Alcune definizioni della statistica
|
|
|
- Benedetta Boscolo
- 7 anni fa
- Visualizzazioni
Transcript
1 Alcune definizioni della statistica Un ramo della matematica applicata che si occupa della raccolta e dell interpretazione dei dati quantitativi e dell uso della teoria delle probabilità per la stima di parametri di una popolazione. Lo studio scientifico dei dati numerici basato sui fenomeni naturali. La procedura matematica per descrivere le probabilità e la distribuzione casuale o non-casuale della materia o del verificarsi degli eventi. Una serie di teoremi matematici che aiuta ad analizzare i dati attribuendo significatività ai risultati. Una raccolta di metodi per raccogliere, organizzare, riassumere, analizzare e interpretare i dati, e per trarre conclusioni basate su di essi. La scienza e l arte di raccogliere, riassumere ed analizzare dati soggetti a variazione casuale (Biology Online)
2 Tipi di statistica Statistica descrittiva: procedure per riassumere e presentare i dati e per descriverli attraverso strumenti matematici Statistica inferenziale: procedure per derivare dai dati già noti, con l aiuto di modelli matematici, affermazioni più generali.
3 Statistica descrittiva: riassunto e presentazione dei dati Riassume i dati per mezzo di tabelle e grafici: Tabelle di frequenza (numero assoluto di casi per categoria) Tabelle percentuali (% di casi per categoria) Tabelle crociate (matrici 2 x 2, 2 x 3, ecc.) Grafici (a barre, lineari, a torta, ecc.)
4 Tipi di variabili I dati della statistica riguardano variabili, cioè grandezze che possono assumere valori differenti. Le variabili possono essere di tipo diverso: Quantitative (i valori sono numeri) continue: altezza, peso, ecc (i valori sono numeri reali). discrete: risultati del lancio di un dado (possono assumere solo certi valori) Qualitative o categoriche (i valori sono rappresentati dall appartenenza a categorie) nominali: maschio/femmina; remissione/recidiva/morte (le categorie non sono ordinate) NB: se le categorie sono solo due, mutuamente esclusive, si parla di variabili binarie o dicotomiche ordinali: <10 anni, fra 10 e 50 anni, > 50 anni (le categorie hanno un ordine)
5 Tipi di variabili In una ricerca, si definisce variabile indipendente quella che viene manipolata direttamente dallo sperimentatore, o in alternativa selezionata attraverso il metodo di campionamento. Per esempio, il fatto che i pazienti siano trattati con un farmaco o con placebo è un esempio di variabile indipendente manipolata direttamente dallo sperimentatore. In alternativa, se viene selezionato un campione di maschi da confrontare con un campione di femmine, il sesso è una variabile indipendente controllata indirettamente attraverso il sistema di campionamento. Al contrario, la variabile dipendente è quella che misuriamo per verificare la sua correlazione con la variabile indipendente. Nei due esempi precedenti, la variabile dipendente potrebbe essere la risposta alla terapia nel primo caso, e l incidenza di una certa patologia nei due sessi nel secondo caso.
6 Statistica descrittiva: descrizione matematica dei dati Fornisce una descrizione sintetica dei dati utilizzando (per i dati quantitativi) metodi numerici: Valutazione del punto centrale dei dati Valutazione della distribuzione dei dati
7 Valutazione del punto centrale dei dati Mediana: il punto centrale è calcolato sulla base dell ordinamento crescente dei dati, e rappresenta la posizione centrale in questo ordinamento. Dati: 2, 5, 6, 13, 14, 45, 47 Mediana = 13 Media aritmetica: è il rapporto fra la somma dei valori e il numero dei valori Dati: 2, 5, 6, 13, 14, 45, 47 Media = 132/7 = 18,85
8 Valutazione della distribuzione dei dati Attorno alla mediana: utilizzando lo stesso principio dell ordinamento crescente dei dati e della loro posizione, è possibile definire vari quantili (per esempio, dividendo in 4 intervalli si ottengono i quartili, e così via). Se si divide in 100 intervalli, si ottengono i percentili. Per esempio, il 75 percentile è il valore del dato che, nell ordinamento crescente, ha un posizione tale che: il 75% dei dati ha un valore inferiore (cioè rimane a sinistra nell ordinamento) il 25% dei dati ha un valore superiore (cioè rimane a destra nell ordinamento) NB: la mediana è il 50 percentile
9 Numero di dati = 121 Ordinamento crescente Mediana: dato n 61: 60 dati (50%) a sinistra, 60 dati (50%) a destra 2, 5, 6, 9,.. 46,.. 157, 542, 3450, 6213, 6578, percentile: dato n 31: 30 dati (25%) a sinistra, 90 dati (75%) a destra 25 percentile = 46 Mediana (50 percentile) = percentile = 542 La media è invece la somma aritmetica dei 121 valori divisa per 121. Può essere molto diversa dalla mediana. Per esempio, in questo caso potrebbe essere molto più alta, perché influenzata dai valori molto alti all estremo destro dei dati.
10 Valutazione della distribuzione dei dati Attorno alla media: la deviazione standard (σ) è la radice quadrata della varianza, un indicatore di dispersione che si ottiene sommando tutti i singoli scarti dalla media, elevando al quadrato e dividendo per il numero di dati. σ 2 = VAR
11
12 La distribuzione normale Una distribuzione normale in una variabile X con media e varianza è una distribuzione statistica con funzione di probabilità: Sul dominio. Mentre statistici e matematici usano uniformemente il termine distribuzione normale, i fisici talvolta la chiamano distribuzione Gaussiana e gli studiosi di scienze sociali si riferiscono ad essa come curva a campana.
13 L ascissa rappresenta i valori. L ordinata rappresenta la densità di probabilità dei valori. Tutta l area sotto la curva rappresenta l insieme di tutti i casi possibili, cioè la probabilità totale (1,0). Le probabilità non sono mai riferite a un punto, ma a un intervallo, e rappresentano il rapporto fra tutti i casi che rientrano in quell intervallo e il totale dei casi
14 In una distribuzione normale perfetta: 68.26% dei casi sono compresi fra -1 e +1 DS attorno alla media 95.46% dei casi sono compresi fra -2 e +2 DS attorno alla media 99.74% dei casi sono compresi fra -3 e +3 DS attorno alla media
15 Z score Lo z-score (chiamato anche standard score, o normal score) è un modo di trasformare un singolo valore di una distribuzione normale nel suo equivalente standardizzato. In altre parole, lo z-score ci dice di quante DS il valore dista dalla media della popolazione.
16
17 Statistica descrittiva per variabili categoriche I dati riguardanti variabili categoriche vengono spesso riportati in forma di tabella (2x2, 2x3, ecc.). La maniera più semplice di descrivere matematicamente i dati è di calcolare le proporzioni. Remissione Popolazione 28 % 56 Malattia Morte Totale
18 Statistica inferenziale La statistica descrittiva, pur aiutandoci a capire le proprietà dei dati in nostro possesso, non aggiunge nulla alle informazioni che già abbiamo. Le sue affermazioni, essendo relative a dati certi, sono certe. La statistica inferenziale, invece, si propone di fare nuove affermazioni a proposito di dati che non possediamo, per mezzo di una elaborazione matematica derivata dalla teoria delle probabilità. Le sue affermazioni, quindi, sono probabilistiche.
19 Statistica inferenziale Il concetto di verità delle affermazioni della statistica inferenziale deve essere ben compreso. Le affermazioni della statistica inferenziale sono matematicamente vere e rigorose (nell ambito della validità del modello matematico che si adotta, e purchè, naturalmente, i calcoli vengano condotti correttamente), ma riguardano esclusivamente la probabilità della verità di altre affermazioni. In altre parole, la statistica inferenziale non ci fornisce certezze sull argomento della nostra ricerca, ma solo certezze sulla probabilità che le nostre asserzioni su tale argomento siano vere. Affermazione vera (se il modello è valido e i calcoli sono corretti) Affermazione N 1 (calcolata dalla statistica inferenziale) Affermazione N 2 (oggetto della ricerca) L affermazione N 2, sulla base dei dati noti, ha il 95% di probabilità di essere vera. Il gruppo A è diverso dal gruppo B relativamente al parametro x Affermazione probabile
20 Statistica inferenziale I problemi che la statistica inferenziale cerca di risolvere sono essenzialmente di due tipi: 1) Problema della stima (per esempio stima di una media): fornisce informazioni sulla media di una popolazione quando sono note media e deviazione standard di un campione della stessa. 2) Problema della verifica di ipotesi (per esempio confronto fra due o più campioni): calcola la probabilità che due campioni, di cui siano note media e deviazione standard, siano campioni derivati da una stessa popolazione oppure da due popolazioni diverse.
21 Campionamento statistico Nell ambito della statistica descrittiva abbiamo finora considerato strumenti per descrivere un intera popolazione quando siano noti tutti i dati ad essa relativi. Ma nella ricerca, in genere, non si conoscono i dati dell intera popolazione, ma solo quelli di un campione. Il campionamento si usa quando si vuole conoscere uno o più parametri di una popolazione, senza doverli misurare in ogni suo elemento. Il campionamento consiste nel selezionare un numero più piccolo di elementi fra tutti quelli che formano una popolazione. Può essere fatto in vari modi, ma deve sempre essere di tipo probabilistico (cioè garantire la casualità della selezione). Parleremo allora di numerosità, media e deviazione standard del campione, e dobbiamo porci il problema di che rapporto esista fra questi valori e la numerosità, la media e la deviazione standard dell intera popolazione.
22 Media del campione e media della popolazione Immaginiamo di avere una popolazione rappresentata da mille persone (per esempio la popolazione degli abitanti maschi di un paese), e di volere conoscere la loro statura. Se conoscessimo la statura di ciascuno dei mille abitanti, potremmo descrivere la popolazione con assoluta precisione in termini di media e deviazione standard.
23 Media del campione e media della popolazione Se però non abbiamo le risorse per misurare la statura di mille abitanti, possiamo scegliere un campione casuale, per esempio di 30 abitanti. Avremo allora una media e una deviazione standard del campione, la cui numerosità è naturalmente 30. Che rapporto c è fra questi valori e quelli dell intera popolazione di mille abitanti?
24 Media del campione e media della popolazione Immaginiamo di ripetere l operazione di campionamento 20 volte, ogni volta con un diverso campione casuale di 30 abitanti. Otterremo 20 medie diverse, e 20 DS diverse. Un concetto importante è che l insieme di queste medie dei campioni tende ad assumere una distribuzione normale, anche se la popolazione di origine non è distribuita normalmente. In altre parole, il processo di campionamento casuale è di per sé un fenomeno che si distribuisce normalmente.
25 Teorema del limite centrale Il teorema del limite centrale afferma appunto che, data una certa popolazione con media μ e DS σ, da cui si estrae un numero infinito di campioni random e di numerosità N, man mano che N aumenta la distribuzione delle medie dei campioni tende a una distribuzione normale, con media μ (uguale a quella della popolazione di origine) e DS = σ/ N. L aspetto sorprendente e non intuitivo di questo teorema è che, qualunque sia la forma della distribuzione della popolazione originale, la distribuzione delle medie dei campioni tende alla distribuzione normale. Spesso la distribuzione normale viene raggiunta rapidamente, anche per valori non molto grandi di N. Ricordate che N è la numerosità del singolo campione, e non il numero di campioni (quest ultimo si assume essere infinito).
26 Teorema del limite centrale Qui sono mostrati i risultati di una simulazione al computer. Il computer ha eseguito un campionamento di numerosità N a partire da una popolazione con distribuzione uniforme (quindi assolutamente diversa da quella normale), e ha calcolato la media. Questa procedura è stata ripetuta 500 volte per ciascuna di quattro numerosità del singolo campione: 1, 4, 7, e 10.
27 Campioni diversi di una popolazione. Le medie dei vari campioni tendono a distribuirsi normalmente. Distribution of Sample Means
28 Errore standard della media (SEM) Lo Standard Error of the Mean (SEM) è una valutazione della deviazione standard di un insieme di medie di campioni. Idealmente si dovrebbe calcolare dividendo la deviazione standard dell intera popolazione ( ) per la radice quadrata della numerosità del campione: Poiché in genere la DS dell intera popolazione non è nota, si può ottenere una stima del SEM utilizzando al posto di la deviazione standard del singolo campione (s) SEM = n SEM = (stimato) s n NOTA: il SEM è sempre più piccolo della DS della popolazione di origine, ed è tanto più piccolo quanto maggiore è la numerosità del campione.
29 L importanza di n In termini più semplici, quando valutiamo la media di un campione, la probabilità che questa media sia simile a quella della popolazione di origine dipende essenzialmente da due fattori: n (la numerosità del campione) s (la deviazione standard del campione Infatti, poiché il SEM è uguale a s / n, quanto più grande è n, e quanto più piccolo è s, tanto più piccolo è il SEM. Un SEM più piccolo significa meno probabilità che la media del campione sia molto diversa da quella della popolazione.
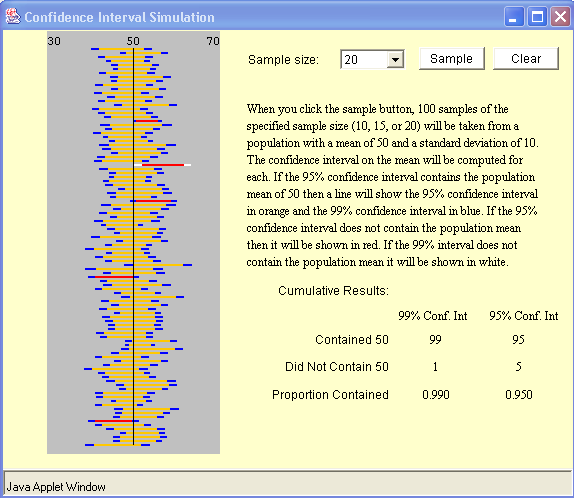
30 Confidence interval: definizioni Confidence interval = intervallo attorno alla media in cui si ha una certa probabilità che cada un valore Confidence limits = i due valori, superiore e inferiore, che delimitano il confidence interval Confidence level = la probabilità per cui si calcola il confidence interval (per esempio 95% o 99%) Z score = il numero di deviazioni standard (moltiplicatore) necessario per ottenere il confidence interval per un certo confidence level Deviazione standard Per esempio, per un confidence level del 95% CI = Media 1,96 x σ Z score Tabella per i Confidence Intervals Confidence level Z score
31 µ ± 1.96 x σ Z score Un confidence interval del 95% è un intervallo di valori, centrato sulla media, che contiene il 95% dei dati dell intera popolazione (ovvero, in cui c è il 95% di probabilità che sia compreso un dato qualunque della popolazione). Corrisponde alla zona ombreggiata del diagramma. Viene in genere definito per mezzo dei due valori a sinistra e a destra della regione (confidence limits). Il valore del 95% è il confidence level, e si ottiene utilizzando come moltiplicatore uno zscore di 1,96. Per ottenere livelli diversi, si usano z-scores appropriati (per esempio, per il 99% si deve moltiplicare per 2,58.
32 CI riferito alla media di un campione Se ci riferiamo a un campione di una popolazione, si definisce il CI della media come l intervallo attorno alla media del campione entro cui c è il 95% (o qualunque altro livello) di probabilità che cada la vera media della popolazione Il CI della media si calcola a partire dall errore standard della media (SEM) del campione
33
34 CI della media: come si calcola Partendo da un campione, il CI della media si può calcolare in due modi diversi: Se è nota la DS σ della popolazione generale: Z score appropriato CI = Media z x SEM Media del campione SEM calcolato usando la DS della popolazione generale ( ) Se non è nota la DS σ della popolazione generale: t appropriato (sostituisce z) CI = Media t x SEM stimato Media del campione SEM calcolato usando la DS del campione (s)
35 Distribuzione z e distribuzione t La z-distribution descrive la distribuzione dei dati in una popolazione normalmente distribuita. Intervallo attorno alla media = Media z x % di dati nell intervallo 80% 90% 95% 99% z La t-distribution (t di Student) è simile alla z, ma tiene conto dei gradi di libertà (cioè della numerosità N del campione 1). Per N che tende all infinito, t tende a z. E opportuno usare la t-distribution in problemi come quello di calcolare il CI per la valutazione della media di una popolazione dalla media di un campione, problemi cioè in cui l incertezza del risultato dipende in modo critico dalla numerosità del campione. t distribution df Probability 50% 90% 95% 98% 99% 99,9% 1 l l l l l
36 Problema della stima della media Riassumendo, il problema della stima è il primo dei due problemi oggetto della statistica inferenziale, e in genere si presenta in questa forma: Popolazione generale (di cui non si conosce né la media né la deviazione standard) Campione (di cui si conoscono N (numerosità), M (Media) e s (DS) Calcolo di un Confidence Inetrval attorno alla media del campione, per un certo Confidence Level, utilizzando N, s, e la tabella t Conclusione: Secondo i dati noti, c è il X% (Confidence Level) di probabilità che la media della popolazione cada entro il CI calcolato
37 Esempio di stima di una media Se la media del campione è, per esempio, 25, e il CI calcolato per un CL del 95% va da 22 a 28 (media 3), allora si può dire che: Secondo i dati a nostra disposizione, l affermazione che la media della popolazione di origine è compresa fra 22 e 28 ha il 95% di probabilità di essere vera. NB: E assolutamente sbagliato, invece, dire che, con il 95% di probabilità, la media della popolazione di origine è uguale a 25
38
39 Stima della % da un campione Per le variabili categoriche, in maniera assolutamente analoga, è possibile stimare la percentuale di una variabile nella popolazione generale a partire da quella nel campione, calcolando un CI. Anche qui si calcola uno SE, di definisce un CL, e si calcola l intervallo. Per esempio, ammettiamo che in uno studio su 165 neonati di peso < 1000 g, 124 (0,7515, cioè 75,15%) abbiano avuto bisogno di ventilazione assistita. Se vogliamo stimare la proporzione nella popolazione generale dei neonati di quel peso che ha bisogno di ventilazione, calcoleremo lo SE (mettiamo che in questo caso sia 0,033). Fissato un CL, per esempio 95%, si sceglie un adatto moltiplicatore (1,96 se si usa la z distribution) e si calcola il CI: 95% CI = 0,7515 1,96 x 0,033 In altre parole, dal campione in esame si può stimare che c è il 95% di probabilità (CL) che la percentuale di neonati sotto il chilo di peso che ha bisogno di ventilazione assistita sia compresa fra 0,687 (cioè il 68,7%) e 0,817 (cioè l 81,7%) (CI)
40 Significato del CI e del CL Riassumendo, il CI è una misura del grado di imprecisione della nostra stima. Più ampio è il CI, più imprecisa è la nostra stima. Al contrario, il CL è una misura del livello di certezza che vogliamo raggiungere. Più alto è il CL, maggiore è la probabilità che la nostra affermazione sia vera. Un CL alto fa aumentare la certezza, ma anche l imprecisione Un CL basso fa diminuire la certezza, ma aumenta la precisione Esempio: La media del mio campione e 15. Quale sarà la vera media della popolazione? A: Sarà compresa fra 14 e 16 La probabilità che questo sia vero è dell 80% (CI stretto e CL basso: alta precisione, minore certezza) B: Sarà compresa fra 12 e 18 La probabilità che questo sia vero è del 95% (CI ampio e CL alto: bassa precisione, maggiore certezza)
41 Verifica di ipotesi La verifica di ipotesi è il secondo tipo di problema affrontato dalla statistica inferenziale. L ipotesi da verificare in questo caso è la cosiddetta ipotesi nulla (null hypothesis)
42 Ipotesi nulla L ipotesi nulla (H0) è un ipotesi che il ricercatore fa riguardo a un parametro della popolazione oggetto della ricerca (in genere la media) e che viene confutata o non confutata dai dati sperimentali. Nel caso più comune, del confronto fra due campioni, la forma dell ipotesi nulla è la seguente: H0: µ1 = µ2 Dove µ1 e µ2 sono le medie delle due popolazioni da cui sono stati tratti i due campioni. Per esempio, se i due campioni si riferiscono a neonati a termine oppure a neonati pretermine, e la variabile misurata è il valore della glicemia a un ora di vita, allora l ipotesi nulla dice che: non c è differenza fra la media dei valori glicemia a un ora di vita nelle due popolazioni. L ipotesi alternativa, cioè che la differenza esiste, prende il nome di H1
43 Ipotesi nulla Molto spesso l ipotesi nulla è l opposto di ciò che si vorrebbe dimostrare. Come vedremo, l ipotesi nulla viene rigettata oppure no a secondo del suo livello di improbabilità. Se l ipotesi nulla viene rigettata, questo è un dato a favore dell ipotesi alternativa. In senso stretto, però, il test statistico non dice nulla sull ipotesi alternativa H1, ma solo sulla probabilità dell ipotesi nulla. Riassumendo: Se H0 viene rigettata perché improbabile, questo è un dato a favore di H1 Se H0 non viene rigettata, questo non vuol dire che H0 debba essere vera. Si può solo dire che, sulla base dei dati raccolti, non la si può considerare abbastanza improbabile.
44 Il p-value (probability value) Ma che vuol dire abbastanza improbabile? Anche nel caso della verifica di ipotesi, è necessario decidere un livello di improbabilità che autorizzi a rigettare l ipotesi nulla. Questo valore si chiama p-value, o soltanto p, e si può definire come la probabilità che il risultato ottenuto (per esempio la differenza fra le medie dei due campioni) sia dovuto al caso, se l ipotesi nulla è vera, cioè se le medie delle popolazioni da cui i campioni sono tratti sono uguali. Il p si esprime come frazione dell unità. Valori di p spesso usati come livello sono: <0,05 (cioè una probabilità < al 5%) <0,01 (cioè una probabilità < all 1%)
45 Il p-value Glicemia a un ora in un campione di neonati a termine Media = M1 Glicemia a un ora in un campione di neonati pretermine Media = M2 M1 > M2 IPOTESI NULLA: La media dei valori di glicemia a un ora nella popolazione di tutti i neonati a termine (μ1) e nella popolazione di tutti i neonati pretermine (μ2) è uguale (μ1 = μ2) SCELTA DEL LIVELLO: Sarà considerato significativo un p < 0,01 A questo punto si dovrà scegliere un modello di analisi statistica appropriato per il tipo di problema (per esempio, in questo caso, il t di Student). Il risultato del calcolo statistico, alla fine, dovrà essere espresso sotto forma di p-value per l ipotesi nulla. SE il p è < a 0,01: l ipotesi nulla viene rigettata, in favore di una possibile ipotesi alternativa. SE il p è > a 0,01: l ipotesi nulla non viene rigettata. Ciò non dimostra che essa sia vera.
46 Errori di tipo I e II SE il p è < a 0,01: l ipotesi nulla viene rigettata, in favore di una possibile ipotesi alternativa. (studio che ha successo) Se però l ipotesi nulla è vera, si commette un errore di tipo I. La probabilità di commettere un errore di tipo I (detta α) è uguale al p-value. Se comunque l ipotesi nulla è falsa, si commette un errore di tipo II. SE il p è > a 0,01: l ipotesi nulla non viene rigettata. Ciò non dimostra che essa sia vera. (studio che non ha successo) La probabilità di commettere un errore di tipo II (detta β) spesso non è calcolabile. La causa più frequente di errore di tipo II è la numerosità insufficiente dei campioni.
47 Errore tipo II e potenza β è la probabilità di commettere un errore di tipo II, cioè di non riuscire a rigettare un ipotesi nulla che è falsa (in altre parole, di non riuscire ad affermare la nostra ipotesi anche se è vera 1- β esprime la potenza di uno studio, cioè la probabilità di non commettere un errore di tipo II Se β è 0,20, la potenza dello studio sarà 0,80, in altre parole lo studio avrà l 80% di probabilità di riuscire a dimostrare la propria ipotesi, se questa è vera
48 Da cosa dipende la potenza? 1. Dalla dimensione reale dell effetto che si vuole dimostrare. In altre parole, quanto più il segnale da rivelare è grande, tanto più facile è, per uno studio, rivelarlo. 2. Dal livello di significatività prefissato (soglia di p). In altre parole, quanto più bassa si pone la soglia di p, tanto più facile è che non si arrivi a quella soglia anche se l ipotesi è vera. Uno studio che vuole essere più affidabile, sarà anche meno potente. 3. Dalla numerosità del campione. Più grande è N, più potente è lo studio. 4. Dalla varianza (o DS) della popolazione di origine. Più grande è la varianza, meno potente è lo studio 5. Da altri fattori: normalità della popolazione, tipo di test statistico adoperato
49 Dimensionamento del campione Un campione troppo piccolo porta più facilmente ad errori di tipo II La numerosità del campione dipende però in modo critico dall entità della differenza esistente fra le due popolazioni relativamente al parametro oggetto dello studio In uno studio RCT, quindi, è importante dimensionare in anticipo il campione, cioè decidere prima quanti soggetti dovranno essere arruolati per rispondere al quesito Il dimensionamento va fatto tenendo conto della differenza più piccola che si ha interesse a cogliere (grandezza del segnale minimo che si considera utile), e del livello di significatività statistica che si desidera raggiungere (cioè, della soglia fissata per il p)
50 Scelta del test appropriato A seconda della forma del problema, si sceglierà un test diverso per la verifica delle ipotesi. E importante ricordare che, qualunque sia il test statistico impiegato, alla fine il risultato dovrà essere espresso sotto la forma di un p-value perché lo si possa interpretare.
51 Di che test ho bisogno? Variabili quantitative in gruppi categorici: confronto fra le medie di due campioni, anche di numerosità diversa (between-subject) t di Student, unpaired Variabili quantitative in un gruppo unico: confronto fra coppie di misurazioni nello stesso soggetto (within-subject) t di Student, paired Variabili qualitative in gruppi categorici: confronto fra conteggi (numero dei casi che ricadono in differenti categorie) Chi quadro Rapporto fra due variabili quantitative continue misurate nello stesso gruppo di soggetti Coefficiente di correlazione r e regressione Variabili quantitative continue o in gruppi categorici: confronto fra le medie di tre o più campioni, e di più variabili indipendenti (analisi covariata) Analisi contemporanea di più variabili dipendenti ANOVA, ANCOVA MANOVA
52 Test di Student unpaired (between-subject design) Due gruppi categorici Maschi Femmine In cui si misura una variabile dipendente quantitativa Bilirubinemia: media, DS Bilirubinemia: media, DS Due gruppi creati a partire da una variabile quantitativa secondo un valore arbitrario O P P U R E EG < 37 sett EG >= 37 sett In cui si misura una variabile dipendente quantitativa Bilirubinemia: media, DS Bilirubinemia: media, DS
53 Test di student paired (within-subject design) Un solo gruppo Neonati a termine Due misurazioni per ciascun soggetto Bilirubina a 2 gg Bilirubina a 4 gg Ogni misurazione viene confrontata con quella corrispondente nello stesso soggetto
54 Varietà di t-test Nel t-test per campioni indipendenti (unpaired) i due campioni si riferiscono a due gruppi di soggetti diversi (per esempio pazienti trattati o non trattati): between-subject design. Nel t-test per campioni appaiati (paired) i due campioni si riferiscono a due diverse misurazioni dello stesso parametro nello stesso gruppo di soggetti (per esempio glicemia prima e dopo un trattamento). In questo caso ci saranno due misurazioni per ogni soggetto, e quindi la numerosità dei due campioni è necessariamente uguale: within-subject design.
55 Il test del t di Student Student è lo pseudonimo con cui William Gosset, pubblicò nel 1908 un lavoro sulla distribuzione t nel caso in cui un campione piccolo venga utilizzato per stimare i parametri della popolazione di origine. La distribuzione t si avvicina a quella normale (distribuzione z) man mano che la numerosità del campione cresce.
56 Il test del t di Student Il test del t di Student applica il concetto di distribuzione t al confronto fra due campioni, in particolare alla distribuzione della differenza fra la media di due campioni derivati dalla stessa popolazione di origine (ipotesi nulla) Distribuzione ideale delle medie di due campioni Tre scenari per la differenza fra due medie Il t-test come esempio di valutazione del rapporto segnale-rumore La formula del t-test
57 Varietà di t-test Per campioni indipendenti, anche di numerosità diversa (unpaired): - campioni con varianza simile (omoschedastico) - campioni con varianza diversa Per campioni appaiati (paired) NB: In tutti i casi il test può essere calcolato a una coda o a due code
58 Varietà di t-test nel test ad una coda, la zona di rifiuto è solamente da una parte della distribuzione (a sinistra quando il segno è negativo, a destra quando è positivo) nel test a due code, la zona di rifiuto è distribuita dalle due parti Il test a due code è più conservativo (vi si ricorre quando non si ha alcuna idea sui possibili risultati) mentre il test ad una coda è più potente
59 T-test Il t-test è un test molto robusto. Questo significa che, se applicato bene, dà risultati affidabili anche quando le popolazioni di origine non hanno una distribuzione normale, soprattutto se le dimensioni dei campioni non sono estremamente ridotte. In tutti i casi in cui non si abbia una comprensione precisa di quale varietà applicare, è più opportuno ricorrere, conservativamente, al test unpaired, a due code, per campioni con varianza differente
60 Chi quadro Il chi quadro si applica quando la variabile dipendente è espressa come conteggi in categorie. I risultati quindi sono espressi sotto forma di una tabella (2x2, 2x3, 3x3, ecc.) Per esempio, se vogliamo valutare il follow-up a 5 anni dei pazienti affetti da una certa patologia a seconda del sesso, ed esprimiamo il risultato come conteggio del numero di pazienti guariti, ancora malati o morti, avremo una tabella 2x3: Guariti Malati Morti Maschi Femmine
61 Come si calcola il chi quadro Il calcolo del chi quadro si basa sul confronto fra frequenze osservate e frequenze attese nelle singole sottocategorie. Le frequenze attese si calcolano a partire dalle frequenze osservate Valori osservati Valori attesi chi (p) = Guariti Malati M F Guariti Malati M F = 36*28 / 57
62 Come passare dal chi quadro al p Il test del chi quadro calcola i valori attesi per ogni cella della tabella, e li confronta con quelli osservati. Il risultato ottenuto, detto appunto chi quadro, viene trasformato in p-value in maniera dipendente dai gradi di libertà (il numero di gradi di libertà di una tabella è uguale al numero di righe meno 1 moltiplicato per il numero di colonne meno 1) df P = 0.05 P = 0.01 P =
63 Risk e Odds Un modo semiquantitativo di esprimere la significatività nel caso di variabili categoriche è rappresentato dai concetti di risk, odds, risk ratio e odds ratio. Immaginiamo una tabella 2x2 che esprima lincidenza di handicap in funzione del peso alla nascita Handicap Non handicap Totale A. < 1000 g B g Si definisce rischio (risk) il rapporto fra i soggetti con outcome e il totale, mentre si definisce probabilità (odds) il rapporto fra soggetti con outcome e soggetti senza. Per A: Risk = 10/52 = 0,19 Odds = 10/42 = 0,24 Per B: Risk = 8/96 = 0,08 Odds = 8/88 = 0,09
64 Risk Ratio e Odds Ratio Se invece confrontiamo i due gruppi fra di loro, otterremo il Risk Ratio (RR, detto anche Relative Risk) e l Odds Ratio (OR). Handicap Non handicap Totale A. < 1000 g B g Per A: Risk = 10/52 = 0,19 Odds = 10/42 = 0,24 Per B: Risk = 8/96 = 0,08 Odds = 8/88 = 0,09 Confronto di A con B: RR = 0,19/0,08 = 2,3 OR = 0,24/0,09 = 2,6
65 Risk Ratio e Odds Ratio: significato Confronto di A con B: RR = 0,19/0,08 = 2,3 OR = 0,24/0,09 = 2,6 Sia il RR che l OR possono essere riportati, in modo semiquantitativo, a un giudizio di significatività nel rigettare l ipotesi nulla. Ecco due tabelle orientative: Table 1. Semiquantitative grading of the relative risk, odds ratio, or rate ratio Reported Relative Risk, Odds Ratio, or Rate Ratio 1 Estimate < or not statistically significant NS > Values <1 indicate decreased risk; values >1 indicate increased risk.
66 Risk Ratio e Odds Ratio: differenza Confronto di A con B: RR = 0,19/0,08 = 2,3 OR = 0,24/0,09 = 2,6 Per outcome rari rispetto all intera popolazione, RR e OR sono quasi uguali. Quanto più l outcome è frequente, tanto più il RR e l OR divergono, tenendo presente che l OR è sempre più grande, cioè più lontano dall unità, del RR.
67 ANOVA Se si confrontano fra loro tre o più gruppi, non è più corretto utilizzare il t-test ripetendolo per tutte le combinazioni. In questo modo la probabilità di avere risultati falsamente significativi cresce al crescere del numero di gruppi. In questi casi si deve usare una metodologia di calcolo più complessa, chiamata ANOVA (ANalysis Of VAriance). Questo metodo tiene conto non solo della devianza totale dei valori, ma anche della devianza tra (between) i gruppi e della devianza entro (within) i gruppi. L ANOVA è un calcolo statistico complesso, e richiede in genere una buona comprensione dei concetti teorici di base.
68 Confronto fra due o più variabili I test considerati finora misurano una variabile in più gruppi. Quando invece si vuole confrontare l andamento di due o più variabili quantitative nello stesso gruppo si ricorre ai test di correlazione e di regressione.
69 Coefficiente di correlazione Il coefficiente di correlazione esprime la probabilità che due variabili siano correlate fra loro, anche se non sussiste necessariamente un rapporto diretto di causalità. La correlazione può essere lineare o di altro tipo (quadratica, ecc.) Un coefficiente di correlazione va da -1 (correlazione negativa) a 1 (correlazione positiva). I valori intorni allo 0 esprimono l assenza di correlazione. Il più semplice coefficiente di correlazione è quello di Pearson, detto r, che misura la correlazione lineare fra due variabili in un campione. r = -1 r=0 r = +1
70 Altri esempi di r
71 Coefficiente di determinazione r2 E il quadrato della correlazione, ed esprime la percentuale della variazione dei valori di y che è spiegata dal modello di regressione associato a x 0 r2 1. Quanto più grande è r2, tanto più forte è la relazione lineare Quanto più r2 è vicino a 1, tanto più sicure sono le nostre predizioni
72 Coefficiente di determinazione Rapporto fra r e r2
73 Come passare da r a p
74 Una riflessione sul significato di p In questo esempio, abbiamo due casi in cui il p è di 0,05, ma il significato è molto diverso In questo campione di 5 casi (N = 5), r è molto alto (0,80), e quindi la correlazione fra le due variabili è elevata. A causa del piccolo numero di rilevazioni, però, la probabilità che questo risultato sia casuale è elevata, e il valore del p si attesta a 0,05. In altre parole, sembra che fra le due variabili ci sia una correlazione molto alta, ma non lo si può dire con molta certezza perché il numero di dati è piccolo In quest altro caso, invece, il numero di dati è molto grande (N = 1000), ma r è piccolo (0,05). Anche qui, p si attesta a 0,05. In altre parole, fra le due variabili c è probabilmente una correlazione, ma la correlazione è di lieve entità
75 Significato generale di un test In altre parole, possiamo considerare il risultato di un test statistico, come il t-test o r, come la misura di un rapporto segnale/rumore. Il segnale è l entità della differenza fra due gruppi di dati nel confronto fra medie (t di Student), o l entità della correlazione fra due variabili (r). Il rumore è la probabilità della generazione casuale di uno pseudosegnale, e dipende in modo critico dalla numerosità dei dati. entità della differenza fra le medie, o della correlazione Segnale variabilità casuale Rumore
76 Regressione Se esiste correlazione fra due variabili, è possibile calcolare una funzione che descriva il rapporto fra le due variabili e che permetta di predire altri valori. Se tale funzione è una linea, si parla di regressione lineare, altrimenti di regressione non lineare. Se le variabili sono più di due, si parla di regressione multipla
77 Un esempio di regressione lineare La formula generale di una linea di regressione è: y = a + bx dove a è il punto di intersezione dell asse Y, e b la pendenza della linea (angolo con l asse X) La linea di regressione viene calcolata in maniera da rendere minima la somma degli scarti quadratici dei singoli valori osservati
78 Predizione Il calcolo di una linea di regressione può permettere di fare predizioni riguardo a valori non osservati
79 Regressione lineare e non lineare
80 Regressione multipla I test di regressione multipla valutano la maniera in cui molte variabili indipendenti influenzano una singola variabile dipendente: per esempio, come vari fattori prognostici influenzano la sopravvivenza in una patologia neoplastica.
81 Regressione multipla lineare e non lineare
82 Curve di Kaplan Meier La curva di Kaplan Meier permette di rappresentare i dati di uno studio in termini di time to event, cioè del tempo necessario perché i pazienti raggiungano un determinato endpoint (per esempio la morte: in questo caso la curva è una curva di sopravvivenza). La curva rappresenra tutti i dati disponibili in termini di percentuale dell evento rispetto al tempo trascorso dall arruolamento, e questo permette di valutare insieme i dati di pazienti arruolati in tempi diversi. Vengono inclusi anche i pazienti che non hanno presentato ancora l endpoint al momento della chiusura dello studio, e quelli dei pazienti persi al follow-up. Tali dati vengono definiti censored e il tempo trascorso fra l arruolamento e la conclusione dello studio, oppure fra l arruolamento e l uscita dallo studio per i persi al follow-up, è rappresentato graficamente con un segno verticale (tick mark).
83
84 Un esempio di curva di Kaplan Meier Example of a Censored Curve with Tick Marks This Group of Patients Has a Minimum Follow-Up of a Little Over a Year
85 Rappresentazione di due gruppi come curva di Kaplan Meier Gap orizzontale: differenza nel tempo di presentazione dell outcome Gap verticale: differenza nell esito finale
86 Valori derivati da una curva Kaplan Meier Mediana = tempo a cui il 50% dei pazienti ha presentato l evento Media = tempo medio di presentazione dell evento
87 Comparison of survival between two groups. Eyeballing the KM curves for the Placebo and 6MP groups, we see that 1. Median survival time is 22.5 m for 6-MP and 8 for placebo (14.5 month difference). 2. The Kaplan-Meier curve for 6-MP group lies above that for the Placebo group and there is a big gap between the two curves: the survival of 6-MP seems to be superior. 3. The gap seems to become bigger as time progresses.
88 Valutazione statistica delle curve di Kaplan Meier L analisi statistica è basata sui principi del chiquadro, che confronta le percentuali attese con quelle osservate. Test: Log rank test. H0: non c è differenza fra le curve A e B H1: la differenza esiste Il risultato finale è espresso come p.
89
90 Confronto fra curve di Kaplan Meier (Log Rank Test) Figure 2: Survival of patients in the low risk group treated by liver resection alone or liver resection plus adjuvant chemotherapy. (n=113; Kaplan-Meier estimate, log-rank test).
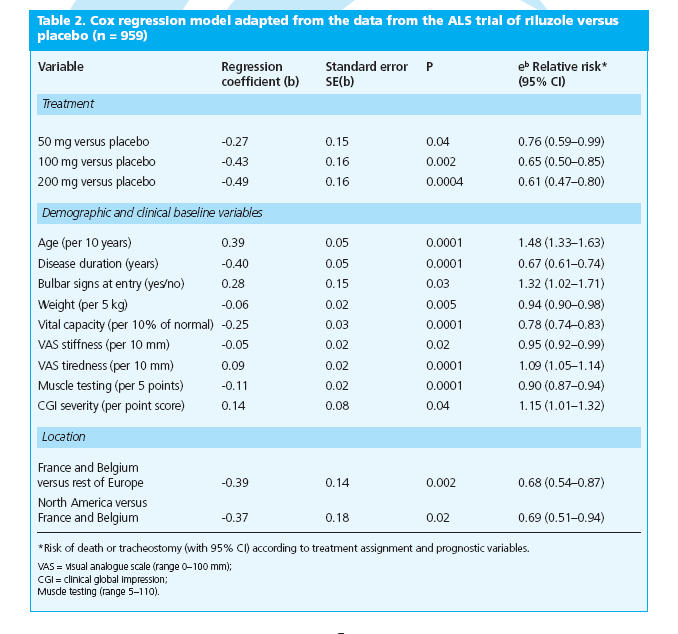
91 Cox regression test E un modello complesso di analisi di regressione multivariata, che permette sia il confronto fra curve di sopravvivenza di tipo Kaplan Meier che il calcolo del contributo di fattori prognostici indipendenti al rischio. Un esempio di valutazione del contributo di fattori diversi al rischio cumulativo
92 Cox proportional hazards model e hazard ratio Il modello di Cox permette di valutare due importanti aspetti nell ambito di una rappresentazione time to event di tipo Kaplan Meier: 1. Calcolo dell hazard ratio, un numero che esprime il rischio relativo fra i due gruppi per unità di tempo 2. Calcolo del contributo indipendente al rischio di più variabili (analisi covariata)
93 Hazard ratio e differenza fra gruppi Non sempre l hazard ratio esprime in modo realistico la differenza clinica fra due gruppi. Come molte misure complesse, il suo significato può essere fuorviante, perché dipende in maniera critica dalla forma delle curve. Se si vuole sapere essenzialmente la rilevanza del significato clinico finale, occorre sempre valutare anche la mediana e la media delle due curve.
94 Cox model Il modello di Cox permette di calcolare il contributo delle singole variabili all outcome, stratificando in maniera complessa per le differenti variabili (analisi covariata)
95
96
97
98
99
100
Teoria e tecniche dei test. Concetti di base
 Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
Teoria e tecniche dei test Lezione 2 2013/14 ALCUNE NOZIONI STATITICHE DI BASE Concetti di base Campione e popolazione (1) La popolazione è l insieme di individui o oggetti che si vogliono studiare. Questi
Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni
 La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
per togliere l influenza di un fattore es.: quoziente di mortalità = morti / popolazione
 Rapporti statistici di composizione la parte rispetto al tutto percentuali di derivazione per togliere l influenza di un fattore es.: quoziente di mortalità = morti / popolazione di frequenza (tassi) rapporti
Rapporti statistici di composizione la parte rispetto al tutto percentuali di derivazione per togliere l influenza di un fattore es.: quoziente di mortalità = morti / popolazione di frequenza (tassi) rapporti
Università del Piemonte Orientale. Corso di Laurea Triennale di Infermieristica Pediatrica ed Ostetricia. Corso di Statistica Medica
 Università del Piemonte Orientale Corso di Laurea Triennale di Infermieristica Pediatrica ed Ostetricia Corso di Statistica Medica Le distribuzioni teoriche di probabilità La distribuzione Normale (o di
Università del Piemonte Orientale Corso di Laurea Triennale di Infermieristica Pediatrica ed Ostetricia Corso di Statistica Medica Le distribuzioni teoriche di probabilità La distribuzione Normale (o di
tabelle grafici misure di
 Statistica Descrittiva descrivere e riassumere un insieme di dati in maniera ordinata tabelle grafici misure di posizione dispersione associazione Misure di posizione Forniscono indicazioni sull ordine
Statistica Descrittiva descrivere e riassumere un insieme di dati in maniera ordinata tabelle grafici misure di posizione dispersione associazione Misure di posizione Forniscono indicazioni sull ordine
Parametri statistici
 SMID a.a. 2004/2005 Corso di Metodi Statistici in Biomedicina Parametri statistici 24/1/2005 Deviazione standard della media La variabilità di una distribuzione può quindi essere espressa da un indice
SMID a.a. 2004/2005 Corso di Metodi Statistici in Biomedicina Parametri statistici 24/1/2005 Deviazione standard della media La variabilità di una distribuzione può quindi essere espressa da un indice
Statistica Inferenziale La verifica di ipotesi. Davide Barbieri
 Statistica Inferenziale La verifica di ipotesi Davide Barbieri Inferenza statistica Inferenza: procedimento di induzione, dal particolare al generale. Stima di un parametro della popolazione partendo da
Statistica Inferenziale La verifica di ipotesi Davide Barbieri Inferenza statistica Inferenza: procedimento di induzione, dal particolare al generale. Stima di un parametro della popolazione partendo da
Il Test di Ipotesi Lezione 5
 Last updated May 23, 2016 Il Test di Ipotesi Lezione 5 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura I anno, II semestre Il test di ipotesi Cuore della statistica inferenziale!
Last updated May 23, 2016 Il Test di Ipotesi Lezione 5 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura I anno, II semestre Il test di ipotesi Cuore della statistica inferenziale!
Dispensa di Statistica
 Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
Dispensa di Statistica 1 parziale 2012/2013 Diagrammi... 2 Indici di posizione... 4 Media... 4 Moda... 5 Mediana... 5 Indici di dispersione... 7 Varianza... 7 Scarto Quadratico Medio (SQM)... 7 La disuguaglianza
Distribuzione Gaussiana - Facciamo un riassunto -
 Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Distribuzione Gaussiana - Facciamo un riassunto - Nell ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un carattere predittivo alla deviazione standard La prossima misura
Statistica Elementare
 Statistica Elementare 1. Frequenza assoluta Per popolazione si intende l insieme degli elementi che sono oggetto di una indagine statistica, ovvero l insieme delle unità, dette unità statistiche o individui
Statistica Elementare 1. Frequenza assoluta Per popolazione si intende l insieme degli elementi che sono oggetto di una indagine statistica, ovvero l insieme delle unità, dette unità statistiche o individui
CORSO DI LAUREA IN INFERMIERISTICA. LEZIONI DI STATISTICA Parte II Elaborazione dei dati Variabilità
 CORSO DI LAUREA IN INFERMIERISTICA LEZIONI DI STATISTICA Parte II Elaborazione dei dati Variabilità Lezioni di Statistica VARIABILITA Si definisce variabilità la proprietà di alcuni fenomeni di assumere
CORSO DI LAUREA IN INFERMIERISTICA LEZIONI DI STATISTICA Parte II Elaborazione dei dati Variabilità Lezioni di Statistica VARIABILITA Si definisce variabilità la proprietà di alcuni fenomeni di assumere
Tutta la scienza è fondata sulle misure (Helmholtz)
") Tutta la scienza è fondata sulle misure (Helmholtz) L acquisizione di una osservazione come DATO SCIENTIFICO richiede che : osserviamo un fenomeno lo quantifichiamo correttamente lo confrontiamo con altri
Tutta la scienza è fondata sulle misure (Helmholtz) L acquisizione di una osservazione come DATO SCIENTIFICO richiede che : osserviamo un fenomeno lo quantifichiamo correttamente lo confrontiamo con altri
UNIVERSITA DEGLI STUDI DI BRESCIA-FACOLTA DI MEDICINA E CHIRURGIA CORSO DI LAUREA IN INFERMIERISTICA SEDE DI DESENZANO dg STATISTICA MEDICA.
 Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Il metodo statistico: prova dell ipotesi, intervallo di confidenza
 Il metodo statistico: prova dell ipotesi, intervallo di confidenza Tratto con modifiche da : Buzzetti, Mastroiacovo. Le prove di efficacia in pediatria. 2000, UTET 1 Il problema Si supponga di voler verificare
Il metodo statistico: prova dell ipotesi, intervallo di confidenza Tratto con modifiche da : Buzzetti, Mastroiacovo. Le prove di efficacia in pediatria. 2000, UTET 1 Il problema Si supponga di voler verificare
10 TEST STATISTICI PER LA VERIFICA DI IPOTESI
 10 TEST STATISTICI PER LA VERIFICA DI IPOTESI Un test statistico è una procedura che permette di decidere tra l ipotesi sperimentale H1 e l ipotesi nulla H0, quantificando la divergenza delle osservazioni
10 TEST STATISTICI PER LA VERIFICA DI IPOTESI Un test statistico è una procedura che permette di decidere tra l ipotesi sperimentale H1 e l ipotesi nulla H0, quantificando la divergenza delle osservazioni
TRACCIA DI STUDIO. Indici di dispersione assoluta per misure quantitative
 TRACCIA DI STUDIO Un indice di tendenza centrale non è sufficiente a descrivere completamente un fenomeno. Gli indici di dispersione assolvono il compito di rappresentare la capacità di un fenomeno a manifestarsi
TRACCIA DI STUDIO Un indice di tendenza centrale non è sufficiente a descrivere completamente un fenomeno. Gli indici di dispersione assolvono il compito di rappresentare la capacità di un fenomeno a manifestarsi
Sperimentazioni di Fisica I mod. A Statistica - Lezione 2
 Sperimentazioni di Fisica I mod. A Statistica - Lezione 2 A. Garfagnini M. Mazzocco C. Sada Dipartimento di Fisica G. Galilei, Università di Padova AA 2014/2015 Elementi di Statistica Lezione 2: 1. Istogrammi
Sperimentazioni di Fisica I mod. A Statistica - Lezione 2 A. Garfagnini M. Mazzocco C. Sada Dipartimento di Fisica G. Galilei, Università di Padova AA 2014/2015 Elementi di Statistica Lezione 2: 1. Istogrammi
Metodi Quantitativi per Economia, Finanza e Management. Lezione n 5 Test d Ipotesi
 Metodi Quantitativi per Economia, Finanza e Management Lezione n 5 Test d Ipotesi Test per lo studio dell associazione tra variabili Nella teoria dei test, il ricercatore fornisce ipotesi riguardo la distribuzione
Metodi Quantitativi per Economia, Finanza e Management Lezione n 5 Test d Ipotesi Test per lo studio dell associazione tra variabili Nella teoria dei test, il ricercatore fornisce ipotesi riguardo la distribuzione
Indice. centrale, dispersione e forma Introduzione alla Statistica Statistica descrittiva per variabili quantitative: tendenza
 XIII Presentazione del volume XV L Editore ringrazia 3 1. Introduzione alla Statistica 5 1.1 Definizione di Statistica 6 1.2 I Rami della Statistica Statistica Descrittiva, 6 Statistica Inferenziale, 6
XIII Presentazione del volume XV L Editore ringrazia 3 1. Introduzione alla Statistica 5 1.1 Definizione di Statistica 6 1.2 I Rami della Statistica Statistica Descrittiva, 6 Statistica Inferenziale, 6
7. STATISTICA DESCRITTIVA
 7. STATISTICA DESCRITTIVA Quando si effettua un indagine statistica si ha a che fare con un numeroso insieme di oggetti, detto popolazione del quale si intende esaminare una o più caratteristiche (matricole
7. STATISTICA DESCRITTIVA Quando si effettua un indagine statistica si ha a che fare con un numeroso insieme di oggetti, detto popolazione del quale si intende esaminare una o più caratteristiche (matricole
Università del Piemonte Orientale. Corsi di laurea triennale di area tecnica. Corso di Statistica Medica. Intervalli di confidenza
 Università del Piemonte Orientale Corsi di laurea triennale di area tecnica Corso di Statistica Medica Intervalli di confidenza Corsi di laurea triennale di area tecnica - Corso di Statistica Medica -
Università del Piemonte Orientale Corsi di laurea triennale di area tecnica Corso di Statistica Medica Intervalli di confidenza Corsi di laurea triennale di area tecnica - Corso di Statistica Medica -
Verifica delle ipotesi
 Statistica inferenziale Stima dei parametri Verifica delle ipotesi Concetti fondamentali POPOLAZIONE o UNIVERSO Insieme degli elementi cui si rivolge il ricercatore per la sua indagine CAMPIONE Un sottoinsieme
Statistica inferenziale Stima dei parametri Verifica delle ipotesi Concetti fondamentali POPOLAZIONE o UNIVERSO Insieme degli elementi cui si rivolge il ricercatore per la sua indagine CAMPIONE Un sottoinsieme
N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle Tabelle riportate alla fine del documento.
 N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle Tabelle riportate alla fine del documento. Esercizio 1 Un chimico che lavora per una fabbrica di batterie, sta cercando una batteria
N.B. Per la risoluzione dei seguenti esercizi, si fa riferimento alle Tabelle riportate alla fine del documento. Esercizio 1 Un chimico che lavora per una fabbrica di batterie, sta cercando una batteria
Capitolo 8. Intervalli di confidenza. Statistica. Levine, Krehbiel, Berenson. Casa editrice: Pearson. Insegnamento: Statistica
 Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Levine, Krehbiel, Berenson Statistica Casa editrice: Pearson Capitolo 8 Intervalli di confidenza Insegnamento: Statistica Corso di Laurea Triennale in Economia Dipartimento di Economia e Management, Università
Tutta la scienza è fondata sulle misure (Helmholtz)
") Tutta la scienza è fondata sulle misure (Helmholtz) L acquisizione di una osservazione come DATO SCIENTIFICO richiede che : osserviamo un fenomeno lo quantifichiamo correttamente lo confrontiamo con altri
Tutta la scienza è fondata sulle misure (Helmholtz) L acquisizione di una osservazione come DATO SCIENTIFICO richiede che : osserviamo un fenomeno lo quantifichiamo correttamente lo confrontiamo con altri
BLAND-ALTMAN PLOT. + X 2i 2 la differenza ( d ) tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i
 tra le due misure per ognuno degli n campioni; d i. X i. = X 1i. X 2i") BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
BLAND-ALTMAN PLOT Il metodo di J. M. Bland e D. G. Altman è finalizzato alla verifica se due tecniche di misura sono comparabili. Resta da comprendere cosa si intenda con il termine metodi comparabili
Università del Piemonte Orientale. Corso di laurea in medicina e chirurgia. Corso di Statistica Medica. Analisi dei dati quantitativi :
 Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale Corso di laurea
Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale Corso di laurea
Test delle Ipotesi Parte I
 Test delle Ipotesi Parte I Test delle Ipotesi sulla media Introduzione Definizioni basilari Teoria per il caso di varianza nota Rischi nel test delle ipotesi Teoria per il caso di varianza non nota Test
Test delle Ipotesi Parte I Test delle Ipotesi sulla media Introduzione Definizioni basilari Teoria per il caso di varianza nota Rischi nel test delle ipotesi Teoria per il caso di varianza non nota Test
Statistica Inferenziale
 Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Statistica Inferenziale a) L Intervallo di Confidenza b) La distribuzione t di Student c) La differenza delle medie d) L intervallo di confidenza della differenza Prof Paolo Chiodini Dalla Popolazione
Università del Piemonte Orientale. Corso di laurea in medicina e chirurgia. Corso di Statistica Medica. Intervalli di confidenza
 Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Intervalli di confidenza Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso
Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Intervalli di confidenza Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso
UNIVERSITA DEGLI STUDI DI BRESCIA-FACOLTA DI MEDICINA E CHIRURGIA CORSO DI LAUREA IN INFERMIERISTICA SEDE DI DESENZANO dg STATISTICA MEDICA.
 Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Lezione 4 DISTRIBUZIONE DI FREQUENZA 1 DISTRIBUZIONE DI PROBABILITA Una variabile i cui differenti valori seguono una distribuzione di probabilità si chiama variabile aleatoria. Es:il numero di figli maschi
Matematica Lezione 22
 Università di Cagliari Corso di Laurea in Farmacia Matematica Lezione 22 Sonia Cannas 14/12/2018 Indici di posizione Indici di posizione Gli indici di posizione, detti anche misure di tendenza centrale,
Università di Cagliari Corso di Laurea in Farmacia Matematica Lezione 22 Sonia Cannas 14/12/2018 Indici di posizione Indici di posizione Gli indici di posizione, detti anche misure di tendenza centrale,
Università del Piemonte Orientale. Corso di laurea in medicina e chirurgia. Corso di Statistica Medica. Analisi dei dati quantitativi :
 Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale Corso di laurea
Università del Piemonte Orientale Corso di laurea in medicina e chirurgia Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale Corso di laurea
Tempo disponibile: 60 minuti
 Corso di Specialistica in Biotecnologie Statistica medica. A.A. 005-006 6 Marzo 006 Tempo disponibile: 60 minuti 1. Conducete uno studio clinico controllato randomizzato di fase III per misurare l'effetto
Corso di Specialistica in Biotecnologie Statistica medica. A.A. 005-006 6 Marzo 006 Tempo disponibile: 60 minuti 1. Conducete uno studio clinico controllato randomizzato di fase III per misurare l'effetto
Statistica. Capitolo 10. Verifica di Ipotesi su una Singola Popolazione. Cap. 10-1
 Statistica Capitolo 1 Verifica di Ipotesi su una Singola Popolazione Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Formulare ipotesi nulla ed ipotesi alternativa
Statistica Capitolo 1 Verifica di Ipotesi su una Singola Popolazione Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Formulare ipotesi nulla ed ipotesi alternativa
Test d ipotesi. Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona. Ipotesi alternativa (H 1 )
") Test d ipotesi Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Nel 900 falsificazione di ipotesi (Karl Popper) TEST D IPOTESI Nell 800 dimostrazione di ipotesi
Test d ipotesi Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Nel 900 falsificazione di ipotesi (Karl Popper) TEST D IPOTESI Nell 800 dimostrazione di ipotesi
Indicatori di Posizione e di Variabilità. Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica
 Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
Indicatori di Posizione e di Variabilità Corso di Laurea Specialistica in SCIENZE DELLE PROFESSIONI SANITARIE DELLA RIABILITAZIONE Statistica Medica Indici Sintetici Consentono il passaggio da una pluralità
Tipi di variabili. Indici di tendenza centrale e di dispersione
 Tipi di variabili. Indici di tendenza centrale e di dispersione L. Boni Variabile casuale In teoria della probabilità, una variabile casuale (o variabile aleatoria o variabile stocastica o random variable)
Tipi di variabili. Indici di tendenza centrale e di dispersione L. Boni Variabile casuale In teoria della probabilità, una variabile casuale (o variabile aleatoria o variabile stocastica o random variable)
Fondamenti di statistica per il miglioramento genetico delle piante. Antonio Di Matteo Università Federico II
 Fondamenti di statistica per il miglioramento genetico delle piante Antonio Di Matteo Università Federico II Modulo 2 Variabili continue e Metodi parametrici Distribuzione Un insieme di misure è detto
Fondamenti di statistica per il miglioramento genetico delle piante Antonio Di Matteo Università Federico II Modulo 2 Variabili continue e Metodi parametrici Distribuzione Un insieme di misure è detto
Analisi della varianza
 Università degli Studi di Padova Facoltà di Medicina e Chirurgia Facoltà di Medicina e Chirurgia - A.A. 2009-10 Scuole di specializzazione Lezioni comuni Disciplina: Statistica Docente: dott.ssa Egle PERISSINOTTO
Università degli Studi di Padova Facoltà di Medicina e Chirurgia Facoltà di Medicina e Chirurgia - A.A. 2009-10 Scuole di specializzazione Lezioni comuni Disciplina: Statistica Docente: dott.ssa Egle PERISSINOTTO
Laboratorio di Chimica Fisica. Analisi Statistica
 Università degli Studi di Bari Dipartimento di Chimica 9 giugno F.Mavelli- Laboratorio Chimica Fisica - a.a. 3-4 F.Mavelli Laboratorio di Chimica Fisica a.a. 3-4 Analisi Statistica dei Dati Analisi Statistica
Università degli Studi di Bari Dipartimento di Chimica 9 giugno F.Mavelli- Laboratorio Chimica Fisica - a.a. 3-4 F.Mavelli Laboratorio di Chimica Fisica a.a. 3-4 Analisi Statistica dei Dati Analisi Statistica
Modelli e procedure per l educazione degli adulti
 CdL SEAFC a.a. 2016-2017 II semestre Pedagogia sperimentale. Modelli e procedure per l educazione degli adulti francesco.agrusti@uniroma3.it T6. Modelli e procedure di valutazione Ultimo appuntamento con
CdL SEAFC a.a. 2016-2017 II semestre Pedagogia sperimentale. Modelli e procedure per l educazione degli adulti francesco.agrusti@uniroma3.it T6. Modelli e procedure di valutazione Ultimo appuntamento con
Breve ripasso di statistica
 Breve ripasso di statistica D.C. Harris, Elementi di chimica analitica, Zanichelli, 1999 Capitolo 4 1 Il protocollo analitico Campionamento: 1. estrazione del campione dal lotto 2. conservazione e trasporto
Breve ripasso di statistica D.C. Harris, Elementi di chimica analitica, Zanichelli, 1999 Capitolo 4 1 Il protocollo analitico Campionamento: 1. estrazione del campione dal lotto 2. conservazione e trasporto
Capitolo 12 La regressione lineare semplice
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
le scale di misura scala nominale scala ordinale DIAGNOSTICA PSICOLOGICA lezione si basano su tre elementi:
 DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it si basano su tre elementi: le scale di misura sistema empirico: un insieme di entità non numeriche (es. insieme di persone; insieme
DIAGNOSTICA PSICOLOGICA lezione! Paola Magnano paola.magnano@unikore.it si basano su tre elementi: le scale di misura sistema empirico: un insieme di entità non numeriche (es. insieme di persone; insieme
TOPOGRAFIA 2013/2014. Prof. Francesco-Gaspare Caputo
 TOPOGRAFIA 2013/2014 L operazione di misura di una grandezza produce un numero reale che esprime il rapporto della grandezza stessa rispetto a un altra, a essa omogenea, assunta come unità di misura. L
TOPOGRAFIA 2013/2014 L operazione di misura di una grandezza produce un numero reale che esprime il rapporto della grandezza stessa rispetto a un altra, a essa omogenea, assunta come unità di misura. L
Università del Piemonte Orientale. Corso di laurea specialistica in biotecnologie mediche. Corso di Statistica Medica. Analisi dei dati quantitativi :
 Università del Piemonte Orientale Corso di laurea specialistica in biotecnologie mediche Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale
Università del Piemonte Orientale Corso di laurea specialistica in biotecnologie mediche Corso di Statistica Medica Analisi dei dati quantitativi : Analisi della varianza Università del Piemonte Orientale
Esercizi di statistica
 Esercizi di statistica Test a scelta multipla (la risposta corretta è la prima) [1] Il seguente campione è stato estratto da una popolazione distribuita normalmente: -.4, 5.5,, -.5, 1.1, 7.4, -1.8, -..
Esercizi di statistica Test a scelta multipla (la risposta corretta è la prima) [1] Il seguente campione è stato estratto da una popolazione distribuita normalmente: -.4, 5.5,, -.5, 1.1, 7.4, -1.8, -..
PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA
 ANALISI DELLA VARIANZA") PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA PROCEDURA/TECNICA DI ANALISI DEI DATI SPECIFICAMENTE DESTINATA A STUDIARE LA RELAZIONE TRA UNA VARIABILE NOMINALE (ASSUNTA
PROCEDURE/TECNICHE DI ANALISI / MISURE DI ASSOCIAZIONE A) ANALISI DELLA VARIANZA PROCEDURA/TECNICA DI ANALISI DEI DATI SPECIFICAMENTE DESTINATA A STUDIARE LA RELAZIONE TRA UNA VARIABILE NOMINALE (ASSUNTA
INTRODUZIONE ALLA STATISTICA
 1 / 31 INTRODUZIONE ALLA STATISTICA A.A.2017/2018 Perchè studiare la statistica 2 / 31 Le decisioni quotidiane sono spesso basate su informazioni incomplete. Perchè studiare la statistica Le decisioni
1 / 31 INTRODUZIONE ALLA STATISTICA A.A.2017/2018 Perchè studiare la statistica 2 / 31 Le decisioni quotidiane sono spesso basate su informazioni incomplete. Perchè studiare la statistica Le decisioni
Elementi di Statistica
 Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Università degli Studi di Palermo Dipartimento di Ingegneria Informatica Informatica ed Elementi di Statistica 3 c.f.u. Anno Accademico 2010/2011 Docente: ing. Salvatore Sorce Elementi di Statistica Statistica
Distribuzione normale
 Distribuzione normale istogramma delle frequenze di un insieme di misure relative a una grandezza che varia con continuità popolazione molto numerosa, costituita da una quantità praticamente illimitata
Distribuzione normale istogramma delle frequenze di un insieme di misure relative a una grandezza che varia con continuità popolazione molto numerosa, costituita da una quantità praticamente illimitata
Ogni misura è composta di almeno tre dati: un numero, un'unità di misura, un'incertezza.
 Ogni misura è composta di almeno tre dati: un numero, un'unità di misura, un'incertezza. Misure ripetute forniscono dati numerici distribuiti attorno ad un valore centrale indicabile con un indice (indice
Ogni misura è composta di almeno tre dati: un numero, un'unità di misura, un'incertezza. Misure ripetute forniscono dati numerici distribuiti attorno ad un valore centrale indicabile con un indice (indice
05. Errore campionario e numerosità campionaria
 Statistica per le ricerche di mercato A.A. 01/13 05. Errore campionario e numerosità campionaria Gli schemi di campionamento condividono lo stesso principio di fondo: rappresentare il più fedelmente possibile,
Statistica per le ricerche di mercato A.A. 01/13 05. Errore campionario e numerosità campionaria Gli schemi di campionamento condividono lo stesso principio di fondo: rappresentare il più fedelmente possibile,
Statistica. Matematica con Elementi di Statistica a.a. 2017/18
 Statistica La statistica è la scienza che organizza e analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva: dalla mole di dati
Statistica La statistica è la scienza che organizza e analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva: dalla mole di dati
LEZIONI IN LABORATORIO Corso di MARKETING L. Baldi Università degli Studi di Milano. Strumenti statistici in Excell
 LEZIONI IN LABORATORIO Corso di MARKETING L. Baldi Università degli Studi di Milano Strumenti statistici in Excell Pacchetto Analisi di dati Strumenti di analisi: Analisi varianza: ad un fattore Analisi
LEZIONI IN LABORATORIO Corso di MARKETING L. Baldi Università degli Studi di Milano Strumenti statistici in Excell Pacchetto Analisi di dati Strumenti di analisi: Analisi varianza: ad un fattore Analisi
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati.
 La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA. Prof.ssa Donatella Siepi tel:
 UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 2 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
UNIVERSITA DEGLI STUDI DI PERUGIA STATISTICA MEDICA Prof.ssa Donatella Siepi donatella.siepi@unipg.it tel: 075 5853525 2 LEZIONE Statistica descrittiva STATISTICA DESCRITTIVA Rilevazione dei dati Rappresentazione
Dipartimento di Fisica a.a. 2003/2004 Fisica Medica 2 Indici statistici 22/4/2005
 Dipartimento di Fisica a.a. 23/24 Fisica Medica 2 Indici statistici 22/4/25 Ricerca statistica La ricerca può essere deduttiva (data una legge teorica nota cerco verifica tramite più misure) ovvero induttiva
Dipartimento di Fisica a.a. 23/24 Fisica Medica 2 Indici statistici 22/4/25 Ricerca statistica La ricerca può essere deduttiva (data una legge teorica nota cerco verifica tramite più misure) ovvero induttiva
Introduzione alla statistica per la ricerca in sanità
 Introduzione alla statistica per la ricerca in sanità Modulo La verifica delle ipotesi: il test statistico dott. Eugenio Traini eugenio.traini@burlo.trieste.it Verifica d Ipotesi - 1 Che cos è un ipotesi
Introduzione alla statistica per la ricerca in sanità Modulo La verifica delle ipotesi: il test statistico dott. Eugenio Traini eugenio.traini@burlo.trieste.it Verifica d Ipotesi - 1 Che cos è un ipotesi
Statistica. POPOLAZIONE: serie di dati, che rappresenta linsieme che si vuole indagare (reali, sperimentali, matematici)
") Statistica La statistica può essere vista come la scienza che organizza ed analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva:
Statistica La statistica può essere vista come la scienza che organizza ed analizza dati numerici per fini descrittivi o per permettere di prendere delle decisioni e fare previsioni. Statistica descrittiva:
LEZIONI DI STATISTICA MEDICA
 LEZIONI DI STATISTICA MEDICA Lezione n.12 - Test statistico Sezione di Epidemiologia & Statistica Medica Università degli Studi di Verona IPOTESI SCIENTIFICA Affermazione che si può sottoporre a verifica
LEZIONI DI STATISTICA MEDICA Lezione n.12 - Test statistico Sezione di Epidemiologia & Statistica Medica Università degli Studi di Verona IPOTESI SCIENTIFICA Affermazione che si può sottoporre a verifica
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati.
 La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
La media e la mediana sono indicatori di centralità, che indicano un centro dei dati. Un indicatore che sintetizza in un unico numero tutti i dati, nascondendo quindi la molteplicità dei dati. Per esempio,
Regressione lineare semplice
 Regressione lineare semplice Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Statistica con due variabili var. nominale, var. nominale: gruppo sanguigno - cancro
Regressione lineare semplice Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Statistica con due variabili var. nominale, var. nominale: gruppo sanguigno - cancro
Confronto fra gruppi: il metodo ANOVA. Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23
 Confronto fra gruppi: il metodo ANOVA 1 / 23") Confronto fra gruppi: il metodo ANOVA Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23 1 Nella popolazione, per ciascun gruppo la distribuzione della variabile risposta
Confronto fra gruppi: il metodo ANOVA Nicola Tedesco (Statistica Sociale) Confronto fra gruppi: il metodo ANOVA 1 / 23 1 Nella popolazione, per ciascun gruppo la distribuzione della variabile risposta
Test d ipotesi. Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona. Ipotesi alternativa (H 1 )
") Test d ipotesi Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Nel 900 falsificazione di ipotesi (Karl Popper) TEST D IPOTESI Nell 800 dimostrazione di ipotesi
Test d ipotesi Prof. Giuseppe Verlato Sezione di Epidemiologia e Statistica Medica, Università di Verona Nel 900 falsificazione di ipotesi (Karl Popper) TEST D IPOTESI Nell 800 dimostrazione di ipotesi
REGRESSIONE E CORRELAZIONE
 REGRESSIONE E CORRELAZIONE Nella Statistica, per studio della connessione si intende la ricerca di eventuali relazioni, di dipendenza ed interdipendenza, intercorrenti tra due variabili statistiche 1.
REGRESSIONE E CORRELAZIONE Nella Statistica, per studio della connessione si intende la ricerca di eventuali relazioni, di dipendenza ed interdipendenza, intercorrenti tra due variabili statistiche 1.
Endpoint di efficacia in oncologia. Valter Torri Istituto Mario Negri
 Endpoint di efficacia in oncologia Valter Torri Istituto Mario Negri Il ciclo di vita di un famaco In clinica classificazione in fasi con obiettivi differenti I: sicurezza II: attività III: efficacia di
Endpoint di efficacia in oncologia Valter Torri Istituto Mario Negri Il ciclo di vita di un famaco In clinica classificazione in fasi con obiettivi differenti I: sicurezza II: attività III: efficacia di
SCHEDA DIDATTICA N 7
 FACOLTA DI INGEGNERIA CORSO DI LAUREA IN INGEGNERIA CIVILE CORSO DI IDROLOGIA PROF. PASQUALE VERSACE SCHEDA DIDATTICA N 7 LA DISTRIBUZIONE NORMALE A.A. 01-13 La distribuzione NORMALE Uno dei più importanti
FACOLTA DI INGEGNERIA CORSO DI LAUREA IN INGEGNERIA CIVILE CORSO DI IDROLOGIA PROF. PASQUALE VERSACE SCHEDA DIDATTICA N 7 LA DISTRIBUZIONE NORMALE A.A. 01-13 La distribuzione NORMALE Uno dei più importanti
Teorema del Limite Centrale
 Teorema del Limite Centrale Teorema. Sia data una popolazione numerica infinita di media µ e deviazione standard σ da cui vengono estratti dei campioni casuali formati ciascuno da n individui, con n abbastanza
Teorema del Limite Centrale Teorema. Sia data una popolazione numerica infinita di media µ e deviazione standard σ da cui vengono estratti dei campioni casuali formati ciascuno da n individui, con n abbastanza
Metodi statistici per le ricerche di mercato
 Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2017-2018 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2017-2018 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
Elementi di Probabilità e Statistica
 Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
Elementi di Probabilità e Statistica Statistica Descrittiva Rappresentazione dei dati mediante tabelle e grafici Estrapolazione di indici sintetici in grado di fornire informazioni riguardo alla distribuzione
Nel modello omoschedastico la varianza dell errore non dipende da i ed è quindi pari a σ 0.
 Regressione [] el modello di regressione lineare si assume una relazione di tipo lineare tra il valore medio della variabile dipendente Y e quello della variabile indipendente X per cui Il modello si scrive
Regressione [] el modello di regressione lineare si assume una relazione di tipo lineare tra il valore medio della variabile dipendente Y e quello della variabile indipendente X per cui Il modello si scrive
CHEMIOMETRIA. CONFRONTO CON VALORE ATTESO (test d ipotesi) CONFRONTO DI VALORI MISURATI (test d ipotesi) CONFRONTO DI RIPRODUCIBILITA (test d ipotesi)
 CONFRONTO DI VALORI MISURATI (test d ipotesi) CONFRONTO DI RIPRODUCIBILITA (test d ipotesi)") CHEMIOMETRIA Applicazione di metodi matematici e statistici per estrarre (massima) informazione chimica (affidabile) da dati chimici INCERTEZZA DI MISURA (intervallo di confidenza/fiducia) CONFRONTO CON
CHEMIOMETRIA Applicazione di metodi matematici e statistici per estrarre (massima) informazione chimica (affidabile) da dati chimici INCERTEZZA DI MISURA (intervallo di confidenza/fiducia) CONFRONTO CON
Corso di Laurea in Economia Aziendale. Docente: Marta Nai Ruscone. Statistica. a.a. 2015/2016
 Corso di Laurea in Economia Aziendale Docente: Marta Nai Ruscone Statistica a.a. 2015/2016 1 Indici di posizione GLI INDICI DI POSIZIONE sono indici sintetici che evidenziano le caratteristiche essenziali
Corso di Laurea in Economia Aziendale Docente: Marta Nai Ruscone Statistica a.a. 2015/2016 1 Indici di posizione GLI INDICI DI POSIZIONE sono indici sintetici che evidenziano le caratteristiche essenziali
Introduzione alla statistica con Excel
 Introduzione alla statistica con Excel Davide Sardina davidestefano.sardina@unikore.it Università degli studi di Enna Kore Corso di Laurea in Servizio Sociale A.A. 2017/2018 Variabili quantitative e qualitative
Introduzione alla statistica con Excel Davide Sardina davidestefano.sardina@unikore.it Università degli studi di Enna Kore Corso di Laurea in Servizio Sociale A.A. 2017/2018 Variabili quantitative e qualitative
Statistica descrittiva
 Statistica descrittiva L obiettivo è quello di descrivere efficacemente i dati prima delle elaborazioni vere e proprie: - mediante rappresentazioni grafiche e tabelle - sintetizzandoli con indici opportuni
Statistica descrittiva L obiettivo è quello di descrivere efficacemente i dati prima delle elaborazioni vere e proprie: - mediante rappresentazioni grafiche e tabelle - sintetizzandoli con indici opportuni
Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva
 Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
Fondamenti di Informatica Ester Zumpano Programmazione con Foglio di Calcolo Cenni di Statistica Descrittiva Lezione 5 Statistica descrittiva La statistica descrittiva mette a disposizione il calcolo di
MISURA DELLA VARIAZIONE CONCOMITANTE (COVARIAZIONE/ CONTROVARIAZIONE) DI VARIABILI CARDINALI O QUASI- CARDINALI
 DI VARIABILI CARDINALI O QUASI- CARDINALI") ANALISI DELLA CORRELAZIONE MISURA DELLA VARIAZIONE CONCOMITANTE (COVARIAZIONE/ CONTROVARIAZIONE) DI VARIABILI CARDINALI O QUASI- CARDINALI VINCOLI CHE SI IMPONGONO ALLA SUA UTILIZZAZIONE: LA RELAZIONE
ANALISI DELLA CORRELAZIONE MISURA DELLA VARIAZIONE CONCOMITANTE (COVARIAZIONE/ CONTROVARIAZIONE) DI VARIABILI CARDINALI O QUASI- CARDINALI VINCOLI CHE SI IMPONGONO ALLA SUA UTILIZZAZIONE: LA RELAZIONE
Distribuzioni e inferenza statistica
 Distribuzioni e inferenza statistica Distribuzioni di probabilità L analisi statistica spesso studia i fenomeni collettivi confrontandoli con modelli teorici di riferimento. Tra di essi, vedremo: la distribuzione
Distribuzioni e inferenza statistica Distribuzioni di probabilità L analisi statistica spesso studia i fenomeni collettivi confrontandoli con modelli teorici di riferimento. Tra di essi, vedremo: la distribuzione
Richiami di inferenza statistica Strumenti quantitativi per la gestione
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Parametri e statistiche Esempi Tecniche di inferenza Stima Precisione delle stime Intervalli
Richiami di inferenza statistica. Strumenti quantitativi per la gestione. Emanuele Taufer
 Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
Richiami di inferenza statistica Strumenti quantitativi per la gestione Emanuele Taufer Inferenza statistica Inferenza statistica: insieme di tecniche che si utilizzano per ottenere informazioni su una
Test d Ipotesi Introduzione
 Test d Ipotesi Introduzione Uno degli scopi più importanti di un analisi statistica è quello di utilizzare i dati provenienti da un campione per fare inferenza sulla popolazione da cui è stato estratto
Test d Ipotesi Introduzione Uno degli scopi più importanti di un analisi statistica è quello di utilizzare i dati provenienti da un campione per fare inferenza sulla popolazione da cui è stato estratto
3.1 Classificazione dei fenomeni statistici Questionari e scale di modalità Classificazione delle scale di modalità 17
 C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
C L Autore Ringraziamenti dell Editore Elenco dei simboli e delle abbreviazioni in ordine di apparizione XI XI XIII 1 Introduzione 1 FAQ e qualcos altro, da leggere prima 1.1 Questo è un libro di Statistica
Corso di STATISTICA EGA - Classe 1 aa Docenti: Luca Frigau, Claudio Conversano
 Corso di STATISTICA EGA - Classe 1 aa 2017-2018 Docenti: Luca Frigau, Claudio Conversano Il corso è organizzato in 36 incontri, per un totale di 72 ore di lezione. Sono previste 18 ore di esercitazione
Corso di STATISTICA EGA - Classe 1 aa 2017-2018 Docenti: Luca Frigau, Claudio Conversano Il corso è organizzato in 36 incontri, per un totale di 72 ore di lezione. Sono previste 18 ore di esercitazione
ESERCIZI DI STATISTICA SOCIALE
 ESERCIZI DI STATISTICA SOCIALE FREQUENZA ASSOLUTA Data una distribuzione semplice di dati, ovvero una serie di microdati, si chiama frequenza assoluta di ogni modalità del carattere studiato il numero
ESERCIZI DI STATISTICA SOCIALE FREQUENZA ASSOLUTA Data una distribuzione semplice di dati, ovvero una serie di microdati, si chiama frequenza assoluta di ogni modalità del carattere studiato il numero
Statistica inferenziale. La statistica inferenziale consente di verificare le ipotesi sulla popolazione a partire dai dati osservati sul campione.
 Statistica inferenziale La statistica inferenziale consente di verificare le ipotesi sulla popolazione a partire dai dati osservati sul campione. Verifica delle ipotesi sulla medie Quando si conduce una
Statistica inferenziale La statistica inferenziale consente di verificare le ipotesi sulla popolazione a partire dai dati osservati sul campione. Verifica delle ipotesi sulla medie Quando si conduce una
Università di Pavia Econometria. Richiami di Statistica. Eduardo Rossi
 Università di Pavia Econometria Richiami di Statistica Eduardo Rossi Università di Pavia Campione casuale Siano (Y 1, Y 2,..., Y N ) variabili casuali tali che le y i siano realizzazioni mutuamente indipendenti
Università di Pavia Econometria Richiami di Statistica Eduardo Rossi Università di Pavia Campione casuale Siano (Y 1, Y 2,..., Y N ) variabili casuali tali che le y i siano realizzazioni mutuamente indipendenti
Statistica (parte II) Esercitazione 4
 Esercitazione 4") Statistica (parte II) Esercitazione 4 Davide Passaretti 03/03/016 Test sulla differenza tra medie (varianze note) Un negozio di scarpe è interessato a capire se le misure delle scarpe acquistate da adulti
Statistica (parte II) Esercitazione 4 Davide Passaretti 03/03/016 Test sulla differenza tra medie (varianze note) Un negozio di scarpe è interessato a capire se le misure delle scarpe acquistate da adulti
Costruzione di macchine. Modulo di: Progettazione probabilistica e affidabilità. Marco Beghini. Lezione 7: Basi di statistica
 Costruzione di macchine Modulo di: Progettazione probabilistica e affidabilità Marco Beghini Lezione 7: Basi di statistica Campione e Popolazione Estrazione da una popolazione (virtualmente infinita) di
Costruzione di macchine Modulo di: Progettazione probabilistica e affidabilità Marco Beghini Lezione 7: Basi di statistica Campione e Popolazione Estrazione da una popolazione (virtualmente infinita) di
La distribuzione delle frequenze. T 10 (s)
") 1 La distribuzione delle frequenze Si vuole misurare il periodo di oscillazione di un pendolo costituito da una sferetta metallica agganciata a un filo (fig. 1). A Figura 1 B Ricordiamo che il periodo
1 La distribuzione delle frequenze Si vuole misurare il periodo di oscillazione di un pendolo costituito da una sferetta metallica agganciata a un filo (fig. 1). A Figura 1 B Ricordiamo che il periodo
INTRODUZIONE AL DOE come strumento di sviluppo prodotto Francesca Campana Parte 2 Concetti di base
 INTRODUZIONE AL DOE come strumento di sviluppo prodotto Francesca Campana Parte Concetti di base Pagina CONCETTI STATISTICI DI PARTENZA - DESCRITTORI DI UNA VARIABILE RANDOM - GRAFICI UTILI - DISTRIBUZIONI
INTRODUZIONE AL DOE come strumento di sviluppo prodotto Francesca Campana Parte Concetti di base Pagina CONCETTI STATISTICI DI PARTENZA - DESCRITTORI DI UNA VARIABILE RANDOM - GRAFICI UTILI - DISTRIBUZIONI
Teoria della stima dei parametri:
 INFERENZA STATISTICA Teoria della verifica dell ipotesi : si verifica, in termini probabilistici, se una certa affermazione relativa alla popolazione è da ritenersi vera sulla base dei dati campionari
INFERENZA STATISTICA Teoria della verifica dell ipotesi : si verifica, in termini probabilistici, se una certa affermazione relativa alla popolazione è da ritenersi vera sulla base dei dati campionari
Statistica inferenziale per variabili quantitative
 Lezione 7: - Z - test e intervalli di Confidenza - t-test per campioni indipendenti e dipendenti Cattedra di Biostatistica Dipartimento di Scienze scperimentali e cliniche, Università degli Studi G. d
Lezione 7: - Z - test e intervalli di Confidenza - t-test per campioni indipendenti e dipendenti Cattedra di Biostatistica Dipartimento di Scienze scperimentali e cliniche, Università degli Studi G. d
Scale di Misurazione Lezione 2
 Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile
Last updated April 26, 2016 Scale di Misurazione Lezione 2 G. Bacaro Statistica CdL in Scienze e Tecnologie per l'ambiente e la Natura II anno, II semestre Tipi di Variabili 1 Scale di Misurazione 1. Variabile