovare nome,
SQL - Structured Query Language
 SQL - Structured Query Language Lab 05 Alessandro Lori Università di Pisa 27 Aprile 2012 Riepilogo esercitazione precedente Operatori insiemistici (UNION, INTERSECT, EXCEPT) Riepilogo esercitazione precedente
SQL - Structured Query Language Lab 05 Alessandro Lori Università di Pisa 27 Aprile 2012 Riepilogo esercitazione precedente Operatori insiemistici (UNION, INTERSECT, EXCEPT) Riepilogo esercitazione precedente
ORDINE DI INSERIMENTO DELLE CHIAVI <35 >35
 LIBRERIA WEB Alberi binari 3. Alberi binari e tecniche di hashing per la gestione delle chiavi Gli indici di un file possono essere trattati in modo efficiente con tecniche che si basano sull uso di alberi
LIBRERIA WEB Alberi binari 3. Alberi binari e tecniche di hashing per la gestione delle chiavi Gli indici di un file possono essere trattati in modo efficiente con tecniche che si basano sull uso di alberi
Basi di dati attive. Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger).
.") Basi di dati attive Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger). Tali regole vengono attivate in modo automatico al verificarsi
Basi di dati attive Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger). Tali regole vengono attivate in modo automatico al verificarsi
Il file system. Le caratteristiche di file, direttorio e partizione sono del tutto indipendenti dalla natura e dal tipo di dispositivo utilizzato.
 Il File System Il file system È quella parte del Sistema Operativo che fornisce i meccanismi di accesso e memorizzazione delle informazioni (programmi e dati) allocate in memoria di massa. Realizza i concetti
Il File System Il file system È quella parte del Sistema Operativo che fornisce i meccanismi di accesso e memorizzazione delle informazioni (programmi e dati) allocate in memoria di massa. Realizza i concetti
CAPITOLO V. DATABASE: Il modello relazionale
 CAPITOLO V DATABASE: Il modello relazionale Il modello relazionale offre una rappresentazione matematica dei dati basata sul concetto di relazione normalizzata. I principi del modello relazionale furono
CAPITOLO V DATABASE: Il modello relazionale Il modello relazionale offre una rappresentazione matematica dei dati basata sul concetto di relazione normalizzata. I principi del modello relazionale furono
Sommario. File Management. File. File Management System
 Sommario File Management Panoramica Organizzazione dei file ed accesso ad essi File Directories Record Blocking Gestione della Memoria Secondaria File I file costituiscono gli elementi fondamentali di
Sommario File Management Panoramica Organizzazione dei file ed accesso ad essi File Directories Record Blocking Gestione della Memoria Secondaria File I file costituiscono gli elementi fondamentali di
Basi di dati II Esame 29 settembre 2014
 Basi di dati II Esame 29 settembre 2014 Rispondere su questo fascicolo. Tempo a disposizione: due ore. Cognome Nome Matricola Domanda 1 (15%) Come dovrebbe essere noto, gli algoritmi che sfruttano i buffer
Basi di dati II Esame 29 settembre 2014 Rispondere su questo fascicolo. Tempo a disposizione: due ore. Cognome Nome Matricola Domanda 1 (15%) Come dovrebbe essere noto, gli algoritmi che sfruttano i buffer
Il file È un insieme di informazioni: programmi. Il File System. Il file system
 Il File System Il file È un insieme di informazioni: programmi d a t i testi rappresentati come insieme di record logici (bit, byte, linee, record, etc.) Ogni file è individuato da (almeno) un nome simbolico
Il File System Il file È un insieme di informazioni: programmi d a t i testi rappresentati come insieme di record logici (bit, byte, linee, record, etc.) Ogni file è individuato da (almeno) un nome simbolico
Ogni ufficio è formato da 100 dipendenti, i quali hanno a loro volta 3 clienti ciascuno. Inoltre, ad ogni ufficio sono stati assegnati 4 fornitori.
 Tecnologia delle Basi Dati Analisi del dbms Postgresql. Luigi Cestoni Prima Parte Descrizione del Database Abbiamo realizzato un database costituito da quattro tabelle: 1. dipendente( id,nome,cognome,eta,telefono,idufficio)
Tecnologia delle Basi Dati Analisi del dbms Postgresql. Luigi Cestoni Prima Parte Descrizione del Database Abbiamo realizzato un database costituito da quattro tabelle: 1. dipendente( id,nome,cognome,eta,telefono,idufficio)
Database Lezione 2. Sommario. - Progettazione di un database - Join - Valore NULL - Operatori aggregati
 Sommario - Progettazione di un database - Join - Valore NULL - Operatori aggregati Progettazione di un database - In un database c'è una marcata distinzione tra i valori in esso contenuti e le operazioni
Sommario - Progettazione di un database - Join - Valore NULL - Operatori aggregati Progettazione di un database - In un database c'è una marcata distinzione tra i valori in esso contenuti e le operazioni
Algoritmi e Strutture Dati
 Algoritmi e Strutture Dati Capitolo 7 Tabelle hash Camil Demetrescu, Irene Finocchi, Giuseppe F. Italiano Implementazioni Dizionario Tempo richiesto dall operazione più costosa: -Liste - Alberi di ricerca
Algoritmi e Strutture Dati Capitolo 7 Tabelle hash Camil Demetrescu, Irene Finocchi, Giuseppe F. Italiano Implementazioni Dizionario Tempo richiesto dall operazione più costosa: -Liste - Alberi di ricerca
Interrogazioni nidificate
 Interrogazioni nidificate Trovare nome, cognome e matricola degli studenti che non hanno fatto esami select Matricola,Nome,Cognome from studenti where matricola all (select studente group by studente)
Interrogazioni nidificate Trovare nome, cognome e matricola degli studenti che non hanno fatto esami select Matricola,Nome,Cognome from studenti where matricola all (select studente group by studente)
Corso di Informatica
 Corso di Informatica Modulo T1 A2 1 Prerequisiti Strutture dati fondamentali Cenni sulle memorie secondarie Struttura file 2 1 Introduzione Le tecnologie costruttive delle memorie secondarie sono evolute,
Corso di Informatica Modulo T1 A2 1 Prerequisiti Strutture dati fondamentali Cenni sulle memorie secondarie Struttura file 2 1 Introduzione Le tecnologie costruttive delle memorie secondarie sono evolute,
SQL e linguaggi di programmazione. Cursori. Cursori. L interazione con l ambiente SQL può avvenire in 3 modi:
 SQL e linguaggi di programmazione L interazione con l ambiente SQL può avvenire in 3 modi: in modo interattivo col server attraverso interfacce o linguaggi ad hoc legati a particolari DBMS attraverso i
SQL e linguaggi di programmazione L interazione con l ambiente SQL può avvenire in 3 modi: in modo interattivo col server attraverso interfacce o linguaggi ad hoc legati a particolari DBMS attraverso i
Laboratorio di Basi di Dati
 Laboratorio di Basi di Dati Docente: Alberto Belussi Lezione 2 Vincoli di integrità Proprietà che devono essere soddisfatte da ogni istanza della base di dati. Il soddisfacimento è definito rispetto al
Laboratorio di Basi di Dati Docente: Alberto Belussi Lezione 2 Vincoli di integrità Proprietà che devono essere soddisfatte da ogni istanza della base di dati. Il soddisfacimento è definito rispetto al
TRIE (albero digitale di ricerca)
") TRIE (albero digitale di ricerca) Struttura dati impiegata per memorizzare un insieme S di n stringhe (il vocabolario V). Tabelle hash le operazioni di dizionario hanno costo O(m) al caso medio per una
TRIE (albero digitale di ricerca) Struttura dati impiegata per memorizzare un insieme S di n stringhe (il vocabolario V). Tabelle hash le operazioni di dizionario hanno costo O(m) al caso medio per una
Lezione 7 SQL (II) Basi di dati bis Docente Mauro Minenna Pag.1
 Basi di dati bis Docente Mauro Minenna Pag.1") Lezione 7 SQL (II) Pag.1 Ancora sugli operatori di confronto tra insiemi Abbiamo già visto IN, EXISTS e UNIQUE. Possiamo anche usare NOT IN, NOT EXISTS e NOT UNIQUE Disponibili anche: op ANY, op ALL Trovare
Lezione 7 SQL (II) Pag.1 Ancora sugli operatori di confronto tra insiemi Abbiamo già visto IN, EXISTS e UNIQUE. Possiamo anche usare NOT IN, NOT EXISTS e NOT UNIQUE Disponibili anche: op ANY, op ALL Trovare
Data Management. Query evaluation. Maurizio Lenzerini, Riccardo Rosati
 Data Management Query evaluation Maurizio Lenzerini, Riccardo Rosati Dipartimento di Ingegneria informatica, automatica e gestionale Sapienza Università di Roma Corso di laurea magistrale in ingegneria
Data Management Query evaluation Maurizio Lenzerini, Riccardo Rosati Dipartimento di Ingegneria informatica, automatica e gestionale Sapienza Università di Roma Corso di laurea magistrale in ingegneria
Relazioni e tabelle. Introduzione alle Basi di Dati Relazionali. Relazioni uno a uno. Esempio
 Relazioni e tabelle Introduzione alle Basi di Dati Relazionali Nelle Basi di Dati relazionali le informazioni sono organizzate in tabelle Le tabelle sono rappresentate mediante griglie suddivise in colonne
Relazioni e tabelle Introduzione alle Basi di Dati Relazionali Nelle Basi di Dati relazionali le informazioni sono organizzate in tabelle Le tabelle sono rappresentate mediante griglie suddivise in colonne
Heap scenario. Ho un insieme dinamico di oggetti, ciascuno identificato con una priorità. (la priorità è semplicemente un numero);
;") Heap Heap scenario Ho un insieme dinamico di oggetti, ciascuno identificato con una priorità. (la priorità è semplicemente un numero); Voglio poter: inserire: nuovi elementi, ciascuno con una data priorità
Heap Heap scenario Ho un insieme dinamico di oggetti, ciascuno identificato con una priorità. (la priorità è semplicemente un numero); Voglio poter: inserire: nuovi elementi, ciascuno con una data priorità
SISTEMI INFORMATIVI E DATABASE
 SISTEMI INFORMATIVI E DATABASE SISTEMA INFORMATIVO AZIENDALE (S.I.) In una realtà aziendale si distingue: DATO elemento di conoscenza privo di qualsiasi elaborazione; insieme di simboli e caratteri. (274,
SISTEMI INFORMATIVI E DATABASE SISTEMA INFORMATIVO AZIENDALE (S.I.) In una realtà aziendale si distingue: DATO elemento di conoscenza privo di qualsiasi elaborazione; insieme di simboli e caratteri. (274,
Array e Oggetti. Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1. Dispensa 12. A. Miola Dicembre 2006
 Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1 Dispensa 12 Array e Oggetti A. Miola Dicembre 2006 http://www.dia.uniroma3.it/~java/fondinf1/ Array e Oggetti 1 Contenuti Array paralleli
Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1 Dispensa 12 Array e Oggetti A. Miola Dicembre 2006 http://www.dia.uniroma3.it/~java/fondinf1/ Array e Oggetti 1 Contenuti Array paralleli
LABORATORIO di INFORMATICA
 Università degli Studi di Cagliari Corso di Laurea Magistrale in Ingegneria per l Ambiente ed il Territorio LABORATORIO di INFORMATICA A.A. 2010/2011 Prof. Giorgio Giacinto IL MODELLO RELAZIONALE http://www.diee.unica.it/giacinto/lab
Università degli Studi di Cagliari Corso di Laurea Magistrale in Ingegneria per l Ambiente ed il Territorio LABORATORIO di INFORMATICA A.A. 2010/2011 Prof. Giorgio Giacinto IL MODELLO RELAZIONALE http://www.diee.unica.it/giacinto/lab
Viene richiesto di MIN CARD(S,E) = 1 UPDATE DELETE MAX CARD(S,E) = 3 INSERT UPDATE
 = 1 UPDATE DELETE MAX CARD(S,E) = 3 INSERT UPDATE") Dato il seguente schema E/R E la sua traduzione nel seguente schema relazionale: disponibile in http://www.dbgroup.unimo.it/sire/20110513/20110513.bak Viene richiesto di 1) Risolvere la seguente interrogazione
Dato il seguente schema E/R E la sua traduzione nel seguente schema relazionale: disponibile in http://www.dbgroup.unimo.it/sire/20110513/20110513.bak Viene richiesto di 1) Risolvere la seguente interrogazione
CONCETTI E ARCHITETTURA DI UN SISTEMA DI BASI DI DATI
 CONCETTI E ARCHITETTURA DI UN SISTEMA DI BASI DI DATI Introduzione alle basi di dati (2) 2 Modelli dei dati, schemi e istanze (1) Nell approccio con basi di dati è fondamentale avere un certo livello di
CONCETTI E ARCHITETTURA DI UN SISTEMA DI BASI DI DATI Introduzione alle basi di dati (2) 2 Modelli dei dati, schemi e istanze (1) Nell approccio con basi di dati è fondamentale avere un certo livello di
Il linguaggio SQL: le viste
 Il linguaggio SQL: le viste Basi di dati 1 Il linguaggio SQL: le viste Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Il linguaggio SQL: le viste Basi di dati 2 Introduzione
Il linguaggio SQL: le viste Basi di dati 1 Il linguaggio SQL: le viste Angelo Montanari Dipartimento di Matematica e Informatica Università di Udine Il linguaggio SQL: le viste Basi di dati 2 Introduzione
Progettazione Fisica - 1. Concetti di Base - 1. Indici. Progettazione di Basi di Dati. Assunzioni Fondamentali
 Università degli Studi di Trieste Progettazione Fisica - 1 Corso di Laurea in Informatica - Basi di Dati Progettazione di Basi di Dati Progettazione Fisica: gli D. Gubiani maggio 2008 Lo schema ottenuto
Università degli Studi di Trieste Progettazione Fisica - 1 Corso di Laurea in Informatica - Basi di Dati Progettazione di Basi di Dati Progettazione Fisica: gli D. Gubiani maggio 2008 Lo schema ottenuto
Introduzione al Livello Fisico: File, Pagine, records e indici
 Introduzione al Livello Fisico: File, Pagine, records e indici Roberto Basili Corso di Basi di Dati a.a. 2007/8 Dati su dispositivi di memorizzazione esterni Dischi: si può leggere qualunque pagina a costo
Introduzione al Livello Fisico: File, Pagine, records e indici Roberto Basili Corso di Basi di Dati a.a. 2007/8 Dati su dispositivi di memorizzazione esterni Dischi: si può leggere qualunque pagina a costo
Bibliografia. INFORMATICA GENERALE Prof. Alberto Postiglione. Scienze della Comunicazione Università di Salerno. Definizione di DB e di DBMS
 INFORMATICA GENERALE DBMS: Introduzione alla gestione dei dati Bibliografia 4 ott 2011 Dia 2 Curtin, Foley, Sen, Morin Vecchie edizioni: 8.4, 8.5, 8.6, 8.7, 8.8 Edizione dalla IV in poi: 6.5, 21.1, 19.4,
INFORMATICA GENERALE DBMS: Introduzione alla gestione dei dati Bibliografia 4 ott 2011 Dia 2 Curtin, Foley, Sen, Morin Vecchie edizioni: 8.4, 8.5, 8.6, 8.7, 8.8 Edizione dalla IV in poi: 6.5, 21.1, 19.4,
MICROSOFT ACCESS IL MODELLO E/R
 MICROSOFT ACCESS IL MODELLO E/R LE ENTITA Le entità di un database sono le singole tabelle che comporranno la struttura del nostro database. Le tabelle sono formate da attributi (o campi) che ne definiscono
MICROSOFT ACCESS IL MODELLO E/R LE ENTITA Le entità di un database sono le singole tabelle che comporranno la struttura del nostro database. Le tabelle sono formate da attributi (o campi) che ne definiscono
Esercizi Capitolo 10 - Code con priorità e insiemi disgiunti
 Esercizi Capitolo 10 - Code con priorità e insiemi disgiunti Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore PDF lo consente,
Esercizi Capitolo 10 - Code con priorità e insiemi disgiunti Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore PDF lo consente,
Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SCENARI TEMPORALI
 Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SCENARI TEMPORALI Dalle dispense originali realizzate dal Prof. Stefano Rizzi (http://www-db.deis.unibo.it/~srizzi/) e
Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SCENARI TEMPORALI Dalle dispense originali realizzate dal Prof. Stefano Rizzi (http://www-db.deis.unibo.it/~srizzi/) e
Informatica 10. appunti dalla lezione del 16/11/2010
 Informatica 10 appunti dalla lezione del 16/11/2010 Memorie Dispositivi in grado di conservare al loro interno informazione per un intervallo di tempo significativo RAM chiavetta USB Hard disk CD/DVD SD
Informatica 10 appunti dalla lezione del 16/11/2010 Memorie Dispositivi in grado di conservare al loro interno informazione per un intervallo di tempo significativo RAM chiavetta USB Hard disk CD/DVD SD
Indici non tradizionali. Indici non tradizionali. Indici bitmap. Indici bitmap. Indici bitmap. Indici bitmap - esempio
 Indici non tradizionali Indici non tradizionali Nel seguito introdurremo tre particolari tipi di indici: indici bitmap: permettono di valutare efficientemente condizioni multiple indici per dati multidimensionali
Indici non tradizionali Indici non tradizionali Nel seguito introdurremo tre particolari tipi di indici: indici bitmap: permettono di valutare efficientemente condizioni multiple indici per dati multidimensionali
Informatica per le Scienze Umane. Introduzione al corso: programma
 Informatica per le Scienze Umane Introduzione al corso: programma 1 Obiettivi del corso Fornire le conoscenze e le competenze necessarie alla rappresentazione e al trattamento consapevole delle informazioni
Informatica per le Scienze Umane Introduzione al corso: programma 1 Obiettivi del corso Fornire le conoscenze e le competenze necessarie alla rappresentazione e al trattamento consapevole delle informazioni
Informatica di Base - 6 c.f.u.
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica di Base - 6 c.f.u. Anno Accademico 2007/2008 Docente: ing. Salvatore Sorce Basi di Dati Sistema informativo Componente
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica di Base - 6 c.f.u. Anno Accademico 2007/2008 Docente: ing. Salvatore Sorce Basi di Dati Sistema informativo Componente
Massimo Benerecetti Tabelle Hash: gestione delle collisioni
 Massimo Benerecetti Tabelle Hash: gestione delle collisioni # Lezione n. Parole chiave: Corso di Laurea: Informatica Insegnamento: Algoritmi e Strutture Dati I Email Docente: bene@na.infn.it A.A. 2009-2010
Massimo Benerecetti Tabelle Hash: gestione delle collisioni # Lezione n. Parole chiave: Corso di Laurea: Informatica Insegnamento: Algoritmi e Strutture Dati I Email Docente: bene@na.infn.it A.A. 2009-2010
File System. Capitolo Silberschatz
 File System Capitolo 10 -- Silberschatz Interfaccia del File System Per gli utenti di un computer, il File System è spesso l aspetto più visibile del SO di quel computer. Il File System fornisce infatti
File System Capitolo 10 -- Silberschatz Interfaccia del File System Per gli utenti di un computer, il File System è spesso l aspetto più visibile del SO di quel computer. Il File System fornisce infatti
Introduzione alle basi di dati
 Introduzione alle basi di dati Marco Botta botta@di.unito.it www.di.unito.it/~botta/didattica/bioinfo.html 1 Sistema Informativo Insieme di strutture in grado di acquisire, elaborare, trasmettere ed archiviare
Introduzione alle basi di dati Marco Botta botta@di.unito.it www.di.unito.it/~botta/didattica/bioinfo.html 1 Sistema Informativo Insieme di strutture in grado di acquisire, elaborare, trasmettere ed archiviare
Corso di Informatica. Software di produttività personale e database. Ing Pasquale Rota
 Corso di Software di produttività personale e database Ing Pasquale Rota Argomenti I programmi di produttività personale Le basi di dati Fogli elettronici Software di produttività personale e database
Corso di Software di produttività personale e database Ing Pasquale Rota Argomenti I programmi di produttività personale Le basi di dati Fogli elettronici Software di produttività personale e database
Alessandra Raffaetà. Esercizio: Cinema
 Lezione 8 S.I.T. PER LA VALUTAZIONE E GESTIONE DEL TERRITORIO Corso di Laurea Magistrale in Scienze Ambientali Alessandra Raffaetà Dipartimento di Informatica Università Ca Foscari Venezia Esercizio: Cinema
Lezione 8 S.I.T. PER LA VALUTAZIONE E GESTIONE DEL TERRITORIO Corso di Laurea Magistrale in Scienze Ambientali Alessandra Raffaetà Dipartimento di Informatica Università Ca Foscari Venezia Esercizio: Cinema
S.I.T. PER LA VALUTAZIONE E GESTIONE DEL TERRITORIO Corso di Laurea Magistrale in Scienze Ambientali. Alessandra Raffaetà
 Lezione 8 S.I.T. PER LA VALUTAZIONE E GESTIONE DEL TERRITORIO Corso di Laurea Magistrale in Scienze Ambientali Alessandra Raffaetà Dipartimento di Informatica Università Ca Foscari Venezia Esercizio: Cinema
Lezione 8 S.I.T. PER LA VALUTAZIONE E GESTIONE DEL TERRITORIO Corso di Laurea Magistrale in Scienze Ambientali Alessandra Raffaetà Dipartimento di Informatica Università Ca Foscari Venezia Esercizio: Cinema
 Da libro di testo Cormen et al. CAP 21: par 21.1, 21.2, 21.3 pagg. 468-477 Strutture dati per insiemi disgiunti Una struttura dati per insiemi disgiunti mantiene una collezione S={S 1,S 2,,S k } di insiemi
Da libro di testo Cormen et al. CAP 21: par 21.1, 21.2, 21.3 pagg. 468-477 Strutture dati per insiemi disgiunti Una struttura dati per insiemi disgiunti mantiene una collezione S={S 1,S 2,,S k } di insiemi
Tipi di dato e Strutture dati elementari
 Tipi di dato e Strutture dati elementari Ing. Paolo Craca Anno accademico 2007/2008 Tipi di dato e Strutture dati elementari 1 / 40 Cosa vedremo in questo seminario 1 Introduzione 2 Pile 3 Code 4 5 Bibliografia
Tipi di dato e Strutture dati elementari Ing. Paolo Craca Anno accademico 2007/2008 Tipi di dato e Strutture dati elementari 1 / 40 Cosa vedremo in questo seminario 1 Introduzione 2 Pile 3 Code 4 5 Bibliografia
Sistema Operativo (Software di base)
") Il Software Il software del PC Il computer ha grandi potenzialità ma non può funzionare senza il software. Il software essenziale per fare funzionare il PC può essere diviso nelle seguenti componenti:
Il Software Il software del PC Il computer ha grandi potenzialità ma non può funzionare senza il software. Il software essenziale per fare funzionare il PC può essere diviso nelle seguenti componenti:
Structured. Language. Basi di Dati. Introduzione. DDL: Data Definition Language. Tipi di dato. Query. Modifica dei Dati
 Basi di Dati Matteo Longhi Structured Query Language Introduzione Standard creato nel 1976 da IBM Aggiornato (versione 2 nel 1992 (ANSI X3.135 e ISO 9075 Consente di: DDL: definire la struttura del DB
Basi di Dati Matteo Longhi Structured Query Language Introduzione Standard creato nel 1976 da IBM Aggiornato (versione 2 nel 1992 (ANSI X3.135 e ISO 9075 Consente di: DDL: definire la struttura del DB
Minimo albero di copertura
 apitolo 0 Minimo albero di copertura efinizione 0.. ato un grafo G = (V, E) non orientato e connesso, un albero di copertura di G è un sottoinsieme T E tale che il sottografo (V, T ) è un albero libero.
apitolo 0 Minimo albero di copertura efinizione 0.. ato un grafo G = (V, E) non orientato e connesso, un albero di copertura di G è un sottoinsieme T E tale che il sottografo (V, T ) è un albero libero.
Trigger. Basi di dati attive. Trigger: regole che specificano azioni attivate automaticamente dal DBMS al verificarsi di determinati eventi
 Basi di dati attive : regole che specificano azioni attivate automaticamente dal DBMS al verificarsi di determinati eventi Oggi fanno parte dello standard SLQ-99 In passato ogni DBMS li implementava seguendo
Basi di dati attive : regole che specificano azioni attivate automaticamente dal DBMS al verificarsi di determinati eventi Oggi fanno parte dello standard SLQ-99 In passato ogni DBMS li implementava seguendo