Un applicazione della modellistica ARCH-GARCH
|
|
|
- Achille Lombardi
- 9 anni fa
- Просмотров:
Транскрипт
1 Un applicazione della modellistica ARCH-GARCH Federico Andreis Tesina per l esame di Metodi Statistici per la Finanza e le Assicurazioni A.A. 2005/2006 Prof. Diego Zappa

2 Il grafico della serie storica dei rendimenti, differenziata di ordine 1, evidenza un andamento in media regolare intorno allo zero, mentre appare esservi una certa disomogeneità nella variabilità, segnale della presenza di eteroschedasticità. Per meglio rendersi conto di tale fatto può essere utile esaminare anche il grafico del quadrato dei valori di tale serie storica, rappresentativo dei momenti secondi. Dai grafici di autocorrelazione ed autocorrelazione parziale riconosciamo il comportamento tipico di un processo stocastico a media mobile (PACF diradante lentamente verso lo zero e ACF che non presenta valori esterni alle bande di confidenza oltre ad un certo lag, che aiuta ad identificarne l ordine), possiamo dunque proporre un tale modello per catturare l evoluzione del fenomeno.

3
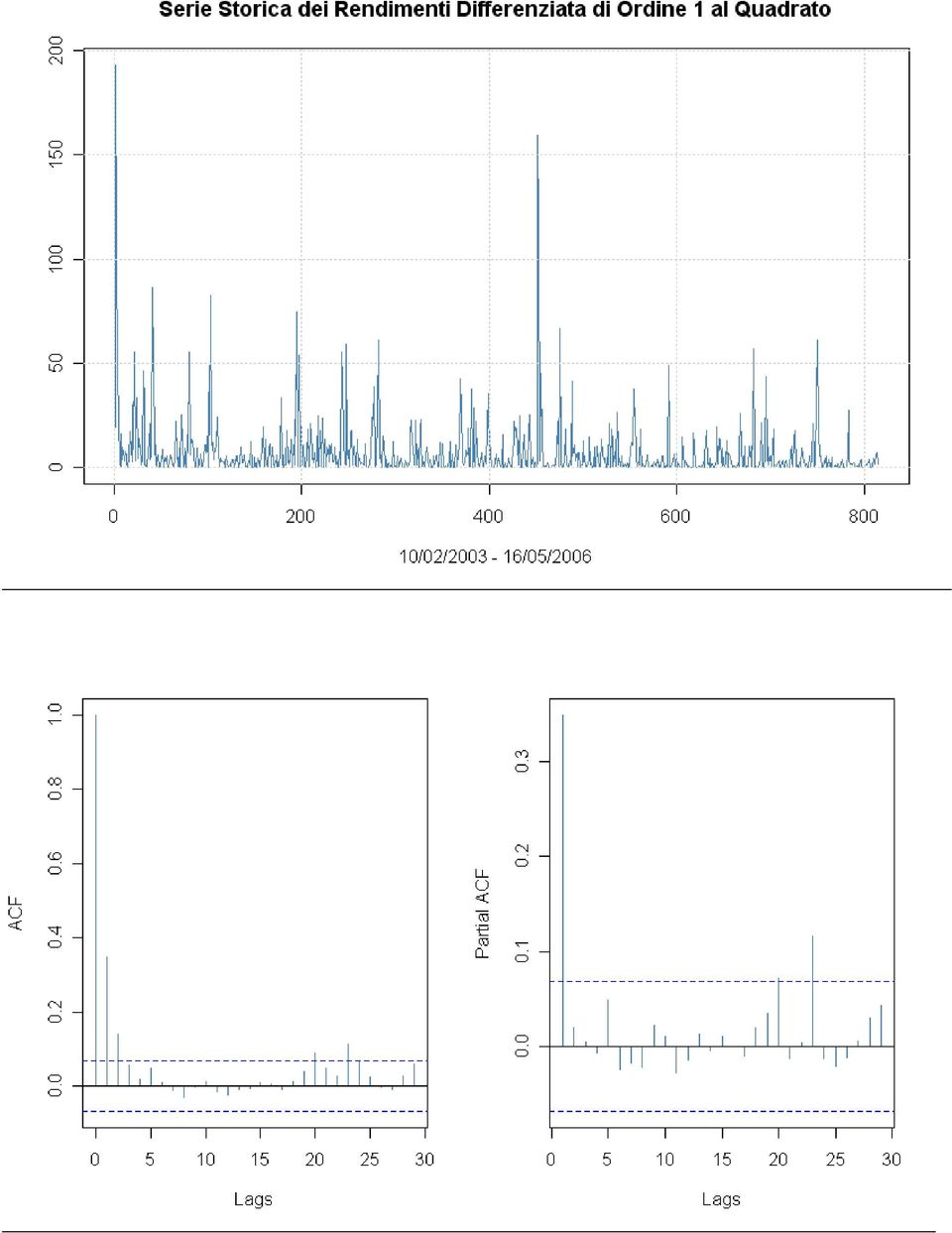
4 Il grafico dei quadrati della serie storica dei rendimenti può ben rappresentare l andamento della variabilità, in quanto il valor medio della serie può essere ragionevolmente considerato pari a zero, e di conseguenza il solo momento secondo dall origine impiegato per il calcolo della varianza. Si nota immediatamente la presenza di sacche di volatilità (clustering), già segnale della presenza di eteroschedasticità, e con l analisi dei grafici di ACF e PACF ravvisiamo forte correlazione seriale (tale comportamento è tipico dei mercati finanziari, dove è noto che a grosse fluttuazioni seguiranno grosse fluttuazioni, così come a piccoli cambiamenti seguiranno piccoli cambiamenti). Questi elementi conducono alla conclusione che la variabilità all interno della serie dei rendimenti considerata non è costante, ovvero l ipotesi di omoschedasticità non può essere accettata; ciò porta alla necessità di configurare un analisi ulteriore introducendo la modellistica GARCH (Generalized Autoregressive Conditional Heteroskedasticity models), la quale, in sostanza, introduce la specificazione di un modello autoregressivo sui quadrati dei residui della serie, e si propone di descrivere l evoluzione della variabilità nel tempo. Al fine di una più accurata analisi del fenomeno risulterà fondamentale la descrizione congiunta del comportamento del suo livello medio e della sua volatilità, considerazione, questa, che ha portato alla definizione di processi stocastici denominati ARMA-GARCH, che fondono le due strutture in un unico modello, il cui proposito sarà di spiegare il livello medio del fenomeno tramite un ARMA e la sua volatilità tramite un GARCH.
.")
5 Commenti Modelli e Test Modello Jarque-Bera Shapiro-Wilk GARCH(1,1) GARCH(1,2) MA(1)GARCH(1,1) MA(2)GARCH(1,1) ARMA(1,1)GARCH(1,1) ARMA(1,2)GARCH(1,1) ( e-08) ( e-09) ( e-13) ( e-10) ( e-13) ( e-08) Ljiung-Box(20) R/R^ ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) LM Arch ( ) ( ) ( ) ( ) ( ) ( ) AIC La tabella presenta i risultati di alcuni test effettuati sui residui standardizzati dei modelli stimati. Come spesso in queste situazioni si è proceduto per tentativi su diverse combinazioni di numero di parametri (tenendo comunque però presenti le informazioni derivanti dall analisi dei grafici di ACF e PACF), al fine di trovare il processo più descrittivo del fenomeno; sono stati riportati i valori delle statistiche insieme al loro p-value, ed infine il criterio informativo di Akaike. Le statistiche di Jarque-Bera e di Shapiro-Wilk vengono impiegate per testare la normalità degli errori, risulta evidente come per ogni modello tale condizione non si verifichi, il p-value del test può considerarsi pari a zero per ognuno dei modelli, portandoci quindi a rifiutare l ipotesi nulla di gaussianità; questo può essere un problema per la perdita delle pregevoli proprietà che la normalità reca con sé, ma sarà possibile tentare di risolverlo introducendo nella stima dei modelli l ipotesi di una distribuzione componente erratica differente. Il test LM (Lagrange Multiplier) sottopone a verifica l ipotesi nulla di assenza di effetti ARCH (omoschedasticità) contro l ipotesi alternativa di presenza (eteroschedasticità); come si nota dalla tabella tutti i modelli eliminano con successo tale componente, i p-value risultano essere molto elevati, non consentendoci di rifiutare l ipotesi nulla. L esistenza di effetti ARCH in seguito all applicazione del modello significherebbe che esso non è stato in grado di spiegare opportunamente l eteroschedasticità del fenomeno. Il test di Ljiung-Box consente di verificare la presenza o meno di autocorrelazione dei residui (il pacchetto impiegato per la stima e i test considera quelli standardizzati per il loro scarto quadratico medio) entro un numero prefissato di lag (in questo caso 20). Un buon modello di analisi della volatilità deve eliminare la correlazione seriale dei residui, tanto sulla componente media (R) quanto su quella di variabilità (R^2). Notiamo come i due modelli GARCH puri, pur facendo scomparire l autocorrelazione fra i residui al quadrato (p-value molto elevato), non riescono a cogliere nulla per quando riguarda i residui (p-value pari a zero), questo è chiaramente dovuto al fatto che non è stato specificato un modello ARMA sottostante, e ne risulta dunque evidente la necessità. Gli altri quattro modelli ARMA-GARCH riescono invece ad eliminare l autocorrelazione
 LM Arch 5.111833 (0.9541389) 4.467431 (0.9734513) 10.86024 (0.5409328) 10.37415 (0.5831728) 10.77531 (0.5482668) 11.16761 (0.5146119) AIC -4.679593-4.687169-4.145016-4.136173-4.142477-4.")
6 in entrambi gli aspetti, sono dunque per questo motivo preferibili ai primi due, nonostante questi presentino un valore di AIC più basso (la regola è the lower, the better, ma essendo l AIC una statistica che risente del numero di parametri impiegati, evidentemente la parsimonia di GARCH(1,1) e GARCH(1,2) in questo senso fa loro guadagnare una ingannevole parvenza di preferibilità). In ultimo consideriamo, appunto, il criterio informativo di Akaike. Come già detto, più basso risulta il valore AIC, maggiormente preferibile risulta il modello; escludendo per quanto poco fa sottolineato i due modelli GARCH puri, tale criterio porterebbe alla scelta di un processo di tipo MA(1)GARCH(1,1), che presenta un AIC pari a , o dell ARMA(1,1)GARCH(1,1), con AIC= Sfortunatamente dall output della stima risulta che per ambedue i modelli svariati parametri (due nel primo, tre nel secondo) risultano essere non significativamente diversi da zero, e quindi sono inutilizzabili (l eliminazione di tali coefficienti porta a dei modelli pressoché privi di capacità esplicativa), e quindi vanno scartati; il modello seguente secondo il criterio di Akaike sarebbe MA(2)GARCH(1,1), ma anche in questa situazione uno dei parametri risulta essere non significativo, in particolare quello relativo alla componente di ordine uno della media mobile. L unico modello a conservare intatta la significatività di tutti i parametri (ad un accettabile livello di confidenza del 90% nel caso peggiore) risulta dunque essere l ultimo, ARMA(1,2)GARCH(1,1), il quale, forse in virtù della sua maggiore articolazione (ben cinque parametri) soddisfa a tutti i requisiti e risulta di utilità nel suo complesso, eliminando la presenza di effetti ARCH e l autocorrelazione fra i residui e i residui al quadrato. L espressione del modello da prendere in esame sarà quindi: y = y + ε ε ε σ ε σ t t 1 t t 1 t t = t t 1.

7 Modelli Analizzati ARMA(0,1) arma(x = fwbrepd1, order = c(0, 1)) Model: ARMA(0,1) Residuals: Min 1Q Median 3Q Max ma <2e-16 *** intercept Fit: sigma^2 estimated as 4.094, Conditional Sum-of-Squares = , AIC = ARMA(1,2) arma(x = fwbrepd1, order = c(1, 2)) Model: ARMA(1,2) Residuals: Min 1Q Median 3Q Max ar < 2e-16 *** ma *** ma < 2e-16 *** intercept Fit: sigma^2 estimated as 3.726, Conditional Sum-of-Squares = , AIC =

8 GARCH(1,1) Title: GARCH Modelling garchfit(formula.mean = ~arma(0, 0), formula.var = ~garch(1, 1), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(0, 0) + ~garch(1, 1) Conditional Distribution: dnorm mu omega alpha1 beta Error Analysis: mu omega *** alpha e-06 *** beta *** Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-08 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

9 MA(1)GARCH(1,1) Title: GARCH Modelling garchfit(formula.mean = ~arma(0, 1), formula.var = ~garch(1, 1), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(0, 1) + ~garch(1, 1) Conditional Distribution: dnorm mu ma1 omega alpha1 beta Error Analysis: mu ma < 2e-16 *** omega alpha beta e-07 *** Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-13 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

10 ARMA(1,2)GARCH(1,1) Title: GARCH Modelling garchfit(formula.mean = ~arma(1, 2), formula.var = ~garch(1, 1), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(1, 2) + ~garch(1, 1) Conditional Distribution: dnorm mu ar1 ma1 ma2 omega alpha1 beta Error Analysis: mu ar e-08 *** ma ma e-09 *** omega ** alpha *** beta < 2e-16 *** Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-08 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

11 ARMA(1,1)GARCH(1,1) Title: GARCH Modelling garchfit(formula.mean = ~arma(1, 1), formula.var = ~garch(1, 1), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(1, 1) + ~garch(1, 1) Conditional Distribution: dnorm mu ar1 ma1 omega alpha1 beta Error Analysis: mu ar ma < 2e-16 *** omega alpha beta *** Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-13 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

12 MA(2)GARCH(1,1) Title: GARCH Modelling garchfit(formula.mean = ~arma(0, 2), formula.var = ~garch(1, 1), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(0, 2) + ~garch(1, 1) Conditional Distribution: dnorm mu ma1 ma2 omega alpha1 beta Error Analysis: mu ma < 2e-16 *** ma omega * alpha ** beta < 2e-16 *** Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-10 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

13 GARCH(1,2) Title: GARCH Modelling garchfit(formula.mean = ~arma(0, 0), formula.var = ~garch(1, 2), series = fwbrepd1, cond.dist = "dnorm", algorithm = "lbfgsb+nm") Mean and Variance Equation: ~arma(0, 0) + ~garch(1, 2) Conditional Distribution: dnorm mu omega alpha1 beta1 beta Error Analysis: mu omega *** alpha e-05 *** beta * beta Log Likelihood: normalized: Standadized Residuals Tests: Statistic p-value Jarque-Bera Test R Chi^ Shapiro-Wilk Test R W e-09 Ljung-Box Test R Q(10) Ljung-Box Test R Q(15) Ljung-Box Test R Q(20) Ljung-Box Test R^2 Q(10) Ljung-Box Test R^2 Q(15) Ljung-Box Test R^2 Q(20) LM Arch Test R TR^ Information Criterion Statistics: AIC BIC SIC HQIC

Statistica Applicata all edilizia Lezione: approccio stocastico all analisi delle serie storiche
 Lezione: approccio stocastico all analisi delle serie storiche E-mail: [email protected] 3 maggio 2011 Programma 1 Approccio stocastico all analisi delle serie storiche Programma Approccio stocastico
Lezione: approccio stocastico all analisi delle serie storiche E-mail: [email protected] 3 maggio 2011 Programma 1 Approccio stocastico all analisi delle serie storiche Programma Approccio stocastico
Esercitazione con R 30 Maggio 2006
 Esercitazione con R 30 Maggio 2006 Previsioni per la serie del PIL statunitense Procediamo ad identificare un modello per la serie storica dei dati trimestrali del PIL statunitense. Carichiamo i dati >
Esercitazione con R 30 Maggio 2006 Previsioni per la serie del PIL statunitense Procediamo ad identificare un modello per la serie storica dei dati trimestrali del PIL statunitense. Carichiamo i dati >
Corso di STATISTICA EGA - Classe 1 aa Docenti: Luca Frigau, Claudio Conversano
 Corso di STATISTICA EGA - Classe 1 aa 2017-2018 Docenti: Luca Frigau, Claudio Conversano Il corso è organizzato in 36 incontri, per un totale di 72 ore di lezione. Sono previste 18 ore di esercitazione
Corso di STATISTICA EGA - Classe 1 aa 2017-2018 Docenti: Luca Frigau, Claudio Conversano Il corso è organizzato in 36 incontri, per un totale di 72 ore di lezione. Sono previste 18 ore di esercitazione
Regressione Lineare Multipla
 Regressione Lineare Multipla Fabio Ruini Abstract La regressione ha come scopo principale la previsione: si mira, cioè, alla costruzione di un modello attraverso cui prevedere i valori di una variabile
Regressione Lineare Multipla Fabio Ruini Abstract La regressione ha come scopo principale la previsione: si mira, cioè, alla costruzione di un modello attraverso cui prevedere i valori di una variabile
STATISTICHE, DISTRIBUZIONI CAMPIONARIE E INFERENZA
 Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria Civile A.A. 2009-10 Facoltà di Ingegneria, Università di Padova Docente: Dott. L. Corain 1 STATISTICHE, DISTRIBUZIONI CAMPIONARIE
Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria Civile A.A. 2009-10 Facoltà di Ingegneria, Università di Padova Docente: Dott. L. Corain 1 STATISTICHE, DISTRIBUZIONI CAMPIONARIE
Facoltà di Scienze Politiche Corso di laurea in Servizio sociale. Compito di Statistica del 7/1/2003
 Compito di Statistica del 7/1/2003 I giovani addetti all agricoltura in due diverse regioni sono stati classificati per età; la distribuzione di frequenze congiunta è data dalla tabella seguente Età in
Compito di Statistica del 7/1/2003 I giovani addetti all agricoltura in due diverse regioni sono stati classificati per età; la distribuzione di frequenze congiunta è data dalla tabella seguente Età in
ANALISI DELLE SERIE STORICHE
 ANALISI DELLE SERIE STORICHE De Iaco S. [email protected] UNIVERSITÀ del SALENTO DIP.TO DI SCIENZE ECONOMICHE E MATEMATICO-STATISTICHE FACOLTÀ DI ECONOMIA 24 settembre 2012 Indice 1 Funzione di
ANALISI DELLE SERIE STORICHE De Iaco S. [email protected] UNIVERSITÀ del SALENTO DIP.TO DI SCIENZE ECONOMICHE E MATEMATICO-STATISTICHE FACOLTÀ DI ECONOMIA 24 settembre 2012 Indice 1 Funzione di
STATISTICA DESCRITTIVA. Elementi di statistica medica GLI INDICI INDICI DI DISPERSIONE STATISTICA DESCRITTIVA
 STATISTICA DESCRITTIVA Elementi di statistica medica STATISTICA DESCRITTIVA È quella branca della statistica che ha il fine di descrivere un fenomeno. Deve quindi sintetizzare tramite pochi valori(indici
STATISTICA DESCRITTIVA Elementi di statistica medica STATISTICA DESCRITTIVA È quella branca della statistica che ha il fine di descrivere un fenomeno. Deve quindi sintetizzare tramite pochi valori(indici
Econometria. lezione 13. validità interna ed esterna. Econometria. lezione 13. AA 2014-2015 Paolo Brunori
 AA 2014-2015 Paolo Brunori popolazione studiata e popolazione di interesse - popolazione studiata: popolazione da cui è stato estratto il campione - popolazione di interesse: popolazione per la quale ci
AA 2014-2015 Paolo Brunori popolazione studiata e popolazione di interesse - popolazione studiata: popolazione da cui è stato estratto il campione - popolazione di interesse: popolazione per la quale ci
Analisi della varianza
 1. 2. univariata ad un solo fattore tra i soggetti (between subjects) 3. univariata: disegni fattoriali 4. univariata entro i soggetti (within subjects) 5. : disegni fattoriali «misti» L analisi della
1. 2. univariata ad un solo fattore tra i soggetti (between subjects) 3. univariata: disegni fattoriali 4. univariata entro i soggetti (within subjects) 5. : disegni fattoriali «misti» L analisi della
TECNICHE DI MISURAZIONE DEI RISCHI DI MERCATO. VALUE AT RISK VaR. Piatti --- Corso Rischi Bancari: VaR 1
 TECNICHE DI MISURAZIONE DEI RISCHI DI MERCATO VALUE AT RISK VaR Piatti --- Corso Rischi Bancari: VaR 1 Limiti delle misure di sensitivity Dipendono dalla fase in cui si trova il mercato non consentono
TECNICHE DI MISURAZIONE DEI RISCHI DI MERCATO VALUE AT RISK VaR Piatti --- Corso Rischi Bancari: VaR 1 Limiti delle misure di sensitivity Dipendono dalla fase in cui si trova il mercato non consentono
Capitolo 12 La regressione lineare semplice
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università
Analisi della varianza a due fattori
 Laboratorio 11 Analisi della varianza a due fattori 11.1 Analisi del dataset PENICILLIN.DAT I dati contenuti nel file penicillin.dat, si riferiscono ad un esperimento di produzione di penicillina tendente
Laboratorio 11 Analisi della varianza a due fattori 11.1 Analisi del dataset PENICILLIN.DAT I dati contenuti nel file penicillin.dat, si riferiscono ad un esperimento di produzione di penicillina tendente
Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009)
") Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009) Quesito: Posso stimare il numero di ore passate a studiare statistica sul voto conseguito all esame? Potrei calcolare il coefficiente di correlazione.
Il modello di regressione (VEDI CAP 12 VOLUME IEZZI, 2009) Quesito: Posso stimare il numero di ore passate a studiare statistica sul voto conseguito all esame? Potrei calcolare il coefficiente di correlazione.
Carta di credito standard. Carta di credito business. Esercitazione 12 maggio 2016
 Esercitazione 12 maggio 2016 ESERCIZIO 1 Si supponga che in un sondaggio di opinione su un campione di clienti, che utilizzano una carta di credito di tipo standard (Std) o di tipo business (Bsn), si siano
Esercitazione 12 maggio 2016 ESERCIZIO 1 Si supponga che in un sondaggio di opinione su un campione di clienti, che utilizzano una carta di credito di tipo standard (Std) o di tipo business (Bsn), si siano
Università degli Studi di Padova
 Università degli Studi di Padova Facoltà di Scienze Statistiche Corso di Laurea in Statistica Economia e Finanza Combinazione di Previsioni per la Volatilità: applicazioni ad un indice di borsa Combination
Università degli Studi di Padova Facoltà di Scienze Statistiche Corso di Laurea in Statistica Economia e Finanza Combinazione di Previsioni per la Volatilità: applicazioni ad un indice di borsa Combination
Variabili aleatorie Parte I
 Variabili aleatorie Parte I Variabili aleatorie Scalari - Definizione Funzioni di distribuzione di una VA Funzioni densità di probabilità di una VA Indici di posizione di una distribuzione Indici di dispersione
Variabili aleatorie Parte I Variabili aleatorie Scalari - Definizione Funzioni di distribuzione di una VA Funzioni densità di probabilità di una VA Indici di posizione di una distribuzione Indici di dispersione
UNIVERSITA DEGLI STUDI DI PADOVA FACOLTA DI SCIENZE STATISTICHE
 UNIVERSITA DEGLI STUDI DI PADOVA FACOLTA DI SCIENZE STATISTICHE CORSO DI LAUREA IN STATISTICA ECONOMIA E FINANZA TESI: Confronto tra modelli predittivi per l inflazione: Una verifica empirica per gli USA.
UNIVERSITA DEGLI STUDI DI PADOVA FACOLTA DI SCIENZE STATISTICHE CORSO DI LAUREA IN STATISTICA ECONOMIA E FINANZA TESI: Confronto tra modelli predittivi per l inflazione: Una verifica empirica per gli USA.
Indici di variabilità ed eterogeneità
 Indici di variabilità ed eterogeneità Corso di STATISTICA Prof. Roberta Siciliano Ordinario di Statistica, Università di apoli Federico II Professore supplente, Università della Basilicata a.a. 011/01
Indici di variabilità ed eterogeneità Corso di STATISTICA Prof. Roberta Siciliano Ordinario di Statistica, Università di apoli Federico II Professore supplente, Università della Basilicata a.a. 011/01
R - Esercitazione 6. Andrea Fasulo Venerdì 22 Dicembre Università Roma Tre
 R - Esercitazione 6 Andrea Fasulo [email protected] Università Roma Tre Venerdì 22 Dicembre 2017 Il modello di regressione lineare semplice (I) Esempi tratti da: Stock, Watson Introduzione all econometria
R - Esercitazione 6 Andrea Fasulo [email protected] Università Roma Tre Venerdì 22 Dicembre 2017 Il modello di regressione lineare semplice (I) Esempi tratti da: Stock, Watson Introduzione all econometria
Analisi delle Serie Storiche con R
 Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Analisi delle Serie Storiche con R Francesca
Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Analisi delle Serie Storiche con R Francesca
REGRESSIONE lineare e CORRELAZIONE. Con variabili quantitative che si possono esprimere in un ampio ampio intervallo di valori
 REGRESSIONE lineare e CORRELAZIONE Con variabili quantitative che si possono esprimere in un ampio ampio intervallo di valori Y X La NATURA e la FORZA della relazione tra variabili si studiano con la REGRESSIONE
REGRESSIONE lineare e CORRELAZIONE Con variabili quantitative che si possono esprimere in un ampio ampio intervallo di valori Y X La NATURA e la FORZA della relazione tra variabili si studiano con la REGRESSIONE
RAPPORTO CER Aggiornamenti
 RAPPORTO CER Aggiornamenti 12 Ottobre 2012 LO SPREAD PROSSIMO VENTURO Quanto potrà scendere lo spread Btp-Bund dopo le misure di austerità fiscale? Per rispondere, forniamo una semplice stima derivata
RAPPORTO CER Aggiornamenti 12 Ottobre 2012 LO SPREAD PROSSIMO VENTURO Quanto potrà scendere lo spread Btp-Bund dopo le misure di austerità fiscale? Per rispondere, forniamo una semplice stima derivata
Università di Pavia Econometria Esercizi 4 Soluzioni
 Università di Pavia Econometria 2008-2009 Esercizi 4 Soluzioni Maggio, 2009 Istruzioni: I commenti devono essere concisi! 1. Dato il modello di regressione lineare, con K regressori con E(ɛ) = 0 e E(ɛɛ
Università di Pavia Econometria 2008-2009 Esercizi 4 Soluzioni Maggio, 2009 Istruzioni: I commenti devono essere concisi! 1. Dato il modello di regressione lineare, con K regressori con E(ɛ) = 0 e E(ɛɛ
Approssimazione normale alla distribuzione binomiale
 Approssimazione normale alla distribuzione binomiale P b (X r) costoso P b (X r) P(X r) per N grande Teorema: Se la variabile casuale X ha una distribuzione binomiale con parametri N e p, allora, per N
Approssimazione normale alla distribuzione binomiale P b (X r) costoso P b (X r) P(X r) per N grande Teorema: Se la variabile casuale X ha una distribuzione binomiale con parametri N e p, allora, per N
COGNOME.NOME...MATR..
 STATISTICA 29.01.15 - PROVA GENERALE (CHALLENGE) Modalità A (A) ai fini della valutazione verranno considerate solo le risposte riportate dallo studente negli appositi riquadri bianchi: in caso di necessità
STATISTICA 29.01.15 - PROVA GENERALE (CHALLENGE) Modalità A (A) ai fini della valutazione verranno considerate solo le risposte riportate dallo studente negli appositi riquadri bianchi: in caso di necessità
Statistica. Capitolo 12. Regressione Lineare Semplice. Cap. 12-1
 Statistica Capitolo 1 Regressione Lineare Semplice Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Spiegare il significato del coefficiente di correlazione lineare
Statistica Capitolo 1 Regressione Lineare Semplice Cap. 1-1 Obiettivi del Capitolo Dopo aver completato il capitolo, sarete in grado di: Spiegare il significato del coefficiente di correlazione lineare
Regressione Lineare Semplice e Correlazione
 Regressione Lineare Semplice e Correlazione 1 Introduzione La Regressione è una tecnica di analisi della relazione tra due variabili quantitative Questa tecnica è utilizzata per calcolare il valore (y)
Regressione Lineare Semplice e Correlazione 1 Introduzione La Regressione è una tecnica di analisi della relazione tra due variabili quantitative Questa tecnica è utilizzata per calcolare il valore (y)
Economia Pubblica e Storia Economica Fausto Pacicco
 Economia Pubblica e Storia Economica Fausto Pacicco [email protected] 1 Possiamo estendere il modello di regressione lineare includendo più di una xx, ottenendo un modello di regressione lineare multipla
Economia Pubblica e Storia Economica Fausto Pacicco [email protected] 1 Possiamo estendere il modello di regressione lineare includendo più di una xx, ottenendo un modello di regressione lineare multipla
Destagionalizzazione, detrendizzazione delle serie storiche
 DATA MINING PER IL MARKETING (63 ore) Marco Riani [email protected] Sito web del corso http://www.riani.it/dmm Destagionalizzazione, detrendizzazione delle serie storiche 1 Serie storica della vendita di
DATA MINING PER IL MARKETING (63 ore) Marco Riani [email protected] Sito web del corso http://www.riani.it/dmm Destagionalizzazione, detrendizzazione delle serie storiche 1 Serie storica della vendita di
Modelli di regressione dinamica
 Modelli di regressione dinamica Matteo Pelagatti 25 giugno 2007 Modello di regressione dinamica Il modello di regressione classico coglie solamente relazioni istantanee tra la variabile esplicative e la
Modelli di regressione dinamica Matteo Pelagatti 25 giugno 2007 Modello di regressione dinamica Il modello di regressione classico coglie solamente relazioni istantanee tra la variabile esplicative e la
STATISTICA A K (60 ore)
") STATISTICA A K (60 ore) Marco Riani [email protected] http://www.riani.it Richiami sulla regressione Marco Riani, Univ. di Parma 1 MODELLO DI REGRESSIONE y i = a + bx i + e i dove: i = 1,, n a + bx i rappresenta
STATISTICA A K (60 ore) Marco Riani [email protected] http://www.riani.it Richiami sulla regressione Marco Riani, Univ. di Parma 1 MODELLO DI REGRESSIONE y i = a + bx i + e i dove: i = 1,, n a + bx i rappresenta
Il test (o i test) del Chi-quadrato ( 2 )
 del Chi-quadrato ( 2 )") Il test (o i test) del Chi-quadrato ( ) I dati: numerosità di osservazioni che cadono all interno di determinate categorie Prima di tutto, è un test per confrontare proporzioni Esempio: confronto tra numero
Il test (o i test) del Chi-quadrato ( ) I dati: numerosità di osservazioni che cadono all interno di determinate categorie Prima di tutto, è un test per confrontare proporzioni Esempio: confronto tra numero
Differenze tra metodi di estrazione
 Lezione 11 Argomenti della lezione: L analisi fattoriale: il processo di estrazione dei fattori Metodi di estrazione dei fattori Metodi per stabilire il numero di fattori Metodi di Estrazione dei Fattori
Lezione 11 Argomenti della lezione: L analisi fattoriale: il processo di estrazione dei fattori Metodi di estrazione dei fattori Metodi per stabilire il numero di fattori Metodi di Estrazione dei Fattori
Taratura statica. Laboratorio n. 3 a.a. 2004-2005. Sito di Misure: http://misure.mecc.polimi.it
 Laboratorio n. 3 a.a. 2004-2005 Taratura statica Prof. Alfredo Cigada 02-2399.8487 [email protected] Ing. Alessandro Basso 02-2399.8488 [email protected] Ing. Massimiliano Lurati 02-2399.8448
Laboratorio n. 3 a.a. 2004-2005 Taratura statica Prof. Alfredo Cigada 02-2399.8487 [email protected] Ing. Alessandro Basso 02-2399.8488 [email protected] Ing. Massimiliano Lurati 02-2399.8448
Cenni all analisi di serie storiche. Prof. Julia Mortera
 Cenni all analisi di serie storiche Prof. Julia Mortera Le serie storiche Serie storiche o temporali: rilevazione del fenomeno sottostante che stiamo misurando (variabile) in specifici momenti nel tempo
Cenni all analisi di serie storiche Prof. Julia Mortera Le serie storiche Serie storiche o temporali: rilevazione del fenomeno sottostante che stiamo misurando (variabile) in specifici momenti nel tempo
ANOVA: ANALISI DELLA VARIANZA Prof. Antonio Lanzotti
 UNIVERSITÀ DEGLI STUDI DI NAPOLI FEDERICO II DIPARTIMENTO DI INGEGNERIA AEROSPAZIALE D.I.A.S. STATISTICA PER L INNOVAZIONE a.a. 007/008 ANOVA: ANALISI DELLA VARIANZA Prof. Antonio Lanzotti A cura di: Ing.
UNIVERSITÀ DEGLI STUDI DI NAPOLI FEDERICO II DIPARTIMENTO DI INGEGNERIA AEROSPAZIALE D.I.A.S. STATISTICA PER L INNOVAZIONE a.a. 007/008 ANOVA: ANALISI DELLA VARIANZA Prof. Antonio Lanzotti A cura di: Ing.
Statistica - metodologie per le scienze economiche e sociali S. Borra, A. Di Ciaccio - McGraw Hill
 - metodologie per le scienze economiche e sociali S. Borra, A. Di Ciaccio - McGraw Hill Es. Soluzione degli esercizi del capitolo 8 home - indice In base agli arrotondamenti effettuati nei calcoli, si
- metodologie per le scienze economiche e sociali S. Borra, A. Di Ciaccio - McGraw Hill Es. Soluzione degli esercizi del capitolo 8 home - indice In base agli arrotondamenti effettuati nei calcoli, si
Nel modello omoschedastico la varianza dell errore non dipende da i ed è quindi pari a σ 0.
 Regressione [] el modello di regressione lineare si assume una relazione di tipo lineare tra il valore medio della variabile dipendente Y e quello della variabile indipendente X per cui Il modello si scrive
Regressione [] el modello di regressione lineare si assume una relazione di tipo lineare tra il valore medio della variabile dipendente Y e quello della variabile indipendente X per cui Il modello si scrive
Risultati esperienza sul lancio di dadi Ho ottenuto ad esempio:
 Dado B (6): 2 2 6 6 6 1 1 3 6 4 6 6 3 1 1 4 1 6 3 6 6 4 6 3 2 4 3 2 6 3 5 5 6 4 3 3 2 1 2 1 6 3 2 4 4 3 6 6 3 2 1 6 6 4 6 1 3 6 6 1 6 2 4 5 3 3 6 2 1 6 6 3 1 2 6 3 1 3 4 6 1 6 4 1 6 4 6 6 6 5 5 2 4 1 2
Dado B (6): 2 2 6 6 6 1 1 3 6 4 6 6 3 1 1 4 1 6 3 6 6 4 6 3 2 4 3 2 6 3 5 5 6 4 3 3 2 1 2 1 6 3 2 4 4 3 6 6 3 2 1 6 6 4 6 1 3 6 6 1 6 2 4 5 3 3 6 2 1 6 6 3 1 2 6 3 1 3 4 6 1 6 4 1 6 4 6 6 6 5 5 2 4 1 2
Analisi grafica residui in R. Da output grafico analisi regressionelm1.csv Vedi dispensa. peso-statura
 Analisi grafica residui in R Da output grafico analisi regressionelm1.csv Vedi dispensa peso-statura 1) Il plot in alto a sinistra mostra gli errori residui contro i loro valori stimati. I residui devono
Analisi grafica residui in R Da output grafico analisi regressionelm1.csv Vedi dispensa peso-statura 1) Il plot in alto a sinistra mostra gli errori residui contro i loro valori stimati. I residui devono
ESERCIZI. Regressione lineare semplice CAPITOLO 12 Levine, Krehbiel, Berenson, Statistica II ed., 2006 Apogeo
 Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università di Padova Docenti: Prof. L. Salmaso, Dott. L. Corain ESERCIZI Regressione lineare semplice
Insegnamento: Statistica Corso di Laurea Triennale in Ingegneria Gestionale Facoltà di Ingegneria, Università di Padova Docenti: Prof. L. Salmaso, Dott. L. Corain ESERCIZI Regressione lineare semplice
Inferenza statistica
 Inferenza statistica Si tratta di un complesso di tecniche, basate sulla teoria della probabilità, che consentono di verificare se sia o no possibile trasferire i risultati ottenuti per un campione ad
Inferenza statistica Si tratta di un complesso di tecniche, basate sulla teoria della probabilità, che consentono di verificare se sia o no possibile trasferire i risultati ottenuti per un campione ad
Indice della lezione. Incertezza e rischio: sinonimi? Le Ipotesi della Capital Market Theory UNIVERSITA DEGLI STUDI DI PARMA FACOLTA DI ECONOMIA
 UNIVERSIT DEGLI STUDI DI PRM FCOLT DI ECONOMI Indice della lezione Corso di Pianificazione Finanziaria Introduzione al rischio Rischio e rendimento per titoli singoli La Teoria di Portafoglio di Markowitz
UNIVERSIT DEGLI STUDI DI PRM FCOLT DI ECONOMI Indice della lezione Corso di Pianificazione Finanziaria Introduzione al rischio Rischio e rendimento per titoli singoli La Teoria di Portafoglio di Markowitz
Il Modello di Scomposizione
 Approccio Classico: Metodi di Scomposizione Il Modello di Scomposizione Il modello matematico ipotizzato nel metodo classico di scomposizione è: y t =f(s t, T t, E t ) dove y t è il dato riferito al periodo
Approccio Classico: Metodi di Scomposizione Il Modello di Scomposizione Il modello matematico ipotizzato nel metodo classico di scomposizione è: y t =f(s t, T t, E t ) dove y t è il dato riferito al periodo
Argomenti trattati. Capitolo 7. Introduzione a rischio, rendimento e costo opportunità del capitale. Il mercato dei capitali: un secolo di storia
 Capitolo 7 Principi di Finanza aziendale 5/ed Richard A. Brealey, Stewart C. Myers, Franklin Allen, Sandro Sandri Introduzione a rischio, rendimento e costo opportunità del capitale Lucidi di Matthew Will
Capitolo 7 Principi di Finanza aziendale 5/ed Richard A. Brealey, Stewart C. Myers, Franklin Allen, Sandro Sandri Introduzione a rischio, rendimento e costo opportunità del capitale Lucidi di Matthew Will
Analisi delle Serie Storiche con R
 Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi delle Serie
Università di Bologna - Facoltà di Scienze Statistiche Laurea Triennale in Statistica e Ricerca Sociale Corso di Analisi di Serie Storiche e Multidimensionali Prof.ssa Marilena Pillati Analisi delle Serie
Sottocampionamento e misure ripetute
 Sottocampionamento e misure ripetute Andrea Onofri February 8, 2012 Contents 1 Sub-sampling 1 2 Misure ripetute 3 1 Sub-sampling Il sottocampionamento è una situazione che si verifica molto di frequente
Sottocampionamento e misure ripetute Andrea Onofri February 8, 2012 Contents 1 Sub-sampling 1 2 Misure ripetute 3 1 Sub-sampling Il sottocampionamento è una situazione che si verifica molto di frequente
CAPITOLO 5 Introduzione ai piani fattoriali
 Douglas C. Montgomery Progettazione e analisi degli esperimenti 2006 McGraw-Hill CAPITOLO 5 Introduzione ai piani fattoriali Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria
Douglas C. Montgomery Progettazione e analisi degli esperimenti 2006 McGraw-Hill CAPITOLO 5 Introduzione ai piani fattoriali Metodi statistici e probabilistici per l ingegneria Corso di Laurea in Ingegneria
LABORATORIO DI PROBABILITA E STATISTICA
 UNIVERSITA DEGLI STUDI DI VERONA LABORATORIO DI PROBABILITA E STATISTICA Docente: Bruno Gobbi 6 ESERCIZI RIEPILOGATIVI PRIME 3 LEZIONI REGRESSIONE LINEARE: SPORT - COLESTEROLO ESERCIZIO 8: La tabella seguente
UNIVERSITA DEGLI STUDI DI VERONA LABORATORIO DI PROBABILITA E STATISTICA Docente: Bruno Gobbi 6 ESERCIZI RIEPILOGATIVI PRIME 3 LEZIONI REGRESSIONE LINEARE: SPORT - COLESTEROLO ESERCIZIO 8: La tabella seguente
Anova e regressione. Andrea Onofri Dipartimento di Scienze Agrarie ed Ambientali Universitá degli Studi di Perugia 22 marzo 2011
 Anova e regressione Andrea Onofri Dipartimento di Scienze Agrarie ed Ambientali Universitá degli Studi di Perugia 22 marzo 2011 Nella sperimentazione agronomica e biologica in genere è normale organizzare
Anova e regressione Andrea Onofri Dipartimento di Scienze Agrarie ed Ambientali Universitá degli Studi di Perugia 22 marzo 2011 Nella sperimentazione agronomica e biologica in genere è normale organizzare
Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni
 La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
La statistica inferenziale Il processo inferenziale consente di generalizzare, con un certo grado di sicurezza, i risultati ottenuti osservando uno o più campioni E necessario però anche aggiungere con
Esercitazione del
 Esercizi sulla regressione lineare. Esercitazione del 21.05.2013 Esercizio dal tema d esame del 13.06.2011. Si consideri il seguente campione di n = 9 osservazioni relative ai caratteri ed Y: 7 17 8 36
Esercizi sulla regressione lineare. Esercitazione del 21.05.2013 Esercizio dal tema d esame del 13.06.2011. Si consideri il seguente campione di n = 9 osservazioni relative ai caratteri ed Y: 7 17 8 36
IDENTIFICAZIONE DEI MODELLI E ANALISI DEI DATI 1 (Prof. S. Bittanti) Ingegneria Informatica 5 CFU. Appello 23 Luglio 2014 Cognome Nome Matricola
 Ingegneria Informatica 5 CFU. Appello 23 Luglio 2014 Cognome Nome Matricola") IDENTIFICAZIONE DEI MODELLI E ANALISI DEI DATI 1 (Prof. S. Bittanti) Ingegneria Informatica 5 CFU. Appello 23 Luglio 201 Cognome Nome Matricola............ Verificare che il fascicolo sia costituito da
IDENTIFICAZIONE DEI MODELLI E ANALISI DEI DATI 1 (Prof. S. Bittanti) Ingegneria Informatica 5 CFU. Appello 23 Luglio 201 Cognome Nome Matricola............ Verificare che il fascicolo sia costituito da
Capitolo 8. Rischio e rendimento. Principi di finanza aziendale. Richard A. Brealey Stewart C. Myers Sandro Sandri. IV Edizione
 Principi di finanza aziendale Capitolo 8 IV Edizione Richard A. Brealey Stewart C. Myers Sandro Sandri Rischio e rendimento Copyright 2003 - The McGraw-Hill Companies, srl 8-2 Argomenti trattati Teoria
Principi di finanza aziendale Capitolo 8 IV Edizione Richard A. Brealey Stewart C. Myers Sandro Sandri Rischio e rendimento Copyright 2003 - The McGraw-Hill Companies, srl 8-2 Argomenti trattati Teoria