Architettura degli Elaboratori e Laboratorio. Matteo Manzali Università degli Studi di Ferrara Anno Accademico
|
|
|
- Lucia Romani
- 5 anni fa
- Visualizzazioni
Transcript
1 Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico
2 Componenti visti Nelle scorse lezioni abbiamo visto come sono realizzati i seguenti componenti: 2
 Esempio: input (00110001)due control")
3 Shifter Componente che implementa l operazione di shift verso destra (o sinistra). E composto da una catena di Mux. In figura è mostrato un circuito che implementa lo shift a sinistra su 8 bit: 3 livelli (3 bit di controllo) Esempio: input ( )due control (010)due output ( )due LSB MSB 3
4 Shifter Nel data path ci servirà un circuito per moltiplicare per 4 gli indirizzi (es. calcolo dell istruzione successiva). Possiamo utilizzare uno shifter a sinistra di 2: 32 bit di input e output 5 bit di controllo (2 5 = 32). bit di controllo hardcoded: (00010)due / 32 / 32 4
5 Bit extender Un circuito con N bit in ingresso e M bit in uscita (dove N < M). Il circuito interpreta i bit in ingresso come rappresentazione binaria di un numero con segno e ne estende i bit: se il numero è positivo i bit aggiunti saranno 0 se il numero è negativo i bit aggiunti saranno 1 16 bit 32 bit 5
6 Il processore MIPS Vedremo un implementazione semplificata del processore MIPS. Copre un sottoinsieme limitato di istruzioni rappresentative dell ISA: aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento di controllo: beq, j Ad ogni ciclo di clock viene eseguita una istruzione completa. Assumiamo che la memoria che tiene le istruzioni (read-only) e la memoria che tiene i dati (read/write) siano separate. Possiamo leggere e scrivere nello stesso ciclo di clock. 6
7 Cosa fa un processore Per ogni istruzione: legge dalla memoria l istruzione il cui indirizzo è nel PC legge dei registri (in base a quanto specificato dall istruzione) A seconda dell istruzione: usa la ALU per calcolare uno tra i seguenti valori: un risultato aritmetico/logico un indirizzo di memoria (registro + offset) l'indirizzo di un branch target accede alla memoria per load/store aggiorna il PC con PC + 4 o con un indirizzo target 7
8 Lettura istruzione Per eseguire un istruzione è necessario prima leggerla dalla memoria. PC è un registro dedicato che contiene l indirizzo dell istruzione attualmente in esecuzione. Escludendo casi di branch o jump, tipicamente la prossima istruzione da eseguire è quella successiva alla corrente. Ogni istruzione è rappresentata da un blocco di 32 bit (4 bye). L istruzione successiva a quella corrente si troverà quindi all indirizzo PC
: Adder a 32 bit 32-bit register Increment by 4 for next instruction")
9 Lettura istruzione Circuito per l incremento del PC (ad ogni ciclo di clock viene aggiunto 4 all indirizzo corrente): Adder a 32 bit 32-bit register Increment by 4 for next instruction 9
10 Istruzioni di tipo R op rs rt rd shamt funct 6 bit 5 bit 5 bit 5 bit 5 bit 6 bit L istruzione viene letta dalla memoria (es. add $s0, $t0, $t1). Vengono selezionati i due registri in lettura (rs e rt) e il registro in scrittura (rd). Vengono generati segnali di controllo dell ALU. Vengono letti i valori dei registri sorgenti e dati in input alla ALU. L ALU esegue l operazione. Il valore in output dalla ALU viene scritto nel registro destinazione. 10
11 Istruzioni di tipo R I segnali di controllo (in blu) verranno affrontati successivamente. Sfruttiamo il fatto che il Register File permette di leggere e scrivere nello stesso ciclo di clock (write after read): possiamo collegare l output dell ALU come input del Write Data 11
12 Istruzioni load op rs rt costante/indirizzo 6 bit 5 bit 5 bit 16 bit L istruzione viene letta dalla memoria (es. lw $t0, 0($a0)). Il valore contenuto nel registro rs viene mandato come primo operando all ALU. L offset viene esteso a 32 bit con segno ed inviato all ALU come secondo operando. Vengono generati segnali di controllo dell ALU. L ALU esegue l operazione, calcolando l indirizzo a cui accedere. Il dato è letto dalla memoria e scritto nel registro rt. 12
13 Istruzioni store op rs rt costante/indirizzo 6 bit 5 bit 5 bit 16 bit L istruzione viene letta dalla memoria (es. sw $t0, 0($a0)). Il valore contenuto nel registro rs viene mandato come primo operando all ALU. L offset viene esteso a 32 bit con segno ed inviato all ALU come secondo operando. Vengono generati segnali di controllo dell ALU. L ALU esegue l operazione, calcolando l indirizzo a cui accedere. Il dato contenuto nel registro rt è scritto nella memoria principale all indirizzo selezionato. 13
14 Istruzioni load/store Componenti necessari (il Register File e la ALU li abbiamo già): Memoria principale Estensione da 16 a 32 bit (con segno) 14
15 Istruzioni load/store Mettiamo tutto assieme (escludendo il PC): 0: usa output dell'alu (istruzione R) 1: usa dati letti da memoria (load) 0: usa valore registro rt (istruzione R) 1: usa offset nell'istruzione (load/store) 15
16 Istruzioni di branch (beq) op rs rt costante/indirizzo 6 bit 5 bit 5 bit 16 bit L istruzione viene letta dalla memoria. L offset viene shiftato a sinistra di 2 bit e esteso a 32 bit con segno. L indirizzo risultante viene sommato con PC + 4 (adder aggiuntivo). I due registri in lettura (rs e rt) vengono passati alla ALU come operandi. La ALU calcola la differenza tra i due operandi. Viene interpretato il segnale zero della ALU per capire se il salto deve o meno avvenire. 16
17 Istruzioni di branch (beq) Componenti necessari: L indirizzo a cui saltare viene sempre calcolato Circuito che fa lo shift a sinistra di 2 bit Si controlla se il segnale zero è alto o basso (con beq se è alto si salta) 17

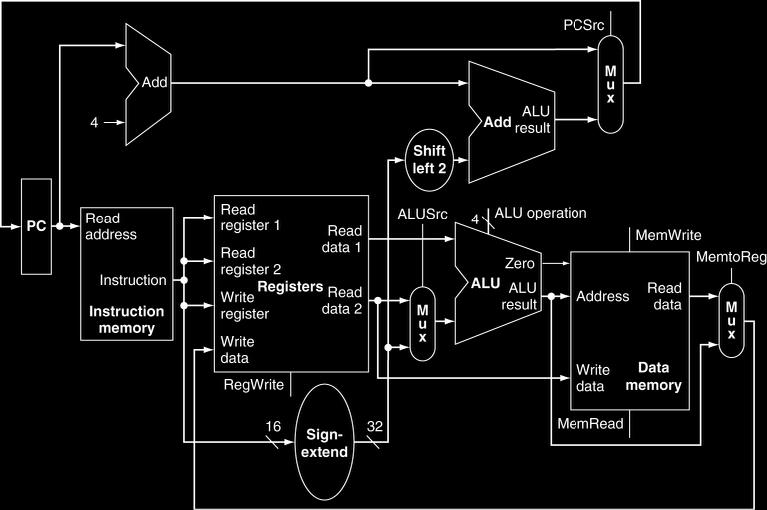
18 Datapath completo 18
19 Unità di controllo Il datapath che abbiamo costruito ha 7 segnali di controllo: RegWrite, ALUSrc, PCSrc, MemWrite, MemtoReg, MemRead 1 bit ALU Operation 4 bit L'unità di controllo del processore ha il compito di generare (direttamente o indirettamente) quei segnali. Segue una logica combinatoria: l'input è dato dall istruzione (i 6 bit del campo op) in output genera i segnali di controllo E composta da due parti: una di controllo generico ed una specifica per l ALU. 19

20 Controllo della ALU L'unità di controllo della ALU deve generare in output i segnali di controllo per la ALU (ALU operation): Per le istruzioni di tipo R la funzione è data dal codice funct nell istruzione. Per le istruzioni load/store la funzione è sempre add. Per la funzione beq la funzione è sempre subtract. 20
 il codice funct dell'istruzione per le istruzioni R I bit ALUOp sono settati dall'unità di controllo")
21 Controllo della ALU L'input all'unità di controllo della ALU è dato da: due bit che indicano a che categoria appartiene l istruzione (ALUOp) il codice funct dell'istruzione per le istruzioni R I bit ALUOp sono settati dall'unità di controllo principale. 21
22 Controllo della ALU Data 1 Data 2 ALU control (4 bit) Funct (6 bit) (2 bit) 22
23 Controllo e istruzioni R-type Load/ Store Branch 0 rs rt rd shamt funct 31:26 25:21 20:16 15:11 10:6 5:0 35 or 43 rs rt address 31:26 25:21 20:16 15:0 4 rs rt address 31:26 25:21 20:16 15:0 opcode always read read, except for load write for R- type and load sign-extend and add Unico input del circuito di controllo principale Richiede un ulteriore segnale di controllo 23
24 Controllo principale Nuovo segnale di controllo 24
25 Segnali di controllo RegDst: 0 il numero del registro su cui scrivere deriva dal campo rt (bits 20:16) 1 il numero del registro su cui scrivere deriva dal campo rd (bits 15:11) RegWrite: 0 nessun effetto 1 il registro specificato in Write register viene scritto con il valore in Write data 25
26 Segnali di controllo ALUSrc: 0 il secondo operando dell ALU deriva dal secondo registro in lettura del Register File 1 il secondo operando dell ALU è l offset con segno ed esteso a 32 bit (bits 15:0) MemRead: 0 nessun effetto 1 il dato presente in memoria principale all indirizzo letto nell input Address viene fornito in output su Read data 26
27 Segnali di controllo MemWrite: 0 nessun effetto 1 il dato presente nell input Write data viene scritto in memoria principale all indirizzo letto nell input Address MemtoReg: 0 il valore passato all input Write data è il risultato dell ALU 1 il valore passato all input Write data è il valore letto dalla memoria principale 27
28 Segnali di controllo PCSrc: 0 il PC diventa PC il PC diventa il risultato della somma tra PC e l offset Ma PCSrc vale 1 quando: stiamo eseguendo un operazione di branch il segnale zero dell ALU è alto Si può quindi ottenere PCSrc mettendo in AND questi due controlli: l unità di controllo avrà un segnale Branch che indica se si sta eseguendo una operazione di branch 28

29 Controllo principale L input dell unità di controllo principale è costituito esclusivamente dall'opcode dell istruzione: X significa don t care (non importa, non significativo) 29
30 Datapath con controllo PCSrc è diventato una combinazione di due segnali 30

31 Istruzioni di tipo R , 0

32 Load , 0
33 Store X X , 0


34 Branch-on-equal X 1 branch AND zero faccio il salto 0 0 X , 1
35 Jump incondizionato Formato J: op indirizzo 6 bit 26 bit L op del jump è (000010)due. Il PC viene aggiornato con una concatenazione di: 4 bit più significativi presi dal PC 26 bit di indirizzo 2 bit meno significativi sono sempre 0 35
36 Calcolo del nuovo indirizzo (prendo i 4 bit più alti dal PC) Jump incondizionato Segnale in uscita Jump Shift di 2 bit + estensione di 2 bit Componenti aggiunti: 1 Shifter e 1 Mux 36
37 Come implementare addi? 37
38 Implementazione di addi E una istruzione di tipo I (come load e store). Il suo comportamento è molto simile alla load: si somma il valore di un registro con una costante Il risultato della ALU non deve essere interpretato come un indirizzo in memoria: MemtoReg 0 (nella load è 1) MemRead 0 (nella load è 1) Basta modificare il comportamento della logica di controllo per farle riconoscere anche l opcode di addi (001000)due 38


39 Come implementare jal? Datapath selezionato per l istruzione jump 39
40 Implementazione di jal E una istruzione di tipo J (come jump). A differenza di jump deve scrive il valore PC + 4 nel registro $ra (31). Devo collegare l output dell adder di PC + 4 a Write data del Register File: aggiungo un input al Mux di MemtoReg (il controllo passa da 1 a 2 bit) Devo poter scrivere il valore 31 nell input Write register : aggiungo un input al Mux di RegDst (il controllo passa da 1 a 2 bit) La logica di controllo deve essere in grado di riconoscere l opcode di jal (000011)due 40
41 Come implementare jr? 41
42 Implementazione di jr E una istruzione di tipo R. op rs rt rd shamt funct 6 bit 5 bit 5 bit 5 bit 5 bit 6 bit op sssss rs rt rd shamt funct Viene codificata passando il numero del registro specificato in rs (tipicamente $ra, ovvero 31) all input Read register 1 del Register File. rt, rd e shamt non sono utilizzati. Il valore letto dal Register File è l indirizzo a cui saltare, quindi viene scritto nel PC (nuovo collegamento al Mux del PC). Necessari collegamenti e controlli aggiuntivi. 42
43 Le eccezioni Fino ad ora abbiamo visto l esecuzione di istruzioni nell area utente della memoria (indirizzo < 0x ). Sappiamo che possono esserci errori durante l esecuzione del programma (accesso ad un area di memoria non consentita, divisione per zero, etc.). In caso di errore l elaboratore smette di eseguire il programma e salta ad un area del kernel dedicata: l indirizzo 0x contiene la prima istruzione di un programma del kernel chiamato exception handler in caso di errore il PC deve essere aggiornato con quell indirizzo (nuovo collegamento al Mux del PC) Necessari collegamenti e controlli aggiuntivi. 43
44 E le altre istruzioni? Il datapath visto ora permette solo l esecuzione di un sottoinsieme di istruzioni MIPS: scopo didattico (come nel libro di testo) approccio utilizzato anche per altri argomenti Per permettere l esecuzione di altre istruzioni è necessario aggiungere componenti hardware e complicare la logica di controllo (come visto per addi). Nelle slides successive vedremo una possibile implementazione del calcolo di prodotto e divisione: non andremo in dettaglio come negli argomenti precedenti 44
45 Prodotto Il prodotto può essere implementato attraverso una serie di somme e shift (come visto nelle scorse lezioni): 1110 x // moltiplicando 0110 = // moltiplicatore = // prodotto Ogni risultato parziale o è zero o è il moltiplicando spostato progressivamente a sinistra. La moltiplicazione si riduce ad una serie di somme e spostamenti a sinistra. 45
46 Prodotto Possibile implementazione in hardware del prodotto (istruzione MULT): Multiplicand 32 bits 32-bit ALU Product (Multiplier) 64 bits Shift Right Write Control 32 bit registro HI 32 bit registro LO LSB controllo se 1 o 0 46
47 Prodotto LSB di LO Multiply Algorithm Version 3 Product0 = 1 Start 1. Test Product0 Product0 = 0 In fase di start scrivo il moltiplicatore nel registro LO 1a. Add multiplicand to the left half of product & place the result in the left half of Product register Sommo il moltiplicando solo alla parte del registro HI Faccio shift di tutto il registro a 64 bit ( HI e LO ) 2. Shift the Product register right 1 bit. 32nd repetition? No: < 32 repetitions Yes: 32 repetitions Done EECC550 - Shaaba 32 ripetizioni per 32 bit 47
48 Divisione Il circuito visto nelle slides precedenti per il prodotto può essere utilizzato anche per implementare la divisione attraverso una serie di differenze: modifiche nella ALU modifiche nella logica di controllo 48
49 Ricapitolando Un datapath contiene i componenti e i collegamenti necessari ad implementare un ISA (Instruction Set Architecture). L implementazione vista è: a singolo ciclo di clock (1 ciclo 1 istruzione) a memorie separate (istruzioni e dati) con un ISA ridotto rispetto al MIPS classico a 32 bit La logica di controllo dice al datapath che cosa fare: si basa su una logica combinatoria riceve in input l istruzione binaria (la parte significativa) 49

50 MARS Aprite MARS: Scrivete qualche istruzione, ad esempio: Salvate Andate su Tools MIPS X-Ray Assemblate Cliccate su Connect to MIPS Eseguite 50
51 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma: wall-clock time tiene conto anche di I/O e delle attese dovute alla condivisione delle risorse con altri programmi CPU time tiene conto solo del tempo in cui il programma usa la CPU Throughput: numero di task/transazioni eseguiti per unità di tempo Altro 51
52 CPU time CPU time = #instructions CPI Clock cycle #instructions: numero di istruzioni nel programma CPI: numero medio di cicli di clock per istruzione Clock cycle: durata di un ciclo di clock 52

53 Istruzioni Non siamo interessati alla quantità statica di istruzioni, ovvero alle linee di codice del programma. Quello che dobbiamo considerare è la quantità dinamica di istruzioni, ovvero quante istruzioni vengono realmente eseguite durante l esecuzione del programma. Il codice seguente contiene 3 linee, ma il numero di istruzioni eseguite sarà 2001: 53
54 CPI Il numero medio di cicli di clock per istruzione (CPI) dipende sia dal processore che dal programma: un programma con molte istruzioni floating point può avere un CPI più alto di un programma che utilizza solo interi un processore può eseguire lo stesso programma molto più velocemente rispetto ad un altro processore meno performante. Nel datapath descritto nelle slides precedenti abbiamo assunto che una istruzione venga eseguita in un ciclo di clock, quindi il CPI è 1. In generale: CPI > 1 a causa di stalli sulla memoria o istruzioni lente CPI < 1 su macchine che eseguono più istruzioni nello stesso ciclo di clock 54
55 Ciclo di clock Un ciclo di clock è l unità di tempo minima richiesta dalla CPU per fare qualcosa: il tempo del ciclo di clock (o periodo) è la lunghezza del ciclo la frequenza di clock è il reciproco del periodo Argomento già introdotto nelle precedenti lezioni. Generalmente una frequenza più alta porta a maggiori prestazioni. 55
56 Performance CPU time = #instructions CPI Clock cycle Per migliorare le performances si può migliorare ogni singolo fattore. Il miglioramento di un fattore può portare al peggioramento degli altri. 56
57 Singolo ciclo di clock Possibili operazioni previste dal datapath: una nuova istruzione viene letta dalla memoria l unità di controllo configura i segnali vengono letti i registri dal Register File viene generato l output della ALU viene effettuata la scrittura o lettura nella memoria principale viene calcolato l indirizzo di branch viene scritto un valore nel Register File viene aggiornato il PC? 57
58 Singolo ciclo di clock Ogni istruzione dell ISA prevede una combinazione di una parte delle operazioni appena descritte. In un ciclo di clock deve poter essere eseguita una istruzione: il ciclo di clock deve essere abbastanza lungo da poter eseguire l istruzione più lenta dell ISA. Ma una volta decisa la lunghezza del ciclo di clock, ogni istruzione durerà esattamente quel tempo (anche se potrebbe essere completata in meno tempo). 58
59 Esempio: lw Esempio del tempo di esecuzione di una lw: I tempi mostrati sono puramente esemplificativi 59
60 Esempio: add Esempio del tempo di esecuzione di una add: I tempi mostrati sono puramente esemplificativi 60
.")
61 Esempio: performance Consideriamo 8 ns come tempo di esecuzione dell istruzione più lenta (lw), allora il ciclo di clock dovrà durare 8 ns. Anche la add impiegherà 8 ns (anche se potenzialmente potrebbe impiegarne sono 6 ns). Poniamo sempre come esempio: istruzioni sw 7 ns istruzioni beq 5 ns E poniamo che in tabella siano mostrate le frequenze di esecuzione delle diverse istruzioni. 61
62 Esempio: performance Con un datapath a singolo ciclo ogni istruzione richiederebbe comunque 8 ns. Se potessimo eseguire le istruzioni alla massima velocità possibile, avremmo che il tempo medio di esecuzione di un istruzione sarebbe: (48% 6 ns) + (22% 8 ns) + (11% 7 ns) + (19% 5 ns) = 6.36 ns Il datapath a singolo ciclo di clock è 8 / 6.36 = 1.26 volte più lento! Questa è una stima molto ottimistica: l accesso alla memoria principale (RAM) è dell ordine di 100 ns. L istruzione più lenta prevede due accessi in memoria, potenzialmente quindi richiederebbe 200 ns (le cache mitigano il problema). 62
63 Esempio: performance I moderni calcolatori non usano il datapath a singolo ciclo di clock per motivi di inefficienza. Nelle prossime lezioni vedremo come questa problematica può essere superata: introduzione del concetto di pipeline 63
Implementazione semplificata
 Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
L'architettura del processore MIPS
 L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
Richiami sull architettura del processore MIPS a 32 bit
 Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Richiami sull architettura del processore MIPS a 32 bit
 Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Il Processore: l Unità di Controllo Principale Barbara Masucci
 Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
Architettura degli Elaboratori Il Processore: l Unità di Controllo Principale Barbara Masucci Punto della situazione Ø Abbiamo visto come costruire l Unità di Controllo della ALU per il processore MIPS
Il processore: unità di elaborazione
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Progettazione dell unità di elaborazioni dati e prestazioni. Il processore: unità di elaborazione. I passi per progettare un processore
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1,
Architettura dei calcolatori e sistemi operativi. Il processore Capitolo 4 P&H
 Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
Architettura dei calcolatori e sistemi operativi Il processore Capitolo 4 P&H 4. 11. 2015 Sommario Instruction Set di riferimento per il processore Esecuzione delle istruzioni Struttura del processore
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D,
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/60 Sommario v La CPU v Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/60 Sommario v La CPU v Sintesi di
Università degli Studi di Cassino
 Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Progetto CPU (ciclo singolo)
") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando
 Salvatore Orlando") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti
 Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
L unità di controllo di CPU a singolo ciclo. Sommario
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2,
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Processore: Datapath & Control. Progetto CPU (ciclo singolo) Rivediamo i formati delle istruzioni. ISA di un MIPS-lite
 Rivediamo i formati delle istruzioni. ISA di un MIPS-lite") Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Università degli Studi di Cassino e del Lazio Meridionale
 Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
CALCOLATORI ELETTRONICI 27 giugno 2017
 CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
Università degli Studi di Cassino
 Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
CALCOLATORI ELETTRONICI 30 agosto 2010
 CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
Architettura degli Elaboratori B Introduzione al corso
 Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
Architettura degli elaboratori MZ Compito A
 Architettura degli elaboratori MZ 16-4-18 Compito A Cognome e Nome: Matricola: Esercizio 1A. Considerate l architettura MIPS a ciclo singolo in Figura (sul retro). Qual è il valore dei segnali che partono
Architettura degli elaboratori MZ 16-4-18 Compito A Cognome e Nome: Matricola: Esercizio 1A. Considerate l architettura MIPS a ciclo singolo in Figura (sul retro). Qual è il valore dei segnali che partono
CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, esecuzione istruzioni tipo J Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione
CALCOLATORI ELETTRONICI 14 giugno 2010
 CALCOLATORI ELETTRONICI 14 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 14 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 1/8 Sommario! I problemi
Il processore: Data path e Control path
 Il processore: Data path e Control path A/A 217/218 1 Elementi di un processore In ogni processore si possono distriguere due elementi fondamentali: Data path Circuiti che eseguono operazioni aritmetico-logiche
Il processore: Data path e Control path A/A 217/218 1 Elementi di un processore In ogni processore si possono distriguere due elementi fondamentali: Data path Circuiti che eseguono operazioni aritmetico-logiche
La Microarchitettura. Davide Bertozzi
 La Microarchitettura Davide Bertozzi Piano di Studio Dove Siamo Architettura del Set di Istruzioni (come «si parla» con un microprocessore, ovvero l interfaccia HW/SW) Microarchitettura di un processore:
La Microarchitettura Davide Bertozzi Piano di Studio Dove Siamo Architettura del Set di Istruzioni (come «si parla» con un microprocessore, ovvero l interfaccia HW/SW) Microarchitettura di un processore:
Architettura degli elaboratori CPU a ciclo singolo
 Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano iferimento sul Patterson: capitolo 4.2, 4.4,
Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano iferimento sul Patterson: capitolo 4.2, 4.4,
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
CPU a ciclo multiplo
 Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli Elaboratori e delle Reti Lezione CPU a ciclo multiplo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L /9 Sommario! I problemi
Architettura degli elaboratori CPU a ciclo singolo
 Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
Architettura degli elaboratori CPU a ciclo singolo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo
CALCOLATORI ELETTRONICI 29 giugno 2015
 CALCOLATORI ELETTRONICI 29 giugno 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Relativamente al confronto tra le implementazioni del processore
CALCOLATORI ELETTRONICI 29 giugno 2015 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1. Relativamente al confronto tra le implementazioni del processore
Architettura degli Elaboratori B. Introduzione al corso. Componenti di un calcolatore convenzionale. (ciclo singolo) Progetto CPU. Contenuti del corso
 Progetto CPU. Contenuti del corso") Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Calcolatori Elettronici B a.a. 2004/2005
 Calcolatori Elettronici B a.a. 2004/2005 Tecniche di Controllo: Esercizi Massimiliano Giacomin Calcolo CPI e Prestazioni nei sistemi a singolo ciclo e multiciclo ) Calcolo prestazioni nei sistemi a singolo
Calcolatori Elettronici B a.a. 2004/2005 Tecniche di Controllo: Esercizi Massimiliano Giacomin Calcolo CPI e Prestazioni nei sistemi a singolo ciclo e multiciclo ) Calcolo prestazioni nei sistemi a singolo
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
Calcolatori Elettronici
 Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo PC emoria indirizzo IR Condizioni SEGNALI DI CONTROLLO dato letto UNITA DI ELABORAZIONE
Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo PC emoria indirizzo IR Condizioni SEGNALI DI CONTROLLO dato letto UNITA DI ELABORAZIONE
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Andrea Torsello, Marta Simeoni " Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Andrea Torsello, Marta Simeoni " Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Argomenti della lezione - Esercizi sulla CPU MIPS a 1 colpo di clock
Architettura degli Elaboratori Lez. 10 Esercizi su CPU MIPS a 1 ciclo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Argomenti della lezione - Esercizi sulla CPU MIPS a 1 colpo di clock
Calcolatori Elettronici B a.a. 2005/2006
 Calcolatori Elettronici B a.a. 25/26 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 25/26 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Unità di controllo della pipeline
 Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
CPU a singolo ciclo: l unità di controllo, istruzioni tipo J
 Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
Architettura degli Elaboratori e delle Reti Lezione 9 CPU a singolo ciclo: l unità di controllo, istruzioni tipo J Pro. A. Borghese, F. Pedersini Dipartimento di Scienze dell Inormazione Università degli
CALCOLATORI ELETTRONICI A 25 gennaio 2011
 CALCOLATORI ELETTRONICI A 25 gennaio 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Supponendo di avere a disposizione dei sommatori full adder (3 ingressi e due uscite)
CALCOLATORI ELETTRONICI A 25 gennaio 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Supponendo di avere a disposizione dei sommatori full adder (3 ingressi e due uscite)
Elementi base per la realizzazione dell unità di calcolo
 Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Elementi base per la realizzazione dell unità di calcolo Memoria istruzioni elemento di stato dove le istruzioni vengono memorizzate e recuperate tramite un indirizzo. ind. istruzione Memoria istruzioni
Le etichette nei programmi. Istruzioni di branch: beq. Istruzioni di branch: bne. Istruzioni di jump: j
 L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
Linguaggio macchina. Architettura degli Elaboratori e delle Reti. Il linguaggio macchina. Lezione 16. Proff. A. Borghese, F.
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/32 Linguaggio
Prova intermedia di Architettura degli elaboratori canale MZ Sterbini Compito A
 Prova intermedia di Architettura degli elaboratori canale MZ Sterbini 13-4-2015 Compito A Cognome e Nome: Matricola: Esercizio 1. (4/30) Nell architettura MIPS a ciclo singolo (fig. sul retro), quali sono
Prova intermedia di Architettura degli elaboratori canale MZ Sterbini 13-4-2015 Compito A Cognome e Nome: Matricola: Esercizio 1. (4/30) Nell architettura MIPS a ciclo singolo (fig. sul retro), quali sono
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Linguaggio macchina e register file
 Linguaggio macchina e register file Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4,
Linguaggio macchina e register file Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4,
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) /46 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) /46 Sommario
Lezione 20. della CPU MIPS. Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano
 Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
Il linguaggio macchina
 Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Architettura degli Elaboratori e delle Reti Lezione 16 Il linguaggio macchina Proff. A. Borghese, F. Pedeini Dipaimento di Scienze dell Informazione Univeità degli Studi di Milano L 16 1/33 Linguaggio
Riassunto. Riassunto. Ciclo fetch&execute. Concetto di programma memorizzato. Istruzioni aritmetiche add, sub, mult, div
 MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
Esercitazione del 30/04/ Soluzioni
 Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
CALCOLATORI ELETTRONICI 9 settembre 2011
 CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
Università degli Studi di Cassino
 Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Corso di Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 2007/2008 Francesco Tortorella Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if
Lezione 20. della CPU MIPS. Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano
 Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Calcolatori Elettronici
 Calcolatori Elettronici CPU multiciclo Massimiliano Giacomin SVANTAGGI DEL PROCESSORE A SINGOLO CICLO Tutte le istruzioni lunghe un ciclo di clock T clock determinato dall istruzione più lenta Istruzioni
Calcolatori Elettronici CPU multiciclo Massimiliano Giacomin SVANTAGGI DEL PROCESSORE A SINGOLO CICLO Tutte le istruzioni lunghe un ciclo di clock T clock determinato dall istruzione più lenta Istruzioni
CPU pipeline hazards
 Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 23 CPU pipeline hazards Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 23 /24 Sommario!
Come si definisce il concetto di performance? Tempo di esecuzione di un programma. numero di task/transazioni eseguiti per unità di tempo
 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base (ESERCIZI) assimiliano Giacomin Esercizio confronto prestazioni pipeline vs. mlticiclo Si consideri la segente combinazione di istrzioni esegite
Calcolatori Elettronici Tecniche Pipeline: Elementi di base (ESERCIZI) assimiliano Giacomin Esercizio confronto prestazioni pipeline vs. mlticiclo Si consideri la segente combinazione di istrzioni esegite
slt $t1,$t2,$t3 if ($t2<$t3) $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante
 $t1=1; Confronto tra registri slti $t1,$t2,100 if ($t2<100)$t1=1; Cfr. registro-costante") Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Istruzioni di confronto Istruzione Significato slt $t1,$t2,$t3 if ($t2
Il linguaggio del calcolatore: linguaggio macchina e linguaggio assembly
 Il linguaggio del calcolatore: linguaggio macchina e linguaggio assembly Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin ORGANIZZAZIONE DEL CALCOLATORE:
Il linguaggio del calcolatore: linguaggio macchina e linguaggio assembly Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin ORGANIZZAZIONE DEL CALCOLATORE:
ISA e linguaggio assembler
 ISA e linguaggio assembler Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1, D2. 1/39 Introduzione
ISA e linguaggio assembler Prof. Alberto Borghese Dipartimento di Informatica borghese@di.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D1, D2. 1/39 Introduzione
Architettura di tipo registro-registro (load/store)
") Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
Caratteristiche principali dell architettura del processore MIPS E un architettura RISC (Reduced Instruction Set Computer) Esegue soltanto istruzioni con un ciclo base ridotto, cioè costituito da poche
ISA (Instruction Set Architecture) della CPU MIPS32
 della CPU MIPS32") Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS32 Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS32 Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Esercitazione 06 Progettazione di una CPU RISC-V
 Esercitazione 06 Progettazione di una CPU RISC-V Gianluca Brilli gianluca.brilli@unimore.it 04/06/19 ARCHITETTURA DEI CALCOLATORI 1 Overview In questa esercitazione andremo a progettare una semplice architettura
Esercitazione 06 Progettazione di una CPU RISC-V Gianluca Brilli gianluca.brilli@unimore.it 04/06/19 ARCHITETTURA DEI CALCOLATORI 1 Overview In questa esercitazione andremo a progettare una semplice architettura
CALCOLATORI ELETTRONICI 27 marzo 2018
 CALCOLATORI ELETTRONICI 27 marzo 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 27 marzo 2018 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
Calcolatori Elettronici B a.a. 2006/2007
 Calcolatori Elettronici B a.a. 26/27 Tecniche di Controllo: Esercizi Massimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Calcolatori Elettronici B a.a. 26/27 Tecniche di Controllo: Esercizi Massimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
CALCOLATORI ELETTRONICI 9 gennaio 2013
 CALCOLATORI ELETTRONICI 9 gennaio 2013 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 9 gennaio 2013 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
Realizzazione a cicli di clock multipli
 Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
Realizzazione a cicli di clock multipli Riprendiamo in esame la realizzazione dell'unità di calcolo per individuare, per ciascuna classe di istruzioni, le componenti utilizzate e suddividere le azioni
Corso di Calcolatori Elettronici MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M.
 di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
di Cassino e del Lazio Meridionale Corso di MIPS: Istruzioni di confronto Istruzioni di controllo Formato delle istruzioni in L.M. Anno Accademico 201/201 Francesco Tortorella Istruzioni di confronto Istruzione
Sia per la II prova intercorso che per le prove di esame è necessaria la PRENOTAZIONE
 Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
L unità di controllo di CPU multi-ciclo. Sommario
 L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
L unità di controllo di CPU multi-ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: Sezione C3 1/24
Un altro tipo di indirizzamento. L insieme delle istruzioni (3) Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando
 Istruz. di somma e scelta con operando (2) Istruzioni di somma e scelta con operando") Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
Un altro tipo di indirizzamento L insieme delle istruzioni (3) Architetture dei Calcolatori (lettere A-I) Tipi di indirizzamento visti finora Indirizzamento di un registro Indirizzamento con registro base
CALCOLATORI ELETTRONICI 20 gennaio 2012
 CALCOLATORI ELETTRONICI 20 gennaio 2012 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita
CALCOLATORI ELETTRONICI 20 gennaio 2012 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si disegni lo schema di un flip-flop master-slave S-R sensibile ai fronti di salita
ISA (Instruction Set Architecture) della CPU MIPS
 della CPU MIPS") Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Uniersità degli Studi di Milano L16-20 1 Linguaggio macchina
Informazioni varie. Lezione 18 Il Set di Istruzioni (5) Dove siamo nel corso. Un quadro della situazione
 Dove siamo nel corso. Un quadro della situazione") Informazioni varie Lezione 18 Il Set di Istruzioni (5) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno La lezione di martedì 20 maggio (9-12) non si tiene
Informazioni varie Lezione 18 Il Set di Istruzioni (5) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno La lezione di martedì 20 maggio (9-12) non si tiene
Pipelining: Unità di Elaborazione e di Controllo Barbara Masucci
 Architettura degli Elaboratori Pipelining: Unità di Elaborazione e di Controllo Barbara Masucci Punto della situazione Ø Abbiamo studiato Ø Una prima implementazione hardware (a ciclo singolo) di un sottoinsieme
Architettura degli Elaboratori Pipelining: Unità di Elaborazione e di Controllo Barbara Masucci Punto della situazione Ø Abbiamo studiato Ø Una prima implementazione hardware (a ciclo singolo) di un sottoinsieme
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS)
") Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Architettura degli elaboratori
 Architettura degli elaboratori - CPU (ciclo singolo) A.A. 26/7 Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori CPU a ciclo singolo Marco
Architettura degli elaboratori - CPU (ciclo singolo) A.A. 26/7 Università degli Studi dell Insubria Dipartimento di Scienze Teoriche e Applicate Architettura degli elaboratori CPU a ciclo singolo Marco
CPU a ciclo multiplo: l unità di controllo
 Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 2 CPU a ciclo multiplo: l unità di controllo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura del processore MIPS
 Architettura del processore IPS Prof. Cristina Silvano Dipartimento di Elettronica e Informazione Politecnico di ilano email: : silvano@elet elet.polimi.itit Sommario Instruction Set semplificato Esecuzione
Architettura del processore IPS Prof. Cristina Silvano Dipartimento di Elettronica e Informazione Politecnico di ilano email: : silvano@elet elet.polimi.itit Sommario Instruction Set semplificato Esecuzione
Pag. 1. Informatica Facoltà di Medicina Veterinaria a.a. 2012/13 prof. Stefano Cagnoni. Architettura del calcolatore (parte II)
") 1 Università degli studi di Parma Dipartimento di Ingegneria dell Informazione Informatica a.a. 2012/13 La inserita nella architettura dell elaboratore Informatica Facoltà di Medicina Veterinaria a.a.
1 Università degli studi di Parma Dipartimento di Ingegneria dell Informazione Informatica a.a. 2012/13 La inserita nella architettura dell elaboratore Informatica Facoltà di Medicina Veterinaria a.a.
Introduzione all'architettura dei Calcolatori. Maurizio Palesi
 Introduzione all'architettura dei Calcolatori Maurizio Palesi 1 Agenda Architettura generale di un Sistema di Elaborazione La memoria principale Il sottosistema di comunicazione La CPU Miglioramento delle
Introduzione all'architettura dei Calcolatori Maurizio Palesi 1 Agenda Architettura generale di un Sistema di Elaborazione La memoria principale Il sottosistema di comunicazione La CPU Miglioramento delle
Architettura degli elaboratori - II Le architetture multi-ciclo
 Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori
Architettura degli elaboratori - II Le architetture multi-ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano 1/41 Sommario Principi ispiratori