Econometria. Universita di Salerno, A.A Fausto Galli
|
|
|
- Vanessa Valentino
- 8 anni fa
- Visualizzazioni
Transcript
1 Econometria Universita di Salerno, A.A Fausto Galli

2 outline PARTE III Capitolo 14 Capitolo 15

3 Introduzione alle regressioni con serie storiche ed alla previsione (SW capitolo 14) I dati in serie storica (o temporale) sono dati raccolti sulla stessa unità d osservazione in diversi intervalli di tempo Consumo aggregato e PIL per un paese (per esempio, 20 anni di osservazioni trimestrali = 80 osservazioni) Tassi di cambio Yen/$, sterlina/$ e Euro/$ (dati giornalieri per 1 anno = 365 osservazioni) Consumo di sigarette pro capite in uno in uno stato
 Consumo di sigarette pro capite in uno in")
4 Esempio 1 di dati serie storica: tasso di inflazione USA

5 Esempio 2: tasso di disoccupazione USA
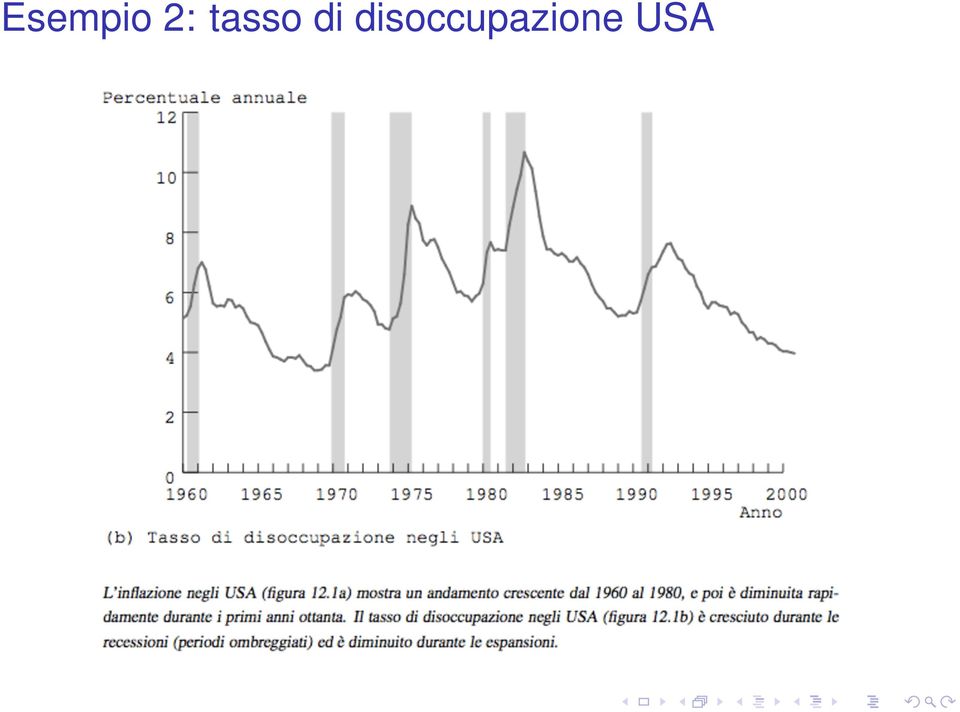
6 Perché utilizzare le serie storiche Per sviluppare modelli di previsione Quale sarà il tasso di inflazione il prossimo anno? Per stimare effetti causali dinamici Se la Fed aumenta il tasso sui Federal Funds ora, quale sarà l effetto sui tassi di inflazione e di disoccupazione in 3 mesi? in 12 mesi? Qual è l effetto nel tempo sul consumo di sigarette di un aumento delle tassa sulle sigarette? Inoltre, a volte non c è altra scelta... I tassi di inflazione e di disoccupazione in un paese possono essere osservati solo nel tempo.

7 I dati in serie storica sollevano nuove questioni tecniche Ritardi temporali Correlazione nel tempo (correlazione seriale o autocorrelazione) Modelli di previsione che non hanno una interpretazione causale (specializzati per la previsione): modelli autoregressi (AR) modelli a ritardi autoregressivi distribuiti (ADL) Condizioni sotto cui gli effetti dinamici possono essere stimati, e come stimare Calcolo degli errori standard quando gli errori sono serialmente correlati

8 L uso dei modelli di regressione per la previsione (SW Par. 14.1) Previsione e stima di effetti causali sono obiettivi molto diversi. Per la previsione, R2 è (molto!) importante La distorsione da variabile omessa non è un problema serio Non ci preoccupiamo troppo di interpretare i coefficienti nei modelli di previsione La validità esterna è di primaria importanza: il modello stimato utilizzando i dati storici deve restare valido nel (prossimo) futuro

9 Introduzione alle serie temporali e alla correlazione seriale (SW Par 14.2) Prima di tutto dobbiamo introdurre qualche notazione ed un po di terminologia. Notazione per dati in serie storiche Y t = valore di Y nel periodo t Dati: Y 1,..., Y T = le T osservazioni in serie storica sulla variabile casuale Y Consideriamo soltanto osservazioni consecutive ed equidistanstanti nel tempo (ad esempio mensili, dal 1960 al 1999, niente mesi mancanti)

10 Possiamo trasformare le variabili in serie storica con ritardi, differenze prime, logaritmi, e tassi di crescita

11 Esempio: tasso trimestrale di inflazione annualizzata CPI nel primo trimestre del 1999 (1999:I) = CPI nel secondo trimestre del 1999 (1999:II) = Variazione percentuale della CPI, da 1999:I a 1999:II = 100 ( ) = 100 ( = 0.703% Variazione percentuale della CPI, 1999:I-1999:II, ad un tasso annualizzato = 4 0, 703 = 2, 81% (percento l anno) Come i tassi di interesse, i tassi di inflazione sono (per una questione di convenzione) espressi in modo annualizzato. Usando l approssimazione logaritmica a variazioni percentuali abbiamo [log(166.03) log(164.87)] = 2, 80%
 Come i tassi di interesse, i tassi")
12 Esempio: l inflazione dei prezzi al consumo USA - primo ritardo e variazione (Bureau of Labor Statistics)

13 Autocorrelazione La correlazione di una serie con i propri valori ritardati è chiamata autocorrelazione o correlazione seriale. La prima autocorrelazione di Y t è corr(y t, Y t 1 ) Il primo autocovarianza di Y t è cov(y t, Y t 1 ) Quindi corr(y t, Y t 1 ) = cov(y t, Y t 1 ) var(yt )var(y t 1 ) = ρ 1 Questi sono correlazioni della popolazione - che descrivono la distribuzione congiunta nella popolazione di (Y t, Y t 1 )
 = cov(y t, Y t 1 ) var(yt )var(y t 1 ) = ρ 1 Questi sono correlazioni della")
14

15 Autocorrelazioni campionarie La j-esima autocorrelazione campionaria è una stima della j esima autocorrelazione della popolazione dove ρ j = ĉov(y t, Y t 1 ) var(y t ) ĉov(y t, Y t 1 ) = 1 T j 1 T t=j+1 (Y t Ȳj+1,T )(Y t j Ȳ1,T j) dove Ȳj+1,T è la media campionaria di Y t calcolata sulle osservazioni t = j + 1,..., T Nota: la somma è su t da j + 1 a T (Perché )?

16 Esempio: Autocorrelazioni di: 1. tasso trimestrale di inflazione negli Stati Uniti 2. variazione da trimestre a trimestre del tasso trimestrale di inflazione

17 Il tasso di inflazione è molto autocorrelato (ρ 1 = 0.85) Tasso di inflazione dell ultimo trimestre contiene molte informazioni sul tasso di inflazione del trimestre presente Il grafico è dominato da oscillazioni pluriennali Ma ci sono ancora movimenti "a sorpresa"!

18 Altri esempi di serie temporali e trasformazioni

19

20 Stazionarietà Concetto chiave per la validità esterna di regressioni temporali. Stazionarietà significa che il passato è come il presente e il futuro, almeno in senso probabilistico. Ci concentreremo sul caso di Y t stazionaria.

21 Autoregressioni (SW Par. 14.3) Un punto di partenza naturale per un modello di previsione è quello di utilizzare i valori passati di Y (cioè, Y t 1, Y t 2,...) per prevedere Y t. Un autoregressione è un modello di regressione in cui Y t è regredita sui propri valori ritardati. Il numero dei ritardi utilizzati come regressori è chiamato l ordine dell autoregressione. In un autoregressione del primo ordine,y t è regredita su Y t 1 In un autoregressione di ordine p, Yt è regredita su Y t 1, Y t 2,..., Y t p
22 Modello autoregressivo del primo ordine, AR(1) Il modello AR(1) della popolazione è Y t = β 0 + β 1 Y t 1 + u t non cerchiamo interpretazioni causali per β 0 e β 1 se β 1 = 0, Y t 1 non è utile per prevedere Y t Il modello AR(1) può essere stimato con una semplice regressione OLS di Y t su Y t 1 Testare H 0 : β 1 = 0 vs. H 1 : β 1 0 verifica l utilità di Y t 1 come previsore di Y t
23 Esempio: AR(1) per la variazione dell inflazione Stimato utilizzando i dati 1962:I-1999:IV: Inf t = Inf t 1 R2 = 0.04 (0.14) (0.106) La variazione ritardata dell inflazione è un predittore utile di quella corrente? t = 0.211/0.106 = 1.99 > 1.96 rifiutiamo H 0 : β 1 = 0 al livello di significatività del 5% Sì, la variazione ritardata dell inflazione è un predittore utile della variazione corrente (ma l R 2 è basso!)
24 Esempio: modello AR(1) con Gretl? genr infl = 400 * log(punew/punew(-1))? diff infl #calcola le differenze? lags d_infl #genera i ritardi? smpl 1962:1 1999:4 #il campione che ci interessa? corrgm infl 8 #correlogramma Funzione di autocorrelazione per infl LAG ACF PACF Q-stat. [p-value] 1 0,8454 *** 0,8454 *** 110,8035 [0,000] 2 0,7536 *** 0,1361 * 199,4247 [0,000] 3 0,7542 *** 0,3171 *** 288,7908 [0,000] 4 0,6514 *** -0,2504 *** 355,8980 [0,000] 5 0,5633 *** -0, ,4331 [0,000] 6 0,5263 *** -0, ,8366 [0,000] 7 0,4420 *** -0, ,3792 [0,000] 8 0,3271 *** -0,1824 ** 499,7706 [0,000]
25 ? ols d_infl const d_infl_1 --robust Modello 1: OLS, usando le osservazioni 1962:1-1999:4 (T = 152) Variabile dipendente: d_infl Errori standard robusti rispetto all eteroschedasticita, variante HC1 coefficiente errore std. rapporto t p-value const 0, , ,1393 0,8894 d_infl_1-0, , ,991 0,0483 ** Media var. dipendente 0, SQM var. dipendente 1, Somma quadr. residui 414,3174 E.S. della regressione 1, R-quadro 0, R-quadro corretto 0, F(1, 150) 3, P-value(F) 0, Log-verosimiglianza -291,8878 Criterio di Akaike 587,7756 Criterio di Schwarz 593,8234 Hannan-Quinn 590,2324 rho -0, Durbin-Watson 2, Note: SQM = scarto quadratico medio; E.S. = errore standard
26 Previsioni e errori di previsione Una nota sulla terminologia: Un valore predetto si riferisce al valore di Y predetto (utilizzando una regressione) per un osservazione nel campione utilizzato per stimare la regressione - questa è la definizione usuale (noi spesso abbiamo usato il termine valore stimato per evitare confusione) Una previsione si riferisce al valore di Y previsto per un osservazione non nel campione utilizzato per stimare la regressione. Valori predetti sono "in sample", cioè nel campione Le previsioni sono le previsioni del futuro ("out of sample"), che non può essere stato usato per stimare la regressione.
27 Previsioni: notazione Y t t 1 = previsione di Y t basata su Y t 1, Y t 2,..., utilizzando i coefficienti della popolazione (quelli vera ma incogniti) Ŷ t t 1 = previsione di Y t basata su Y t 1, Y t 2,..., utilizzando i coefficienti stimati utilizzando i dati del periodo fino a t 1. Per un AR(1), Y t t 1 = β 0 + β 1 Y t 1 Ŷ t t 1 = β 0 + β 1 Y t 1, dove β 0 e β 1 sono stati stimati utilizzando i dati fino a t 1.
28 Errore di previsione L errore di previsione per un periodo in avanti è, Y t Ŷt t 1 La distinzione tra un errore di previsione ed un residuo è la stessa che tra una previsione e un valore predetto: un residuo è "in-sampe" un errore di previsione è "out-of-sample" - il valoredi Y t non viene utilizzato per la stima dei coefficienti di regressione
29 La radice dell errore quadratico medio di previsione (RMSFE) RMSFE = E[Y t Ŷt t 1] 2 L RMSFE è una misura della dispersione della distribuzione dell errore di previsione. L RMSFE è come la deviazione standard di u t, salvo che si concentra esplicitamente sull errore di previsione calcolato utilizzando coefficienti stimati, non utilizzando la retta di regressione della popolazione. L RMSFE è una misura della grandezza dell "errore" di previsione tipico
30 Esempio: previsione dell inflazione con AR(1) AR(1) stimato utilizzando i dati 1962:I-1999:IV: Inf t = Inf t 1 Inf 1999:III = 2.8 (unità in percentuale annualizzate) Inf 1999:IV = 3.2 Inf 1999:IV = 0.4 Quindi, la previsione di Inf 2000:I è, quindi Inf 2000:I 1999:IV = 0, 02 0, 211 0, 4 = Înf 2000:I 1999:IV = Inf 1999:IV + Inf 2000:I 1999:IV = = 3.1
31 Il modello autoregressivo di ordine p, AR(p) Y t = β 0 + β 1 Y t 1 + β 2 Y t β p Y t p + u t Il modello AR (p) utilizza p ritardi della Y come regressori Il modello AR (1) è un caso particolare I coefficienti non hanno una interpretazione causale Per verificare l ipotesi che Y t 2,..., Y t p non aiutano ulteriormente la previsione di Y t, al di là di Y t 1, possimao usare un test F Possiamo utilizzare i test t o F per determinare l ordine di ritardo p O, meglio, determiniamo p utilizzando i "criteri di informazione" (vedi sezione 14.5 SW)
32 Esempio: modello AR(4) per l inflazione Inf t = Inf t Inf t 2 + 0, 19Inf t 3 (0.12) (0.10) (0.09) (0.10) Statistica F per i 2, 3 e 4 è 6,43 (p-valore <0.001) R2 aumenta da 0.04 a 0.21 aggiungendo i ritardi 2, 3 e 4 Quindi, possiamo concludere che i lag 2, 3 e 4 (congiuntamente) aiutano a prevedere le variazioni dell inflazione
33 Esempio: AR(4) con Gretl? ols d_infl const d_infl(-1 to -4) --robust Modello 2: OLS, usando le osservazioni 1962:1-1999:4 (T = 152) Variabile dipendente: d_infl Errori standard robusti rispetto all eteroschedasticita, variante HC1 coefficiente errore std. rapporto t p-value const 0, , ,1917 0,8483 d_infl_1-0, , ,095 0,0379 ** d_infl_2-0, , ,637 0,0004 *** d_infl_3 0, , ,290 0,0235 ** d_infl_4-0, , ,3586 0,7204 Media var. dipendente 0, SQM var. dipendente 1, Somma quadr. residui 343,7395 E.S. della regressione 1, R-quadro 0, R-quadro corretto 0, F(4, 147) 6, P-value(F) 0, Log-verosimiglianza -277,6949 Criterio di Akaike 565,3899 Criterio di Schwarz 580,5093 Hannan-Quinn 571,5319 rho 0, Durbin-Watson 1,989650? omit d_infl_2 d_infl_3 d_infl_4 --quiet Ipotesi nulla: i parametri della regressione valgono zero per le variabili d_infl_2, d_infl_3, d_infl_4 Statistica test: F robusta(3, 147) = 6,42957, p-value 0,
34 Digressione:. Abbiamo usato Inf, non Inf, nell AR. Qual è il motivo? Il modello AR(1) di Inf t 1 è un modello AR(2) di Inf t Inf t = β 0 + β 1 Inf t 1 + u t oppure Inf t Inf t 1 = β 0 + β 1 (Inf t 1 Inf t 2 ) + u t oppure Inf t = Inf t 1 + β 0 + β 1 Inf t 1 β 1 Inf t 2 + u t oppure Inf t = β 0 + (1 + β 1 )Inf t 1 β 1 Inf t 2 + u t. Quindi, perché usare Inf t invece che Inf t?
35 Modello AR(1) per Inf t : Inf t = β 0 + β 1 Inf t 1 + u t Modello AR(2) per Inf t : Inf t = γ 0 + γ 1 Inf t 1 + γ 2 Inf t 2 + v t Quando Y t è fortemente autocorrelato, lo stimatore OLS del coefficiente AR è distorto verso lo zero. Nel caso estremo che il coefficiente AR = 1, Y t non è più stazionario! Le innovazioni u t si accumulano e Y t esplode. Se Y t non è stazionario, tutta la teoria della regressione con cui lavoriamo non vale più. Qui, Inf t è molto autocorrelato, quindi per restare su un terreno favorevole, specifichiamo la regressione in differenze.
36 Regressioni temporali con predittori addizionali e il modello autoregressivo misto (ADL) (SW Par. 12.4) Finora abbiamo considerato modelli di previsione che utilizzano solo i valori passati di Y Ha senso aggiungere altre variabili (X) che potrebbero essere predittori utili di Y, aggiungendosi al valore predittivo dei valori ritardati di Y : Y t =β 0 + β 1 Y t β p Y t p + δ 1 X t δ r X t r + u t Questo è un modello autoregressivo (autoregressive distributed lag, ADL).
37 Esempio: disoccupazione ritardata e inflazione Secondo la "curva di Phillips", se la disoccupazione è sopra il suo valore equilibrio o "naturale", il tasso di inflazione aumenta. Cioè, Inf t dovrebbe essere correlato a valori ritardati del tasso di disoccupazione, con un coefficiente negativo Il tasso di disoccupazione in cui l inflazione non aumenta né diminuisce è spesso chiamato NAIRU (non-accelerating rate of inflation rate of unemployment). Questo rapporto è presente nei dati economici degli Stati Uniti? Questa relazione può essere sfruttata per prevedere l inflazione?
38 La "curva di Phillips" empirica Il NAIRU è il valore di u per cui Inf = 0
39 Esempio: ADL (4,4) per l inflazione Inf t = Inf t Inf t Inf t Inf t 4 (0.47) (0.09) (0.10) (0.08) (0.09) 2.68Unem t Unem t Unem t Unem t 4 (0.44) (0.47) (0.89) (0.89) R 2 = un grande miglioramento rispetto all AR(4), per il quale R 2 = 0.21
40 Esempio: dinf e unem con Gretl? ols d_infl 0 d_infl(-1 to -4) LHUR(-1 to -4) --robust Modello 5: OLS, usando le osservazioni 1962:1-1999:4 (T = 152) Variabile dipendente: d_infl Errori standard robusti rispetto all eteroschedasticita, variante HC1 coefficiente errore std. rapporto t p-value const 1, , ,801 0,0058 *** d_infl_1-0, , ,919 0,0001 *** d_infl_2-0, , ,404 0,0009 *** d_infl_3 0, , ,8538 0,3946 d_infl_4-0, , ,3983 0,6910 LHUR_1-2, , ,681 7,24e-08 *** LHUR_2 3, , ,860 0,0002 *** LHUR_3-1, , ,168 0,2448 LHUR_4 0, , ,1628 0,8709 Media var. dipendente 0, SQM var. dipendente 1, Somma quadr. residui 268,7935 E.S. della regressione 1, R-quadro 0, R-quadro corretto 0, F(8, 143) 7, P-value(F) 7,27e-09 Log-verosimiglianza -259,0034 Criterio di Akaike 536,0069 Criterio di Schwarz 563,2218 Hannan-Quinn 547,0625 rho - 0, Durbin-Watson 2,005690
41 Il test dell ipotesi congiunta che nessuna delle X sia un predittore utile, oltre ai valori ritardati di Y, è chiamato test di causalità di Granger "Causalità " è un termine infelice qui: causalità di Granger si riferisce semplicemente al contenuto predittivo (marginale).
42 Scelta della lunghezza dei ritardi utilizzando i criteri d informazione (SW Par. 14.5) Le stime della regressione per l inflazione viste sopra contengono uno o quattro ritardi dei predittori. Un ritardo potrebbe aver senso, ma perché quattro? Più in generale, quanti ritardi includere all interno di un regressione temporale? In pratica, scegliere l ordine p di un autoregressione richiede di bilanciare il beneficio dell includere più ritardi con il costo della maggiore incertezza della stima. Da una parte, se l ordine di un autoregressione stimata è troppo basso, si ometteranno informazioni potenzialmente importanti. Dall altra, se troppo alto, ci si ritroverà a stimare più coefficienti del necessario.
43 Diversi approcci I tre approcci che vedremo possono essere utilizzati sia per i modelli AR(p) che nelle regressioni temporali con predittori multipli. Nel secondo caso, un trucchetto conveniente è quello di richiedere che tutti i regressori abbiano lo stesso numero di ritardi, cioè che p = q 1 =... = q k. 1) Statistica F. Un approccio per scegliere p è di iniziare con un modello con molti ritardi e implementare una serie di test di ipotesi sul ritardo finale (testing down). Il problema di questo metodo è che produce modelli troppo grandi
44 2) BIC. Un modo per aggirare questo problema è di stimare p minimizzando un "criterio d informazione". Uno di questi criteri d informazione è il BIC (Bayes Information Criterion), detto anche criterio di Schwarz. BIC(p) = ln(ssr(p)/t ) + (p + 1) ln(t )/T dove SSR(p) è la somma dei quadrati dei residui della stima AR(p). SSR(p) decresce (o almeno non cresce) quando si aggiunge un ritardo, il secondo termine dipende dal numero di coefficienti stimati e cresce quando viene aggiunto un ritardo. Si può dimostrare che il numero di ritardi che minimizza il BIC è uno stimatore consistente dell ordine dell autoregressione.
45 Esempio: BIC per l inflazione USA
46 3) AIC. Un alternativa è il criterio di informazione di Akaike, AIC(p) = ln(ssr(p)/t ) + (p + 1)2/T. Nell AIC, il termine ln(t ) del BIC è sostituito da 2. dal punto di vista teorico, il secondo termine nell AIC non è sufficientemente grande da assicurare che sia scelta la corretta lunghezza dei ritardi, nemmeno asintoticamente, quindi lo stimatore AIC di p non è consistente. Nonostante questo, l AIC è ampiamente utilizzato in pratica.
47 Non stazionarietà I: i trend (SW Par. 14.6) Finora abbiamo sempre fatto l ipotesi che tutte le variabili siano stazionarie. Se la variabile dipendente o i regressori sono non stazionari, allora i convenzionali test di ipotesi, gli intervalli di confidenza e le previsioni non sono attendibili. La precisa natura del problema e la soluzione dipendono dalla natura della non stazionarietà. Vedremo due tipi principali di non-stazionarietà : I i trend, stocastico e deterministico (slurp, qui gli econometrici ci vanno a nozze), II le rotture strutturali (accenneremo soltanto).
48 Per trend si intende il movimento persistente di lungo periodo di una variabile nel corso del tempo. Una variabile temporale fluttua attorno al suo trend. Trend deterministico. E una funzione non aleatoria del tempo. Ad esempio, un trend deterministico potrebbe essere lineare nel tempo Trend stocastico. E aleatorio e varia nel corso del tempo. Ad esempio, un trend stocastico nell inflazione potrebbe mostrare un prolungato periodo di aumento seguito da un prolungato periodo di diminuzione. In econometria si considera più appropriato modellare le serie temporali di carattere economico come se avessero un trend stocastico piuttosto che deterministico.
49 La random walk Il modello più semplice di una variabile con un trend stocastico è la passeggiata aleatoria (random walk). Una serie temporale Y t segue una passeggiata aleatoria se la variazione in Y t è iid, cioè se Y t = Y t 1 + u t, dove u t è iid o almeno ha media condizionata nulla, cioè E(u t Y t 1, Y t 2,...) = 0. L idea di base di una passeggiata aleatoria è che il valore di una serie domani sia pari al suo valore oggi più un cambiamento imprevedibile, quindi la miglior previsione del valore domani è il suo valore oggi. Possiamo aggiustare il modello per includere la tendenza della serie a crescere o a diminuire aggiungendo un termine di deriva (drift):. Y t = β 0 + Y t 1 + u t
50 Se Y t segue una random walk, allora è non stazionaria: la varianza della rw aumenta nel corso del tempo, e così cambia la distribuzione di Y t. Poichè la varianza della rw incrementa senza un limite, le sue autocorrelazioni della popolazione non sono definite (prima autocovarianza e varianza sono infinite e il rapporto non è ben definito). Tuttavia, le autocorrelazioni campionarie convergono in probabilità ad uno.
51 Radici unitarie Il modello della passeggiata aleatoria è un caso particolare del modello AR(1) in cui β 1 = 1. Quando invece β 1 < 1 e u t è stazionario, la distribuzione congiunta di Y t e dei suoi ritardi non dipende da t e Y t è stazionario. La condizione analoga affinché un AR(p) sia stazionario è più complicata e coinvolge le radici (gli zeri) del polinomio 1 β 1 z β 2 z 2... β p z p. Se una di queste radici è uguale ad uno, il processo AR(p) non è stazionario, in caso contrario, lo è. Per questo, si parla spesso di "processo con radice unitaria" (unit root process) per indicare le serie con trend stocastico.
52 Problemi causati dalle radici unitarie Le radici unitarie (caso generale della random walk) sono un problema non banale nell analisi delle serie storiche: sono difficili da individuare e se non sono riconosciute portano con sé problemi molto rilevanti: 1. lo stimatore del coefficiente autoregressivo nell AR(1) è distorto verso zero se il suo vero valore è uno; 2. le statistiche t sui regressori con un trend stocastico possono avere distribuzione non normale, anche per grandi campioni; 3. possono dare luogo a regressione spuria.
53 1. Distorsione del coefficiente autoregressivo. Poiché Y + t è non stazionario, non valgono le assunzioni dei minimi quadrati per le regressioni temporali quindi in generale non si può contare sul fatto che gli stimatori e le statistiche test abbiano la loro usuale distribuzione normale per grandi campioni. Qui infatti, lo stimatore di ˆβ 1, è consistente, ma ha una distribuzione non normale, anche per grandi campioni. La distribuzione asintotica di ˆβ1 è traslata verso zero. Il valore atteso di ˆβ1 è approssimativamente E( ˆβ 1 ) = 1 5.3/T.
54 2. Distribuzione non normale della statistica t. Se un regressore ha un trend stocastico, la statistica t degli OLS può avere una distribuzione non normale sotto l ipotesi nulla, anche per grandi campioni. Questo implica che intervalli di confidenza e test non possono essere condotti nel modo usuale. In generale, la distribuzione di questa statistica t non si trova sulle tavole perchè dipende dalla relazione tra il regressore in questione e gli altri regressori.
55 3. Regressione spuria. I trend stocastici possono fare sì che due serie appaiano in relazione quando in realtà non lo sono, un problema chiamato regressione spuria. Ad esempio, l inflazione USA cresce rapidamente dalla metà degli anni 60 fino ad inizio 80, e allo stesso tempo anche il PIL giapponese cresceva velocemente Se stimiamo nel periodo otteniamo ÛSinfl t = JPgdp t. Se stimamo nel periodo ÛSinfl t = JPgdp t. I trend stocastici dominano le regressioni e determinano valori poco informativi dei parametri. In generale, non si usano variabili con radici unitarie nelle regressioni, prendete le differenze!. Esiste un eccezione importante, detta cointegrazione, che però qui non vedremo.
56 Come individuare le radici unitarie E molto importante se le nostre serie contengono una random walk o invece sono stazionarie. Possiamo cominciare con un ispezione del grafico e del correlograma: una serie stazionaria tende a tornare "velocemente" alla media (mean reverting), coefficienti di autocorrelazione bassi sono indice di stazionarietà. Esistono test formali. Il più usato è quello di Dickey-Fuller, di cui vediamo solo degli accenni.
57 Test di Dickey-Fuller Il punto di partenza è il modello autoregressivo. Nel contesto di un modello AR(1), l ipotesi nulla che Y t abbia una radice unitaria si riduce a verificare H 0 : β 1 = 1 vs. H 0 : β 1 < 1 in Y t = β 0 + β 1 Y t 1 + u t. Per ragioni tecniche, riscriviamo l ipotesi in questo modo: H 0 : δ 1 = 0 vs. H 0 : δ 1 < 0 in Y t = δ 0 + δ 1 Y t 1 + u t. La statistica t è calcolata usando la versione non robusta (classica), ed ha una distribuzione non normale, piuttosto complicata. Esistono varianti ed estensioni di questo test, per modelli AR(p) (ADF), per trend, con o senza costante...
58
59 Sommario Per scopi di previsione, non è importante avere coefficienti con una interpretazione causale! Previsioni semplici e affidabili possono essere prodotte usando modelli AR(p) - che sono generalmente previsioni "benchmark" contro le quali possono essere valutati i modelli di previsione più complicati Predittori addizionali possono essere aggiunti: il risultato è il modello autoregressivo misto (ADL) Stazionarietà significa che i modelli possono essere utilizzati al di fuori dell intervallo di dati con cui sono stati stimati L assenza di stazionarietà cambia le regole del gioco in misura sostanziale Ora abbiamo gli strumenti necessari per stimare effetti causali dinamici...
60 Stima di effetti causali dinamici (SW capitolo 15) Un effetto causale dinamico e l effetto su Y di una variazione di X nel tempo. Per esempio: L effetto di un aumento delle tasse sulle sigarette sul consumo di sigarette quest anno, il prossimo anno, in 5 anni; L effetto di una variazione del tasso sui Fed Funds sull inflazione, questo mese, in 6 mesi, in 1 anno; L effetto di una gelata in Florida sul prezzo del succo di arancia concentrato in 1 mese, 2 mesi, 3 mesi...
61 I dati sul succo d arancia (SW par. 15.1) Dati Mensili, gennaio dicembre 2000 (T = 612) Price = prezzo di congelati OJ (un sotto-componente dell indice dei prezzi alla produzione; US Bureau of Labor Statistics) ChgP% = variazione percentuale del prezzo ad un tasso annuo, in modo che %ChgP t = 1200 ln(price t ) FDD = numero di giorni di gelata moltiplicato per gradi Fahrenheit al disotto dello zero centigrado, registrato a Orlando FL Esempio: se novembre ha 2 giornate con bassa temperatura <32 F, uno a 30 F ed uno a 25 F, FDD Nov = = 9
62 Prezzi, variazioni e giorni di gelata
63 Regressione iniziale %ChgP t = FDD t (0.22) (0.13) Relazione positiva statisticamente significativa Più gelate o gelate peggiori, prezzo sale Errori standard: non i soliti - qui sono robusti ad eteroschedasticità ed autocorrelazione (HAC) - di più su questo più tardi Ma qual è l effetto di FDD nel corso del tempo?
64 Effetti causali dinamici SW par 15.2 Esempio: Qual è l effetto del fertilizzante sulla produzione di pomodori? Un esperimento randomizzato controllato ideale Fertilizzare alcuni appezzamenti e non altri (assegnazione casuale) Misurare il rendimento nel tempo - su raccolti ripetuti - per stimare effetto causale del fertilizzante su: il rendimento nel primo anno dell esperimento il rendimento nel secondo anno dell esperimento... Il risultato (in un esperimento grande) è l effetto causale di fertilizzante sul rendimento k anni dopo.
65 Nelle applicazioni con serie storiche, non siamo in grado di condurre un esperimento randomizzato controllato ideale come queste: Abbiamo un solo mercato statunitense del succo d arancia... Non possiamo assegnare casualmente FDD a repliche diverse del mercato del succo d arancia USA (?) Non possiamo misurare il risultato medio (calcolato sulle entità ") in tempi diversi - abbiamo una sola entità Quindi non possiamo stimare l effetto causale in momenti diversi usando lo stimatore delle differenze
66 Idea alternativa di esperimento: Diamo casualmente alle stesse entità trattamenti (FDD t ) diversi in tempi diversi Misuriamo la variabile risultato (%ChgP t ) La popolazione consiste nella stessa entità (mercato succo d arancia USA), ma in tempi diversi Se i soggetti "diversi" sono estratti dalla stessa distribuzione - cioè, se Y t, X t sono stazionarie - allora l effetto causale dinamico può essere dedotto dalle stime OLS della regressione di Y t sui valori ritardati di X t. Questo stimatore (regressione di Y t su X t e ritardi di X t ) è chiamato a ritardi distribuiti (distributed lag estimator).
67 Effetti causali dinamici e modello a ritardi distribuiti Il modello a ritardi distribuiti è : Y t = β 0 + β 1 X t β p X t r + u t β 1 = effetto dell impatto di variazioni di X = Effetto della variazione di X t su Y t, tenendo il passato di X costante β 2 = moltiplicatore dinamico a un periodo = Effetto della variazione di X t 1 su Y t, tenendo costante X t, X t 2, X t 3,... β 3 = moltiplicatore dinamico a tre periodi = Effetto della variazione di X t 2 su Y t, tenendo costante X t, X t 1, X t 3,... Moltiplicatori dinamici cumulativi Esempio: il moltiplicatore dinamico cumulativo a due periodi è β 1 + β 2 + β 3 (ecc.)
68 Esogeneità nelle regressioni temporali Esogeneità (passato e presente) X è esogena, se E(u t X t, X t 1, X t 2,...) = 0. Esogeneità stretta (passato, presente e futuro) X è strettamente esogena, se E(u t..., X t+1, X t, X t 1,...) = 0. L esogeneità stretta implica l esogeneità Per ora supponiamo che X sia esogena - torneremo (brevemente) sul caso di stretta esogeneità più tardi. Se X è esogena, gli OLS stimano l effetto causale dinamico su Y di una variazione in X. In particolare,...
69 Stima degli effetti causali dinamici con regressori esogeni (SW par. 15.3) Y t = β 0 + β 1 X t β r+1 X t r + u t Ipotesi del modello a ritardi distribuiti (distributed lag model) 1. E(u t X t, X t 1, X t 2,...). = 0 (X è esogeno) Y e X hanno distribuzioni stazionarie; 2.2 (Y t, X t )e(y t j, X t j ), diventano indipendenti al crescere di j 3. Y e X hanno otto momenti finiti diversi da zero 4. Non c è perfetta multicollinearità.
70 Le ipotesi 1 e 4 sono familiari L ipotesi 3 è familiare, ad eccezione di 8 (non quattro) momenti finiti - questo ha a che fare con gli stimatori HAC degli SE L ipotesi 2 è diversa - prima richiedeva che (X i e Y i ) fossero iid - ora diventa più complicata. 2.1 Y e X hanno distribuzioni stazionarie; Se e così, i coefficienti non cambiano all interno del campione (validità interna); ed i risultati possono essere estrapolati fuori del campione (validità esterna). Questo è il momento della serie controparte della parte "identicamente distribuite" di IID
71 2.2 (Y t, X t ) e (Y t j, X t j ) diventano indipendenti al crescere di j Intuitivamente, questo dice che abbiamo esperimenti separati per periodi di tempo che sono ampiamente separati Con i dati sezionali, abbiamo ipotizzato che Y e X fossero i.i.d., una conseguenza del campionamento casuale semplice - questo consentiva di usare un teorema del limite centrale (CLT). Una versione del CLT vale per variabili in serie storica che diventano indipendenti man mano che aumenta la loro separazione temporale - l ipotesi 2.2 è che la controparte in serie storica dell ipotesi di distribuzione i.i.d.
72 Sotto le ipotesi del modello a ritardi distribuiti: L OLS produce stimatori consistenti di β 1, β 2,..., β r (i moltiplicatori dinamici) La distribuzione campionaria dei β i è normale Tuttavia, la formula per la varianza di questa distribuzione campionaria non è la solita dai dati sezionali (i.i.d.), poiché u t non è i.i.d. ma è serialmente correlato. Questo significa che i soliti errori standard sono sbagliati Dobbiamo usare, invece, SE che sono robusti sia all autocorrelazione che all eteroschedasticità...
73 SE consistenti ad autocorrelazione ed eteroschedasticità (HAC) (SW Par 15.4) Quando u t è serialmente correlato, la varianza della distribuzione campionaria dello stimatore OLS è differente. Di conseguenza, abbiamo bisogno di usare una formula diversa per gli errori standard. Questo è facile da fare utilizzando Gretl e la maggior parte (ma non tutti) degli altri software statistici.
74 La matematica... Consideriamo il caso senza ritardi: Y t = β 0 + β 1 X t + u t Ricordiamo che che lo stimatore OLS è : quindi... β 1 = 1 T T t 1 (X t X)(Y t Ȳ ) T t 1 (X t X) 2 1 T
75 β 1 β 1 = 1 T T t 1 (X t X)u t T t 1 (X t X) vedi SW Appendice T 1 T T t 1 v t σ 2 X in grandi campioni dove v t = (X t X)u t. Quindi, in grandi campioni var( β 1 ) = var( 1 T T i 1 v t ) (σ 2 X )2
76 Che cosa succede con i dati di serie storiche? Consideriamo T = 2: var(1/t 2 v t ) = var[1/2(v 1 + v 2 )] i 1 = 1/4[var(v 1 ) + var(v 2 ) + 2cov(v 1, v 2 )] = 1/2σv 2 + 1/2ρ 1 σv, 2 (ρ 1 = corr(v 1, v 2 )) = 1/2σvf 2 2, dove f 2 = (1 + ρ 1 ) In dati i.i.d. (cross-section), ρ 1 = 0, quindi f 2 = 1, il che da la solita formula per var( β) Nei dati in serie storica, ρ 1 0 quindi var( β) non è data dalla formula che conosciamo Gli standard error convenzionali degli OLS sono sbagliati quando u t è autocorrelata
77 Espressione della varianza di β per T generico quindi var(1/t var( β 1 ) = T t=1 [ 1 T v i ) = σ2 v T f T σ 2 v (σ 2 X )2 ] f T dove f T = T 1 j=1 ( T j T ) ρ j. Gli errori standard degli OLS sono sbagliati per un fattore f T (che puo essere grande!).
78 Errori standard HAC In presenza di autocorrelazione, gli SE convenzionali OLS (anche quelli robusti all eteroschedasticità ) sono sbagliati. Quindi, abbiamo bisogno di una nuova formula che produca degli SE che siano robusti sia all eteroschedasticità, sia all autocorrelazione. Abbiamo bisogno di errori standard Heteroskedasticy and Autocorrelation Consistent (HAC) Se conoscessimo il fattore f T potremmo fare l aggiustamento. Ma figuriamoci se conosciamo il fattore f T... Dipende da autocorrelazioni sconosciute. Gli errori standard HAC rimpiazzano f T con una sua stima.
79 var β 1 = [ 1 T σ 2 v (σ 2 X )2 ] f T dove f T = T 1 j=1 ( T j T ) ρ j Lo stimatore più comunemente usato di f T è : m 1 f T = j=1 ( m j m ) ρ j ft sono pesi detti a volte di "Newey-West" ρ j è uno stimatore di ρ j m e detto parametro di troncamento Che parametro di troncamento usare in pratica? Buon senso... Si può provare m = 0.75T 1/3
80 Una dubbio amletico Dobbiamo usare gli standard error HAC quando stimiamo un AR o un modello ADL? NO. Il problema di cui gli SE HAC sono la soluzione sorge quando u t è serialmente correlato Se gli u t sono serialmente incorrelati, gli SE OLS vanno bene Nei modelli AR e ADL, gli errori sono serialmente incorrelati se abbiamo inserito abbastanza ritardi della Y Se si include un numero sufficiente ritardi di Y, allora il termine di errore non può essere previsto con Y passato, o equivalentemente da u passato - quindi gli u t sono serialmente incorrelati
81 Stima degli effetti causali dinamici con regressori strettamente esogeni (SW Par. 15.5) X è strettamente esogena se E(u t..., X t+1, X t, X t 1,...) = 0 Se X è strettamente esogena, ci sono modi più efficaci per stimare gli effetti causali dinamici che con una regressione con ritardi distribuiti. Minimi quadradi generalizzati (GLS) Ritardi distribuiti autoregressivi (ADL) Ma la condizione di stretta esogeneità è molto forte, per cui questa condizione è raramente plausibile in pratica. Quindi non ci occuperemo di stima GLS o ADL di effetti causali dinamici (paragrafo 15.5 è facoltativo)
82 Analisi dei dati sul prezzo del succo d arancia (SW Par 15.6) Qual è l effetto causale dinamico (quali sono i moltiplicatori dinamici) di un aumento unitario di FDD sui prezzi del succo d arancia? %ChgP t = β 0 + β 1 FDD t β r+1 FDD t r + u t Che r da usare? Proviamo 18? (Meglio stare un po alti e scendere) Che m (parametro di troncamento di Newey-West) usare? Proviamo m = /3 = 6, 4 7.
83
84
85
86
87 Questi moltiplicatori dinamici sono state stati stimati utilizzando un modello a ritardi distribuiti. Dovremmo tentare di ottenere stime più efficienti utilizzando un modello GLS o un modello ADL? FDD è strettamente esogena nella regressione a ritardi distribuiti? %ChgP t = β 0 + β 1 FDD t β r+1 FDD t r + u t I trader di commodity sul succo d arancia non possono cambiare il tempo. Quindi questo significa che corr(u t, FDD t+1 ) = 0, giusto?
88 Quando è possibile stimare gli effetti dinamici causali? Cioè, quando è plausibile l esogeneità? (SW Par. 15.7) Nei seguenti esempi, X è esogena? X è strettamente esogena? Esempi: 1. Y = prezzi succo d arancia, X = FDD a Orlando 2. Y = esportazioni della UE, X = PIL USA (effetto del reddito negli USA sulla domanda di esportazioni UE) 3. Y = tasso di inflazione negli USA, X = variazione percentuale dei prezzi mondiali del petrolio (stabilito dall OPEC) (effetto delle decisioni OPEC sull inflazione) 4. Y = crescita del PIL, X = tasso sui fed funds (effetto della politica monetaria sulla crescita del PIL) 5. Y = variazione del tasso di inflazione, X = tasso di disoccupazione (curva di Phillips)
89 Esogeneità E necessario valutare esogeneità e esogeneità stretta caso per caso. L esogeneità spesso non è plausibile in dati in serie storica a causa di causalità simultanea. L esogeneità stretta è raramente plausibile in dati in serie storica a causa dei feedback.
90 Stima degli effetti causali dinamici: Riassunto (SW Par. 15.8) Gli effetti causali dinamici sono misurabili in teoria con un esperimento randomizzato controllato con misure ripetute nel tempo. Quando X è esogena, è possibile stimare gli effetti causali dinamici utilizzando una regressione con ritardi distribuiti Se u è serialmente correlato, gli standard error OLS convenzionali non sono corretti, è necessario utilizzare la versione HAC. Non esiste una procedura automatica per decidere se X è esogeno. Bisogna riflettere!
lezione 18 AA 2015-2016 Paolo Brunori
 AA 2015-2016 Paolo Brunori Previsioni - spesso come economisti siamo interessati a prevedere quale sarà il valore di una certa variabile nel futuro - quando osserviamo una variabile nel tempo possiamo
AA 2015-2016 Paolo Brunori Previsioni - spesso come economisti siamo interessati a prevedere quale sarà il valore di una certa variabile nel futuro - quando osserviamo una variabile nel tempo possiamo
Analisi statistica delle funzioni di produzione
 Analisi statistica delle funzioni di produzione Matteo Pelagatti marzo 28 Indice La funzione di produzione di Cobb-Douglas 2 2 Analisi empirica della funzione di produzione aggregata 3 Sommario Con la
Analisi statistica delle funzioni di produzione Matteo Pelagatti marzo 28 Indice La funzione di produzione di Cobb-Douglas 2 2 Analisi empirica della funzione di produzione aggregata 3 Sommario Con la
E naturale chiedersi alcune cose sulla media campionaria x n
 Supponiamo che un fabbricante stia introducendo un nuovo tipo di batteria per un automobile elettrica. La durata osservata x i delle i-esima batteria è la realizzazione (valore assunto) di una variabile
Supponiamo che un fabbricante stia introducendo un nuovo tipo di batteria per un automobile elettrica. La durata osservata x i delle i-esima batteria è la realizzazione (valore assunto) di una variabile
CORSO DI STATISTICA (parte 2) - ESERCITAZIONE 8
 - ESERCITAZIONE 8") CORSO DI STATISTICA (parte 2) - ESERCITAZIONE 8 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Test delle ipotesi sulla varianza In un azienda che produce componenti meccaniche, è stato
CORSO DI STATISTICA (parte 2) - ESERCITAZIONE 8 Dott.ssa Antonella Costanzo a.costanzo@unicas.it Esercizio 1. Test delle ipotesi sulla varianza In un azienda che produce componenti meccaniche, è stato
Verifica di ipotesi e intervalli di confidenza nella regressione multipla
 Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Verifica di ipotesi e intervalli di confidenza nella regressione multipla Eduardo Rossi 2 2 Università di Pavia (Italy) Maggio 2014 Rossi MRLM Econometria - 2014 1 / 23 Sommario Variabili di controllo
Lineamenti di econometria 2
 Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) Aspetti Statistici della Regressione Aspetti Statistici della Regressione
Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) Aspetti Statistici della Regressione Aspetti Statistici della Regressione
Regressione Mario Guarracino Data Mining a.a. 2010/2011
 Regressione Esempio Un azienda manifatturiera vuole analizzare il legame che intercorre tra il volume produttivo X per uno dei propri stabilimenti e il corrispondente costo mensile Y di produzione. Volume
Regressione Esempio Un azienda manifatturiera vuole analizzare il legame che intercorre tra il volume produttivo X per uno dei propri stabilimenti e il corrispondente costo mensile Y di produzione. Volume
LEZIONE n. 5 (a cura di Antonio Di Marco)
") LEZIONE n. 5 (a cura di Antonio Di Marco) IL P-VALUE (α) Data un ipotesi nulla (H 0 ), questa la si può accettare o rifiutare in base al valore del p- value. In genere il suo valore è un numero molto piccolo,
LEZIONE n. 5 (a cura di Antonio Di Marco) IL P-VALUE (α) Data un ipotesi nulla (H 0 ), questa la si può accettare o rifiutare in base al valore del p- value. In genere il suo valore è un numero molto piccolo,
Analisi di scenario File Nr. 10
 1 Analisi di scenario File Nr. 10 Giorgio Calcagnini Università di Urbino Dip. Economia, Società, Politica giorgio.calcagnini@uniurb.it http://www.econ.uniurb.it/calcagnini/ http://www.econ.uniurb.it/calcagnini/forecasting.html
1 Analisi di scenario File Nr. 10 Giorgio Calcagnini Università di Urbino Dip. Economia, Società, Politica giorgio.calcagnini@uniurb.it http://www.econ.uniurb.it/calcagnini/ http://www.econ.uniurb.it/calcagnini/forecasting.html
Esercitazione n.2 Inferenza su medie
 Esercitazione n.2 Esercizio L ufficio del personale di una grande società intende stimare le spese mediche familiari dei suoi impiegati per valutare la possibilità di attuare un programma di assicurazione
Esercitazione n.2 Esercizio L ufficio del personale di una grande società intende stimare le spese mediche familiari dei suoi impiegati per valutare la possibilità di attuare un programma di assicurazione
1. Distribuzioni campionarie
 Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
Università degli Studi di Basilicata Facoltà di Economia Corso di Laurea in Economia Aziendale - a.a. 2012/2013 lezioni di statistica del 3 e 6 giugno 2013 - di Massimo Cristallo - 1. Distribuzioni campionarie
1 Serie di Taylor di una funzione
 Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
Analisi Matematica 2 CORSO DI STUDI IN SMID CORSO DI ANALISI MATEMATICA 2 CAPITOLO 7 SERIE E POLINOMI DI TAYLOR Serie di Taylor di una funzione. Definizione di serie di Taylor Sia f(x) una funzione definita
1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:
 Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario:") Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
Esempi di domande risposta multipla (Modulo II) 1) Si consideri un esperimento che consiste nel lancio di 5 dadi. Lo spazio campionario: 1) ha un numero di elementi pari a 5; 2) ha un numero di elementi
Statistiche campionarie
 Statistiche campionarie Sul campione si possono calcolare le statistiche campionarie (come media campionaria, mediana campionaria, varianza campionaria,.) Le statistiche campionarie sono stimatori delle
Statistiche campionarie Sul campione si possono calcolare le statistiche campionarie (come media campionaria, mediana campionaria, varianza campionaria,.) Le statistiche campionarie sono stimatori delle
Analisi bivariata. Dott. Cazzaniga Paolo. Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it
 Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione : analisi delle relazioni tra due caratteristiche osservate sulle stesse unità statistiche studio del comportamento di due caratteri
Dip. di Scienze Umane e Sociali paolo.cazzaniga@unibg.it Introduzione : analisi delle relazioni tra due caratteristiche osservate sulle stesse unità statistiche studio del comportamento di due caratteri
Matematica generale CTF
 Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Successioni numeriche 19 agosto 2015 Definizione di successione Monotonìa e limitatezza Forme indeterminate Successioni infinitesime Comportamento asintotico Criterio del rapporto per le successioni Definizione
Inferenza statistica. Statistica medica 1
 Inferenza statistica L inferenza statistica è un insieme di metodi con cui si cerca di trarre una conclusione sulla popolazione sulla base di alcune informazioni ricavate da un campione estratto da quella
Inferenza statistica L inferenza statistica è un insieme di metodi con cui si cerca di trarre una conclusione sulla popolazione sulla base di alcune informazioni ricavate da un campione estratto da quella
Applicazione alla domanda di sigarette (SW Par 12.4)
") Applicazione alla domanda di sigarette (SW Par 12.4) Perche ci interessa conoscere l elastica della domanda di sigarette? Teoria della tassazione ottimale: l imposta ottimale e l inverso dell elastica
Applicazione alla domanda di sigarette (SW Par 12.4) Perche ci interessa conoscere l elastica della domanda di sigarette? Teoria della tassazione ottimale: l imposta ottimale e l inverso dell elastica
Macroeconomia, Esercitazione 2. 1 Esercizi. 1.1 Moneta/1. 1.2 Moneta/2. 1.3 Moneta/3. A cura di Giuseppe Gori (giuseppe.gori@unibo.
 acroeconomia, Esercitazione 2. A cura di Giuseppe Gori (giuseppe.gori@unibo.it) 1 Esercizi. 1.1 oneta/1 Sapendo che il PIL reale nel 2008 è pari a 50.000 euro e nel 2009 a 60.000 euro, che dal 2008 al
acroeconomia, Esercitazione 2. A cura di Giuseppe Gori (giuseppe.gori@unibo.it) 1 Esercizi. 1.1 oneta/1 Sapendo che il PIL reale nel 2008 è pari a 50.000 euro e nel 2009 a 60.000 euro, che dal 2008 al
Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B. Evento prodotto: Evento in cui si verifica sia A che B ; p(a&b) = p(a) x p(b/a)
 che avvenga A, una volta accaduto B. Evento prodotto: Evento in cui si verifica sia A che B ; p(a&b) = p(a) x p(b/a)") Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B Eventi indipendenti: un evento non influenza l altro Eventi disgiunti: il verificarsi di un evento esclude l altro Evento prodotto:
Probabilità condizionata: p(a/b) che avvenga A, una volta accaduto B Eventi indipendenti: un evento non influenza l altro Eventi disgiunti: il verificarsi di un evento esclude l altro Evento prodotto:
Test statistici di verifica di ipotesi
 Test e verifica di ipotesi Test e verifica di ipotesi Il test delle ipotesi consente di verificare se, e quanto, una determinata ipotesi (di carattere biologico, medico, economico,...) è supportata dall
Test e verifica di ipotesi Test e verifica di ipotesi Il test delle ipotesi consente di verificare se, e quanto, una determinata ipotesi (di carattere biologico, medico, economico,...) è supportata dall
Università di Firenze - Corso di laurea in Statistica Seconda prova intermedia di Statistica. 18 dicembre 2008
 Università di Firenze - Corso di laurea in Statistica Seconda prova intermedia di Statistica 18 dicembre 008 Esame sull intero programma: esercizi da A a D Esame sulla seconda parte del programma: esercizi
Università di Firenze - Corso di laurea in Statistica Seconda prova intermedia di Statistica 18 dicembre 008 Esame sull intero programma: esercizi da A a D Esame sulla seconda parte del programma: esercizi
2. Leggi finanziarie di capitalizzazione
 2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
2. Leggi finanziarie di capitalizzazione Si chiama legge finanziaria di capitalizzazione una funzione atta a definire il montante M(t accumulato al tempo generico t da un capitale C: M(t = F(C, t C t M
Capitolo 13: L offerta dell impresa e il surplus del produttore
 Capitolo 13: L offerta dell impresa e il surplus del produttore 13.1: Introduzione L analisi dei due capitoli precedenti ha fornito tutti i concetti necessari per affrontare l argomento di questo capitolo:
Capitolo 13: L offerta dell impresa e il surplus del produttore 13.1: Introduzione L analisi dei due capitoli precedenti ha fornito tutti i concetti necessari per affrontare l argomento di questo capitolo:
Test d ipotesi. Statistica e biometria. D. Bertacchi. Test d ipotesi
 In molte situazioni una raccolta di dati (=esiti di esperimenti aleatori) viene fatta per prendere delle decisioni sulla base di quei dati. Ad esempio sperimentazioni su un nuovo farmaco per decidere se
In molte situazioni una raccolta di dati (=esiti di esperimenti aleatori) viene fatta per prendere delle decisioni sulla base di quei dati. Ad esempio sperimentazioni su un nuovo farmaco per decidere se
La distribuzione Normale. La distribuzione Normale
 La Distribuzione Normale o Gaussiana è la distribuzione più importante ed utilizzata in tutta la statistica La curva delle frequenze della distribuzione Normale ha una forma caratteristica, simile ad una
La Distribuzione Normale o Gaussiana è la distribuzione più importante ed utilizzata in tutta la statistica La curva delle frequenze della distribuzione Normale ha una forma caratteristica, simile ad una
Inflazione e Produzione. In questa lezione cercheremo di rispondere a domande come queste:
 Inflazione e Produzione In questa lezione cercheremo di rispondere a domande come queste: Da cosa è determinata l Inflazione? Perché le autorità monetarie tendono a combatterla? Attraverso quali canali
Inflazione e Produzione In questa lezione cercheremo di rispondere a domande come queste: Da cosa è determinata l Inflazione? Perché le autorità monetarie tendono a combatterla? Attraverso quali canali
Slide Cerbara parte1 5. Le distribuzioni teoriche
 Slide Cerbara parte1 5 Le distribuzioni teoriche I fenomeni biologici, demografici, sociali ed economici, che sono il principale oggetto della statistica, non sono retti da leggi matematiche. Però dalle
Slide Cerbara parte1 5 Le distribuzioni teoriche I fenomeni biologici, demografici, sociali ed economici, che sono il principale oggetto della statistica, non sono retti da leggi matematiche. Però dalle
PIL : produzione e reddito
 PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
PIL : produzione e reddito La misura della produzione aggregata nella contabilità nazionale è il prodotto interno lordo o PIL. Dal lato della produzione : oppure 1) Il PIL è il valore dei beni e dei servizi
Inferenza statistica I Alcuni esercizi. Stefano Tonellato
 Inferenza statistica I Alcuni esercizi Stefano Tonellato Anno Accademico 2006-2007 Avvertenza Una parte del materiale è stato tratto da Grigoletto M. e Ventura L. (1998). Statistica per le scienze economiche,
Inferenza statistica I Alcuni esercizi Stefano Tonellato Anno Accademico 2006-2007 Avvertenza Una parte del materiale è stato tratto da Grigoletto M. e Ventura L. (1998). Statistica per le scienze economiche,
Temi di Esame a.a. 2012-2013. Statistica - CLEF
 Temi di Esame a.a. 2012-2013 Statistica - CLEF I Prova Parziale di Statistica (CLEF) 11 aprile 2013 Esercizio 1 Un computer è collegato a due stampanti, A e B. La stampante A è difettosa ed il 25% dei
Temi di Esame a.a. 2012-2013 Statistica - CLEF I Prova Parziale di Statistica (CLEF) 11 aprile 2013 Esercizio 1 Un computer è collegato a due stampanti, A e B. La stampante A è difettosa ed il 25% dei
LE SUCCESSIONI 1. COS E UNA SUCCESSIONE
 LE SUCCESSIONI 1. COS E UNA SUCCESSIONE La sequenza costituisce un esempio di SUCCESSIONE. Ecco un altro esempio di successione: Una successione è dunque una sequenza infinita di numeri reali (ma potrebbe
LE SUCCESSIONI 1. COS E UNA SUCCESSIONE La sequenza costituisce un esempio di SUCCESSIONE. Ecco un altro esempio di successione: Una successione è dunque una sequenza infinita di numeri reali (ma potrebbe
Capitolo 12 La regressione lineare semplice
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 12 La regressione lineare semplice Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara
Introduzione alle relazioni multivariate. Introduzione alle relazioni multivariate
 Introduzione alle relazioni multivariate Associazione e causalità Associazione e causalità Nell analisi dei dati notevole importanza è rivestita dalle relazioni causali tra variabili Date due variabili
Introduzione alle relazioni multivariate Associazione e causalità Associazione e causalità Nell analisi dei dati notevole importanza è rivestita dalle relazioni causali tra variabili Date due variabili
Teoria delle code. Sistemi stazionari: M/M/1 M/M/1/K M/M/S
 Teoria delle code Sistemi stazionari: M/M/1 M/M/1/K M/M/S Fabio Giammarinaro 04/03/2008 Sommario INTRODUZIONE... 3 Formule generali di e... 3 Leggi di Little... 3 Cosa cerchiamo... 3 Legame tra N e le
Teoria delle code Sistemi stazionari: M/M/1 M/M/1/K M/M/S Fabio Giammarinaro 04/03/2008 Sommario INTRODUZIONE... 3 Formule generali di e... 3 Leggi di Little... 3 Cosa cerchiamo... 3 Legame tra N e le
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 29-Analisi della potenza statistica vers. 1.0 (12 dicembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Elementi di Psicometria con Laboratorio di SPSS 1 29-Analisi della potenza statistica vers. 1.0 (12 dicembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Istituzioni di Statistica e Statistica Economica
 Istituzioni di Statistica e Statistica Economica Università degli Studi di Perugia Facoltà di Economia, Assisi, a.a. 2013/14 Esercitazione n. 4 A. Si supponga che la durata in giorni delle lampadine prodotte
Istituzioni di Statistica e Statistica Economica Università degli Studi di Perugia Facoltà di Economia, Assisi, a.a. 2013/14 Esercitazione n. 4 A. Si supponga che la durata in giorni delle lampadine prodotte
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 5-Indici di variabilità (vers. 1.0c, 20 ottobre 2015) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Elementi di Psicometria con Laboratorio di SPSS 1 5-Indici di variabilità (vers. 1.0c, 20 ottobre 2015) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Elementi di Psicometria con Laboratorio di SPSS 1
 Elementi di Psicometria con Laboratorio di SPSS 1 12-Il t-test per campioni appaiati vers. 1.2 (7 novembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
Elementi di Psicometria con Laboratorio di SPSS 1 12-Il t-test per campioni appaiati vers. 1.2 (7 novembre 2014) Germano Rossi 1 germano.rossi@unimib.it 1 Dipartimento di Psicologia, Università di Milano-Bicocca
3. Confronto tra medie di due campioni indipendenti o appaiati
 BIOSTATISTICA 3. Confronto tra medie di due campioni indipendenti o appaiati Marta Blangiardo, Imperial College, London Department of Epidemiology and Public Health m.blangiardo@imperial.ac.uk MARTA BLANGIARDO
BIOSTATISTICA 3. Confronto tra medie di due campioni indipendenti o appaiati Marta Blangiardo, Imperial College, London Department of Epidemiology and Public Health m.blangiardo@imperial.ac.uk MARTA BLANGIARDO
Lineamenti di econometria 2
 Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) La Regressione Multipla La Regressione Multipla La regressione multipla
Lineamenti di econometria 2 Camilla Mastromarco Università di Lecce Master II Livello "Analisi dei Mercati e Sviluppo Locale" (PIT 9.4) La Regressione Multipla La Regressione Multipla La regressione multipla
Esercizio 1. Verifica di ipotesi sulla media (varianza nota), p-value del test
, p-value del test") STATISTICA (2) ESERCITAZIONE 6 05.03.2014 Dott.ssa Antonella Costanzo Esercizio 1. Verifica di ipotesi sulla media (varianza nota), p-value del test Il preside della scuola elementare XYZ sospetta che
STATISTICA (2) ESERCITAZIONE 6 05.03.2014 Dott.ssa Antonella Costanzo Esercizio 1. Verifica di ipotesi sulla media (varianza nota), p-value del test Il preside della scuola elementare XYZ sospetta che
Statistica. Lezione 6
 Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
Università degli Studi del Piemonte Orientale Corso di Laurea in Infermieristica Corso integrato in Scienze della Prevenzione e dei Servizi sanitari Statistica Lezione 6 a.a 011-01 Dott.ssa Daniela Ferrante
VARIANZA CAMPIONARIA E DEVIAZIONE STANDARD. Si definisce scarto quadratico medio o deviazione standard la radice quadrata della varianza.
 VARIANZA CAMPIONARIA E DEVIAZIONE STANDARD Si definisce varianza campionaria l indice s 2 = 1 (x i x) 2 = 1 ( xi 2 n x 2) Si definisce scarto quadratico medio o deviazione standard la radice quadrata della
VARIANZA CAMPIONARIA E DEVIAZIONE STANDARD Si definisce varianza campionaria l indice s 2 = 1 (x i x) 2 = 1 ( xi 2 n x 2) Si definisce scarto quadratico medio o deviazione standard la radice quadrata della
CAPITOLO 8 LA VERIFICA D IPOTESI. I FONDAMENTI
 VERO FALSO CAPITOLO 8 LA VERIFICA D IPOTESI. I FONDAMENTI 1. V F Un ipotesi statistica è un assunzione sulle caratteristiche di una o più variabili in una o più popolazioni 2. V F L ipotesi nulla unita
VERO FALSO CAPITOLO 8 LA VERIFICA D IPOTESI. I FONDAMENTI 1. V F Un ipotesi statistica è un assunzione sulle caratteristiche di una o più variabili in una o più popolazioni 2. V F L ipotesi nulla unita
Esercizi test ipotesi. Prof. Raffaella Folgieri Email: folgieri@mtcube.com aa 2009/2010
 Esercizi test ipotesi Prof. Raffaella Folgieri Email: folgieri@mtcube.com aa 2009/2010 Verifica delle ipotesi - Esempio quelli di Striscia la Notizia" effettuano controlli casuali per vedere se le pompe
Esercizi test ipotesi Prof. Raffaella Folgieri Email: folgieri@mtcube.com aa 2009/2010 Verifica delle ipotesi - Esempio quelli di Striscia la Notizia" effettuano controlli casuali per vedere se le pompe
f(x) = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da
 = 1 x. Il dominio di questa funzione è il sottoinsieme proprio di R dato da") Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
Data una funzione reale f di variabile reale x, definita su un sottoinsieme proprio D f di R (con questo voglio dire che il dominio di f è un sottoinsieme di R che non coincide con tutto R), ci si chiede
Esercitazione #5 di Statistica. Test ed Intervalli di Confidenza (per una popolazione)
") Esercitazione #5 di Statistica Test ed Intervalli di Confidenza (per una popolazione) Dicembre 00 1 Esercizi 1.1 Test su media (con varianza nota) Esercizio n. 1 Il calore (in calorie per grammo) emesso
Esercitazione #5 di Statistica Test ed Intervalli di Confidenza (per una popolazione) Dicembre 00 1 Esercizi 1.1 Test su media (con varianza nota) Esercizio n. 1 Il calore (in calorie per grammo) emesso
Scelta intertemporale: Consumo vs. risparmio
 Scelta intertemporale: Consumo vs. risparmio Fino a questo punto abbiamo considerato solo modelli statici, cioè modelli che non hanno una dimensione temporale. In realtà i consumatori devono scegliere
Scelta intertemporale: Consumo vs. risparmio Fino a questo punto abbiamo considerato solo modelli statici, cioè modelli che non hanno una dimensione temporale. In realtà i consumatori devono scegliere
Domande a scelta multipla 1
 Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Domande a scelta multipla Domande a scelta multipla 1 Rispondete alle domande seguenti, scegliendo tra le alternative proposte. Cercate di consultare i suggerimenti solo in caso di difficoltà. Dopo l elenco
Il mercato dei beni in economia aperta
 Il mercato dei beni in economia aperta La differenza tra economia aperta e chiusa In una economia chiusa tutta la produzione viene venduta entro i confini nazionali, la domanda nazionale di beni (la spesa
Il mercato dei beni in economia aperta La differenza tra economia aperta e chiusa In una economia chiusa tutta la produzione viene venduta entro i confini nazionali, la domanda nazionale di beni (la spesa
Metodi statistici per l economia (Prof. Capitanio) Slide n. 9. Materiale di supporto per le lezioni. Non sostituisce il libro di testo
 Slide n. 9. Materiale di supporto per le lezioni. Non sostituisce il libro di testo") Metodi statistici per l economia (Prof. Capitanio) Slide n. 9 Materiale di supporto per le lezioni. Non sostituisce il libro di testo 1 TEST D IPOTESI Partiamo da un esempio presente sul libro di testo.
Metodi statistici per l economia (Prof. Capitanio) Slide n. 9 Materiale di supporto per le lezioni. Non sostituisce il libro di testo 1 TEST D IPOTESI Partiamo da un esempio presente sul libro di testo.
La regressione lineare applicata a dati economici
 La regressione lineare applicata a dati economici Matteo Pelagatti 7 febbraio 2008 Indice 1 Il modello lineare 2 2 La stima dei coefficienti e le ipotesi classiche 2 3 Le conseguenze del venir meno di
La regressione lineare applicata a dati economici Matteo Pelagatti 7 febbraio 2008 Indice 1 Il modello lineare 2 2 La stima dei coefficienti e le ipotesi classiche 2 3 Le conseguenze del venir meno di
Le Serie Storiche e l Analisi del Ciclo Economico
 Le Serie Storiche e l Analisi del Ciclo Economico Dr. Giuseppe Rose (PhD. MSc. London) Università degli Studi della Calabria Macroeconomia Applicata Prof.ssa Patrizia Ordine (Ph.D. MPhil. Oxford) a.a.
Le Serie Storiche e l Analisi del Ciclo Economico Dr. Giuseppe Rose (PhD. MSc. London) Università degli Studi della Calabria Macroeconomia Applicata Prof.ssa Patrizia Ordine (Ph.D. MPhil. Oxford) a.a.
Capitolo 4 Probabilità
 Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 4 Probabilità Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara Docenti: Dott.
Levine, Krehbiel, Berenson Statistica II ed. 2006 Apogeo Capitolo 4 Probabilità Insegnamento: Statistica Corso di Laurea Triennale in Economia Facoltà di Economia, Università di Ferrara Docenti: Dott.
Moneta e Tasso di cambio
 Moneta e Tasso di cambio Come si forma il tasso di cambio? Determinanti del tasso di cambio nel breve periodo Determinanti del tasso di cambio nel lungo periodo Che cos è la moneta? Il controllo dell offerta
Moneta e Tasso di cambio Come si forma il tasso di cambio? Determinanti del tasso di cambio nel breve periodo Determinanti del tasso di cambio nel lungo periodo Che cos è la moneta? Il controllo dell offerta
Analisi di dati di frequenza
 Analisi di dati di frequenza Fase di raccolta dei dati Fase di memorizzazione dei dati in un foglio elettronico 0 1 1 1 Frequenze attese uguali Si assuma che dalle risposte al questionario sullo stato
Analisi di dati di frequenza Fase di raccolta dei dati Fase di memorizzazione dei dati in un foglio elettronico 0 1 1 1 Frequenze attese uguali Si assuma che dalle risposte al questionario sullo stato
Capitolo 26. Stabilizzare l economia: il ruolo della banca centrale. Principi di economia (seconda edizione) Robert H. Frank, Ben S.
 Robert H. Frank, Ben S.") Capitolo 26 Stabilizzare l economia: il ruolo della banca centrale In questa lezione Banca centrale Europea (BCE) e tassi di interesse: M D e sue determinanti; M S ed equilibrio del mercato monetario;
Capitolo 26 Stabilizzare l economia: il ruolo della banca centrale In questa lezione Banca centrale Europea (BCE) e tassi di interesse: M D e sue determinanti; M S ed equilibrio del mercato monetario;
Capitolo 4: Ottimizzazione non lineare non vincolata parte II. E. Amaldi DEIB, Politecnico di Milano
 Capitolo 4: Ottimizzazione non lineare non vincolata parte II E. Amaldi DEIB, Politecnico di Milano 4.3 Algoritmi iterativi e convergenza Programma non lineare (PNL): min f(x) s.v. g i (x) 0 1 i m x S
Capitolo 4: Ottimizzazione non lineare non vincolata parte II E. Amaldi DEIB, Politecnico di Milano 4.3 Algoritmi iterativi e convergenza Programma non lineare (PNL): min f(x) s.v. g i (x) 0 1 i m x S
Corso di Psicometria Progredito
 Corso di Psicometria Progredito 3.1 Introduzione all inferenza statistica Prima Parte Gianmarco Altoè Dipartimento di Pedagogia, Psicologia e Filosofia Università di Cagliari, Anno Accademico 2013-2014
Corso di Psicometria Progredito 3.1 Introduzione all inferenza statistica Prima Parte Gianmarco Altoè Dipartimento di Pedagogia, Psicologia e Filosofia Università di Cagliari, Anno Accademico 2013-2014
LE FUNZIONI A DUE VARIABILI
 Capitolo I LE FUNZIONI A DUE VARIABILI In questo primo capitolo introduciamo alcune definizioni di base delle funzioni reali a due variabili reali. Nel seguito R denoterà l insieme dei numeri reali mentre
Capitolo I LE FUNZIONI A DUE VARIABILI In questo primo capitolo introduciamo alcune definizioni di base delle funzioni reali a due variabili reali. Nel seguito R denoterà l insieme dei numeri reali mentre
EQUAZIONI DIFFERENZIALI. 1. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x 2 log t (d) x = e t x log x (e) y = y2 5y+6
 x = x 2 log t (d) x = e t x log x (e) y = y2 5y+6") EQUAZIONI DIFFERENZIALI.. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x log t (d) x = e t x log x (e) y = y 5y+6 (f) y = ty +t t +y (g) y = y (h) xy = y (i) y y y = 0 (j) x = x (k)
EQUAZIONI DIFFERENZIALI.. Trovare tutte le soluzioni delle equazioni differenziali: (a) x = x log t (d) x = e t x log x (e) y = y 5y+6 (f) y = ty +t t +y (g) y = y (h) xy = y (i) y y y = 0 (j) x = x (k)
Metodi statistici per le ricerche di mercato
 Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2014-2015 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
Metodi statistici per le ricerche di mercato Prof.ssa Isabella Mingo A.A. 2014-2015 Facoltà di Scienze Politiche, Sociologia, Comunicazione Corso di laurea Magistrale in «Organizzazione e marketing per
Lezione n. 2 (a cura di Chiara Rossi)
") Lezione n. 2 (a cura di Chiara Rossi) QUANTILE Data una variabile casuale X, si definisce Quantile superiore x p : X P (X x p ) = p Quantile inferiore x p : X P (X x p ) = p p p=0.05 x p x p Graficamente,
Lezione n. 2 (a cura di Chiara Rossi) QUANTILE Data una variabile casuale X, si definisce Quantile superiore x p : X P (X x p ) = p Quantile inferiore x p : X P (X x p ) = p p p=0.05 x p x p Graficamente,
RISCHIO E CAPITAL BUDGETING
 RISCHIO E CAPITAL BUDGETING Costo opportunità del capitale Molte aziende, una volta stimato il loro costo opportunità del capitale, lo utilizzano per scontare i flussi di cassa attesi dei nuovi progetti
RISCHIO E CAPITAL BUDGETING Costo opportunità del capitale Molte aziende, una volta stimato il loro costo opportunità del capitale, lo utilizzano per scontare i flussi di cassa attesi dei nuovi progetti
APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI
 APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI Indice 1 Le frazioni algebriche 1.1 Il minimo comune multiplo e il Massimo Comun Divisore fra polinomi........ 1. Le frazioni algebriche....................................
APPUNTI DI MATEMATICA LE FRAZIONI ALGEBRICHE ALESSANDRO BOCCONI Indice 1 Le frazioni algebriche 1.1 Il minimo comune multiplo e il Massimo Comun Divisore fra polinomi........ 1. Le frazioni algebriche....................................
risulta (x) = 1 se x < 0.
 = 1 se x < 0.") Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Questo file si pone come obiettivo quello di mostrarvi come lo studio di una funzione reale di una variabile reale, nella cui espressione compare un qualche valore assoluto, possa essere svolto senza necessariamente
Economia Aperta. In questa lezione: Analizziamo i mercati dei beni e servizi in economia aperta. Analizziamo i mercati finanziari in economia aperta
 Economia Aperta In questa lezione: Analizziamo i mercati dei beni e servizi in economia aperta Analizziamo i mercati finanziari in economia aperta 167 Economia aperta applicata ai mercati dei beni mercati
Economia Aperta In questa lezione: Analizziamo i mercati dei beni e servizi in economia aperta Analizziamo i mercati finanziari in economia aperta 167 Economia aperta applicata ai mercati dei beni mercati
Serie numeriche e serie di potenze
 Serie numeriche e serie di potenze Sommare un numero finito di numeri reali è senza dubbio un operazione che non può riservare molte sorprese Cosa succede però se ne sommiamo un numero infinito? Prima
Serie numeriche e serie di potenze Sommare un numero finito di numeri reali è senza dubbio un operazione che non può riservare molte sorprese Cosa succede però se ne sommiamo un numero infinito? Prima
Siamo così arrivati all aritmetica modulare, ma anche a individuare alcuni aspetti di come funziona l aritmetica del calcolatore come vedremo.
 DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
DALLE PESATE ALL ARITMETICA FINITA IN BASE 2 Si è trovato, partendo da un problema concreto, che con la base 2, utilizzando alcune potenze della base, operando con solo addizioni, posso ottenere tutti
Esame di Statistica del 17 luglio 2006 (Corso di Laurea Triennale in Biotecnologie, Università degli Studi di Padova).
.") Esame di Statistica del 17 luglio 2006 (Corso di Laurea Triennale in Biotecnologie, Università degli Studi di Padova). Cognome Nome Matricola Es. 1 Es. 2 Es. 3 Es. 4 Somma Voto finale Attenzione: si consegnano
Esame di Statistica del 17 luglio 2006 (Corso di Laurea Triennale in Biotecnologie, Università degli Studi di Padova). Cognome Nome Matricola Es. 1 Es. 2 Es. 3 Es. 4 Somma Voto finale Attenzione: si consegnano
Macroeconomia. Laura Vici. laura.vici@unibo.it. www.lauravici.com/macroeconomia LEZIONE 6. Rimini, 6 ottobre 2015. La ripresa dell Italia
 Macroeconomia Laura Vici laura.vici@unibo.it www.lauravici.com/macroeconomia LEZIONE 6 Rimini, 6 ottobre 2015 Macroeconomia 140 La ripresa dell Italia Il Fondo Monetario internazionale ha alzato le stime
Macroeconomia Laura Vici laura.vici@unibo.it www.lauravici.com/macroeconomia LEZIONE 6 Rimini, 6 ottobre 2015 Macroeconomia 140 La ripresa dell Italia Il Fondo Monetario internazionale ha alzato le stime
Il modello generale di commercio internazionale
 Capitolo 6 Il modello generale di commercio internazionale adattamento italiano di Novella Bottini 1 Struttura della presentazione Domanda e offerta relative Benessere e ragioni di scambio Effetti della
Capitolo 6 Il modello generale di commercio internazionale adattamento italiano di Novella Bottini 1 Struttura della presentazione Domanda e offerta relative Benessere e ragioni di scambio Effetti della
Ai fini economici i costi di un impresa sono distinti principalmente in due gruppi: costi fissi e costi variabili. Vale ovviamente la relazione:
 1 Lastoriadiun impresa Il Signor Isacco, che ormai conosciamo per il suo consumo di caviale, decide di intraprendere l attività di produttore di caviale! (Vuole essere sicuro della qualità del caviale
1 Lastoriadiun impresa Il Signor Isacco, che ormai conosciamo per il suo consumo di caviale, decide di intraprendere l attività di produttore di caviale! (Vuole essere sicuro della qualità del caviale
 Stima per intervalli Nei metodi di stima puntuale è sempre presente un ^ errore θ θ dovuto al fatto che la stima di θ in genere non coincide con il parametro θ. Sorge quindi l esigenza di determinare una
Stima per intervalli Nei metodi di stima puntuale è sempre presente un ^ errore θ θ dovuto al fatto che la stima di θ in genere non coincide con il parametro θ. Sorge quindi l esigenza di determinare una
Lezione 18 1. Introduzione
 Lezione 18 1 Introduzione In questa lezione vediamo come si misura il PIL, l indicatore principale del livello di attività economica. La definizione ed i metodi di misura servono a comprendere a quali
Lezione 18 1 Introduzione In questa lezione vediamo come si misura il PIL, l indicatore principale del livello di attività economica. La definizione ed i metodi di misura servono a comprendere a quali
b. Che cosa succede alla frazione di reddito nazionale che viene risparmiata?
 Esercitazione 7 Domande 1. L investimento programmato è pari a 100. Le famiglie decidono di risparmiare una frazione maggiore del proprio reddito e la funzione del consumo passa da C = 0,8Y a C = 0,5Y.
Esercitazione 7 Domande 1. L investimento programmato è pari a 100. Le famiglie decidono di risparmiare una frazione maggiore del proprio reddito e la funzione del consumo passa da C = 0,8Y a C = 0,5Y.
Tasso di interesse e capitalizzazione
 Tasso di interesse e capitalizzazione Tasso di interesse = i = somma che devo restituire dopo un anno per aver preso a prestito un euro, in aggiunta alla restituzione dell euro iniziale Quindi: prendo
Tasso di interesse e capitalizzazione Tasso di interesse = i = somma che devo restituire dopo un anno per aver preso a prestito un euro, in aggiunta alla restituzione dell euro iniziale Quindi: prendo
Il sistema monetario
 Il sistema monetario Premessa: in un sistema economico senza moneta il commercio richiede la doppia coincidenza dei desideri. L esistenza del denaro rende più facili gli scambi. Moneta: insieme di tutti
Il sistema monetario Premessa: in un sistema economico senza moneta il commercio richiede la doppia coincidenza dei desideri. L esistenza del denaro rende più facili gli scambi. Moneta: insieme di tutti
Calcolo del Valore Attuale Netto (VAN)
") Calcolo del Valore Attuale Netto (VAN) Il calcolo del valore attuale netto (VAN) serve per determinare la redditività di un investimento. Si tratta di utilizzare un procedimento che può consentirci di
Calcolo del Valore Attuale Netto (VAN) Il calcolo del valore attuale netto (VAN) serve per determinare la redditività di un investimento. Si tratta di utilizzare un procedimento che può consentirci di
ESERCIZI DI MATEMATICA FINANZIARIA DIPARTIMENTO DI ECONOMIA E MANAGEMENT UNIFE A.A. 2015/2016. 1. Esercizi 4
 ESERCIZI DI MATEMATICA FINANZIARIA DIPARTIMENTO DI ECONOMIA E MANAGEMENT UNIFE A.A. 2015/2016 1. Esercizi 4 Piani di ammortamento Esercizio 1. Un debito di 1000e viene rimborsato a tasso annuo i = 10%
ESERCIZI DI MATEMATICA FINANZIARIA DIPARTIMENTO DI ECONOMIA E MANAGEMENT UNIFE A.A. 2015/2016 1. Esercizi 4 Piani di ammortamento Esercizio 1. Un debito di 1000e viene rimborsato a tasso annuo i = 10%
FONDAMENTI DI PSICOMETRIA - 8 CFU
 Ψ FONDAMENTI DI PSICOMETRIA - 8 CFU STIMA DELL ATTENDIBILITA STIMA DELL ATTENDIBILITA DEFINIZIONE DI ATTENDIBILITA (affidabilità, fedeltà) Grado di accordo tra diversi tentativi di misurare uno stesso
Ψ FONDAMENTI DI PSICOMETRIA - 8 CFU STIMA DELL ATTENDIBILITA STIMA DELL ATTENDIBILITA DEFINIZIONE DI ATTENDIBILITA (affidabilità, fedeltà) Grado di accordo tra diversi tentativi di misurare uno stesso
Esercizi di Macroeconomia per il corso di Economia Politica
 Esercizi di Macroeconomia per il corso di Economia Politica (Gli esercizi sono suddivisi in base ai capitoli del testo di De Vincenti) CAPITOLO 3. IL MERCATO DEI BENI NEL MODELLO REDDITO-SPESA Esercizio.
Esercizi di Macroeconomia per il corso di Economia Politica (Gli esercizi sono suddivisi in base ai capitoli del testo di De Vincenti) CAPITOLO 3. IL MERCATO DEI BENI NEL MODELLO REDDITO-SPESA Esercizio.
Principi di Economia - Macroeconomia Esercitazione 3 Risparmio, Spesa e Fluttuazioni di breve periodo Soluzioni
 Principi di Economia - Macroeconomia Esercitazione 3 Risparmio, Spesa e Fluttuazioni di breve periodo Soluzioni Daria Vigani Maggio 204. In ciascuna delle seguenti situazioni calcolate risparmio nazionale,
Principi di Economia - Macroeconomia Esercitazione 3 Risparmio, Spesa e Fluttuazioni di breve periodo Soluzioni Daria Vigani Maggio 204. In ciascuna delle seguenti situazioni calcolate risparmio nazionale,
Misure della dispersione o della variabilità
 QUARTA UNITA Misure della dispersione o della variabilità Abbiamo visto che un punteggio di per sé non ha alcun significato e lo acquista solo quando è posto a confronto con altri punteggi o con una statistica.
QUARTA UNITA Misure della dispersione o della variabilità Abbiamo visto che un punteggio di per sé non ha alcun significato e lo acquista solo quando è posto a confronto con altri punteggi o con una statistica.
Modello keynesiano: il settore reale
 Macro 4 Modello keynesiano: il settore reale La macroeconomia keynesiana La macroeconomia si occupa di studiare i meccanismi di determinazione delle grandezze economiche aggregate, così come definite dalla
Macro 4 Modello keynesiano: il settore reale La macroeconomia keynesiana La macroeconomia si occupa di studiare i meccanismi di determinazione delle grandezze economiche aggregate, così come definite dalla
Il modello generale di commercio internazionale
 Capitolo 6 Il modello generale di commercio internazionale [a.a. 2015/16 ] adattamento italiano di Novella Bottini (ulteriore adattamento di Giovanni Anania, Margherita Scoppola e Francesco Aiello) 6-1
Capitolo 6 Il modello generale di commercio internazionale [a.a. 2015/16 ] adattamento italiano di Novella Bottini (ulteriore adattamento di Giovanni Anania, Margherita Scoppola e Francesco Aiello) 6-1
Un modello matematico di investimento ottimale
 Un modello matematico di investimento ottimale Tiziano Vargiolu 1 1 Università degli Studi di Padova Liceo Scientifico Benedetti Venezia, giovedì 30 marzo 2011 Outline 1 Investimento per un singolo agente
Un modello matematico di investimento ottimale Tiziano Vargiolu 1 1 Università degli Studi di Padova Liceo Scientifico Benedetti Venezia, giovedì 30 marzo 2011 Outline 1 Investimento per un singolo agente
Equilibrio bayesiano perfetto. Giochi di segnalazione
 Equilibrio bayesiano perfetto. Giochi di segnalazione Appunti a cura di Stefano Moretti, Silvia VILLA e Fioravante PATRONE versione del 26 maggio 2006 Indice 1 Equilibrio bayesiano perfetto 2 2 Giochi
Equilibrio bayesiano perfetto. Giochi di segnalazione Appunti a cura di Stefano Moretti, Silvia VILLA e Fioravante PATRONE versione del 26 maggio 2006 Indice 1 Equilibrio bayesiano perfetto 2 2 Giochi
Statistica. Esercitazione 15. Alfonso Iodice D Enza iodicede@unicas.it. Università degli studi di Cassino. Statistica. A. Iodice
 Esercitazione 15 Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () 1 / 18 L importanza del gruppo di controllo In tutti i casi in cui si voglia studiare l effetto di un certo
Esercitazione 15 Alfonso Iodice D Enza iodicede@unicas.it Università degli studi di Cassino () 1 / 18 L importanza del gruppo di controllo In tutti i casi in cui si voglia studiare l effetto di un certo
8 Elementi di Statistica
 8 Elementi di Statistica La conoscenza di alcuni elementi di statistica e di analisi degli errori è importante quando si vogliano realizzare delle osservazioni sperimentali significative, ed anche per
8 Elementi di Statistica La conoscenza di alcuni elementi di statistica e di analisi degli errori è importante quando si vogliano realizzare delle osservazioni sperimentali significative, ed anche per
Lezione 5: Gli investimenti e la scheda IS
 Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 5: Gli investimenti e la scheda IS Facoltà di Scienze della Comunicazione Università di Teramo Comovimento di C e Y -Italia
Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 5: Gli investimenti e la scheda IS Facoltà di Scienze della Comunicazione Università di Teramo Comovimento di C e Y -Italia
LEZIONE 3. Ing. Andrea Ghedi AA 2009/2010. Ing. Andrea Ghedi AA 2009/2010
 LEZIONE 3 "Educare significa aiutare l'animo dell'uomo ad entrare nella totalità della realtà. Non si può però educare se non rivolgendosi alla libertà, la quale definisce il singolo, l'io. Quando uno
LEZIONE 3 "Educare significa aiutare l'animo dell'uomo ad entrare nella totalità della realtà. Non si può però educare se non rivolgendosi alla libertà, la quale definisce il singolo, l'io. Quando uno
SPC e distribuzione normale con Access
 SPC e distribuzione normale con Access In questo articolo esamineremo una applicazione Access per il calcolo e la rappresentazione grafica della distribuzione normale, collegata con tabelle di Clienti,
SPC e distribuzione normale con Access In questo articolo esamineremo una applicazione Access per il calcolo e la rappresentazione grafica della distribuzione normale, collegata con tabelle di Clienti,
Analisi Costi-Benefici
 Politica economica (A-D) Sapienza Università di Rome Analisi Costi-Benefici Giovanni Di Bartolomeo Sapienza Università di Roma Scelta pubblica Intervento pubblico realizzazione di progetti esempi: infrastrutture,
Politica economica (A-D) Sapienza Università di Rome Analisi Costi-Benefici Giovanni Di Bartolomeo Sapienza Università di Roma Scelta pubblica Intervento pubblico realizzazione di progetti esempi: infrastrutture,
Schemi delle Lezioni di Matematica Generale. Pierpaolo Montana
 Schemi delle Lezioni di Matematica Generale Pierpaolo Montana A volte i fenomeni economici che ci interessano non variano con continuitá oppure non possono essere osservati con continuitá, ma solo a intervalli
Schemi delle Lezioni di Matematica Generale Pierpaolo Montana A volte i fenomeni economici che ci interessano non variano con continuitá oppure non possono essere osservati con continuitá, ma solo a intervalli
Crescita della moneta e inflazione
 Crescita della moneta e inflazione Alcune osservazioni e definizioni L aumento del livello generale dei prezzi è detto inflazione. Ultimi 60 anni: variazione media del 5% annuale. Effetto: i prezzi sono
Crescita della moneta e inflazione Alcune osservazioni e definizioni L aumento del livello generale dei prezzi è detto inflazione. Ultimi 60 anni: variazione media del 5% annuale. Effetto: i prezzi sono
Blanchard Amighini Giavazzi, Macroeconomia Una prospettiva europea, Il Mulino 2011. Il modello IS-LM in economia aperta
 Capitolo VI. Il modello IS-LM in economia aperta 1. I mercati dei beni in economia aperta Economia aperta applicata a mercati dei beni: l opportunità per i consumatori e le imprese di scegliere tra beni
Capitolo VI. Il modello IS-LM in economia aperta 1. I mercati dei beni in economia aperta Economia aperta applicata a mercati dei beni: l opportunità per i consumatori e le imprese di scegliere tra beni
Matematica 1 - Corso di Laurea in Ingegneria Meccanica
 Matematica 1 - Corso di Laurea in Ingegneria Meccanica Esercitazione su massimi e minimi vincolati 9 dicembre 005 Esercizio 1. Considerare l insieme C = {(x,y) R : (x + y ) = x } e dire se è una curva
Matematica 1 - Corso di Laurea in Ingegneria Meccanica Esercitazione su massimi e minimi vincolati 9 dicembre 005 Esercizio 1. Considerare l insieme C = {(x,y) R : (x + y ) = x } e dire se è una curva
Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale
 Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale Facoltà di Scienze della Comunicazione Università di Teramo Scelta
Corso di Scienza Economica (Economia Politica) prof. G. Di Bartolomeo Lezione 10: Il problema del consumatore: Preferenze e scelta ottimale Facoltà di Scienze della Comunicazione Università di Teramo Scelta