Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano
|
|
|
- Franca Bianco
- 5 anni fa
- Visualizzazioni
Transcript
1 Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano ESERCITAZIONI DEL 20 e 27 APRILE 2012 Sommario 1.1 VENDITA Dimensioni = { PROD, DATA,CASSA,COM } Esercizio A (20 Aprile 2012) : SCHEMA5: NS DATA, {PROD,DATA} CASSA Specifica dei pattern in SQL OLAP Cubo OLAP: Specifica dei pattern per dimensioni degeneri Aggregabilità in presenza di Dipendenze Funzionali tra le dimensioni Nota sulle Dipendenze Funzionali Soluzione Esercizio B (27 Aprile 2012) Cubo OLAP : specifica dei pattern Esercizio C : confronto FD tra dimensioni e attributi cross dimensionali
2 1.1 VENDITA Dimensioni = { PROD, DATA,CASSA,COM } Si considerano 6 differenti DBO, cioè 6 DBO con differente schema. Per confrontarli si effettua uno schema di Fatto che ha SEMPRE le stesse dimensioni : { PROD, DATA,CASSA,COM} In questo modo si potrà in particolare discutere l effetto delle FD tra le dimensioni: infatti, i differenti schemi comportano differenti FD sulle dimensioni. MISURE: NUMEROVENDITE = COUNT(*) NUMEROCLIENTI = COUNT(DISTINCT NS), dove NS è il NumeroScontrino Di ogni DBO si considera il suo schema E/R ed il corrispondente schema relazionale SCHEMA1 VENDITA(NV,PROD,CASSA, COMM,NS,DATA) SCHEMA2 : NS DATA VENDITA(NV,PROD,CASSA, COMM, NS:SCONTRINO) SCONTRINO(NS,DATA) SCHEMA3 : NS DATA, NS CASSA VENDITA(NV,PROD, COMM, NS:SCONTRINO) SCONTRINO(NS,DATA,CASSA) SCHEMA4: NS DATA, PROD CASSA VENDITA(NV,PROD:PRODOTTO COMM, NS:SCONTRINO) SCONTRINO(NS,DATA) PRODOTTO(PROD, CASSA) SCHEMA5: NS DATA, {PROD,DATA} CASSA 2
3 VENDITA(NV,PROD:PRODOTTO COMM, NS:SCONTRINO) SCONTRINO(NS,DATA:DATA) DATA(DATA) PRODOTTO(PROD) ALLACASSA(PROD:PRODOTTO, DATA:DATA, CASSA) SCHEMA6: NS DATA, {PROD,DATA} CASSA, CASSA COMM Si toglie COMM da VENDITA e si reifica ALLACASSA: VENDITA(NV,PROD:PRODOTTO NS:SCONTRINO) SCONTRINO(NS,DATA:DATA) DATA(DATA) PRODOTTO(PROD) ALLACASSA(PROD:PRODOTTO, DATA:DATA, CASSA:CASSA) CASSA(CASSA, COMM) NUMEROCLIENTI = COUNT(DISTINCT NS), dove NS è il NumeroScontrino La presenza della FD: NS DATA comporta che 1) NUMEROCLIENTI è aggregabile rispetto a DATA 2) NUMEROCLIENTI non è aggregabile rispetto alle altre dimensioni Nel seguito si vuole discutere come le FD tra le dimensioni influenzino l aggregabilità della misura NUMEROCLIENTI. 3
4 Nota. Nella specifica del compito scritto: Consideriamo un DBO con il seguente schema E/R ed il corrispondente schema relazionale (nello schema relazionale ci possono essere vincoli di integrità aggiuntivi) Questo significa che viene dato lo schema E/R ma per non complicarlo molto, alcune cose particolari vengono aggiunte solo nello schema relazionale, cioè vengono considerate come aggiunte allo schema relazionale: queste aggiunte riguardano chiavi, FD sia elencate esplicitamente che date attraverso l aggiunta di tabelle Ad esempio nel compito scritto, invece di riportare lo schema E/R dello SCHEMA6 che risulta complicato a causa della reificazione introdotta per esprimere la FD: CASSA COMM, viene dato il seguente schema E/R più semplice senza la FD: CASSA COMM e tale FD viene aggiunta allo schema relazionale (ricordiamo che la FD è un vincolo di integrità) VENDITA(NV,PROD:PRODOTTO NS:SCONTRINO) SCONTRINO(NS,DATA:DATA) DATA(DATA) PRODOTTO(PROD) ALLACASSA(PROD:PRODOTTO, DATA:DATA, CASSA,COMM) FD: CASSA COMM Si noti che ALLACASSA(PROD:PRODOTTO, DATA:DATA, CASSA,COMM) FD: CASSA COMM È equivalente a ALLACASSA(PROD:PRODOTTO,DATA:DATA, CASSA:CASSA) CASSA(CASSA, COMM) Estremizzando il discorso: per specificare lo SCHEMA5 si può considerare uno schema costituito dalla sola entità VENDITA (quindi il relazionale costituito da una sola relazione VENDITA) ed aggiungere nel relazionale le due FD: VENDITA(NV,PROD,CASSA, COMM,NS,DATA) {PROD,DATA} CASSA NS DATA Questo può essere utile per creare i dati di prova del DBO (come abbiamo fatto ad esempio in In questo caso lo schema E/R e del tutto incompleto in quanto non contiene, non esprime praticamente niente. Normalmente nel compito si cerca di dare uno schema E/R il più completo possibile, lasciando fuori due tipologie di FD 1) Quelle più semplici, classico esempio DATA MESE, MESE ANNO 2) Quelle più complicate, quali CASSA COMM nello schema precedente 4
5 1.2 Esercizio A (20 Aprile 2012) : SCHEMA5: NS DATA, {PROD,DATA} CASSA La presenza della FD: NS DATA comporta che 1) NUMEROCLIENTI è aggregabile rispetto a DATA 2) NUMEROCLIENTI non è aggregabile rispetto alle altre dimensioni Quindi NUMCLIENTI è calcolabile per i pattern che contengono { PROD, CASSA,COMM } P0= {PROD, CASSA,COMM,DATA} P1= {PROD, CASSA,COMM } A questi pattern verranno aggiunti quelli equivalenti grazie alla FD tra le dimensioni. Il risultato finale sarà che NUMCLIENTI è calcolabile per tutti i pattern che contengono {PROD,COM}. Prendendo in considerazione le FD tra le dimensioni, cioè la sola FD2: {PROD,DATA} CASSA e per ciascuno dei due pattern P0 e P1 si controlla se grazie a tali FD si possono ricavare dei pattern equivalenti e quindi tali per cui NUMCLIENTI sia calcolabile anche per tali pattern. Per FD2: {PROD,DATA} CASSA il primo pattern P0 è equivalente a P2= {PROD, COMM,DATA}. Quindi NUMCLIENTI è calcolabile per i pattern P0= {PROD, CASSA,COMM,DATA} P1= {PROD, CASSA,COMM } P2= {PROD, COMM,DATA} Individuati l insieme di pattern P per i quali NUMCLIENTI è calcolabile, si vuole ora scrivere una espressione per individuare P sia in SQL OLAP che nel cubo OLAP: in questo modo sarà possibile visualizzare NUMCLIENTI solo per i pattern in P (oppure visualizzarlo in modo diverso per i restanti pattern: segno, indicazione * oppure un colore diverso) Specifica dei pattern in SQL OLAP Ricordiamo che in SQL OLAP, dato un pattern P = {A1,., An}, un suo sub pattern P1={A1,, Ak}, con k <= n è individuato dalla condizione C_P1: G(A1)=0 AND G(Ak)=0 AND G(Ak+1)=1 AND G(An)=1 Dove G =GROUPING. Per individuare un insiemi di pattern, si deve effettuare la somma logica (l OR) delle condizioni. Quindi per individuare l insieme di pattern per i quali NUMCLIENTI è calcolabile P0={PROD, CASSA,COMM,DATA} P1={PROD, CASSA,COMM} P2= {PROD, COMM,DATA} Si dovrà scrivere in SQL OLAP G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 0 G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 1 G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 OR OR Anche se non necessario, l espressione si può semplificare tramite i teoremi dell Algebra Booleana o con le mappe di Karnaugh ( Ad esempio G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 0 G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 1 OR è equivalente a G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 e quindi la precedente espressione si può semplificare in G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 5
6 La semplificazione non è necessaria, ha il solo scopo di ridurre il codice SQL da scrivere SELECT COM, PROD,CASSA,DATA, NUMCLIENTI = CASE WHEN ( G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 ) THEN SUM(NC) ELSE END, NVENDITE=SUM(NVENDITE) FROM FACT_TABLE GROUP BY PROD,CASSA,DATA,COM WITH CUBE Oppure, per realizzare solo l insieme di pattern per i quali NUMCLIENTI è calcolabile SELECT COM, PROD,CASSA,DATA, NUMCLIENTI = SUM(NC), NVENDITE=SUM(NVENDITE) FROM FACT_TABLE GROUP BY PROD,CASSA,DATA,COM WITH CUBE HAVING ( G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0) Ricordiamo che lo scopo delle interrogazioni SQL OLAP, oltre a quello di effettuare alcune analisi direttamente in SQL, cioè senza usare uno specifico sistema OLAP, è anche quello di verificare i risultati: ad esempio, nel nostro caso grazie alla precedente interrogazione possiamo verificare se il calcolo della misura NUMCLIENTI è corretta (effettuando un confronto con i risultati ottenuti nel DBO). Inoltre le interrogazioni SQL OLAP servono anche per verificare il passo successivo di realizzazione ed alimentazione del Cubo OLAP Cubo OLAP: Specifica dei pattern per dimensioni degeneri Per scrivere i pattern in Analysis Service si deve riscrivere G(A)=0 e G(A)=1 in termini di condizioni sui membri dei livelli in cui è mappato l attributo A. Nel nostro esempio, vogliamo riscrivere G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 Nel caso più semplice in cui A corrisponde all unico livello della dimensione D (ovvero nel caso in cui la dimensione sia degenere) e la dimensione D ha il livello speciale (ALL) allora G(A)=0 equivale a D.CURRENTMEMBER.LEVEL.ORDINAL <> 0 G(A)=1 equivale a D.CURRENTMEMBER.LEVEL.ORDINAL = 0 Si noti che senza il livello speciale (ALL) G(A)=1 non può essere ottenuto e quindi non si riesce ad ottenere il totale per quella Dimensione. Quindi per scrivere : G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 Si deve tradurre ciascun pattern e poi mettere in OR le espressioni ottenute PROD.CURRENTMEMBER.LEVEL.ORDINAL <> 0 AND CASSA.CURRENTMEMBER.LEVEL.ORDINAL <> 0 AND COMM.CURRENTMEMBER.LEVEL.ORDINAL <> 0 OR PROD.CURRENTMEMBER.LEVEL.ORDINAL <> 0 AND CASSA.CURRENTMEMBER.LEVEL.ORDINAL = 0 AND COMM.CURRENTMEMBER.LEVEL.ORDINAL <> 0 AND DATA.CURRENTMEMBER.LEVEL.ORDINAL <> 0 6
7 1.3 Aggregabilità in presenza di Dipendenze Funzionali tra le dimensioni Nella sezione precedente è stato determinato che NUMCLIENTI è calcolabile per i pattern P0= {PROD, CASSA,COMM,DATA} P1= {PROD, CASSA,COMM } P2= {PROD, COMM,DATA} Ora, considerato che NUMCLIENTI è aggregabile rispetto a DATA, verifichiamo se togliendo DATA da P2= {PROD, COMM,DATA} NUMCLIENTI è ancora calcolabile? La risposta è positiva quindi NUMCLIENTI è calcolabile anche per P3= {PROD, COMM } In definitiva NUMCLIENTI è calcolabile per i pattern P0= {PROD, CASSA,COMM,DATA} P1= {PROD, CASSA,COMM } P2= {PROD, COMM,DATA} P3= {PROD, COMM } Espressione SQL OLAP: G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 0 OR G(PROD)=0 AND G(CASSA)=0 AND G(COMM)=0 AND G(DATA) = 1 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 0 OR G(PROD)=0 AND G(CASSA)=1 AND G(COMM)=0 AND G(DATA) = 1 Semplificando questa espressione si ottiene G(PROD)=0 AND G(COMM)=0. In definitiva NUMCLIENTI è calcolabile per tutti i pattern che contengono PROD e COMM, cioè che contengono {PROD,COM}. Riassumendo: la FD: NS DATA comporta che NUMCLIENTI è calcolabile per i pattern che contengono { PROD, CASSA,COMM }. Questo insieme si può estendere considerando la FD tra le dimensioni FD2: {PROD,DATA} CASSA concludendo che NUMCLIENTI è calcolabile per tutti i pattern che contengono {PROD,COM}. E' possibile calcolare questo risultato con un altro procedimento, che generalmente risulta più semplice : il procedimento è quello di semplificare prima P0 sulla base delle FD tra le dimensioni e quindi considerare le non aggregabilità; In presenza di FD tra le dimensioni, per calcolare l insieme dei pattern per i quali NUMCLIENTI è calcolabile si procede come segue: 1) Si considera l insieme delle dimensioni, cioè il pattern primario P0= {PROD, CASSA,COMM,DATA} 2) Si semplifica P0 considerando le FD tra le dimensioni, nell esempio FD2:{PROD,DATA} CASSA P0_key= {PROD, CASSA,COMM,DATA} Per semplificazione si intende l eliminazione di una dimensione Di tale che esista una FD tra le dimensioni X Di. Con queste eliminazioni si individua tra tutti i pattern equivalenti a P0 quello più piccolo ; tale insieme viene indicato con P0_key. 3) Si considera P0_key ; dato che NUMCLIENTI è non aggregabile rispetto a PROD, CASSA e COMM allora è calcolabile per tutti i pattern di P0_key che contengono PROD, CASSA e COMM. In termini più generali, data una misura M sia M_NA = { D1,, Dk } l insieme delle dimensioni per le quali M è non aggregabile; allora M può essere calcolato per ogni sottoinsieme che contiene M_NA P0_key Nel nostro esempio NUMEROCLIENTI_NA = {PROD, CASSA,COMM } e quindi l intersezione risulta {PROD, COMM }: Si ottiene quindi lo stesso risultato visto in precedenza. 7
8 Questo discorso può essere generalizzato: si può verificare che una qualsiasi misura è sempre aggregabile rispetto ad una dimensione in P0 ma non in P0_key (nel nostro esempio rispetto a CASSA) e pertanto il controllo delle non aggregabilità può essere effettuato rispetto a P0_key. In definitiva il procedimento che seguiremo è così schematizzabile: 1) Si considera l insieme delle dimensioni, cioè il pattern primario P0 = {D1,, Dn }. 2) Si semplifica P0 considerando le FD tra le dimensioni. Per semplificazione si intende l eliminazione di una Di tale che esista una FD tra le dimensioni X Di. Con queste eliminazioni si individua tra tutti i pattern equivalenti a P0 quello più piccolo ; tale insieme viene indicato con P0_key. Algoritmo di semplificazione di P0 P0_key = P0; FOR i=1 to i=n, se esiste una FD : X Di, dove X P0, Di P0 togliere Di da P0_key : P0_key = P0_key { Di } 3) Si valutano le aggregabilità delle misure rispetto alle sole dimensioni in P0_key : misura M non aggregabile per M_NA = {D1,, Dk }, Di P0_key 4) allora M si può calcolare per i pattern di P0 che contengono M_NA = { D1,, Dk }. Tale insieme è caratterizzato da Nota sulle Dipendenze Funzionali G(D1) = 0 AND AND G(Dk) = 0 Dato P0 = {D1,, Dn } se consideriamo P0 come una relazione P0(D1,, Dn) l operazione di semplificare P0 = {D1,, Dn } equivale a calcolare una chiave P0_key di P0: intuitivamente P0_key è tra tutti i pattern equivalenti a P0 quello più piccolo (ricordiamo il concetto di chiave: una chiave deve essere minimale pag 74 del libro di Sistemi Informativi) Si noti che P0_key Di, per ogni i. Il problema di individuare P0_key è quindi riconducibile al problema di trovare una chiave (e, più in generale, le chiavi) di una relazione, dato un insieme di FD. Il problema è discusso in Sezione 5.2. RAGIONAMENTO SULLE DIPENDENZE FUNZIONALI del libro di Sistemi Informativi dove è anche presentato un algoritmo generale per individuare le chiavi (Algoritmo KEY) Esempio: P0(A,B,C) con le seguenti tre FD: A B, B C, C A P0 ha tre chiavi : chiave1 = A, chiave2=b e chiave3=c In questo caso il nostro algoritmo di semplificazione di P0 dato in precedenza non funzionerebbe, in quanto restituirebbe P0_key vuoto! Questo è dovuto alla particolarità dell esempio: si ha un ciclo sulle FD, cioè partendo da A si arriva ad A. In definitiva, l algoritmo dato per la semplificazione di P0 funziona salvo casi particolari. 8
9 1.3.2 Soluzione Per i 6 differenti schemi dati in precedenza si riporta la discussione per le dipendenze funzionali tra le dimensioni e la misura NUMCLIENTI SCHEMA1 Non ci sono FD tra le dimensioni, quindi P0_key = P0 = {PROD, CASSA,COMM,DATA} Non ci sono FD del tipo NS Dimensione: NUMCLIENTI è non aggregabile rispetto a PROD, CASSA,COMM,DATA NUMCLIENTI è calcolabile per i pattern che contengono {PROD, CASSA,COMM,DATA} cioè solo per P0 = {PROD, CASSA,COMM,DATA} Tale insieme di pattern (che in questo caso è un unico pattern) è caratterizzato da G(PROD) = 0 AND G(CASSA) = 0 AND G(COMM) = 0 AND G(DATA) = 0 SCHEMA2 : NS DATA Non ci sono FD tra le dimensioni, quindi P0_key = P0 = {PROD, CASSA,COMM,DATA} Per la FD NS DATA: NUMCLIENTI è non aggregabile rispetto a PROD, CASSA,COMM NUMCLIENTI è calcolabile per i pattern che contengono {PROD, CASSA,COMM }. Tale insieme di pattern è caratterizzato da G(PROD) = 0 AND G(CASSA) = 0 AND G(COMM) = 0 SCHEMA3 : NS DATA, NS CASSA Non ci sono FD tra le dimensioni, quindi P0_key = P0 = {PROD, CASSA,COMM,DATA} Per le FD NS DATA e NS CASSA: NUMCLIENTI è non aggregabile rispetto a PROD, COMM NUMCLIENTI è calcolabile per i pattern che contengono {PROD, COMM }. Tale insieme di pattern è caratterizzato da G(PROD) = 0 AND G(COMM) = 0 9
10 SCHEMA4: NS DATA, PROD CASSA Per la FD PROD CASSA tra le dimensioni, P0_key ={PROD, COMM,DATA} Si noti che questo è lo SCHEMA2 con in più la FD PROD CASSA tra le dimensioni; le non aggregabilità vengono valutate direttamente con riferimento a P0_key Per la FD NS DATA: NUMCLIENTI è non aggregabile rispetto a PROD, COMM NUMCLIENTI è calcolabile per i pattern di P0_key che contengono {PROD, COMM }. Tale insieme di pattern è caratterizzato da: G(PROD) = 0 AND G(COMM) = 0 Nello schema di Fatto risultante verrà indicata per NUMCLIENTI la non aggregabilità rispetto a PROD, COMM. SCHEMA5: NS DATA, {PROD,DATA} CASSA Per la FD {PROD,DATA} CASSA tra le dimensioni, P0_key ={PROD, COMM,DATA} Si noti che questo è lo SCHEMA2 con in più la FD PROD CASSA tra le dimensioni; le non aggregabilità vengono valutate direttamente con riferimento a P0_key Per la FD NS DATA: NUMCLIENTI è non aggregabile rispetto a PROD, COMM NUMCLIENTI è calcolabile per i pattern di P0_key che contengono {PROD, COMM }. Tale insieme di pattern è caratterizzato da G(PROD) = 0 AND G(COMM) = 0 Nello schema di Fatto risultante verrà indicata per NUMCLIENTI la non aggregabilità rispetto a PROD, COMM. (vedere eserciziob ) SCHEMA6: NS DATA, {PROD,DATA} CASSA, CASSA COMM Per le FD {PROD,DATA} CASSA e CASSA COMM tra le dimensioni, P0_key ={PROD, DATA} Si noti che questo è lo SCHEMA2 con in più le due FD tra le dimensioni; le non aggregabilità vengono valutate direttamente con riferimento a P0_key Per la FD NS DATA: NUMCLIENTI è non aggregabile rispetto a PROD NUMCLIENTI è calcolabile per i pattern di P0_key che contengono {PROD }. Tale insieme di pattern è caratterizzato da G(PROD) = 0 Nello schema di Fatto risultante verrà indicata per NUMCLIENTI la non aggregabilità rispetto a PROD, COMM. (vedere esercizioc ) 10

 CATEG(CAT,REP) E questo è appunto lo schema del DBO dato (http://www.")
 Si noti che nello schema per laa tabella PRODOTTO ci sono erroneamente anche CAT,REP e")



11 1.4 Esercizio B (27 Aprile 2012) Si prende in esame lo SCHEMA5: NS DATA, {PROD,DATA} CASSA considerando il caso di una dimensione PRODOTTO non più degenere ma con una gerarchia associata; VENDITA( NV,PROD,CASSA, COMM,NS,DATA) {PROD,DATA} CASSA NS DATA PRODOTTO(PROD,TIPO:TIPO) TIPO(TIPO,CAT:CATEG,GRUPPO) CATEG(CAT,REP) E questo è appunto lo schema del DBO dato ( unimo.it/sia/aprile bak) Si noti che nello schema per laa tabella PRODOTTO ci sono erroneamente anche CAT,REP e GRUPPO; questo è un refuso della costruzione del DB: per costruire c dei dati di prova, si riporta prima una tabella PRODOTTO con tutti gli attributi che servono PRODOTTO(PROD,TIPO,CAT,GRUPPO, REP) Si riempie quindi PRODOTTO rispettando le FD E alla finee riporto tutto nelle tabelle TIPOO e CATEG, Ad esempio: insert into CATEG select DISTINCT CAT, REP R from PRODOTTO Schema di Fatto VENDITA: come discusso in precedenza per NUMCLIENTI viene indicataa la non aggregabilità rispetto a PROD, COMM. SnowFlake Schema FACT_TABLE(PRODOTTO:dtPRODOTTO, DATA,COMM, CASSA, NUMVENDITE, NUMCLIENTI) dtprodotto(prodotto,tipo:dttipo) dttipo(tipo,gruppo, CAT:dtCAT) dtcat(cat, REP) ) 11































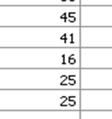

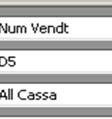
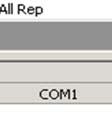
12 1.5 Cubo OLAP : specifica dei pattern Nella precedente sezionee abbiamo visto come specificaree i pattern per p dimensioni degeneri. Nel caso generale occorre considerare che una dimensione del cubo ha più di d un livelloo e che per tradurre t una dimensione dello schema di fatto si usano più dimensioni del cubo: Nel nostro Cubo VENDITA si avranno quindi due dimensioni GRUPPO, con livelli GRUPPO, TIPO, PROD, indicando i livelli da quelloo superiore: GRUPPO (livello= =1), TIPO (livello=2) e PROD (livello=3) REP, con livelli REP (livello= 1), CAT, TIPO, PROD (livello=4) Ogni cella del cubo è individuata da un valore (membro secondo la terminologt gia AS) per ogni dimensione (sia le dimensioni classiche che la dimensione particolare Measures) : Ad esempio l ultima cella in basso a destra (con visualizzato il valore 25) è individuata come segue: Dimensione DATA: membro D5 (del livello DATA.DATA) Dimensione CASSA: membro ALL CASSA (del livello CASSA.( ALL)) Dimensione REP: membro ALL REP (del livello REP.(ALL)) Dimensione COMM: membro COM1 (del livello COMM.COM) Dimensione GRUPPO: membro P5 (del livello GRUPPO.Prod) Dimensione Measures: membro NumVendite (del livello Measures. MeasuresLevel) 12
: nei nostri esempi non usando chiavi surrogate Key e Name coincidono.")

 ), allora [GRUPPO].CurrentMember.")
![name : è il nome del membro, ovvero cosa viene visualizzato [GRUPPO].CurrentMember.](/docs-images/94/119262267/images/13-3.jpg "level: è il i livello ; per un livello si può ottenere il nome e la posizione: [GRUPPO].")
![CurrentMember.level.name = PROD [GRUPPO].CurrentMember.level.ordinal =3 G(PROD)=0 equivale a GRUPPO.](/docs-images/94/119262267/images/13-4.jpg "CURRENTMEMBER.LEVEL.ORDINAL = 3 REP.CURRENTMEMBER.LEVEL. ORDINAL = 4 OR La condizione GRUPPO.")

 equivale a GRUPPO.ORDINALL = 3 G(PROD)=0 equivale quindi a IsLeaf(GRUPPO.")
 G(PROD)=0 AND G(COMM)=0 equivale in definitiva a (IsLeaf(GRUPPO.")
 Questa espressione definisce quindii i pattern all interno del Cubo Olap")
13 Ogni membro ha una Key (per individuare il membro) e un Name (valore che viene visualizzato): nei nostri esempi non usando chiavi surrogate Key e Name coincidono. Per ogni cella del cubo la funzione DIMENSION N.CURRENTMEMBER restituisce il membro di DIMENSIONN corrispondente allaa cella corrente. Ad esempio, se GRUPPO.CURRENTMEMBER è il membro P7 (del livello GRUPPO.Prod) ), allora [GRUPPO].CurrentMember.name : è il nome del membro, ovvero cosa viene visualizzato [GRUPPO].CurrentMember.level: è il i livello ; per un livello si può ottenere il nome e la posizione: [GRUPPO].CurrentMember.level.name = PROD [GRUPPO].CurrentMember.level.ordinal =3 G(PROD)=0 equivale a GRUPPO.CURRENTMEMBER.LEVEL.ORDINAL = 3 REP.CURRENTMEMBER.LEVEL. ORDINAL = 4 OR La condizione GRUPPO.CURRENTMEMBER.LEVEL.ORDINAL = 3 si può scrivere attraverso la funzione booleana IsLeaf che applicata ad un membro è true se il membro è una foglia, false altrimenti, quindi IsLeaf(GRU UPPO. CURRENTMEMBER) equivale a GRUPPO.CURRENTMEMBER.LEVEL.ORDINALL = 3 G(PROD)=0 equivale quindi a IsLeaf(GRUPPO. CURRENTMEMBER) OR IsLeaf(REP. CURRENTMEMBER) G(PROD)=0 AND G(COMM)=0 equivale in definitiva a (IsLeaf(GRUPPO. CURRENTMEMBER) OR IsLeaf( (REP. CURRENTMEMBER) ) AND IsLeaf(COMM. CURRENTMEMBER) Questa espressione definisce quindii i pattern all interno del Cubo Olap O per i quali NUMCLIENTI è calcolabile, allora verrà usata per definire una nuova misura (membro calcolato) come Iif(( (IsLeaf(GRUPPO. CURRENTMEMBER) OR IsLeaf(REP. CURRENTMEMBER) ) AND IsLeaf(COMM. CURRENTMEMBER), [Measures].[Nc], ) 13
14 1.6 Esercizio C : confronto FD tra dimensioni e attributi cross dimensionali Si prende in esame lo SCHEMA6: NS DATA, {PROD,DATA}} CASSA, CASSA COMM C (considerando ancora la dimensione PRODOTTO con una gerarchiaa associata come nell ESERCIZIO B) e si confrontano due differenti soluzioni 1. Schema di Fatto Vendita con dimensioni {PROD,DATA, CASSA, COMM } 2. Schema di Fatto Vendita con dimensioni {PROD,DATA } e attributo cross dimensionale Riportiamo le specifiche: Consideriamo un DBO con il seguente schema E/R edd il corrispondente schema relazionale (nello schema relazionale ci possono essere vincoli di integrità aggiuntivi): VENDITA(NV,PROD: PRODOTTO NS:SCONTRINO) SCONTRINO(NS,DATA:DATA) DATA(DATA) PRODOTTO(PROD,TIPO:TIPO) ALLACASSA(PROD:PRODOTTO, DA ATA:DATA, CASSA,COMM) FD: CASSA COMM TIPO(TIPO,CAT:CATEG,GRUPPO) CATEG(CAT,REP) 1. Progetto Concettuale e Logico dello Schema di Fatto Vendita con dimensioni {PROD,DATA, CASSA, COMM } e misure NUMVENDITEE e NUMCLIENTI. 2. Progetto Concettuale e Logico dello Schema di Fatto Vendita con dimensioni {PROD,DATA, } e misure NUMVENDITE e NUMCLIENTI. 14
Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SQL-OLAP. Estensioni OLAP in SQL
 Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SQL-OLAP Estensioni OLAP in SQL Estensioni OLAP in SQL SQL99 è stato il primo standard SQL ad offrire soluzioni per l analisi
Sistemi Informativi Avanzati Anno Accademico 2011/2012 Prof. Domenico Beneventano SQL-OLAP Estensioni OLAP in SQL Estensioni OLAP in SQL SQL99 è stato il primo standard SQL ad offrire soluzioni per l analisi
Definizione e calcolo delle misure
 Definizione e calcolo delle misure! Misure Derivate! Misure Calcolate! Misure Derivate e Progetto Logico! Calcolo delle Misure! Aggregabilità Misure Derivate " Sono misure definite a partire da altre misure
Definizione e calcolo delle misure! Misure Derivate! Misure Calcolate! Misure Derivate e Progetto Logico! Calcolo delle Misure! Aggregabilità Misure Derivate " Sono misure definite a partire da altre misure
Esercizio con attributo cross-dimensionale - transazionale
 Esercizio con attributo cross-dimensionale - transazionale TIPO (,CITTA) DI QTY CITTA (,ANNO) SCONTRINO(NSC, :) (,TIPO) VENDITA IN VENDITA(NSC:SCONTRINO,:, :,QTY,PU) IN PU NSC ANNO SCONTRINO DEL Viene
Esercizio con attributo cross-dimensionale - transazionale TIPO (,CITTA) DI QTY CITTA (,ANNO) SCONTRINO(NSC, :) (,TIPO) VENDITA IN VENDITA(NSC:SCONTRINO,:, :,QTY,PU) IN PU NSC ANNO SCONTRINO DEL Viene
Estensioni del linguaggio SQL per interrogazioni OLAP
 Sistemi Informativi Avanzati Anno Accademico 2012/2013 Prof. Domenico Beneventano Estensioni del linguaggio SQL per interrogazioni OLAP Esempio! Esempio delle vendite con scontrino (nella tabella, per
Sistemi Informativi Avanzati Anno Accademico 2012/2013 Prof. Domenico Beneventano Estensioni del linguaggio SQL per interrogazioni OLAP Esempio! Esempio delle vendite con scontrino (nella tabella, per
ESEMPIO DI PROVA PRATICA
 ESEMPIO DI PROVA PRATICA Sono dati Schema di Fatto VENDITA QTY: misura normale ADDITIVA PU: misura calcolata come PU_TOTALE/NVENDITE dove a) PU_TOTALE misura normale additiva b) NVENDITE misura normale
ESEMPIO DI PROVA PRATICA Sono dati Schema di Fatto VENDITA QTY: misura normale ADDITIVA PU: misura calcolata come PU_TOTALE/NVENDITE dove a) PU_TOTALE misura normale additiva b) NVENDITE misura normale
Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano. Archi multipli
 Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Archi multipli Capitoli 5.2.5 e 9.1.4 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Archi multipli Capitoli 5.2.5 e 9.1.4 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Sistemi Informativi Avanzati Anno Accademico 2012/2013 Prof. Domenico Beneventano. Archi multipli
 Sistemi Informativi Avanzati Anno Accademico 2012/2013 Prof. Domenico Beneventano Archi multipli Capitoli 5.2.5 e 9.1.4 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Sistemi Informativi Avanzati Anno Accademico 2012/2013 Prof. Domenico Beneventano Archi multipli Capitoli 5.2.5 e 9.1.4 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Un arco multiplo corrisponde ad un associazione molti-a-molti: il padre (libro) non determina funzionalmente il figlio (autore)
 non determina funzionalmente il figlio (autore)") Arco Multiplo Schema di fatto contenente un arco multiplo: genere autore libro VENDITA numero incasso data mese anno arco multiplo (AM) Per illustrare il concetto di arco multiplo si parte da uno schema
Arco Multiplo Schema di fatto contenente un arco multiplo: genere autore libro VENDITA numero incasso data mese anno arco multiplo (AM) Per illustrare il concetto di arco multiplo si parte da uno schema
! Un arco multiplo corrisponde ad un associazione molti-a-molti: il padre (libro) non determina funzionalmente il figlio (autore)
 non determina funzionalmente il figlio (autore)") Arco Multiplo! Schema di fatto contenente un arco multiplo: genere autore libro VENDITA numero incasso data mese anno arco multiplo (AM) " Per illustrare il concetto di arco multiplo si parte da uno schema
Arco Multiplo! Schema di fatto contenente un arco multiplo: genere autore libro VENDITA numero incasso data mese anno arco multiplo (AM) " Per illustrare il concetto di arco multiplo si parte da uno schema
ESEMPIO DI COPERTURA DI ARCHI OPZIONALI
 ESEMPIO DI COPERTURA DI ARCHI OPZIONALI Di seguito è riportato un esempio per illustrare la Copertura di un arco opzionale (PAG. 22 dei lucidi MODELLAZIONE CONCETTUALE). A tale scopo si considera un DBO
ESEMPIO DI COPERTURA DI ARCHI OPZIONALI Di seguito è riportato un esempio per illustrare la Copertura di un arco opzionale (PAG. 22 dei lucidi MODELLAZIONE CONCETTUALE). A tale scopo si considera un DBO
Misure. Definizione delle misure
 Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Misure In parte dal Capitolo 5 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Misure In parte dal Capitolo 5 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Misure. Definizione delle misure. Sistemi Informativi Avanzati Anno Accademico 2015/2016 Prof. Domenico Beneventano. Glossario delle Misure
 Sistemi Informativi Avanzati Anno Accademico 2015/2016 Prof. Domenico Beneventano Misure In parte dal Capitolo 5 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
Sistemi Informativi Avanzati Anno Accademico 2015/2016 Prof. Domenico Beneventano Misure In parte dal Capitolo 5 del libro Data Warehouse - teoria e pratica della Progettazione Autori: Matteo Golfarelli,
ESEMPIO TELEFONATE. Esempio di progettazione con indicazioni per lo svolgimento della Tesina. DIAGRAMMA RELAZIONALE
 ESEMPIO TELEFONATE Esempio di progettazione con indicazioni per lo svolgimento della Tesina. DIAGRAMMA RELAZIONALE NOTA: Molte tabelle hanno come chiave un identificatore ID che è stato rinominato (è possibile
ESEMPIO TELEFONATE Esempio di progettazione con indicazioni per lo svolgimento della Tesina. DIAGRAMMA RELAZIONALE NOTA: Molte tabelle hanno come chiave un identificatore ID che è stato rinominato (è possibile
Fatto Esame : Sintesi per la prima consegna
 Fatto Esame : Sintesi per la prima consegna Diagramma Relazionale http://dbgroup.unimo.it/sia/esercitazioninovembre2015/db_esempiofattoesamenovembre2015.bak SCHEMA RELAZIONALE (con incluse AK e FD derivanti
Fatto Esame : Sintesi per la prima consegna Diagramma Relazionale http://dbgroup.unimo.it/sia/esercitazioninovembre2015/db_esempiofattoesamenovembre2015.bak SCHEMA RELAZIONALE (con incluse AK e FD derivanti
Schema Del DB Operazionale TELEFONATE
 Schema Del DB Operazionale TELEFONATE Costruire lo Schema di Fatto per analizzare le chiamate considerando come dimensioni TelefonoDA e TelefonoA, Data e Fascia, intesa come FasciaOraria della chiamata
Schema Del DB Operazionale TELEFONATE Costruire lo Schema di Fatto per analizzare le chiamate considerando come dimensioni TelefonoDA e TelefonoA, Data e Fascia, intesa come FasciaOraria della chiamata
Il BACKUP è disponibile in http://www.dbgroup.unimo.it/sia/esercizio_21_novembre_2013/esercizio_21_novembre_2013.bak
 ESEMPIO DELLE VENDITE: MISURE ED AGGREGABILITA E l esempio discusso nelle dispense è Dispense : http://www.dbgroup.unimo.it/sia/sia_2014_progettazionediundw_misure.pdf esteso e dettagliato. Il BACKUP è
ESEMPIO DELLE VENDITE: MISURE ED AGGREGABILITA E l esempio discusso nelle dispense è Dispense : http://www.dbgroup.unimo.it/sia/sia_2014_progettazionediundw_misure.pdf esteso e dettagliato. Il BACKUP è
SCHEMA RELAZIONALE 1
 SCHEMA RELAZIONALE 1 DIAGRAMMA RELAZIONALE 2 Analisi e riconciliazione della sorgente operazionale I concetti principali sono EMPLOYEES, DEPARTMENTS, JOBS e JOB_HISTORY; inoltre cʼè una componente geografica
SCHEMA RELAZIONALE 1 DIAGRAMMA RELAZIONALE 2 Analisi e riconciliazione della sorgente operazionale I concetti principali sono EMPLOYEES, DEPARTMENTS, JOBS e JOB_HISTORY; inoltre cʼè una componente geografica
Basi di dati 8 settembre 2015 Esame Compito A Tempo a disposizione: due ore. Libri chiusi.
 Basi di dati 8 settembre 2015 Esame Compito A Tempo a disposizione: due ore. Libri chiusi. Cognome: Nome: Matricola: Domanda 1 (15%) Considerare la base di dati relazionale contenente le seguenti relazioni:
Basi di dati 8 settembre 2015 Esame Compito A Tempo a disposizione: due ore. Libri chiusi. Cognome: Nome: Matricola: Domanda 1 (15%) Considerare la base di dati relazionale contenente le seguenti relazioni:
Corso di. Basi di Dati I. 9. Esercitazioni in SQL: Check, asserzioni, viste
 Corso di Basi di Dati 9. Esercitazioni in SQL: Check, asserzioni, viste A.A. 2016 2017 Check Come abbiamo visto, SQL permette di specificare vincoli sugli attributi e le tabelle attraverso il comando check
Corso di Basi di Dati 9. Esercitazioni in SQL: Check, asserzioni, viste A.A. 2016 2017 Check Come abbiamo visto, SQL permette di specificare vincoli sugli attributi e le tabelle attraverso il comando check
ESEMPIO: RITARDI & BIGLIETTI
 ESEMPIO: RITARDI & BIGLIETTI! Fatto Ritardi: l analisi a livello volo giornaliero, considerando l aeroporto di partenza, la città e lo stato di arrivo e la compagnia! Fatto Biglietti: l analisi deve considerare
ESEMPIO: RITARDI & BIGLIETTI! Fatto Ritardi: l analisi a livello volo giornaliero, considerando l aeroporto di partenza, la città e lo stato di arrivo e la compagnia! Fatto Biglietti: l analisi deve considerare
Lezione 7 SQL (II) Basi di dati bis Docente Mauro Minenna Pag.1
 Basi di dati bis Docente Mauro Minenna Pag.1") Lezione 7 SQL (II) Pag.1 Ancora sugli operatori di confronto tra insiemi Abbiamo già visto IN, EXISTS e UNIQUE. Possiamo anche usare NOT IN, NOT EXISTS e NOT UNIQUE Disponibili anche: op ANY, op ALL Trovare
Lezione 7 SQL (II) Pag.1 Ancora sugli operatori di confronto tra insiemi Abbiamo già visto IN, EXISTS e UNIQUE. Possiamo anche usare NOT IN, NOT EXISTS e NOT UNIQUE Disponibili anche: op ANY, op ALL Trovare
σ data 15/12/2013 data 20/12/2014
 Dato lo schema: Basi di Dati Prof. Alfredo Pulvirenti A.A. 2014-2015 Prova in itinere 18 dicembre 2014 (A) EVENTO(id, titolo, data, categoria, costo_partecipazione, idcatering) ORGANIZZATORE(id,idevento)
Dato lo schema: Basi di Dati Prof. Alfredo Pulvirenti A.A. 2014-2015 Prova in itinere 18 dicembre 2014 (A) EVENTO(id, titolo, data, categoria, costo_partecipazione, idcatering) ORGANIZZATORE(id,idevento)
Le variabili logiche possono essere combinate per mezzo di operatori detti connettivi logici. I principali sono:
 Variabili logiche Una variabile logica (o booleana) è una variable che può assumere solo uno di due valori: Connettivi logici True (vero identificato con 1) False (falso identificato con 0) Le variabili
Variabili logiche Una variabile logica (o booleana) è una variable che può assumere solo uno di due valori: Connettivi logici True (vero identificato con 1) False (falso identificato con 0) Le variabili
Interrogare una base di dati: algebra relazionale e SQL. Savino Castagnozzi Giorgio Macauda Michele Meomartino Salvatore Picerno Massimiliano Sartor
 Interrogare una base di dati: algebra relazionale e SQL Savino Castagnozzi Giorgio Macauda Michele Meomartino Salvatore Picerno Massimiliano Sartor Contesto didattico Il seguente materiale didattico è
Interrogare una base di dati: algebra relazionale e SQL Savino Castagnozzi Giorgio Macauda Michele Meomartino Salvatore Picerno Massimiliano Sartor Contesto didattico Il seguente materiale didattico è
Algebra di Boole. Andrea Passerini Informatica. Algebra di Boole
 Andrea Passerini passerini@disi.unitn.it Informatica Variabili logiche Una variabile logica (o booleana) è una variable che può assumere solo uno di due valori: True (vero identificato con 1) False (falso
Andrea Passerini passerini@disi.unitn.it Informatica Variabili logiche Una variabile logica (o booleana) è una variable che può assumere solo uno di due valori: True (vero identificato con 1) False (falso
Structured Query Language
 IL LINGUAGGIO SQL Structured Query Language Contiene sia il DDL sia il DML, quindi consente di: Definire e creare il database Effettuare l inserimento, la cancellazione, l aggiornamento dei record di un
IL LINGUAGGIO SQL Structured Query Language Contiene sia il DDL sia il DML, quindi consente di: Definire e creare il database Effettuare l inserimento, la cancellazione, l aggiornamento dei record di un
QL (Query Language) Alice Pavarani
 Alice Pavarani") QL (Query Language) Alice Pavarani QL Query Language Linguaggio di interrogazione dei dati, permette di: Interrogare la base di dati per estrarre informazioni Elaborare i dati Il risultato di un interrogazione
QL (Query Language) Alice Pavarani QL Query Language Linguaggio di interrogazione dei dati, permette di: Interrogare la base di dati per estrarre informazioni Elaborare i dati Il risultato di un interrogazione
APPUNTI LEZIONE 22 OTTOBRE 2015 Diagramma relazionale del DB https://dl.dropboxusercontent.com/u/ /sitoweb/adventureworkslt_sia.
 APPUNTI LEZIONE 22 OTTOBRE 2015 Diagramma relazionale del DB https://dl.dropboxusercontent.com/u/15491020/sitoweb/adventureworkslt_sia.bak 1 Per generare il diagramma relazionale : quindi aggiungere le
APPUNTI LEZIONE 22 OTTOBRE 2015 Diagramma relazionale del DB https://dl.dropboxusercontent.com/u/15491020/sitoweb/adventureworkslt_sia.bak 1 Per generare il diagramma relazionale : quindi aggiungere le
PROVA SCRITTA DI TECNOLOGIA DATABASE 02/12/2004 Corso di Laurea Specialistica in Ingegneria Informatica - NOD PROF.
 PROVA SCRITTA DI TECNOLOGIA DATABASE 02/12/2004 Corso di Laurea Specialistica in Ingegneria Informatica - NOD PROF. SONIA BERGAMASCHI Esercizio 1 (punti 20) Dato il seguente schema relazionale: FOTOGRAFO(CODF,NOME,NAZIONE)
PROVA SCRITTA DI TECNOLOGIA DATABASE 02/12/2004 Corso di Laurea Specialistica in Ingegneria Informatica - NOD PROF. SONIA BERGAMASCHI Esercizio 1 (punti 20) Dato il seguente schema relazionale: FOTOGRAFO(CODF,NOME,NAZIONE)
BASE DI DATI. Esercizio: Campionato corse Progettazione concettuale Progettazione logica. Informatica Umanistica Università di Pisa
 BASE DI DAI Esercizio: Campionato corse Progettazione concettuale Progettazione logica Informatica Umanistica Università di Pisa Esercizio: campionato corse Si vuole costruire una base di dati che contenga
BASE DI DAI Esercizio: Campionato corse Progettazione concettuale Progettazione logica Informatica Umanistica Università di Pisa Esercizio: campionato corse Si vuole costruire una base di dati che contenga
Basi di Dati 1 Prof. L. Tanca e F. A. Schreiber APPELLO DEL 1 OTTOBRE 2015 Tempo: 2h30m
 Basi di Dati 1 Prof. L. Tanca e F. A. Schreiber APPELLO DEL 1 OTTOBRE 2015 Tempo: 2h30m Si consideri il seguente schema di base di dati, che vuole memorizzare informazioni relative ai viaggi di lavoro
Basi di Dati 1 Prof. L. Tanca e F. A. Schreiber APPELLO DEL 1 OTTOBRE 2015 Tempo: 2h30m Si consideri il seguente schema di base di dati, che vuole memorizzare informazioni relative ai viaggi di lavoro
Basi di dati I 6 settembre 2018 Tempo a disposizione: un ora e 45 minuti.
 Tempo a disposizione: un ora e 45 minuti. Cognome: : Matricola: Domanda 1 (15%) Considerare le seguenti quattro relazioni su uno stesso schema: (A) 2 4000 1000 3000 true 3 3000 1000 2200 true (C) 2 4000
Tempo a disposizione: un ora e 45 minuti. Cognome: : Matricola: Domanda 1 (15%) Considerare le seguenti quattro relazioni su uno stesso schema: (A) 2 4000 1000 3000 true 3 3000 1000 2200 true (C) 2 4000
Estensioni del linguaggio SQL per interrogazioni OLAP
 Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Estensioni del linguaggio SQL per interrogazioni OLAP Outline! Esempio introduttivo e motivazioni! Introduzione al modello
Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Estensioni del linguaggio SQL per interrogazioni OLAP Outline! Esempio introduttivo e motivazioni! Introduzione al modello
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 27 Giugno 2007 COGNOME: NOME: MATRICOLA: Si prega di risolvere gli esercizi direttamente sui fogli del testo, negli spazi indicati. Usare il foglio protocollo solo per la
Prova Scritta di Basi di Dati 27 Giugno 2007 COGNOME: NOME: MATRICOLA: Si prega di risolvere gli esercizi direttamente sui fogli del testo, negli spazi indicati. Usare il foglio protocollo solo per la
Basi di Dati Prof. L. Tanca e F. A. Schreiber APPELLO DEL 6 MARZO 2015 Tempo: 2h30m
 Basi di Dati Prof. L. Tanca e F. A. Schreiber APPELLO DEL 6 MARZO 2015 Tempo: 2h30m Si consideri il seguente schema di base di dati, che vuole memorizzare alcune informazioni relative a Twitter. TWEET
Basi di Dati Prof. L. Tanca e F. A. Schreiber APPELLO DEL 6 MARZO 2015 Tempo: 2h30m Si consideri il seguente schema di base di dati, che vuole memorizzare alcune informazioni relative a Twitter. TWEET
ESEMPIO DI TRIGGER PER IL CONTROLLO DELLE PROPRIETÀ COPERTURA DI UNA GERARCHIA (ARGOMENTO SVOLTO IN CLASSE IL 25 MAGGIO 2011)
") ESEMPIO DI TRIGGER PER IL CONTROLLO DELLE PROPRIETÀ COPERTURA DI UNA GERARCHIA (ARGOMENTO SVOLTO IN CLSE IL 25 MAGGIO 2011) Dato il seguente schema E/R consideriamo solo le due gerarchie relative a MANAGER/SEGRETARIA/IMPIEGATO
ESEMPIO DI TRIGGER PER IL CONTROLLO DELLE PROPRIETÀ COPERTURA DI UNA GERARCHIA (ARGOMENTO SVOLTO IN CLSE IL 25 MAGGIO 2011) Dato il seguente schema E/R consideriamo solo le due gerarchie relative a MANAGER/SEGRETARIA/IMPIEGATO
Basi di Dati: Elementi
 Basi di Dati: Elementi Docente: Prof. Pierangela Samarati Appello di Maggio online - 22 Maggio 2010 Tempo a disposizione 2:00h Soluzioni Domanda 1) Illustrare e commentare le diverse fasi del ciclo di
Basi di Dati: Elementi Docente: Prof. Pierangela Samarati Appello di Maggio online - 22 Maggio 2010 Tempo a disposizione 2:00h Soluzioni Domanda 1) Illustrare e commentare le diverse fasi del ciclo di
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 17 Febbraio 2004 NOME: COGNOME: MATRICOLA: Cercare di risolvere gli esercizi sul foglio del testo. Esercizio Punti previsti 1 9 2 12 3 9 3 3 Totale 33 Punti assegnati Esercizio
Prova Scritta di Basi di Dati 17 Febbraio 2004 NOME: COGNOME: MATRICOLA: Cercare di risolvere gli esercizi sul foglio del testo. Esercizio Punti previsti 1 9 2 12 3 9 3 3 Totale 33 Punti assegnati Esercizio
Operatori aggregati. Operatori aggregati. Interrogazioni con raggruppamento. Interrogazioni con raggruppamento
 Operatori aggregati In algebra relazionale le espressioni vengono valutate sulle singole tuple in successione. Talvolta però possono essere necessarie informazioni derivabili dall esame di tutte le tuple
Operatori aggregati In algebra relazionale le espressioni vengono valutate sulle singole tuple in successione. Talvolta però possono essere necessarie informazioni derivabili dall esame di tutte le tuple
Esempio di progettazione di un DW
 Esempio di progettazione di un DW! La sorgente dati è costituita da un unico DataBase SQL-Server con informazioni sui Manifesti degli Studi e gli orari delle lezioni. Viene considerato il progetto di un
Esempio di progettazione di un DW! La sorgente dati è costituita da un unico DataBase SQL-Server con informazioni sui Manifesti degli Studi e gli orari delle lezioni. Viene considerato il progetto di un
Basi di dati I 27 gennaio 2016 Esame Compito A Tempo a disposizione: un ora e quarantacinque minuti. Libri chiusi.
 Basi di dati I 27 gennaio 2016 Esame Compito A Tempo a disposizione: un ora e quarantacinque minuti. Libri chiusi. Cognome: Nome: Matricola: Domanda 1 (20%) Lo schema concettuale seguente rappresenta un
Basi di dati I 27 gennaio 2016 Esame Compito A Tempo a disposizione: un ora e quarantacinque minuti. Libri chiusi. Cognome: Nome: Matricola: Domanda 1 (20%) Lo schema concettuale seguente rappresenta un
Esercitazione 7 Correzione della prova di autovalutazione
 Esercitazione 7 Correzione della prova di autovalutazione Basi di dati - prof. Silvio Salza - a.a. 2017-2018 E7-1 Specifiche dello schema ER Si vuole progettare una base di dati che rappresenta l'organizzazione
Esercitazione 7 Correzione della prova di autovalutazione Basi di dati - prof. Silvio Salza - a.a. 2017-2018 E7-1 Specifiche dello schema ER Si vuole progettare una base di dati che rappresenta l'organizzazione
Basi di dati I 10 luglio 2017 Tempo a disposizione: un ora e 30 minuti.
 Tempo a disposizione: un ora e 30 minuti. Cognome: Nome: Matricola: Domanda 1 (20%) Considerare le seguenti quattro relazioni su uno stesso schema: (A) 2 4000 1000 3000 true 3 3000 1000 2200 true (C) 2
Tempo a disposizione: un ora e 30 minuti. Cognome: Nome: Matricola: Domanda 1 (20%) Considerare le seguenti quattro relazioni su uno stesso schema: (A) 2 4000 1000 3000 true 3 3000 1000 2200 true (C) 2
Esercizio: Esame. In questo esercizio sono dettagliati tutti i passi richiesti per la prima consegna della tesina
 Esercizio: Esame In questo esercizio sono dettagliati tutti i passi richiesti per la prima consegna della tesina Il punto di partenza è il diagramma relazionale del DBO con la relativa documentazione Per
Esercizio: Esame In questo esercizio sono dettagliati tutti i passi richiesti per la prima consegna della tesina Il punto di partenza è il diagramma relazionale del DBO con la relativa documentazione Per
ESERCIZI IN LOGO & COMPITI SCRITTI ANNO ACCADEMICO 2002/2003 PROF. DOMENICO BENEVENTANO. L esame consiste in una prova scritta formata da due parti:
 ESERCIZI IN LOGO & COMPITI SCRITTI ANNO ACCADEMICO 2002/2003 PROF. DOMENICO BENEVENTANO MODALITÀ D ESAME L esame consiste in una prova scritta formata da due parti: La prima parte, da realizzare usando
ESERCIZI IN LOGO & COMPITI SCRITTI ANNO ACCADEMICO 2002/2003 PROF. DOMENICO BENEVENTANO MODALITÀ D ESAME L esame consiste in una prova scritta formata da due parti: La prima parte, da realizzare usando
Corso di Informatica - prova scritta del 28/01/2008
 Corso di Informatica - prova scritta del 28/01/2008 Esercizio 1 Il DB riportato in figura contiene dati riguardanti l attività di una videoteca che noleggia sia film su DVD, sia videogiochi. Sono indicati
Corso di Informatica - prova scritta del 28/01/2008 Esercizio 1 Il DB riportato in figura contiene dati riguardanti l attività di una videoteca che noleggia sia film su DVD, sia videogiochi. Sono indicati
Basi di Dati: Corso di laboratorio
 Basi di Dati: Corso di laboratorio Lezione 4 Raffaella Gentilini 1 / 46 Sommario 1 Join di Tabelle Join Naturale Theta Join Join Esterno 2 3 Funzioni d aggregazione La Clausola GROUP BY La Clausola HAVING
Basi di Dati: Corso di laboratorio Lezione 4 Raffaella Gentilini 1 / 46 Sommario 1 Join di Tabelle Join Naturale Theta Join Join Esterno 2 3 Funzioni d aggregazione La Clausola GROUP BY La Clausola HAVING
Basi di Dati. Concetti Avanzati
 Basi di Dati Concetti Avanzati Concetti Avanzati Raggruppamenti Clausole GROUP BY e HAVING Forma Generale della SELECT Nidificazione Uso nel DML e DDL Nidificazione, Viste e Potere Espressivo Esecuzione
Basi di Dati Concetti Avanzati Concetti Avanzati Raggruppamenti Clausole GROUP BY e HAVING Forma Generale della SELECT Nidificazione Uso nel DML e DDL Nidificazione, Viste e Potere Espressivo Esecuzione
Basi di dati I Prova di autovalutazione 1 novembre 2016 Soluzioni
 Basi di dati I Prova di autovalutazione 1 novembre 2016 Soluzioni Domanda 1 Si consideri una base di dati sulle relazioni R 1 (A, B, C) R 2 (D, E, F ) Scrivere interrogazioni in SQL equivalenti alle seguenti
Basi di dati I Prova di autovalutazione 1 novembre 2016 Soluzioni Domanda 1 Si consideri una base di dati sulle relazioni R 1 (A, B, C) R 2 (D, E, F ) Scrivere interrogazioni in SQL equivalenti alle seguenti
Dalla tabella alla funzione canonica
 Dalla tabella alla funzione canonica La funzione canonica è la funzione logica associata alla tabella di verità del circuito che si vuole progettare. Essa è costituita da una somma di MinTerm con variabili
Dalla tabella alla funzione canonica La funzione canonica è la funzione logica associata alla tabella di verità del circuito che si vuole progettare. Essa è costituita da una somma di MinTerm con variabili
Basi di dati attive. Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger).
.") Basi di dati attive Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger). Tali regole vengono attivate in modo automatico al verificarsi
Basi di dati attive Una base di dati è ATTIVA quando consente la definizione e la gestione di regole di produzione (regole attive o trigger). Tali regole vengono attivate in modo automatico al verificarsi
SQL: Structured Query Language. T. Catarci, M. Scannapieco, Corso di Basi di Dati, A.A. 2008/2009, Sapienza Università di Roma
 SQL: Structured Query Language 1 SQL:Componenti Principali Data Manipulation Language (DML): interrogazioni, inserimenti, cancellazioni, modifiche Data Definition Language (DDL): creazione, cancellazione
SQL: Structured Query Language 1 SQL:Componenti Principali Data Manipulation Language (DML): interrogazioni, inserimenti, cancellazioni, modifiche Data Definition Language (DDL): creazione, cancellazione
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 3 Luglio 2002 NOTE: I punti previsti per ogni esercizio si riferiscono ad uno svolgimento completamente corretto. NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2
Prova Scritta di Basi di Dati 3 Luglio 2002 NOTE: I punti previsti per ogni esercizio si riferiscono ad uno svolgimento completamente corretto. NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2
SQL - Sottointerrogazioni correlate
 SQL - Sottointerrogazioni correlate negli esempi visti ogni subquery viene eseguita una volta per tutte ed il valore (o insieme di valori) è usato nella clausola WHERE della query esterna è possibile definire
SQL - Sottointerrogazioni correlate negli esempi visti ogni subquery viene eseguita una volta per tutte ed il valore (o insieme di valori) è usato nella clausola WHERE della query esterna è possibile definire
Sistemi Informativi Avanzati
 Anno Accademico 2012/2013 Sistemi Informativi Avanzati Corso di Laurea Magistrale in Ingegneria Gestionale Domenico Beneventano Andrea Scavolini Introduzione 1 Obiettivi Il corso si propone di fornire
Anno Accademico 2012/2013 Sistemi Informativi Avanzati Corso di Laurea Magistrale in Ingegneria Gestionale Domenico Beneventano Andrea Scavolini Introduzione 1 Obiettivi Il corso si propone di fornire
D B M G D B M G 2. Sistemi informativi. Linguaggio SQL: costrutti avanzati
 Sistemi informativi D B M G Linguaggio SQL: costrutti avanzati Gestione delle transazioni SQL per le applicazioni Controllo dell accesso Gestione degli indici D B M G 2 Pag. 1 2007 Politecnico di Torino
Sistemi informativi D B M G Linguaggio SQL: costrutti avanzati Gestione delle transazioni SQL per le applicazioni Controllo dell accesso Gestione degli indici D B M G 2 Pag. 1 2007 Politecnico di Torino
Interrogazioni complesse. SQL avanzato 1
 Interrogazioni complesse SQL avanzato Classificazione delle interrogazioni complesse Query con ordinamento Query con aggregazione Query con raggruppamento Query binarie Query annidate SQL avanzato 2 Esempio
Interrogazioni complesse SQL avanzato Classificazione delle interrogazioni complesse Query con ordinamento Query con aggregazione Query con raggruppamento Query binarie Query annidate SQL avanzato 2 Esempio
Data warehouse Analisi dei dati
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, D MG B Data warehouse Analisi dei dati DATA WAREHOUSE: OLAP - 1 Database
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of Database and data mining group, D MG B Data warehouse Analisi dei dati DATA WAREHOUSE: OLAP - 1 Database
B a s i d i D a t i ( M o d u l o T e o r i a ) P r o v a s c r i t t a
 P r o v a s c r i t t a") Matricola Cognome Nome B a s i d i D a t i ( M o d u l o T e o r i a ) P r o v a s c r i t t a Durata: 2 ore e 15 minuti Avvertenze: è severamente vietato consultare libri e appunti. DOMANDE PRELIMINARI
Matricola Cognome Nome B a s i d i D a t i ( M o d u l o T e o r i a ) P r o v a s c r i t t a Durata: 2 ore e 15 minuti Avvertenze: è severamente vietato consultare libri e appunti. DOMANDE PRELIMINARI
Esercitazione 4: Trigger in DB2
 Esercitazione 4: Trigger in DB2 Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: esercitazione4.pdf Sistemi Informativi L-B Definire trigger
Esercitazione 4: Trigger in DB2 Sistemi Informativi L-B Home Page del corso: http://www-db.deis.unibo.it/courses/sil-b/ Versione elettronica: esercitazione4.pdf Sistemi Informativi L-B Definire trigger
Database Lezione 2. Sommario. - Progettazione di un database - Join - Valore NULL - Operatori aggregati
 Sommario - Progettazione di un database - Join - Valore NULL - Operatori aggregati Progettazione di un database - In un database c'è una marcata distinzione tra i valori in esso contenuti e le operazioni
Sommario - Progettazione di un database - Join - Valore NULL - Operatori aggregati Progettazione di un database - In un database c'è una marcata distinzione tra i valori in esso contenuti e le operazioni
INTRODUZIONE AI DBMS. Inoltre i fogli elettronici. Mentre sono poco adatti per operazioni di. Prof. Alberto Postiglione
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
INTRODUZIONE AI DBMS
 Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Informatica Generale (AA 07/08) Corso di laurea in Scienze della Comunicazione Facoltà di Lettere e Filosofia Università degli Studi di Salerno : Introduzione alla Gestione dei Dati Prof. Alberto Postiglione
Basi di Dati. Esercitazione SQL. Paolo Papotti. 19 maggio 2005
 Basi di Dati Esercitazione SQL 19 maggio 2005 Paolo Papotti Considerando la seguente base di dati: Fornitori (CodiceFornitore, Nome, Indirizzo, Città) Prodotti (CodiceProdotto, Nome, Marca, Modello) Catalogo
Basi di Dati Esercitazione SQL 19 maggio 2005 Paolo Papotti Considerando la seguente base di dati: Fornitori (CodiceFornitore, Nome, Indirizzo, Città) Prodotti (CodiceProdotto, Nome, Marca, Modello) Catalogo
INTRODUZIONE AL 2 TEST IN ITINERE. a.a
 INTRODUZIONE AL 2 TEST IN ITINERE a.a. 2014-15 Modalità d esame Tipologia degli studenti: A(ll). Non Sufficienti al Primo Test in Itinere (su tutto il programma sino ad SQL base). Si presentano su tutto
INTRODUZIONE AL 2 TEST IN ITINERE a.a. 2014-15 Modalità d esame Tipologia degli studenti: A(ll). Non Sufficienti al Primo Test in Itinere (su tutto il programma sino ad SQL base). Si presentano su tutto
IL LINGUAGGIO SQL LE BASI
 IL LINGUAGGIO SQL LE BASI DB DI RIFERIMENTO PER GLI ESEMPI 2 ESPRESSIONI NELLA CLAUSOLA SELECT La SELECT list può contenere non solo attributi, ma anche espressioni: Le espressioni possono comprendere
IL LINGUAGGIO SQL LE BASI DB DI RIFERIMENTO PER GLI ESEMPI 2 ESPRESSIONI NELLA CLAUSOLA SELECT La SELECT list può contenere non solo attributi, ma anche espressioni: Le espressioni possono comprendere
SQL terza parte D O C E N T E P R O F. A L B E R T O B E L U S S I. Anno accademico 2010/11
 SQL terza parte D O C E N T E P R O F. A L B E R T O B E L U S S I Anno accademico 2010/11 Operatori aggregati Costituiscono una estensione delle normali interrogazioni SQL (non hanno corrispondenza in
SQL terza parte D O C E N T E P R O F. A L B E R T O B E L U S S I Anno accademico 2010/11 Operatori aggregati Costituiscono una estensione delle normali interrogazioni SQL (non hanno corrispondenza in
VISTE. 19/11/2015 Concetti Avanzati - SQL 71
 VISTE 19/11/2015 Concetti Avanzati - SQL 71 Viste Le Viste Logiche o Viste o View possono essere definite come delle tabelle virtuali, i cui dati sono riaggregazioni dei dati contenuti nelle tabelle fisiche
VISTE 19/11/2015 Concetti Avanzati - SQL 71 Viste Le Viste Logiche o Viste o View possono essere definite come delle tabelle virtuali, i cui dati sono riaggregazioni dei dati contenuti nelle tabelle fisiche
Il Dimensional Fact Model
 Il Dimensional Fact Model Per le slides si ringrazia il Prof. Stefano Rizzi (http://www-db.deis.unibo.it/~srizzi/) e il Dott. Angelo Sironi Quale formalismo? Mentre è universalmente riconosciuto che un
Il Dimensional Fact Model Per le slides si ringrazia il Prof. Stefano Rizzi (http://www-db.deis.unibo.it/~srizzi/) e il Dott. Angelo Sironi Quale formalismo? Mentre è universalmente riconosciuto che un
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 1 Luglio 2008 COGNOME: NOME: MATRICOLA: Si prega di risolvere gli esercizi direttamente sui fogli del testo, negli spazi indicati. Usare il foglio protocollo solo per la brutta
Prova Scritta di Basi di Dati 1 Luglio 2008 COGNOME: NOME: MATRICOLA: Si prega di risolvere gli esercizi direttamente sui fogli del testo, negli spazi indicati. Usare il foglio protocollo solo per la brutta
Basi di dati I 28 gennaio 2014 Compito A Tempo a disposizione: un ora e quarantacinque minuti.
 Basi di dati I 28 gennaio 2014 Compito A Tempo a disposizione: un ora e quarantacinque minuti. Cognome: : Matricola: Domanda 1 (10%) Considerare i due schemi seguenti a) Professore Afferenza Dipartimento
Basi di dati I 28 gennaio 2014 Compito A Tempo a disposizione: un ora e quarantacinque minuti. Cognome: : Matricola: Domanda 1 (10%) Considerare i due schemi seguenti a) Professore Afferenza Dipartimento
Il sistema informativo deve essere di tipo centralizzato e accessibile mediante un computer server installato nella rete locale dell albergo.
 PROBLEMA. Un albergo di una grande città intende gestire in modo automatizzato sia le prenotazioni sia i soggiorni e realizzare un database. Ogni cliente viene individuato, tra l altro, con i dati anagrafici,
PROBLEMA. Un albergo di una grande città intende gestire in modo automatizzato sia le prenotazioni sia i soggiorni e realizzare un database. Ogni cliente viene individuato, tra l altro, con i dati anagrafici,
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 29 Giugno 2004 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati per
Prova Scritta di Basi di Dati 29 Giugno 2004 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati per
Gestione delle informazioni. Tot. h 10. Base di Dati. Tot. h 56. Grafica in C# - Laboratorio- Tot. h 40. Dipartimento Informatica Materia Informatica
 Dipartimento Informatica Materia Informatica Classe 5 Tec Ore/anno 198 A.S. 2018-2019 MODULI COMPETENZE UNITA di APPRENDIMENTO Gestione delle informazioni Tot. h 10 Base di Dati Tot. h 56 Grafica in C#
Dipartimento Informatica Materia Informatica Classe 5 Tec Ore/anno 198 A.S. 2018-2019 MODULI COMPETENZE UNITA di APPRENDIMENTO Gestione delle informazioni Tot. h 10 Base di Dati Tot. h 56 Grafica in C#
SQL. Università degli Studi di Salerno. Corso di Laurea in Scienze della Comunicazione Informatica generale (matr. Dispari) Docente: Angela Peduto
 Docente: Angela Peduto") SQL Università degli Studi di Salerno Corso di Laurea in Scienze della Comunicazione Informatica generale (matr. Dispari) Docente: Angela Peduto A.A. 2005/2006 Select La forma di select cui siamo arrivati
SQL Università degli Studi di Salerno Corso di Laurea in Scienze della Comunicazione Informatica generale (matr. Dispari) Docente: Angela Peduto A.A. 2005/2006 Select La forma di select cui siamo arrivati
Basi di Dati. SOLUZIONE della Prova Scritta del 12 Gennaio 2007
 Basi di Dati SOLUZIONE della Prova Scritta del 12 Gennaio 2007 Schema Relazionale per gli Esercizi 1 e 2 Considerare lo schema di base di dati contenente le relazioni: Rivista (codice: string, : string,
Basi di Dati SOLUZIONE della Prova Scritta del 12 Gennaio 2007 Schema Relazionale per gli Esercizi 1 e 2 Considerare lo schema di base di dati contenente le relazioni: Rivista (codice: string, : string,
Esercitazioni Informatica A. M. M. Bersani
 Esercitazioni Informatica A M. M. Bersani A.A. 2012/2013 Codifiche Scriviamo n b per intendere il numero n rappresentato in base 2, se b = 2, in base 10, se b = 10, e C2 se b = C2. L operatore mod è un
Esercitazioni Informatica A M. M. Bersani A.A. 2012/2013 Codifiche Scriviamo n b per intendere il numero n rappresentato in base 2, se b = 2, in base 10, se b = 10, e C2 se b = C2. L operatore mod è un
Basi di Dati Corso di Laura in Informatica Umanistica
 Basi di Dati Corso di Laura in Informatica Umanistica Appello del 28/06/2010 Parte 1: Algebra Relazionale e linguaggio SQL Docente: Giuseppe Amato Sia dato il seguente schema di base di dati per la gestione
Basi di Dati Corso di Laura in Informatica Umanistica Appello del 28/06/2010 Parte 1: Algebra Relazionale e linguaggio SQL Docente: Giuseppe Amato Sia dato il seguente schema di base di dati per la gestione
Basi di Dati. Esercitazione SQL. 17 novembre 2011
 Basi di Dati Esercitazione SQL 17 novembre 2011 Esercitazione 2 Considerando la seguente base di dati: Fornitori (CodiceFornitore, Nome, Indirizzo, Città) Prodotti (CodiceProdotto, Nome, Marca, Modello)
Basi di Dati Esercitazione SQL 17 novembre 2011 Esercitazione 2 Considerando la seguente base di dati: Fornitori (CodiceFornitore, Nome, Indirizzo, Città) Prodotti (CodiceProdotto, Nome, Marca, Modello)
formulare in SQL una interrogazione per ciascuno dei seguenti punti:
 Basi di Dati Esercitazione SQL 13 maggio 2004 Ing. Paolo Cappellari Ing. Paolo Papotti Esercitazione 2 Considerando la seguente base di dati: Fornitori CodiceFornitore, Nome, Indirizzo, Città) Prodotti
Basi di Dati Esercitazione SQL 13 maggio 2004 Ing. Paolo Cappellari Ing. Paolo Papotti Esercitazione 2 Considerando la seguente base di dati: Fornitori CodiceFornitore, Nome, Indirizzo, Città) Prodotti
Basi di dati I 8 luglio 2016 Esame Compito A Tempo a disposizione: un ora e trenta minuti.
 Basi di dati I 8 luglio 2016 Esame Compito A Tempo a disposizione: un ora e trenta minuti. Cognome: Nome: Matricola: Domanda 1 (20%) Considerare la base di dati relazionale contenente le seguenti relazioni:
Basi di dati I 8 luglio 2016 Esame Compito A Tempo a disposizione: un ora e trenta minuti. Cognome: Nome: Matricola: Domanda 1 (20%) Considerare la base di dati relazionale contenente le seguenti relazioni:
Architetture per l analisi dei dati
 Architetture per l analisi dei dati Esercizio 8.1 Progettare un cubo multidimensionale relativo all analisi dei sinistri per una compagnia assicurativa, basandosi sulle specifiche accennate nel paragrafo
Architetture per l analisi dei dati Esercizio 8.1 Progettare un cubo multidimensionale relativo all analisi dei sinistri per una compagnia assicurativa, basandosi sulle specifiche accennate nel paragrafo
Basi di dati I 19 settembre 2016 Tempo a disposizione: un ora e 45 minuti.
 Tempo a disposizione: un ora e 45 minuti. Cognome: Nome: Matricola: Domanda 1 (15%) Considerare la relazione Stipendi(Matricola,StipLordo,Tasse,Netto,OK) Spiegare (sinteticamente ma in modo chiaro) quali
Tempo a disposizione: un ora e 45 minuti. Cognome: Nome: Matricola: Domanda 1 (15%) Considerare la relazione Stipendi(Matricola,StipLordo,Tasse,Netto,OK) Spiegare (sinteticamente ma in modo chiaro) quali
Primo Compitino di Basi di Dati
 Primo Compitino di Basi di Dati 19 Aprile 2004 Svolgere gli esercizi direttamente sul foglio del testo Usare fogli aggiuntivi solo in mancanza di spazio. NOME: COGNOME: MATRICOLA: Esercizio Punti previsti
Primo Compitino di Basi di Dati 19 Aprile 2004 Svolgere gli esercizi direttamente sul foglio del testo Usare fogli aggiuntivi solo in mancanza di spazio. NOME: COGNOME: MATRICOLA: Esercizio Punti previsti
Basi di Dati: Corso di laboratorio
 Basi di Dati: Corso di laboratorio Lezione 4 Raffaella Gentilini 1 / 48 Sommario 1 Join di Tabelle Join Naturale Theta Join Join Esterno 2 La Clausola HAVING 3 2 / 48 Join Naturale Theta Join Join Esterno
Basi di Dati: Corso di laboratorio Lezione 4 Raffaella Gentilini 1 / 48 Sommario 1 Join di Tabelle Join Naturale Theta Join Join Esterno 2 La Clausola HAVING 3 2 / 48 Join Naturale Theta Join Join Esterno
Misure (parte II) Gerarchie Incomplete
 Gerarchie Incomplete") Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Misure (parte II) Gerarchie Incomplete Esempio Schema di Fatto STUDENTE(STUDENTE,,REGIONE,), DF:! REGIONE (,,) REGIONE!
Sistemi Informativi Avanzati Anno Accademico 2013/2014 Prof. Domenico Beneventano Misure (parte II) Gerarchie Incomplete Esempio Schema di Fatto STUDENTE(STUDENTE,,REGIONE,), DF:! REGIONE (,,) REGIONE!
Compito Basi di Dati. Tempo concesso : 90 minuti 21 Gennaio 05 Nome: Cognome: Matricola: Esercizio 1
 Nome: Cognome: Matricola: Esercizio 1 Si considerino le seguenti specifiche relative alla realizzazione del sistema informativo di un vivaio di piante e si definisca il relativo schema E/R (usando la metodologia
Nome: Cognome: Matricola: Esercizio 1 Si considerino le seguenti specifiche relative alla realizzazione del sistema informativo di un vivaio di piante e si definisca il relativo schema E/R (usando la metodologia
ATTRIBUTO o ASSOCIAZIONE?
 ATTRIBUTO o ASSOCIAZIONE? Uno studente ha CF e facoltà (identificata dal nome) : I due schemi sono equivalenti (stessa informazione) : è da preferire il primo in quanto più semplice! Nel primo schema NOMEFACOLTÀ
ATTRIBUTO o ASSOCIAZIONE? Uno studente ha CF e facoltà (identificata dal nome) : I due schemi sono equivalenti (stessa informazione) : è da preferire il primo in quanto più semplice! Nel primo schema NOMEFACOLTÀ
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 22 Settembre 2003 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati
Prova Scritta di Basi di Dati 22 Settembre 2003 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati
Basi di dati. Gabriella Trucco
 Basi di dati Gabriella Trucco gabriella.trucco@unimi.it Algebra relazionale Definizione: insieme di operazioni (query) che servono per manipolare relazioni (tabelle). Formalizzazione matematica del modo
Basi di dati Gabriella Trucco gabriella.trucco@unimi.it Algebra relazionale Definizione: insieme di operazioni (query) che servono per manipolare relazioni (tabelle). Formalizzazione matematica del modo
PROGRAMMAZIONE ANNO SCOLASTICO 2018/2019
 Istituto Istruzione Superiore Cristoforo Colombo Liceo Scientifico delle Scienze applicate Liceo Scientifico Sportivo Istituto Tecnologico indirizzo Costruzioni Ambiente e Territorio Istituto Tecnico Economico:
Istituto Istruzione Superiore Cristoforo Colombo Liceo Scientifico delle Scienze applicate Liceo Scientifico Sportivo Istituto Tecnologico indirizzo Costruzioni Ambiente e Territorio Istituto Tecnico Economico:
Introduzione alla programmazione Algoritmi e diagrammi di flusso. Sviluppo del software
 Introduzione alla programmazione Algoritmi e diagrammi di flusso F. Corno, A. Lioy, M. Rebaudengo Sviluppo del software problema idea (soluzione) algoritmo (soluzione formale) programma (traduzione dell
Introduzione alla programmazione Algoritmi e diagrammi di flusso F. Corno, A. Lioy, M. Rebaudengo Sviluppo del software problema idea (soluzione) algoritmo (soluzione formale) programma (traduzione dell
Data warehouse Analisi dei dati
 atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of B MG ata warehouse: analisi dei dati atabase and data mining group, M B G ata warehouse Analisi dei dati
atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of B MG ata warehouse: analisi dei dati atabase and data mining group, M B G ata warehouse Analisi dei dati
Data warehouse: analisi dei dati
 atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and
atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and ata Mining Group of atabase and
Informatica documentale Laurea in Scienze della Comunicazione Prova scritta del 25 giugno Cognome e nome: Matricola:
 Informatica documentale Laurea in Scienze della Comunicazione Prova scritta del 25 giugno 2012 Cognome e nome: Matricola: Parte prima Domanda 1 Domanda 2 Domanda 3 Totale Istruzioni: È vietato portare
Informatica documentale Laurea in Scienze della Comunicazione Prova scritta del 25 giugno 2012 Cognome e nome: Matricola: Parte prima Domanda 1 Domanda 2 Domanda 3 Totale Istruzioni: È vietato portare
d. Cancellazione del valore 5 e. Inserimento del valore 1
 Esercizio1 Si consideri un albero binario non vuoto in cui a ciascun nodo v è associato un numero reale v.val. Scrivere un algoritmo che, dato in input l'albero T e un numero reale x, restituisce true
Esercizio1 Si consideri un albero binario non vuoto in cui a ciascun nodo v è associato un numero reale v.val. Scrivere un algoritmo che, dato in input l'albero T e un numero reale x, restituisce true
Esercitazione Simulazione Compito
 Esercitazione Simulazione Compito 04/12/2015 Compito del 26/05/2014 1.1 Il comando DELETE FROM Utenti WHERE alias = gino dove alias è una primary key: (a)elimina zero o una riga (b) elimina un numero imprecisato
Esercitazione Simulazione Compito 04/12/2015 Compito del 26/05/2014 1.1 Il comando DELETE FROM Utenti WHERE alias = gino dove alias è una primary key: (a)elimina zero o una riga (b) elimina un numero imprecisato
8 SQL : Check, Asserzioni,Viste
 Corso di Laurea in Ingegneria Gestionale SAPIENZA Università di Roma Esercitazioni del corso di Basi di Dati Prof.ssa Catarci e Prof.ssa Scannapieco Anno Accademico 2011/2012 8 SQL : Check, Asserzioni,Viste
Corso di Laurea in Ingegneria Gestionale SAPIENZA Università di Roma Esercitazioni del corso di Basi di Dati Prof.ssa Catarci e Prof.ssa Scannapieco Anno Accademico 2011/2012 8 SQL : Check, Asserzioni,Viste
Riconoscere e formalizzare le dipendenze funzionali
 Riconoscere e formalizzare le dipendenze funzionali Giorgio Ghelli 25 ottobre 2007 1 Riconoscere e formalizzare le dipendenze funzionali Non sempre è facile indiduare le dipendenze funzionali espresse
Riconoscere e formalizzare le dipendenze funzionali Giorgio Ghelli 25 ottobre 2007 1 Riconoscere e formalizzare le dipendenze funzionali Non sempre è facile indiduare le dipendenze funzionali espresse
Prova Scritta di Basi di Dati
 Prova Scritta di Basi di Dati 30 Settembre 2002 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati
Prova Scritta di Basi di Dati 30 Settembre 2002 NOME: COGNOME: MATRICOLA: Esercizio Punti previsti 1 10 2 12 3 8 4 3 Totale 33 Punti assegnati Esercizio 1 (Punti 10) Si vuole sviluppare una base di dati