Principali Database biologici
|
|
|
- Graziano Angelini
- 5 anni fa
- Visualizzazioni
Transcript
 Proteine: -Sequenze delle proteine ottenute in modo diretto (degradazione di Edman) -Sequenze proteiche ricavate dalle sequenze nucleotidiche")
1 Principali Database biologici Acidi nucleici: -Sequenze DNA genomico -Sequenze di trascritti (mrna) La maggior quantità di dati biologici presenti nei database è rappresentata da sequenze di acidi nucleici -Sequenze EST (corte sequenze di trascritti) Proteine: -Sequenze delle proteine ottenute in modo diretto (degradazione di Edman) -Sequenze proteiche ricavate dalle sequenze nucleotidiche (traduzione) -Studi di espressione proteica (gel bidimensionale e spettrometria di massa) -Cristallografia e determinazione delle strutture secondarie e terziarie Noi ci occuperemo soprattutto delle sequenze nucleotidiche ed in parte delle sequenze proteiche 1
2 Sequenze di acidi nucleici Alla fine degli anni 70 Maxam-Gilbert e Sanger hanno ideato due differenti tecniche per il sequenziamento del DNA basato sulla sintesi del DNA in vitro in presenza di opportuni terminatori marcati. Le sequenze che si ricavano hanno la direzione 5 3 (domanda: lo stampo per la sintesi di queste sequenze che direzione avrà?) Oggi sono disponibili delle nuovissime tecniche con le quali è possibile ottenere più di mezzo milione di sequenze in un singolo esperimento (queste nuove tecniche produrranno una nuova rivoluzione nella ricerca genomica) ATTENZIONE: Con le attuali tecniche di sequenziamento si ottengono solo corte sequenze (inferiori a 1000 bp): all aumentare della lunghezza si perde in risoluzione ed in qualità. Le basi non risolte vengono indicate con n 2
3 Esempio: Le sequenze lunghe hanno una scarsa qualità al 3 >CF5530xx.0 Ggagcccggacgtccaagagatgtcttctgggagccactgggcaattgccagggctccaggaagggctctggctcaggt Tgcagacagctgagaaaagatggccctgtcagccaccctctctcagtctgaaacatccaacatccccagaaggcttagc ecc. ecc Tgaagtagaggggccttcaaactactttatactagtgatagtttgagttaggtaagcatnttaaagctgnntggtgat Aaagaaggcagcttangattctgtggttgggaaacaagtgtagtccgcttccccttttttangaaagccctgttaaaa tangctnatttgnnaacat Frammenti di un cromatogramma (output del sequenziamento ottenuto col metodo Sanger) Se si vogliono conoscere lunghe sequenze di DNA, è necessario sequenziare frammenti del DNA e poi assemblare le corte sequenze in modo che si sovrappongano tra loro Sequenze parziali Sequenza assemblata 3
4 Come si ottengono le sequenze di DNA Il DNA viene frammentato e poi amplificato con tecniche di biologia molecolare (es. inserimento dei frammenti all interno di cloni batterici che replicandosi riproducono anche il DNA esogeno). I differenti frammenti vengono poi sequenziati. Solo con l assemblaggio delle sequenze ottenute da questi frammenti si ottengono le lunghe sequenze di DNA presenti nei database. (Ricordate che, se nei DB trovate record contenenti lunghi sequenze (maggiori di un migliaio di basi), queste sicuramente sono il frutto di un assemblaggio di corte sequenze.) Come si ottengono le sequenze di mrna L mrna (meno stabile del DNA) deve essere preventivamente trasformato in cdna (da una molecola di mrna si ottiene prima una copia complementare di DNA (per questo si chiama cdna) a singolo filamento che poi viene resa a doppia elica. Si procede poi come per il DNA Nota: l insieme dei batteri contenenti gli inserti di DNA esogeno viene detto libreria di DNA (o libreria di cdna) 4
5 Perché si sequenzia anche l mrna (non è sufficiente conoscere solo le sequenze di DNA)? Risposte: - Per conoscere le sequenze codificanti (negli eucarioti superiori, solo il 3% del genoma è codificante). Si possono così individuare le sequenze geniche e distinguere gli esoni dagli introni. - Per conoscere le sequenze che fiancheggiano le regioni codificanti e quindi le regolazioni della trascrizione dei geni. - Per conoscere la sequenza proteica (traducendo la sequenza nucleotidica) e studiare quindi la relativa proteina. - Per conoscere varianti (splicing alternativi) dello stesso gene e quindi probabili funzioni differenti - Sequenziando mrna in tessuti differenti o momenti differenti si può conoscere l espressione genica: determinare quando (sviluppo o momento particolare) e dove (quale tessuto) un particolare gene viene espresso L insieme degli mrna (RNA messaggeri o trascritti) espressi in un organismo viene definito trascrittoma 5
6 Importanze delle Sequenze EST (Expressed Sequence Tag) Per individuare un trascritto non serve conoscere tutta la sua sequenza, ma è sufficiente identificarne una parte. Da questo presupposto sono stati sviluppati progetti di sequenziamento di corte sequenze di cdna chiamate EST (Expressed Sequence Tag) che hanno permesso di tracciare numerosi profili trascrizionali (espressione genica di un particolare tessuto o in un particolare momento o in presenza di una particolare malattia genetica). Attualmente nei database esistono più di 30 milioni di sequenze di EST di cui circa 8 milioni relative a Homo sapiens (human) e più di 4 milioni relative a topo 3 UTR Seq. codificante 5 UTR ATG EST 5 TAA polya AAAAAAAAA EST 3 6
 EMBL datalibrary GenBank DDBJ Europa")
7 I database primari Cosa sono i database primari? Sono i contenitori di tutte le sequenze prodotte nel mondo e rese disponibili alla comunità scientifica. Memorizzano essenzialmente le sequenze e poche altra informazioni generiche correlate (laboratorio dove è avvenuto il sequenziamento, data, specie, descrizione ) EMBL datalibrary GenBank DDBJ Europa USA Giappone I tre database si aggiornano quotidianamente scambiandosi i dati ricevuti durante la giornata, in modo che sia sufficiente interrogare solo uno dei tre. 7
 http://www.ebi.ac.")
8 EBI European Bioinformatics Institute (Hinxton Cambridge, UK) 8

9 NCBI 9

10 DDBJ 10
11 Banche Dati derivate Le banche dati primarie contengono tutte le sequenze conosciute, di tutti gli organismi, genomiche di mrna ecc., per rendere organica la ricerca sono state costruite delle banche dati derivate che raggruppano solo dati relativi a specifici argomenti. Esempi: - Database sequenze genomiche: GDB (uomo), MGI (topo), SGD (lievito) - Database di geni e trascritti: UniGene, LocusLink, dbest, ecc. - Inoltre database dei fattori di trascrizione, dbsnp (di polimorfismi) e molti altri. Esistono poi dei database integrati che raggruppano i dati provenienti da differenti database fornendo informazioni particolareggiate di argomenti specifici Allegato alla prima esercitazione troverete un elenco (non completo) di questi database 11
12 Sistemi di interrogazione alle banche dati (sistemi di "retrieval ) Esistono dei sistemi integrati che permettono di interrogare, attraverso il web, in modo semplice ed intuitivo le banche dati biologiche. I tre sistemi principali sono: ENTREZ associato a GENBANK SRS associato a EMBL DBGET associato a DDBJ I sistemi integrati forniscono una interfaccia WEB omogenea a tutti i database gestiti dal sistema. FORM DI QUERY 1 2 SISTEMA INTEGRATO PAGINA DI RISPOSTA 5 PC UTENTE RETE 4 DB1 3 DBn COMPUTER SERVER REMOTO 12


13 SRS è un sistema aperto, può essere installato su calcolatori differenti (server) e può integrare banche dati strutturate su altri server SRS o altre banche dati previa strutturazione o indicizzazione nel sistema SRS. Come SRS, anche ENTREZ è un sistema disponibile via web per la ricerca e l estrazione dei dati da banche dati di sequenze nucleotidiche, proteiche, dalla banca dati bibliografica MEDLINE, dalla banca dati delle malattie mendeliane OMIM, e da ogni banca dati sviluppata dall NCBI. E un sistema chiuso e non è possibile ottenere il software che gestisce il sistema. 13

, all EBI esistono siti")
14 Esistono molti tipi di siti e/o database biologici, in questo corso ci soffermeremo solo su alcuni Qui sono riportati i link di Entrez (NCBI), all EBI esistono siti corrispondenti 14


15 Qui invece sono riportati i link presenti all ABI con EB-eye la semplice interfaccia grafica All EBI è comunque possibile accedere direttamente al sistema SRS per formulare query complesse 15
 Da qui si possono scaricare interi database di sequenze in formato flat-file testuale (via FTP) Osservate che le query, sono molto")
16 NUCLEOTIDE (versione 2012) Da qui si possono scaricare interi database di sequenze in formato flat-file testuale (via FTP) Osservate che le query, sono molto simili a quelle di PubMed. In generale, l NCBI sta adottando uno stesso metodo di immissioni dati per le ricerche nei propri database 16
17 Advanced Search (versione 2012) Operatori Multirighe Help menù (dal 2012) (dal 2012) 17
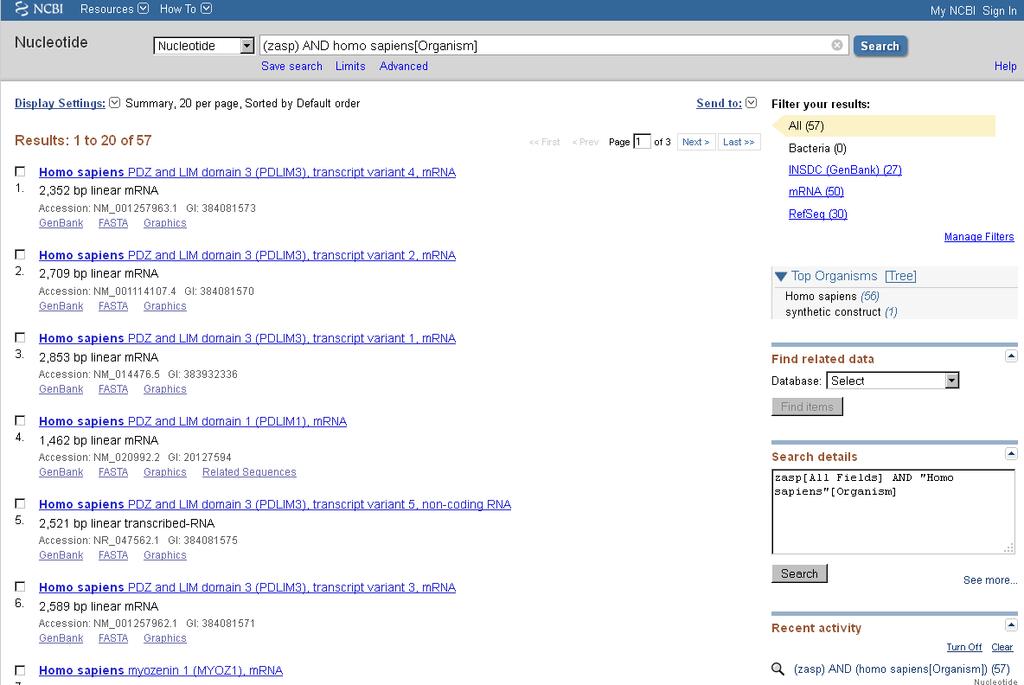
18 18
19 Vedere Sample GenBank Record per un esempio completo di record nucleotidico (file allegato alle lezioni Sample GenBamk Record.pdf oppure al sito ) Attenzione che il nome dei campi dei record ottenuti dall EMBL possono essere rappresentati in modo differente. (vedi esempio qui sotto) 19
20 In questo corso ci limiteremo ad approfondire i contenuti solo di particolari campi dei alcuni database biologici. Fra parentesi gli headers (a due caratteri) dei corrispondenti campi utilizzati dall EMBL ACCESSION (AC): codice identificativo del record. SOURCE (OS): abbreviazione del nome dell organismo (specificato poi meglio qui sotto). -ORGANISM (OC): The formal scientific name for the source organism (genus and species, where appropriate) and its lineage, based on the phylogenetic classification scheme used in the NCBI Taxonomy Database. REFERENCE (RN): riferimenti bibliografici (nei relativi sottocampi). FEATURES (FT): Regioni o siti della sequenza considerati interessanti. Descritti in più sottocampi. I più importanti: - source: in un record, può essere riportata una lunga sequenza. E possibile scrivere delle annotazioni a parti specifiche della sequenza facendo riferimento alla localizzazione seguita da una o più righe che iniziano con / - gene: dati del relativo gene (se esiste ed è conosciuto): inizio e fine della sequenza, poi negli altri sottocampi, nome del gene ed eventuali link (db_xref). - 5 UTR: la sequenza 5 UTR (inizio e fine). - CDS: la sequenza codificante (inizio e fine) e poi negli altri sottocampi link al DB (protein_id) (ad altri DB (db_xref), da ricordare link ad OMIM: /db_xref= MIM xx, traduzione (se conosciuta), - 3 UTR: la sequenza 3 UTR (inizio e fine). ORIGIN (SQ) : la sequenza scritta come stringa di caratteri. 20
21 LOCUS DEFINITION ACCESSION VERSION KEYWORDS SOURCE ORGANISM REFERENCE AUTHORS TITLE JOURNAL PUBMED REFERENCE AUTHORS TITLE JOURNAL PUBMED REFERENCE AUTHORS TITLE JOURNAL MMAJ bp mrna linear ROD 19-MAR-2001 Mus musculus telethonin complete cdna. AJ AJ GI: telethonin. Mus musculus (house mouse) Mus musculus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Euarchontoglires; Glires; Rodentia; Sciurognathi; Muroidea; Muridae; Murinae; Mus. 1 Valle,G., Faulkner,G., De Antoni,A., Pacchioni,B., Pallavicini,A., Pandolfo,D., Tiso,N., Toppo,S., Trevisan,S. and Lanfranchi,G. Telethonin, a novel sarcomeric protein of heart and skeletal muscle FEBS Lett. 415 (2), (1997) Moreira,E.S., Wiltshire,T.J., Faulkner,G., Nilforoushan,A., Vainzof,M., Suzuki,O.T., Valle,G., Reeves,R., Zatz,M., Passos-Bueno,M.R. and Jenne,D.E. Limb-girdle muscular dystrophy type 2G is caused by mutations in the gene encoding the sarcomeric protein telethonin Nat. Genet. 24 (2), (2000) (bases 1 to 949) Ievolella,C. Direct Submission Submitted (10-FEB-1998) Ievolella C., CRIBI Biotechnology Centre, Universita' di Padova, viale G.Colombo 3, 35121, ITALY 21
22 Cross-Ref. Traduzione Struttura delle FEATURES o FT (Feature Table) (Regioni o siti della sequenza considerati interessanti): I campi cerchiati sono importanti; necessario ricordare il loro significato Per questo, vedere nelle px diapositive Possono essere riportate più regioni particolari. Ognuna è caratterizzata dalla definizione (es. source, gene, 5 UTR ecc.) seguita dalla localizzazione (location) punto di inizio e di fine della regione, seguite da una o più righe che iniziano con / e che riportano note caratteristiche di tale regione (Qualifiers). 22
23 Se nella sequenza esistono regioni geniche, allora vengono riportati anche i dati relativi al gene, alle regioni codificanti (CDS) e alla sequenza proteica La regione della sequenza identificata come gene (inizio- fine) (in questo caso corrisponde alla sequenza completa) CDS (coding sequence): la sequenza codificante inizia in 15 e finisce in 518 GO (GENE ONTOLOGY) Link al DB delle proteine Link ad OMIM (database di malattie genetiche Sequenza Proteina 23
24 Altri dettagli delle Features Source: in un record può essere riportata una lunga sequenza. E possibile scrivere delle annotazioni a parti specifiche della sequenza facendo riferimento alla localizzazione seguita da una o più righe che iniziano con / con riportate particolari annotazioni specifiche. 5 UTR: Qui è riporta (se si conosce) la localizzazione della sequenza NON codificante posta a monte dell mrna. In questo caso 1-36 CDS (coding sequence): la sequenza codificante inizia in 37e finisce in UTR: Qui è riporta (se si conosce) la localizzazione della sequenza NON codificante posta a valle dell mrna 24
25 IL FORMATO FASTA Spesso i programmi che effettuano analisi bioinformatiche sulle sequenze richiedono che esse vengano date come input in questo formato particolare: FASTA è un formato per la descrizione di una sequenza grezza. Consiste essenzialmente in una parte iniziale di intestazione, di solito limitata a una linea di testo, e da una o più linee che riportano una sequenza di DNA o di amminoacidi usando l alfabeto standard. Ecco un esempio: Riga di intestazione Interruzione di riga >37463.f1 g83244 telethonin ecc. ACGTGACTGCTACGTACGGGCGTTACGACTGCTACGACGCATGCTATGTC GTAGCAGCCGTGTACACGTGTTTATTCGTAGGGCTTCTA > Simbolo d inizio della riga di intestazione Sequenza L intestazione (la prima riga del file precedente) `e riconoscibile perchè ha inizio con il simbolo >. Il testo che segue tale simbolo nella stessa riga può essere strutturato liberamente: di solito, la prima cosa che si trova scritta `e un accession number, ossia l identificatore della sequenza che ne permette il reperimento 25


26 SEQUENZA Per recuperare la sequenza nucleotidica in formato FASTA 26
27 Database NON RIDONDANTI : RefSeq, UniGene, Gene Come già detto: nei database primari sono inserite tutte le sequenze conosciute ottenute sperimentalmente e/o ricostruite. La stessa regione genomica o lo stesso trascritto possono essere stati sequenziati più volte. Quindi ci aspettiamo, in molti casi, che la stessa sequenza sia presente più volte. Per evitare problemi di ridondanza sono stati creati dei database semplificati senza ripetizioni di informazioni. In particolare: In RefSeq sono rappresentate, in modo non ridondante, tutte le sequenze genomiche, sequenze di mrna e di proteine. In UniGene Sono rappresentate in modo non ridondante, le sequenze ottenute dal sequenziamento dei trascritti (mrna) Gene: è un sottoinsieme di RefSeq con rappresentate solo le sequenze geniche. Domanda: che differenza c è tra una sequenza genica ed una sequenza di un trascritto? 27
 collection aims to provide a comprehensive, integrated, non-redundant set of sequences, including genomic DNA, transcript (RNA), and protein products.")

28 The Reference Sequence (RefSeq) collection aims to provide a comprehensive, integrated, non-redundant set of sequences, including genomic DNA, transcript (RNA), and protein products. RefSeq is a baseline for medical, functional, and diversity studies; they provide a stable reference for genome annotation, gene identification and characterization, mutation and polymorphism analysis, expression studies, and comparative analyses RefSeq are derived from GenBank records but differ in that each RefSeq is a synthesis of information, not an archived unit of primary research data. Similar to a review article in the literature, a RefSeq represents the consolidation of information by a particular group at a particular time. UniGene: An Organized View of the Transcriptome. Each UniGene entry is a set of transcript sequences that appear to come from the same transcription locus (gene or expressed pseudogene), together with information on protein similarities, gene expression, cdna clone reagents, and genomic location. 28
29 Gene ( oppure Entrez Gene is NCBI's database for gene-specific information. It does not include all known or predicted genes; instead Entrez Gene focuses on the genomes that have been completely sequenced, that have an active research community to contribute gene-specific information, or that are scheduled for intense sequence analysis. The content of Entrez Gene represents the result of curation and automated integration of data from NCBI's Reference Sequence project (RefSeq) Continua 29

30 Si aprono 4 paragrafi: - Summary - Genomic context - Genomic regions, transripts and product - Bibliography Continua record NCBI-Gene 30

31 Continua record NCBI-Gene Importante: le frecce indicano il senso della trascrizione Per questa parte, vedere px diapositiva 31
32 Vengono riportate 6 isoforme (varianti dello stesso gene), dovute a splicing alternativo dello stesso gene Osservate gli introni e gli esoni, le regioni codificanti e le regioni UTR Esoni: sono rappresentati dalle linee più spesse Introni: sono rappresentati dalle linee più sottili Le regioni UTR sono di colore più chiaro Importante osservare il senso della trascrizione: un gene può essere codificato dal filamento senso (detto anche + o forward ) o dal filamento antisenso (detto anche - o reverse) Possibili domande: Quanti introni, quanti esoni sono rappresentati? Il gene è codificato dal filamento + (forwars) oppure dal filamento - (reverse)? Qual è il senso della trascrizione? Quante isoforme sono visibili? Le diverse isoforme sono dovute a splicing alternativo? 32
33 Banche Dati proteiche Un secondo grande aggregato di banche dati è quello relativo alle proteine. Esistono Database di strutture come PDB, che è la Banca dati di riferimento per i dati strutturali 3D di proteine ottenuti, ad esempio, mediante analisi cristallografiche ai raggi X e/o NMR (risonanza magnetica). In questo corso, però, ci interesseremo solo di database di sequenze proteiche, in particolare a) NCBI-Protein e b) UniProtKB. Tenere presente che, le sequenze proteiche possono essere ottenute tramite: -Sequenziamento diretto della proteina -Traduzione da sequenze nucleotidiche per le quali sia stata individuata o predetta la regione codificante (CDS) di un gene a) NCBI-Protein: The Protein database is a collection of sequences from several sources, including translations from annotated coding regions in GenBank, RefSeq and TPA (Third Party Annotation), as well as records from SwissProt, PIR, PRF, and PDB. Il sito, da dove si possono effettuare ricerche, è simile a quello degli altri database dell NCBI. Anche la struttura dei record è molto simile a quelli già visti per i DB di sequenze nucleotidiche. Durante un esercitazione, proveremo a fare una interrogazione a questa banca dati. 33
 banca dati di riferimento (protein knowledgebase) sviluppata a Ginevra. Si divide in due sezioni: SWISS-PROT Contiene informazioni accuratamente annotate, spesso a mano.")
34 In questo sito, oltre al database UniProtKB, esistono anche altri interessanti DB e utili tool per analizzare proteine b) UniProtKB ( ) banca dati di riferimento (protein knowledgebase) sviluppata a Ginevra. Si divide in due sezioni: SWISS-PROT Contiene informazioni accuratamente annotate, spesso a mano. ( In maggio 2011 esistevano entries) TrEMBL (TRanslated EMBL) risultato della traduzione automatica in aminoacidi di tutte le sequenze annotate nella banca dati EMBL come codificanti proteine; supplemento a SWISS-PROT. (In maggio 2011 esistevano entries) The mission of UniProt is to provide the scientific community with a comprehensive, highquality and freely accessible resource of protein sequence and functional information. Questo Database è molto interessante perché, oltre che riportare le principali caratteristiche delle proteine (sequenze, strutture, ecc.), vengono riportati anche altri dati come: -Descrizione dettagliata della funzione della proteina -Eventuali domini funzionali -Interazioni con altre proteine -Localizzazione subcellulare -Espressione tissutale (in quali tipi di cellule/tessuti viene espressa la proteina) -Eventuali variazioni/mutazioni con riferimenti bibliografici -Eventuali coinvolgimenti in malattie genetiche -Similarità con altre proteine 34
35 Alcuni paragrafi riportati in un foglio html, ottenuto da UniProtKB Continua record Swiss-Prot 35
36 Continua record Swiss-Prot >sp O15273 TELT_HUMAN Telethonin OS=Homo sapiens GN=TCAP PE=1 SV=1 MATSELSCEVSEENCERREAFWAEWKDLTLSTRPEEGCSLHEEDTQRHETYHQQGQCQVL VQRSPWLMMRMGILGRGLQEYQLPYQRVLPLPIFTPAKMGATKEEREDTPIQLQELLALE TALGGQCVDRQEVAEITKQLPPVVPVSKPGALRRSLSRSMSQEAQRG 36
37 Domini proteici Molte proteine, specialmente quelle di grandi dimensioni, sono formate da più parti funzionali organizzate in strutture tridimensionali distinte che vengono chiamate domini proteici. E una sottostruttura di una catena polipeptidica che si ripiega in una struttura compatta e stabile, in grado di esercitare una particolare funzione. Esempio: l emoglobina è formata da 4 domini legati covalentemente tra loro. La Mioglobina, invece, è formata da un solo dominio (simile a quelli dell emoglobina) Esempio: alcuni fattori di trascrizione hanno due domini, uno in grado legarsi con una particolare sequenza di DNA, l altro in grado di attivare la trascrizione. Fattore di trascrizione activation domain Complesso della trascrizione DNA binding domain DNA Seq. DNA promotore 37
 contenenti domini PDZ e LIM.")
38 Altri esempi di domini proteici Src Tyrosine Kinase SH3 Attività di regolazione SH2 Attività di regolazione Kinase: dominio chinasico con attività catalitica Altro esempio: Proteine (Zasp, ALP, CLP, ecc.) contenenti domini PDZ e LIM. Questi domini possono interagire e legare altre proteine Proteine formate da più di un dominio si sono probabilmente evolute per fusione di geni che contenevano tali domini e questo è stato un fattore importante nell evoluzione. nell evoluzione 38
39 Esempi: Domini LIM associati ad altri domini (Sono riportate solo alcune strutture proteiche contenenti il LIM domain) PFAM: PROSITE: SMART: InterPro: sono database contenenti domini funzionali delle proteine 39

40 Pfam The Pfam database is a large collection of protein families. Proteins are generally composed of one or more functional regions, commonly termed domains. Different combinations of domains give rise to the diverse range of proteins found in nature. The identification of domains that occur within proteins can therefore provide insights into their function. Esempio: voglio ricerca i domini presenti nella proteina ZASP Continua 40

41 Continua da scelta PDZ Domain Possono essere visualizzati le principali architetture proteiche che possiedono domini PDZ 41

42 Mutazioni (alterazioni della sequenza nucleotidica di un gene) possono riflettersi in alterazioni della funzionalità della proteina da esso codificata. Questo mutazioni possono causare le cosiddette malattie genetiche. Esempio: una mutazione a carico del gene della β globina fa sì che una particolare base del gene venga sostituita con un altra, ciò altera il codone e nella proteina ciò si riflette nella sostituzione di un glutamato con una valina e in una ridotta funzionalità della proteina che causa una malattia genetica detta anemia a cellule falciformi (anemia falciforme). Il database OMIM cataloga le malattie genetiche, fornisce descrizioni particolareggiate delle malattie e delle possibili cause (mutazioni). In laboratorio approfondiremo ed utilizzeremo questo DB 42

43 Database di malattie genetiche (umane) Anche qui possiamo fare ricerche complesse Esempio di una query (telethonin): da notare l estensiva descrizione di quanto noto sulla/e malattia/e determinate da mutazioni a carico del gene in esame 43
44 Purtroppo non esiste un modo univoco per indicare un gene (esempio potete trovare scritto subunit 4 o subunit iv (nella prima esercitazione affronterete questo problema)), anche i geni che io ho chiamato telethonin o zasp possono essere scritti in modi differenti (tcap, LDB3). Questo crea confusione e non facilita la ricerca informatica The Human Genome Organisation (HUGO) (è una organizzazione scientifica internazionale che promuove e sostiene le collaborazioni internazionali nella genetica umana) ha istituito un comitato allo scopo di dare un unico nome significativo a tutti i geni umani. Con questo intento è stato costruito il database HGNC (HUGO Gene Nomenclature Committee) 44
, per non generare confusioni è però necessario usare una terminologia")
45 Oltre che esistere differenti nomi per lo stesso gene/proteina, possono esistere o essere adottati anche differenti modi per descrivere le loro funzioni e le loro localizzazioni. A volte è corretto assegnare differenti funzioni ad una molecola biologica (spesso una proteina svolge più di una funzione), per non generare confusioni è però necessario usare una terminologia univoca per ogni funzione. Per questo motivo è stato fondato il database GeneOntology che fornisce una definizione precisa del ruolo svolto dalle singole proteine tramite un vocabolario (delle ontologie) che consenta di definire in modo corretto e non arbitrario il o i processi biologici cui una proteina partecipa, la/e sue funzioni molecolari e la/e sue localizzazioni cellulare. Troverete spesso link con la sigla GO questi rimandano al database della gene ontology 45
46 46
Principali Database biologici
 Principali Database biologici Acidi nucleici: -Sequenze DNA genomico -Sequenze di trascritti (mrna) La maggior quantità di dati biologici presenti nei database è rappresentata da sequenze di acidi nucleici
Principali Database biologici Acidi nucleici: -Sequenze DNA genomico -Sequenze di trascritti (mrna) La maggior quantità di dati biologici presenti nei database è rappresentata da sequenze di acidi nucleici
Banche Dati proteiche
 Banche Dati proteiche Un altro grande database è UniProt, The Universal Protein Resource (http://www.uniprot.org/) nel quale sono radunate le sequenze proteiche, e le annotazione delle stesse, ottenute
Banche Dati proteiche Un altro grande database è UniProt, The Universal Protein Resource (http://www.uniprot.org/) nel quale sono radunate le sequenze proteiche, e le annotazione delle stesse, ottenute
Informatica e Bioinformatica A. A
 GQuery (http://www.ncbi.nlm.nih.gov/gquery/) è il punto di partenza per eseguire query su tutti o parte dei database dell NCBI: si basa sul sistema di interrogazione ENTREZ Informatica e Bioinformatica
GQuery (http://www.ncbi.nlm.nih.gov/gquery/) è il punto di partenza per eseguire query su tutti o parte dei database dell NCBI: si basa sul sistema di interrogazione ENTREZ Informatica e Bioinformatica
Laboratorio di Bioinformatica I. Parte 2. Dott. Sergio Marin Vargas (2014 / 2015)
") Laboratorio di Bioinformatica I Banche dati Parte 2 Dott. Sergio Marin Vargas (2014 / 2015) Google Scholar https://scholar.google.it/ E un motore di ricerca di Google, specializzato nella ricerca di articoli
Laboratorio di Bioinformatica I Banche dati Parte 2 Dott. Sergio Marin Vargas (2014 / 2015) Google Scholar https://scholar.google.it/ E un motore di ricerca di Google, specializzato nella ricerca di articoli
Corso di Elementi di Bioinformatica
 Corso di Elementi di Bioinformatica Laurea Triennale in Informatica I dati e le banche dati in Bioinformatica Anno Accademico 2015-2016 Docente del laboratorio: Raffaella Rizzi 1 Il DNA (oggetto biologico)
Corso di Elementi di Bioinformatica Laurea Triennale in Informatica I dati e le banche dati in Bioinformatica Anno Accademico 2015-2016 Docente del laboratorio: Raffaella Rizzi 1 Il DNA (oggetto biologico)
Bellini Lara matricola: Tesina di Biologia Molecolare 2
 Bellini Lara matricola: 594736 Tesina di Biologia Molecolare 2 Argomento: Scegli una proteina di Drosophila e trovala in Uniprot.Descrivi le informazioni presenti nel record ed i collegamenti a risorse
Bellini Lara matricola: 594736 Tesina di Biologia Molecolare 2 Argomento: Scegli una proteina di Drosophila e trovala in Uniprot.Descrivi le informazioni presenti nel record ed i collegamenti a risorse
DataBase Biologici 1
 DataBase Biologici 1 Lo sviluppo di tecnologie strumentali sempre più sofisticate ha portato ad una enorme produzione di dati biologici. Per la gestione di questi dati è quindi necessario disporre di potenti
DataBase Biologici 1 Lo sviluppo di tecnologie strumentali sempre più sofisticate ha portato ad una enorme produzione di dati biologici. Per la gestione di questi dati è quindi necessario disporre di potenti
Database biologici (banche di dati biologici)
") 1 Lo sviluppo di tecnologie strumentali sempre più sofisticate ha portato ad una enorme produzione di dati biologici. Per la gestione di questi dati è quindi necessario disporre di potenti sistemi di archiviazione
1 Lo sviluppo di tecnologie strumentali sempre più sofisticate ha portato ad una enorme produzione di dati biologici. Per la gestione di questi dati è quindi necessario disporre di potenti sistemi di archiviazione
Laboratorio di Elementi di Bioinformatica
 Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2016/2017 I dati in Bioinformatica Docente del laboratorio: Raffaella Rizzi 1 Il DNA (oggetto biologico)
Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2016/2017 I dati in Bioinformatica Docente del laboratorio: Raffaella Rizzi 1 Il DNA (oggetto biologico)
Laboratorio di Bioinformatica I. Parte 1. Dott. Sergio Marin Vargas (2014 / 2015)
") Laboratorio di Bioinformatica I Banche dati Parte 1 Dott. Sergio Marin Vargas (2014 / 2015) Introduzione a NCBI National Center for Biotechnology Information (NCBI) http://www.ncbi.nlm.nih.gov/ NCBI Databases
Laboratorio di Bioinformatica I Banche dati Parte 1 Dott. Sergio Marin Vargas (2014 / 2015) Introduzione a NCBI National Center for Biotechnology Information (NCBI) http://www.ncbi.nlm.nih.gov/ NCBI Databases
GENOMA. Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine CONTENUTO FUNZIONE. Progetti genoma in centinaia di organismi
 GENOMA EVOLUZIONE CONTENUTO FUNZIONE STRUTTURA Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine Progetti genoma in centinaia di organismi Importante la sintenia tra i genomi The
GENOMA EVOLUZIONE CONTENUTO FUNZIONE STRUTTURA Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine Progetti genoma in centinaia di organismi Importante la sintenia tra i genomi The
Provate rispondere alle domande, se ci riuscirete, sarete pronti a superare l esame per quanto riguarda la parte di bioinformatica.
 Per aiutarvi ho elaborato (frettolosamente) questi quesiti che dovrebbero aiutarvi ad individuare gli argomenti importanti del corso ed a darvi un idea delle domande che potrebbero esservi poste all esame.
Per aiutarvi ho elaborato (frettolosamente) questi quesiti che dovrebbero aiutarvi ad individuare gli argomenti importanti del corso ed a darvi un idea delle domande che potrebbero esservi poste all esame.
Laboratorio di Elementi di Bioinformatica
 Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2015/2016 Parsing di un file in formato EMBL (parte I) Docente del laboratorio: Raffaella Rizzi 1 Esercizio
Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2015/2016 Parsing di un file in formato EMBL (parte I) Docente del laboratorio: Raffaella Rizzi 1 Esercizio
Il progetto Genoma Umano è iniziato nel E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA.
 Il progetto Genoma Umano è iniziato nel 1990. E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA. Progetto internazionale finanziato da vari paesi, affidato
Il progetto Genoma Umano è iniziato nel 1990. E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA. Progetto internazionale finanziato da vari paesi, affidato
Bioinformatica. Analisi del genoma
 Bioinformatica Analisi del genoma GABRIELLA TRUCCO CREMA, 5 APRILE 2017 Cosa è il genoma? Insieme delle informazioni biologiche, depositate nella sequenza di DNA, necessarie alla costruzione e mantenimento
Bioinformatica Analisi del genoma GABRIELLA TRUCCO CREMA, 5 APRILE 2017 Cosa è il genoma? Insieme delle informazioni biologiche, depositate nella sequenza di DNA, necessarie alla costruzione e mantenimento
Laboratorio di Elementi di Bioinformatica
 Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2017/2018 ati in Bioinformatica ocente: Raffaella Rizzi 1 Outline ü Cos è un NA genomico e un RNA? Outline
Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2017/2018 ati in Bioinformatica ocente: Raffaella Rizzi 1 Outline ü Cos è un NA genomico e un RNA? Outline
GENE PREDICTION AND ANNOTATION
 GENE PREDICTION AND ANNOTATION ...AGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTG ATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGAC
GENE PREDICTION AND ANNOTATION ...AGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTG ATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGACGATGGAGTACGATCGTGATGTCTAGCTGATGTCAGTAAGGATGAC
Dal gene alla proteina
 Dal gene alla proteina Il collegamento tra geni e proteine La trascrizione e la traduzione sono i due principali processi che legano il gene alla proteina: uno sguardo panoramico Le informazioni genetiche
Dal gene alla proteina Il collegamento tra geni e proteine La trascrizione e la traduzione sono i due principali processi che legano il gene alla proteina: uno sguardo panoramico Le informazioni genetiche
Informatica e Bioinformatica: Basi di Dati
 Informatica e Bioinformatica: Date TBD Bioinformatica I costi di sequenziamento e di hardware descrescono vertiginosamente si hanno a disposizione sempre più dati e hardware sempre più potente e meno costoso...
Informatica e Bioinformatica: Date TBD Bioinformatica I costi di sequenziamento e di hardware descrescono vertiginosamente si hanno a disposizione sempre più dati e hardware sempre più potente e meno costoso...
Interazioni proteina-dna
 Interazioni proteina-dna 1) Proteine che legano la doppia elica del DNA in maniera non sequenza-specifica: histone-like proteins (HU protein) 2) Proteine che legano strutture particolari del DNA: - single
Interazioni proteina-dna 1) Proteine che legano la doppia elica del DNA in maniera non sequenza-specifica: histone-like proteins (HU protein) 2) Proteine che legano strutture particolari del DNA: - single
Introduzione alla Genomica
 Laboratorio di Bioinformatica I Introduzione alla Genomica Dott. Sergio Marin Vargas (2014 / 2015) Il Genoma umano Gene codificanti proteine Gene non codificanti proteine Geni codificanti proteine 3 Il
Laboratorio di Bioinformatica I Introduzione alla Genomica Dott. Sergio Marin Vargas (2014 / 2015) Il Genoma umano Gene codificanti proteine Gene non codificanti proteine Geni codificanti proteine 3 Il
Banche dati molti dati sulle proteine derivano dalle banche dati primarie
 Banche dati Banche dati Si possono raggruppare in varie categorie in base al tipo di dato biologico che raccolgono e organizzano, ma ce ne sono alcune che sono da considerarsi fondamentali: - banche dati
Banche dati Banche dati Si possono raggruppare in varie categorie in base al tipo di dato biologico che raccolgono e organizzano, ma ce ne sono alcune che sono da considerarsi fondamentali: - banche dati
07/01/2015. Come si ferma una macchina in corsa? Il terminatore. Terminazione intrinseca (rho-indipendente)
") Come si ferma una macchina in corsa? Il terminatore Terminazione intrinseca (rho-indipendente) Terminazione dipendente dal fattore Rho (r) 1 Operoni: gruppi di geni parte di una unica unità trascrizionale
Come si ferma una macchina in corsa? Il terminatore Terminazione intrinseca (rho-indipendente) Terminazione dipendente dal fattore Rho (r) 1 Operoni: gruppi di geni parte di una unica unità trascrizionale
DOGMA CENTRALE DELLA BIOLOGIA. Secondo il dogma centrale della biologia, il DNA dirige la. sintesi del RNA che a sua volta guida la sintesi delle
 DOGMA CENTRALE DELLA BIOLOGIA Secondo il dogma centrale della biologia, il DNA dirige la sintesi del RNA che a sua volta guida la sintesi delle proteine. Tuttavia il flusso unidirezionale di informazioni
DOGMA CENTRALE DELLA BIOLOGIA Secondo il dogma centrale della biologia, il DNA dirige la sintesi del RNA che a sua volta guida la sintesi delle proteine. Tuttavia il flusso unidirezionale di informazioni
Bioinformatica ed applicazioni di bioinformatica strutturale!
 Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
TRASCRIZIONE DEL DNA. Formazione mrna
 TRASCRIZIONE DEL DNA Formazione mrna Trascrizione Processo mediante il quale l informazione contenuta in una sequenza di DNA (gene) viene copiata in una sequenza complementare di RNA dall enzima RNA polimerasi
TRASCRIZIONE DEL DNA Formazione mrna Trascrizione Processo mediante il quale l informazione contenuta in una sequenza di DNA (gene) viene copiata in una sequenza complementare di RNA dall enzima RNA polimerasi
Sommario. Presentazione dell opera Ringraziamenti
 Sommario Presentazione dell opera Ringraziamenti XI XII Capitolo 1 Introduzione alla bioinformatica 1 1.1 Cenni introduttivi 1 1.2 Pietre miliari della bioinformatica 2 1.3 Infrastrutture bioinformatiche
Sommario Presentazione dell opera Ringraziamenti XI XII Capitolo 1 Introduzione alla bioinformatica 1 1.1 Cenni introduttivi 1 1.2 Pietre miliari della bioinformatica 2 1.3 Infrastrutture bioinformatiche
Il Corso sarà tenuto nei giorni di Lunedì, Mercoledì e Venerdì dalle ore 17 alle ore 19.
 Docente: Prof. Alfredo Ferro Il Corso sarà tenuto nei giorni di Lunedì, Mercoledì e Venerdì dalle ore 17 alle ore 19. Programma del Corso DATA ARGOMENTO 09/03/2011 Introduzione al corso. Slides Panoramica
Docente: Prof. Alfredo Ferro Il Corso sarà tenuto nei giorni di Lunedì, Mercoledì e Venerdì dalle ore 17 alle ore 19. Programma del Corso DATA ARGOMENTO 09/03/2011 Introduzione al corso. Slides Panoramica
Laboratorio di Elementi di Bioinformatica
 Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2016/2017 Formato GTF per annotare un gene Docente del laboratorio: Raffaella Rizzi 1 GTF (Gene Transfer
Laboratorio di Elementi di Bioinformatica Laurea Triennale in Informatica (codice: E3101Q116) AA 2016/2017 Formato GTF per annotare un gene Docente del laboratorio: Raffaella Rizzi 1 GTF (Gene Transfer
L organizzazione del genoma. Prof. Savino; dispense di Biologia Molecolare, Corso di Laurea in Biotecnologie
 L organizzazione del genoma L organizzazione del genoma Fino ad ora abiamo studiato la regolazione dell espressione genica prendendo come esempio singoli geni dei batteri. Ma quanti geni ci sono in un
L organizzazione del genoma L organizzazione del genoma Fino ad ora abiamo studiato la regolazione dell espressione genica prendendo come esempio singoli geni dei batteri. Ma quanti geni ci sono in un
IPOTESI UN GENE-UN ENZIMA
 IPOTESI UN GENE-UN ENZIMA DNA: contiene tutte le informazioni per definire lo sviluppo e la fisiologia della cellula: ma come svolge questa funzione? Beadle e Tatum (1941): studiando mutanti della comune
IPOTESI UN GENE-UN ENZIMA DNA: contiene tutte le informazioni per definire lo sviluppo e la fisiologia della cellula: ma come svolge questa funzione? Beadle e Tatum (1941): studiando mutanti della comune
Database genomici primari
 Esercitazione di laboratorio di bioinformatica Seconda parte: I principali database genomici e proteomici Slide ricavate dal corso di Laboratorio Integrato di Biologia Computazionale Francesca Cordero
Esercitazione di laboratorio di bioinformatica Seconda parte: I principali database genomici e proteomici Slide ricavate dal corso di Laboratorio Integrato di Biologia Computazionale Francesca Cordero
Ricevimento Studenti: Lunedì previa prenotazione. Cenci lab
 Cenci lab Giovanni Cenci Dip.to Biologia e Biotecnologie C. Darwin Sezione Genetica Piano 2 -Citofono 3/4 0649912-655 (office) 0649912-843 (lab) giovanni.cenci@uniroma1.it Ricevimento Studenti: Lunedì
Cenci lab Giovanni Cenci Dip.to Biologia e Biotecnologie C. Darwin Sezione Genetica Piano 2 -Citofono 3/4 0649912-655 (office) 0649912-843 (lab) giovanni.cenci@uniroma1.it Ricevimento Studenti: Lunedì
Tesina di Biologia Molecolare II
 MELATO GIULIA 595033 Tesina di Biologia Molecolare II Mostra un albero filogenetico con la relazione tra Uomo, Topo e Ratto. Che banca dati è disponibile per quest'ultimo organismo? Descrivi alcune caratteristiche
MELATO GIULIA 595033 Tesina di Biologia Molecolare II Mostra un albero filogenetico con la relazione tra Uomo, Topo e Ratto. Che banca dati è disponibile per quest'ultimo organismo? Descrivi alcune caratteristiche
Basi di dati biologiche
 Basi di dati biologiche Seminario per il corso di Basi di Dati II Luana Rinaldi luana.rinaldi@gmail.com AGENDA: Introduzione alla bioinformatica; Concetti Biologici; Banche dati biologiche; Collaborazioni
Basi di dati biologiche Seminario per il corso di Basi di Dati II Luana Rinaldi luana.rinaldi@gmail.com AGENDA: Introduzione alla bioinformatica; Concetti Biologici; Banche dati biologiche; Collaborazioni
Nozioni base di Biologia
 Nozioni base di Biologia Ripercorriamo velocemente i principali concetti di biologia indispensabili per capire la Bioinformatica: verranno approfonditi in altri corsi. Gli organismi viventi possiedono
Nozioni base di Biologia Ripercorriamo velocemente i principali concetti di biologia indispensabili per capire la Bioinformatica: verranno approfonditi in altri corsi. Gli organismi viventi possiedono
RELAZIONE di BIOLOGIA MOLECOLARE
 NOME: Marini Selena MATRICOLA: 592330 RELAZIONE di BIOLOGIA MOLECOLARE CHE ORGANISMO MODELLO È DICTYOSTELIUM? CHE RISORSE BIOINFORMATICHE AGEVOLANO I RICERCATORI CHE LO STUDIANO? Dictyostelium è un genere
NOME: Marini Selena MATRICOLA: 592330 RELAZIONE di BIOLOGIA MOLECOLARE CHE ORGANISMO MODELLO È DICTYOSTELIUM? CHE RISORSE BIOINFORMATICHE AGEVOLANO I RICERCATORI CHE LO STUDIANO? Dictyostelium è un genere
LA BIOLOGIA MOLECOLARE E UNA BRANCA DELLA BIOLOGIA CHE STUDIA LE BASI MOLECOLARI DELLE FUNZIONI BIOLOGICHE, PONENDO UNA PARTICOLARE ATTENZIONE A QUEI
 CONCETTI DI BASE LA BIOLOGIA MOLECOLARE E UNA BRANCA DELLA BIOLOGIA CHE STUDIA LE BASI MOLECOLARI DELLE FUNZIONI BIOLOGICHE, PONENDO UNA PARTICOLARE ATTENZIONE A QUEI PROCESSI CHE COINVOLGONO GLI ACIDI
CONCETTI DI BASE LA BIOLOGIA MOLECOLARE E UNA BRANCA DELLA BIOLOGIA CHE STUDIA LE BASI MOLECOLARI DELLE FUNZIONI BIOLOGICHE, PONENDO UNA PARTICOLARE ATTENZIONE A QUEI PROCESSI CHE COINVOLGONO GLI ACIDI
Genomica, proteomica, genomica strutturale, banche dati.
 Genomica, proteomica, genomica strutturale, banche dati. Alcune pietre miliari della biologia anno risultato 1866 Mendel scopre i geni 1944 il DNA è il materiale genetico 1951 prima sequenza di una proteina
Genomica, proteomica, genomica strutturale, banche dati. Alcune pietre miliari della biologia anno risultato 1866 Mendel scopre i geni 1944 il DNA è il materiale genetico 1951 prima sequenza di una proteina
Bioinformatica. :studio dei problemi biologici attraverso le metodologie dell'informatica
 Bioinformatica :studio dei problemi biologici attraverso le metodologie dell'informatica Sinomimi: biochimica computazionale, biologia molecolare computazionale Viceversa: Biocomputazione, algoritmi genetici,
Bioinformatica :studio dei problemi biologici attraverso le metodologie dell'informatica Sinomimi: biochimica computazionale, biologia molecolare computazionale Viceversa: Biocomputazione, algoritmi genetici,
Patologie da analizzare
 Fasi cruciali Scelta della patologia da analizzare Scelta del campione da analizzare Scelta dell approccio da utilizzare Scelta della tecnica da utilizzare Analisi statistica del dati Conferme con approcci
Fasi cruciali Scelta della patologia da analizzare Scelta del campione da analizzare Scelta dell approccio da utilizzare Scelta della tecnica da utilizzare Analisi statistica del dati Conferme con approcci
Strategie di annotazione di geni e genomi
 Strategie di annotazione di geni e genomi Dr. Giovanni Emiliani giovanni.emiliani@unifi.it Bioinformatica A.A. 2011-1012 Concetti generali Le nuove tecnologie consentono l ottenimento di una grande mole
Strategie di annotazione di geni e genomi Dr. Giovanni Emiliani giovanni.emiliani@unifi.it Bioinformatica A.A. 2011-1012 Concetti generali Le nuove tecnologie consentono l ottenimento di una grande mole
Corso di Laurea in Chimica e Tecnologie Farmaceu6che a.a Università di Catania. La stru(ura del gene. Stefano Forte
 Corso di Laurea in Chimica e Tecnologie Farmaceu6che a.a. 2014-2015 Università di Catania La stru(ura del gene Stefano Forte I Geni Il gene è l'unità ereditaria e funzionale degli organismi viventi. La
Corso di Laurea in Chimica e Tecnologie Farmaceu6che a.a. 2014-2015 Università di Catania La stru(ura del gene Stefano Forte I Geni Il gene è l'unità ereditaria e funzionale degli organismi viventi. La
Laboratorio di Metodologie e Tecnologie Genetiche ESERCITAZIONE DI BIOINFORMATICA
 Laboratorio di Metodologie e Tecnologie Genetiche ESERCITAZIONE DI BIOINFORMATICA Bioinformatica - Scienza interdisciplinare coinvolgente la biologia, l informatica, la matematica e la statistica per l
Laboratorio di Metodologie e Tecnologie Genetiche ESERCITAZIONE DI BIOINFORMATICA Bioinformatica - Scienza interdisciplinare coinvolgente la biologia, l informatica, la matematica e la statistica per l
Come facciamo ad isolare un gene da un organismo? Utilizziamo una libreria ovvero una collezione dei geni del genoma del cromosoma di un organismo
 Come facciamo ad isolare un gene da un organismo? Utilizziamo una libreria ovvero una collezione dei geni del genoma del cromosoma di un organismo GENOMA di alcuni organismi viventi raffigurato come libri
Come facciamo ad isolare un gene da un organismo? Utilizziamo una libreria ovvero una collezione dei geni del genoma del cromosoma di un organismo GENOMA di alcuni organismi viventi raffigurato come libri
LA TRASCRIZIONE NEGLI EUCARIOTI
 LA TRASCRIZIONE NEGLI EUCARIOTI NEGLI EUCARIOTI TRASCRIZIONE E TRADUZIONE SONO DUE EVENTI SEPARATI CHE AVVENGONO IN DUE DIVERSI COMPARTIMENTI CELLULARI: NUCLEO E CITOPLASMA. INOLTRE, A DIFFERENZA DEI
LA TRASCRIZIONE NEGLI EUCARIOTI NEGLI EUCARIOTI TRASCRIZIONE E TRADUZIONE SONO DUE EVENTI SEPARATI CHE AVVENGONO IN DUE DIVERSI COMPARTIMENTI CELLULARI: NUCLEO E CITOPLASMA. INOLTRE, A DIFFERENZA DEI
Corso di Bioinformatica e analisi dei genomi, docente Silvia Fuselli. Esercizi ricerche in banche dati
 Corso di Bioinformatica e analisi dei genomi, docente Silvia Fuselli Esercizi ricerche in banche dati 1) Nel romanzo fantasy Jurassic Park di Michael Crichton sulla possibilità di clonare i dinosauri,
Corso di Bioinformatica e analisi dei genomi, docente Silvia Fuselli Esercizi ricerche in banche dati 1) Nel romanzo fantasy Jurassic Park di Michael Crichton sulla possibilità di clonare i dinosauri,
Banche Dati. Docente: Dr. Antinisca DI MARCO
 Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@di.univaq.it La biologia molecolare produce una grande mole di dati che può essere memorizzata in database general-purpose o specialized (es. immunological):
Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@di.univaq.it La biologia molecolare produce una grande mole di dati che può essere memorizzata in database general-purpose o specialized (es. immunological):
Strumenti della Genetica Molecolare Umana (3) Capitoli 6-7-8
 Capitoli 6-7-8") Strumenti della Genetica Molecolare Umana (3) Capitoli 6-7-8 Piccolo test: trova al differenza Gel 2 Gel 1 Gel 1. digestione DNA genomico Gel 2. Digestione inserto cloni genomici BANCHE DI DNA RICOMBINANTE
Strumenti della Genetica Molecolare Umana (3) Capitoli 6-7-8 Piccolo test: trova al differenza Gel 2 Gel 1 Gel 1. digestione DNA genomico Gel 2. Digestione inserto cloni genomici BANCHE DI DNA RICOMBINANTE
REGOLAZIONE DELL ESPRESSIONE GENICA. Controllo trascrizionale in E. coli. Esempio: Lac operon
 REGOLAZIONE DELL ESPRESSIONE GENICA Controllo trascrizionale in E. coli Esempio: Lac operon Nel genoma di un batterio ci sono circa 4000 geni Nel genoma umano ci sono circa 25000 geni. Espressione costitutiva:
REGOLAZIONE DELL ESPRESSIONE GENICA Controllo trascrizionale in E. coli Esempio: Lac operon Nel genoma di un batterio ci sono circa 4000 geni Nel genoma umano ci sono circa 25000 geni. Espressione costitutiva:
Banche dati biologiche
 Banche dati biologiche Tipi di basi di dati Acidi nucleici GenBank, EMBL Data Library, DNA Data Bank of Japan Sequenze proteiche PIR, Swiss-Prot, TrEMBL, UniProt Strutture Protein Data Bank Pubblicazioni
Banche dati biologiche Tipi di basi di dati Acidi nucleici GenBank, EMBL Data Library, DNA Data Bank of Japan Sequenze proteiche PIR, Swiss-Prot, TrEMBL, UniProt Strutture Protein Data Bank Pubblicazioni
Database di sequenze. Dati di sequenza. Caratteristiche dei dati della biologia molecolare. I dati ed i problemi della bioinformatica
 I dati ed i problemi della bioinformatica Giorgio Valentini DSI Università degli Studi di Milano 1 Caratteristiche dei dati della biologia molecolare Diverse tipologie di dati bio-molecolari Per ogni tipo
I dati ed i problemi della bioinformatica Giorgio Valentini DSI Università degli Studi di Milano 1 Caratteristiche dei dati della biologia molecolare Diverse tipologie di dati bio-molecolari Per ogni tipo
Tecnologia del DNA ricombinante
 Tecnologia del DNA ricombinante Scoperte rivoluzionarie che hanno permesso lo studio del genoma e della funzione dei singoli geni Implicazioni enormi nel progresso della medicina: comprensione malattie
Tecnologia del DNA ricombinante Scoperte rivoluzionarie che hanno permesso lo studio del genoma e della funzione dei singoli geni Implicazioni enormi nel progresso della medicina: comprensione malattie
Bioinformatica. Marin Vargas, Sergio Paul
 Bioinformatica Marin Vargas, Sergio Paul 2014 Wikipedia: La bioinformatica è una disciplina scientifica dedicata alla risoluzione di problemi biologici a livello molecolare con metodi informatici. La bioinformatica
Bioinformatica Marin Vargas, Sergio Paul 2014 Wikipedia: La bioinformatica è una disciplina scientifica dedicata alla risoluzione di problemi biologici a livello molecolare con metodi informatici. La bioinformatica
FORMAZIONE DEL LEGAME PEPTIDICO
 AMINOACIDI FORMAZIONE DEL LEGAME PEPTIDICO SEQUENZA AMINOACIDICA DELL INSULINA STRUTTURA SECONDARIA DELLE PROTEINE STRUTTURA TERZIARIA DELLE PROTEINE STRUTTURA QUATERNARIA DELLE PROTEINE Definizione Processi
AMINOACIDI FORMAZIONE DEL LEGAME PEPTIDICO SEQUENZA AMINOACIDICA DELL INSULINA STRUTTURA SECONDARIA DELLE PROTEINE STRUTTURA TERZIARIA DELLE PROTEINE STRUTTURA QUATERNARIA DELLE PROTEINE Definizione Processi
II LEZIONE. Database di interesse per la genetica e la biologia molecolare. Portali per l'accesso a database e servizi bioinformatici
 II LEZIONE Database di interesse per la genetica e la biologia molecolare Portali per l'accesso a database e servizi bioinformatici DATABASE DI GENETICA E BIOLOGIA MOLECOLARE OMIM Online Mendelian Inheritance
II LEZIONE Database di interesse per la genetica e la biologia molecolare Portali per l'accesso a database e servizi bioinformatici DATABASE DI GENETICA E BIOLOGIA MOLECOLARE OMIM Online Mendelian Inheritance
Modulo Laboratorio A.A. 2014/2015
 Biochimica - Laboratorio di Bioinformatica I (CdL. Bioinformatica) Bioinformatica e banche dati biologiche (CdL. Biotecnologie) Modulo Laboratorio A.A. 2014/2015 Docente: Dr. Sergio Marin Vargas Mail:
Biochimica - Laboratorio di Bioinformatica I (CdL. Bioinformatica) Bioinformatica e banche dati biologiche (CdL. Biotecnologie) Modulo Laboratorio A.A. 2014/2015 Docente: Dr. Sergio Marin Vargas Mail:
Vai al sito: Incolla nel box vuoto la sequenza nucleotidica
 Identificare il gene a cui appartiene la sequenza (sonda) e la sua posizione sul cromosoma. Per raggiungere l obiettivo della prima parte dell attività devi usare il software BLAT (BLAST- Like Alignment
Identificare il gene a cui appartiene la sequenza (sonda) e la sua posizione sul cromosoma. Per raggiungere l obiettivo della prima parte dell attività devi usare il software BLAT (BLAST- Like Alignment
10/30/16. non modificato CAP al 5 e poly-a al 3. RNA messaggero: soggetto a splicing
 procarioti eucarioti poli-cistronico mono-cistronico non modificato CAP al 5 e poly-a al 3 RNA messaggero: procarioti eucarioti policistronico monocistronico non modificato CAP al 5 e poly-a al 3 continuo
procarioti eucarioti poli-cistronico mono-cistronico non modificato CAP al 5 e poly-a al 3 RNA messaggero: procarioti eucarioti policistronico monocistronico non modificato CAP al 5 e poly-a al 3 continuo
Gasparini Alessandra BIM
 Gasparini Alessandra 592026-BIM Pfam è una banca dati di famiglie proteiche creata dal Wellcome Trust Sanger Institute a partire dal database Pfamseq basato su Uniprot. Le famiglie proteiche di Pfam sono
Gasparini Alessandra 592026-BIM Pfam è una banca dati di famiglie proteiche creata dal Wellcome Trust Sanger Institute a partire dal database Pfamseq basato su Uniprot. Le famiglie proteiche di Pfam sono
Indice generale. Nozioni fondamentali. Prefazione XIII
 Prefazione XIII A Nozioni fondamentali CAPITOLO 1 La biologia essenziale 3 1.1 Genomi, genomica e avvento della Bioinformatica 3 1.2 Genoma dei procarioti 5 1.2.1 Struttura e dimensioni 5 1.2.2 Proprietà
Prefazione XIII A Nozioni fondamentali CAPITOLO 1 La biologia essenziale 3 1.1 Genomi, genomica e avvento della Bioinformatica 3 1.2 Genoma dei procarioti 5 1.2.1 Struttura e dimensioni 5 1.2.2 Proprietà
26. Bioinformatica. contiene materiale protetto da copyright, ad esclusivo uso personale; non è consentita diffusione ed utilizzo di tipo commerciale
 26. Bioinformatica contiene materiale protetto da copyright, ad esclusivo uso personale; non è consentita diffusione ed utilizzo di tipo commerciale Lo sviluppo delle Biotecnologie ha consentito di elevare
26. Bioinformatica contiene materiale protetto da copyright, ad esclusivo uso personale; non è consentita diffusione ed utilizzo di tipo commerciale Lo sviluppo delle Biotecnologie ha consentito di elevare
Regolazione dell espressione genica
 Regolazione dell espressione genica definizioni Gene attivato quando viene trascritto in RNA e il suo messaggio tradotto in molecole proteiche specifiche Espressione genica processo complessivo con cui
Regolazione dell espressione genica definizioni Gene attivato quando viene trascritto in RNA e il suo messaggio tradotto in molecole proteiche specifiche Espressione genica processo complessivo con cui
SINTESI E MATURAZIONE DEGLI RNA CELLULARI
 SINTESI E MATURAZIONE DEGLI RNA CELLULARI PER TRASCRIZIONE SI INTENDE LA SINTESI DI UNA MOLECOLA DI RNA COMPLEMENTARE AD UNO STAMPO DI DNA. GLI RNA CELLULARI SONO DISTINTI IN TRE PRINCIPALI CATEGORIE:
SINTESI E MATURAZIONE DEGLI RNA CELLULARI PER TRASCRIZIONE SI INTENDE LA SINTESI DI UNA MOLECOLA DI RNA COMPLEMENTARE AD UNO STAMPO DI DNA. GLI RNA CELLULARI SONO DISTINTI IN TRE PRINCIPALI CATEGORIE:
SINTESI E MATURAZIONE DEGLI RNA CELLULARI
 SINTESI E MATURAZIONE DEGLI RNA CELLULARI PER TRASCRIZIONE SI INTENDE LA SINTESI DI UNA MOLECOLA DI RNA COMPLEMENTARE AD UNO STAMPO DI DNA. GLI RNA CELLULARI SONO DISTINTI IN TRE PRINCIPALI CATEGORIE:
SINTESI E MATURAZIONE DEGLI RNA CELLULARI PER TRASCRIZIONE SI INTENDE LA SINTESI DI UNA MOLECOLA DI RNA COMPLEMENTARE AD UNO STAMPO DI DNA. GLI RNA CELLULARI SONO DISTINTI IN TRE PRINCIPALI CATEGORIE:
Dal Genoma all Epigenoma..
 Dal Genoma all Epigenoma.. Nel 2001 sono stati pubblicati i risultati della mappatura del genoma umano (progetto genoma umano) che hanno mostrato la sequenze delle basi che formano il nostro materiale
Dal Genoma all Epigenoma.. Nel 2001 sono stati pubblicati i risultati della mappatura del genoma umano (progetto genoma umano) che hanno mostrato la sequenze delle basi che formano il nostro materiale
Informatica e Bioinformatica
 Corso di studi in Biologia A.A. 2013-2014 Informatica e Bioinformatica Alessandro Vezzi, PhD Dipartimento di Biologia III piano sud Lab n 15 Telefono 049 827 6243 E-mail: alessandro.vezzi@unipd.it Informatica
Corso di studi in Biologia A.A. 2013-2014 Informatica e Bioinformatica Alessandro Vezzi, PhD Dipartimento di Biologia III piano sud Lab n 15 Telefono 049 827 6243 E-mail: alessandro.vezzi@unipd.it Informatica
IL GENOMA DELLA CELLULA VEGETALE
 IL GENOMA DELLA CELLULA VEGETALE I GENOMI DELLE CELLULE VEGETALI Genoma nucleare Geni per il funzionamento globale della cellula vegetale Condivisi o specifici per la cellula vegetale Genoma plastidiale
IL GENOMA DELLA CELLULA VEGETALE I GENOMI DELLE CELLULE VEGETALI Genoma nucleare Geni per il funzionamento globale della cellula vegetale Condivisi o specifici per la cellula vegetale Genoma plastidiale
METODOLOGIE BIOCHIMICHE ESERCITAZIONE DI BIOINFORMATICA
 METODOLOGIE BIOCHIMICHE ESERCITAZIONE DI BIOINFORMATICA Scopo di questa esercitazione è apprendere l utilizzo di internet per: STUDIO DELLA STRUTTURA E DELLA FUNZIONE DELLE PROTEINE Conoscere i database
METODOLOGIE BIOCHIMICHE ESERCITAZIONE DI BIOINFORMATICA Scopo di questa esercitazione è apprendere l utilizzo di internet per: STUDIO DELLA STRUTTURA E DELLA FUNZIONE DELLE PROTEINE Conoscere i database
Lezione 3. Genoma umano come esempio di genoma eucariote
 Lezione 3 Genoma umano come esempio di genoma eucariote Schema della lezione Sommario degli elementi contenuti in un genoma eucariote Variabilità: dove si trova e come si definisce I grandi progetti internazionali
Lezione 3 Genoma umano come esempio di genoma eucariote Schema della lezione Sommario degli elementi contenuti in un genoma eucariote Variabilità: dove si trova e come si definisce I grandi progetti internazionali
LA SINTESI PROTEICA LE MOLECOLE CHE INTERVENGONO IN TALE PROCESSO SONO:
 LA SINTESI PROTEICA La sintesi proteica è il processo che porta alla formazione delle proteine utilizzando le informazioni contenute nel DNA. Nelle sue linee fondamentali questo processo è identico in
LA SINTESI PROTEICA La sintesi proteica è il processo che porta alla formazione delle proteine utilizzando le informazioni contenute nel DNA. Nelle sue linee fondamentali questo processo è identico in
microrna Struttura e Funzione
 microrna Struttura e Funzione Cinzia Di Pietro Università degli Studi di Catania Dipartimento di Scienze Biomediche e Biotecnologiche Sezione di Biologia e Genetica G. Sichel I MicroRNAs (mirnas) sono
microrna Struttura e Funzione Cinzia Di Pietro Università degli Studi di Catania Dipartimento di Scienze Biomediche e Biotecnologiche Sezione di Biologia e Genetica G. Sichel I MicroRNAs (mirnas) sono
Le biotecnologie. Sadava et al. Biologia La scienza della vita Zanichelli editore 2010
 Le biotecnologie 1 Cosa sono le biotecnologie? Le biotecnologie sono tutte quelle tecniche utilizzate (fin dall antichità) per produrre sostanze specifiche a partire da organismi viventi o da loro derivati.
Le biotecnologie 1 Cosa sono le biotecnologie? Le biotecnologie sono tutte quelle tecniche utilizzate (fin dall antichità) per produrre sostanze specifiche a partire da organismi viventi o da loro derivati.
EVOLUZIONE MOLECOLARE. Silvia Fuselli
 EVOLUZIONE MOLECOLARE Silvia Fuselli silvia.fuselli@unife.it TESTI Organizzazione del corso Graur and Li, Fundamentals of molecular evolution, Sinauer 2000 Michael Lynch, The Origins of Genome Architecture,
EVOLUZIONE MOLECOLARE Silvia Fuselli silvia.fuselli@unife.it TESTI Organizzazione del corso Graur and Li, Fundamentals of molecular evolution, Sinauer 2000 Michael Lynch, The Origins of Genome Architecture,
Proteine. Enzimi Fattori di Trascrizione Proteine di Membrana (trasportatori, canale, recettori di membrana)
") Proteine Enzimi Fattori di Trascrizione Proteine di Membrana (trasportatori, canale, recettori di membrana) Ormoni e Fattori di crescita Anticorpi Trasporto Trasporto (emoglobina, LDL, HDL.) Fenotipo Proteine
Proteine Enzimi Fattori di Trascrizione Proteine di Membrana (trasportatori, canale, recettori di membrana) Ormoni e Fattori di crescita Anticorpi Trasporto Trasporto (emoglobina, LDL, HDL.) Fenotipo Proteine
LA TRASCRIZIONE. Dipartimento di Scienze Agronomiche e Genetica Vegetale Agraria Giovanna Attene
 LA TRASCRIZIONE Dipartimento di Scienze Agronomiche e Genetica Vegetale Agraria Giovanna Attene GLI ACIDI RIBONUCLEICI Nelle cellule nucleate la sintesi proteica avviene nel citoplasma, mentre il DNA si
LA TRASCRIZIONE Dipartimento di Scienze Agronomiche e Genetica Vegetale Agraria Giovanna Attene GLI ACIDI RIBONUCLEICI Nelle cellule nucleate la sintesi proteica avviene nel citoplasma, mentre il DNA si
David Sadava, H. Craig Heller, Gordon H. Orians, William K. Purves, David M. Hillis. Biologia La scienza della vita
 1 David Sadava, H. Craig Heller, Gordon H. Orians, William K. Purves, David M. Hillis Biologia La scienza della vita 2 B - L ereditarietà e l evoluzione La regolazione genica negli eucarioti 3 I genomi
1 David Sadava, H. Craig Heller, Gordon H. Orians, William K. Purves, David M. Hillis Biologia La scienza della vita 2 B - L ereditarietà e l evoluzione La regolazione genica negli eucarioti 3 I genomi
Corso di Genetica -Lezione 12- Cenci
 Corso di Genetica -Lezione 12- Cenci Il codice genetico: Come triplette dei quattro nucleotidi specificano 20 aminoacidi, rendendo possibile la traduzione dell informazione da catena nucleotidica a sequenza
Corso di Genetica -Lezione 12- Cenci Il codice genetico: Come triplette dei quattro nucleotidi specificano 20 aminoacidi, rendendo possibile la traduzione dell informazione da catena nucleotidica a sequenza
REGOLAZIONE DELLA TRASCRIZIONE NEGLI EUCARIOTI
 LEZIONE XI REGOLAZIONE DELLA TRASCRIZIONE NEGLI EUCARIOTI Dott. Paolo Cascio IL PROMOTORE DEL VIRUS SV 40 PRESENTA 1 SEQUENZA TATA E 3 CG BOX. PIU LONTANO, PERO, SONO SITUATE ALTRE 2 REGIONI PIUTTOSTO
LEZIONE XI REGOLAZIONE DELLA TRASCRIZIONE NEGLI EUCARIOTI Dott. Paolo Cascio IL PROMOTORE DEL VIRUS SV 40 PRESENTA 1 SEQUENZA TATA E 3 CG BOX. PIU LONTANO, PERO, SONO SITUATE ALTRE 2 REGIONI PIUTTOSTO
COME È FATTO? Ogni filamento corrisponde ad una catena di nucleotidi
 Il DNA Il DNA è una sostanza che si trova in ogni cellula e contiene tutte le informazioni sulla forma e sulle funzioni di ogni essere vivente: eppure è una molecola incredibilmente semplice. COME È FATTO?
Il DNA Il DNA è una sostanza che si trova in ogni cellula e contiene tutte le informazioni sulla forma e sulle funzioni di ogni essere vivente: eppure è una molecola incredibilmente semplice. COME È FATTO?
DATABASE DI GENETICA E BIOLOGIA MOLECOLARE
 DATABASE DI GENETICA E BIOLOGIA MOLECOLARE OMIM Online Mendelian Inheritance in Man EntrezGene curated sequence and descriptive information about genetic loci GenCards HGMD dbsnp database of human genes,
DATABASE DI GENETICA E BIOLOGIA MOLECOLARE OMIM Online Mendelian Inheritance in Man EntrezGene curated sequence and descriptive information about genetic loci GenCards HGMD dbsnp database of human genes,
(definizione nata nel 1994 da Mark Wilkins)
") CL3 Biotecnologie Proteomics is the discipline that studies the proteome: it describes all possible protein products expressed by a cell as the timespecific and cell-specific complement of the genome.
CL3 Biotecnologie Proteomics is the discipline that studies the proteome: it describes all possible protein products expressed by a cell as the timespecific and cell-specific complement of the genome.
Biblioteche Digitali. Pasquale Savino ISTI - CNR
 Pasquale Savino ISTI - CNR Programma del corso Introduzione alle Esempi di (con esercitazioni) Architettura e tecnologie di base delle Biblioteche Digitali Progettazione di una Biblioteca Digitale (con
Pasquale Savino ISTI - CNR Programma del corso Introduzione alle Esempi di (con esercitazioni) Architettura e tecnologie di base delle Biblioteche Digitali Progettazione di una Biblioteca Digitale (con
Metodologie citogenetiche. Metodologie molecolari. Formulare la domanda Utilizzare la metodica appropriata
 In base al potere di risoluzione della tecnica Metodologie citogenetiche Metodologie molecolari Formulare la domanda Utilizzare la metodica appropriata 1 DNA RNA PROTEINE DNA Cromosomi (cariotipo, FISH,
In base al potere di risoluzione della tecnica Metodologie citogenetiche Metodologie molecolari Formulare la domanda Utilizzare la metodica appropriata 1 DNA RNA PROTEINE DNA Cromosomi (cariotipo, FISH,
Lezione 8. Ricerche in banche dati (databases) attraverso l uso di BLAST
 attraverso l uso di BLAST") Lezione 8 Ricerche in banche dati (databases) attraverso l uso di BLAST BLAST: Basic Local Alignment Search Tool Basic Local Alignment Search Tool. Altschul et al. 1990,1994,1997 Sviluppato per rendere
Lezione 8 Ricerche in banche dati (databases) attraverso l uso di BLAST BLAST: Basic Local Alignment Search Tool Basic Local Alignment Search Tool. Altschul et al. 1990,1994,1997 Sviluppato per rendere
Lezione 8. Ricerche in banche dati (databases) attraverso l uso di BLAST
 attraverso l uso di BLAST") Lezione 8 Ricerche in banche dati (databases) attraverso l uso di BLAST BLAST: Basic Local Alignment Search Tool Basic Local Alignment Search Tool. Altschul et al. 1990,1994,1997 Sviluppato per rendere
Lezione 8 Ricerche in banche dati (databases) attraverso l uso di BLAST BLAST: Basic Local Alignment Search Tool Basic Local Alignment Search Tool. Altschul et al. 1990,1994,1997 Sviluppato per rendere
Esercitazione 1 parte 1- database e motori di ricerca
 Esercitazione 1 parte 1- database e motori di ricerca Una breve introduzione sui database biologici Esistono molti centri di bioinformatica che hanno sviluppato diversi database; talvolta questi database
Esercitazione 1 parte 1- database e motori di ricerca Una breve introduzione sui database biologici Esistono molti centri di bioinformatica che hanno sviluppato diversi database; talvolta questi database
Laboratorio di Informatica 2004/ 2005 Corso di laurea in biotecnologie - Novara Viviana Patti Esercitazione 7 2.
 Laboratorio di Informatica 2004/ 2005 Corso di laurea in biotecnologie - Novara Viviana Patti patti@di.unito.it Esercitazione 7 1 Info&Bio Bio@Lab Allineamento di sequenze Esercitazione 7 2 1 Es2: Allineamento
Laboratorio di Informatica 2004/ 2005 Corso di laurea in biotecnologie - Novara Viviana Patti patti@di.unito.it Esercitazione 7 1 Info&Bio Bio@Lab Allineamento di sequenze Esercitazione 7 2 1 Es2: Allineamento
Nel codice genetico, una tripletta di nucleotidi codifica per un aminoacido
 Il codice genetico: Come triplette dei quattro nucleotidi specificano 20 aminoacidi, rendendo possibile la traduzione dell informazione da catena nucleotidica a sequenza di aminoacidi. Come le mutazioni
Il codice genetico: Come triplette dei quattro nucleotidi specificano 20 aminoacidi, rendendo possibile la traduzione dell informazione da catena nucleotidica a sequenza di aminoacidi. Come le mutazioni
La mappatura dei geni umani. SCOPO conoscere la localizzazione dei geni per identificarne la struttura e la funzione
 La mappatura dei geni umani SCOPO conoscere la localizzazione dei geni per identificarne la struttura e la funzione Un grande impulso alla costruzione di mappe genetiche è stato dato da le tecniche della
La mappatura dei geni umani SCOPO conoscere la localizzazione dei geni per identificarne la struttura e la funzione Un grande impulso alla costruzione di mappe genetiche è stato dato da le tecniche della
DNA Proteine Cellule. Il DNA contiene l informazione per sintetizzare le proteine. proteine cellule. Essere vivente. geni
 Sintesi Proteica DNA Proteine Cellule Il DNA contiene l informazione per sintetizzare le proteine geni Essere vivente proteine cellule Essere vivente Il DNA si tiene tutta la gloria, Le proteine fanno
Sintesi Proteica DNA Proteine Cellule Il DNA contiene l informazione per sintetizzare le proteine geni Essere vivente proteine cellule Essere vivente Il DNA si tiene tutta la gloria, Le proteine fanno
Biotecnologie. Screening delle genoteche con le sonde geniche
 Biotecnologie Screening delle genoteche con le sonde geniche Giancarlo Dessì http://www.giand.it Licenza Creative Commons BY-NC-SA (BY: attribuzione, NC: uso non commerciale, SA: condividi allo stesso
Biotecnologie Screening delle genoteche con le sonde geniche Giancarlo Dessì http://www.giand.it Licenza Creative Commons BY-NC-SA (BY: attribuzione, NC: uso non commerciale, SA: condividi allo stesso
Frontiere della Biologia Molecolare
 Prof. Giorgio DIECI Dipartimento di Bioscienze Università degli Studi di Parma Frontiere della Biologia Molecolare Milano, 4 marzo 2016 Fotografia al microscopio elettronico di una plasmacellula NUCLEO
Prof. Giorgio DIECI Dipartimento di Bioscienze Università degli Studi di Parma Frontiere della Biologia Molecolare Milano, 4 marzo 2016 Fotografia al microscopio elettronico di una plasmacellula NUCLEO
Biologia Molecolare e Bioinformatica
 Biologia Molecolare e Bioinformatica Molecular Biology and Bioinformatics CFU 12 SSD BIO/11 a.a. 2018-2019 Corso di laurea in Biotecnologie Agro-Ambientali e Alimentari Docente: Maria Luisa Chiusano Tel.
Biologia Molecolare e Bioinformatica Molecular Biology and Bioinformatics CFU 12 SSD BIO/11 a.a. 2018-2019 Corso di laurea in Biotecnologie Agro-Ambientali e Alimentari Docente: Maria Luisa Chiusano Tel.
Codice Genetico (segue)
") CODICE GENETICO Nucleotidi, acidi nucleici CODICE GENETICO Codice mediante il quale la sequenza nucleotidica di una molecola di DNA o di RNA specifica la sequenza amminoacidica di un polipeptide. Consiste
CODICE GENETICO Nucleotidi, acidi nucleici CODICE GENETICO Codice mediante il quale la sequenza nucleotidica di una molecola di DNA o di RNA specifica la sequenza amminoacidica di un polipeptide. Consiste
La struttura della cromatina
 La struttura della cromatina Istoni e nucleosomi La cromatina Il DNA all interno del nucleo eucariotico è associato a delle proteine. Il complesso DNA-proteina si chiama cromatina. Se nuclei interfasici
La struttura della cromatina Istoni e nucleosomi La cromatina Il DNA all interno del nucleo eucariotico è associato a delle proteine. Il complesso DNA-proteina si chiama cromatina. Se nuclei interfasici
Genomi vegetali Da 7x10 7 bp per genoma aploide (130Mbp diploide, 5 cromosomi) di Arabidopsis thaliana alle 1,5x10 11 bp ( Mbp=150Gbp) di una
 di Arabidopsis thaliana alle 1,5x10 11 bp ( Mbp=150Gbp) di una") Genomi vegetali Da 7x10 7 bp per genoma aploide (130Mbp diploide, 5 cromosomi) di Arabidopsis thaliana alle 1,5x10 11 bp (150.000Mbp=150Gbp) di una Liliacea. Tra le graminacee il frumento ha un genoma
Genomi vegetali Da 7x10 7 bp per genoma aploide (130Mbp diploide, 5 cromosomi) di Arabidopsis thaliana alle 1,5x10 11 bp (150.000Mbp=150Gbp) di una Liliacea. Tra le graminacee il frumento ha un genoma