Allineamenti multipli
|
|
|
- Cipriano Rosi
- 6 anni fa
- Visualizzazioni
Transcript
1 Allineamenti multipli
2 Allineamenti multipli Finora ci siamo occupati di allineamenti a coppie (pairwise), ma il modo migliore per conoscere le caratteristiche di una determinata famiglia è allineare molte proteine a funzione analoga. I siti funzionalmente o strutturalmente più rilevanti tendono a mantenersi invariati nelle proteine omologhe, mentre i siti meno importanti possono cambiare anche molto. Osservare e studiare le conservazioni significa capire come le famiglie di proteine funzionano, cosa la rende diverse tra loro, se esistono o meno relazioni filogenetiche inter- e intra- famiglia. In questo modo è possibile individuare la funzione di una proteina ignota solo osservando la sequenza dei suoi residui.
3 Similitudine e omologia Omologia: carattere QUALITATIVO che posseggono quelle sequenze che derivano da un antenato comune in seguito al processo evolutivo. O due geni sono omologhi o non lo sono. Non esiste una percentuale di omologia. Similitudine: carattere QUANTITATIVO che origina da un allineamento. Il grado di identità che si determina tra i residui allineati o il fatto che residui simili possano corrispondere in un allineamento, può essere quantificato disponendo di metri di valutazione oggettivi, come le matrici di sostituzione. => un alta similitudine tra proteine può essere indice di omologia, ma non si può escludere il contrario. Esistono infatti proteine molto simili (specie nei siti attivi) in organismi filogeneticamente non correlati tra loro e proteine molto diverse che possono essere ricondotte a omologhe mediante altri studi.
4 Geni ortologhi e geni paraloghi Geni ortologhi: geni simili riscontrabili in organismi correlati tra loro. Il fenomeno della speciazione porta alla divergenza dei geni e quindi delle proteine che essi codificano. es. l α-globina di uomo e di topo hanno iniziato a divergere circa 80 milioni di anni fa, quando avvenne la divisione che dette vita ai primati e ai roditori. => I due geni sono da considerarsi ortologhi. Geni paraloghi: geni originati dalla duplicazione di un unico gene nello stesso organismo. es. α-globina e β-globina umana hanno iniziato a divergere in seguito alla duplicazione di un gene globinico ancestrale. => I due geni sono da considerarsi paraloghi.
.")
5 Sequenze simili per allineamento multiplo Le sequenze da multi-allineare in genere si ottengono dalla ricerca in banca dati mediante i sistemi di ricerca per similarità come BLAST e FASTA (ma ce ne sono anche molti altri...). Visto che derivano già da un allineamento a coppie (anche se prodotto con metodi euristici) e visto che si prendono in considerazione sequenze che hanno un alto score (o un basso expect), l allineamento multiplo su questi dataset dovrebbe dare risultati soddisfacenti.
6 Allineamento progressivo Un allineamento esatto come quello dei pairwise esaustivi richiederebbe un algoritmo di ordine O(L N ), cioè un numero di operazioni che cresce con la lunghezza delle sequenze elevato al numero di sequenze stesse 3 proteine da 200 residui = ordine 8 x proteine da 100 residui = ordine Ovviamente i tempi di elaborazione sarebbero interminabili. E stata quindi proposta una soluzione semplice ed elegante: L ALLINEAMENTO PROGRESSIVO DI COPPIE DI SEQUENZE basandosi sull assunto che se una proteina può essere allineata con una seconda e una seconda con una terza, allora deve esistere un allineamento che le comprenda tutte e tre.
7 Diagramma dell allineamento progressivo N sequenze (dataset) disposte a caso, non allineate Allineare tutte le proteine con tutte le proteine, a coppie N(N-1)/2 allineamenti Determinare un albero guida basato sui punteggi di similarità di tutte le coppie A partire dalla coppia più simile, allinearla, determinare le colonne conservate, e allineare le coppie successive mantenendo queste colonne e ri-calcolando lo score complessivo N sequenze (dataset) allineate
8 Allineamento pairwise: tutte contro tutte Sappiamo che esistono 2 metodi per determinare i punteggi di allineamenti pairwise: 1. Smith-Waterman: programmazione dinamica, esaustiva, lenta. 2. Metodo dei k-tuples (o w-mers), euristico, veloce. La velocità di questo step è fondamentale se si hanno tante sequenze da allineare, ma è altrettanto vero che se si fanno errori in questa fase, questi si propagano all allineamento finale.
9 L albero guida per la clusterizzazione Dati degli scores a coppie, è possibile determinare quale sia il miglior modo per passare da una proteina all altra seguendo un ordine che può essere ritenuto una progressione evolutiva. I metodi (rapidi) per costruire degli alberi dato un set di scores sono essenzialmente due: Neighbour Joining (NJ) Unweighted Pair Group Method with Arithmetic mean (UPGMA) Questi basano i loro schemi topologici sulle cosiddette Matrici di Distanza (le vedremo meglio più avanti), che hanno un significato inverso rispetto agli scores: Score: maggiore => sequenze più simili Distanza: maggiore => sequenze più distanti => più diverse
10 L albero guida e la clusterizzazione 2 1 Hbb_human - 2 Hbb_horse.17-3 Hba_human Hba_horse Myg_whale b_hu b_ho a_hu a_ho M_w E una matrice di distanze, minore è il numero, maggiore è la similitudine Ordine di allineamento PEEKSAVTALWGKVN--VDEVGG Hbb_human GEEKAAVLALWDKVN--EEEVGG Hbb_horse PADKTNVKAAWGKVGAHAGEYGA Hba_human AADKTNVKAAWSKVGGHAGEYGA Hba_horse EHEWQLVLHVWAKVEAGVAGHGQ Myg_whale Allineamento finale
, ma ne esistono versioni scaricabili (standalone) gratuite che")
11 Clustal Higgins & Sharp 1989 ClustalW è il programma per gli allineamenti multipli progressivi più noto e più utilizzato. E disponibile sul server EBI, richiamato anche dalle pagine dei risultati quando si fanno ricerche di similitudine (FASTA o BLAST), ma ne esistono versioni scaricabili (standalone) gratuite che girano sotto tutte le piattaforme. Esiste anche una versione con interfaccia grafica, ClustalX. Caratteristiche: - l algoritmo pesa diversamente le sequenze e cambia matrice man mano che aggiunge proteine a diversità crescente - è possibile aggiungere sequenze a quelle già allineate, basandosi su allineamenti preesistenti. - è possibile effettuare allineamenti strutturali.

12 Clustal W Interfaccia interattiva


13 Clustal X versione grafica di Clustal W

14 Uso delle penalty mask Le penalty mask sono serie di numeri da 1 a 9 da scrivere come fossero una sequenza di aminoacidi. Sono state pensate per alterare i criteri di inserimento dei gap in base ad informazioni che possono derivare da svariate fonti.!ss_hba_huma..aaaaaaaaaaaaaaaa.aaaaaaaaaaaaaaaaaaaaaaa...aaaaaaaaa!gm_hba_huma HBA_HUMA VLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHFDLSHGSAQVKGHGK In queste zone l inserimento dei gap è sfavorito. Se si conosce la struttura di una delle proteine, questa verrà utilizzata per la costruzione dei punteggi di penalità nell allineamento a coppie preliminare: infatti in una famiglia di proteine, la struttura terziaria e quella secondaria tendono a conservarsi più della struttura primaria.
15 Valutare la qualità di un multi-allineamento La cosa più comune da fare è sommare tutti gli score di tutte le possibili coppie di proteine allineate. In genere si pesano i valori in base alla similitudine nello stesso cluster per evitare che alcuni di essi prevalgano su altri nel conteggio finale. Ottengo così una WSP (Weighted Sum of Pairs): N-1 N N: numero di sequenze WSP score = ΣΣW ij S(A ij ) i = 1 j = 1 i,j: coppia di sequenze S: punteggio di similarità della coppia W: peso per la coppia Il valore complessivo della WSP dipende dai criteri di punteggio utilizzati nell allineamento più che da considerazioni biologiche, ma è comunque un criterio valido per tutti gli allineamenti con gli stessi parametri Uno score così è chiamato Objective Function (OF)
16 Allineamento iterativo Clustal è caratterizzato dalla produzione dell albero guida per procedere con gli allineamenti tra sequenze progressivamente meno correlate. Ogni volta che viene aggiunta una sequenza però l albero non viene ri-calcolato, quindi eventuali errori iniziali non vengono corretti. Un modo per correggere tali errori è di operare una serie di iterazioni dopo ogni aggiunta, mirando a massimizzare con vari metodi la WSP globale e a coppie, ricreando ogni volta un nuovo albero, finché l allineamento si stabilizza.
17 Allineamento multiplo: locale o globale? Clustal nelle sue procedure di allineamento massimizza gli score cercando di estendere l allinamento lungo tutte le sequenze disponibili => fa un tipo di allineamento globale. Le stesse considerazioni viste per gli allineamenti pairwise valgono ancora, quindi biologicamente è meglio trovare allineamenti locali che globali. Nei MSA in realtà il problema è più complesso, perché dipende dalla similarità iniziale media tra le sequenze in esame, qualcosa che si può valutare solo a posteriori. => I nuovi metodi progressivi aggiustano i MSA esistenti 1. Cercando blocchi di massima conservazione. 2. Creando dei pattern da essi. 3. Usando i pattern per ricreare altri allineamenti possibili.
 non utilizza il metodo UPGMA né il NJ per calcolare le distanze nella fase di generazione dell albero guida, ma un sistema più veloce e preciso")
 ottimizza l algoritmo di Clustal introducendo dopo l allineamento multiplo un sistema di scoring complesso che permette di imparare le zone calde")
18 Altri programmi per il multi-allineamento Kalign ( non utilizza il metodo UPGMA né il NJ per calcolare le distanze nella fase di generazione dell albero guida, ma un sistema più veloce e preciso basato sui pattern e sulla ricerca delle stringhe con gap (algoritmo di Wu- Mabner). T-Coffee ( ottimizza l algoritmo di Clustal introducendo dopo l allineamento multiplo un sistema di scoring complesso che permette di imparare le zone calde e aggiustare l allineamento in base a queste, permettendo la fusione di allineamenti fatti con metodi diversi.

, le informazioni aggiuntive che riguardano l allineamento stesso.")
19 Visualizzazione dei multi-allineamenti Visualizzare bene un multi-allineamento è importantissimo per apprezzare le informazioni che esso può fornire. L output dei programmi di multiallineamento è una stringa contenente le sequenze allineate formattate in modi diversi secondo vari standard: MSF, NEXUS, PHYLIP, CLUSTAL, FASTA In questi cambia l intestazione, la porzione di proteina che si trova sulla stessa linea (per leggere tutto l allineamento sulla stessa schermata), le informazioni aggiuntive che riguardano l allineamento stesso. Esistono programmi come ReadSeq in grado di convertire un formato in un altro agevolmente.
20 Formati principali CLUSTAL FASTA NEXUS MSF PHYLIP

21 Utilizzo dei colori I file raw-text possono essere utilizzati per visualizzare le colonne, ma è possibile associare colori diversi per residui con caratteristiche chimico fisiche diverse. Questo facilita molto la visualizzazione dei multiallineamenti. La gestione dei colori negli allineamenti è in genere effettuata da programmi complessi che hanno compiti ben più sofisticati della semplice colorazione, integrando veri e propri ambienti di analisi bioinformatica. Esempi importanti sono BioEdit o CLC Sequence Viewer.


22
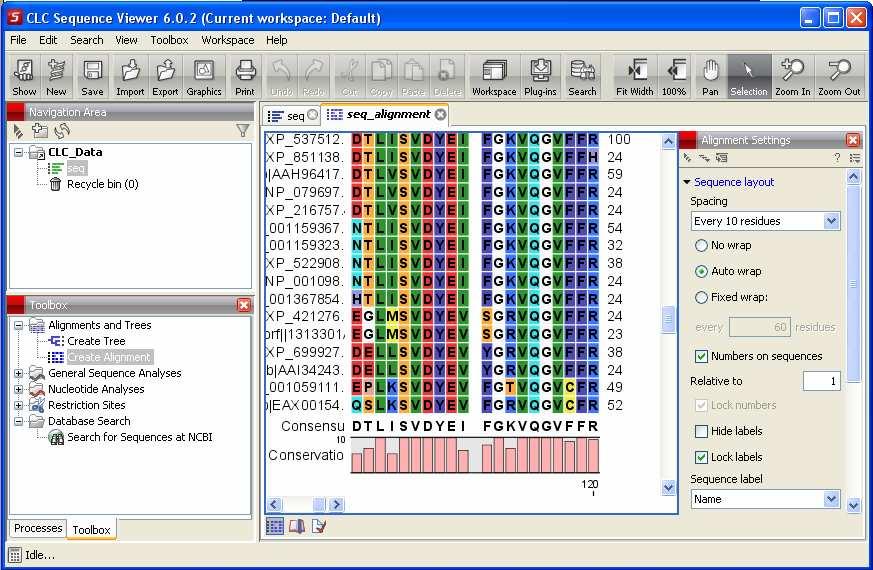
23
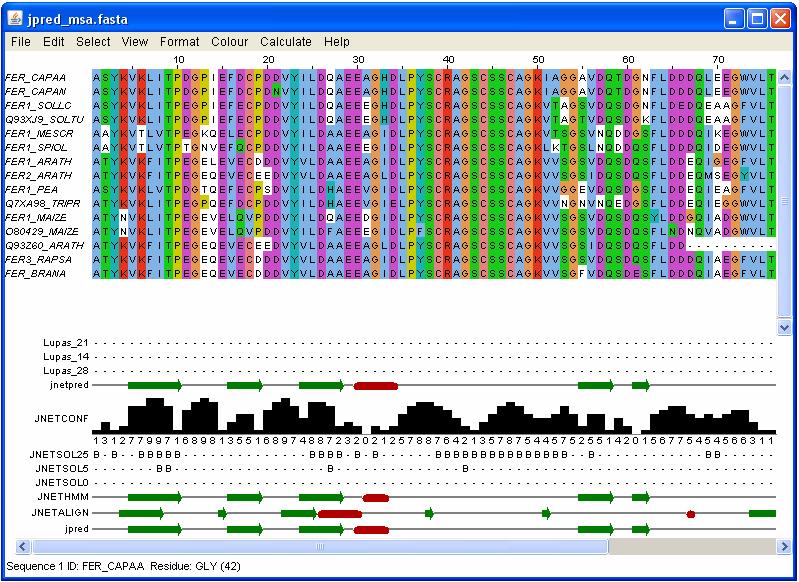
24
25 Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione e che ha le seguenti caratteristiche: Riassume un multi-allineamento Non è identica a nessuna delle proteine del dataset Si possono definire dei simboli che la definiscano e che indichino anche conservazioni non perfette in una posizione E possibile utilizzare una formattazione precisa che permetta di capire anche le variazioni in una posizione, non solo le conservazioni.

26 Tipi di sequenze consenso Consenso esatto Consenso a simboli GRVQGV--R------A--LG -GWV GRVQGh-aRvvvvvvAvvLGivGWV GRVQG[VI]-[FY]R------A L----GWY GRVQGV--R-6A LG--GWV Consenso con variazioni Consenso con ripetizioni


27 WebLogo E un tipo di visualizzazione un po banale ma rende bene l idea delle posizioni conservate su tratti di DNA/Proteine. In pratica per ogni colonna viene riportata una lettera (Base /AA) tanto più grande quanto maggiore sarà la sua presenza in quella posizione dell allineamento.
28 Profili dei multi-allineamenti Un multi-allineamento genera molte più informazioni per l individuazione dei residui importanti per una famiglia di proteine di tanti allineamenti a coppie. Diventa quindi basilare poter riassumere le conservazioni osservate in un unico formato. Inoltre multi-allineare proteine divergenti tra loro è molto più informativo rispetto alla stessa analisi fatta su proteine molto simili. Un PROFILO è un metodo di SCORING in cui ad ognuno dei venti amino acidi viene assegnato un punteggio basato sulla frequenza e sul valore in una matrice di sostituzione. Ogni cella di un profilo esprime quindi il peso da attribuire ad ogni aminoacido in quella posizione Sequenza consenso I venti amino acidi
29 I profili e PSI-BLAST Esistono numerosi programmi che creano i profili (es. profilemaker del pacchetto GCG): quasi tutti riportano sulla prima colonna la sequenza CONSENSO, cioè una sequenza derivante da tutti gli allineamenti e contenente solo i residui più frequenti. PSI-Blast è una specializzazione di Blast che opera in modalità ricorsiva: Query BLAST Primi N risultati Allineamento Profilo Consenso Finché i risultati si stabilizzano I profili possono quindi dare preziose informazioni ed essere utilizzato per una ricerca in banca dati. Ad ogni iterazione successiva verranno individuate nuove sequenze, in modo più o meno accurato a seconda delle scelte fatte in precedenza. Il risultato è che si riescono ad ottenere match con proteine più distanti filogeneticamente, ma sempre ben correlate tra loro.
30 Algoritmi ad apprendimento automatico Se si possiedono dei buoni modelli probabilistici che descrivano bene l informazione contenuta in un contesto biologico, è possibile far imparare le relazioni che il modello propone ad un computer. L applicazione pratica di questo concetto si ritrova in: 1- Hidden Markov Models 2- Reti neurali 3- Algoritmi genetici Proprio perché oggi disponiamo di un gran numero di informazioni ma piuttosto disordinate, è possibile cercare di istruire un computer allo scopo di capire da solo le relazioni che intercorrono tra i vari elementi, lasciando ad esso il compito di indovinare i risultati.
.")
31 Hidden Markov Models (HMMs) Sono modelli matematici che descrivono le probabilità di trovare una data sequenza in un database (che può essere anche un dataset di proteine multiallineamte) conoscendo il contenuto del database. Una catena di Markov è un insieme di numeri in successione in cui ogni numero dipende solo dai k numeri che lo precedono (k si definisce come l ordine della catena). Questi numeri possono essere probabilità, e quindi una catena di Markov è come un modello che descrive le probabilità condizionate di avere un residuo data uno o più serie di residui precedenti. Il programma più utilizzato basato su questi modelli è HMMER che ha come input un multiallineamento precedente (o una ricerca i banca dati) ed è in grado di cercare in banca dati utilizzando non le sequenze ma solo i profili che da essi vengono generati.
32 Hidden Markov Models (HMMs) i 0,5 A 0,9 0,1 0,25 B 0,8 o Data la sequenza ABCD è possibile stabilire la sua probabilità moltiplicando le probabilità di ogni evento. Catena di Markov di ordine zero: p(1234) = p(1)* p(2)* p(3)* p(4) 0,5 C 0,95 D Catena di Markov di ordine uno: P(1234) = p(12)*p(23)*p(34) Il grafico sopra mostra le relazioni probabilistiche che stanno alla base di una sequenza di es. 4 residui (o basi) secondo una matrice precisa e secondo dei criteri osservati nel database, così da stabilire in modo completo tutti i percorsi possibili, posto che ogni evento dipenda solo dall evento successivo. E poi possibile determinare le probabilità se gli eventi non sono indipendenti, ma dipendono dai k eventi successivi (catena di Markov di ordine k).
33 Applicazioni dei modelli di Markov Gli eventi sono definiti stati della catena, ma sono nascosti e legati da relazioni di probabilità predeterminate, fin quando non si chiede al modello di generare (emettere) i simboli appropriati. Ogni stato allora emetterà il suo simbolo a seconda degli eventi precedenti. 0,25 0,25 0,25 0,25 Input: mi serve una sequenza di 10 nucleotidi che abbia una probabilità P di presentarsi I 0,5 0,25 0,25 0,25 O Output: una sequenza di 10 residui con probabilità P di verificarsi 0,5 0,25 0,1 0,1 0,1 0,7 Input: che probabilità ho che questa sequenza si presenti per caso nel database? Output: la probabilità è P
34 Le reti neurali Sono circuiti di informazioni con una fissato numero di nodi (STATI) in cui immagazzinare le informazioni risultanti dalle varie interconnessioni ed una precisa ARCHITETTURA, cioè una struttura di interconnessione dei nodi. Se fornisco ad una rete neurale una informazione e il suo risultato (un TRAINING SET), gli stati memorizzano il modo di andare dall informazione al risultati sfruttando le interconnessioni. Ripetendo molte volte il training con set diversi ma ugualmente veri, alla fine la rete è in grado di arrivare da sola al risultato. Se fornisco alla rete una informazione con risultato incognito, essa risponderà con il risultato che per lei è appropriato, dato quello che ha imparato dai training set. es. fornendo un numero di multiallineamenti esatti, la rete impara a multiallineare, e alla fine, data una serie di sequenze, sarà in grado di multiallinearle.
35 Algoritmi genetici Se consideriamo un problema che ha una soluzione dipendente da n parametri e da k valori, una esplorazione completa richiede k n operazioni. Ma se noi sappiamo come si può evolvere il sistema (perchè abbiamo un training set o sappiamo le regole) per ricavare il risultato, sappiamo che alcuni passaggi non sono possibili o non si sono mai verificati, e sappiamo che ci sono percorsi che sono preferiti ad altri. Se l algoritmo viene modellato per rispettare gli schemi osservati e viene calcolata per ogni passaggio una FITNESS, cioè un valore di attendibilità, posso arrivare entro un certo numero di cicli ad avere un risultato che ha una fitness ottimale per le mie aspettative
36 Procedura di un algoritmo genetico cromosomi generazione valutazione della fitness selezione del cromosoma con fitness maggiore mutazione e crossing-over nuovi cromosomi sostituiscono i precedenti stop posso simulare un crossing over tra due sequenze visto che so come avviene il crossing over. posso simulare la mutagenesi visto che conosco le frequenze di mutazioni e gli eventi mutageni che accadono
Allineamenti multipli
 Allineamenti multipli Finora ci siamo occupati di allineamenti a coppie (pairwise), ma il modo migliore per conoscere le caratteristiche di una determinata famiglia è allineare molte proteine a funzione
Allineamenti multipli Finora ci siamo occupati di allineamenti a coppie (pairwise), ma il modo migliore per conoscere le caratteristiche di una determinata famiglia è allineare molte proteine a funzione
Allineamento multiplo
 Allineamento multiplo Allineamenti multipli Il modo migliore per conoscere le caratteristiche di una determinata famiglia è allineare molte proteine a funzione analoga. I siti funzionalmente o strutturalmente
Allineamento multiplo Allineamenti multipli Il modo migliore per conoscere le caratteristiche di una determinata famiglia è allineare molte proteine a funzione analoga. I siti funzionalmente o strutturalmente
Le sequenze consenso
 Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Le sequenze consenso Si definisce sequenza consenso una sequenza derivata da un multiallineamento che presenta solo i residui più conservati per ogni posizione riassume un multiallineamento. non è identica
Algoritmi di Allineamento
 Algoritmi di Allineamento CORSO DI BIOINFORMATICA Corso di Laurea in Biotecnologie Università Magna Graecia Catanzaro Outline Similarità Allineamento Omologia Allineamento di Coppie di Sequenze Allineamento
Algoritmi di Allineamento CORSO DI BIOINFORMATICA Corso di Laurea in Biotecnologie Università Magna Graecia Catanzaro Outline Similarità Allineamento Omologia Allineamento di Coppie di Sequenze Allineamento
Filogenesi molecolare
 Filogenesi molecolare Geni ortologhi e geni paraloghi Geni ortologhi: geni simili riscontrabili in organismi correlati tra loro. Il fenomeno della speciazione porta alla divergenza dei geni e quindi delle
Filogenesi molecolare Geni ortologhi e geni paraloghi Geni ortologhi: geni simili riscontrabili in organismi correlati tra loro. Il fenomeno della speciazione porta alla divergenza dei geni e quindi delle
ALLINEAMENTI MULTIPLI
 ALLINEAMENTI MULTIPLI Identificazione di siti funzionalmente importanti Dimostrazione di omologia Filogenesi molecolare Ricerca di somiglianze deboli ma significative in banche dati Predizione di struttura
ALLINEAMENTI MULTIPLI Identificazione di siti funzionalmente importanti Dimostrazione di omologia Filogenesi molecolare Ricerca di somiglianze deboli ma significative in banche dati Predizione di struttura
FASTA: Lipman & Pearson (1985) BLAST: Altshul (1990) Algoritmi EURISTICI di allineamento
 BLAST: Altshul (1990) Algoritmi EURISTICI di allineamento") Algoritmi EURISTICI di allineamento Sono nati insieme alle banche dati, con lo scopo di permettere una ricerca per similarità rapida anche se meno accurata contro le migliaia di sequenze depositate. Attualmente
Algoritmi EURISTICI di allineamento Sono nati insieme alle banche dati, con lo scopo di permettere una ricerca per similarità rapida anche se meno accurata contro le migliaia di sequenze depositate. Attualmente
BLAST. W = word size T = threshold X = elongation S = HSP threshold
 BLAST Blast (Basic Local Aligment Search Tool) è un programma che cerca similarità locali utilizzando l algoritmo di Altschul et al. Anche Blast, come FASTA, funziona: 1. scomponendo la sequenza query
BLAST Blast (Basic Local Aligment Search Tool) è un programma che cerca similarità locali utilizzando l algoritmo di Altschul et al. Anche Blast, come FASTA, funziona: 1. scomponendo la sequenza query
Corso di Bioinformatica. Docente: Dr. Antinisca DI MARCO
 Corso di Bioinformatica Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@univaq.it Analisi Filogenetica Gene Ancestrale duplicazione genica La filogenesi è lo studio delle relazioni evolutive tra
Corso di Bioinformatica Docente: Dr. Antinisca DI MARCO Email: antinisca.dimarco@univaq.it Analisi Filogenetica Gene Ancestrale duplicazione genica La filogenesi è lo studio delle relazioni evolutive tra
Quarta lezione. 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST
 Quarta lezione 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST Ricerca di omologhe in banche dati Proteina vs. proteine Gene (traduzione in aa) vs. proteine Gene vs. geni
Quarta lezione 1. Ricerca di omologhe in banche dati. 2. Programmi per la ricerca: FASTA BLAST Ricerca di omologhe in banche dati Proteina vs. proteine Gene (traduzione in aa) vs. proteine Gene vs. geni
Allineamenti di sequenze: concetti e algoritmi
 Allineamenti di sequenze: concetti e algoritmi 1 globine: a- b- mioglobina Precoce esempio di allineamento di sequenza: globine (1961) H.C. Watson and J.C. Kendrew, Comparison Between the Amino-Acid Sequences
Allineamenti di sequenze: concetti e algoritmi 1 globine: a- b- mioglobina Precoce esempio di allineamento di sequenza: globine (1961) H.C. Watson and J.C. Kendrew, Comparison Between the Amino-Acid Sequences
Allineamenti Multipli di Sequenze
 Allineamenti Multipli di Sequenze 1 Allineamento multiplo di sequenze: obiettivi di oggi Definire un allineamento multiplo di sequenze; com è generato; comprendere i principali metodi. Introdurre i database
Allineamenti Multipli di Sequenze 1 Allineamento multiplo di sequenze: obiettivi di oggi Definire un allineamento multiplo di sequenze; com è generato; comprendere i principali metodi. Introdurre i database
Organizzazione del genoma umano
 Organizzazione del genoma umano Famiglie di geni o geniche Copie multiple di geni, tutte con sequenza identica o simile. La famiglia multigenica corrisponde a un insieme di geni correlati che si sono evoluti
Organizzazione del genoma umano Famiglie di geni o geniche Copie multiple di geni, tutte con sequenza identica o simile. La famiglia multigenica corrisponde a un insieme di geni correlati che si sono evoluti
FASTA. Lezione del
 FASTA Lezione del 10.03.2016 Omologia vs Similarità Quando si confrontano due sequenze o strutture si usano spesso indifferentemente i termini somiglianza o omologia per indicare che esiste un rapporto
FASTA Lezione del 10.03.2016 Omologia vs Similarità Quando si confrontano due sequenze o strutture si usano spesso indifferentemente i termini somiglianza o omologia per indicare che esiste un rapporto
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Filogenesi Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Introduzione alla
Riconoscimento e recupero dell informazione per bioinformatica Filogenesi Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Introduzione alla
Il progetto Genoma Umano è iniziato nel E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA.
 Il progetto Genoma Umano è iniziato nel 1990. E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA. Progetto internazionale finanziato da vari paesi, affidato
Il progetto Genoma Umano è iniziato nel 1990. E stato possibile perchè nel 1986 era stato sviluppato il sequenziamento automatizzato del DNA. Progetto internazionale finanziato da vari paesi, affidato
Laboratorio di Bioinformatica I. Filogenesi. Dott. Sergio Marin Vargas (2014 / 2015)
") Laboratorio di Bioinformatica I Filogenesi Dott. Sergio Marin Vargas (2014 / 2015) Evoluzione Selezione Naturale Selezione Artificiale Variazione casuale Risultato Variazioni Casuali Mutazioni favorite
Laboratorio di Bioinformatica I Filogenesi Dott. Sergio Marin Vargas (2014 / 2015) Evoluzione Selezione Naturale Selezione Artificiale Variazione casuale Risultato Variazioni Casuali Mutazioni favorite
Alberi filogenetici. File: alberi_filogenetici.odp. Riccardo Percudani 02/03/04
 Alberi filogenetici The tree of life Albero filogenetico costruito con le sequenze della subunità piccola dell RNA ribosomale. Tutte le forme viventi condividono un comune ancestore (LCA, last common ancestor
Alberi filogenetici The tree of life Albero filogenetico costruito con le sequenze della subunità piccola dell RNA ribosomale. Tutte le forme viventi condividono un comune ancestore (LCA, last common ancestor
AUTOMA A STATI FINITI
 Gli Automi Un Automa è un dispositivo, o un suo modello in forma di macchina sequenziale, creato per eseguire un particolare compito, che può trovarsi in diverse configurazioni più o meno complesse caratterizzate
Gli Automi Un Automa è un dispositivo, o un suo modello in forma di macchina sequenziale, creato per eseguire un particolare compito, che può trovarsi in diverse configurazioni più o meno complesse caratterizzate
Allineamento e similarità di sequenze
 Allineamento e similarità di sequenze Allineamento di Sequenze L allineamento tra due o più sequenza può aiutare a trovare regioni simili per le quali si può supporre svolgano la stessa funzione; La similarità
Allineamento e similarità di sequenze Allineamento di Sequenze L allineamento tra due o più sequenza può aiutare a trovare regioni simili per le quali si può supporre svolgano la stessa funzione; La similarità
InfoBioLab I ENTREZ. ES 1: Ricerca di sequenze di aminoacidi in banche dati biologiche
 InfoBioLab I ES 1: Ricerca di sequenze di aminoacidi in banche dati biologiche Esercizio 1 - obiettivi: Ricerca di 2 proteine in ENTREZ Salva i flat file che descrivono le 2 proteine in formato testo Importa
InfoBioLab I ES 1: Ricerca di sequenze di aminoacidi in banche dati biologiche Esercizio 1 - obiettivi: Ricerca di 2 proteine in ENTREZ Salva i flat file che descrivono le 2 proteine in formato testo Importa
Modello computazionale per la predizione di siti di legame per fattori di trascrizione
 Modello computazionale per la predizione di siti di legame per fattori di trascrizione Attività di tirocinio svolto presso il Telethon Institute of Genetics and Medicine Relatori Prof. Giuseppe Trautteur
Modello computazionale per la predizione di siti di legame per fattori di trascrizione Attività di tirocinio svolto presso il Telethon Institute of Genetics and Medicine Relatori Prof. Giuseppe Trautteur
ALLINEAMENTO DI SEQUENZE
 ALLINEAMENTO DI SEQUENZE Procedura per comparare due o piu sequenze, volta a stabilire un insieme di relazioni biunivoche tra coppie di residui delle sequenze considerate che massimizzino la similarita
ALLINEAMENTO DI SEQUENZE Procedura per comparare due o piu sequenze, volta a stabilire un insieme di relazioni biunivoche tra coppie di residui delle sequenze considerate che massimizzino la similarita
Sommario. Presentazione dell opera Ringraziamenti
 Sommario Presentazione dell opera Ringraziamenti XI XII Capitolo 1 Introduzione alla bioinformatica 1 1.1 Cenni introduttivi 1 1.2 Pietre miliari della bioinformatica 2 1.3 Infrastrutture bioinformatiche
Sommario Presentazione dell opera Ringraziamenti XI XII Capitolo 1 Introduzione alla bioinformatica 1 1.1 Cenni introduttivi 1 1.2 Pietre miliari della bioinformatica 2 1.3 Infrastrutture bioinformatiche
UNIVERSITÀ DEGLI STUDI DI MILANO. Bioinformatica. A.A semestre II. 4 Evoluzione e filogenesi
 Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre II 4 Evoluzione e filogenesi FILOGENETICA CS Definzione Studio delle relazioni evolutive tra
Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre II 4 Evoluzione e filogenesi FILOGENETICA CS Definzione Studio delle relazioni evolutive tra
Z-score. lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random
/ deviazione standard random") Z-score lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random è una misura di quanto il valore di opt si discosta dalla deviazione standard media. indica di quante dev.
Z-score lo Z-score è definito come: Z-score = (opt query - M random)/ deviazione standard random è una misura di quanto il valore di opt si discosta dalla deviazione standard media. indica di quante dev.
q xi Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p i >0;
 Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p1 p6 p i >0; 6! i=1 p i =1 Sequenza di dna/proteine x con probabilita q x Probabilita dell intera sequenza n " i!1 q xi Massima verosimiglianza
Modelli probabilis-ci Lanciando un dado abbiamo sei parametri p1 p6 p i >0; 6! i=1 p i =1 Sequenza di dna/proteine x con probabilita q x Probabilita dell intera sequenza n " i!1 q xi Massima verosimiglianza
Ricevimento Studenti: Lunedì previa prenotazione. Cenci lab
 Cenci lab Giovanni Cenci Dip.to Biologia e Biotecnologie C. Darwin Sezione Genetica Piano 2 -Citofono 3/4 0649912-655 (office) 0649912-843 (lab) giovanni.cenci@uniroma1.it Ricevimento Studenti: Lunedì
Cenci lab Giovanni Cenci Dip.to Biologia e Biotecnologie C. Darwin Sezione Genetica Piano 2 -Citofono 3/4 0649912-655 (office) 0649912-843 (lab) giovanni.cenci@uniroma1.it Ricevimento Studenti: Lunedì
Filogenesi molecolare
 Filogenesi molecolare Evoluzione dei geni Gene ancestrale Gene duplicazione genica Gene speciazione Gene 1 Gene 1 ortologhi paraloghi ortologhi Gene 2 Gene 2 Specie 1 Specie 2 Proteine o acidi nucleici?
Filogenesi molecolare Evoluzione dei geni Gene ancestrale Gene duplicazione genica Gene speciazione Gene 1 Gene 1 ortologhi paraloghi ortologhi Gene 2 Gene 2 Specie 1 Specie 2 Proteine o acidi nucleici?
UNIVERSITÀ DEGLI STUDI DI MILANO. Bioinformatica. A.A semestre I. Allineamento veloce (euristiche)
") Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I 3 Allineamento veloce (euristiche) Banche dati primarie e secondarie Esistono due categorie
Docente: Matteo Re UNIVERSITÀ DEGLI STUDI DI MILANO C.d.l. Informatica Bioinformatica A.A. 2013-2014 semestre I 3 Allineamento veloce (euristiche) Banche dati primarie e secondarie Esistono due categorie
GENOMA. Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine CONTENUTO FUNZIONE. Progetti genoma in centinaia di organismi
 GENOMA EVOLUZIONE CONTENUTO FUNZIONE STRUTTURA Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine Progetti genoma in centinaia di organismi Importante la sintenia tra i genomi The
GENOMA EVOLUZIONE CONTENUTO FUNZIONE STRUTTURA Analisi di sequenze -- Analisi di espressione -- Funzione delle proteine Progetti genoma in centinaia di organismi Importante la sintenia tra i genomi The
Biologia Molecolare Computazionale
 Biologia Molecolare Computazionale Paolo Provero - paolo.provero@unito.it 2008-2009 Argomenti Allineamento di sequenze Ricostruzione di alberi filogenetici Gene prediction Allineamento Allineamento di
Biologia Molecolare Computazionale Paolo Provero - paolo.provero@unito.it 2008-2009 Argomenti Allineamento di sequenze Ricostruzione di alberi filogenetici Gene prediction Allineamento Allineamento di
Allineamenti a coppie
 Laboratorio di Bioinformatica I Allineamenti a coppie Dott. Sergio Marin Vargas (2014 / 2015) ExPASy Bioinformatics Resource Portal (SIB) http://www.expasy.org/ Il sito http://myhits.isb-sib.ch/cgi-bin/dotlet
Laboratorio di Bioinformatica I Allineamenti a coppie Dott. Sergio Marin Vargas (2014 / 2015) ExPASy Bioinformatics Resource Portal (SIB) http://www.expasy.org/ Il sito http://myhits.isb-sib.ch/cgi-bin/dotlet
Lezione 7. Allineamento di sequenze biologiche
 Lezione 7 Allineamento di sequenze biologiche Allineamento di sequenze Determinare la similarità e dedurre l omologia Allineare Definire il numero di passi necessari per trasformare una sequenza nell altra
Lezione 7 Allineamento di sequenze biologiche Allineamento di sequenze Determinare la similarità e dedurre l omologia Allineare Definire il numero di passi necessari per trasformare una sequenza nell altra
SISTEMI LINEARI. x y + 2t = 0 2x + y + z t = 0 x z t = 0 ; S 3 : ; S 5x 2y z = 1 4x 7y = 3
 SISTEMI LINEARI. Esercizi Esercizio. Verificare se (,, ) è soluzione del sistema x y + z = x + y z = 3. Trovare poi tutte le soluzioni del sistema. Esercizio. Scrivere un sistema lineare di 3 equazioni
SISTEMI LINEARI. Esercizi Esercizio. Verificare se (,, ) è soluzione del sistema x y + z = x + y z = 3. Trovare poi tutte le soluzioni del sistema. Esercizio. Scrivere un sistema lineare di 3 equazioni
Ricerca di omologia di sequenza
 Ricerca di omologia di sequenza RICERCA DI OMOLOGIA DI SEQUENZA := Data una sequenza (query), una banca dati, un sistema per il confronto e una soglia statistica trovare le sequenze della banca più somiglianti
Ricerca di omologia di sequenza RICERCA DI OMOLOGIA DI SEQUENZA := Data una sequenza (query), una banca dati, un sistema per il confronto e una soglia statistica trovare le sequenze della banca più somiglianti
Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni:
: Allineamento di sequenze (parte 1) Antonella Meloni:") Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni: antonella.meloni@ifc.cnr.it Sequenza A= stringa formata da N simboli, dove i simboli apparterranno ad un certo alfabeto. A
Lezione 2 (10/03/2010): Allineamento di sequenze (parte 1) Antonella Meloni: antonella.meloni@ifc.cnr.it Sequenza A= stringa formata da N simboli, dove i simboli apparterranno ad un certo alfabeto. A
Esercizio: Ricerca di sequenze in banche dati e allineamento multiplo (adattato da una lezione del Prof. Paiardini)
") Esercizio: Ricerca di sequenze in banche dati e allineamento multiplo (adattato da una lezione del Prof. Paiardini) Collegatevi al sito www.ncbi.nlm.nih.gov/blast. Apparirà una pagina nella quale le versioni
Esercizio: Ricerca di sequenze in banche dati e allineamento multiplo (adattato da una lezione del Prof. Paiardini) Collegatevi al sito www.ncbi.nlm.nih.gov/blast. Apparirà una pagina nella quale le versioni
Ricerche con BLAST (Laboratorio)
") Laboratorio di Bioinformatica I Ricerche con BLAST (Laboratorio) Dott. Sergio Marin Vargas (2014 / 2015) NCBI BLAST BLAST: Basic Local Alignment Search Tool http://blast.ncbi.nlm.nih.gov/blast.cgi NCBI
Laboratorio di Bioinformatica I Ricerche con BLAST (Laboratorio) Dott. Sergio Marin Vargas (2014 / 2015) NCBI BLAST BLAST: Basic Local Alignment Search Tool http://blast.ncbi.nlm.nih.gov/blast.cgi NCBI
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Riconoscimento e recupero dell informazione per bioinformatica Clustering: introduzione Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Una definizione
Relazione sequenza-struttura e funzione
 Biotecnologie applicate alla progettazione e sviluppo di molecole biologicamente attive A.A. 2010-2011 Modulo di Biologia Strutturale Relazione sequenza-struttura e funzione Marco Nardini Dipartimento
Biotecnologie applicate alla progettazione e sviluppo di molecole biologicamente attive A.A. 2010-2011 Modulo di Biologia Strutturale Relazione sequenza-struttura e funzione Marco Nardini Dipartimento
Markov Chains and Markov Chain Monte Carlo (MCMC)
") Markov Chains and Markov Chain Monte Carlo (MCMC) Alberto Garfagnini Università degli studi di Padova December 11, 2013 Catene di Markov Discrete dato un valore x t del sistema ad un istante di tempo fissato,
Markov Chains and Markov Chain Monte Carlo (MCMC) Alberto Garfagnini Università degli studi di Padova December 11, 2013 Catene di Markov Discrete dato un valore x t del sistema ad un istante di tempo fissato,
Sistemi di Elaborazione delle Informazioni
 SCUOLA DI MEDICINA E CHIRURGIA Università degli Studi di Napoli Federico II Corso di Sistemi di Elaborazione delle Informazioni Dott. Francesco Rossi a.a. 2016/2017 1 I linguaggi di programmazione e gli
SCUOLA DI MEDICINA E CHIRURGIA Università degli Studi di Napoli Federico II Corso di Sistemi di Elaborazione delle Informazioni Dott. Francesco Rossi a.a. 2016/2017 1 I linguaggi di programmazione e gli
Esercitazioni di statistica
 Esercitazioni di statistica Misure di associazione: Indipendenza assoluta e in media Stefania Spina Universitá di Napoli Federico II stefania.spina@unina.it 22 ottobre 2014 Stefania Spina Esercitazioni
Esercitazioni di statistica Misure di associazione: Indipendenza assoluta e in media Stefania Spina Universitá di Napoli Federico II stefania.spina@unina.it 22 ottobre 2014 Stefania Spina Esercitazioni
Cenni di apprendimento in Reti Bayesiane
 Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
Sistemi Intelligenti 216 Cenni di apprendimento in Reti Bayesiane Esistono diverse varianti di compiti di apprendimento La struttura della rete può essere nota o sconosciuta Esempi di apprendimento possono
2. Algoritmi e Programmi
 12 2. Algoritmi e Programmi Dato un problema, per arrivare ad un programma che lo risolva dobbiamo: individuare di cosa dispongo: gli input; definire cosa voglio ottenere: gli output; trovare un metodo
12 2. Algoritmi e Programmi Dato un problema, per arrivare ad un programma che lo risolva dobbiamo: individuare di cosa dispongo: gli input; definire cosa voglio ottenere: gli output; trovare un metodo
Excel. Il foglio di lavoro. Il foglio di lavoro Questa viene univocamente individuata dalle sue coordinate Es. F9
 Excel Un foglio di calcolo o foglio elettronico è un programma formato da: un insieme di righe e di colonne visualizzate sullo schermo in una finestra scorrevole in cui è possibile disporre testi, valori,
Excel Un foglio di calcolo o foglio elettronico è un programma formato da: un insieme di righe e di colonne visualizzate sullo schermo in una finestra scorrevole in cui è possibile disporre testi, valori,
Algoritmi greedy. Gli algoritmi che risolvono problemi di ottimizzazione devono in genere operare una sequenza di scelte per arrivare alla soluzione
 Algoritmi greedy Gli algoritmi che risolvono problemi di ottimizzazione devono in genere operare una sequenza di scelte per arrivare alla soluzione Gli algoritmi greedy sono algoritmi basati sull idea
Algoritmi greedy Gli algoritmi che risolvono problemi di ottimizzazione devono in genere operare una sequenza di scelte per arrivare alla soluzione Gli algoritmi greedy sono algoritmi basati sull idea
MATEMATICA SCUOLA PRIMARIA CLASSE SECONDA TRAGUARDI PER LO SVILUPPO DELLE COMPETENZE RELATIVI A NUMERI
 MATEMATICA SCUOLA PRIMARIA CLASSE SECONDA NUMERI L alunno si muove con sicurezza nel calcolo scritto e mentale con i numeri naturali e sa valutare l opportunità di ricorrere a una calcolatrice. OBIETTIVI
MATEMATICA SCUOLA PRIMARIA CLASSE SECONDA NUMERI L alunno si muove con sicurezza nel calcolo scritto e mentale con i numeri naturali e sa valutare l opportunità di ricorrere a una calcolatrice. OBIETTIVI
Lez. 8 La Programmazione. Prof. Pasquale De Michele (Gruppo 2) e Raffaele Farina (Gruppo 1) 1
 e Raffaele Farina (Gruppo 1) 1") Lez. 8 La Programmazione Prof. Pasquale De Michele (Gruppo 2) e Raffaele Farina (Gruppo 1) 1 Dott. Pasquale De Michele Dott. Raffaele Farina Dipartimento di Matematica e Applicazioni Università di Napoli
Lez. 8 La Programmazione Prof. Pasquale De Michele (Gruppo 2) e Raffaele Farina (Gruppo 1) 1 Dott. Pasquale De Michele Dott. Raffaele Farina Dipartimento di Matematica e Applicazioni Università di Napoli
Intelligenza Artificiale. Clustering. Francesco Uliana. 14 gennaio 2011
 Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Intelligenza Artificiale Clustering Francesco Uliana 14 gennaio 2011 Definizione Il Clustering o analisi dei cluster (dal termine inglese cluster analysis) è un insieme di tecniche di analisi multivariata
Elementi di Informatica e Programmazione
 Università degli Studi di Brescia Elementi di Informatica e Programmazione ESERCITAZIONE Docente: A. Saetti Esercitatori: M. Sechi, A. Bonisoli Vers. 04/10/2017 Docente: Alessandro Saetti Elementi di informatica
Università degli Studi di Brescia Elementi di Informatica e Programmazione ESERCITAZIONE Docente: A. Saetti Esercitatori: M. Sechi, A. Bonisoli Vers. 04/10/2017 Docente: Alessandro Saetti Elementi di informatica
Corso di Intelligenza Artificiale A.A. 2016/2017
 Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Università degli Studi di Cagliari Corsi di Laurea Magistrale in Ing. Elettronica Corso di Intelligenza rtificiale.. 26/27 Esercizi sui metodi di apprendimento automatico. Si consideri la funzione ooleana
Analisi dei dati con Excel
 Analisi dei dati con Excel memo I primi rudimenti Operazioni base Elementi caratteristici di excel sono: la barra delle formule con la casella nome ed il bottone inserisci funzione, nonché righe, colonne
Analisi dei dati con Excel memo I primi rudimenti Operazioni base Elementi caratteristici di excel sono: la barra delle formule con la casella nome ed il bottone inserisci funzione, nonché righe, colonne
Problemi e algoritmi. Il che cosa ed il come. Il che cosa ed il come. Il che cosa e il come
 Problemi e algoritmi Il che cosa e il come Problema: descrive che cosa si deve calcolare Specifica (di un algoritmo): descrive che cosa calcola un algoritmo Algoritmo: descrive come effettuare un calcolo
Problemi e algoritmi Il che cosa e il come Problema: descrive che cosa si deve calcolare Specifica (di un algoritmo): descrive che cosa calcola un algoritmo Algoritmo: descrive come effettuare un calcolo
EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0
 Pagina I EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0 Modulo 4 Foglio elettronico Il seguente Syllabus è relativo al Modulo 4, Foglio elettronico, e fornisce i fondamenti per il test di tipo
Pagina I EUROPEAN COMPUTER DRIVING LICENCE SYLLABUS VERSIONE 5.0 Modulo 4 Foglio elettronico Il seguente Syllabus è relativo al Modulo 4, Foglio elettronico, e fornisce i fondamenti per il test di tipo
2.2 Alberi di supporto di costo ottimo
 . Alberi di supporto di costo ottimo Problemi relativi ad alberi hanno numerose applicazioni: progettazione di reti (comunicazione, teleriscaldamento,...) protocolli reti IP memorizzazione compatta di
. Alberi di supporto di costo ottimo Problemi relativi ad alberi hanno numerose applicazioni: progettazione di reti (comunicazione, teleriscaldamento,...) protocolli reti IP memorizzazione compatta di
Lezione 1. Le molecole di base che costituiscono la vita
 Lezione 1 Le molecole di base che costituiscono la vita Le molecole dell ereditarietà 5 3 L informazione ereditaria di tutti gli organismi viventi, con l eccezione di alcuni virus, è a carico della molecola
Lezione 1 Le molecole di base che costituiscono la vita Le molecole dell ereditarietà 5 3 L informazione ereditaria di tutti gli organismi viventi, con l eccezione di alcuni virus, è a carico della molecola
Laboratorio di Algoritmi e Strutture Dati
 Laboratorio di Algoritmi e Strutture Dati Docente: Camillo Fiorentini 8 gennaio 8 Il problema è simile all esercizio 5.6 del libro di testo di algoritmi (Introduzione agli algoritmi e strutture dati, T.
Laboratorio di Algoritmi e Strutture Dati Docente: Camillo Fiorentini 8 gennaio 8 Il problema è simile all esercizio 5.6 del libro di testo di algoritmi (Introduzione agli algoritmi e strutture dati, T.
Sviluppo di programmi
 Sviluppo di programmi Per la costruzione di un programma conviene: 1. condurre un analisi del problema da risolvere 2. elaborare un algoritmo della soluzione rappresentato in un linguaggio adatto alla
Sviluppo di programmi Per la costruzione di un programma conviene: 1. condurre un analisi del problema da risolvere 2. elaborare un algoritmo della soluzione rappresentato in un linguaggio adatto alla
Lez. 5 La Programmazione. Prof. Salvatore CUOMO
 Lez. 5 La Programmazione Prof. Salvatore CUOMO 1 2 Programma di utilità: Bootstrap All accensione dell elaboratore (Bootsrap), parte l esecuzione del BIOS (Basic Input Output System), un programma residente
Lez. 5 La Programmazione Prof. Salvatore CUOMO 1 2 Programma di utilità: Bootstrap All accensione dell elaboratore (Bootsrap), parte l esecuzione del BIOS (Basic Input Output System), un programma residente
L A B C di R. Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010
 L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
L A B C di R 0 20 40 60 80 100 2 3 4 5 6 7 8 Stefano Leonardi c Dipartimento di Scienze Ambientali Università di Parma Parma, 9 febbraio 2010 La scelta del test statistico giusto La scelta della analisi
Sistemi Web per il turismo - lezione 3 -
 Sistemi Web per il turismo - lezione 3 - Software Si definisce software il complesso di comandi che fanno eseguire al computer delle operazioni. Il termine si contrappone ad hardware, che invece designa
Sistemi Web per il turismo - lezione 3 - Software Si definisce software il complesso di comandi che fanno eseguire al computer delle operazioni. Il termine si contrappone ad hardware, che invece designa
Cercare il percorso minimo Ant Colony Optimization
 Cercare il percorso minimo Ant Colony Optimization Author: Luca Albergante 1 Dipartimento di Matematica, Università degli Studi di Milano 4 Aprile 2011 L. Albergante (Univ. of Milan) PSO 4 Aprile 2011
Cercare il percorso minimo Ant Colony Optimization Author: Luca Albergante 1 Dipartimento di Matematica, Università degli Studi di Milano 4 Aprile 2011 L. Albergante (Univ. of Milan) PSO 4 Aprile 2011
Luigi Piroddi
 Automazione industriale dispense del corso (a.a. 2008/2009) 10. Reti di Petri: analisi strutturale Luigi Piroddi piroddi@elet.polimi.it Analisi strutturale Un alternativa all analisi esaustiva basata sul
Automazione industriale dispense del corso (a.a. 2008/2009) 10. Reti di Petri: analisi strutturale Luigi Piroddi piroddi@elet.polimi.it Analisi strutturale Un alternativa all analisi esaustiva basata sul
Come si sceglie l algoritmo di allineamento? hanno pezzi di struttura simili? appartengono alla stessa famiglia? svolgono la stessa funzione?
 Come si sceglie l algoritmo di allineamento? Domande: le due proteine hanno domini simili? hanno pezzi di struttura simili? appartengono alla stessa famiglia? svolgono la stessa funzione? hanno un antenato
Come si sceglie l algoritmo di allineamento? Domande: le due proteine hanno domini simili? hanno pezzi di struttura simili? appartengono alla stessa famiglia? svolgono la stessa funzione? hanno un antenato
Metodi di Distanza. G.Allegrucci riproduzione vietata
 Metodi di Distanza La misura più semplice della distanza tra due sequenze nucleotidiche è contare il numero di siti nucleotidici che differiscono tra le due sequenze Quando confrontiamo siti omologhi in
Metodi di Distanza La misura più semplice della distanza tra due sequenze nucleotidiche è contare il numero di siti nucleotidici che differiscono tra le due sequenze Quando confrontiamo siti omologhi in
Lezione 6. Analisi di sequenze biologiche e ricerche in database
 Lezione 6 Analisi di sequenze biologiche e ricerche in database Schema della lezione Allinemento: definizioni Allineamento di due sequenze Ricerca di singola sequenza in banche dati (Alignment-based database
Lezione 6 Analisi di sequenze biologiche e ricerche in database Schema della lezione Allinemento: definizioni Allineamento di due sequenze Ricerca di singola sequenza in banche dati (Alignment-based database
Introduzione alla programmazione Esercizi risolti
 Esercizi risolti 1 Esercizio Si determini se il diagramma di flusso rappresentato in Figura 1 è strutturato. A B C D F E Figura 1: Diagramma di flusso strutturato? Soluzione Per determinare se il diagramma
Esercizi risolti 1 Esercizio Si determini se il diagramma di flusso rappresentato in Figura 1 è strutturato. A B C D F E Figura 1: Diagramma di flusso strutturato? Soluzione Per determinare se il diagramma
Unità aritmetica e logica
 Aritmetica del calcolatore Capitolo 9 Unità aritmetica e logica n Esegue le operazioni aritmetiche e logiche n Ogni altra componente nel calcolatore serve questa unità n Gestisce gli interi n Può gestire
Aritmetica del calcolatore Capitolo 9 Unità aritmetica e logica n Esegue le operazioni aritmetiche e logiche n Ogni altra componente nel calcolatore serve questa unità n Gestisce gli interi n Può gestire
Linguaggi, Traduttori e le Basi della Programmazione
 Corso di Laurea in Ingegneria Civile Politecnico di Bari Sede di Foggia Fondamenti di Informatica Anno Accademico 2011/2012 docente: Prof. Ing. Michele Salvemini Sommario Il Linguaggio I Linguaggi di Linguaggi
Corso di Laurea in Ingegneria Civile Politecnico di Bari Sede di Foggia Fondamenti di Informatica Anno Accademico 2011/2012 docente: Prof. Ing. Michele Salvemini Sommario Il Linguaggio I Linguaggi di Linguaggi
Calcolare con il computer: Excel. Saro Alioto 1
 Calcolare con il computer: Excel Saro Alioto 1 Excel è un programma che trasforma il vostro computer in un foglio a quadretti. In altri termini con Excel potrete fare calcoli, tabelle, grafici, ecc...
Calcolare con il computer: Excel Saro Alioto 1 Excel è un programma che trasforma il vostro computer in un foglio a quadretti. In altri termini con Excel potrete fare calcoli, tabelle, grafici, ecc...
Corso di Informatica Generale (C. L. Economia e Commercio) Ing. Valerio Lacagnina Rappresentazione dei numeri relativi
 Ing. Valerio Lacagnina Rappresentazione dei numeri relativi") Codice BCD Prima di passare alla rappresentazione dei numeri relativi in binario vediamo un tipo di codifica che ha una certa rilevanza in alcune applicazioni: il codice BCD (Binary Coded Decimal). È un
Codice BCD Prima di passare alla rappresentazione dei numeri relativi in binario vediamo un tipo di codifica che ha una certa rilevanza in alcune applicazioni: il codice BCD (Binary Coded Decimal). È un
Introduzione all algebra
 Introduzione all algebra E. Modica http://dida.orizzontescuola.it Didattica OrizzonteScuola Espressioni letterali come modelli nei problemi Espressioni come modello di calcolo Esempio di decodifica Premessa
Introduzione all algebra E. Modica http://dida.orizzontescuola.it Didattica OrizzonteScuola Espressioni letterali come modelli nei problemi Espressioni come modello di calcolo Esempio di decodifica Premessa
Programmazione dinamica
 Programmazione dinamica Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Violetta Lonati Programmazione
Programmazione dinamica Violetta Lonati Università degli studi di Milano Dipartimento di Informatica Laboratorio di algoritmi e strutture dati Corso di laurea in Informatica Violetta Lonati Programmazione
RICERCA DI PATTERN E DI MOTIVI DEFINIZIONE DI MOTIVO
 RICERCA DI PATTERN E DI MOTIVI Uno dei primi scopi della biologia computazionale consiste nel rispondere alla domanda: data una nuova sequenza, cosa si può dire sulla funzione, o sulle funzioni, in essa
RICERCA DI PATTERN E DI MOTIVI Uno dei primi scopi della biologia computazionale consiste nel rispondere alla domanda: data una nuova sequenza, cosa si può dire sulla funzione, o sulle funzioni, in essa
Il concetto di calcolatore e di algoritmo
 Il concetto di calcolatore e di algoritmo Elementi di Informatica e Programmazione Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin Informatica
Il concetto di calcolatore e di algoritmo Elementi di Informatica e Programmazione Percorso di Preparazione agli Studi di Ingegneria Università degli Studi di Brescia Docente: Massimiliano Giacomin Informatica
Esercizi su algebra lineare, fattorizzazione LU e risoluzione di sistemi lineari
 Esercizi su algebra lineare, fattorizzazione LU e risoluzione di sistemi lineari 4 maggio Nota: gli esercizi più impegnativi sono contrassegnati dal simbolo ( ) Esercizio Siano 3 6 8 6 4 3 3 ) determinare
Esercizi su algebra lineare, fattorizzazione LU e risoluzione di sistemi lineari 4 maggio Nota: gli esercizi più impegnativi sono contrassegnati dal simbolo ( ) Esercizio Siano 3 6 8 6 4 3 3 ) determinare
PROGRAMMAZIONE DISCIPLINARE LICEO SCIENTIFICO OPZIONE SCIENZE APPLICATE INFORMATICA CLASSE TERZA
 PROGRAMMAZIONE DISCIPLINARE PROGRAMMAZIONE DISCIPLINARE LICEO SCIENTIFICO OPZIONE SCIENZE APPLICATE INFORMATICA CLASSE TERZA 1. Competenze: le specifiche competenze di base disciplinari previste dalla
PROGRAMMAZIONE DISCIPLINARE PROGRAMMAZIONE DISCIPLINARE LICEO SCIENTIFICO OPZIONE SCIENZE APPLICATE INFORMATICA CLASSE TERZA 1. Competenze: le specifiche competenze di base disciplinari previste dalla
Algoritmi. Pagina 1 di 5
 Algoritmi Il termine algoritmo proviene dalla matematica e deriva dal nome di in algebrista arabo del IX secolo di nome Al-Khuwarizmi e sta ad indicare un procedimento basato su un numero finito operazioni
Algoritmi Il termine algoritmo proviene dalla matematica e deriva dal nome di in algebrista arabo del IX secolo di nome Al-Khuwarizmi e sta ad indicare un procedimento basato su un numero finito operazioni
scaricato da I peptidi risultano dall unione di due o più aminoacidi mediante un legame COVALENTE
 Legame peptidico I peptidi risultano dall unione di due o più aminoacidi mediante un legame COVALENTE tra il gruppo amminico di un aminoacido ed il gruppo carbossilico di un altro. 1 Catene contenenti
Legame peptidico I peptidi risultano dall unione di due o più aminoacidi mediante un legame COVALENTE tra il gruppo amminico di un aminoacido ed il gruppo carbossilico di un altro. 1 Catene contenenti
Metodo dei minimi quadrati e matrice pseudoinversa
 Scuola universitaria professionale della Svizzera italiana Dipartimento Tecnologie Innovative Metodo dei minimi quadrati e matrice pseudoinversa Algebra Lineare Semestre Estivo 2006 Metodo dei minimi quadrati
Scuola universitaria professionale della Svizzera italiana Dipartimento Tecnologie Innovative Metodo dei minimi quadrati e matrice pseudoinversa Algebra Lineare Semestre Estivo 2006 Metodo dei minimi quadrati
RAPPRESENTAZIONE GLI ALGORITMI NOTAZIONE PER LA RAPPRESENTAZIONE DI UN ALGORITMO
 RAPPRESENTAZIONE GLI ALGORITMI NOTAZIONE PER LA RAPPRESENTAZIONE DI UN ALGORITMO Rappresentazione degli algoritmi Problema Algoritmo Algoritmo descritto con una qualche notazione Programma Defne del procedimento
RAPPRESENTAZIONE GLI ALGORITMI NOTAZIONE PER LA RAPPRESENTAZIONE DI UN ALGORITMO Rappresentazione degli algoritmi Problema Algoritmo Algoritmo descritto con una qualche notazione Programma Defne del procedimento
Algoritmi in C++ (seconda parte)
") Algoritmi in C++ (seconda parte) Introduzione Obiettivo: imparare a risolvere problemi analitici con semplici programmi in C++. Nella prima parte abbiamo imparato: generazione di sequenze di numeri casuali
Algoritmi in C++ (seconda parte) Introduzione Obiettivo: imparare a risolvere problemi analitici con semplici programmi in C++. Nella prima parte abbiamo imparato: generazione di sequenze di numeri casuali
Problemi, algoritmi, calcolatore
 Problemi, algoritmi, calcolatore Informatica e Programmazione Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin Problemi, algoritmi, calcolatori Introduzione
Problemi, algoritmi, calcolatore Informatica e Programmazione Ingegneria Meccanica e dei Materiali Università degli Studi di Brescia Prof. Massimiliano Giacomin Problemi, algoritmi, calcolatori Introduzione
Informatica e Bioinformatica: Basi di Dati
 Informatica e Bioinformatica: Date TBD Bioinformatica I costi di sequenziamento e di hardware descrescono vertiginosamente si hanno a disposizione sempre più dati e hardware sempre più potente e meno costoso...
Informatica e Bioinformatica: Date TBD Bioinformatica I costi di sequenziamento e di hardware descrescono vertiginosamente si hanno a disposizione sempre più dati e hardware sempre più potente e meno costoso...
A W T V A S A V R T S I A Y T V A A A V R T S I A Y T V A A A V L T S I
 COME CALCOLARE IL PUNTEIO DI UN ALLINEAMENTO? Il problema del calcolo del punteggio di un allineamento può essere considerato in due modi diversi che, però, sono le due facce di una stessa medaglia al
COME CALCOLARE IL PUNTEIO DI UN ALLINEAMENTO? Il problema del calcolo del punteggio di un allineamento può essere considerato in due modi diversi che, però, sono le due facce di una stessa medaglia al
Unità di apprendimento 6. Dal problema al programma
 Unità di apprendimento 6 Dal problema al programma Unità di apprendimento 6 Lezione 2 Impariamo a fare i diagrammi a blocchi In questa lezione impareremo: come descrivere l algoritmo risolutivo utilizzando
Unità di apprendimento 6 Dal problema al programma Unità di apprendimento 6 Lezione 2 Impariamo a fare i diagrammi a blocchi In questa lezione impareremo: come descrivere l algoritmo risolutivo utilizzando
numeri quantici orbitale spin
 La funzione d onda ψ definisce i diversi stati in cui può trovarsi l elettrone nell atomo. Nella sua espressione matematica, essa contiene tre numeri interi, chiamati numeri quantici, indicati con le lettere
La funzione d onda ψ definisce i diversi stati in cui può trovarsi l elettrone nell atomo. Nella sua espressione matematica, essa contiene tre numeri interi, chiamati numeri quantici, indicati con le lettere
Insiemi numerici. Teoria in sintesi NUMERI NATURALI
 Insiemi numerici Teoria in sintesi NUMERI NATURALI Una delle prime attività matematiche che viene esercitata è il contare gli elementi di un dato insieme. I numeri con cui si conta 0,,,. sono i numeri
Insiemi numerici Teoria in sintesi NUMERI NATURALI Una delle prime attività matematiche che viene esercitata è il contare gli elementi di un dato insieme. I numeri con cui si conta 0,,,. sono i numeri
Evoluzione delle molecole biologiche
 Evoluzione delle molecole biologiche Un video (in inglese): clic Evoluzione delle emoglobine (I) Un esempio classico di evoluzione delle macromolecole biologiche è dato dall emoglobina(hb), la molecola
Evoluzione delle molecole biologiche Un video (in inglese): clic Evoluzione delle emoglobine (I) Un esempio classico di evoluzione delle macromolecole biologiche è dato dall emoglobina(hb), la molecola
SOLUZIONI DEL 1 0 TEST DI PREPARAZIONE ALLA 1 a PROVA INTERMEDIA
 SOLUZIONI DEL 1 0 TEST DI PREPARAZIONE ALLA 1 a PROVA INTERMEDIA 1 Esercizio 0.1 Dato P (A) = 0.5 e P (A B) = 0.6, determinare P (B) nei casi in cui: a] A e B sono incompatibili; b] A e B sono indipendenti;
SOLUZIONI DEL 1 0 TEST DI PREPARAZIONE ALLA 1 a PROVA INTERMEDIA 1 Esercizio 0.1 Dato P (A) = 0.5 e P (A B) = 0.6, determinare P (B) nei casi in cui: a] A e B sono incompatibili; b] A e B sono indipendenti;
Bioinformatica ed applicazioni di bioinformatica strutturale!
 Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
Bioinformatica ed applicazioni di bioinformatica strutturale! Bioinformatica! Le banche dati! Programmi per estrarre ed analizzare i dati! I numeri! Cellule nell uomo! Geni nell uomo! Genoma umano Il dogma
ALGEBRA LINEARE PARTE II
 DIEM sez. Matematica Finanziaria Marina Resta Università degli studi di Genova Dicembre 005 Indice PREMESSA INVERSA DI UNA MATRICE DETERMINANTE. DETERMINANTE DI MATRICI ELEMENTARI................. MATRICI
DIEM sez. Matematica Finanziaria Marina Resta Università degli studi di Genova Dicembre 005 Indice PREMESSA INVERSA DI UNA MATRICE DETERMINANTE. DETERMINANTE DI MATRICI ELEMENTARI................. MATRICI
Distanza di Edit. Speaker: Antinisca Di Marco Data:
 Distanza di Edit Speaker: Antinisca Di Marco Data: 14-04-2016 Confronto di sequenze Il confronto tra sequenze in biologia computazionale è la base per: misurare la similarità tra le sequenze allineamento
Distanza di Edit Speaker: Antinisca Di Marco Data: 14-04-2016 Confronto di sequenze Il confronto tra sequenze in biologia computazionale è la base per: misurare la similarità tra le sequenze allineamento
Corso di Calcolo Numerico
 Corso di Laurea in Ingegneria Gestionale Sede di Fermo Corso di 3 - CALCOLO NUMERICO DELLE DERIVATE Introduzione Idea di base Introduzione Idea di base L idea di base per generare un approssimazione alla
Corso di Laurea in Ingegneria Gestionale Sede di Fermo Corso di 3 - CALCOLO NUMERICO DELLE DERIVATE Introduzione Idea di base Introduzione Idea di base L idea di base per generare un approssimazione alla
Mini-Corso di Informatica
 Mini-Corso di Informatica CALCOLI DI PROCESSO DELL INGEGNERIA CHIMICA Ing. Sara Brambilla Tel. 3299 sara.brambilla@polimi.it Note sulle esercitazioni Durante le esercitazioni impareremo a implementare
Mini-Corso di Informatica CALCOLI DI PROCESSO DELL INGEGNERIA CHIMICA Ing. Sara Brambilla Tel. 3299 sara.brambilla@polimi.it Note sulle esercitazioni Durante le esercitazioni impareremo a implementare
Tesina di Biologia Molecolare II
 MELATO GIULIA 595033 Tesina di Biologia Molecolare II Mostra un albero filogenetico con la relazione tra Uomo, Topo e Ratto. Che banca dati è disponibile per quest'ultimo organismo? Descrivi alcune caratteristiche
MELATO GIULIA 595033 Tesina di Biologia Molecolare II Mostra un albero filogenetico con la relazione tra Uomo, Topo e Ratto. Che banca dati è disponibile per quest'ultimo organismo? Descrivi alcune caratteristiche
Riconoscimento e recupero dell informazione per bioinformatica
 Riconoscimento e recupero dell informazione per bioinformatica Clustering: similarità Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizioni
Riconoscimento e recupero dell informazione per bioinformatica Clustering: similarità Manuele Bicego Corso di Laurea in Bioinformatica Dipartimento di Informatica - Università di Verona Sommario Definizioni
Corso di Analisi Numerica
 Corso di Laurea in Ingegneria Informatica Corso di 4 - DERIVAZIONE NUMERICA Lucio Demeio Dipartimento di Scienze Matematiche 1 Calcolo numerico delle derivate 2 3 Introduzione Idea di base L idea di base
Corso di Laurea in Ingegneria Informatica Corso di 4 - DERIVAZIONE NUMERICA Lucio Demeio Dipartimento di Scienze Matematiche 1 Calcolo numerico delle derivate 2 3 Introduzione Idea di base L idea di base