Modelli probabilistici
|
|
|
- Italo Miele
- 8 anni fa
- Visualizzazioni
Transcript
1 Modelli probabilistici Davide Cittaro e Marco Stefani Master bioinformatica 2003 Introduzione L obiettivo di presente lavoro è la classificazione di un insieme di proteine, definite da 27 valori numerici, detti attributi. Il significato degli attributi è sconosciuto, quindi nessuna analisi preventiva è stata possibile, come risulta impossibile verificare la qualità dei dati stessi. Un meta-attributo specifica a quale classe appartiene la proteina; ciò permette una classificazione di tipo supervisionato, che offre il vantaggio di poter misurare l errore commesso dal modello durante la fase di verifica. Gli strumenti software La nostra ricerca cerca di individuare il miglior classificatore per questo specifico insieme di dati, utilizzando due applicazioni, Weka e BN PowerSoft, che permettono di costruire dei classificatori di vario tipo. Weka offre un ampia collezione di classificatori sia supervisionati che non supervisionati. Il comportamento di ogni classificatore può essere modificato e controllato da un insieme specifico di parametri. Individuati i modelli più interessanti, Weka dà la possibilità di definire un ciclo di esperimenti in cui un numero arbitrario di classificatori può essere provato su un insieme di dati; anche il numero di esperimenti è definito dall utente. Diventa facile così confrontare i risultati dei vari classificatori sugli stessi dati, e verificare la stabilità del modello durante le reiterazioni. BN PowerSoft utilizza solo dei modelli bayesiani. In questo caso, la scelta obbligata del classificatore è compensata dal miglior controllo sulla creazione e l addestramento della rete. Gli esperimenti Di seguito riportiamo una breve descrizione del lavoro svolto con i due programmi descritti e i risultati dei relativi esperimenti. Le descrizioni dettagliate dei risultati sono memorizzate in file esterni, i cui riferimenti sono riportati di fianco ai risultati sintetici. WEKA Per trovare i migliori classificatori abbiamo usato Weka Explorer. Abbiamo condotto una serie di test con classificatori che usano metodi di analisi diversi. In tutti i casi, il primo esperimento si è sempre svolto con i parametri di default. Abbiamo verificato le differenze date da un insieme discretizzato rispetto ai dati non modificati. In qualche circostanza abbiamo provato variazioni diverse, come la normalizzazione o la standardizzazione dei dati. La mancanza di miglioramenti ci ha però fatto desistere

2 dall utilizzarli con maggior frequenza. Anche la discretizzazione, quando non peggiora i risultati, non influisce significativamente sulla capacità di classificazione. Nella fase di validazione abbiamo privilegiato la cross-validation rispetto all hold out perché la consideriamo più affidabile nella verifica del modello: ogni istanza viene usata, in momenti diversi, sia nell addestramento che nel test, riducendo la possibilità di classificare male eventuali casi anomali. La valutazione complessiva del classificatore si basa sulla percentuale dei risultati corretti; come risulta dalla Tabella 1, i risultati ottenuti variano sensibilmente, dal 74,59% di ZeroR all 87,48% di IBk. Per semplificare la lettura dei risultati degli esperimenti, mostriamo una tabella riassuntiva con i parametri più significativi. Cliccando sul nome del classificatore, si può accedere alla sezione corrispondente nell Appendice A, che mostra i dati più significativi. I nomi dei file che contengono tutti i dettagli dell esperimento sono elencati nella colonna File. Nome Validazione Opzioni % Corretti File ZeroR XV 10 fold D 74,59 R001/M001 NaiveBayes XV 10 fold D 80,83 R002/M002 NaiveBayes XV 10 fold 80,01 R003/M003 J48 XV 10 fold 82,95 R004/M004 J48 XV 10 fold D 83,09 R005/M005 JRip XV 10 fold 84,15 R006/M006 JRip XV 10 fold D 82,49 R007/M007 JRip HO 66% 84,91 R008/M008 JRip HO 75% 84,95 R009/M009 K* Xv 10 fold 87,43 R010/M010 K* XV 10 fold D 84,57 R011/M011 SMO XV 10 fold D 83,40 R012/M012 Neural Networks HO 75% 84,83 R013/M013 NaiveBayesSimple XV 10 fold 79,81 R014/M014 NaiveBayesUpdateable XV 10 fold 80,01 R015/M015 IB1 XV 10 fold 87,31 R016/M016 IBk XV 10 fold 87,48 R017/M017 IB1 XV 10 fold Ds 82,52 R018/M018 IB1 XV 10 fold D 83,83 R019/M019 IB1 XV 10 fold N 87,31 R020/M020 IB1 XV 10 fold S R021/M021 K* XV 10 fold D 84,43 R022/M022 K* HO 66% D 84,82 R023/M023 K* XV 10 fold A 87,43 R024/M024 IBk HO 66% 86,67 R025/M025 Tabella 1 Classificatori analizzati con Weka Legenda Validazione: XV: Cross validation HO: Hold out Opzioni: D: discretizzazione Ds: discretizzazione supervisionata N: normalizzazione S: standardizzazione A: autoblend (un opzione specifica di K*)

3 Dalla tabella risulta immediatamente che, globalmente, il miglior classificatore è IBk, e che in generale tutti i classificatori basati sulla distanza (IB1, IBk, K*), hanno una buona prestazione. Per i migliori classificatori riportiamo anche i risultati ripartiti per le singole classi. JRip IBk J P P P P P P2 La capacità di classificare correttamente la classe P1 in generale è più elevata rispetto a P2. IBk è il più bilanciato sulle due classi, ottenendo una buona classificazione per entrambe. Nel caso degli altri due, la capacità di discriminare la classe P2 è scarsa: con una percentuale prossima al 50% di veri positivi, essi hanno una capacità di riconoscere P2 paragonabile al lancio di una moneta. Con i migliori classificatori trovati delle categorie lazy, rules e tree, abbiamo svolto con Weka Experimenter dei cicli di test che confrontano direttamente i risultati tra loro e permettono di valutare la stabilità del modello. Non abbiamo preso in considerazione i classificatori bayesiani, perché hanno risultati inferiori rispetto a quelli usati. I classificatori usati sono IBk, JRip e J48. Abbiamo eseguito tre cicli di esperimenti in cui è stato cambiato il metodo di validazione: Ciclo 1: cross-validation con 10 fold o File: expris001/expdef001 Ciclo 2: hold-out al 66% con selezione casuale ad ogni iterazione o File: expris002/expdef002 Ciclo 3: hold-out al 66% conservando la divisione dei due sottoinsiemi o File: expris003/expdef003 Per ogni ciclo abbiamo eseguito 10 ripetizioni. Sotto sono riportati i risultati espressi come percentuale di classificati correttamente. Ciclo 1 Dataset (1) rules.jrip '-F (2) trees.j48.j4 (3) lazy.ibk '-K protein (100) 83.86( 1.64) 82.46( 1.9 ) 87.49( 1.62) v (v/ /*) (0/1/0) (1/0/0) Ciclo 2 Dataset (1) rules.jrip '-F (2) trees.j48.j4 (3) lazy.ibk '-K protein (10) 82.71( 1.29) 81.45( 0.67) 86.94( 0.63) v

4 Ciclo 3 Dataset (v/ /*) (0/1/0) (1/0/0) (1) rules.jrip '-F (2) trees.j48.j4 (3) lazy.ibk '-K protein (1) 81.46(Inf ) 81.29(Inf ) 87 (Inf ) (v/ /*) (0/1/0) (0/1/0) Tra parentesi viene riportata la deviazione standard. I metodi di validazione non influiscono significativamente sulla capacità di classificazione, e IBk si conferma globalmente come il migliore classificatore e il più stabile: sia in termini assoluti che relativi la sua deviazione standard è minore rispetto agli altri. In Tabella 2 riportiamo la sensitività e la specificità per i classificatori usati durante i cicli di esperimenti: essi sono due indicatori importanti per valutare l effettiva capacità del modello di discriminare le proteine. Le formule usate per calcolare i due parametri sono Sensitività: TP / (TP + FN) Specificità: TP / (TP + FP) Esperimento JRip J48 IBk Ciclo 1 Specificità 0,94 0,90 0,92 Sensibilità 0,86 0,87 0,92 Ciclo 2 Specificità 0,94 0,89 0,91 Sensibilità 0,85 0,86 0,91 Ciclo 3 Specificità 0,93 0,87 0,92 Sensibilità 0,84 0,88 0,91 Tabella 2 Specificità e sensibilità JRip mostra contemporaneamente la migliore sensitività e la peggiore specificità, cioè tende a generare un numero di falsi positivi superiore agli altri due modelli. IBk è il più equilibrato, e complessivamente il suo è il comportamento migliore, perché riesce a filtrare meglio i falsi positivi e bilanciare così la minor capacità di classificazione corretta. J48 è il classificatore che si comporta complessivamente peggio. Occorre comunque tenere presente che le differenze sono dell ordine dei centesimi di punto, rendendo le differenze minime. CHENG I dati sono stati subito divisi in due sottoinsiemi per i dati di training e quelli di test, con percentuale di hold-out del 33%. I dati di training sono stati discretizzati con il modulo di pre-processing secondo il metodo supervisionato in base all entropia della classe, che da test preliminari è risultato il più efficiente. Con il modulo Constructor abbiamo poi costruito la rete delle relazioni causa-effetto tra gli attributi dell intero insieme di dati, sperimentando i due valori di soglia 1,0 e 5,0. La soglia influisce direttamente sulla quantità di relazioni trovate: una soglia bassa permette di identificare le relazioni più deboli, e viceversa. In Figura 1 e Figura 2 vengono mostrate le reti prodotte.

5 Figura 1 Relazioni causa-effetto con soglia 1,0 Figura 2 - Relazioni causa-effetto con soglia 5,0 Con il modulo Predictor abbiamo infine costruito una serie di reti bayesiane che variano per alcuni parametri fondamentali dell architettura. Nella costruzione delle reti abbiamo ridefinito le relazioni causa-effetto utilizzando i risultati del Constructor, ma non avendo notato alcuna variazione, anche dal punto di vista numerico, abbiamo deciso di ignorare questi risultati, e di proseguire gli esperimenti utilizzando solo le relazioni causa-effetto di default. Non abbiamo cambiato gli altri parametri, come l ordinamento totale o parziale, perché non abbiamo informazioni sufficienti sul significato degli attributi.

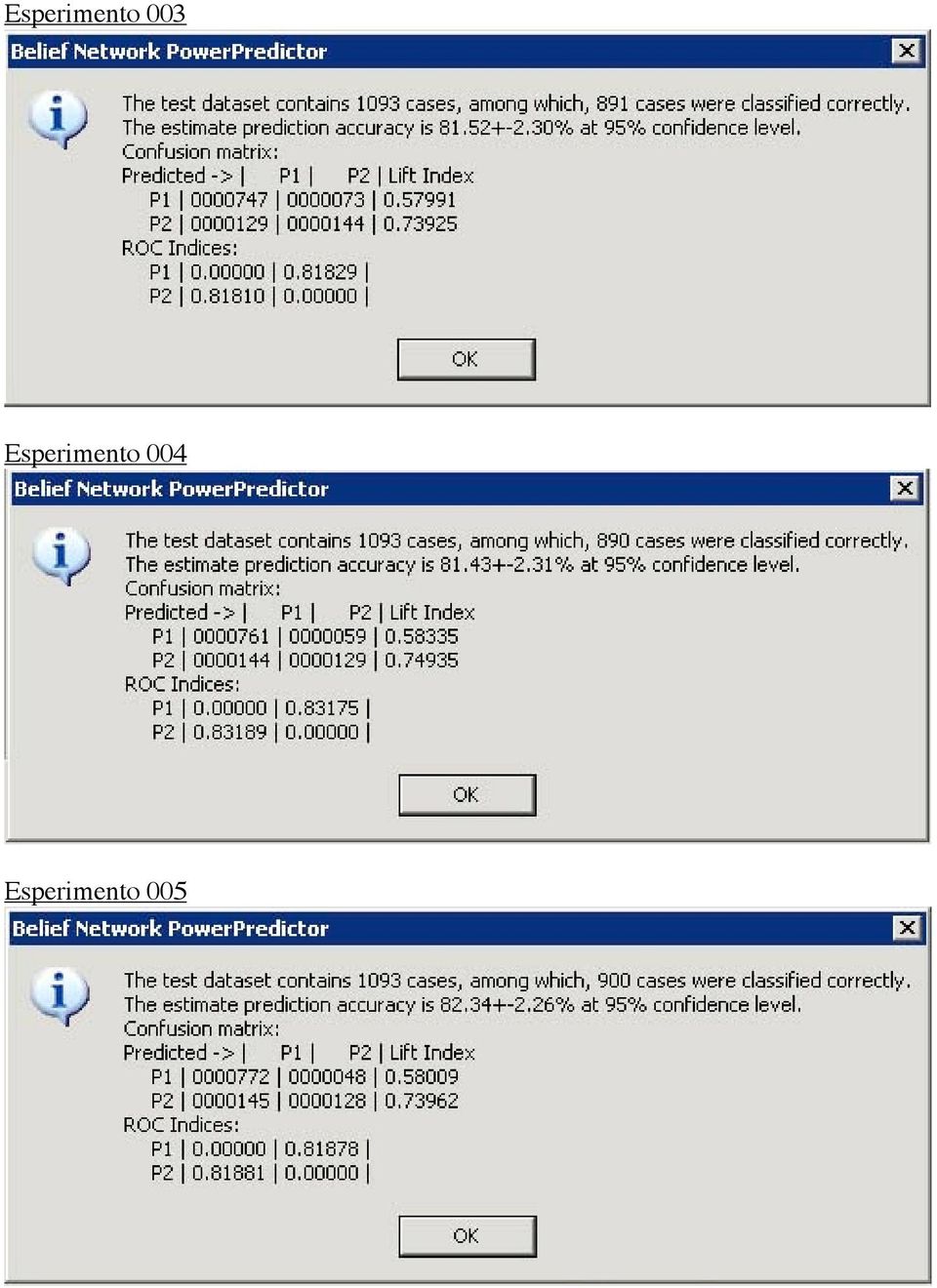
6 Per ogni configurazione abbiamo generato una rete singola e una multipla. I risultati sono riassunti in Tabella 3. Anche in questo caso, è possibile cliccare sul nome dell esperimento per andare alla relativa sezione dell Appendice B che riporta i risultati riassuntivi del classificatore; agli esperimenti abbiamo anche affiancato il riferimento al file che definisce la rete prodotta. Gli altri file prodotti hanno lo stesso nome e una diversa estensione che li identifica: jpg per le immagini delle reti costruite da Predictor o nel caso delle multinet, al nome viene aggiunto p1 o p2 per identificare le due classi bnc per i classificatori log per i file di log txt per i file analitici dei risultati dne per le relazioni causa-effetto in forma analitica, mostrate in Figura 1 e Figura 2. In questo caso i file si chiamano ce1.dne e ce5.dne rispettivamente Esperimento Archittettura Soglia Risultato File 001 S Automatica 81,70±2,29% bn001.bnc 002 M Automatica 82,62±2,25% bn002.bnc 003 S 1,0 81,52±2,30% bn003.bnc 004 M 1,0 81,43±2,31% bn004.bnc 005 S 0,5 82,34±2,26% bn005.bnc 006 M 0,5 83,07±2,22% bn006.bnc 007 S 0,3 81,70±2,29% bn007.bnc 008 M 0,3 82,98±2,23% bn008.bnc 009 S 2,0 80,60±2,34% bn009.bnc 010 M 2,0 80,42±2,35% bn010.bnc 011 S 5,0 79,96±2,37% bn011.bnc 012 M 5,0 75,02±2,57% bn012.bnc Legenda Architettura: S: Rete singola M: rete multipla Tabella 3 Parametri degli esperimenti e risultati In Figura 3 vengono mostrate le percentuali di classificazioni corrette rispetto alla soglia usata, per le due tipologie di reti: per entrambe, il comportamento con soglia bassa è migliore, con il massimo intorno a 0,5. Allontanandosi da questo intorno, i risultati degradano vistosamente, e continuando a sinistra si incorre nell over-fitting, dovuto ad un eccessivo numero di relazioni rispetto al numero di istanze. Aumentando la soglia, il peggioramento è per tutte e due monotono decrescente. Nell intervallo [1, 2] il comportamento delle reti è sostanzialmente identico, ma oltre quest intervallo la rete semplice offre la prestazione migliore senza degradare tanto quanto la multi-net. La single-net mostra complessivamente una stabilità superiore.

7 % classificati corretti Single net Multi net soglia Figura 3 Capacità di classificazione al variare della soglia CONCLUSIONI La migliore delle reti semplici costruite da Cheng, con una percentuale di classificazioni corrette dell 82,34%, ha prestazioni leggermente superiori rispetto alle reti bayesiane di Weka, che raggiungono al massimo una percentuale dell 80,82%. Rispetto alle altre tipologie di classificatori, però, si può notare come in nessun caso le reti bayesiane ottengano risultati superiori; a maggior ragione, esse non sono in grado di ottenere percentuali di classificazione paragonabili al migliore classificatore generato da Weka, IBk, che classifica correttamente l 87,48% delle proteine.

8 Appendice A: Risultati Weka ZeroR discretizzato Definisce l estremo inferiore del risultato della classificazione: classificando gli elementi nella classe più numerosa, predice la media per le classi numeriche o la moda per le classi nominali Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic 0 Mean absolute error Root mean squared error Relative absolute error % Root relative squared error 100 % P P a = P b = P2 NaiveBayes discretizzato Classificatore probabilistico che si basa sugli stimatori di classe. Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P2

9 a = P b = P2 NaiveBayes Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 J48 Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 J48 discretizzato Correctly Classified Instances %

10 Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 JRip Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 JRip discretizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error %

11 P P a = P b = P2 JRip 66% === Evaluation on test split === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances P P a = P b = P2 JRip 75% === Evaluation on test split === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances P P a = P1

12 b = P2 K* Classificatore basato sulle istanze: istanze simili appartengono a classi simili Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 K* discretizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 SMO discretizzato

13 Un algoritmo per l addestramento dei SVM: trasforma il loro risultato in probabilità applicando una funzione sigmoide normale che non si adatta ai dati. Questa implementazione sostituisce globalmente tutti i valori mancanti e trasforma gli attributi nominali in attributi binari Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic 0.47 Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 Neural Networks 75% === Evaluation on test split === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances P P a = P b = P2 Naive Bayes Simple Un classificatore bayesiano semplice in cui gli attributi numerici sono modellati con una distribuzione normale

14 Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 NaiveBayes Updateable Variante del precedente. Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 IB1 Usa una semplice misura della distanza: per ogni istanza dell insieme di test, cerca la minore distanza tra le istanze del training set, e la assegna a quella classe.

15 Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 IBk Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 IB1 discretizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error %

16 P P a = P b = P2 IB1 discretizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 IB1 normalizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P2

17 a = P b = P2 IB1 standardizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 K* discretizzato Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 K* discretizzato 66% === Evaluation on test split ===

18 Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances P P a = P b = P2 K* autoblend Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % P P a = P b = P2 IBk 66% === Evaluation on test split === Correctly Classified Instances % Incorrectly Classified Instances % Kappa statistic Mean absolute error Root mean squared error Relative absolute error % Root relative squared error % Total Number of Instances 1193

19 P P a = P b = P2 Appendice B: Risultati Cheng Esperimento 001 Esperimento 002

20 Esperimento 003 Esperimento 004 Esperimento 005
21 Esperimento 006 Esperimento 007 Esperimento 008
22 Esperimento 009 Esperimento 010 Esperimento 011
23 Esperimento 012
Classificazione di un data set di proteine con Weka
 MODELLI PROBABILISTICI Classificazione di un data set di proteine con Weka SOFIA CIVIDINI 2 INTRODUZIONE Negli ultimi due decenni si è assistito ad un aumento esponenziale nella quantità dell informazione
MODELLI PROBABILISTICI Classificazione di un data set di proteine con Weka SOFIA CIVIDINI 2 INTRODUZIONE Negli ultimi due decenni si è assistito ad un aumento esponenziale nella quantità dell informazione
Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B. Evento prodotto: Evento in cui si verifica sia A che B ; p(a&b) = p(a) x p(b/a)
 che avvenga A, una volta accaduto B. Evento prodotto: Evento in cui si verifica sia A che B ; p(a&b) = p(a) x p(b/a)") Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B Eventi indipendenti: un evento non influenza l altro Eventi disgiunti: il verificarsi di un evento esclude l altro Evento prodotto:
Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B Eventi indipendenti: un evento non influenza l altro Eventi disgiunti: il verificarsi di un evento esclude l altro Evento prodotto:
SPC e distribuzione normale con Access
 SPC e distribuzione normale con Access In questo articolo esamineremo una applicazione Access per il calcolo e la rappresentazione grafica della distribuzione normale, collegata con tabelle di Clienti,
SPC e distribuzione normale con Access In questo articolo esamineremo una applicazione Access per il calcolo e la rappresentazione grafica della distribuzione normale, collegata con tabelle di Clienti,
Aprire WEKA Explorer Caricare il file circletrain.arff Selezionare random split al 66% come modalità di test Selezionare J48 come classificatore e
 Alberi di decisione Aprire WEKA Explorer Caricare il file circletrain.arff Selezionare random split al 66% come modalità di test Selezionare J48 come classificatore e lanciarlo con i parametri di default.
Alberi di decisione Aprire WEKA Explorer Caricare il file circletrain.arff Selezionare random split al 66% come modalità di test Selezionare J48 come classificatore e lanciarlo con i parametri di default.
PIATTAFORMA DOCUMENTALE CRG
 SISTEMA DI GESTIONE DOCUMENTALE DMS24 PIATTAFORMA DOCUMENTALE CRG APPLICAZIONE PER LE PROCEDURE DI GARE D AMBITO 1 AGENDA 1. Introduzione 2. I Livelli di accesso 3. Architettura di configurazione 4. Accesso
SISTEMA DI GESTIONE DOCUMENTALE DMS24 PIATTAFORMA DOCUMENTALE CRG APPLICAZIONE PER LE PROCEDURE DI GARE D AMBITO 1 AGENDA 1. Introduzione 2. I Livelli di accesso 3. Architettura di configurazione 4. Accesso
Statistica. Lezione 6
 Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
Database. Si ringrazia Marco Bertini per le slides
 Database Si ringrazia Marco Bertini per le slides Obiettivo Concetti base dati e informazioni cos è un database terminologia Modelli organizzativi flat file database relazionali Principi e linee guida
Database Si ringrazia Marco Bertini per le slides Obiettivo Concetti base dati e informazioni cos è un database terminologia Modelli organizzativi flat file database relazionali Principi e linee guida
Progettaz. e sviluppo Data Base
 Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
Progettaz. e sviluppo Data Base! Progettazione Basi Dati: Metodologie e modelli!modello Entita -Relazione Progettazione Base Dati Introduzione alla Progettazione: Il ciclo di vita di un Sist. Informativo
4 3 4 = 4 x 10 2 + 3 x 10 1 + 4 x 10 0 aaa 10 2 10 1 10 0
 Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Rappresentazione dei numeri I numeri che siamo abituati ad utilizzare sono espressi utilizzando il sistema di numerazione decimale, che si chiama così perché utilizza 0 cifre (0,,2,3,4,5,6,7,8,9). Si dice
Ricerca di outlier. Ricerca di Anomalie/Outlier
 Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Ricerca di outlier Prof. Matteo Golfarelli Alma Mater Studiorum - Università di Bologna Ricerca di Anomalie/Outlier Cosa sono gli outlier? L insieme di dati che sono considerevolmente differenti dalla
Mon Ami 3000 Provvigioni agenti Calcolo delle provvigioni per agente / sub-agente
 Prerequisiti Mon Ami 3000 Provvigioni agenti Calcolo delle provvigioni per agente / sub-agente L opzione Provvigioni agenti è disponibile per le versioni Vendite, Azienda Light e Azienda Pro. Introduzione
Prerequisiti Mon Ami 3000 Provvigioni agenti Calcolo delle provvigioni per agente / sub-agente L opzione Provvigioni agenti è disponibile per le versioni Vendite, Azienda Light e Azienda Pro. Introduzione
Capitolo 3. L applicazione Java Diagrammi ER. 3.1 La finestra iniziale, il menu e la barra pulsanti
 Capitolo 3 L applicazione Java Diagrammi ER Dopo le fasi di analisi, progettazione ed implementazione il software è stato compilato ed ora è pronto all uso; in questo capitolo mostreremo passo passo tutta
Capitolo 3 L applicazione Java Diagrammi ER Dopo le fasi di analisi, progettazione ed implementazione il software è stato compilato ed ora è pronto all uso; in questo capitolo mostreremo passo passo tutta
Versione 7.0 Taglie e Colori. Negozio Facile
 Versione 7.0 Taglie e Colori Negozio Facile Negozio Facile: Gestione taglie e colori Il concetto di base dal quale siamo partiti è che ogni variante taglia/colore sia un articolo a se stante. Partendo
Versione 7.0 Taglie e Colori Negozio Facile Negozio Facile: Gestione taglie e colori Il concetto di base dal quale siamo partiti è che ogni variante taglia/colore sia un articolo a se stante. Partendo
4 Dispense di Matematica per il biennio dell Istituto I.S.I.S. Gaetano Filangieri di Frattamaggiore EQUAZIONI FRATTE E SISTEMI DI EQUAZIONI
 119 4 Dispense di Matematica per il biennio dell Istituto I.S.I.S. Gaetano Filangieri di Frattamaggiore EQUAZIONI FRATTE E SISTEMI DI EQUAZIONI Indice degli Argomenti: TEMA N. 1 : INSIEMI NUMERICI E CALCOLO
119 4 Dispense di Matematica per il biennio dell Istituto I.S.I.S. Gaetano Filangieri di Frattamaggiore EQUAZIONI FRATTE E SISTEMI DI EQUAZIONI Indice degli Argomenti: TEMA N. 1 : INSIEMI NUMERICI E CALCOLO
REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE
 N. 1235/2011 DELLA COMMISSIONE") 30.11.2011 Gazzetta ufficiale dell Unione europea L 317/17 REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE del 29 novembre 2011 recante modifica del regolamento (CE) n. 1222/2009 del Parlamento europeo
30.11.2011 Gazzetta ufficiale dell Unione europea L 317/17 REGOLAMENTO (UE) N. 1235/2011 DELLA COMMISSIONE del 29 novembre 2011 recante modifica del regolamento (CE) n. 1222/2009 del Parlamento europeo
GESTIONE AVANZATA DEI MATERIALI
 GESTIONE AVANZATA DEI MATERIALI Divulgazione Implementazione/Modifica Software SW0003784 Creazione 23/01/2014 Revisione del 27/06/2014 Numero 1 Una gestione avanzata dei materiali strategici e delle materie
GESTIONE AVANZATA DEI MATERIALI Divulgazione Implementazione/Modifica Software SW0003784 Creazione 23/01/2014 Revisione del 27/06/2014 Numero 1 Una gestione avanzata dei materiali strategici e delle materie
LA STATISTICA si interessa del rilevamento, dell elaborazione e dello studio dei dati; studia ciò che accade o come è fatto un gruppo numeroso di
 STATISTICA LA STATISTICA si interessa del rilevamento, dell elaborazione e dello studio dei dati; studia ciò che accade o come è fatto un gruppo numeroso di oggetti; cerca, attraverso l uso della matematica
STATISTICA LA STATISTICA si interessa del rilevamento, dell elaborazione e dello studio dei dati; studia ciò che accade o come è fatto un gruppo numeroso di oggetti; cerca, attraverso l uso della matematica
1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:
 Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:") Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
A intervalli regolari ogni router manda la sua tabella a tutti i vicini, e riceve quelle dei vicini.
 Algoritmi di routing dinamici (pag.89) UdA2_L5 Nelle moderne reti si usano algoritmi dinamici, che si adattano automaticamente ai cambiamenti della rete. Questi algoritmi non sono eseguiti solo all'avvio
Algoritmi di routing dinamici (pag.89) UdA2_L5 Nelle moderne reti si usano algoritmi dinamici, che si adattano automaticamente ai cambiamenti della rete. Questi algoritmi non sono eseguiti solo all'avvio
GESTIONE AVANZATA DEI MATERIALI
 GESTIONE AVANZATA DEI MATERIALI Divulgazione Implementazione/Modifica Software SW0003784 Creazione 23/01/2014 Revisione del 25/06/2014 Numero 1 Una gestione avanzata dei materiali strategici e delle materie
GESTIONE AVANZATA DEI MATERIALI Divulgazione Implementazione/Modifica Software SW0003784 Creazione 23/01/2014 Revisione del 25/06/2014 Numero 1 Una gestione avanzata dei materiali strategici e delle materie
LEZIONE 3. Ing. Andrea Ghedi AA 2009/2010. Ing. Andrea Ghedi AA 2009/2010
 LEZIONE 3 "Educare significa aiutare l'animo dell'uomo ad entrare nella totalità della realtà. Non si può però educare se non rivolgendosi alla libertà, la quale definisce il singolo, l'io. Quando uno
LEZIONE 3 "Educare significa aiutare l'animo dell'uomo ad entrare nella totalità della realtà. Non si può però educare se non rivolgendosi alla libertà, la quale definisce il singolo, l'io. Quando uno
TRASMISSIONE RAPPORTO ARBITRALE IN FORMATO PDF
 TRASMISSIONE RAPPORTO ARBITRALE IN FORMATO PDF Come da disposizioni di inizio stagione, alcune Delegazioni provinciali hanno richiesto la trasmissione dei referti arbitrali solo tramite fax o tramite mail.
TRASMISSIONE RAPPORTO ARBITRALE IN FORMATO PDF Come da disposizioni di inizio stagione, alcune Delegazioni provinciali hanno richiesto la trasmissione dei referti arbitrali solo tramite fax o tramite mail.
FLASHINVESTOR Manuale dell Utente
 FLASHINVESTOR Manuale dell Utente Questa breve guida ha lo scopo di aiutare l utente a prendere confidenza con il prodotto in modo da sfruttarne appieno tutte le potenzialità. Abbiamo cercato di realizzare
FLASHINVESTOR Manuale dell Utente Questa breve guida ha lo scopo di aiutare l utente a prendere confidenza con il prodotto in modo da sfruttarne appieno tutte le potenzialità. Abbiamo cercato di realizzare
Data mining: classificazione DataBase and Data Mining Group of Politecnico di Torino
 DataBase and Data Mining Group of Database and data mining group, Database and data mining group, DataBase and Data Mining Group of DataBase and Data Mining Group of So dati insieme di classi oggetti etichettati
DataBase and Data Mining Group of Database and data mining group, Database and data mining group, DataBase and Data Mining Group of DataBase and Data Mining Group of So dati insieme di classi oggetti etichettati
Progetto ASTREA WP2: Sistema informativo per il monitoraggio del sistema giudiziario
 Progetto ASTREA WP2: Sistema informativo per il monitoraggio del sistema giudiziario Nell ambito di questa attività è in fase di realizzazione un applicativo che metterà a disposizione dei policy makers,
Progetto ASTREA WP2: Sistema informativo per il monitoraggio del sistema giudiziario Nell ambito di questa attività è in fase di realizzazione un applicativo che metterà a disposizione dei policy makers,
Mining Positive and Negative Association Rules:
 Mining Positive and Negative Association Rules: An Approach for Confined Rules Alessandro Boca Alessandro Cislaghi Premesse Le regole di associazione positive considerano solo gli item coinvolti in una
Mining Positive and Negative Association Rules: An Approach for Confined Rules Alessandro Boca Alessandro Cislaghi Premesse Le regole di associazione positive considerano solo gli item coinvolti in una
WG-TRANSLATE Manuale Utente WG TRANSLATE. Pagina 1 di 15
 WG TRANSLATE Pagina 1 di 15 Sommario WG TRANSLATE... 1 1.1 INTRODUZIONE... 3 1 TRADUZIONE DISPLAY FILE... 3 1.1 Traduzione singolo display file... 4 1.2 Traduzione stringhe da display file... 5 1.3 Traduzione
WG TRANSLATE Pagina 1 di 15 Sommario WG TRANSLATE... 1 1.1 INTRODUZIONE... 3 1 TRADUZIONE DISPLAY FILE... 3 1.1 Traduzione singolo display file... 4 1.2 Traduzione stringhe da display file... 5 1.3 Traduzione
Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete Neuronale
 Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete euronale Descrizione Il presente lavoro, facente segiuto a quanto descritto precedentemente, ha il fine di: 1) introdurre
Identificazione dei Parametri Caratteristici di un Plasma Circolare Tramite Rete euronale Descrizione Il presente lavoro, facente segiuto a quanto descritto precedentemente, ha il fine di: 1) introdurre
Test statistici di verifica di ipotesi
 Test e verifica di ipotesi Test e verifica di ipotesi Il test delle ipotesi consente di verificare se, e quanto, una determinata ipotesi (di carattere biologico, medico, economico,...) è supportata dall
Test e verifica di ipotesi Test e verifica di ipotesi Il test delle ipotesi consente di verificare se, e quanto, una determinata ipotesi (di carattere biologico, medico, economico,...) è supportata dall
Gestione Turni. Introduzione
 Gestione Turni Introduzione La gestione dei turni di lavoro si rende necessaria quando, per garantire la continuità del servizio di una determinata struttura, è necessario che tutto il personale afferente
Gestione Turni Introduzione La gestione dei turni di lavoro si rende necessaria quando, per garantire la continuità del servizio di una determinata struttura, è necessario che tutto il personale afferente
Librerie digitali. Video. Gestione di video. Caratteristiche dei video. Video. Metadati associati ai video. Metadati associati ai video
 Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Video Librerie digitali Gestione di video Ogni filmato è composto da più parti Video Audio Gestito come visto in precedenza Trascrizione del testo, identificazione di informazioni di interesse Testo Utile
Regione Toscana. ARPA Fonte Dati. Manuale Amministratore. L. Folchi (TAI) Redatto da
 Redatto da") ARPA Fonte Dati Regione Toscana Redatto da L. Folchi (TAI) Rivisto da Approvato da Versione 1.0 Data emissione 06/08/13 Stato DRAFT 1 Versione Data Descrizione 1,0 06/08/13 Versione Iniziale 2 Sommario
ARPA Fonte Dati Regione Toscana Redatto da L. Folchi (TAI) Rivisto da Approvato da Versione 1.0 Data emissione 06/08/13 Stato DRAFT 1 Versione Data Descrizione 1,0 06/08/13 Versione Iniziale 2 Sommario
Documenti Tecnici Informatica e Farmacia Vega S.p.A.
 Nuova gestione Offerte al pubblico Wingesfar: istruzioni per le farmacie Novembre 2009 Documenti Tecnici Informatica e Farmacia Vega S.p.A. Premessa La gestione delle Offerte al pubblico è stata oggetto
Nuova gestione Offerte al pubblico Wingesfar: istruzioni per le farmacie Novembre 2009 Documenti Tecnici Informatica e Farmacia Vega S.p.A. Premessa La gestione delle Offerte al pubblico è stata oggetto
Anno 1. Definizione di Logica e operazioni logiche
 Anno 1 Definizione di Logica e operazioni logiche 1 Introduzione In questa lezione ci occuperemo di descrivere la definizione di logica matematica e di operazioni logiche. Che cos è la logica matematica?
Anno 1 Definizione di Logica e operazioni logiche 1 Introduzione In questa lezione ci occuperemo di descrivere la definizione di logica matematica e di operazioni logiche. Che cos è la logica matematica?
HR - Sicurezza. Parma 17/12/2015
 HR - Sicurezza Parma 17/12/2015 FG Software Produce software gestionale da più di 10 anni Opera nel mondo del software qualità da 15 anni Sviluppa i propri software con un motore completamente proprietario
HR - Sicurezza Parma 17/12/2015 FG Software Produce software gestionale da più di 10 anni Opera nel mondo del software qualità da 15 anni Sviluppa i propri software con un motore completamente proprietario
Più processori uguale più velocità?
 Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
Più processori uguale più velocità? e un processore impiega per eseguire un programma un tempo T, un sistema formato da P processori dello stesso tipo esegue lo stesso programma in un tempo TP T / P? In
ATTIVAZIONE SCHEDE ETHERNET PER STAMPANTI SATO SERIE ENHANCED
 ATTIVAZIONE SCHEDE ETHERNET PER STAMPANTI SATO SERIE ENHANCED Il collegamento normale delle schede Ethernet è eseguito installando la scheda e collegando la macchina al sistema. Di norma una rete Ethernet
ATTIVAZIONE SCHEDE ETHERNET PER STAMPANTI SATO SERIE ENHANCED Il collegamento normale delle schede Ethernet è eseguito installando la scheda e collegando la macchina al sistema. Di norma una rete Ethernet
CONTROLLO DI GESTIONE DELLO STUDIO
 CONTROLLO DI GESTIONE DELLO STUDIO Con il controllo di gestione dello studio il commercialista può meglio controllare le attività svolte dai propri collaboratori dello studio nei confronti dei clienti
CONTROLLO DI GESTIONE DELLO STUDIO Con il controllo di gestione dello studio il commercialista può meglio controllare le attività svolte dai propri collaboratori dello studio nei confronti dei clienti
H1 Hrms Gestione eventi/scadenze automatiche
 Sintesi H1 Hrms Gestione eventi/scadenze automatiche Il presente documento nasce con lo scopo di illustrare la funzionalità all interno di H1 hrms relativa alla procedura di gestione degli eventi e delle
Sintesi H1 Hrms Gestione eventi/scadenze automatiche Il presente documento nasce con lo scopo di illustrare la funzionalità all interno di H1 hrms relativa alla procedura di gestione degli eventi e delle
Cosa dobbiamo già conoscere?
 Cosa dobbiamo già conoscere? Insiemistica (operazioni, diagrammi...). Insiemi finiti/numerabili/non numerabili. Perché la probabilità? In molti esperimenti l esito non è noto a priori tuttavia si sa dire
Cosa dobbiamo già conoscere? Insiemistica (operazioni, diagrammi...). Insiemi finiti/numerabili/non numerabili. Perché la probabilità? In molti esperimenti l esito non è noto a priori tuttavia si sa dire
Manuale d uso Albo Online per le Scuole
 Manuale d uso Albo Online per le Scuole Accedere come utente al sito Joomla della scuola. Accedere all Albo Online per le Scuole dai link presenti sul sito web scolastico. Cliccare su Modifica la configurazione.
Manuale d uso Albo Online per le Scuole Accedere come utente al sito Joomla della scuola. Accedere all Albo Online per le Scuole dai link presenti sul sito web scolastico. Cliccare su Modifica la configurazione.
Sistemi Informativi Territoriali. Map Algebra
 Paolo Mogorovich Sistemi Informativi Territoriali Appunti dalle lezioni Map Algebra Cod.735 - Vers.E57 1 Definizione di Map Algebra 2 Operatori locali 3 Operatori zonali 4 Operatori focali 5 Operatori
Paolo Mogorovich Sistemi Informativi Territoriali Appunti dalle lezioni Map Algebra Cod.735 - Vers.E57 1 Definizione di Map Algebra 2 Operatori locali 3 Operatori zonali 4 Operatori focali 5 Operatori
Inflazione. L indice dei prezzi al consumo ci consente quindi di introdurre anche il concetto di inflazione:
 Il potere di acquisto cambia nel tempo. Un euro oggi ha un potere di acquisto diverso da quello che aveva 5 anni fa e diverso da quello che avrà fra 20 anni. Come possiamo misurare queste variazioni? L
Il potere di acquisto cambia nel tempo. Un euro oggi ha un potere di acquisto diverso da quello che aveva 5 anni fa e diverso da quello che avrà fra 20 anni. Come possiamo misurare queste variazioni? L
EasyPrint v4.15. Gadget e calendari. Manuale Utente
 EasyPrint v4.15 Gadget e calendari Manuale Utente Lo strumento di impaginazione gadget e calendari consiste in una nuova funzione del software da banco EasyPrint 4 che permette di ordinare in maniera semplice
EasyPrint v4.15 Gadget e calendari Manuale Utente Lo strumento di impaginazione gadget e calendari consiste in una nuova funzione del software da banco EasyPrint 4 che permette di ordinare in maniera semplice
1 Serie di Taylor di una funzione
 Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
ANNO SCOLASTICO 2014-2015
 ATTIVITÀ DI SPERIMENTAZIONE IN CLASSE PREVISTA NELL AMBITO DEL PROGETTO M2014 PROMOSSO DALL ACCADEMIA DEI LINCEI PER LE SCUOLE PRIMARIE E SECONDARIE DI I GRADO ANNO SCOLASTICO 2014-2015 Il Centro matematita,
ATTIVITÀ DI SPERIMENTAZIONE IN CLASSE PREVISTA NELL AMBITO DEL PROGETTO M2014 PROMOSSO DALL ACCADEMIA DEI LINCEI PER LE SCUOLE PRIMARIE E SECONDARIE DI I GRADO ANNO SCOLASTICO 2014-2015 Il Centro matematita,
I sistemi di numerazione
 I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
I sistemi di numerazione 01-INFORMAZIONE E SUA RAPPRESENTAZIONE Sia dato un insieme finito di caratteri distinti, che chiameremo alfabeto. Utilizzando anche ripetutamente caratteri di un alfabeto, si possono
VALORE DELLE MERCI SEQUESTRATE
 La contraffazione in cifre: NUOVA METODOLOGIA PER LA STIMA DEL VALORE DELLE MERCI SEQUESTRATE Roma, Giugno 2013 Giugno 2013-1 Il valore economico dei sequestri In questo Focus si approfondiscono alcune
La contraffazione in cifre: NUOVA METODOLOGIA PER LA STIMA DEL VALORE DELLE MERCI SEQUESTRATE Roma, Giugno 2013 Giugno 2013-1 Il valore economico dei sequestri In questo Focus si approfondiscono alcune
Capitolo 25: Lo scambio nel mercato delle assicurazioni
 Capitolo 25: Lo scambio nel mercato delle assicurazioni 25.1: Introduzione In questo capitolo la teoria economica discussa nei capitoli 23 e 24 viene applicata all analisi dello scambio del rischio nel
Capitolo 25: Lo scambio nel mercato delle assicurazioni 25.1: Introduzione In questo capitolo la teoria economica discussa nei capitoli 23 e 24 viene applicata all analisi dello scambio del rischio nel
3.5.1.1 Aprire, preparare un documento da utilizzare come documento principale per una stampa unione.
 Elaborazione testi 133 3.5 Stampa unione 3.5.1 Preparazione 3.5.1.1 Aprire, preparare un documento da utilizzare come documento principale per una stampa unione. Abbiamo visto, parlando della gestione
Elaborazione testi 133 3.5 Stampa unione 3.5.1 Preparazione 3.5.1.1 Aprire, preparare un documento da utilizzare come documento principale per una stampa unione. Abbiamo visto, parlando della gestione
Strutture di Memoria 1
 Architettura degli Elaboratori e Laboratorio 17 Maggio 2013 Classificazione delle memorie Funzionalitá: Sola lettura ROM, Read Only Memory, generalmente usata per contenere le routine di configurazione
Architettura degli Elaboratori e Laboratorio 17 Maggio 2013 Classificazione delle memorie Funzionalitá: Sola lettura ROM, Read Only Memory, generalmente usata per contenere le routine di configurazione
Piano di gestione della qualità
 Piano di gestione della qualità Pianificazione della qualità Politica ed obiettivi della qualità Riferimento ad un eventuale modello di qualità adottato Controllo della qualità Procedure di controllo.
Piano di gestione della qualità Pianificazione della qualità Politica ed obiettivi della qualità Riferimento ad un eventuale modello di qualità adottato Controllo della qualità Procedure di controllo.
Progetto: ARPA Fonte Dati. ARPA Fonte Dati. Regione Toscana. Manuale Amministratore
 ARPA Fonte Dati Regione Toscana 1 Redatto da L. Folchi (TAI) Rivisto da Approvato da Versione 1.1 Data emissione 09/10/13 Stato FINAL 2 Versione Data Descrizione 1,0 06/08/13 Versione Iniziale 1.1 09/10/2013
ARPA Fonte Dati Regione Toscana 1 Redatto da L. Folchi (TAI) Rivisto da Approvato da Versione 1.1 Data emissione 09/10/13 Stato FINAL 2 Versione Data Descrizione 1,0 06/08/13 Versione Iniziale 1.1 09/10/2013
Guida all uso di Java Diagrammi ER
 Guida all uso di Java Diagrammi ER Ver. 1.1 Alessandro Ballini 16/5/2004 Questa guida ha lo scopo di mostrare gli aspetti fondamentali dell utilizzo dell applicazione Java Diagrammi ER. Inizieremo con
Guida all uso di Java Diagrammi ER Ver. 1.1 Alessandro Ballini 16/5/2004 Questa guida ha lo scopo di mostrare gli aspetti fondamentali dell utilizzo dell applicazione Java Diagrammi ER. Inizieremo con
1. Distribuzioni campionarie
 Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
FORMULE: Operatori matematici
 Formule e funzioni FORMULE Le formule sono necessarie per eseguire calcoli utilizzando i valori presenti nelle celle di un foglio di lavoro. Una formula inizia col segno uguale (=). La formula deve essere
Formule e funzioni FORMULE Le formule sono necessarie per eseguire calcoli utilizzando i valori presenti nelle celle di un foglio di lavoro. Una formula inizia col segno uguale (=). La formula deve essere
Valutazione delle Prestazioni. Valutazione delle Prestazioni. Architetture dei Calcolatori (Lettere. Tempo di risposta e throughput
 Valutazione delle Prestazioni Architetture dei Calcolatori (Lettere A-I) Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Valutazione delle Prestazioni Architetture dei Calcolatori (Lettere A-I) Valutazione delle Prestazioni Prof. Francesco Lo Presti Misura/valutazione di un insieme di parametri quantitativi per caratterizzare
Automazione Industriale (scheduling+mms) scheduling+mms. adacher@dia.uniroma3.it
 scheduling+mms. adacher@dia.uniroma3.it") Automazione Industriale (scheduling+mms) scheduling+mms adacher@dia.uniroma3.it Introduzione Sistemi e Modelli Lo studio e l analisi di sistemi tramite una rappresentazione astratta o una sua formalizzazione
Automazione Industriale (scheduling+mms) scheduling+mms adacher@dia.uniroma3.it Introduzione Sistemi e Modelli Lo studio e l analisi di sistemi tramite una rappresentazione astratta o una sua formalizzazione
LABORATORIO-EXCEL N. 2-3 XLSTAT- Pro Versione 7 VARIABILI QUANTITATIVE
 LABORATORIO-EXCEL N. 2-3 XLSTAT- Pro Versione 7 VARIABILI QUANTITATIVE DESCRIZIONE DEI DATI DA ESAMINARE Sono stati raccolti i dati sul peso del polmone di topi normali e affetti da una patologia simile
LABORATORIO-EXCEL N. 2-3 XLSTAT- Pro Versione 7 VARIABILI QUANTITATIVE DESCRIZIONE DEI DATI DA ESAMINARE Sono stati raccolti i dati sul peso del polmone di topi normali e affetti da una patologia simile
Le equazioni. Diapositive riassemblate e rielaborate da prof. Antonio Manca da materiali offerti dalla rete.
 Le equazioni Diapositive riassemblate e rielaborate da prof. Antonio Manca da materiali offerti dalla rete. Definizione e caratteristiche Chiamiamo equazione l uguaglianza tra due espressioni algebriche,
Le equazioni Diapositive riassemblate e rielaborate da prof. Antonio Manca da materiali offerti dalla rete. Definizione e caratteristiche Chiamiamo equazione l uguaglianza tra due espressioni algebriche,
Raccomandazione del Parlamento europeo 18/12/2006 CLASSE PRIMA COMPETENZE ABILITÀ CONOSCENZE. Operare con i numeri
 COMPETENZA CHIAVE MATEMATICA Fonte di legittimazione Raccomandazione del Parlamento europeo 18/12/2006 CLASSE PRIMA COMPETENZE ABILITÀ CONOSCENZE L alunno utilizza il calcolo scritto e mentale con i numeri
COMPETENZA CHIAVE MATEMATICA Fonte di legittimazione Raccomandazione del Parlamento europeo 18/12/2006 CLASSE PRIMA COMPETENZE ABILITÀ CONOSCENZE L alunno utilizza il calcolo scritto e mentale con i numeri
Inferenza statistica. Statistica medica 1
 Inferenza statistica L inferenza statistica è un insieme di metodi con cui si cerca di trarre una conclusione sulla popolazione sulla base di alcune informazioni ricavate da un campione estratto da quella
Inferenza statistica L inferenza statistica è un insieme di metodi con cui si cerca di trarre una conclusione sulla popolazione sulla base di alcune informazioni ricavate da un campione estratto da quella
IL PROCESSO DI BUDGETING. Dott. Claudio Orsini Studio Cauli, Marmocchi, Orsini & Associati Bologna
 IL PROCESSO DI BUDGETING Dott. Claudio Orsini Studio Cauli, Marmocchi, Orsini & Associati Bologna Il processo di budgeting Il sistema di budget rappresenta l espressione formalizzata di un complesso processo
IL PROCESSO DI BUDGETING Dott. Claudio Orsini Studio Cauli, Marmocchi, Orsini & Associati Bologna Il processo di budgeting Il sistema di budget rappresenta l espressione formalizzata di un complesso processo
MService La soluzione per ottimizzare le prestazioni dell impianto
 MService La soluzione per ottimizzare le prestazioni dell impianto Il segreto del successo di un azienda sta nel tenere sotto controllo lo stato di salute delle apparecchiature degli impianti. Dati industriali
MService La soluzione per ottimizzare le prestazioni dell impianto Il segreto del successo di un azienda sta nel tenere sotto controllo lo stato di salute delle apparecchiature degli impianti. Dati industriali
Modellazione dei dati in UML
 Corso di Basi di Dati e Sistemi Informativi Modellazione dei dati in UML Angelo Montanari Dipartimento di Matematica e Informatica Università degli Studi di Udine Introduzione UML (Unified Modeling Language):
Corso di Basi di Dati e Sistemi Informativi Modellazione dei dati in UML Angelo Montanari Dipartimento di Matematica e Informatica Università degli Studi di Udine Introduzione UML (Unified Modeling Language):
Codifiche a lunghezza variabile
 Sistemi Multimediali Codifiche a lunghezza variabile Marco Gribaudo marcog@di.unito.it, gribaudo@elet.polimi.it Assegnazione del codice Come visto in precedenza, per poter memorizzare o trasmettere un
Sistemi Multimediali Codifiche a lunghezza variabile Marco Gribaudo marcog@di.unito.it, gribaudo@elet.polimi.it Assegnazione del codice Come visto in precedenza, per poter memorizzare o trasmettere un
Accreditamento Soggetti Formatori in materia di Sicurezza sul Lavoro
 Linee guida per l utilizzo del sistema informativo Pag.1 di 12 Linee guida per l utilizzo del sistema informativo Accreditamento Soggetti Formatori in materia di Sicurezza sul Lavoro Il presente documento
Linee guida per l utilizzo del sistema informativo Pag.1 di 12 Linee guida per l utilizzo del sistema informativo Accreditamento Soggetti Formatori in materia di Sicurezza sul Lavoro Il presente documento
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 10-Il test t per un campione e la stima intervallare (vers. 1.1, 25 ottobre 2015) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia,
Elementi di Psicometria con Laboratorio di SPSS 1 10-Il test t per un campione e la stima intervallare (vers. 1.1, 25 ottobre 2015) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia,
Cosa sono i due pulsanti nell header?
 Cosa sono i due pulsanti nell header? I due pulsanti nell header (testata) del sito offrono accesso diretto a schede informative che illustrano una sintesi divulgativa dei principali diritti e doveri in
Cosa sono i due pulsanti nell header? I due pulsanti nell header (testata) del sito offrono accesso diretto a schede informative che illustrano una sintesi divulgativa dei principali diritti e doveri in
Teoria in sintesi 10. Attività di sportello 1, 24 - Attività di sportello 2, 24 - Verifica conclusiva, 25. Teoria in sintesi 26
 Indice L attività di recupero 6 Funzioni Teoria in sintesi 0 Obiettivo Ricerca del dominio e del codominio di funzioni note Obiettivo Ricerca del dominio di funzioni algebriche; scrittura del dominio Obiettivo
Indice L attività di recupero 6 Funzioni Teoria in sintesi 0 Obiettivo Ricerca del dominio e del codominio di funzioni note Obiettivo Ricerca del dominio di funzioni algebriche; scrittura del dominio Obiettivo
Come valutare le caratteristiche aerobiche di ogni singolo atleta sul campo
 Come valutare le caratteristiche aerobiche di ogni singolo atleta sul campo Prima di organizzare un programma di allenamento al fine di elevare il livello di prestazione, è necessario valutare le capacità
Come valutare le caratteristiche aerobiche di ogni singolo atleta sul campo Prima di organizzare un programma di allenamento al fine di elevare il livello di prestazione, è necessario valutare le capacità
Corso di Amministrazione di Reti A.A. 2002/2003
 Struttura di Active Directory Corso di Amministrazione di Reti A.A. 2002/2003 Materiale preparato utilizzando dove possibile materiale AIPA http://www.aipa.it/attivita[2/formazione[6/corsi[2/materiali/reti%20di%20calcolatori/welcome.htm
Struttura di Active Directory Corso di Amministrazione di Reti A.A. 2002/2003 Materiale preparato utilizzando dove possibile materiale AIPA http://www.aipa.it/attivita[2/formazione[6/corsi[2/materiali/reti%20di%20calcolatori/welcome.htm
f(x) = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da
 = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da") Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
6.5. Risultati simulazioni sistema rifiuti e riscaldamento
 Capitolo 6 Risultati pag. 301 6.5. Risultati simulazioni sistema rifiuti e riscaldamento Come già detto nel paragrafo 5.8, i risultati riportati in questo paragrafo fanno riferimento alle concentrazione
Capitolo 6 Risultati pag. 301 6.5. Risultati simulazioni sistema rifiuti e riscaldamento Come già detto nel paragrafo 5.8, i risultati riportati in questo paragrafo fanno riferimento alle concentrazione
Esercizio 1: trading on-line
 Esercizio 1: trading on-line Si realizzi un programma Java che gestisca le operazioni base della gestione di un fondo per gli investimenti on-line Creazione del fondo (con indicazione della somma in inizialmente
Esercizio 1: trading on-line Si realizzi un programma Java che gestisca le operazioni base della gestione di un fondo per gli investimenti on-line Creazione del fondo (con indicazione della somma in inizialmente
GESTIONE FATTURE (VELINE)
") GESTIONE FATTURE (VELINE) Sommario Importazione Veline da Excel... 2 Generazione di una Velina da uno o più Ordini... 3 Creazione di una Velina prelevando i prodotti da più Ordini... 4 Gestione scadenze
GESTIONE FATTURE (VELINE) Sommario Importazione Veline da Excel... 2 Generazione di una Velina da uno o più Ordini... 3 Creazione di una Velina prelevando i prodotti da più Ordini... 4 Gestione scadenze
( x) ( x) 0. Equazioni irrazionali
 ( x) 0. Equazioni irrazionali") Equazioni irrazionali Definizione: si definisce equazione irrazionale un equazione in cui compaiono uno o più radicali contenenti l incognita. Esempio 7 Ricordiamo quanto visto sulle condizioni di esistenza
Equazioni irrazionali Definizione: si definisce equazione irrazionale un equazione in cui compaiono uno o più radicali contenenti l incognita. Esempio 7 Ricordiamo quanto visto sulle condizioni di esistenza
Mon Ami 3000 Produzione interna/esterna Gestione della produzione interna/esterna
 Mon Ami 3000 Produzione interna/esterna Gestione della produzione interna/esterna Introduzione Questa guida illustra tutte le funzioni e le procedure da eseguire per gestire correttamente un ciclo di produzione
Mon Ami 3000 Produzione interna/esterna Gestione della produzione interna/esterna Introduzione Questa guida illustra tutte le funzioni e le procedure da eseguire per gestire correttamente un ciclo di produzione
PROGETTO SEGNALAZIONE E GESTIONE RECLAMI/DISSERVIZI
 PROGETTO SEGNALAZIONE E GESTIONE RECLAMI/DISSERVIZI Sintesi del progetto : La nuova procedura di gestione dei reclami è seguita dall URP dall inizio alla fine, secondo il seguente iter: il cittadino segnala
PROGETTO SEGNALAZIONE E GESTIONE RECLAMI/DISSERVIZI Sintesi del progetto : La nuova procedura di gestione dei reclami è seguita dall URP dall inizio alla fine, secondo il seguente iter: il cittadino segnala
COMUNE DI SOLBIATE ARNO
 SISTEMA DI MISURAZIONE E VALUTAZIONE DEL PERSONALE DIPENDENTE Approvato con deliberazione della Giunta Comunale n. 98 del 14.11.2013 1 GLI ELEMENTI DEL SISTEMA DI VALUTAZIONE Oggetto della valutazione:obiettivi
SISTEMA DI MISURAZIONE E VALUTAZIONE DEL PERSONALE DIPENDENTE Approvato con deliberazione della Giunta Comunale n. 98 del 14.11.2013 1 GLI ELEMENTI DEL SISTEMA DI VALUTAZIONE Oggetto della valutazione:obiettivi
Federico Laschi. Conclusioni
 Lo scopo di questa tesi è stato quello di proporre alcuni algoritmi di allocazione dinamica della capacità trasmissiva, basati su tecniche di predizione on-line dei processi di traffico. Come prima analisi
Lo scopo di questa tesi è stato quello di proporre alcuni algoritmi di allocazione dinamica della capacità trasmissiva, basati su tecniche di predizione on-line dei processi di traffico. Come prima analisi
Progetto di simulazione molecolare per il corso di Complementi di algoritmi A.A. 2005-06
 Progetto di simulazione molecolare per il corso di Complementi di algoritmi A.A. 2005-06 13 febbraio 2006 1 Descrizione Il progetto si compone delle seguenti fasi: 1. caricamento di soluzioni in formato
Progetto di simulazione molecolare per il corso di Complementi di algoritmi A.A. 2005-06 13 febbraio 2006 1 Descrizione Il progetto si compone delle seguenti fasi: 1. caricamento di soluzioni in formato
CABINE ELETTRICHE DI TRASFORMAZIONE
 Cabtrasf_parte_prima 1 di 8 CABINE ELETTRICHE DI TRASFORMAZIONE parte prima Una cabina elettrica è il complesso di conduttori, apparecchiature e macchine atto a eseguire almeno una delle seguenti funzioni:
Cabtrasf_parte_prima 1 di 8 CABINE ELETTRICHE DI TRASFORMAZIONE parte prima Una cabina elettrica è il complesso di conduttori, apparecchiature e macchine atto a eseguire almeno una delle seguenti funzioni:
Come masterizzare dischi con Nero 11
 Come masterizzare dischi con Nero 11 Non c è dubbio che Nero è diventato un sinonimo di masterizzatore di dischi, data la lunga esperienza sul mercato. Molte persone pensano in questo programma nel momento
Come masterizzare dischi con Nero 11 Non c è dubbio che Nero è diventato un sinonimo di masterizzatore di dischi, data la lunga esperienza sul mercato. Molte persone pensano in questo programma nel momento
e/fiscali - Rel. 03.03.03 e/fiscali Installazione
 e/fiscali - Rel. 03.03.03 e/fiscali Installazione INDICE 1 REQUISITI... 3 1.1.1 Requisiti applicativi... 3 2 PROCEDURA DI INSTALLAZIONE... 4 2.0.1 Versione fix scaricabile dal sito... 4 2.1 INSTALLAZIONE...
e/fiscali - Rel. 03.03.03 e/fiscali Installazione INDICE 1 REQUISITI... 3 1.1.1 Requisiti applicativi... 3 2 PROCEDURA DI INSTALLAZIONE... 4 2.0.1 Versione fix scaricabile dal sito... 4 2.1 INSTALLAZIONE...
Strumenti e metodi per la redazione della carta del pericolo da fenomeni torrentizi
 Versione 2.0 Strumenti e metodi per la redazione della carta del pericolo da fenomeni torrentizi Corso anno 2011 E. MANUALE UTILIZZO HAZARD MAPPER Il programma Hazard Mapper è stato realizzato per redarre,
Versione 2.0 Strumenti e metodi per la redazione della carta del pericolo da fenomeni torrentizi Corso anno 2011 E. MANUALE UTILIZZO HAZARD MAPPER Il programma Hazard Mapper è stato realizzato per redarre,
Anno 3. Funzioni: dominio, codominio e campo di esistenza
 Anno 3 Funzioni: dominio, codominio e campo di esistenza 1 Introduzione In questa lezione parleremo delle funzioni. Ne daremo una definizione e impareremo a studiarne il dominio in relazione alle diverse
Anno 3 Funzioni: dominio, codominio e campo di esistenza 1 Introduzione In questa lezione parleremo delle funzioni. Ne daremo una definizione e impareremo a studiarne il dominio in relazione alle diverse
Analisi di dati di frequenza
 Analisi di dati di frequenza Fase di raccolta dei dati Fase di memorizzazione dei dati in un foglio elettronico 0 1 1 1 Frequenze attese uguali Si assuma che dalle risposte al questionario sullo stato
Analisi di dati di frequenza Fase di raccolta dei dati Fase di memorizzazione dei dati in un foglio elettronico 0 1 1 1 Frequenze attese uguali Si assuma che dalle risposte al questionario sullo stato
Organizzazione degli archivi
 COSA E UN DATA-BASE (DB)? è l insieme di dati relativo ad un sistema informativo COSA CARATTERIZZA UN DB? la struttura dei dati le relazioni fra i dati I REQUISITI DI UN DB SONO: la ridondanza minima i
COSA E UN DATA-BASE (DB)? è l insieme di dati relativo ad un sistema informativo COSA CARATTERIZZA UN DB? la struttura dei dati le relazioni fra i dati I REQUISITI DI UN DB SONO: la ridondanza minima i
PIL : produzione e reddito
 PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
Programma Gestione Presenze Manuale autorizzatore. Versione 1.0 25/08/2010. Area Sistemi Informatici - Università di Pisa
 - Università di Pisa Programma Gestione Presenze Manuale autorizzatore Versione 1.0 25/08/2010 Email: service@adm.unipi.it 1 1 Sommario - Università di Pisa 1 SOMMARIO... 2 2 ACCESSO AL PROGRAMMA... 3
- Università di Pisa Programma Gestione Presenze Manuale autorizzatore Versione 1.0 25/08/2010 Email: service@adm.unipi.it 1 1 Sommario - Università di Pisa 1 SOMMARIO... 2 2 ACCESSO AL PROGRAMMA... 3
Rappresentazione grafica di entità e attributi
 PROGETTAZIONE CONCETTUALE La progettazione concettuale, ha il compito di costruire e definire una rappresentazione corretta e completa della realtà di interesse, e il prodotto di tale attività, è lo schema
PROGETTAZIONE CONCETTUALE La progettazione concettuale, ha il compito di costruire e definire una rappresentazione corretta e completa della realtà di interesse, e il prodotto di tale attività, è lo schema
Matematica generale CTF
 Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Disegni di Ricerca e Analisi dei Dati in Psicologia Clinica. Indici di Affidabilità
 Disegni di Ricerca e Analisi dei Dati in Psicologia Clinica Indici di Affidabilità L Attendibilità È il livello in cui una misura è libera da errore di misura È la proporzione di variabilità della misurazione
Disegni di Ricerca e Analisi dei Dati in Psicologia Clinica Indici di Affidabilità L Attendibilità È il livello in cui una misura è libera da errore di misura È la proporzione di variabilità della misurazione
Il documento rappresenta una guida sintetica al processo di affido pratiche agli operatori in recuper@2.0
 Il documento rappresenta una guida sintetica al processo di affido pratiche agli operatori in recuper@2.0 ver 1.0 del 19/03/2013 Saranno trattati le varie modalità di affido, in particolare l affido diretto,
Il documento rappresenta una guida sintetica al processo di affido pratiche agli operatori in recuper@2.0 ver 1.0 del 19/03/2013 Saranno trattati le varie modalità di affido, in particolare l affido diretto,
Principi generali. Vercelli 9-10 dicembre 2005. G. Bartolozzi - Firenze. Il Pediatra di famiglia e gli esami di laboratorio ASL Vercelli
 Il Pediatra di famiglia e gli esami di laboratorio ASL Vercelli Principi generali Carlo Federico Gauss Matematico tedesco 1777-1855 G. Bartolozzi - Firenze Vercelli 9-10 dicembre 2005 Oggi il nostro lavoro
Il Pediatra di famiglia e gli esami di laboratorio ASL Vercelli Principi generali Carlo Federico Gauss Matematico tedesco 1777-1855 G. Bartolozzi - Firenze Vercelli 9-10 dicembre 2005 Oggi il nostro lavoro
Regressione non lineare con un modello neurale feedforward
 Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
Reti Neurali Artificiali per lo studio del mercato Università degli studi di Brescia - Dipartimento di metodi quantitativi Marco Sandri (sandri.marco@gmail.com) Regressione non lineare con un modello neurale
Veneto Lavoro via Ca' Marcello 67/b, 30172 Venezia-Mestre tel.: 041/2919311
 Veneto Lavoro via Ca' Marcello 67/b, 30172 Venezia-Mestre tel.: 041/2919311 INDICE 1. INTRODUZIONE... 3 1.1 SCADENZA... 3 1.2 CAUSALE DA UTILIZZARE... 3 2. MODALITÀ OPERATIVE DI COMUNICAZIONE DATI... 4
Veneto Lavoro via Ca' Marcello 67/b, 30172 Venezia-Mestre tel.: 041/2919311 INDICE 1. INTRODUZIONE... 3 1.1 SCADENZA... 3 1.2 CAUSALE DA UTILIZZARE... 3 2. MODALITÀ OPERATIVE DI COMUNICAZIONE DATI... 4
HBase Data Model. in più : le colonne sono raccolte in gruppi di colonne detti Column Family; Cosa cambia dunque?
 NOSQL Data Model HBase si ispira a BigTable di Google e perciò rientra nella categoria dei column store; tuttavia da un punto di vista logico i dati sono ancora organizzati in forma di tabelle, in cui
NOSQL Data Model HBase si ispira a BigTable di Google e perciò rientra nella categoria dei column store; tuttavia da un punto di vista logico i dati sono ancora organizzati in forma di tabelle, in cui
Sistema per scambi/cessioni di Gas al Punto di Scambio Virtuale
 Sistema per scambi/cessioni di Gas al Punto di Scambio Virtuale Modulo Bacheca 1 INDICE 1 Generalità...3 2 Accesso al sistema...4 2.1 Requisiti tecnici 5 3 Elenco funzioni e tasti di navigazione...6 3.1
Sistema per scambi/cessioni di Gas al Punto di Scambio Virtuale Modulo Bacheca 1 INDICE 1 Generalità...3 2 Accesso al sistema...4 2.1 Requisiti tecnici 5 3 Elenco funzioni e tasti di navigazione...6 3.1