Schema della lezione. 1. Non correttezza ( bias ) dovuta a variabili omesse
|
|
|
- Valentina Eleonora Pisani
- 6 anni fa
- Visualizzazioni
Transcript
1 Schema della lezione 1. Non correttezza ( bias ) dovuta a variabili omesse 2. Causalità e analsi di regressione 3. Regressione multipla e OLS 4. Misure di bontà della regressione 5. Distribuzione campionaria di OLS 1
2 Non correttezza Bias dovuta a variabili omesse L errore u nasce a causa di fattori che influezano Y e che non sono inclusi nella regressione; per questo motivo ci aspettiamo che esistano sempre delle variabili omesse. A volte, l omissione di queste variabili porta a stimatori OLS bias o non corretti 2
3 Nel caso di non correttezza dovuta a variabili omesse, il fattore omesso Z deve essere: 1. Un fattore determinante di Y (i.e. Z è parte di u); 2. Correlato con i regressori X (i.e. corr(z,x) 0) Entrambe queste condizioni devono essere verificate affinchè l omissione di Z dia origine a un bias 3
4 Nell esempio dei voti: 1. La bravura in inglese (se l inglese non è lingua madre) plausibilmente influenza i voti: Z (=lingua madre non è inglese) determina Y. 2. Le comunità di immigrati sono di solito meno benestanti e godono di un minore budget di spesa scolastica e di conseguenza un alto STR: Z (= inglese non è lingua madre: appartenenza a comunità di immigrati) è correlato con X. Di conseguenza, ˆ β 1 è non corretto, ma è più grande o più piccolo del suo valore corretto? Cosa suggerisce il senso comune? Se non ci sono indizi, si ricorre alla formula 4
5 Consideriamo nuovamente la formula ˆ 1 n i= 1 β β 1 = n i= 1 ( X X ) u i ( X X ) i 2 dove v i = (X i X )u i (X i µ X )u i. Per le Assunzioni già fatte Assunzione 1, i = E[(X i µ X )u i ] = cov(x i,u i ) = 0. Ma cov(x i,u i ) = σ Xu => E[(X i µ X )u i ] 0? 5
6 Formula della non correttezza dovuta a variabili omesse In generale (cioè, anche se l Assunzione #1 non è vera), ˆ β p 1 β 1 + Se un fattore omesso Z è sia: σ u ρ σ X (1) un determinante di Y (cioè, è contenuto in u); sia (2) correlato con X, Allora ρ Xu 0 e lo stimatore OLS ˆ β 1 non è corretto (e non è consistente) e ρ Xu determina il segno dell errore Se ignoriamo il fatto che i bambini possono avere una lingua madre diversa dall inglese allora il senso comune ci suggerisce che la stima dell effetto classe è maggiore di quanto dovrebbe essere È effettivamente questo quello che succede con i nostri dati? Xu 6

7 I distretti con meno bimbi di lingua madre diversa dall inglese hanno voti più alti I distretti con meno bimbi di lingua madre diversa dall inglese hanno classi più piccole Fra i distretti con una percentuale comparabile di bambini con lingua madre diversa dall inglese, l effetto della grandezza della classe è minore (la differenza totale fra i test = 7.4) 7
8 Digressione su causalità e analisi di regressione Cosa vogliamo stimare? Cos è con precisione un effetto causale? In questo corso, definiamo un effetto causale quello misurabile da un esperimento casuale ideale e controllato. 8
9 Esperimento ideale casuale controllato Ideale: tutti i soggetti seguono lo stesso protocollo tutti lo eseguono perfettamente, non ci sono errori nel riportare i dati, etc. Casuale: le entità della popolazione di interesse sono casualmente assegnate a un trattamento o a un gruppo di controllo (non ci sono fattori che confondono l assegnazione) Controllato: avere un gruppo di controllo permette di misurare gli effetti differenziali del trattamento Esperimento: il trattamento è assegnato come se fosse un esperimento. Le entità non sono scelte in base ad un qualsiasi criterio, non c è causalità inversa. 9
10 Nel nostro esempio Il trattamento non è assegnato casualmente Considerando la percentuale di bimbi per cui l inglese non è lingua madre. È possibile che Z = PctEL è: 1. un determinante di Y; e 2. correlato con X. Il gruppo di controllo e di trattamento sono sistematicamente (non casualmente) diversi corr(str,pctel) 0 10
11 Esperimenti casuali controllati: Casuali + controllati significa che ogni differenza fra il gruppo di controllo e quello di trattamento è casuale i gruppi non sono sistematicamente correlati Possiamo eliminare la differenza sistematica in PctEL fra i distretti esaminando l effetto della grandezza della classe fra i distretti con lo stesso PctEL. Se l unica differenza sistematica fra i gruppi è la PctEL, allora possiamo riconoscere le caratteristiche di un esperimento casuale controllato all interno di ogni gruppo PctEL. Questo è un modo di controllare per l effetto di PctEL quando stimiamo STR. 11
12 2 modi per rimediare al problema delle variabili omesse 1. Condurre un esperimento controllato e casuale in cui STR è assegnato casualmente: PctEL è ancora una determinante dei Voti ma PctEL è non correlato con STR. (difficile da realizzare in pratica. 2. Aggiungere PctEL come regressore 12
13 Il modello di regressione multipla della popolazione Consideriamo il caso di 2 regressori: Y i = β 0 + β 1 X 1i + β 2 X 2i + u i, i = 1,,n Y variabile dependente X 1, X 2 2 variabili independenti (regressori) (Y i, X 1i, X 2i ) denotano l i ma osservazione di Y, X 1, e X 2. β 0 = intercetta della popolazione sconosciuta β 1 = effetto di una variazione di X 1 su Y, tenendo X 2 constante β 2 = effetto di una variazione di X 2 su Y, tenendo X 1 constante u i = errore di regressione (fattori omessi) 13
14 Interpretazione dei coefficienti nella regressione multipla Y i = β 0 + β 1 X 1i + β 2 X 2i + u i, i = 1,,n Consideriamo di far variare X 1 di X 1 tenendo X 2 costante: Retta di regressione della popolazione prima della variazione: Y = β 0 + β 1 X 1 + β 2 X 2 E dopo: Y + Y = β 0 + β 1 (X 1 + X 1 ) + β 2 X 2 14
15 Prima: Y = β 0 + β 1 (X 1 ) + β 2 X 2 Dopo: Y + Y = β 0 + β 1 (X 1 + X 1 ) + β 2 X 2 Differenza: Y = β 1 X 1 Perciò: β 1 = Y X 1, tenendo X 2 constante β 2 = Y X 2, tenendo X 1 constante β 0 = valore previsto di Y quando X 1 = X 2 = 0. 15
16 Con 2 regressori, lo stimatore OLS risolve il seguente problema: n min [ Y ( b + b X + b X )] b0, b1, b2 i 0 1 1i 2 2i i= 1 2 Lo stimatore OLS minimizza la differenza fra i valori attuali e quelli previsti dalla regressione Il problema di minimizzazione si risolve utilizzando il calcolo Otteniamo così β 0 e β 1. 16
17 Es: Vˆ oti= STR Includiamo la nuova variabile (PctEL): Vˆ oti = STR 0.65PctEL Che succede al coefficiente di STR? Perchè? (Nota: corr(str, PctEL) = 0.19) 17
18 Multiple regression in STATA reg testscr str pctel, robust; Regression with robust standard errors Number of obs = 420 F( 2, 417) = Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str pctel _cons oti Vˆ = STR 0.65PctEL 18
19 Misure di bontà della regressione Attuale = predetto + residuo: Y i = Y ˆi + u ˆi SER = deviation standard di u ˆi (con correzione per g.l.) RMSE = deviation standard di u ˆi (senza correzione per g.l.) R 2 = frazione della varianza di Y spiegata da X 2 R = aggiustato R 2 = R 2 con correzione per g.l; 2 R < R 2 19
20 R 2 e 2 R L R 2 ha la stessa definizione vista per il caso di un singolo regressore R 2 = ESS TSS = 1 SSR, TSS dove ESS = n n n ˆ ˆ 2 ( Yi Y ), SSR = 2 uˆ i, TSS = 2 ( Yi Y ). i= 1 i= 1 i= 1 Ma cresce sempre quando aggiungiamo un regressore 20
21 R 2 L 2 R corregge questo problema Aggiustato R 2 : 2 R = 1 n 1 SSR n k 1 TSS Nota che 2 R < R 2, se n è grande diventano molto simili 21
22 (1) Vˆ oti = STR, R 2 =.05, SER = 18.6 (2) Vˆ oti = STR 0.65PctEL, R 2 =.426, 2 R =.424, SER =
23 Assunzioni per la Regressione Multipla Y i = β 0 + β 1 X 1i + β 2 X 2i + + β k X ki + u i, i = 1,,n 1. E(u X 1 = x 1,, X k = x k ) = (X 1i,,X ki,y i ), i =1,,n, are i.i.d. 3. grandi outliers sono rari: X 1,, X k ; E(, E( Y ) <. 4 i 4. non c è perfetta multicollinearità. 4 4 X 1i) <,, E( X ki) < 23
24 Assunzione #1 E(u X 1 = x 1,, X k = x k ) = 0 Stessa interpretazione del caso di un singolo regressore. Se c è una variabile omessa in (1) allora questa condizione non è più valida Il fallimento di questa condizione conduce al problema della bias dovuta a variabili omesse La soluzione se è possibile è di includerre le variabili omesse nella regressione. 24
25 Assunzione #2: (X 1i,,X ki,y i ), i =1,,n, sono i.i.d. Soddisfatta se i dati sono raccolti in campionamento casuale semplice. Assunzione #3: grandi outliers sono rari Stessa assunzione vista per il caso di un singolo regressore 25
26 Assunzione #4: Non c è multicollinearità perfetta Multicollinearità perfetta si ha quando un regressore è il risultato di una funzione lineare esatta di altri regressori Es: se includiamo STR due volte: regress testscr str str, robust Regression with robust standard errors Number of obs = 420 F( 1, 418) = Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str str (dropped) _cons
27 Multicollinearità Perfetta e Imperfetta Ulteriori esempi di multicollinearità perfetta: Regressione dei Voti su: una costante = 1 per tutti i valori, D, D i = 1 se STR 20, e = 0 altrimenti, B, B i = 1 se STR >20, e = 0 altrimenti, di conseguenza B i = 1 D i, multicollinearità perfetta Dovremmo eliminare l intercetta o una delle due dummy 27
28 La trappola dummy Supponiamo di avere un insieme di molte variabili binarie che sono mutualmente esclusive ed esaustive ( ci sono categorie multiple e ogni osservazione ricade in una e una sola categoria (tipicamente quando si inserisce la categoria altri ). Se includiamo tutte queste dummy e una costante avremmo un caso di multicollinearità perfetta. Soluzione : 1. Omettere uno dei gruppi, oppure 2. Omettere l intercetta Attenzione: cambia l interpretazione dei coefficienti!!! 28
29 multicollinearità perfetta di solito è dovuta a errori nelle definizioni dei regressori o da stranezze nei dati se c è multicollinearità perfetta, il software automaticamente elimina uno dei regressori a caso. La soluzione è di eliminare uno dei regressori 29
30 multicollinearità imperfetta: due o più regressori sono altamente correlati. Il diagramma a nuvola fra due variabili altamente correlate si approssima a una linea retta. 30
31 multicollinearità imperfetta implica che la stima di uno o più coefficienti di regressione non sarà precisa Intuitivamente: il coefficiente di X 1 misura l effetto di X 1 tenendo costante X 2 ; ma se X 1 e X 2 sono correlate, c è poca variazione di X 1 una volta che teniamo costante X 2 i dati sono poco informativi su quello che succede quando X 1 varia e X 2 è costante, la varianza dello stimatore OLS del coefficiente di X 1 sarà grande. multicollinearità imperfetta implica grandi standard error per uno o più coefficienti OLS 31
32 Distribuzione Campionaria dello stimatore OLS Sotto le 4 Assunzioni OLS, La distribuzione esatta di ˆ β 1 in campioni finiti ha media β 1, la var( ˆ β 1) è inversamente proporzionale a n; così come per ˆ β 2. Oltre alla media e varianza l esatta distribuzione di ˆ β1è complicata a parte che per n grande ˆ β 1 è consistente: ˆ p β 1 β 1 (Legge dei grandi numeri) ˆ β1 E( ˆ β1) si distribuisce approssimativamente come N(0,1) var( ˆ ) β 1 (CLT) Ciò vale per tutti ˆ β 2,, ˆk β Niente di nuovo! 32
33 Test d Ipotesi nelle regressioni multiple ˆ β E( ˆ β ) var( ˆ β ) ~N(0,1) (CLT). Le ipotesi su β 1 possono essere testate usando la usuale t- statistica, e gli intervalli di confidenza { ˆ β 1 ± 1.96 SE( ˆ β 1 )}. Così come per β 2,, β k. ˆ β 1 e ˆ β 2 sono generalmente non independentemente e identicamente distribuite così come le statistiche-t. 33
34 Es: (1) Vˆ oti = STR (10.4) (0.52) (2) Vˆ oti= STR 0.650PctEL (8.7) (0.43) (0.031) Il coefficiente di STR nella (2) è l effetto che una variazione di una unità di STR ha su Voti, tenendo costante PctEL nei distretti. Il coefficiente di STR diminuisce L intervallo di confidenza diventa { 1.10 ± } = ( 1.95, 0.26) la statistica t di β STR = 0 è t = 1.10/0.43 =
35 Standard errors in multiple regression in STATA reg testscr str pctel, robust; Regression with robust standard errors Number of obs = 420 F( 2, 417) = Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str pctel _cons Vˆ oti = STR 0.650PctEL (8.7) (0.43) (0.031) Nota che gli standard error sono robusti!!! 35
36 Test d Ipotesi Congiunta Definiamo Expn = la spesa per alunno: TestScore i = β 0 + β 1 STR i + β 2 Expn i + β 3 PctEL i + u i L ipotesi che le risorse scolastiche non contano corrisponde a testare che sia STR che Expn non sono significative: H 0 : β 1 = 0 e β 2 = 0 vs. H 1 : sia β 1 0 che β 2 0 o entrambi Voti i = β 0 + β 1 STR i + β 2 Expn i + β 3 PctEL i + u i 36
37 H 0 : β 1 = 0 e β 2 = 0 vs. H 1 : sia β 1 0 che β 2 0 o entrambi Un ipotesi congiunta specifica un valore per più di un coefficiente, impone un vincolo. In generale, una ipotesi congiunta dà origine a q restrizioni. Nell esempio, q = 2, e le 2 restrizioni sono β 1 = 0 e β 2 = 0. Utilizziamo la statistica F per accettare o rifiutare l ipotesi nulla 37
38 In grandi campioni, F si distribuisce come una 2 χ q /q. Valori critici di 2 χ q /q nelle apposite tavole statistiche q valori critici al 5% (il caso di prima) p-valore = probabilità nella coda della distribuzione della oltre la statistica-f attualmente calcolata. 2 χ q /q 38
39 reg testscr str expn_stu pctel, r; Regression with robust standard errors Number of obs = 420 F( 3, 416) = Prob > F = R-squared = Root MSE = Robust testscr Coef. Std. Err. t P> t [95% Conf. Interval] str expn_stu pctel _cons NOTE test str expn_stu; The test command follows the regression ( 1) str = 0.0 There are q=2 restrictions being tested ( 2) expn_stu = 0.0 F( 2, 416) = 5.43 The 5% critical value for q=2 is 3.00 Prob > F = Stata computes the p-value for you 39
40 Le regressioni Vincolate (V) e Non Vincolate (NV) Test nel caso di errori omoschedastici: Es: I coefficienti di STR e Expn sono uguali a zero? Modello non vincolato (sotto H 1 ): Voti i = β 0 + β 1 STR i + β 2 Expn i + β 3 PctEL i + u i Modello vincolato (sotto H 0 ): Voti i = β 0 + β 3 PctEL i + u i Il numero di vincoli sotto H 0 è q = 2 R 2 sarà alto nel caso non vincolato 40
41 statistica-f nel caso di errori omoschedastici: dove: F q,n-k 1 = ( 2 2 R ) NV RV / q ( 2 1 R )/( n k 1) NV 2 R V = R 2 del modello vincolato 2 R NV = R 2 del modello non vincolato q = numero di vincoli sotto ipotesi nulla k NV = numero di regressori nel modello non ristretto NV 41
42 Modello ristretto: Vˆ oti = PctEL, (1.0) (0.032) Modello non ristretto: 2 R V = Vˆ oti= STR Expn 0.656PctEL (15.5) (0.48) (1.59) (0.032) 2 R NV= , k NV= 3, q = 2 dunque F = = ( 2 2 R ) NV RV / q ( 2 1 R )/( n k 1) NV NV ( ) / 2 (1.4366) /( ) Note: F robusta alla eteroschedast = 5.43 =
43 2 La distribuzione F sta ad una /q come la distribuzione t n 1 sta alla distribuzione N(0,1) χ q 2 La F q, e la /q sono approssimativamente uguali χ q Di regola si deve sempre utilizzare la F-statistica 2 robusta (F q, ) ed i valori critici riferiti a χ q /q 43
44 Test di più di un coefficiente con una singola restrizione Y i = β 0 + β 1 X 1i + β 2 X 2i + u i, i = 1,,n Consideriamo il seguente test di ipotesi, H 0 : β 1 = β 2 vs. H 1 : β 1 β 2 La ipotesi nulla impone una singola restrizione (q = 1) su più di un coefficiente non è un ipotesi congiunta con restrizioni multiple (come nel caso di β 1 = 0 e β 2 = 0). 44
45 Ci sono due metodi per testare restizioni single su coefficienti multipli: 1. Trasformare la regressione in modo che la restrizione diventa una restrizione su un singolo coefficiente in una restrizione equivalente, opp, 2. Fare direttamente il test 45
46 Metodo #1: Trasformiamo la regressione Y i = β 0 + β 1 X 1i + β 2 X 2i + u i H 0 : β 1 = β 2 vs. H 1 : β 1 β 2 Aggiungendo e sottraendo β 2 X 1i : Y i = β 0 + β 1 X 1i ( β 2 X 1i ) (+ β 2 X 1i ) +β 2 X 2i + u i Y i = β 0 + (β 1 β 2 ) X 1i + β 2 (X 1i + X 2i ) + u i opp Y i = β 0 + γ 1 X 1i + β 2 W i + u i dove γ 1 = β 1 β 2 W i = X 1i + X 2i 46
47 (a) Sistema originale: Y i = β 0 + β 1 X 1i + β 2 X 2i + u i H 0 : β 1 = β 2 vs. H 1 : β 1 β 2 (b)transformato sistema: Y i = β 0 + γ 1 X 1i + β 2 W i + u i dove γ 1 = β 1 β 2 e W i = X 1i + X 2i H 0 : γ 1 = 0 vs. H 1 : γ 1 0 Il nostro test diventa γ 1 = 0 nella specificatione (b). 47
48 Metodo #2: Fare il test direttamente Y i = β 0 + β 1 X 1i + β 2 X 2i + u i Es: H 0 : β 1 = β 2 vs. H 1 : β 1 β 2 Voti i = β 0 + β 1 STR i + β 2 Expn i + β 3 PctEL i + u i Test β 1 = β 2 vs. β 1 β 2 (2-code): Per i dettagli sono utili le esercitazioni: quasi ogni software ha il suo modo di scrivere queste restrizioni 48
49 Un approccio generale per selezionare le variabili e specificare un modello Specificare un modello di riferimento o benchmark Specificare a insieme di possibili variabili candidate come alternative plausibili la scelta di una candidata rispetto ad un altra cambia il valore di (β 1 )? la variabile candidata è statisticamente significativa? possiamo semplicemente mirare a massimizzare R 2? 49
50 Digressione sulle misure di bontà cercando solo il massimo di R 2 2 and R potremmo ottenere uno stimatore non corretto e perdere contatto con il nostro reale obiettivo. Un R 2 2 (o R ) alto significa che i regressori scelti spiegano bene le variazioni di Y. Un R 2 2 (o R ) non significa che abbiamo eliminato il problema delle variabili omesse. Un R 2 2 (o R ) non significa che abbiamo ottenuto uno stimatore corretto dell effetto causale (β 1 ). Un R 2 2 (o R ) non significa che le variabili incluse sono statisticamente significative. 50
51 Es: Variabili a disposizione nel data set: student-teacher ratio (STR) percentuale di bimbi che non hanno inglese come lingua madre (PctEL) spesa scolastica per alunno (Expen) nome del distretto percentuale di bambini che potrebbero ricevere sussidi o il pranzo gratis reddito medio per distretto Quali di queste variabili includere? 51
52 Torniamo a guardare i dati 52
53 Digressione: presentazione dei risultati di una regressione Una tabella di risultati di una regressione dovrebbe includere: I coefficienti stimati standard errors misure di bontà numero di osservazioni statistica-f ogni altra informazione che riteniamo opportuna. Per esempio: 53
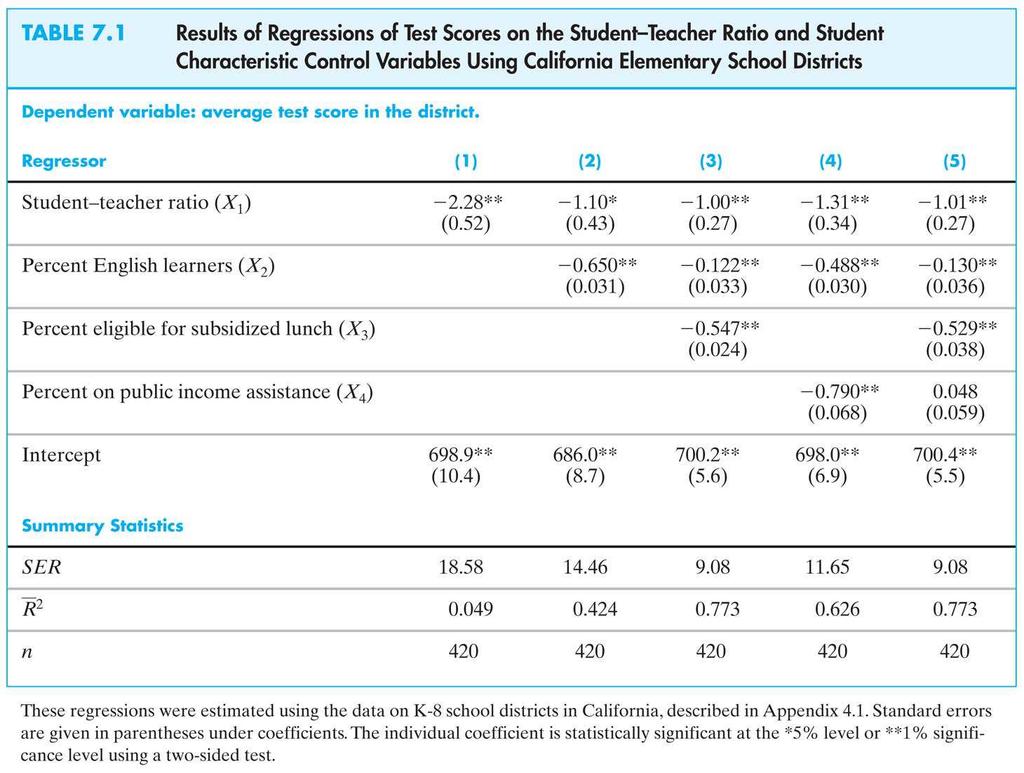
54 54
55 la regressione multipla ci permette di stimare l effetto di una variazione di X 1 su Y, tenendo constante X 2. Se possiamo misurare una variabile, possiamo evitare di fornire stime non corrette semplicemente includendola. Non c è una regola unica. L approccio più comune è quello di specificare un modello di base, basato su un ragionamento a-priori e poi esplorare altre ragionevoli alternative 55
Regressione lineare multipla
 Regressione lineare multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Aprile 2014 Rossi Regressione lineare Econometria - 2014 1 / 31 Outline 1 La distorsione da variabili omesse 2 Causalità 3 Misure
Regressione lineare multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Aprile 2014 Rossi Regressione lineare Econometria - 2014 1 / 31 Outline 1 La distorsione da variabili omesse 2 Causalità 3 Misure
Regressione lineare con un solo regressore
 Regressione lineare con un solo regressore La regressione lineare è uno strumento che ci permette di stimare e di fare inferenza sui coefficienti incogniti di una retta. Lo scopo principale è di stimare
Regressione lineare con un solo regressore La regressione lineare è uno strumento che ci permette di stimare e di fare inferenza sui coefficienti incogniti di una retta. Lo scopo principale è di stimare
Regressioni Non Lineari
 Regressioni Non Lineari Fino ad ora abbiamo solo considerato realazioni lineari Ma le relazioni lineari non costituiscono sempre le migliori approssimazioni La regressione multipla può anche essere formulata
Regressioni Non Lineari Fino ad ora abbiamo solo considerato realazioni lineari Ma le relazioni lineari non costituiscono sempre le migliori approssimazioni La regressione multipla può anche essere formulata
lezione 7 AA Paolo Brunori
 AA 2016-2017 Paolo Brunori dove siamo arrivati? - se siamo interessati a studiare l andamento congiunto di due fenomeni economici - possiamo provare a misurare i due fenomeni e poi usare la lineare semplice
AA 2016-2017 Paolo Brunori dove siamo arrivati? - se siamo interessati a studiare l andamento congiunto di due fenomeni economici - possiamo provare a misurare i due fenomeni e poi usare la lineare semplice
Analisi della regressione multipla
 Analisi della regressione multipla y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inferenza Assunzione del Modello Classico di Regressione Lineare (CLM) Sappiamo che, date le assunzioni Gauss- Markov,
Analisi della regressione multipla y = β 0 + β 1 x 1 + β 2 x 2 +... β k x k + u 2. Inferenza Assunzione del Modello Classico di Regressione Lineare (CLM) Sappiamo che, date le assunzioni Gauss- Markov,
Regressione Lineare con un Singolo Regressore
 Regressione Lineare con un Singolo Regressore Quali sono gli effetti dell introduzione di pene severe per gli automobilisti ubriachi? Quali sono gli effetti della riduzione della dimensione delle classi
Regressione Lineare con un Singolo Regressore Quali sono gli effetti dell introduzione di pene severe per gli automobilisti ubriachi? Quali sono gli effetti della riduzione della dimensione delle classi
Regressioni con Panel Data
 Regressioni con Panel Data Un insieme di dati panel contiene osservazioni riguardanti più di un individuo, dove ogni entità è osservata in due o più periodi di tempo. Esempi ipotetici: Dati su 420 distretti
Regressioni con Panel Data Un insieme di dati panel contiene osservazioni riguardanti più di un individuo, dove ogni entità è osservata in due o più periodi di tempo. Esempi ipotetici: Dati su 420 distretti
R - Esercitazione 6. Andrea Fasulo Venerdì 22 Dicembre Università Roma Tre
 R - Esercitazione 6 Andrea Fasulo fasulo.andrea@yahoo.it Università Roma Tre Venerdì 22 Dicembre 2017 Il modello di regressione lineare semplice (I) Esempi tratti da: Stock, Watson Introduzione all econometria
R - Esercitazione 6 Andrea Fasulo fasulo.andrea@yahoo.it Università Roma Tre Venerdì 22 Dicembre 2017 Il modello di regressione lineare semplice (I) Esempi tratti da: Stock, Watson Introduzione all econometria
Regressione con una variabile dipendente binaria
 Regressione con una variabile dipendente binaria Fino ad ora abbiamo considerato solo variabili dipendenti countinue: Che succede se Y è binaria? Y = va al college, o no; X = anni di istruzione Y = fumatore,
Regressione con una variabile dipendente binaria Fino ad ora abbiamo considerato solo variabili dipendenti countinue: Che succede se Y è binaria? Y = va al college, o no; X = anni di istruzione Y = fumatore,
Esercitazione del
 Esercizi sulla regressione lineare. Esercitazione del 21.05.2013 Esercizio dal tema d esame del 13.06.2011. Si consideri il seguente campione di n = 9 osservazioni relative ai caratteri ed Y: 7 17 8 36
Esercizi sulla regressione lineare. Esercitazione del 21.05.2013 Esercizio dal tema d esame del 13.06.2011. Si consideri il seguente campione di n = 9 osservazioni relative ai caratteri ed Y: 7 17 8 36
Statistica. Capitolo 12. Regressione Lineare Semplice. Cap. 12-1
 Statistica Capitolo 1 Regressione Lineare Semplice Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Spiegare il significato del coefficiente di correlazione lineare
Statistica Capitolo 1 Regressione Lineare Semplice Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Spiegare il significato del coefficiente di correlazione lineare
Test delle Ipotesi Parte I
 Test delle Ipotesi Parte I Test delle Ipotesi sulla media Introduzione Definizioni basilari Teoria per il caso di varianza nota Rischi nel test delle ipotesi Teoria per il caso di varianza non nota Test
Test delle Ipotesi Parte I Test delle Ipotesi sulla media Introduzione Definizioni basilari Teoria per il caso di varianza nota Rischi nel test delle ipotesi Teoria per il caso di varianza non nota Test
Regressione lineare con un solo regressore (Cap 4)
") Regressione lineare con un solo regressore (Cap 4) La regressione lineare è uno strumento che ci permette di stimare e di fare inferenza sui coefficienti angolari di una popolazione. Il nostro scopo è
Regressione lineare con un solo regressore (Cap 4) La regressione lineare è uno strumento che ci permette di stimare e di fare inferenza sui coefficienti angolari di una popolazione. Il nostro scopo è
Esercizi di statistica
 Esercizi di statistica Test a scelta multipla (la risposta corretta è la prima) [1] Il seguente campione è stato estratto da una popolazione distribuita normalmente: -.4, 5.5,, -.5, 1.1, 7.4, -1.8, -..
Esercizi di statistica Test a scelta multipla (la risposta corretta è la prima) [1] Il seguente campione è stato estratto da una popolazione distribuita normalmente: -.4, 5.5,, -.5, 1.1, 7.4, -1.8, -..
lezione 8 AA Paolo Brunori
 AA 2016-2017 Paolo Brunori regressione multipla con n = k Immaginate di voler studiare i determinanti del voto all esame di econometria Y = β 1 X 1 + u Y i = β 1 H i + u i H=ore studiate alla settimana
AA 2016-2017 Paolo Brunori regressione multipla con n = k Immaginate di voler studiare i determinanti del voto all esame di econometria Y = β 1 X 1 + u Y i = β 1 H i + u i H=ore studiate alla settimana
Minimi quadrati vincolati e test F
 Minimi quadrati vincolati e test F Impostazione del problema Spesso, i modelli econometrici che stimiamo hanno dei parametri che sono passibili di interpretazione diretta nella teoria economica. Consideriamo
Minimi quadrati vincolati e test F Impostazione del problema Spesso, i modelli econometrici che stimiamo hanno dei parametri che sono passibili di interpretazione diretta nella teoria economica. Consideriamo
Statistica Inferenziale
 Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Variabili indipendenti qualitative. In molte applicazioni si rende necessario l introduzione di un fattore a due o più livelli.
 Variabili indipendenti qualitative Di solito le variabili nella regressione sono variabili continue In molte applicazioni si rende necessario l introduzione di un fattore a due o più livelli Ad esempio:
Variabili indipendenti qualitative Di solito le variabili nella regressione sono variabili continue In molte applicazioni si rende necessario l introduzione di un fattore a due o più livelli Ad esempio:
Regressione Lineare Semplice e Correlazione
 Regressione Lineare Semplice e Correlazione 1 Introduzione La Regressione è una tecnica di analisi della relazione tra due variabili quantitative Questa tecnica è utilizzata per calcolare il valore (y)
Regressione Lineare Semplice e Correlazione 1 Introduzione La Regressione è una tecnica di analisi della relazione tra due variabili quantitative Questa tecnica è utilizzata per calcolare il valore (y)
Il modello di regressione lineare multipla. Il modello di regressione lineare multipla
 Introduzione E la generalizzazione del modello di regressione lineare semplice: per spiegare il fenomeno d interesse Y vengono introdotte p, con p > 1, variabili esplicative. Tale generalizzazione diventa
Introduzione E la generalizzazione del modello di regressione lineare semplice: per spiegare il fenomeno d interesse Y vengono introdotte p, con p > 1, variabili esplicative. Tale generalizzazione diventa
lezione 9 AA Paolo Brunori
 AA 2016-2017 Paolo Brunori Dove siamo arrivati? - la regressione lineare multipla ci permette di stimare l effetto della variabile X sulla Y tenendo ferme tutte le altre variabili osservabili che hanno
AA 2016-2017 Paolo Brunori Dove siamo arrivati? - la regressione lineare multipla ci permette di stimare l effetto della variabile X sulla Y tenendo ferme tutte le altre variabili osservabili che hanno
lezione n. 6 (a cura di Gaia Montanucci) Verosimiglianza: L = = =. Parte dipendente da β 0 e β 1
 Verosimiglianza: L = = =. Parte dipendente da β 0 e β 1") lezione n. 6 (a cura di Gaia Montanucci) METODO MASSIMA VEROSIMIGLIANZA PER STIMARE β 0 E β 1 Distribuzione sui termini di errore ε i ε i ~ N (0, σ 2 ) ne consegue : ogni y i ha ancora distribuzione normale,
lezione n. 6 (a cura di Gaia Montanucci) METODO MASSIMA VEROSIMIGLIANZA PER STIMARE β 0 E β 1 Distribuzione sui termini di errore ε i ε i ~ N (0, σ 2 ) ne consegue : ogni y i ha ancora distribuzione normale,
Econometria. lezione 13. validità interna ed esterna. Econometria. lezione 13. AA 2014-2015 Paolo Brunori
 AA 2014-2015 Paolo Brunori popolazione studiata e popolazione di interesse - popolazione studiata: popolazione da cui è stato estratto il campione - popolazione di interesse: popolazione per la quale ci
AA 2014-2015 Paolo Brunori popolazione studiata e popolazione di interesse - popolazione studiata: popolazione da cui è stato estratto il campione - popolazione di interesse: popolazione per la quale ci
Carta di credito standard. Carta di credito business. Esercitazione 12 maggio 2016
 Esercitazione 12 maggio 2016 ESERCIZIO 1 Si supponga che in un sondaggio di opinione su un campione di clienti, che utilizzano una carta di credito di tipo standard (Std) o di tipo business (Bsn), si siano
Esercitazione 12 maggio 2016 ESERCIZIO 1 Si supponga che in un sondaggio di opinione su un campione di clienti, che utilizzano una carta di credito di tipo standard (Std) o di tipo business (Bsn), si siano
Test F per la significatività del modello
 Test F per la significatività del modello Per verificare la significatività dell intero modello si utilizza il test F Si vuole verificare l ipotesi H 0 : β 1 = 0,, β k = 0 contro l alternativa che almeno
Test F per la significatività del modello Per verificare la significatività dell intero modello si utilizza il test F Si vuole verificare l ipotesi H 0 : β 1 = 0,, β k = 0 contro l alternativa che almeno
Funzioni di regressione non lineari
 Funzioni di regressione non lineari Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2013 Rossi Regressione nonlineare Econometria - 2013 1 / 25 Sommario Funzioni di regressione non lineari - note
Funzioni di regressione non lineari Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2013 Rossi Regressione nonlineare Econometria - 2013 1 / 25 Sommario Funzioni di regressione non lineari - note
Questo calcolo richiede che si conoscano media e deviazione standard della popolazione.
 Università del Piemonte Orientale Corso di laurea in biotecnologie Corso di Statistica Medica La distribuzione t - student 1 Abbiamo visto nelle lezioni precedenti come il calcolo del valore Z, riferito
Università del Piemonte Orientale Corso di laurea in biotecnologie Corso di Statistica Medica La distribuzione t - student 1 Abbiamo visto nelle lezioni precedenti come il calcolo del valore Z, riferito
Richiami di statistica
 Richiami di statistica Eduardo Rossi 2 2 Università di Pavia (Italy) Marzo 2014 Rossi Statistica Econometria - 2014 1 / 61 Indice 1 Esempio 2 Elementi di probabilità 3 Stima 4 Verifica di ipotesi Rossi
Richiami di statistica Eduardo Rossi 2 2 Università di Pavia (Italy) Marzo 2014 Rossi Statistica Econometria - 2014 1 / 61 Indice 1 Esempio 2 Elementi di probabilità 3 Stima 4 Verifica di ipotesi Rossi
Statistica di base per l analisi socio-economica
 Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Laurea Magistrale in Management e comunicazione d impresa Statistica di base per l analisi socio-economica Giovanni Di Bartolomeo gdibartolomeo@unite.it Definizioni di base Una popolazione è l insieme
Regressione lineare semplice
 Regressione lineare semplice Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Statistica con due variabili var. nominale, var. nominale: gruppo sanguigno - cancro
Regressione lineare semplice Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Statistica con due variabili var. nominale, var. nominale: gruppo sanguigno - cancro
Università del Piemonte Orientale. Corso di laurea in medicina e chirurgia. Corso di Statistica Medica. La distribuzione t - student
 Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica La distribuzione t - student 1 Abbiamo visto nelle lezioni precedenti come il calcolo del valore Z,
Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica La distribuzione t - student 1 Abbiamo visto nelle lezioni precedenti come il calcolo del valore Z,
Distribuzioni campionarie
 1 Inferenza Statistica Descrittiva Distribuzioni campionarie Statistica Inferenziale: affronta problemi di decisione in condizioni di incertezza basandosi sia su informazioni a priori sia sui dati campionari
1 Inferenza Statistica Descrittiva Distribuzioni campionarie Statistica Inferenziale: affronta problemi di decisione in condizioni di incertezza basandosi sia su informazioni a priori sia sui dati campionari
Il Test di Ipotesi Lezione 5
 Last updated May 23, 2016 Il Test di Ipotesi Lezione 5 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura I anno, II semestre Il test di ipotesi Cuore della statistica inferenziale!
Last updated May 23, 2016 Il Test di Ipotesi Lezione 5 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura I anno, II semestre Il test di ipotesi Cuore della statistica inferenziale!
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
STATISTICA (2) ESERCITAZIONE Dott.ssa Antonella Costanzo
 ESERCITAZIONE Dott.ssa Antonella Costanzo") STATISTICA (2) ESERCITAZIONE 7 11.03.2014 Dott.ssa Antonella Costanzo Esercizio 1. Test di indipendenza tra mutabili In un indagine vengono rilevate le informazioni su settore produttivo (Y) e genere (X)
STATISTICA (2) ESERCITAZIONE 7 11.03.2014 Dott.ssa Antonella Costanzo Esercizio 1. Test di indipendenza tra mutabili In un indagine vengono rilevate le informazioni su settore produttivo (Y) e genere (X)
La verifica delle ipotesi
 La verifica delle ipotesi Se abbiamo un idea di quale possa essere il valore di un parametro incognito possiamo sottoporlo ad una verifica, che sulla base di un risultato campionario, ci permetta di decidere
La verifica delle ipotesi Se abbiamo un idea di quale possa essere il valore di un parametro incognito possiamo sottoporlo ad una verifica, che sulla base di un risultato campionario, ci permetta di decidere
PROBABILITÀ ELEMENTARE
 Prefazione alla seconda edizione XI Capitolo 1 PROBABILITÀ ELEMENTARE 1 Esperimenti casuali 1 Spazi dei campioni 1 Eventi 2 Il concetto di probabilità 3 Gli assiomi della probabilità 3 Alcuni importanti
Prefazione alla seconda edizione XI Capitolo 1 PROBABILITÀ ELEMENTARE 1 Esperimenti casuali 1 Spazi dei campioni 1 Eventi 2 Il concetto di probabilità 3 Gli assiomi della probabilità 3 Alcuni importanti
Statistica multivariata Donata Rodi 17/10/2016
 Statistica multivariata Donata Rodi 17/10/2016 Quale analisi? Variabile Dipendente Categoriale Continua Variabile Indipendente Categoriale Chi Quadro ANOVA Continua Regressione Logistica Regressione Lineare
Statistica multivariata Donata Rodi 17/10/2016 Quale analisi? Variabile Dipendente Categoriale Continua Variabile Indipendente Categoriale Chi Quadro ANOVA Continua Regressione Logistica Regressione Lineare
Statistica Applicata all edilizia: il modello di regressione
 Statistica Applicata all edilizia: il modello di regressione E-mail: orietta.nicolis@unibg.it 27 aprile 2009 Indice Il modello di Regressione Lineare 1 Il modello di Regressione Lineare Analisi di regressione
Statistica Applicata all edilizia: il modello di regressione E-mail: orietta.nicolis@unibg.it 27 aprile 2009 Indice Il modello di Regressione Lineare 1 Il modello di Regressione Lineare Analisi di regressione
CORSO DI STATISTICA (parte 2) - ESERCITAZIONE 5
 - ESERCITAZIONE 5") CORSO DI STATISTICA (parte 2) - ESERCITAZIONE Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Approssimazione normale della Poisson (TLC) In un determinato tratto di strada il numero di incidenti
CORSO DI STATISTICA (parte 2) - ESERCITAZIONE Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Approssimazione normale della Poisson (TLC) In un determinato tratto di strada il numero di incidenti
Dispensa di Statistica
 Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
lezione 10 AA Paolo Brunori
 AA 2016-2017 Paolo Brunori Redditi svedesi - il dataset contiene i dati di reddito di 838 individui - il dataset contiene le variabili: sex = sesso age = età edu = anni di istruzione y_gross = reddito
AA 2016-2017 Paolo Brunori Redditi svedesi - il dataset contiene i dati di reddito di 838 individui - il dataset contiene le variabili: sex = sesso age = età edu = anni di istruzione y_gross = reddito
Verifica di ipotesi e intervalli di confidenza nella regressione multipla
 Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Università del Piemonte Orientale Corso di Laurea in Medicina e Chirurgia. Corso di Statistica Medica. Correlazione. Regressione Lineare
 Università del Piemonte Orientale Corso di Laurea in Medicina e Chirurgia Corso di Statistica Medica Correlazione Regressione Lineare Corso di laurea in medicina e chirurgia - Statistica Medica Correlazione
Università del Piemonte Orientale Corso di Laurea in Medicina e Chirurgia Corso di Statistica Medica Correlazione Regressione Lineare Corso di laurea in medicina e chirurgia - Statistica Medica Correlazione
La multicollinearità sorge quando c è un elevata correlazione tra due o più variabili esplicative.
 Lezione 14 (a cura di Ludovica Peccia) MULTICOLLINEARITA La multicollinearità sorge quando c è un elevata correlazione tra due o più variabili esplicative. In un modello di regressione Y= X 1, X 2, X 3
Lezione 14 (a cura di Ludovica Peccia) MULTICOLLINEARITA La multicollinearità sorge quando c è un elevata correlazione tra due o più variabili esplicative. In un modello di regressione Y= X 1, X 2, X 3
Capitolo 8. Intervalli di confidenza. Statistica. Levine, Krehbiel, Berenson. Casa editrice: Pearson. Insegnamento: Statistica
 Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA
 Metodi per l Analisi dei Dati Sperimentali AA009/010 IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA Sommario Massima Verosimiglianza Introduzione La Massima Verosimiglianza Esempio 1: una sola misura sperimentale
Metodi per l Analisi dei Dati Sperimentali AA009/010 IL CRITERIO DELLA MASSIMA VEROSIMIGLIANZA Sommario Massima Verosimiglianza Introduzione La Massima Verosimiglianza Esempio 1: una sola misura sperimentale
L indagine campionaria Lezione 3
 Anno accademico 2007/08 L indagine campionaria Lezione 3 Docente: prof. Maurizio Pisati Variabile casuale Una variabile casuale è una quantità discreta o continua il cui valore è determinato dal risultato
Anno accademico 2007/08 L indagine campionaria Lezione 3 Docente: prof. Maurizio Pisati Variabile casuale Una variabile casuale è una quantità discreta o continua il cui valore è determinato dal risultato
obbligatorio - n. iscrizione sulla lista
 02.09.2015 - appello di STATISTICA per studenti ENE - docente: E. Piazza obbligatorio - n. iscrizione sulla lista il presente elaborato si compone di 5 (cinque) pagine se non ve lo ricordate siete fritti;
02.09.2015 - appello di STATISTICA per studenti ENE - docente: E. Piazza obbligatorio - n. iscrizione sulla lista il presente elaborato si compone di 5 (cinque) pagine se non ve lo ricordate siete fritti;
Gli errori nella verifica delle ipotesi
 Gli errori nella verifica delle ipotesi Nella statistica inferenziale si cerca di dire qualcosa di valido in generale, per la popolazione o le popolazioni, attraverso l analisi di uno o più campioni E
Gli errori nella verifica delle ipotesi Nella statistica inferenziale si cerca di dire qualcosa di valido in generale, per la popolazione o le popolazioni, attraverso l analisi di uno o più campioni E
βˆ (pendenza della retta) =
 =") LA MODELLAZIONE EMPIRICA DELLE RELAZIONI ECONOMICHE: APPLICAZIONI IN STATA 7 Maria Elena Bontempi e.bontempi@economia.unife.it V LEZIONE: OLS multivariato: effetti parziali, multicollinearità Scopo dell
LA MODELLAZIONE EMPIRICA DELLE RELAZIONI ECONOMICHE: APPLICAZIONI IN STATA 7 Maria Elena Bontempi e.bontempi@economia.unife.it V LEZIONE: OLS multivariato: effetti parziali, multicollinearità Scopo dell
LEZIONE N. 11 ( a cura di MADDALENA BEI)
") LEZIONE N. 11 ( a cura di MADDALENA BEI) F- test Assumiamo l ipotesi nulla H 0 :β 1,...,Β k =0 E diverso dal verificare che H 0 :B J =0 In realtà F - test è più generale H 0 :Aβ=0 H 1 :Aβ 0 A è una matrice
LEZIONE N. 11 ( a cura di MADDALENA BEI) F- test Assumiamo l ipotesi nulla H 0 :β 1,...,Β k =0 E diverso dal verificare che H 0 :B J =0 In realtà F - test è più generale H 0 :Aβ=0 H 1 :Aβ 0 A è una matrice
Università degli Studi di Bari Dipartimento di Scienze Economiche e Metodi Matematici. Corso di Econometria
 Università degli Studi di Bari Dipartimento di Scienze Economiche e Metodi Matematici Corso di Econometria Corsi di Laurea Magistrale in Economia degli Intermediari e dei Mercati Finanziari 8 CFU Statistica
Università degli Studi di Bari Dipartimento di Scienze Economiche e Metodi Matematici Corso di Econometria Corsi di Laurea Magistrale in Economia degli Intermediari e dei Mercati Finanziari 8 CFU Statistica
STATISTICA ESERCITAZIONE 13
 STATISTICA ESERCITAZIONE 13 Dott. Giuseppe Pandolfo 9 Marzo 2015 Errore di I tipo: si commette se l'ipotesi nulla H 0 viene rifiutata quando essa è vera Errore di II tipo: si commette se l'ipotesi nulla
STATISTICA ESERCITAZIONE 13 Dott. Giuseppe Pandolfo 9 Marzo 2015 Errore di I tipo: si commette se l'ipotesi nulla H 0 viene rifiutata quando essa è vera Errore di II tipo: si commette se l'ipotesi nulla
Esercitazione 3 - Statistica II - Economia Aziendale Davide Passaretti 23/5/2017
 Esercitazione 3 - Statistica II - Economia Aziendale Davide Passaretti 3/5/017 Contents 1 Intervalli di confidenza 1 Intervalli su un campione 1.1 Intervallo di confidenza per la media................................
Esercitazione 3 - Statistica II - Economia Aziendale Davide Passaretti 3/5/017 Contents 1 Intervalli di confidenza 1 Intervalli su un campione 1.1 Intervallo di confidenza per la media................................
05. Errore campionario e numerosità campionaria
 Statistica per le ricerche di mercato A.A. 01/13 05. Errore campionario e numerosità campionaria Gli schemi di campionamento condividono lo stesso principio di fondo: rappresentare il più fedelmente possibile,
Statistica per le ricerche di mercato A.A. 01/13 05. Errore campionario e numerosità campionaria Gli schemi di campionamento condividono lo stesso principio di fondo: rappresentare il più fedelmente possibile,
CHEMIOMETRIA. CONFRONTO CON VALORE ATTESO (test d ipotesi) CONFRONTO DI VALORI MISURATI (test d ipotesi) CONFRONTO DI RIPRODUCIBILITA (test d ipotesi)
 CONFRONTO DI VALORI MISURATI (test d ipotesi) CONFRONTO DI RIPRODUCIBILITA (test d ipotesi)") CHEMIOMETRIA Applicazione di metodi matematici e statistici per estrarre (massima) informazione chimica (affidabile) da dati chimici INCERTEZZA DI MISURA (intervallo di confidenza/fiducia) CONFRONTO CON
CHEMIOMETRIA Applicazione di metodi matematici e statistici per estrarre (massima) informazione chimica (affidabile) da dati chimici INCERTEZZA DI MISURA (intervallo di confidenza/fiducia) CONFRONTO CON
3.1 Classificazione dei fenomeni statistici Questionari e scale di modalità Classificazione delle scale di modalità 17
 C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
Il modello di regressione lineare multipla con regressori stocastici
 Università di Pavia Il modello di regressione lineare multipla con regressori stocastici Eduardo Rossi Il valore atteso condizionale Modellare l esperimento casuale bivariato nel quale le variabili casuali
Università di Pavia Il modello di regressione lineare multipla con regressori stocastici Eduardo Rossi Il valore atteso condizionale Modellare l esperimento casuale bivariato nel quale le variabili casuali
Statistica per le ricerche di mercato. 11. La regressione lineare multipla
 Statistica per le ricerche di mercato A.A. 2012/13 Dr. L.Secondi 11. La regressione lineare multipla 1 Modello di regressione lineare multipla Il modello di regressione multipla estende il modello di regressione
Statistica per le ricerche di mercato A.A. 2012/13 Dr. L.Secondi 11. La regressione lineare multipla 1 Modello di regressione lineare multipla Il modello di regressione multipla estende il modello di regressione
Approssimazione normale alla distribuzione binomiale
 Approssimazione normale alla distribuzione binomiale P b (X r) costoso P b (X r) P(X r) per N grande Teorema: Se la variabile casuale X ha una distribuzione binomiale con parametri N e p, allora, per N
Approssimazione normale alla distribuzione binomiale P b (X r) costoso P b (X r) P(X r) per N grande Teorema: Se la variabile casuale X ha una distribuzione binomiale con parametri N e p, allora, per N
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 10-Significatività statistica per la correlazione vers. 1.0 (5 novembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università
Elementi di Psicometria con Laboratorio di SPSS 1 10-Significatività statistica per la correlazione vers. 1.0 (5 novembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università
Restrizioni lineari nel MRLM: esempi
 Restrizioni lineari nel MRLM: esempi Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2013 Rossi Restrizioni lineari: esempi Econometria - 2013 1 / 22 Funzione di produzione Cobb-Douglas Esempio GDP
Restrizioni lineari nel MRLM: esempi Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2013 Rossi Restrizioni lineari: esempi Econometria - 2013 1 / 22 Funzione di produzione Cobb-Douglas Esempio GDP
Il metodo della regressione
 Il metodo della regressione Consideriamo il coefficiente beta di una semplice regressione lineare, cosa significa? È una differenza tra valori attesi Anche nel caso classico di variabile esplicativa continua
Il metodo della regressione Consideriamo il coefficiente beta di una semplice regressione lineare, cosa significa? È una differenza tra valori attesi Anche nel caso classico di variabile esplicativa continua
STATISTICA A K (60 ore)
") STATISTICA A K (60 ore) Marco Riani mriani@unipr.it http://www.riani.it Richiami sulla regressione Marco Riani, Univ. di Parma 1 MODELLO DI REGRESSIONE y i = a + bx i + e i dove: i = 1,, n a + bx i rappresenta
STATISTICA A K (60 ore) Marco Riani mriani@unipr.it http://www.riani.it Richiami sulla regressione Marco Riani, Univ. di Parma 1 MODELLO DI REGRESSIONE y i = a + bx i + e i dove: i = 1,, n a + bx i rappresenta
STATISTICA 1, metodi matematici e statistici Introduzione al linguaggio R Esercitazione 7:
 esercitazione 7 p. 1/13 STATISTICA 1, metodi matematici e statistici Introduzione al linguaggio R Esercitazione 7: 20-05-2004 Luca Monno Università degli studi di Pavia luca.monno@unipv.it http://www.lucamonno.it
esercitazione 7 p. 1/13 STATISTICA 1, metodi matematici e statistici Introduzione al linguaggio R Esercitazione 7: 20-05-2004 Luca Monno Università degli studi di Pavia luca.monno@unipv.it http://www.lucamonno.it
Regressione lineare semplice: inferenza
 Regressione lineare semplice: inferenza Eduardo Rossi 2 2 Università di Pavia (Italy) Marzo 2014 Rossi Regressione lineare semplice Econometria - 2014 1 / 60 Outline 1 Introduzione 2 Verifica di ipotesi
Regressione lineare semplice: inferenza Eduardo Rossi 2 2 Università di Pavia (Italy) Marzo 2014 Rossi Regressione lineare semplice Econometria - 2014 1 / 60 Outline 1 Introduzione 2 Verifica di ipotesi
STATISTICHE, DISTRIBUZIONI CAMPIONARIE E INFERENZA
 Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria Civile A.A. 2009-10 Facoltà di Ingegneria, Università di Padova Docente: Dott. L. Corain 1 STATISTICHE, DISTRIBUZIONI CAMPIONARIE
Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria Civile A.A. 2009-10 Facoltà di Ingegneria, Università di Padova Docente: Dott. L. Corain 1 STATISTICHE, DISTRIBUZIONI CAMPIONARIE
UNIVERSITÀ DEGLI STUDI DI PERUGIA
 SIGI, Statistica II, esercitazione n. 3 1 UNIVERSITÀ DEGLI STUDI DI PERUGIA FACOLTÀ DI ECONOMIA CORSO DI LAUREA S.I.G.I. STATISTICA II Esercitazione n. 3 Esercizio 1 Una v.c. X si dice v.c. esponenziale
SIGI, Statistica II, esercitazione n. 3 1 UNIVERSITÀ DEGLI STUDI DI PERUGIA FACOLTÀ DI ECONOMIA CORSO DI LAUREA S.I.G.I. STATISTICA II Esercitazione n. 3 Esercizio 1 Una v.c. X si dice v.c. esponenziale
Il modello lineare misto
 Il modello lineare misto (capitolo 9) A M D Marcello Gallucci Univerisità Milano-Bicocca Lezione: 15 GLM Modello Lineare Generale vantaggi Consente di stimare le relazioni fra due o più variabili Si applica
Il modello lineare misto (capitolo 9) A M D Marcello Gallucci Univerisità Milano-Bicocca Lezione: 15 GLM Modello Lineare Generale vantaggi Consente di stimare le relazioni fra due o più variabili Si applica
Il modello di regressione
 Il modello di regressione Capitolo e 3 A M D Marcello Gallucci Milano-Bicocca Lezione: II Concentti fondamentali Consideriamo ora questa ipotetica ricerca: siamo andati in un pub ed abbiamo contato quanti
Il modello di regressione Capitolo e 3 A M D Marcello Gallucci Milano-Bicocca Lezione: II Concentti fondamentali Consideriamo ora questa ipotetica ricerca: siamo andati in un pub ed abbiamo contato quanti
0 altimenti 1 soggetto trova lavoroentro 6 mesi}
 Lezione n. 16 (a cura di Peluso Filomena Francesca) Oltre alle normali variabili risposta che presentano una continuità almeno all'interno di un certo intervallo di valori, esistono variabili risposta
Lezione n. 16 (a cura di Peluso Filomena Francesca) Oltre alle normali variabili risposta che presentano una continuità almeno all'interno di un certo intervallo di valori, esistono variabili risposta
Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009)
") Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009) Quesito: Posso stimare il numero di ore passate a studiare statistica sul voto conseguito all esame? Potrei calcolare il coefficiente di correlazione.
Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009) Quesito: Posso stimare il numero di ore passate a studiare statistica sul voto conseguito all esame? Potrei calcolare il coefficiente di correlazione.
Introduzione all Analisi della Varianza (ANOVA)
") Introduzione all Analisi della Varianza (ANOVA) AMD Marcello Gallucci marcello.gallucci@unimib.it Variabili nella Regressione Nella regressione, la viariabile dipendente è sempre quantitativa e, per quello
Introduzione all Analisi della Varianza (ANOVA) AMD Marcello Gallucci marcello.gallucci@unimib.it Variabili nella Regressione Nella regressione, la viariabile dipendente è sempre quantitativa e, per quello
N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle Tabelle riportate alla fine del documento.
 N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle abelle riportate alla fine del documento. Esercizio 1 La concentrazione media di sostanze inquinanti osservata nelle acque di un fiume
N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle abelle riportate alla fine del documento. Esercizio 1 La concentrazione media di sostanze inquinanti osservata nelle acque di un fiume
lezione 5 AA Paolo Brunori
 AA 2016-2017 Paolo Brunori dove eravamo arrivati - le stime OLS ci consentono di approssimare linearmente la relazione fra una variabile dipendente (Y) e una indipendente (X) - i parametri stimati su un
AA 2016-2017 Paolo Brunori dove eravamo arrivati - le stime OLS ci consentono di approssimare linearmente la relazione fra una variabile dipendente (Y) e una indipendente (X) - i parametri stimati su un
Ipotesi statistiche (caso uno-dimensionale) Ipotesi poste sulla (distribuzione di) popolazione per raggiungere una decisione sulla popolazione stessa
 Ipotesi poste sulla (distribuzione di) popolazione per raggiungere una decisione sulla popolazione stessa") Ipotesi statistiche (caso uno-dimensionale) Ipotesi poste sulla (distribuzione di) popolazione per raggiungere una decisione sulla popolazione stessa L ipotesi che si vuole testare: H 0 (ipotesi nulla)
Ipotesi statistiche (caso uno-dimensionale) Ipotesi poste sulla (distribuzione di) popolazione per raggiungere una decisione sulla popolazione stessa L ipotesi che si vuole testare: H 0 (ipotesi nulla)
Principi di analisi causale Lezione 3
 Anno accademico 2007/08 Principi di analisi causale Lezione 3 Docente: prof. Maurizio Pisati Approccio causale Nella maggior parte dei casi i ricercatori sociali utilizzano la regressione per stimare l
Anno accademico 2007/08 Principi di analisi causale Lezione 3 Docente: prof. Maurizio Pisati Approccio causale Nella maggior parte dei casi i ricercatori sociali utilizzano la regressione per stimare l
LE DISTRIBUZIONI CAMPIONARIE
 LE DISTRIBUZIONI CAMPIONARIE Argomenti Principi e metodi dell inferenza statistica Metodi di campionamento Campioni casuali Le distribuzioni campionarie notevoli: La distribuzione della media campionaria
LE DISTRIBUZIONI CAMPIONARIE Argomenti Principi e metodi dell inferenza statistica Metodi di campionamento Campioni casuali Le distribuzioni campionarie notevoli: La distribuzione della media campionaria
Esercitazione 8 del corso di Statistica 2
 Esercitazione 8 del corso di Statistica Prof. Domenico Vistocco Dott.ssa Paola Costantini 6 Giugno 8 Decisione vera falsa è respinta Errore di I tipo Decisione corretta non è respinta Probabilità α Decisione
Esercitazione 8 del corso di Statistica Prof. Domenico Vistocco Dott.ssa Paola Costantini 6 Giugno 8 Decisione vera falsa è respinta Errore di I tipo Decisione corretta non è respinta Probabilità α Decisione
Politecnico di Milano - Scuola di Ingegneria Industriale. II Prova in Itinere di Statistica per Ingegneria Energetica 25 luglio 2011
 Politecnico di Milano - Scuola di Ingegneria Industriale II Prova in Itinere di Statistica per Ingegneria Energetica 25 luglio 2011 c I diritti d autore sono riservati. Ogni sfruttamento commerciale non
Politecnico di Milano - Scuola di Ingegneria Industriale II Prova in Itinere di Statistica per Ingegneria Energetica 25 luglio 2011 c I diritti d autore sono riservati. Ogni sfruttamento commerciale non
Il modello di regressione lineare multivariata
 Il modello di regressione lineare multivariata Eduardo Rossi 2 2 Università di Pavia (Italy) Aprile 2013 Rossi MRLM Econometria - 2013 1 / 39 Outline 1 Notazione 2 il MRLM 3 Il modello partizionato 4 Collinearità
Il modello di regressione lineare multivariata Eduardo Rossi 2 2 Università di Pavia (Italy) Aprile 2013 Rossi MRLM Econometria - 2013 1 / 39 Outline 1 Notazione 2 il MRLM 3 Il modello partizionato 4 Collinearità
Test per la correlazione lineare
 10 Test per la correlazione lineare Istituzioni di Matematica e Statistica 2015/16 E. Priola 1 Introduzione alla correlazione lineare Problema: In base ai dati che abbiamo possiamo dire che c è una qualche
10 Test per la correlazione lineare Istituzioni di Matematica e Statistica 2015/16 E. Priola 1 Introduzione alla correlazione lineare Problema: In base ai dati che abbiamo possiamo dire che c è una qualche
Analisi descrittiva: calcolando medie campionarie, varianze campionarie e deviazioni standard campionarie otteniamo i dati:
 Obiettivi: Esplicitare la correlazione esistente tra l altezza di un individuo adulto e la lunghezza del suo piede e del suo avambraccio. Idea del progetto: Il progetto nasce dall idea di acquistare scarpe
Obiettivi: Esplicitare la correlazione esistente tra l altezza di un individuo adulto e la lunghezza del suo piede e del suo avambraccio. Idea del progetto: Il progetto nasce dall idea di acquistare scarpe
Esercitazione 9 del corso di Statistica (parte seconda)
") Esercitazione 9 del corso di Statistica (parte seconda) Dott.ssa Paola Costantini 17 Marzo 9 Esercizio 1 Esercizio Un economista del Ministero degli Esteri desidera verificare se gli accordi di negoziazione
Esercitazione 9 del corso di Statistica (parte seconda) Dott.ssa Paola Costantini 17 Marzo 9 Esercizio 1 Esercizio Un economista del Ministero degli Esteri desidera verificare se gli accordi di negoziazione
Capitolo 2 Le misure delle grandezze fisiche
 Capitolo 2 Le misure delle grandezze fisiche Gli strumenti di misura Gli errori di misura Il risultato di una misura Errore relativo ed errore percentuale Propagazione degli errori Rappresentazione di
Capitolo 2 Le misure delle grandezze fisiche Gli strumenti di misura Gli errori di misura Il risultato di una misura Errore relativo ed errore percentuale Propagazione degli errori Rappresentazione di
Data Mining. Prova parziale del 20 aprile 2017: SOLUZIONE
 Università degli Studi di Padova Corso di Laurea Magistrale in Informatica a.a. 2016/2017 Data Mining Docente: Annamaria Guolo Prova parziale del 20 aprile 2017: SOLUZIONE ISTRUZIONI: La durata della prova
Università degli Studi di Padova Corso di Laurea Magistrale in Informatica a.a. 2016/2017 Data Mining Docente: Annamaria Guolo Prova parziale del 20 aprile 2017: SOLUZIONE ISTRUZIONI: La durata della prova
Analisi di Regressione Multivariata. β matrice incognita dei coeff. di regressione (regr. lineare in β)
") Analisi di Regressione Multivariata Regressione: metodologia per dedurre info e per anticipare risposte di una variabile dip. Modello classico di regressione lineare: Y {z} n k = {z} X β + ρ {z} {z} n
Analisi di Regressione Multivariata Regressione: metodologia per dedurre info e per anticipare risposte di una variabile dip. Modello classico di regressione lineare: Y {z} n k = {z} X β + ρ {z} {z} n
Laboratorio di Didattica di elaborazione dati 5 STIMA PUNTUALE DEI PARAMETRI. x i. SE = n.
 5 STIMA PUNTUALE DEI PARAMETRI [Adattato dal libro Excel per la statistica di Enzo Belluco] Sia θ un parametro incognito della distribuzione di un carattere in una determinata popolazione. Il problema
5 STIMA PUNTUALE DEI PARAMETRI [Adattato dal libro Excel per la statistica di Enzo Belluco] Sia θ un parametro incognito della distribuzione di un carattere in una determinata popolazione. Il problema
Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni
 La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3
 Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Ulteriori conoscenze di informatica Elementi di statistica Esercitazione3 Sui PC a disposizione sono istallati diversi sistemi operativi. All accensione scegliere Windows. Immettere Nome utente b## (##
Università del Piemonte Orientale Specializzazioni di area sanitaria Statistica Medica
 Università del Piemonte Orientale Specializzazioni di area sanitaria Statistica Medica Regressione Lineare e Correlazione Argomenti della lezione Determinismo e variabilità Correlazione Regressione Lineare
Università del Piemonte Orientale Specializzazioni di area sanitaria Statistica Medica Regressione Lineare e Correlazione Argomenti della lezione Determinismo e variabilità Correlazione Regressione Lineare
Confronto fra gruppi: il metodo ANOVA. Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23
 Confronto fra gruppi: il metodo ANOVA 1 / 23") Confronto fra gruppi: il metodo ANOVA Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23 1 Nella popolazione, per ciascun gruppo la distribuzione della variabile risposta
Confronto fra gruppi: il metodo ANOVA Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23 1 Nella popolazione, per ciascun gruppo la distribuzione della variabile risposta
Metodi statistici per la ricerca sociale Capitolo 7. Confronto tra Due Gruppi Esercitazione
 Metodi statistici per la ricerca sociale Capitolo 7. Confronto tra Due Gruppi Esercitazione Alessandra Mattei Dipartimento di Statistica, Informatica, Applicazioni (DiSIA) Università degli Studi di Firenze
Metodi statistici per la ricerca sociale Capitolo 7. Confronto tra Due Gruppi Esercitazione Alessandra Mattei Dipartimento di Statistica, Informatica, Applicazioni (DiSIA) Università degli Studi di Firenze
Statistica Metodologica
 Statistica Metodologica Esercizi di Probabilita e Inferenza Silvia Figini e-mail: silvia.figini@unipv.it Problema 1 Sia X una variabile aleatoria Bernoulliana con parametro p = 0.7. 1. Determinare la media
Statistica Metodologica Esercizi di Probabilita e Inferenza Silvia Figini e-mail: silvia.figini@unipv.it Problema 1 Sia X una variabile aleatoria Bernoulliana con parametro p = 0.7. 1. Determinare la media
Fondamenti di statistica per il miglioramento genetico delle piante. Antonio Di Matteo Università Federico II
 Fondamenti di statistica per il miglioramento genetico delle piante Antonio Di Matteo Università Federico II Modulo 2 Variabili continue e Metodi parametrici Distribuzione Un insieme di misure è detto
Fondamenti di statistica per il miglioramento genetico delle piante Antonio Di Matteo Università Federico II Modulo 2 Variabili continue e Metodi parametrici Distribuzione Un insieme di misure è detto
Statistica4-29/09/2015
 Statistica4-29/09/2015 Raccogliere i dati con il maggior numero di cifre significative ed arrotondare eventualmente solo al momento dei calcoli (min. 3); nella grande maggioranza delle ricerche biologiche
Statistica4-29/09/2015 Raccogliere i dati con il maggior numero di cifre significative ed arrotondare eventualmente solo al momento dei calcoli (min. 3); nella grande maggioranza delle ricerche biologiche
Università di Pavia. Test diagnostici. Eduardo Rossi
 Università di Pavia Test diagnostici Eduardo Rossi Test diagnostici Fase di controllo diagnostico: controllo della coerenza tra quanto direttamente osservato e le ipotesi statistiche adottate Ipotesi MRLM
Università di Pavia Test diagnostici Eduardo Rossi Test diagnostici Fase di controllo diagnostico: controllo della coerenza tra quanto direttamente osservato e le ipotesi statistiche adottate Ipotesi MRLM
Facoltà di Scienze Statistiche Corso di Laurea in Statistica ed Informatica per l Azienda ESERCIZI DI ALLENAMENTO a.a.
 Facoltà di Scienze Statistiche Corso di Laurea in Statistica ed Informatica per l Azienda ESERCIZI DI ALLENAMENTO a.a. 2008 PARTE I 1. Si consideri il seguente modello di regressione lineare su dati cross
Facoltà di Scienze Statistiche Corso di Laurea in Statistica ed Informatica per l Azienda ESERCIZI DI ALLENAMENTO a.a. 2008 PARTE I 1. Si consideri il seguente modello di regressione lineare su dati cross