Sistemi Intelligenti Learning: l apprendimento degli agenti
|
|
|
- Fulvio Graziani
- 8 anni fa
- Visualizzazioni
Transcript


1 Sistemi Intelligenti Learning: l apprendimento degli agenti Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Scienze dell Informazione [email protected] 1/45 Riassunto Gli agenti Il Reinforcement Learning Gli elementi del RL Un esempio: tris 2/45 1
2 Why agents are important? Agente (software): essere software che svolge servizi per conto di un altro programma, solitamente in modo automatico ed invisibile. Tali software vengono anche detti agenti intelligenti They are seen as a natural metaphor for conceptualising and building a wide range of complex computer systems (the world contains many passive objects, but it also contains very many active components as well); They cut across a wide range of different technology and application areas, including telecoms, human-computer interfaces, distributed systems, WEB and so on; They are seen as a natural development in the search for ever-more powerful abstractions with which to build computer systems. 3/45 Agente - Può scegliere un azione sull ambiente tra un insieme continuo o discreto. - L azione dipende dalla situazione. La situazione è riassunta nello stato del sistema. - L agente monitora continuamente l ambiente (input) e modifica continuamente lo stato. - La scelta dell azione è non banale e richiede un certo grado di intelligenza. - L agente ha una memoria intelligente. 4/45 2
3 Agent Schematic diagram of an agent x t+1 STATE Conditionaction rule (vocabulary) What the world is like now (internal representation)? What action I should do now? y t Sensors Actuators u t Environment u input, x, stato; y, uscita x(t+1) = g(x(t),u(t) y(t)= f(x(t)) 5/45 L agente Inizialmente l attenzione era concentrata sulla progettazione dei sistemi di controllo. Valutazione, sintesi L intelligenza artificiale e la computational intelligence hanno consentito di spostare l attenzione sull apprendimento delle strategie di controllo e più in generale di comportamento. Macchine dotate di meccanismi (algoritmi, SW), per apprendere. 6/45 3
4 I vari tipi di apprendimento x(t+1) = f[x(t),u(t)] y(t) = g[x(t)] Ambiente Agente Supervisionato (learning with a teacher). Viene specificato per ogni pattern di input, il pattern desiderato in output. Non-supervisionato (learning without a teacher). Estrazione di similitudine statistiche tra pattern di input. Clustering. Mappe neurali. Apprendimento con rinforzo (reinforcement learning, learning with a critic). L ambiente fornisce un informazione puntuale, di tipo qualitativo, ad esempio success or fail. 7/45 I - Apprendimento supervisionato y(t) = g[w; u(t)] u R n y R m min J(.) { w} J = Y D Y D è l uscita desiderata nota. g( W; U ) Si tratta di un problema di minimizzazione di una cifra di merito, J(.), nello spazio dei parametri W, che caratterizzano l agente. Appredimento supervisionato si applica a problemi di classificazione o di regressione. Soluzione iterativa: Obbiettivo: se esiste una soluzione, trovare W in modo iterativo tale che l insieme dei pesi W nuovo ottenuto come: W nuovo =W vecchio + W dia luogo a un errore sulle uscite di norma minore che con W vecchio Capacità di generalizzazione Modello globale vs insieme di modelli locali. 8/45 4
5 Esempio Apprendimento Supervisionato Task di classificazione Uscita booleana 9/45 Riconoscimento della scrittura (progetto su un problema ridotto) 1. Determinare il tipo di training example adatti al problema. 2. Definire un training set rappresentativo. Training set = coppie di input / output (ruolo del supervisore umano). 3. Preprocessing. Determinare quali feature è opportuno estrarre dai pattern in ingresso perchè costituiscano l input per l agente. 4. Determinare i dati utilizzati per l apprendimento (quali -> rappresentatività; e quanti -> tanti ma non troppi.). 5. Determinare le modalità di apprendimento: empirical risk minimization, structural risk minimization. 6. Determinare come valutare l apprendimento (e.g. through cross-validation). 10/45 5
6 Apprendimento supervisionato Flusso..... T Controllo della portata di un condizionatore in funzione della temperatura. Imparo una funzione continua a partire da alcuni campioni. 11/45 Clustering Raggruppamento degli input in classi omogenee tra loro. Raggruppamento per colore Raggruppamento per forme Raggruppamento per tipi.. 12/45 6
7 Apprendimento non-supervisionato: Clustering & Classificazione Descrizione numerica dell oggetto: altezza, colore, forma, posizione,. SPAZIO DEI CAMPIONI / DELLE FEATURES Classificatore Classi omogene dell oggetto: (classe A, classe B, ) SPAZIO DELLE CLASSI 13/45 Classificazione Un interpretazione geometrica: Mappatura dello spazio dei campioni nello spazio delle classi. Classe 1 Classe 2 Campione X Classe 3 SPAZIO DEI CAMPIONI / DELLE FEATURES (CARATTERISTICHE) SPAZIO DELLE CLASSI Che differenza c è rispetto al clustering? Cos è un concetto? 14/45 7







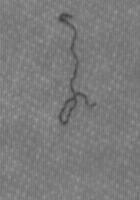
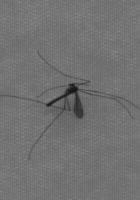





8 Riconoscimento difetti in linee di produzione (finanziato da Electronic Systems: ) regolari irregolari allungati fili insetti macchie su denso Anche: pieghe, arruffati Difetti Classificazione real-time e apprendimento. Feature extraction + SVM 15/45 Esempio di clustering Tesi: ricerca immagini su WEB. Clustering -> Indicizzazione 16/45 8
9 A cosa serve il clustering? Compressione dati (telecomunicazioni, immagini, ); Segmentazione (bio)immagini; Controllo robot; Indicizzazione Riconoscimento automatico; Pattern recognition; Ricostruzione superfici; A cosa serve la classificazione? 17/45 Riconoscimento difetti in linee di produzione (finanziato da Electronic Systems: ) regolari irregolari allungati fili insetti macchie su denso Anche: pieghe, arruffati Difetti Classificazione real-time e apprendimento. Feature extraction + SVM 18/45 9
10 Riassunto Gli agenti Il Reinforcement Learning Gli elementi del RL Un esempio: tris 19/45 Reinforcement learning Nell apprendimento supervisionato, esiste un teacher che dice al sistema quale è l uscita corretta (learning with a teacher). Non sempre e possibile. Spesso si ha a disposizione solamente un informazione qualitativa (a volte binaria, giusto/sbagliato successo/fallimento), puntuale. Questa è un informazione qualitativa. L informazione disponibile si chiama segnale di rinforzo. Non dà alcuna informazione su come aggiornare il comportamento dell agente (e.g. i pesi). Non è possibile definire una funzione costo o un gradiente. Obbiettivo: creare degli agenti intelligenti che abbiano una machinery per apprendere dalla loro esperienza. 20/45 10
11 Reinforcement Learning: caratteristiche Apprendimento mediante interazione con l ambiente. Un agente isolato non apprende. L apprendimento è funzione del raggiungimento di uno o più obbiettivi. Non è necessariamente prevista una ricompensa ad ogni istante di tempo. Le azioni vengono valutate mediante la ricompensa a lungo termine ad esse associata (delayed reward). Il meccanismo di ricerca delle azioni migliori è imparentato con la ricerca euristica: trial-and-error. L agente sente l input, modifica lo stato e genera un azione che massimizza la ricompensa a lungo termine. 21/45 Exploration vs Exploitation Esplorazione (exploration) dello spazio delle azioni per scoprire le azioni migliori. Un agente che esplora solamente raramente troverà una buona soluzione. Le azioni migliori vengono scelte ripetutamente (exploitation) perchè garantiscono ricompensa (reward). Se un agente non esplora nuove soluzioni potrebbe venire surclassato da nuovi agenti più dinamici. Occorre non interrompere l esplorazione. Occorre un approccio statistico per valutare le bontà delle azioni. Exploration ed exploitation vanno bilanciate. Come? 22/45 11
12 Dove agisce un agente? L agente ha un comportamento goal-directed ma agisce in un ambiente incerto non noto a priori o parzialmente noto. Esempio: planning del movimento di un robot. Un agente impara interagendo con l ambiente. Planning può essere sviluppato mentre si impara a conoscere l ambiente (mediante le misure operate dall agente stesso). La strategia è vicina al trial-and-error. 23/45 L ambiente Model of the environment. E uno sviluppo relativamente recente. Da valutazione implicita dello svolgersi delle azioni future (trial-and-error) a valutazione esplicita mediante modello dell ambiente della sequenza di azioni e stati futuri (planning) = dal sub-simblico al simbolico; emerging intelligence. Incorporazione di AI: - Planning (pianificazione delle azioni). - Viene rinforzato il modulo di pianificazione dell agente. -Incorporazione della conoscenza dell ambiente: -- Modellazione dell ambiente (non noto o parzialmente noto). 24/45 12
13 Relazione con l AI Gli agenti hanno dei goal da soddisfare. Approccio derivato dall AI. Nell apprendimento con rinforzo vengono utilizzati strumenti che derivano da aree diverse dall AI: Ricerca operativa. Teoria del controllo. Statistica. L agente impara facendo. Deve selezionare i comportamente che ripetutamente risultano favorevoli a lungo termine. 25/45 Esempi Un giocatore di scacchi. Per ogni mossa ha informazione sulle configurazioni di pezzi che può creare e sulle possibili contro-mosse dell avversario. Una gazzella in 6 ore impara ad alzarsi e correre a 40km/h. Come fa un robot veramente autonomo ad imparare a muoversi in una stanza per uscirne? (cf. competizione Robocare@home). Come impostare i parametri di una raffineria (pressione petrolio, portata.) in tempo reale, in modo da ottenere il massimo rendimento o la massima qualità? 26/45 13
14 Caratteristiche degli esempi Parole chiave: Interazione con l ambiente. L agente impara dalla propria esperienza. Obbiettivo dell agente. Incertezza o conoscenza parziale dell ambiente. Osservazioni: Le azioni modificano lo stato (la situazione), cambiano le possibilità di scelta in futuro (delayed reward). L effetto di un azione non si può prevedere completamente. L agente ha a disposizione una valutazione globale del suo comportamento. Deve sfruttare questa informazione per migliorare le sue scelte. Le scelte migliorano con l esperienza. I problemi possono avere orizzonte temporale finito od infinito. 27/45 Riassunto Gli agenti Il Reinforcement Learning Gli elementi del RL Un esempio: tris 28/45 14
15 I tue tipi di rinforzo L agente deve scoprire quale azione (policy) fornisca la ricompensa massima provando le varie azioni (trial-and-error) sull ambiente. Learning is an adaptive change of behavior and that is indeed the reason of its existence in animals and man (K. Lorentz, 1977). Rinforzo puntuale istante per istante, azione per azione (condizionamento classico). Rinforzo puntuale una-tantum (condizionamento operante), viene rinforzato una catena di azioni, un comportamento. 29/45 Il Condizionamento classico L agente deve imparare una (o più) trasformazione tra input e output. Queste trasformazioni forniscono un comportamento che l ambiente premia. Il segnale di rinforzo è sempre lo stesso per ogni coppia input output. Esempio: risposte riflesse Pavolviane. Campanello (stimolo condizionante) prelude al cibo. Questo induce una risposta (salivazione). La risposta riflessa ad uno stimolo viene evocata da uno stimolo condizionante. Stimolo-Risposta. Lo stimolo condizionante (campanello = input) induce la salivazione (uscita) in risposta al campanello. 30/45 15
16 Condizionamento operante Reinforcement learning (operante). Interessa un comportamento. Una sequenza di input / output che può essere modificata agendo sui parametri che definiscono il comportamento dell agente. Il condizionamento arriva in un certo istante di tempo (spesso una-tantum) e deve valutare tutta la sequenza temporale di azioni, anche quelle precedenti nel tempo. Comportamenti = Sequenza di azioni 31/45 Gli attori del RL Policy. Descrive l azione scelta dall agente: mapping tra stato (input dall ambiente) e azioni. Funzione di controllo. Le policy possono avere una componente stocastica. Viene utilizzato un modello adeguato del comportamento dell agente (e.g. tabella, funzione continua parametrica ). Reward function. Ricompensa immediata. Associata all azione intrapresa in un certo stato. Può essere data al raggiungimento di un goal (esempio: successo / fallimento). E uno scalare. Rinforzo primario. Value function. Cost-to-go. Ricompensa a lungo termine. Somma dei reward: costi associati alle azioni scelte istante per istante + costo associato allo stato finale. Orizzonte temporale ampio. Rinforzo secondario. Ambiente. Può essere non noto o parzialmente noto. L agente deve costruirsi una rappresentazione dell ambiente. Quale delle due è più difficile da ottenere? L agente agisce per massimizzare la funzione Value o Reward? 32/45 16
17 Proprietà del rinforzo L ambiente o l interazione può essere complessa. Il rinforzo può avvenire solo dopo una più o meno lunga sequenza di azioni (delayed reward). E.g. agente = giocatore di scacchi. ambiente = avversario. Problemi collegati: temporal credit assignement. structural credit assignement. L apprendimento non è più da esempi, ma dall osservazione del proprio comportamento nell ambiente. 33/45 Riassunto Reinforcement learning. L agente viene modificato, rinforzando le azioni che sono risultate buone a lungo termine. E quindi una classe di algoritmi iterativi. Self-discovery of a successful strategy (it does not need to be optimal!). La strategia (di movimento, di gioco) non è data a- priori ma viene appresa attraverso trial-and-error. Credit assignement (temporal and structural). Come possiamo procedere in modo efficiente nello scoprire una strategia di successo? Cosa vuol dire modificare l agente? 34/45 17
18 Riassunto Gli agenti Il Reinforcement Learning Gli elementi del RL Un esempio: tris (progetto) 35/45 Gli attori del RL Policy. Descrive l azione scelta dall agente: mapping tra stato e azioni. Funzione di controllo. Ambiente. Descrive tutto quello su cui agisce la policy. Generalmente è non noto o parzialmente noto e deve essere scoperto. Non viene modellato esplicitamente, ma viene stimata la sua reazione alla policy mediante la value function. Reward function. Ricompensa immediata. Associata all azione intrapresa in un certo stato. Può essere data al raggiungimento di un goal (esempio: successo / fallimento). E uno scalare associato allo stato dell agente. Rinforzo primario. Value function. Cost-to-go. Ricompensa a lungo termine. Somma dei reward + costi associati alle azioni scelte istante per istante. Orizzonte temporale ampio. Rinforzo secondario. Ricompensa attesa. Ciclo dell agente (le tre fasi sono sequenziali): 1) Implemento una policy 2) Aggiorno la Value function 3) Aggiorno la policy. 36/45 18
19 Commenti Con molti stati è impossibile esplorarli tutti Generalizzazione. Dalle funzioni combinatorie alle funzioni continue. Può essere inserita della conoscenza a-priori sia sulla policy che sulla Value function. 37/45 Apprendimento della strategia per il gioco del tris 1) We can use classical game theory solution like minmax. This can work for the optimal opponent, not for our actual opponent. 2) We can use dynamic programming optimization, but we need a model of the opponent. 3) We can try a policy and see what happens for many games (evolutionary style, exhaustive search). What can we do? 38/45 19
20 Come impostare il problema mediante RL? State configuration of X and O Value (of the state) probability of winning associated to that state. Which is the probability of a state in which we have 3 X in a row (or column or diagonal)? Which is the probability of a state in which we have 3 0 in a row (or column or diagonal)? We set all the other states to /45 Come decidere la mossa? Supponiamo di essere in una configurazione non terminale. Per ogni mossa valida, possiamo valutare il valore della nuova configurazione che si verrebbe a trovare. Come? Possiamo occasionalmente scegliere delle mosse esploratorie. Quando non ha senso scegliere delle mosse esploratorie? Dobbiamo perciò capire qual è il valore delle diverse configurazioni della scacchiera. 40/45 20
21 Come stimare il valore di ogni configurazione? V(s(t)) V(s(t)) + α [V(s(t+1) V(s)] Tendo ad avvicinare il valore della mia configurazione al valore della configurazione successiva. Esempio di temporal difference learning. Diminuendo α con il numero di partite, la policy converge alla policy ottima per un avversario fissato (cioè che utilizzi sempre la strategia, ovvero sia la stessa distribuzione statistica di mosse). Diminuendo α con il numero di partite, ma tenendolo > 0, la policy converge alla policy ottima anche per un avversario che cambi molto lentamente la sua strategia. 41/45 Esempio O X O X O X O X X X X X scelta perdente -> dopo la mossa dell avversario ho uno stato con value function = 0. X scelta neutrale -> dopo la mossa dell avversario ho uno stato con value function intermedia (pareggio). X scelta vincente -> vado in una configurazione con value function = 1. Cambio la policy e rivaluto la Value function. 42/45 21

22 Cosa fa l agente? Ciclo dell agente (le tre fasi sono sequenziali): 1) Implemento una policy 2) Aggiorno la Value function 3) Aggiorno la policy. 43/45 Riflessioni su RL ed il gioco del tris Supponete che l agente dotato di RL giochi, invece che con un avveresario, contro sé stesso. Cosa pensate che succeda? Secondo voi impararebbe una diversa strategia di gioco? Molte posizioni del tris sembrano diverse ma sono in realtà la stessa per effetto delle simmetrie. Come si può modificare l algoritmo di RL (definizione dello stato) per sfruttare le simmetrie? Come si può migliorare il meccanismo di apprendimento? Supponiamo che l avversario non sfrutti le simmetrie. In questo caso noi possiamo sfruttarle? E vero che configurazioni della scacchiera equivalenti per simmetria devono avere la stessa funzione valore. Potete pensare a modi per migliorare il gioco dell agente? Potete pensare a metodi migliori (più veloci, più robusti.) perché un agente impari a giocare a tris? 44/45 22
23 Riassunto Gli agenti Il Reinforcement Learning Gli elementi del RL Un esempio: tris (progetto) 45/45 23
Università di Bergamo Facoltà di Ingegneria. Intelligenza Artificiale. Paolo Salvaneschi A3_1 V1.3. Agenti
 Università di Bergamo Facoltà di Ingegneria Intelligenza Artificiale Paolo Salvaneschi A3_1 V1.3 Agenti Il contenuto del documento è liberamente utilizzabile dagli studenti, per studio personale e per
Università di Bergamo Facoltà di Ingegneria Intelligenza Artificiale Paolo Salvaneschi A3_1 V1.3 Agenti Il contenuto del documento è liberamente utilizzabile dagli studenti, per studio personale e per
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Sistemi Intelligenti. Riassunto
 Sistemi Intelligenti Learning and Clustering Alberto Borghese and Iuri Frosio Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento t di Scienze dell Informazione
Sistemi Intelligenti Learning and Clustering Alberto Borghese and Iuri Frosio Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento t di Scienze dell Informazione
Apprendimento per Rinforzo
 Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari 11 febbraio 2009 Sommario Apprendimento del Controllo Politiche di Controllo che scelgono azioni
Laurea Magistrale in Informatica Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari 11 febbraio 2009 Sommario Apprendimento del Controllo Politiche di Controllo che scelgono azioni
Intelligenza Artificiale
 Intelligenza Artificiale Introduzione Introduzione 1 Riferimenti } S. Russell, P. Norvig, Artificial Intelligence: a Modern Approach, Prentice Hall, 2010, III edizione (versione in italiano: Intelligenza
Intelligenza Artificiale Introduzione Introduzione 1 Riferimenti } S. Russell, P. Norvig, Artificial Intelligence: a Modern Approach, Prentice Hall, 2010, III edizione (versione in italiano: Intelligenza
Intelligenza Artificiale. Lezione 6bis. Sommario. Problemi di soddisfacimento di vincoli: CSP. Vincoli CSP RN 3.8, 4.3, 4.5.
 Sommario Intelligenza Artificiale CSP RN 3.8, 4.3, 4.5 Giochi RN 5 Lezione 6bis Intelligenza Artificiale Daniele Nardi, 2004 Lezione 6bis 0 Intelligenza Artificiale Daniele Nardi, 2004 Lezione 6bis 1 Problemi
Sommario Intelligenza Artificiale CSP RN 3.8, 4.3, 4.5 Giochi RN 5 Lezione 6bis Intelligenza Artificiale Daniele Nardi, 2004 Lezione 6bis 0 Intelligenza Artificiale Daniele Nardi, 2004 Lezione 6bis 1 Problemi
Intelligenza Artificiale. Soft Computing: Reti Neurali Generalità
 Intelligenza Artificiale Soft Computing: Reti Neurali Generalità Neurone Artificiale Costituito da due stadi in cascata: sommatore lineare (produce il cosiddetto net input) net = S j w j i j w j è il peso
Intelligenza Artificiale Soft Computing: Reti Neurali Generalità Neurone Artificiale Costituito da due stadi in cascata: sommatore lineare (produce il cosiddetto net input) net = S j w j i j w j è il peso
Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione
 Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Corso di Bioinformatica Machine Learning: apprendimento, generalizzazione e stima dell errore di generalizzazione Giorgio Valentini DI Università degli Studi di Milano 1 Metodi di machine learning I metodi
Reti Neurali. Corso di AA, anno 2016/17, Padova. Fabio Aiolli. 2 Novembre Fabio Aiolli Reti Neurali 2 Novembre / 14. unipd_logo.
 Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Reti Neurali Corso di AA, anno 2016/17, Padova Fabio Aiolli 2 Novembre 2016 Fabio Aiolli Reti Neurali 2 Novembre 2016 1 / 14 Reti Neurali Artificiali: Generalità Due motivazioni diverse hanno spinto storicamente
Reti Neurali in Generale
 istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
istemi di Elaborazione dell Informazione 76 Reti Neurali in Generale Le Reti Neurali Artificiali sono studiate sotto molti punti di vista. In particolare, contributi alla ricerca in questo campo provengono
Algoritmi e giochi combinatori
 Algoritmi e giochi combinatori Panoramica Giochi combinatori Programmi che giocano Albero di un gioco L algoritmo Minimax 1 Perché studiare i giochi? Problemi che coinvolgono agenti in competizione tra
Algoritmi e giochi combinatori Panoramica Giochi combinatori Programmi che giocano Albero di un gioco L algoritmo Minimax 1 Perché studiare i giochi? Problemi che coinvolgono agenti in competizione tra
Apprendimento Automatico (Feature Selection e Kernel Learning)
") Apprendimento Automatico (Feature Selection e Kernel Learning) Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Servono tutti gli attributi? Gli
Apprendimento Automatico (Feature Selection e Kernel Learning) Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Servono tutti gli attributi? Gli
Introduzione al controllo
 Corso di Robotica 2 Introduzione al controllo Prof. Alessandro De Luca A. De Luca Cosa vuol dire controllare un robot? si possono dare diversi livelli di definizione completare con successo un programma
Corso di Robotica 2 Introduzione al controllo Prof. Alessandro De Luca A. De Luca Cosa vuol dire controllare un robot? si possono dare diversi livelli di definizione completare con successo un programma
INTRODUZIONE ALLA TEORIA DEI GIOCHI
 Corso di Identificazione dei Modelli e Controllo Ottimo Prof. Franco Garofalo INTRODUZIONE ALLA TEORIA DEI GIOCHI A cura di Elena Napoletano [email protected] Teoria dei Giochi Disciplina che studia
Corso di Identificazione dei Modelli e Controllo Ottimo Prof. Franco Garofalo INTRODUZIONE ALLA TEORIA DEI GIOCHI A cura di Elena Napoletano [email protected] Teoria dei Giochi Disciplina che studia
Marketing - Corso progredito Consumer Behavior
 Corso Progredito - Corso progredito Consumer Behavior Quarta unità didattica L apprendimento L APPRENDIMENTO L apprendimento consiste nella modificazione permanente del comportamento dovuta all esperienza
Corso Progredito - Corso progredito Consumer Behavior Quarta unità didattica L apprendimento L APPRENDIMENTO L apprendimento consiste nella modificazione permanente del comportamento dovuta all esperienza
Introduzione alle Reti Neurali
 Introduzione alle Reti Neurali Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: [email protected] @famo2spaghi http://stegua.github.com Reti Neurali Terminator
Introduzione alle Reti Neurali Stefano Gualandi Università di Pavia, Dipartimento di Matematica email: twitter: blog: [email protected] @famo2spaghi http://stegua.github.com Reti Neurali Terminator
Algoritmi di Ricerca
 Algoritmi di Ricerca Contenuto Algoritmi non informati Nessuna conoscenza sul problema in esame Algoritmi euristici Sfruttano conoscenze specifiche sul problema Giochi Quando la ricerca è ostacolata da
Algoritmi di Ricerca Contenuto Algoritmi non informati Nessuna conoscenza sul problema in esame Algoritmi euristici Sfruttano conoscenze specifiche sul problema Giochi Quando la ricerca è ostacolata da
Algoritmi di ricerca locale
 Algoritmi di ricerca locale Utilizzati in problemi di ottimizzazione Tengono traccia solo dello stato corrente e si spostano su stati adiacenti Necessario il concetto di vicinato di uno stato Non si tiene
Algoritmi di ricerca locale Utilizzati in problemi di ottimizzazione Tengono traccia solo dello stato corrente e si spostano su stati adiacenti Necessario il concetto di vicinato di uno stato Non si tiene
Modelli matematici e Data Mining
 Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
Modelli matematici e Data Mining Introduzione I modelli matematici giocano un ruolo critico negli ambienti di business intelligence e sistemi di supporto alle decisioni. Essi rappresentano un astrazione
Corso di Ingegneria del Software. Modelli di produzione del software
 Corso di Ingegneria del Software a.a. 2009/2010 Mario Vacca [email protected] 1. Concetti di base Sommario 2. 2.1 Modello a cascata 2.2 Modelli incrementali 2.3 2.4 Comparazione dei modelli 2.5
Corso di Ingegneria del Software a.a. 2009/2010 Mario Vacca [email protected] 1. Concetti di base Sommario 2. 2.1 Modello a cascata 2.2 Modelli incrementali 2.3 2.4 Comparazione dei modelli 2.5
Intelligenza collettiva Swarm intelligence
 Intelligenza collettiva Swarm intelligence Andrea Roli [email protected] DEIS Alma Mater Studiorum Università di Bologna Intelligenza collettiva p. 1 Swarm Intelligence Intelligenza collettiva p. 2
Intelligenza collettiva Swarm intelligence Andrea Roli [email protected] DEIS Alma Mater Studiorum Università di Bologna Intelligenza collettiva p. 1 Swarm Intelligence Intelligenza collettiva p. 2
Tecniche Computazionali Avanzate
 Tecniche Computazionali Avanzate Modelli Probabilistici per le Decisioni A.A. 2007/08 Enza Messina Markov Decision Problem Come utilizare la conoscenza dell ambiente per prendere decisioni nel caso in
Tecniche Computazionali Avanzate Modelli Probabilistici per le Decisioni A.A. 2007/08 Enza Messina Markov Decision Problem Come utilizare la conoscenza dell ambiente per prendere decisioni nel caso in
La Teoria dei Giochi. (Game Theory)
") La Teoria dei Giochi. (Game Theory) Giochi simultanei, Giochi sequenziali, Giochi cooperativi. Mario Sportelli Dipartimento di Matematica Università degli Studi di Bari Via E. Orabona, 4 I-70125 Bari (Italy)
La Teoria dei Giochi. (Game Theory) Giochi simultanei, Giochi sequenziali, Giochi cooperativi. Mario Sportelli Dipartimento di Matematica Università degli Studi di Bari Via E. Orabona, 4 I-70125 Bari (Italy)
Machine Learning -1. Seminari di Sistemi Informatici. F.Sciarrone-Università Roma Tre
 Machine Learning -1 Seminari di Sistemi Informatici Sommario Problemi di apprendimento Well-Posed Esempi di problemi well-posed Progettazione di un sistema di apprendimento Scelta della Training Experience
Machine Learning -1 Seminari di Sistemi Informatici Sommario Problemi di apprendimento Well-Posed Esempi di problemi well-posed Progettazione di un sistema di apprendimento Scelta della Training Experience
A.A. 2006/2007 Laurea di Ingegneria Informatica. Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio
 A.A. 2006/2007 Laurea di Ingegneria Informatica Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio Obbiettivi Acquisire familiarità con la nozione di oggetto Apprendere le proprietà
A.A. 2006/2007 Laurea di Ingegneria Informatica Fondamenti di C++ Horstmann Capitolo 3: Oggetti Revisione Prof. M. Angelaccio Obbiettivi Acquisire familiarità con la nozione di oggetto Apprendere le proprietà
MACHINE LEARNING e DATA MINING Introduzione. a.a.2015/16 Jessica Rosati [email protected]
 MACHINE LEARNING e DATA MINING Introduzione a.a.2015/16 Jessica Rosati [email protected] Apprendimento Automatico(i) Branca dell AI che si occupa di realizzare dispositivi artificiali capaci di
MACHINE LEARNING e DATA MINING Introduzione a.a.2015/16 Jessica Rosati [email protected] Apprendimento Automatico(i) Branca dell AI che si occupa di realizzare dispositivi artificiali capaci di
Music Information Retrieval
 : Manipolazione del segnale audio e Music Information Retrieval Music Information Retrieval lezione 9: 11/04/2016 Sound and Music Computing Definizione e scopo Studio della catena di comunicazione relativa
: Manipolazione del segnale audio e Music Information Retrieval Music Information Retrieval lezione 9: 11/04/2016 Sound and Music Computing Definizione e scopo Studio della catena di comunicazione relativa
Calcolo di equilibri auto-confermanti
 Calcolo di equilibri auto-confermanti nei giochi in forma estesa con due giocatori Fabio Panozzo Politecnico di Milano 3 maggio 2010 Fabio Panozzo (Politecnico di Milano) Calcolo di equilibri auto-confermanti
Calcolo di equilibri auto-confermanti nei giochi in forma estesa con due giocatori Fabio Panozzo Politecnico di Milano 3 maggio 2010 Fabio Panozzo (Politecnico di Milano) Calcolo di equilibri auto-confermanti
Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE. Francesco Tura. F. Tura
 Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE Francesco Tura [email protected] 1 Lo strumento dell informatico: ELABORATORE ELETTRONICO [= calcolatore = computer] Macchina multifunzionale Macchina
Informatica ALGORITMI E LINGUAGGI DI PROGRAMMAZIONE Francesco Tura [email protected] 1 Lo strumento dell informatico: ELABORATORE ELETTRONICO [= calcolatore = computer] Macchina multifunzionale Macchina
Minimizzazione a più livelli di reti combinatorie Cristina Silvano
 Minimizzazione a più livelli di reti combinatorie Cristina Silvano Università degli Studi di Milano Dipartimento di Scienze dell Informazione Milano (Italy) Sommario Modello booleano e modello algebrico
Minimizzazione a più livelli di reti combinatorie Cristina Silvano Università degli Studi di Milano Dipartimento di Scienze dell Informazione Milano (Italy) Sommario Modello booleano e modello algebrico
Modelli e Metodi per la Simulazione (MMS)
") Modelli e Metodi per la Simulazione (MMS) [email protected] Programma La simulazione ad eventi discreti, è una metodologia fondamentale per la valutazione delle prestazioni di sistemi complessi (di
Modelli e Metodi per la Simulazione (MMS) [email protected] Programma La simulazione ad eventi discreti, è una metodologia fondamentale per la valutazione delle prestazioni di sistemi complessi (di
Minimizzazione di Reti Logiche Combinatorie Multi-livello
 Minimizzazione di Reti Logiche Combinatorie Multi-livello Maurizio Palesi Maurizio Palesi 1 Introduzione I circuiti logici combinatori sono molto spesso realizzati come reti multi-livello di porte logiche
Minimizzazione di Reti Logiche Combinatorie Multi-livello Maurizio Palesi Maurizio Palesi 1 Introduzione I circuiti logici combinatori sono molto spesso realizzati come reti multi-livello di porte logiche
Cenni di ottimizzazione dinamica
 Cenni di ottimizzazione dinamica Testi di riferimento: K. Dixit Optimization in Economic Theory. Second Edition, 1990, Oxford: Oxford University Press. A. C. Chiang Elements of Dynamic Optimization, 1992,
Cenni di ottimizzazione dinamica Testi di riferimento: K. Dixit Optimization in Economic Theory. Second Edition, 1990, Oxford: Oxford University Press. A. C. Chiang Elements of Dynamic Optimization, 1992,
Simulazione. D.E.I.S. Università di Bologna DEISNet
 Simulazione D.E.I.S. Università di Bologna DEISNet http://deisnet.deis.unibo.it/ Introduzione Per valutare le prestazioni di un sistema esistono due approcci sostanzialmente differenti Analisi si basa
Simulazione D.E.I.S. Università di Bologna DEISNet http://deisnet.deis.unibo.it/ Introduzione Per valutare le prestazioni di un sistema esistono due approcci sostanzialmente differenti Analisi si basa
Circuiti e algoritmi per l elaborazione dell informazione
 Università di Roma La Sapienza Facoltà di Ingegneria Laurea Specialistica in Ingegneria Elettronica Orientamento: Circuiti e algoritmi per l elaborazione dell informazione L x[n] y[n] Circuito: V g (t)
Università di Roma La Sapienza Facoltà di Ingegneria Laurea Specialistica in Ingegneria Elettronica Orientamento: Circuiti e algoritmi per l elaborazione dell informazione L x[n] y[n] Circuito: V g (t)
Cercare il percorso minimo Ant Colony Optimization
 Cercare il percorso minimo Ant Colony Optimization Author: Luca Albergante 1 Dipartimento di Matematica, Università degli Studi di Milano 4 Aprile 2011 L. Albergante (Univ. of Milan) PSO 4 Aprile 2011
Cercare il percorso minimo Ant Colony Optimization Author: Luca Albergante 1 Dipartimento di Matematica, Università degli Studi di Milano 4 Aprile 2011 L. Albergante (Univ. of Milan) PSO 4 Aprile 2011
Teorie dell apprendimento, teorie della mente e dida0ca. Romina Nes+
 Teorie dell apprendimento, teorie della mente e dida0ca Romina Nes+ E fu la mente. Le strategie e le metodologie didattiche sono influenzate dalle teorie della mente e dalle teorie dell apprendimento.
Teorie dell apprendimento, teorie della mente e dida0ca Romina Nes+ E fu la mente. Le strategie e le metodologie didattiche sono influenzate dalle teorie della mente e dalle teorie dell apprendimento.
Per un vocabolario filosofico dell informatica. Angelo Montanari Dipartimento di Matematica e Informatica Università degli Studi di Udine
 Per un vocabolario filosofico dell informatica Angelo Montanari Dipartimento di Matematica e Informatica Università degli Studi di Udine Udine, 11 maggio, 2015 Obiettivi del corso In un ciclo di seminari,
Per un vocabolario filosofico dell informatica Angelo Montanari Dipartimento di Matematica e Informatica Università degli Studi di Udine Udine, 11 maggio, 2015 Obiettivi del corso In un ciclo di seminari,
Scale di Misurazione Lezione 2
 Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Apprendimento Automatico (Lezione 1)
") Apprendimento Automatico (Lezione 1) Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Orario 40 ore di lezione in aula (5cfu) 8 ore di laboratorio
Apprendimento Automatico (Lezione 1) Fabio Aiolli www.math.unipd.it/~aiolli Sito web del corso www.math.unipd.it/~aiolli/corsi/1516/aa/aa.html Orario 40 ore di lezione in aula (5cfu) 8 ore di laboratorio
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista
 Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Minimizzazione di Reti Logiche Combinatorie Multi-livello. livello
 Minimizzazione di Reti Logiche Combinatorie Multi-livello livello Maurizio Palesi Maurizio Palesi 1 Introduzione I circuiti logici combinatori sono molto spesso realizzati come reti multi-livello di porte
Minimizzazione di Reti Logiche Combinatorie Multi-livello livello Maurizio Palesi Maurizio Palesi 1 Introduzione I circuiti logici combinatori sono molto spesso realizzati come reti multi-livello di porte
Sistemi e modelli. Sistemi
 Sistemi e modelli Obbiettivo: sviluppare metodologie e strumenti di analisi quantitativa della QoS di sistemi costruzione e soluzione di modelli per la valutazione di prestazioni e affidabilità di sistemi
Sistemi e modelli Obbiettivo: sviluppare metodologie e strumenti di analisi quantitativa della QoS di sistemi costruzione e soluzione di modelli per la valutazione di prestazioni e affidabilità di sistemi
Fondamenti di Automatica Prof. Giuseppe Oriolo. Introduzione
 Fondamenti di Automatica Prof. Giuseppe Oriolo Introduzione cos è automatica: disciplina che studia le modalità attraverso le quali una sequenza di eventi desiderati avviene in maniera autonoma (Wikipedia)
Fondamenti di Automatica Prof. Giuseppe Oriolo Introduzione cos è automatica: disciplina che studia le modalità attraverso le quali una sequenza di eventi desiderati avviene in maniera autonoma (Wikipedia)
Apprendimento Automatico
 Metodologie per Sistemi Intelligenti Apprendimento Automatico Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo regionale di Como Intelligenza Artificiale "making a machine
Metodologie per Sistemi Intelligenti Apprendimento Automatico Prof. Pier Luca Lanzi Laurea in Ingegneria Informatica Politecnico di Milano Polo regionale di Como Intelligenza Artificiale "making a machine
Cenni di apprendimento in Reti Bayesiane
 Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2.
 Scuola Sec. SECONDO Grado Gara 2 IND - 15/16 ESERCIZIO 1 Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2. Sono date le seguenti regole: regola(1,[a],b)
Scuola Sec. SECONDO Grado Gara 2 IND - 15/16 ESERCIZIO 1 Si faccia riferimento all Allegato A - OPS 2016, problema ricorrente REGOLE E DEDUZIONI, pagina 2. Sono date le seguenti regole: regola(1,[a],b)
Reti Logiche (Nettuno) Test di autovalutazione del 19/5/94
 Test di autovalutazione del 19/5/94") Test di autovalutazione del 19/5/94 Al fine di rilevare errori di trasmissione, un dato numerico compreso tra 0 e 9 viene trasmesso utilizzando il cosiddetto codice 2 su 5, ossia trasmettendo 5 bit nei
Test di autovalutazione del 19/5/94 Al fine di rilevare errori di trasmissione, un dato numerico compreso tra 0 e 9 viene trasmesso utilizzando il cosiddetto codice 2 su 5, ossia trasmettendo 5 bit nei
Algoritmi Genetici. Alessandro Bollini
 Alessandro Bollini [email protected] Dipartimento di Informatica e Sistemistica Università di Pavia Via Ferrata, 1 27100 Pavia Algoritmi Genetici Algoritmo genetico Algoritmo evolutivo. Modello evolutivo
Alessandro Bollini [email protected] Dipartimento di Informatica e Sistemistica Università di Pavia Via Ferrata, 1 27100 Pavia Algoritmi Genetici Algoritmo genetico Algoritmo evolutivo. Modello evolutivo
I giochi con avversario. I giochi con avversario. Introduzione. Giochi come problemi di ricerca. Il gioco del NIM.
 I giochi con avversario I giochi con avversario Maria Simi a.a. 26/27 Regole semplici e formalizzabili eterministici, due giocatori, turni alterni, zero-sum, informazione perfetta (ambiente accessibile)
I giochi con avversario I giochi con avversario Maria Simi a.a. 26/27 Regole semplici e formalizzabili eterministici, due giocatori, turni alterni, zero-sum, informazione perfetta (ambiente accessibile)
Un paio di esempi su serie e successioni di funzioni
 Un paio di esempi su serie e successioni di funzioni 29 novembre 2010 1 Successione di funzioni Ricordiamo innanzitutto un po di definizioni. Definizione 1. Una successione di funzioni è una corrispondenza
Un paio di esempi su serie e successioni di funzioni 29 novembre 2010 1 Successione di funzioni Ricordiamo innanzitutto un po di definizioni. Definizione 1. Una successione di funzioni è una corrispondenza
Programma operativo Regione Lombardia/Ministero del Lavoro/Fondo Sociale Europeo, Obiettivo 3 Misura C3
 Programma operativo Regione Lombardia/Ministero del Lavoro/Fondo Sociale Europeo, Obiettivo 3 Misura C3 Progetto ID 24063 Moduli e contenuti professionalizzanti inseriti nei corsi di laurea e diplomi universitari
Programma operativo Regione Lombardia/Ministero del Lavoro/Fondo Sociale Europeo, Obiettivo 3 Misura C3 Progetto ID 24063 Moduli e contenuti professionalizzanti inseriti nei corsi di laurea e diplomi universitari
Corso di Storia della Pedagogia. Momenti e problemi della pedagogia del Novecento. 03. Il comportamentismo: le teorie
 SSIS Lazio 2006-2007 Indirizzi Tecnologico ed Economico-Giuridico Corso di Storia della Pedagogia Momenti e problemi della pedagogia del Novecento 03. Il comportamentismo: le teorie Prof.ssa Eleonora Guglielman
SSIS Lazio 2006-2007 Indirizzi Tecnologico ed Economico-Giuridico Corso di Storia della Pedagogia Momenti e problemi della pedagogia del Novecento 03. Il comportamentismo: le teorie Prof.ssa Eleonora Guglielman
Moduli combinatori Barbara Masucci
 Architettura degli Elaboratori Moduli combinatori Barbara Masucci Punto della situazione Ø Abbiamo studiato le reti logiche e la loro minimizzazione Ø Obiettivo di oggi: studio dei moduli combinatori di
Architettura degli Elaboratori Moduli combinatori Barbara Masucci Punto della situazione Ø Abbiamo studiato le reti logiche e la loro minimizzazione Ø Obiettivo di oggi: studio dei moduli combinatori di
Sviluppo di programmi
 Sviluppo di programmi Per la costruzione di un programma conviene: 1. condurre un analisi del problema da risolvere 2. elaborare un algoritmo della soluzione rappresentato in un linguaggio adatto alla
Sviluppo di programmi Per la costruzione di un programma conviene: 1. condurre un analisi del problema da risolvere 2. elaborare un algoritmo della soluzione rappresentato in un linguaggio adatto alla
LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI
 Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Read Online and Download Ebook LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO TESTAMENTO VERSIONE RIVEDUTA BY GIOVANNI LUZZI DOWNLOAD EBOOK : LA SACRA BIBBIA: OSSIA L'ANTICO E IL NUOVO Click link bellow and
Studio e implementazione di un OCR per auto-tele-lettura dei contatori di gas e acqua
 POLITECNICO DI MILANO Corso di Laurea in Ingegneria Informatica Dipartimento di Elettronica e Informazione Studio e implementazione di un OCR per auto-tele-lettura dei contatori di gas e acqua AI & R Lab
POLITECNICO DI MILANO Corso di Laurea in Ingegneria Informatica Dipartimento di Elettronica e Informazione Studio e implementazione di un OCR per auto-tele-lettura dei contatori di gas e acqua AI & R Lab
Intelligenza Artificiale
 Intelligenza Artificiale 17 Marzo 2005 Nome e Cognome: Matricola: ESERCIZIO N 1 Ricerca Cieca 5 punti 1.A) Elencare in modo ordinato i nodi (dell'albero sotto) che vengono scelti per l'espansione dalle
Intelligenza Artificiale 17 Marzo 2005 Nome e Cognome: Matricola: ESERCIZIO N 1 Ricerca Cieca 5 punti 1.A) Elencare in modo ordinato i nodi (dell'albero sotto) che vengono scelti per l'espansione dalle
La simulazione è l'imitazione di un processo o di un sistema reale per un
 1 2 La simulazione è l'imitazione di un processo o di un sistema reale per un determinato periodo di tempo. La simulazione è l'imitazione di un processo o di un sistema reale per un determinato periodo
1 2 La simulazione è l'imitazione di un processo o di un sistema reale per un determinato periodo di tempo. La simulazione è l'imitazione di un processo o di un sistema reale per un determinato periodo
Elementi di Probabilità e Statistica
 Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A.
 L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A. Corso di Economia Industriale Lezione dell 8/01/2010 Valutazione delle peformance Obiettivo: valutare le attività di
L efficienza e la valutazione delle performance Concetti ed introduzione alla D.E.A. Corso di Economia Industriale Lezione dell 8/01/2010 Valutazione delle peformance Obiettivo: valutare le attività di
Sistemi di Elaborazione delle Informazioni
 SCUOLA DI MEDICINA E CHIRURGIA Università degli Studi di Napoli Federico II Corso di Sistemi di Elaborazione delle Informazioni Dott. Francesco Rossi a.a. 2016/2017 1 I linguaggi di programmazione e gli
SCUOLA DI MEDICINA E CHIRURGIA Università degli Studi di Napoli Federico II Corso di Sistemi di Elaborazione delle Informazioni Dott. Francesco Rossi a.a. 2016/2017 1 I linguaggi di programmazione e gli
Il calcolatore universale, origini e nuovi paradigmi
 Il calcolatore universale, origini e nuovi paradigmi Lucia Pomello Università degli studi di Milano Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione 24 febbraio 2017 L evoluzione dell
Il calcolatore universale, origini e nuovi paradigmi Lucia Pomello Università degli studi di Milano Bicocca Dipartimento di Informatica, Sistemistica e Comunicazione 24 febbraio 2017 L evoluzione dell
Sistemi di Interpretazione dati e Diagnosi Overview
 Università di Bergamo Facoltà di Ingegneria Intelligenza Artificiale Paolo Salvaneschi A10_1 V1.0 Sistemi di Interpretazione dati e Diagnosi Overview Il contenuto del documento è liberamente utilizzabile
Università di Bergamo Facoltà di Ingegneria Intelligenza Artificiale Paolo Salvaneschi A10_1 V1.0 Sistemi di Interpretazione dati e Diagnosi Overview Il contenuto del documento è liberamente utilizzabile
I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO
 BY BRUNO OSIMO") I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO READ ONLINE AND DOWNLOAD EBOOK : I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO
I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO CON ESEMPI BASATI SULLA TRADUZIONE DELLA BIBBIA (ITALIAN EDITION) BY BRUNO OSIMO READ ONLINE AND DOWNLOAD EBOOK : I CAMBIAMENTI PROTOTESTO-METATESTO, UN MODELLO