Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval
|
|
|
- Guido Colli
- 5 anni fa
- Visualizzazioni
Transcript

1 Filippo Geraci 1
2 Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate per reperire una specifica informazione all interno di un certo insieme di dati (tipicamente molto grande) 2
3 Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate per reperire una specifica informazione all interno di un certo insieme di dati (tipicamente molto grande) 3
4 Parte 1 4






5 Documento Documento Documento Documento Query Parsing, filtering, conversione Indice Ranking Risposta 5
6 Indicizzazione dei documenti e delle query Qual è il miglior modo di rappresentarle? Valutazione della query (processo di retrieval) Qual è il livello di affinità tra query e dicumento? Valutazione del sistema Quant è efficiente? Quanti dei documenti trovati sono rilevanti? (Precision) Riesce a trovare tutti i documenti rilevanti? (recall) 6
 Recall:")
")


7 Precision: percentuale di documenti rilevanti tra quelli restituiti (B/C) Recall: percentuale rilevanti resituiti rispetto al totale contenuto nella raccolta (B/A) Precision e Recall sono tra loro collegate, per esempio aumentando il numero di documenti ritrovati aumenta la recall e diminuisce la precision. Database docuenti Documenti rilevanti Documenti trovati A B C D 7
8 I documenti tipicamente trattati sono di tre tipi: Testi, video/immagini, suoni Ogni tipo di documento utilizza tecniche diverse In comune rimane lo schema della piattaforma di IR Spesso servono molti parser per supportare formati diversi dello stesso tipo di documento 8






9 Parser word Parser pdf 9
10 In information retrieval si calcola spesso la distanza fra due elementi Maggiore similarità vuol dire minore distanza e viceversa Tipicamente gli elementi sono rappresentati da vettori n-dimensionali Il passaggio da un documento ad un vettore dipende dal tipo di documento 10
11 Cosine similarity Si trasforma in una distanza Dove sono due vettori 11
12 Siano sono due insiemi di features, il coefficiente di jaccard si definisce come: Per due vettori il coefficiente può essere generalizzato come: 12

13 Siano due vettori, la distanza di minkowski è definita come: p=1 si riduce alla manatthan distance p=2 si riduce alla norma euclidea Se p è infinito si ha la norma infinito 13

 e norma infinito")
14 Le curve in rosso giallo e blu hanno la stessa manatthan distance Palle unitarie in norma 1 (rosso), norma 2 (verde) e norma infinito (blu) 14
15 15
16 L esame di S.I.A è costituito da una prova scritta ed una prova orale. Il voto può variare da 18 a
17 Normalizzazione del testo Rimozione della punteggiatura Rimozione numeri e sigle Conversione dei caratteri in minuscolo Ordinamento in ordine lessicografico Rimuovo duplicati, ma ne ricordo la cardinalità Devo rricordare le posizioni nella fase di indicizzazione Rimozione delle stop words Vengono rimosse parole poco significative Esempio: connettivi, articoli, preposizioni Liste solitamente note a priori, oppure basate su analisi delle frequenze delle parole nel testo 17

18 L esame di S.I.A è costituito da una prova scritta ed una prova orale. Il voto può variare da 18 a 30. costituito esame orale prova (2) scritta variare voto 18

19 La stessa parola può apparire in diverse forme pur mantenendo lo stesso significato Usato per incrementare l efficacia in una ricerca e ridurre la dimensione dell'indice Stem: porzione della parola rimasta dopo aver rimosso i suoi suffissi o prefissi Nasce il problema della correttezza Serve un algoritmo per ogni lingua computer compute computes computing computed computation comput 19
20 Stemming aggressivo organization army organ arm Stemming timido european creation europe create 20

21 Term frequency: numero di volte in cui un termine compare nel documento Document frequency: numero di documenti in cui compare ll termine INVERSO Il TF-IDF è un peso associato ad ogni termine in un documento 21
22 Uno score alto nel modello TF-IDF si ottiene da un valore alto di term frequency in un dato documento ed un valore basso del document frequency nell'intero dataset. Documenti memorizzati come matrice Ogni documento è un vettore in uno spazio n-dimensionale 22
23 Descrittività del modello Qual è il contesto del documento? Importante per recall Discriminazione Come distinguo questo documento dagli altri? Importante per precision La rimozione di stopwords migliora la discriminazione riducendo il numero di parole in comune tra documenti dissimili Lo stemming migliora la decrittività rendendo uguali parole simili La migliore rappresentazione dei documenti deve bilanciare questi aspetti 23
24 Data una query q ed un documento d viene assegnato un punteggio alla rilevanza della coppia (q, d) Questo valore è una stima della rilevanza di d per q Modelli di retrieval: Booleano (basato su logica booleana query simili ad una formula) Spazio vettoriale (dove documenti e query sono vettori e la similarità è il coseno dell'angolo) Probabilistico (query in linguaggio naturale, cerca di valutare la probabilità che q ed d siano correlate) 24

25 Proiettare i documenti e la query in punti di uno spazio euclideo ad alta dimensione e valutare la distanza 25



26 La correlazione tra query e documenti dipende solo dal testo Non si considerano i sinonimi Vota Antonio, vota Antonio, vota Antonio, vota Antonio, vota Antonio, vota Antonio 26










27 credevo che l'azzurro dei tuoi occhi per me fosse sempre cielo il pomeriggio è troppo azzurro e lungo per me per sognare un cielo azzurro all'orizzonte senza nuvole 1 Azzurro Cielo Credevo 1 4 Fosse 9 5 Lungo 7 6 Me Nuvole 9 8 Occhi 6 9 Orizzonte 7 10 Per Pomeriggio 2 12 Sempre Senza 8 14 Sognare 2 15 Troppo 4 16 Tuoi 5 Azzurro Cielo

28 28
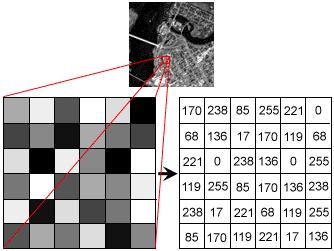
29 Fonte: 29

30 Una feature è una rappresentazione, tramite un vettore di valori numerici, di una immagine In genere una feature è una caratteristica facilmente misurabile dell immagine L immagine in esame viene quindi descritta concatenando i suoi vettori di features Si devono scegliere features che misurano caratteristiche diverse per avere una descrizione accurata 30
![Divido il range [0, 255] in k bins Assegno i pixel ai bin corrispondenti Ottengo un vettore di k componenti ognuna contenente il](/docs-images/95/124493613/images/31-4.jpg "numero di pixel in quell intervallo di colore Formula di conversione Gray = R *0.33 + G *0.33 + B *0.")
31 Divido il range [0, 255] in k bins Assegno i pixel ai bin corrispondenti Ottengo un vettore di k componenti ognuna contenente il numero di pixel in quell intervallo di colore Formula di conversione Gray = R * G * B *0.34 Gray, R,G,B compresi tra 0 e
32 32
33 Parte 2 33

34 Suddivide un insieme di oggetti in gruppi omogenei Procedure indipendenti dal tipo di dati Utilizzabile anche quando non sono disponibili informaioni a-priori sul dominio dei dati; Non possono essere introdotte ottimizzazioni dipendenti dal particolare problema Cluster hypothesis Se due oggetti sono molto simili ed il primo e anche simile ad un terzo oggetto, molto probabilmente anche tra il secondo ed il terzo oggetto esiste una similarità 34
35 Tramite tecnologie di information retrieval si trasformano i dati in punti appartenenti ad uno spazio vettoriale (in alcuni casi euclideo) e si lavora su quello Indipendente dal tipo di dato 35









36 Hard (non-overlapping Soft (fuzzy) Clustering Gerarchico Partizionale Divisivo Agglomerativo 36
37 Hard clustering: un elemento appartiene solo e soltanto ad un cluster Soft clustering: un elemento può appartenere a più cluster Solitamente viene associato un valore di peso (probabilità) di appartenenza dell elemento ad ogni cluster
38 Richiede l intera matrice delle distanze Produce dendrogramm Tagliando l albero a vari livelli si ottiene un numero diverso di cluster 38
39 1. Per ogni cluster seleziona una coppia di punti diametrali 2. Se un cluster soddisfa il criterio di partizionamento allora: a) Dividi il cluster usando come centri la coppia selezionata nel punto 1 b) Torna al punto 1 3. Se non ci sono più cluster da dividere fermati Criteri di partizionamento Ogni cluster fino a che tutti i cluster non hanno un solo elemento (albero completo) Il più grande (albero bilanciato) 39
40 1. All inizio ad ogni punto si associa un cluster 2. Ad ogni iterazione a) Costruisci la matrice delle distanze tra cluster b) Unisci i cluster in accordo al criterio di linkage 3. Ricomincia dal punto 2 finché tutti i punti sono in un unico cluster HAC è l algoritmo gerarchico più usato Computazionalmente costoso Produce intero albero 40
41 Distanza tra i due elementi più vicini appartenenti a cluster diversi Forza due cluster ad unirsi solo in base a due elementi non considerando gli altri Crea effetto concatenazione 41
42 Distanza tra i due elementi più lontani appartenenti a cluster diversi Crea cluster molto compatti Non tollerante a dati contententi rumore 42
43 Media tra le distanze di tutti gli elementi appartenenti a cluster diversi Robusto rispetto a concatenazione e rumore Computazionalemte costoso 43
44 Algoritmo FPF (furthest point first) Il modo più intuitivo e veloce Minimizza il massimo raggio dei cluster Algoritmo k-means Il più usato Minimizza la somma dei quadrati delle distanze dei punti dal centroide di riferimento 44
45 45
46 46
47 47
48 48
49 49
50 Inizializzazione Main loop Verifica terminazione Algoritmo k-means Assegna ogni punto al centroide più vicino Aggiorna il centroide 1. Per ogni dimensione del punto calcola il valore intermedio In uno spazio euclideo equivale al baricentro 50
51 Inizializzazione Main loop Verifica terminazione Inizializzazione Punti casuali Centri calcolati con FPF One pass k-means (McQueen) 1. Centroidi inizialmente scelti casualmente 2. Aggiungo un punto al cluster con il centroide più vicino 3. Aggiorno il centroide 4. Ricomincio dal punt 2 finche non finisco i punti da assegnare 51
52 Dipende dal problema in esame Se sono pochi il contenuto non è omogeneo Se sono troppi si rischia di spezzare cluster omogenei Dunque? Soluzioni dipendenti dal problema Possono non essere possibili Approcci teorici Sempre disponibili Indipendenti dal problema 52
 compra(latte) compra(x, divano 2 posti ) compra (X, poltrona ) fatturato (X, > 100M ) struttura(x, Spa ) compra(x, Jaguar ) Applicazioni market basket analysis profili")
53 Permette di identificare condizioni che si verificano contemporaneamente con elevata frequenza Rileva pattern che si ripetono su determinati attributi e ne deriva regole di implicazione del tipo A B Esempi compra(farina, biscotti) compra(latte) compra(x, divano 2 posti ) compra (X, poltrona ) fatturato (X, > 100M ) struttura(x, Spa ) compra(x, Jaguar ) Applicazioni market basket analysis profili clienti (abitudini di acquisto) ottimizzazione delle manutenzioni 53
54 Viene valutata in base a: Confidenza: misura la certezza del pattern Supporto: misura la frequenza con cui il pattern è presente sulla base di dati Esempio: Compra(X, divano 2 posti ) Compra (X, poltrona ) [c.85%;s.30%] L 85% di tutti coloro che comprano un divano 2 posti compra anche una poltrona Nel 30% delle vendite il cliente ha comprato sia un divano a due posti che una poltrona 54
55 Data la registrazione delle transazioni di un supermercato: una transazione è un insieme di oggetti acquistati contemporaneamente da un utente trovare gli oggetti che più di frequente sono stati acquistati insieme TID CID Data Prod. Q.tà /1/05 farina /1/05 lievito /1/05 latte /1/05 carne /1/05 farina /1/05 lievito /1/05 latte /1/05 farina /1/05 latte /1/05 farina /1/05 lievito /1/05 carne /1/05 vino 6 55
56 56
57 Costruzione di modelli per Predire gli eventi futuri Stimare il valore di elementi non noti Classificazione Definizione di criteri che permettono di assegnare un soggetto ad una classe Predizione Calcolo di funzioni di tendenza continue tramite l interpolazione dei dati noti 57
58 Costruzione basata su esempi Il modello deriva da un sottoinsieme significativo dei dati esistenti L efficacia viene testata su un sottoinsieme diverso (disgiunto) dei dati Se il modello si rivela efficace può essere usato come predittore Applicazioni Propensione all acquisto dei clienti Qualità dei fornitori Affidabilità dei prodotti 58
59 Permette di indicare l appartenenza di un elemento ad una certa classe Diversi tipi di modelli Analisi statistiche Regole associative Alberi di decisione Reti bayesiane (Naïve Bayes ne è un caso) Reti neurali 59
60 Struttura di classificazione basata sulla valutazione di condizioni del tipo if-thenelse Nodi interni Attributi del soggetto da classificare Archi in uscita Etichettati con i valori che l attributo può assumere Nodi foglia Classi La classificazione avviene seguendo un percorso guidato dai valori assunti dagli attributi dell elemento da classificare Esempio di albero di decisione che suddivide in due classi 60
61 Rappresentano un insieme di regole che permettono di fare la predizione automaticamente Sono costruiti automaticamente usando i dati disponibili Altro esempio: le caratteristiche di rischio dei clienti dell assicurazione Età <23 23 utilitaria no auto Sportiva, furgone sì no 61
62 La realizzazione dell albero si basa su due fasi Costruzione Raffinamento Costruzione Si cerca un buon criterio C per dividere dataset nei sottoinsiemi D1, D2 un buon criterio dovrebbe minimizzare la profondità dell albero Si costruisce un nodo che usa il criterio C e si applica ricorsivamente l algoritmo a D1 e D2 Raffinamento L albero costruito viene semplificato eliminando i rami meno importanti 62
 Dal training (solo")
63 Sia i sistemi di clustering che quelli di classificazione devono essere valutati prima di affidare le decisioni strategiche aziendali al sistema La bontà del sistema dipende: Dal modello Dagli algoritmi usati Dal numero di cluster (solo clustering) Dal training (solo classificazione) 63




64 Misure interne Misure esterne Modelli matematici Sempre disponibili Non correlati al problema Confronto con il ground truth Spesso non disponibili Correlate al problema 64

65 Gruppi molto omogenei indicano buon clustering/ classificazione Gruppi molto separati indicano buon clustering/ classificazione Due oggetti sono mates se appartengono allo stesso gruppo Alta omogeneità, bassa separazione indicano migliori risultati 65
66 Dato un raggruppamento c j ed una classe GT i si definiscono La precision misura la probabilità che un elemento della classe GT i sia anche nel gruppo c j La recall misura la probabilità che un elemento nel gruppo c j sia anche della classe GT i 66

67 Dato un clustering/classificazione ed il suo ground truth,precision e recall possono essere combinate insieme: F-measure per una classe Estensione all intero raggruppamento 67
Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval
 Information retrieval") Filippo Geraci Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate
Filippo Geraci Data mining: attività di scoperta di informazione latente all interno di un certo insieme di dati (tipicamente molto grande) Information retrieval (IR): insieme delle tecnologie utilizzate
Sistemi informativi aziendali struttura e processi
 Sistemi informativi aziendali struttura e processi Data mining Copyright 2011 Pearson Italia Uso dei Data Warehouse Esistono tre tipi di applicazioni front-end per data warehouse Analisi statica (reporting)
Sistemi informativi aziendali struttura e processi Data mining Copyright 2011 Pearson Italia Uso dei Data Warehouse Esistono tre tipi di applicazioni front-end per data warehouse Analisi statica (reporting)
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Cluster Analysis. La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. per modellare!
 La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
La Cluster Analysis è il processo attraverso il quale vengono individuati raggruppamenti dei dati. Le tecniche di cluster analysis vengono usate per esplorare i dati e non per modellare! La cluster analysis
Riconoscimento e recupero dell informazione per bioinformatica. Clustering: validazione. Manuele Bicego
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: validazione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizione
Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello
 Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Tesina di Intelligenza Artificiale Uso dell algoritmo di Quantizzazione Vettoriale per la determinazione del numero di nodi dello strato hidden in una rete neurale multilivello Roberto Fortino S228682
Modelli di recupero. Modello di recupero booleano
 Modelli di recupero L obiettivo è recuperare i documenti che sono verosimilmente rilevanti all interrogazione. Vi sono vari modelli di recupero, che possono essere suddivisi in due grandi famiglie: exact
Modelli di recupero L obiettivo è recuperare i documenti che sono verosimilmente rilevanti all interrogazione. Vi sono vari modelli di recupero, che possono essere suddivisi in due grandi famiglie: exact
Regole associative Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 2006/2007
 Regole associative Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 26/27 Introduzione Le regole associative si collocano tra i metodi di apprendimento non supervisionato e sono volte
Regole associative Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 26/27 Introduzione Le regole associative si collocano tra i metodi di apprendimento non supervisionato e sono volte
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
QUANTIZZATORE VETTORIALE
 QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
QUANTIZZATORE VETTORIALE Introduzione Nel campo delle reti neurali, la scelta del numero di nodi nascosti da usare per un determinato compito non è sempre semplice. Per tale scelta potrebbe venirci in
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Riconoscimento e recupero dell informazione per bioinformatica Clustering: metodologie Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Tassonomia
Ricerca di outlier. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Riconoscimento automatico di oggetti (Pattern Recognition)
") Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Riconoscimento automatico di oggetti (Pattern Recognition) Scopo: definire un sistema per riconoscere automaticamente un oggetto data la descrizione di un oggetto che può appartenere ad una tra N classi
Statistica per l Impresa
 Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Statistica per l Impresa a.a. 207/208 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 2 maggio 208 Indice Analisi dei Gruppi: Introduzione Misure di distanza e indici di similarità 3. Metodi gerarchici
Classificazione Mario Guarracino Laboratorio di Sistemi Informativi Aziendali a.a. 2006/2007
 Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Classificazione Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo target categorico. A partire da un insieme
Linguistica computazionale: task sul linguaggio naturale"
 Linguistica computazionale: task sul linguaggio naturale" Cristina Bosco 2015 Informatica applicata alla comunicazione multimediale NLP e subtask Ci focalizziamo su alcuni subtask rappresentativi:" Information
Linguistica computazionale: task sul linguaggio naturale" Cristina Bosco 2015 Informatica applicata alla comunicazione multimediale NLP e subtask Ci focalizziamo su alcuni subtask rappresentativi:" Information
Introduzione all analisi di arrays: clustering.
 Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Statistica per la Ricerca Sperimentale Introduzione all analisi di arrays: clustering. Lezione 2-14 Marzo 2006 Stefano Moretti Dipartimento di Matematica, Università di Genova e Unità di Epidemiologia
Classificazione Mario Guarracino Data Mining a.a. 2010/2011
 Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Classificazione Mario Guarracino Data Mining a.a. 2010/2011 Introduzione I modelli di classificazione si collocano tra i metodi di apprendimento supervisionato e si rivolgono alla predizione di un attributo
Data mining: classificazione
 DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group of DataBase and Data Mining Group
SAGA: sequence alignment by genetic algorithm. ALESSANDRO PIETRELLI Soft Computing
 SAGA: sequence alignment by genetic algorithm ALESSANDRO PIETRELLI Soft Computing Bologna, 25 Maggio 2007 Multi Allineamento di Sequenze (MSAs) Cosa sono? A cosa servono? Come vengono calcolati Multi Allineamento
SAGA: sequence alignment by genetic algorithm ALESSANDRO PIETRELLI Soft Computing Bologna, 25 Maggio 2007 Multi Allineamento di Sequenze (MSAs) Cosa sono? A cosa servono? Come vengono calcolati Multi Allineamento
SDE Marco Riani
 SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
SDE 2017 Marco Riani mriani@unipr.it http://www.riani.it LA CLASSIFICAZIONE Problema generale della scienza (Linneo, ) Analisi discriminante Cluster Analysis (analisi dei gruppi) ANALISI DISCRIMINANTE
Misura della performance di ciascun modello: tasso di errore sul test set
 Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Confronto fra modelli di apprendimento supervisionato Dati due modelli supervisionati M 1 e M costruiti con lo stesso training set Misura della performance di ciascun modello: tasso di errore sul test
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato
 Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
Ingegneria della Conoscenza e Sistemi Esperti Lezione 2: Apprendimento non supervisionato Dipartimento di Elettronica e Informazione Politecnico di Milano Apprendimento non supervisionato Dati un insieme
I Componenti del processo decisionale 7
 Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Indice Introduzione 1 I Componenti del processo decisionale 7 1 Business intelligence 9 1.1 Decisioni efficaci e tempestive........ 9 1.2 Dati, informazioni e conoscenza....... 12 1.3 Ruolo dei modelli
Apprendimento basato sulle istanze
 Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Apprendimento basato sulle istanze Apprendimento basato sulle istanze Apprendimento: semplice memorizzazione di tutti gli esempi Classificazione di una nuova istanza x j : reperimento degli
Alberi di Regressione
 lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
lberi di Regressione Caso di studio di Metodi vanzati di Programmazione 2015-2016 Corso Data Mining Lo scopo del data mining è l estrazione (semi) automatica di conoscenza nascosta in voluminose basi di
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista
 Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Alberi Decisionali Per l analisi del mancato rinnovo all abbonamento di una rivista Il problema L anticipazione del fenomeno degli abbandoni da parte dei propri clienti, rappresenta un elemento fondamentale
Applicazioni della SVD
 Applicazioni della SVD Gianna M. Del Corso Dipartimento di Informatica, Università di Pisa, Italy 28 Marzo 2014 1 Le applicazioni presentate 2 Text Mining 3 Algoritmo di riconoscimento di volti Le Applicazioni
Applicazioni della SVD Gianna M. Del Corso Dipartimento di Informatica, Università di Pisa, Italy 28 Marzo 2014 1 Le applicazioni presentate 2 Text Mining 3 Algoritmo di riconoscimento di volti Le Applicazioni
Parallel Frequent Set Counting
 Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2001-02 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Sistemi di Elaborazione dell Informazione 170. Caso Non Separabile
 Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Sistemi di Elaborazione dell Informazione 170 Caso Non Separabile La soluzione vista in precedenza per esempi non-linearmente separabili non garantisce usualmente buone prestazioni perchè un iperpiano
Parte 5. Modello Vector Space ed il ranking. Michelangelo Diligenti 1
 Parte 5 Modello Vector Space ed il ranking dei risultati Michelangelo Diligenti 1 Modello Vector-Space T termini distinti che formano vocabolario V computer Casa Lavoro Giochi I termini sono incorrelati
Parte 5 Modello Vector Space ed il ranking dei risultati Michelangelo Diligenti 1 Modello Vector-Space T termini distinti che formano vocabolario V computer Casa Lavoro Giochi I termini sono incorrelati
Informatica per le discipline umanistiche 2 lezione 11
 Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
Informatica per le discipline umanistiche 2 lezione 11 Come si fa a costruire una base di dati? Dipende. Le persone che si iscrivono in università forniscono dati che popolano il database dellʼuniversità
Sistemi Informativi Territoriali
 ANNO ACCADEMICO 2002-2003 SISTEMI INFORMATIVI GEOGRAFICI (SIT) GEOGRAPHICAL INFORMATION SYSTEMS (GIS) Sistemi Informativi Territoriali 2. La progettazione concettuale: il modello GEO-ER ALBERTO BELUSSI
ANNO ACCADEMICO 2002-2003 SISTEMI INFORMATIVI GEOGRAFICI (SIT) GEOGRAPHICAL INFORMATION SYSTEMS (GIS) Sistemi Informativi Territoriali 2. La progettazione concettuale: il modello GEO-ER ALBERTO BELUSSI
L A B C di R. Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010
 L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
Tecniche di riconoscimento statistico
 On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
On AIR s.r.l. Tecniche di riconoscimento statistico Applicazioni alla lettura automatica di testi (OCR) Parte 9 Alberi di decisione Ennio Ottaviani On AIR srl ennio.ottaviani@onairweb.com http://www.onairweb.com/corsopr
Linguistica computazionale: come accedere all informazione codificata nel linguaggio naturale (seconda parte)"
") Linguistica computazionale: come accedere all informazione codificata nel linguaggio naturale (seconda parte)" Cristina Bosco 2014 Informatica applicata alla comunicazione multimediale NLP e subtask Ci
Linguistica computazionale: come accedere all informazione codificata nel linguaggio naturale (seconda parte)" Cristina Bosco 2014 Informatica applicata alla comunicazione multimediale NLP e subtask Ci
Test di ipotesi. Test
 Test di ipotesi Test E una metodologia statistica che consente di prendere una decisione. Esempio: Un supermercato riceve dal proprio fornitore l assicurazione che non più del 5% delle mele di tipo A dell
Test di ipotesi Test E una metodologia statistica che consente di prendere una decisione. Esempio: Un supermercato riceve dal proprio fornitore l assicurazione che non più del 5% delle mele di tipo A dell
Teoria e tecniche dei test
 Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Teoria e tecniche dei test Lezione 9 LA STANDARDIZZAZIONE DEI TEST. IL PROCESSO DI TARATURA: IL CAMPIONAMENTO. Costruire delle norme di riferimento per un test comporta delle ipotesi di fondo che è necessario
Richiami di probabilità. Decision Theory e Utilità. Richiami di probabilità. assumere certi valori in un insieme x 1, x 2, x n (dominio)
") 9 lezione Scaletta argomenti: Probabilità Richiami di probabilità Reti Bayesiane Decision Theory e Utilità 1 Richiami di probabilità - La formalizzazione deriva da Boole - Concetto di VARIABILE CASUALE
9 lezione Scaletta argomenti: Probabilità Richiami di probabilità Reti Bayesiane Decision Theory e Utilità 1 Richiami di probabilità - La formalizzazione deriva da Boole - Concetto di VARIABILE CASUALE
Data Science e Tecnologie per le Basi di Dati
 Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Data Science e Tecnologie per le Basi di Dati Esercitazione #3 Data mining BOZZA DI SOLUZIONE Domanda 1 (a) Come mostrato in Figura 1, l attributo più selettivo risulta essere Capital Gain, perché rappresenta
Learning and Clustering
 Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Learning and Clustering Alberto Borghese Università degli Studi di Milano Laboratorio di Sistemi Intelligenti Applicati (AIS-Lab) Dipartimento di Informatica alberto.borghese@unimi.it 1/48 Riassunto I
Cluster Analysis Distanze ed estrazioni Marco Perugini Milano-Bicocca
 Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Cluster Analysis Distanze ed estrazioni M Q Marco Perugini Milano-Bicocca 1 Scopi Lo scopo dell analisi dei Clusters è di raggruppare casi od oggetti sulla base delle loro similarità in una serie di caratteristiche
Introduzione. SONIA: A Service for Organizing Networked Information Autonomously. Breve descrizione del sistema. Un sistema modulare
 Seminario di ELN A.A. 2002/2003 SONIA: A Service for Organizing Networked Information Autonomously Stud. Davide D Alessandro Prof. Amedeo Cappelli Introduzione Crescita esponenziale dell informazione on-line
Seminario di ELN A.A. 2002/2003 SONIA: A Service for Organizing Networked Information Autonomously Stud. Davide D Alessandro Prof. Amedeo Cappelli Introduzione Crescita esponenziale dell informazione on-line
Distribuzione Gaussiana - Facciamo un riassunto -
 Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Parallel Frequent Set Counting
 Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2010-11 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Parallel Frequent Set Counting Progetto del corso di Calcolo Parallelo AA 2010-11 Salvatore Orlando 1 Cosa significa association mining? Siano dati un insieme di item un insieme di transazioni, ciascuna
Statistica per l Impresa
 Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Statistica per l Impresa a.a. 2017/2018 Tecniche di Analisi Multidimensionale Analisi dei Gruppi 23 aprile 2018 Indice 1. Analisi dei Gruppi: Introduzione 2. Misure di distanza e indici di similarità 3.
Computazione per l interazione naturale: classificazione probabilistica
 Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione uomo-macchina II Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it
Naïve Bayesian Classification
 Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Naïve Bayesian Classification Di Alessandro rezzani Sommario Naïve Bayesian Classification (o classificazione Bayesiana)... 1 L algoritmo... 2 Naive Bayes in R... 5 Esempio 1... 5 Esempio 2... 5 L algoritmo
Microsoft Access. Nozioni di base. Contatti: Dott.ssa Silvia Bonfanti
 Microsoft Access Nozioni di base Contatti: Dott.ssa Silvia Bonfanti silvia.bonfanti@unibg.it Introduzione In questa lezione vedremo lo strumento Microsoft Access ed impareremo come realizzare con esso
Microsoft Access Nozioni di base Contatti: Dott.ssa Silvia Bonfanti silvia.bonfanti@unibg.it Introduzione In questa lezione vedremo lo strumento Microsoft Access ed impareremo come realizzare con esso
Teoria e Tecniche del Riconoscimento Clustering
 Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Clustering Sommario Tassonomia degli algoritmi di clustering Algoritmi partizionali: clustering sequenziale
Facoltà di Scienze MM. FF. NN. Università di Verona A.A. 2010-11 Teoria e Tecniche del Riconoscimento Clustering Sommario Tassonomia degli algoritmi di clustering Algoritmi partizionali: clustering sequenziale
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Classificazione Bayesiana
 Classificazione Bayesiana Selezionare, dato un certo pattern x, la classe ci che ha, a posteriori, la massima probabilità rispetto al pattern: P(C=c i x)>p(c=c j x) j i Teorema di Bayes (TDB): P(A B) =
Classificazione Bayesiana Selezionare, dato un certo pattern x, la classe ci che ha, a posteriori, la massima probabilità rispetto al pattern: P(C=c i x)>p(c=c j x) j i Teorema di Bayes (TDB): P(A B) =
Indice generale. Introduzione. Capitolo 1 Essere uno scienziato dei dati... 1
 Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Introduzione...xi Argomenti trattati in questo libro... xi Dotazione software necessaria... xii A chi è rivolto questo libro... xii Convenzioni utilizzate... xiii Scarica i file degli esempi... xiii Capitolo
Esercizi Capitolo 11 - Strutture di dati e progettazione di algoritmi
 Esercizi Capitolo 11 - Strutture di dati e progettazione di algoritmi Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore
Esercizi Capitolo 11 - Strutture di dati e progettazione di algoritmi Alberto Montresor 19 Agosto, 2014 Alcuni degli esercizi che seguono sono associati alle rispettive soluzioni. Se il vostro lettore
Constraint Satisfaction Problems
 Constraint Satisfaction Problems Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 19/03/2018 Constraint Satisfaction problem Fino ad ora ogni stato è stato modellizzato come una
Constraint Satisfaction Problems Corso di Intelligenza Artificiale, a.a. 2017-2018 Prof. Francesco Trovò 19/03/2018 Constraint Satisfaction problem Fino ad ora ogni stato è stato modellizzato come una
Le Tecniche di Data Mining
 Cluster Analysis Le Tecniche di Data Mining Le rinciali tecniche di data mining che vedremo sono: Ø Ø Cluster Analysis Alberi Decisionali Cluster Analysis La Cluster Analysis è una tecnica di data mining
Cluster Analysis Le Tecniche di Data Mining Le rinciali tecniche di data mining che vedremo sono: Ø Ø Cluster Analysis Alberi Decisionali Cluster Analysis La Cluster Analysis è una tecnica di data mining
Data mining per le scienze sociali
 Data mining per le scienze sociali Davide Sardina davidestefano.sardina@unikore.it Università degli studi di Enna Kore Corso di Laurea in Servizio Sociale A.A. 2017/2018 Scienza dei dati Data Mining Dall
Data mining per le scienze sociali Davide Sardina davidestefano.sardina@unikore.it Università degli studi di Enna Kore Corso di Laurea in Servizio Sociale A.A. 2017/2018 Scienza dei dati Data Mining Dall
Data Science A.A. 2018/2019
 Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 5 Data Mining Data Science 2018/2019 1 Data Mining Processo di esplorazione e analisi di un insieme di dati, generalmente di grandi
Metodi di classificazione
 I metodi di classificazione sono metodi utilizzati per trovare modelli statistici capaci di assegnare ciascun oggetto di provenienza incognita ad una delle classi esistenti. L applicazione di questi metodi
I metodi di classificazione sono metodi utilizzati per trovare modelli statistici capaci di assegnare ciascun oggetto di provenienza incognita ad una delle classi esistenti. L applicazione di questi metodi
Elementi di analisi matematica e complementi di calcolo delle probabilita T
 Elementi di analisi matematica e complementi di calcolo delle probabilita T Presentiamo una raccolta di quesiti per la preparazione alla prova orale di Elementi di analisi matematica e complementi di calcolo
Elementi di analisi matematica e complementi di calcolo delle probabilita T Presentiamo una raccolta di quesiti per la preparazione alla prova orale di Elementi di analisi matematica e complementi di calcolo
Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive
 Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Sistemi Intelligenti 1 Richiamo di Concetti di Apprendimento Automatico ed altre nozioni aggiuntive Libro di riferimento: T. Mitchell Sistemi Intelligenti 2 Ingredienti Fondamentali Apprendimento Automatico
Suffix Trees. Docente: Nicolò Cesa-Bianchi versione 21 settembre 2017
 Complementi di Algoritmi e Strutture Dati Suffix Trees Docente: Nicolò Cesa-Bianchi versione 21 settembre 2017 In generale, possiamo trovare tutte le occorrenze di un pattern y in un testo x in tempo O(
Complementi di Algoritmi e Strutture Dati Suffix Trees Docente: Nicolò Cesa-Bianchi versione 21 settembre 2017 In generale, possiamo trovare tutte le occorrenze di un pattern y in un testo x in tempo O(
Le sequenze consenso
 Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Statistica multivariata 27/09/2016. D.Rodi, 2016
 Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
Statistica multivariata 27/09/2016 Metodi Statistici Statistica Descrittiva Studio di uno o più fenomeni osservati sull INTERA popolazione di interesse (rilevazione esaustiva) Descrizione delle caratteristiche
TRIE (albero digitale di ricerca)
") TRIE (albero digitale di ricerca) Struttura dati impiegata per memorizzare un insieme S di n stringhe (il vocabolario V). Tabelle hash le operazioni di dizionario hanno costo O(m) al caso medio per una
TRIE (albero digitale di ricerca) Struttura dati impiegata per memorizzare un insieme S di n stringhe (il vocabolario V). Tabelle hash le operazioni di dizionario hanno costo O(m) al caso medio per una
Maria Prandini Dipartimento di Elettronica e Informazione Politecnico di Milano
 Note relative a test di bianchezza rimozione delle componenti deterministiche da una serie temporale a supporto del Progetto di Identificazione dei Modelli e Analisi dei Dati Maria Prandini Dipartimento
Note relative a test di bianchezza rimozione delle componenti deterministiche da una serie temporale a supporto del Progetto di Identificazione dei Modelli e Analisi dei Dati Maria Prandini Dipartimento
Array e Oggetti. Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1. Dispensa 12. A. Miola Dicembre 2006
 Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1 Dispensa 12 Array e Oggetti A. Miola Dicembre 2006 http://www.dia.uniroma3.it/~java/fondinf1/ Array e Oggetti 1 Contenuti Array paralleli
Corso di Laurea Ingegneria Informatica Fondamenti di Informatica 1 Dispensa 12 Array e Oggetti A. Miola Dicembre 2006 http://www.dia.uniroma3.it/~java/fondinf1/ Array e Oggetti 1 Contenuti Array paralleli
lezione n. 6 (a cura di Gaia Montanucci) Verosimiglianza: L = = =. Parte dipendente da β 0 e β 1
 Verosimiglianza: L = = =. Parte dipendente da β 0 e β 1") lezione n. 6 (a cura di Gaia Montanucci) METODO MASSIMA VEROSIMIGLIANZA PER STIMARE β 0 E β 1 Distribuzione sui termini di errore ε i ε i ~ N (0, σ 2 ) ne consegue : ogni y i ha ancora distribuzione normale,
lezione n. 6 (a cura di Gaia Montanucci) METODO MASSIMA VEROSIMIGLIANZA PER STIMARE β 0 E β 1 Distribuzione sui termini di errore ε i ε i ~ N (0, σ 2 ) ne consegue : ogni y i ha ancora distribuzione normale,
Funzioni di un GIS Analisi spaziale
 Sistemi Informativi Funzioni di un GIS Analisi spaziale Come per ogni Sistema Informativo le funzioni di un SIT sono : acquisizione gestione analisi rappresentazione Funzioni di un SIT dei dati (territoriali)
Sistemi Informativi Funzioni di un GIS Analisi spaziale Come per ogni Sistema Informativo le funzioni di un SIT sono : acquisizione gestione analisi rappresentazione Funzioni di un SIT dei dati (territoriali)
Lecture 14. Association Rules
 Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
Lecture 14 Association Rules Giuseppe Manco Readings: Chapter 6, Han and Kamber Chapter 14, Hastie, Tibshirani and Friedman Association Rule Mining Dato un insieme di transazioni, trovare le regole che
standardizzazione dei punteggi di un test
 DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it standardizzazione dei punteggi di un test serve a dare significato ai punteggi che una persona ottiene ad un test, confrontando la
Luigi Piroddi
 Automazione industriale dispense del corso (a.a. 2008/2009) 10. Reti di Petri: analisi strutturale Luigi Piroddi piroddi@elet.polimi.it Analisi strutturale Un alternativa all analisi esaustiva basata sul
Automazione industriale dispense del corso (a.a. 2008/2009) 10. Reti di Petri: analisi strutturale Luigi Piroddi piroddi@elet.polimi.it Analisi strutturale Un alternativa all analisi esaustiva basata sul
Big Data: tecnologie, metodologie e applicazioni per l analisi dei dati massivi
 Big Data: tecnologie, metodologie e applicazioni per l analisi dei dati massivi Ministero Dello Sviluppo Economico Istituto Superiore delle Comunicazioni e delle Tecnologie dell Informazione Seminario
Big Data: tecnologie, metodologie e applicazioni per l analisi dei dati massivi Ministero Dello Sviluppo Economico Istituto Superiore delle Comunicazioni e delle Tecnologie dell Informazione Seminario
Rischio statistico e sua analisi
 F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
F94 Metodi statistici per l apprendimento Rischio statistico e sua analisi Docente: Nicolò Cesa-Bianchi versione 7 aprile 018 Per analizzare un algoritmo di apprendimento dobbiamo costruire un modello
Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale
 UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
UNIVERSITA DEGLI STUDI DI PERUGIA Dipartimento di Chimica, Biologia e Biotecnologie Via Elce di Sotto, 06123 Perugia Corso di Laurea di Scienze biomolecolari e ambientali Laurea magistrale Corso di ANALISI
Librerie digitali. Strumenti di ricerca. Ricerca di informazioni nelle Digital library
 Librerie digitali Strumenti di ricerca Ricerca di informazioni nelle Digital library Data un interrogazione da parte di un utente gli strumenti di ricerca permetto di identificare i dati che soddisfano
Librerie digitali Strumenti di ricerca Ricerca di informazioni nelle Digital library Data un interrogazione da parte di un utente gli strumenti di ricerca permetto di identificare i dati che soddisfano
Possibile applicazione
 p. 1/4 Assegnamento Siano dati due insiemi A e B entrambi di cardinalità n. Ad ogni coppia (a i,b j ) A B è associato un valore d ij 0 che misura la "incompatibilità" tra a i e b j, anche interpretabile
p. 1/4 Assegnamento Siano dati due insiemi A e B entrambi di cardinalità n. Ad ogni coppia (a i,b j ) A B è associato un valore d ij 0 che misura la "incompatibilità" tra a i e b j, anche interpretabile
Modelli di Information Retrieval
 Modelli di Information Retrieval Roberto Basili Basi di Dati Distribuite a.a. 2004-2005 1 Documenti, Informazioni e Struttura 2 Modelli di Retrieval Un modello di IR specifica (almeno) : Rappresentazione
Modelli di Information Retrieval Roberto Basili Basi di Dati Distribuite a.a. 2004-2005 1 Documenti, Informazioni e Struttura 2 Modelli di Retrieval Un modello di IR specifica (almeno) : Rappresentazione
record a struttura fissa
 Modello Relazionale E un modello logico: definisce tipi attraverso il costruttore relazione, che organizza i dati secondo record a struttura fissa, rappresentabili attraverso tabelle. Es. (relazioni INSEGNAMENTO
Modello Relazionale E un modello logico: definisce tipi attraverso il costruttore relazione, che organizza i dati secondo record a struttura fissa, rappresentabili attraverso tabelle. Es. (relazioni INSEGNAMENTO
Data Journalism. Analisi dei dati. Angelica Lo Duca
 Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Data Journalism Analisi dei dati Angelica Lo Duca angelica.loduca@iit.cnr.it Obiettivo L obiettivo dell analisi dei dati consiste nello scoprire trend, pattern e relazioni nascosti nei dati. di analisi
Appunti di statistica ed analisi dei dati
 Appunti di statistica ed analisi dei dati Indice generale Appunti di statistica ed analisi dei dati...1 Analisi dei dati...1 Calcolo della miglior stima di una serie di misure...3 Come si calcola μ...3
Appunti di statistica ed analisi dei dati Indice generale Appunti di statistica ed analisi dei dati...1 Analisi dei dati...1 Calcolo della miglior stima di una serie di misure...3 Come si calcola μ...3
Data Science A.A. 2018/2019
 Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 6 Modelli di Classificazione Data Science 2018/2019 1 Definizione Si collocano tra i metodi di apprendimento supervisionato e mirano
Corso di Laurea Magistrale in Economia Data Science A.A. 2018/2019 Lez. 6 Modelli di Classificazione Data Science 2018/2019 1 Definizione Si collocano tra i metodi di apprendimento supervisionato e mirano
Dizionari Liste invertite e Trie
 Dizionari Liste invertite e Trie Lucidi tratti da Crescenzi Gambosi Grossi, Strutture di dati e algoritmi Progettazione, analisi e visualizzazione Addison-Wesley, 2006 Dizionari Universo U delle chiavi
Dizionari Liste invertite e Trie Lucidi tratti da Crescenzi Gambosi Grossi, Strutture di dati e algoritmi Progettazione, analisi e visualizzazione Addison-Wesley, 2006 Dizionari Universo U delle chiavi
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Soluzioni degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Funzione primaria del sistema informativo Supportare chi fa funzionare l azienda attraverso la propria attività Supporto necessario in aree diverse,
 Filippo Geraci Funzione primaria del sistema informativo Supportare chi fa funzionare l azienda attraverso la propria attività Supporto necessario in aree diverse, con livello di astrazione che sale man
Filippo Geraci Funzione primaria del sistema informativo Supportare chi fa funzionare l azienda attraverso la propria attività Supporto necessario in aree diverse, con livello di astrazione che sale man
Computazione per l interazione naturale: classificazione probabilistica
 Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it boccignone.di.unimi.it/in_2016.html
Computazione per l interazione naturale: classificazione probabilistica Corso di Interazione Naturale Prof. Giuseppe Boccignone Dipartimento di Informatica Università di Milano boccignone@di.unimi.it boccignone.di.unimi.it/in_2016.html
Relazione progetto Fondamenti di Analisi dati e Laboratorio
 Università degli Studi di Catania Dipartimento di Matematica e Informatica Corso di Laurea in Informatica magistrale Relazione progetto Fondamenti di Analisi dati e Laboratorio Cancemi Damiano - W82000075
Università degli Studi di Catania Dipartimento di Matematica e Informatica Corso di Laurea in Informatica magistrale Relazione progetto Fondamenti di Analisi dati e Laboratorio Cancemi Damiano - W82000075
Esercizi svolti. delle matrici
 Esercizi svolti. astratti. Si dica se l insieme delle coppie reali (x, y) soddisfacenti alla relazione x + y è un sottospazio vettoriale di R La risposta è sì, perchè l unica coppia reale che soddisfa
Esercizi svolti. astratti. Si dica se l insieme delle coppie reali (x, y) soddisfacenti alla relazione x + y è un sottospazio vettoriale di R La risposta è sì, perchè l unica coppia reale che soddisfa
RICHIAMI DI CALCOLO DELLE PROBABILITÀ
 UNIVERSITA DEL SALENTO INGEGNERIA CIVILE RICHIAMI DI CALCOLO DELLE PROBABILITÀ ing. Marianovella LEONE INTRODUZIONE Per misurare la sicurezza di una struttura, ovvero la sua affidabilità, esistono due
UNIVERSITA DEL SALENTO INGEGNERIA CIVILE RICHIAMI DI CALCOLO DELLE PROBABILITÀ ing. Marianovella LEONE INTRODUZIONE Per misurare la sicurezza di una struttura, ovvero la sua affidabilità, esistono due
Operazioni puntuali. Tipi di elaborazioni Operatori puntuali Look Up Table Istogramma
 Tipi di elaborazioni Operatori puntuali Look Up Table Istogramma Analisi di Basso Livello In ingresso abbiamo le immagini provenienti dai sensori. In uscita si hanno un insieme di matrici ognuna delle
Tipi di elaborazioni Operatori puntuali Look Up Table Istogramma Analisi di Basso Livello In ingresso abbiamo le immagini provenienti dai sensori. In uscita si hanno un insieme di matrici ognuna delle
Alberi di Decisione. Corso di AA, anno 2017/18, Padova. Fabio Aiolli. 23 Ottobre Fabio Aiolli Alberi di Decisione 23 Ottobre / 16
 Alberi di Decisione Corso di AA, anno 2017/18, Padova Fabio Aiolli 23 Ottobre 2017 Fabio Aiolli Alberi di Decisione 23 Ottobre 2017 1 / 16 Alberi di decisione (Decision Trees) In molte applicazioni del
Alberi di Decisione Corso di AA, anno 2017/18, Padova Fabio Aiolli 23 Ottobre 2017 Fabio Aiolli Alberi di Decisione 23 Ottobre 2017 1 / 16 Alberi di decisione (Decision Trees) In molte applicazioni del
relazioni classe 1 a 2 a 3 a
 MATEMATICA relazioni classe 1 a 2 a 3 a TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE 5. Ricerca dati per ricavare informazioni e costruisce rappresentazioni (tabelle e grafici). Ricava informazioni anche
MATEMATICA relazioni classe 1 a 2 a 3 a TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE 5. Ricerca dati per ricavare informazioni e costruisce rappresentazioni (tabelle e grafici). Ricava informazioni anche
Clustering con Weka. L interfaccia. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna. Algoritmo utilizzato per il clustering
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi. Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna
 Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
Clustering con Weka Testo degli esercizi Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna L interfaccia Algoritmo utilizzato per il clustering E possibile escludere un sottoinsieme
COMPITO DI RICERCA OPERATIVA. (5 punti) Sia dato il seguente problema di PL: min x 1 + x 2 x 1 + x 2 3 x 1 + x 2 2 2x 1 + x 2 3.
 Sia dato il seguente problema di PL: min x 1 + x 2 x 1 + x 2 3 x 1 + x 2 2 2x 1 + x 2 3.") COMPITO DI RICERCA OPERATIVA ESERCIZIO 1. (5 punti) Sia dato il seguente problema di PL: min x 1 + x 2 x 1 + x 2 x 1 + x 2 2 2x 1 + x 2 x 1 0 x 2 0 Si trasformi questo problema in forma standard e lo si
COMPITO DI RICERCA OPERATIVA ESERCIZIO 1. (5 punti) Sia dato il seguente problema di PL: min x 1 + x 2 x 1 + x 2 x 1 + x 2 2 2x 1 + x 2 x 1 0 x 2 0 Si trasformi questo problema in forma standard e lo si
P2p la teoria dei sistemi complessi per modellare reti p2p
 P2p la teoria dei sistemi complessi per modellare reti p2p 1 Peer to Peer Per P2P si intende: un sistema decentralizzato un sistema auto-organizzato un sistema nel quale i nodi mantengono indipendenza
P2p la teoria dei sistemi complessi per modellare reti p2p 1 Peer to Peer Per P2P si intende: un sistema decentralizzato un sistema auto-organizzato un sistema nel quale i nodi mantengono indipendenza
Clustering. Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi
 Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità
Clustering Leggere il Capitolo 15 di Riguzzi et al. Sistemi Informativi Clustering Raggruppare le istanze di un dominio in gruppi tali che gli oggetti nello stesso gruppo mostrino un alto grado di similarità