Design of Parallel Algorithm
|
|
|
- Fortunato Rossi
- 4 anni fa
- Visualizzazioni
Transcript
1 Design of Parallel Algorithm Programmazione Concorrente, Parallela e su Cloud Carmine Spagnuolo, Ph.D.
2 Plan 1 Progettazione di Programmi Tecniche Le problematiche Esempio 1: Array processing Esempio 2: Heat equation
3 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone
4 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica
5 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore
6 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic
7 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic analizza il codice ed identifica opportunità con calcolo dei pesi (esempio: loops)
8 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic analizza il codice ed identifica opportunità con calcolo dei pesi (esempio: loops) possibili errori, mancanza flessibilità, limitato a parti del codice
9 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic analizza il codice ed identifica opportunità con calcolo dei pesi (esempio: loops) possibili errori, mancanza flessibilità, limitato a parti del codice Compilatore programmer directed
10 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic analizza il codice ed identifica opportunità con calcolo dei pesi (esempio: loops) possibili errori, mancanza flessibilità, limitato a parti del codice Compilatore programmer directed direttive al compilatore per aiutarlo a parallelizzare
11 Parallelizzazione di programmi Tipicamente una operazione manuale: compito complesso, error-prone Esistono tool per la parallelizzazione automatica che assistono il programmatore Compilatore fully automatic analizza il codice ed identifica opportunità con calcolo dei pesi (esempio: loops) possibili errori, mancanza flessibilità, limitato a parti del codice Compilatore programmer directed direttive al compilatore per aiutarlo a parallelizzare difficile da usare
12 Uno sguardo al problema/programma Problema parallelizzabile o no
13 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale
14 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma
15 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma Uso di profiler per identificare dove viene fatto la maggior parte del lavoro
16 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma Uso di profiler per identificare dove viene fatto la maggior parte del lavoro Identifica i bottlenecks
17 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma Uso di profiler per identificare dove viene fatto la maggior parte del lavoro Identifica i bottlenecks Sincronizzazione, I/O
18 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma Uso di profiler per identificare dove viene fatto la maggior parte del lavoro Identifica i bottlenecks Sincronizzazione, I/O Identificare gli inibitori del parallelismo
19 Uno sguardo al problema/programma Problema parallelizzabile o no Esempio per Fibonacci: il calcolo di F k+2 usa valori di F k+1 e F k. Soluzione non banale Identificare gli hotspots del programma Uso di profiler per identificare dove viene fatto la maggior parte del lavoro Identifica i bottlenecks Sincronizzazione, I/O Identificare gli inibitori del parallelismo dipendenze tra dati
20 Presentazione 1 Progettazione di Programmi Tecniche Le problematiche Esempio 1: Array processing Esempio 2: Heat equation
21 Partitioning Uno dei primi passi é dividere il problema in pezzi discreti di lavoro
22 Partitioning Uno dei primi passi é dividere il problema in pezzi discreti di lavoro... che possono essere distribuiti
23 Partitioning Uno dei primi passi é dividere il problema in pezzi discreti di lavoro... che possono essere distribuiti Due maniere fondamentale di fare partitioning:
24 Partitioning Uno dei primi passi é dividere il problema in pezzi discreti di lavoro... che possono essere distribuiti Due maniere fondamentale di fare partitioning: Domain decomposition: i dati che appartengono al problema vengono decomposti ed ogni task lavora su una porzione dei dati
25 Partitioning Uno dei primi passi é dividere il problema in pezzi discreti di lavoro... che possono essere distribuiti Due maniere fondamentale di fare partitioning: Domain decomposition: i dati che appartengono al problema vengono decomposti ed ogni task lavora su una porzione dei dati Functional decomposition: decomposizione secondo il tipo di lavoro da fare, assegnato a ciascun task
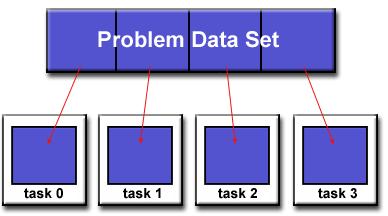
26 Domain decomposition - 1
27 Domain decomposition - 2

28 Functional decomposition

29 Functional decomposition: esempio - 1 Modellazione di un ecosistema

30 Functional decomposition: esempio - 2 Signal processing in pipeline

31 Functional decomposition: esempio - 3 Modello del clima
32 Presentazione 1 Progettazione di Programmi Tecniche Le problematiche Esempio 1: Array processing Esempio 2: Heat equation
33 La comunicazione Dato il problema, potrebbe non essere necessaria
34 La comunicazione Dato il problema, potrebbe non essere necessaria Tipico partizionamento di una immagine in regioni, con calcoli in locale
35 La comunicazione Dato il problema, potrebbe non essere necessaria Tipico partizionamento di una immagine in regioni, con calcoli in locale... oppure potrebbe essere necessaria
36 La comunicazione Dato il problema, potrebbe non essere necessaria Tipico partizionamento di una immagine in regioni, con calcoli in locale... oppure potrebbe essere necessaria Fattori da considerare
37 La comunicazione Dato il problema, potrebbe non essere necessaria Tipico partizionamento di una immagine in regioni, con calcoli in locale... oppure potrebbe essere necessaria Fattori da considerare influenzano le scelte del programmatore nella progettazione
38 Comunicazione: i fattori - 1 Costo di comunicazione
39 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare
40 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck)
41 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck) competizione per risorse limitate (bus)
42 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck) competizione per risorse limitate (bus) Latency vs. Bandwidth
43 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck) competizione per risorse limitate (bus) Latency vs. Bandwidth facendo il package di molti messaggi piccoli in un unico messaggio grande, può risultare più efficiente
44 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck) competizione per risorse limitate (bus) Latency vs. Bandwidth facendo il package di molti messaggi piccoli in un unico messaggio grande, può risultare più efficiente Visibilità della comunicazione (esplicita o implicita)
45 Comunicazione: i fattori - 1 Costo di comunicazione cicli macchina e risorse sono usate per comunicare invece che per calcolare necessario a volte sincronizzare (bottleneck) competizione per risorse limitate (bus) Latency vs. Bandwidth facendo il package di molti messaggi piccoli in un unico messaggio grande, può risultare più efficiente Visibilità della comunicazione (esplicita o implicita) Sincrona/Asincrona (blocking/non-blocking)
46 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective
47 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective Operazioni diverse:
48 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective Operazioni diverse: broadcast
49 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective Operazioni diverse: broadcast scatter
50 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective Operazioni diverse: broadcast scatter gather

51 Comunicazione: i fattori - 2 Scope della comunicazione: point-to-point o collective Operazioni diverse: broadcast scatter gather reduction
52 Comunicazione: i fattori - 3: efficienza Dipendenza da implementazioni efficienti su una particolare piattaforma
53 Comunicazione: i fattori - 3: efficienza Dipendenza da implementazioni efficienti su una particolare piattaforma Efficienza della comunicazione asincrona rispetto a quella sincrona

54 Comunicazione: i fattori - 4: complessità
55 Sincronizzazione Barrier: ogni task si blocca alla barriera, fino a che tutti sono lì, in attesa
56 Sincronizzazione Barrier: ogni task si blocca alla barriera, fino a che tutti sono lì, in attesa Lock/semaforo: protegge sezioni critiche
57 Sincronizzazione Barrier: ogni task si blocca alla barriera, fino a che tutti sono lì, in attesa Lock/semaforo: protegge sezioni critiche Operazioni sincrone di comunicazione
58 Dipendenza dei dati Esiste dipendenza tra istruzioni se l ordine di esecuzione influenza il risultato
59 Dipendenza dei dati Esiste dipendenza tra istruzioni se l ordine di esecuzione influenza il risultato Esiste dipendenza dati se task differenti usano contemporaneamente gli stessi dati
60 Dipendenza dei dati Esiste dipendenza tra istruzioni se l ordine di esecuzione influenza il risultato Esiste dipendenza dati se task differenti usano contemporaneamente gli stessi dati Gestione:
61 Dipendenza dei dati Esiste dipendenza tra istruzioni se l ordine di esecuzione influenza il risultato Esiste dipendenza dati se task differenti usano contemporaneamente gli stessi dati Gestione: su memoria distribuita: comunicazione sulle richieste di dati a punti di sincronizzazione
62 Dipendenza dei dati Esiste dipendenza tra istruzioni se l ordine di esecuzione influenza il risultato Esiste dipendenza dati se task differenti usano contemporaneamente gli stessi dati Gestione: su memoria distribuita: comunicazione sulle richieste di dati a punti di sincronizzazione su memoria condivisa: read/write sincronizzate
63 Esempi di dipendenza Il valore di A[j 1] deve essere calcolato prima di A[j] : data dependence dovuta a loop
64 Esempi di dipendenza Il valore di A[j 1] deve essere calcolato prima di A[j] : data dependence dovuta a loop se i due valori sono su task diversi, necessaria sincronizzazione e comunicazione
65 Esempi di dipendenza Il valore di A[j 1] deve essere calcolato prima di A[j] : data dependence dovuta a loop se i due valori sono su task diversi, necessaria sincronizzazione e comunicazione Dipendenza non dovuta a loop
66 Esempi di dipendenza Il valore di A[j 1] deve essere calcolato prima di A[j] : data dependence dovuta a loop se i due valori sono su task diversi, necessaria sincronizzazione e comunicazione Dipendenza non dovuta a loop il valore di Y dipende da comunicazione tra task o sequenzializzazione scritture su X

67 Bilanciamento del carico Importante che tutti i task siano occupati per tutto il tempo
68 Come bilanciare il carico Equipartizionare il lavoro: a volte facile, a volte impossibile
69 Come bilanciare il carico Equipartizionare il lavoro: a volte facile, a volte impossibile macchine eterogenee, work eterogeneo ed impredicibile
70 Come bilanciare il carico Equipartizionare il lavoro: a volte facile, a volte impossibile macchine eterogenee, work eterogeneo ed impredicibile Assegnamento dinamico del lavoro: con uno scheduler, a cui i task richiedono un altro batch di lavoro
71 Granularità Granularità: rapporto tra computazione e comunicazione
72 Granularità Granularità: rapporto tra computazione e comunicazione Parallelismo fine-grain

73 Granularità Granularità: rapporto tra computazione e comunicazione Parallelismo fine-grain Parallelismo coarse-grain
74 Fine vs. Coarse Fine-grain:
75 Fine vs. Coarse Fine-grain: facilita il bilanciamento
76 Fine vs. Coarse Fine-grain: facilita il bilanciamento alto overhead di comunicazione
77 Fine vs. Coarse Fine-grain: facilita il bilanciamento alto overhead di comunicazione Coarse-grain:
78 Fine vs. Coarse Fine-grain: facilita il bilanciamento alto overhead di comunicazione Coarse-grain: maggiori opportunità di miglioramento prestazioni (minor overhead di comunicazione)
79 Fine vs. Coarse Fine-grain: facilita il bilanciamento alto overhead di comunicazione Coarse-grain: maggiori opportunità di miglioramento prestazioni (minor overhead di comunicazione) carico difficile da bilanciare
80 Input/Output In generale, I/O é un problema per il parallelismo
81 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS)
82 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system
83 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system Possibili ottimizzazioni particolari (Google File system)
84 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system Possibili ottimizzazioni particolari (Google File system) Linee guida:
85 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system Possibili ottimizzazioni particolari (Google File system) Linee guida: 1 se possibile, evitatelo
86 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system Possibili ottimizzazioni particolari (Google File system) Linee guida: 1 se possibile, evitatelo 2 sostituire accesso parallelo ad un accesso sequenziale seguito dalla distribuzione dei dati
87 Input/Output In generale, I/O é un problema per il parallelismo Specialmente se condotto sulla rete (NFS) Esistono sistemi paralleli di file system Possibili ottimizzazioni particolari (Google File system) Linee guida: 1 se possibile, evitatelo 2 sostituire accesso parallelo ad un accesso sequenziale seguito dalla distribuzione dei dati 3 rendere i file univoci
88 Il costo del calcolo parallelo Complessità:
89 Il costo del calcolo parallelo Complessità: progettazione, codifica, debugging, tuning, manutenzione
90 Il costo del calcolo parallelo Complessità: progettazione, codifica, debugging, tuning, manutenzione Portabilità
91 Il costo del calcolo parallelo Complessità: progettazione, codifica, debugging, tuning, manutenzione Portabilità migliorata con standard, ma ancora un problema (OSs, HW)
92 Il costo del calcolo parallelo Complessità: progettazione, codifica, debugging, tuning, manutenzione Portabilità migliorata con standard, ma ancora un problema (OSs, HW) Scalabilità:
93 Il costo del calcolo parallelo Complessità: progettazione, codifica, debugging, tuning, manutenzione Portabilità migliorata con standard, ma ancora un problema (OSs, HW) Scalabilità: un obiettivo con molti fattori in gioco (memoria, banda di rete, latenza, processori, librerie usate, etc. )
94 Presentazione 1 Progettazione di Programmi Tecniche Le problematiche Esempio 1: Array processing Esempio 2: Heat equation
95 Il problema: array processing Calcolo sull elemento, indipendente dagli altri
96 Il problema: array processing Calcolo sull elemento, indipendente dagli altri Il codice sequenziale sarebbe:
97 Il problema: array processing Calcolo sull elemento, indipendente dagli altri Il codice sequenziale sarebbe: Embarassingly parallel
98 Array processing: soluzione 1 Ogni processore ha una porzione
99 Array processing: soluzione 1 Ogni processore ha una porzione Calcolo indipendente = nessuna comunicazione

100 Array processing: soluzione 1 Ogni processore ha una porzione Calcolo indipendente = nessuna comunicazione Scelta del partizionamento unicamente influenzato da efficienza della cache
101 Soluzione 1 con SPMD Modello Single Program Multiple Data (simile a SIMD)
102 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico
103 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei
104 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei se la funzione da calcolare é estremamente veloce da calcolare per certi input (ad esempio, 0) e particolarmente onerosa in altri, allora la distribuzione in pezzi di ugual dimensione può non bilanciare il carico
105 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei se la funzione da calcolare é estremamente veloce da calcolare per certi input (ad esempio, 0) e particolarmente onerosa in altri, allora la distribuzione in pezzi di ugual dimensione può non bilanciare il carico Miglioramento con il pool di task
106 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei se la funzione da calcolare é estremamente veloce da calcolare per certi input (ad esempio, 0) e particolarmente onerosa in altri, allora la distribuzione in pezzi di ugual dimensione può non bilanciare il carico Miglioramento con il pool di task Processo Master: mantiene il pool di task e li distribuisce su richiesta ai worker, ottenendo (e assemblando) i risultati
107 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei se la funzione da calcolare é estremamente veloce da calcolare per certi input (ad esempio, 0) e particolarmente onerosa in altri, allora la distribuzione in pezzi di ugual dimensione può non bilanciare il carico Miglioramento con il pool di task Processo Master: mantiene il pool di task e li distribuisce su richiesta ai worker, ottenendo (e assemblando) i risultati Processo Worker: ripete: chiedi un task, eseguilo e invia risultati al master
108 Array processing: soluzione 2 Limiti della soluzione statica per il bilanciamento del carico non efficiente con processori eterogenei se la funzione da calcolare é estremamente veloce da calcolare per certi input (ad esempio, 0) e particolarmente onerosa in altri, allora la distribuzione in pezzi di ugual dimensione può non bilanciare il carico Miglioramento con il pool di task Processo Master: mantiene il pool di task e li distribuisce su richiesta ai worker, ottenendo (e assemblando) i risultati Processo Worker: ripete: chiedi un task, eseguilo e invia risultati al master Bilanciamento dinamico del carico (dimensionamento del task (=granularità) critico per le prestazioni)
109 Soluzione 2
110 Presentazione 1 Progettazione di Programmi Tecniche Le problematiche Esempio 1: Array processing Esempio 2: Heat equation
111 Il problema - 1 La equazione descrive il cambiamento della temperature nel tempo
112 Il problema - 1 La equazione descrive il cambiamento della temperature nel tempo Alta al centro e zero all esterno, all inizio
113 Il problema - 1 La equazione descrive il cambiamento della temperature nel tempo Alta al centro e zero all esterno, all inizio Nel tempo, calcolare il cambiamento

114 Il problema - 1 La equazione descrive il cambiamento della temperature nel tempo Alta al centro e zero all esterno, all inizio Nel tempo, calcolare il cambiamento Problema che richiede comunicazione tra task
115 Il problema - 2 Calcolo basato sul valore dei vicini
 + C y (U x,y+1 + U x,y 1 2 U x,y")
116 Il problema - 2 Calcolo basato sul valore dei vicini U x,y = U x,y + C x (U x+1,y + U x 1,y 2 U x,y ) + C y (U x,y+1 + U x,y 1 2 U x,y )
117 Codice seriale Il codice seriale apparirebbe così:
118 Soluzione 1 Soluzione SPMD
119 Soluzione 1 Soluzione SPMD Array partizionato
120 Soluzione 1 Soluzione SPMD Array partizionato Elementi interni non dipendono da altri task
121 Soluzione 1 Soluzione SPMD Array partizionato Elementi interni non dipendono da altri task Elementi al confine hanno bisogno di comunicazione

122 Soluzione 1 Soluzione SPMD Array partizionato Elementi interni non dipendono da altri task Elementi al confine hanno bisogno di comunicazione Master-worker
123 Soluzione 1 - codice Soluzione SPMD
124 Soluzione 1 - codice Soluzione SPMD Convergenza indicata da stabilità nella soluzione

125 Soluzione 1 - codice Soluzione SPMD Convergenza indicata da stabilità nella soluzione Nel ciclo: send, receive, update array...
126 Critiche alla soluzione 1 Comunicazione blocking: collo di bottiglia
127 Critiche alla soluzione 1 Comunicazione blocking: collo di bottiglia Si può migliorare comunicazione non-blocking
128 Critiche alla soluzione 1 Comunicazione blocking: collo di bottiglia Si può migliorare comunicazione non-blocking L idea: aggiornare l interno della propria zona, mentre si attendono i dati del bordo.
129 Soluzione 2 - codice La comunicazione non-blocking viene solo iniziata
130 Soluzione 2 - codice La comunicazione non-blocking viene solo iniziata Poi si passa al calcolo dell interno...
131 Soluzione 2 - codice La comunicazione non-blocking viene solo iniziata Poi si passa al calcolo dell interno e si termina quando si ricevono i dati dall esterno
Disegnare programmi paralleli
 Disegnare programmi paralleli Parallelizzazione automatica versus manuale Parallelizzazione manuale, complessa e costosa Parallelizzazione auotamica: completamente automatica (i loop sono i target piu'
Disegnare programmi paralleli Parallelizzazione automatica versus manuale Parallelizzazione manuale, complessa e costosa Parallelizzazione auotamica: completamente automatica (i loop sono i target piu'
Sommario. Analysis & design delle applicazioni parallele. Tecniche di partizionamento. Load balancing. Comunicazioni
 Sommario Analysis & design delle applicazioni parallele Tecniche di partizionamento Load balancing Comunicazioni Misura delle prestazioni parallele 2 Primi passi: analizzare il problema Prima di iniziare
Sommario Analysis & design delle applicazioni parallele Tecniche di partizionamento Load balancing Comunicazioni Misura delle prestazioni parallele 2 Primi passi: analizzare il problema Prima di iniziare
Sommario. Elementi di Parallelismo. Misura delle prestazioni parallele. Tecniche di partizionamento. Load Balancing. Comunicazioni
 Sommario Elementi di Parallelismo Misura delle prestazioni parallele Tecniche di partizionamento Load Balancing Comunicazioni 2 Problema 1: Serie di Fibonacci Calcolare e stampare i primi N elementi della
Sommario Elementi di Parallelismo Misura delle prestazioni parallele Tecniche di partizionamento Load Balancing Comunicazioni 2 Problema 1: Serie di Fibonacci Calcolare e stampare i primi N elementi della
Parallel Programming Patterns
 Parallel Programming Patterns Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ Algoritmi Avanzati--modulo 2 2 Parallel Programming
Parallel Programming Patterns Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna http://www.moreno.marzolla.name/ Algoritmi Avanzati--modulo 2 2 Parallel Programming
Storia dell informatica e del calcolo automatico. Murano Aniello D Avino Assunta
 Storia dell informatica e del calcolo automatico Docente corso Docente abilitante Murano Aniello D Avino Assunta Negli ultimi anni sono state delineate le principali caratteristiche architetturali delle
Storia dell informatica e del calcolo automatico Docente corso Docente abilitante Murano Aniello D Avino Assunta Negli ultimi anni sono state delineate le principali caratteristiche architetturali delle
Sistemi RAID. Motivazioni Concetti di base Livelli RAID. Sommario
 Sistemi RAID 1 Motivazioni Concetti di base Livelli RAID Sommario 2 1 Motivazione L evoluzione tecnologica ha permesso di avere dischi sempre più piccoli e meno costosi E facile equipaggiare un sistema
Sistemi RAID 1 Motivazioni Concetti di base Livelli RAID Sommario 2 1 Motivazione L evoluzione tecnologica ha permesso di avere dischi sempre più piccoli e meno costosi E facile equipaggiare un sistema
Introduzione ai thread
 Introduzione ai thread Processi leggeri. Immagine di un processo (codice, variabili locali e globali, stack, descrittore). Risorse possedute: : (file aperti, processi figli, dispositivi di I/O..),. L immagine
Introduzione ai thread Processi leggeri. Immagine di un processo (codice, variabili locali e globali, stack, descrittore). Risorse possedute: : (file aperti, processi figli, dispositivi di I/O..),. L immagine
Metriche e Strumenti. di Valutazione delle Prestazioni. nel Calcolo Parallelo. (cenni) Speedup
 Speedup") Metriche e Strumenti di Valutazione delle Prestazioni nel Calcolo Parallelo (cenni) Definizione 1 (Speedup Ideale) Speedup Rapporto tra il tempo di esecuzione del migliore algoritmo sequenziale T* ed il
Metriche e Strumenti di Valutazione delle Prestazioni nel Calcolo Parallelo (cenni) Definizione 1 (Speedup Ideale) Speedup Rapporto tra il tempo di esecuzione del migliore algoritmo sequenziale T* ed il
Modelli di programmazione parallela
 Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
Modelli di programmazione parallela Oggi sono comunemente utilizzati diversi modelli di programmazione parallela: Shared Memory Multi Thread Message Passing Data Parallel Tali modelli non sono specifici
Scuola di Calcolo Scientifico con MATLAB (SCSM) 2017 Palermo 31 Luglio - 4 Agosto 2017
 2017 Palermo 31 Luglio - 4 Agosto 2017") Scuola di Calcolo Scientifico con MATLAB (SCSM) 2017 Palermo 31 Luglio - 4 Agosto 2017 www.u4learn.it Alessandro Bruno Introduzione al calcolo parallelo Approcci per il calcolo parallelo Programmazione
Scuola di Calcolo Scientifico con MATLAB (SCSM) 2017 Palermo 31 Luglio - 4 Agosto 2017 www.u4learn.it Alessandro Bruno Introduzione al calcolo parallelo Approcci per il calcolo parallelo Programmazione
Corso di Linguaggi di Programmazione
 Corso di Linguaggi di Programmazione Lezione 20 Alberto Ceselli alberto.ceselli@unimi.it Dipartimento di Tecnologie dell Informazione Università degli Studi di Milano 14 Maggio 2013 Programmazione concorrente:
Corso di Linguaggi di Programmazione Lezione 20 Alberto Ceselli alberto.ceselli@unimi.it Dipartimento di Tecnologie dell Informazione Università degli Studi di Milano 14 Maggio 2013 Programmazione concorrente:
Sommario. Analysis & design delle applicazioni parallele. Misura delle prestazioni parallele. Tecniche di partizionamento.
 Sommario Analysis & design delle applicazioni parallele Misura delle prestazioni parallele Tecniche di partizionamento Comunicazioni Load balancing 2 Primi passi: analizzare il problema Prima di iniziare
Sommario Analysis & design delle applicazioni parallele Misura delle prestazioni parallele Tecniche di partizionamento Comunicazioni Load balancing 2 Primi passi: analizzare il problema Prima di iniziare
I THREAD O PROCESSI LEGGERI
 I THREAD O PROCESSI Processi (pesanti): LEGGERI entità autonome con poche risorse condivise (si prestano poco alla scrittura di applicazioni fortemente cooperanti) Ogni processo può essere visto come Immagine
I THREAD O PROCESSI Processi (pesanti): LEGGERI entità autonome con poche risorse condivise (si prestano poco alla scrittura di applicazioni fortemente cooperanti) Ogni processo può essere visto come Immagine
verso espandibili eterogenei tempo di accesso tempo di risposta throughput
 I/O Un calcolatore è completamente inutile senza la possibile di caricare/ salvare dati e di comunicare con l esterno Input / Output (I/O): insieme di architetture e dispositivi per il trasferimento di
I/O Un calcolatore è completamente inutile senza la possibile di caricare/ salvare dati e di comunicare con l esterno Input / Output (I/O): insieme di architetture e dispositivi per il trasferimento di
Sistemi a processori multipli
 Sistemi a processori multipli Sommario Classificazione e concetti di base Sistemi multi-processore Sistemi multi-computer (cluster) Sistemi distribuiti Obiettivo comune Risolvere problemi di dimensioni
Sistemi a processori multipli Sommario Classificazione e concetti di base Sistemi multi-processore Sistemi multi-computer (cluster) Sistemi distribuiti Obiettivo comune Risolvere problemi di dimensioni
Architetture Applicative Altri Esempi
 Architetture Applicative Altri Esempi Alessandro Martinelli alessandro.martinelli@unipv.it 15 Aprile 2014 Architetture Applicative Altri Esempi di Architetture Applicative Architetture con più Applicazioni
Architetture Applicative Altri Esempi Alessandro Martinelli alessandro.martinelli@unipv.it 15 Aprile 2014 Architetture Applicative Altri Esempi di Architetture Applicative Architetture con più Applicazioni
Studio degli algoritmi
 COMPLESSITÀ COMPUTAZIONALE DEGLI ALGORITMI Fondamenti di Informatica a.a.2006/07 Prof. V.L. Plantamura Dott.ssa A. Angelini Studio degli algoritmi Dato un problema P, le problematiche riguardano: Sintesi
COMPLESSITÀ COMPUTAZIONALE DEGLI ALGORITMI Fondamenti di Informatica a.a.2006/07 Prof. V.L. Plantamura Dott.ssa A. Angelini Studio degli algoritmi Dato un problema P, le problematiche riguardano: Sintesi
SISTEMI OPERATIVI THREAD. Giorgio Giacinto Sistemi Operativi
 SISTEMI OPERATIVI THREAD 2 Motivazioni» Un programma complesso può eseguire in modo concorrente più funzioni attraverso la creazione e gestione di processi figli attraverso il meccanismo dei thread» La
SISTEMI OPERATIVI THREAD 2 Motivazioni» Un programma complesso può eseguire in modo concorrente più funzioni attraverso la creazione e gestione di processi figli attraverso il meccanismo dei thread» La
CLASSIFICAZIONE DEI SISTEMI OPERATIVI (in ordine cronologico)
") CLASSIFICAZIONE DEI SISTEMI OPERATIVI (in ordine cronologico) - Dedicati Quelli dei primi sistemi operativi. La macchina viene utilizzata da un utente per volta che può eseguire un solo programma per volta.
CLASSIFICAZIONE DEI SISTEMI OPERATIVI (in ordine cronologico) - Dedicati Quelli dei primi sistemi operativi. La macchina viene utilizzata da un utente per volta che può eseguire un solo programma per volta.
Il Sistema Operativo Thread
 ISTITUTO TECNICO SECONDO BIENNIO GIORGIO PORCU www.thegiorgio.it Sommario Processo e Immagine LightWeight Process Realizzazione di Implementazione di Multitasking e Multithreading Stati di un 2 3 Processo
ISTITUTO TECNICO SECONDO BIENNIO GIORGIO PORCU www.thegiorgio.it Sommario Processo e Immagine LightWeight Process Realizzazione di Implementazione di Multitasking e Multithreading Stati di un 2 3 Processo
Calcolo Parallelo. Domanda. In particolare. Qual è l algoritmo parallelo. PROBLEMA: Prodotto Matrice-Vettore
 Calcolo Parallelo Algoritmi Paralleli per il prodotto Matrice-Vettore Laura Antonelli PROBLEMA: Prodotto Matrice-Vettore Progettazione di un algoritmo parallelo per architettura MIMD a memoria distribuita
Calcolo Parallelo Algoritmi Paralleli per il prodotto Matrice-Vettore Laura Antonelli PROBLEMA: Prodotto Matrice-Vettore Progettazione di un algoritmo parallelo per architettura MIMD a memoria distribuita
Estensioni all architettura di Von Neumann
 Estensioni all architettura di Von Neumann Vito Perrone Corso di Informatica A per Gestionali Indice Limiti dell architettura di Von Neumann Estensioni all architettura di Von Neumann CISC e RISC 2 1 La
Estensioni all architettura di Von Neumann Vito Perrone Corso di Informatica A per Gestionali Indice Limiti dell architettura di Von Neumann Estensioni all architettura di Von Neumann CISC e RISC 2 1 La
verso espandibili eterogenei tempo di accesso tempo di risposta throughput
 I/O Un calcolatore è completamente inutile senza la possibile di caricare/ salvare dati e di comunicare con l esterno Input / Output (I/O): insieme di architetture e dispositivi per il trasferimento di
I/O Un calcolatore è completamente inutile senza la possibile di caricare/ salvare dati e di comunicare con l esterno Input / Output (I/O): insieme di architetture e dispositivi per il trasferimento di
La vera difficoltà non è progettare architetture
 Superamento dei 10 Pflops Progettazione di algoritmi e software paralleli diffusione dei cluster e avvento dei multicore il modo con cui è stato sviluppato il software fino ad ora scomparirà tra pochi
Superamento dei 10 Pflops Progettazione di algoritmi e software paralleli diffusione dei cluster e avvento dei multicore il modo con cui è stato sviluppato il software fino ad ora scomparirà tra pochi
Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo Riferimenti 2 Questo materiale deriva dalle slide del prof. Lanzi per il corso di Informatica B, A.A. 2009/2010 Il materiale presente in
Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo Riferimenti 2 Questo materiale deriva dalle slide del prof. Lanzi per il corso di Informatica B, A.A. 2009/2010 Il materiale presente in
Porte logiche di base. Cenni circuiti, reti combinatorie, reti sequenziali
 Porte logiche di base Cenni circuiti, reti combinatorie, reti sequenziali NOT AND A R A B R OR A R B Quindi NAND o NOR sono complete circuiti con solo porte NAND o solo porte NOR. Reti combinatorie Rete
Porte logiche di base Cenni circuiti, reti combinatorie, reti sequenziali NOT AND A R A B R OR A R B Quindi NAND o NOR sono complete circuiti con solo porte NAND o solo porte NOR. Reti combinatorie Rete
Elettronica per l informatica. Cosa c è nell unità A. Unità A: Bus di comunicazione. A.1 Architetture di interconnessione A.2 Esempi commerciali
 Elettronica per l informatica 1 Cosa c è nell unità A Unità A: Bus di comunicazione A.1 Architetture di interconnessione A.2 Esempi commerciali 2 Contenuto dell unità A Architetture di interconnessione
Elettronica per l informatica 1 Cosa c è nell unità A Unità A: Bus di comunicazione A.1 Architetture di interconnessione A.2 Esempi commerciali 2 Contenuto dell unità A Architetture di interconnessione
PROBLEMA. Progettare un algoritmo parallelo per architettura MIMD-DM per il calcolo dell integrale definito: R = dominio di integrazione
 PROBLEMA Progettare un algoritmo parallelo per architettura MIMD-DM per il calcolo dell integrale definito: R f ( t 1, t2, K, tn) dt1dt2 Kdt n R = dominio di integrazione 1 Esempio: n=2 R A R f ( t1, t2)
PROBLEMA Progettare un algoritmo parallelo per architettura MIMD-DM per il calcolo dell integrale definito: R f ( t 1, t2, K, tn) dt1dt2 Kdt n R = dominio di integrazione 1 Esempio: n=2 R A R f ( t1, t2)
Architetture della memoria
 Architetture della memoria Un elemento determinante per disegnare una applicazione parallela e' l architettura della memoria della macchina che abbiamo a disposizione. Rispetto all architettura della memoria
Architetture della memoria Un elemento determinante per disegnare una applicazione parallela e' l architettura della memoria della macchina che abbiamo a disposizione. Rispetto all architettura della memoria
Sistemi in tempo reale: applicazioni alla robotica. Sistemi in tempo reale: applicazioni alla robotica p.1/15
 Sistemi in tempo reale: applicazioni alla robotica Sistemi in tempo reale: applicazioni alla robotica p.1/15 Sistemi operativi Hardware Firmware Kernel Driver Applicazioni Interfacce Sistemi in tempo reale:
Sistemi in tempo reale: applicazioni alla robotica Sistemi in tempo reale: applicazioni alla robotica p.1/15 Sistemi operativi Hardware Firmware Kernel Driver Applicazioni Interfacce Sistemi in tempo reale:
Laboratorio di Informatica I
 Struttura della lezione Lezione 2: Introduzione al corso Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Classificazione degli elaboratori Alcuni concetti base: la struttura
Struttura della lezione Lezione 2: Introduzione al corso Vittorio Scarano Laboratorio di Informatica I Corso di Laurea in Informatica Classificazione degli elaboratori Alcuni concetti base: la struttura
Prestazioni 1. Prestazioni 2. Prestazioni 3
 Valutazione delle Prestazioni Architetture dei Calcolatori Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare le prestazioni
Valutazione delle Prestazioni Architetture dei Calcolatori Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare le prestazioni
Calcolatori Elettronici
 Calcolatori Elettronici Valutazione delle Prestazioni Francesco Lo Presti Rielaborate da Salvatore Tucci Valutazione delle Prestazioni q Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Calcolatori Elettronici Valutazione delle Prestazioni Francesco Lo Presti Rielaborate da Salvatore Tucci Valutazione delle Prestazioni q Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Macchine Astratte. Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari. Linguaggi di Programmazione feb, 2016
 Macchine Astratte Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari Linguaggi di Programmazione 010194 29 feb, 2016 Sommario 1 Introduzione Macchina astratta Interprete Implementazione
Macchine Astratte Nicola Fanizzi Dipartimento di Informatica Università degli Studi di Bari Linguaggi di Programmazione 010194 29 feb, 2016 Sommario 1 Introduzione Macchina astratta Interprete Implementazione
Global Virtual Time (GVT) e Approfondimenti sul Time Warp
 e Approfondimenti sul Time Warp") Global Virtual Time (GVT) e Approfondimenti sul Time Warp Gabriele D Angelo gda@cs.unibo.it http://www.cs.unibo.it/~gdangelo Dipartimento di Scienze dell Informazione Università degli Studi di Bologna
Global Virtual Time (GVT) e Approfondimenti sul Time Warp Gabriele D Angelo gda@cs.unibo.it http://www.cs.unibo.it/~gdangelo Dipartimento di Scienze dell Informazione Università degli Studi di Bologna
Come aumentare le prestazioni Cenni alle architetture avanzate
 Politecnico di Milano Come aumentare le prestazioni Cenni alle architetture avanzate Mariagiovanna Sami Richiamo: CPI CPI = (cicli di clock della CPU richiesti dall esecuzione di un programma)/ numero
Politecnico di Milano Come aumentare le prestazioni Cenni alle architetture avanzate Mariagiovanna Sami Richiamo: CPI CPI = (cicli di clock della CPU richiesti dall esecuzione di un programma)/ numero
SCD. Sistemi distribuiti: introduzione. Sistemi distribuiti: introduzione. Sistemi distribuiti: introduzione
 Anno accademico 2004/5 Corso di Sistemi Concorrenti e Distribuiti Tullio Vardanega, tullio.vardanega@math.unipd.it SCD Definizione Un sistema distribuito è un insieme di elaboratori indipendenti capaci
Anno accademico 2004/5 Corso di Sistemi Concorrenti e Distribuiti Tullio Vardanega, tullio.vardanega@math.unipd.it SCD Definizione Un sistema distribuito è un insieme di elaboratori indipendenti capaci
Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo Riferimenti Questo materiale deriva dalle slide del prof. Lanzi per il corso di Informatica B, A.A. 2009/2010 Il materiale presente in queste
Introduzione al Calcolo Parallelo Algoritmi e Calcolo Parallelo Riferimenti Questo materiale deriva dalle slide del prof. Lanzi per il corso di Informatica B, A.A. 2009/2010 Il materiale presente in queste
Criteri da tenere a mente
 2 Alcune considerazioni sul progetto di soluzioni software Criteri da tenere a mente Lo stile di programmazione è importante leggibilità (commenti / nomi significativi di variabili / indentazioni /...)
2 Alcune considerazioni sul progetto di soluzioni software Criteri da tenere a mente Lo stile di programmazione è importante leggibilità (commenti / nomi significativi di variabili / indentazioni /...)
MPI. MPI e' il risultato di un notevole sforzo di numerosi individui e gruppi in un periodo di 2 anni, tra il 1992 ed il 1994
 MPI e' acronimo di Message Passing Interface Rigorosamente MPI non è una libreria ma uno standard per gli sviluppatori e gli utenti, che dovrebbe essere seguito da una libreria per lo scambio di messaggi
MPI e' acronimo di Message Passing Interface Rigorosamente MPI non è una libreria ma uno standard per gli sviluppatori e gli utenti, che dovrebbe essere seguito da una libreria per lo scambio di messaggi
Programmi per calcolo parallelo. Calcolo parallelo. Esempi di calcolo parallelo. Misure di efficienza. Fondamenti di Informatica
 FONDAMENTI DI INFORMATICA rof IER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Calcolo parallelo e sistemi multiprocessore 2000 ier Luca Montessoro (si veda la nota di copyright
FONDAMENTI DI INFORMATICA rof IER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Calcolo parallelo e sistemi multiprocessore 2000 ier Luca Montessoro (si veda la nota di copyright
Scalabilità Energetica di Algoritmi Paralleli su Architetture Multicore. Gennaro Cordasco
 Scalabilità Energetica di Algoritmi Paralleli su Architetture Multicore Gennaro Cordasco Outline Motivazioni Scalabilità Computazionale vs Scalabilità Energetica Modelli Computazionali e Assunzioni Una
Scalabilità Energetica di Algoritmi Paralleli su Architetture Multicore Gennaro Cordasco Outline Motivazioni Scalabilità Computazionale vs Scalabilità Energetica Modelli Computazionali e Assunzioni Una
Progettazione ed implementazione di un sistema di calcolo distribuito ibrido multithread/multiprocesso per HPC: applicazione all imaging medico
 Progettazione ed implementazione di un sistema di calcolo distribuito ibrido multithread/multiprocesso per HPC: applicazione all imaging medico Relatore: Chiar.mo Prof. Renato Campanini Correlatore: Dott.
Progettazione ed implementazione di un sistema di calcolo distribuito ibrido multithread/multiprocesso per HPC: applicazione all imaging medico Relatore: Chiar.mo Prof. Renato Campanini Correlatore: Dott.
Valutazione delle Prestazioni Barbara Masucci
 Architettura degli Elaboratori Valutazione delle Prestazioni Barbara Masucci Punto della situazione Ø Abbiamo studiato Ø Una prima implementazione hardware (a ciclo singolo) di un sottoinsieme dell IS
Architettura degli Elaboratori Valutazione delle Prestazioni Barbara Masucci Punto della situazione Ø Abbiamo studiato Ø Una prima implementazione hardware (a ciclo singolo) di un sottoinsieme dell IS
Introduzione al multithreading
 Introduzione al multithreading Il Multithreading consiste nella possibilità di scomporre le attività di elaborazione di un programma applicativo in più parti, dette Thread, in modo che esse possano essere
Introduzione al multithreading Il Multithreading consiste nella possibilità di scomporre le attività di elaborazione di un programma applicativo in più parti, dette Thread, in modo che esse possano essere
sistemi distribuiti Sistemi distribuiti - architetture varie classificazioni classificazione di Flynn (1972)
") Esempi di applicazioni comunicazione di dati Sistemi Distribuiti fra terminali di un sistema di elaborazione - fra sistemi di elaborazione sistemi distribuiti o centralizzati es. packed-switced networks
Esempi di applicazioni comunicazione di dati Sistemi Distribuiti fra terminali di un sistema di elaborazione - fra sistemi di elaborazione sistemi distribuiti o centralizzati es. packed-switced networks
Calcolo parallelo e sistemi multiprocessore
 FONDAMENTI DI INFORMATICA rof IER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Calcolo parallelo e sistemi multiprocessore 2000 ier Luca Montessoro (si veda la nota di copyright
FONDAMENTI DI INFORMATICA rof IER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Calcolo parallelo e sistemi multiprocessore 2000 ier Luca Montessoro (si veda la nota di copyright
Sottosistemi ed Architetture Memorie
 Sottosistemi ed Architetture Memorie CORSO DI CALCOLATORI ELETTRONICI I CdL Ingegneria Biomedica (A-I) DIS - Università degli Studi di Napoli Federico II La memoria centrale Memoria centrale: array di
Sottosistemi ed Architetture Memorie CORSO DI CALCOLATORI ELETTRONICI I CdL Ingegneria Biomedica (A-I) DIS - Università degli Studi di Napoli Federico II La memoria centrale Memoria centrale: array di
Intel Parallel Studio Seminar Milano 22 Giugno 2010
 Dal seriale al parallelo Come ottimizzare le applicazioni Visual Studio per macchine multi-core: Intel Parallel Studio Ciro Fiorillo Lead Software Architect Agenda 09:15 Saluto di benvenuto e apertura
Dal seriale al parallelo Come ottimizzare le applicazioni Visual Studio per macchine multi-core: Intel Parallel Studio Ciro Fiorillo Lead Software Architect Agenda 09:15 Saluto di benvenuto e apertura
Componenti principali. Programma cablato. Architettura di Von Neumann. Programma cablato. Cos e un programma? Componenti e connessioni
 Componenti principali Componenti e connessioni Capitolo 3 CPU (Unita Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro 1 2 Architettura di Von Neumann Dati e instruzioni in memoria
Componenti principali Componenti e connessioni Capitolo 3 CPU (Unita Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro 1 2 Architettura di Von Neumann Dati e instruzioni in memoria
Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 29/6/2017
 Nome e Cognome Matricola Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 29/6/2017 La prova dura 60 minuti Durante la prova non è consentito consultare
Nome e Cognome Matricola Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 29/6/2017 La prova dura 60 minuti Durante la prova non è consentito consultare
Prima prova intercorso. Lezione 10 Logica Digitale (4) Dove siamo nel corso. Un quadro della situazione
 Dove siamo nel corso. Un quadro della situazione") Prima prova intercorso Lezione Logica Digitale (4) Vittorio carano Architettura Corso di Laurea in Informatica Università degli tudi di alerno Architettura (2324). Vi.ttorio carano Mercoledì 9 Novembre,
Prima prova intercorso Lezione Logica Digitale (4) Vittorio carano Architettura Corso di Laurea in Informatica Università degli tudi di alerno Architettura (2324). Vi.ttorio carano Mercoledì 9 Novembre,
Ottimizzazioni 2 Corso di sviluppo Nvidia CUDATM. Davide Barbieri
 Ottimizzazioni 2 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Parallelismo a livello di Thread Occupazione dei multiprocessori Latenza Parallelismo a livello di istruzione Parallelismo
Ottimizzazioni 2 Corso di sviluppo Nvidia CUDATM Davide Barbieri Panoramica Lezione Parallelismo a livello di Thread Occupazione dei multiprocessori Latenza Parallelismo a livello di istruzione Parallelismo
Capitolo 4 Parte 1 Le infrastrutture hardware. Il processore La memoria centrale La memoria di massa Le periferiche di I/O
 Capitolo 4 Parte 1 Le infrastrutture hardware Il processore La memoria centrale La memoria di massa Le periferiche di I/O Funzionalità di un calcolatore Trasferimento Elaborazione Controllo Memorizzazione
Capitolo 4 Parte 1 Le infrastrutture hardware Il processore La memoria centrale La memoria di massa Le periferiche di I/O Funzionalità di un calcolatore Trasferimento Elaborazione Controllo Memorizzazione
MATRICE TUNING competenze versus unità didattiche, Corso di Laurea in Informatica (classe L-31), Università degli Studi di Cagliari
, Università degli Studi di Cagliari") A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
A: CONOSCENZA E CAPACITA DI COMPRENSIONE Conoscere e saper comprendere i fondamenti della matematica discreta (insiemi, interi, relazioni e funzioni, calcolo combinatorio) Conoscere e saper comprendere
Pipeline nel Mondo Reale
 Pipeline nel Mondo Reale Luca Abeni May 26, 2016 Pipeline Ideali... Abbiamo visto come fare il bucato eseguire un istruzione macchina usando un pipeline... Pipeline a 5 stadi: Fetch Decode Exec Memory
Pipeline nel Mondo Reale Luca Abeni May 26, 2016 Pipeline Ideali... Abbiamo visto come fare il bucato eseguire un istruzione macchina usando un pipeline... Pipeline a 5 stadi: Fetch Decode Exec Memory
Influenza dell' I/O sulle prestazioni (globali) di un sistema
 di un sistema") Influenza dell' I/O sulle prestazioni (globali) di un sistema Tempo totale per l'esecuzione di un programma = tempo di CPU + tempo di I/O Supponiamo di avere un programma che viene eseguito in 100 secondi
Influenza dell' I/O sulle prestazioni (globali) di un sistema Tempo totale per l'esecuzione di un programma = tempo di CPU + tempo di I/O Supponiamo di avere un programma che viene eseguito in 100 secondi
Elenco sezioni libro di testo Ed. 5 Tra parentesi le corrispondenze per l'ed. 7.
 Elenco sezioni libro di testo Ed. 5 Tra parentesi le corrispondenze per l'ed. 7. Modulo 1 - Architettura del calcolatore Unità 1 - Architettura e funzionamento dei sistemi di elaborazione Lezione 1 - Macchina
Elenco sezioni libro di testo Ed. 5 Tra parentesi le corrispondenze per l'ed. 7. Modulo 1 - Architettura del calcolatore Unità 1 - Architettura e funzionamento dei sistemi di elaborazione Lezione 1 - Macchina
2. Cenni di sistemi operativi
 2. Cenni di sistemi operativi Andrea Marongiu (andrea.marongiu@unimore.it) Paolo Valente Contiene slides dal corso «Sistemi Operativi» dei prof. Gherardi/Scandurra dell Università degli studi di Bergamo
2. Cenni di sistemi operativi Andrea Marongiu (andrea.marongiu@unimore.it) Paolo Valente Contiene slides dal corso «Sistemi Operativi» dei prof. Gherardi/Scandurra dell Università degli studi di Bergamo
Cosa è un programma. Informatica di Base -- R.Gaeta 18
 Cosa è un programma Il programma è la scatola nera che risolve il problema computazionale; Il programma è una sequenza di istruzioni che devono essere eseguite; Il programma è la traduzione per il computer
Cosa è un programma Il programma è la scatola nera che risolve il problema computazionale; Il programma è una sequenza di istruzioni che devono essere eseguite; Il programma è la traduzione per il computer
Architetture dei Calcolatori (Lettere
 Architetture dei Calcolatori (Lettere J-Z) Valutazione delle Prestazioni Ing.. Davide D AmicoD Valutazione delle Prestazioni Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Architetture dei Calcolatori (Lettere J-Z) Valutazione delle Prestazioni Ing.. Davide D AmicoD Valutazione delle Prestazioni Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
PROCESSI NON SEQUENZIALI E TIPI DI INTERAZIONE
 PROCESSI NON SEQUENZIALI E TIPI DI INTERAZIONE 1 ALGORITMO, PROGRAMMA, PROCESSO Algoritmo Procedimento logico che deve essere eseguito per risolvere un determinato problema. Programma Descrizione di un
PROCESSI NON SEQUENZIALI E TIPI DI INTERAZIONE 1 ALGORITMO, PROGRAMMA, PROCESSO Algoritmo Procedimento logico che deve essere eseguito per risolvere un determinato problema. Programma Descrizione di un
Architetture Evolute nei Sistemi Informativi. architetture evolute 1
 Architetture Evolute nei Sistemi Informativi architetture evolute 1 Scalabilità delle Applicazioni carico: insieme di tutte le applicazioni (query) scalabilità: abilità di conservare prestazioni elevate
Architetture Evolute nei Sistemi Informativi architetture evolute 1 Scalabilità delle Applicazioni carico: insieme di tutte le applicazioni (query) scalabilità: abilità di conservare prestazioni elevate
Componenti principali
 Componenti e connessioni Capitolo 3 Componenti principali n CPU (Unità Centrale di Elaborazione) n Memoria n Sistemi di I/O n Connessioni tra loro Architettura di Von Neumann n Dati e instruzioni in memoria
Componenti e connessioni Capitolo 3 Componenti principali n CPU (Unità Centrale di Elaborazione) n Memoria n Sistemi di I/O n Connessioni tra loro Architettura di Von Neumann n Dati e instruzioni in memoria
Input/Output. bus, interfacce, periferiche
 Architettura degli Elaboratori e delle Reti Lezione 29 Input/Output: bus, interfacce, periferiche Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 29 Input/Output: bus, interfacce, periferiche Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Note sulle forme di parallelismo a livello di processi
 Architetture Parallele e Distribuite, 2006-07 Note sulle forme di parallelismo a livello di processi Queste note integrano il contenuto del cap. VIII riguardo alla risoluzione e valutazione di programmi
Architetture Parallele e Distribuite, 2006-07 Note sulle forme di parallelismo a livello di processi Queste note integrano il contenuto del cap. VIII riguardo alla risoluzione e valutazione di programmi
Macchine Astratte. Luca Abeni. February 22, 2017
 Macchine Astratte February 22, 2017 Architettura dei Calcolatori - 1 Un computer è composto almeno da: Un processore (CPU) Esegue le istruzioni macchina Per fare questo, può muovere dati da/verso la memoria
Macchine Astratte February 22, 2017 Architettura dei Calcolatori - 1 Un computer è composto almeno da: Un processore (CPU) Esegue le istruzioni macchina Per fare questo, può muovere dati da/verso la memoria
Indice PARTE A. Prefazione Gli Autori Ringraziamenti dell Editore La storia del C. Capitolo 1 Computer 1. Capitolo 2 Sistemi operativi 21 XVII XXIX
 Indice Prefazione Gli Autori Ringraziamenti dell Editore La storia del C XVII XXIX XXXI XXXIII PARTE A Capitolo 1 Computer 1 1.1 Hardware e software 2 1.2 Processore 3 1.3 Memorie 5 1.4 Periferiche di
Indice Prefazione Gli Autori Ringraziamenti dell Editore La storia del C XVII XXIX XXXI XXXIII PARTE A Capitolo 1 Computer 1 1.1 Hardware e software 2 1.2 Processore 3 1.3 Memorie 5 1.4 Periferiche di
Informatica B a.a 2005/06 (Meccanici 4 squadra) PhD. Ing. Michele Folgheraiter
 PhD. Ing. Michele Folgheraiter") Informatica B a.a 2005/06 (Meccanici 4 squadra) Scaglione: da PO a ZZZZ PhD. Ing. Michele Folgheraiter Funzionamento macchina di von Neumann clock Memoria Centrale: Tutta l informazione prima di essere
Informatica B a.a 2005/06 (Meccanici 4 squadra) Scaglione: da PO a ZZZZ PhD. Ing. Michele Folgheraiter Funzionamento macchina di von Neumann clock Memoria Centrale: Tutta l informazione prima di essere
Architettura dei sistemi di elaborazione: La CPU: Architettura (parte 2)
") Architettura dei sistemi di elaborazione: La CPU: Architettura (parte 2) ALU L unità aritmetico logica o ALU rappresenta l apparato muscolare di un calcolatore, il dispositivo cioè che esegue le operazioni
Architettura dei sistemi di elaborazione: La CPU: Architettura (parte 2) ALU L unità aritmetico logica o ALU rappresenta l apparato muscolare di un calcolatore, il dispositivo cioè che esegue le operazioni
Calcolo numerico e programmazione Programmazione
 Calcolo numerico e programmazione Programmazione Tullio Facchinetti 11 maggio 2012 14:05 http://robot.unipv.it/toolleeo La programmazione la programmazione è l insieme delle
Calcolo numerico e programmazione Programmazione Tullio Facchinetti 11 maggio 2012 14:05 http://robot.unipv.it/toolleeo La programmazione la programmazione è l insieme delle
Componenti e connessioni. Capitolo 3
 Componenti e connessioni Capitolo 3 Componenti principali CPU (Unità Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro Architettura di Von Neumann Dati e instruzioni in memoria (lettura
Componenti e connessioni Capitolo 3 Componenti principali CPU (Unità Centrale di Elaborazione) Memoria Sistemi di I/O Connessioni tra loro Architettura di Von Neumann Dati e instruzioni in memoria (lettura
Argomento della lezione N. 2. Argomento della lezione N. 1. Presentazione del corso.
 Argomento della lezione N. 1 Presentazione del corso. Argomento della lezione N. 2 Concetti introduttivi. Rappresentazione dell'informazione. Rappresentazione di caratteri (tabella ASCII). 05/10/1998 05/10/1998
Argomento della lezione N. 1 Presentazione del corso. Argomento della lezione N. 2 Concetti introduttivi. Rappresentazione dell'informazione. Rappresentazione di caratteri (tabella ASCII). 05/10/1998 05/10/1998
ACSO Programmazione di Sistema e Concorrente
 ACSO Programmazione di Sistema e Concorrente P2 Modello Thread 2/12/2015 programma e parallelismo il tipo di parallelismo dipende dal grado di cooperazione (scambio di informazione) necessario tra attività
ACSO Programmazione di Sistema e Concorrente P2 Modello Thread 2/12/2015 programma e parallelismo il tipo di parallelismo dipende dal grado di cooperazione (scambio di informazione) necessario tra attività
COMPLESSITÀ COMPUTAZIONALE DEGLI ALGORITMI
 COMPLESSITÀ COMPUTAZIONALE DEGLI ALGORITMI Fondamenti di Informatica a.a.200.2005/06 Prof. V.L. Plantamura Dott.ssa A. Angelini Confronto di algoritmi Uno stesso problema può essere risolto in modi diversi,
COMPLESSITÀ COMPUTAZIONALE DEGLI ALGORITMI Fondamenti di Informatica a.a.200.2005/06 Prof. V.L. Plantamura Dott.ssa A. Angelini Confronto di algoritmi Uno stesso problema può essere risolto in modi diversi,
Gestione del processore. Il modello a thread
 Gestione del processore Il modello a thread 1 Il modello a thread : motivazioni Nel modello a processi, ogni processo ha il suo spazio di indirizzamento privato ed il modo per interagire è quello di utilizzare
Gestione del processore Il modello a thread 1 Il modello a thread : motivazioni Nel modello a processi, ogni processo ha il suo spazio di indirizzamento privato ed il modo per interagire è quello di utilizzare
Valutazione delle Prestazioni
 Valutazione delle Prestazioni Misure per le Prestazioni T durata del ciclo di clock [secondi] F numero cicli di clock al secondo [hertz] F 1 / T T 1 / F Exe_Time X tempo di esecuzione (CPU) di un programma
Valutazione delle Prestazioni Misure per le Prestazioni T durata del ciclo di clock [secondi] F numero cicli di clock al secondo [hertz] F 1 / T T 1 / F Exe_Time X tempo di esecuzione (CPU) di un programma
Dispositivi per il controllo
 Dispositivi per il controllo ordini di comando PARTE DI COMANDO PARTE DI POTENZA Controllori monolitici Controllori con architettura a bus Controllori basati su PC informazioni di ritorno PLC (Programmable
Dispositivi per il controllo ordini di comando PARTE DI COMANDO PARTE DI POTENZA Controllori monolitici Controllori con architettura a bus Controllori basati su PC informazioni di ritorno PLC (Programmable
Input/Output. bus, interfacce, periferiche
 Architettura degli Elaboratori e delle Reti Lezione 29 Input/Output: bus, interfacce, periferiche Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Lezione 29 Input/Output: bus, interfacce, periferiche Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 22/1/2019
 Nome e Cognome Matricola Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 22/1/2019 La prova dura 60 minuti Durante la prova non è consentito consultare
Nome e Cognome Matricola Corso di High Performance Computing Ingegneria e Scienze Informatiche Università di Bologna Prova Scritta, 22/1/2019 La prova dura 60 minuti Durante la prova non è consentito consultare
Architettura degli Elaboratori, Domanda 1
 Architettura degli Elaboratori, 2007-08 Appello del 16 gennaio 2008 Domanda 1 Un processo Q opera su due array di interi, A[][] e B [][], con = 1K. Il valore di A è ottenuto da un unità di I/O; il valore
Architettura degli Elaboratori, 2007-08 Appello del 16 gennaio 2008 Domanda 1 Un processo Q opera su due array di interi, A[][] e B [][], con = 1K. Il valore di A è ottenuto da un unità di I/O; il valore
Tipi di Bus. Bus sincrono. Comunicazioni nell elaboratore (e oltre) Bus sincroni e asincroni Standard commerciali (PCI,SCSI,USB)
 Bus sincroni e asincroni Standard commerciali (PCI,SCSI,USB)") Comunicazioni nell elaboratore (e oltre) Bus sincroni e asincroni Standard commerciali (PCI,SCSI,USB) Architettura degli Elaboratori (Prima Unità) Renato.LoCigno@dit.unitn.it www.dit.unitn.it/~locigno/didattica/archit/02-03/index.html
Comunicazioni nell elaboratore (e oltre) Bus sincroni e asincroni Standard commerciali (PCI,SCSI,USB) Architettura degli Elaboratori (Prima Unità) Renato.LoCigno@dit.unitn.it www.dit.unitn.it/~locigno/didattica/archit/02-03/index.html
I thread. Non bastavano i processi?
 I thread Non bastavano i processi? 1 Il modello a thread : motivazioni Nel modello a processi, ogni processo ha il suo spazio di indirizzamento, vediamo cosa significa... 2 Spazi di indirizzamento distinti
I thread Non bastavano i processi? 1 Il modello a thread : motivazioni Nel modello a processi, ogni processo ha il suo spazio di indirizzamento, vediamo cosa significa... 2 Spazi di indirizzamento distinti
Calcolatori Elettronici B a.a. 2004/2005
 Calcolatori Elettronici B a.a. 2004/2005 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Unità funzionali Unità funzionali: Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in
Calcolatori Elettronici B a.a. 2004/2005 RETI LOGICHE: RICHIAMI Massimiliano Giacomin 1 Unità funzionali Unità funzionali: Elementi di tipo combinatorio: - valori di uscita dipendono solo da valori in
Compilatori e Livelli di Compilazione
 Compilatori e Livelli di Compilazione Il compilatore Il programmatore ha a disposizione un ampia scelta di compilatori sviluppati per diversi sistemi operativi quali Linux/Unix, Windows, Macintosh. Oltre
Compilatori e Livelli di Compilazione Il compilatore Il programmatore ha a disposizione un ampia scelta di compilatori sviluppati per diversi sistemi operativi quali Linux/Unix, Windows, Macintosh. Oltre
5 Thread. 5 Thread. 5 Thread. Ad un generico processo, sono associati, in maniera univoca, i seguenti dati e le seguenti informazioni:
 1 Ad un generico processo, sono associati, in maniera univoca, i seguenti dati e le seguenti informazioni: codice del programma in esecuzione un area di memoria contenente le strutture dati dichiarate
1 Ad un generico processo, sono associati, in maniera univoca, i seguenti dati e le seguenti informazioni: codice del programma in esecuzione un area di memoria contenente le strutture dati dichiarate
Corso di Informatica
 Corso di Informatica Modulo T2 1-Concetti fondamentali 1 Prerequisiti Hardware e software Uso pratico elementare di un sistema operativo Software di base e software applicativo 2 1 Introduzione Iniziamo
Corso di Informatica Modulo T2 1-Concetti fondamentali 1 Prerequisiti Hardware e software Uso pratico elementare di un sistema operativo Software di base e software applicativo 2 1 Introduzione Iniziamo
Architettura degli Elaboratori
 Architettura degli Elaboratori a.a. 2013/14 appello straordinario, 13 aprile 2015 Riportare nome, cognome, numero di matricola e corso A/B Domanda 1 Si consideri la seguente gerarchia di memoria memoria
Architettura degli Elaboratori a.a. 2013/14 appello straordinario, 13 aprile 2015 Riportare nome, cognome, numero di matricola e corso A/B Domanda 1 Si consideri la seguente gerarchia di memoria memoria
2. Finalità generali previste dalle indicazioni nazionali
 2. Finalità generali previste dalle indicazioni nazionali Le Linee Guida ministeriali per i curricola del Secondo biennio dell Istituto Tecnico Tecnologico, Indirizzo Informatica e Telecomunicazioni -
2. Finalità generali previste dalle indicazioni nazionali Le Linee Guida ministeriali per i curricola del Secondo biennio dell Istituto Tecnico Tecnologico, Indirizzo Informatica e Telecomunicazioni -
Classificazione delle Architetture Parallele
 Università degli Studi di Roma Tor Vergata Facoltà di Ingegneria Classificazione delle Architetture Parallele Corso di Sistemi Distribuiti Valeria Cardellini Anno accademico 2009/10 Architetture parallele
Università degli Studi di Roma Tor Vergata Facoltà di Ingegneria Classificazione delle Architetture Parallele Corso di Sistemi Distribuiti Valeria Cardellini Anno accademico 2009/10 Architetture parallele
Tecniche di gestione dell I/O
 CEFRIEL Consorzio per la Formazione e la Ricerca in Ingegneria dell Informazione Politecnico di Milano Tecniche di gestione dell I/O Ottobre 2001 Docente William Fornaciari Politecnico di Milano {fornacia,
CEFRIEL Consorzio per la Formazione e la Ricerca in Ingegneria dell Informazione Politecnico di Milano Tecniche di gestione dell I/O Ottobre 2001 Docente William Fornaciari Politecnico di Milano {fornacia,
Architettura degli Elaboratori
 Architettura degli Elaboratori Appello del 8 giugno 2011 e seconda prova di verifica intermedia Domanda 1 (tutti) Una unità di elaborazione U, comunicante con una unità di ingresso e una di uscita, è descritta
Architettura degli Elaboratori Appello del 8 giugno 2011 e seconda prova di verifica intermedia Domanda 1 (tutti) Una unità di elaborazione U, comunicante con una unità di ingresso e una di uscita, è descritta
BASI DI DATI DISTRIBUITE
 BASI DI DATI DISTRIBUITE Definizione 2 Un sistema distribuito è costituito da un insieme di nodi (o di siti) di elaborazione una rete dati che connette fra loro i nodi Obiettivo: far cooperare i nodi per
BASI DI DATI DISTRIBUITE Definizione 2 Un sistema distribuito è costituito da un insieme di nodi (o di siti) di elaborazione una rete dati che connette fra loro i nodi Obiettivo: far cooperare i nodi per
Reti di Calcolatori COMMS Reti di Calcolatori 1. Il modello Client/Server. I Sistemi di Rete
 Reti di Calcolatori INFOS COS.. - 2004-2005 Reti di Calcolatori 1 I Sistemi di Rete Dal punto di vista del programmatore o dell utente la rete è il servizio di interconnessione tre due o più unità computazionali
Reti di Calcolatori INFOS COS.. - 2004-2005 Reti di Calcolatori 1 I Sistemi di Rete Dal punto di vista del programmatore o dell utente la rete è il servizio di interconnessione tre due o più unità computazionali
Di cosa parliamo oggi?
 Di cosa parliamo oggi? Oggi parliamo di Analisi di Algoritmi Analisi di Algoritmi = valutazione delle risorse usate da algoritmi per risolvere un dato problema Risorse = Tempo impiegato dall algoritmo
Di cosa parliamo oggi? Oggi parliamo di Analisi di Algoritmi Analisi di Algoritmi = valutazione delle risorse usate da algoritmi per risolvere un dato problema Risorse = Tempo impiegato dall algoritmo
Corso di Programmazione Concorrente
 Corso di Programmazione Concorrente Programmazione Concorrente: Introduzione Valter Crescenzi crescenz@dia.uniroma3.it http://crescenzi.inf.uniroma3.it Sommario Concetti fondamentali e terminologia Programma
Corso di Programmazione Concorrente Programmazione Concorrente: Introduzione Valter Crescenzi crescenz@dia.uniroma3.it http://crescenzi.inf.uniroma3.it Sommario Concetti fondamentali e terminologia Programma
Simulazioni Monte Carlo in ambiente OpenACC
 Simulazioni Monte Carlo in ambiente OpenACC Una semplice parallelizzazione su GPU Monte Carlo Hybrid Monte Carlo per modello XY Calcolo parallelo su GPU OpenACC Interoperabilità Risultati e conclusioni
Simulazioni Monte Carlo in ambiente OpenACC Una semplice parallelizzazione su GPU Monte Carlo Hybrid Monte Carlo per modello XY Calcolo parallelo su GPU OpenACC Interoperabilità Risultati e conclusioni
Input / Output. M. Dominoni A.A. 2002/2003. Input/Output A.A. 2002/2003 1
 Input / Output M. Dominoni A.A. 2002/2003 Input/Output A.A. 2002/2003 1 Struttura del Computer 4 componenti strutturali: CPU: controlla le operazioni del computer Memoria Centrale: immagazinamento dati
Input / Output M. Dominoni A.A. 2002/2003 Input/Output A.A. 2002/2003 1 Struttura del Computer 4 componenti strutturali: CPU: controlla le operazioni del computer Memoria Centrale: immagazinamento dati
Programmazione Concorrente, Parallela e su Cloud
 2019 Programmazione Concorrente, Parallela e su Cloud Algoritmi per memoria condivisa Carmine Spagnuolo, Ph.D. Finding the Minimum in O(logn) Time Algoritmo sequenziale, T (n) = n 1 = O(n): 1: m := a[1];
2019 Programmazione Concorrente, Parallela e su Cloud Algoritmi per memoria condivisa Carmine Spagnuolo, Ph.D. Finding the Minimum in O(logn) Time Algoritmo sequenziale, T (n) = n 1 = O(n): 1: m := a[1];
Valutazione delle prestazioni
 Valutazione delle prestazioni Architetture dei Calcolatori (lettere A-I) Valutazione delle prestazioni Misura/valutazione di un insieme di parametri quantitativi per Quantificare le caratteristiche di
Valutazione delle prestazioni Architetture dei Calcolatori (lettere A-I) Valutazione delle prestazioni Misura/valutazione di un insieme di parametri quantitativi per Quantificare le caratteristiche di