Schema generale. Realizzazione della macchina hardware. Varietà di architetture HW. Gerarchie di macchine. varietà di sistemi operativi!
|
|
|
- Beniamino Martelli
- 6 anni fa
- Visualizzazioni
Transcript
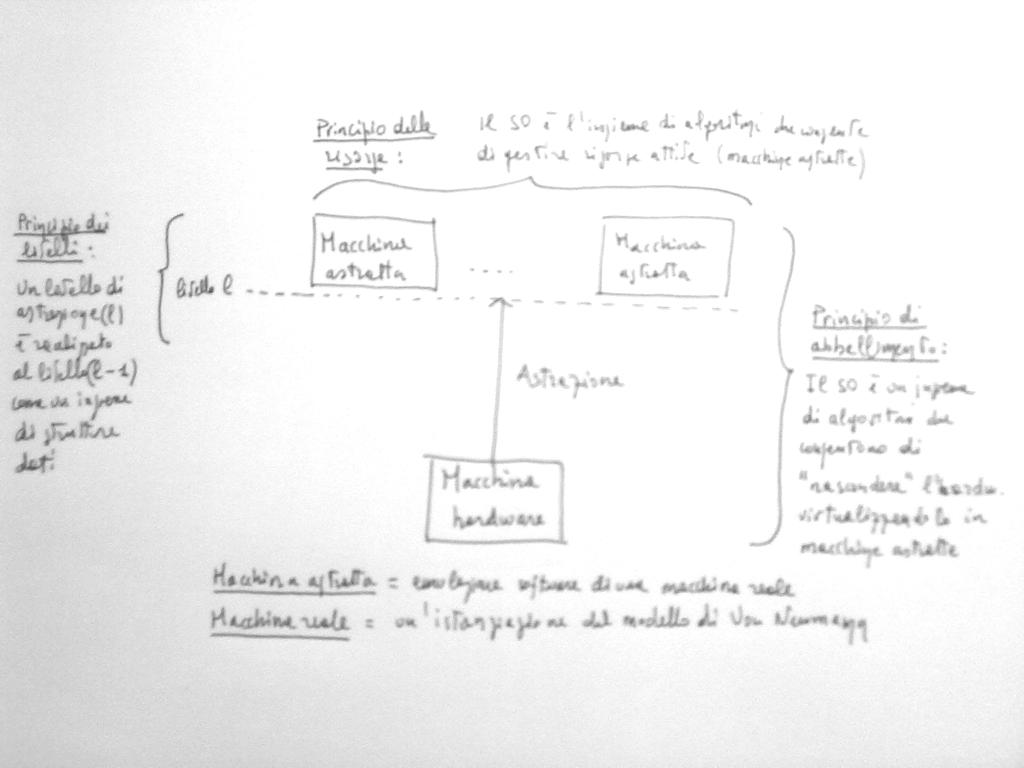






1 Schema di definizione di n Sistema Operativo Schema generale Realizzazione della macchina hardware Varietà di architettre HW Gerarchie di macchine varietà di sistemi operativi!
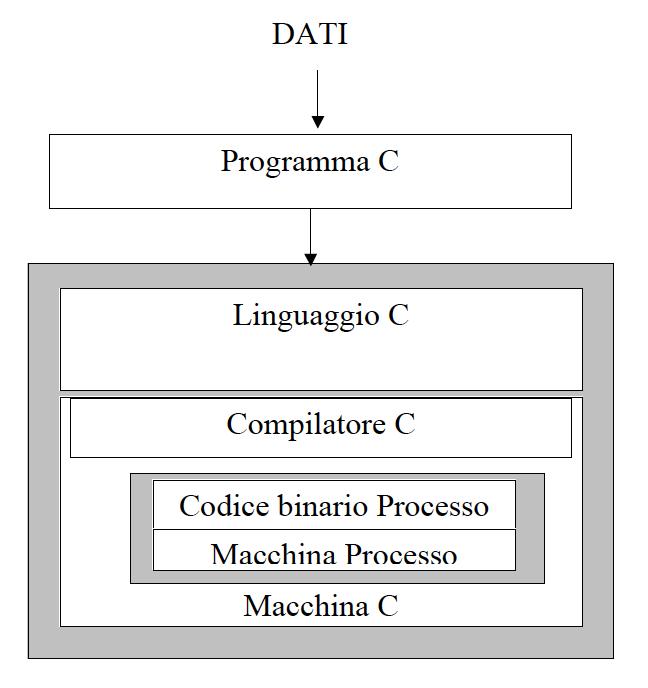
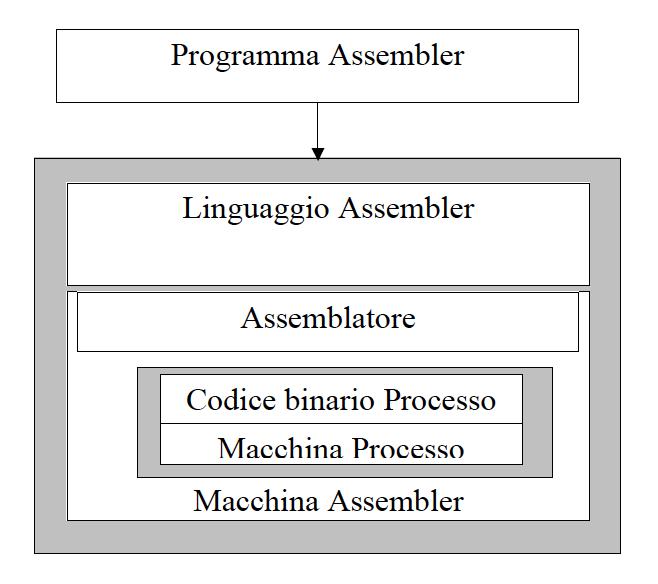
2 Tradzione Tradzione Sorce int a, b, c, d;... a = b c; d = a - 100; Assembly Langage ; Code for a = b c load R3,b load R,c add R3,R store R3,a ; Code for d = a load R,=100 sbtract R3,R store R3,d Assembly Langage ; Code for a = b c load R3,b load R,c add R3,R store R3,a ; Code for d = a load R,=100 sbtract R3,R store R3,d achine Langage Architettra di von Nemann Architettra di von Nemann: memoria Central Processing Unit (CPU) Data Path Control Unit (CU) Central Processing Unit (CPU) Data Path Control Unit (CU) Address Bs Data Bs Address Bs Data Bs Primary emory Unit (Eectable emory) Device Interface Primary emory Unit (Eectable emory) Device Interface
3 emoria centrale Architettra di von Nemann AR DR Central Processing Unit (CPU) Command read Data Path Control Unit (CU) Read Op: 1. Load AR con indirizzo 2. Load Command con read 3. Trasferisci dato in DR Contiene programmi dati n-1 Address Bs Data Bs Primary emory Unit (Eectable emory) Device Interface Progetto del Datapath Progetto del Datapath Address Bs Data Bs Central Processing Unit (CPU) Data Path Primary emory Unit (Eectable emory) Control Unit (CU) Device Interface Eqivalenza acchina <-> Lingaggio Progettazione del set di istrzioni Filosofia RISC vs CISC Scelta del formato dell istrzione: dove stanno gli operandi? (registro/memoria) qanti operandi? Determinazione del set di istrzioni Scelta delle modalità di indirizzamento
4 Progetto del Datapath Un programma esegibile dalla macchina di Von Nemann consiste in na lista di istrzioni registrate in memoria centrale Possibili formati di n istrzione C.O. Op1 Op2 Op3 C.O. Op1 Op2 C.O. C.O. Op1 13 ADD R3 LOAD 100 JUP 20 HALT Progetto del Datapath Il set di istrzioni definisce il lingaggio della macchina Istrzioni di LOAD / STORE LOAD Rd Ind!!! Rd <- em[ind] STORE Rs Ind!! Rs -> em[ind] Istrzioni aritmetico/logiche ADD Rd Rs1 Rs2!! Rd <- Rs1 Rs2 SUB Rd Rs1 Rs2!! Rd <- Rs1 - Rs2 ULT Rd Rs1 Rs2!! Rd <- Rs1 Rs2 DIV!Rd Rs1 Rs2!! Rd <- Rs1 / Rs2 OR!Rd Rs1 Rs2!! Rd <- Rs1 or Rs2 AND! Rd Rs1 Rs2!! Rd <- Rs1 and Rs2 1 Progetto del Datapath Istrzioni di confronto, confronto/salto, salto SLT Rd Rs1 Rs2!! se Rs1 < Rs2 allora Rd<-1!!!!!! altrimenti Rd <- 0 BEQ Rs1 Rs2 Ind!! se Rs1 = Rs2 va!!!!! all istrzione di indirizzo Ind BNEQ Rs1 Rs2 Ind!! se Rs1! Rs2 va!!!!! all istrzione di indirizzo Ind JUP Ind!!! va all istrzione di indirizzo!!!! Ind Altre... HALT!!! Termina l eseczione del!!!! programma Progetto del Datapath Si possono tilizzare diverse modalità di indirizzamento per specificare n operando Indirizzamento a registro: ADD R3 R3 Indirizzamento immediato: ADD R3 #50 R R R
5 Indirizzamento in memoria: Assolto: LOAD 2 R3 R em cc em cc Indirizzamento in memoria: Con spiazzamento: LOAD 1() R3 R em cc em cc cc Progetto del Datapath Le istrzioni sono esegite na alla volta secondo l'ordine specificato nel programma Qando si incontra n istrzione di controllo, si altera il flsso seqenziale stabilendo il nmero d ordine della sccessiva istrzione da esegire. ESEPIO Come esempio consideriamo n programma che esege la somma di de nmeri letti in memoria e salva il risltato in memoria. 0 LOAD LOAD 10 2 ADD R3 3 STORE R3 108 HALT 20
6 Progetto del Datapath ESEPIO: che cosa compta il segente programma? 0 LOAD R0 #100 1 LOAD 1(R0) 2 LOAD 2(R0) 3 BEQ #0 6 DIV R3 5 STORE R3 3(R0) 6 HALT R0 R em 10 0 Progetto del Datapath: registri! I registri generali:,,, Rn! il registro degli indirizzi di memoria AR emory Address Register! il registro dei dati di memoria DR emory Data Register! il contatore di programma Program Conter! il registro della istrzione corrente IR Instrction Register! il registro di stato PSR Program Stats Register 22 Progetto del Datapath: registri Progetto del Datapath: registri Registro degli indirizzi di memoria (AR emory Address Register) indica l'indirizzo della locazione di memoria che si vole selezionare; Registro dei dati di memoria (DR emory Data Register): contiene il dato proveniente dalla locazione di memoria selezionata o il dato che si vole memorizzare nella locazione di memoria selezionata;! Contatore di programma ( Program Conter) ha la fnzione di gidare il flsso della eseczione di n programma, infatti il so contento indica l'indirizzo della prossima istrzione da esegire;! Registro della istrzione corrente (IR Instrction Register) contiene l'istrzione da decodificare ed esegire.! Registro di stato (PSR Program Stats Register) contiene informazioni sllo stato di fnzionamento della macchina. 23 2
7 Data-path: la ALU Realizzazione del Datapath... Rn Right Operand Left Operand Reslt Fnctional Unit load R3,b load R,c add R3,R store R3,a Stats Registers AR PSR A.L.U. CU RG IR Data Path DR To/from Primary emory Progetto dell nità di controllo Progetto CU: macchina a stati finiti Central Processing Unit (CPU) Data Path Control Unit (CU) Fetch Address Bs Data Bs Decode Primary emory Unit (Eectable emory) Device Interface Eecte
8 Progetto CU: macchina a stati finiti <- 1 istrzione Progetto CU: macchina a stati finiti fetch decode AR <- DR <- em[ar] IR <- DR <- 1 DECODE = <indirizzo di partenza>; IR = memory[]; haltflag = FALSE; while(haltflag not SET) { eecte(ir); = sizeof(instruct); IR = memory[]; // fetch phase }; HALT? no EXEC eecte si 29 Progetto CU: macchina a stati finiti Le varie piccole operazioni che costitiscono ciascna fase del ciclo, vengono dette microoperazioni (µop) Assmiamo che ciascna µop avvenga in n ciclo di clock AR <- DR <- mem[ar] Progetto CU: macchina a stati finiti L eseczione stessa di na istrzione è decomposta in tante µop Esempio: LOAD 100 AR <- OP(100) DR <- mem[ar] <- DR Nell architettra semplificata che stiamo descrivendo, la lettra di n dato in memoria IR <- DR <
![Progetto CU: macchina a stati finiti Architettre reali: datapath Esempio: STORE 100 AR <- OP(100) DR <- mem[ar] <- DR La scrittra di n dato in memoria costa : (fetch)1(decode)3(eecte)= 8 cicli di](/docs-images/73/68749645/images/9-0.jpg "clock 33 Architettre reali (IPS) Architettre reali (IPS) PlayStation & Nintendo 6 1. Fetch instrction, from memory @. 2. Increment. 3. Decode instrction.. Fetch operands, from registers or memory. 5.")
9 Progetto CU: macchina a stati finiti Architettre reali: datapath Esempio: STORE 100 AR <- OP(100) DR <- mem[ar] <- DR La scrittra di n dato in memoria costa : (fetch)1(decode)3(eecte)= 8 cicli di clock 33 Architettre reali (IPS) Architettre reali (IPS) PlayStation & Nintendo 6 1. Fetch instrction, from 2. Increment. 3. Decode instrction.. Fetch operands, from registers or memory. 5. Eecte operation. 6. Store reslt(s), in registers or memory. Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory
10 Architettre reali (IPS) pipeline Architettre reali (IPS) pipeline 1. Fetch instrction, from and increment IF 2. Decode instrction, & fetch operands from registers ID 3. Eection operation or calclate memory address EX 1 Stage 1 Stage 2 Stage 3 Stage Stage 5. Read or write memory E 5. Store reslt(s), in registers or memory WB Assmiamo che ciascno stadio tilizzi HW non tilizzato da altri stadi: si ottiene n PARALLELISO DI ESECUZIONE del flsso di controllo Instrctions Stage 1 Stage 2 Stage 3 Stage Stage 5 Stage 1 Stage 2 Stage 3 Stage Stage 5 Stage 1 Stage 2 Stage 3 Stage Stage 5 Stage 1 Stage 2 Stage 3 Stage Stage Time Step (Clock Cycle) IF stage IF stage ID/EX EX/E ID/EX EX/E E/WB E/WB IF/ID IF/ID <<2 <<2 Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Sign Et. Sign Et. Fetch instrction, em[]. New = either or branch target of previos instrction. (Case of branch delay slot.) Separate instrction & data memories is a convenient partial lie for diagrams. Accessing memory within 1 cycle is a partial lie. ore later Reslts of each stage mst be stored in registers for net stage. 39 0
11 ID/EX ID stage EX/E ID/EX ID stage EX/E E/WB E/WB IF/ID IF/ID <<2 <<2 Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Sign Et. Sign Et. Read 2 sorce registers. (Even if instr. only ses 1.) Compte branch target = Sign-et(address)<<2. Possibly write destination register of earlier instrction. Remember, net instrction eecting IF stage. Store destination register for possible later se. Registers can be read & written in same cycle sch that read old vales. 1 2 ID/EX EX stage EX/E ID/EX E stage EX/E E/WB E/WB IF/ID IF/ID <<2 <<2 Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Instr. emory read1 read2 write data Generalprpose Registers ALU Data emory Sign Et. Sign Et. Choose which bits specify destination register. Compte arithmetic/logic, address calclation, or condition testing where 2 nd operand is from register or immediate. 3 Possibly read or write memory. Remember, accessing memory within 1 cycle is a partial lie.
12 ID/EX WB stage EX/E Il problema dell I/O IF/ID E/WB Central Processing Unit (CPU) Instr. emory read1 read2 write data <<2 Sign Et. Generalprpose Registers ALU Zero Data emory Address Bs Data Bs Data Path Control Unit (CU) Primary emory Unit (Eectable emory) Device Interface Possibly write reslt into register. Choose reslt from either memory or ALU. 5 Il problema dell I/O Il problema dell I/O CU AR PSR A.L.U. RG IR DR DATAIN SIN DATAOUT SOUT 8

13 Il problema dell I/O: modifica del set di istrzioni Il problema dell I/O: l interfaccia HW /SW Possiamo incrementare il nostro set di istrzioni per gestire l I/O Software nella CPU Application Program Abstract I/O achine Device manager programma per gestire il device controller READ Ind Disp em[ind] <- DATAIN Disp WRITE Ind Disp! em[ind] -> DATAOUT Disp Device Controller Device Device Controller Interface... bsy done Error code... Command Stats Data 0 Logic Data 1 Data n-1 bsy done 0 0 idle 0 1 finished 1 0 working Software bsy done 0 0 idle 0 1 finished 1 0 working Hardware Polling I/O // Start the device while((bsy == 1) (done == 1)) wait(); // Device I/O complete done = 0; bsy while((bsy == 0) && (done == 1)) wait(); // Do the I/O operation bsy = 1; done

14 Step1. SO single-thread Step 2: I/O con interrzioni CPU InterrptReqest flag Device Device Device CPU Interrpt Pending Spporto: macchina HW elementare Device Device Device Anatomia di n interrzione Interrpt Disk CPU controller controller 1 6 Hardware! Richiesta -> controller -> disco! Disco risponde-> controller->interrpt controller! Interrpt controller -> CPU 1: Interrpt Instrction n Instrction n1 Operating system Interrpt handler Software 3: Retrn odifica del flsso di controllo (Hardware) GESTIONE INTERRUZIONI si si <- 1 istrzione INTERRUPT? AR <- DR <- em[ar] IR <- DR <- 1 DECODE HALT? no no EXEC
![odifica del flsso di controllo (Hardware) = <indirizzo di partenza; IR = memory[]; haltflag = FALSE; while(haltflag not SET) { eecte(ir); = sizeof(instruct); IR = memory[]; if(interrptreqest)](/docs-images/73/68749645/images/15-1.jpg "{/*interrzione*/ memory[0] = ; /*salva all indirizzo 0*/ = memory[1] /*salta all indirizzo 1*/ }; memory[1] contiene l indirizzo dell interrpt handler Step 2: Protezione dello spazio di")
15 odifica del flsso di controllo (Hardware) = <indirizzo di partenza; IR = memory[]; haltflag = FALSE; while(haltflag not SET) { eecte(ir); = sizeof(instruct); IR = memory[]; if(interrptreqest) {/*interrzione*/ memory[0] = ; /*salva all indirizzo 0*/ = memory[1] /*salta all indirizzo 1*/ }; memory[1] contiene l indirizzo dell interrpt handler Step 2: Protezione dello spazio di indirizzamento Address 02ffff 02b fff dfff 0 User program and data User program and data Operating system Registri BASE e LIIT Limit Base Address 02ffff 02d000 02bfff fff dfff 0 User data User data User program Operating system Limit 2 Base 2 Limit 1 Base 1 Step 2. SO mlti-thread Step 3: Dal-ode odalità Utente/Kernel PSR ode: 1=ser, 0=kernel Enable: 1=on, 0=off ode Enable ode Enable ode Enable Old Prev Cr Total CPU time percentage acchina HW elementare Interrpt controllo elementare dello spazio di indirizzamento Kernel mode time percentage
16 PSR Step 3: Dal-ode name nmber information C S ode: 1=ser, 0=kernel Enable: 1=on, 0=off E ode Enable ode Enable Old Prev ode Enable Cr BadVaddr 8 memory address at which address eception occrred Stats 12 interrpt mask and enable bits Case 13 eception type and pending interrpts E(IAR) 1 address of instrction that cased eception B Trappole di sistema operativo (trap): interrpt software Firefo: read(int filedescriptor, void *bffer, int nmbytes) ser mode kernel mode trap a kernel mode trap handler salva registri trova sys_read( ) handler nella vector table sys_read( ) kernel rotine ripristina stato app, ritorna in ser mode 62 resme Trappole di sistema operativo (trap): interrpt software Trappole di sistema operativo (trap): parte hardware trap 1 ode S 2 Branch Table 3 eectetrap(argment) { setode(spervisor); switch(argment) { case 1: = memory[1001]; // Trap handler 1 case 2: = memory[1002]; // Trap handler 2... case n: = memory[1000n];// Trap handler n }; Trsted Code User Spervisor

 Step 3.")
17 Step 3: Protezione dello spazio di indirizzamento Step 3: Protezione dello spazio di indirizzamento CPU chip CPU Indirizzi virtali da CPU a U Indirizzi fisici s bs U emory Disk controller Uso della memoria virtale (vista Hardware) Step 3. SO lti-process Il qadro finale acchina HW elementare Interrpt odo K/U U
CALCOLATORI ELETTRONICI B 23 giugno 2008
 CALCOLATORI ELETTRONICI B 23 gigno 28 NOE: COGNOE: ATR: Scrivere chiaramente in caratteri maiscoli a stampa. Si considerino, mostrati nelle figre alla pagina segente, il datapath ed il diagramma a stati
CALCOLATORI ELETTRONICI B 23 gigno 28 NOE: COGNOE: ATR: Scrivere chiaramente in caratteri maiscoli a stampa. Si considerino, mostrati nelle figre alla pagina segente, il datapath ed il diagramma a stati
Un quadro della situazione. Cosa abbiamo fatto. Lezione 29 La Pipeline. Dove stiamo andando.. Perché: Università degli Studi di Salerno
 Un qadro della sitazione Lezione 29 La Pipeline Vittorio Scarano Architettra Corso di Larea in Informatica Università degli Stdi di Salerno Inpt/Otpt emoria Principale Sistema di Interconnessione istri
Un qadro della sitazione Lezione 29 La Pipeline Vittorio Scarano Architettra Corso di Larea in Informatica Università degli Stdi di Salerno Inpt/Otpt emoria Principale Sistema di Interconnessione istri
Organizzazione pipeline della CPU
 Organizzazione pipeline della CPU Calcolatori Elettronici-Ingegneria Telematica 1 Eseczione seqenziale Eseczione_seqenziale.ee Calcolatori Elettronici-Ingegneria Telematica 2 Eseczione pipeline Eseczione_pipeline.ee
Organizzazione pipeline della CPU Calcolatori Elettronici-Ingegneria Telematica 1 Eseczione seqenziale Eseczione_seqenziale.ee Calcolatori Elettronici-Ingegneria Telematica 2 Eseczione pipeline Eseczione_pipeline.ee
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base (ESERCIZI) assimiliano Giacomin Esercizio confronto prestazioni pipeline vs. mlticiclo Si consideri la segente combinazione di istrzioni esegite
Calcolatori Elettronici Tecniche Pipeline: Elementi di base (ESERCIZI) assimiliano Giacomin Esercizio confronto prestazioni pipeline vs. mlticiclo Si consideri la segente combinazione di istrzioni esegite
Calcolatori Elettronici
 Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo PC emoria indirizzo IR Condizioni SEGNALI DI CONTROLLO dato letto UNITA DI ELABORAZIONE
Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo PC emoria indirizzo IR Condizioni SEGNALI DI CONTROLLO dato letto UNITA DI ELABORAZIONE
Lezione 28 Il processore: unità di controllo (1)
") Lezione 8 Il processore: nità di lo () Vittorio Scarano rchitettra Corso di Larea in Informatica Università degli Stdi di Salerno Organizzazione della lezione Definizione della nità di lo rchitettra. Vi.ttorio
Lezione 8 Il processore: nità di lo () Vittorio Scarano rchitettra Corso di Larea in Informatica Università degli Stdi di Salerno Organizzazione della lezione Definizione della nità di lo rchitettra. Vi.ttorio
Problemi dell implementazione singolo ciclo
 Corso di Data path mlticiclo Anno Accademico 26/27 Francesco Tortorella Problemi dell implementazione singolo ciclo Arithmetic & Logical PC Inst emory Reg File m ALU m setp Load PC Inst emory Reg File
Corso di Data path mlticiclo Anno Accademico 26/27 Francesco Tortorella Problemi dell implementazione singolo ciclo Arithmetic & Logical PC Inst emory Reg File m ALU m setp Load PC Inst emory Reg File
Cosa abbiamo fatto. Dove stiamo andando.. Perché: per poter capire cosa deve offrire al programmatore il processore come istruzioni
 Un qadro della sitazione Lezione Il Processore: Unità di Elaborazione () Vittorio Scarano rchitettra Corso di Larea in Informatica Università degli Stdi di Salerno rchitettra (-). Vi.ttorio Scarano Inpt/Otpt
Un qadro della sitazione Lezione Il Processore: Unità di Elaborazione () Vittorio Scarano rchitettra Corso di Larea in Informatica Università degli Stdi di Salerno rchitettra (-). Vi.ttorio Scarano Inpt/Otpt
Corso di Architettura (Prof. Scarano) 09/06/2002
 09/06/2002") Lezione 3 La pipeline Vittorio Scarano rchitettra orso di Larea in Informatica Università degli Stdi di Salerno 2 Organizzazione della lezione La pipeline il concetto alcni problemi (le criticità) e le
Lezione 3 La pipeline Vittorio Scarano rchitettra orso di Larea in Informatica Università degli Stdi di Salerno 2 Organizzazione della lezione La pipeline il concetto alcni problemi (le criticità) e le
Corso di. Realizzazione del Data path Data path a ciclo singolo. Anno Accademico 2006/2007 Francesco Tortorella
 Corso di Realizzazione del path path a ciclo singolo Anno Accademico 26/27 Francesco Tortorella (si ringrazia il prof.. De Santo per il materiale presente in qeste slides) Realizzazione del data path.
Corso di Realizzazione del path path a ciclo singolo Anno Accademico 26/27 Francesco Tortorella (si ringrazia il prof.. De Santo per il materiale presente in qeste slides) Realizzazione del data path.
Gestione degli hazard
 Gestione degli hazard etodologie di progettazione Hardware/Software- LS Ing. Informatica Limiti alla eseczione pipeline: i conflitti ( Hazard ) I conflitti (Hazard) impediscono che na istrzione venga esegita
Gestione degli hazard etodologie di progettazione Hardware/Software- LS Ing. Informatica Limiti alla eseczione pipeline: i conflitti ( Hazard ) I conflitti (Hazard) impediscono che na istrzione venga esegita
Astrazione dell implementazione. Il processore: unità di elaborazione e unità di controllo (2) Il controllo della ALU.
 Il controllo della ALU.") Astrazione dell implementazione Il processore: nità di elaborazione e nità di lo (2) Architettre dei Calcolatori (lettere A-I) Ideal emory ress Net ress Rd Rs Rt 5 5 5 Rw Ra Rb -bit Registers A B als Conditions
Astrazione dell implementazione Il processore: nità di elaborazione e nità di lo (2) Architettre dei Calcolatori (lettere A-I) Ideal emory ress Net ress Rd Rs Rt 5 5 5 Rw Ra Rb -bit Registers A B als Conditions
Calcolatori Elettronici B a.a. 2008/2009
 Calcolatori Elettronici B a.a. 28/29 RICHIAI DI CALCOLATORI A assimiliano Giacomin Livello architettrale Livello logico Livello circitale Livello del layot IL LIVELLO HARDWARE istrzioni macchina ISA Reti
Calcolatori Elettronici B a.a. 28/29 RICHIAI DI CALCOLATORI A assimiliano Giacomin Livello architettrale Livello logico Livello circitale Livello del layot IL LIVELLO HARDWARE istrzioni macchina ISA Reti
Il processore: unità di elaborazione e unità di controllo (3)
") Il processore: nità di elaborazione e nità di lo () rchitettre dei Calcolatori (lettere -I) Limitazione del ciclo singolo I tempi di accesso per le diverse istrzioni variano, ad esempio ccesso in memoria:
Il processore: nità di elaborazione e nità di lo () rchitettre dei Calcolatori (lettere -I) Limitazione del ciclo singolo I tempi di accesso per le diverse istrzioni variano, ad esempio ccesso in memoria:
Calcolatori Elettronici
 Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo Condizioni SEGNALI DI CONTROLLO PC emoria indirizzo IR dato letto UNITA DI ELABORAZIONE
Calcolatori Elettronici CPU a singolo ciclo assimiliano Giacomin Schema del processore (e memoria) Unità di controllo Condizioni SEGNALI DI CONTROLLO PC emoria indirizzo IR dato letto UNITA DI ELABORAZIONE
Architettura e funzionamento del calcolatore
 FONDAMENTI DI INFORMATICA Prof PIER LUCA MONTESSORO Università degli Studi di Udine Architettura e funzionamento del calcolatore Modello di calcolatore Si farà uso di un modello semplificato di elaboratore
FONDAMENTI DI INFORMATICA Prof PIER LUCA MONTESSORO Università degli Studi di Udine Architettura e funzionamento del calcolatore Modello di calcolatore Si farà uso di un modello semplificato di elaboratore
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Parte di Controllo La Parte Controllo (Control) della CPU è un circuito sequenziale istruzioni eseguite in più cicli di clock
Calcolatori Elettronici B a.a. 2005/2006
 Calcolatori Elettronici B a.a. 25/26 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 25/26 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Controllo di un processore a singolo ciclo
 Controllo di n processore a singolo ciclo NB: schema stilizzato (in particolare, non corrisponde al IPS) Unità di controllo combinatoria controlli comandi ck write read write EORI DTI REGISTRI P C emoria
Controllo di n processore a singolo ciclo NB: schema stilizzato (in particolare, non corrisponde al IPS) Unità di controllo combinatoria controlli comandi ck write read write EORI DTI REGISTRI P C emoria
Il processore: unità di elaborazione
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Marta Simeoni, Andrea Torsello Architettura degli Elaboratori 1 1 Istruzioni
Unità di controllo della pipeline
 Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
Unità di controllo della pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 6.3 /5 Sommario La CPU
Richiami sull architettura del processore MIPS a 32 bit
 Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Caratteristiche principali dell architettura del processore MIPS Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini E un architettura RISC
Calcolatori Elettronici A a.a. 2008/2009
 Calcolatori Elettronici A a.a. 28/29 CPU mlticiclo: Esercizi assimiliano Giacomin De tipologie di esercizi standard Calcolo delle prestazioni nei sistemi a singolo ciclo e mlticiclo (e confronto) Implementazione
Calcolatori Elettronici A a.a. 28/29 CPU mlticiclo: Esercizi assimiliano Giacomin De tipologie di esercizi standard Calcolo delle prestazioni nei sistemi a singolo ciclo e mlticiclo (e confronto) Implementazione
Un quadro della situazione. Cosa abbiamo fatto. Lezione 30 Valutazione delle Prestazioni. Dove stiamo andando.. Perché:
 Un quadro della situazione Lezione 3 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
Un quadro della situazione Lezione 3 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/31 http:\\borghese.di.unimi.it\
Università degli Studi di Cassino
 Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
Corso di Realizzazione del path path a ciclo singolo Anno Accademico 24/25 Francesco Tortorella Realizzazione del data path. Analizzare l instruction set => Specifiche sul datapath il significato di ciascuna
Richiami sull architettura del processore MIPS a 32 bit
 Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Richiami sull architettura del processore MIPS a 32 bit Architetture Avanzate dei Calcolatori Valeria Cardellini Caratteristiche principali dell architettura del processore MIPS E un architettura RISC
Calcolatori Elettronici B a.a. 2007/2008
 Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Calcolatori Elettronici B a.a. 27/28 Tecniche Pipeline: Elementi di base assimiliano Giacomin Reg[IR[2-6]] = DR Dal processore multiciclo DR= em[aluout] em[aluout] =B Reg[IR[5-]] =ALUout CASO IPS lw sw
Architetture dei Calcolatori (Lettere. Organizzazione di un Calcolatore. Processore. Il Processore. Livello 1: Macchina Firmware Microarchitettura
 Architettra a Livelli: Livelli e Architettre dei Calcolatori (Lettere A-I) Il Processore Ing.. Francesco Lo Presti Livello : Livello del Lingaggio acchina (ISA) acchina nda come appare al programmatore
Architettra a Livelli: Livelli e Architettre dei Calcolatori (Lettere A-I) Il Processore Ing.. Francesco Lo Presti Livello : Livello del Lingaggio acchina (ISA) acchina nda come appare al programmatore
Università degli Studi di Cassino
 Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Corso di Realizzazione del Data path Data path a ciclo singolo Anno Accademico 27/28 Francesco Tortorella (si ringrazia il prof. M. De Santo per parte del materiale presente in queste slides) Realizzazione
Calcolatori Elettronici
 Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Calcolatori Elettronici Tecniche Pipeline: Elementi di base Massimiliano Giacomin 1 Esecuzione delle istruzioni MIPS con multiciclo: rivisitazione - esame dell istruzione lw (la più complessa) - in rosso
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Architettura degli Elaboratori
 Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Andrea Torsello, Marta Simeoni " Architettura degli Elaboratori 1 1 Istruzioni
Architettura degli Elaboratori Linguaggio macchina e assembler (caso di studio: processore MIPS) slide a cura di Salvatore Orlando, Andrea Torsello, Marta Simeoni " Architettura degli Elaboratori 1 1 Istruzioni
Architetture dei Calcolatori (Lettere. Organizzazione di un Calcolatore. Processore. Il Processore. Livello 1: Macchina Firmware Microarchitettura
 Architettra a Livelli: Livelli e Architettre dei Calcolatori (Lettere A-I) Il Processore Prof. Francesco Lo Presti Livello : Livello del Lingaggio acchina (ISA) acchina nda come appare al programmatore
Architettra a Livelli: Livelli e Architettre dei Calcolatori (Lettere A-I) Il Processore Prof. Francesco Lo Presti Livello : Livello del Lingaggio acchina (ISA) acchina nda come appare al programmatore
La pipeline. Sommario
 La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
La pipeline Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson edizione 5: 4.5 e 4.6 1/28 http:\\borghese.di.unimi.it\
Come si definisce il concetto di performance? Tempo di esecuzione di un programma. numero di task/transazioni eseguiti per unità di tempo
 Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Performance Come si definisce il concetto di performance? Tempo di esecuzione di un programma Wall-clock time CPU time tiene conto solo del tempo in cui il programma usa la CPU user time + system time
Processore. Memoria I/O. Control (Parte di controllo) Datapath (Parte operativa)
 Datapath (Parte operativa)") Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Processore Memoria Control (Parte di controllo) Datapath (Parte operativa) I/O Memoria La dimensione del Register File è piccola registri usati per memorizzare singole variabili di tipo semplice purtroppo
Hazard sul controllo. Sommario
 Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/30 Sommario Riorganizzazione
Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/30 Sommario Riorganizzazione
Progettazione dell unità di elaborazioni dati e prestazioni. Il processore: unità di elaborazione. I passi per progettare un processore
 Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Il processore: unità di elaborazione Architetture dei Calcolatori (lettere A-I) Progettazione dell unità di elaborazioni dati e prestazioni Le prestazioni di un calcolatore sono determinate da: Numero
Progetto CPU (ciclo singolo)
") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando
 Salvatore Orlando") Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Progetto CPU (ciclo singolo) Salvatore Orlando Arch. Elab. - S. Orlando 1 Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Semplificato in modo
Instruction Level Parallelism Andrea Gasparetto
 Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Tutorato di architettura degli elaboratori Instruction Level Parallelism Andrea Gasparetto andrea.gasparetto@unive.it IF: Instruction Fetch (memoria istruzioni) ID: Instruction decode e lettura registri
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS)
") Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Linguaggio assembler e linguaggio macchina (caso di studio: processore MIPS) Salvatore Orlando Arch. Elab. - S. Orlando 1 Livelli di astrazione Scendendo di livello, diventiamo più concreti e scopriamo
Un quadro della situazione. Lezione 15 Il Set di Istruzioni (2) Le operazioni e gli operandi. Dove siamo nel corso. Cosa abbiamo fatto
 Le operazioni e gli operandi. Dove siamo nel corso. Cosa abbiamo fatto") Un quadro della situazione Lezione 15 Il Set di Istruzioni (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
Un quadro della situazione Lezione 15 Il Set di Istruzioni (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
CALCOLATORI ELETTRONICI 27 giugno 2017
 CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
CALCOLATORI ELETTRONICI 27 giugno 2017 NOME: COGNOME: MATR: Scrivere nome, cognome e matricola chiaramente in caratteri maiuscoli a stampa 1 Di seguito è riportato lo schema di una ALU a 32 bit in grado
Microelettronica Corso introduttivo di progettazione di sistemi embedded
 Microelettronica Corso introduttivo di progettazione di sistemi embedded Organizzazione hardware del processore ARM prof. Stefano Salvatori A.A. 2017/2018 Eccetto dove diversamente specificato, i contenuti
Microelettronica Corso introduttivo di progettazione di sistemi embedded Organizzazione hardware del processore ARM prof. Stefano Salvatori A.A. 2017/2018 Eccetto dove diversamente specificato, i contenuti
Università degli Studi di Cassino e del Lazio Meridionale
 Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
Università degli Studi di Cassino e del Lazio Meridionale di Calcolatori Elettronici Realizzazione del Data path a ciclo singolo Anno Accademico 22/23 Alessandra Scotto di Freca Si ringrazia il prof.francesco
Stall on load e Hazard sul controllo
 Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
Stall on load e Hazard sul controllo
 Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
Stall on load e Hazard sul controllo Prof. N.Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/38 Sommario Identificazione
CALCOLATORI ELETTRONICI 14 giugno 2010
 CALCOLATORI ELETTRONICI 14 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 14 giugno 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
Processore: Datapath & Control. Progetto CPU (ciclo singolo) Rivediamo i formati delle istruzioni. ISA di un MIPS-lite
 Rivediamo i formati delle istruzioni. ISA di un MIPS-lite") Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Processore: Datapath & Control Possiamo finalmente vedere il progetto di un processore MIPS-like semplificato Progetto CPU (ciclo singolo) Semplificato in modo tale da eseguire solo: istruzioni di memory-reference:
Stall on load e Hazard sul controllo. Sommario
 Stall on load e Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/31 Sommario
Stall on load e Hazard sul controllo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento al Patterson: 4.7, 4.8 1/31 Sommario
Architettura degli Elaboratori B. Introduzione al corso. Componenti di un calcolatore convenzionale. (ciclo singolo) Progetto CPU. Contenuti del corso
 Progetto CPU. Contenuti del corso") Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Contenuti del corso Progetto della CPU CPU in grado di eseguire un sottoinsieme di istruzioni MIPS in
Un quadro della situazione. Lezione 14 Il Set di Istruzioni (2) Dove siamo nel corso. I principi di progetto visti finora. Cosa abbiamo fatto
 Dove siamo nel corso. I principi di progetto visti finora. Cosa abbiamo fatto") Un quadro della situazione Lezione 14 Il Set di Istruzioni (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
Un quadro della situazione Lezione 14 Il Set di Istruzioni (2) Vittorio Scarano Architettura Corso di Laurea in Informatica Università degli Studi di Salerno Input/Output Sistema di Interconnessione Registri
Sia per la II prova intercorso che per le prove di esame è necessaria la PRENOTAZIONE
 Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
Seconda Prova Intercorso ed Esami di Febbraio Lezione 24 Valutazione delle Prestazioni Vittorio Scarano rchitettura Corso di Laurea in Informatica Università degli Studi di Salerno Seconda prova intercorso:
CPU. ALU e Registri della CPU. Elementi della CPU. CPU e programmazione (Parte 1) Central Processing Unit, processore
 Central Processing Unit, processore") CPU CPU e programmazione (Parte 1) La CPU (Central Processing Unit) e` in grado di eseguire dei programmi, cioe` sequenze di istruzioni elementari ( istruzioni macchina ) Idea fondamentale dell'architettura
CPU CPU e programmazione (Parte 1) La CPU (Central Processing Unit) e` in grado di eseguire dei programmi, cioe` sequenze di istruzioni elementari ( istruzioni macchina ) Idea fondamentale dell'architettura
Il set istruzioni di MIPS Modalità di indirizzamento. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
Architettura degli Elaboratori e delle Reti Il set istruzioni di MIPS Modalità di indirizzamento Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano
L unità di controllo di CPU a singolo ciclo
 L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D,
L unità di controllo di CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Informatica alberto.borghese@unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 4.2, 4.4, D,
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock. Prof. Andrea Sterbini
 Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Architettura degli Elaboratori Lez. 8 CPU MIPS a 1 colpo di clock Prof. Andrea Sterbini sterbini@di.uniroma1.it Argomenti Progetto della CPU MIPS a 1 colpo di clock - Istruzioni da implementare - Unità
Fetch Decode Execute Program Counter controllare esegue prossima
 Stored Program Istruzioni sono stringhe di bit Programmi: sequenze di istruzioni Programmi (come i dati) memorizzati in memoria La CPU legge le istruzioni dalla memoria (come i dati) Ciclo macchina (ciclo
Stored Program Istruzioni sono stringhe di bit Programmi: sequenze di istruzioni Programmi (come i dati) memorizzati in memoria La CPU legge le istruzioni dalla memoria (come i dati) Ciclo macchina (ciclo
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti
 Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
Architettura degli Elaboratori e delle Reti Lezione 18 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 18 1/2 Sommario!
Calcolatori Elettronici T Ingegneria Informatica. ISA DLX: implementazione pipelined
 Calcolatori Elettronici T Ingegneria Informatica ISA DL: implementazione pipelined Principio del Pipelining Il pipelining è oggi la principale tecnica di base impiegata per rendere veloce una CP. L idea
Calcolatori Elettronici T Ingegneria Informatica ISA DL: implementazione pipelined Principio del Pipelining Il pipelining è oggi la principale tecnica di base impiegata per rendere veloce una CP. L idea
Architettura degli Elaboratori B Introduzione al corso
 Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
Architettura degli Elaboratori B Introduzione al corso Salvatore Orlando Arch. Elab. - S. Orlando 1 Componenti di un calcolatore convenzionale Studieremo il progetto e le prestazioni delle varie componenti
CALCOLATORI ELETTRONICI 30 agosto 2010
 CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 30 agosto 2010 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche di AND, OR e NOT la funzione combinatoria (a
ARCHITETTURA DI UN ELABORATORE! Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40).!
.!") ARCHITETTURA DI UN ELABORATORE! Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40).! MACCHINA DI VON NEUMANN! UNITÀ FUNZIONALI fondamentali! Processore
ARCHITETTURA DI UN ELABORATORE! Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40).! MACCHINA DI VON NEUMANN! UNITÀ FUNZIONALI fondamentali! Processore
L'architettura del processore MIPS
 L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
L'architettura del processore MIPS Piano della lezione Ripasso di formati istruzione e registri MIPS Passi di esecuzione delle istruzioni: Formato R (istruzioni aritmetico-logiche) Istruzioni di caricamento
Architettura e funzionamento del calcolatore
 FONDAMENTI DI INFORMATICA Prof PIER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Architettura e funzionamento del calcolatore 2000 Pier Luca Montessoro (si veda la nota di copyright
FONDAMENTI DI INFORMATICA Prof PIER LUCA MONTESSORO Facoltà di Ingegneria Università degli Studi di Udine Architettura e funzionamento del calcolatore 2000 Pier Luca Montessoro (si veda la nota di copyright
ARCHITETTURA DI UN ELABORATORE. Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40).
.") ARCHITETTURA DI UN ELABORATORE Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40). MACCHINA DI VON NEUMANN UNITÀ FUNZIONALI fondamentali Processore (CPU)
ARCHITETTURA DI UN ELABORATORE Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40). MACCHINA DI VON NEUMANN UNITÀ FUNZIONALI fondamentali Processore (CPU)
Calcolatori Elettronici B a.a. 2005/2006
 Calcolatori Elettronici B a.a. 25/26 Tecniche di Controllo: Esercizi assimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Calcolatori Elettronici B a.a. 25/26 Tecniche di Controllo: Esercizi assimiliano Giacomin Due tipologie di esercizi Calcolo delle prestazioni nei sistemi a singolo ciclo e multiciclo (e confronto) Implementazione
Linguaggio macchina. 3 tipi di istruzioni macchina. Istruzioni per trasferimento dati. Istruzioni logico/aritmetiche
 3 tipi di istruzioni macchina Linguaggio macchina e assembler 1) trasferimento tra RAM e registri di calcolo della CPU 2) operazioni aritmetiche: somma, differenza, moltiplicazione e divisione 3) operazioni
3 tipi di istruzioni macchina Linguaggio macchina e assembler 1) trasferimento tra RAM e registri di calcolo della CPU 2) operazioni aritmetiche: somma, differenza, moltiplicazione e divisione 3) operazioni
Macchine Astratte. Luca Abeni. February 22, 2017
 Macchine Astratte February 22, 2017 Architettura dei Calcolatori - 1 Un computer è composto almeno da: Un processore (CPU) Esegue le istruzioni macchina Per fare questo, può muovere dati da/verso la memoria
Macchine Astratte February 22, 2017 Architettura dei Calcolatori - 1 Un computer è composto almeno da: Un processore (CPU) Esegue le istruzioni macchina Per fare questo, può muovere dati da/verso la memoria
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) 1/44 Sommario
Istruzioni di trasferimento dati
 Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
Istruzioni di trasferimento dati Leggere dalla memoria su registro: lw (load word) Scrivere da registro alla memoria: sw (store word) Esempio: Codice C: A[8] += h A è un array di numeri interi Codice Assembler:
Architettura dell elaboratore
 Architettura dell elaboratore Riprendiamo il discorso lasciato in sospeso ad inizio corso Riepilogando I programmi e i dati risiedono nella memoria secondaria Per essere eseguiti (i programmi) e usati
Architettura dell elaboratore Riprendiamo il discorso lasciato in sospeso ad inizio corso Riepilogando I programmi e i dati risiedono nella memoria secondaria Per essere eseguiti (i programmi) e usati
Architettura dell elaboratore
 Architettura dell elaboratore Riprendiamo il discorso lasciato in sospeso ad inizio corso Riepilogando I programmi e i dati risiedono nella memoria secondaria Per essere eseguiti (i programmi) e usati
Architettura dell elaboratore Riprendiamo il discorso lasciato in sospeso ad inizio corso Riepilogando I programmi e i dati risiedono nella memoria secondaria Per essere eseguiti (i programmi) e usati
La CPU a singolo ciclo
 La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) /46 Sommario
La CPU a singolo ciclo Prof. Alberto Borghese Dipartimento di Scienze dell Informazione borghese@dsi.unimi.it Università degli Studi di Milano Riferimento sul Patterson: capitolo 5 (fino a 5.4) /46 Sommario
Istruzioni e linguaggio macchina
 Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
Istruzioni e linguaggio macchina I linguaggi macchina sono composti da istruzioni macchina, codificate in binario, con formato ben definito processori diversi hanno linguaggi macchina simili scopo: massimizzare
FONDAMENTI DI INFORMATICA Lezione n. 10
 FONDAMENTI DI INFORMATICA Lezione n. 10 CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO In questa lezione viene analizzata l'architettura di base di un sistema
FONDAMENTI DI INFORMATICA Lezione n. 10 CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO In questa lezione viene analizzata l'architettura di base di un sistema
Le etichette nei programmi. Istruzioni di branch: beq. Istruzioni di branch: bne. Istruzioni di jump: j
 L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
L insieme delle istruzioni (2) Architetture dei Calcolatori (lettere A-I) Istruzioni per operazioni logiche: shift Shift (traslazione) dei bit di una parola a destra o sinistra sll (shift left logical):
ARCHITETTURA DI UN ELABORATORE
 ARCHITETTURA DI UN ELABORATORE memoria centrale Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40). John von Neumann (Neumann János) (December 28, 1903
ARCHITETTURA DI UN ELABORATORE memoria centrale Ispirata al modello della Macchina di Von Neumann (Princeton, Institute for Advanced Study, anni 40). John von Neumann (Neumann János) (December 28, 1903
Il calcolatore. È un sistema complesso costituito da un numero elevato di componenti. è strutturato in forma gerarchica
 Il calcolatore È un sistema complesso costituito da un numero elevato di componenti. è strutturato in forma gerarchica ogni livello di descrizione è caratterizzato da una struttura rappresentante l organizzazione
Il calcolatore È un sistema complesso costituito da un numero elevato di componenti. è strutturato in forma gerarchica ogni livello di descrizione è caratterizzato da una struttura rappresentante l organizzazione
Riassunto. Riassunto. Ciclo fetch&execute. Concetto di programma memorizzato. Istruzioni aritmetiche add, sub, mult, div
 MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
MIPS load/store word, con indirizzamento al byte aritmetica solo su registri Istruzioni Significato add $t1, $t2, $t3 $t1 = $t2 + $t3 sub $t1, $t2, $t3 $t1 = $t2 - $t3 mult $t1, $t2 Hi,Lo = $t1*$t2 div
FONDAMENTI DI INFORMATICA Lezione n. 10
 FONDAMENTI DI INFORMATICA Lezione n. 10 CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO In questa lezione viene analizzata l'architettura di base di un sistema
FONDAMENTI DI INFORMATICA Lezione n. 10 CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO In questa lezione viene analizzata l'architettura di base di un sistema
Architettura del processore MIPS
 Architettura del processore IPS Prof. Cristina Silvano Dipartimento di Elettronica e Informazione Politecnico di ilano email: : silvano@elet elet.polimi.itit Sommario Instruction Set semplificato Esecuzione
Architettura del processore IPS Prof. Cristina Silvano Dipartimento di Elettronica e Informazione Politecnico di ilano email: : silvano@elet elet.polimi.itit Sommario Instruction Set semplificato Esecuzione
CALCOLATORI ELETTRONICI 9 settembre 2011
 CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
CALCOLATORI ELETTRONICI 9 settembre 2011 NOME: COGNOME: MATR: Scrivere chiaramente in caratteri maiuscoli a stampa 1. Si implementi per mezzo di porte logiche AND, OR e NOT la funzione combinatoria (a
Calcolatori Elettronici T Ingegneria Informatica. DLX: implementazione sequenziale
 Calcolatori Elettronici T Ingegneria Informatica DLX: implementazione sequenziale Datapath e Unità di Controllo La struttura di una CPU, come tutte le reti logiche sincrone che elaborano dati, può essere
Calcolatori Elettronici T Ingegneria Informatica DLX: implementazione sequenziale Datapath e Unità di Controllo La struttura di una CPU, come tutte le reti logiche sincrone che elaborano dati, può essere
Calcolatore: sottosistemi
 Calcolatore: sottosistemi Processore o CPU (Central Processing Unit) Memoria centrale Sottosistema di input/output (I/O) CPU I/O Memoria Calcolatore: organizzazione a bus Il processore o CPU Unità di controllo
Calcolatore: sottosistemi Processore o CPU (Central Processing Unit) Memoria centrale Sottosistema di input/output (I/O) CPU I/O Memoria Calcolatore: organizzazione a bus Il processore o CPU Unità di controllo
Implementazione semplificata
 Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
Il processore 168 Implementazione semplificata Copre un sottoinsieme limitato di istruzioni rappresentative dell'isa MIPS aritmetiche/logiche: add, sub, and, or, slt accesso alla memoria: lw, sw trasferimento
La CPU e la Memoria. Sistemi e Tecnologie Informatiche 1. Struttura del computer. Sistemi e Tecnologie Informatiche 2
 La CPU e la Memoria Sistemi e Tecnologie Informatiche 1 Struttura del computer Sistemi e Tecnologie Informatiche 2 1 I registri La memoria contiene sia i dati che le istruzioni Il contenuto dei registri
La CPU e la Memoria Sistemi e Tecnologie Informatiche 1 Struttura del computer Sistemi e Tecnologie Informatiche 2 1 I registri La memoria contiene sia i dati che le istruzioni Il contenuto dei registri
Fondamenti di Informatica B
 Fondamenti di Informatica B Lezione n. 10 Alberto Broggi Gianni Conte A.A. 2005-2006 Fondamenti di Informatica B CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO
Fondamenti di Informatica B Lezione n. 10 Alberto Broggi Gianni Conte A.A. 2005-2006 Fondamenti di Informatica B CPU-MEMORIA CICLO PRINCIPALE CPU ARCHITETTURA BASE UNITÀ DI ESECUZIONE E UNITÀ DI CONTROLLO
Esercitazione del 30/04/ Soluzioni
 Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
Esercitazione del 30/04/2010 - Soluzioni Una CPU a ciclo singolo come pure una CPU multi ciclo eseguono una sola istruzione alla volta. Durante l esecuzione parte dell hardware della CPU rimane inutilizzato
CPU a singolo ciclo. Lezione 18. Sommario. Architettura degli Elaboratori e delle Reti. Proff. A. Borghese, F. Pedersini
 Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Architettura degli Elaboratori e delle Reti Lezione 8 CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Scienze dell Informazione Università degli Studi di Milano L 8 /33 Sommario! La
Architettura degli Elaboratori e Laboratorio. Matteo Manzali Università degli Studi di Ferrara Anno Accademico
 Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Componenti visti Nelle scorse lezioni abbiamo visto come sono realizzati i seguenti
Architettura degli Elaboratori e Laboratorio Matteo Manzali Università degli Studi di Ferrara Anno Accademico 2016-2017 Componenti visti Nelle scorse lezioni abbiamo visto come sono realizzati i seguenti
Progetto CPU a singolo ciclo
 Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Architettura degli Elaboratori e delle Reti Progetto CPU a singolo ciclo Proff. A. Borghese, F. Pedersini Dipartimento di Informatica Università degli Studi di Milano 1/50 Sommario! La CPU! Sintesi di
Lezione 20. della CPU MIPS. Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano
 Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio
Architettura degli Elaboratori Lezione 20 ISA (Instruction Set Architecture) della CPU MIPS Prof. Federico Pedersini Dipartimento di Informatica Università degli Studi di Milano L16-20 1/29 Linguaggio